はじめに
ここでは、EDASalon 第6回 - 日本の統計データ(e-Stat)のデータラングリング大会の犯罪統計データを使用し、データクレンジングを行い、犯罪統計の推移を可視化することが目的である。
数年分のデータを一度に処理することを念頭においていたため、特定の行番号や特定の値を場当たり的に指定して加工する方法は避けた。
ローデータの状況および問題点
読み込み時のローデータの状況は下記の通り。データクレンジングする際の項目をまとめてみた。rowidはこのノートで説明する際に、場所を特定するために追加した番号であって、データクレンジングの処理過程では使用していない。また、これ以降で行の番号を指定しているときは、rowidを意味する。
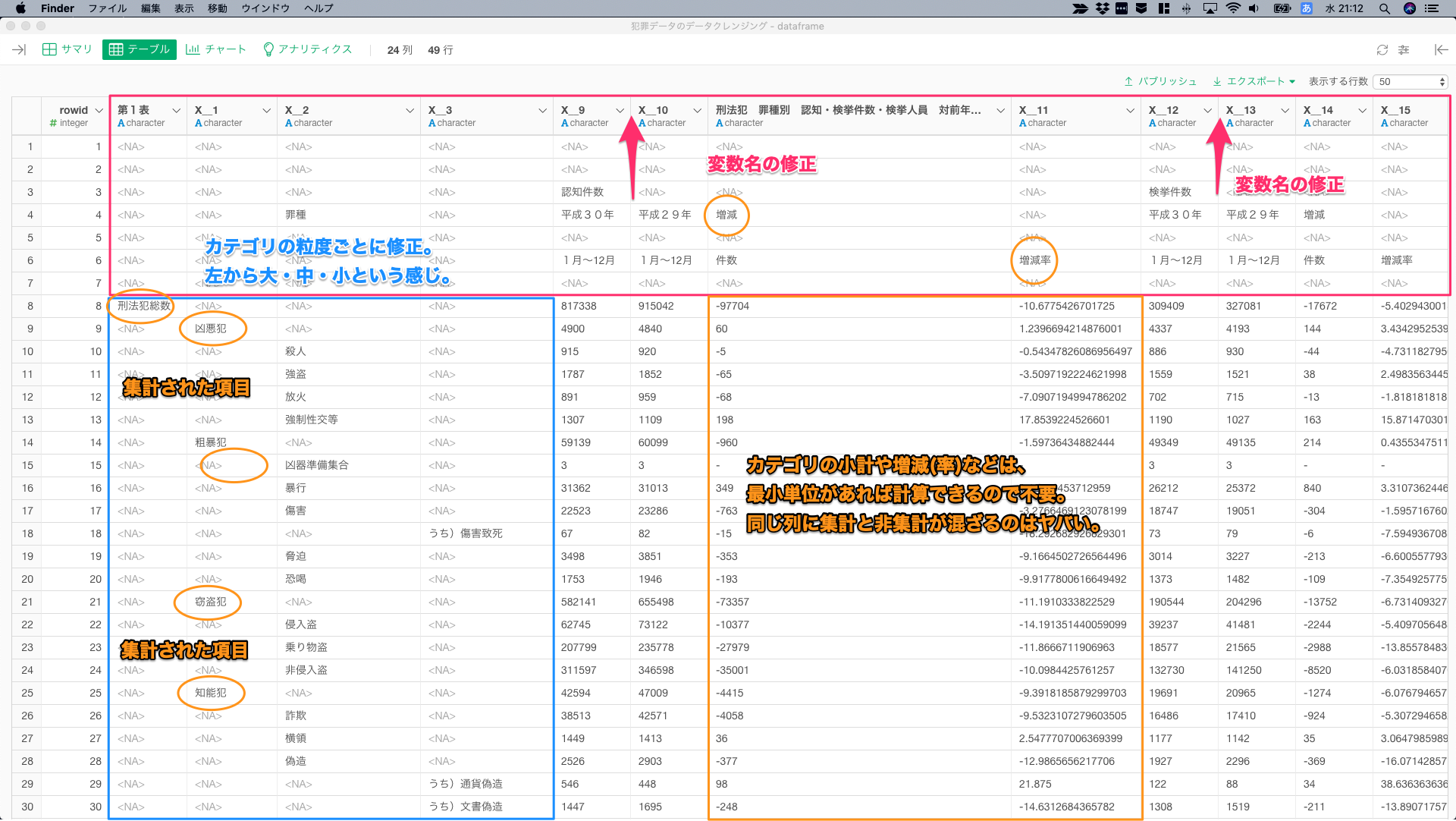
- 赤枠:カラム名を1~7行目の情報で修正
- 青枠:カテゴリの粒度を揃えて、左から大・中・小という粒度で修正
- 橙色:集計と非集計の値の調整。最小粒度の値があれば集計は可能。
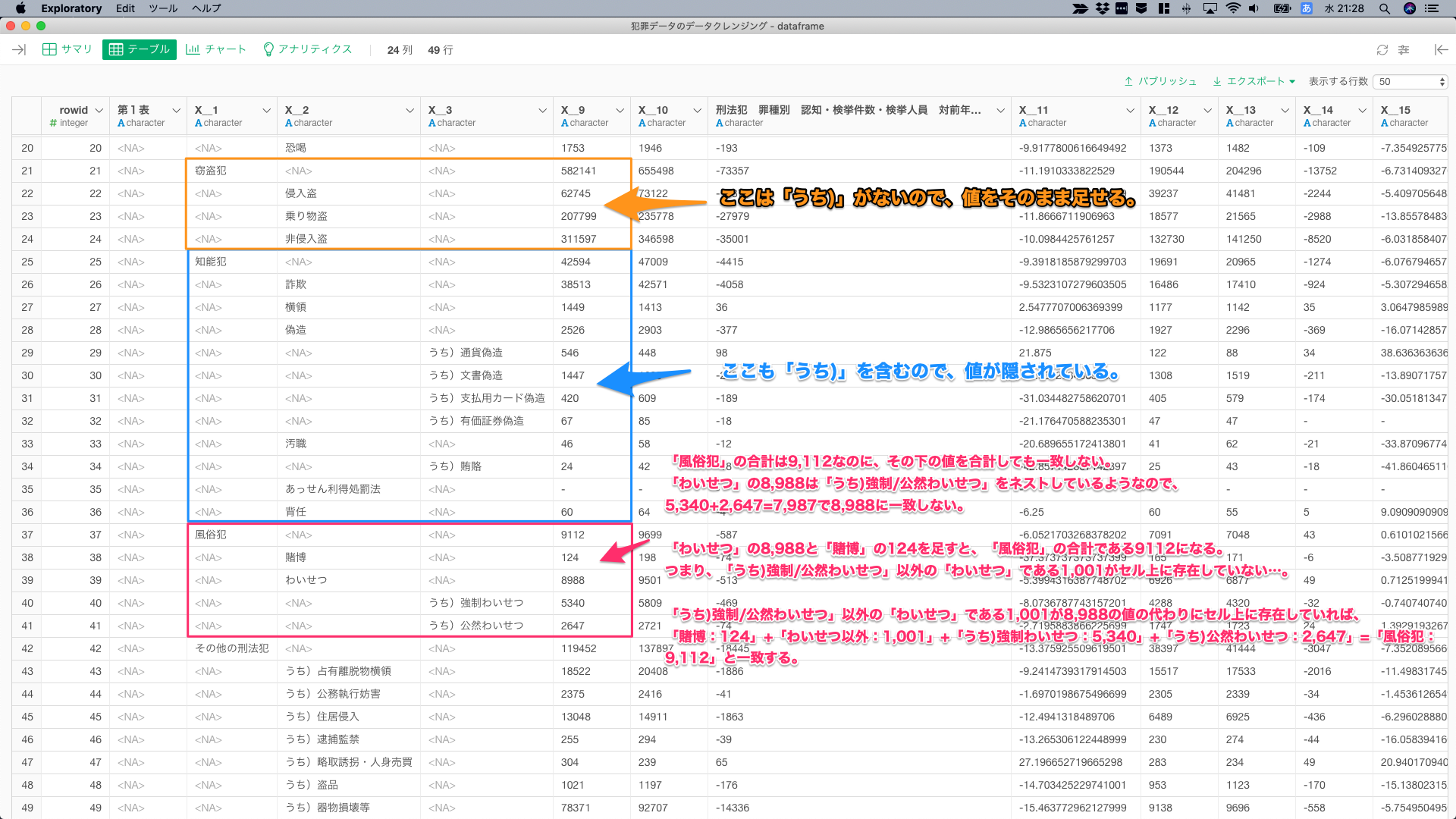
1番厄介な問題はここである。下記の通り、本来はあるべき値が隠されしまっている(計算すれば復元できるという意味)。このままでは、直感的に分析できず、何をするにも条件をづけるなど、データラングリングストレスが増え、集計ミスのもとになる。
「風俗犯」の合計は9,112だけれど、その下の値を合計しても一致しない。また、「わいせつ」の8,988は「うち)強制/公然わいせつ」をネストしているようだが、5,340+2,647=7,987で8,988に一致しない。
つまり、「わいせつ」の8,988と「賭博」の124を足すと、「風俗犯」の合計である9112になるので、「うち)強制/公然わいせつ」以外の「わいせつ」である1,001という値がセル上に存在していないことになる。1,001という値が8,988の値の代わりにセル上に存在していれば、「賭博:124」+「わいせつ以外:1,001」+「うち)強制わいせつ:5,340」+「うち)公然わいせつ:2,647」=「風俗犯:9,112」と一致するので、素直にグループ化して合計しても問題は発生しない。
状況および問題点は以上の通りである。したがって、①変数名を修正し、②カテゴリの粒度を修正し、③集計・非集計の混在を修正し、隠された値を復元すれば、分析に使いやすいデータとなる。
①変数名の修正
ここでは、H29とH30の認知件数と検挙件数に対象を限定しているが、他の列も同じ構造なので、列を追加しても問題は発生しない。
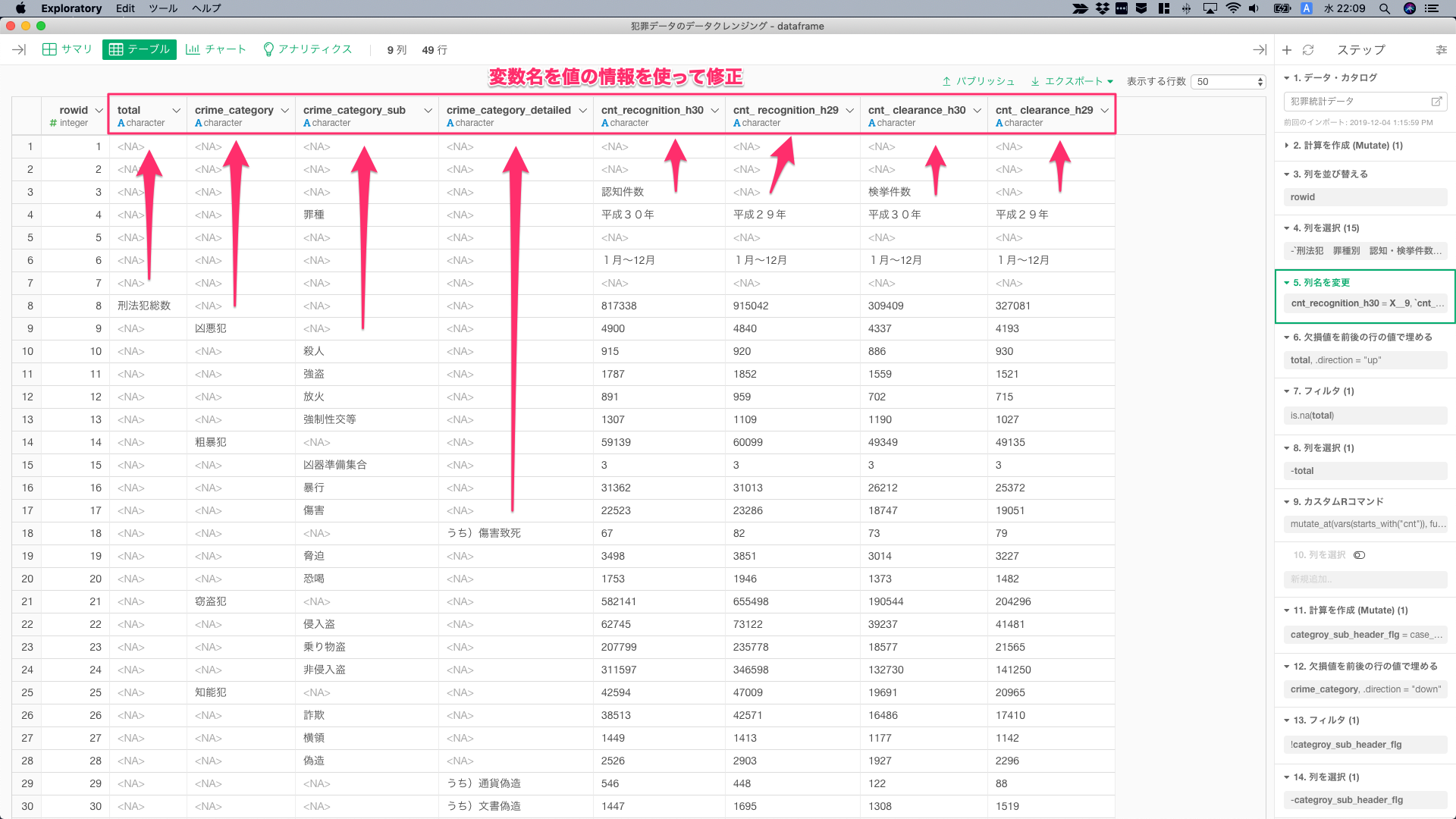
不要な列を削除し、変数名を各要素の値から修正した。後のクレンジング作業で、グルーピングして処理できるように、カテゴリはcrime_**、件数はcnt_**_h*というようにプレフィックスをつけておいた。
赤枠とそれ以外の行を二分できる情報を持っている変数がなかったので、totalの「刑法犯総数」をfill()で補完し、8行目から上の部分を「刑法犯総数」かNAかの2値の状態に加工しフィルタ。
8行目から上の部分を消すにあたり、削除したい行の一番下の部分に位置するので、この部分を境に分割できれば、仮にデータを変更して、8行目から上の部分に不要な行(サブタイトルとか、備考とか)が増えても自動で処理を反映させられる。
そして、35行目の「あっせん利得処罰法」の行をみると、-(ハイフン)があるようで、cnt_**_h*が文字型にパースされているので、これを数値型に修正。さきほど名前を変更した際に付与したプレフィックスを使い、starts_with("cnt")でcnt_**の列を数値型に型変換。
mutate_at(vars(starts_with("cnt")), funs(parse_number))②カテゴリの粒度を修正
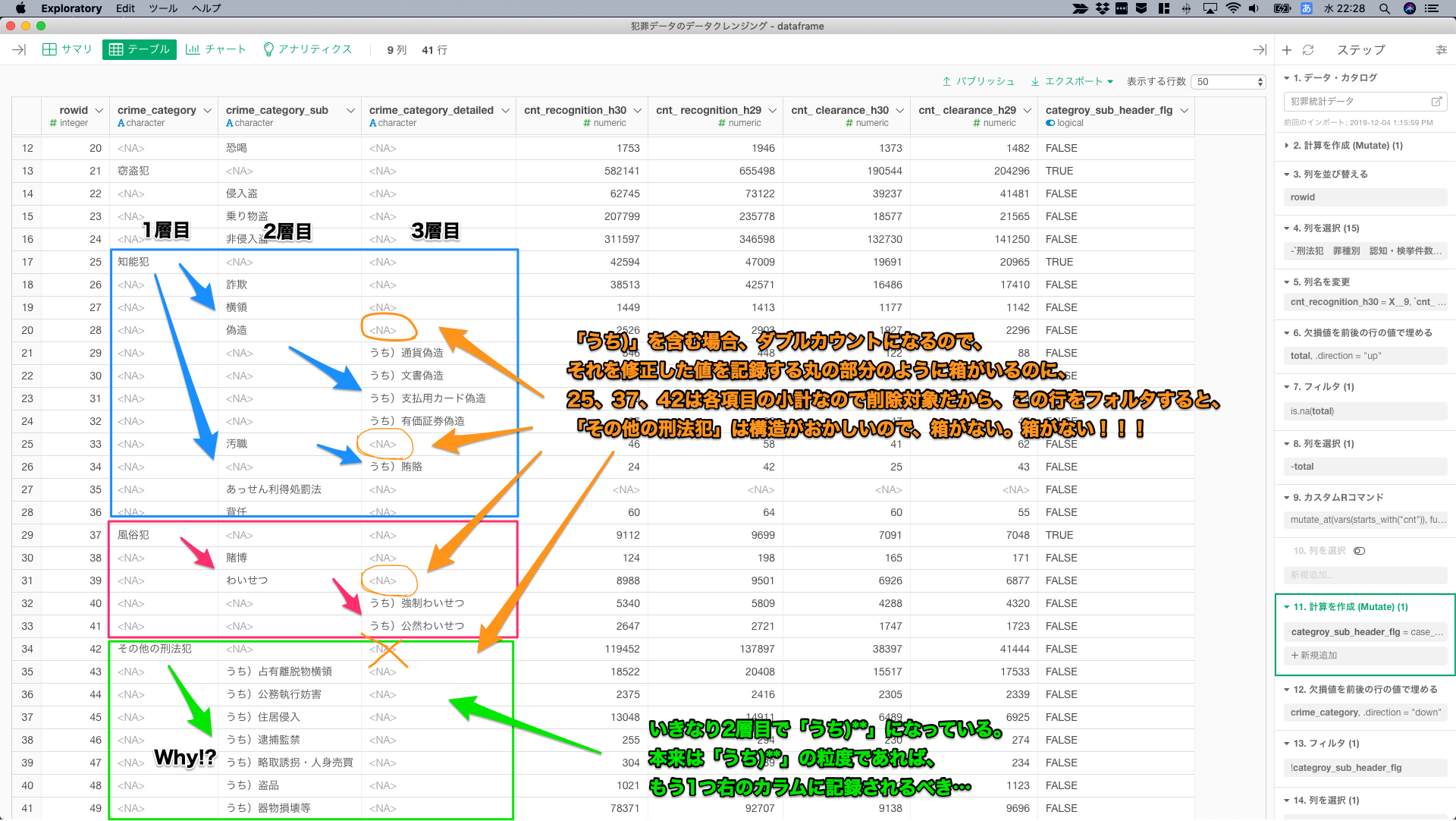
カテゴリの粒度を修正していく。データを眺めると緑枠の「その他の刑法犯」だけ、同じ構造を持っていないことがわかる。
目論見としては、「うち)**」を含む場合、それを修正した値を格納する橙色の丸の部分のように箱がいるのに、rowidが25、37、42は各項目の集計行なので削除対象。なので、この行をフォルタすると、「その他の刑法犯」は構造がおかしいので、箱がなくなってしまう。
「その他の刑法犯」だけ箱、集計を削除せず、値を格納するための箱としてフィルタの対象外とするcase_when()を書くことにする。
そして、集計行をフィルタする前に、欠損値を補完して、crime_categoryをキレイな状態にする。下記の画像の青枠のNAを補完して埋めるが、group_by()しないと、「その他の刑法犯」の部分が誤って埋まるので注意した。
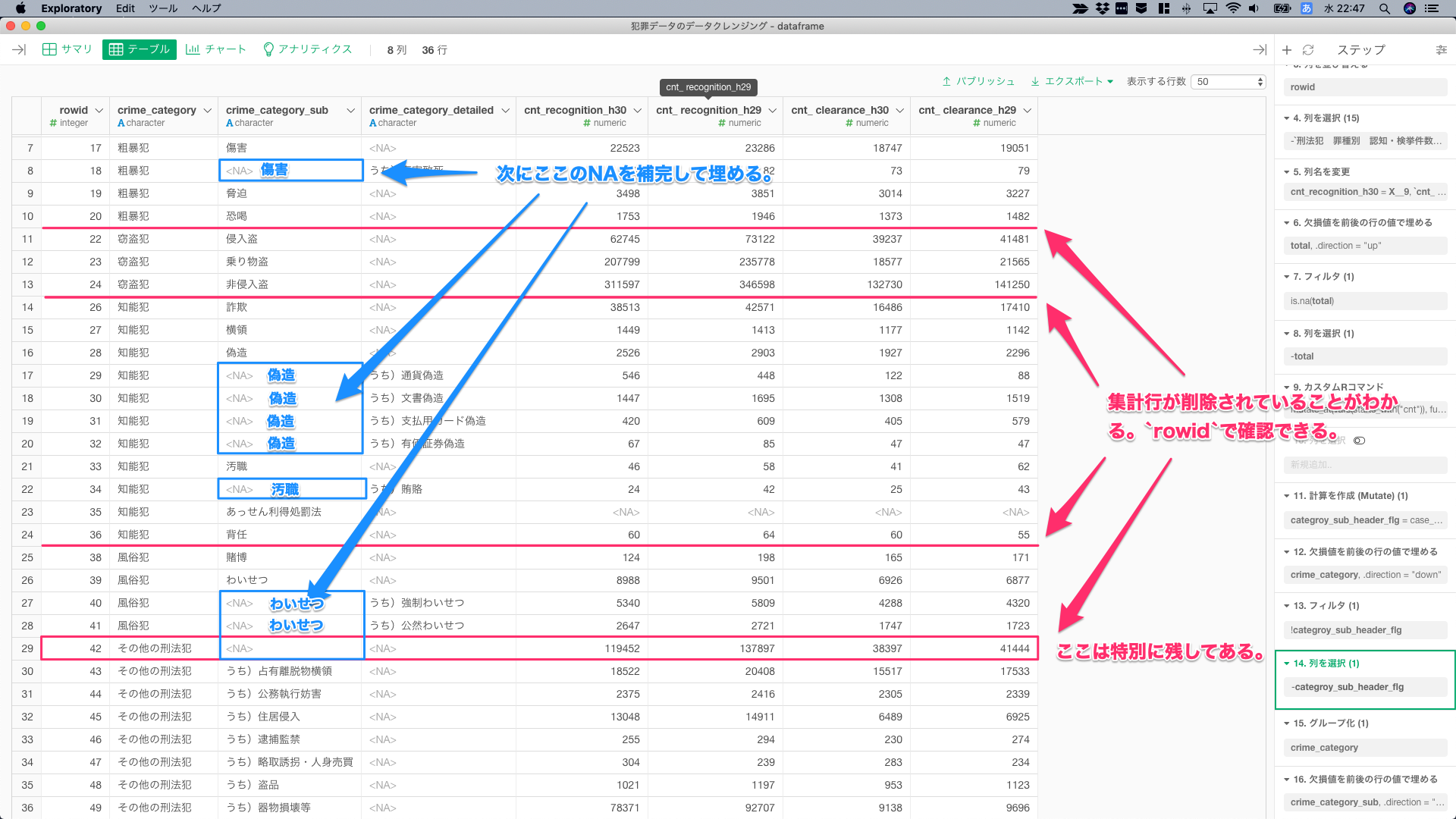
内訳がない青枠のところは、そのまま2層目のカテゴリをスライドして、「うち)**」の1行、上の行は、「うち)**」の1行上の行というパターンだけを特定して、内訳以外の行を表す「うち以外)**」という値に修正するために、lead()でずらして、ここのパターンを特定するための列を作る。
crime_category_detailedはNAだけど、lead()でずらした行は、NAではないというパターンは、「うち)**」の1行上の行しかない。
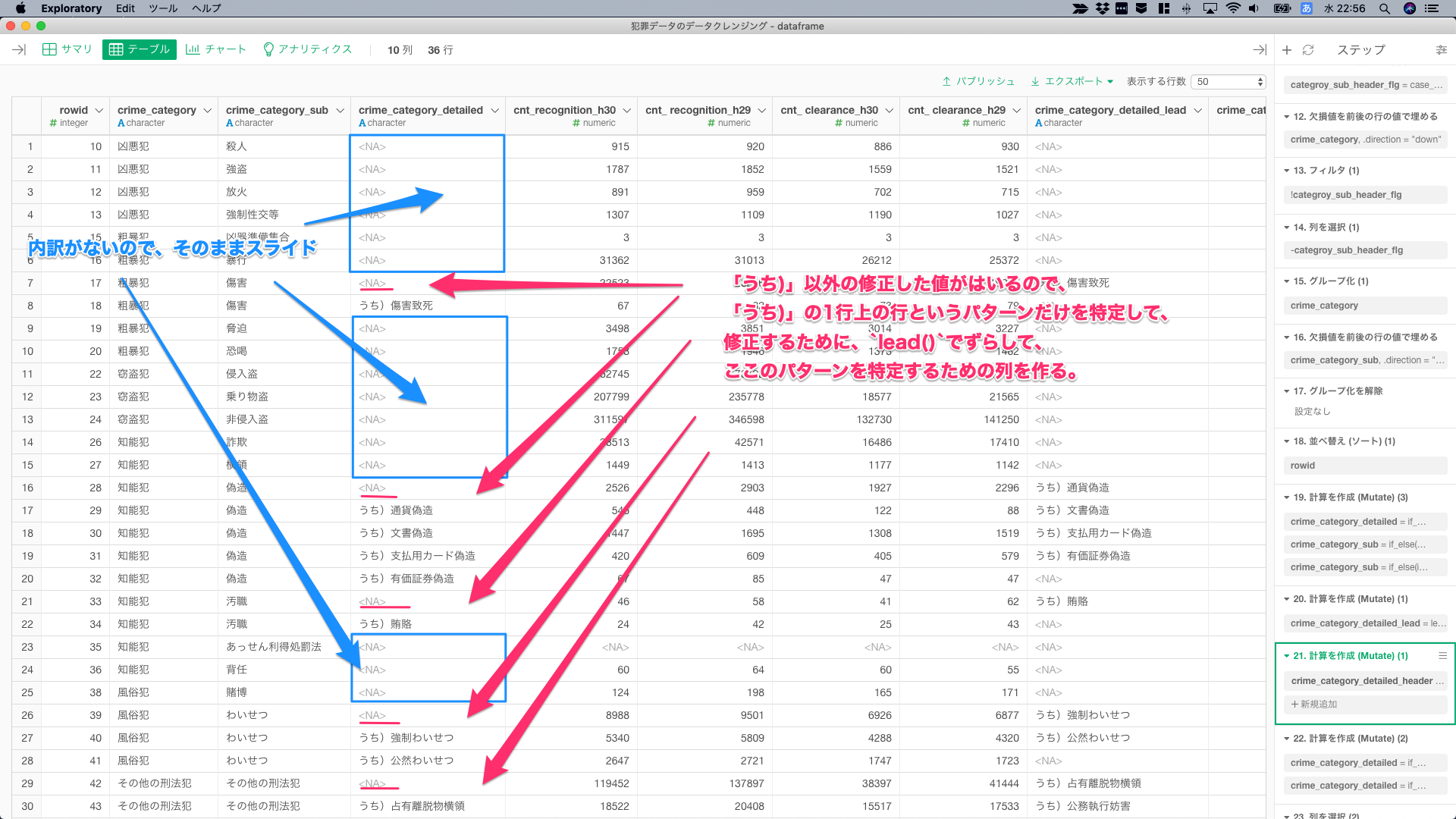
処理した後はこんな感じ。
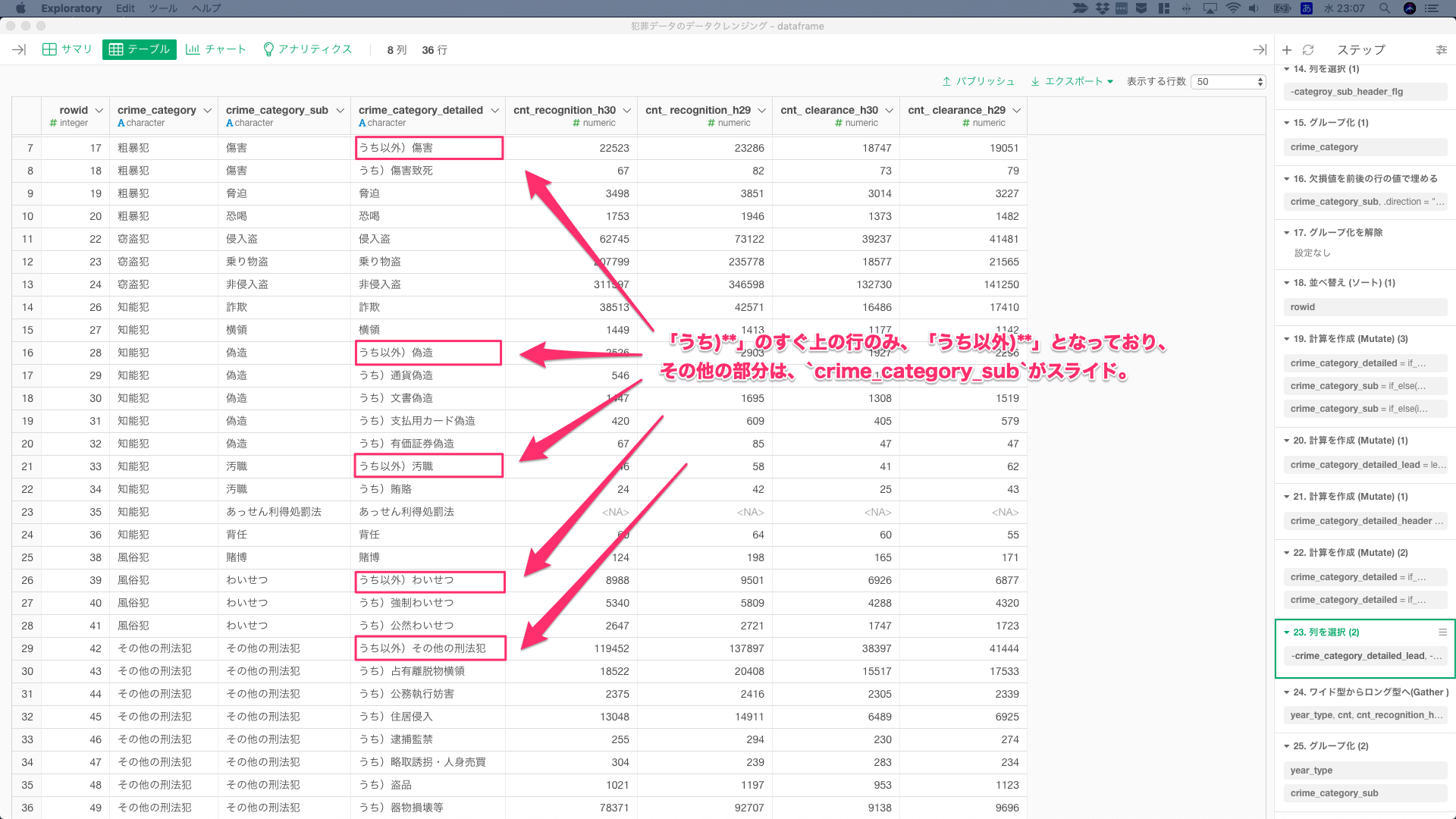
③「うち以外)**」の値の修正
「うち以外)**」の行の値は、集計する件数の列分、一度に修正したいので、Wide型からLong型に構造変換を行う。
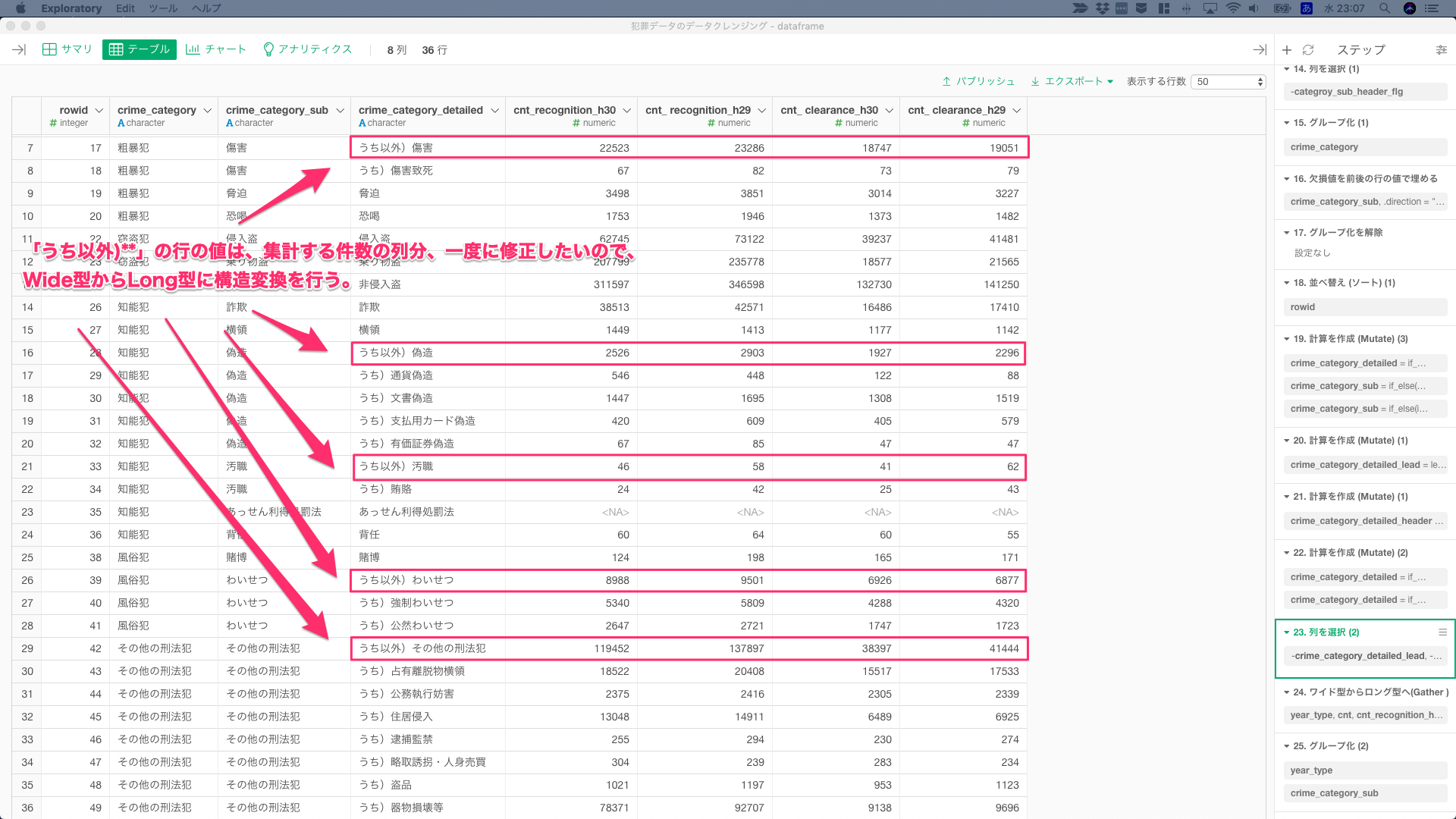
gather()した際に、年度と件数項目はyear_typeという変数名にした。Long型に構造変換したので、そのyear_typeを含め、crime_category_subでgroup_by()して、件数を合計する。
ここから訳がわからないことを言うが(集計がおかしいという意味ではない)、
「うち)**」に関するところは、「うち)**」と「うち以外)**」の合計が入っているので、この合計から「うち以外)**」の値を引けば、差分の値が計算できる。「うち)**」に関係がないカテゴリの新しい列には同じ値が入る。
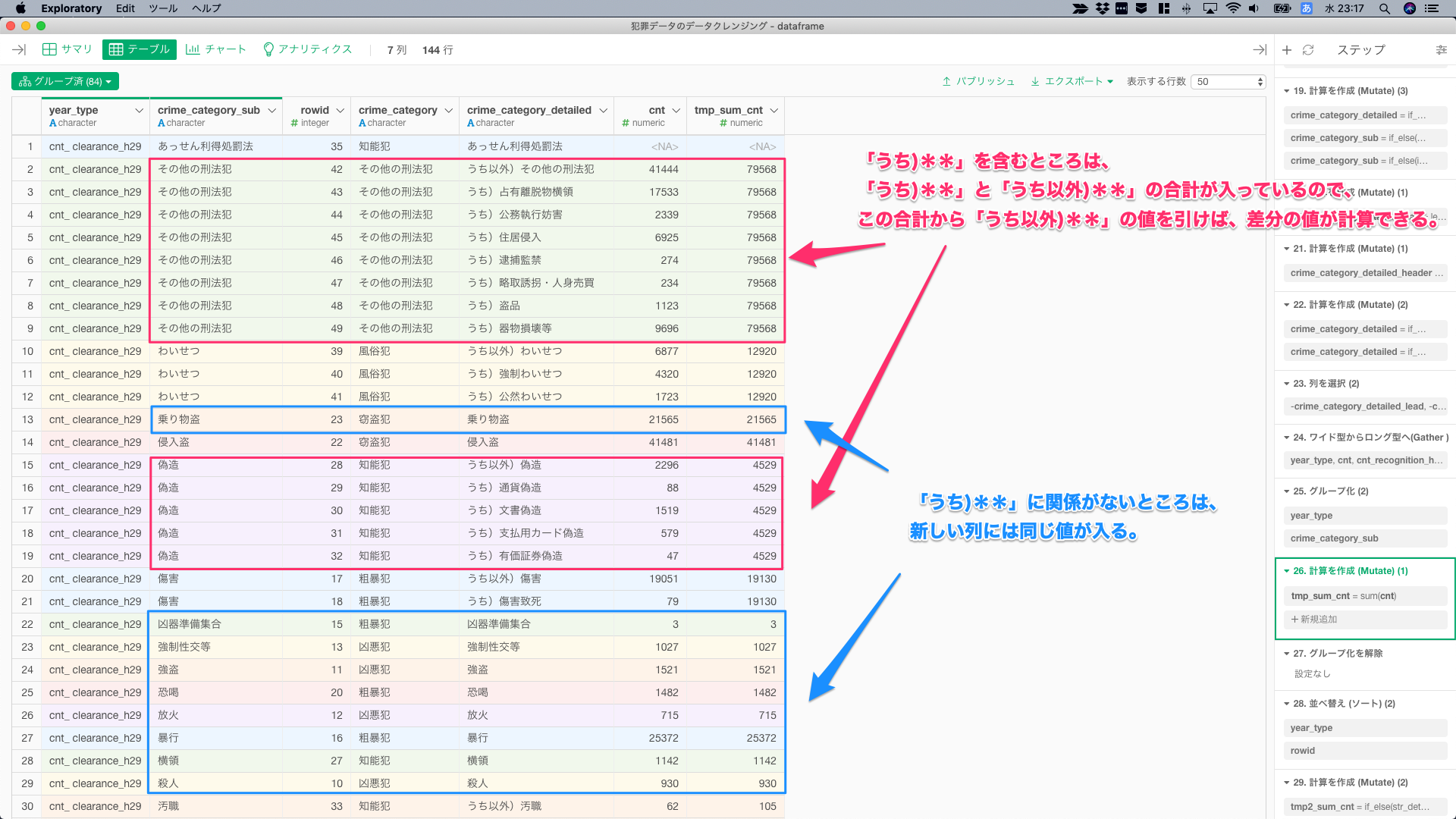
「うち以外)**」の値のみを修正する。「風俗犯」の小計は9,112である。「うち以外)わいせつ:8,988」は、「風俗犯:9,112」から「賭博:124」を引いた値。なので 「うち以外)**」と「うち)**」の合計:16,975から、「うち以外)わいせつ:8,988」を引いて、「うち以外)わいせつ:8,988」から、値:7,987を引けば、「うち以外)わいせつ」の修正値cnt_modifiedがでる。
他にもっと簡単な方法があるはずですが、思いつきませんでした。だいたい、来年になってデータ追加されたから更新しようとこのコードをみると、この部分で頭を抱えると思う。
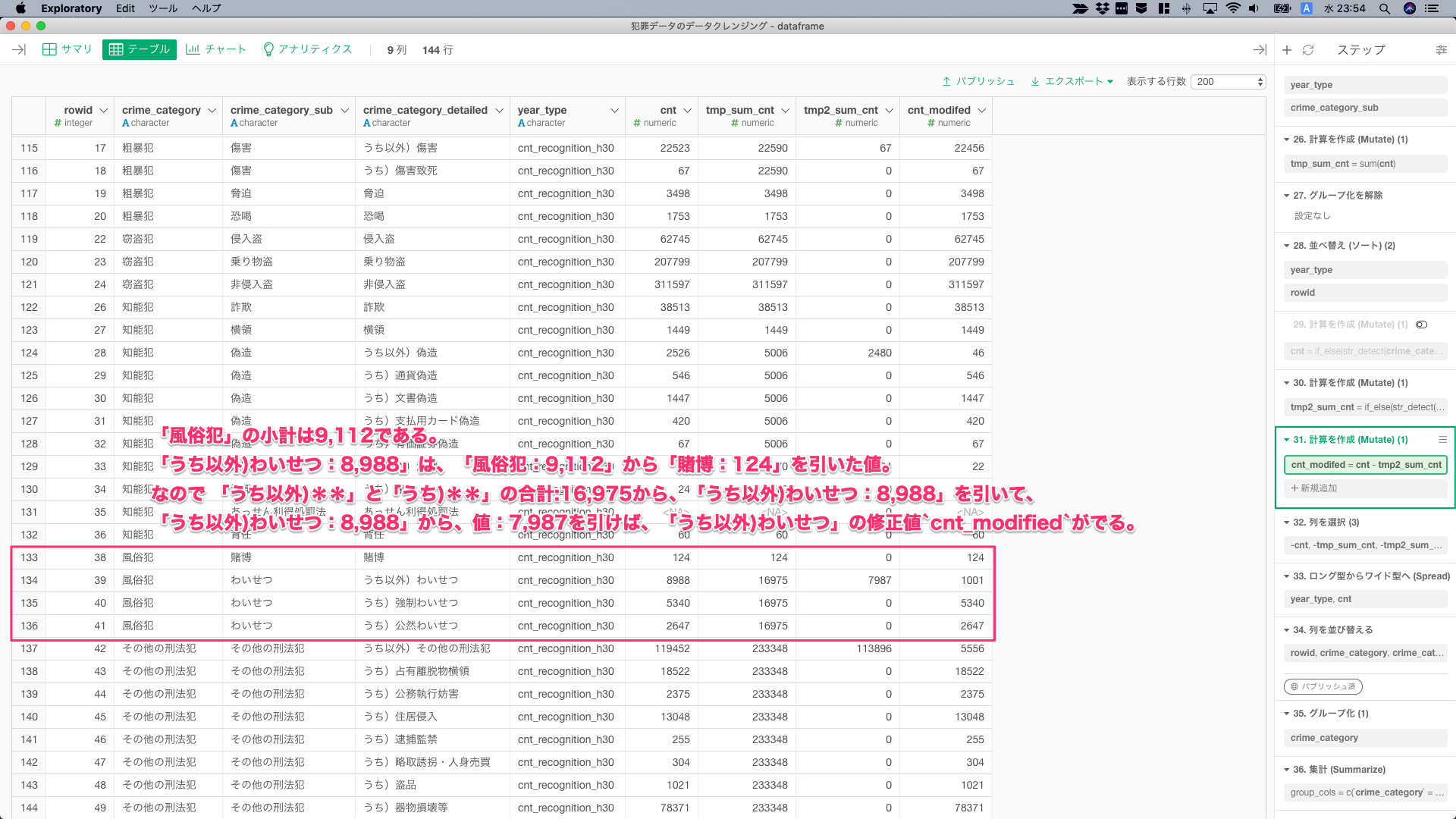
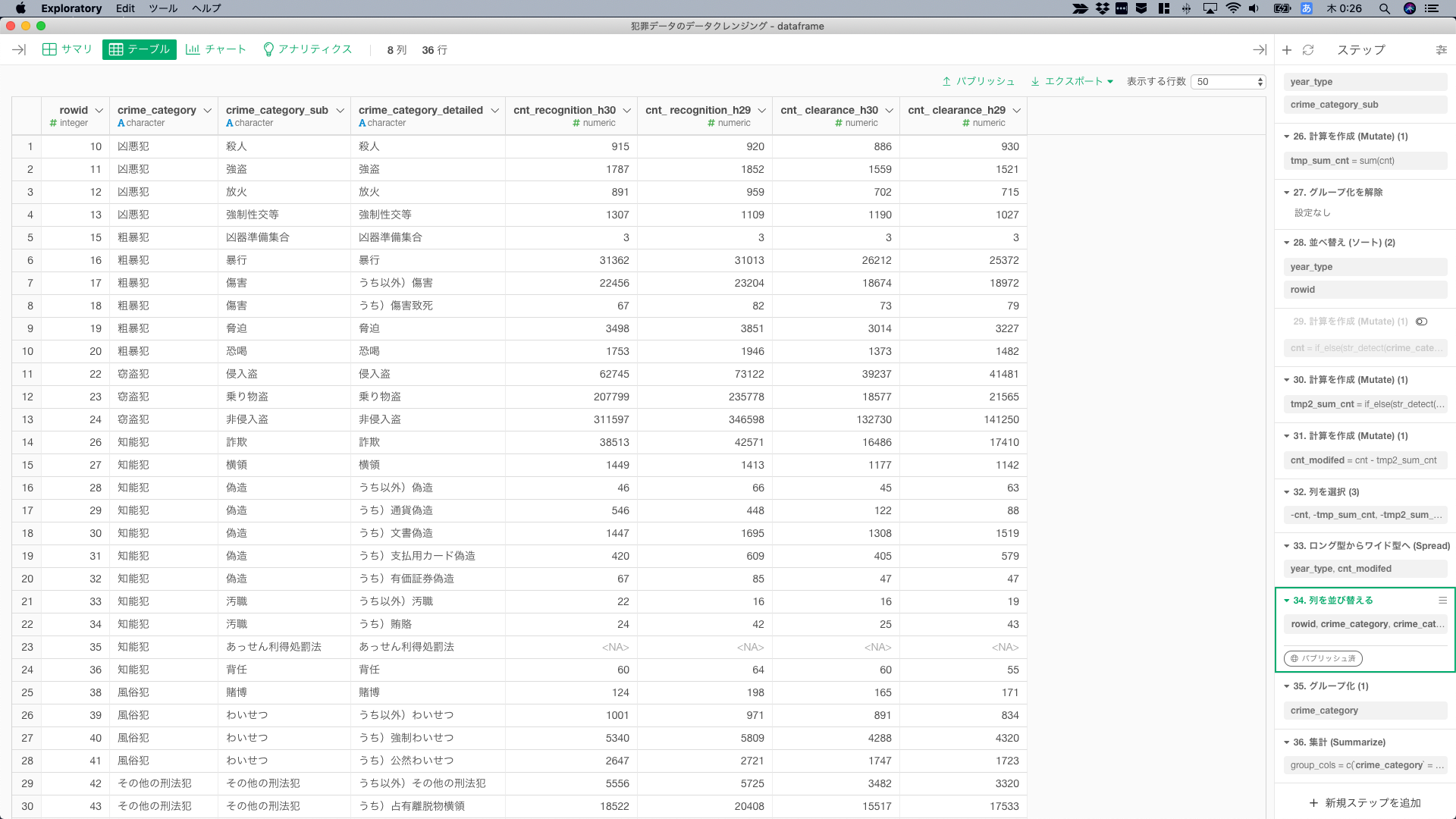
あとは、もとのレイアウトに戻すために、Long型からWide型に変換すれば、Excelライクな表の完成。
検証
左からExcelのローデータ、クレンジング済みデータ、検証フラグである。「うち以外)**」の部分以外は数字が一致している。ここは、修正値をクレンジングデータでは記録しているので、FALSEで問題ない。
「その他の刑法犯」の部分は、「うち以外)**」の部分を入れる箱がないので、Excelのローデータだと一番下に追加して計算したので、この部分の検証フラグはTRUEで問題ない。
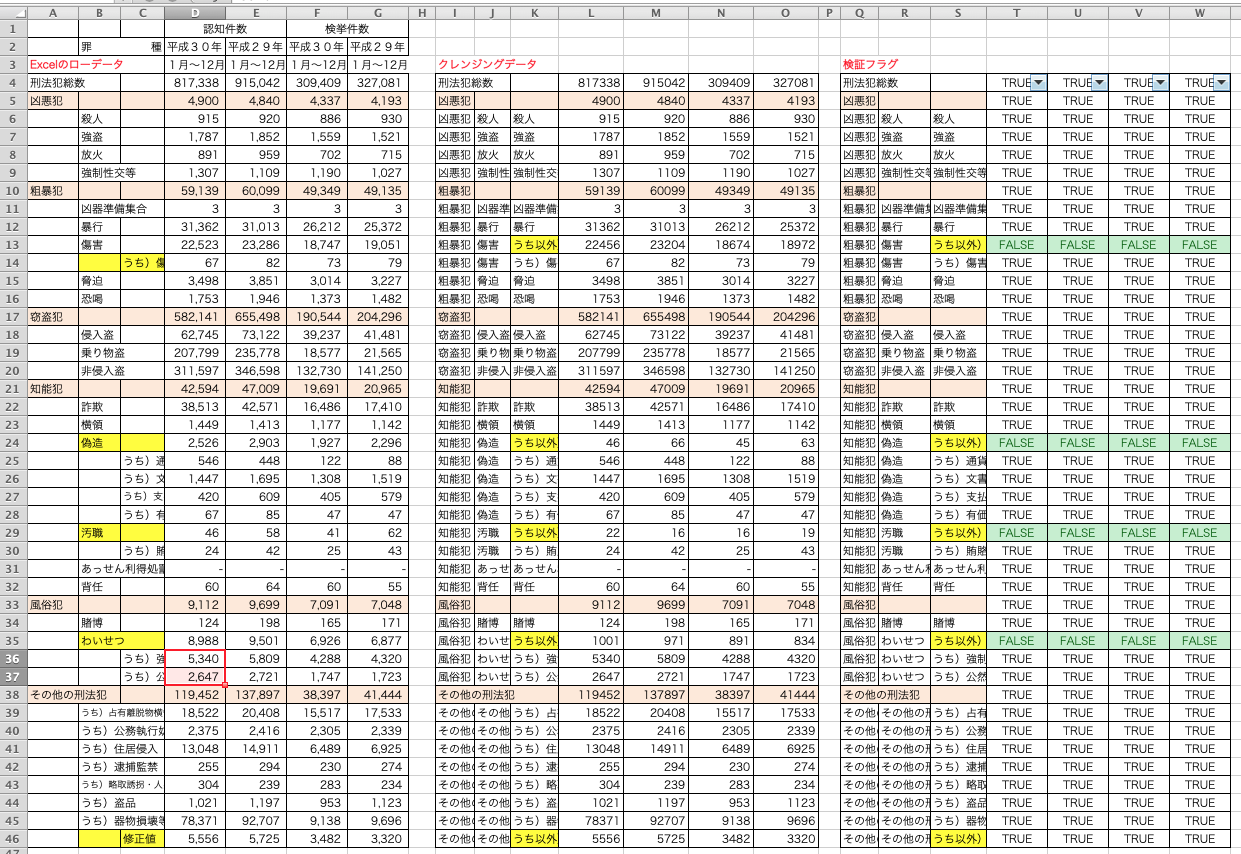
また、オレンジ色の行は集計行であるが、この部分は、Excelのローデータのレイアウトにあわせて、行を追加し、各項目ごとに合計した値であり、「うち以外)**」の部分を含めて集計しても、クレンジング済みデータの総合計、項目ごとの合計値、非集計データの合計と一致している。

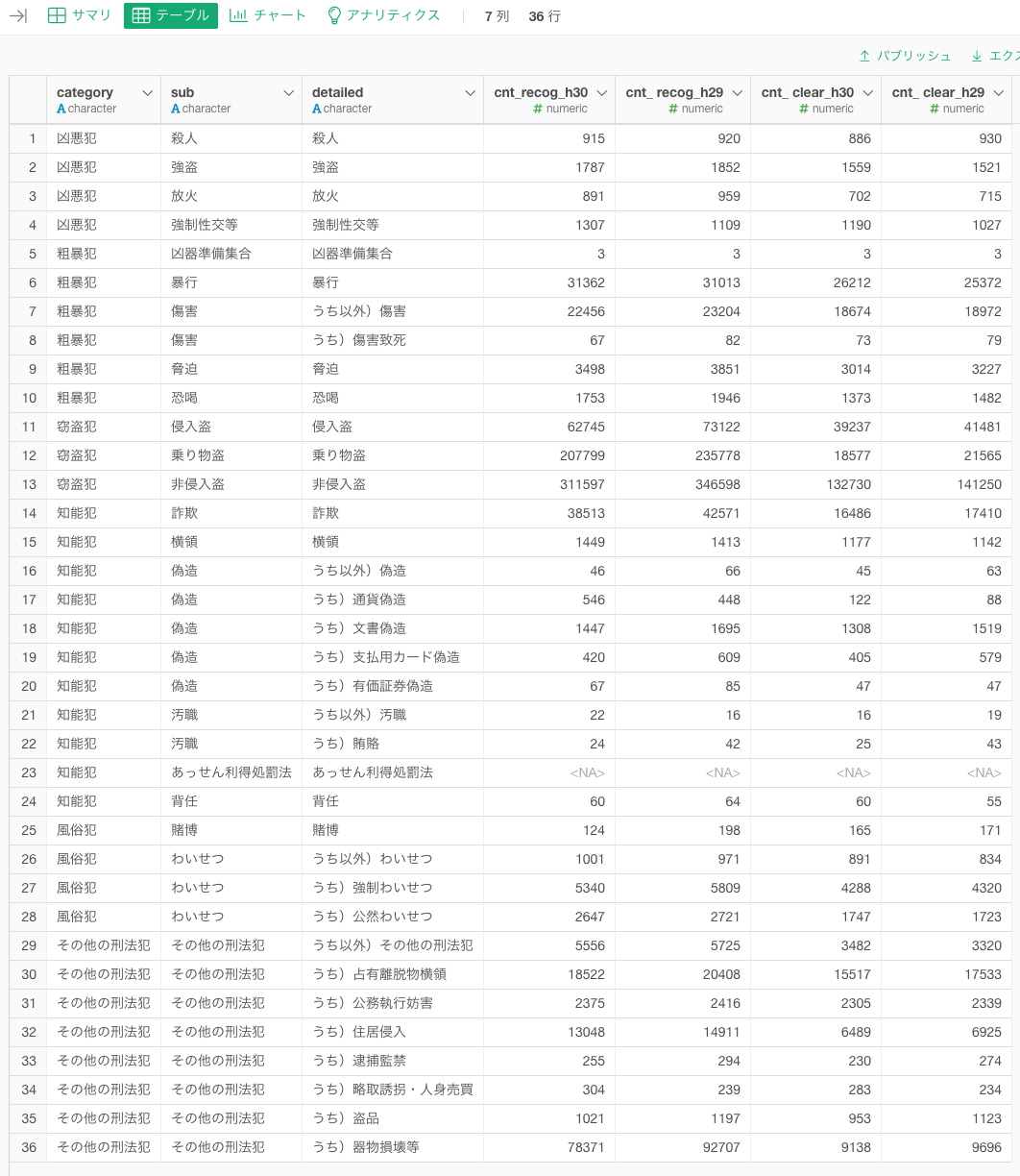
最終形のデータはこれ。
認知件数の前年比比較
認知件数の前年比を可視化しておく。グループ単位はcrime_category。凶悪犯がH29と比較して増加している。
認知件数をドリルダウンして最小粒度のcrime_category_detailedで可視化してみる。crime_categoryの単位では、凶悪犯が増加していたが、細分化すると、項目によっては、犯罪が増加している項目もある。
crime_category単位でみると、凶悪犯のみが増加していたが、他のグループでは、他のグループ内での認知件数が減少したことによって、crime_category単位では減少という結果になっていることがわかる。
追記:2008~2018年の統計データを可視化
最新のH30年のデータクレンジングで使用したRスクリプトは、同じ構造の犯罪データのExcelであれば処理が使い回せるので、これをちょこっとだけいじり、2008~2018年の統計データを読み込んで、認知件数の推移を可視化する。
2007年以前は、2008年以降とはセルの値の位置が異なっていたり、pdfだったりするので、スクリプトが使い回せない。したがって、2008年以降20年分を対象にした。
知能犯(詐欺、横領、偽造、汚職、背任)とかは、近年、件数があがっている傾向があるみたい。
まとめ
このExcelのデータを最初に見た限り、どうクレンジングするとかを考える前に、手で直したほうが早いとは思った。手で直せば、10分もかからないと思うが、10分×20年分と考えると、200分かかるのと、同じ作業を20回も正確に繰り返す自信はない。
そして、来年に新しいデータが来た時に、Excelを手で修正していれば、きっと作業手順書があっても再現できないし、そもそも担当は会社を辞めてるかもしれない。そうなると、再現するのは非常に困難かと思う。
したがって、分析からインサイトを掘り出すことも大切ではあるが、Reproducibility(再生可能性)、再現可能性 (Replicability)も同じくらい重要だと個人的には思うので、このようにデータをクレンジングした次第である。とか言いつつ、確認したけど、間違ってたらごめんなさい…。
Rスクリプト(追記こみ)
# wd <- setwd(dir = "/Users/user/Desktop/tmp")
#
# xls_list <- list.files(path = wd,
# pattern = "xls$",
# full.names = TRUE)
#
# res <- dplyr::tibble()
#
# for (i in seq_along(xls_list)) {
# df_crime <- exploratory::read_excel_file(xls_list[[i]], sheet = "第1表", na = c('','NA'), skip=0, col_names=TRUE, trim_ws=TRUE, col_types="text") %>%
# readr::type_convert() %>%
# exploratory::clean_data_frame() %>%
# # 年度間で変数名が違うけど位置は変わらないので、いやだけど数字で指定する
# dplyr::select(1,2,3,4,10) %>%
# dplyr::mutate(rowid = row_number()) %>%
# exploratory::reorder_cols(rowid) %>%
# # 年度間で変数名が違うけど位置は変わらないので、いやだけど数字で指定する
# dplyr::rename(total = "第1表", category = "...2", sub = "...3", detail = "...4", cnt_recog = "...10") %>%
# tidyr::fill(total, .direction = "up") %>%
# dplyr::filter(is.na(total)) %>%
# dplyr::select(-total) %>%
# dplyr::mutate(cnt_recog = readr::parse_number(cnt_recog)) %>%
# dplyr::mutate(categroy_sub_header_flg = dplyr::case_when(category =="その他の刑法犯" & is.na(sub)==TRUE ~ FALSE,
# is.na(category)==FALSE & is.na(sub)==TRUE ~ TRUE, # その他の刑法犯を除いたheader
# is.na(category)==TRUE & is.na(sub)==FALSE ~ FALSE,
# is.na(category)==TRUE & is.na(sub)==TRUE ~ FALSE)) %>%
# tidyr::fill(category, .direction = "down") %>%
# dplyr::filter(!categroy_sub_header_flg) %>%
# dplyr::select(-categroy_sub_header_flg) %>%
# dplyr::group_by(category) %>%
# tidyr::fill(sub, .direction = "down") %>%
# dplyr::ungroup() %>%
# dplyr::arrange(rowid) %>%
# dplyr::mutate(detail = dplyr::if_else(category =="その他の刑法犯" & is.na(detail), sub, detail),
# sub = dplyr::if_else(sub == detail, NA_character_, sub, missing = sub),
# sub = dplyr::if_else(is.na(sub), category, sub),
# detail_lead = lead(detail,1),
# detail_header = dplyr::if_else(is.na(detail) & !is.na(detail_lead),1,0),
# detail = dplyr::if_else(is.na(detail)==TRUE & detail_header == 1, paste0("うち以外)",sub), detail),
# detail = dplyr::if_else(is.na(detail), sub, detail)) %>%
# dplyr::select(-detail_lead, -detail_header) %>%
# dplyr::group_by(sub) %>%
# dplyr::mutate(tmp_sum_cnt = sum(cnt_recog)) %>%
# dplyr::ungroup() %>%
# dplyr::arrange(rowid) %>%
# dplyr::mutate(tmp2_sum_cnt = dplyr::if_else(str_detect(detail, "以外"), tmp_sum_cnt - cnt_recog, 0),
# cnt_modifed = cnt_recog - tmp2_sum_cnt) %>%
# dplyr::select(-cnt_recog, -tmp_sum_cnt, -tmp2_sum_cnt) %>%
# # H20~H30のデータなのでloopで西暦をふる。データの読み込み順もソート。
# dplyr::mutate(year = 2007 + i)
#
# res <- res %>% dplyr::bind_rows(df_crime)
# }
#
# write_csv(res, "crime_data_h20_h30.csv")