番外編:彼(彼女)らはどこにいくのか…
はじめに
ここでは、自転車のシェアリングサービスの利用履歴データをもとステーション間の移動を可視化することで、どのように自転車が使われているを探索する。
きっかけは、ここまでのEDAsalonの投稿をみるとRegisterdユーザーは通勤、帰宅の時間にレンタル数が多くなる傾向があると指摘(自分含め)されているが、それは本当なんだろうか…と疑問に思ったのがきっかけである。
しかし、そこを中心に調べるというよりも、単純に「彼(彼女)らはどこにいくのか…」が気になったので、探索的にデータ分析を行った。今回は元のデータセットが絡んでいないので、番外編とした。
データの紹介
そこで、capitalbikeshareが公開しているトリップデータとステーションデータを利用し、自転車の移動を可視化してみる。
今回は最新の2019年7月の利用履歴のみをダウンロードして使用している。また、ステーションデータはXML形式だったので、カスタムスクリプトを記述してインポートしている。XML::xmlToDataFrame("URL")で一発で変換できるらしいが、エラーが解消できなかったので、下記のようになっている。
library(XML)
library(RCurl)
url <- "https://feeds.capitalbikeshare.com/stations/stations.xml"
df_station <- url %>%
RCurl::getURL() %>%
XML::xmlParse() %>%
XML::xmlToDataFrame(., stringsAsFactors = FALSE)
df_stationバイクステーションを可視化
まずはバイクステーションを可視化してみる。色の濃さはnbBikesという自転車の数の多さで色分けしている。
ワシントンDCが中心で、道路沿い、都市部に集中していることが分かる。「東:Kettring」「西:Reston」「北:Whaton、Rockvile」「南:Alexandria、National Harbor」の範囲で駐輪場が設置されているようである。
移動パターンを可視化
トリップデータにはステーションの地点情報がないので、ステーションデータから取得する。加工内容は記事末尾にスクリプトを転記しておくので、そちらを確認ください。EDFファイルもダウンロードできるようにしている。
可視化した結果がこれである。色の濃さはスタートポイントとエンドポイントの組み合わせ(遷移パターン)の多さで色付けしている。
ワシントンDC内での移動や、ワシントンDCからRestonの方角への移動が多いようにも見える。色付けがうまくできなかった。組み合わせ(遷移パターン)の多さなので整数のグラデーションと不透明を組み合わせて表現したかったが、UI上でのやり方が分からなかった。
TOP50に限定
TOP50に限定するとこのようになる。
下記、Google Earthの画像を参考にしてみると、左端:リンカーン記念堂あたり、真ん中:ワシントン記念塔、右端:アメリカ合衆国議会議事堂の上のUnionStation駅あたりを移動しているようである。
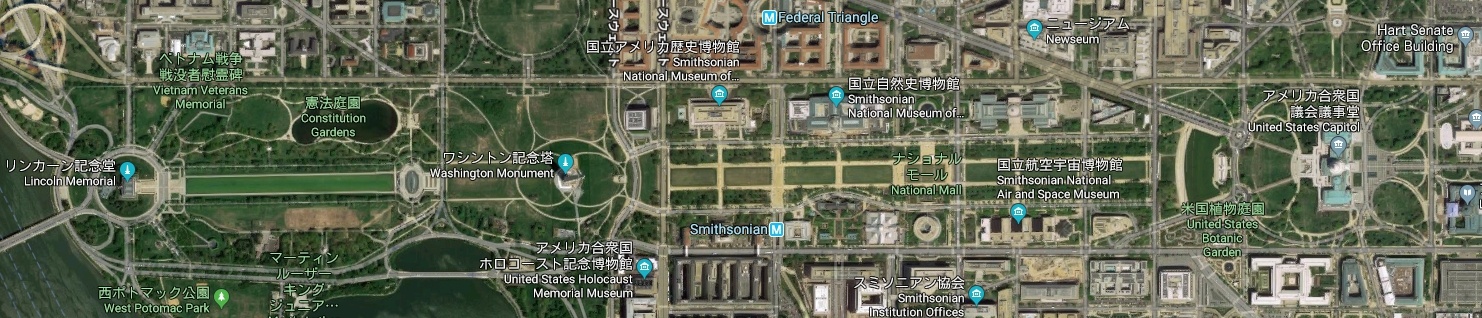 Source | From Google Earth
Source | From Google Earth
理由は…わからない。ワシントンDCというより、アメリカに行ったことすらないので…駅はあるけど不便とか、そこに会社が集中しているとか、情報がない…
TOP100に限定
TOP100に限定するとこのようになる。
先ほどよりも移動範囲が広くなっている。あたり前ではあるが、短距離移動が基本的には多く、中距離、長距離と範囲が広がっていくようである。
おわりに
単純に「彼(彼女)らはどこにいくのか…」が気になったので、探索的にデータ分析を行った結果、彼(彼女)らはどうやらこの緑あたりを移動することが多いようである。
Source | From Google Earth
移動するのはわかったが、なぜそこを移動するのかはわからないままである…。トリップデータには、RegistredかCausualかの変数もあるので、それを使うと、また違った結果がみえるかもしれない。というよりも、これまでに指摘されているようにレンタル数の傾向が大きく変わるようなので、違った結果が出るはずであるが…疲れたのでここらへんで終わることにする。
Rスクリプト
処理が間違ってたらごめんなさい…
# Set libPaths.
.libPaths("C:\\Users\\sugiura.teruaki\\.exploratory\\R\\3.6")
# Load required packages.
library(janitor)
library(lubridate)
library(hms)
library(tidyr)
library(stringr)
library(readr)
library(forcats)
library(RcppRoll)
library(dplyr)
library(tibble)
library(bit64)
library(exploratory)
# Custom R function as Data.
bike_station.func <- function(){
library(XML)
library(RCurl)
url <- "https://feeds.capitalbikeshare.com/stations/stations.xml"
df_station <- url %>%
RCurl::getURL() %>%
XML::xmlParse() %>%
XML::xmlToDataFrame(., stringsAsFactors = FALSE)
df_station
}
# Steps to produce bike_station
`bike_station` <- bike_station.func() %>%
readr::type_convert() %>%
exploratory::clean_data_frame() %>%
select(-id, -terminalName, -lastCommWithServer, -installed, -locked, -installDate, -removalDate, -temporary, -public, -nbEmptyDocks, -latestUpdateTime) %>%
select(-nbBikes)
# Steps to produce the output
exploratory::select_columns(exploratory::clean_data_frame(exploratory::read_delim_file("C:\\Users\\sugiura.teruaki\\Desktop\\201907-capitalbikeshare-tripdata" , ",", quote = "\"", skip = 0 , col_names = TRUE , na = c('','NA') , locale=readr::locale(encoding = "UTF-8", decimal_mark = ".", grouping_mark = "," ), trim_ws = TRUE , progress = FALSE)),"Start station","End station","Member type") %>%
readr::type_convert() %>%
group_by(`Start station`, `End station`) %>%
summarize_group(group_cols = c(`Start station` = "Start station", `End station` = "End station"),group_funs = c("none", "none"),Number_of_Rows = n()) %>%
arrange(desc(Number_of_Rows)) %>%
rename(rank = Number_of_Rows) %>%
mutate(combination_no = row_number()) %>%
gather(start_end, station, `End station`, `Start station`, na.rm = TRUE, convert = TRUE) %>%
arrange(combination_no) %>%
left_join(bike_station, by = c("station" = "name"))