日本の住所データで遊んでみる
はじめに
唐突に始まりますが、こんな分析の依頼を受けたとします。
Q : 「大学の所在地の一覧データ」はあるから、各都道府県の「大学の数」と「15~19歳の人口」は関係がありそうなのか調べて?東京都とか、大阪って、どこに大学集まってるの?
(関係あるに決まってるだろ!というツッコミは容赦いただきたい。フィクションです。)この手のデータ分析を依頼されるたびに感じることがあります。日本の住所データは扱いにくい。日本に限らず、世界的にもそうかもしれないし、私の技術不足と言われれば、そのとおりなのですが…。
文字列のデータに対しては、やはり正規表現を使い、抽出したい部分を適切に抽出できれば、見える世界も変わってくるのかもしれませんが、私は正規表現が苦手です…。
例えば、こんな住所のデータを見た日に絶望しかありません。
建物名 : 志布志市志布志町志布志の志布志市役所志布志支所
読み方 : しぶし_しぶしちょう_しぶし_の_しぶししやくしょ_しぶしししょ
住所 : 鹿児島県志布志市志布志町志布志2丁目1-1
建物名 : 相国寺
住所 : 京都府京都市上京区今出川通烏丸東入上る二筋目東入下る相国寺門前町
読み方 : きょうとふ_きょうとし_かみぎょうく_いまでがわどおり_からすまひがしいるあがる_ふたすじめひがしいるくだるそ_うこくじもんぜんまち(読み方これでいいのか…?)冗談はさておき、住所データは扱いにくいですが、{zipangu}というパッケージがあります。このパッケージは日本のデータを分析する際に、頻繁に遭遇する全角、元号、祝日の判定処理を効率的に行うための関数や便利なデータセットを提供しているRパッケージです。
{zipangu}は、諸事情により利用ができない{Nippon}というRパッケージの代替え、そしてより便利な機能を提供することを目指している素晴らしいパッケージです。また、現時点(2019年12月6日時点)では使用できる機能は限定的とのことで、今後、機能が追加されていくとのことです。詳細は下記を参照ください。
ここではExploratoryのデータカタログと{zipangu}パッケージを使って、日本の住所データを用いた分析を行います。
大学所在地一覧のデータを探索する
分析の軸となるデータはこのような「大学の所在地一覧」のデータです。国内大学の位置データ Location Data of Universitiesを一部、加工したものを使用します。地図はノートが重くなるので、画像にしています。
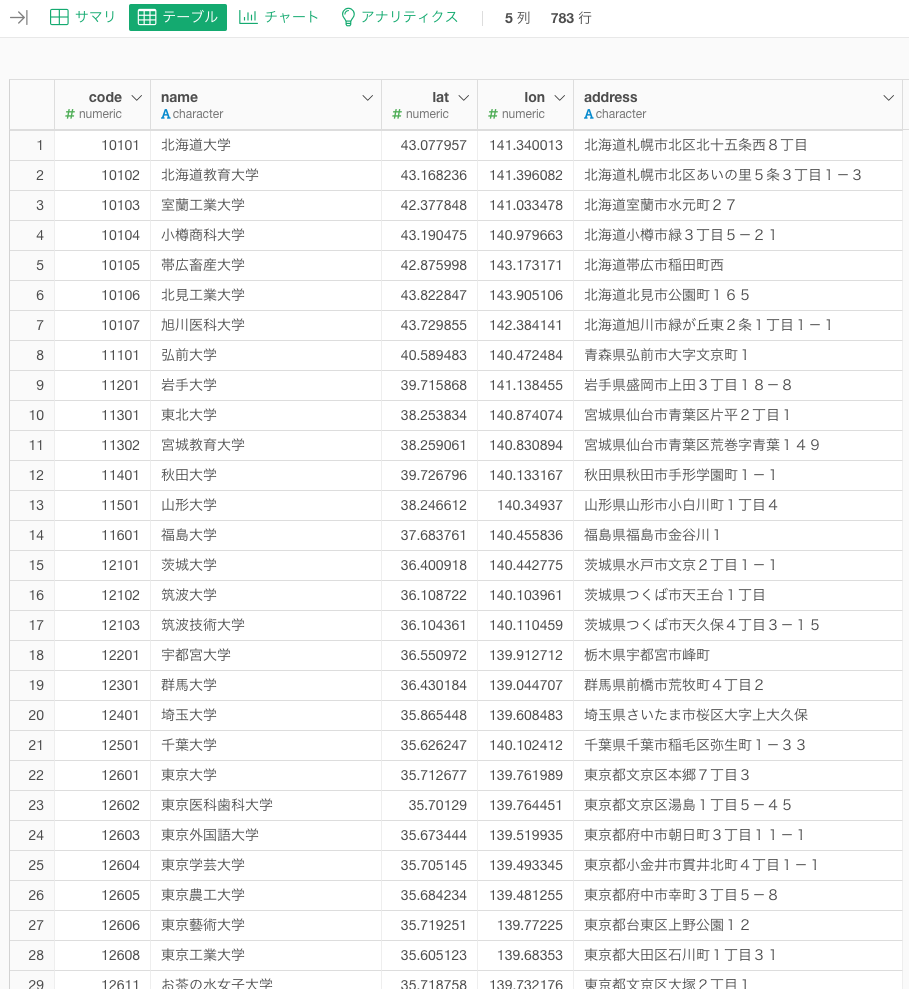
緯度経度の情報を使って可視化してみるとこんな感じです。東京、大阪、愛知、福岡に集中していることがわかります。
もう少しドリルダウンして、市区町村単位で探索しておきたいところです。しかし、市区町村単位のデータはないので、addressから抽出しないといけません。
そんな時に、addressを簡単に分割できる関数が{zipangu}パッケージから提供されています。下記の例のように、separate_address()を利用すると簡単に住所を分割できます。
zipangu::separate_address("鹿児島県志布志市志布志町志布志2丁目1-1")
## $prefecture
## [1] "鹿児島県"
##
## $city
## [1] "志布志市"
##
## $street
## [1] "志布志町志布志2丁目1-1"
zipangu::separate_address("京都府京都市上京区今出川通烏丸東入上る二筋目東入下る相国寺門前町")
## $prefecture
## [1] "京都府"
##
## $city
## [1] "京都市上京区"
##
## $street
## [1] "今出川通烏丸東入上る二筋目東入下る相国寺門前町"
Exploratoryで{zipangu}パッケージを使用できるように、まずExploratoryにパッケージをインストールしておきます。インストールの仕方は下記のドキュメントを読んでください。
複数の住所データを一度に分割できるように、separate_address()のラッパー関数をExploratoryのカスタムRファンクションとして保存しておきます。
rlangとか::、!!はおまじないみたいなものだと思ってください。また、ラッパー関数に誤りがあれば申し訳ありません…様々な面において、ご自身で改善されることを願います。
library(zipangu)
separate_address_wrapper <- function(data, address) {
address_enq <- rlang::enquo(address)
address_vec <- data %>%
dplyr::select(!!address_enq) %>%
dplyr::pull()
tmp_frame <- purrr::map_dfr(.x = address_vec,
.f = function(x){
zipangu::separate_address(x)
})
res <- data %>%
dplyr::bind_cols(tmp_frame)
return(res)
}上記のRスクリプトをコピーしてエディターに貼り付け、保存ボタンをクリックします。
これで準備が整ったので、下記のスクリプトをカスタムRコマンドとして、ステップに追加すれば、addressを分割できます。
separate_address_wrapper(address = address)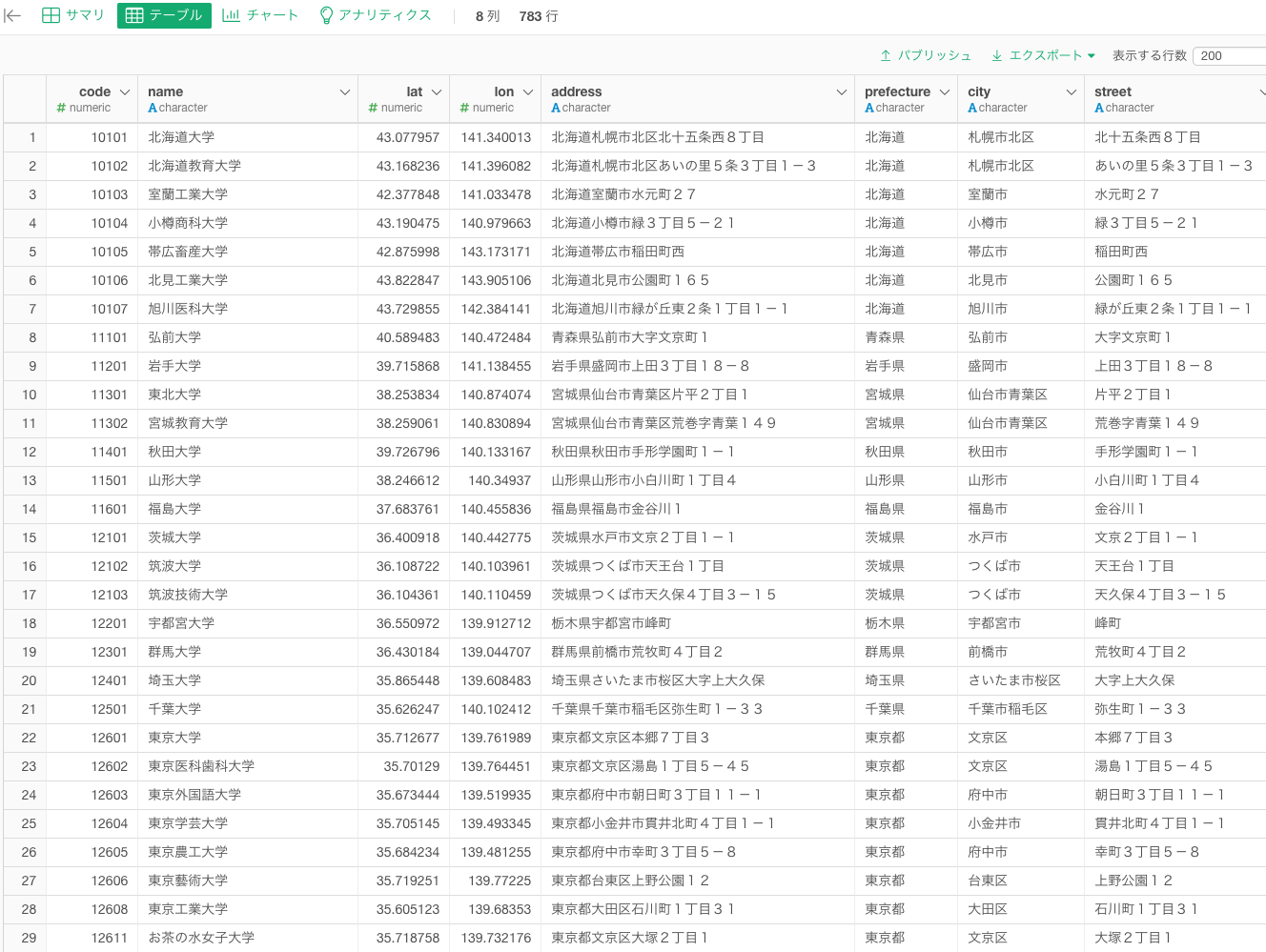
そして、この後に市区町村単位で可視化するために、prefectureとcityを文字列結合したprefecture_cityを作っておきます。
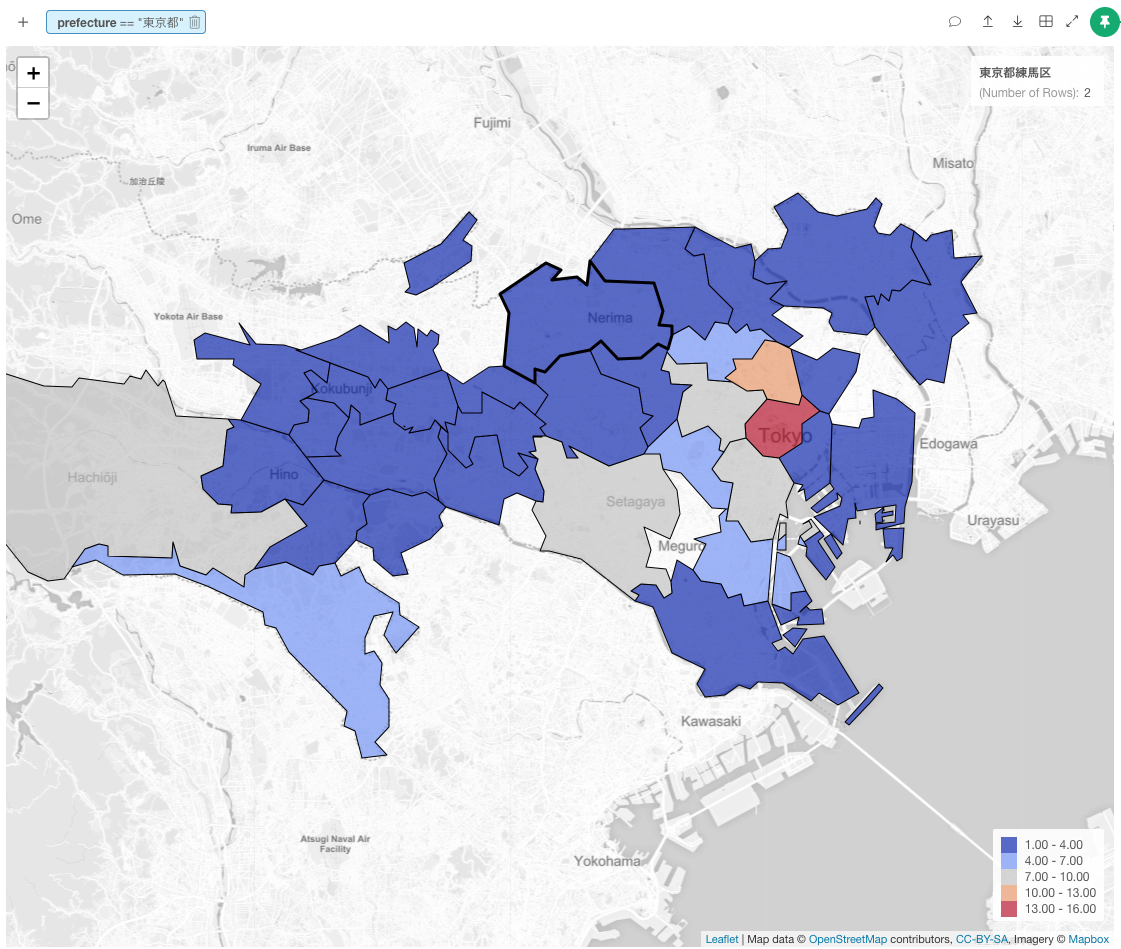
チャート上で東京に限定し、市区町村単位で可視化すると、新宿区、文京区、世田谷区、千代田区、港区に大学が集まっているようです。
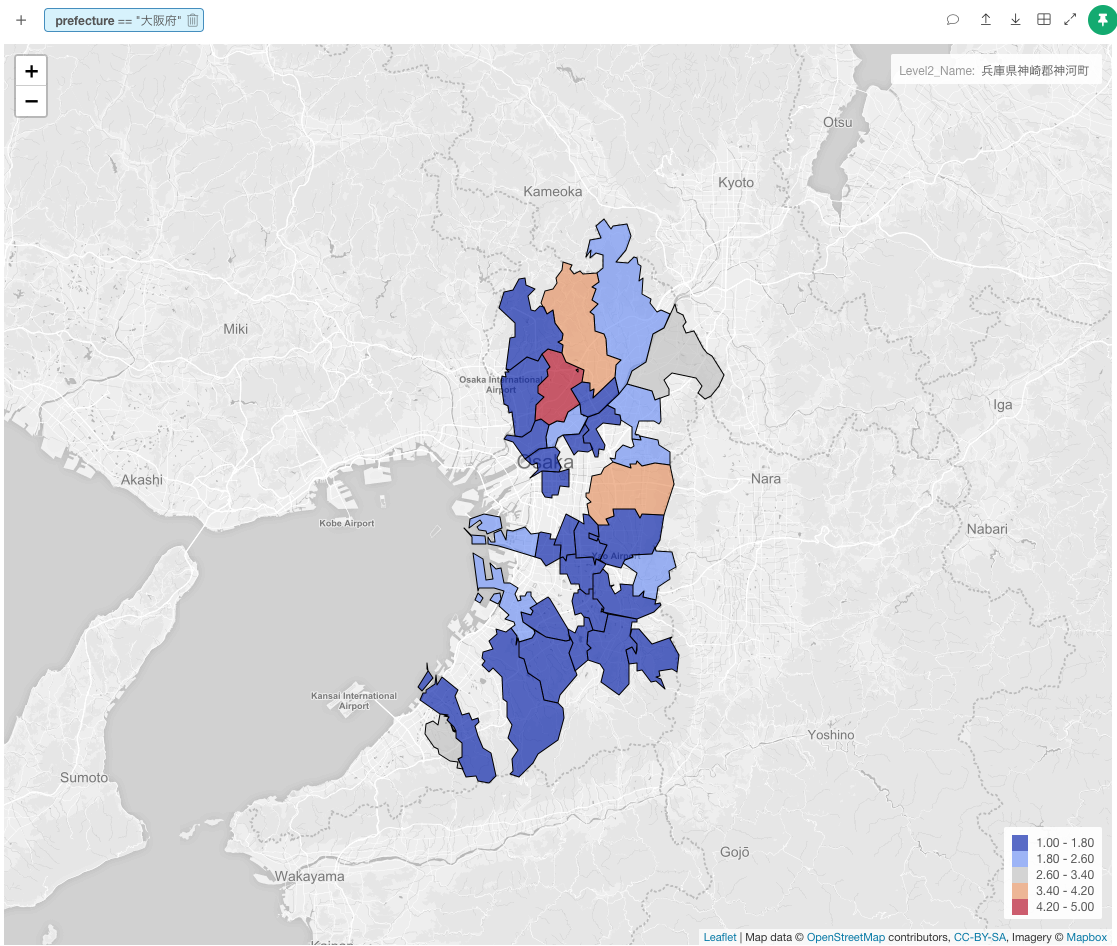
次は、同じくチャート上で大阪に限定し、市区町村単位で可視化します。吹田市、東大阪市に大学が集まっているようです。
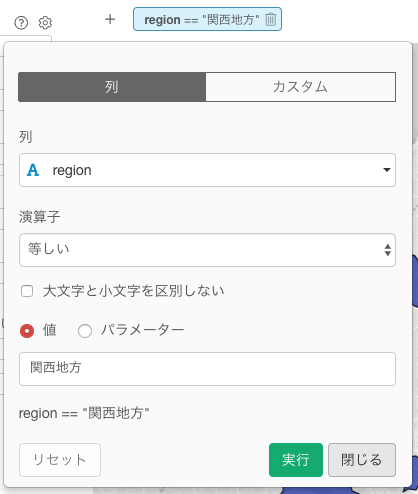
ちょっと範囲を限定しすぎたので、範囲を広げるために、関西地方でフィルターしてみたいところですが、地方単位のデータは現状のデータにはないので、加工します。
データ加工の方針としては、下記が思いつきます。
- Excelで都道府県と地方の対応表を作成する。
- 都道府県を地方に振り分ける
case_when()を書く。
パターン1の方針をとった場合、あまり明るい未来はみえません。プロジェクトのフォルダ構成を勝手にいじられる、Excelのファイル名をいじられるなどで、再度プロジェクトを開けると、Excelのリンクが切れて、エラーが表示される。 そうでなくても、北海道は東北に、沖縄は九州に勝手に分類し直されるなどして、再現性が破綻する未来が予想できます。
パターン2の方針は、なくはないかもしれませんが、Rパッケージにはデータセットが付属している場合があります。{zipangu}パッケージには、下記のようなjpnprefsというデータが付いており、これを使えば、jpnprefsから地方(region)を取得できます。
jpnprefs
#> # A tibble: 47 x 5
#> jis_code prefecture_kanji prefecture region major_island
#> <chr> <chr> <chr> <chr> <chr>
#> 1 01 北海道 Hokkaido Hokkaido Hokkaido
#> 2 02 青森県 Aomori-ken Tohoku Honshu
#> 3 03 岩手県 Iwate-ken Tohoku Honshu
#> 4 04 宮城県 Miyagi-ken Tohoku Honshu
#> 5 05 秋田県 Akita-ken Tohoku Honshu
#> 6 06 山形県 Yamagata-ken Tohoku Honshu
#> 7 07 福島県 Fukushima-ken Tohoku Honshu
#> 8 08 茨城県 Ibaraki-ken Kanto Honshu
#> 9 09 栃木県 Tochigi-ken Kanto Honshu
#> 10 10 群馬県 Gunma-ken Kanto Honshu
#> # … with 37 more rows下記のスクリプトをカスタムRコマンドとして、ステップに追加すれば、地方(region)を取得できます。(※通常のステップのメニューからの結合方法がわからなかったので、カスタムRコマンドとして追加しました。)
dplyr::left_join(x = ., y = zipangu::jpnprefs, by = c("prefecture" = "prefecture_kanji"))これでチャート上でも、地方単位で簡単にフィルタできるようになりました。regionは英語から日本語に変換しています。
では、関西地方で可視化します。これを見る限り、京都市左京区が関西地方では一番多いみたいです。
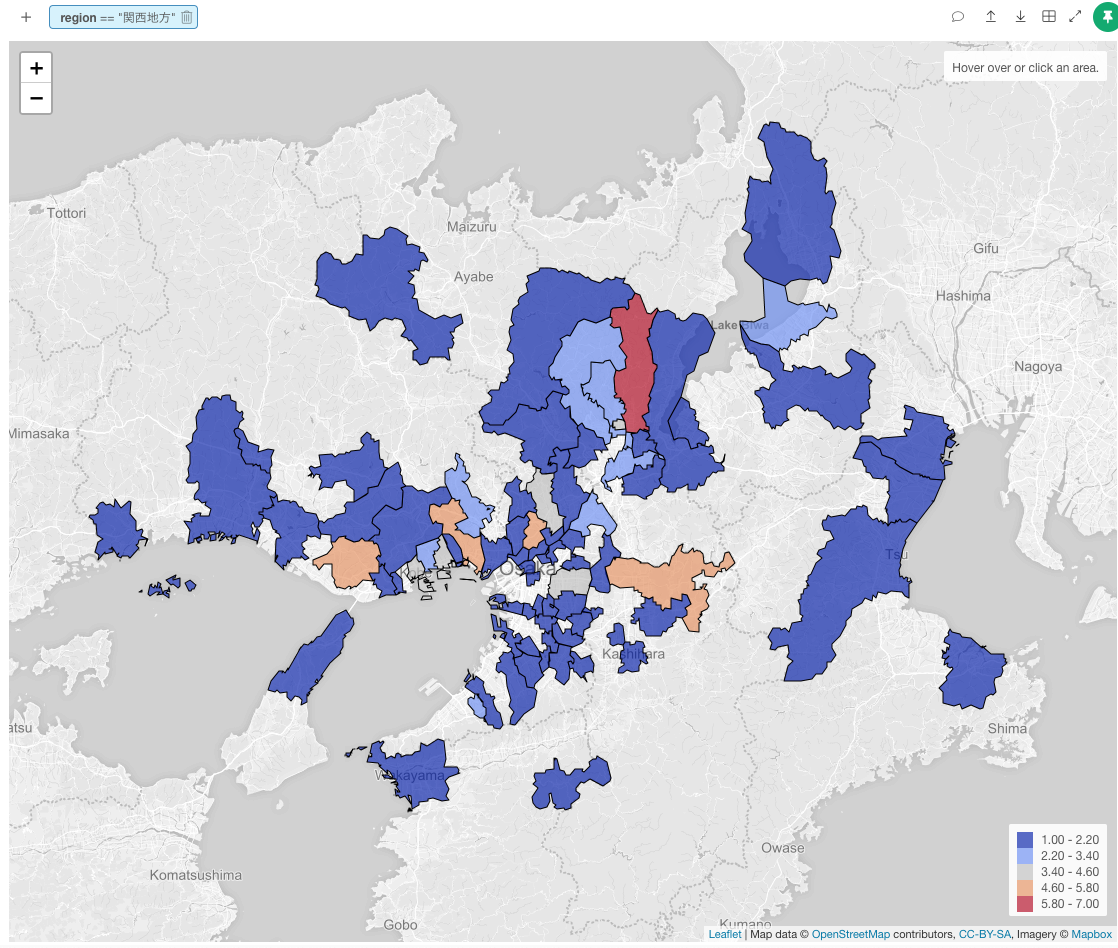
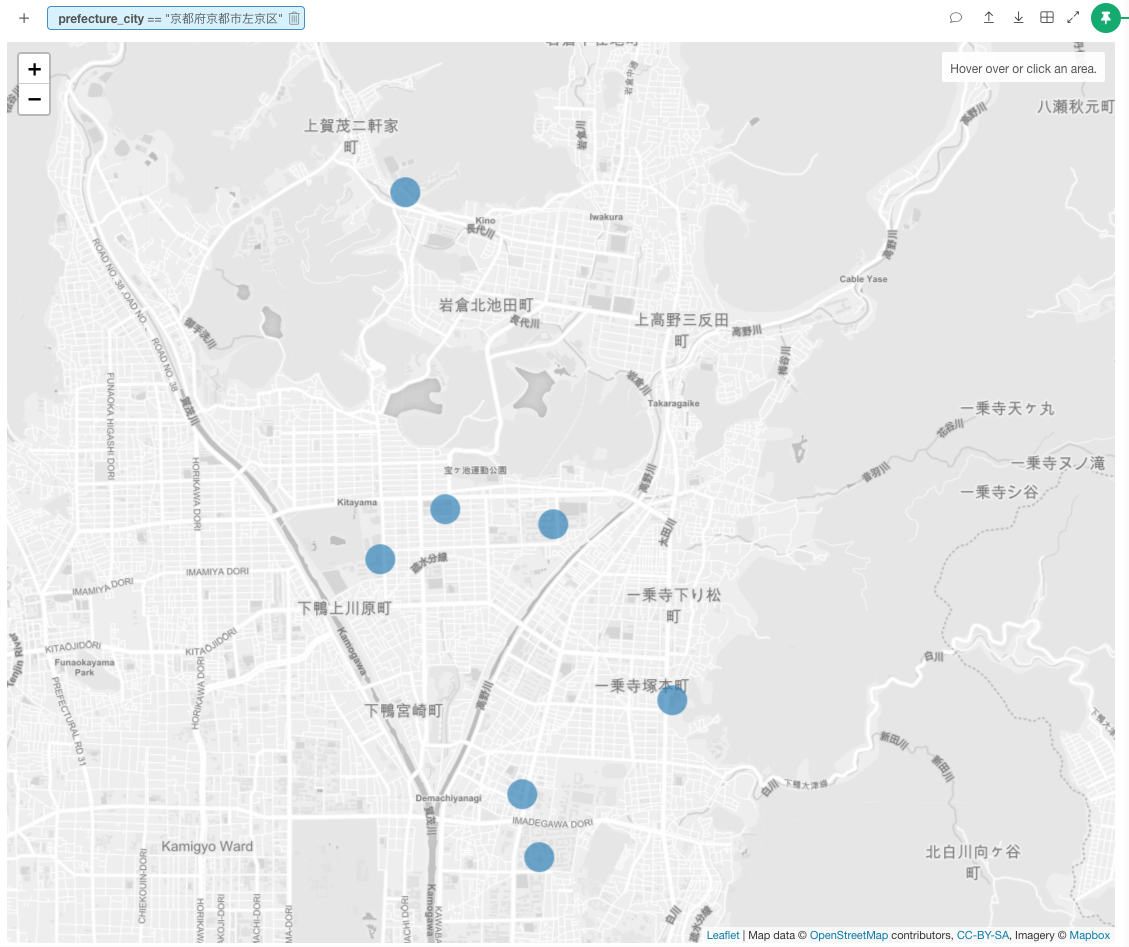
さらに探索すると、京都市左京区には、7つの大学がこのように分布しています。左京区って結構広いんですね。
人口一覧のデータを探索する
「各都道府県別の15~19歳の人口一覧」のデータを探すところからです。おそらく総務省のExcelとか、e-statとかRESASとかにあるんだろうと思いますが、どれも手がかかりそうです…。
こんなときは、誰かに最初に一度だけ、どこかからデータを取得するもろもろのスクリプトを書いてもらい、Exploratoryのデータカタログに入れておけば、あとはExploratoryで更新するだけでデータが利用できるとのことです(昨日のオンラインセミナーで教えてもらいました)。
ということで、「都道府県別人口構成」というRESASのデータをデータカタログから利用できるように誰かがしてくれたので、ありがたくそれを使わせていただきます。
「都道府県別人口構成」データはこのような感じです。
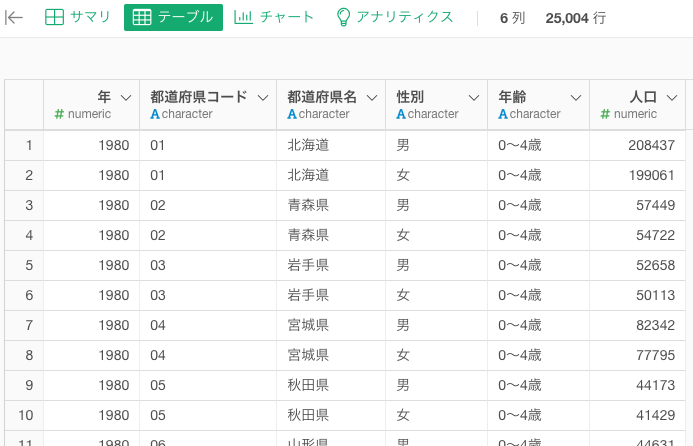
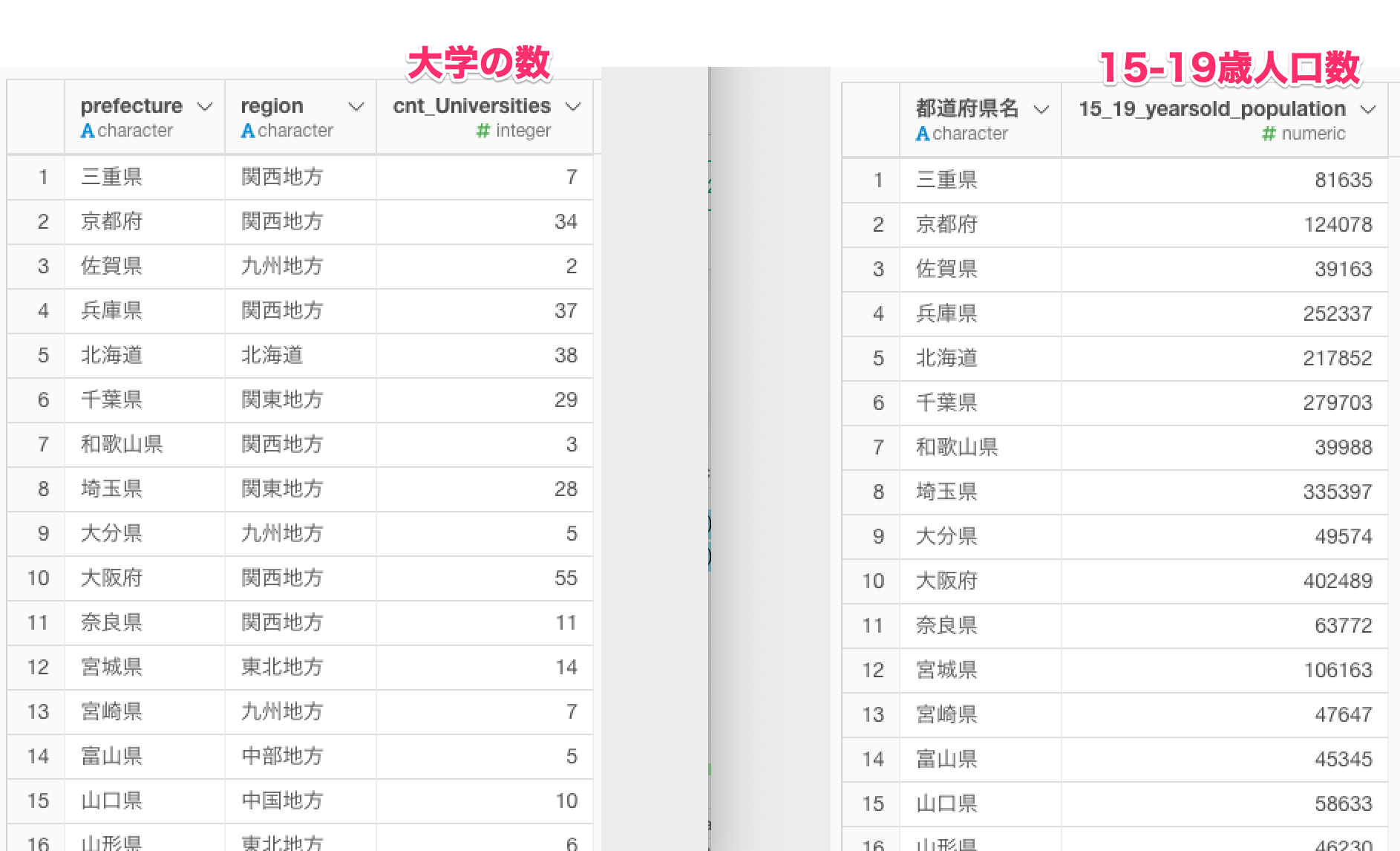
このデータは「大学の所在地一覧」データと結合するので、「都道府県別人口構成」データは、2020年時点の15~19歳にフィルタし、都道府県ごとに人口を合計しておきます。
また、「大学の所在地一覧」もデータの単位をあわせておきたいので、都道府県ごとに大学数をカウントしておきます。
「大学の数」と「15歳〜19歳の人口」の関係を探索する
各都道府県の「大学の数」と「15〜19歳の人口」は関係がありそうなのか調べていきます。データが分割されている状態なので、ジョインして、「大学の数」と「15〜19歳の人口」の散布図をみてみます。
これを見る限り、「大学の数」と「15~19歳の人口」は、関係性がありそうです。視覚的にわかるよくするために、散布図に回帰直線をひっぱっておきました。
「東京都」だけ値が飛び抜けています(外れ値)。他の集団とは、同じように考えないほうがいいかもしれません。
※ 回帰係数が有意とかどうこう言いませんから、「なんでもかんでも直線当てはめ警察」に連絡するのは勘弁してください。そんな警察がいるのかは知りませんが…噂にはいると聞きました。
相関係数も計算しておきます。ピアソンの相関係数は0.877なので、正の相関があると言えそうです。
「東京都」を除外した散布図はこんな感じです。
ピアソンの相関係数は0.899になり、さきほどよりも少し、相関が強くなりました。
以上のデータ探索を持ちまして、質問に対する回答としては、
A :
東京は、新宿区、文京区、世田谷区、千代田区、港区に大学が集まっていて、大阪は、吹田市、東大阪市に大学が集まってます。ちなみに関西だと京都市左京区に集まっています。
また、各都道府県の「大学の数」と「15~19歳の人口」は正の相関(ρ=0.877)があります。質問を回答すると、さらに深堀りの依頼がくるとは思いますが、こんな感じでしょうか。
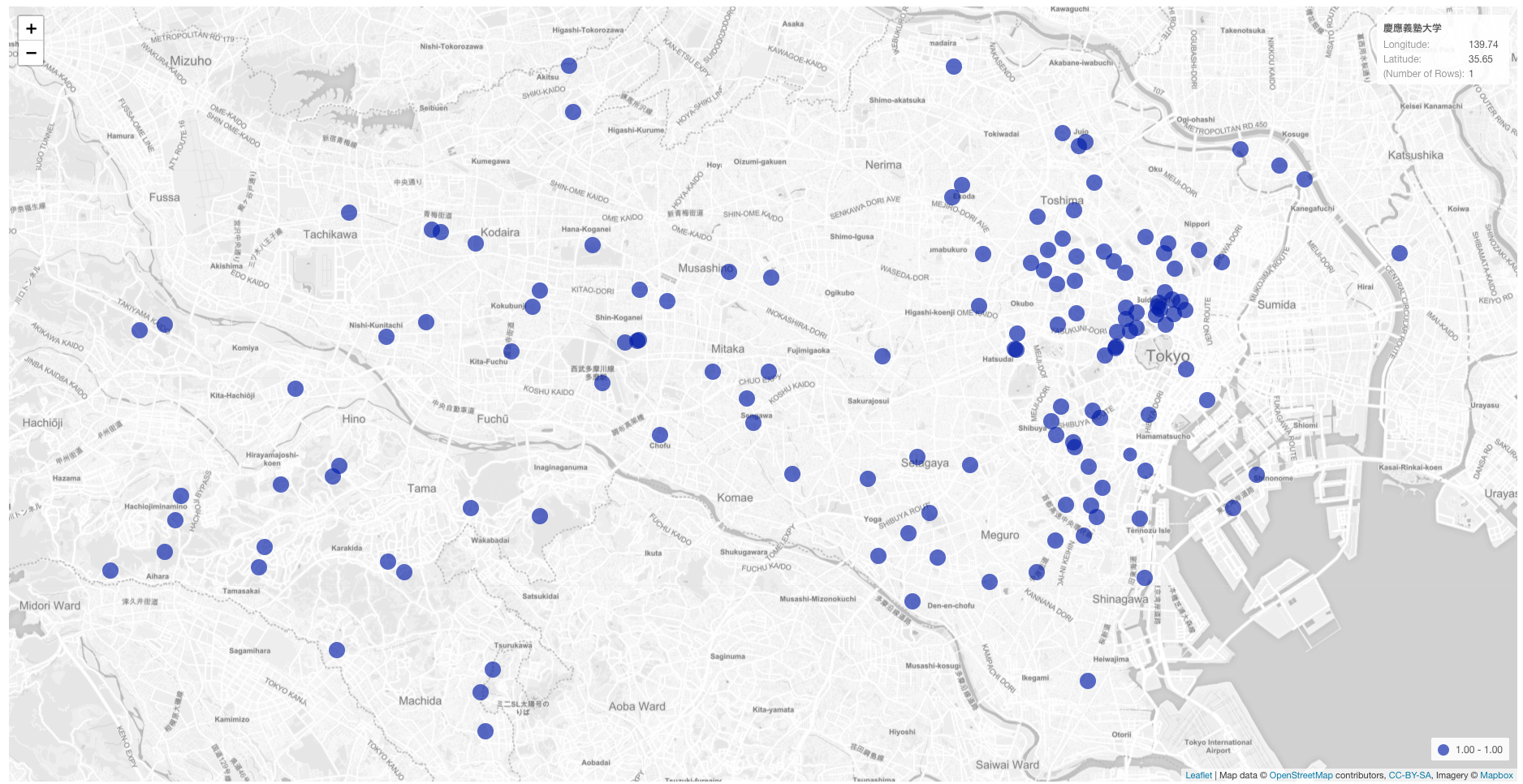
ちなみに東京都にある大学の分布はこうなります。多すぎだろ…笑
こうやって、加工して、可視化して、データの探索を簡単にできるのがExploratoryのいいとこですね。
以上でおわりです。言い忘れましたが、私はExploratory社の社員ではなく、プロダクトのファンの一人です。