<style> .column-wrap:after{ content: "."; display: block; height: 0; font-size:0; clear: both; visibility:hidden; } .column1 { float: left; width: 48%; } .column2 { float: right; width: 48%; } .column2 table{ font-size:80%; } </style> # 競馬の予測モデルを自作した話  --- ## プロフィール <div class="column-wrap"> <div class="column1"> <img class="profilePic img" alt="" src="https://scontent-nrt1-1.xx.fbcdn.net/v/t1.0-1/p320x320/10614233_291685427703756_7424349314725922500_n.jpg?oh=47e02ae2c9ed54869f85b1392e63397b&oe=5A63E2C6"> </div> <div class="column2"> <ul> <li style="font-weight:bold">小嶋 景人(@keito0366)</li> <li>株式会社メンバーズ</li> <li>客先常駐ディレクターやってます。</li> <li>データサイエンス・ブートキャンプ 2回目参加者です。</li> </ul> </div> </div> --- ## なぜ競馬? - いろんな人が分析してる🔬 - 練習にはちょうどいい! - 過去に馬術してた🏇 - 感覚的にも理解しやすそう! - **馬が好き😍** - 好きこそ物の上手なれ! --- ## 戦略 前回は連対率を予測し、複勝転がしでやったが惨敗だった。 今回は1位になる確率を予測し、単勝で勝てるかどうかをとことん検証する。 ちなみに最終的に決まった戦略は以下。 - 10,11レースの - 信頼性42%以上で1位になると予想した - 単勝 ※今回は新馬、未勝利は予測の対象外とする。 --- ## どのデータ? データはnetkeiba.comの2006~2017年のデータをお借りした。 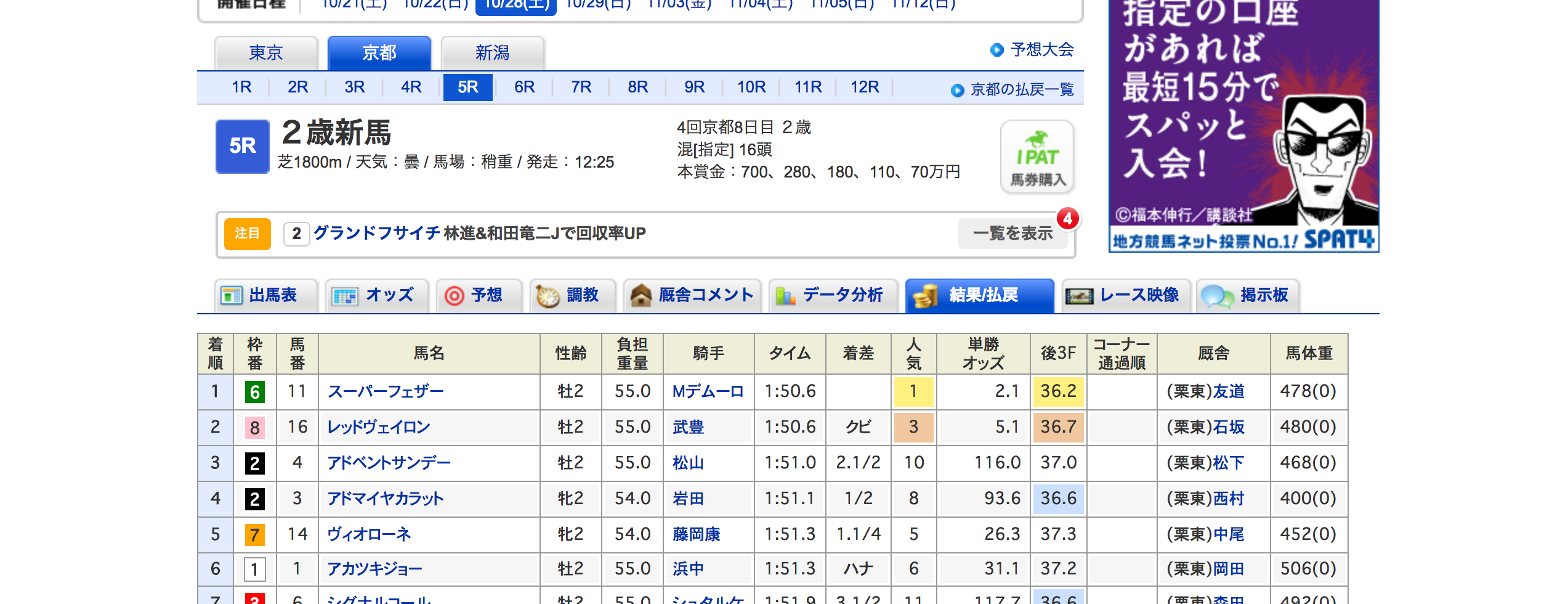 ---  --- ## 準備 pythonはデータをスクレイピングするため、Exploratryは分析・予測モデル構築のために使用。 - python - pandas - numpy - Exploratry - R - random forest - XGboost --- ## STEP1 重要な指標を特定する <div class="column-wrap"> <div class="column1"> <p>最初のステップとしてとりあえずどのデータが1位になるために重要なのかを Analyticsビューの変数重要度でざっくり把握する。 <br> ※一部抜粋 </p> <p>当たり前だけど、オッズと人気度が一番重要らしい。</p> </div> <div class="column2"> <table> <thead> <tr> <th>Variable</th> <th>Importance</th> </tr> </thead> <tbody> <tr> <td>単勝オッズ</td> <td>857.28</td> </tr> <tr> <td>人気</td> <td>585.14</td> </tr> <tr> <td>重量</td> <td>347.90</td> </tr> <tr> <td>複勝率</td> <td>330.62</td> </tr> <tr> <td>連対率</td> <td>270.73</td> </tr> <tr> <td>体重差</td> <td>261.38</td> </tr> <tr> <td>出場回数</td> <td>241.54</td> </tr> <tr> <td>単勝率</td> <td>237.66</td> </tr> <tr> <td>2位入賞率</td> <td>236.11</td> </tr> <tr> <td>馬番</td> <td>226.01</td> </tr> </tbody> </table> </div> </div> --- ## STEP2 ライバルを決める 今回は1番人気のみで予想した場合との比較で効果を測定してみる。 なので、1番人気かつ実際に1位だった場合の混同行列(Confusion Matrix)を出してみる。 <script data-id="viz_2MFsJJqNHusK" data-object-name="viz_race_raw_4" data-viz="race_raw_4" data-height="" data-width="" ></script><div id="loading-viz_2MFsJJqNHusK" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> 1番人気の馬だけに賭け続けたら30%の確率で当たるみたいだということがわかる。 --- ## STEP3 ランダムフォレストで予想する この結果を持って、ランダムフォレストで試しに予想してみる。 <script data-id="viz_5CAU8Y4vH2SW" data-object-name="viz__random_forest_1" data-viz="_random_forest_1" data-height="" data-width="" ></script><div id="loading-viz_5CAU8Y4vH2SW" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> 買った馬券が当たった確率は23.32%だった。☹️ 人気度だけで予想した時よりも低い。 そして無駄に処理が長い。 --- ## STEP4 XGboostで予想する 同じ要領でXGboostの予測精度を確認してみる。 <script data-id="viz_EsVNpmpJ2mcC" data-object-name="viz__xgboost_1" data-viz="_xgboost_1" data-height="" data-width="" ></script><div id="loading-viz_EsVNpmpJ2mcC" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> 22.31%で少しだけ下がった。☹️ 処理は結構早かった。 人気度と比べて7.76%負けてる。 --- ## STEP5 西田式スピード指数で予想する 競馬の有名な指数らしいスピード指数というものを使って予想してみる。 http://www.rightniks.ne.jp/index.php?action=whatspidx_contents&name=sikumi 予想の仕方は、スピード指数が一番高いものを1位であると判断する。 <script data-id="viz_7xQdVfF5CSYt" data-object-name="viz__speed_index_1" data-viz="_speed_index_1" data-height="" data-width="" ></script><div id="loading-viz_7xQdVfF5CSYt" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> 6.92%だけだった。☹️エラーもたくさんある。 まあ前走のスピード指数を予測にしてるから新馬とかのデータがないのは当然っちゃ当然か。 --- ## 中身を確認する 正解率は低かったが、順位が上がるほどスピード指数も上がっていることから、順位を予想するには有益なデータであるということがわかった。 ※19位になっているのは、順位外となった馬を一時的に19位にしている。 <script data-id="viz_Wf2LAWtiHKiD" data-object-name="viz__speed_index_37" data-viz="_speed_index_37" data-height="" data-width="" ></script><div id="loading-viz_Wf2LAWtiHKiD" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- ## STEP6 予測走破タイムで予想する XGboostは回帰もできちゃうのでタイムを予想してみる。 上記で作成したスピード指数も使ってもう一回モデルを構築する。 該当レースの中で一番タイムが短い馬を1位と判断する。 <script data-id="viz_QwF3XCZRmKPT" data-object-name="viz__time_1" data-viz="_time_1" data-height="" data-width="" ></script><div id="loading-viz_QwF3XCZRmKPT" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> 結果は的中率9%だった。 全然参考にならない☹️ --- でも一応中身も確認してみる。 <script data-id="viz_Cr660rhzVjqJ" data-object-name="viz__time_21" data-viz="_time_21" data-height="" data-width="" ></script><div id="loading-viz_Cr660rhzVjqJ" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> 一応それっぽく予測してるっぽいことはわかる。 --- 相関係数は99%を超えた。 <script data-id="analytics_I6jmgi7jUSwT" data-object-name="analytics__time_1" data-viz="table" data-analysis="_time_1" data-height="" data-width="" ></script><div id="loading-analytics_I6jmgi7jUSwT" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> エラーも±3秒くらい。 <script data-id="viz_9RWZkpPcleh8" data-object-name="viz__time_22" data-viz="_time_22" data-height="" data-width="" ></script><div id="loading-viz_9RWZkpPcleh8" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- 予測タイムの信頼区間が実際のタイムの中に入っているか確認してみる。 <script data-id="viz_CHYdOggM8MSO" data-object-name="viz__time_38" data-viz="_time_38" data-height="" data-width="" ></script><div id="loading-viz_CHYdOggM8MSO" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> 約50%が該当していることがわかった。 このデータだけではレースには勝てないけど、有益な情報であることがわかった。 --- ## STEP7 順位をそれぞれ予想する XGboostには他クラス分類もできる機能があるので使ってみる。 上記の指標といろいろ追加したものを使って1−18くらいの順位をそれぞれ予想してみる。 <script data-id="viz_W1coZl8mAbHF" data-object-name="viz__category_23" data-viz="_category_23" data-height="" data-width="" ></script><div id="loading-viz_W1coZl8mAbHF" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> 21.44%でパッとしない☹️ --- <script data-id="viz_6OyQWmL3QxLV" data-object-name="viz__category_1" data-viz="_category_1" data-height="" data-width="" ></script><div id="loading-viz_6OyQWmL3QxLV" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> ヒートマップを見ると、実際に1位であったパターンが最も多いが、はずしたパターンもたくさんあるという事実は無視できない。 --- <script data-id="viz_SdQRG1MQExCw" data-object-name="viz__category_24" data-viz="_category_24" data-height="" data-width="" ></script><div id="loading-viz_SdQRG1MQExCw" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> 精度もよくない。 複勝率を見てみると約40%の確率で当たっていることから、先ほどのデータ同様に**レースには勝てないけど有益な情報**っぽいことがわかった。 <script data-id="viz_iuIvvSYcoIJb" data-object-name="viz__category_39" data-viz="_category_39" data-height="" data-width="" ></script><div id="loading-viz_iuIvvSYcoIJb" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- ## STEP8 アンサンブルする 上記で予測した結果と確率などのデータを元にXGboostの二項分類で1位になるかを予想してみる。 <script data-id="viz_0qVssOT4Kpbt" data-object-name="viz__prediction_test_old_1" data-viz="_prediction_test_old_1" data-height="" data-width="" ></script><div id="loading-viz_0qVssOT4Kpbt" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> だいぶ改善された。 --- # なぜ改善されたのか? 先ほど説明した変数をたくさん使いました。 --- <div class="column-wrap"> <div class="column1"> <ul> <li>horse_number</li> <li>frame_nunber</li> <li>age</li> <li>basis_weight</li> <li>weight_pm</li> <li>round_name</li> <li>cnt_cumsum</li> <li>x1st_and_2nd_ratio</li> <li>nyusho_ratio</li> <li>x1st_ratio_lag</li> <li>weight</li> <li>race_condition</li> <li>basis_weight_index</li> <li>x2nd_ratio_lag</li> <li>x3rd_ratio_lag</li> <li>speed_index_horse</li> <li>speed_index_jockey</li> <li>speed_index_breeder</li> <li>last_date_diff</li> </ul> </div> <div class="column2"> <ul> <li>shiba</li> <li>predicted_probability_1</li> <li>predicted_label_rank</li> <li>predited_probability_rank</li> <li>popularity</li> <li>win</li> <li>is_jockey_some</li> <li>predicted_value</li> <li>predicted_probability_19</li> <li>predicted_probability_18</li> <li>predicted_probability_17</li> <li>predicted_probability_16</li> <li>predicted_probability_15</li> <li>predicted_probability_14</li> <li>predicted_probability_13</li> <li>predicted_probability_12</li> <li>predicted_probability_11</li> <li>predicted_probability_10</li> <li>predicted_probability_9</li> <li>predicted_probability_8</li> <li>predicted_probability_7</li> <li>predicted_probability_6</li> <li>predicted_probability_5</li> <li>predicted_probability_4</li> <li>predicted_probability_3</li> <li>predicted_probability_2</li> </ul> </div> </div> --- 意外に調教師のスピード指数(speed_index_breeder)も重要らしいことがわかった。 <script data-id="viz_VzACwWPr3N5x" data-object-name="viz_xgboost_1" data-viz="xgboost_1" data-height="" data-width="" ></script><div id="loading-viz_VzACwWPr3N5x" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- AUCも9越え <script data-id="viz_h3uDrVUXpqmf" data-object-name="viz_xgboost_copy_1_1" data-viz="xgboost_copy_1_1" data-height="" data-width="" ></script><div id="loading-viz_h3uDrVUXpqmf" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- ## STEP9 データを調整する 上記で作ったモデルのパラメータをいろいろいじってみた。 また論文やテレビや記事でみた良さそうな指標もいろいろ試してみた。 - 経験は成績に影響するのか? - 乗換えの発生は成績に影響するのか? - 天気は影響するのか? などなど --- ## 検証 これまでは正答率を上げるために努力してきたが、次からは上記のSTEPで作ったモデルの特徴を把握し、馬券を買ったら儲けが出るのかをシミュレーションする。 それを持って利益が出るように改善していく。 --- # まずはモデルの中身を把握する --- ### ラウンド別正答率 8,9,10,11レース目が精度が高い。 <script data-id="viz_XrVEw103ZJL0" data-object-name="viz__prediction_test_old_26" data-viz="_prediction_test_old_26" data-height="" data-width="" ></script><div id="loading-viz_XrVEw103ZJL0" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- ### 人気別正答率 1番人気の正答率と回数が多い。 かなり人気に依存していることがわかる。 <script data-id="viz_27FjRvKdpwkX" data-object-name="viz__prediction_test_old_27" data-viz="_prediction_test_old_27" data-height="" data-width="" ></script><div id="loading-viz_27FjRvKdpwkX" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- ### 信頼度別正答率 0.55を超えると正解している割合が増えていることがわかる。 8,9,10,11レース目でpredicted probabilityが0.55以上のものが買いなのかな。 0.4くらいだと外れる割合の方が多いみたい。 <script data-id="viz_8lhimn7NOnwq" data-object-name="viz__prediction_test_old_28" data-viz="_prediction_test_old_28" data-height="" data-width="" ></script><div id="loading-viz_8lhimn7NOnwq" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- ## 結局いくら儲かったのか? 実際に馬券を買って、どのくらいの利益ができるのかを検証してみた。 30%のテスト用データで回収率600%で50万円くらい儲かるかもしれないことがわかった。 100円づつ賭けただけで結構いいスコアになった。 <script data-id="viz_gcoExHYMbDrR" data-object-name="viz__prediction_test_old_31" data-viz="_prediction_test_old_31" data-height="" data-width="" ></script><div id="loading-viz_gcoExHYMbDrR" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- 予想した推移を見てみると、万馬券もいくつか出ている。 (万馬券に依存しすぎじゃね。。。?) <script data-id="viz_Vxe1I5CjT6HF" data-object-name="viz__prediction_test_old_31" data-viz="_prediction_test_old_31" data-height="" data-width="" ></script><div id="loading-viz_Vxe1I5CjT6HF" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> <script data-id="viz_mcGoDoBQrGLQ" data-object-name="viz__prediction_test_old_25" data-viz="_prediction_test_old_25" data-height="" data-width="" ></script><div id="loading-viz_mcGoDoBQrGLQ" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- ## 8,9,10,11レースだけを対象に予測した馬券を買った場合 データを8,9,10,11レースだけに絞って再度モデルを構築してみた。 正答率は改善された。 <script data-id="viz_HBRbJRxZkeEK" data-object-name="viz__prediction_test_old_copy_1_1" data-viz="_prediction_test_old_copy_1_1" data-height="" data-width="" ></script><div id="loading-viz_HBRbJRxZkeEK" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- でも利益はかなり減っている。 買う件数が減ったからっぽい。 回収率も減ってる。。😱 <script data-id="viz_c7bXrkNnnrsi" data-object-name="viz__prediction_test_old_copy_1_31" data-viz="_prediction_test_old_copy_1_31" data-height="" data-width="" ></script><div id="loading-viz_c7bXrkNnnrsi" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- ## 最終的に完成したモデルは? 最終的に出来上がったモデルの精度と、実際に馬券を買ってどのくらい儲けが出るのかを今一度シミュレーションしてみる。 馬券の買い方は、信頼性(小数点切り捨て)*100 ただし、信頼性が低かったら100円だけ賭けるという戦略(?)にする。 --- 馬場の状況別に見てみると、回収率1000%超えがいくつかある。 <script data-id="viz_yVUYWSt9b4aZ" data-object-name="viz_prediction_test_32" data-viz="prediction_test_32" data-height="" data-width="" ></script><div id="loading-viz_yVUYWSt9b4aZ" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- 推移を見てみると大勝ちしなくてもそこそこの勝ちが続いていることがわかる。 <script data-id="viz_u9ofVj3zSkrY" data-object-name="viz_prediction_test_16" data-viz="prediction_test_16" data-height="" data-width="" ></script><div id="loading-viz_u9ofVj3zSkrY" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- ROCも0.9017になった。 <script data-id="viz_IR0DbUGSSNSR" data-object-name="viz_roc_1" data-viz="roc_1" data-height="" data-width="" ></script><div id="loading-viz_IR0DbUGSSNSR" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> <script data-id="viz_7gQcIeP5HfKK" data-object-name="viz__prediction_test_copy_2_1" data-viz="_prediction_test_copy_2_1" data-height="" data-width="" ></script><div id="loading-viz_7gQcIeP5HfKK" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- 1位だと予想した馬の実際の順位。 正答率も70%になった。結果的に人気度だけで当てる確率の倍以上になった。 <script data-id="viz_HHxIincJxEBN" data-object-name="viz_prediction_test_20" data-viz="prediction_test_20" data-height="" data-width="" ></script><div id="loading-viz_HHxIincJxEBN" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> <script data-id="viz_iw9XJphdHPJk" data-object-name="viz_prediction_test_12" data-viz="prediction_test_12" data-height="" data-width="" ></script><div id="loading-viz_iw9XJphdHPJk" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- 信頼性が高いほど正解する割合も増えている。 信頼性が50%前後だと外れる可能性も高いことがわかる。 <script data-id="viz_vqwuEeUVqQ1a" data-object-name="viz_prediction_test_9" data-viz="prediction_test_9" data-height="" data-width="" ></script><div id="loading-viz_vqwuEeUVqQ1a" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div> --- ## まとめ <div class="column-wrap"> <div class="column1"> <p>この2週間くらいで記事では書ききれないほどいろんなパラメーターや指標やモデルを触ってみて、ROCカーブやP-valueなどを確認しながら改善しまくった結果、当初の<strong>2倍以上</strong>の精度に昇華させることができた。 </p> </div> <div class="column2"> <table> <thead> <tr> <th style="text-align:left">施行</th> <th style="text-align:left">正答率</th> </tr> </thead> <tbody> <tr> <td style="text-align:left">1番人気</td> <td style="text-align:left">30.07%</td> </tr> <tr> <td style="text-align:left">ランダムフォレスト</td> <td style="text-align:left">23.32%</td> </tr> <tr> <td style="text-align:left">XGboost_二項分類</td> <td style="text-align:left">22.31%</td> </tr> <tr> <td style="text-align:left">スピード指数</td> <td style="text-align:left">6.92%</td> </tr> <tr> <td style="text-align:left">XGboost_回帰</td> <td style="text-align:left">9.25%</td> </tr> <tr> <td style="text-align:left">XGboost_カテゴリ</td> <td style="text-align:left">21.44%</td> </tr> <tr> <td style="text-align:left">アンサンブル</td> <td style="text-align:left">46.37%</td> </tr> <tr> <td style="text-align:left">調整後</td> <td style="text-align:left">51.49%</td> </tr> <tr> <td style="text-align:left">最終</td> <td style="text-align:left"><strong>🎉69.20%🎉</strong></td> </tr> </tbody> </table> </div> </div> --- ### 実際に予想してみた 先日の天皇賞で予測した結果、 **🎉見事的中🎉** 実際に買っていたら1,000円くらい儲けがでてた。 <script data-id="viz_KgpueqNT9Tnk" data-object-name="viz_prediction_rank_8" data-viz="prediction_rank_8" data-height="" data-width="" ></script><div id="loading-viz_KgpueqNT9Tnk" style="width:100%; height:400px; display:table;margin-bottom:38px" class="viz-rendering-error"><div style="width:100%; height:100%; display:table-cell; vertical-align:middle; text-align:center; font-size:14px; color:#999; background-color:white;font-family:sans-serif "><div>Loading... </div></div></div>