Google BigQueryのデータをExploratoryを使って分析してみる
ペタバイト規模のデータでもSQLで高速にクエリできるGoogle BigQueryは、エンタープライズ、スタートアップなどを含め多くの企業でアナリティクスデータウェアハウスとしての確固たる地位を築いています。今日はExploratory Desktopを使って、Google BigQueryにアクセスし、データを取得し、簡単に分析しはじめる方法について見てみましょう。
始める前に
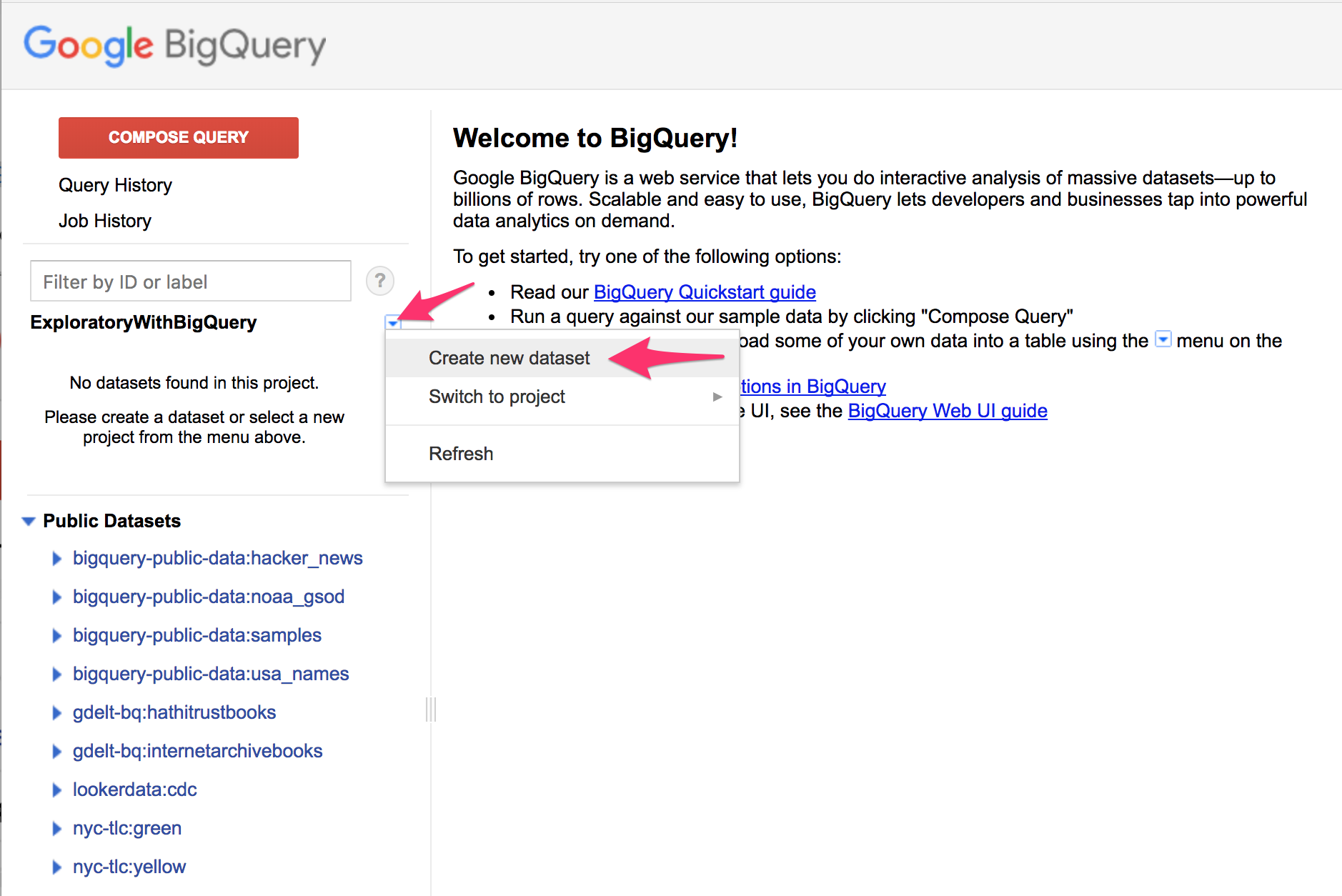
これまでにGoogle BigQueryをお使いでない場合、まず事前準備としてGoogle Cloud Platformでプロジェクトを作成し、Google BigQueryでデータセットを作成する必要があります。
事前にお使いのGoogleアカウントに請求用のクレジットカード情報を入力しておく必要があります。
Google BigQueryのプロジェクトを作成する
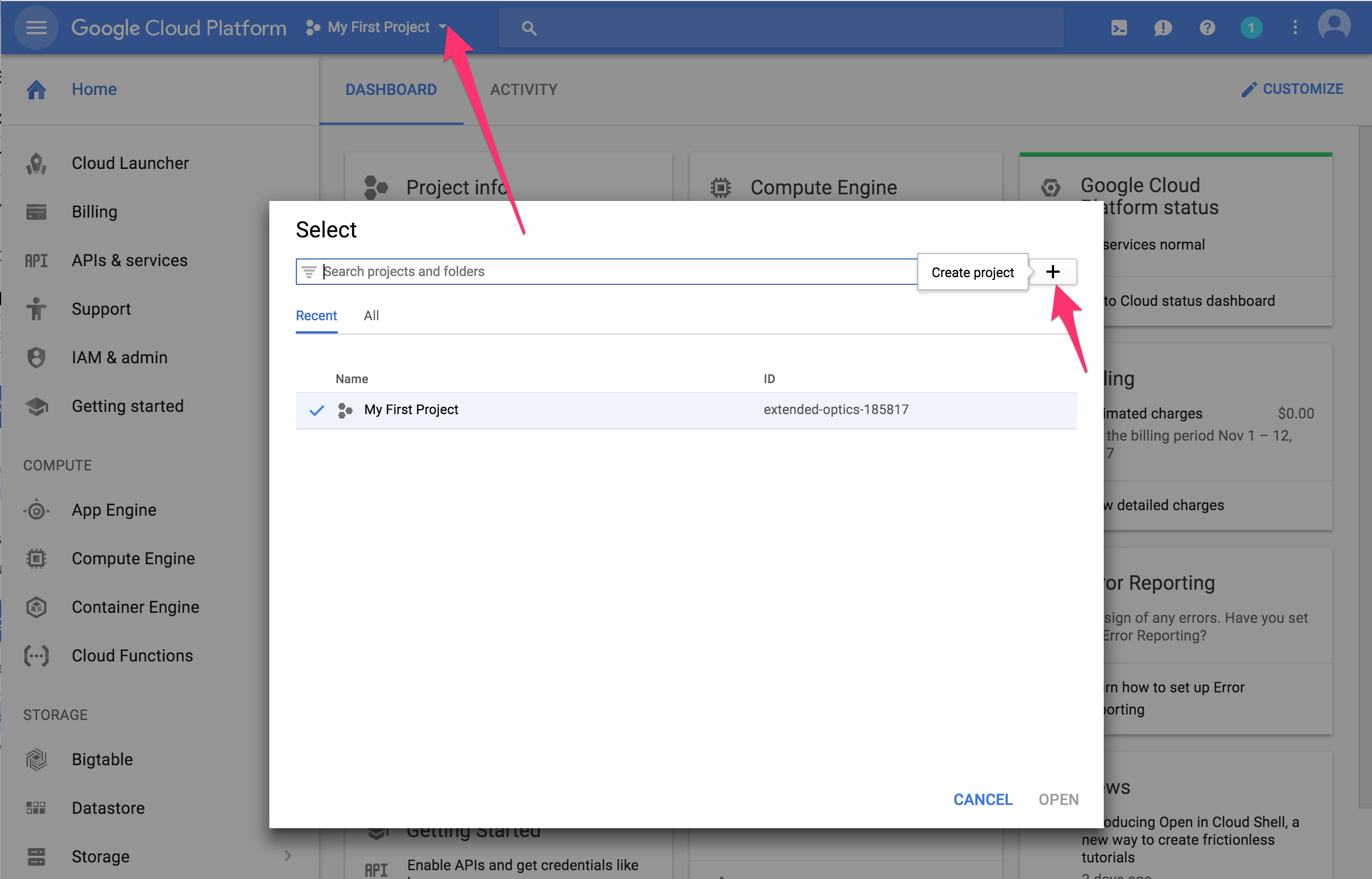
Google Cloud Platform Consoleにアクセスし、新規にプロジェクトを作成します。
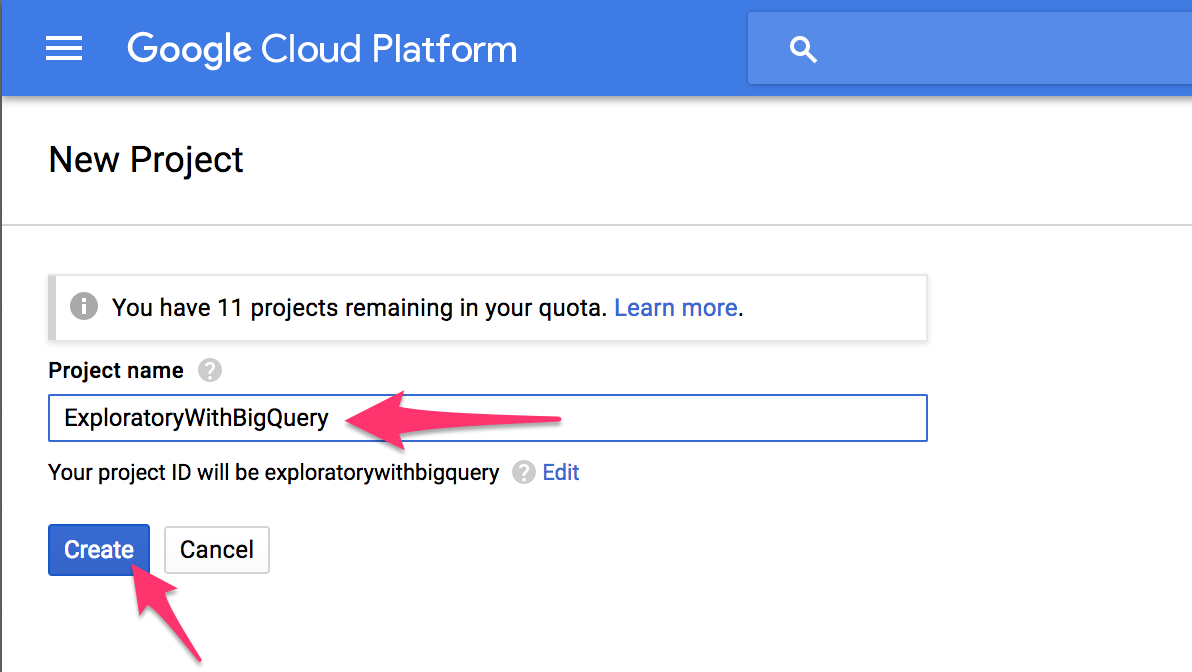
プロジェクト名を入力し、Createボタンをクリックします。
Google Cloud Storageのバケットを作成する (オプショナル)
Google BigQuery側で実行したクエリの結果が比較的大きい際に、Google Colud Storage経由でダウンロードのスピードを速くすることができます。このオプションを使うには、事前にGoogle Cloud Storageにバケット(Bucket)を作成しておきます。
Google Cloud Storage Browserにアクセスし、Create Bucketボタンをクリックします。
Bucketの名前を入力して、Createボタンをクリックします。
ExploratoryでGoogleBigQueryの設定
プロジェクトのヘッダーメニューから、Google BigQueryを選択します。
すると、Googleのアカウントを選択する画面がブラウザで起動しますので、BigQueryにアクセスするのに使うアカウントを選びます。
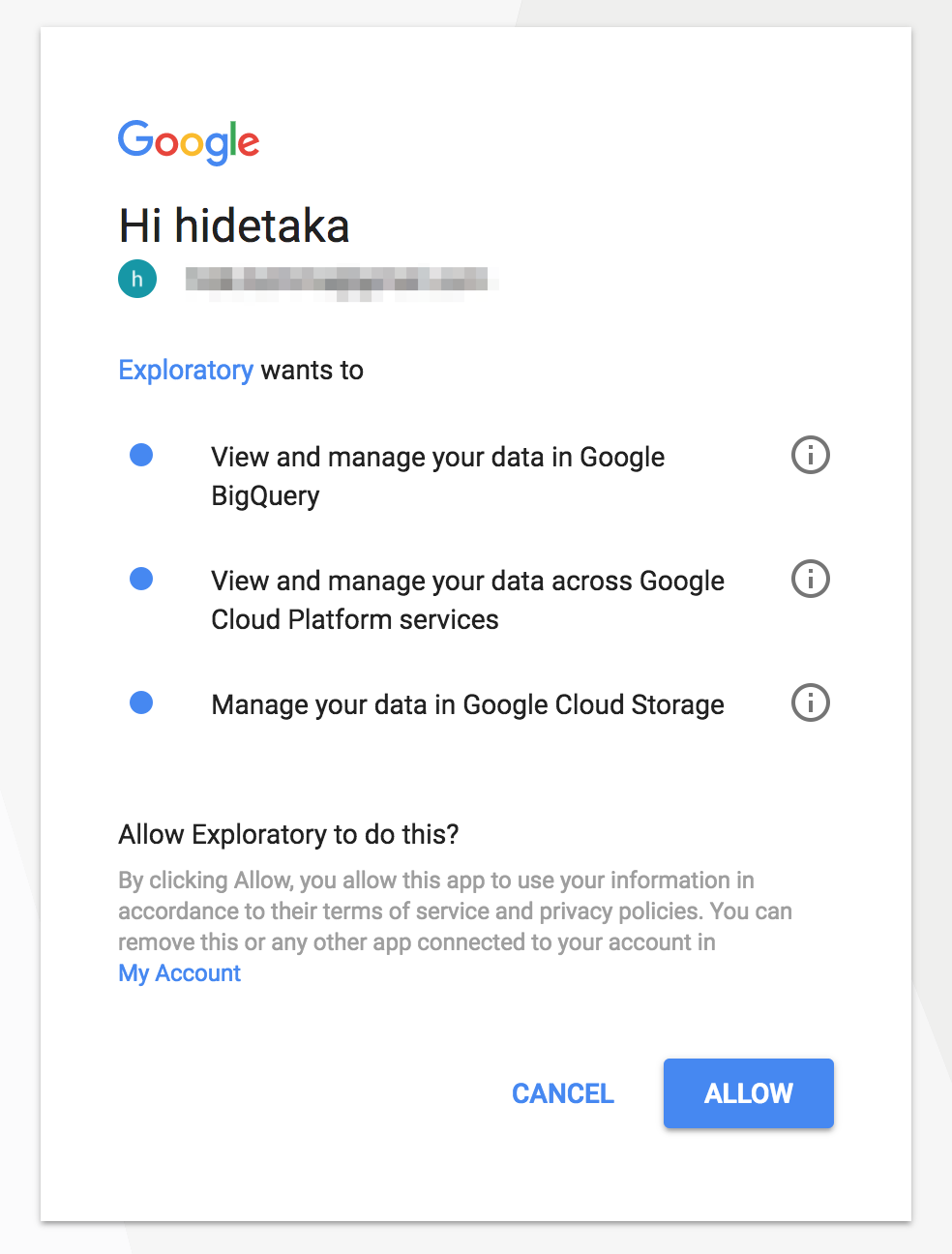
次に、ExploratoryがGoogle BigQueryにアクセスするのに必要な権限の認証用の画面がブラウザで表示されるので、ALLOWボタンをクリックします。
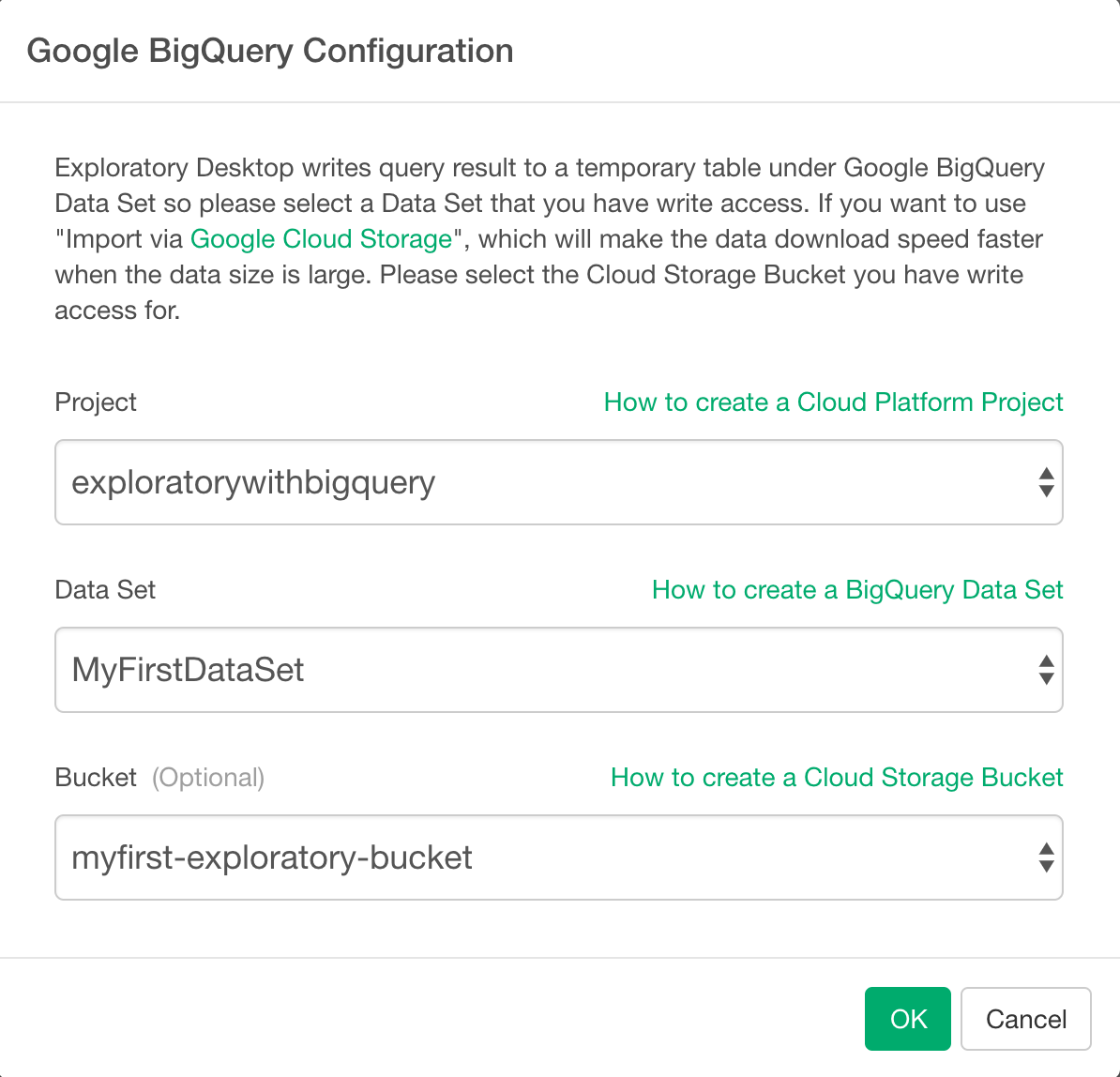
すると、Exploratory DesktopのGoogle BigQueryの詳細設定ダイアログが開きます。先ほど、作ったプロジェクトとデータセットと、(作ってある場合は)バケットを選択し、OKボタンをクリックします。
GoogleBig Queryからデータを取ってくる
Exploratory Desktopで新規にプロジェクトを作成し、(または既存のプロジェクトをオープンし)、データフレームのラベルの隣の、プラス(+)ボタンをクリックします。そして、データベースデータを選びます。
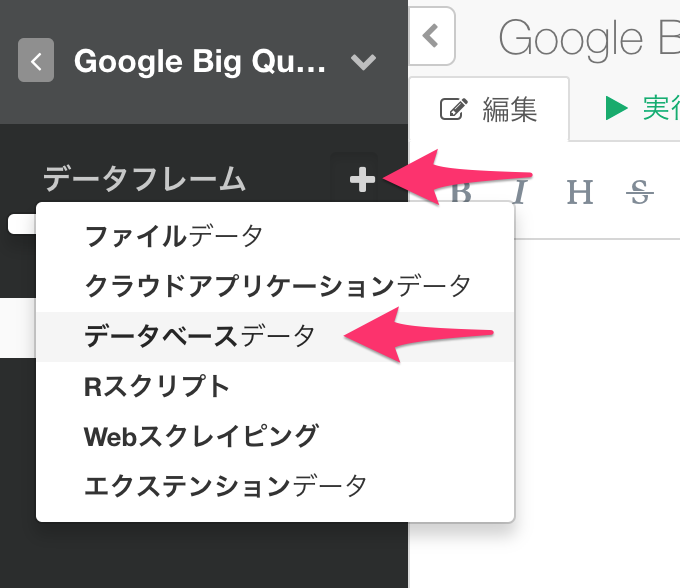
データソースの選択ダイアログで、Google BigQueryを選びます。

すると、データインポートダイアログが開くので、ここでSQLを書いて、データの取得 ボタンをクリックすると、データをプレビューできます。
今回はデモのため、Google BigQuery側ですでに用意されているサンプル、アメリカで生まれた新生児の情報を格納しているnatalityテーブルを使ってみましょう。生まれた子供の体重、生まれてくるまでの妊娠期間、州、母親の人種、母親の年齢、タバコを吸うかどうかなどのデータを取得するために、以下のクエリーを実行すると、11.05GBのデータに対して処理が走り、クエリーの結果の約640万行のうち、200行分だけプレビューしていることがわかります。ちなみに検索条件を2003年以降にしているのは、タバコを吸うかどうかは2003年からしかデータがないからです。また死産のケースは取り除いてます。
SELECT
weight_pounds,
state,
year, month, day
child_race, plurality,
mother_race, mother_age,
cigarette_use, cigarettes_per_day,
alcohol_use, drinks_per_week,
father_race,
father_age,
is_male,
gestation_weeks
FROM
[bigquery-public-data.samples.natality]
WHERE state is NOT NULL
AND gestation_weeks is NOT NULL
AND year >= 2003
AND born_dead = 0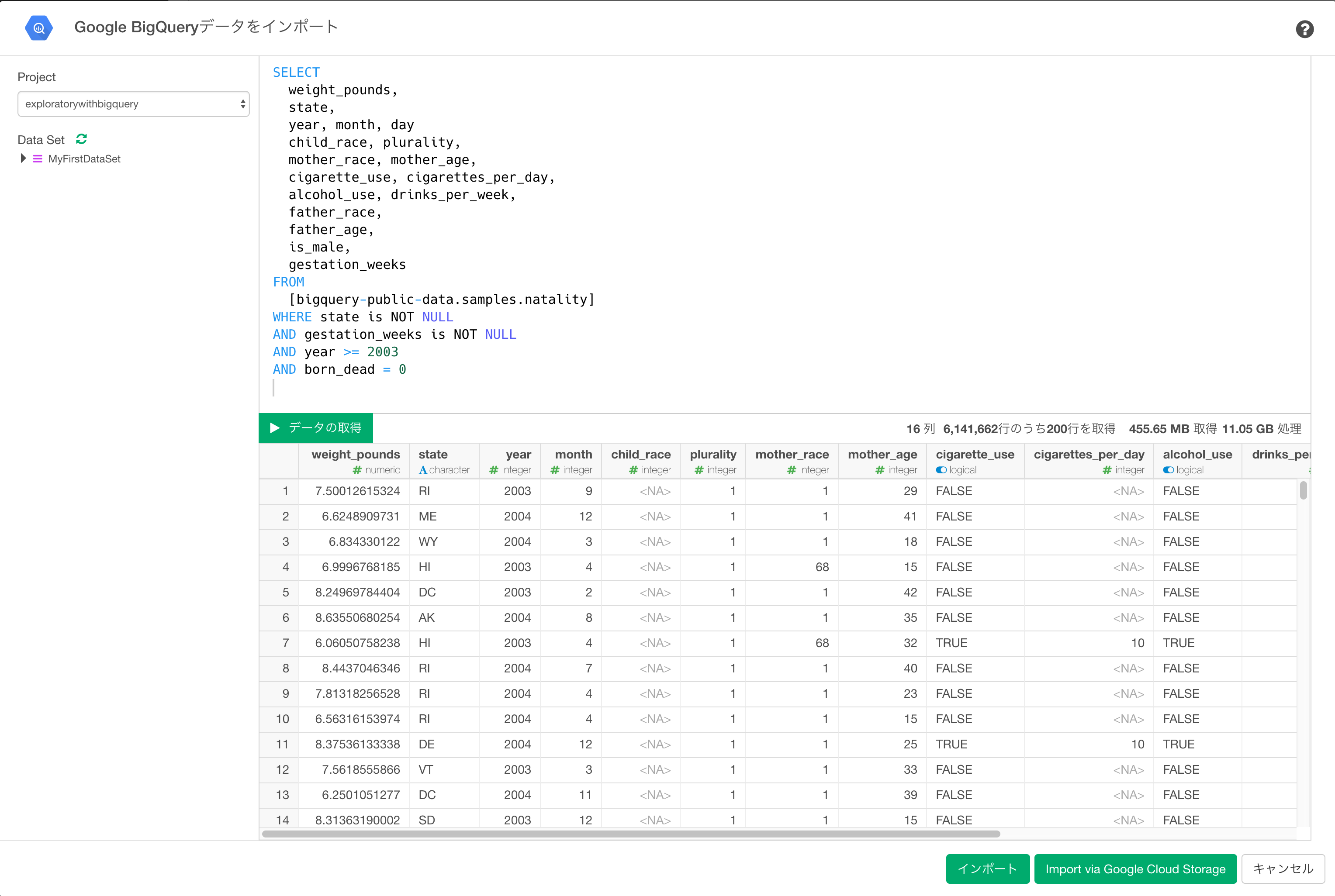
またお使いのPCのメモリのサイズによってはエラーが出る場合があるので、データサイズを絞ってExploratoryに取り込んでみましょう。例えば、100万行にサンプリングその場合は上のSQLの最後にAND RAND() > 1000000 / 6141662 を追加すると6,141,662行から約100万行をサンプリングすることができます。 ここで、6141662は元のクエリーで返ってくる行数、1000000がサンプル後の大体の件数です。 SQL分にこのサンプリング用の条件を追加して、
SELECT
weight_pounds,
state,
year, month, day
child_race, plurality,
mother_race, mother_age,
cigarette_use, cigarettes_per_day,
alcohol_use, drinks_per_week,
father_race,
father_age,
is_male,
gestation_weeks
FROM
[bigquery-public-data.samples.natality]
WHERE state is NOT NULL
AND gestation_weeks is NOT NULL
AND year >= 2003
AND born_dead = 0
AND RAND() > 1000000 / 6141662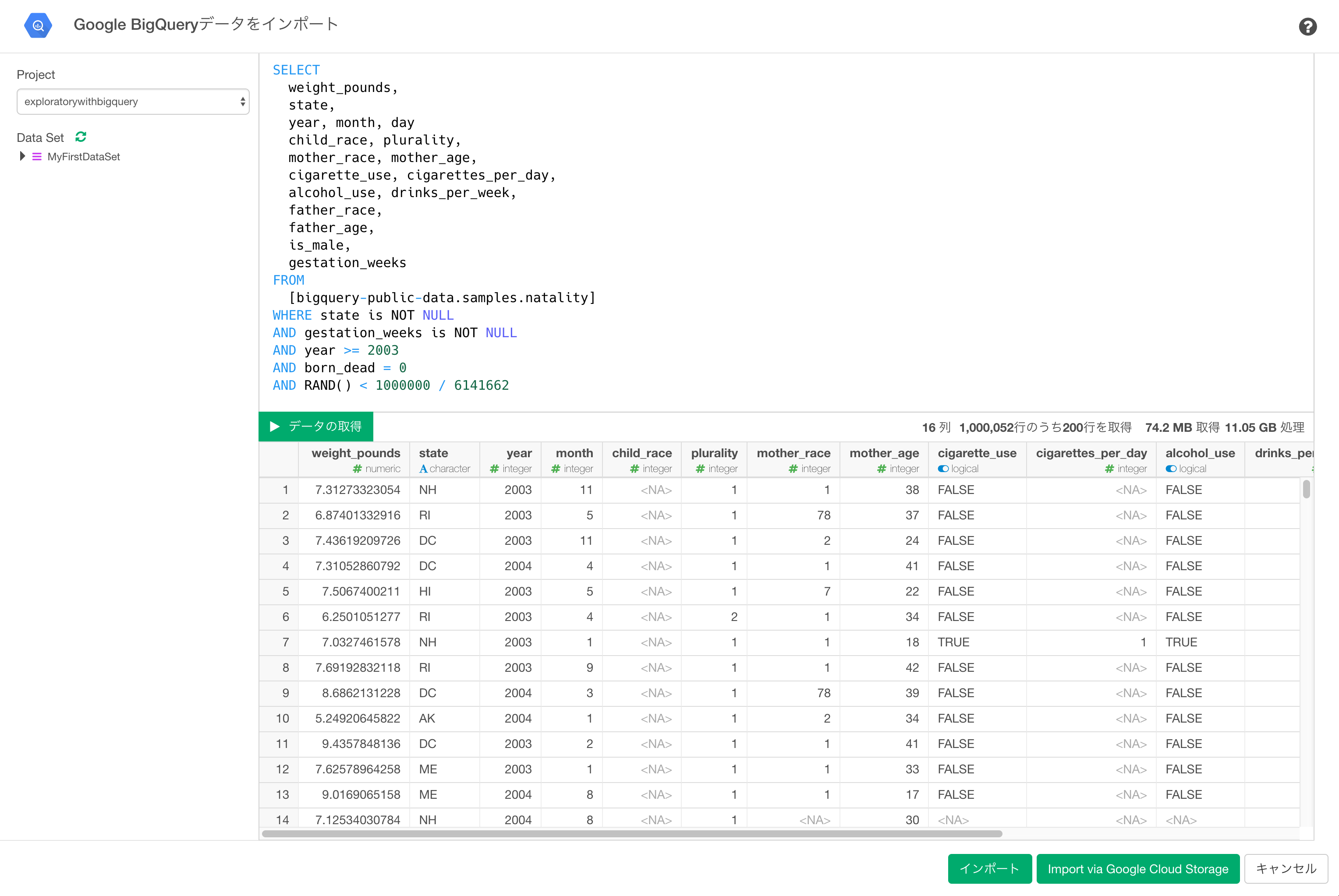
データの取得ボタンを押して、データ件数が絞り込まれたのを確認し、 インポートボタンをクリックすると、サンプリング後のクエリーの実行結果の全件をExploratoryに取り込むことができます。このクエリの結果を取り込む際には、データを圧縮してインポートできるImport via Google Cloud Storageオプションの方が速いので、Import via Google Cloud Storageボタンをクリックします。
すると、サマリビューでExploratoryに約100万行のデータがインポートされたことがわかります。
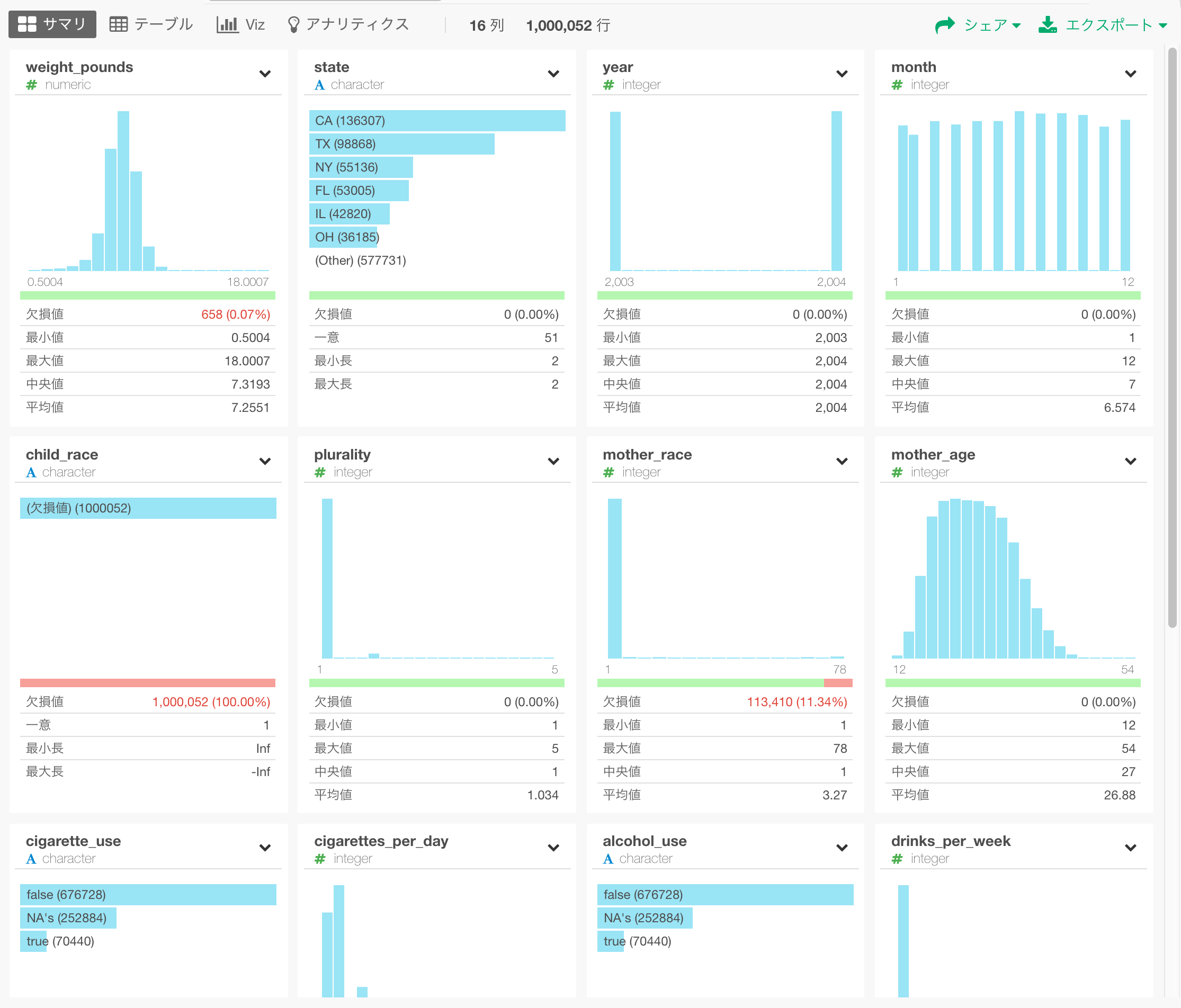
データの可視化
まずは、産まれてきた新生児の体重の中央値をアメリカの地図の上に表示してみましょう。すると、北部の方が南部よりも色が濃い(体重の中央値が大きい)傾向があるのがわかります。
アナリティクス:何が早産に影響をおよぼすのか?
さて、インポートしたデータを見ると、妊娠何週目で産まれたきたかというのを記録しているgestation_weeksというカラムがあるので、ヒストグラムにして分布をみてみましょう。
すると、割合は少ないですがかなり低い数字の週のところまで分布しているのが、分かります。一般に、妊娠37週前に産まれてくると早産となるため、gestation_weeksを元に、37週目前ならTRUE (早産)、後ならFALSE(早産でない)というカラムを作っておいて、色に割り当てています。
では早産になるかどうかに、どの変数(カラム)が影響を持っているのでしょうか?これを知るために変数重要度アナリティクスを使って分析してみましょう。
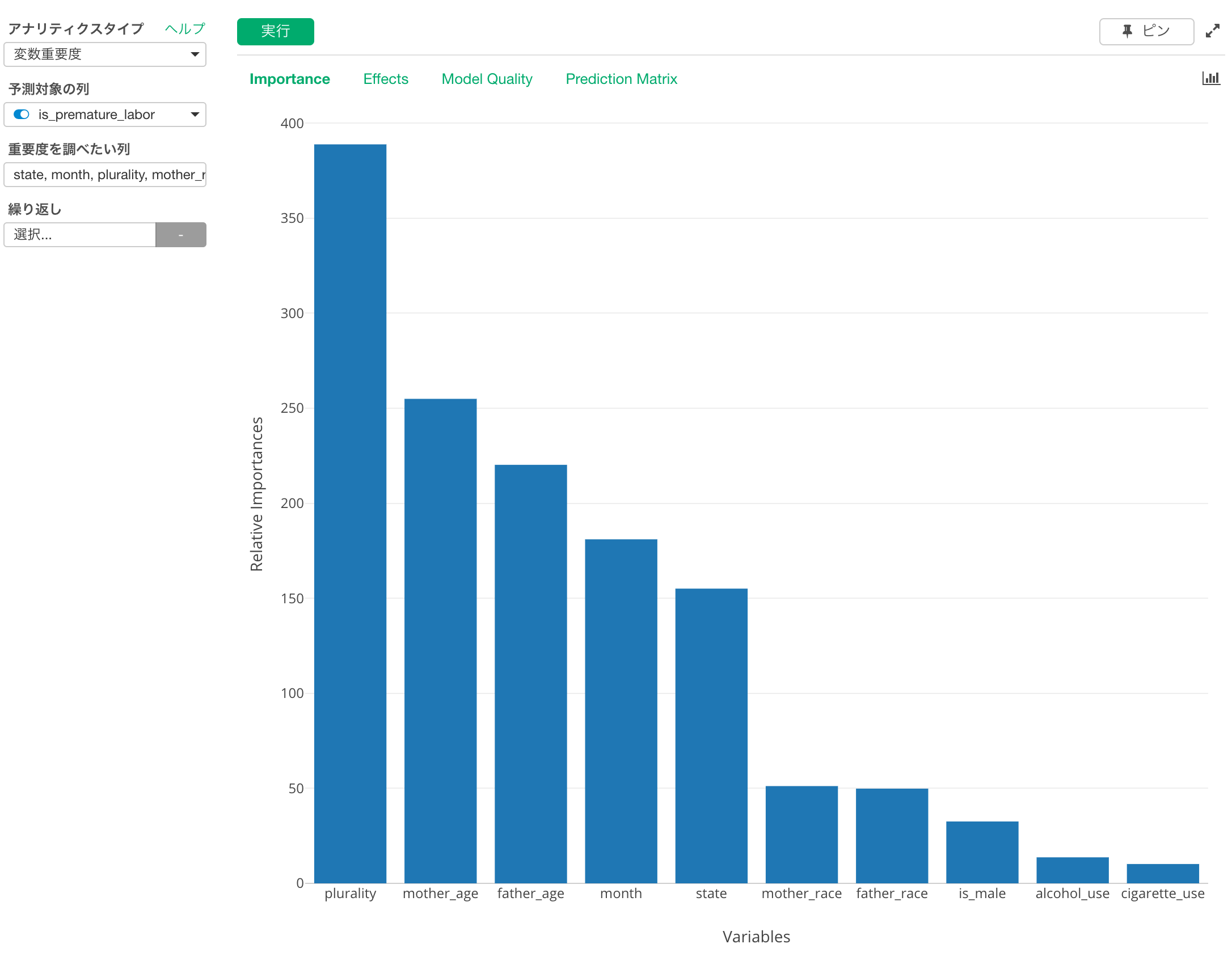
すると、双子かそれ以上(plurarity)、母親の年齢(mother_age)、父親の年齢(father_age)といった変数が早産であるかどうかということにおよぼす影響度が他に比べて高いことがわかります。すっかり、アルコールやタバコの利用が影響高いのかと思っていただけに意外です。
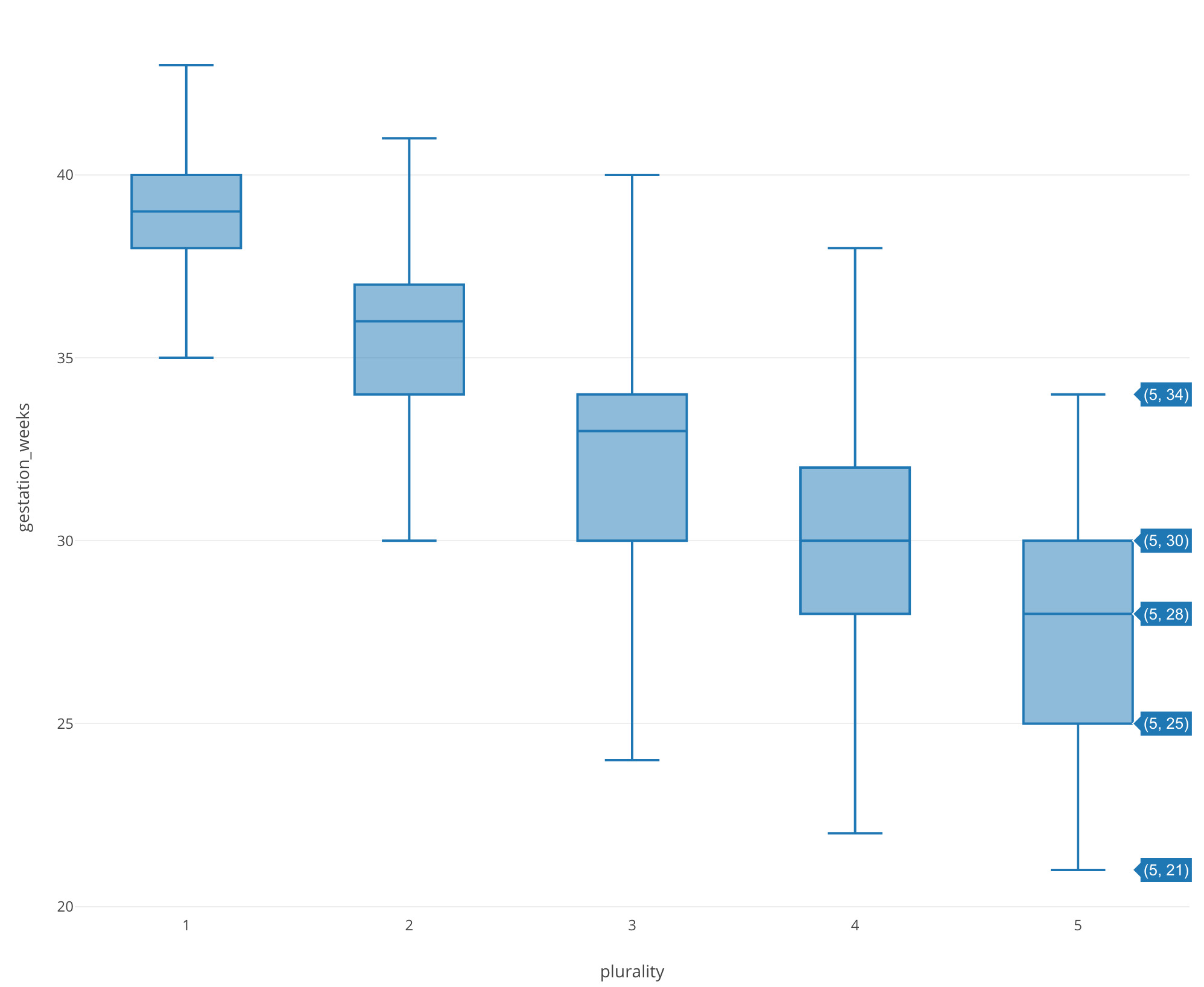
では、この結果を確認するために、一番影響度の大きいplurarity を使ってgestation_weekの箱ひげ図をみてみましょう。
すると、確かに双子、三つ子となるにつれて分布が早い週にシフトしていることが確認できました。
なお、変数重要度のアナリティクスに関しての詳細は、こちらに、うちのCEO、西田が作った簡単なビデオがあるのでご覧ください。
まとめ
今日はGoogle BigQueryのデータをSQLを書いてExploratoryの中にインポートして、さくっと可視化とアルゴリズムを使った分析をおこなってみました。最初は、どうやってBigQueryのデータをExploratoryに取り込むのかをみなさんに知っていただこうと思って、How-to的なものを書く予定でしたが、変数重要度アナリティクスを使うことで、思わぬインサイトが得られてしまいました!;)
まだExploratory Desktopをお持ちでない場合は、こちらから30日間無料でお試しいただけます。
注意: データインポートのサイズの制限
2017/11/18 現在、Exploratory Desktopの不具合のために、クラウドストレージ経由で巨大なサイズのデータをインポートすると、以下のエラーでインポートできないことがあります。修正は次のパッチに含まれますが、それまでの間はSQLクエリのwhere句を追加することで、インポートするデータのサイズを絞ってお試しください。
Error in read_tokens_(data, tokenizer, col_specs, col_names, locale_, : ignoring SIGPIPE signal目安としては、bigquery-public-data.samples.natalityでは100万行でお試しいただけます。