Exploratory v6.1をリリースしました!
Exploratory v6.1のリリースをアナウンスできることに興奮しています! 🎉🎉🎉
今回のリリースでは、主に3つの領域にフォーカスしました。
まず1つ目が、UIです。ExploratoryのコアとなるUIのフレームワークをアップグレードしました。これにより将来のリリースでUIとUXを改善することが可能になります。
2つ目は、パフォーマンスです。今回、データ保存ファイルをRDS(Rのバイナリデータ形式)からParquetに変更しました。これによりExploratoryの全体的なパフォーマンスを向上しました。
3つ目は、既存機能の改善となります。サマリービュー、チャート、アナリティクス、パラメータの各機能を改善しました。
そこで、これらの概要について、紹介させていただきます。
パフォーマンスの改善
今回のパフォーマンス改善は、Exploratoryの裏側で行われているのですが、これは既存のデータフレームを開くときに感じていただけます。
Exploratoryにデータをインポートするとき、これまではローカルのハードディスクにRDSというバイナリ形式で保存していました。このデータはデータラングリングを始める前のソースステップ(右側の最初のステップ)のデータです。
Exploratoryではプロジェクトを再度開く、またはExploratoryを再起動して改めてデータフレームを開くときに、CSVやExcel、データベースなどの元のデータソースからデータを再読み込みするのではなく、RDSファイルからメモリにデータをロードしていました。
これはデータの読み込み時のパフォーマンスを向上させるためです。RDS形式からのデータを利用することで元のデータソースからデータを読み込むよりもはるかに高速に、データを読み込みむことができます。
そして、v6.1のリリース(正確にはv6.1.2です)では、データの保存形式をRDSから、ビッグデータの世界でデータの転送によく使われるParquetという新しい形式に切り替えました。
この切り替えには大きなメリットが4つあります。
データファイル容量の縮小
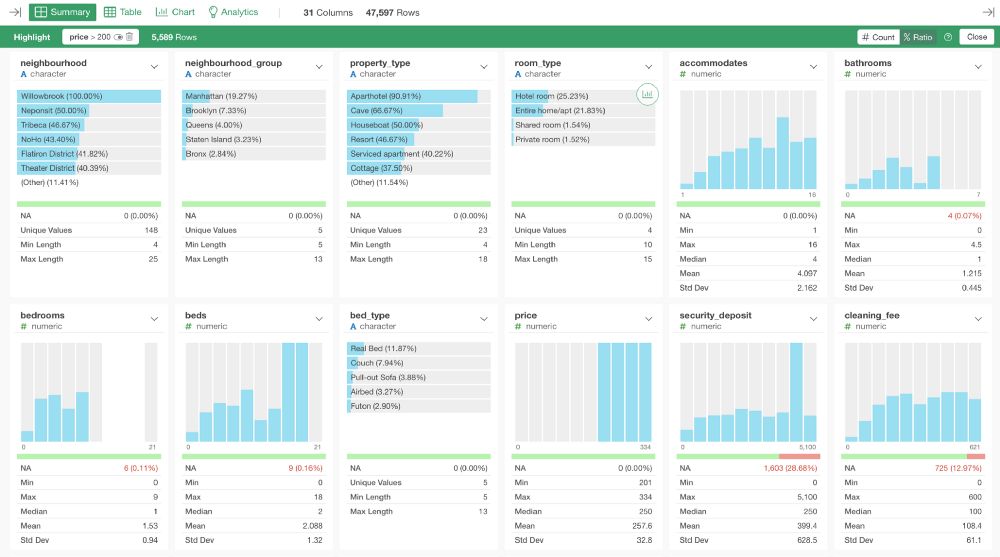
まず、Parquetを使用した場合のファイルサイズは、RDSを使用した場合よりもはるかに小さくなります。例えば、30列200万行のサンプルデータでテストしてみました。
するとRDS形式で保存した場合、データファイルの容量は約480MB(メガバイト)でした。それに対してParquet形式では27MBしかありませんでした! 🔥
データ容量は以前の5%程度です。
読み取り/書き込み時間の大幅な高速化
Parquet形式のデータを使う2つ目のメリットはファイルの読み書きの速さです。 200万行のRDSファイルの読み込みには約6秒かかりますが、Parquetでは約4.8秒です。 また同じRDSファイルの書き込み(作成)には約5.6秒かかりますが、Parquetでは約1.8秒です。

これは2つのことを意味しています。
Exploratoryを起動してデータフレームを開くときや、プロジェクトを開き直すとき、データは高速で読み込まれます。データサイズにもよりますが、一瞬のように感じることもあるはずです。💥💥💥
また、キャッシュされたステップでもParquet形式のデータを使用するように切り替えています。
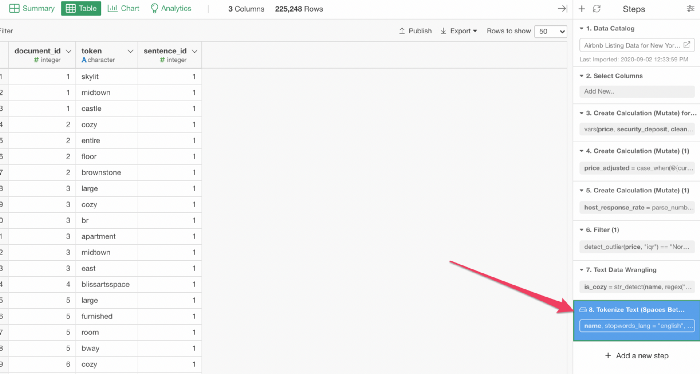
キャッシュされたステップはParquetファイルからデータを読み込み、ステップ自体は実行されません。Parquetファイルを利用することで読み書きが高速になるので、キャッシュされたステップにもメリットがあります。
ちなみに、「キャッシュ」アイコンをクリックすると、全てのステップでデータをキャッシュすることができます。
パブリッシュの高速化
3つ目のメリットは、Parquetにより、ファイルサイズが小さくなったことで、データ(またはチャートやダッシュボードなど)をサーバー(Exploratory Cloudまたはコラボレーション・サーバーのいずれか)にパブリッシュする際の速度も格段に速くなりました。
Exploratoryではデータをパブリッシュする際に、まずデータファイルを圧縮します。そして、RDSファイルではデータを圧縮することで大幅にサイズを小さくしています。 例えば前述のRDSファイルでは30MBまでデータサイズを小さくすることができます。
ParquetファイルはRDSファイルに比べて大幅に小さくなることはありませんが、それでも圧縮されたParquetファイルの方がRDSファイルより小さくなります。

この30%のデータサイズの縮小は、複数のデータフレームやチャートを含むダッシュボードを利用するときに、大きなパフォーマンスの差となります。
サーバー上でのインタラクティブモードの初期化時間の大幅な短縮
最後に、4つ目のメリットは、サーバー上でのインタラクティブモードの初期化時のパフォーマンスにあります。
データやチャート、ダッシュボード、ノート、スライド内でパラメータを作成してサーバーにパブリッシュすると、それらを共有された人や自分自身がWebブラウザからパラメーターを利用できるようになります。
なおパラメーターは、「パラメーター」スイッチをクリックしてインタラクティブモードを有効にすることで利用が可能です。
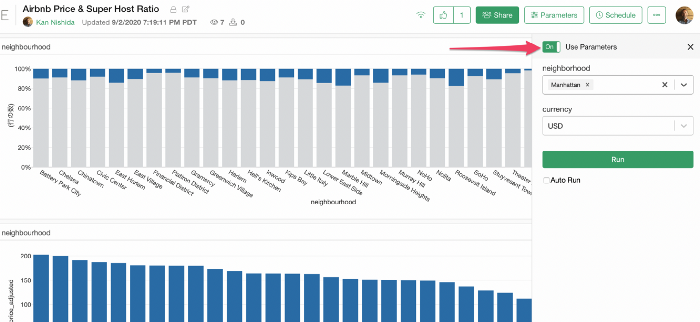
Parquetファイルによりデータの読み込み時間が高速化されたおかげで、サーバのメモリスペースにデータがロードされるのにかかる時間が以前よりも、はるかに速くなりました。
以上の4つがParquetファイルに切り替えることのメリットです。🎉
サマリービュー - ハイライトモード
前回のv6.0リリースでは、ハイライトと相関という2つの新しいモードを導入したのですが、導入以来、これらの機能について多くのユーザーからポジティブなフィードバックをもらっています。
ハイライトモードと相関モードを含む、このサマリービューは、私たちにとって、データサイエンスを民主化するための方法なので、どうすれば、さらに改善できるかを常に考えています。
そこでv6.1では、ハイライトモードに大きな改良を加えました。
チャートのアイコンをクリックすることで、チャートビューでサマリビューと完全に同じチャートを作成できるようになりました。
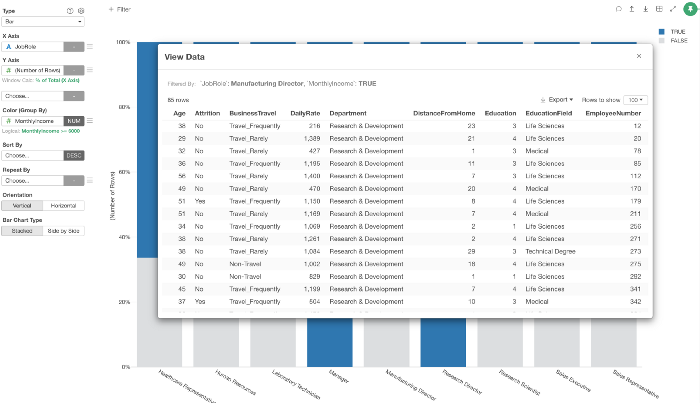
例えば、従業員に関するデータを持っていたとして、ハイライトの条件を「月収が6,000ドル以上」とします。
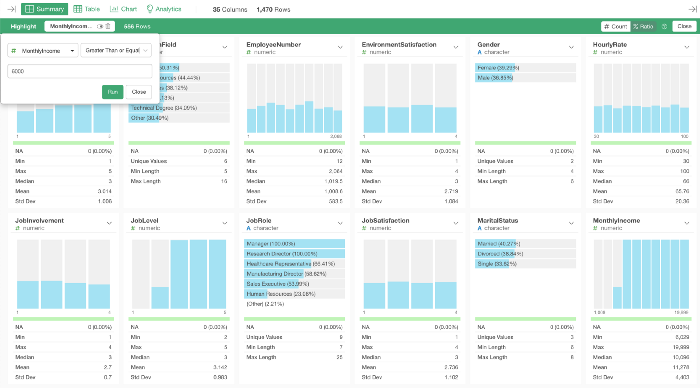
すると、Job Role(職種)ごとの月収が6,000ドル以上の従業員の比率はどうなっているでしょうか?
Job Role(職種)のチャートの上部にあるチャートアイコンをクリックしてみます。
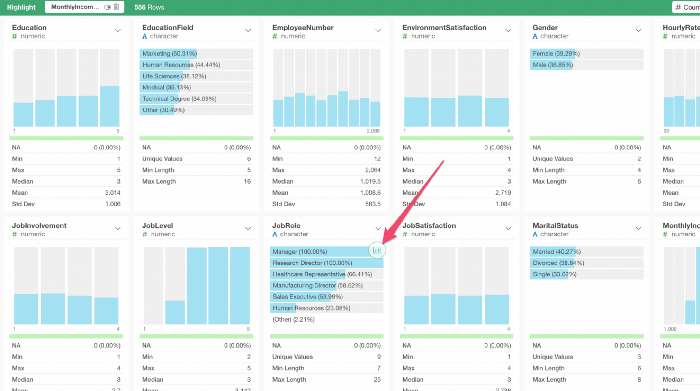
そうすると、同じ条件で塗り分けられたチャートができあがります。
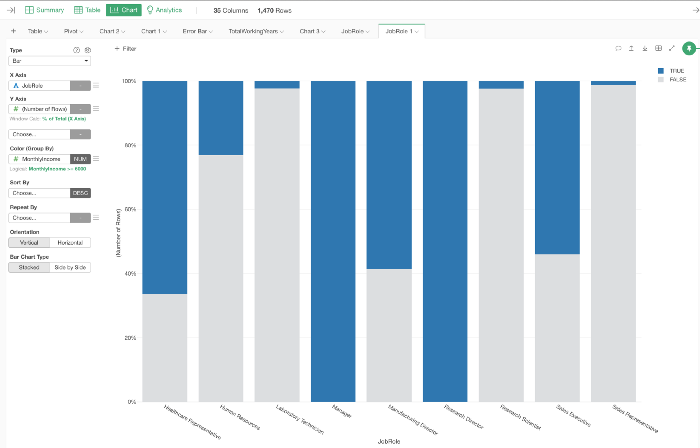
ここから、チャートの設定をカスタマイズしたり、設定した条件に合致する従業員の詳細を確認することができます。
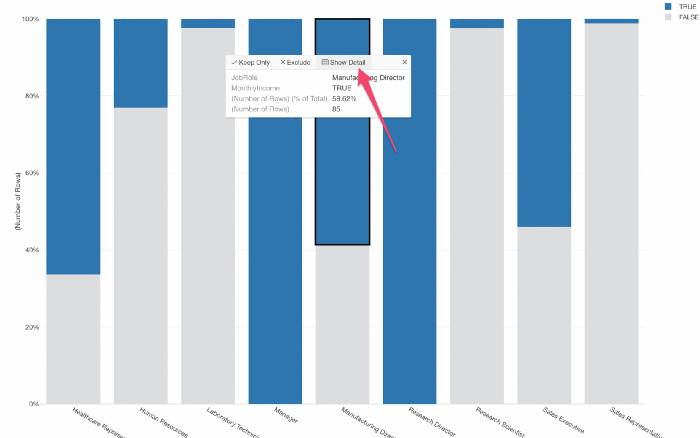
チャート
ロジカライズ - TRUE または FALSE
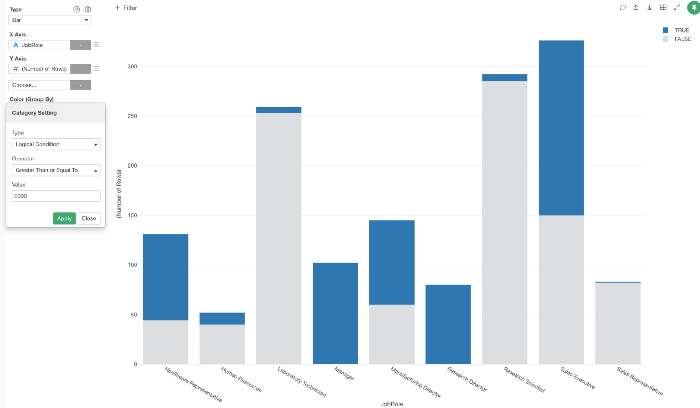
論理条件を設定して、色分けされたチャートを作成できるようになりました。
例えば、職種(X軸)と給料のレベル別(色)に従業員の数を可視化するチャートを作成したとします。
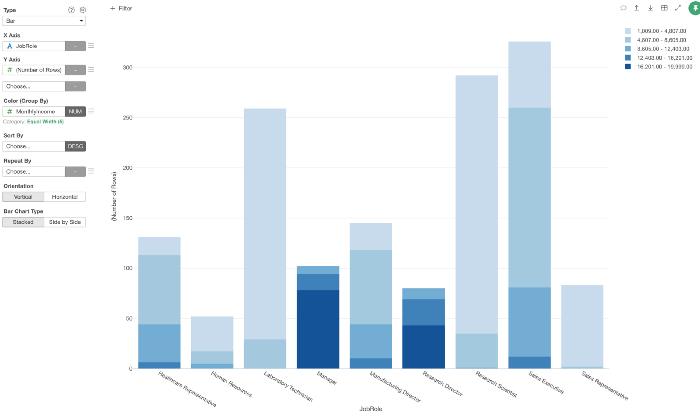
Monthly Income(給料)を「等幅」で5つのグループに分類するのではなく、「6,000ドル以上かどうか」という条件で、「True」か「False」のどちらかに「ロジカライズ」してみてみたらどのような結果が得られるでしょうか。
緑色のテキストリンクをクリックして、「カテゴリの作成」ダイアログを表示させます。
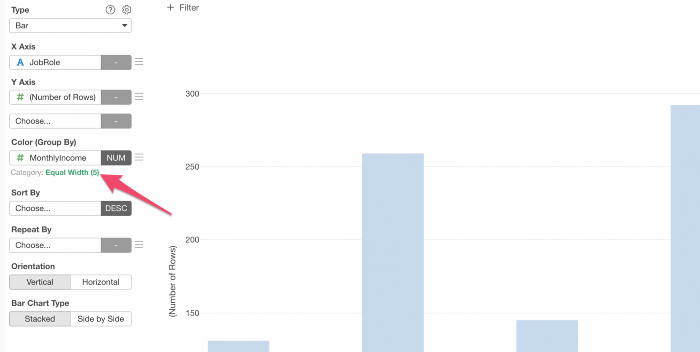
タイプメニューから「論理条件」を選択して条件を設定します。
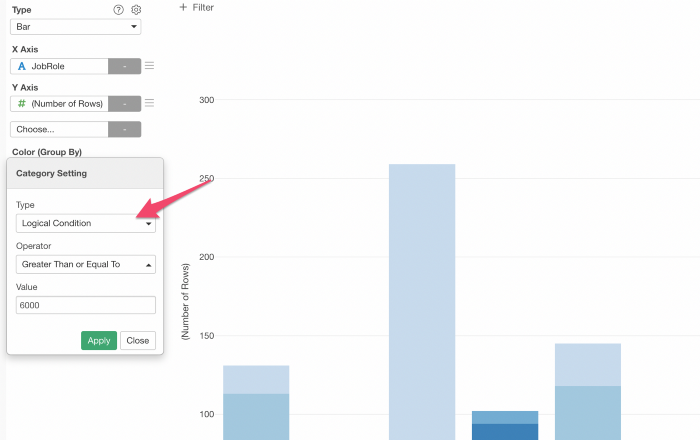
これにより、条件を満たした人は青(True)、それ以外の人はグレーの2色に分けられます。
なおnumeric型の列だけでなく、character、logical、date型の列などについても「ロジカライズ」することができます。
例えば、職種(X軸)ごとに従業員の教育分野(色)の比率を表したグラフがあったとします。
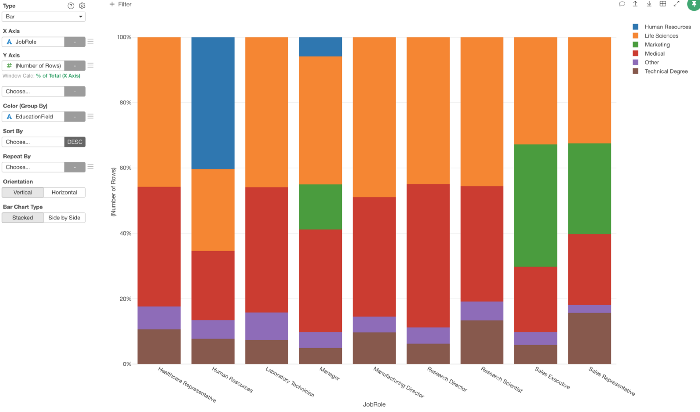
そして「ライフサイエンス」と「医療」の教育を受けた従業員が、それぞれの職種でどのような割合で構成されているかを知りたいとします。
そういったときは色(グループ化)のメニューから「カテゴリー」を選択します。
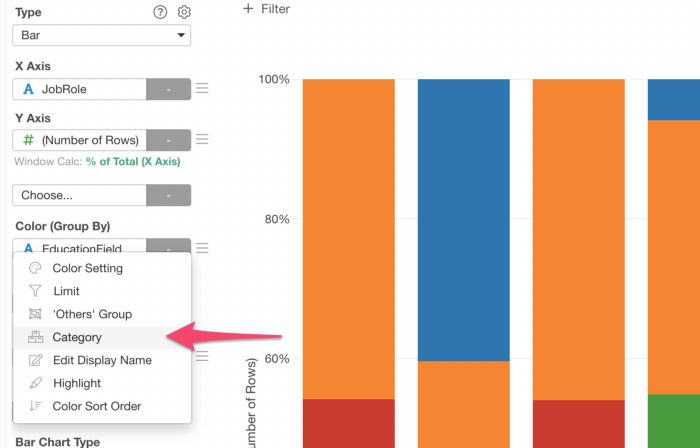
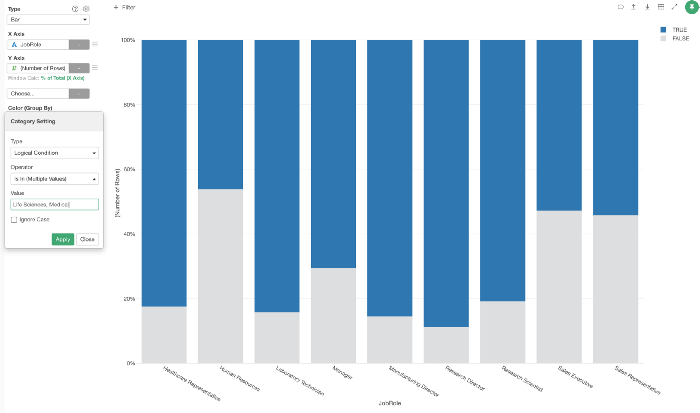
そして、「ライフサイエンスまたは医療のどれかに等しい」という条件を作ることができます。
ピボット / テーブル - URL
例えば、Webページのタイトルを表す列と、それに対応する指標とURLを列に持つデータがあったとします。
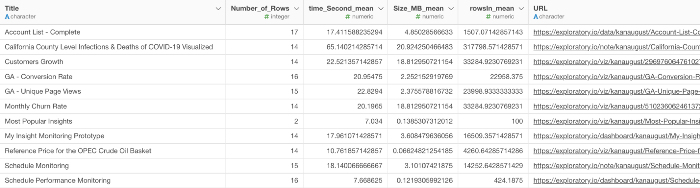
そしてチャートビューのテーブルで、URLの列を利用して、タイトルをURLリンク付きのテキストにして、タイトルをクリックして対応するページを開けるようにしたいとします。
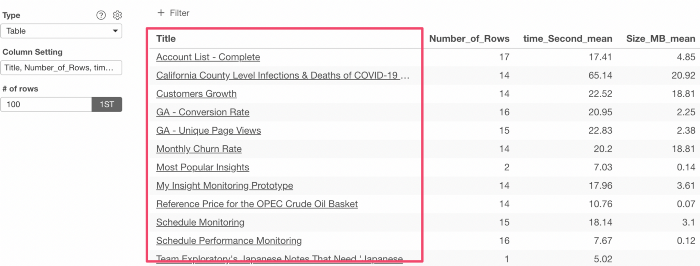
このようなURLリンク付きのテキストは、テーブルまたはピボットテーブルの設定で以下のシンタックスを使用して作成することができます。
${column_name}
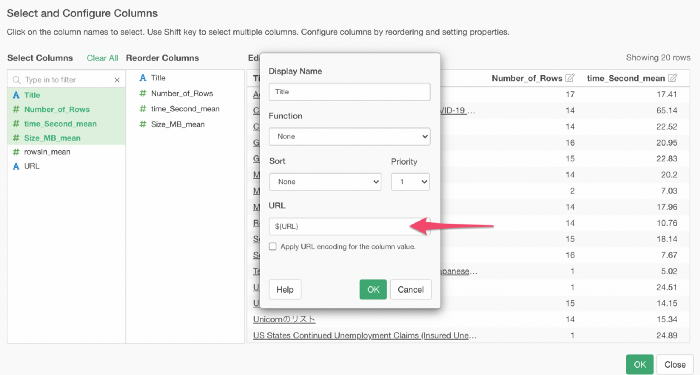
単純に他の列のURLの値を使いたい場合は、「列の値をURLエンコードする」にチェックを入れる必要はありません。 では、どのような場合にチェックを入れるのでしょうか。
このオプションは例えば以下のようなURLのテキストを作成するときに使います。
https://google.com?q=${State_Name}
こういったときには、いくつかの特殊文字をエンコードする必要があります。例えば、'North Carolina' にはスペースが含まれており、URLの一部としてエンコードする必要があります。
アナリティクス
アナリティクスのスイッチ
v6.1では、列の選択を維持したまま、アルゴリズムを簡単に切り替えることができます。
例えば、ロジスティック回帰モデルを作成したとします。
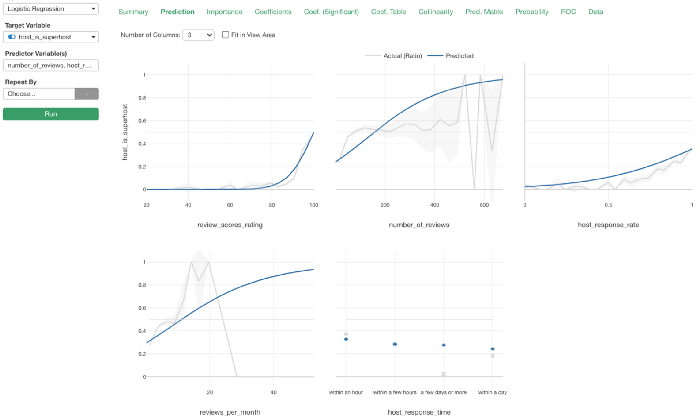
もし、ランダムフォレストのモデルで、同じ内容の予測モデルを作成し、両者を比較したかったとします。
そういったときは、まず、作成したロジスティック回帰のモデルを複製します。
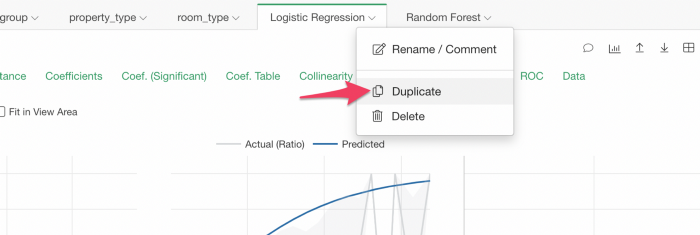
続いてアナリティクスのタイプをランダムフォレストに変更します。
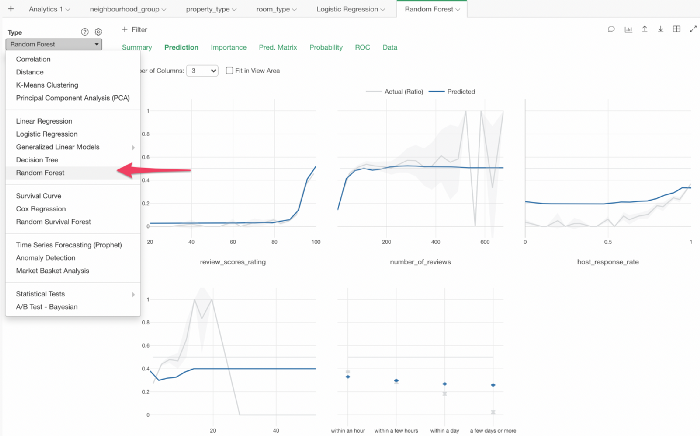
以前に比べて、モデル間の比較が格段に楽になりました!
データソース
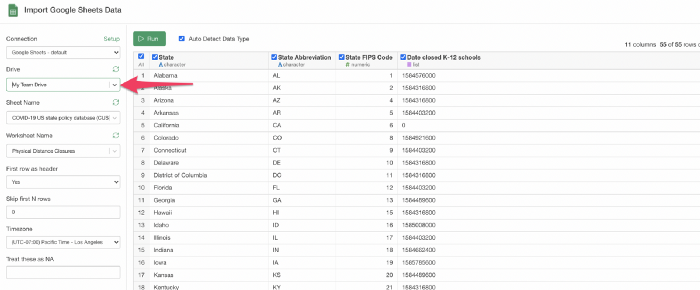
Google Sheet
チームドライブで作成、共有されているスプレッドシートにアクセスできるようになりました。
パラメーター
パラメーターの全体的な使用感を改善しました。
UIデザイン
まず、ドロップダウンやスライダー、カレンダーピッカーなどのUIのデザインをアップデートしました。
新しいカレンダーピッカーは見た目が良くなっただけでなく、機能性も向上しています。
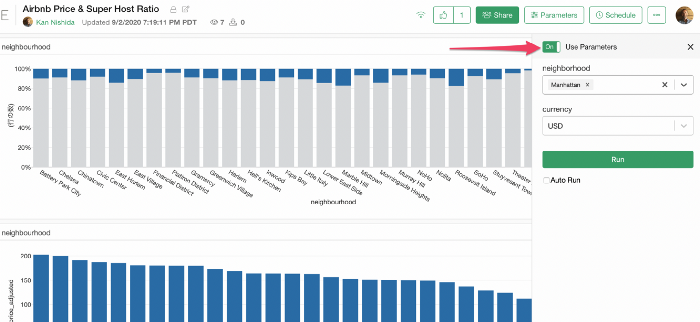
サーバーでのインタラクティブモード
データ、チャート、ダッシュボード、ノート、スライドでパラメータを作成して、Exploratoryのクラウドサーバーまたはコラボレーションサーバーにパブリッシュすると、自分だけでなく、それらを共有された人もウェブブラウザからパラメータを利用することができます。
パラメータを利用するには、「on」ボタンをクリックしてインタラクティブモードを有効にしてください。
先程、紹介しましたが、今回データの保存形式をRDSからParquetに変更ました。この変更により、インタラクティブモードを有効にするために必要な、最初のデータの読み込みが格段に速くなりました。
また、インタラクティブモードをより速くするために、もう一つのことを行いました。
私たちは独自の接続プールシステムを構築しました。この接続プールシステムは常に稼働していて、インタラクティブモードを有効にするリクエストにすぐに対応できるようになっています。
この二つの変更のおかげで、最初の接続パフォーマンスは以前よりもずっと速くなっています。🔥
Quoteオプション
通常パラメータは、文字値の場合はダブルクォートで値を返します。これにより、例えばWHERE句の中でパラメーターはうまく機能するわけです。
SELECT *
FROM employee
WHERE department = @{department_parameter}しかし、パラメータを使って列名を変更したい場合には、うまく機能しないということがあります。
SELECT @{select_columns}
FROM employee例えば以下のようなパラメーターを設定していたとします。
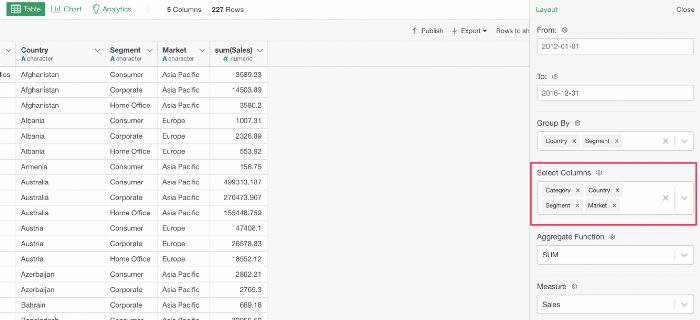
この場合、以下のようにクエリが返ります。
SELECT "Category, Country, Segment, Market"そして、このままクエリを実行すると期待している結果を得ることはできません。
クエリがうまく動くには'select_columns' のパラメーターがダブルクォートを含まない列名を返すようにする必要があるからです。
そこで以下のようにパラメータ句の中で'quote'引数を使うことができます。
SELECT @{select_columns, quote = FALSE}
FROM employee具体的に以下のようなパラメータを設定していたとします。
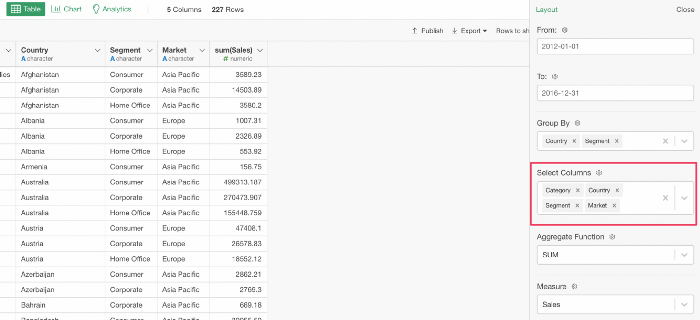
すると以下のクエリが返ります。
SELECT Category, Country, Segment, Market
FROM employeeこれは小さな改善のように見えますが、特にSQLクエリをより柔軟にパラメータ化したい場合には大きな意味があります。
例えば、次のような SQL クエリではほとんどがパラメータ化されています。
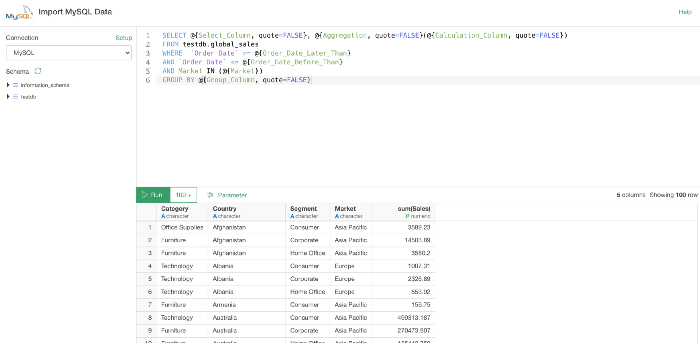
これによりパラメータペインのUIからSQLクエリを操作することができます。
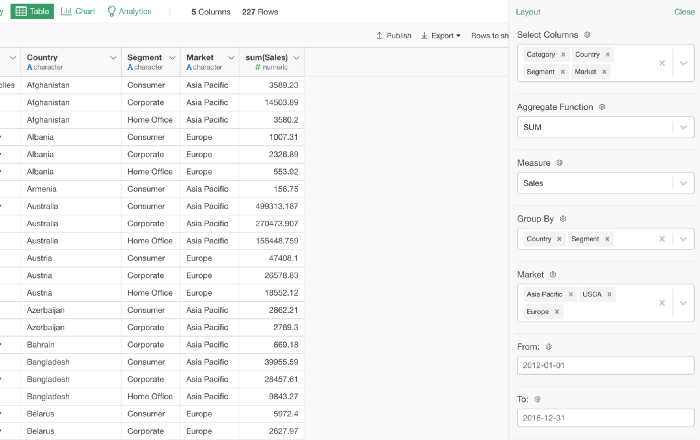
このようなものを作って、SQLに詳しくないチームの人に共有することを想像してみてください! 😎
なお、この引数はSQLクエリだけではなく、MongoDBのクエリにも対応しています。💪
Exploratory v6.1の紹介は以上ですが、他にもたくさんの機能強化やバグフィックスがあります。全てのリストはリリースノートにありますので、ぜひチェックしてみてください。
そして、Exploratory v6.1はダウンロードページからダウンロードすることが可能です!
Exploratoryを試す!
まだExploratoryのアカウントをお持ちでない方は、Exploratoryのウェブサイトよりぜひサインアップしてみて下さい。30日の無料トライアル(クレジットカードの入力なし)ができます。
さらに、現役の学生または先生の方は無料で使える「コミュニティ」版も用意しております!