線形回帰モデルをステップとして作り、新しいデータで予測する方法
Exploratoryでは、線形回帰モデルをアナリティクス・ビューで簡単に作成し、可視化することもできますが、 それ以外にもステップ(右側)としてモデルを作成することができます。新しいデータにモデルを適用し予測したい、テストデータを作ってそれをもとに検証したい、などといったときには、この方法が便利です。
こちらのノートでその方法を簡単に説明します。
線形回帰モデルの作成
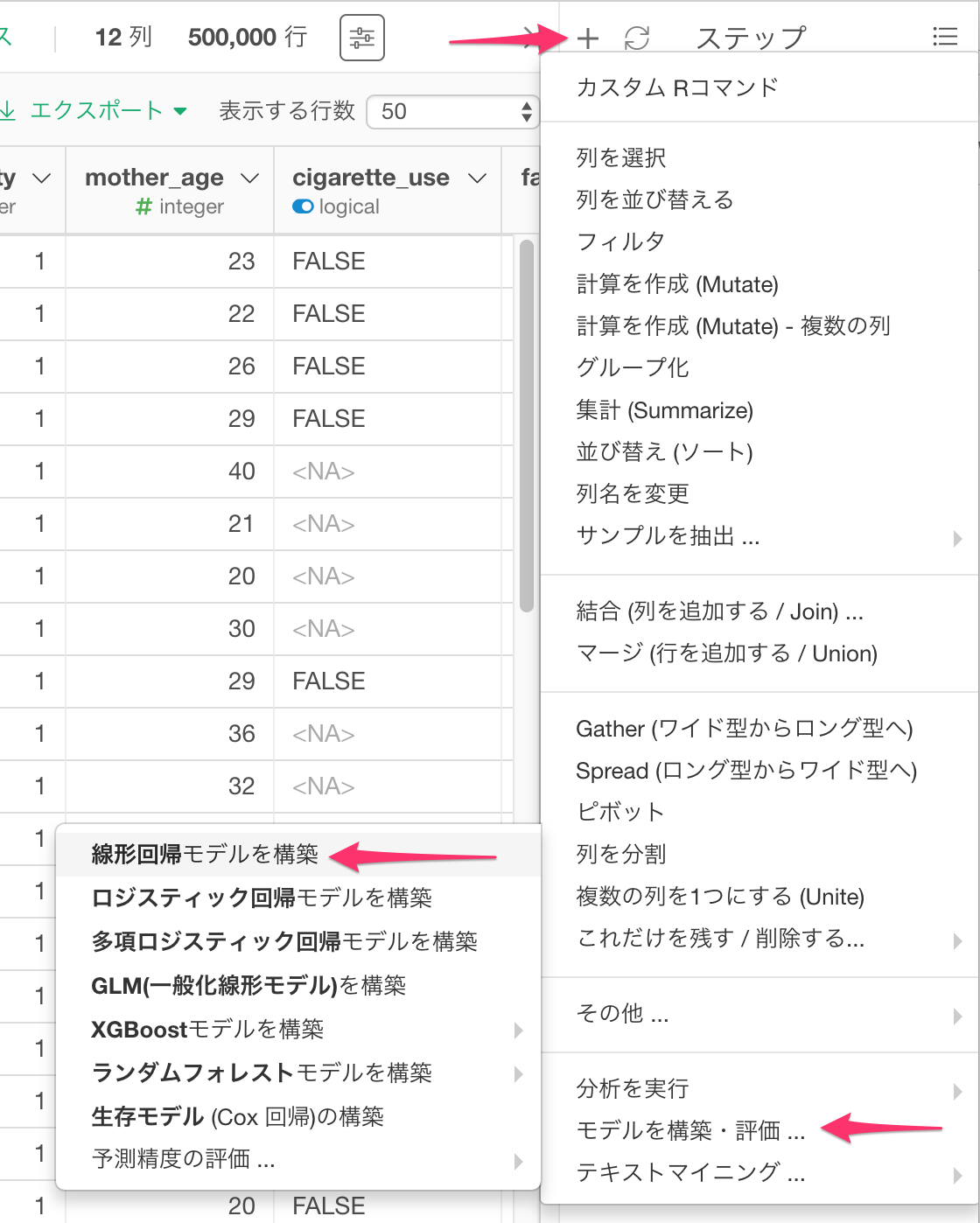
ステップの左にあるプラスボタンをクリックして、メニューからモデルを構築・評価を選択し、線形回帰モデルを構築を選びます。
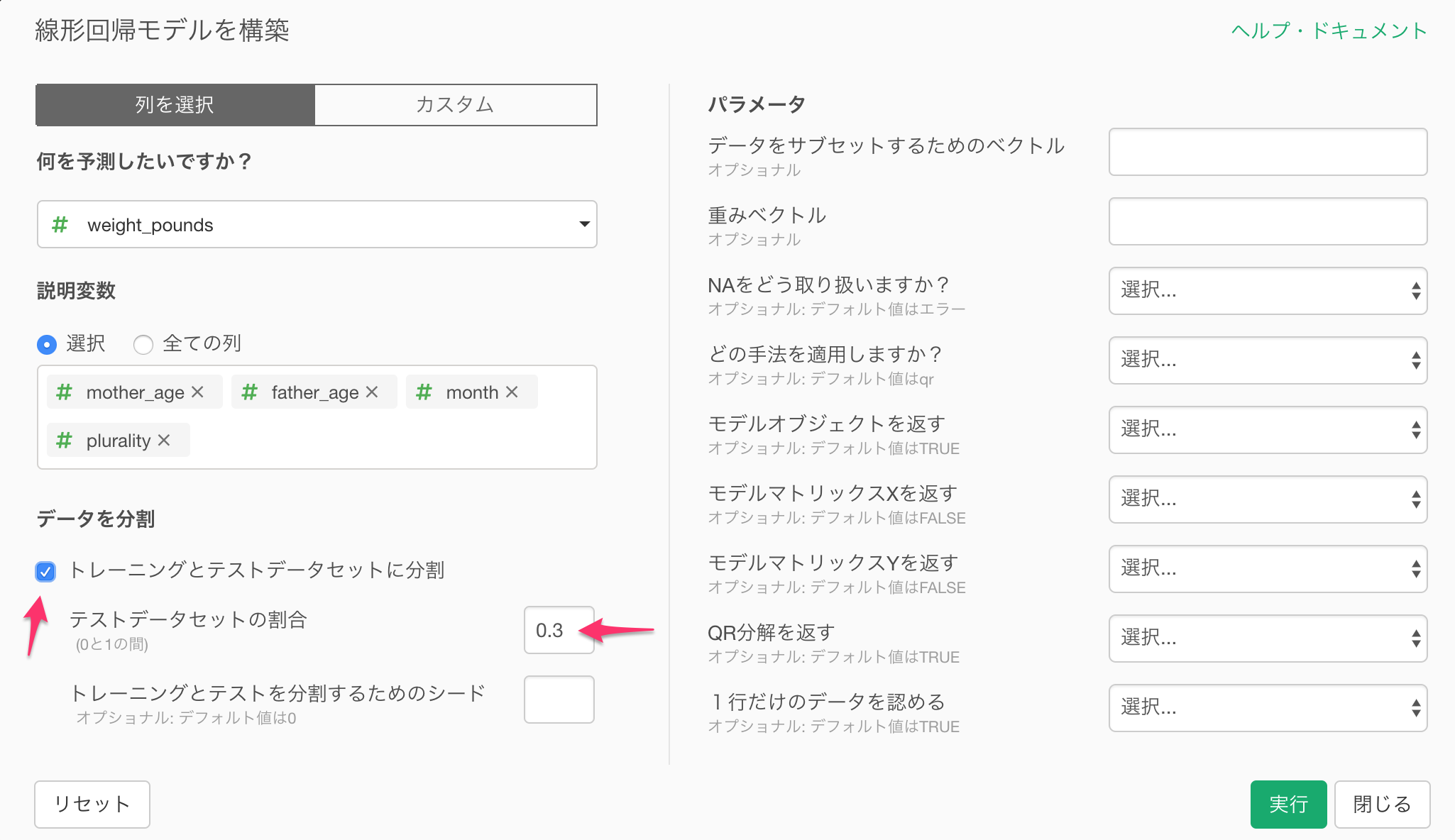
例えば、母親の年齢(monther_age)、父親の年齢(father_age)、胎児数(plurality)、生まれた月(month)を使って新生児の体重(weight_pounds)を予測するモデルを作る場合は、以下のダイアログで予測したい列にweight_pounds列を、説明変数の列に、monther_age, father_age, month, plurarityを割り当てます。
トレーニング用とテスト用のデータセットに分割する際は、テストデータ・セットの割合を指定します。この例では0.3つまり30%のデータをテストデータセットに、70%のデータをモデルをトレーニングするデータセットにしています。準備ができたので実行ボタンをクリックします。
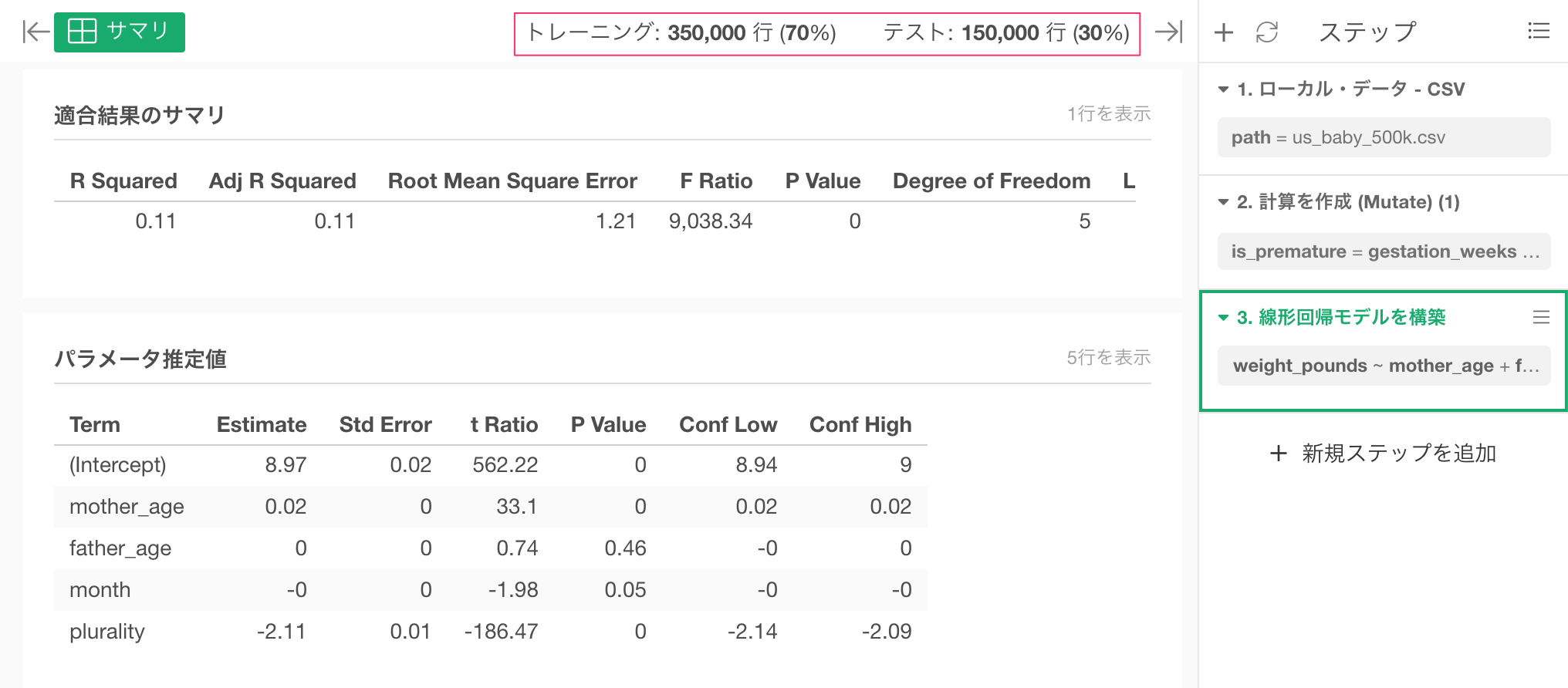
すると、実行結果のサマリやパラメータ推定値を以下のように確認できます。また、データがトレーニング用とテスト用に分割されているのがわかります。
テストデータで予測
作成したモデルを使い、テストデータに適用して予測するには、プラスボタンをクリックし、テストデータで予測を選択します。
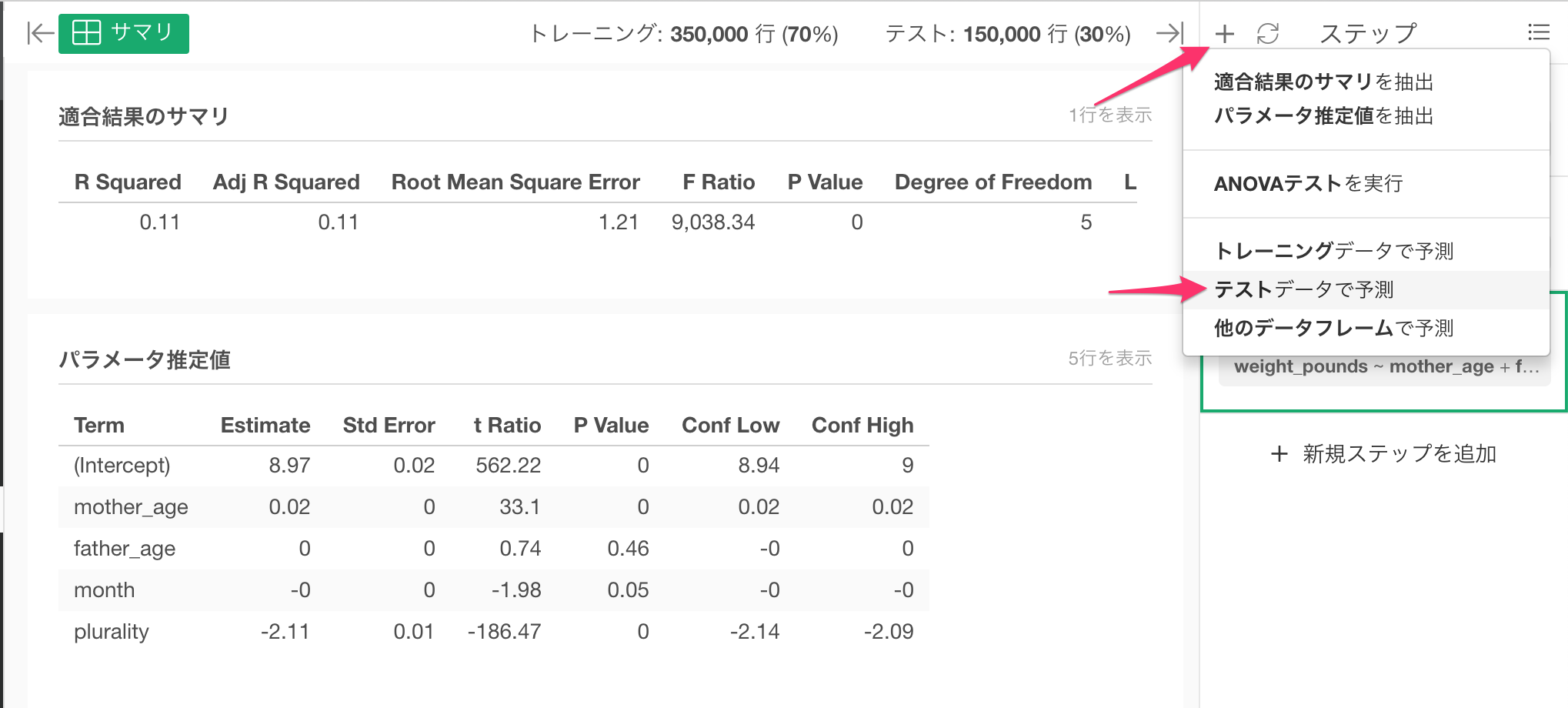
予測ダイアログが開くので、実行をクリックします。
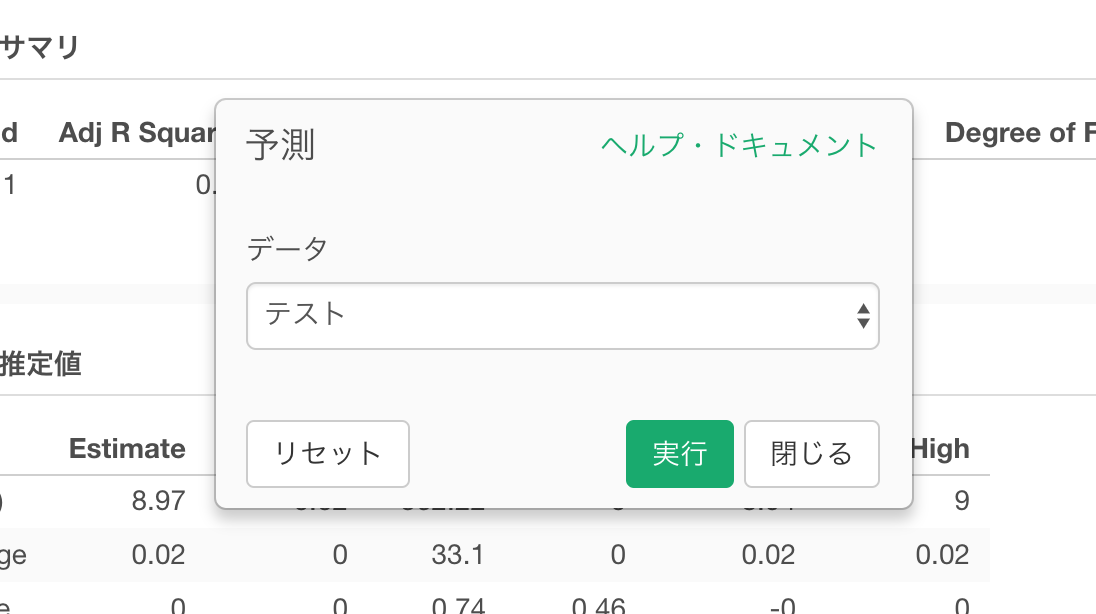
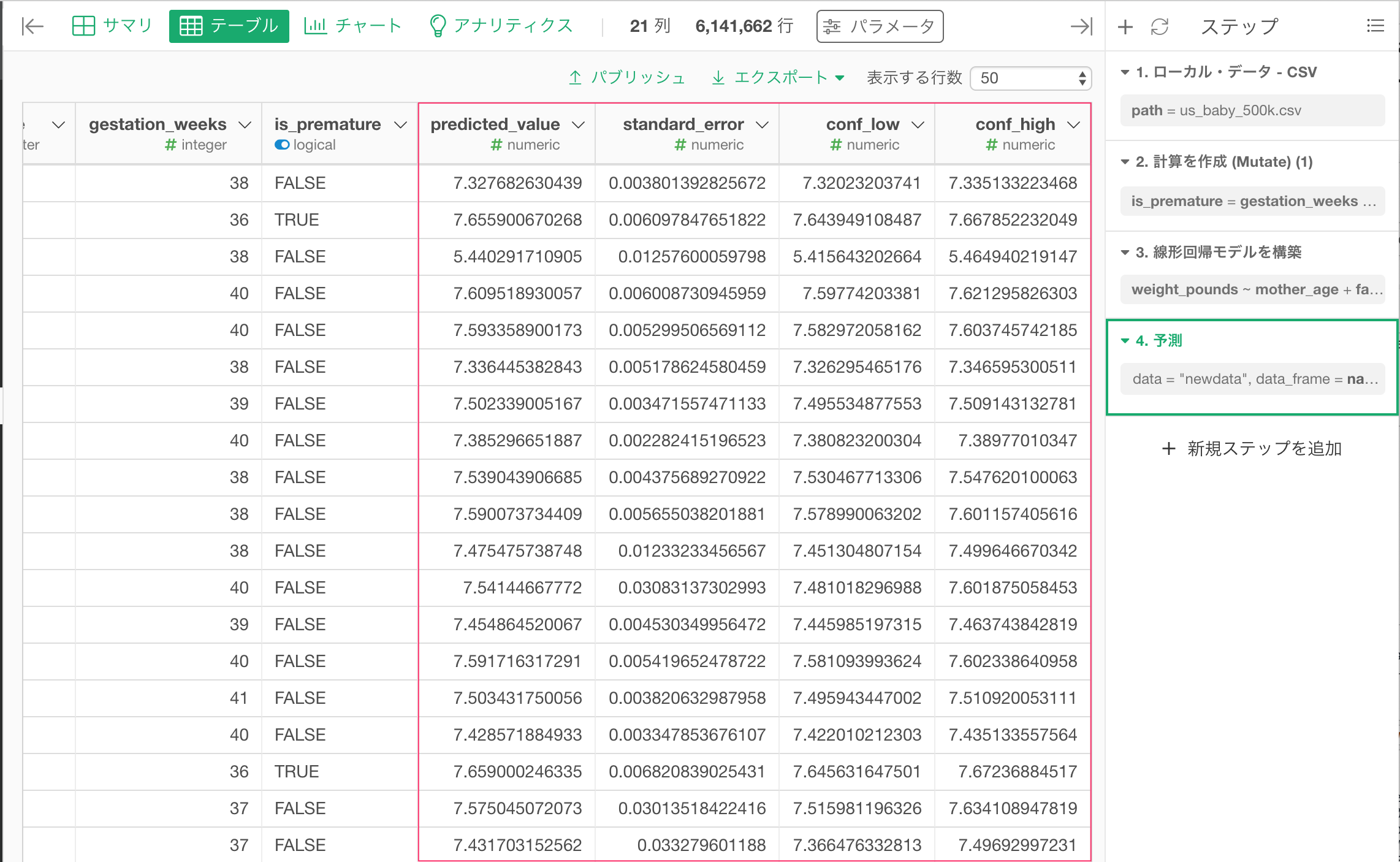
すると、予測された値がpredicted_value という列に計算されます。また標準誤差や信頼区間の情報もstandard_errorやconf_low/conf_highの列で確認できます。
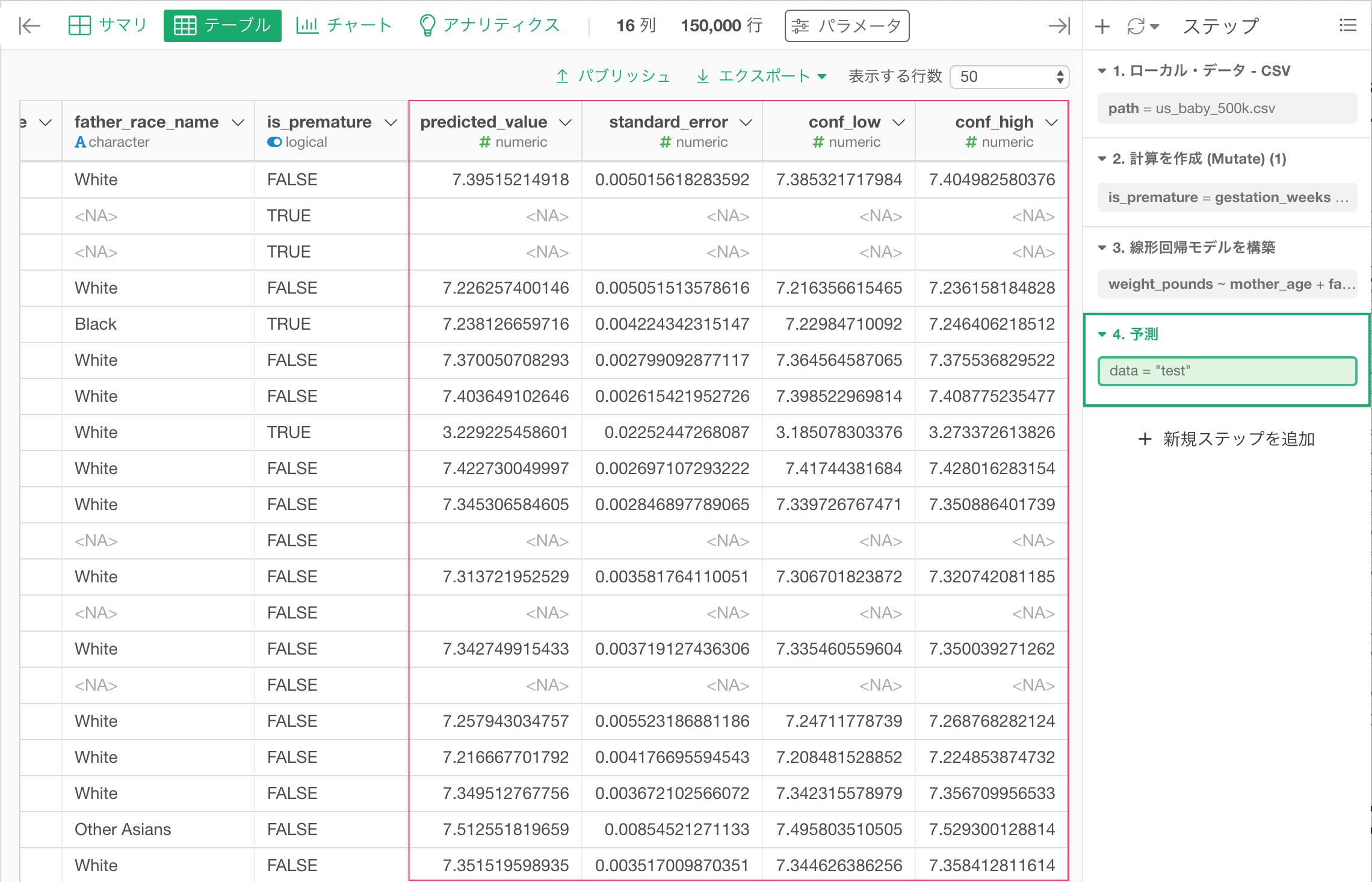
他のデータフレームのデータで予測
テストデータとは別に、予測したいデータフレームがある場合、先程のテストデータでの予測を作成したステップのトークンをクリックし、ダイアログで他のデータフレーム をデータとして選択し、予測対象のデータフレームを選択します。
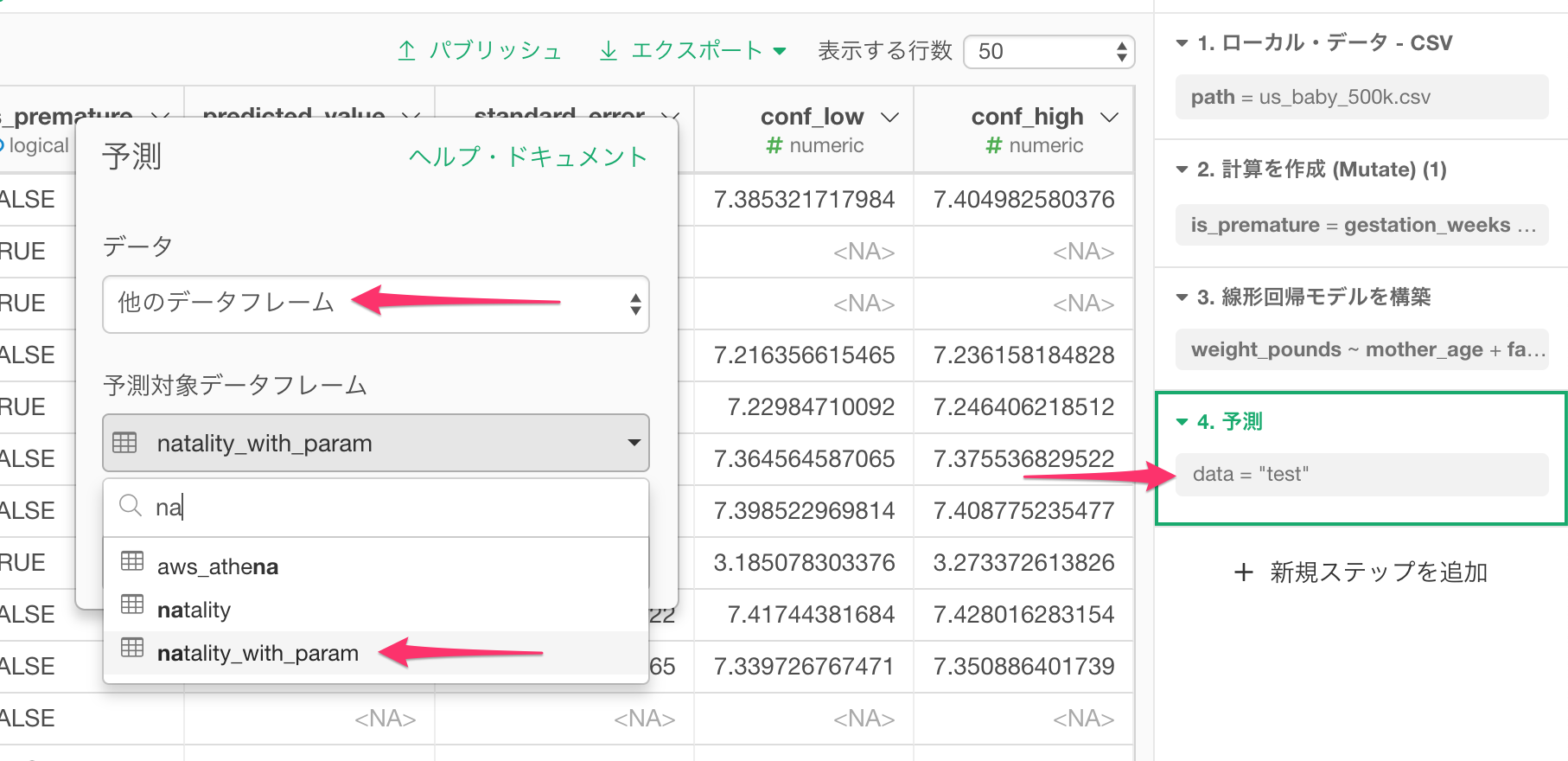
すると先程同様、予測結果がpredicted_valueという列に計算されます。
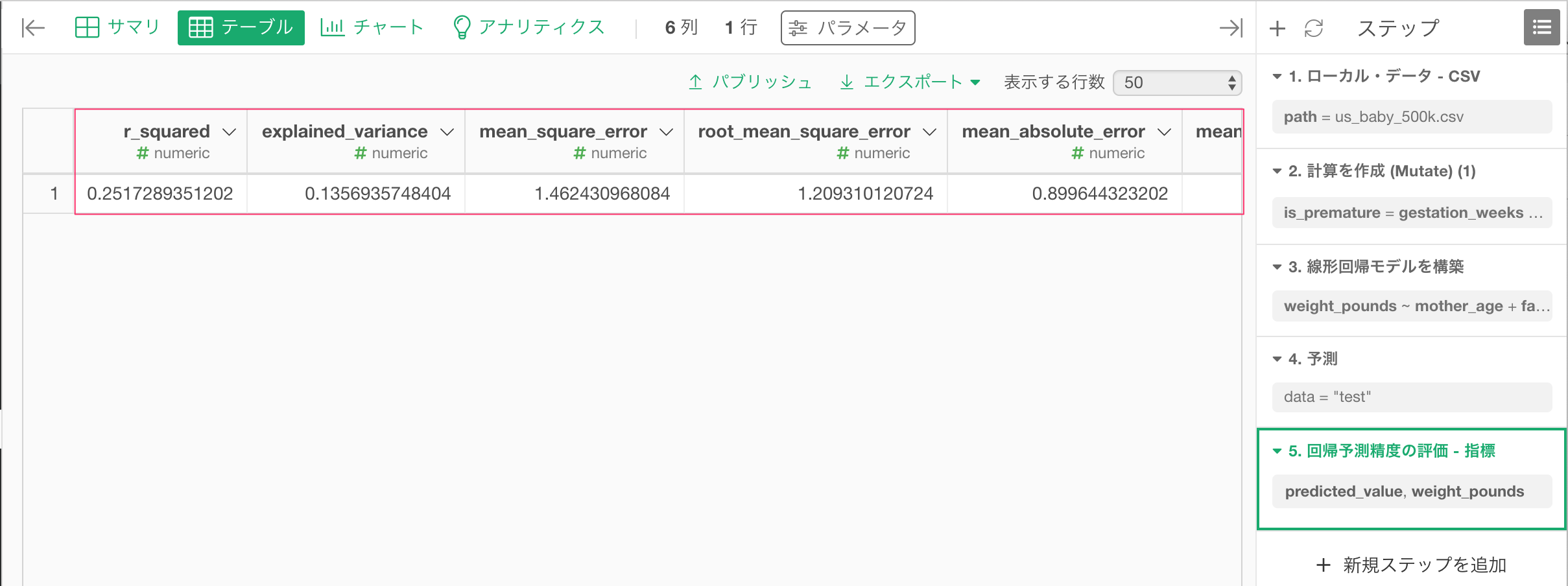
予測精度の評価
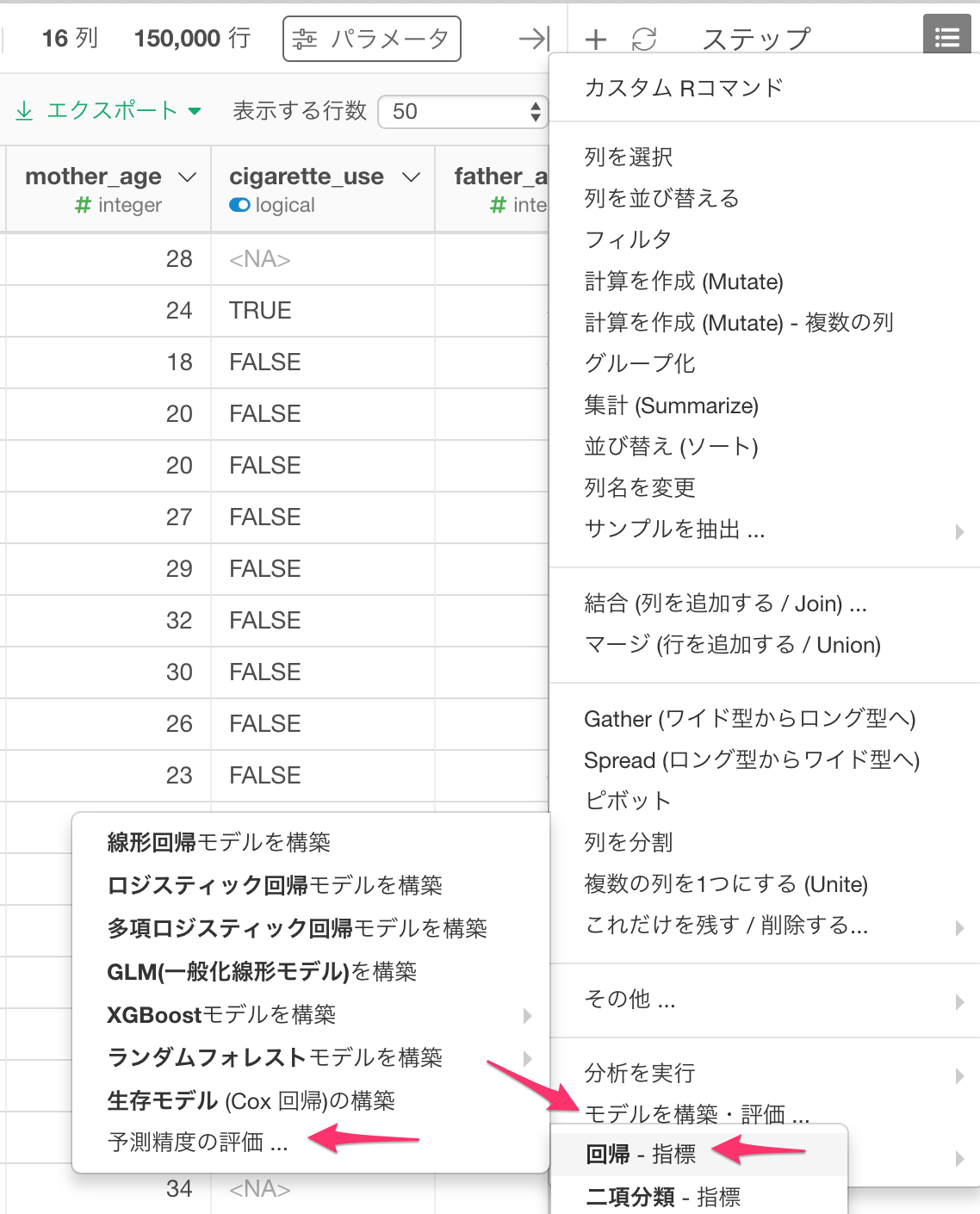
適用した予測の制度を評価するには、プラスボタンからモデルを構築・評価を選択し、予測精度の評価…、回帰 を選びます。
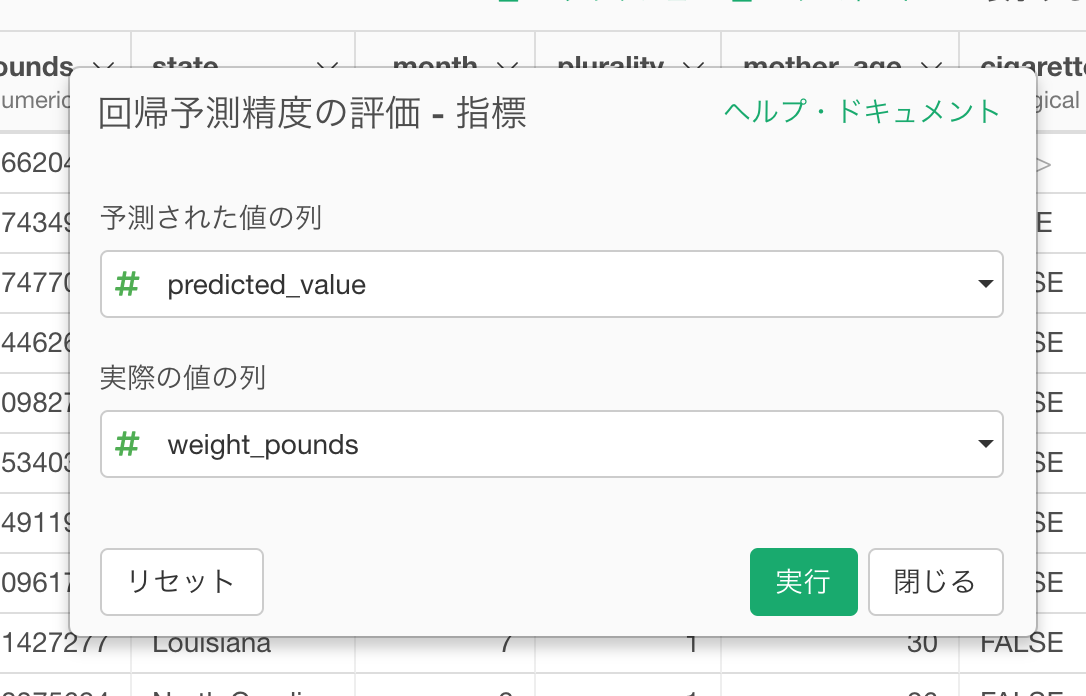
予測された値の列にpredicted_value列が、実際の値の列にweight_pounds列が入っているのを確認して、実行をクリックします。
すると決定係数等のモデルの予測精度の評価のための情報を確認できます。