はじめに (2020年2月15日)
ここでは、EDA Salon 第8回 - YouTubeのトレンディングデータを使って、探索的データ分析を行う。データを見る前から特定の目的があった訳ではないが、とりあえずデータを眺めていたら違和感を感じたので、その違和感を解消するためにデータを探索することにした。
先にまとめておくと、このデータは変である。たぶん。追記を含めて、おかしな点は下記のとおり。
- データが完全重複している。
- 重複処理後において、
video_id == "#NAME?"は、複数のcategoryを持っている。 - 重複処理後において、次の日に
viewsが下がる。 - 重複処理後において、
video_id == q8v9MvManKEは、複数のcountryを持っている。
今回のノートは、探索的データ分析(Data Explratory Analysis)ではなく、探索的データ品質診断(Data Quality Diagnosis)になってしまっている。
探索する上での条件
country == "japan"に限定している。
違和感のキッカケと謎
最初にこのデータを見たとき、Youtubeの動画の一覧、いわゆるマスタデータみたいなものだと思っていた。なので、データを眺めていたときに、publish_timeはあっておかしくはないが、trending_dateという日付のデータに違和感を感じた。
気付くのが遅いが、そのときにYouTubeのトレンディングデータという意味がわかった。
このデータは、どうやらトレンド入りしている各動画の履歴データということがわかった。
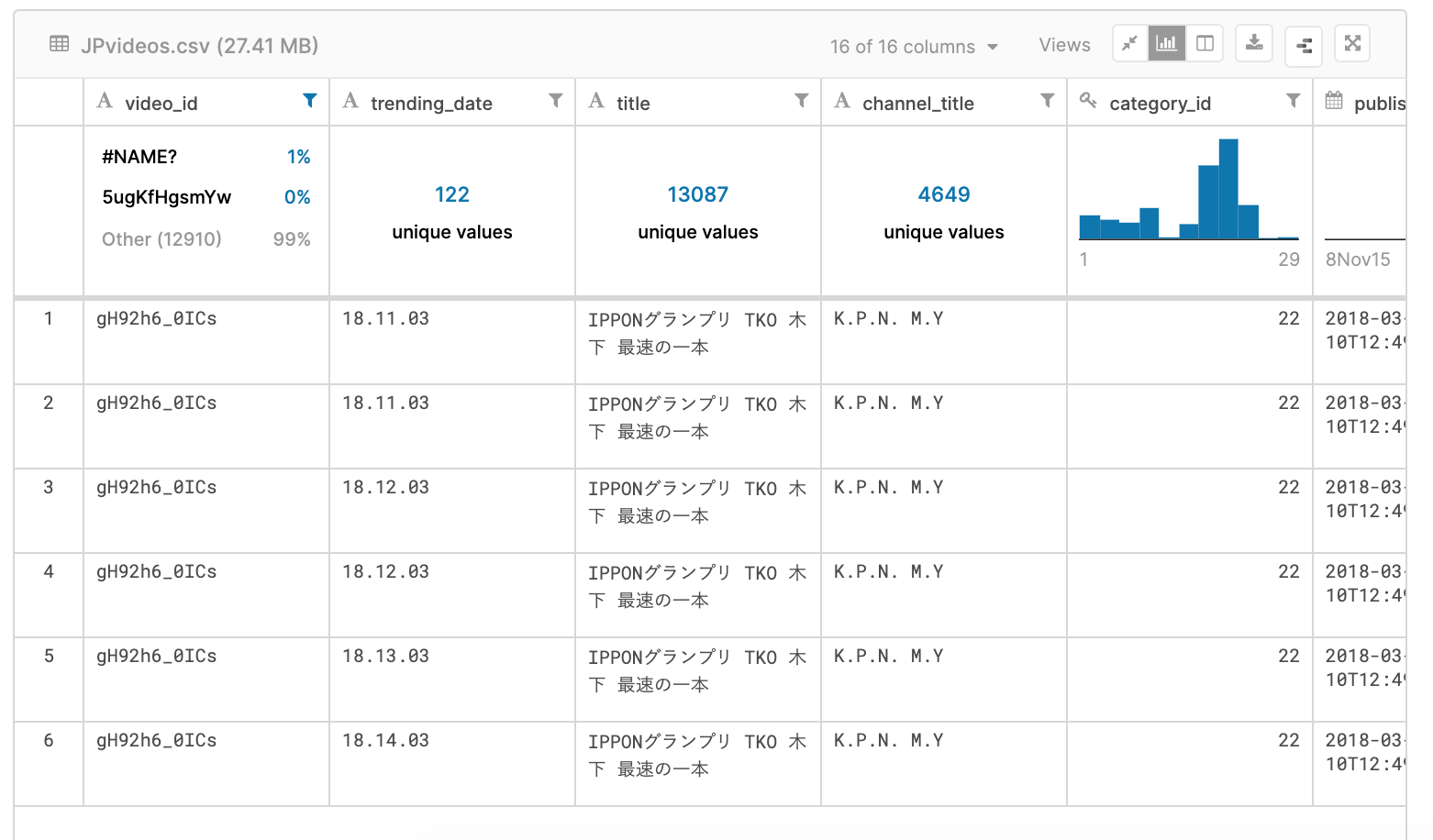
これは、video_id == "gH92h6_0ICs"に限定して、この動画のviewsを折れ線で可視化したもの。
この動画は4日間(2018年03月11日〜2018年03月14日)トレンド入りしており、そのviewsの変化がこの折れ線グラフで表現されている。そして、この折れ線を見たときに、何か変な嫌な感じがした。
トレンドとしてランクされている動画の履歴データなのであれば、viewsは積み重なっていくので、n-1日のviewsよりもn日のviewsのほうが多くなるはずだと思ったからである。
そのようなデータ構造であれば谷があることがおかしい。
一方で、もしかすると、その日に獲得したviewsを記録しているデータという可能性もある。前者ではなく、後者であれば、谷があってもおかしくはない。
少し考えたあとに、もしやと思い、この違和感を解消するために、video_id == "gH92h6_0ICs"に限定したまま、group_by_all()とdistinct()を使い、データが完全に重複している可能性があるかどうかを検証してみた。


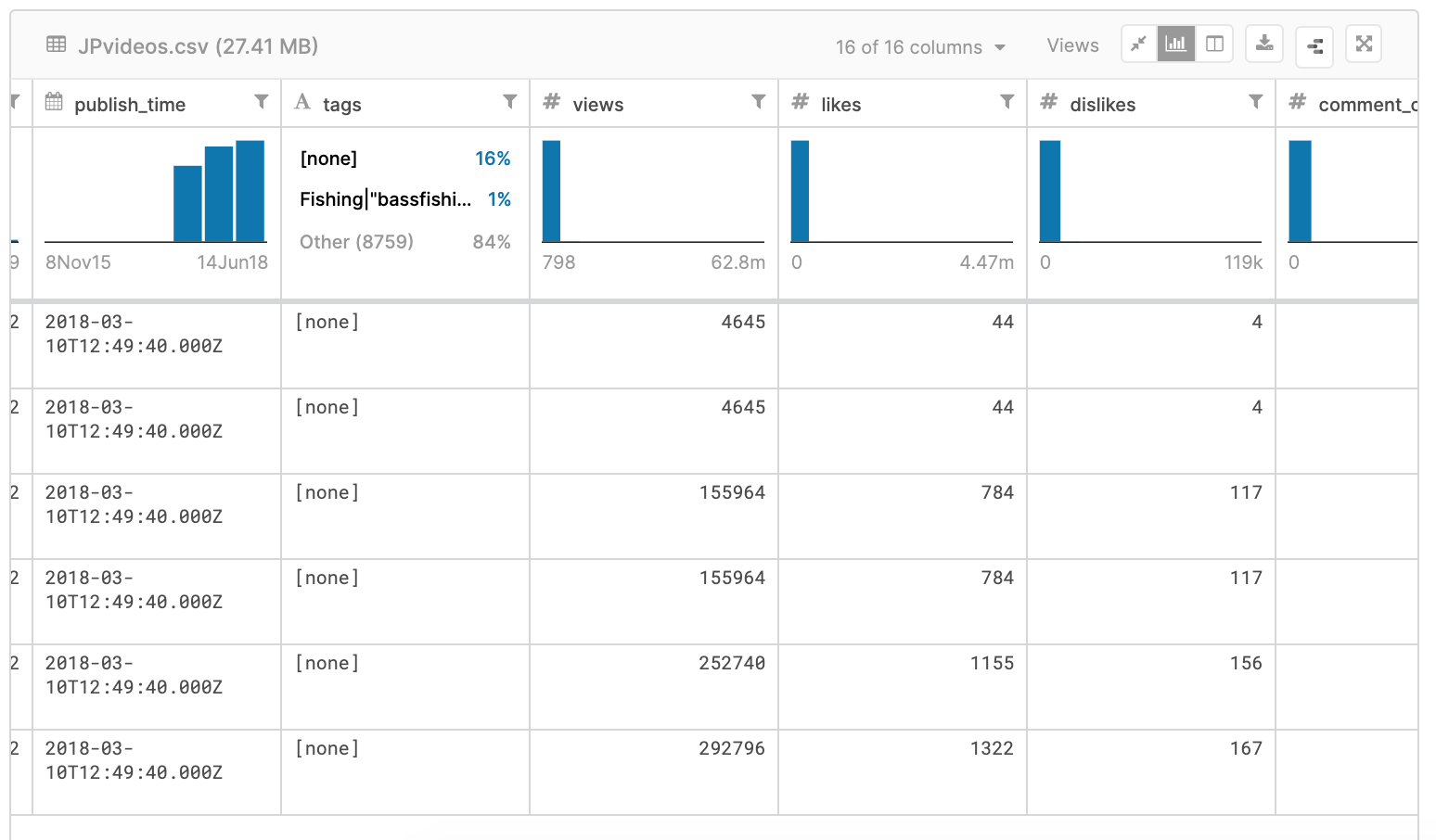
重複を削除したデータでviewsを折れ線グラフで可視化するとこうなる。
さきほどのような奇妙な谷もなくなっており、こちらのほうが違和感もない。
その日に獲得したviewsを記録しているデータなのかもしれないという考え方は、trending_dateの日付は同じで、viewsなどの記録が異なっていれば、おかしくはない。例えば12時と24時に記録されるなども考えられるためである。しかし、その場合であれば、各trending_dateの日付で2行づつないとおかしい。
ということで、video_id == "gH92h6_0ICs"のフィルタを外し、country == "japan"の状態で、20,523行に対して、group_by_all()とdistinct()を使い、データが完全に重複している可能性があるかどうかを検証してみたところ、5,677行が完全に重複しており、14,846行に減ってしまった。
20523 - 14846
[1] 56775,677行も重複しているデータがあるのは変である。
データが重複してしまう原因はいくつか考えられる。例えば、データベースにインサートする場合にトラブルが起こり、インサートが2重になってしまっている場合や、Joinの結合キーが足りていない状態で、適切にレコードを識別できないままjoinされ、その後の加工で、それらに関する変数が削除されているような場合、このような重複データに見える場合がある。
その他にも、単純にそもそもの変数が足りておらず、レコードを一意にできない場合もあるが、今回はviewなどの数値が同じという点で、この可能性はほぼない。
このような場合、実務であればデータベースの管理者なり、設計者と話をして、問題を解決することになるが、今回のデータは、Kaggleで公開されているデータらしいので、なぜ、データが重複しているのかは不明である。もしかすると、KaggleのDisccusionに記載されているのかもしれないが。
それとも、根本的に私の考え方が変なのかもしれないが…。ちなみに、country == "United States"で同じように重複を確認すると、40,949行から40,901行となり48行ほど減ってしまう。
なんだかこのデータは変である。
追記1 (2020年2月16日)
実際にKaggleのdiscussionにトピックはあるみたいだけど、謎は解明されていない。
データ提供元のKaggleのdataも見てみたが、ここの時点で重複しているようである。
また、この重複によってviewの集計にどの程度の差が出るのか検証してみた。検証方法としては、単純に「重複を削除していないデータ」と「重複を削除していないデータ」を比較する。
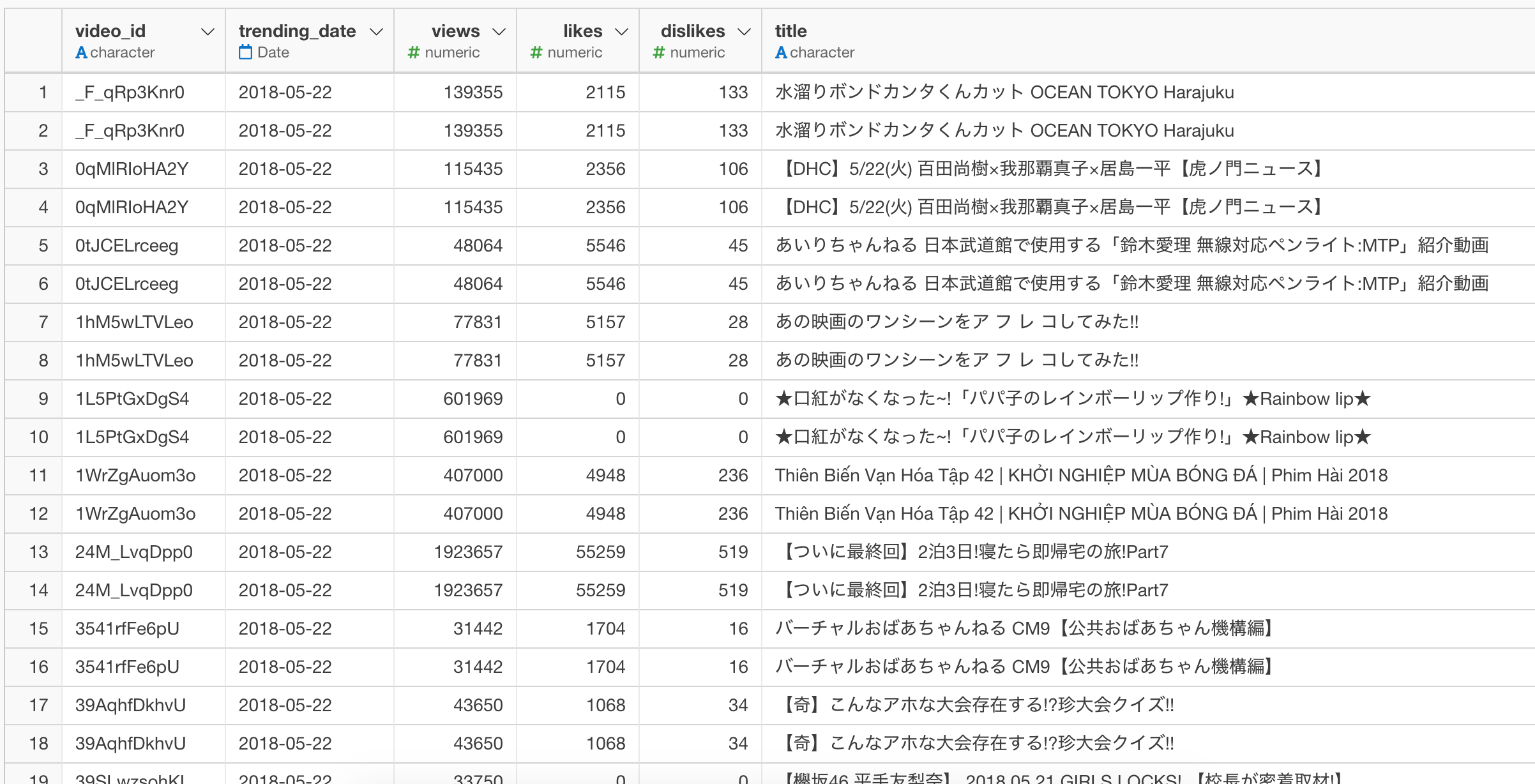
まずは折れ線グラフで重ねて可視化してみる。2018年5月22日が飛び抜けて差がある。
この日の実際のデータを確認してみると、なんだが変なのは一目瞭然である。
また、単純に各データごとにviewを合計して差を確認する。これでは、相当な差があることはわかるが、実際の数値がわからない。
具体的な数値を計算すると、口が塞がらないほどの差がある。これが、実際の仕事でviewではなく、売上金額や広告施策の評価のレポートだったことを想像すると・・・絶句である。
探索的にデータを確認してチェックするのは大切ですね…。
追記2 (2020年2月23日)
このような重複データがあると、実務の経験上、他にもおかしな点が出てくることはよくあるので、更にデータを探索してみたら、おかしな点を見つけた。
group_by_all()とdistinct()してあるデータで、country == "Japan"かつvideo_id == "#NAME?"は、複数のcategoryを含んでおり、日付もバラバラな状態。

country == "United States"では、video_id == "#NAME?"というのは存在しないようではあるが、重複を削除しても、viewsが次の日に下がっているデータがある。
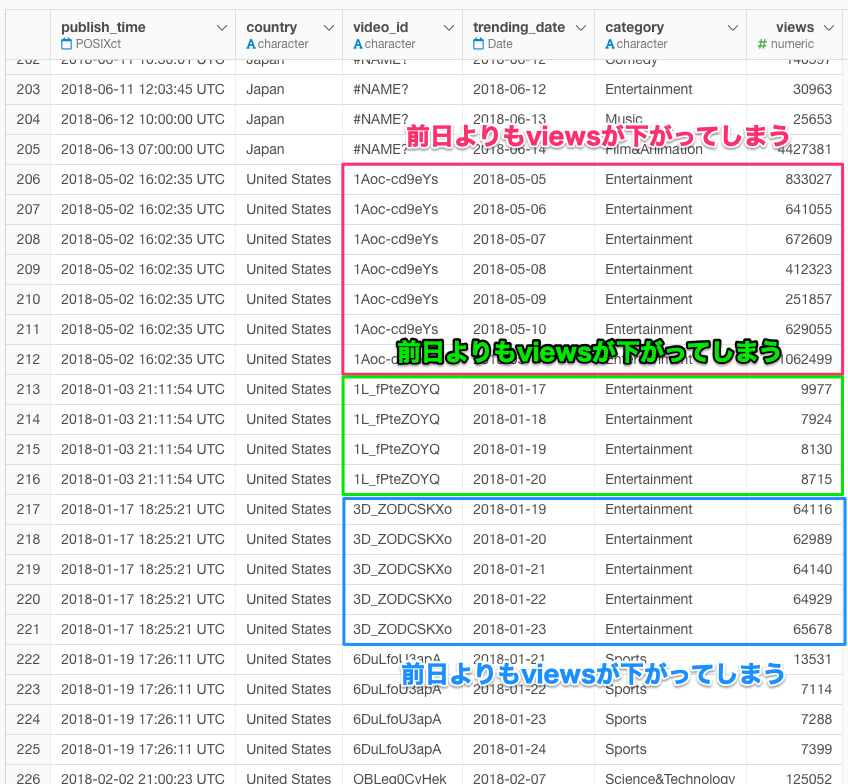
これらを可視化するとこんな感じである。
その他にも、video_id == q8v9MvManKEは、複数のcountryを持っているようである。
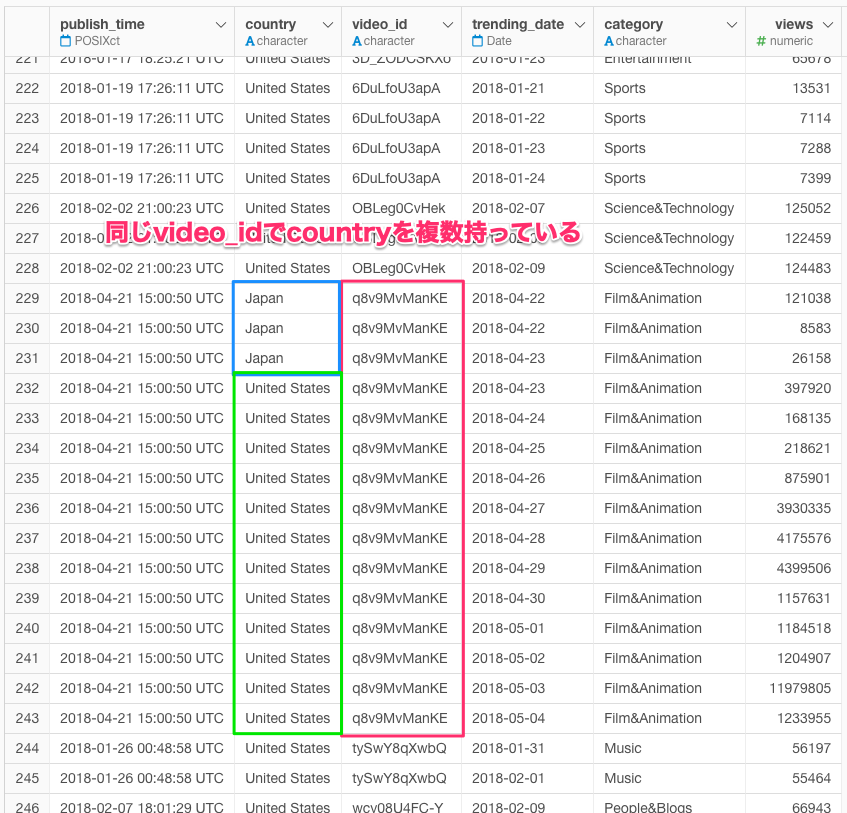
以降、自戒の念を込めて。
重箱の隅をつつく小姑のようになってしまったが、Garbage In Garbage Outという有名な言葉があるように、「無意味なデータ」からの「無意味な分析結果」そして「無意味な施策展開」からの「無意味の効果測定」は総じて「無意味」なので、データ分析(Data analysis)の前のData (Quality) Diagnosisは大切だと思ったEDAsalonでした。