- はじめに
- サンプルデータ
- LDAをやってみる
- アウトプット
- スクリプト
はじめに
ここでは、Exploratoryを使って、トピックモデリングをやってみようと思います。
別の機会で、ノートを書くことがあったので、そのノートから実行する部分を抜き出して、誰かの参考になればと思い、パブリッシュしておきます。調べてみた限り、現状、ExploratoryのサイトにLDAのHowto記事がなかったので・・・たぶん。あったらごめんなさい。
トピックモデルは潜在的意味を推定するためのモデルとか言われているやつで、ここではLatent Dirichlet Allocation(LDA)を取り上げます。モデルの説明については取り扱わないので、参考書などを参照ください。
サンプルデータ
サンプルデータはKaggleのAmazonレビューデータを使用します。
また、レビューデータのProductIdがB007JFMH8Mのレビューに限定します。このクッキーのレビューは913件です。

Amazonのサイトによると、このクッキーの特徴は下記の通りです。
- 全粒粉のオーツ麦で作られている
- レーズンやスパイスが入っている
- 1食当たり10グラムの全粒穀物
- 食物繊維の良い供給源
LDAをやってみる
インポートしたデータはこんな感じです。
ここでは、このレビューを文字の処理 >> トークン化 >> 文字の処理 >> 単語のカウント >> 文書単語行列(DTM) >> LDAという順番で処理します。この手順が絶対に正しいというわけでもないので、参考程度にしていただければと思います。
文書単語行列(DTM) >> LDAの部分が、Rのトピックモデリングを紹介しているブログなどでは、分割して処理するスクリプトが紹介されているのが一般的かと思います・・・が、Exploratoryでは、各ステップでデータフレームを返す必要があるため(間違ってたら、すいません。)、紹介されているスクリプトをそのまま利用すると、データフレームを返さないので、エラーになってしまいます。
なので、その一連の処理を下記の関数で行い、LDAの結果を得ることにします。
文書単語行列(DTM)の変換とLDAの計算は、各処理がデータサイズによっては重たくなるので、試行錯誤をすることを考えると分けたかったのですが、あまり良い方法が思いつきませんでした・・・。
# pacman::p_load(topicmodels, tidytext)
do_lda <- function(data, document, term, value, weighting, k, matrix, seed){
document_enquo <- rlang::enquo(document)
term_enquo <- rlang::enquo(term)
value_enquo <- rlang::enquo(value)
res <- tidytext::cast_sparse(data = data, row = !!document_enquo, column = !!term_enquo, value = !!value_enquo) %>%
tm::as.DocumentTermMatrix(x = ., weighting = weighting) %>%
topicmodels::LDA(x = ., k = k, control = list(seed = seed)) %>%
broom::tidy(., matrix = matrix)
return(res)
}ここでは、tf-idf変換などはせずに素直にカウントし、トピック数は2で「トピックごとの単語の出現確率(beta)」を計算しています。他にも、gammaなどもあるので、詳しくは下記を参照ください。
アウトプット
トピックごとの単語の出現確率TOP10は下記となりました。例えば、2行目、12行目のsoftは、トピック1に出現する確率はおよそ5.6%である一方で、トピック2に出現する確率はおよそ3%と解釈できます。このようにトピックに含まれる単語から各トピックを検討することになります。
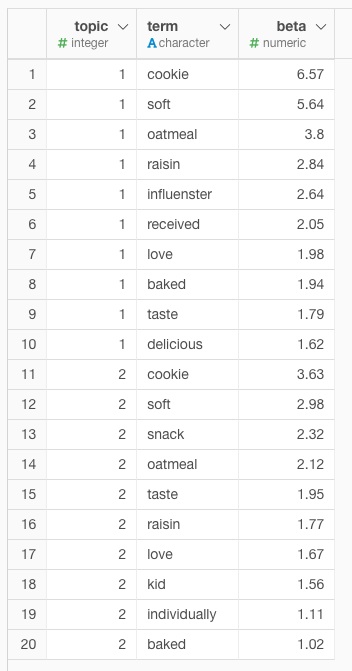
このままでは見にくいので可視化します。
| カテゴリ | 単語 | トピック内容 |
|---|---|---|
| トピック1 | cookie, soft, oatmeal, Influenster, received, delicious | InfluensterのレビューからAmazonの商品を買う? |
| トピック2 | cookie, soft, kid, snack, individually | 子どものお菓子 |
どうでしょうか。トピック1では、クッキーの評価とは関係なさそうなInfluenster, receivedがよく出現するようです。Influensterを最初に見た時に、誤字かと思ったのですが、receivedという単語が気になったので、検索してみたところ、レビュープラットフォーム「Influenster」というサービスが実際にアメリカにはあるそうです。
このことからトピック1は「Influensterのレビューがキッカケ(通知をreceived?)で、Amazonで商品を買った」というようなトピックがあるのかもしれません。
一方でトピック2では、kid, snack, individuallyというトピック1には出現しいくい単語が出現しやすいことから「子どものお菓子」というトピックなのかもしれません。
cookie, softなどは両方のトピックに共通して出現している単語がありますが、これはLDAのハードクラスタリング方式によるもので、トピックに単語の重なりが含まれることから、それを表現しているLDAの長所とも言われるそうです。
他にも、トピック1とトピック2のbetaの対数比をとって、差が最も大きいもに着目する方法などもあったりあしますが、ちょっと時間がなくなったので、ここまでとします。
間違いがあったら申し訳ないです・・・
スクリプト
# Set libPaths.
.libPaths("/Users/aki/.exploratory/R/3.6")
# Load required packages.
library(janitor)
library(lubridate)
library(hms)
library(tidyr)
library(stringr)
library(readr)
library(forcats)
library(RcppRoll)
library(dplyr)
library(tibble)
library(bit64)
library(exploratory)
# Steps to produce the output
exploratory::read_delim_file("../committed_data/amazon_review.csv" , ",", quote = "\"", skip = 0 , col_names = TRUE , na = c('','NA') , locale=readr::locale(encoding = "UTF-8", decimal_mark = ".", grouping_mark = "," ), trim_ws = TRUE , progress = FALSE) %>%
readr::type_convert() %>%
exploratory::clean_data_frame() %>%
select(-ProductId) %>%
mutate(Text = str_clean(Text), Text = str_replace_all(Text, "<.*?>", "")) %>%
unnest_tokens(word, Text) %>%
mutate(word = str_replace_all(word, "_", ""),
word = str_to_lower(word)) %>%
mutate(word = purrr::map(.x = word, .f = function(x){
SemNetCleaner::singularize(x)
})) %>%
unnest(word) %>%
anti_join(stop_words, by = "word") %>%
filter(word %nin% c("cooky", "loved", "oat", "wa", "quaker")) %>%
count(UserId, word) %>%
do_lda(
data = .,
document = UserId,
term = word,
value = n,
weighting = tm::weightTf,
k = 2,
matrix = "beta",
seed = 1989
) %>%
group_by(topic) %>%
top_n(10, beta) %>%
arrange(topic, desc(beta)) %>%
mutate(beta = round(beta * 100,2)) %>%
ungroup()