SparklyrでExploratoryからSparkに接続してみる (SQL編)
ビッグデータ分析基盤として、もはや定番となっているApache Spark。今日はExploratoryからsparklyrというRのパッケージを使って、Apache Sparkに接続しデータを活用する方法をご説明します。
sparklyrを使うメリットとしては、 SQLでSparkにSQLクエリを投げることができるという点があります。(他にもSparkならではの分散処理や、ユーザー定義関数の実行もありますが、これはまた別のポストで説明します)
例えば、Sparkにアメリカの航空会社の遅延データがあったとすると、以下のようにSQLクエリを投げてSparkからデータを取得できます。
# SparkにSQLクエリを投げる
library(DBI)
flights <- dbGetQuery(sc, 'SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN,
ORIGIN_CITY_NAME, DEST, DEST_CITY_NAME, DEP_TIME, DEP_DELAY, ARR_DELAY FROM flights WHERE DEP_DELAY <= 0')
flights %>% collect()Sparkというと、ScalaやPython等のプログラミング言語を使ってアクセスする方法もありますが、やはりSQLクエリでアクセスできるのは多くのSQLを知っているユーザーには嬉しい機能ではないでしょうか。
ということで、今日はExploratoryの中から、sparklyrを使ってSparkにSQLクエリーを投げて、その結果だけをスマートに取ってくるにはどうするかということを紹介をしたいと思います。
準備
まずは最初に、sparklyrというRパッケージと、Javaをインストールします。
sparklyrパッケージのインストール
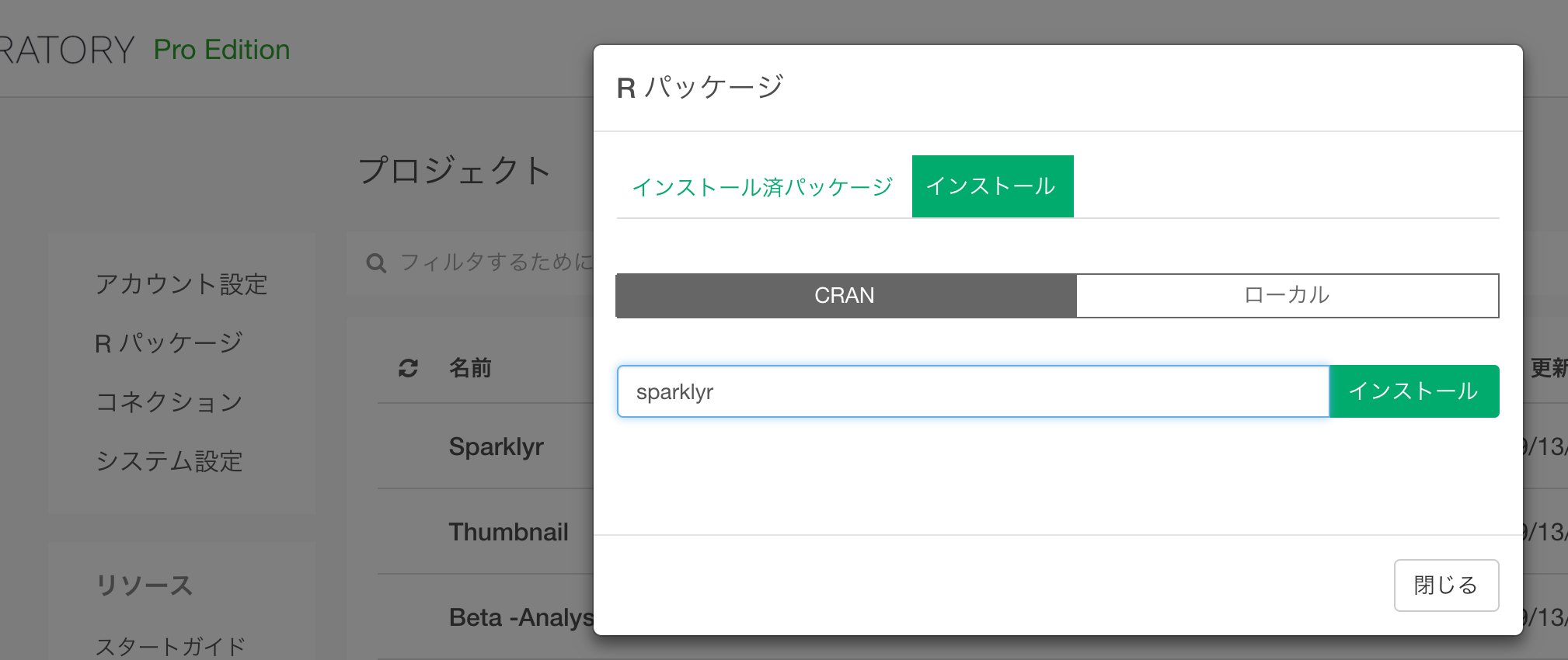
ExploratoryからSparkに接続するには、sparklyrというというRから直接SparkにアクセスするためのRのパッケージをインストールする必要があります。 Exploratoryの中で、CRANからsparklyrパッケージを以下のように直接インストールします。
Javaのインストール
お使いのマシンにJavaがインストールされてない場合は、 こちらからダウンロードしてインストールしてください。
SparkからSQLでデータを読み込む
次に、Rスクリプトを使ったデータソースでSparkにsparklyrを使って接続します。
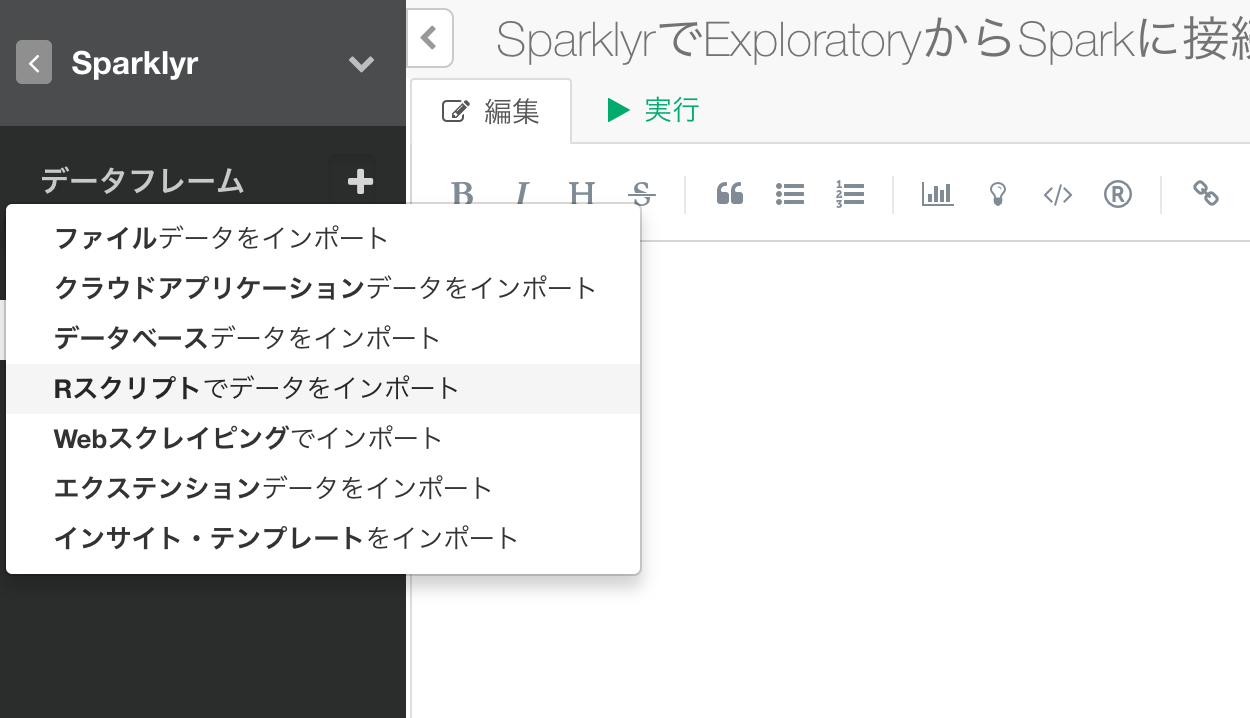
Rスクリプトの中で、次のようにSparkに接続します。(ここではlocalにデプロイしたSparkを例として取り上げています。)
# Sparkに接続 (ローカルのマシンの例)
# 環境変数の設定
Sys.setenv(SPARK_HOME = "/Users/hidekoji/spark/spark-2.2.0-bin-hadoop2.7")
# sparklyrを読み込む
library(sparklyr)
# Sparkに接続する
sc <- spark_connect(master = "spark://Hidetakas-MacBook-Pro.local:7077")さて、次に、Spark上にすでに読み込まれているSpark Data Frame flightsに対して、DBIパッケージのdbGetQuery関数を使って、出発州毎の平均出発遅延を計算してみましょう。Sparkに投げるSQLクエリは以下の通りです。
# DBIパッケージをロード
library(DBI)
flights <- dbGetQuery(sc, 'SELECT ORIGIN_STATE_ABR, AVG(DEP_DELAY) AS DEP_DELAY_AVG
FROM flights
GROUP BY ORIGIN_STATE_ABR')
flights %>% collect()最後のcollect()はクエリの実行結果をデータフレームにするための関数です。この記事の一番最後にこの2つのセクションをまとめたスクリプトがありますので、コピー & ペーストとして、必要な部分を変更して試せます。

データの取得ボタンをクリックして結果を確認し、保存ボタンをクリックし、データフレームとして保存します。
データを保存すると、このようにサマリビューで、結果を確認できます。
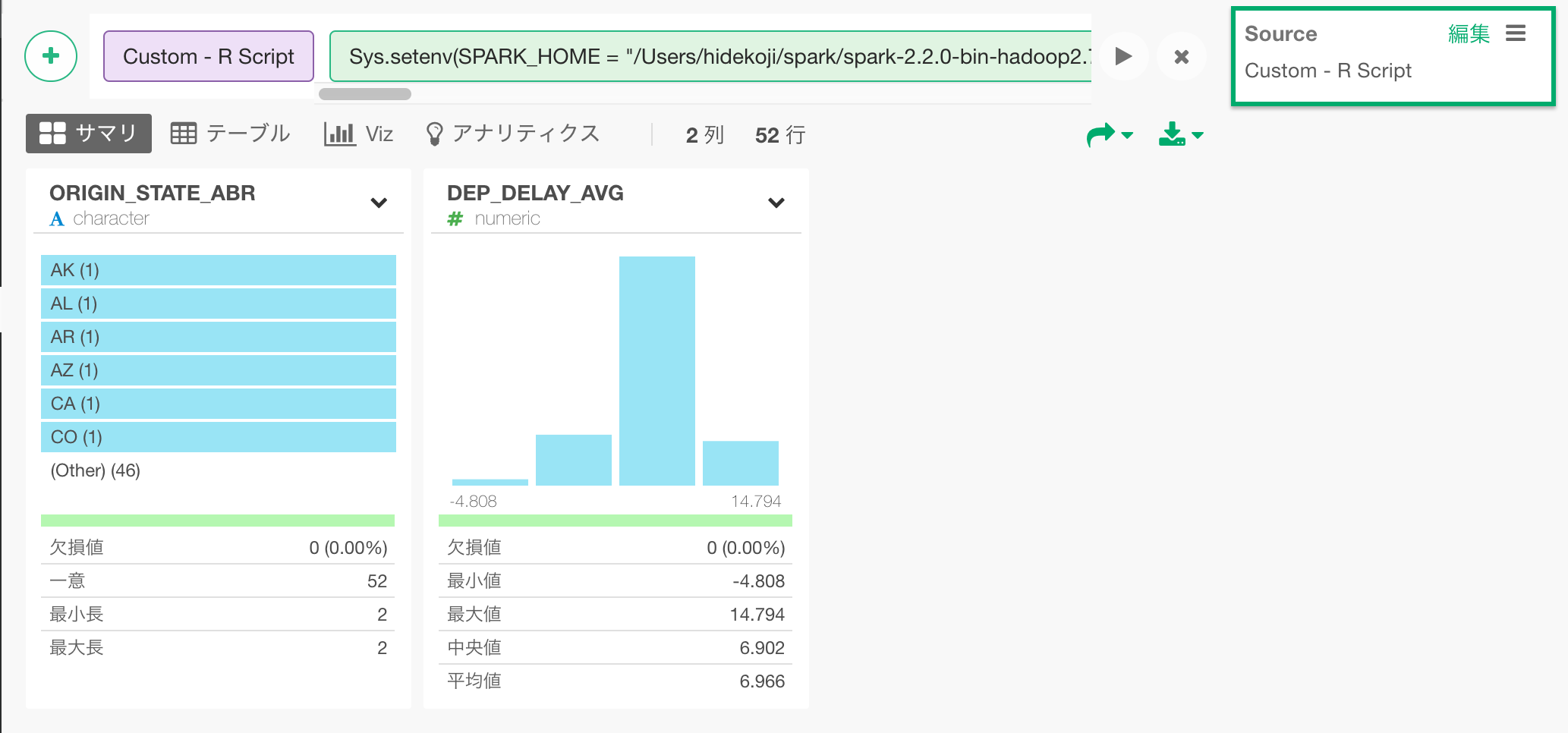
このSQLクエリの結果、州毎の平均遅延情報を地図の上に可視化してみましょう。
まとめ
sparklyrを使うと、このようにSparkに接続して、ScalaやPythonでプログラミングしなくても、SQLクエリでデータを取得し、可視化やさらなる分析が可能になります。
データサイエンスを本格的に学んでみたいという方へ
今年10月に、Exploratory社がシリコンバレーで行っている研修プログラムを日本向けにした、データサイエンス・ブートキャンプの第3回目が東京で行われます。本格的に上記のようなデータサイエンスの手法を、プログラミングなしで学んでみたい方、そういった手法を日々のビジネスに活かしてみたい方はぜひこの機会に、参加を検討してみてはいかがでしょうか。こちらに詳しい情報がありますのでぜひご覧ください。
補足
この例を試すには
以下のスクリプトをRスクリプトデータソースとしてコピー & ペーストして、必要に応じて変更後実行してください。
# Sparkに接続 (ローカルのマシンの例)
# 環境変数の設定
Sys.setenv(SPARK_HOME = "/Users/hidekoji/spark/spark-2.2.0-bin-hadoop2.7")
# sparklyrを読み込む
library(sparklyr)
# Sparkに接続する
sc <- spark_connect(master = "spark://Hidetakas-MacBook-Pro.local:7077")
# DBIパッケージをロード
library(DBI)
flights <- dbGetQuery(sc, 'SELECT ORIGIN_STATE_ABR, AVG(DEP_DELAY) AS DEP_DELAY_AVG
FROM flights
GROUP BY ORIGIN_STATE_ABR')
flights %>% collect()