//————————————–
【お断り】
データフレームに対するmap()とnest()という見方、説明をします。map()というか、map族とでもいいますか、purrrパッケージは、ここで紹介している以外にも多くのことができますが、Exploratoryでは、データフレームが中心なので、そのように説明している点ご了承ください。また、細かい関数の挙動なんかも省いています。
//————————————–
はじめに
なかなかふざけたタイトルで始まったわけですが、内容は至って真面目です。社でExploratory並びにRの布教(進捗は良くない)を行う上で、資料を作る機会があったので、こちらにも展開しておきます。
問題
よくあるのが「これを繰り返して、計算したいんですよね。どうにか、なりません?」とか「この繰り返してやるやつ、もっと効率よくやりたいけど、どうにかなりませんかね?」という「繰り返す」という問題です。
繰り返すというとfor-loopとかになるわけですが、Exploratoryでfor-loopを使うとなると、関数を書いて、その中で使って、結果を出力するということをするわけですが、「for-loopとかで関数を書かなくても、ちょっとカスタムRスクリプトを書けば計算できるよ」というのが本日のお話です。
それに必要なのが、お題に書いたtidyrパッケージのnest()とpurrrパッケージのmap()です。
サンプルデータと分析の概要
サンプルデータ(生成方法は末尾参照)はこんなデータを使います。segが0か1をとるカテゴリ変数で、何らかの観測された0以上の連続変数v1、v2、v3、v4、v5です。
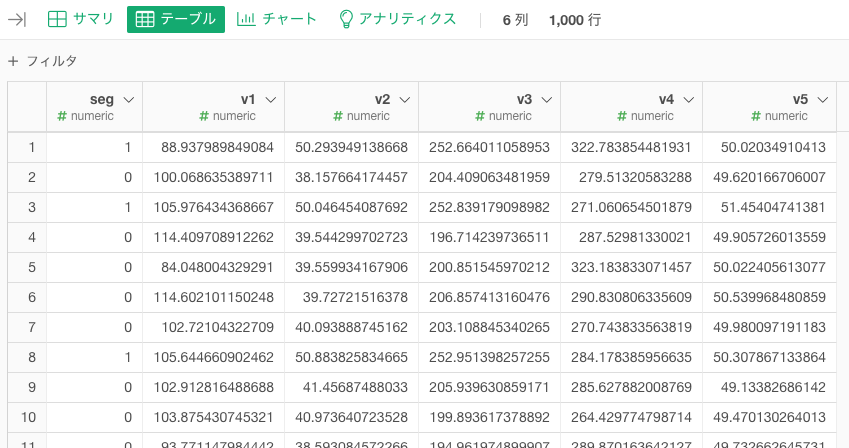
分析としては、「v1からv5の値の平均値について、segが0と1ごとで差があるのか、平均値の差をt検定したい。」「加えて、segごとに平均値とその差をv1からv5ごとにグラフ化したい。」というものです。前半部分を書き下すとこんな感じです。
segごとにv1の平均値に差があるのかt検定したい。segごとにv2の平均値に差があるのかt検定したい。segごとにv3の平均値に差があるのかt検定したい。segごとにv4の平均値に差があるのかt検定したい。segごとにv5の平均値に差があるのかt検定したい。
なんか数字の部分だけが変わっているので、ここをなんとか繰り返しできれば、簡単にできそうな感じです。これをできるようにしてくれれるが、tidyパッケージのnest()とpurrrパッケージのmap()です。
「segごとに」という部分をnest()がやってくれ、繰り返して「t検定したい」という部分をmap()がやってくれます。
ではデータの加工からやっていきましょう。
グループにまとめる
まずは「segごとに」という部分をnest()でやっていきましょう。nest()はgroup_by()と似ていて、カテゴリごとに、グループを作ってくれる関数です。
nest()に「*ごとにグループにしてほしい」と解釈してもらうためには、提供する情報として、「v1、v2、…、v5という5列の情報を渡す」か、「v1、v2、…、v5の5列を1列にまとめて、行ごとにグループと解釈できるようにして情報を渡す」かのどっちかです。nest()は後者のようにデータを渡すことで利用できるので、そのようにデータを加工します。考え方は、group_by()と同じですね。
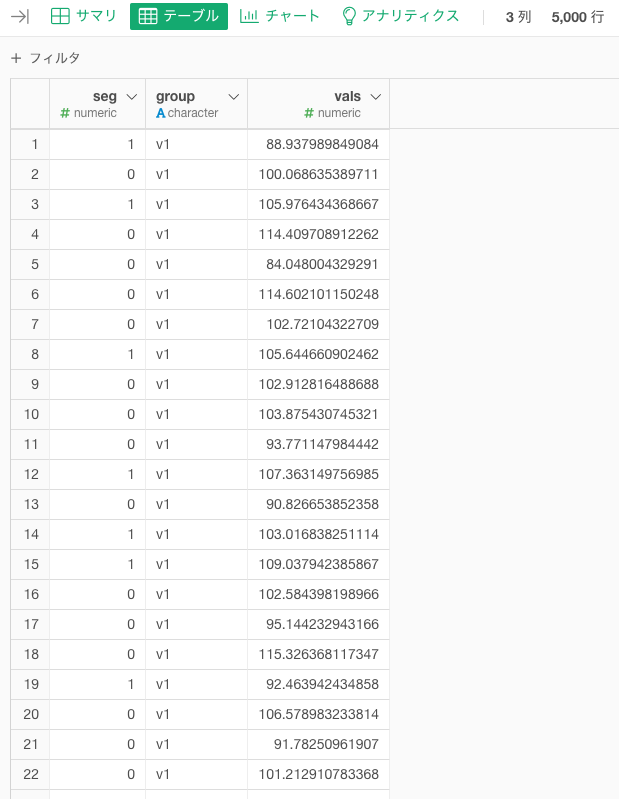
横に広がっている列を行にするのは、言い換えると、Wide型なデータをLong型に変換することなので、これはUIからgather()を使えば、実現できますね。やってきましょう。
こんな感じのデータになるはずです。列名はkey:groupとvalue:valsという名前にします。
そして、「v1、v2、…、v5の5列を1列にまとめて、行ごとにグループと解釈できるようにして情報を渡す」ことができるようになったので、カスタムRスクリプトのステップを呼び出して、nest()を使います。グループの単位にしたい変数を-をつけて呼び出します。
# group_by(group) %>% nest()でも良い
nest(-group)こんな感じの見慣れないデータフレームなりますが、groupのカテゴリごとに、その他の列のデータを畳み込んで1つにして格納しています。ですが、よく見てみると、「segごとに」データをまとめる、という目標が達成できてます。これは、データフレームの中にリストを入れるということをやっています。
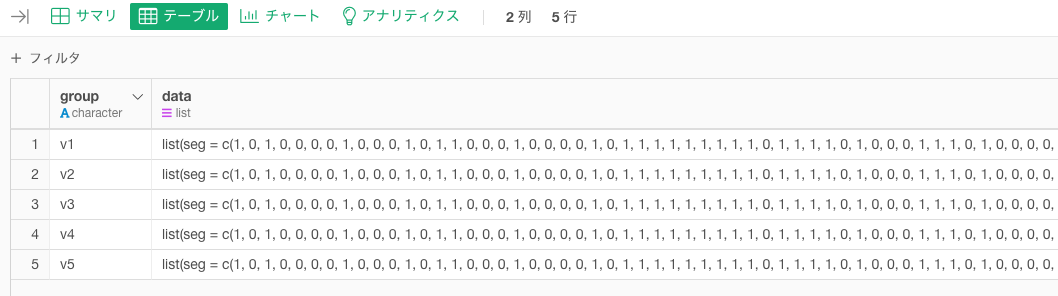
このように「segごとに」という加工が終われば、map()を組み合わせます。
繰り返して計算する
ここからは、map()を使って繰り返して計算していきましょう。map()はリストを繰り返して計算してくれる関数です。
mutateのステップを開いて、下記のように書きます。呪文のように見えるかもしれませんが、「segごとに、dataをt.test()に渡してあげてください」という感じの意味です。t.test()の中では、「渡されたdataのvalsの値をsegごとにt検定してください」という感じです。
purrr::map(.x = data,
.f = function(x){t.test(x$vals ~ x$seg, var.equal = FALSE)})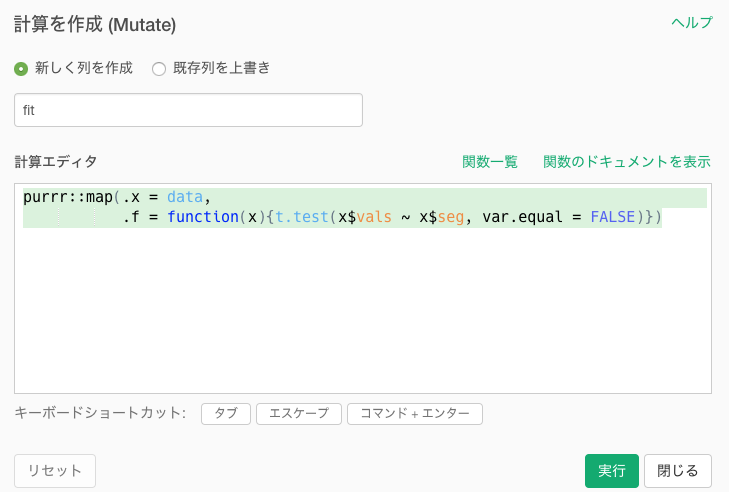
次に、もう一度、mutateステップから下記のように書きます。意味としては「さきほどt検定の関数が計算した結果(fit)から、モデルのサマリレベルの情報を取得してください(glance())」という内容です。そんな便利なことをしてくれるが、glance()というbroomパッケージの関数です。
purrr::map(.x = fit, .f = function(x){broom::glance(x)})
この作業が終わると、データフレームにはfitとglancedという列ができています。計算結果がリストで返ってきています。
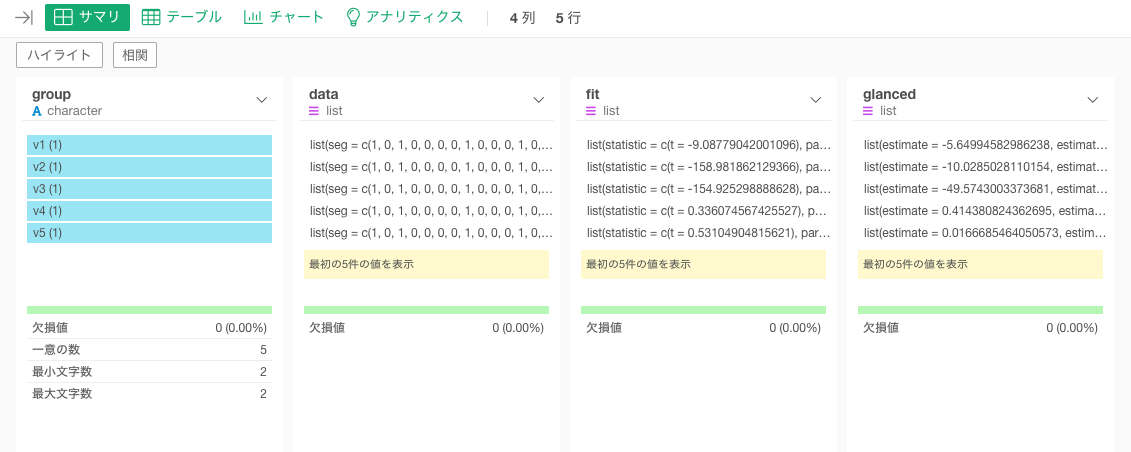
ここまでくれば、「v1からv5の値の平均値について、segが0と1ごとで差があるのか、平均値の差のt検定をしたい。」というのは終わっています。「segごとに平均値と差をv1からv5ごとにグラフ化したい。」という問題を解決しましょう。
グループを展開する
このままでは、平均値に差があるのかどうかすらわかりません。グループを展開しましょう。UIから展開できます。「リストの項目を行に展開」というところです。
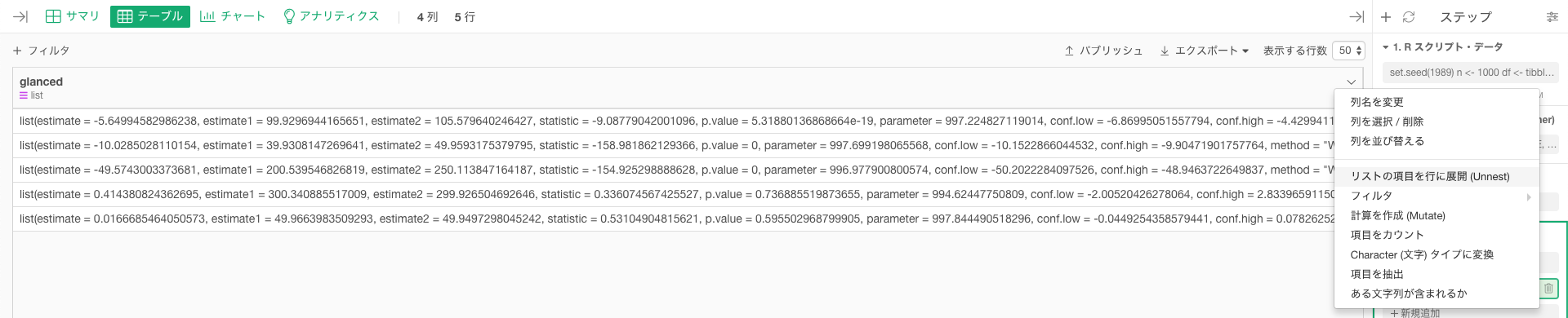
この後に不要な列をselect()で消すとこんな感じになります。

v1からv5の値の平均値について、segが0と1ごとで差があるのか、平均値の差の検定できていますね。ちなみにここまでであれば、最初のWide型からLong型への変換が終わった時点でUIの方からでもできます。「先に言えよ、別にグラフにしたくないよ」という方はごめんなさい。

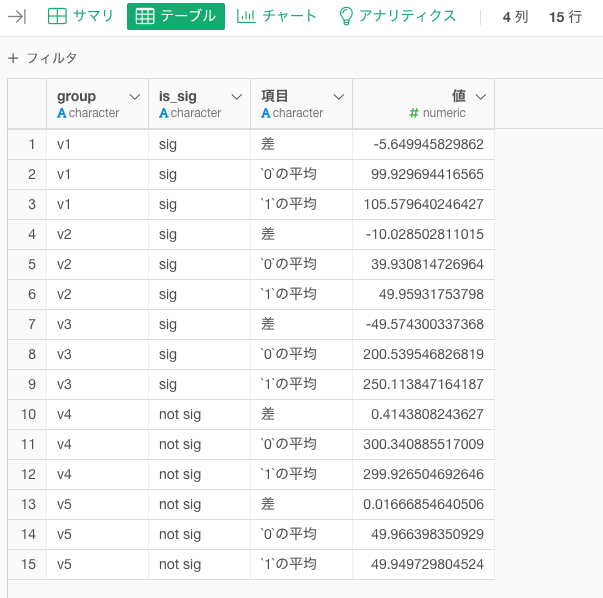
こちらの「segごとに平均値と差をv1からv5ごとにグラフ化したい。」という問題を解決しましょう。これも最初と同じですね。その前に、5%有意なのかフラグis_sigを計算して、名前をUIの結果と同じようにしておきます。
「segごとに平均値と差」として機械に解釈させるためには、「『0の平均値』と『1の平均値』と『差』の3列をわたす」か「これらを1列にして渡すか」のいずれかです。これも列として渡すほうが効率的に作業できるので、加工します。
こんな感じになります
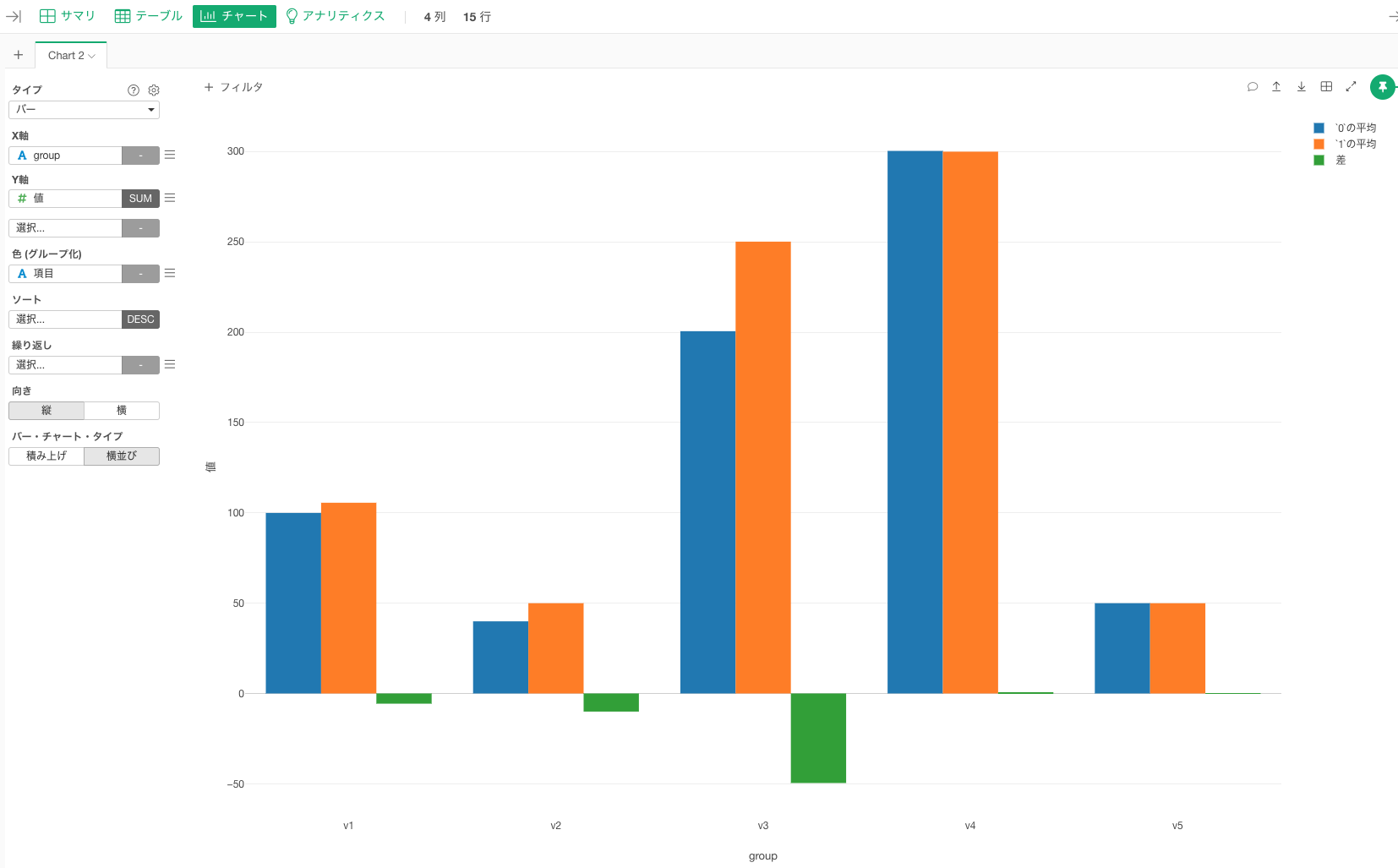
あとはこれをチャートビューで可視化すれば目的達成です。左の青色から順番にgroup:v1のseg:0の平均値、seg:1の平均値、平均値の差です。これがグループごとに繰り返しています。
こんな感じで計算しなくても「UIのt検定の結果をデータフレームに複製すればいいではないか?」と思うかもしれませんが、そうすると「複製の部分」は手動になるということなので、データが変わったりすると、入れ替えるだけは「手動」なので時間がもったいないです。1回ならまだしも毎日とか、毎週とか同じような分析を定例でやるとなると、面倒です。なので、こうしておけば面倒を減らせます。
まとめ
t検定を例にしましたが、これ以外でも「○○ごとに✕✕をする」ということはできます。以上、「nest関数とmap関数でExploratroyを更に便利にするの巻」でした。ちゃんちゃん。
データの生成
set.seed(1989)
n <- 1000
df <- tibble(seg = sample(c(0,1), n, replace = TRUE),
v1 = rnorm(n, 100, 10) + if_else(seg == 1, 5, 0),
v2 = rnorm(n, 50, 1) + if_else(seg == 0, -10, 0),
v3 = rnorm(n, 200, 5) + if_else(seg == 1, 50, 0),
v4 = rnorm(n, 300, 20) + if_else(seg == 0, 0.5, 0),
v5 = rnorm(n, 50, 0.5) + if_else(seg == 1, 100, 0))