
最近、日本では国会が色々と荒れていますが、それを受けてTwitterでは安倍首相に関してどんなことが話題になっているのか気になるところです。そこで今日は安倍首相に言及しているTweetデータを使ってテキスト分析してみようと思います。
ここで一つチャレンジなのは、日本語のテキスト分析になると、英語などの言語と違い、単語と単語の間にスペースがないので、トークナイズ(単語ごとに分ける)するのが難しいという点です。ただ、知ってる人も多いかと思いますが、オープンソースで、MeCabという、Google 日本語入力開発者の一人である工藤拓さん等によって開発されたライブラリを使うと日本語をトークナイズするのが簡単にできます。さらに都合のいいことに、RでMeCabが使えるように、石田基広さんが作られたRMeCabというRパッケージがあるので、それを使うと簡単にRで、つまりはExploratoryの中でテキスト・データをトークナイズしていくことができます。
今日は、そのMeCabのインストール、さらにそれをExploratoryの中で使うためのセットアップ、そしてTweetデータに対するテキスト分析を順を追って説明していきたいと思います。
セットアップ
Mecabと辞書をインストール
Mecabと辞書のインストールはこちらを参照してください。
RMeCabにある機能を、Exploratoryで使いやすくするように、関数を定義する
RMeCabのトークナイズの関数をExploratoryの中で使いやすくするように関数を定義しましょう。
プロジェクトの中で、左側にある、スクリプトの隣にあるプラスボタンを押します。
名前をつけて、作成します。

スクリプトを入力して、左上の保存ボタンをクリックします。
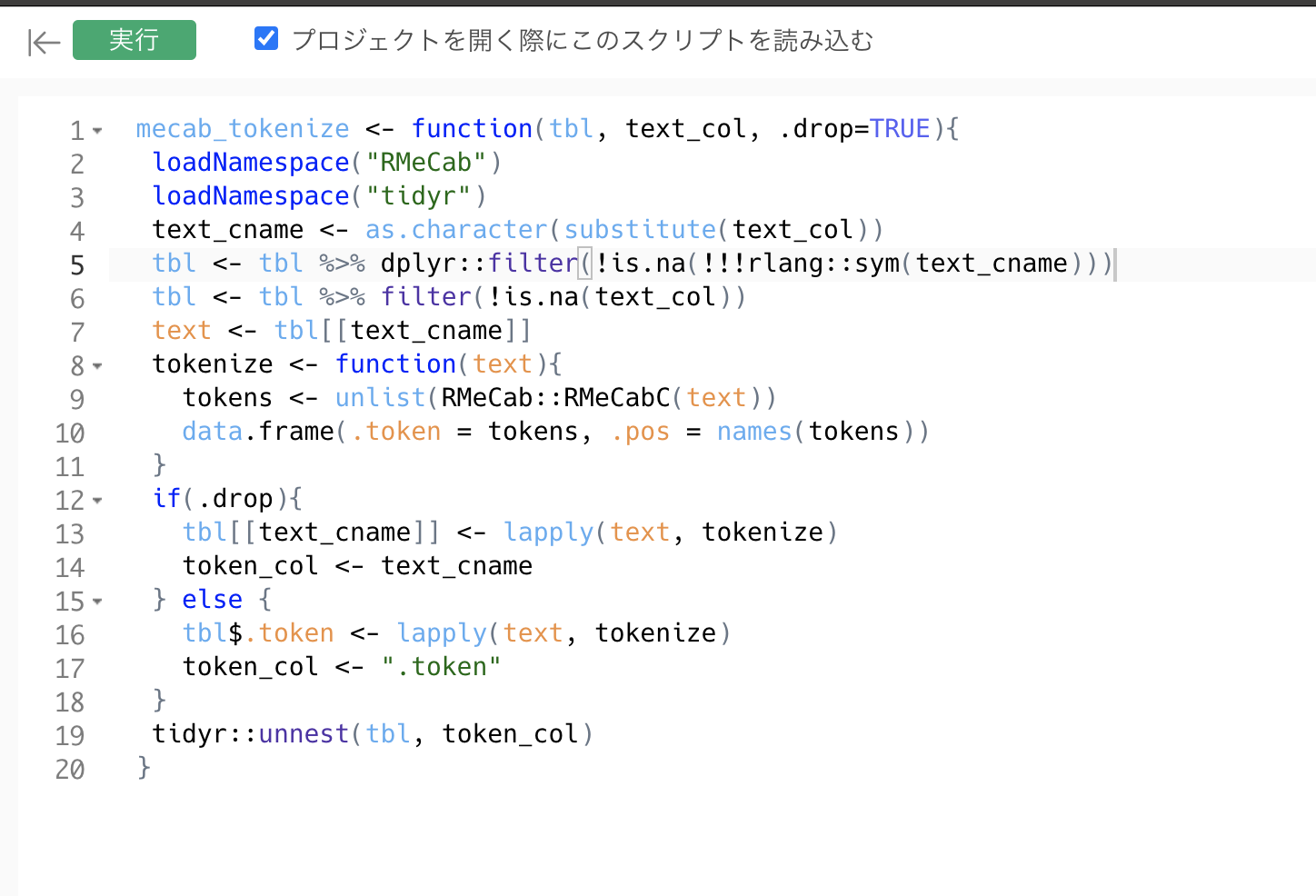
スクリプトの中身は以下の通りです。この mecab_tokenize という関数は、データフレームを入力として受け取り、指定された列に入っているテキストを、RMeCabCという関数を使って形態素解析します。そして結果を .token という列としてデータフレームに足します。
mecab_tokenize <- function(tbl, text_col, .drop=TRUE){
loadNamespace("RMeCab")
loadNamespace("tidyr")
text_cname <- as.character(substitute(text_col))
tbl <- tbl %>% dplyr::filter(!is.na(!!!rlang::sym(text_cname)))
text <- tbl[[text_cname]]
tokenize <- function(text){
tokens <- unlist(RMeCab::RMeCabC(text))
data.frame(.token = tokens, .pos = names(tokens))
}
if(.drop){
tbl[[text_cname]] <- lapply(text, tokenize)
token_col <- text_cname
} else {
tbl$.token <- lapply(text, tokenize)
token_col <- ".token"
}
tidyr::unnest(tbl, token_col)
}WindowsでMecabをインストール時に文字コードをShift-JISで使用するように指定した場合は、以下のスクリプトを使います。
注意:Windowsで文字コードがShift-JISの場合、以下のスクリプトを実行した際に、文字コードの変換の失敗のため生成されるトークンの件数が少なくなる場合があります。その場合は、WindowsでUTF-8を利用可能にする の手順に従って、WindowsおよびExploratoryでUTF-8を利用可能にし、文字コードの変換がいらない上記の方のmecab_tokenizeで試してください。
mecab_tokenize <- function(tbl, text_col, .drop=TRUE){
loadNamespace("RMeCab")
loadNamespace("tidyr")
text_cname <- as.character(substitute(text_col))
tbl <- tbl %>% dplyr::filter(!is.na(!!!rlang::sym(text_cname)))
text <- tbl[[text_cname]]
tokenize <- function(text){
# WindowsでMecabをインストール時に文字コードをShift JISで使う場合
# 文字コードをUTF8からcp932に変換しておく
textSjis <- iconv(text, from="UTF8", to="cp932")
if(is.na(textSjis)) {
# 変換に失敗したものは空文字だとRMeCabCが動かないので空白にしておく。
textSjis = " "
}
tokens <- unlist(RMeCab::RMeCabC(textSjis))
#UTF8に戻す
tokensUTF8 <- iconv(tokens, from="cp932", to="UTF8")
data.frame(.token = tokensUTF8, .pos = names(tokensUTF8))
}
if(.drop){
tbl[[text_cname]] <- lapply(text, tokenize)
token_col <- text_cname
} else {
tbl$.token <- lapply(text, tokenize)
token_col <- ".token"
}
tidyr::unnest(tbl, token_col)
}これで、前準備は完了です。
安倍首相に言及しているTweetをTwitterからインポートする。
注意:現在のバージョン (8.4) ではTwitterデータソースはサポートされておりません。
それではまず、安倍首相に言及しているTweetをTwitterからインポートしましょう。
Tweetをインポート
プロジェクトを開き、画面左側のデータフレームの隣にあるプラスボタンをクリックして、クラウドアプリケーションデータを選択します。
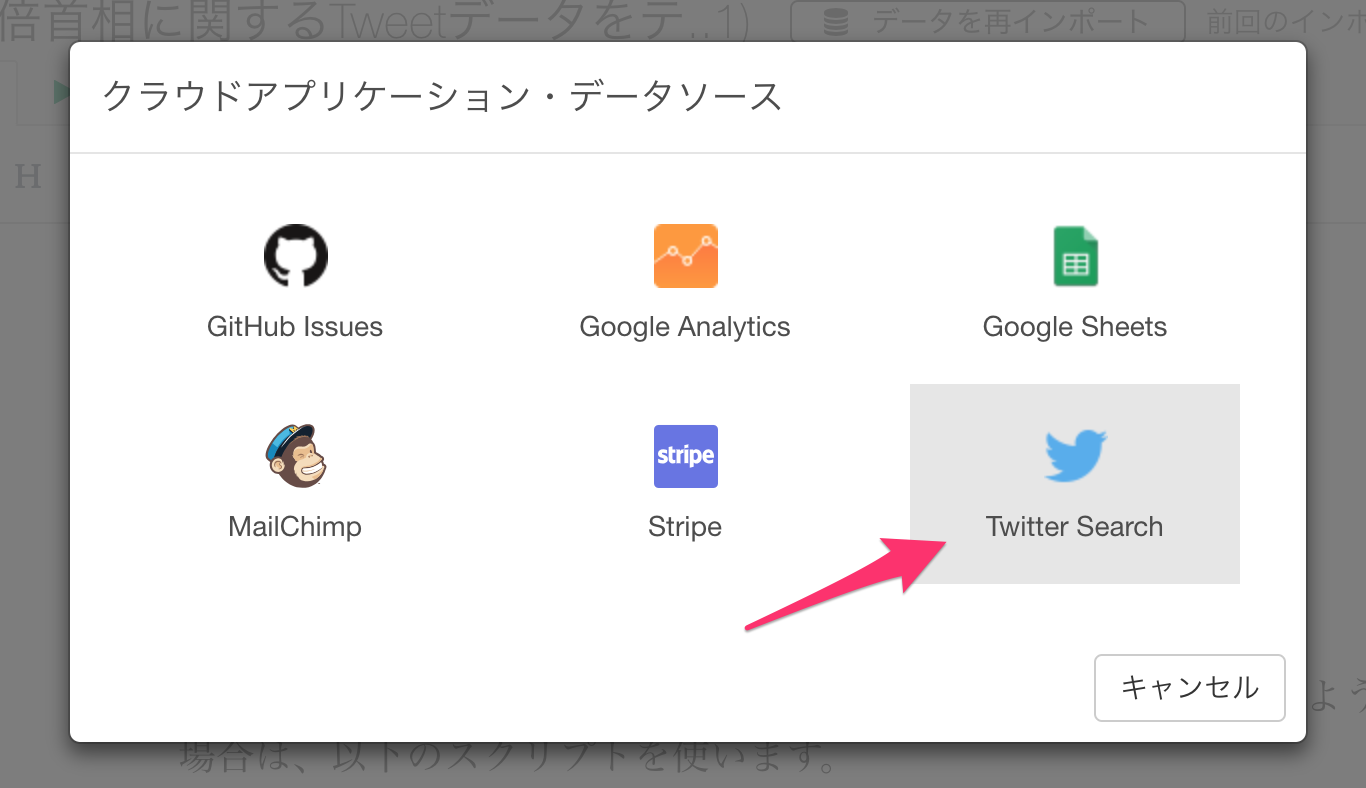
Twitter Searchをリストから選択します。
インポートのダイアログで以下のパラメタを指定します。
- 言語:日本語
- 最近:7日分
- リツイート:含まない
- センチメント:スコアしない
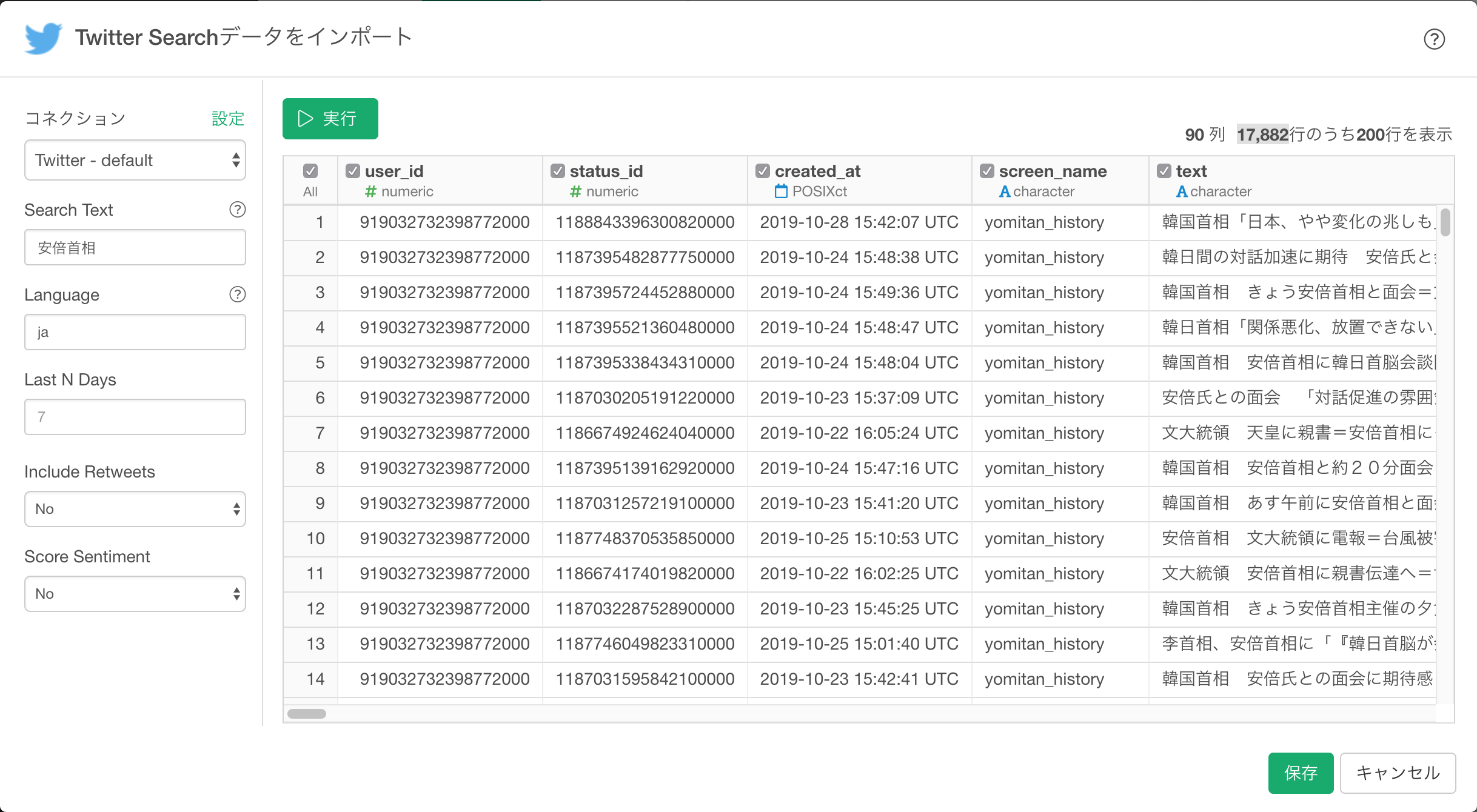
データの取得ボタン をクリックします。無事Tweetが表示されたら、次に インポート をクリックします。
安倍首相に関するTweetがインポートできました。

テキスト分析をする
では早速Tweetデータを分析してみましょう。
データ数を絞る
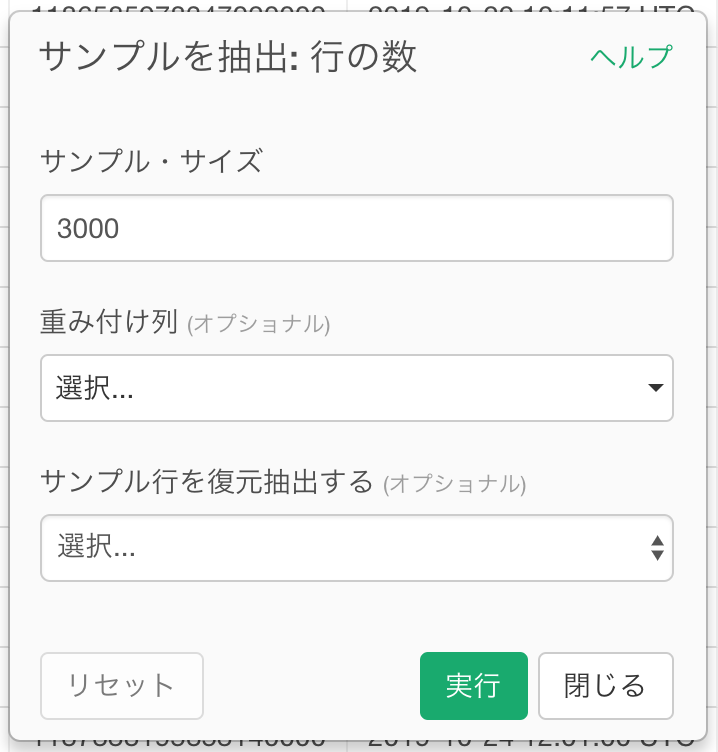
取得したTweet数が多い場合、処理が終わらないことがありますので、まずは3000件に行数を絞ってみましょう。
画面右側の上にあるプラスボタンを押すと、メニューが出て来るのでサンプルを抽出を選び、行の数を選択します。

サンプル・サイズを3000にします。
トークナイズする
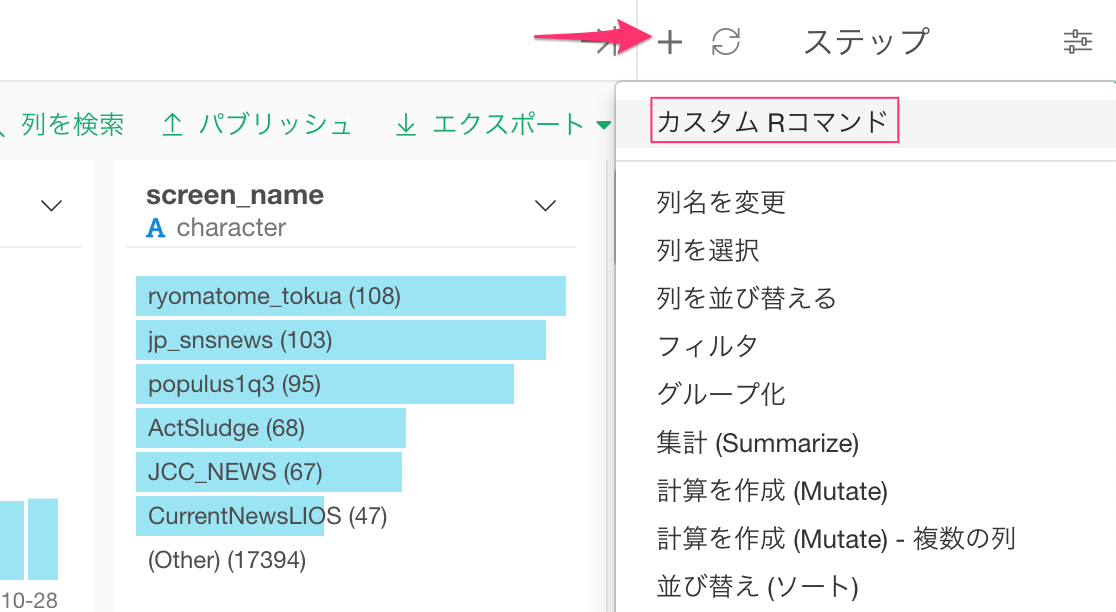
Tweetテキストのデータを分析する最初のステップとして、さきほど登録したmecab_tokenizeという関数を使ってテキストをトークナイズします。この関数はデータフレームをインプットにとり、トークナイズした結果をアウトプットとして出力するので、カスタムコマンド・モードにして、この関数を呼びます。
画面右側の上にあるプラスボタンを押すと、メニューが出て来るのでカスタムRコマンドを選びます。
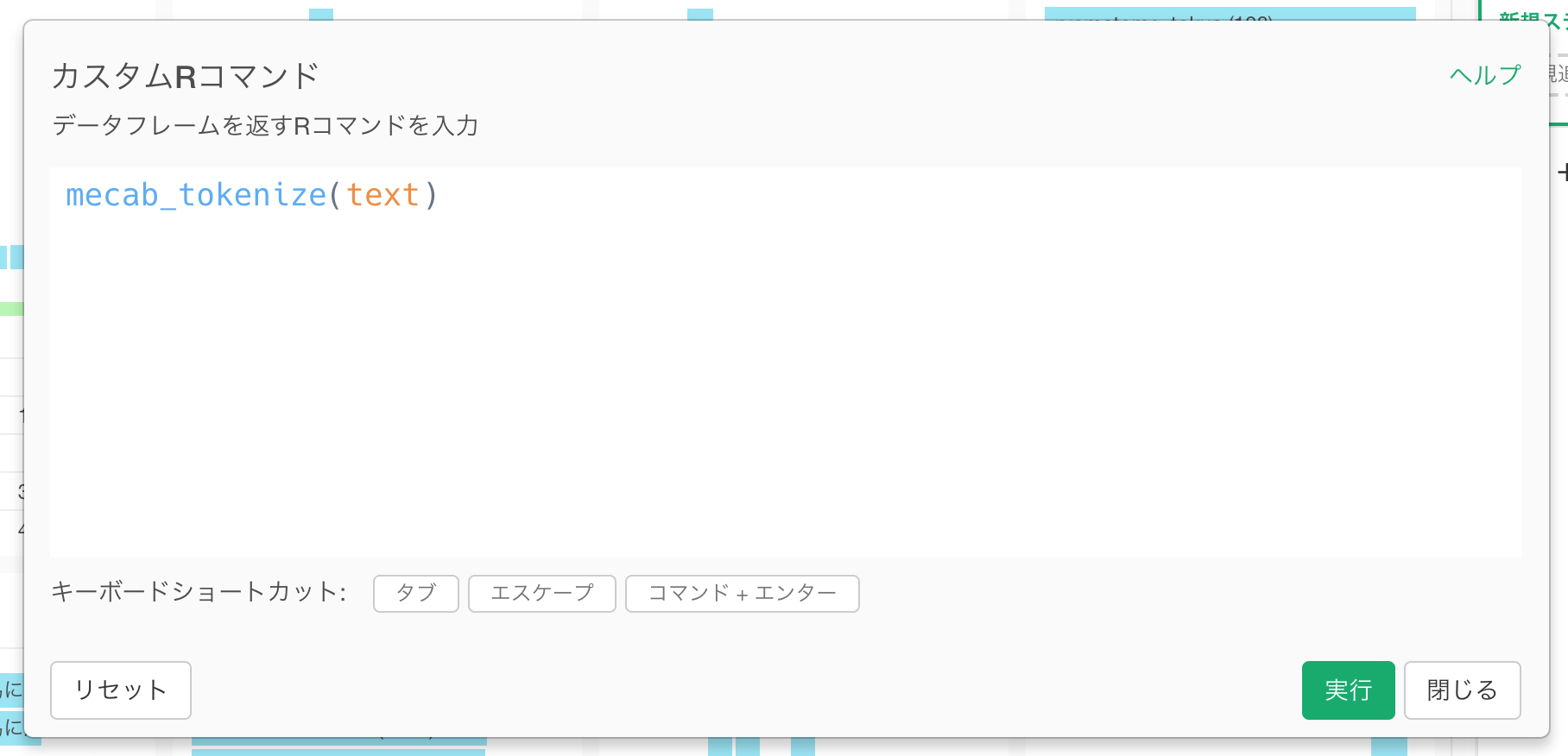
以下のコマンドを入力します。引数にはtext列を指定します。
mecab_tokenize(text)すると、Tweetのテキストのトークナイズが行われ、品詞ごとに分割されます。

注意:Windowsの場合は、管理者権限がないWindowsユーザーでExploratoryを実行していると、トークナイズの処理が正しく実行されず処理が完了しないことがあります。その場合は、管理者権限を持つWindowsのユーザーでExploraotryを起動して試してください。
ストップ・ワード(stopwords)を取り除く
下の赤く囲った部分のように、どこにでもよく出てくる単語なので、テキスト分析する上では特徴のない単語が多く含まれているのが分かります。こうした単語はストップ・ワード(stopwords)と呼ばれます。
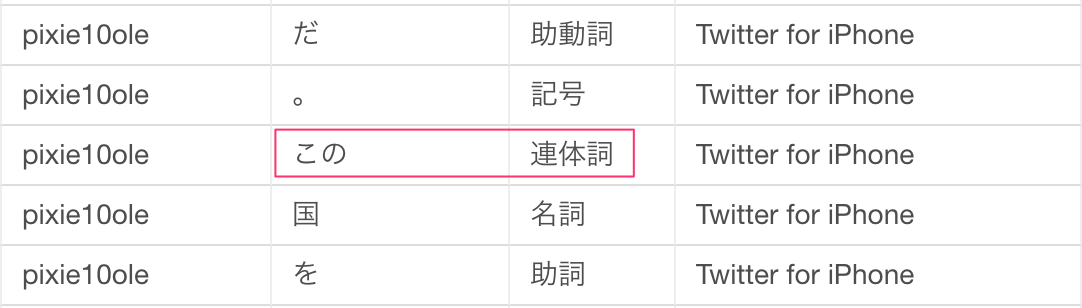
さっそく、これらの単語を取り除きましょう。 列のメニューからフィルタ -> ストップワードを除くを選びます。
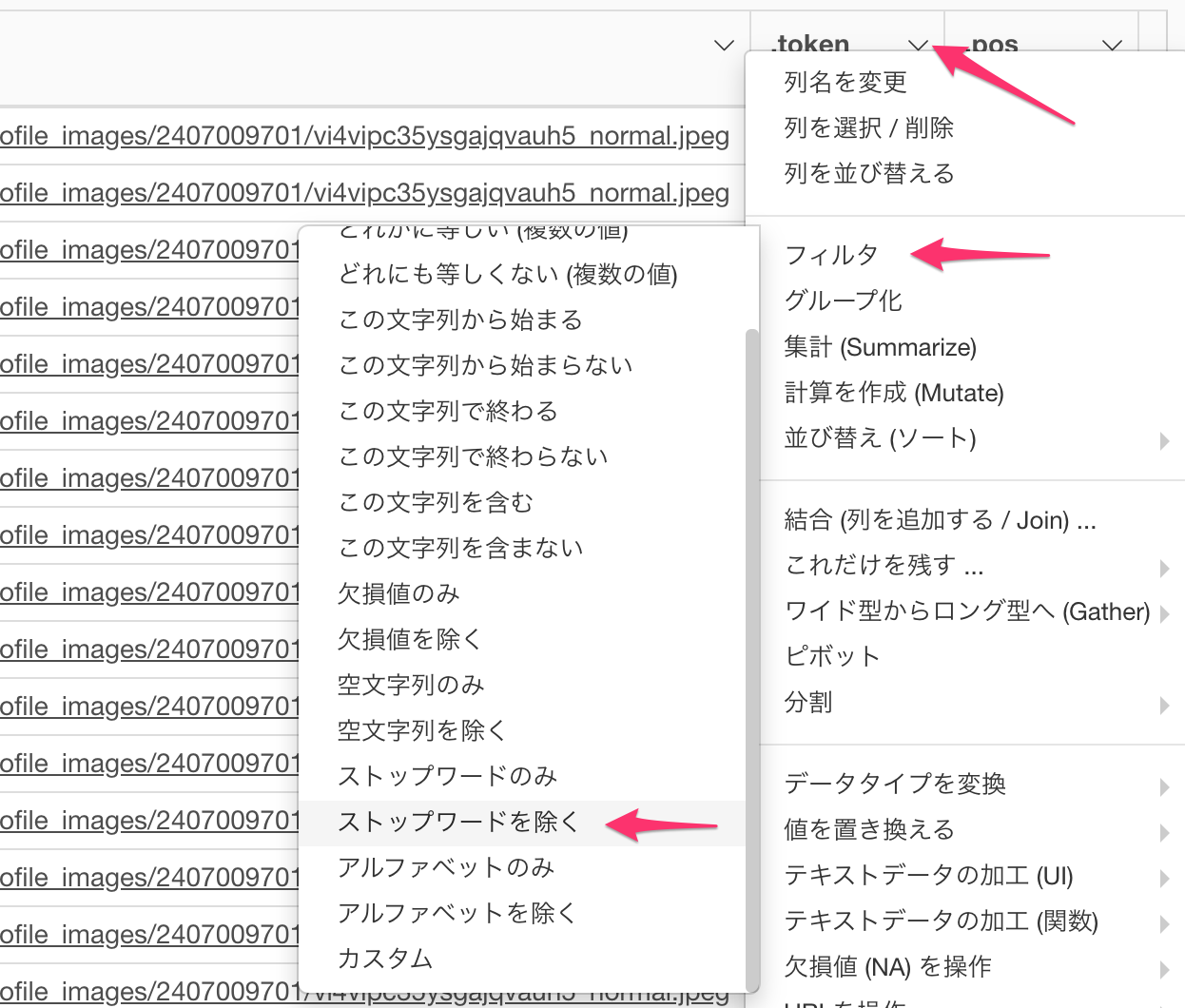
言語に日本語を選択して実行します。
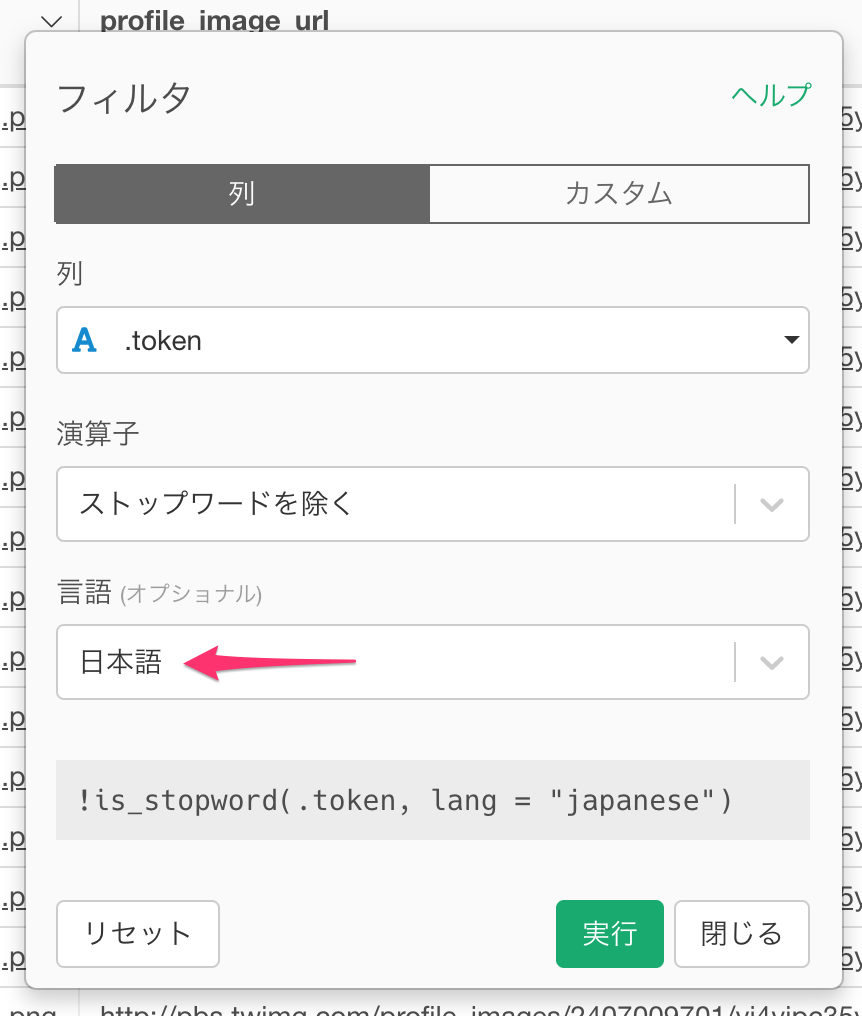
これでストップ・ワードが取り除かれました。
さらに不要なデータを取り除く
次に、データを見ていくと下の図のように記号がいくつか入っていることに気が付きます。また、助詞や助動詞や副詞や接頭詞なども不要です。名詞と動詞だけにフィルタリングしましょう。
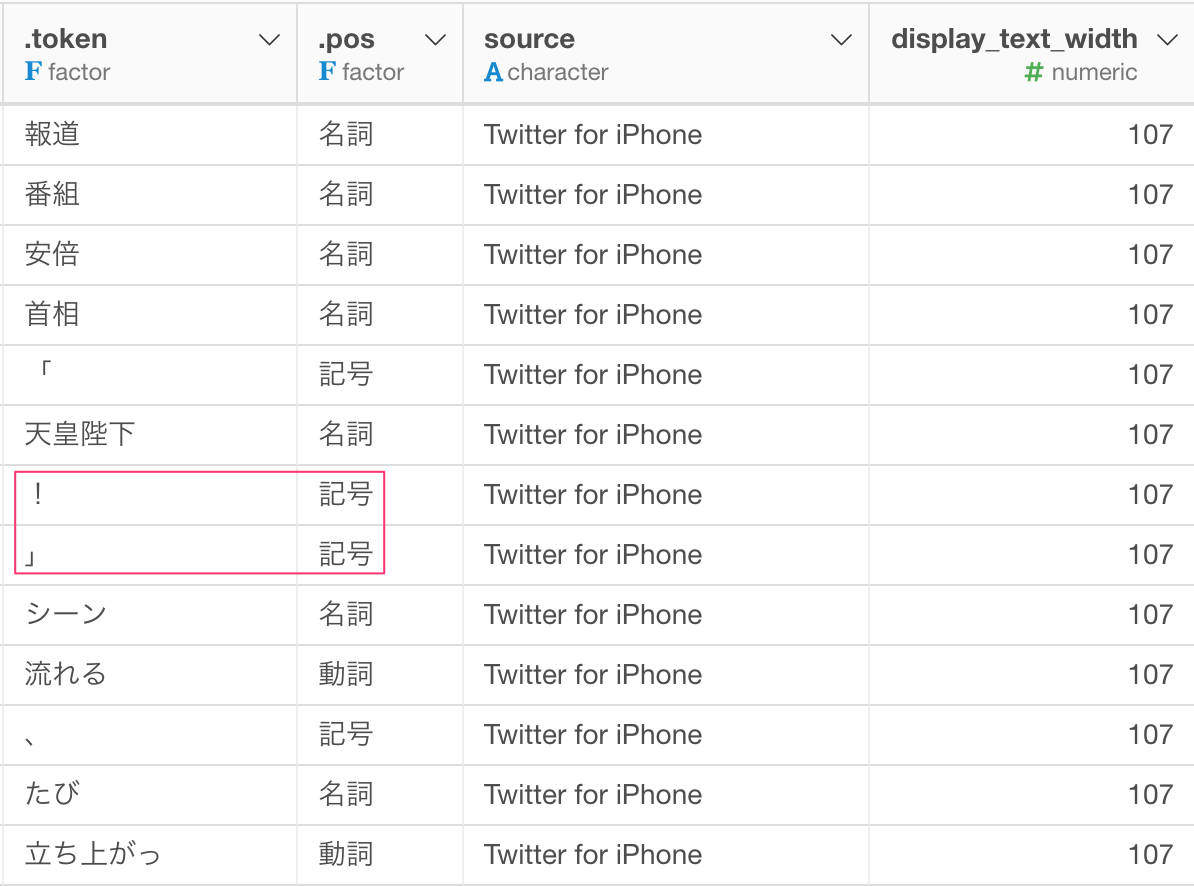
列のメニューからフィルタ -> どれかに等しいを選びます。

条件を確認して、OKを押します。
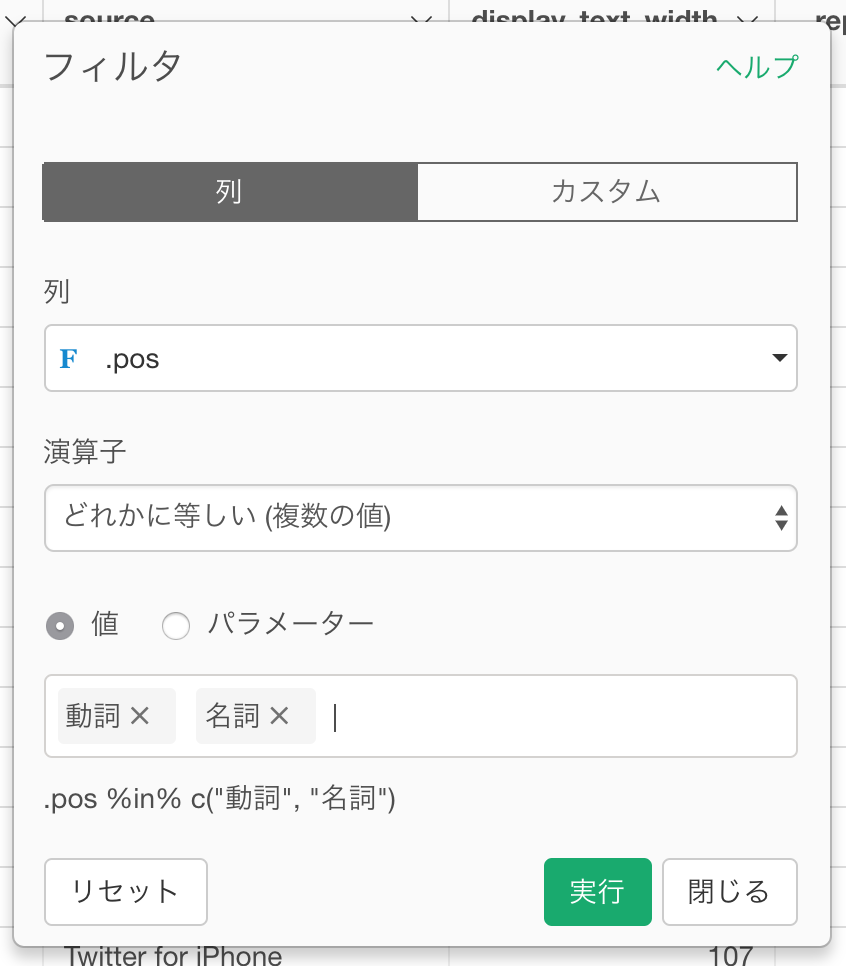
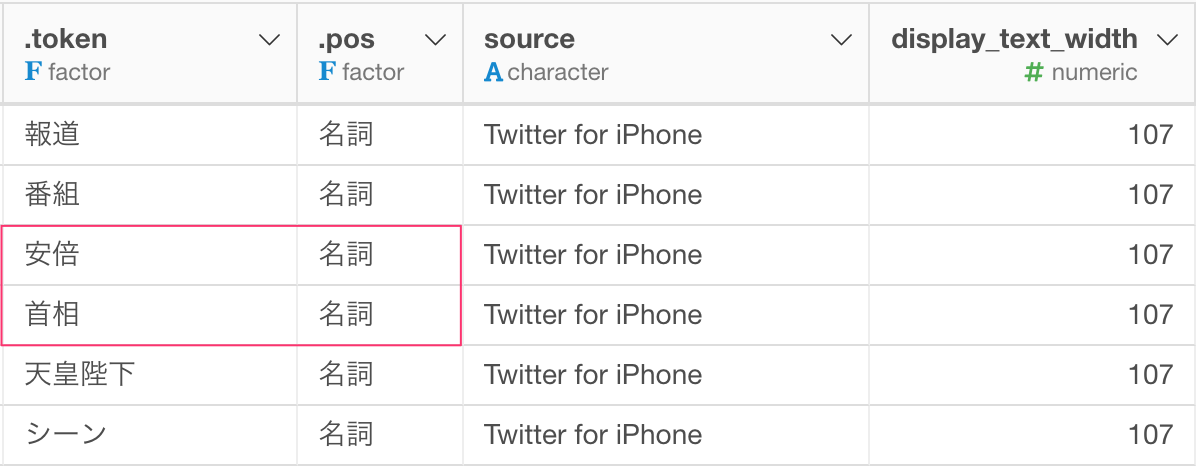
安倍や首相と言った単語も自明すぎるので合わせて取り除きます。
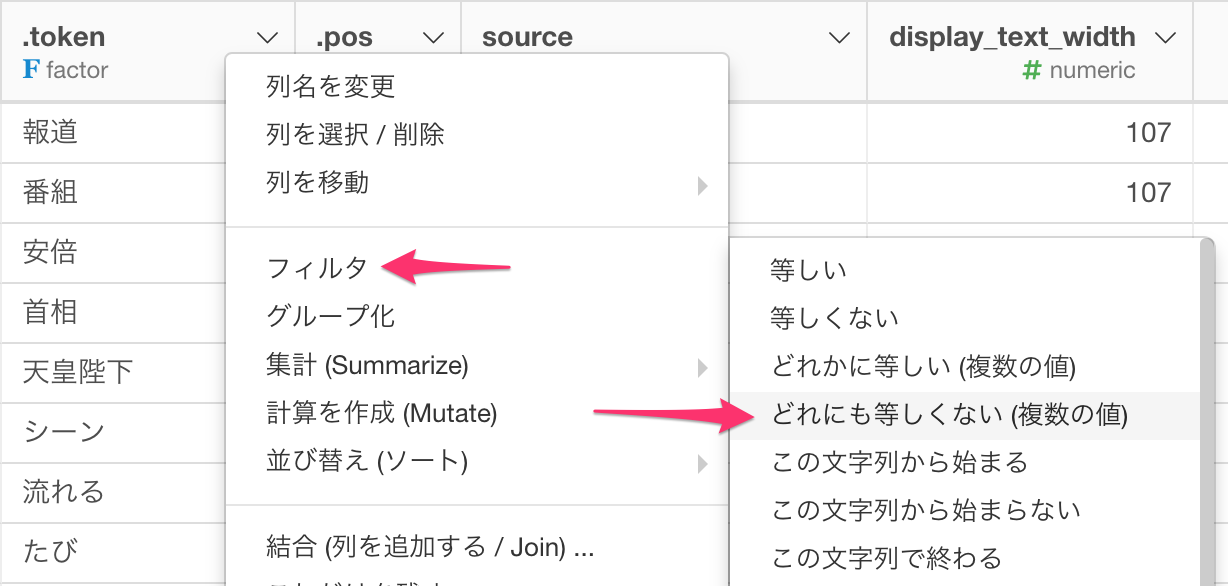
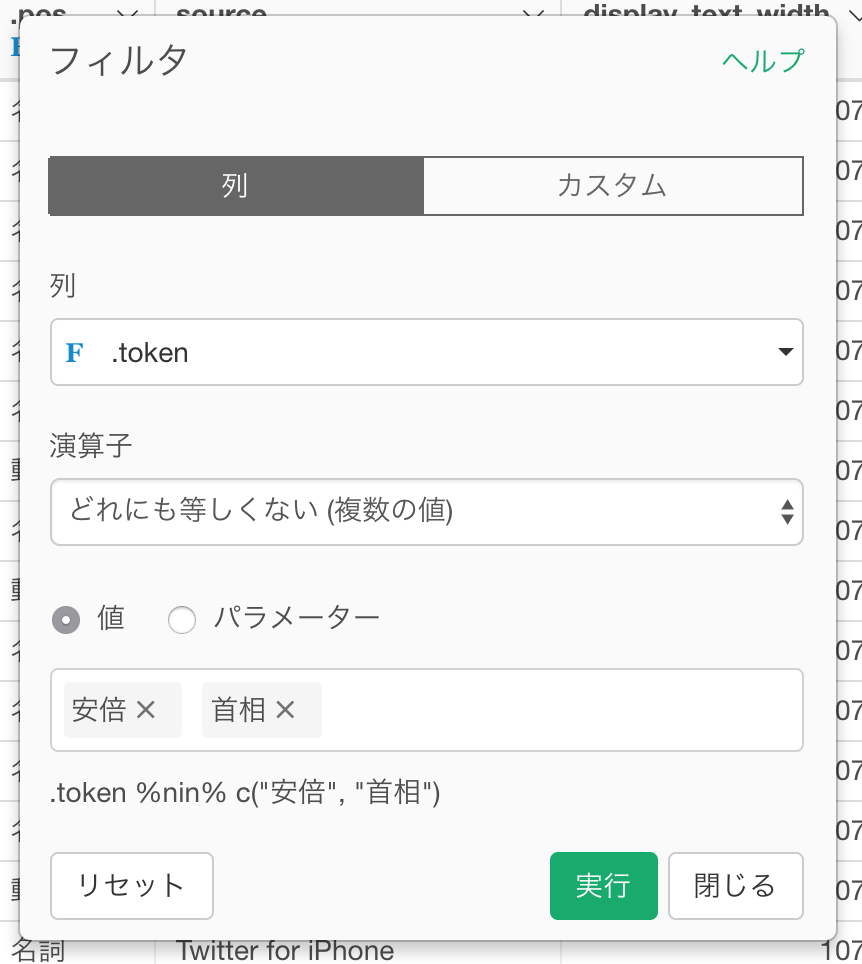
どれにも等しくないというフィルタの条件が使えます。
次に、文字数が1文字以下のテキストデータも意味がないので取り除きましょう。
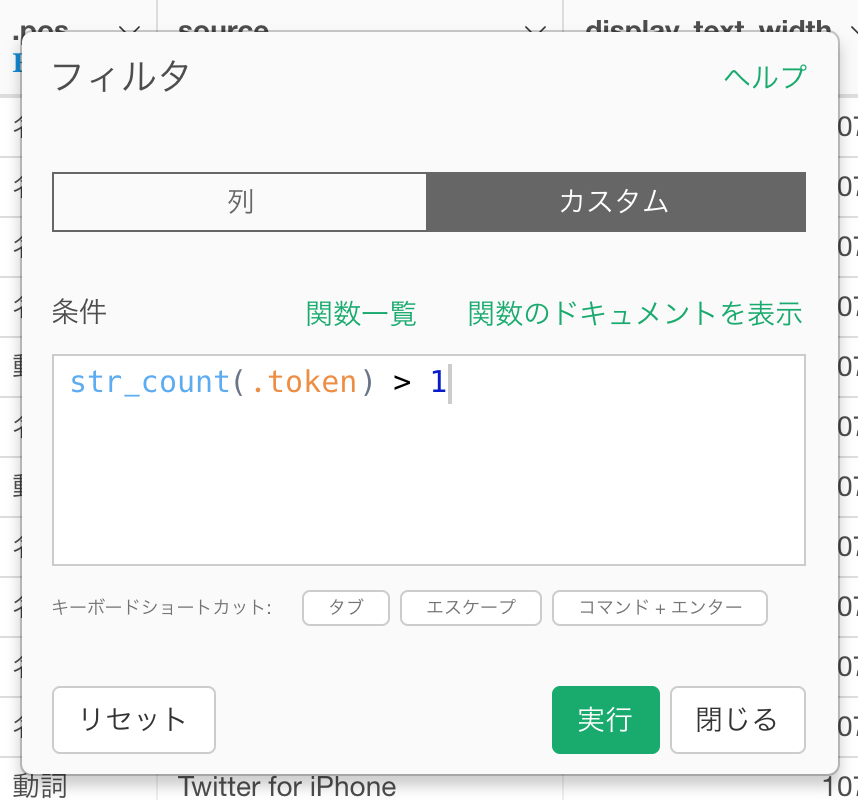
これで不要な単語はほとんど取り除くことができました。
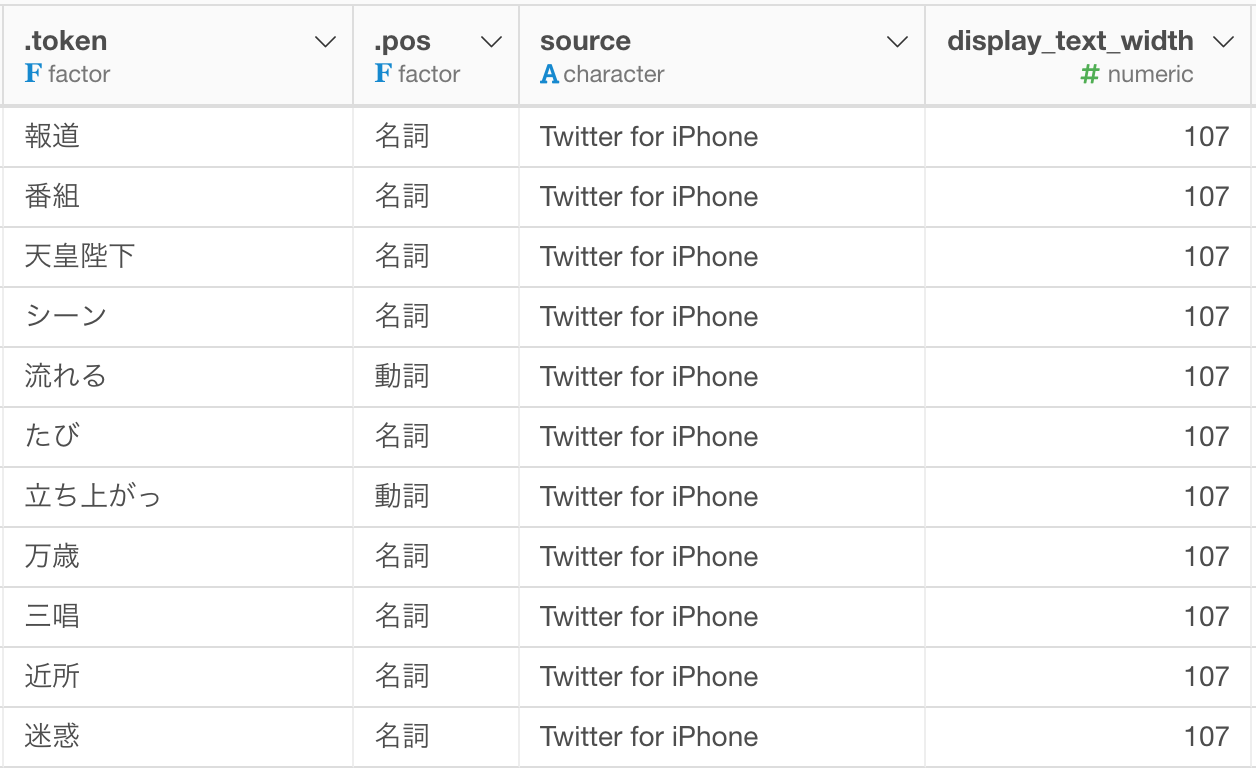
頻出単語を調べる
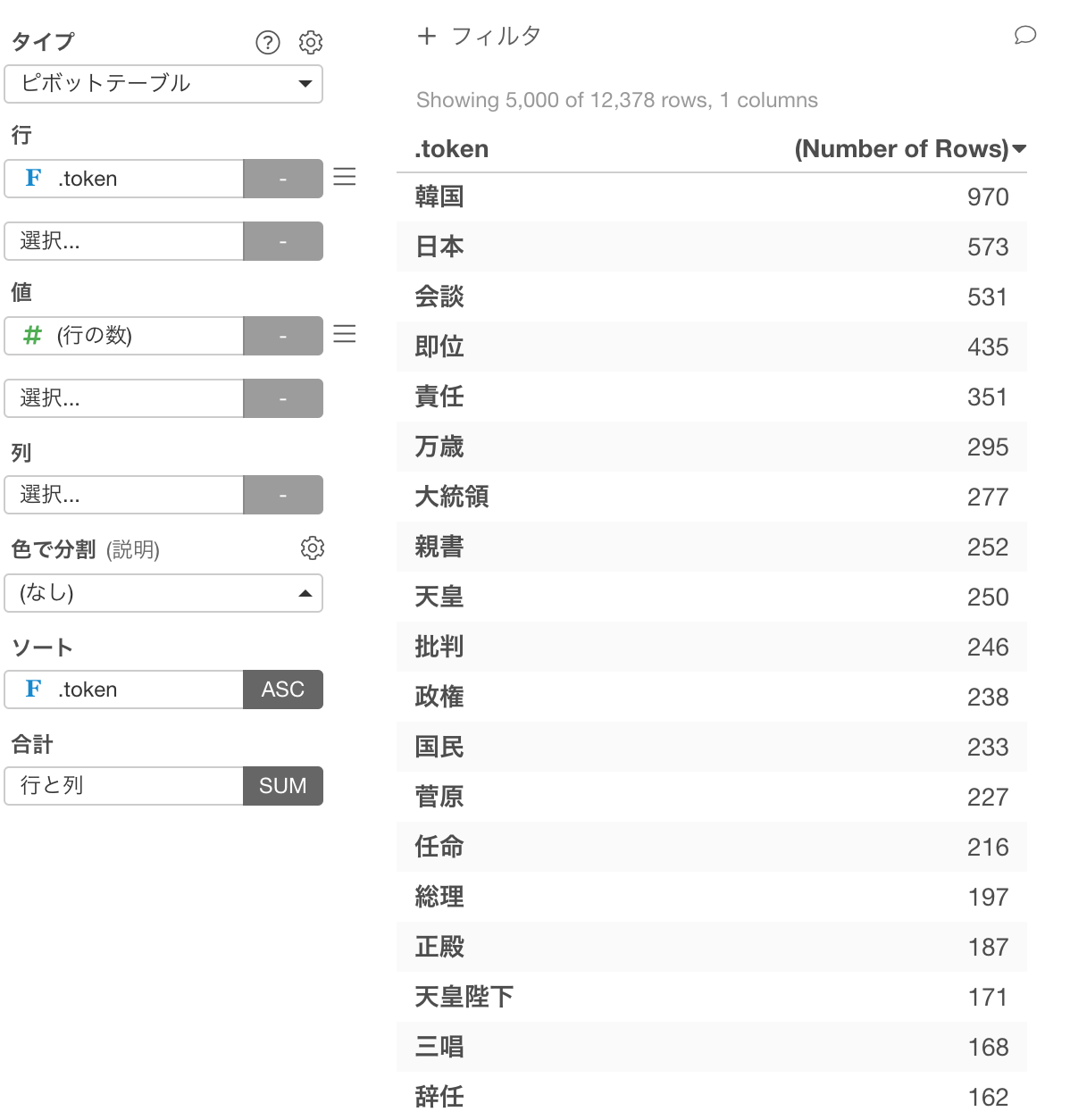
それではまず、最もよく頻出している単語を見てみましょう。Vizのビューに行って、ピボットテーブルを作ります。行に.token列を割り当てて、ソートに.token列を割り当てて頻度の降順をセットして頻度の多い順にデータを並べます。すると、韓国、日本、会談などの単語が多く使われていることがわかります。
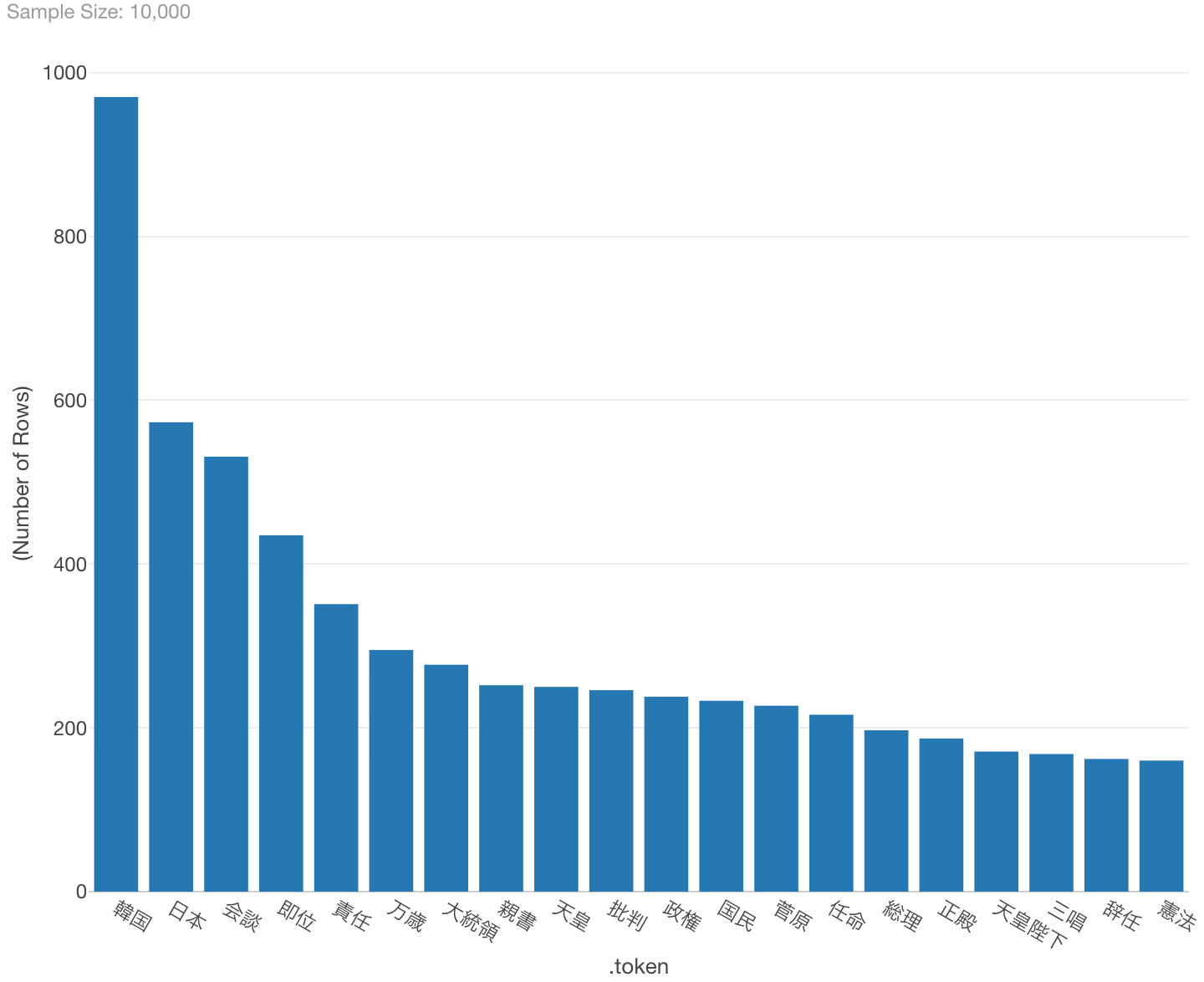
バーチャートで同じく頻出順に上位20を並べると、次のようになります。
ワードクラウド
上記のような頻出単語のようなテキストをもっと見やすくするために使われる可視化の手法として、ワードクラウドというのがあります。Exploratoryではチャートの一つとしてサポートしております。新規にチャートを追加し、タイプにワード・クラウド、単語に.token列を指定します。
出力結果は以下のようになります。韓国、会談といった頻出回数の多い単語が大きめのフォントサイズで表示されていることが確認できます。

色を変えたいときは、色で分割のメニューからカラーパレットを変えることもできます。
例えば、緑色の濃淡で表現したい場合は、以下のように設定します。濃い色をより頻度の高い単語に割り当てるにはカラーパレットを逆順にするにチェックを入れます。

また、ある程度以上の頻度の単語を表示させたり、横向にしたい単語の割合を設定することもできます。
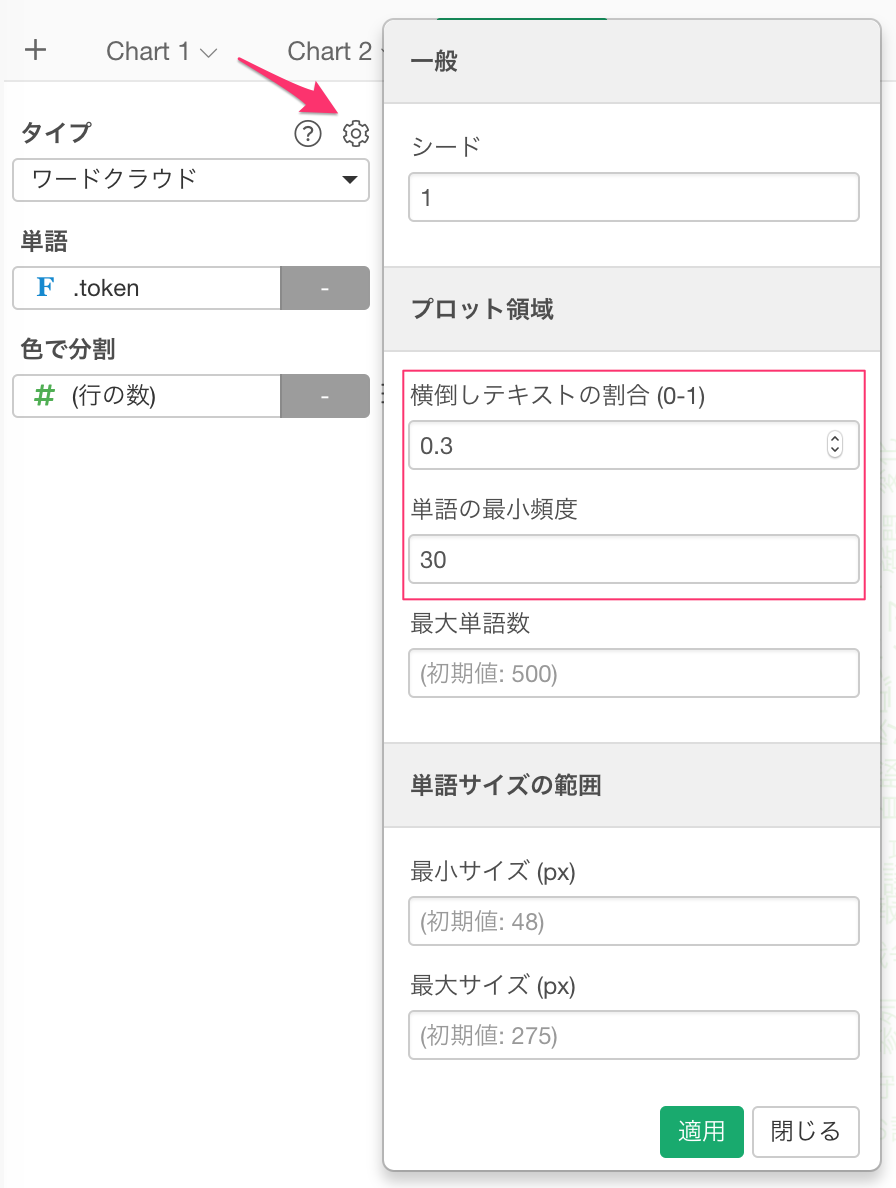
すると、表示結果が以下のように変わります。

長くなってきたのでは、Part 1はここまでにして、Part 2ではトークンからNグラムを作成し、TF-IDF、クラスタリングとさらにテキスト分析をしてみます。
まとめ
今日はTwitterから安倍首相に言及されたTweetをインポートし、RMeCabでトークナイズして、ストップ・ワード等を取り除き、頻出する単語が何かを確認するところまで見てきました。
自分で試してみる
まだExploratoryをお持ちでない方は、この機会にぜひ試してみて下さい!
こちらのページよりサインアップ(無料)した後、Exploratoryをダウンロードし始めることができます!
データサイエンスを学ぶ

データサイエンスやデータ分析の手法を1から体系的に学び、現場で使えるレベルのスキルを身につけていただくためのトレーニングを定期的に開催しています。
データを使ってビジネスの問題を解決していくための、質問や仮説の構築の仕方などを含めたデータリテラシーも基礎から身につけていただくものとなっております。
ぜひこの機会に参加をご検討ください!