前回までのおさらい
前回はTwitterから安倍首相に言及されたTweetをインポートし、RMeCabでトークナイズして、ストップワード等を取り除き、頻出する単語が何かを確認するところまで見てきました。Part 2では、Tweetのテキストから、Tweetをクラスタリングして類似性を分析してみます。
Tweetのクラスタリングまでの道のり
安倍首相に関するTweetを、類似するクラスタにクラスタリングするには
- 前回単語分けされた安倍首相関連のTweetsのテキストを使う
- Nグラムのアルゴリズムを使って1単語と2単語の組み合わせのテキストを作成
- TF-IDFのアルゴリズムを使ってそれぞれのTweetを数値化する
- SVDのアルゴリズムを使って次元削減する
- K-Meansクラスタリングのアルゴリズムを使ってTweetsを似た者同士のグループに分ける
という手順を踏んでいきます。では早速順場に見ていきましょう。
前回単語分けされた安倍首相関連のTweetsのテキストを使う
前回Part1で説明した、1)単語分けして、2)ストップワードを取り除いた安倍首相に関するTweetデータをここでは使います。
Nグラムのアルゴリズムを使って1単語と2単語の組み合わせのテキストを作成
Part1でトークナイズしたトークン(形態素)からNグラムを生成します。Nグラムとはテキスト内の連続するn個の表記単位(gram)でNが 1ならユニグラム(uni-gram)、2ならバイグラム(bi-gram)、3ならトリグラムまたはトライグラム(tri-gram)と呼ばれます。
token列の列ヘッダーメニューよりテキストデータの加工(UI) -> Nグラムトークンを作成 を選びます。
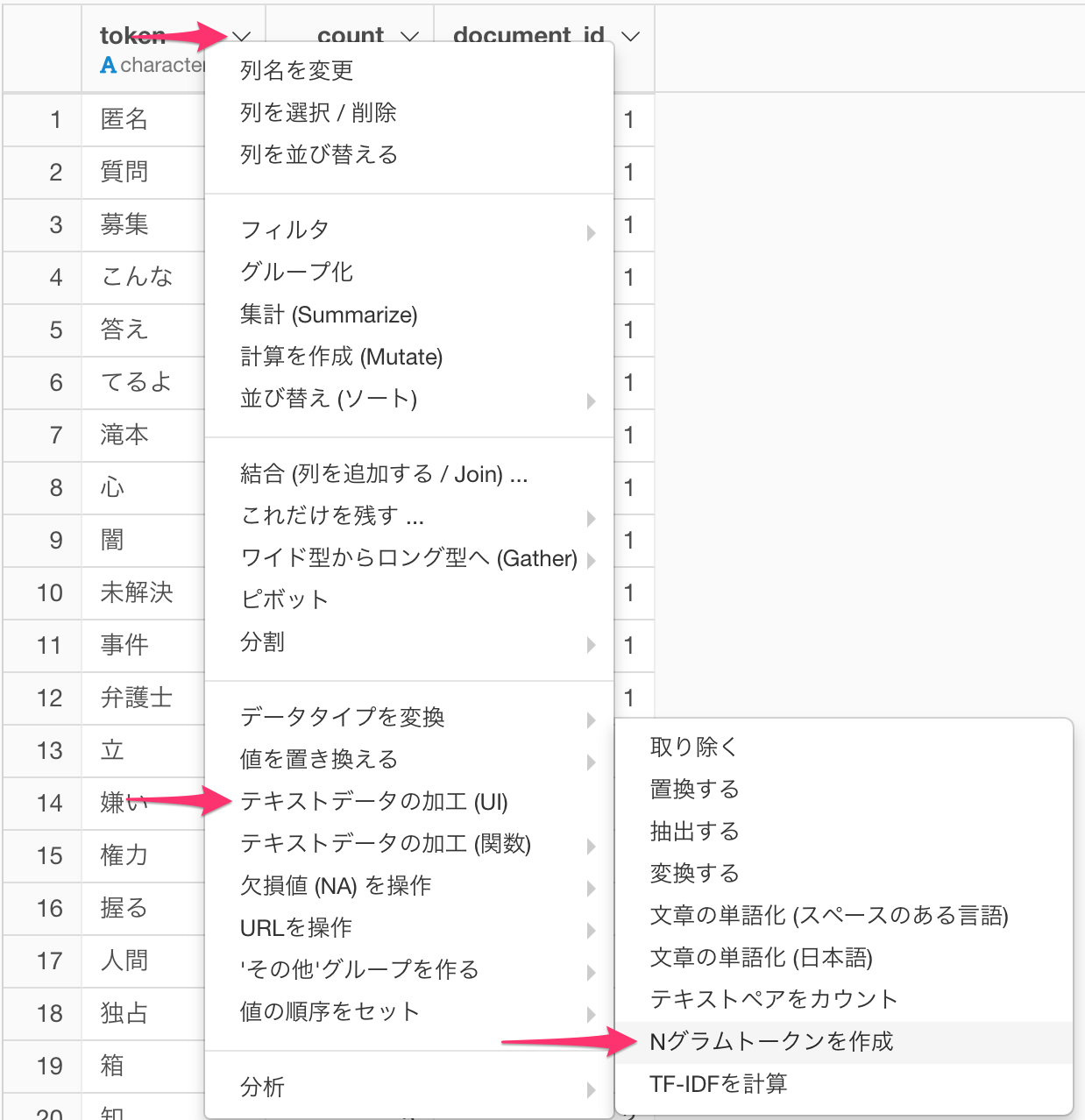
トークナイズされたテキストがある列にtoken 列を指定します。また、ここでは、1 tweet = 1文書 = 1センテンスとして扱うので、文書ID列とセンテンスID列両方にdocument_id 列(RMeCabを利用している場合はstatus_id列)を指定します。
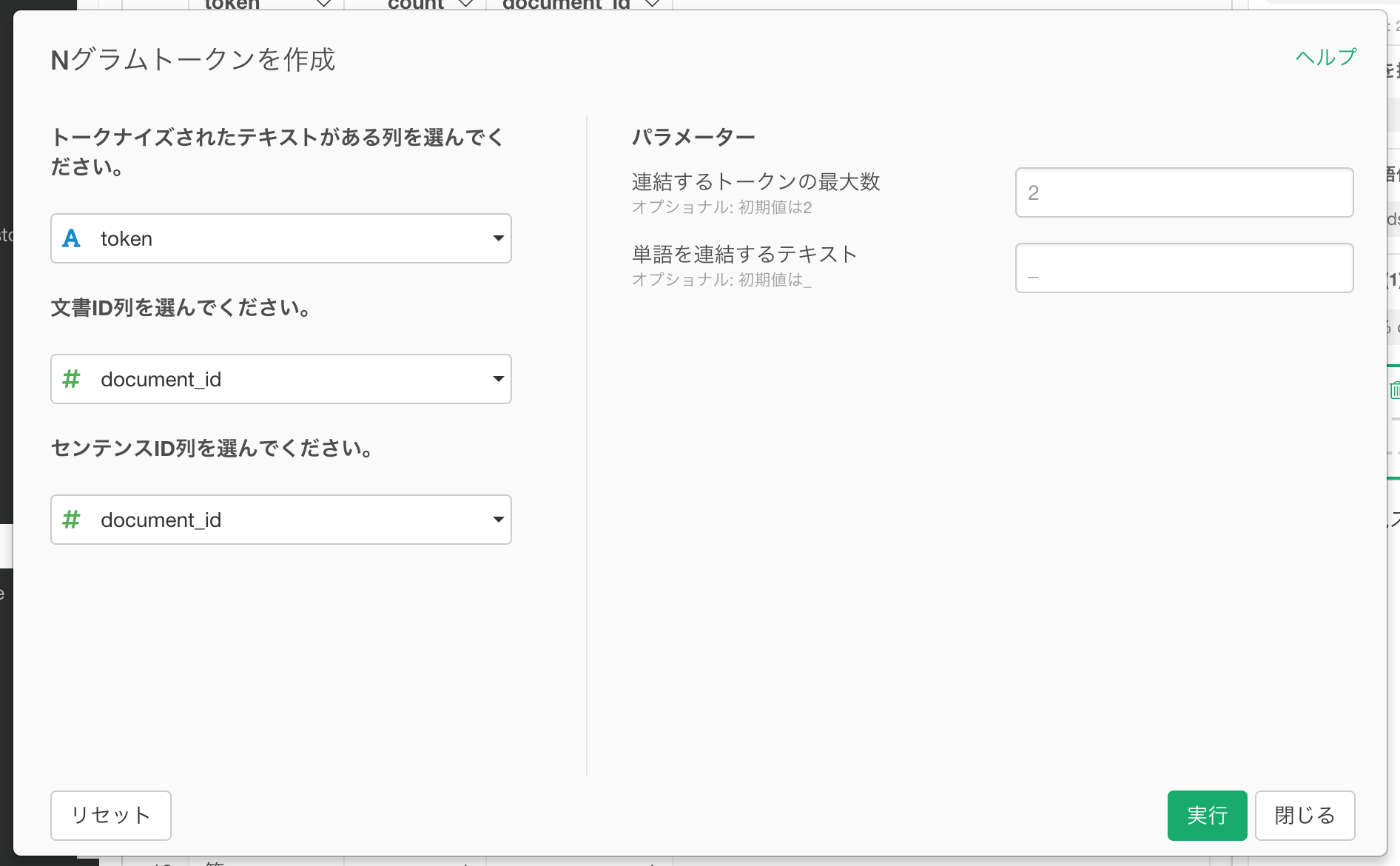
すると、以下のようなNグラムが生成されます。バイグラムの時はウイルス_対策のように2つの単語が**_** で接続されているのが分かります。
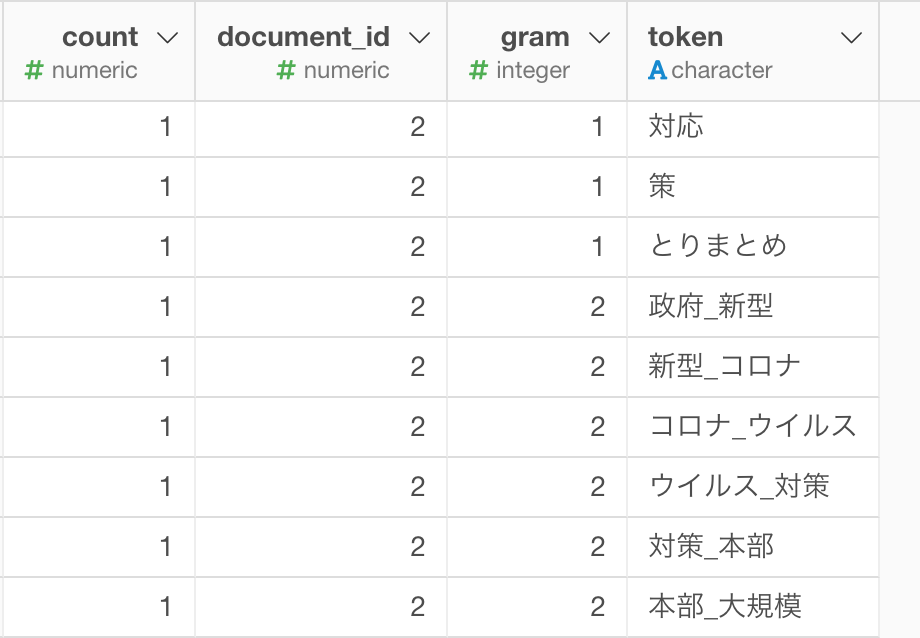
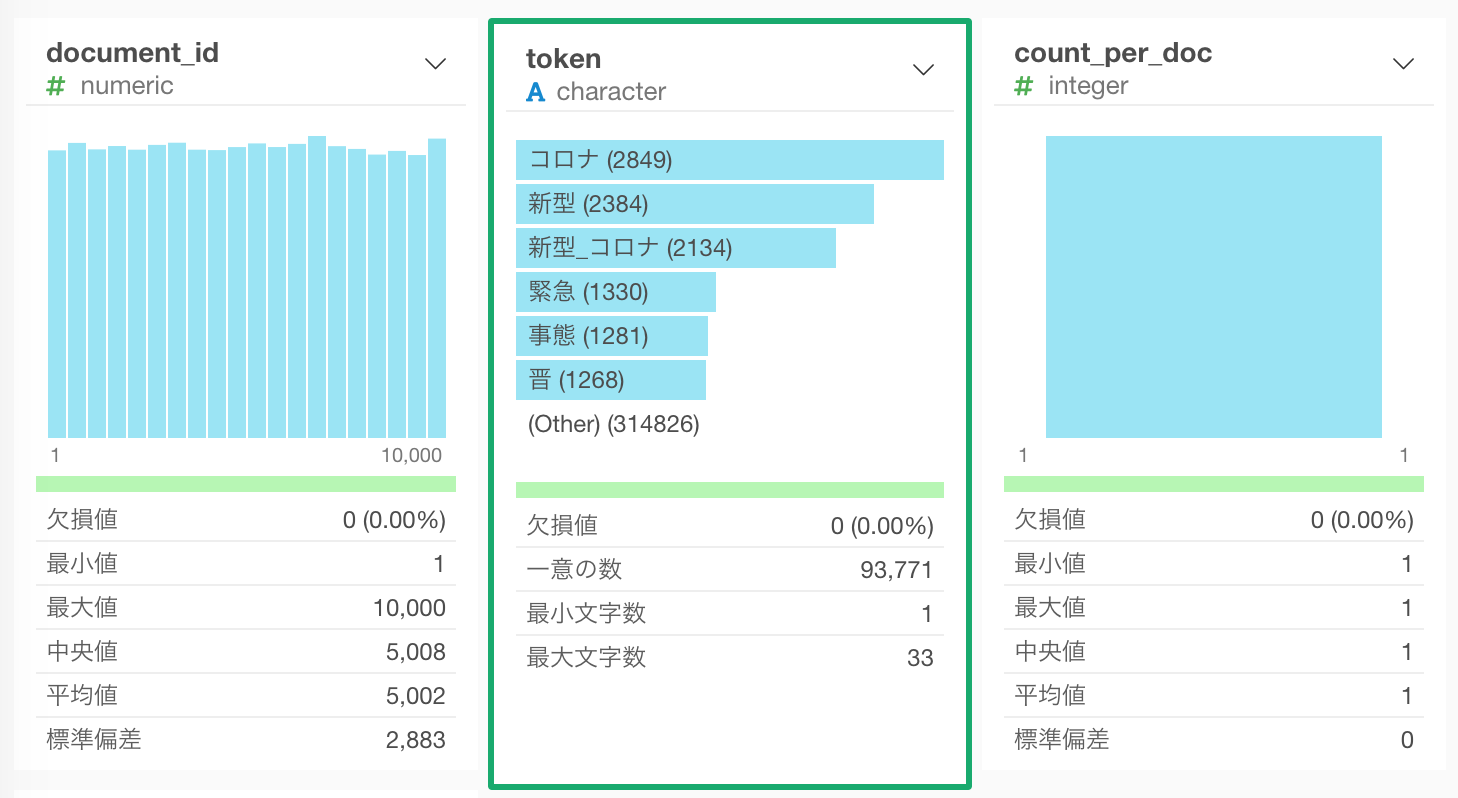
これをバーチャートにすると、 コロナ、新型 といったN グラム(1つなのでユニグラム)が上位に来ているのが分かります。 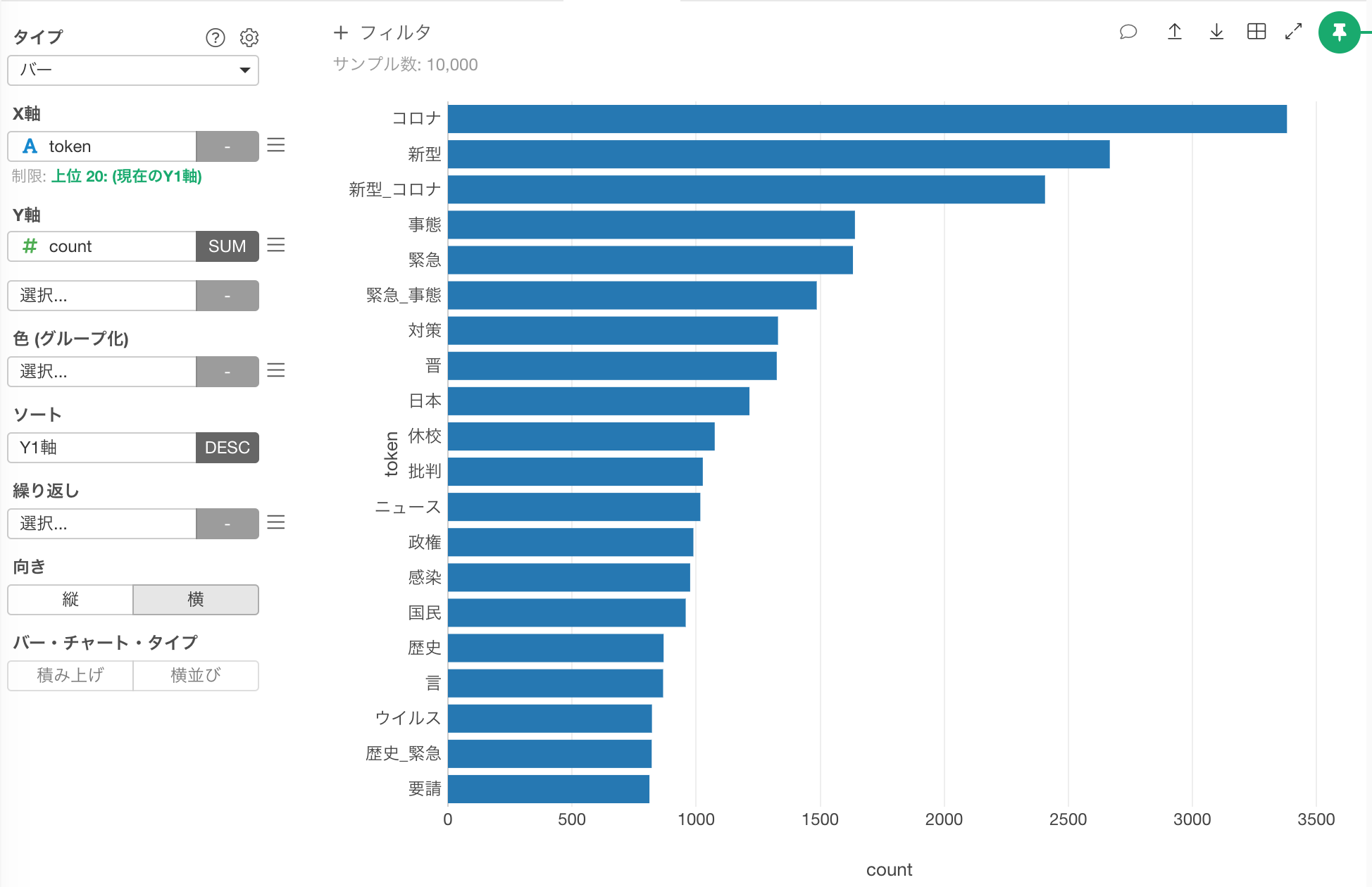
TF-IDFのアルゴリズムを使ってそれぞれのTweetを数値化する
TF-IDFは文書に含まれる単語がどれだけ重要かを示す手法の一つで、TF (= Term Frequency: 単語の出現頻度)とIDF (Inverse Document Frequency: 逆文書類度)の2つを使って計算します。TFはここではあるTweetに何回このNグラムが出現したのかを、IDFは沢山あるTweet全体の中で、このNグラムが何回現れたかの逆数を示します。これは、その単語が他のTweetにはなかなか出現しない「レアな単語」なら高い値を、「色々なTweetによく出現する単語」なら低い値を示すものです。つまりレアな単語は、そのTweetの特徴を判別するのに有用ということになります。
token列の列ヘッダーメニューより、テキストデータの加工(UI) -> TF-IDFを計算 を選びます。
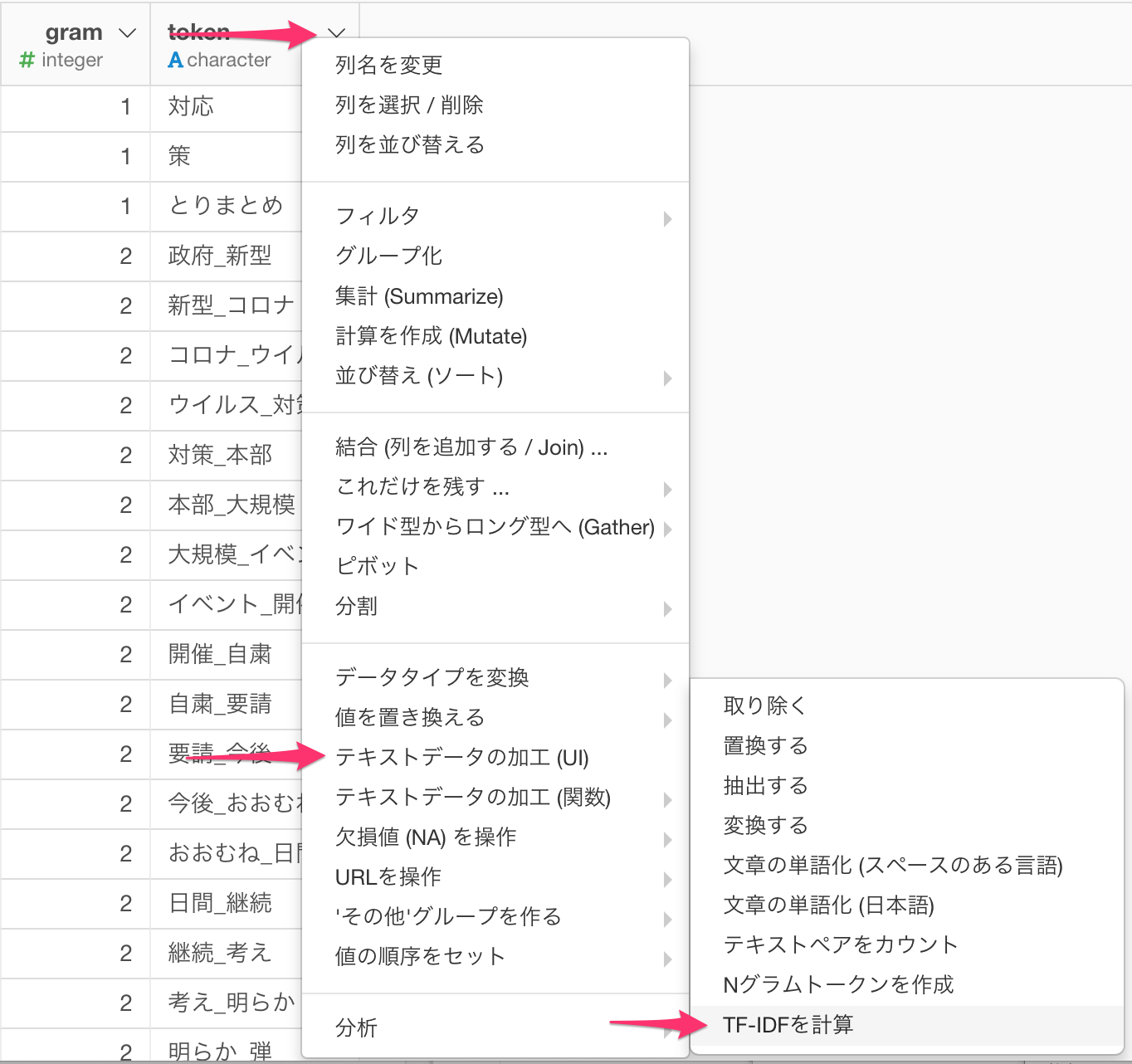
文書ID列にdocument_id列 (RMeCabを利用した場合はstatus_id列)を、トークナイズされたテキストがある列にtoken列を選びます。
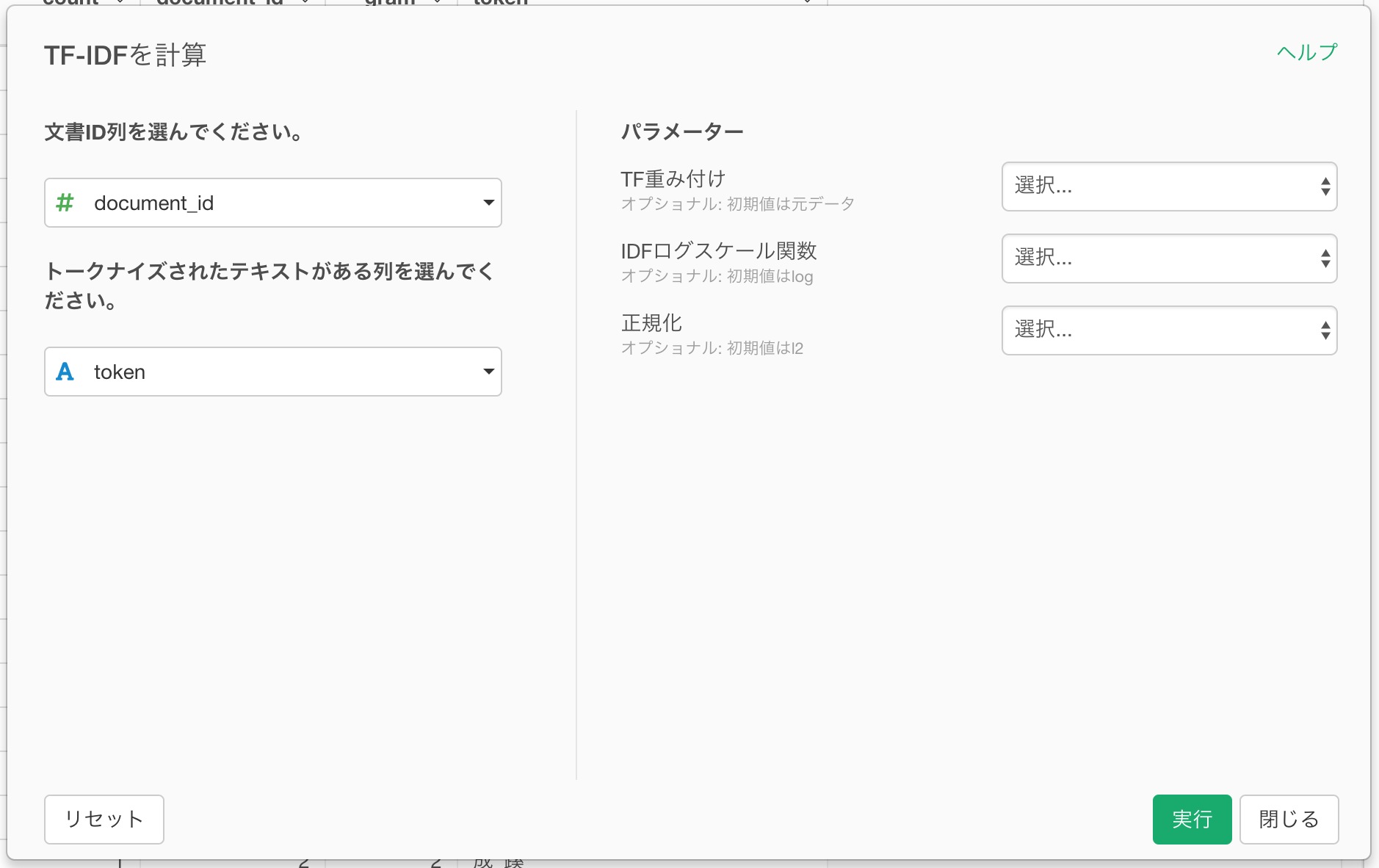
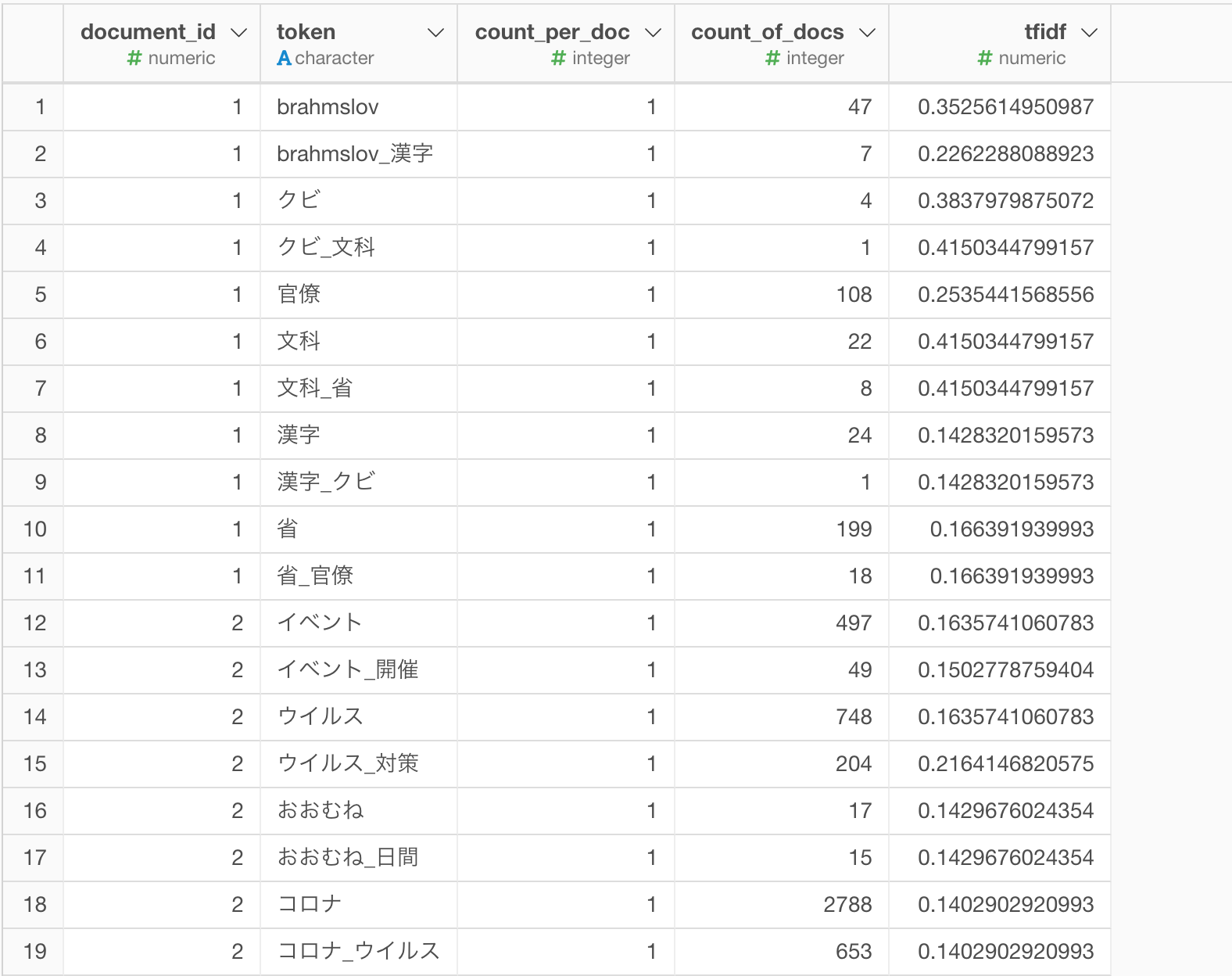
実行ボタンを押すと、次のようにTF-IDFが計算されます。
SVDのアルゴリズムを使って次元削減する
実はテキスト分析のときにはこれら一つ一つのユニークな単語のことを次元と言います。ここで、縦(行)に文書のID、この場合だとそれぞれのTweetのID、そして横(列)にそれぞれの単語が割り当てられたマトリックスのようなものを想像してみて下さい。そうすると、それぞれのTweetの特徴が、それぞれの列にある単語に対する数値(スコア)によって決まるわけです。
しかし、ここで気をつけなくてはいけないのは、その列の数が93,771個(次元)あるということです。しかしそもそもそれぞれのTweetは140単語以下なので、ほとんどの列(次元)は0もしくはNAとなっているはずです。つまり以下の表のようなスッカスカのマトリックスであるということです。
こうしたデータをそのまま使ってクラスタリング等のアルゴリズムを適用すると結果に歪みが生じてしまいます。こういったことをCurse of High Dimensionality (次元の呪い) と言ったりします
そこで、本質的な特徴を残しつつ、重要でない情報量を削減することができる次元削減という手法を使うことになるのですが、ここでは、SVD (Singular Value Decomposition: 特異値分解)という次元削減のアルゴリズムを使ってみます。
データをサンプルする
SVDはとてもコンピューターのリソースを必要とする処理なので、データ量によっては処理に非常に時間がかかります、ここでは一旦データをサンプルして量を減らします。
ステップの横のプラス(+)ボタンをクリックし、サンプルを抽出.. -> 行の数を選びます。
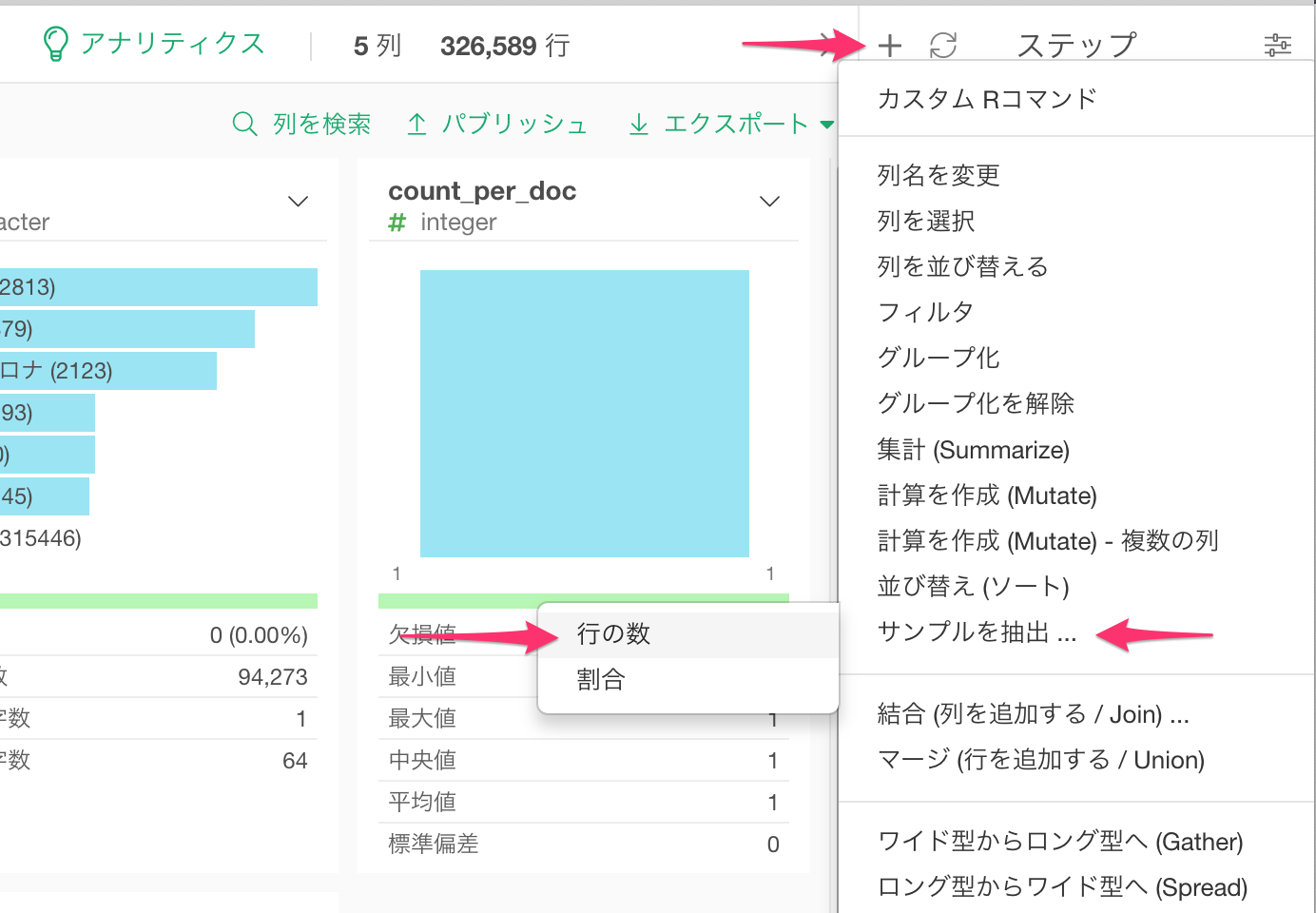
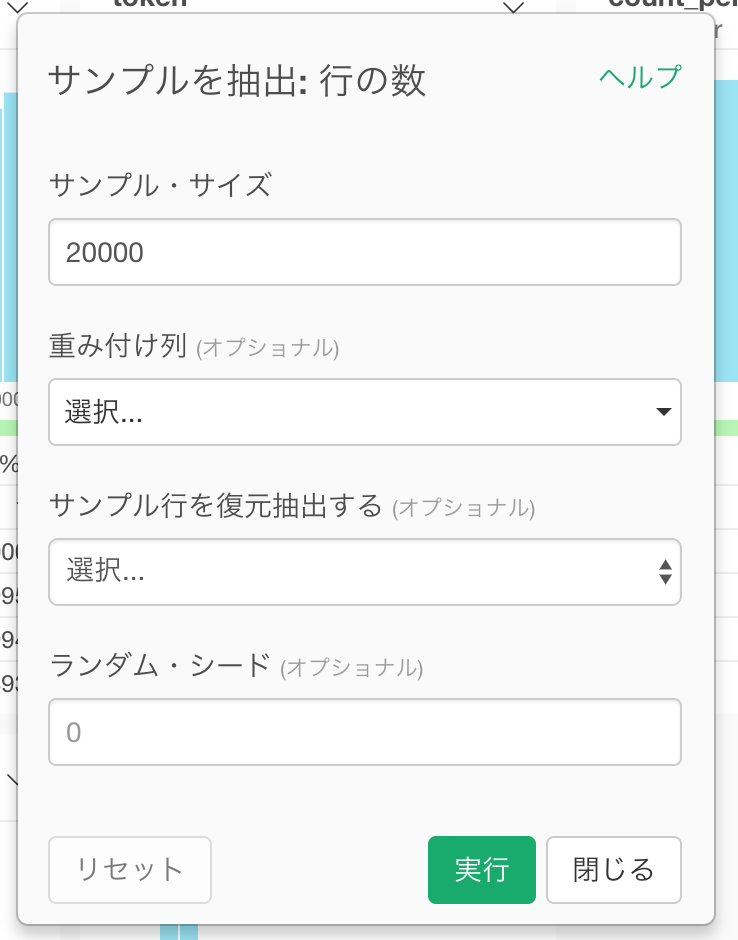
抽出行数はここでは20,000行を指定してますが、この数字はお使いのマシンのスペックによって調整してください。ちなみに、こちらを試したMacbook Pro (Mid 2015, プロセッサー2.8GHz Intel Core i7, メモリ16GB)では、20,000行で、20分以上かかりました。
SVDを実行
ステップの上のプラスボタンをクリックし、分析を実行 -> SVD (Singuar Value Decomposition) を選択します。
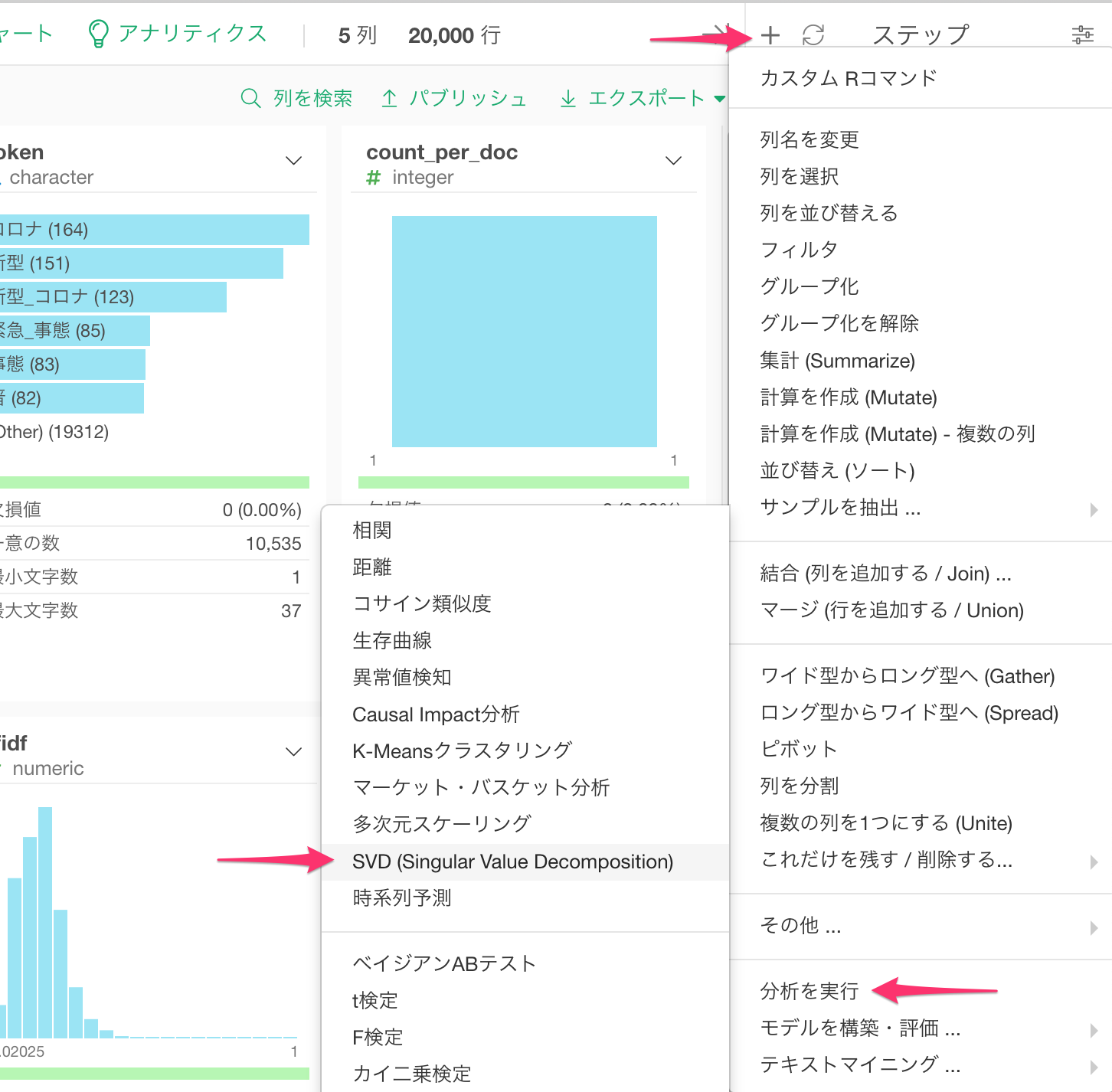
今回はTweet毎に単語をtfidfの値に基づいて次元削減をしたいので、「どの次元を削減しますか?」に列内のカテゴリの次元を、「列を選択」にTweetのIDであるdocument_idを (RMeCabを利用した場合はstatus_idを)、ディメンジョンにNグラムであるtokenを、メジャーにtfidfを指定します。また、この例では4次元まで次元数を減らしてみるので、次元数には4を指定します。
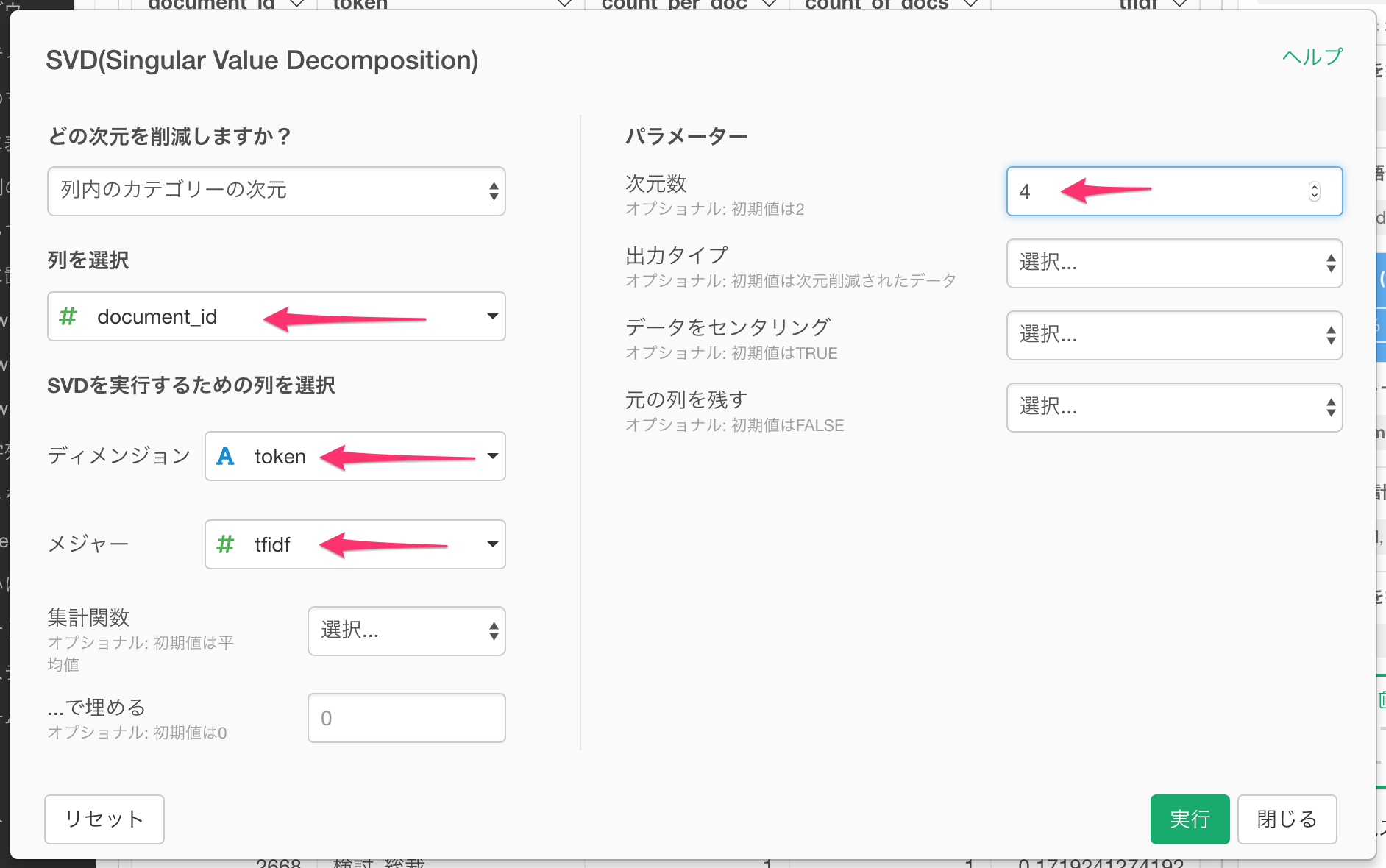
実行すると、以下のようにTweet毎に4つまで次元数が削減されました。
結果をキャッシュする
SVDの処理は非常に重いので、この結果をキャシュすることで、SVDが毎回実行されることを防ぎます。SVDのステップの上をマウスでホバーすると、ステップデータをキャッシュのアイコンが表示されるのでこちらをクリックします。
無事キャッシュされると、ステップの色が青く変わります。
K-Meansクラスタリングのアルゴリズムを使ってTweetsを似た者同士のグループに分ける
さて、無事次元数も4つまで削減されたので、この4つの次元を用いて、Tweetをクラスタリングします。ここではK-Meansというアルゴリズムを使います。
データをロング型からワイド型へ変換
今、SVDを実行した結果はロング型のデータフレームとなっています。つまり、 new.dimensionという列に各次元(1,2,3,4)が、value列にそれぞれの値が入る 縦長なデータフレームとなっています。
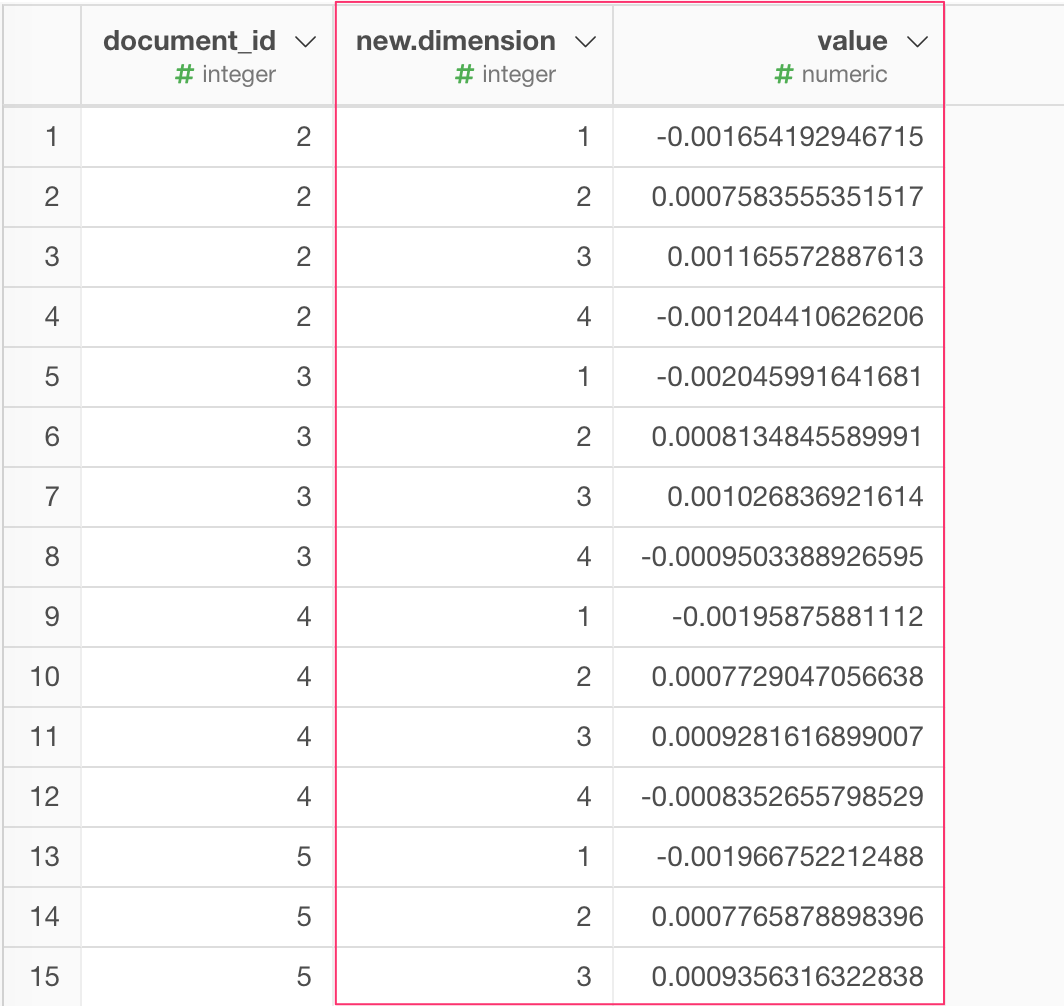
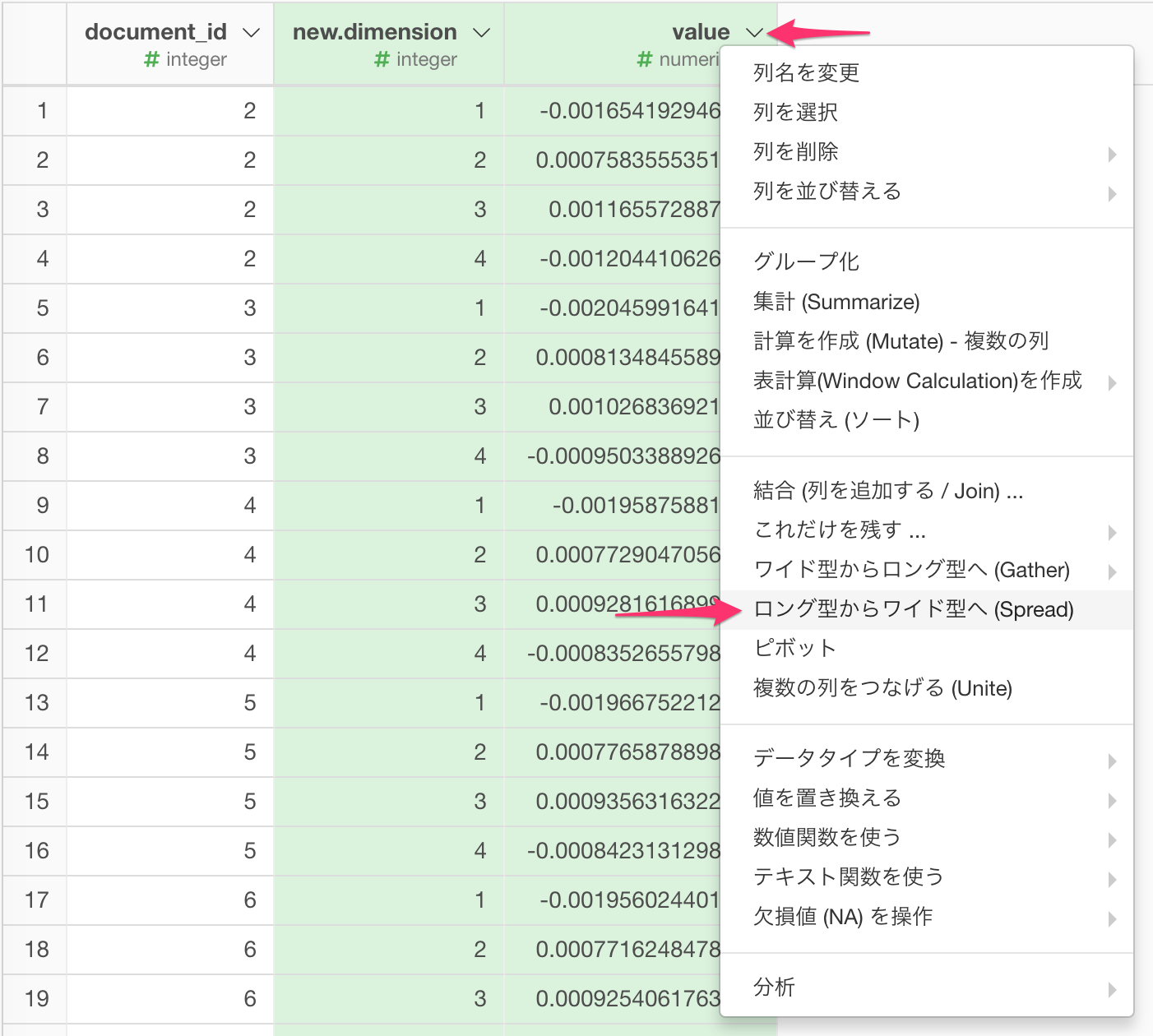
K-Meansクラスタリングでは、データがワイド型、つまり、1つの次元(変数)が1列であることを前提としているので、ワイド型に変換しましょう。new.dimensionとvalueの列をコマンドキーとクリック( Windowsの場合はコントロールキーとクリック)で両方選択し、列のメニューからSpread (ロング型からワイド型へ)を選びます。
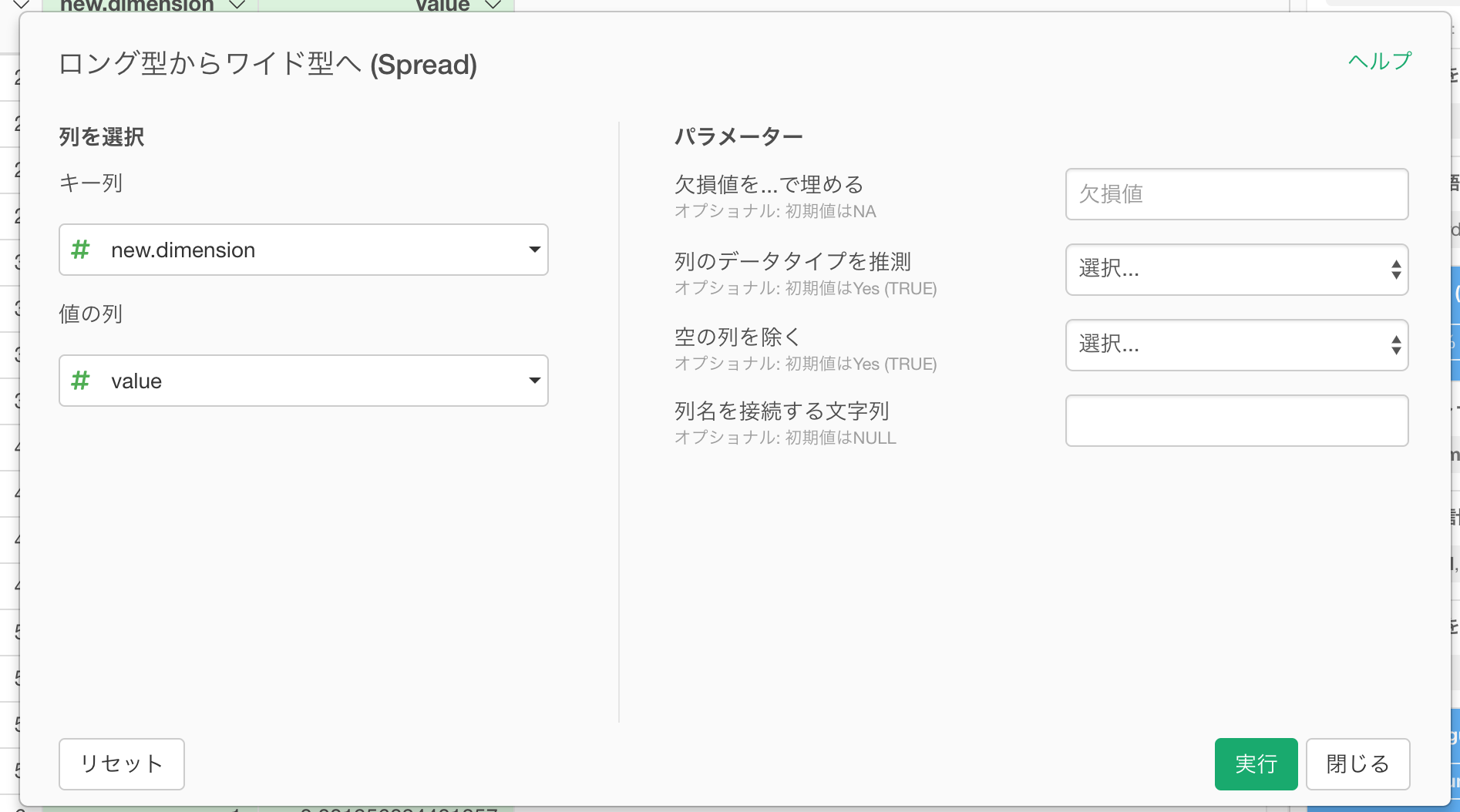
開いたダイアログで、キー列にnew.dimension、値の列にvalueが指定されているのを確認し、実行ボタンを押します。
すると、以下のように、一つの次元(変数)が一つの列で、1つのTweetが1つの行であるワイド型のデータになります。
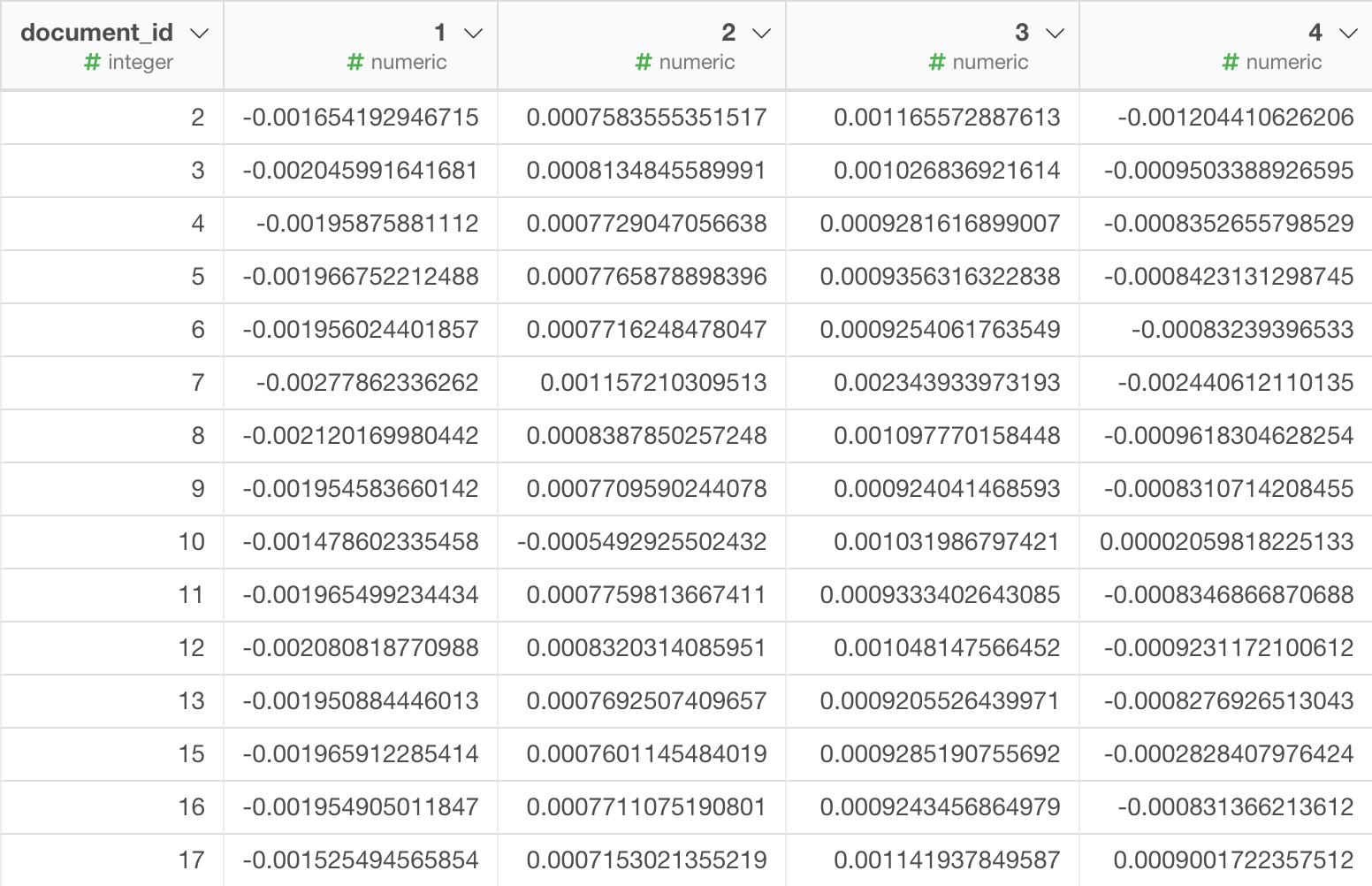
K-Meansでクラスタに分ける
アナリティクスビューに行き、プラス(+)ボタンをクリックして新規にアナリティクスを作成します。タイプにはK-Meansクラスタリングを選択します。
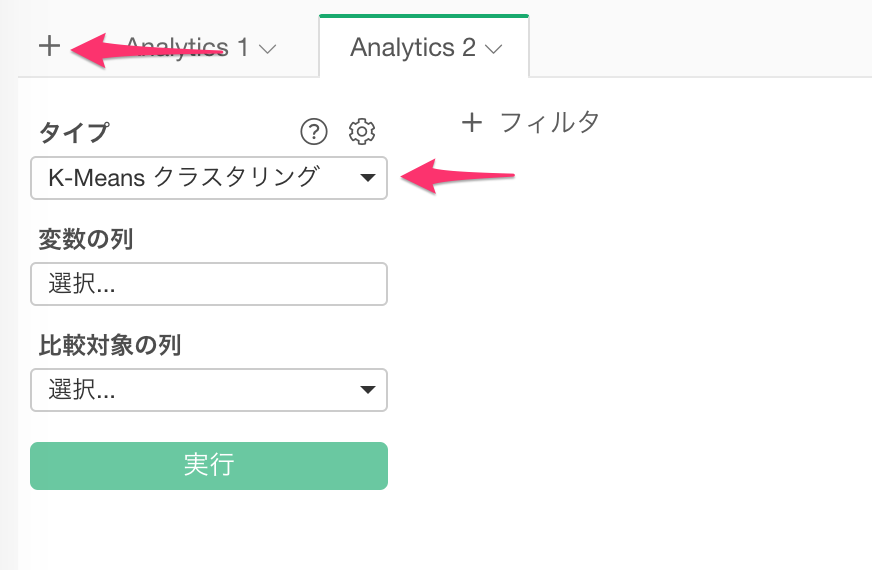
次に、変数の列をクリックします。SVDによって作成された4つの次元の列を選択し、OKボタンをクリックします。
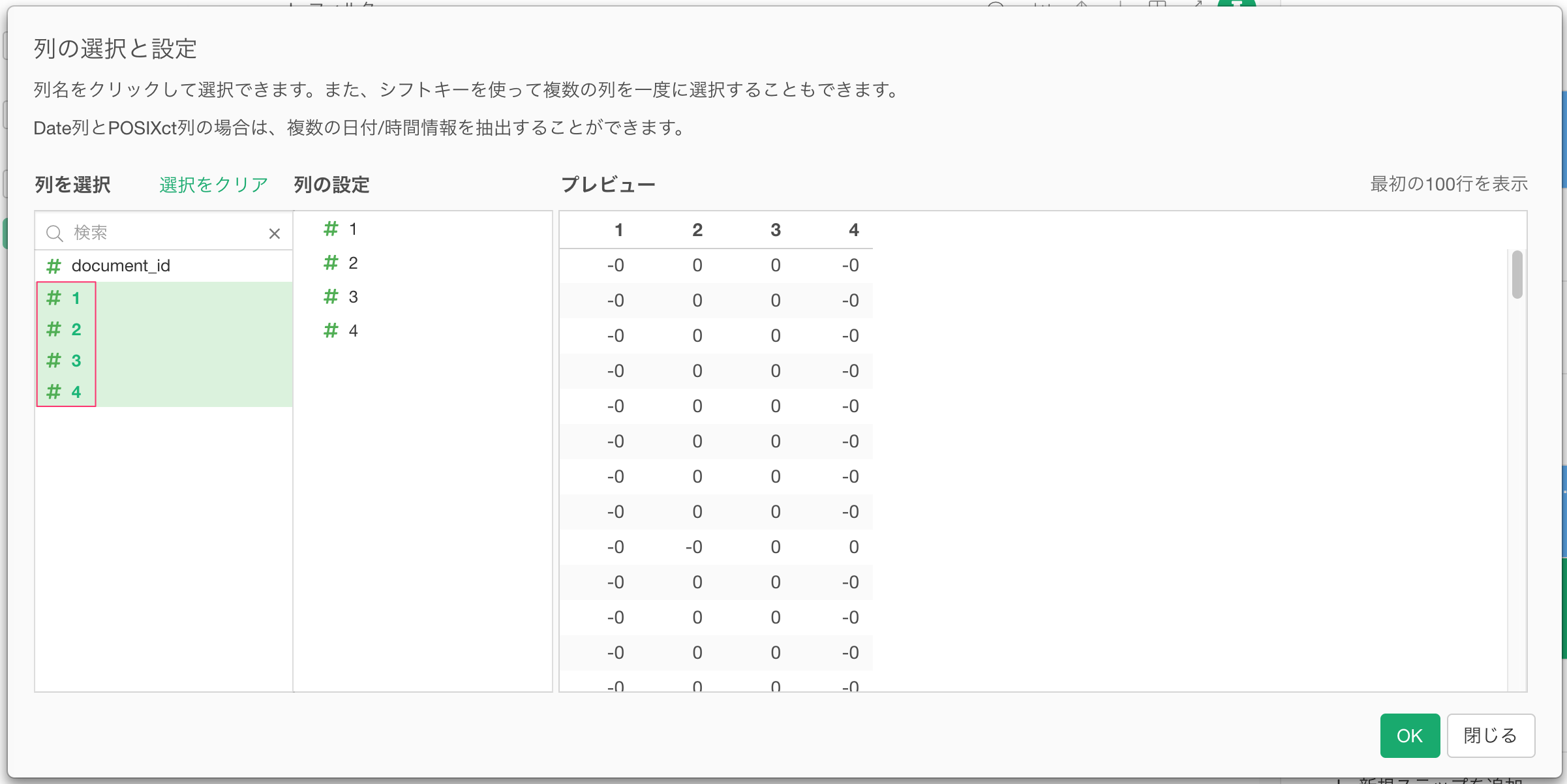
次に、最適なクラスターの数を調べるためにに、ギアのアイコンをクリックします。
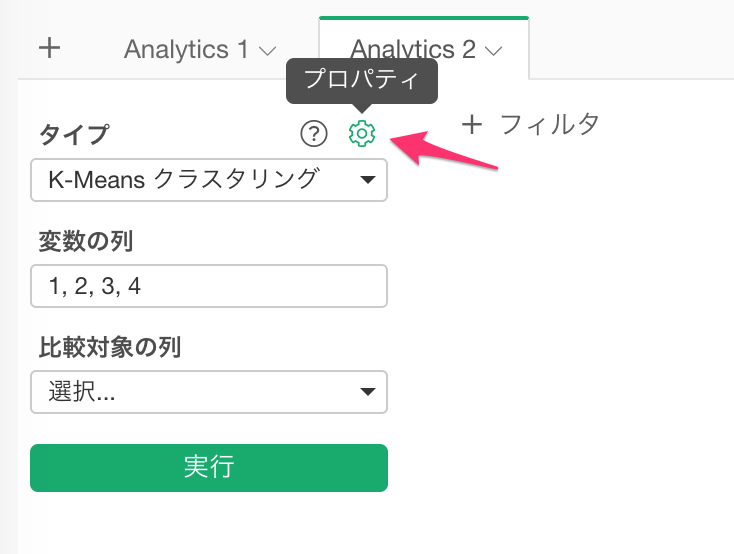
ダイアログを下の方にスクロールすると、エルボー・メソッドというセクションがあるので、「最適なクラスターの数を探索する」にTRUEを指定し、適用ボタンをクリックします。
すると、エルボー・メソッドにより、最適なクラスターの数はこのケースでは8個であることが分かりました。ちなみに、肘(エルボー)のようにカーブが曲がっている点が最適な点となります。
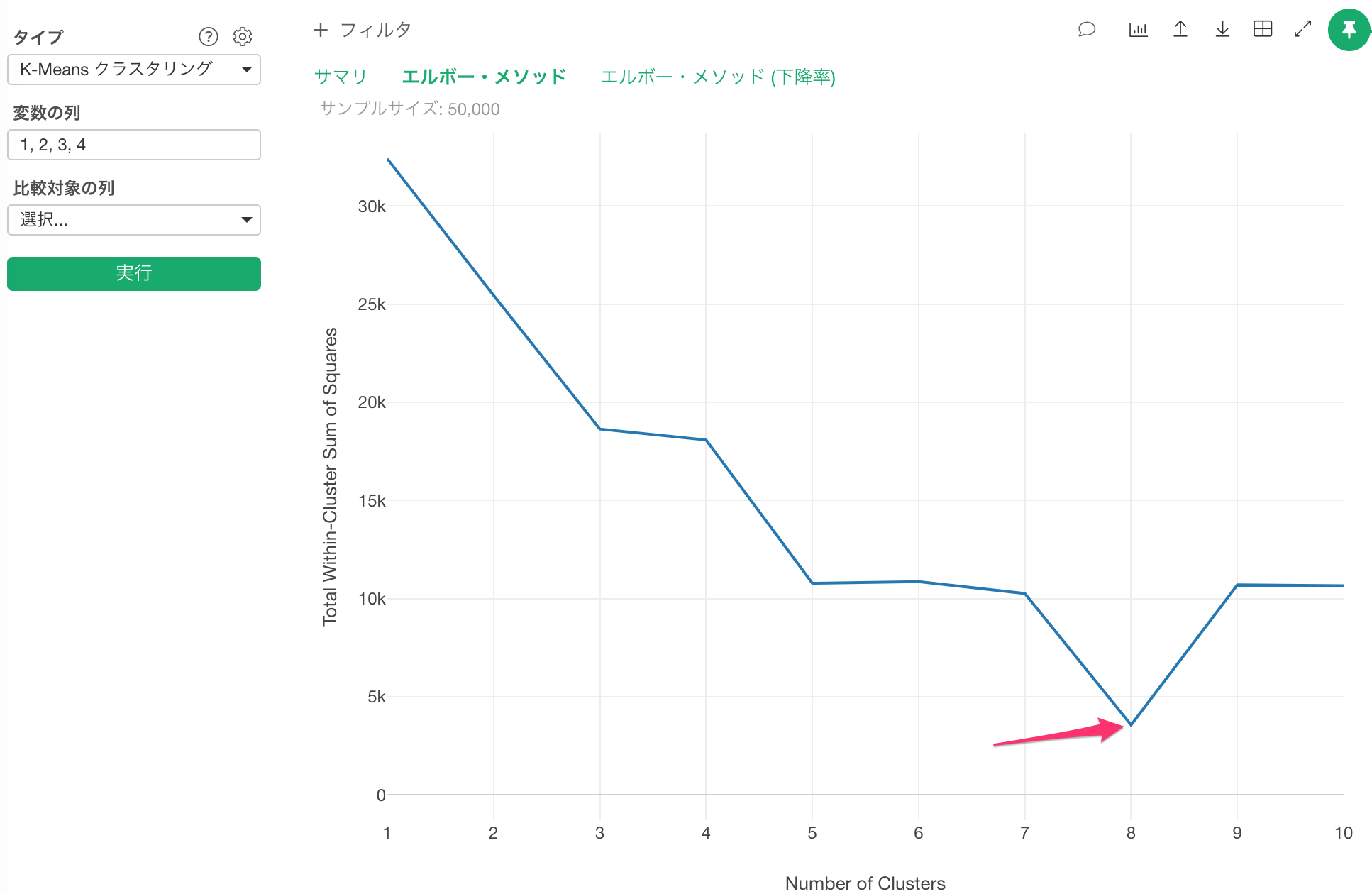
エルボー・メソッドの詳細は最適なk-meansのkを見つけるというブログを参照してください。
さて、最適なクラスターの数が8個だと分かったので、もう一度ギアのアイコンをクリックします。
クラスターの数に8を指定します。
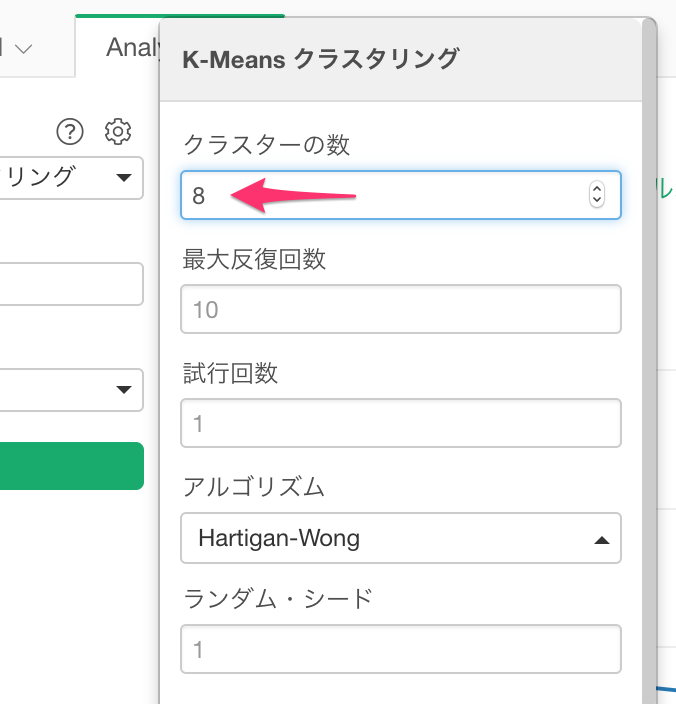
先程TRUEと指定した、エルボー・メソッドの最適なクラスターの数を探索するにFALSEを指定して、適用ボタンをクリックします。
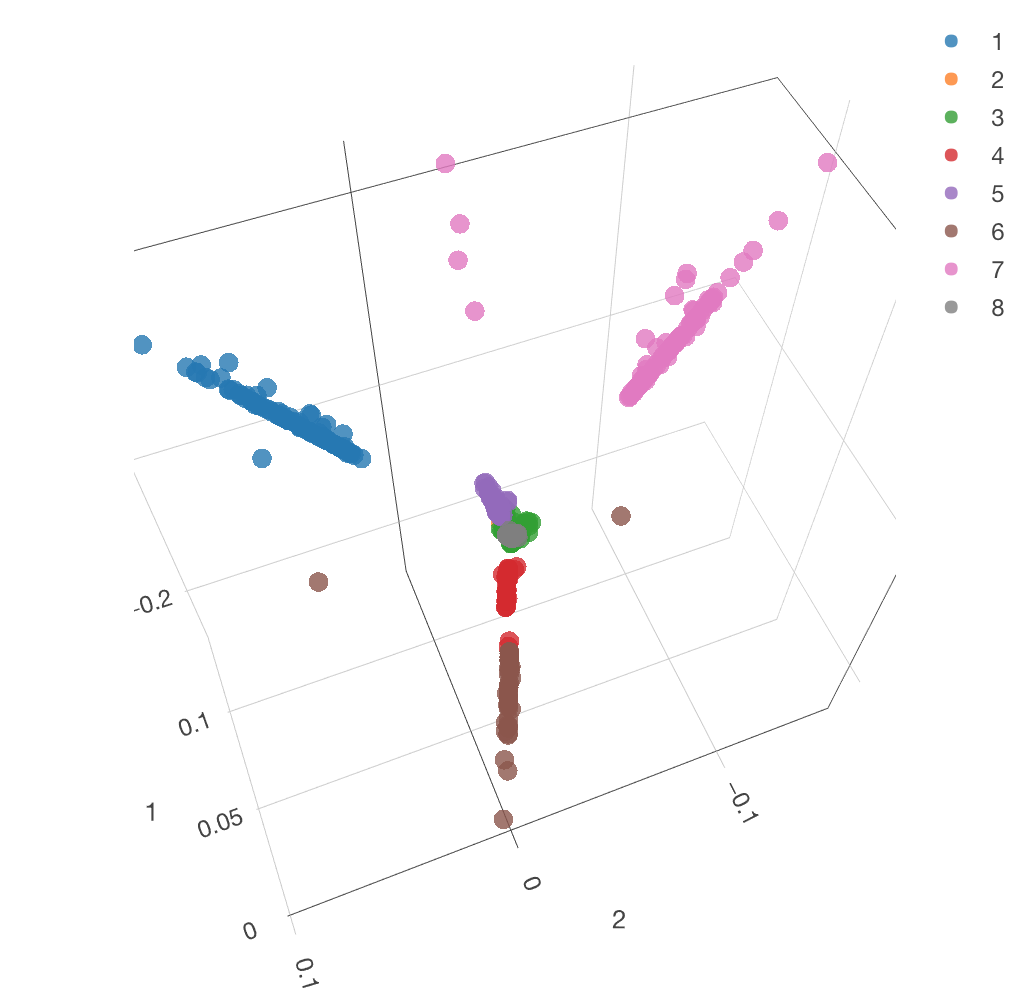
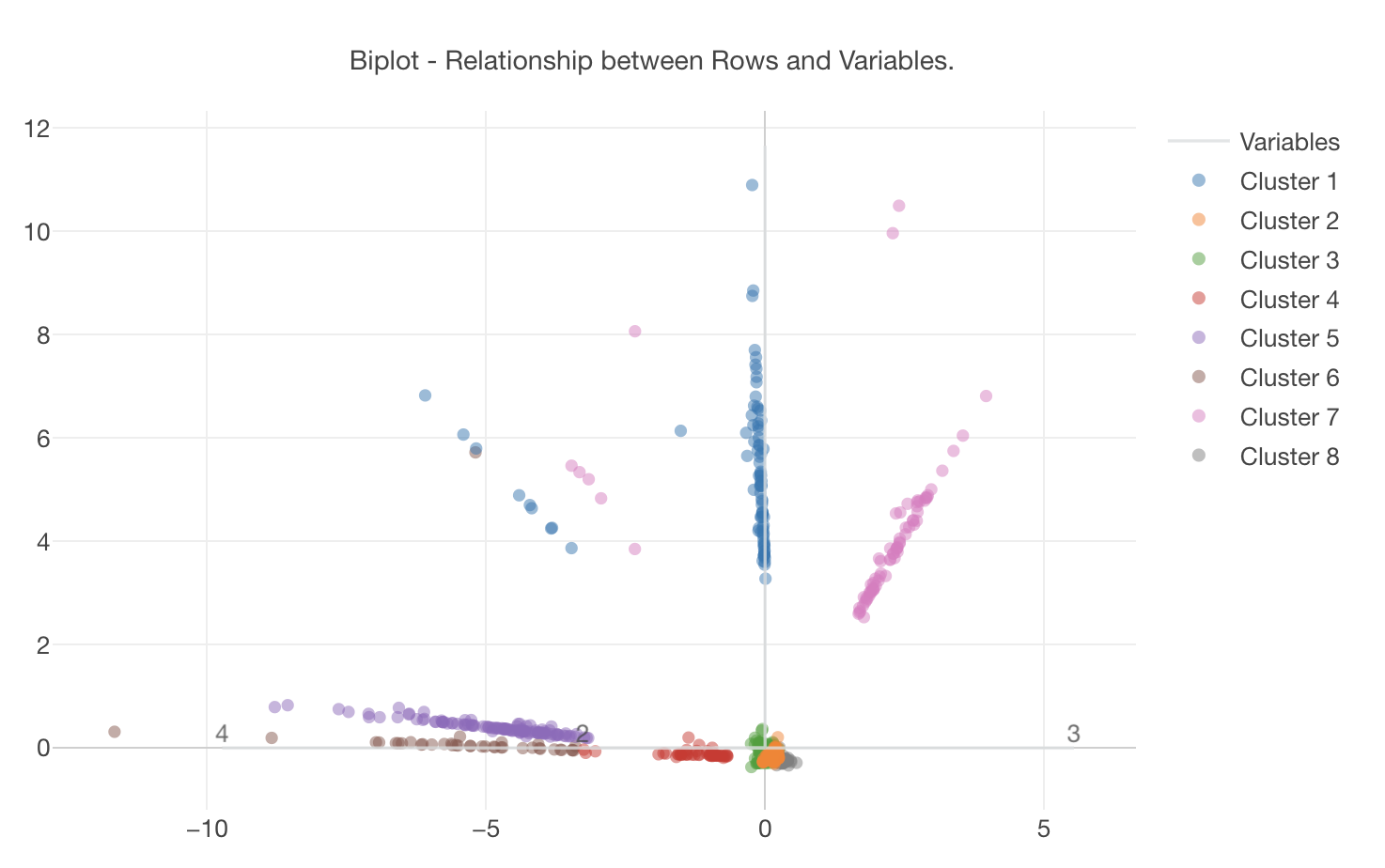
すると、今度は次のように、各クラスターがバイプロットとして表示されます。ピンクのクラスター7が右の方に、 青いクラスター1が上の方に、紫ーのクラスター5が左の方に固まっているのが分かります。
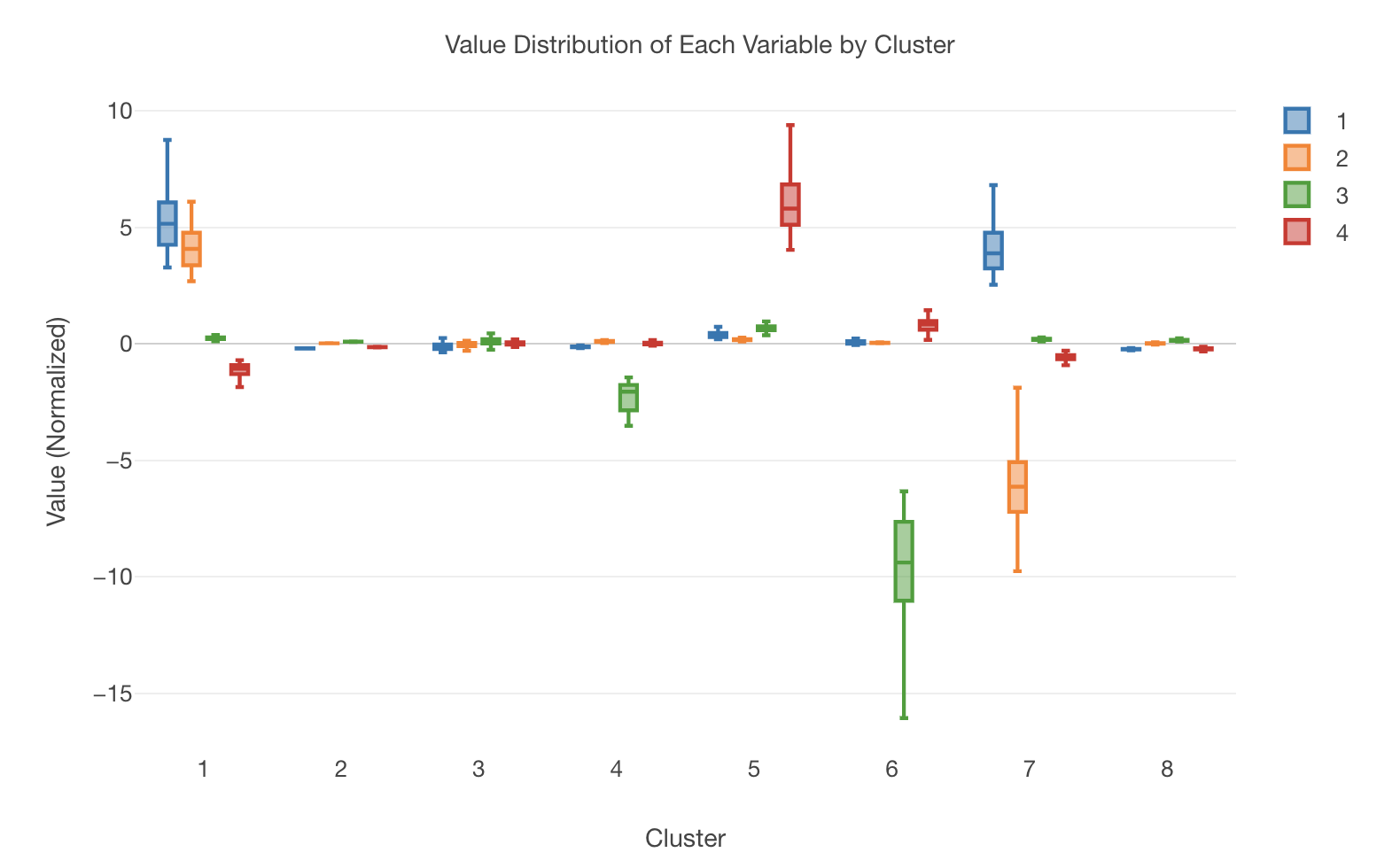
箱ひげ図で見ると、1から4の次元のクラスター毎の特徴が分かります。クラスター1は1と2の次元、クラスター5は4の次元、クラスター6は3の次元が、クラスター7は1と2の次元に特徴があるのが分かります。
クラスタリングの結果を可視化する
では、計算されたクラスターの情報を使ってTweetを可視化してみましょう。
まずは、データの緑のリンクをクリックします。するとclusterという列が追加されているのが分かります。
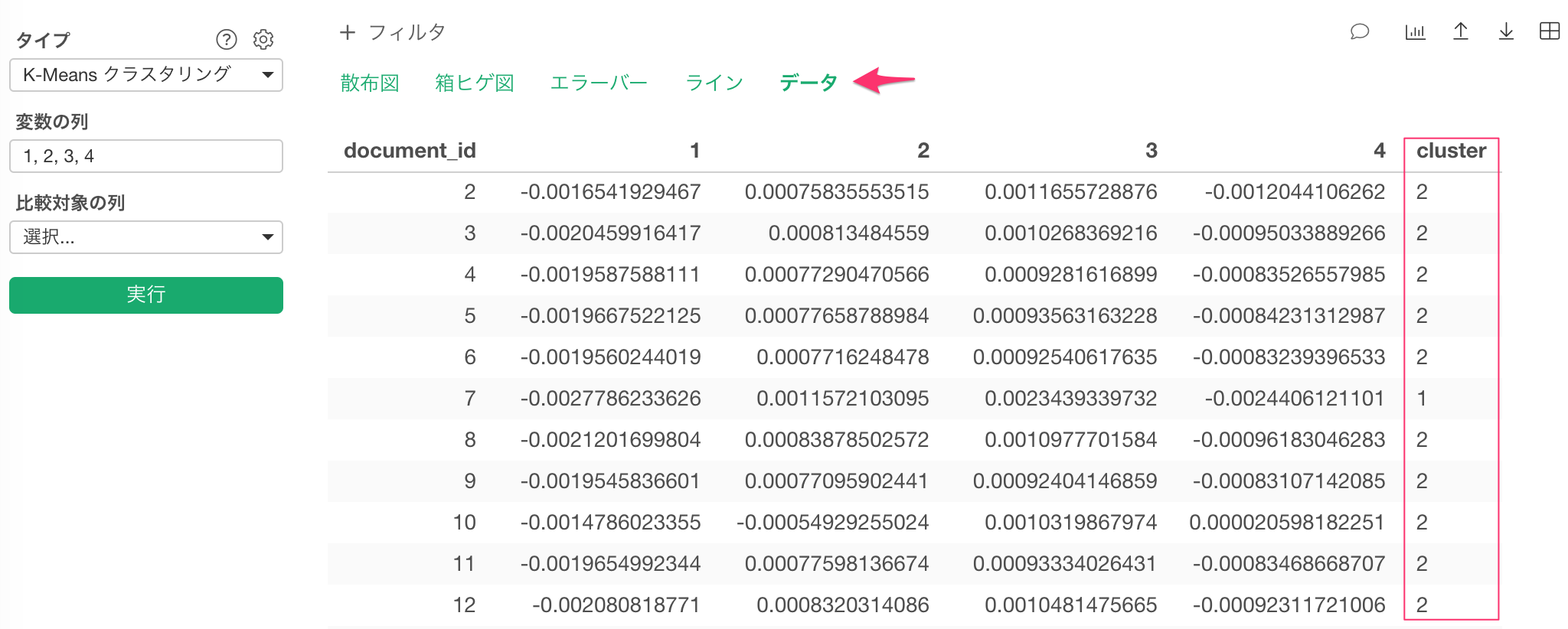
ここで、このデータを新規のデータフレームとして保存します。 下向きの矢印のアイコンをクリックします。
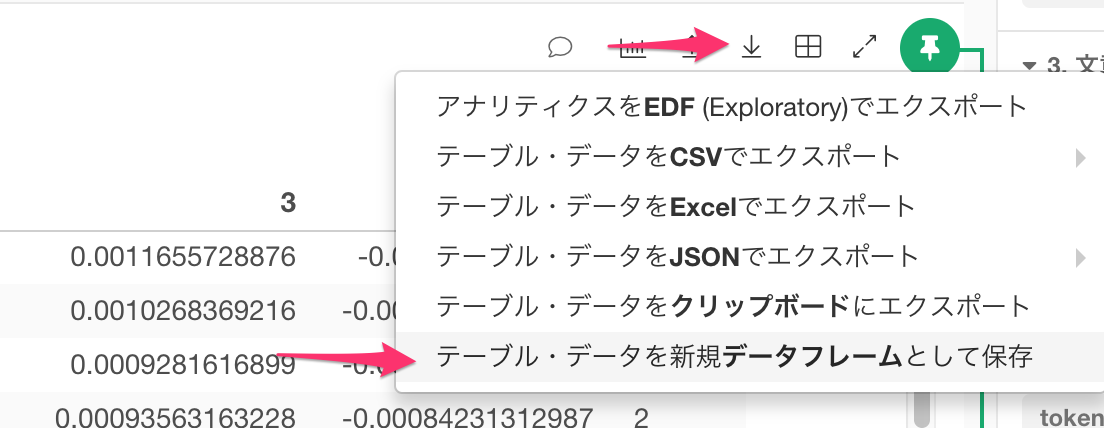
Twitter_Clusterと名前をつけてデータフレームとして保存します。
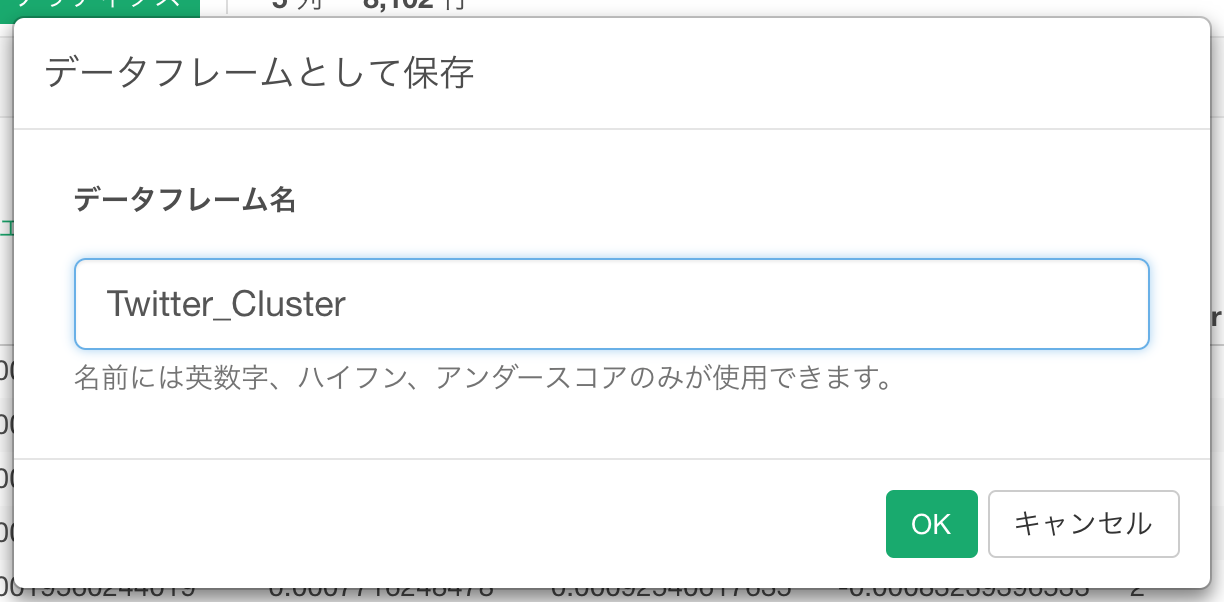
ところで、このクラスタを計算したデータフレームには、Tweetのテキスト情報は残っていません。
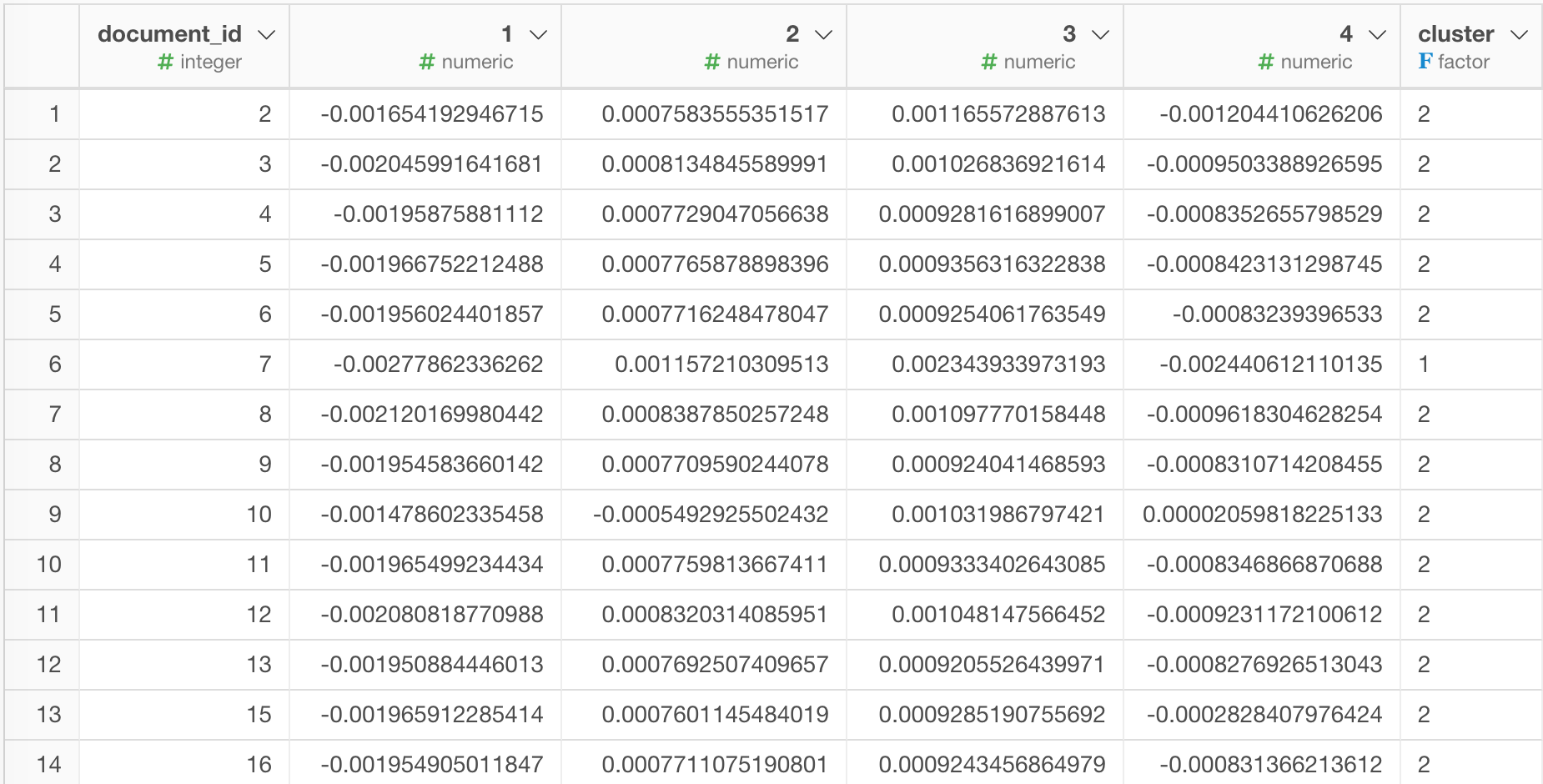
そこで、可視化のためにクラスタの情報と元のTweet情報と結合します。
元のTweet情報を持つブランチを作成
SVDとK-Meansクラスタリングを実行した後には、上の表を見てわかる通り、text列はありません。しかし、もともとのデータフレームの先頭のステップ(画面右側のステップの先頭)に行くと、元々のTweetがtext列に残っているのが下の図のように分かります。
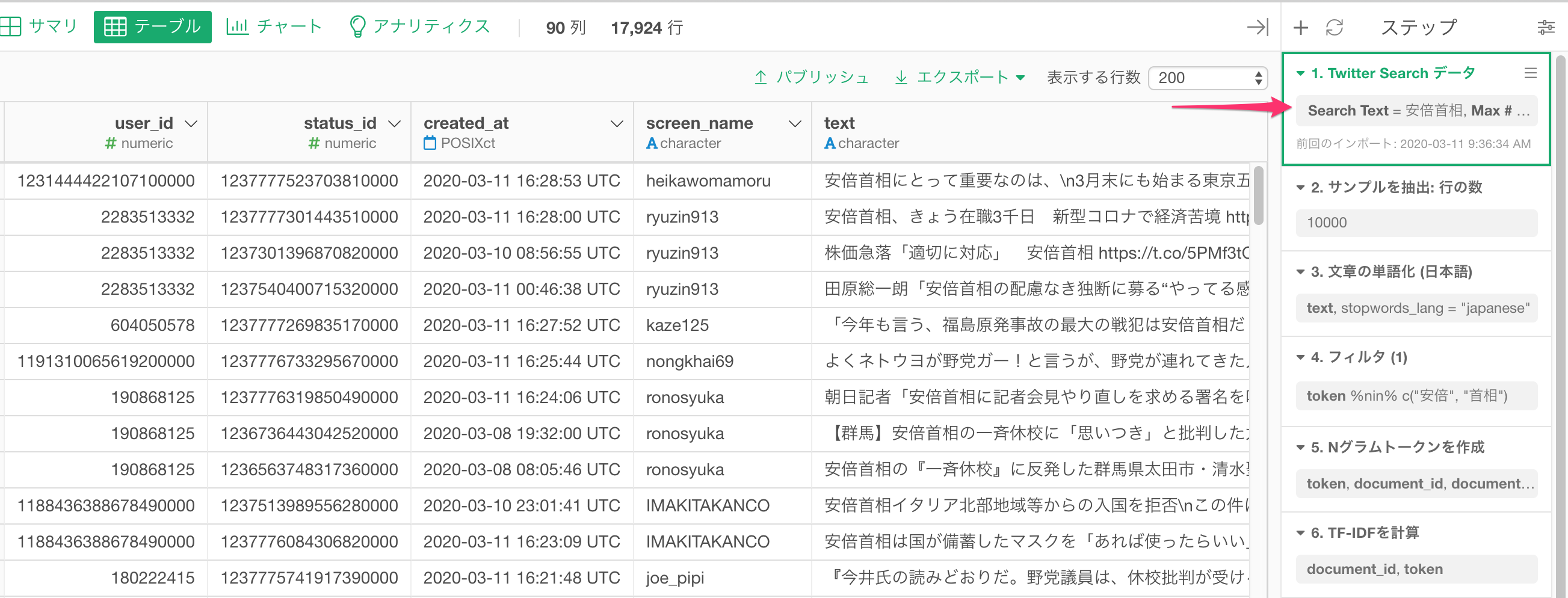
このTweetのテキスト情報をスナップショットとして保存しておくために、元のデータフレームの一番先頭のソースのステップ(画面右側のステップの先頭)のメニューをクリックし、ブランチの作成を選びます。
!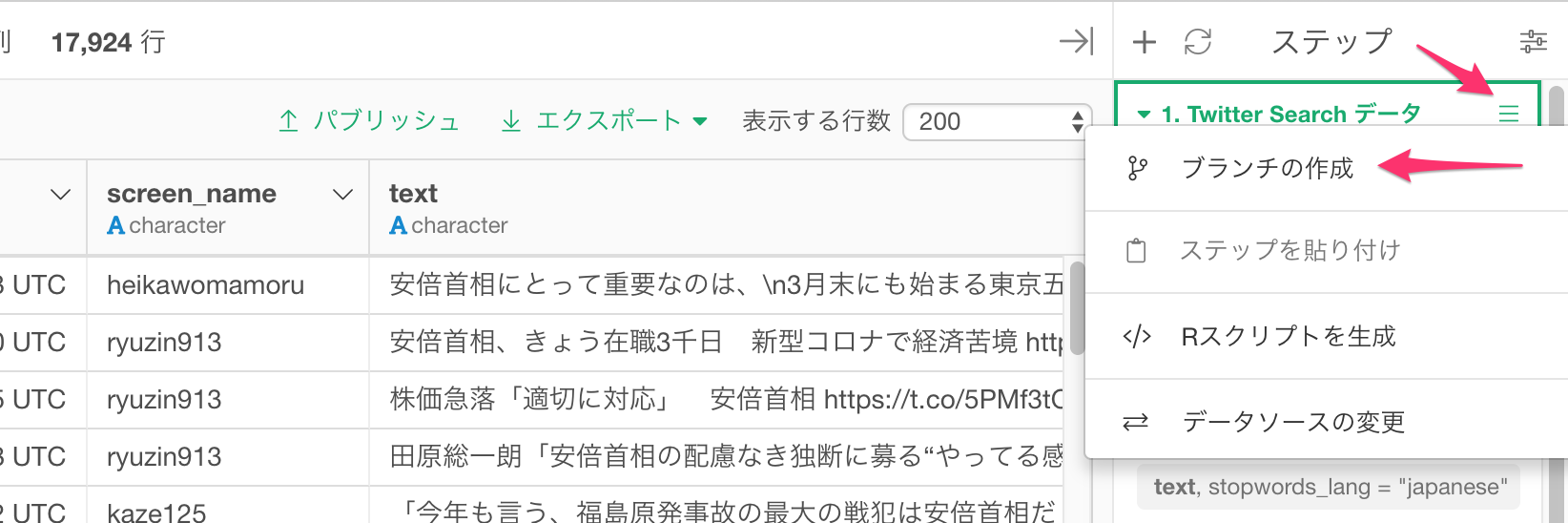
Twitter_Search_Sourceと名前を入れて作成ボタンをクリックします。
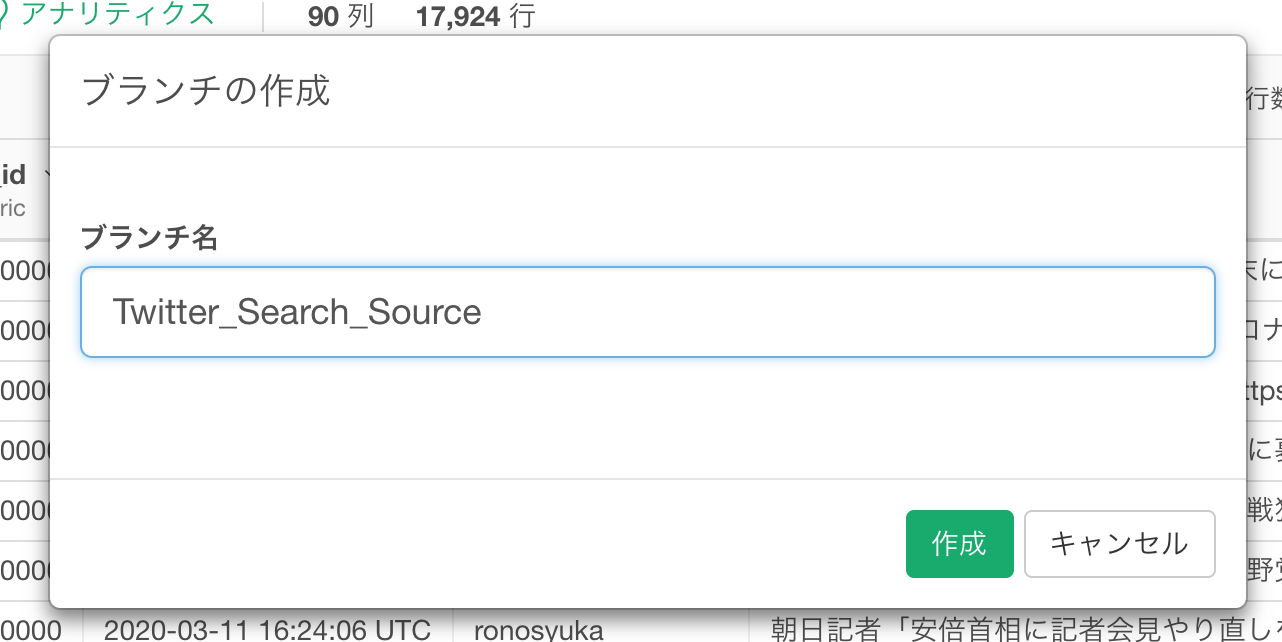
すると、画面左手のツリーのデータフレームのセクションにがTweeter_Search_Sourceというブランチが元のデータフレームの下に出来たのが確認できます。
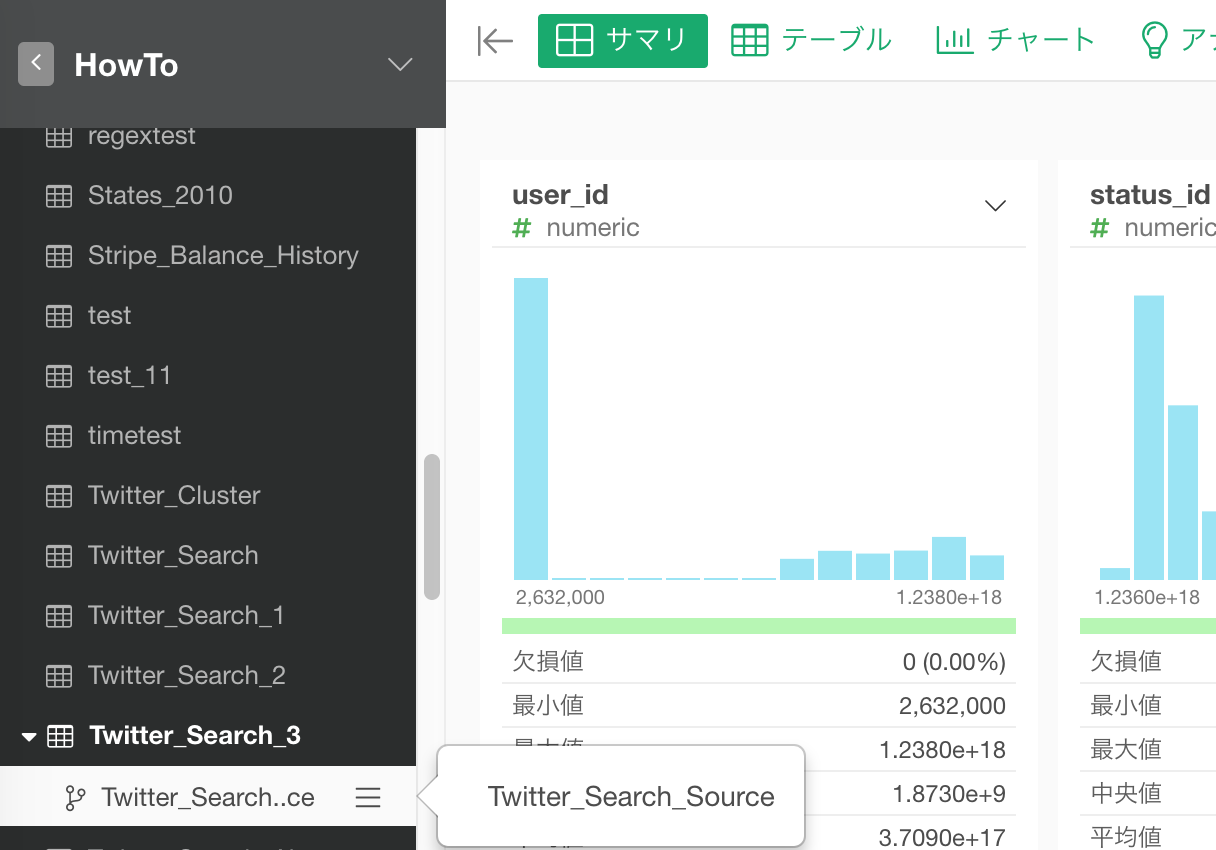
最終的に必要なのは結合キーに使うdocument_id (RMeCabを利用した場合はstatus_id) と、Tweet情報のtext列ですが、元のTweetにはdocument_idがありません。これは行番号なので、プラス(+)ボタンを押して、その他 -> 行番号を追加を選択します。
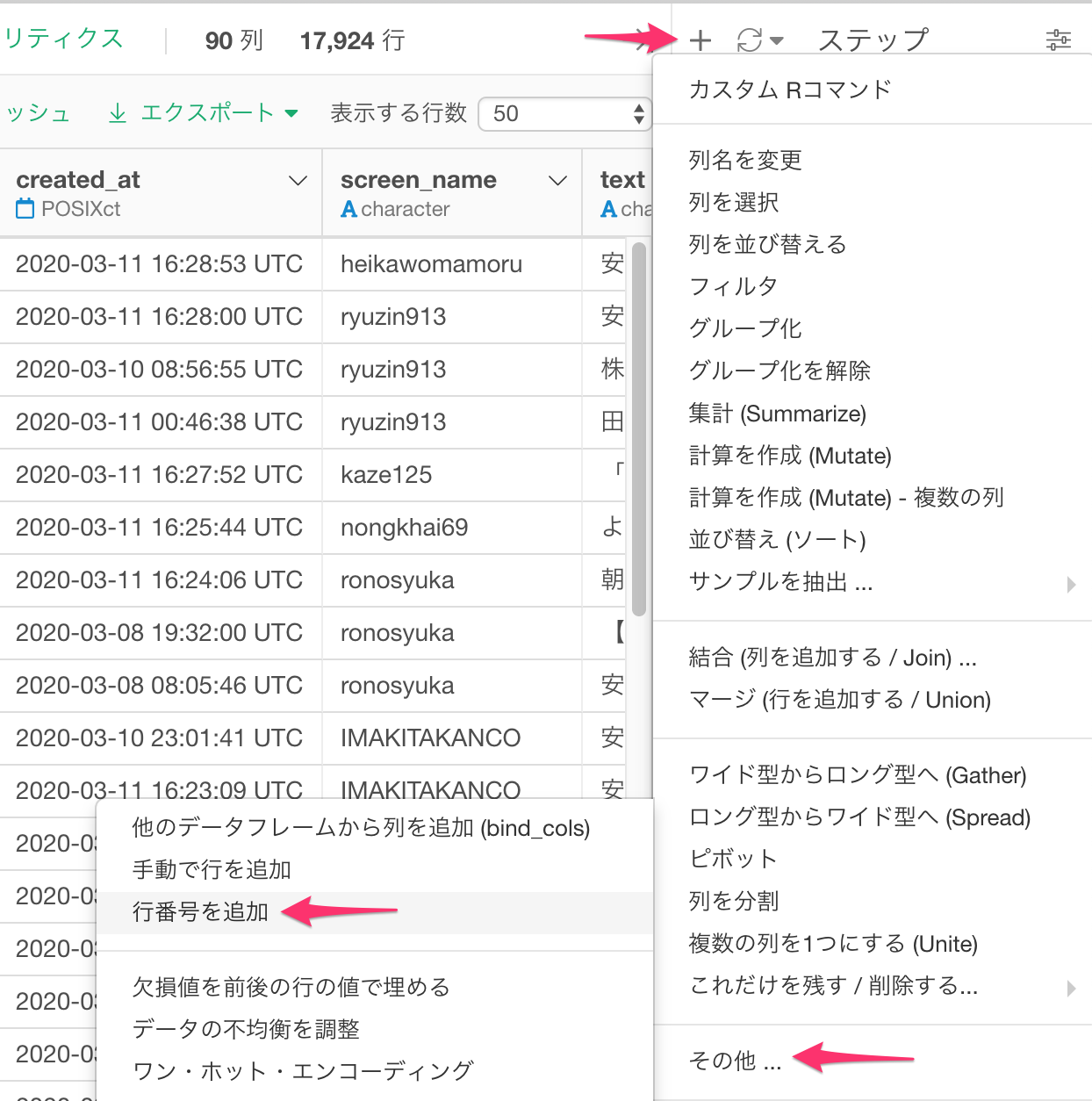
新規列名として、document_id (RMeCabを利用した場合はstatus_id) と入力し、実行します。 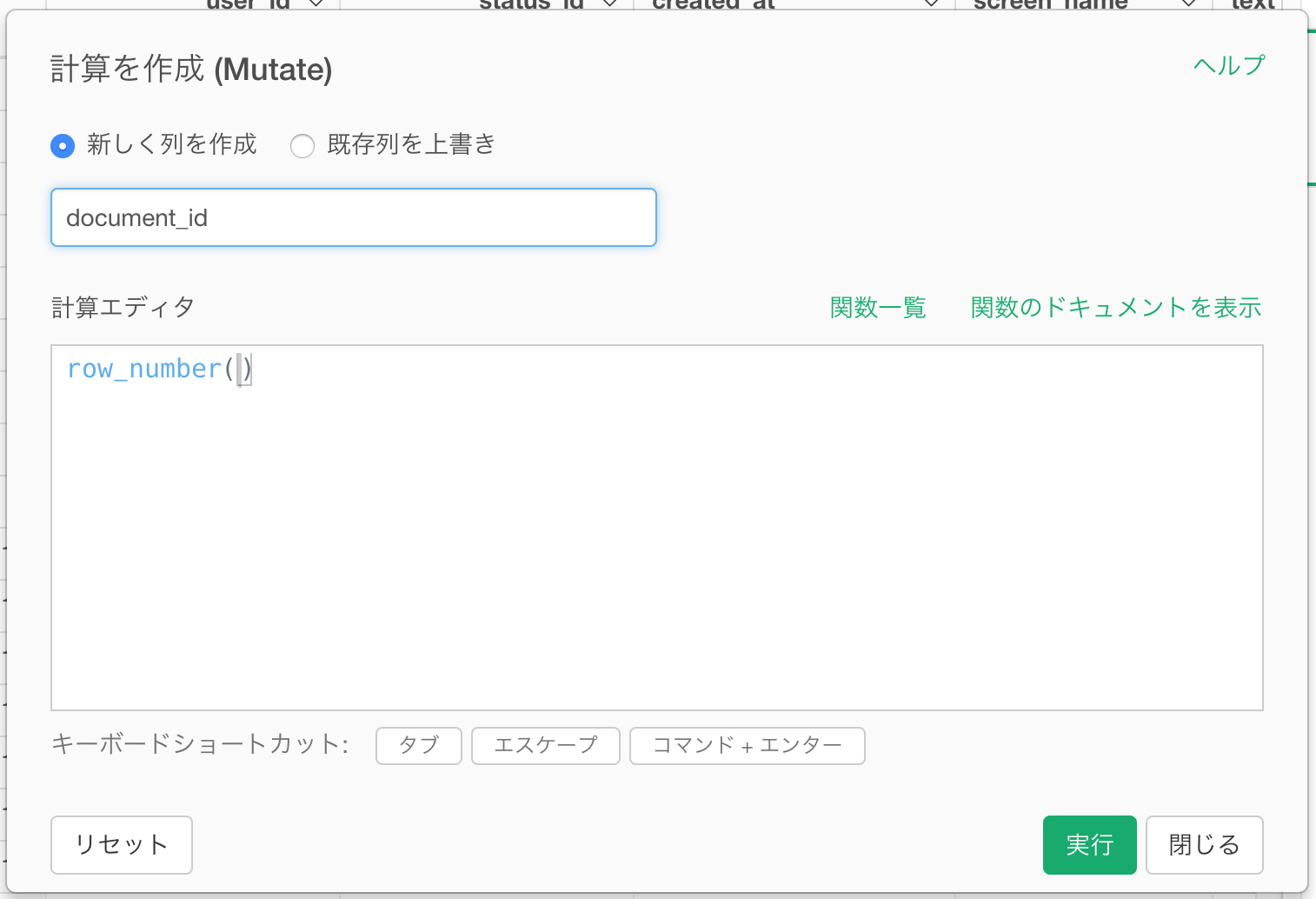
今作成した行番号と、text列だけを残します。列メニューより、列を選択 / 削除を選びます。
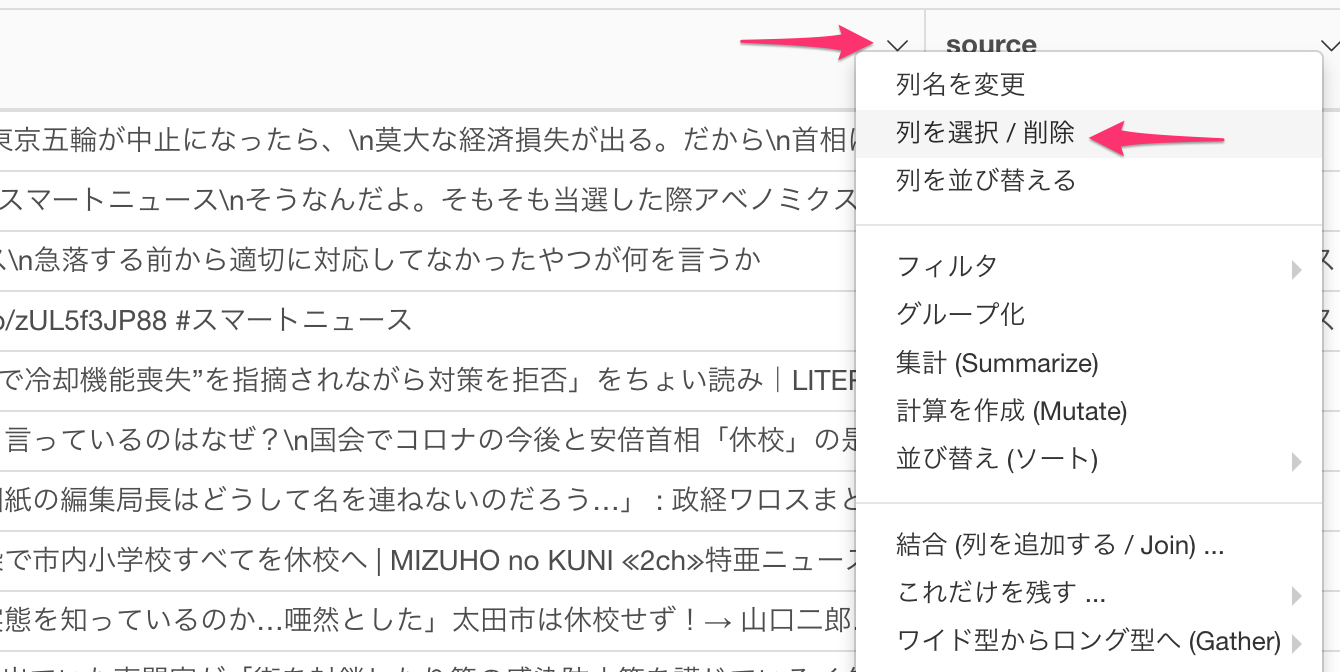
textとdocument_id (RMeCabを利用した場合はstatus_id) を選び、実行ボタンをクリックします。
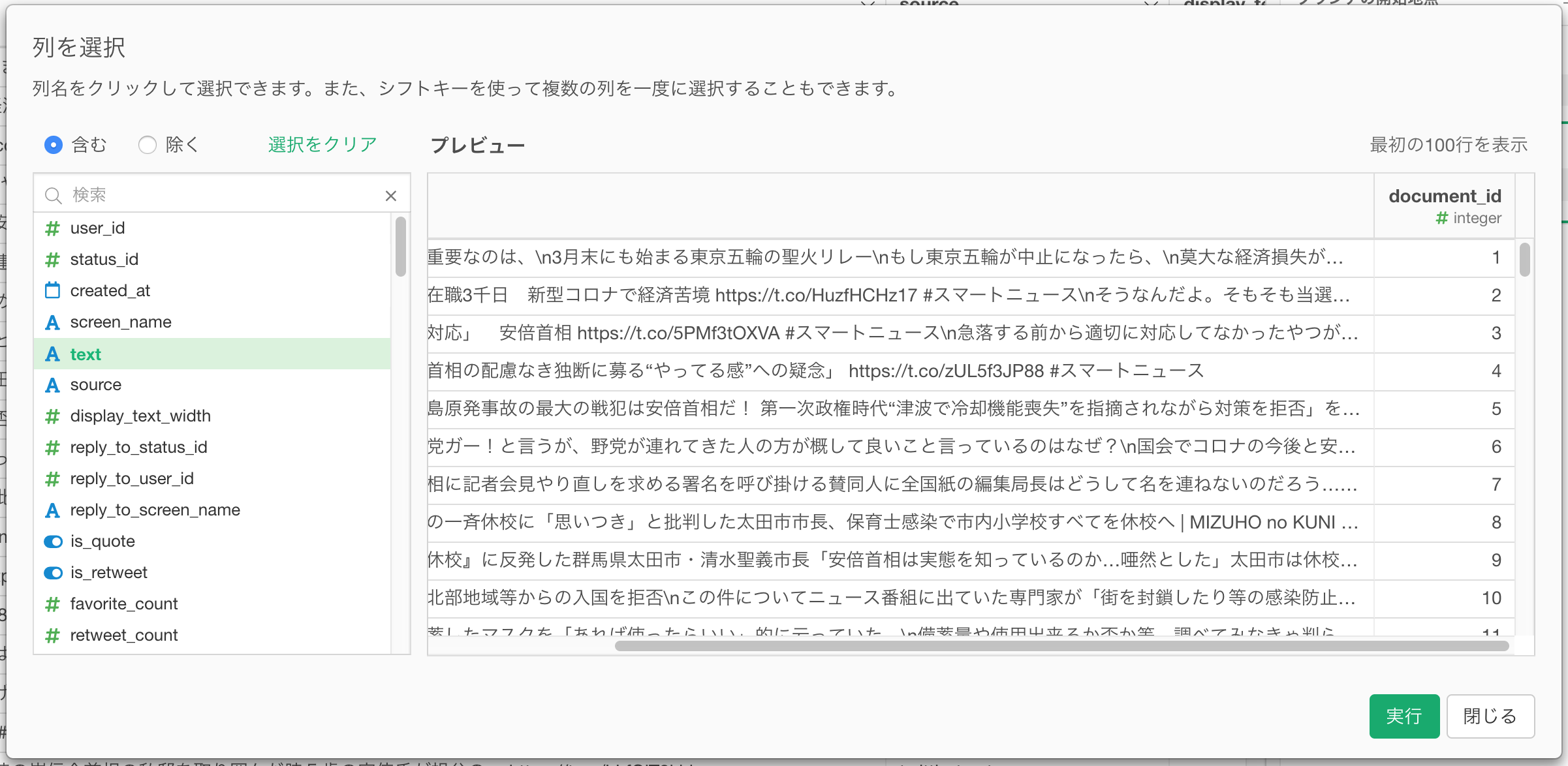
document_id (RMeCabを利用した場合はstatus_id)と、Tweet情報のtext列だけになりました。
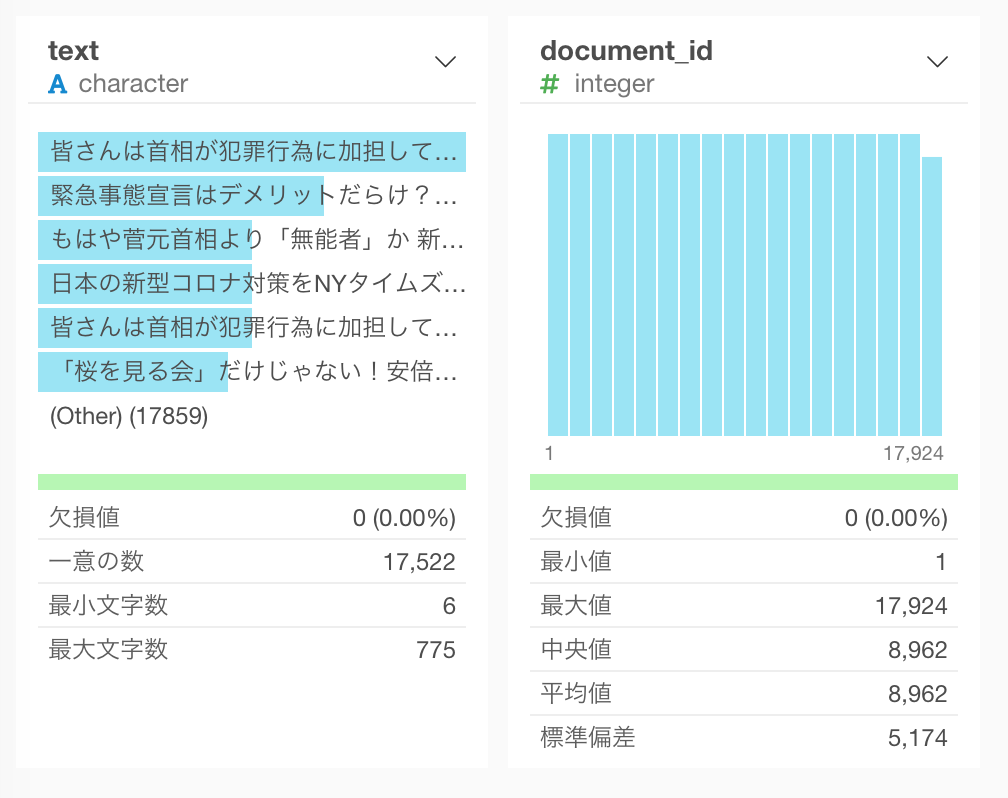
さて、クラスタを計算したデータフレーム(Tweeter_Cluster)に戻り、先ほどとったスナップショット(Twitter_Search_Sourceというブランチ)と結合して、text列を持ってきましょう。document_id (RMeCabを利用した場合はstatus_id) の列ヘッダーメニューより、結合 (列を追加する / Join)...を選びます。
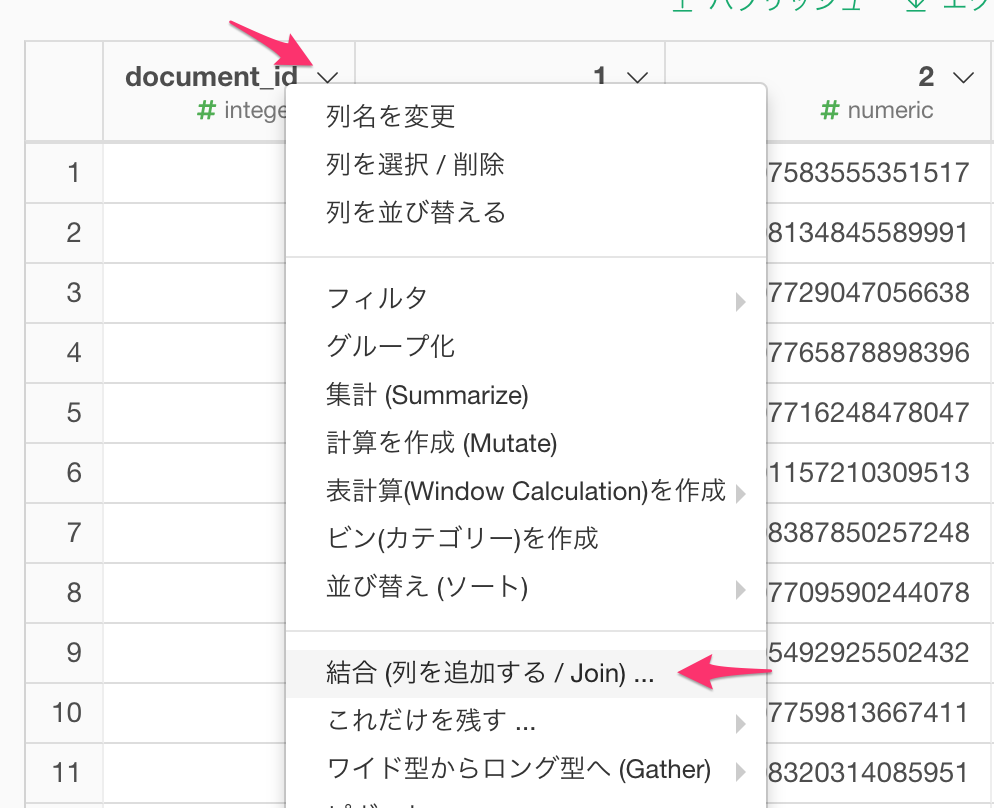
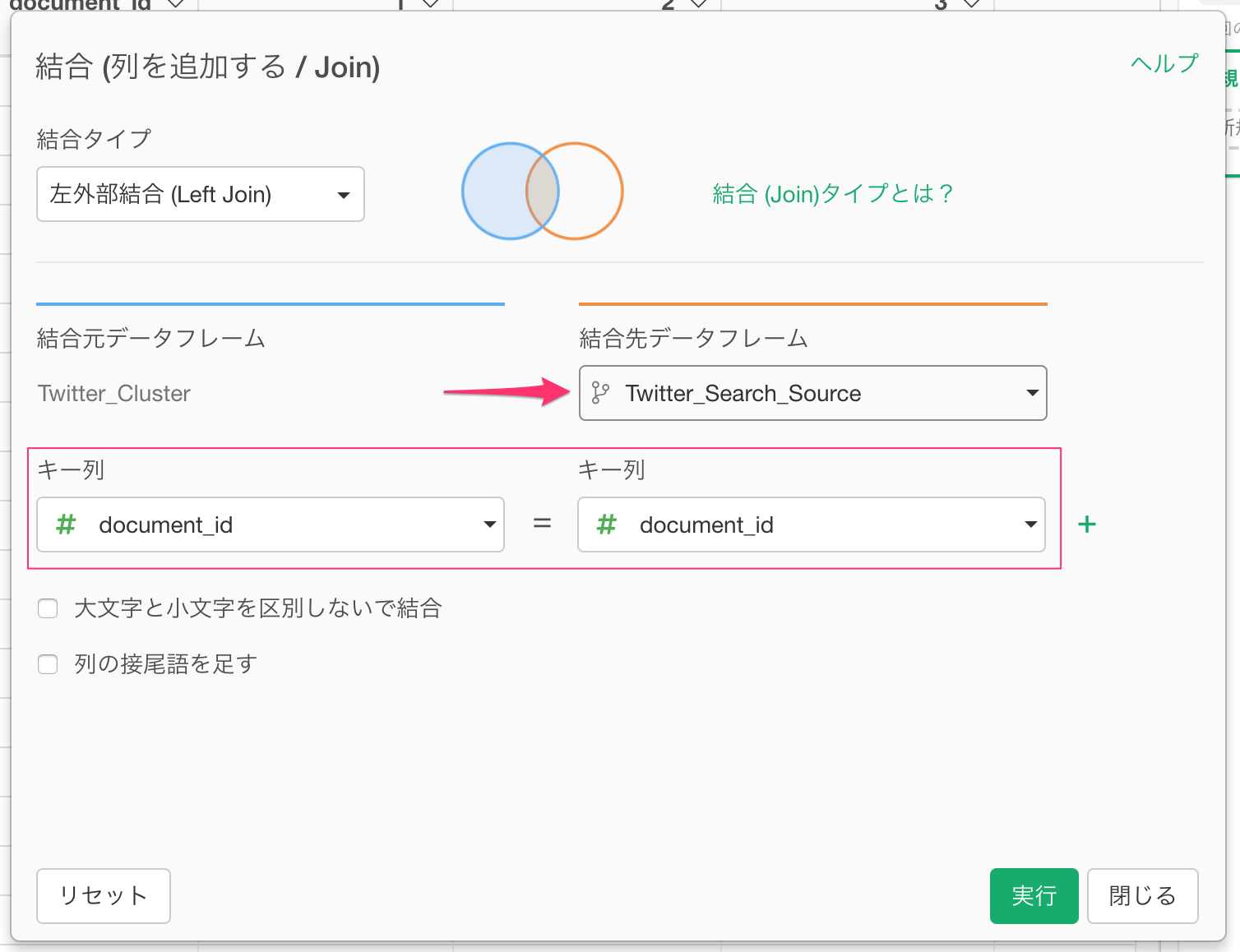
結合の相手先に、今作成したブランチ(Twitter_Search_Source)を指定し、マッチさせる列にdocument_id (RMeCabを利用した場合はstatus_id) をそれぞれ指定し、実行ボタンをクリックします。
これでクラスタとSVDの計算結果(1から4の列)とTweetのテキストが以下のように一つのデータフレームに結合されました。
散布図でTweetのクラスタを可視化
次にチャートビューに行き、散布図を作成します。X軸に1列を、Y軸に2列を、Z軸に3列を割り当てます。次に色で分割にcluster列、ラベルにtext列をそれぞれ割り当てます。
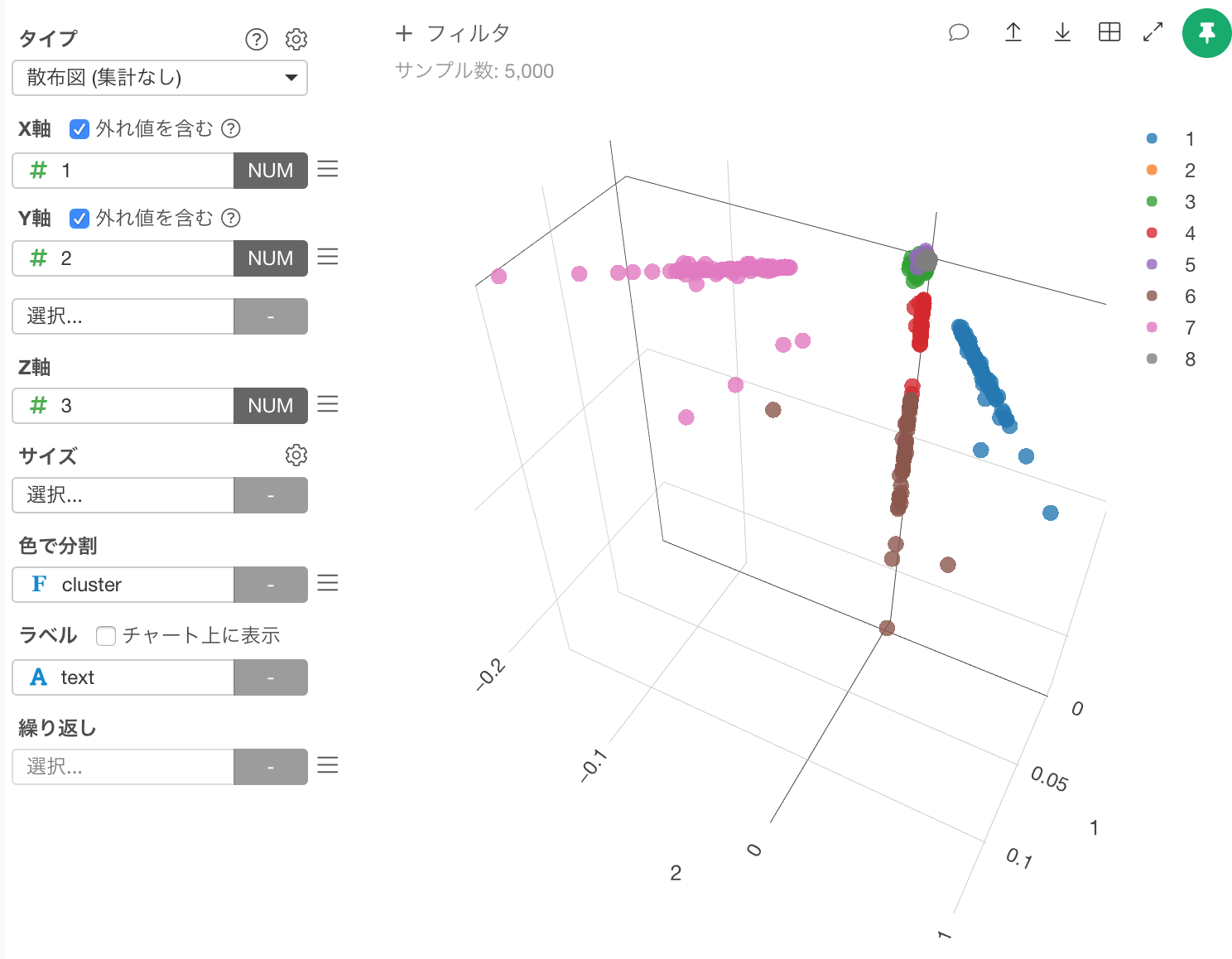
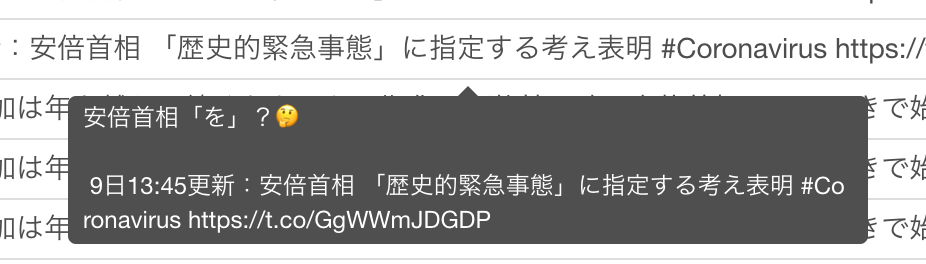
散布図に8つのクラスタが可視化されました。それぞれの点をホバーすると、次のようにTweetのテキストの内容を確認できます。例えば茶色のクラスター6のある一点をマウスでホバーすると、次のようなTweetであることが分かります。
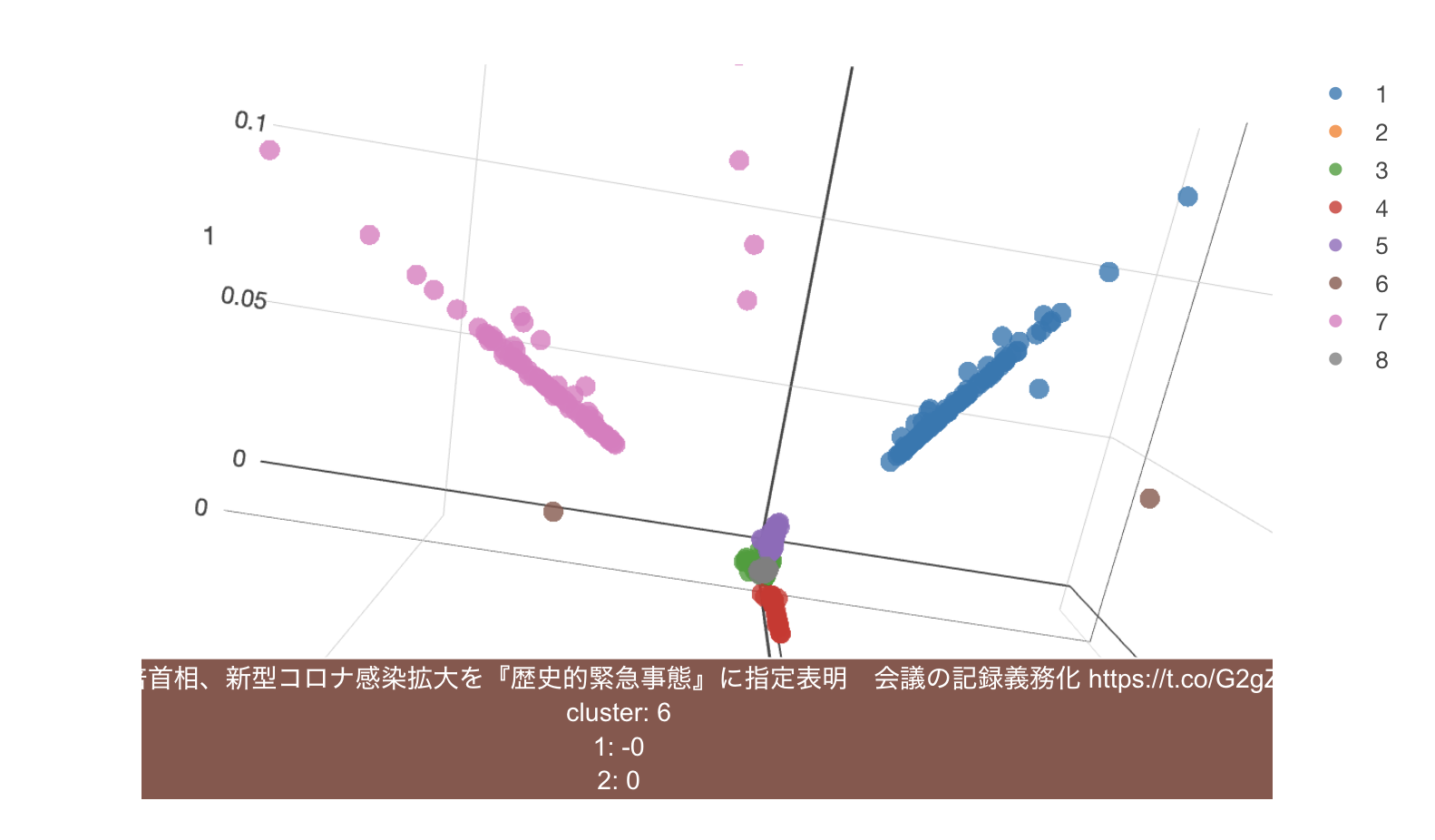
クラスタ毎の特徴
では次に、各クラスタ毎に頻出する単語をみて、クラスタ毎の特徴を確認してみましょう。そのためには単語とクラスタの情報を一つのデータフレームに集める必要があります。
SVDとK-Meansを実行した後には、単語を保持するtoken列はありません。しかし 元のデータフレームの単語を導出したのステップ(画面右側のNグラムトークンを作成のステップ)に行くと、元々の単語がtoken列に残っているのが下の図のように分かります。
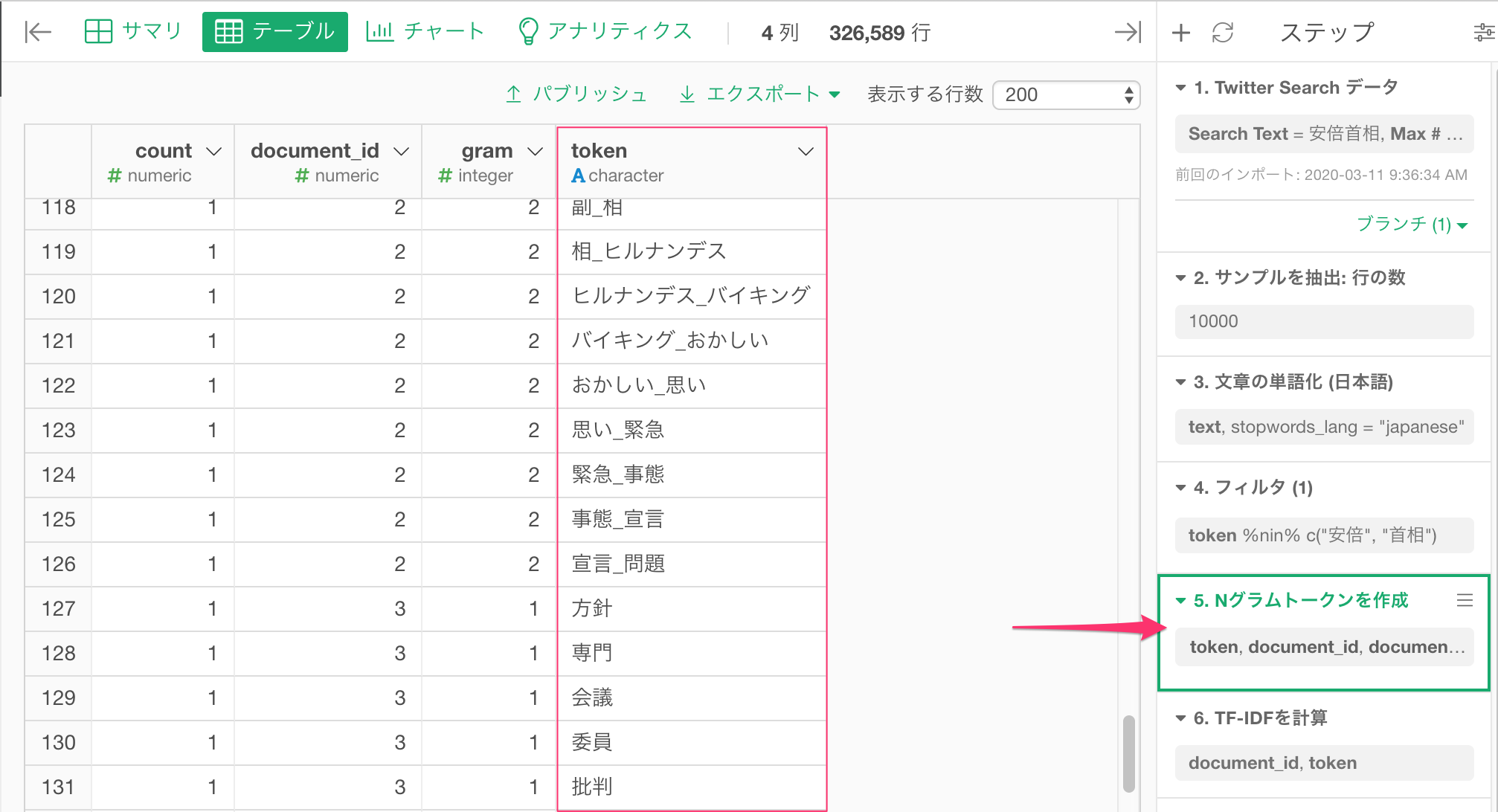
この単語情報をスナップショットとして保存しておくために、このデータフレームのNグラムトークンを作成のステップのメニューをクリックし、ブランチの作成を選びます。
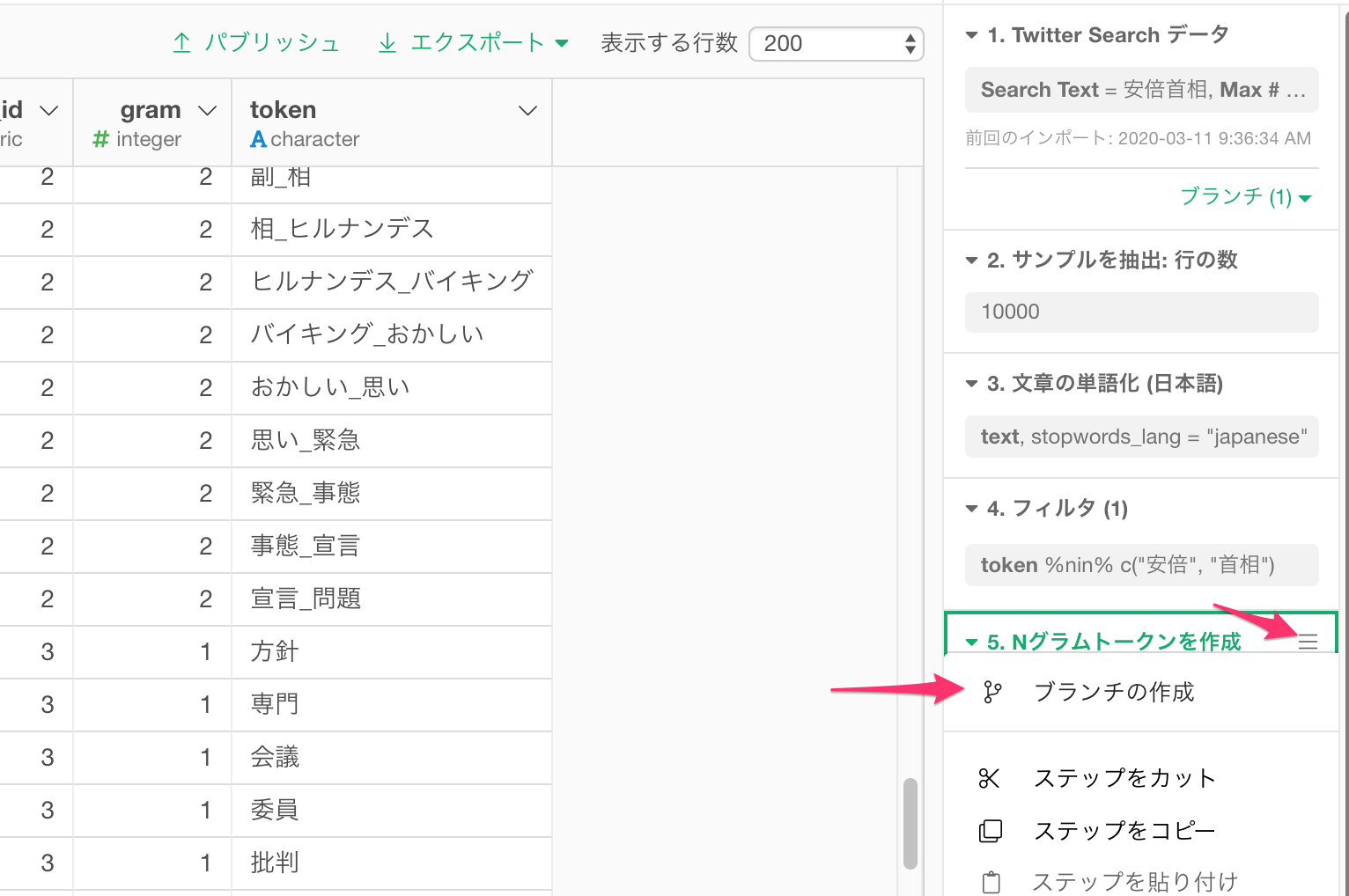
Twitter_Ngramという名前のブランチを作成します。
クラスタ情報を持つデータフレームの下に、単語情報を持つTwitter_Ngramができました。
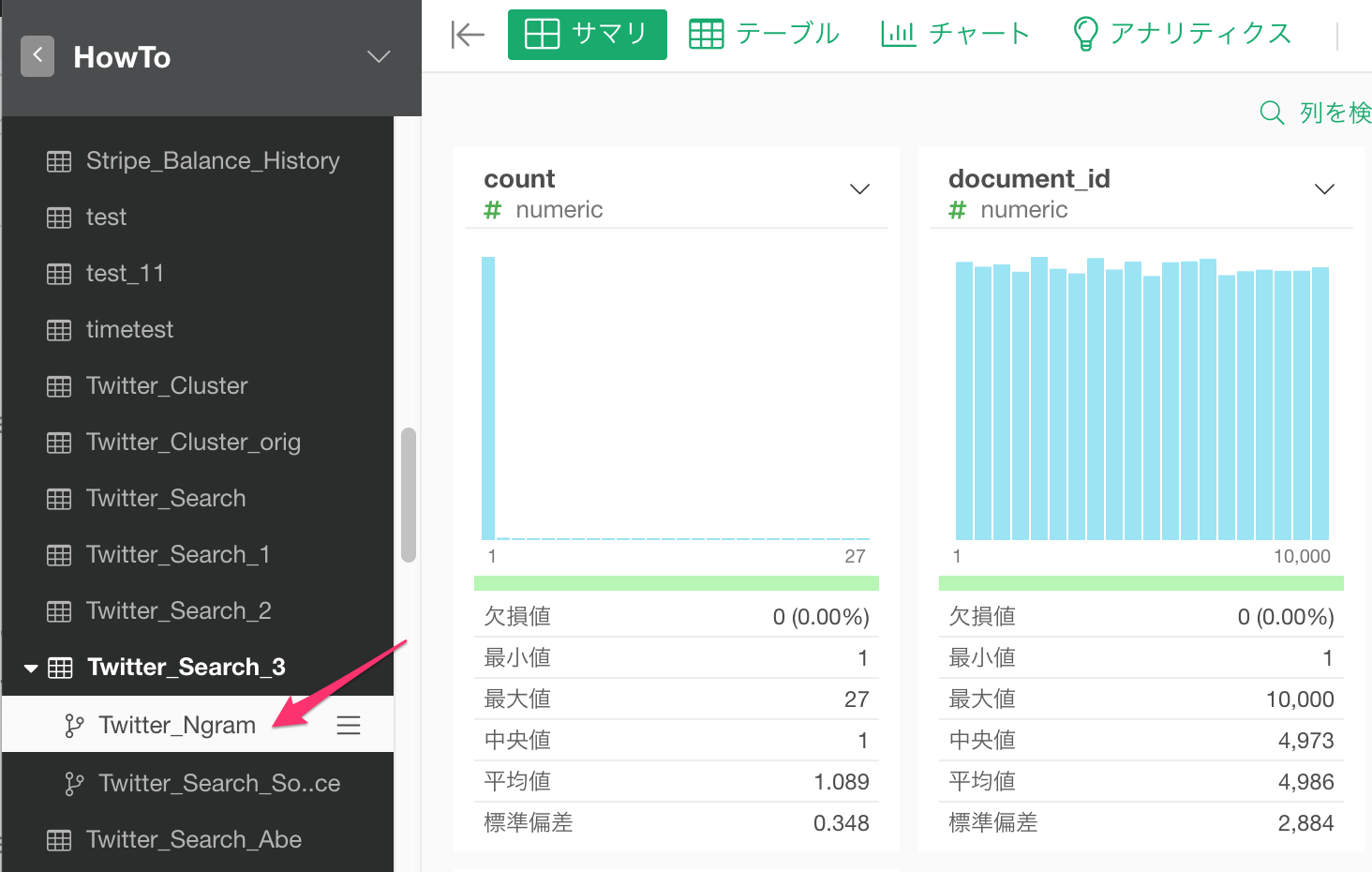
最終的に必要なのは結合キーに使うdocument_id (RMeCabを利用した場合はstatus_id) と、単語情報のtoken列だけなので、先ほどと同じようにこの2つの列だけを残します。document_id列 (RMeCabを利用した場合はstatus_id列) をtoken列の列ヘッダーメニューからし、列を選択 / 削除 を選びます。
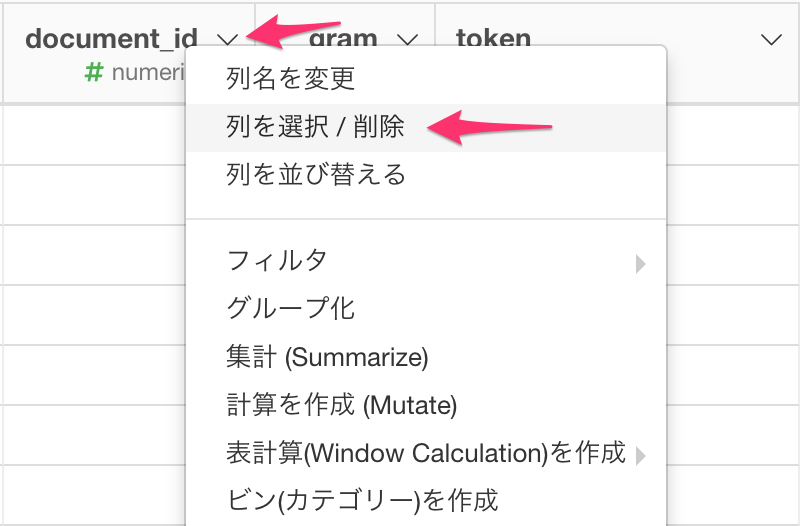
document_id (RMeCabを利用した場合はstatus_id) とtokenを選択し、実行ボタンをクリックします。
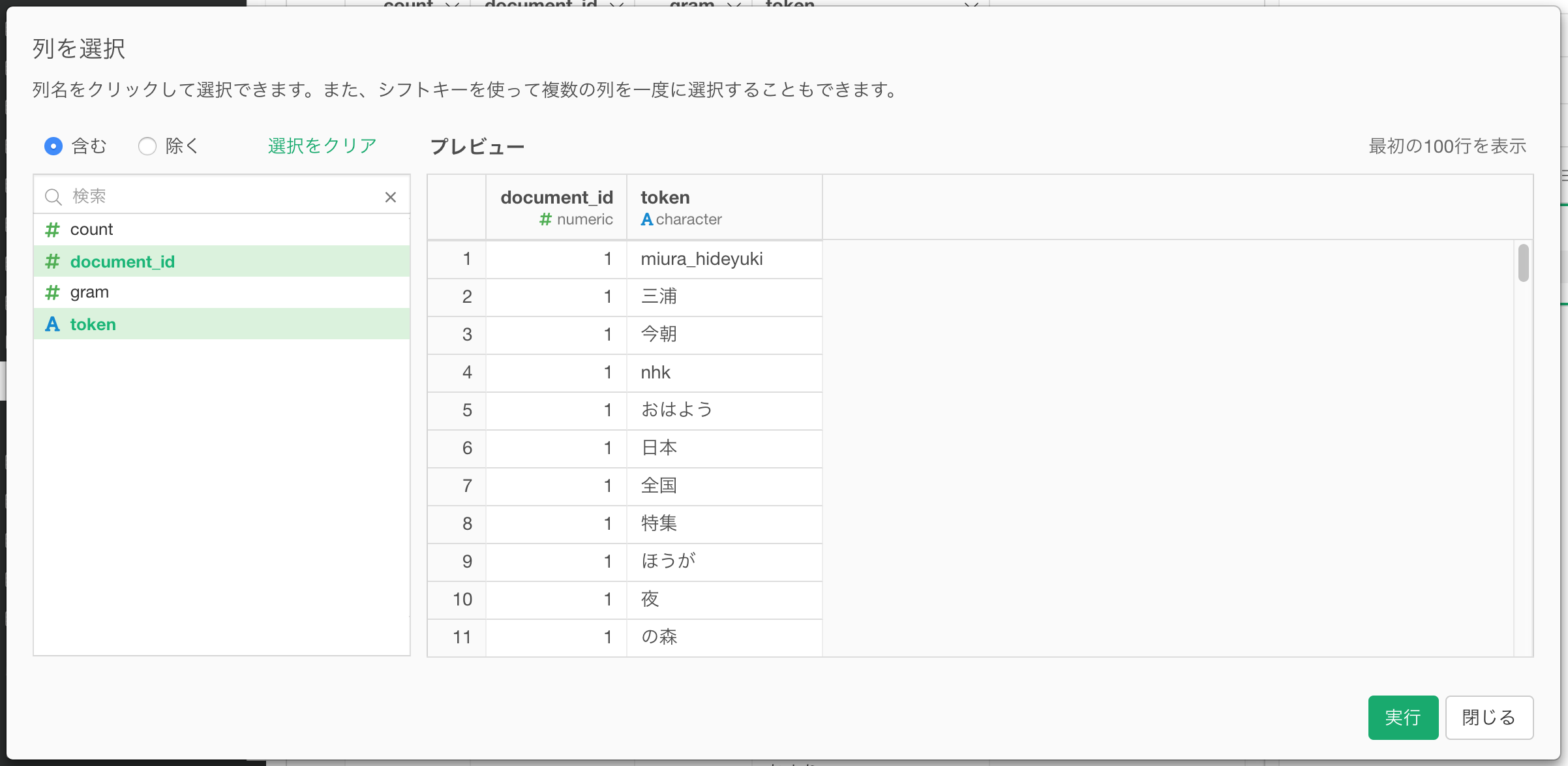
document_id (RMeCabを利用した場合はstatus_id) と、単語情報のtoken列だけになりました。
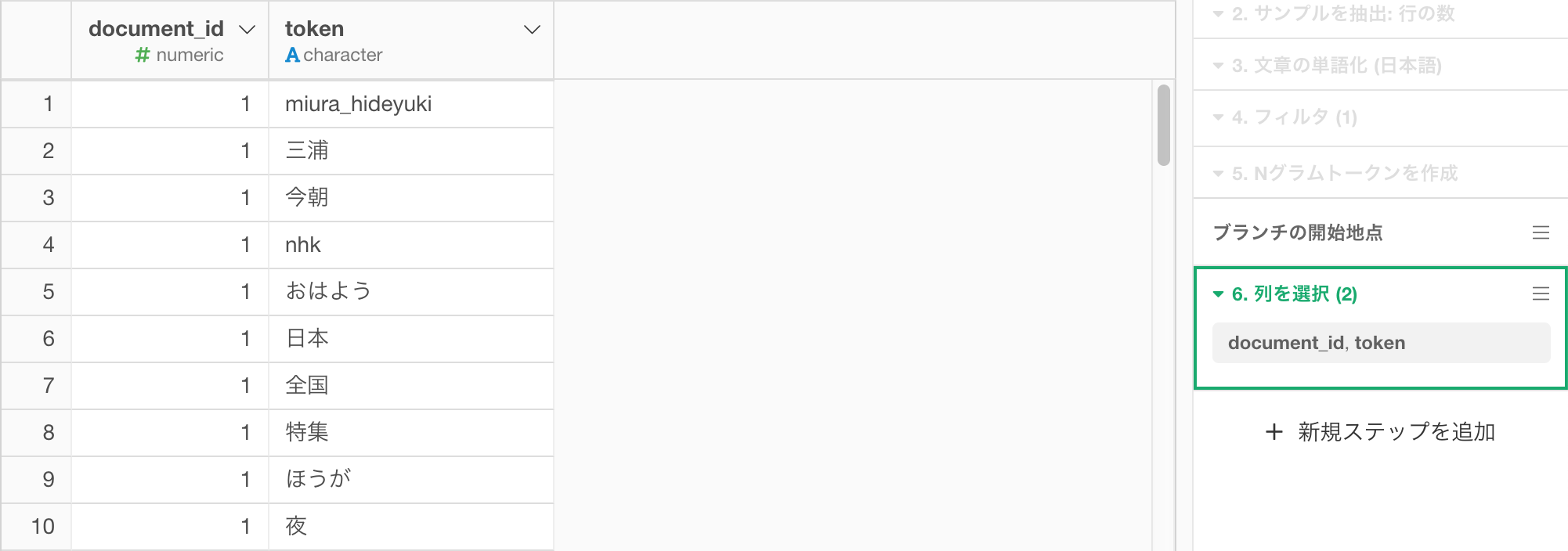
さて、SVD及びクラスタを計算したデータフレーム(Twitter_Cluster)に戻り、先ほどとったスナップショット(Twitter_Ngramというブランチ)のtoken列をtweet_abeデータフレームに結合しましょう。
列ヘッダーメニューから、結合をメニューから選びます。
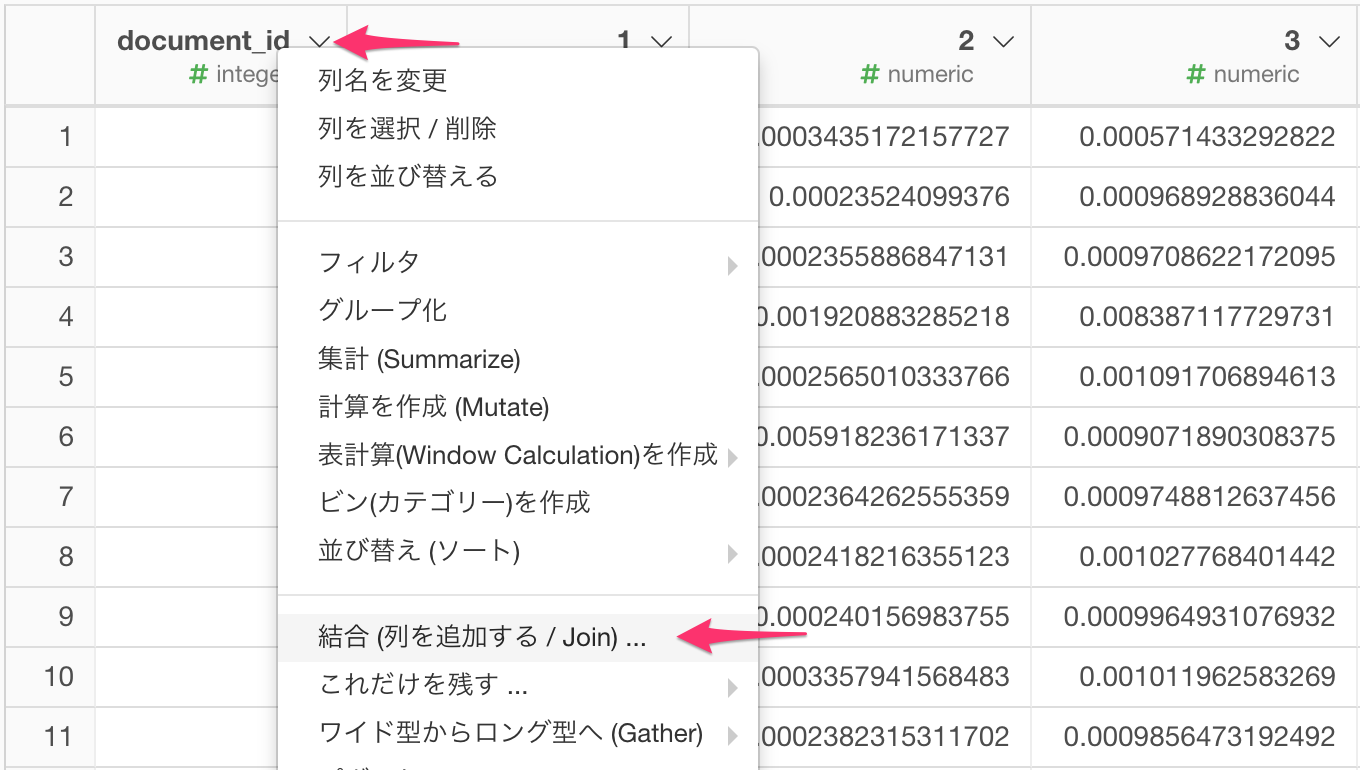
結合の相手先に、今作成したブランチ(Twitter_Ngram)を指定し、マッチさせる列にdocument_id (RMeCabを利用した場合はstatus_id) をそれぞれ指定し、実行ボタンをクリックします。
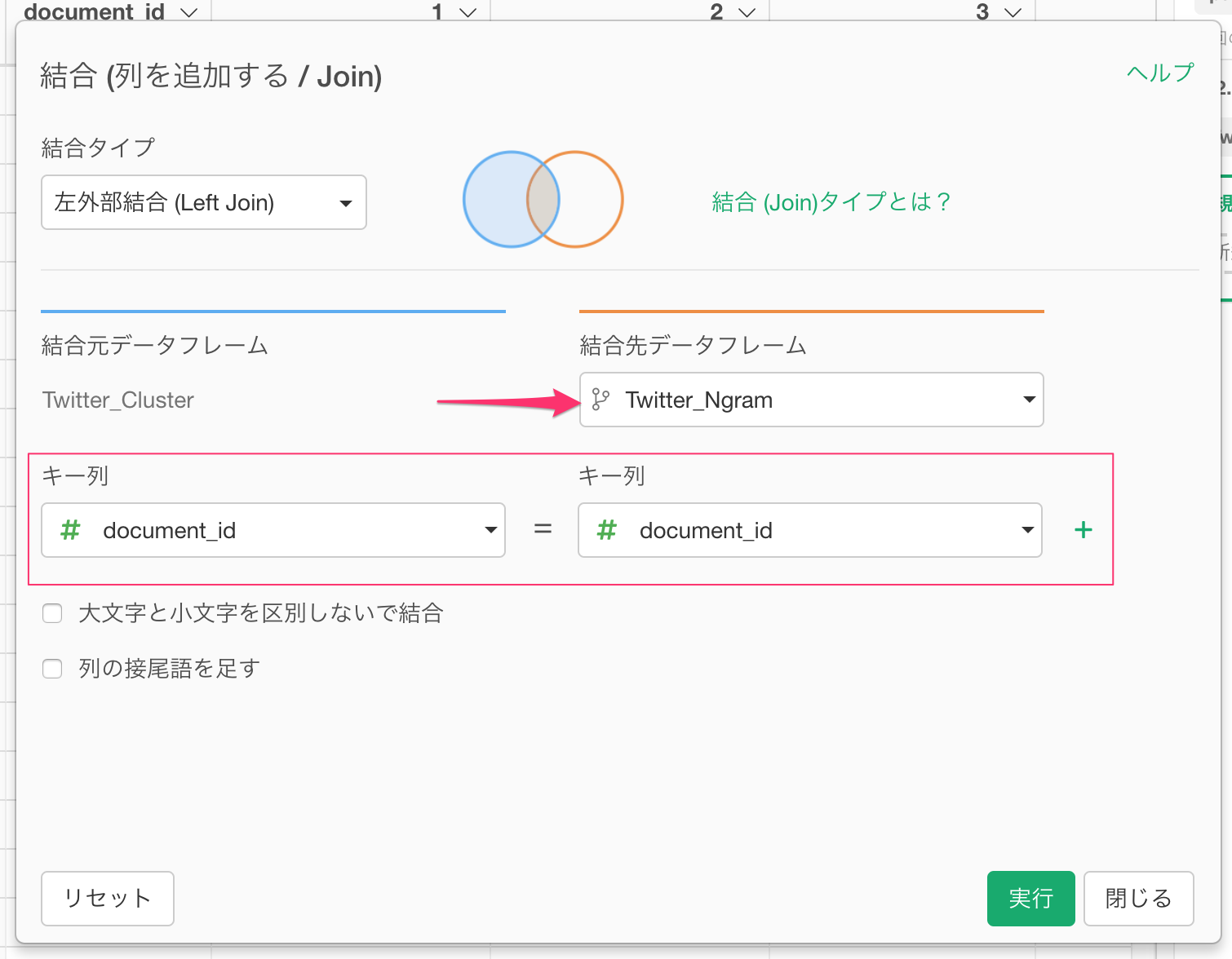
これでクラスタとSVDの計算結果(1から4の列)と単語が以下のように一つのデータフレームに結合されました。
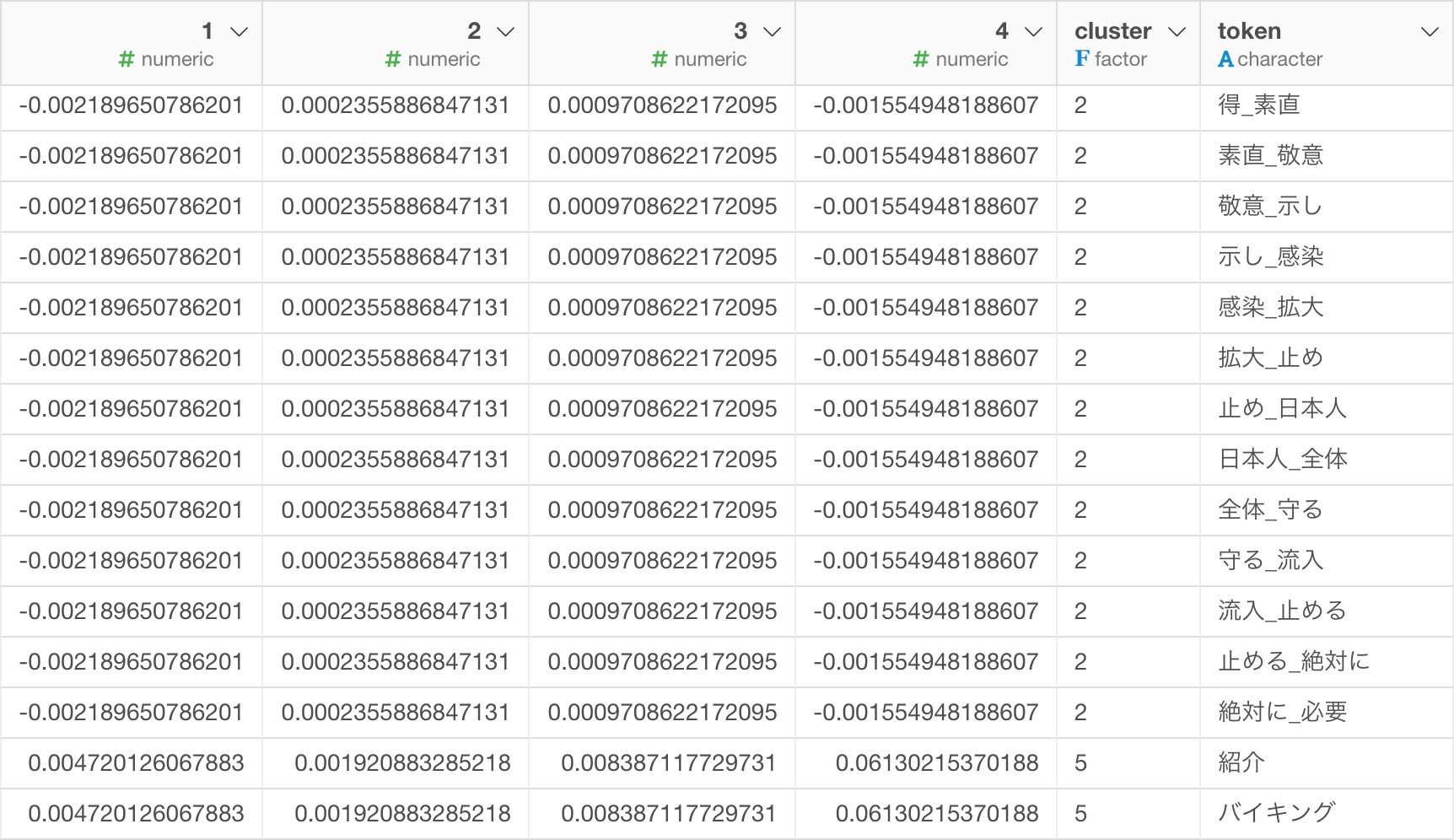
クラスタ毎のTop 20の頻出単語を計算しましょう。
まずは、cluster列の列ヘッダーメニューより、集計を選択します。
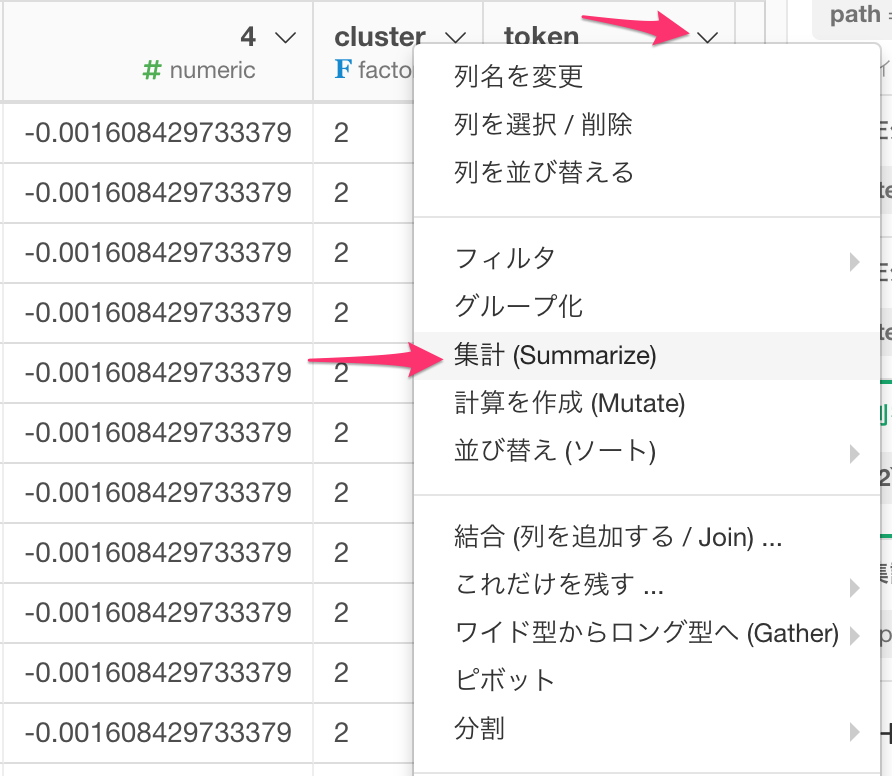
clusterとtokenでグループ化して、値に行の数を選択し、各件数を集計して、単語の出現頻度を求めます。
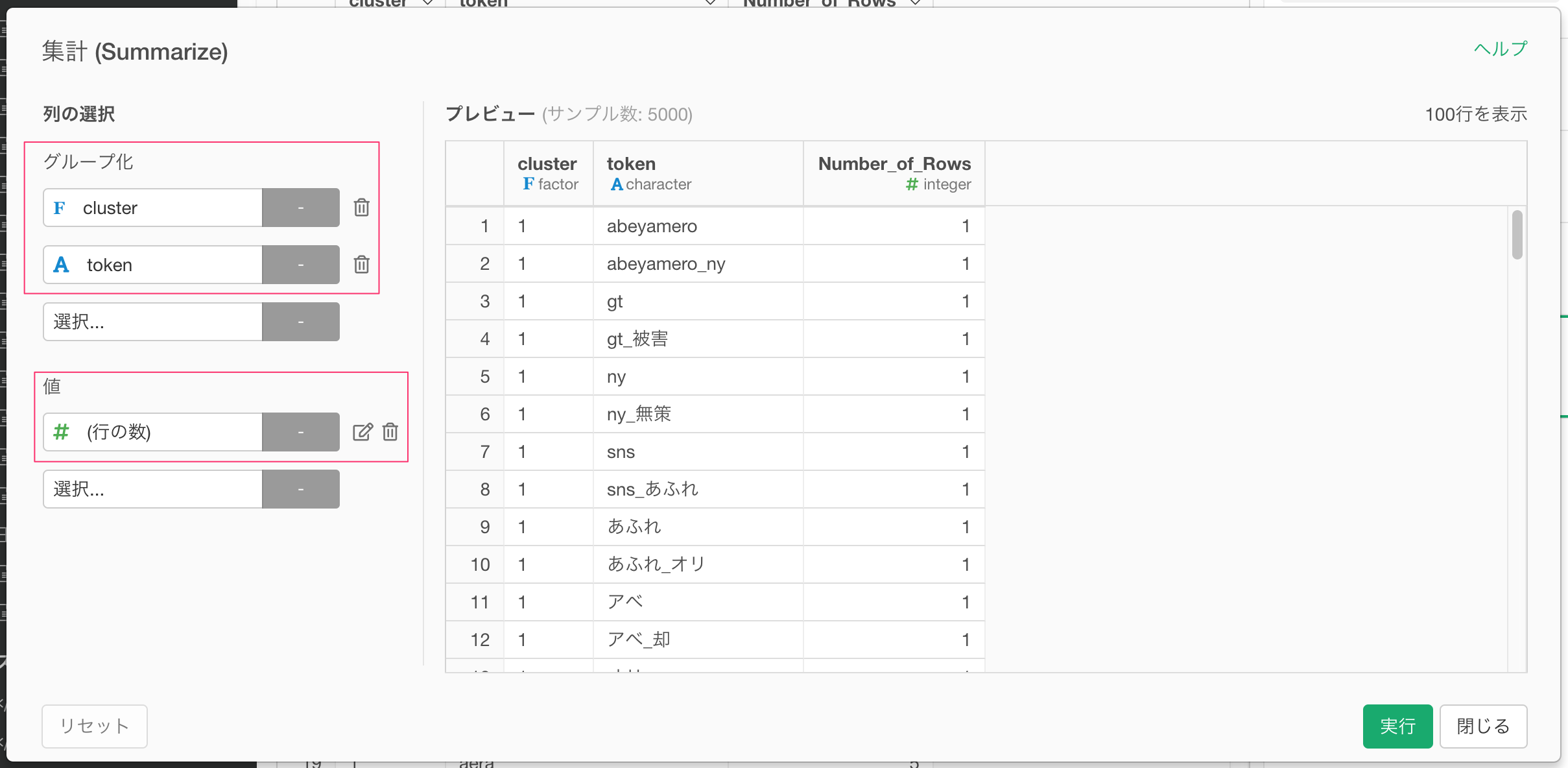
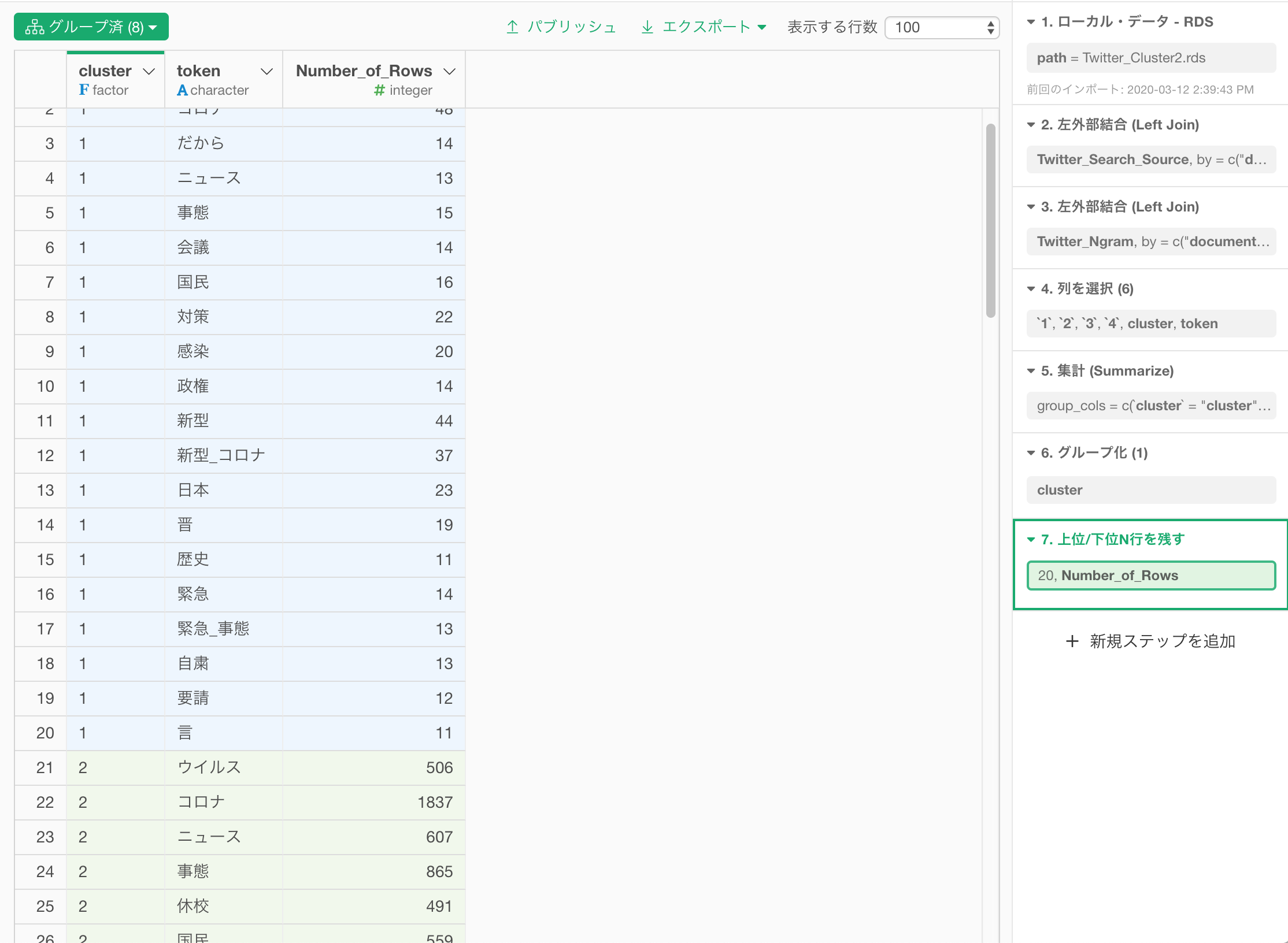
すると以下のようにデータの集計結果が得られます。
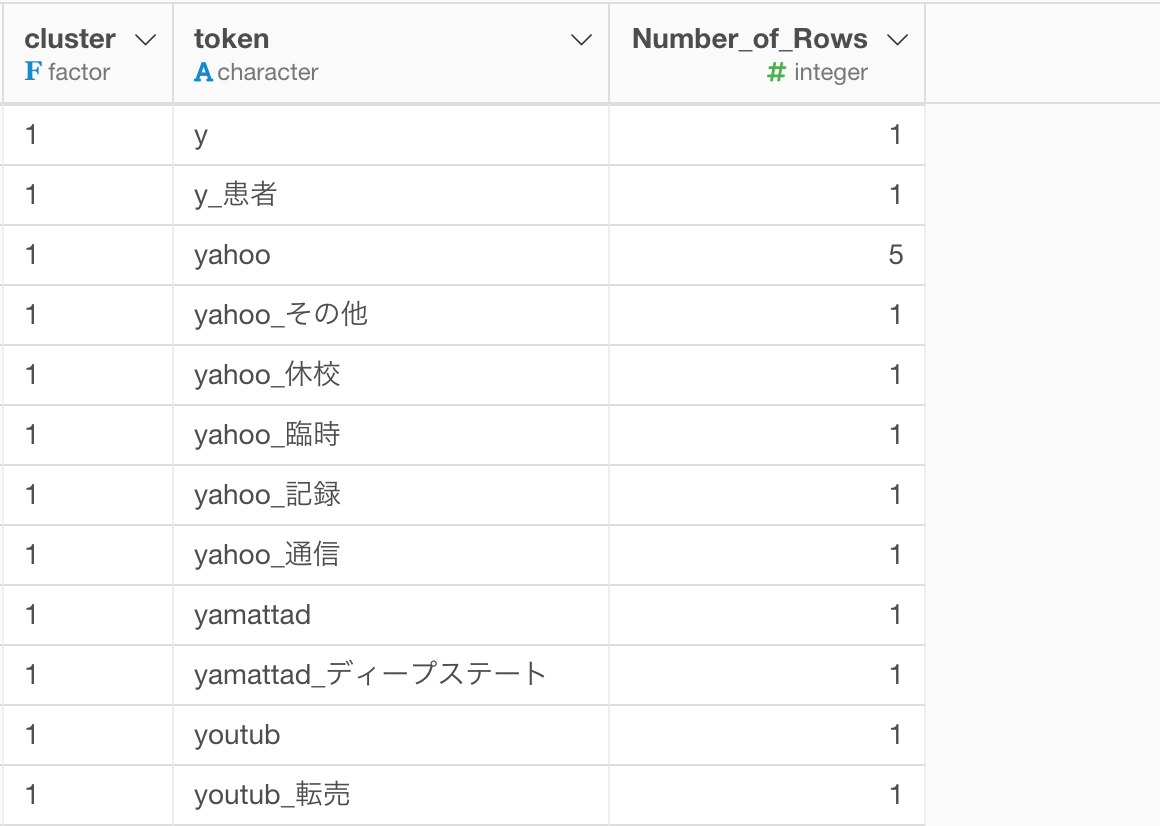
次に、各クラスタで頻度が上位の20だけに残します。まずは、各クラスタ毎にグループ化します。
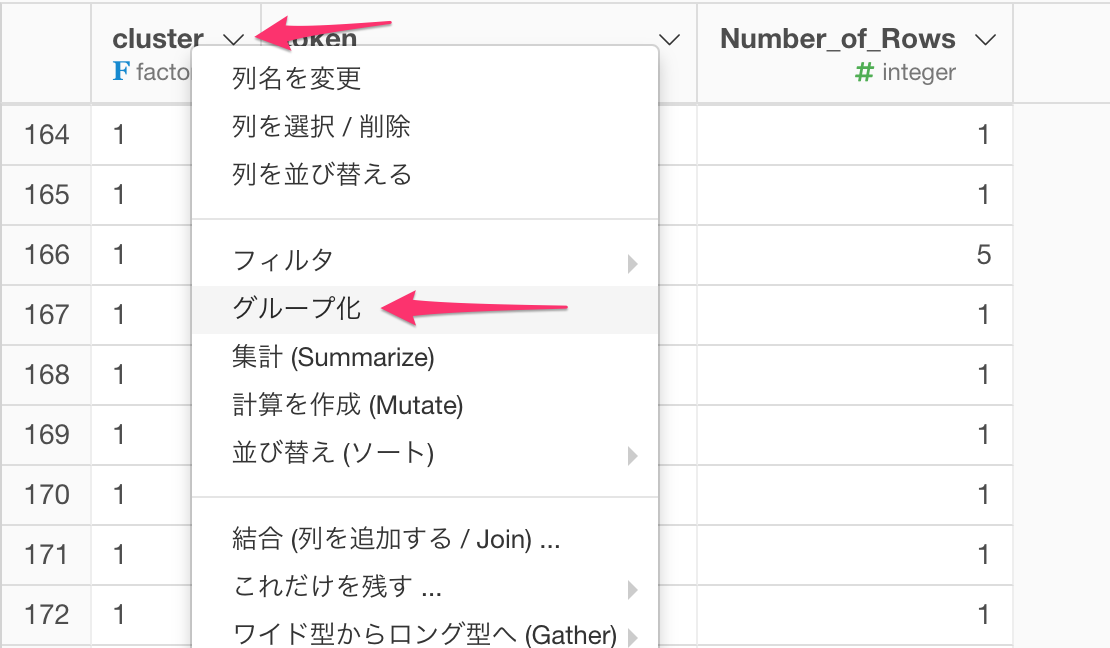
次に、プラス(+)メニューから、これだけを残す / 削除する... -> 上位N を選択します。
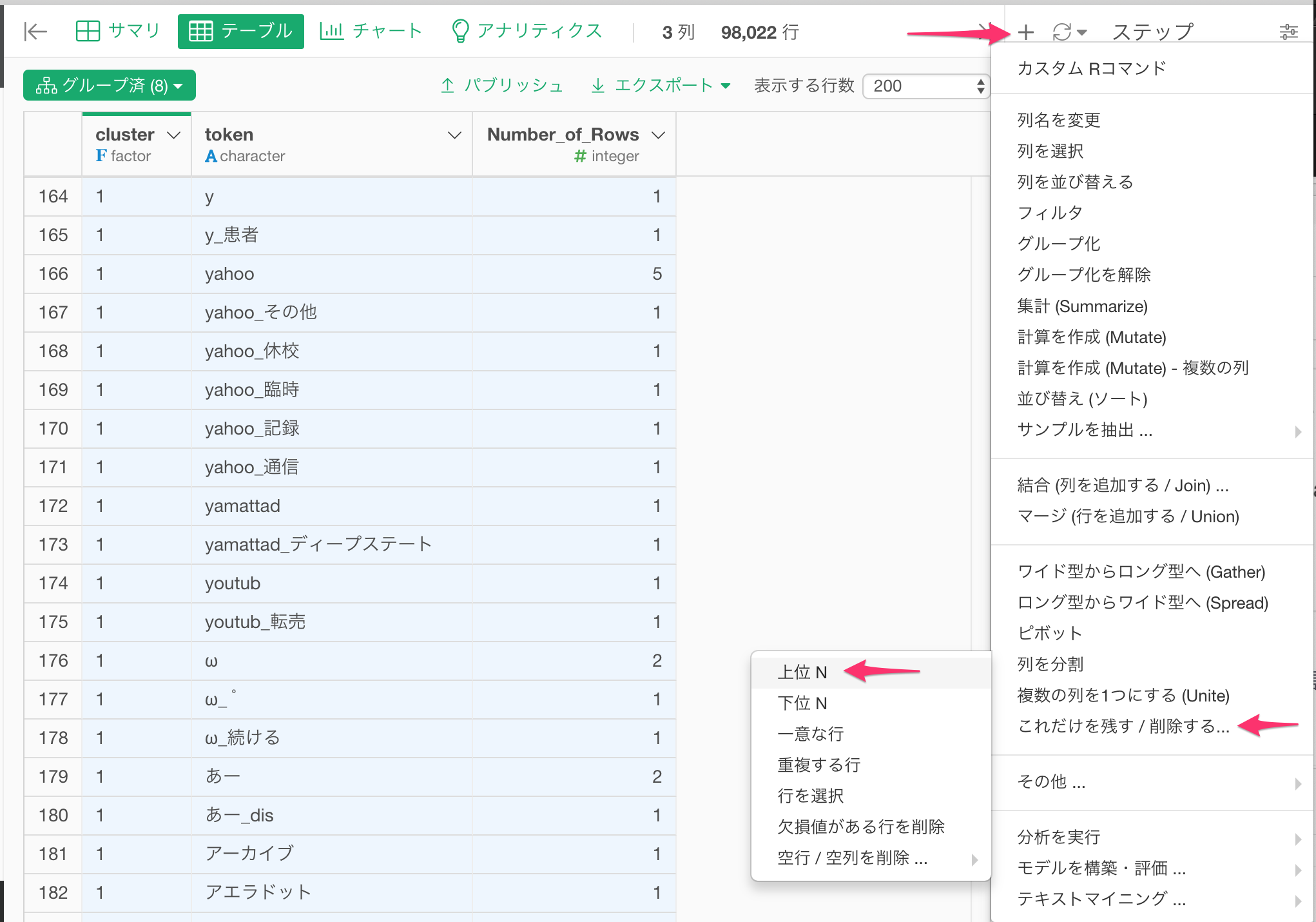
20を指定して、実行します。
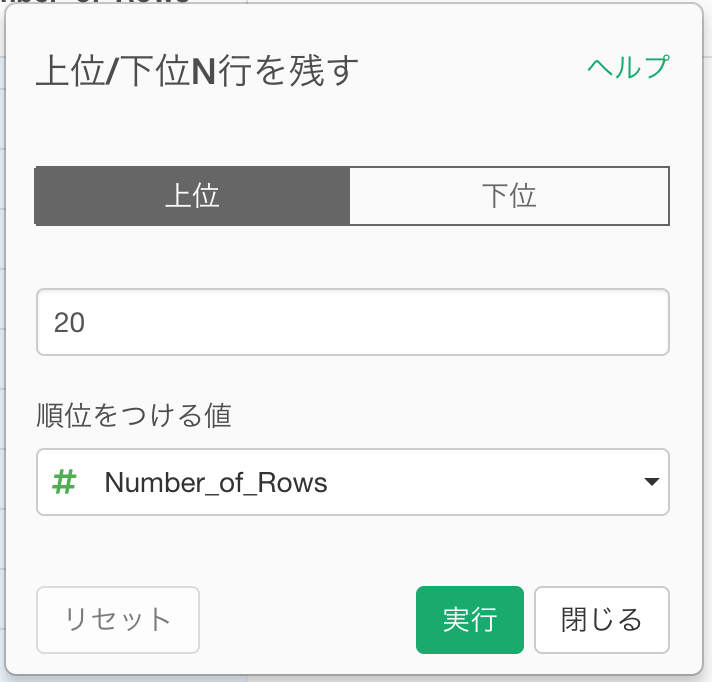
すると、以下のような結果になります。
チャートビューに行き、バーチャートで、繰り返しにcluster列を割り当てて、先ほど上位20までに絞った各単語の頻度を見ると、以下のようになります。
上のバーチャートを見てみると、「コロナ」や「新型」等のどのグループにも出てくる単語を除いて、それぞれのクラスタを特徴付ける単語は以下のようです。
- クラスタ 1 (青色) - 歴史
- クラスタ 2 (オレンジ) - 批判、休校
- クラスタ 3 (緑) - 総理、内閣
- クラスタ 4 (赤) - 宣言、主導
- クラスタ 5 (紫) -自粛、混乱
- クラスタ 6 (茶) - 現場
- クラスタ 7 (ピンク) - 大臣、イベント
- クラスタ 8 (グレー) - 要請
では各クラスタに実際にどんなTweetがあるのか例を見てみましょう。
クラスタ 1(青色) - 歴史
クラスタ 2 (オレンジ) - 批判、休校

クラスタ 3 (緑)- 総理、内閣

クラスタ 4 (赤) - 宣言、主導

クラスタ 5 (紫) - 自粛、混乱

クラスタ 6 (茶) - 現場

クラスタ 7 (ピンク) - 大臣、イベント

クラスタ 8 (グレー) - 要請

まとめ
今日は、いくつものアルゴリズムを使って最終的に安倍首相関連のTweetを8つのタイプに分け、それぞれの特徴をつかんでみました。もう一度簡単に振り返ると、以下のようなステップをたどりました。
- 前回単語分けされた安倍首相関連のTweetsのテキストを使う
- Nグラムのアルゴリズムを使って1単語と2単語の組み合わせのテキストを作成
- TF-IDFのアルゴリズムを使ってそれぞれのTweetを数値化する
- SVDのアルゴリズムを使って次元削減する
- K-Meansクラスタリングのアルゴリズムを使ってTweetsを似た者同士のグループに分ける
こうすることで、見かけ上は数値化されていないテキストのようなものでも類似度を計算することができ、一見ばらばらでたくさんあるように見えるTweetのようなテキストデータの全体像が効率的に浮かび上がってくるわけです。
自分で試してみる
まだExploratoryをお持ちでない方は、この機会にぜひ試してみて下さい!
こちらのページよりサインアップ(無料)した後、Exploratoryをダウンロードし始めることができます!
データサイエンスを学ぶ

データサイエンスやデータ分析の手法を1から体系的に学び、現場で使えるレベルのスキルを身につけていただくためのトレーニングを定期的に開催しています。
データを使ってビジネスの問題を解決していくための、質問や仮説の構築の仕方などを含めたデータリテラシーも基礎から身につけていただくものとなっております。
ぜひこの機会に参加をご検討ください!