
最近、日本の政界も色々騒ぎがありますが、それを受けてTwitterでは安倍首相に関してどんなことが話題になっているのか気になるところです。そこで今日は安倍首相に言及しているTweetデータを使ってテキスト分析してみようと思います。
ここで一つチャレンジなのは、日本語のテキスト分析になると、英語などの言語と違い、単語と単語の間にスペースがないので、単語化(トークナイズ)するのが難しいという点です。Exploratoryでは5.5.3というバージョンから日本語の単語化(トークナイズ)をMeCabなど外部のソフトウェアをインストールしなくてもできるようになりました。
安倍首相に言及しているTweetをTwitterからインポートする。
それではまず、安倍首相に言及しているTweetをTwitterからインポートしましょう。
Tweetをインポート
注意: Exploratoryの最新のバージョンではTwitterデータソースはサポートされておりません。
プロジェクトを開き、画面左側のデータフレームの隣にあるプラスボタンをクリックして、クラウドアプリケーションデータを選択します。
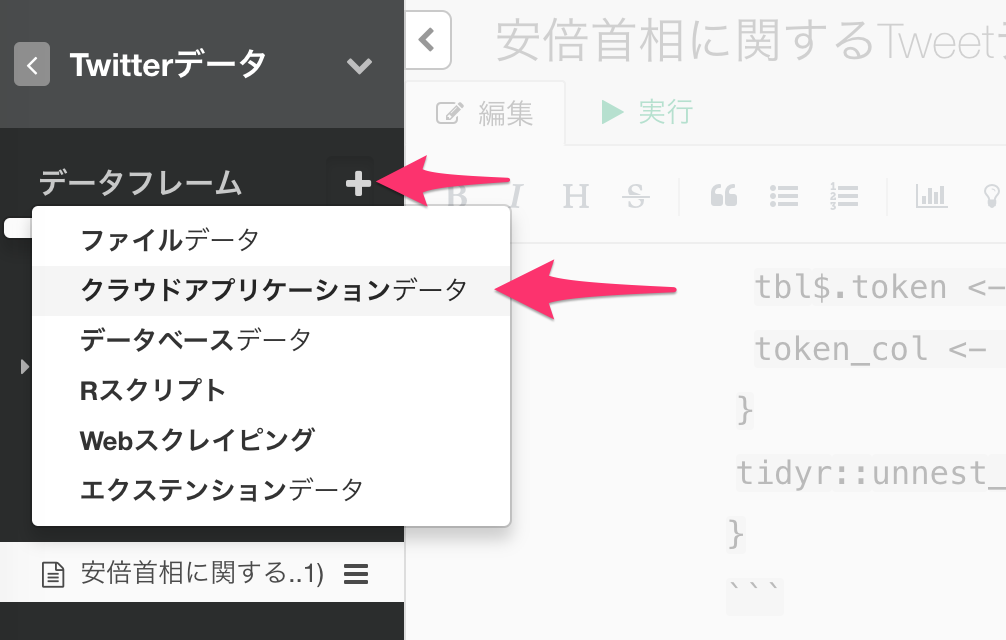
Twitter Searchをリストから選択します。
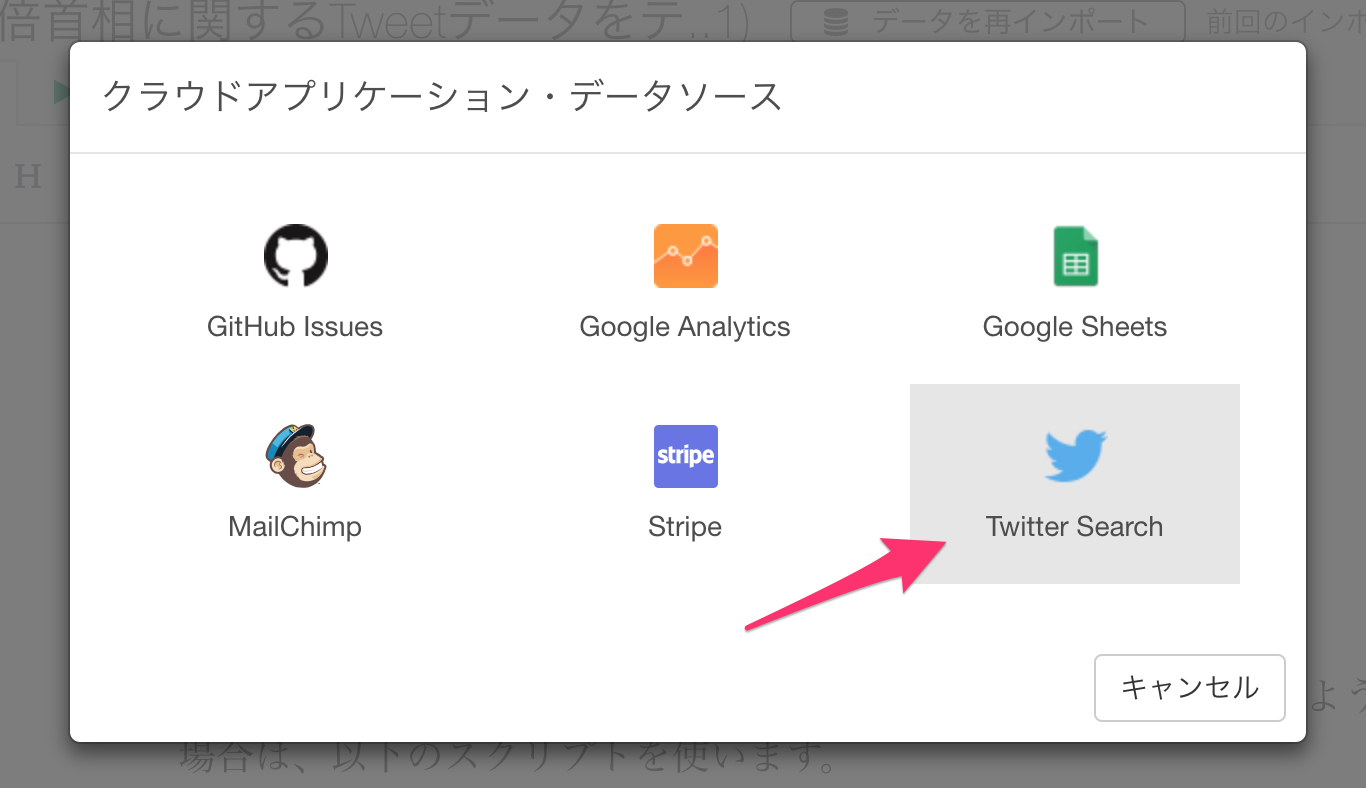
インポートのダイアログで以下のパラメーターを指定します。
- 言語:日本語
- 直近N日間:7
- リツイートを含む:いいえ
- センチメントを計算する:いいえ
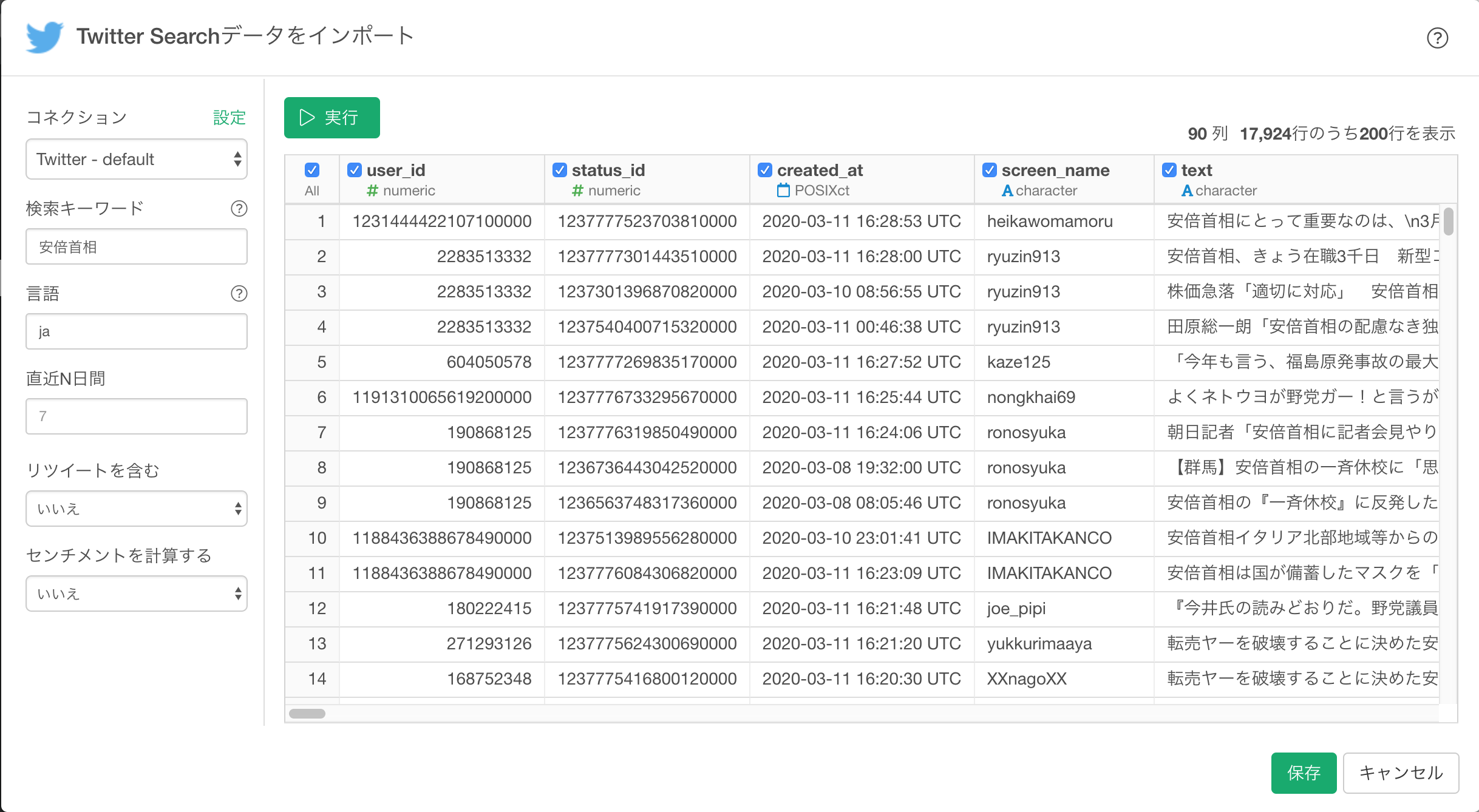
実行 ボタンをクリックします。無事Tweetが表示されたら、次に 保存 ボタンをクリックします。
安倍首相に関するTweetがインポートできました。
テキスト分析をする
では早速Tweetデータを分析してみましょう。
単語のカウント(ワードクラウド)
アナリティクスのタブをクリックし、新規にアナリティクスを作成します。タイプには「テキスト分析」の下にある「単語のカウント」を選択します。
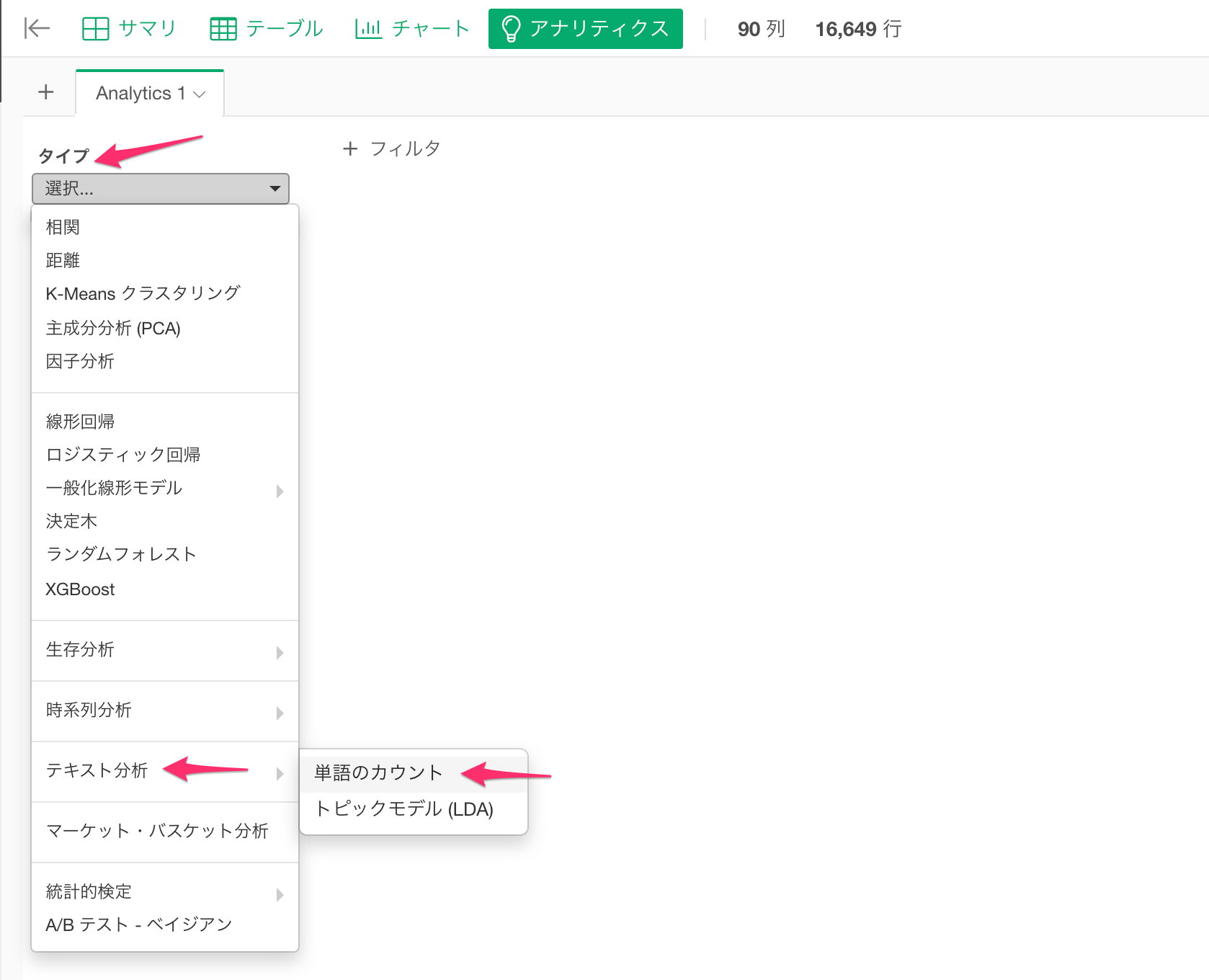
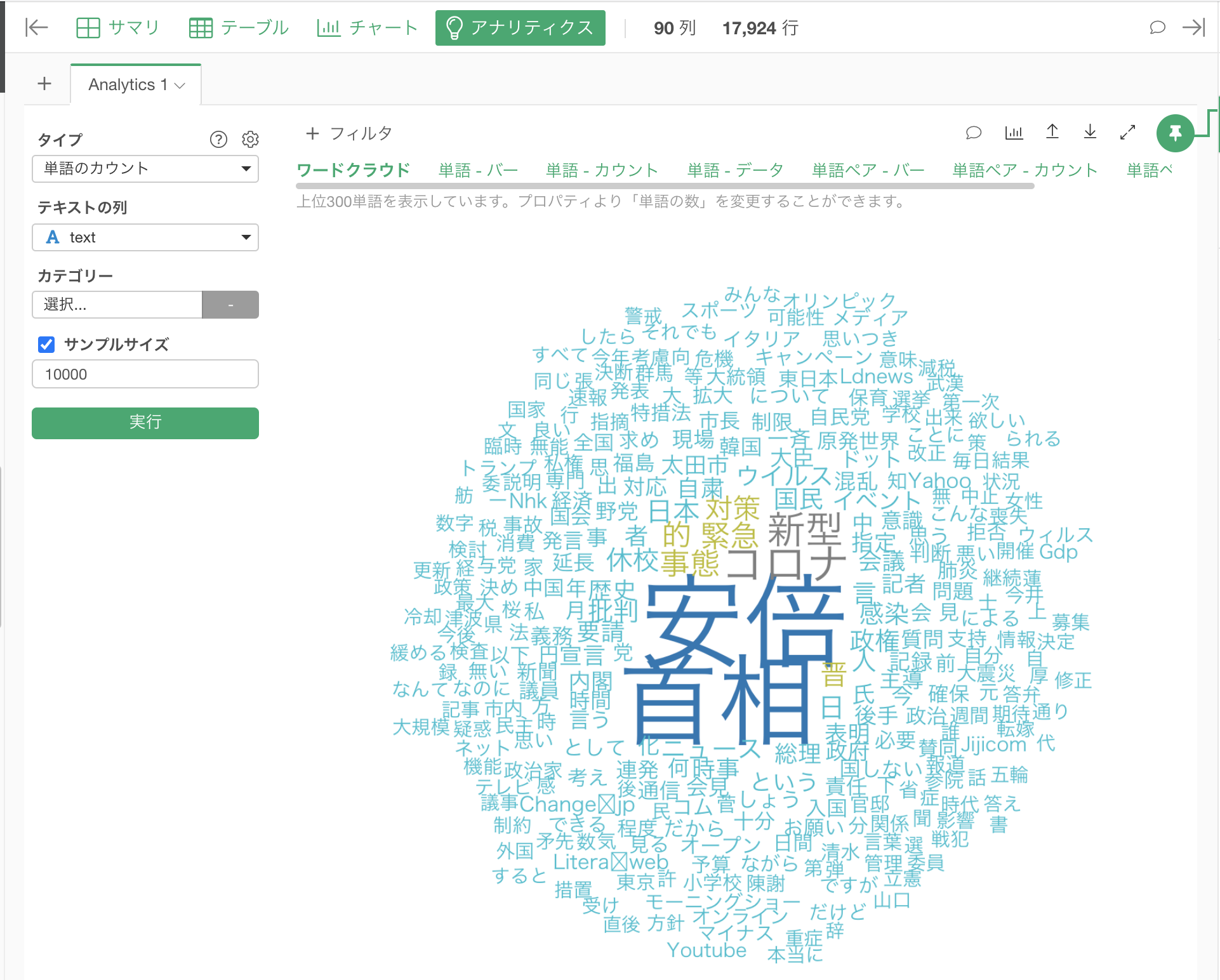
「テキストの列」にtext列を選択し、サンプルサイズを10000にしてまずは実行してみます。
ストップワードを追加する
安倍や首相と言った単語は自明すぎるので、歯車のアイコンをクリックし、テキストの単語化の設定のダイアログで、「追加するストップワード」に安倍,首相とカンマ(,)で区切って入力し、適用ボタンをクリックします。
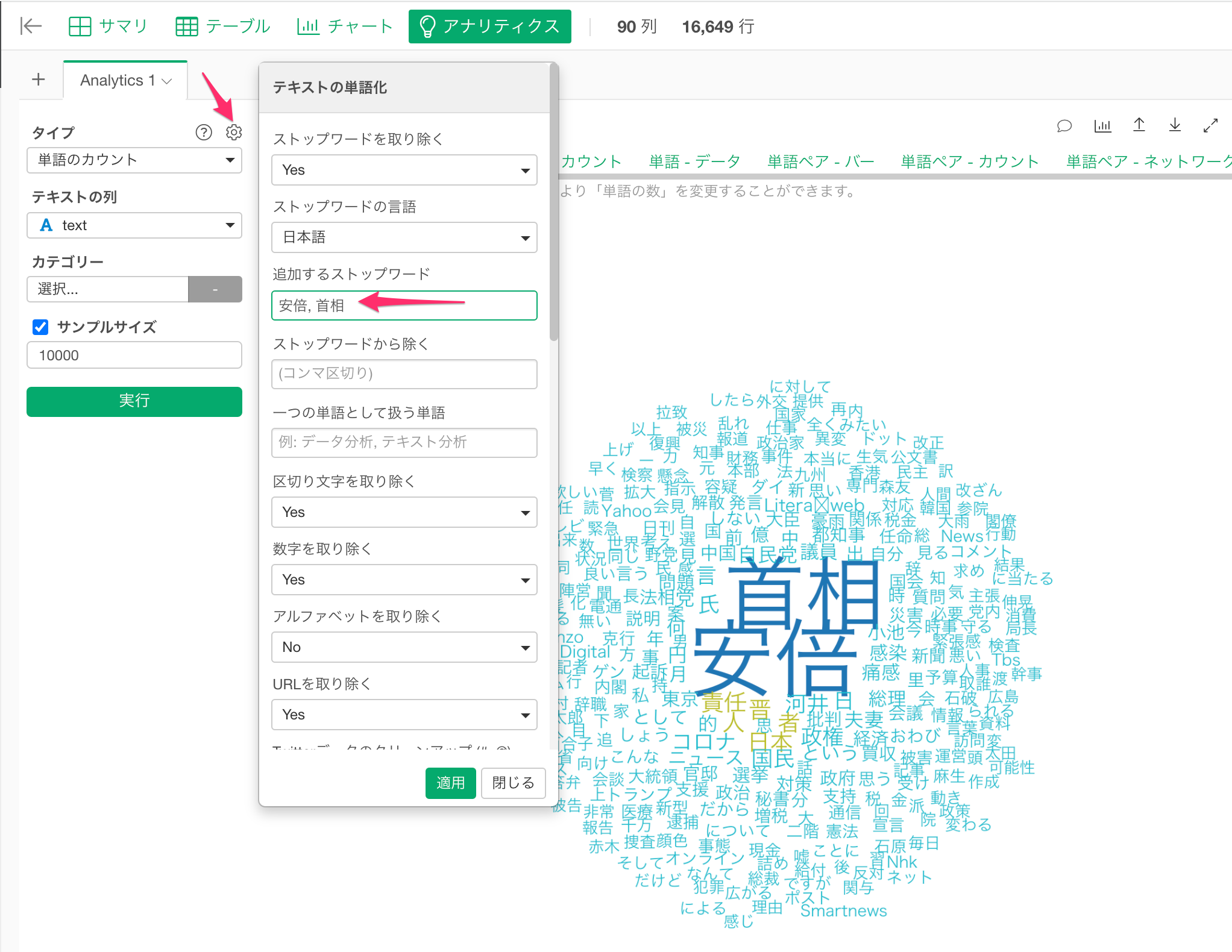
これで不要な単語を取り除くことができました。
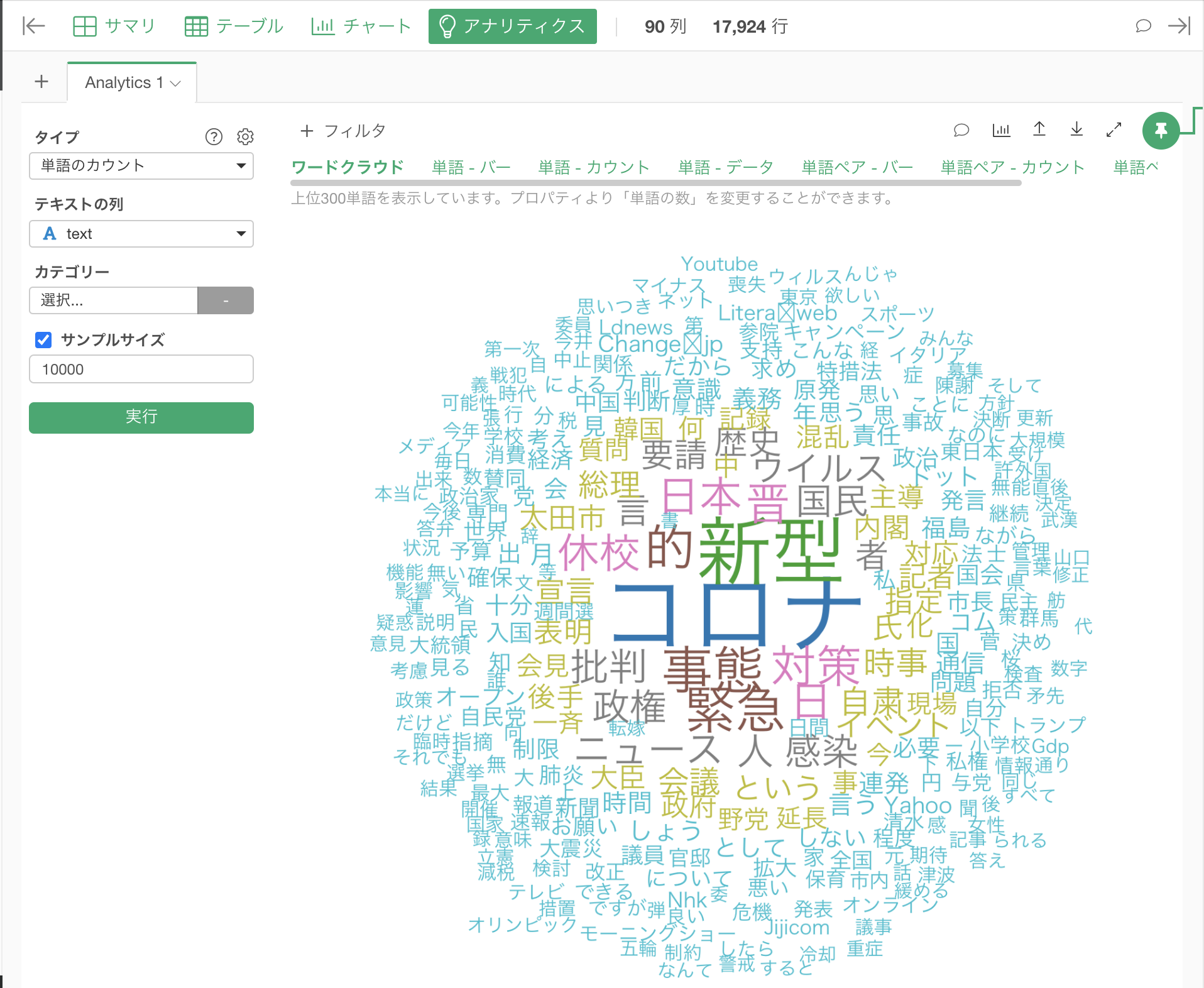
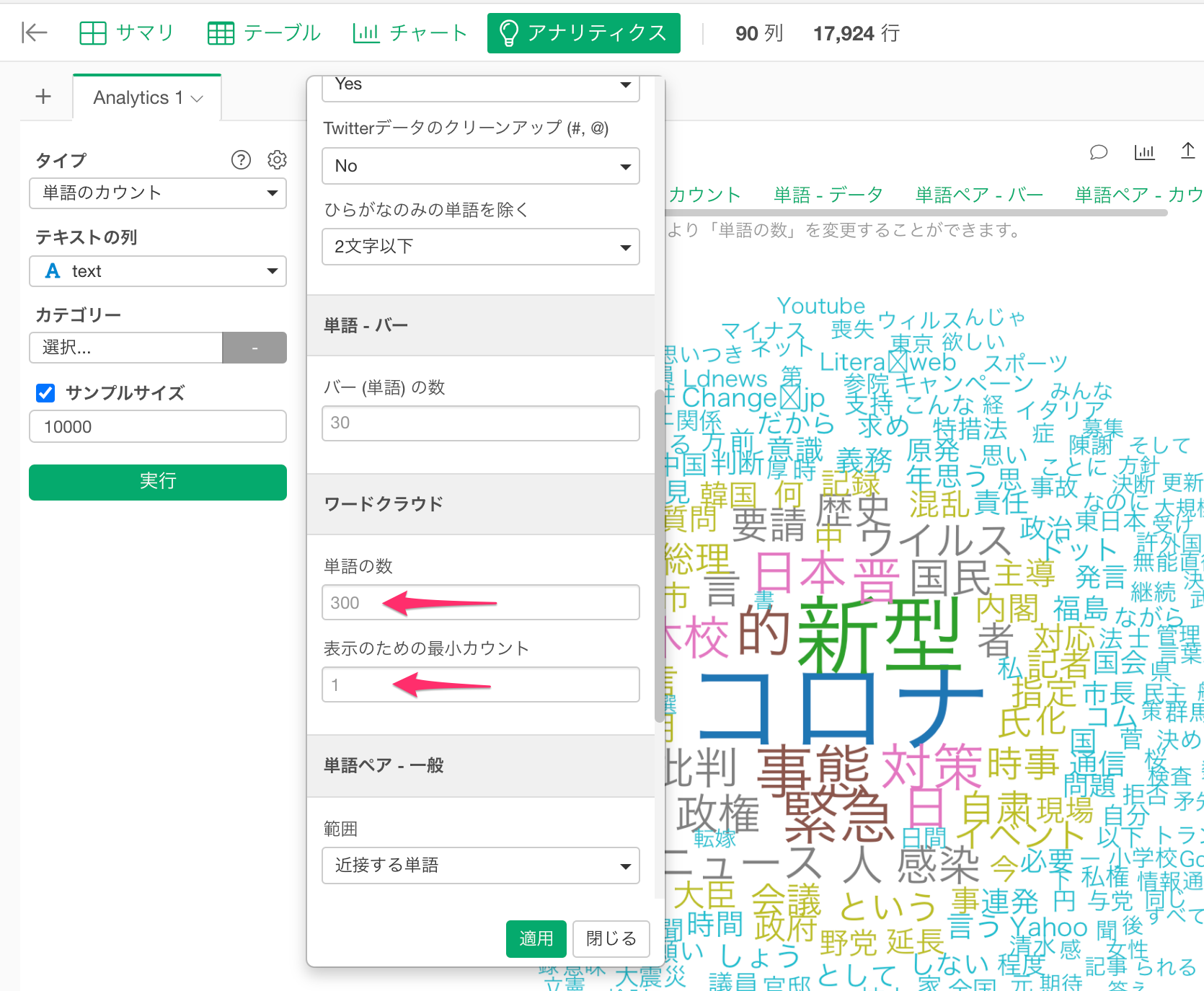
単語数の変更
また、表示させる単語数や、表示のための最小カウントなども同じ設定ダイアログで変更できます。
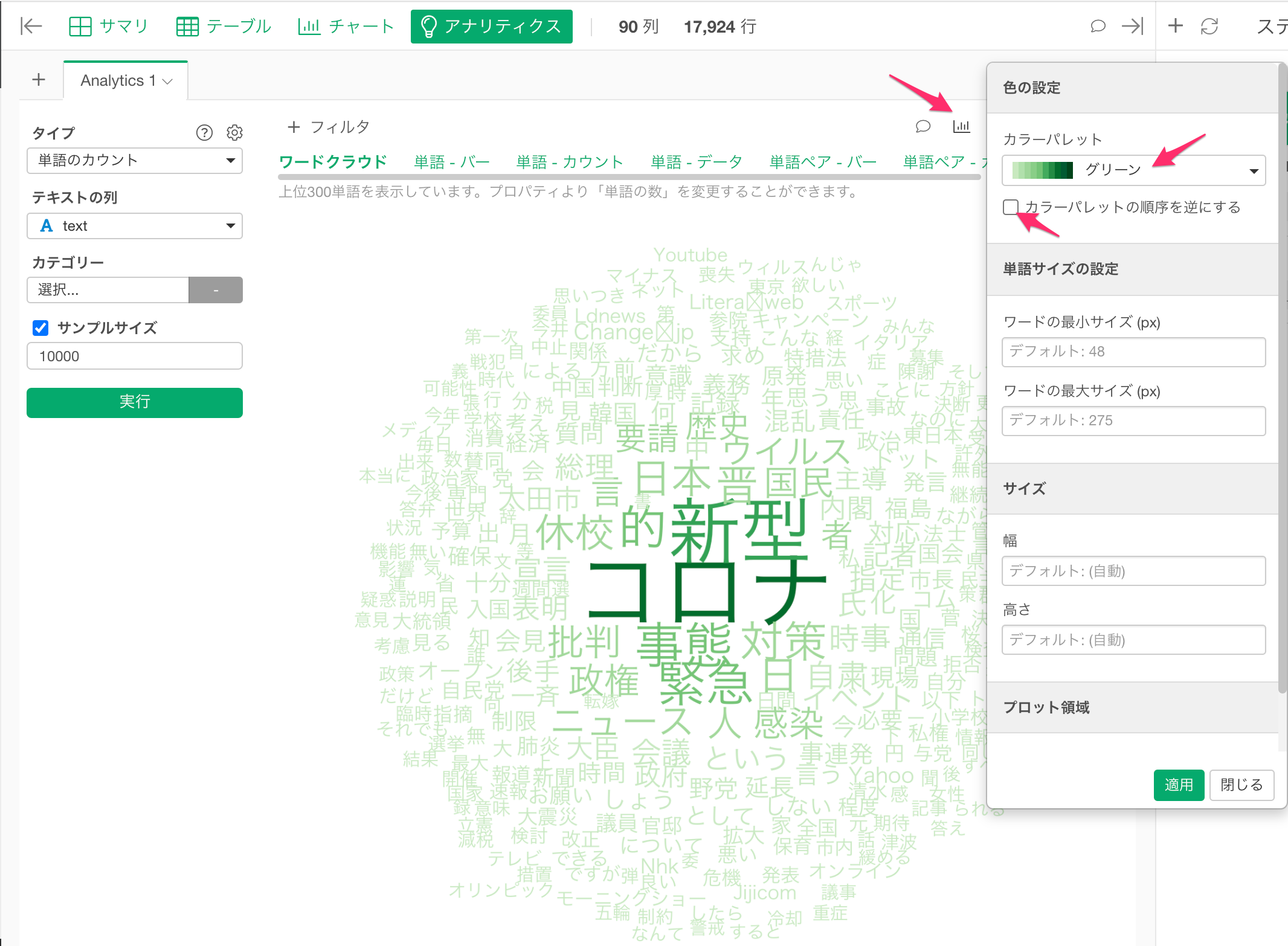
ワードクラウドの色を変更する
色を変えたいときは、アナリティクスのチャートのアイコンをクリックして設定ダイアログからカラーパレットを変えることもできます。
例えば、緑色の濃淡で表現したい場合は、以下のように設定します。濃い色をより頻度の高い単語に割り当てるにはカラーパレットを逆順にするのチェックを外します。
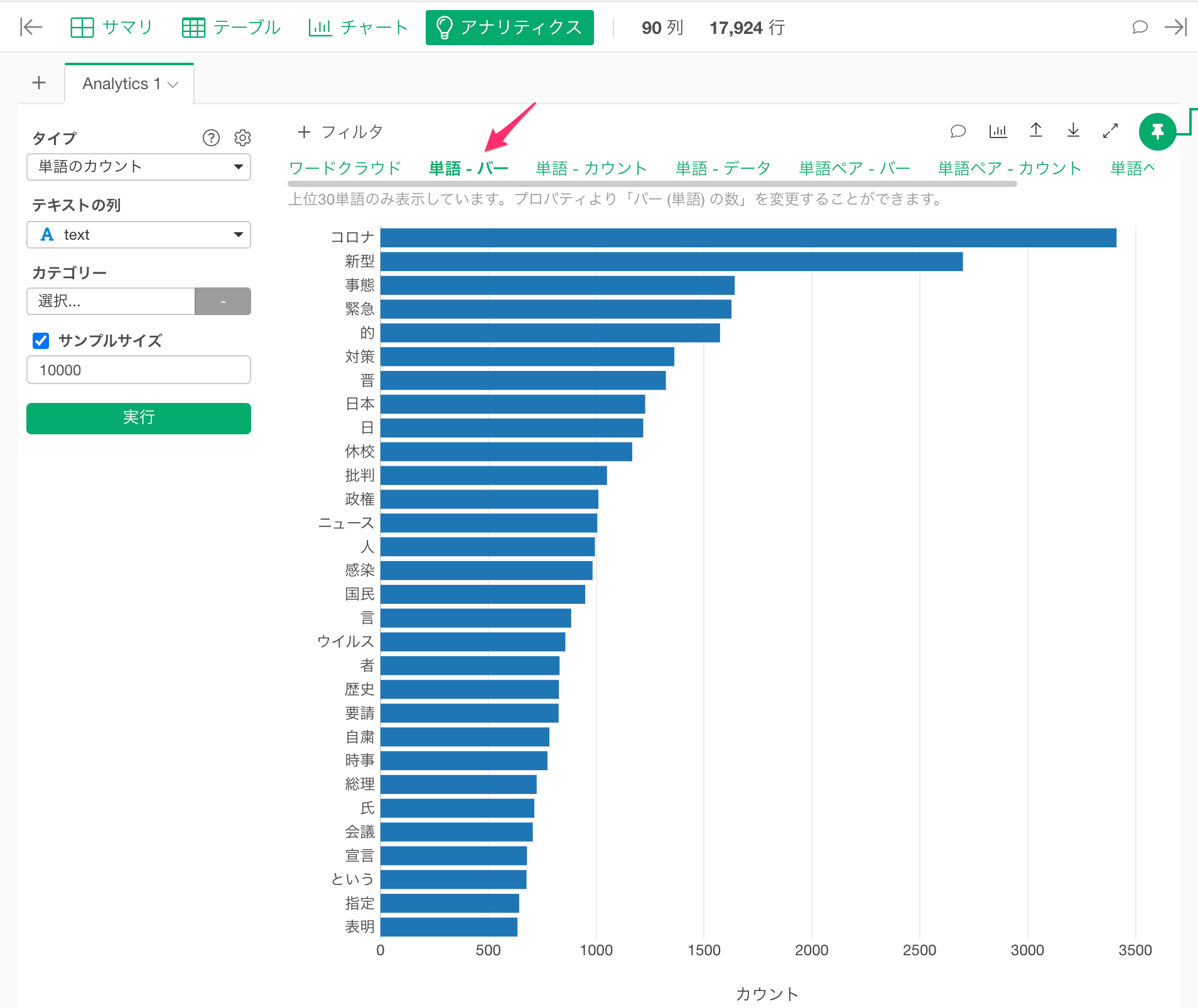
頻出単語を調べる
次に最もよく頻出している単語を見てみましょう。「単語 - バー」のリンクをクリックします。すると、コロナ、新型、事態などの単語が多く使われていることがわかります。(この記事は2020年3月11日時点のデータを使っています。)
長くなってきたのでは、Part 1はここまでにして、Part 2ではトークンからNグラムを作成し、TF-IDF、クラスタリングとさらにテキスト分析をしてみます。
まとめ
今日はTwitterから安倍首相に言及されたTweetをインポートし、RMeCabでトークナイズして、ストップ・ワード等を取り除き、頻出する単語が何かを確認するところまで見てきました。
まだExploratory Desktopをお持ちでない場合は、こちらから30日間無料でお試しいただけます。
データサイエンスを本格的に学んでみたいという方へ
Exploratory社がシリコンバレーで行っているトレーニングプログラムを日本向けにした、データサイエンス・ブートキャンプを定期的に東京で行っております。データサイエンスの手法を基礎から体系的に、プログラミングなしで学んでみたい方、そういった手法を日々のビジネスに活かしてみたい方はぜひこの機会に、参加を検討してみてください。