SQLがややこしいのでdplyrでクエリーを書いて直接データベースからデータを取ってくる。
例えば、アメリカの航空会社の飛行遅延データが入ったPostgreSQLのデータベースがあるとします。このデータベースに対して、それぞれの州の平均の遅延時間を計算するSQLを書くとすると以下のようになります。
SELECT "ORIGIN_STATE_ABR", AVG("DEP_DELAY") AS "DEP_DELAY_AVG"
FROM "airline"
GROUP BY "ORIGIN_STATE_ABR"しかし、Exploratoryのユーザー、もしくは今時のRのユーザーならdplyrの文法(データ・ラングリングのグラマーと言われているもの)に慣れていると思いますが、実は、これが生のSQLクエリを書く代わりにそのまま使えるのです。つまり、以下のようなdplyrのクエリーを書くと、dplyrが裏で適したSQLのクエリに変換してくれて、それをデータベースで処理させた後に結果を返してくれます。
group_by(ORIGIN_STATE_ABR) %>%
summarize(DEP_DELAY_AVG = mean(DEP_DELAY))これが真価を発揮するのはSQLのクエリーがだんだん複雑になってくるときです。SQLを書いたことがある人はお分かりになると思うのですが、色々やり始めると、副問い合わせのネストが混みいってきて、何がどうなっているのか書いている本人にも分かりにくくなり、悪いことに、周りの人にとって解読不能なものになりがちです。
例えば、以下のような表計算(Window Function)をし始めたときなどは、こうした問題にぶつかりがちです。
group_by(CARRIER, ORIGIN_STATE_ABR) %>%
summarize(DEP_DELAY_AVG = mean(DEP_DELAY), counts = n()) %>%
mutate(ratio = counts/sum(counts))これをSQLで書くと以下のようになります。
SELECT "CARRIER", "ORIGIN_STATE_ABR", "DEP_DELAY_AVG", "counts", "counts" / sum("counts") OVER (PARTITION BY "CARRIER") AS "ratio"
FROM (SELECT "CARRIER", "ORIGIN_STATE_ABR", AVG("DEP_DELAY") AS "DEP_DELAY_AVG", count(*) AS "counts"
FROM "airline"
GROUP BY "CARRIER", "ORIGIN_STATE_ABR") "zovxinlfni"こうなってくると、SQLクエリの中に副問い合わせが現れ始めて、手で書くのはだんだん生産性が落ちてきます。
ということで、今日はExploratoryの中から、直接dplyrを使ってデータベースにクエリーを投げて、その結果だけをスマートに取ってくるにはどうするかということを紹介をしたいと思います。
どのようにやるのか?
では、Exploratory Desktopでどのようにやるのか早速見ていきましょう。
Rスクリプトデータソースの作成
次に、Rスクリプトを使ったデータソースでデータベースにdplyrとdbplyrを使って接続します。
Rスクリプトの中で、次のようにデータベースに接続します。(ここではPostgreSQLを例として取り上げています。)
library(dplyr)
# Connection to Postgres
con <- DBI::dbConnect(RPostgreSQL::PostgreSQL(),
host = "localhost",
port = 5432,
dbname = "postgres",
user = "your_user",
password = "your_password" )次に、接続したデータベースからairlineテーブルを選択します。
# Get Table
flights_db <- tbl(con, "airline")まずは、出発した州毎の平均出発遅延時間を問い合わせるdplyrのクエリを書いてみます。
flights_db %>%
group_by(ORIGIN_STATE_ABR) %>%
summarize(DEP_DELAY_AVG = mean(DEP_DELAY)) %>%
collect()最後のcollect()はクエリの実行結果をデータフレームにするための関数です。
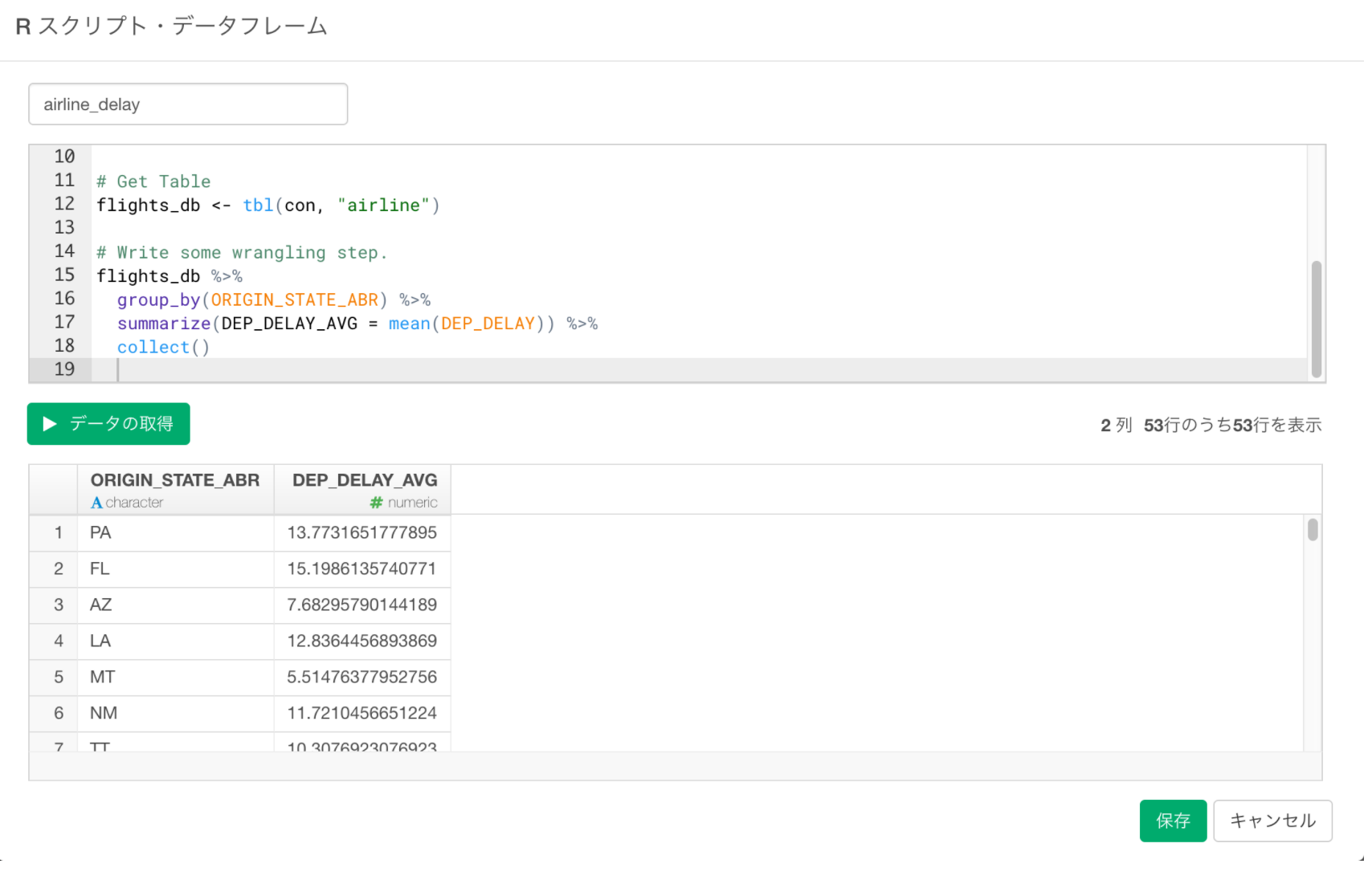
データの取得ボタンををクリックして結果を確認し、保存ボタンをクリックし、データフレームとして保存します。
すると、このようにサマリーのビューが表示されます。
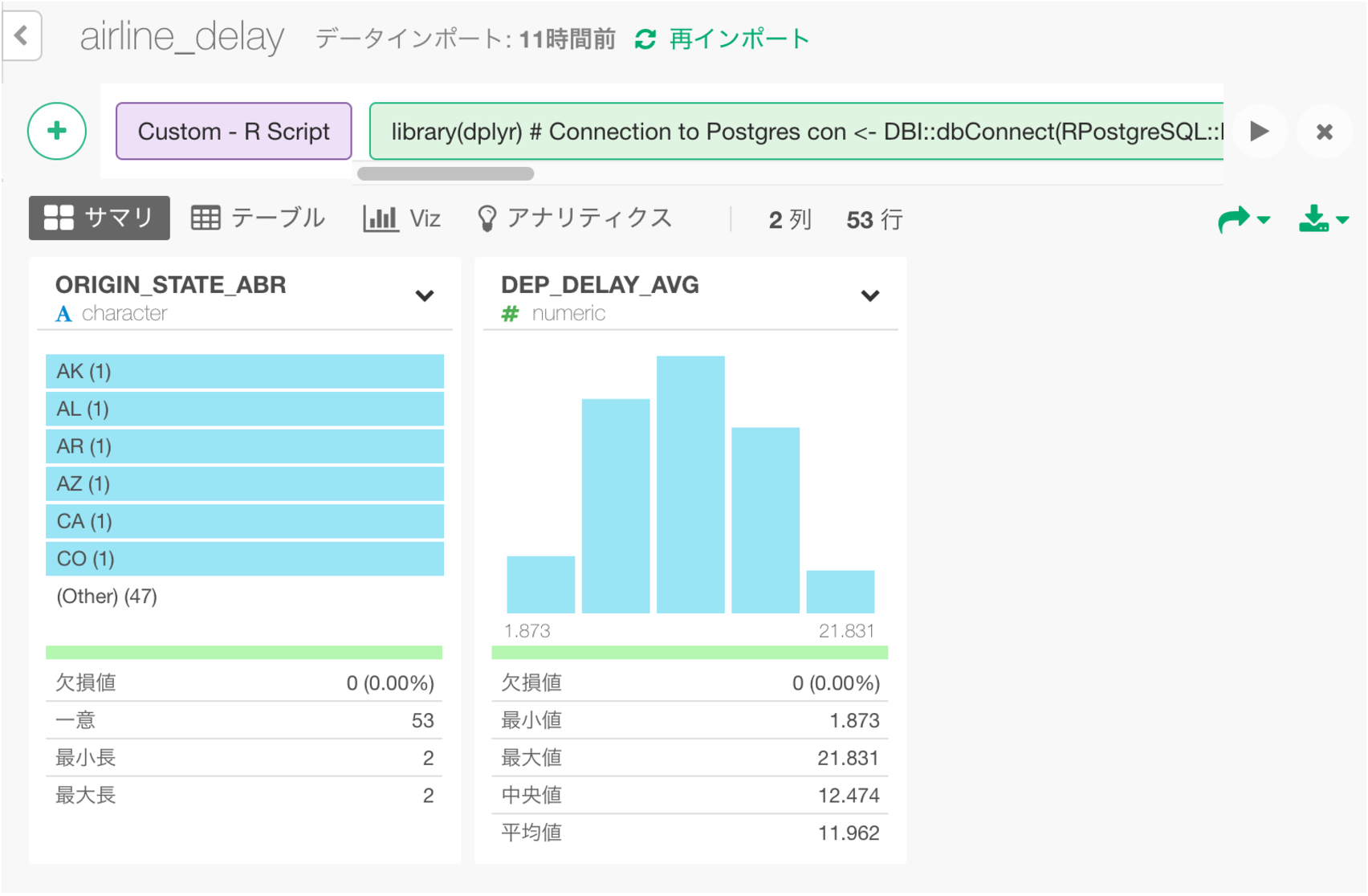
さらに、このデータフレームを使って、以下のように州毎の平均出発遅延時間を地図上に可視化できます。
さて、次に、各航空会社毎に平均出発遅延のトップ10の州を計算してみましょう。dplyrのクエリは以下の通りです。
flights_db %>%
group_by(CARRIER, ORIGIN_STATE_ABR) %>%
summarize(DEP_DELAY_AVG = mean(DEP_DELAY)) %>%
top_n(10, DEP_DELAY_AVG) %>%
collect()データを保存すると、このような結果になります。
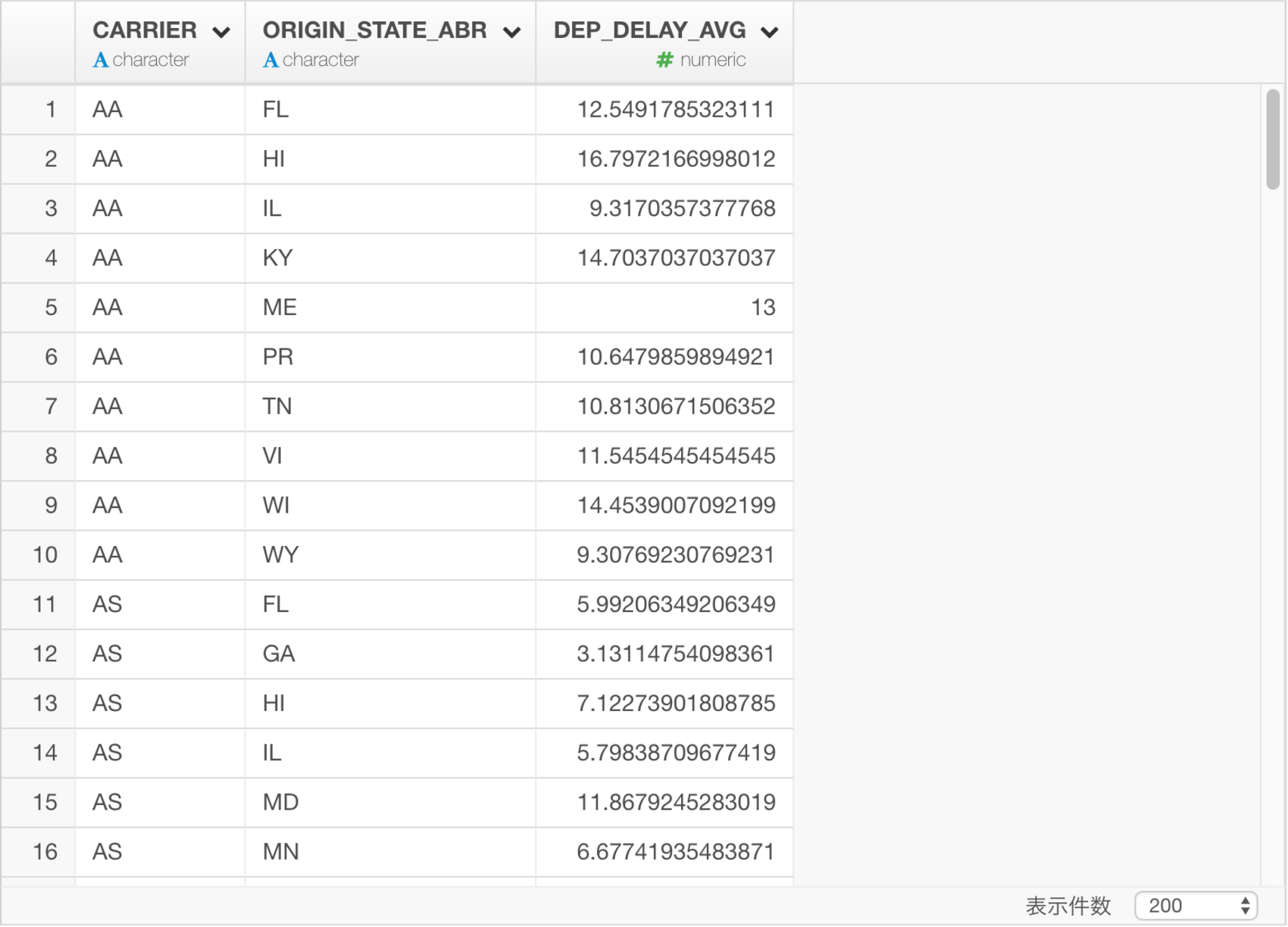
これは、以下のSQLのクエリと同等です。dplyrのクエリと比べると、だいぶ複雑になっていることが分かります。
SELECT "CARRIER", "ORIGIN_STATE_ABR", "DEP_DELAY_AVG"
FROM (SELECT "CARRIER", "ORIGIN_STATE_ABR", "DEP_DELAY_AVG", rank() OVER (PARTITION BY "CARRIER" ORDER BY "DEP_DELAY_AVG" DESC) AS "zzz2"
FROM (SELECT "CARRIER", "ORIGIN_STATE_ABR", AVG("DEP_DELAY") AS "DEP_DELAY_AVG"
FROM "airline"
GROUP BY "CARRIER", "ORIGIN_STATE_ABR") "akblwapghp") "xgqydqtjzm"
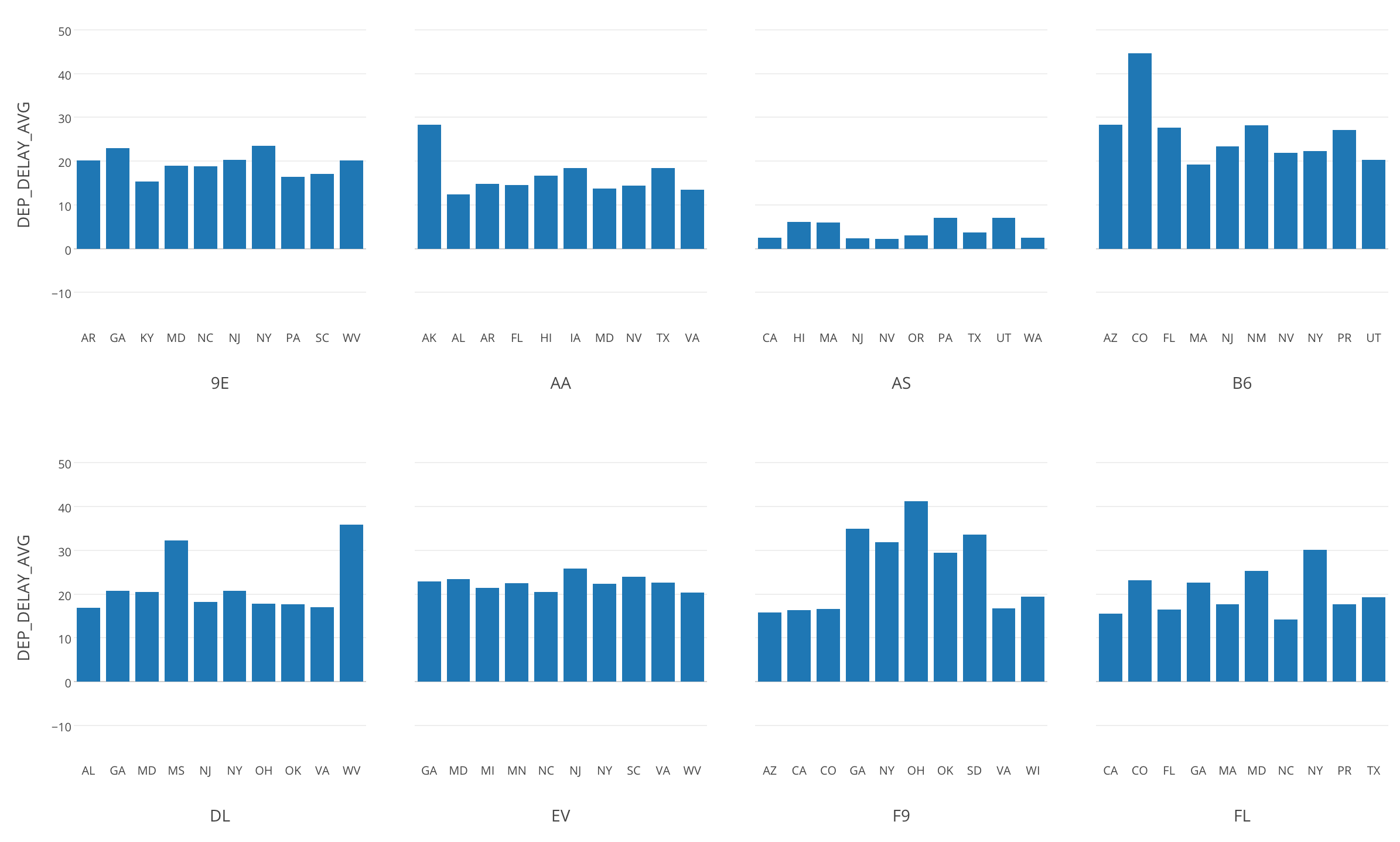
WHERE ("zzz2" <= 10.0)このdplyrのクエリの結果をバー・チャートにして、「繰り返し」に航空会社を割り当てると、航空会社毎の出発遅延時間Top10の州を可視化できます。
次に、航空会社毎に、出発州毎の平均の到着遅延時間(DEP_DELAY_AVG)と、その州で何便のフライトがあったか(counts)と、それがその航空会社の全フライトのどれくらいの割合を占めるのか(ratio)を計算します。
flights_db %>%
group_by(CARRIER, ORIGIN_STATE_ABR) %>%
summarize(DEP_DELAY_AVG = mean(DEP_DELAY), counts = n()) %>%
mutate(ratio = counts/sum(counts)) %>%
collect()データを保存すると、このような結果になります。
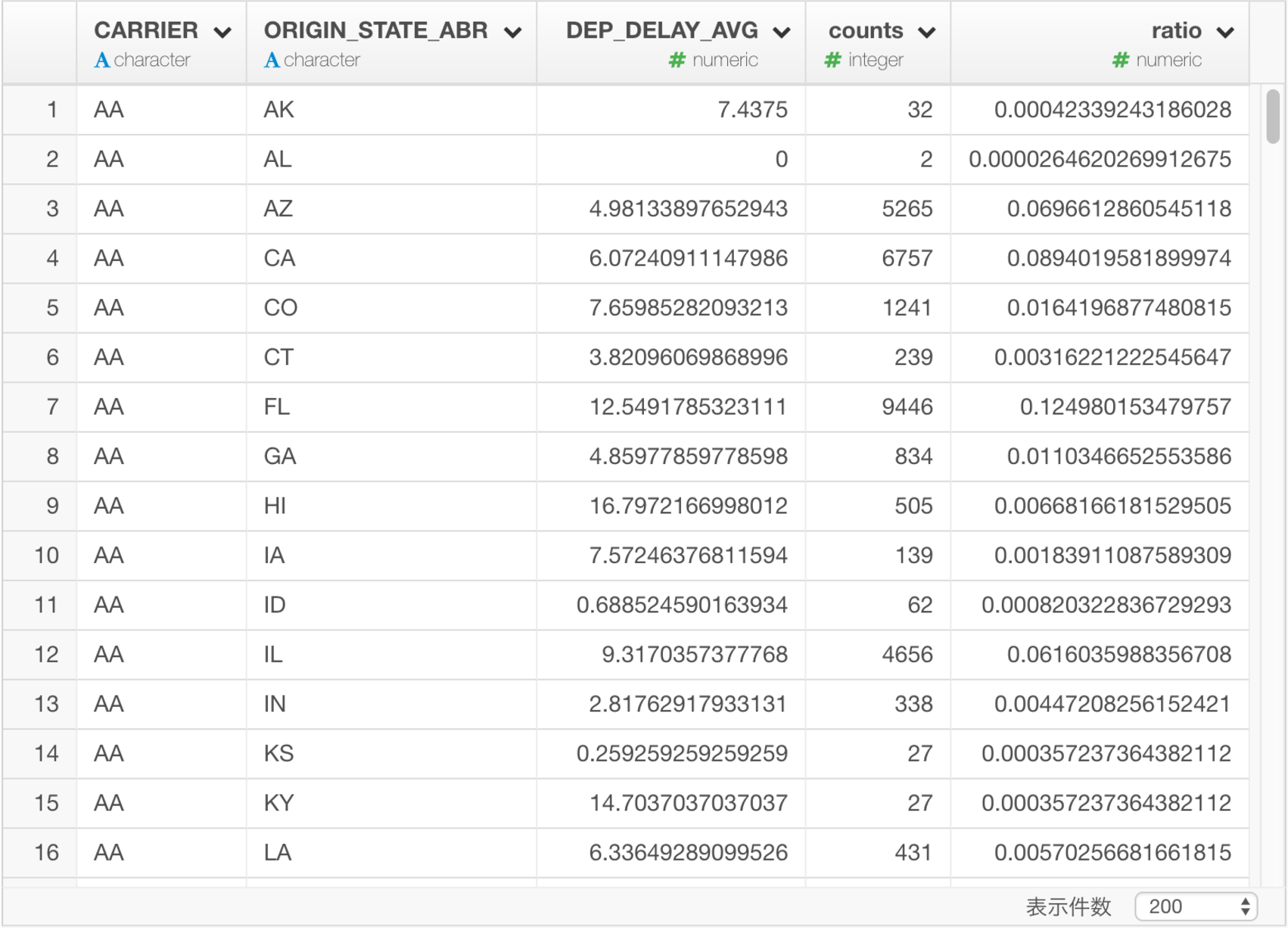
これをSQLで実現するには、次のような副問い合わせを含むクエリを書かないといけません。このような場合に、dplyrのシンプルなクエリのメリットが強く感じられると思います。
SELECT "CARRIER", "ORIGIN_STATE_ABR", "DEP_DELAY_AVG", "counts", "counts" / sum("counts") OVER (PARTITION BY "CARRIER") AS "ratio"
FROM (SELECT "CARRIER", "ORIGIN_STATE_ABR", AVG("DEP_DELAY") AS "DEP_DELAY_AVG", count(*) AS "counts"
FROM "airline"
GROUP BY "CARRIER", "ORIGIN_STATE_ABR") "zovxinlfni"dplyrのクエリを書いて作成したデータフレームをバーチャートにして可視化します。「色で分割」に州を割り当てると、州毎のレートが分かりやすくなります。
まとめ
dbplyrとdplyrを使うと、このようにデータベースに接続して、複雑なSQLクエリを書かなくても、煩雑な処理を簡潔なdplyrのコマンドでこなすことができます。特に表計算関数(Window Function)などを扱う際に、真価を発揮します。
データ分析をさらに学んでみたいという方へ
今年10月に、Exploratory社がシリコンバレーで行っている研修プログラムを日本向けにした、データサイエンス・ブートキャンプの第3回目が東京で行われます。本格的に上記のようなデータサイエンスの手法を、プログラミングなしで学んでみたい方、そういった手法を日々のビジネスに活かしてみたい方はぜひこの機会に、参加を検討してみてはいかがでしょうか。こちらに詳しい情報がありますのでぜひご覧ください。