Exploratory v6.2をリリースしました!
Exploratory v6.2のリリースをアナウンスできることに興奮しています! 🎉🎉🎉
いつものように、多くの新しい機能を追加したり、様々な機能を強化しましたので、ここでは以下の領域の簡単な概要を説明します。
- サマリビュー
- アナリティクス
- チャート
- データ・ラングリング
- ダッシュボード
- パラメーター
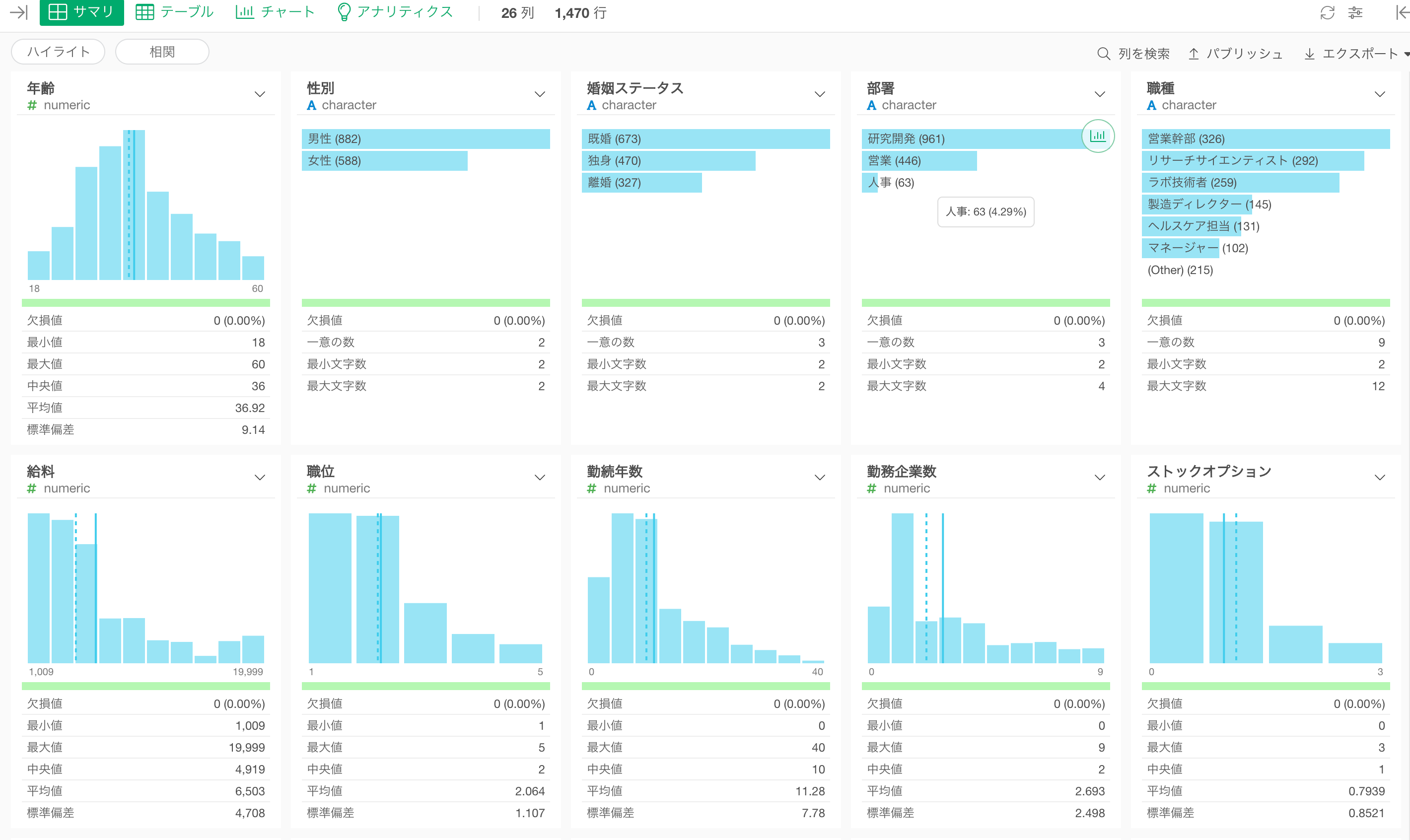
サマリビュー
中央値と平均値のレファレンスライン
数値列のヒストグラム上で、平均値と中央値のレファレンスラインを確認できるようになりました。
アナリティクス
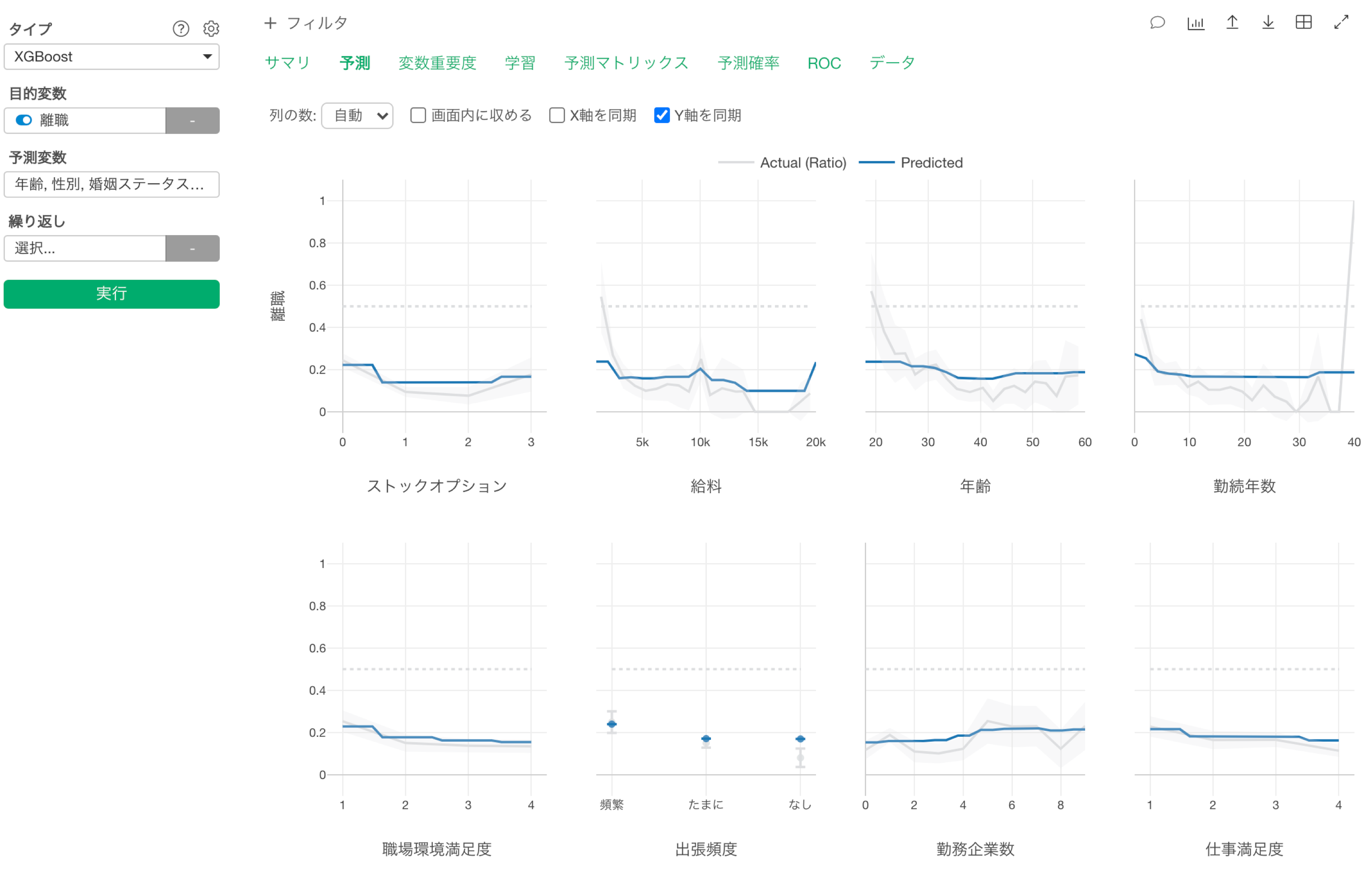
XGBoost
ようやく、アナリティクスビューにXGBoostを追加しました。🔥
XGBoostは以前から、ステップで利用が可能でしたが、アナリティクスビューで利用可能なタイプに追加することで、XGBoostを利用してモデルを構築することが簡単になりました。さらに、すべての機械学習/統計学習モデルに共通する、モデル解釈をサポートする文法ベースのタブと可視化チャートのおかげで、そこからインサイトを得ることもはるかに簡単になりました。
例えば、"予測タブ"ではある変数の値が変化したときの予測値が表示されます。
学習
XGBoostに特徴的なのは「学習」タブで、これは学習回数が増えることで、どのように予測モデルが改善されるかを示しています。
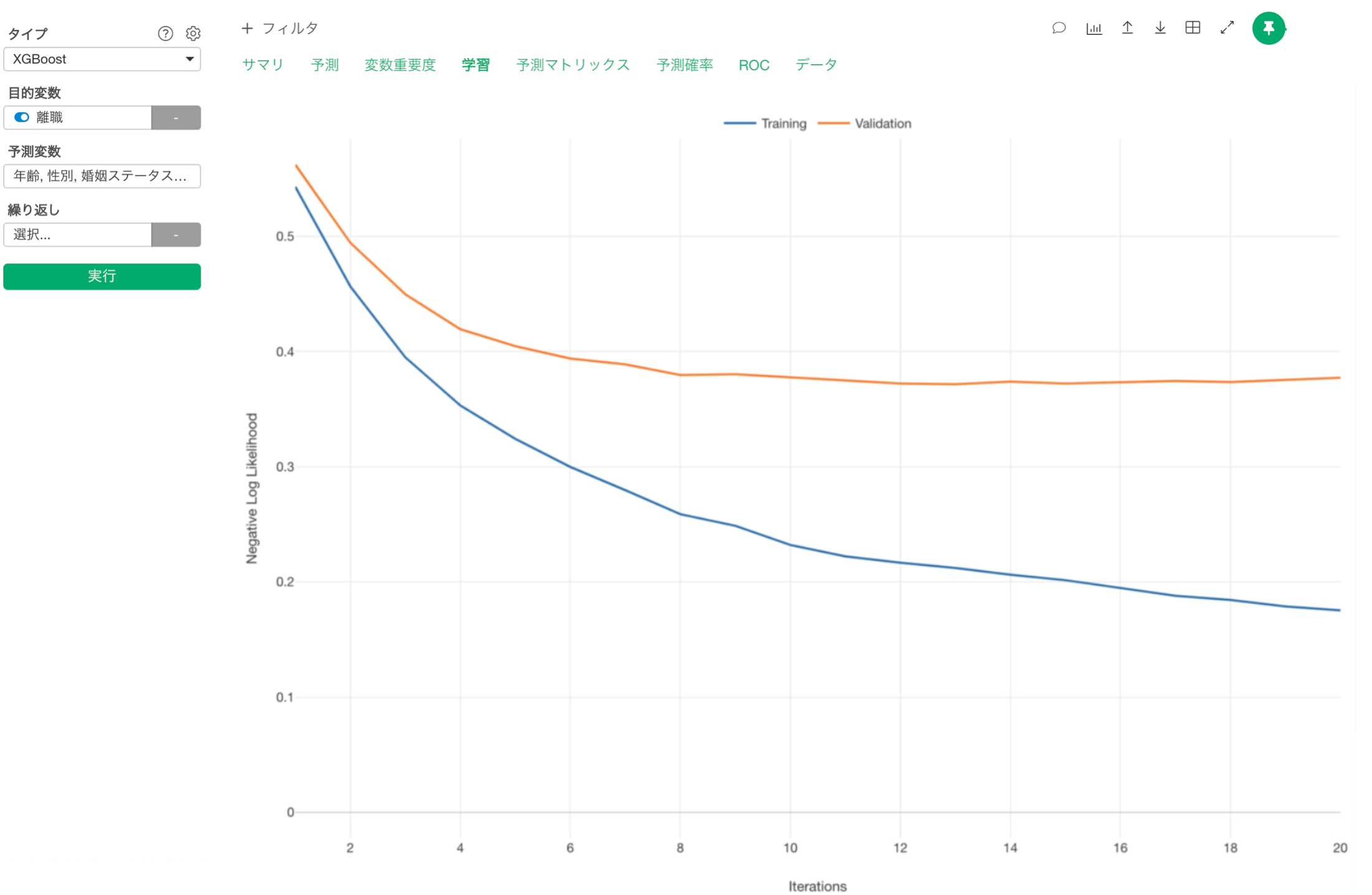
例えば、上のチャートでは、トレーニングデータでの学習回数を増やすにつれて、「Negatvie Log Likelihood(負の対数尤度:小さい方が良い)」で評価されるモデルの品質が向上し続けていることがわかります(青色のライン)。
ただ、テストデータ(オレンジ色のライン)を見ると10回目くらいの学習で改善が止まっていることがわかります。
そういったときは、プロパティから学習回数を設定することができます。
時系列予測 - ARIMA
ついに時系列予測のファミリーにARIMAが加わりました。🔥
例えば、カリフォルニア州、フロリダ州、ニューヨーク州、テキサス州の各州について、今後12ヶ月間の電気料金を予測するARIMA(Auto Arima)のモデルを構築してみました。
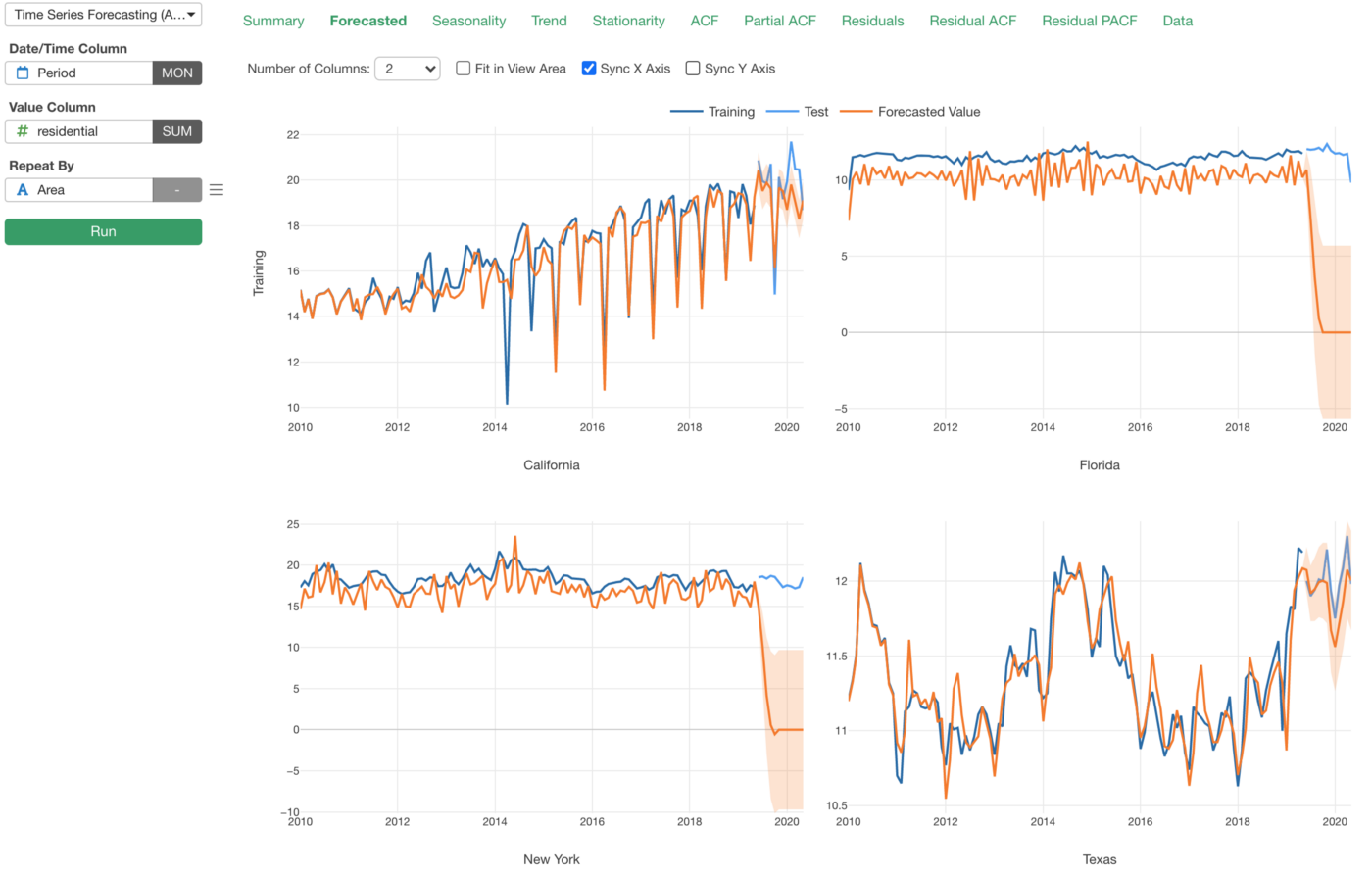
ARIMAは、時系列予測のアルゴリズムの1つのProphetとは異なり、モデルの構築により多くの知識を必要とします。
しかし、ARIMAには「Auto Arima」と呼ばれる自動モデル構築機能があり、デフォルトでオンになっています。そのため、ARIMAがどういったモデルであるかを知らなくても、ARIMAベースのモデルの構築を始めることができ、季節性とトレンドタブからインサイトを得ることができます。
ARIMAについて詳しく知っていれば、様々なタブで表示される情報を使って、プロパティからモデルを手動で調整することもできます。
なお上記のチャートを見ると、カリフォルニア州(左上)とテキサス州(右下)ではかなり良い結果が出ていますが、他の2つの州ではあまり良い結果が出ていないことが分かります。
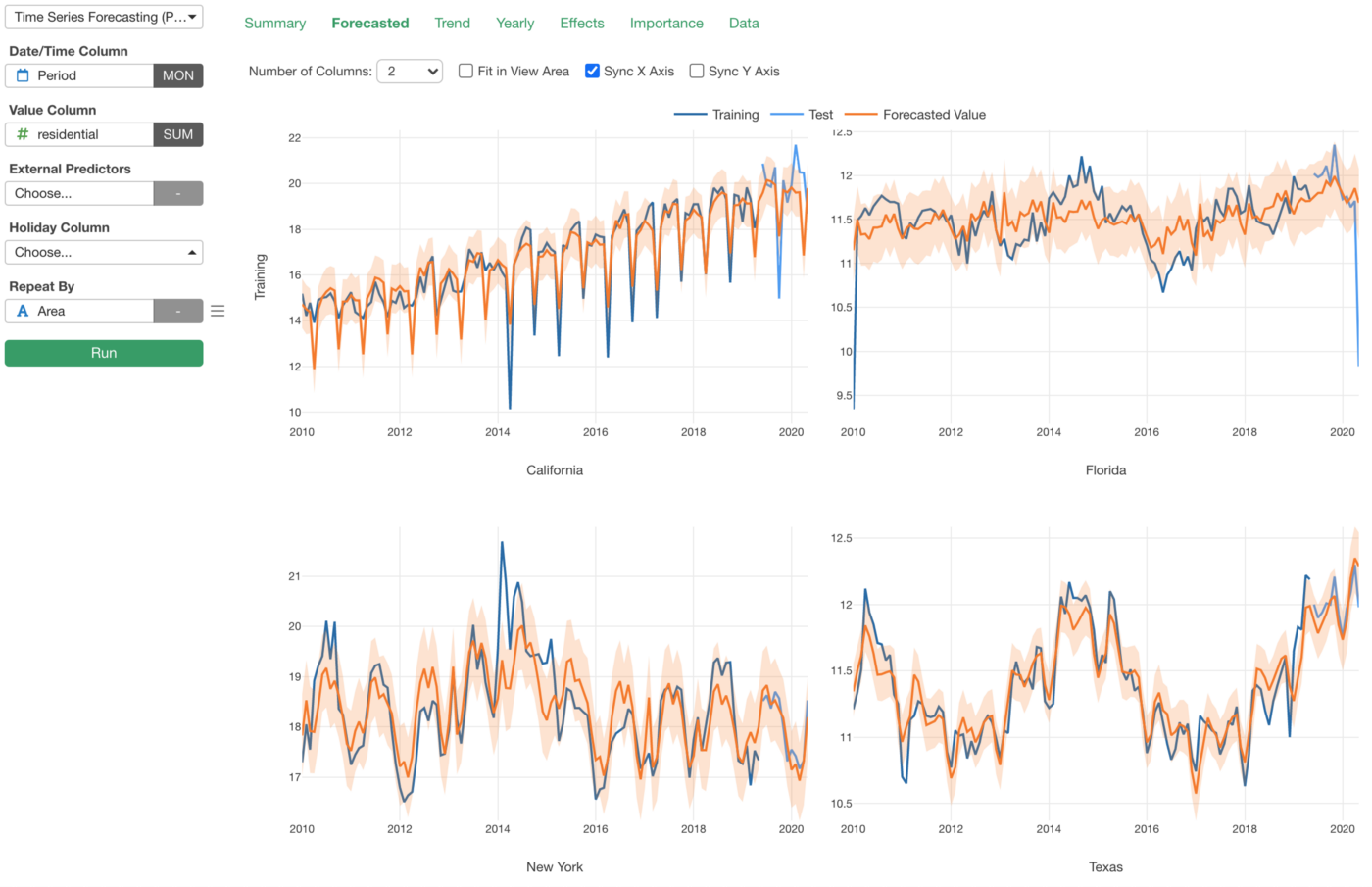
参考までに、下記にProphetを利用して同じ指標を予測したモデルがあります。すべての州で、モデルが実際のデータにフィットしており、いい結果が得られていることが分かります。
仮説検定 - t検定
t検定では、2つのグループの平均の差が有意であるかどうかを見ていて、通常、P値をその閾値として利用します。
例えば、女性の従業員と男性の従業員の間の平均給料の差が、各職種において有意であるかどうかを確認するために、t検定を実行したとします。
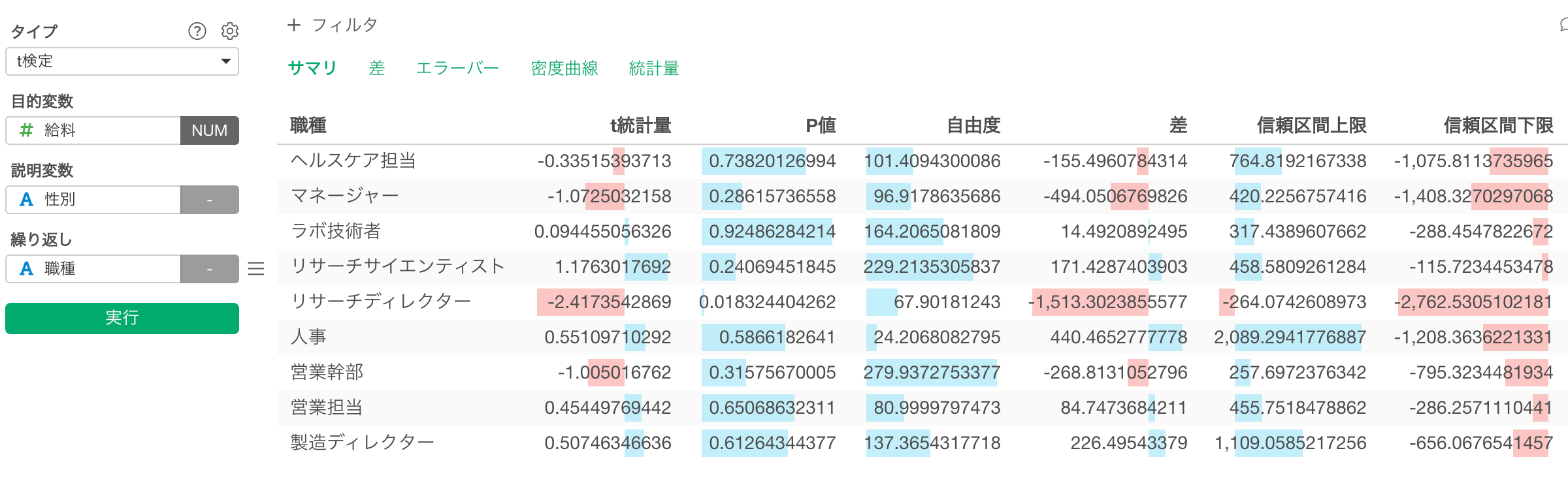
サマリタブのp値の列を見てみると、5%(0.05)を閾値とした場合、下の方のリサーチサイエンティストのみ有意であることが分かります。
しかし、P値はサンプルサイズや差の程度によって決まるので、p値だけではその有意性を判断できないことが多いです。結果的にp値の閾値となりうるものは何なのかということは、終わりのない議論になってしまうこともあります。
そこで、この問題に対処するには2つの方法があります。
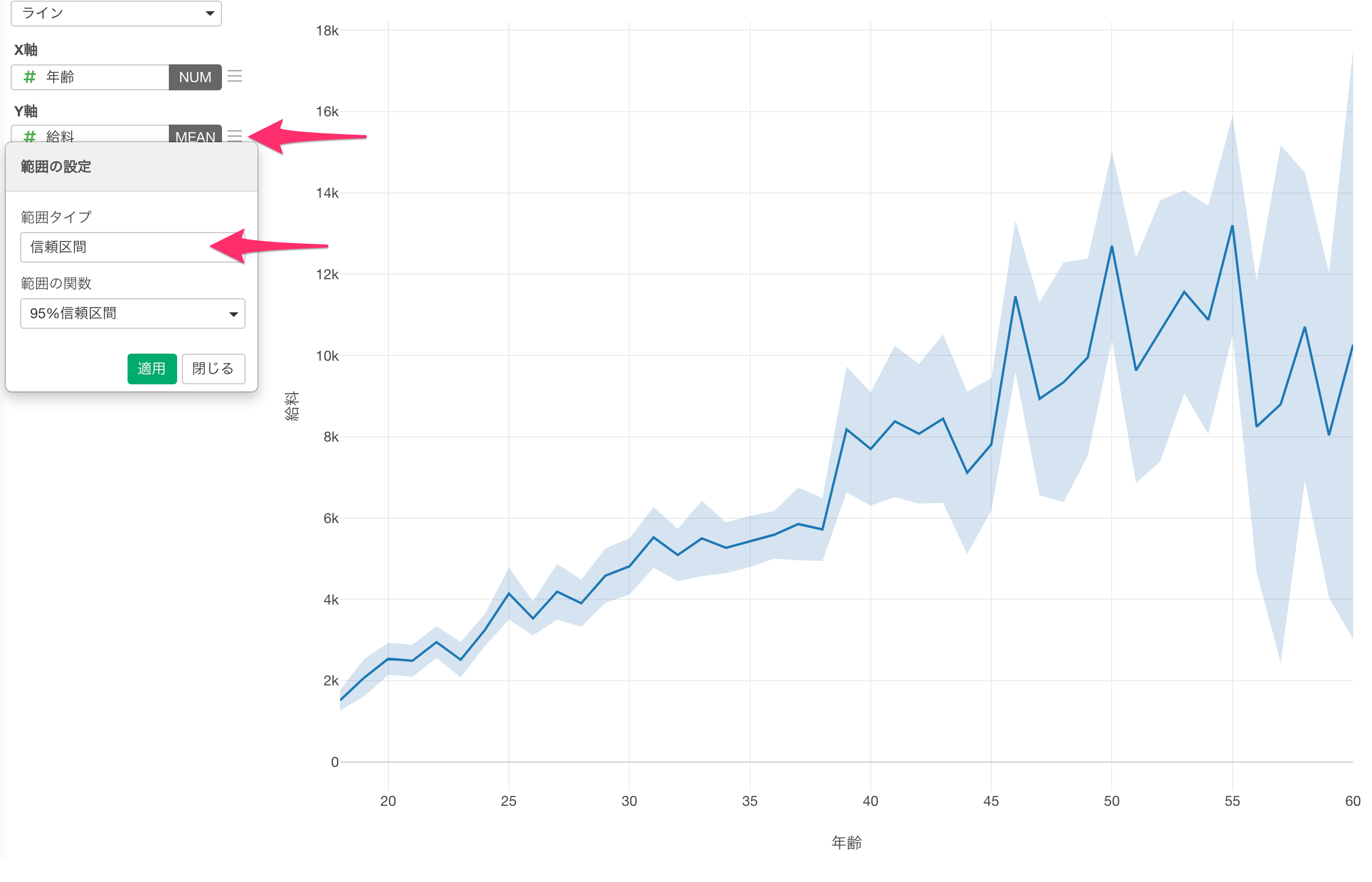
1つは、同じサマリタブにある効果量と検出力を利用することです。もう1つは、同じくサマリタブで確認できる差の信頼区間を使用する方法です。v6.2のリリースでは、新しい「差」タブが追加され、エラーバーで信頼区間を確認できます。
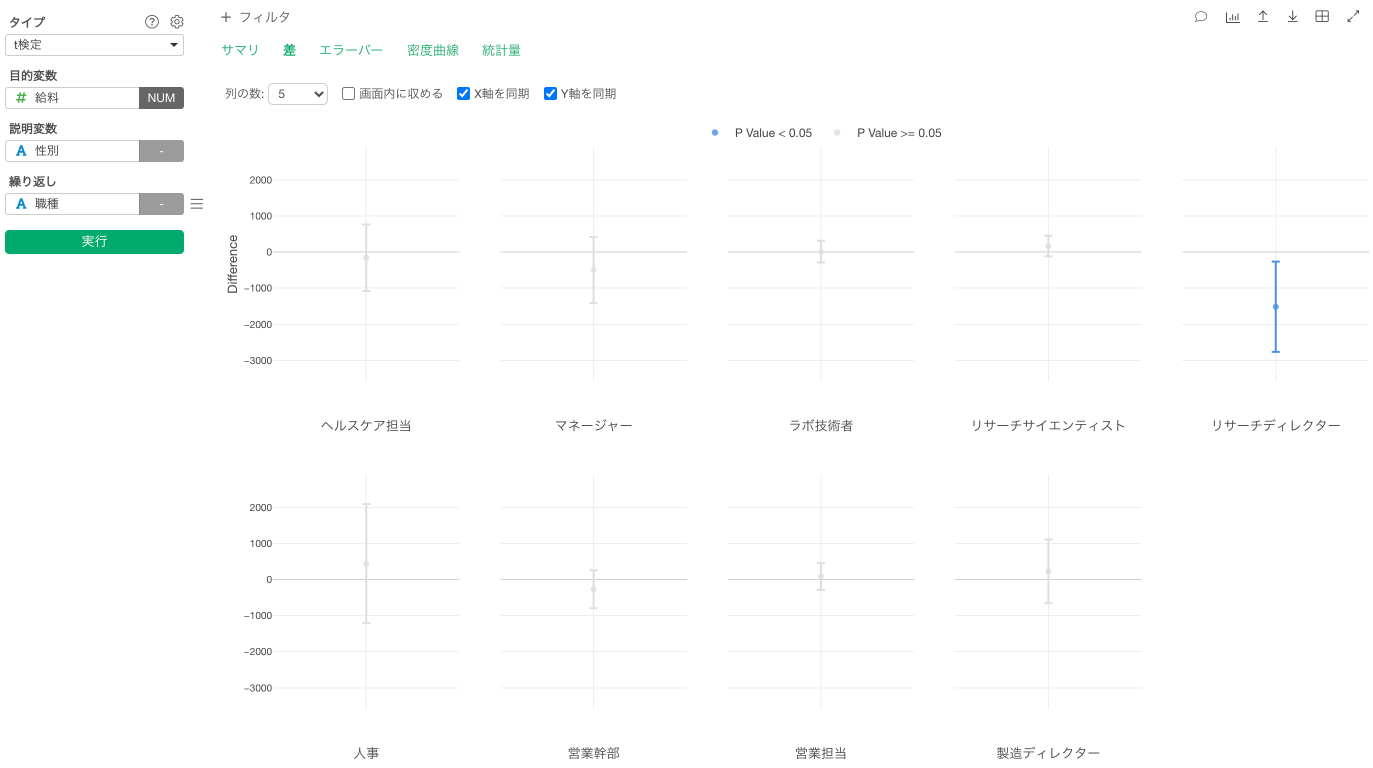
エラーバーに0が含まれる場合は、95%の確率で本当の差が0になる可能性があることを意味しており、したがって、全く差がないかもしれません。
なお理論上、より多くのデータ( 今回のケースで言うとより多くの従業員のデータ)があれば、信頼区間の範囲は短くなります。従って、もしあなたが望んで、それができるのであれば、有意になるまでデータを追加することができます。しかし、これは「Pハッキング」と呼ばれています。
あなたは、テストに十分なデータ(または十分なパワー)があることを確認したい一方で、とんでもない量のデータを追加することでテストをごまかしたくもないはずです。
そういったときに信頼区間が便利に使えます。これは、どのくらいの差があるのかを可視化するのに役立ち、それが有意かどうかだけではなく、より多くの情報を与えてくれます。
チャート
ラインチャートでの信頼区間
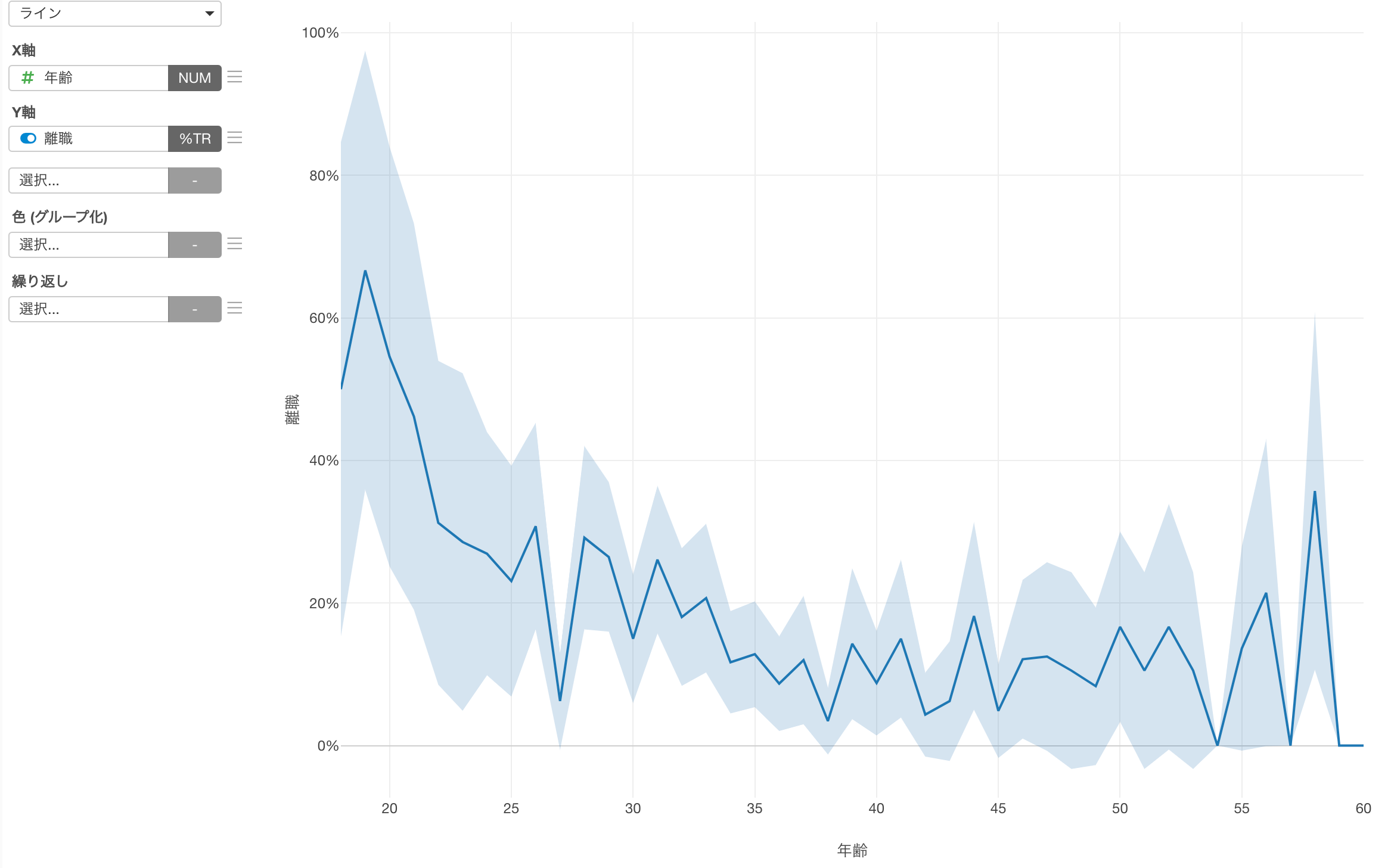
Y軸が平均または比率のいずれかのときに、信頼区間をラインと一緒に表示できるようになりました。
平均
割合
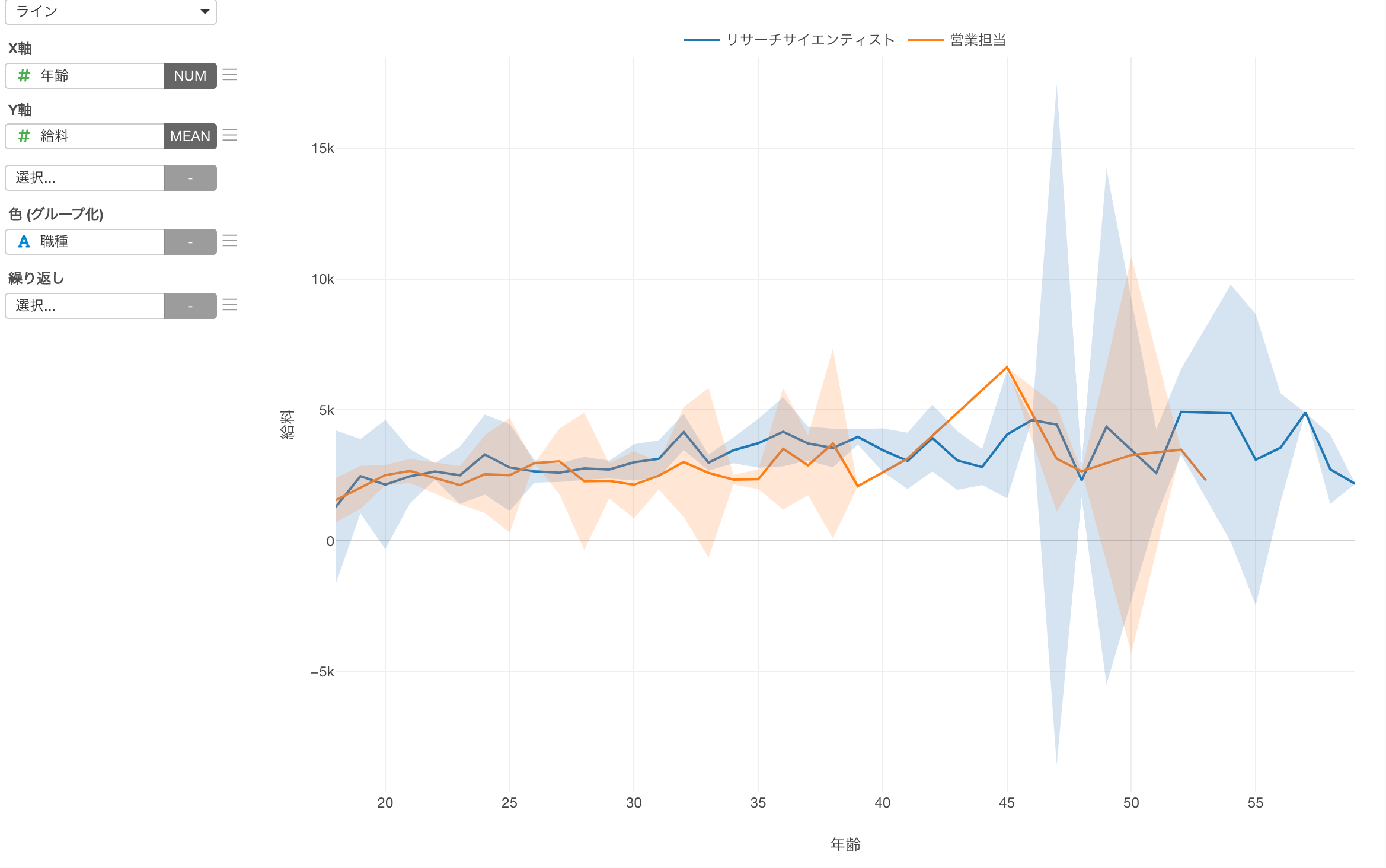
色(グループ化)または繰り返しを利用して複数の対象を可視化した際は、色ごとまたは、繰り返ししたグループごとに信頼区間が表示されます。
エラーバー - 割合
今回、計算タイプに「割合(%)」を選択した際に、割合の計算の分母をコントロールする「割合の対象」を導入しました。
例えば、ロジカル型の列に「離職」を選択し、計算に集計関数に「TRUEの数」を選択していたとします。
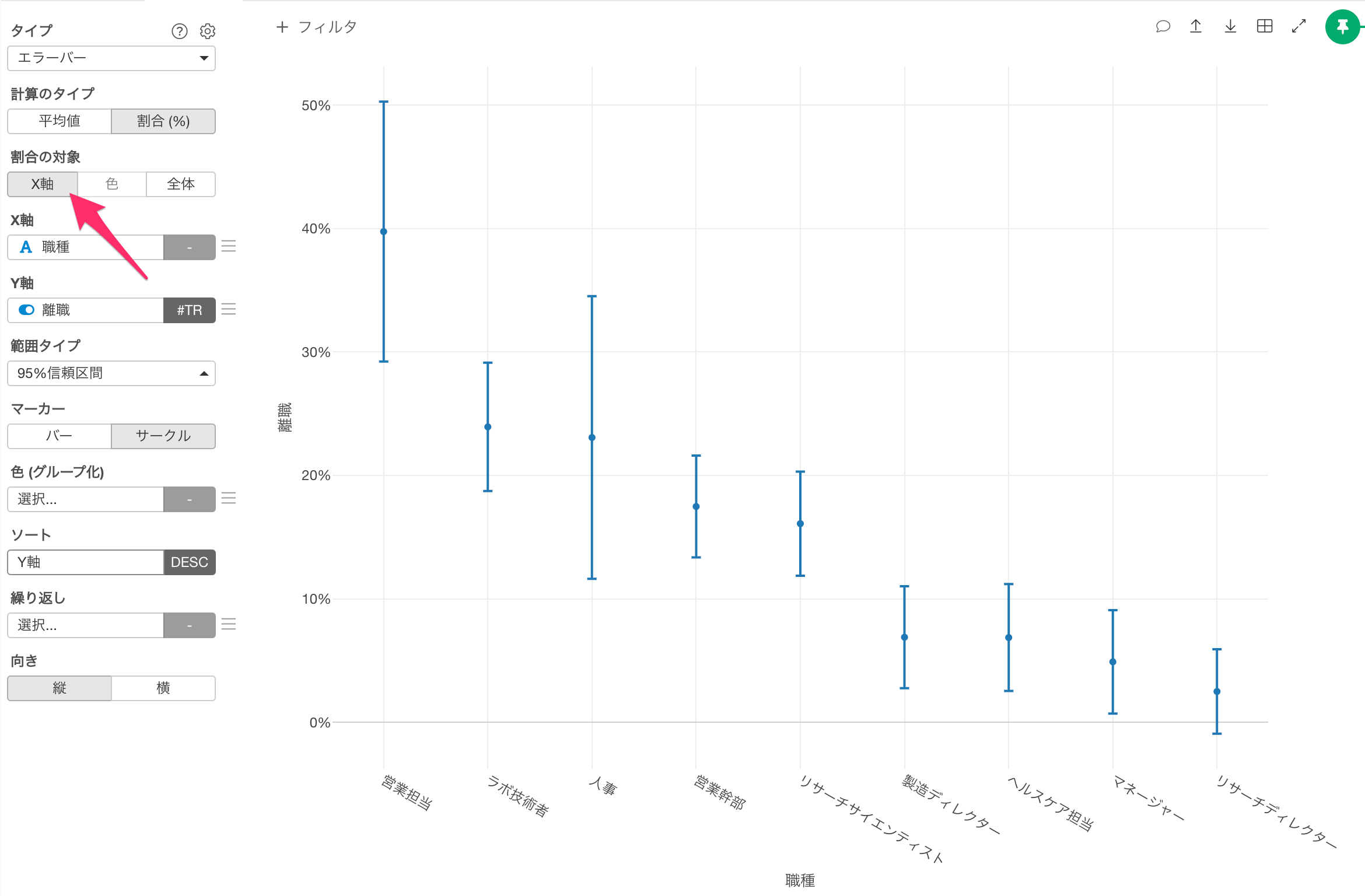
割合の対象に「X軸」を選択しているので、エラーバーが表示されている各比率は、職種ごとのTRUEの割合を示しています。
値のない(NA)レベルの削除
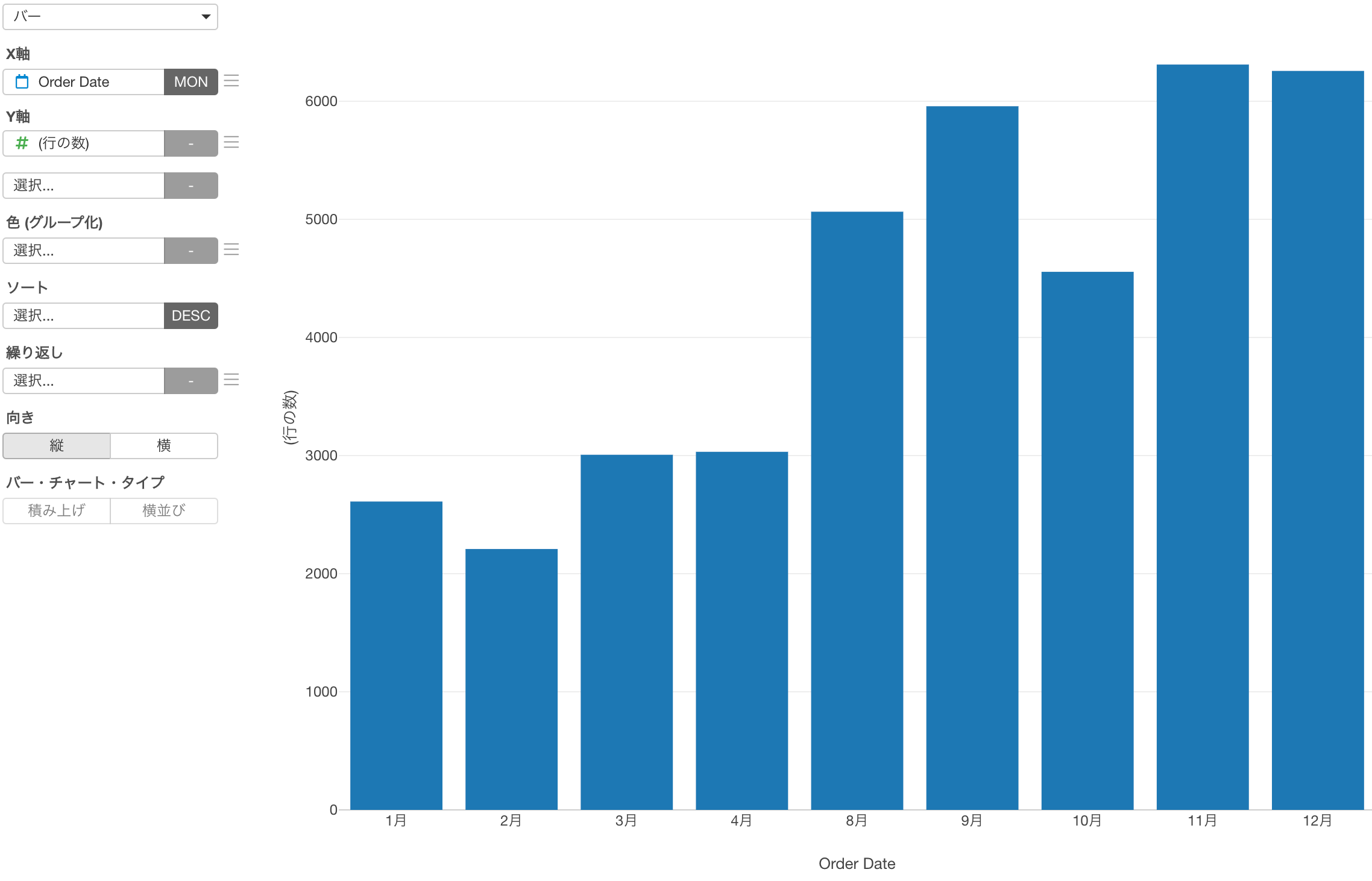
ファクター型のデータは、見た目はキャラクター型に似ていますが、順序(またはレベル)情報を持つことができる特殊なデータです。例えば、月の情報は順番を持っているので、キャラクター型ではなくファクター型に設定した方が良いと言えます。(1月、2月、3月など。)
このようなファクター型の列をX軸に選択すると、'1月'で始まり'12月'で終わるように順序を維持するだけでなく、値が全くない場合でも、すべての月名の表示を保ちます。
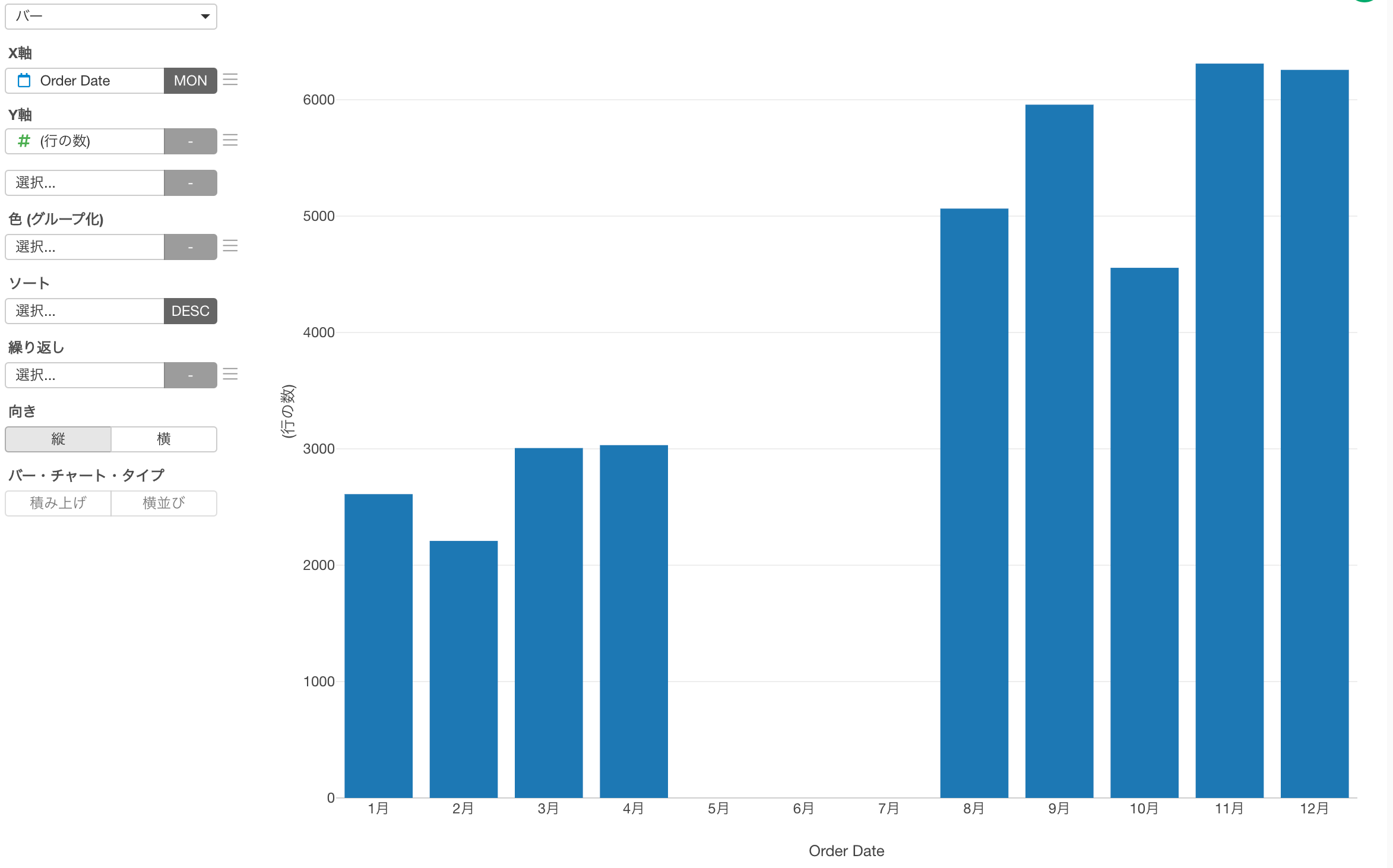
しかし、値のないレベル(または値)を表示したくないこともあるでしょう。そのようなときには、「値がない場合の処理」のダイアログからそれらのレベルまたは値を非表示にすることができるようになりました。

値のないレベルを表示するか、非表示にするかをコントロールできます。
データ・ラングリング
ステップ内でトークンを無効にする
データを加工している最中に予期しないエラーや結果が発生すると、問題の発生場所がわからずに混乱してしまうことがあります。これは、「計算を作成」などのステップ内に多くのトークン(操作)がある場合に特に発生します。
この問題に対処するために、各トークンの「無効化」をサポートしました。
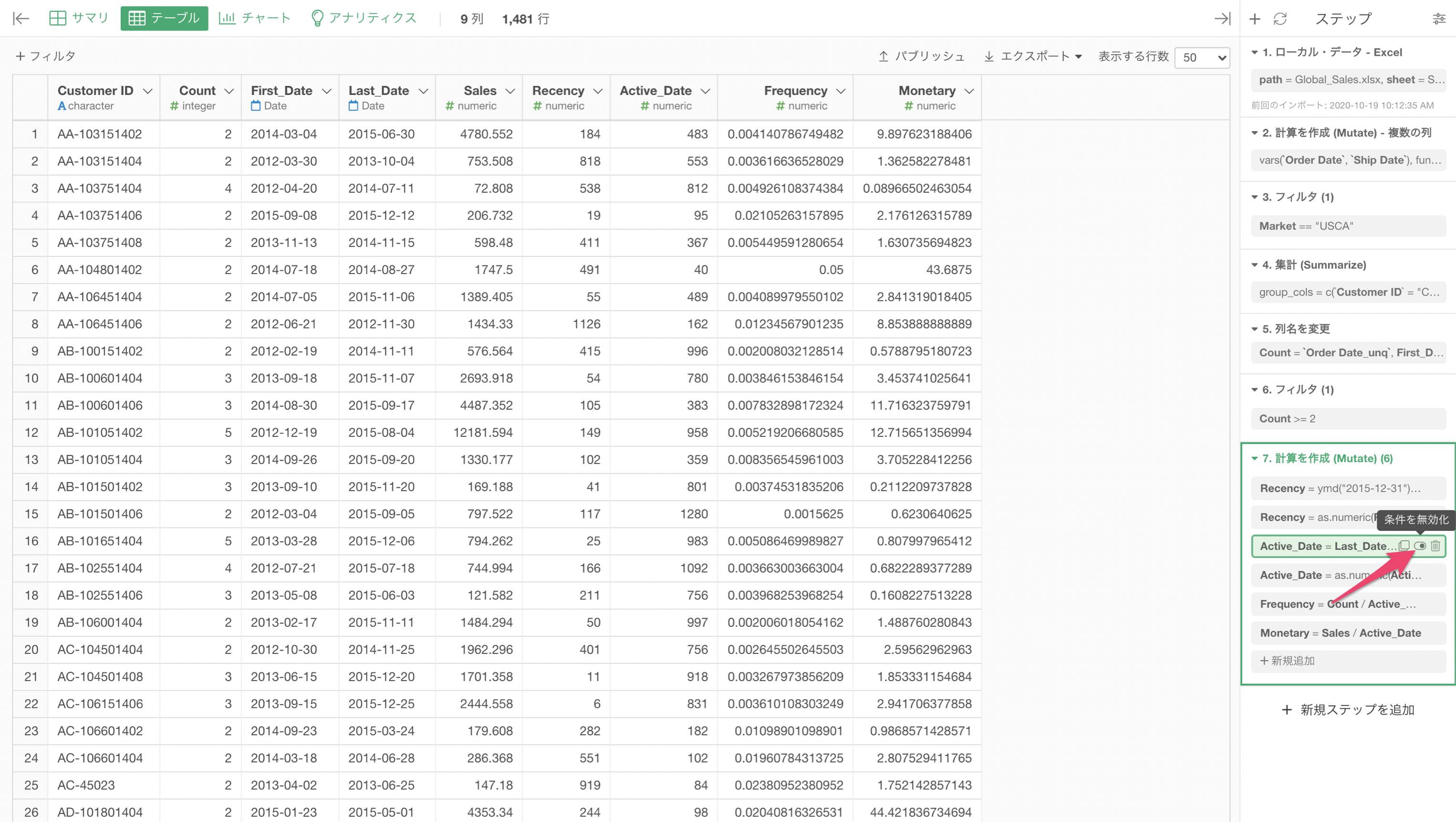
したがって、トークンを無効にすることで、どのトークンがエラーを引き起こしているのか、期待通りに機能しているのかを確認できます。
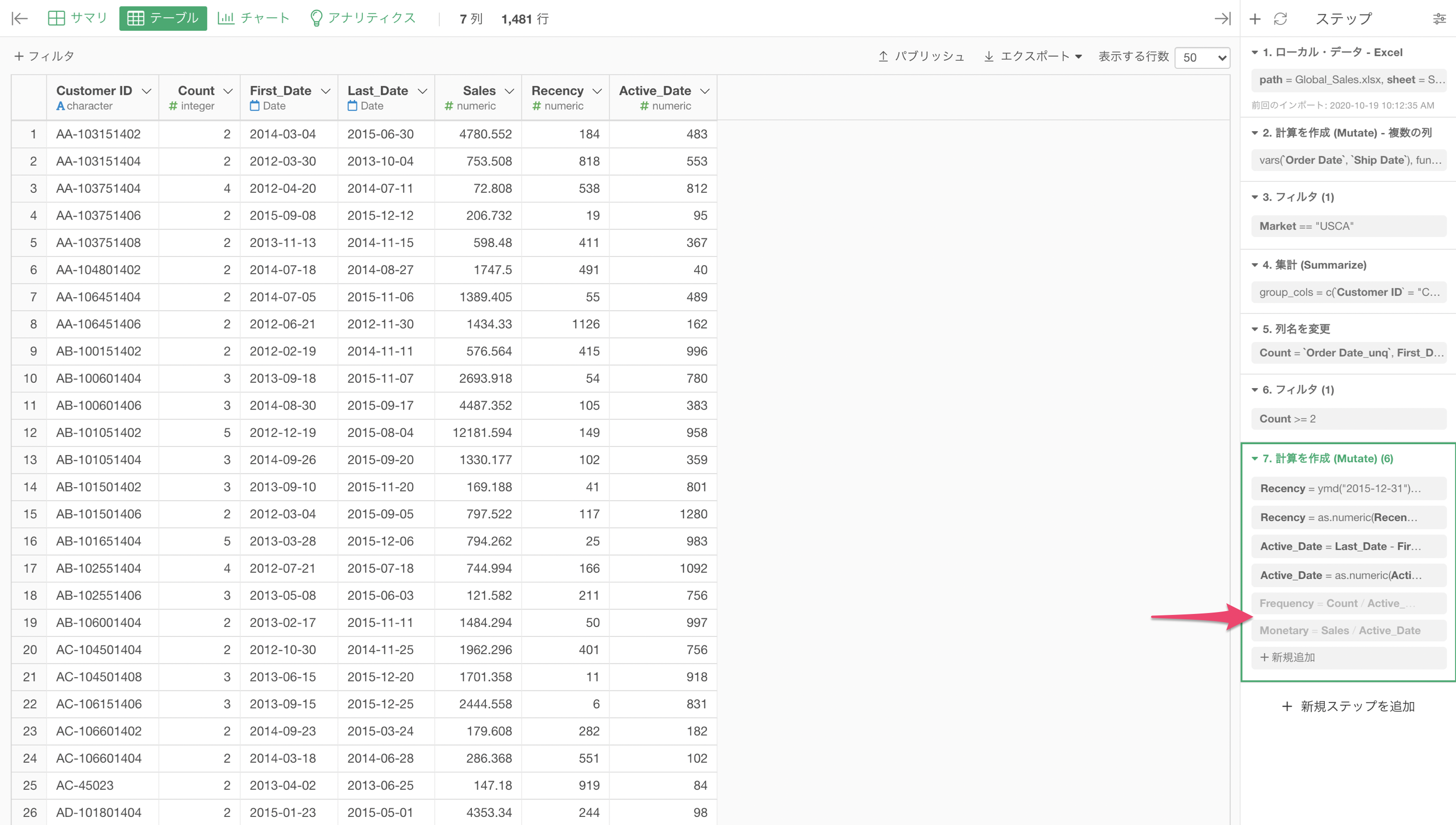
ご想像の通り、これはフィルターステップでも役に立ちます。
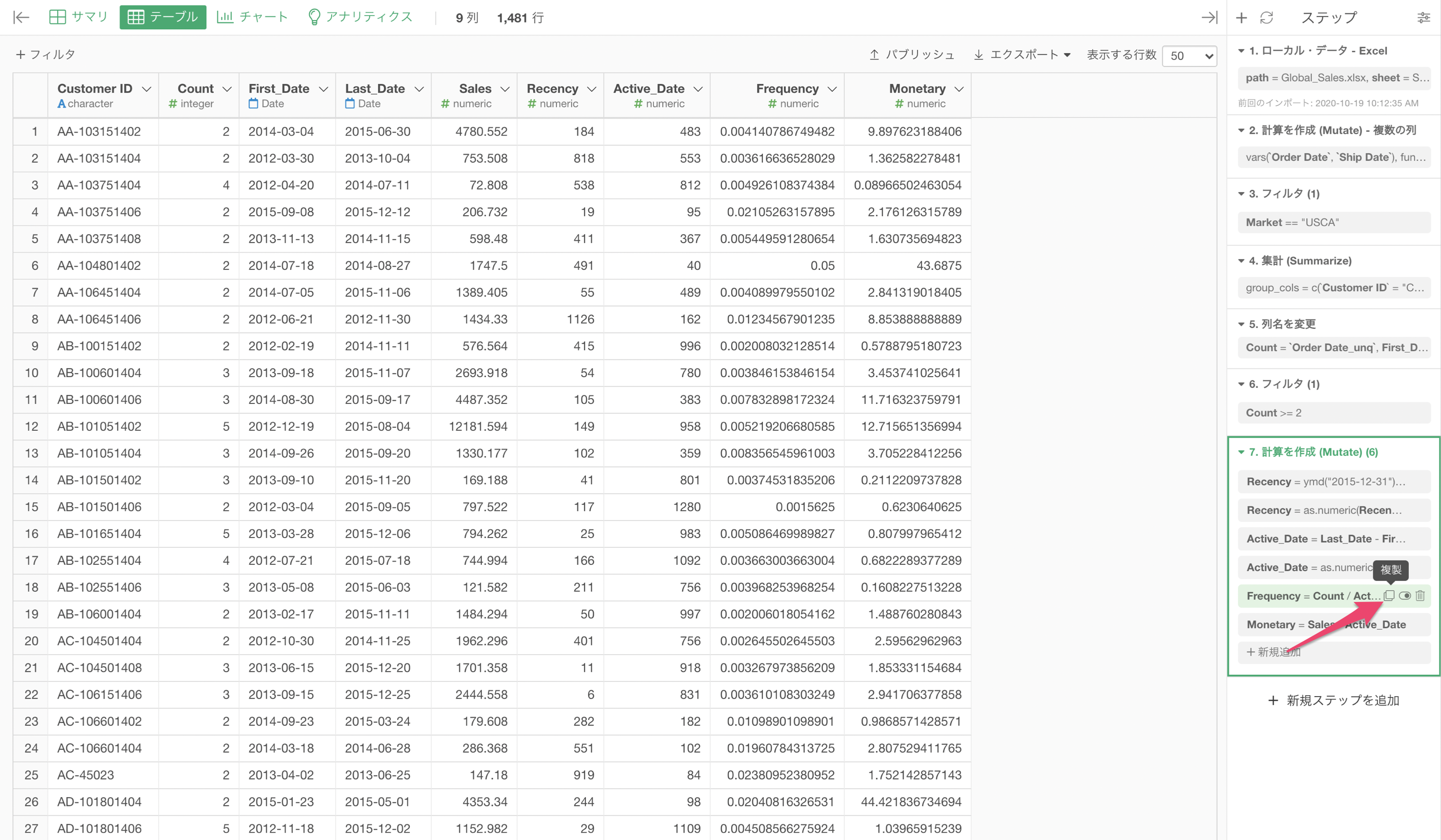
ステップ内でトークンを複製する
トークンから「複製」のボタンをクリックすると、既存のトークンを複製(コピー)して、同様の計算を作成できます。
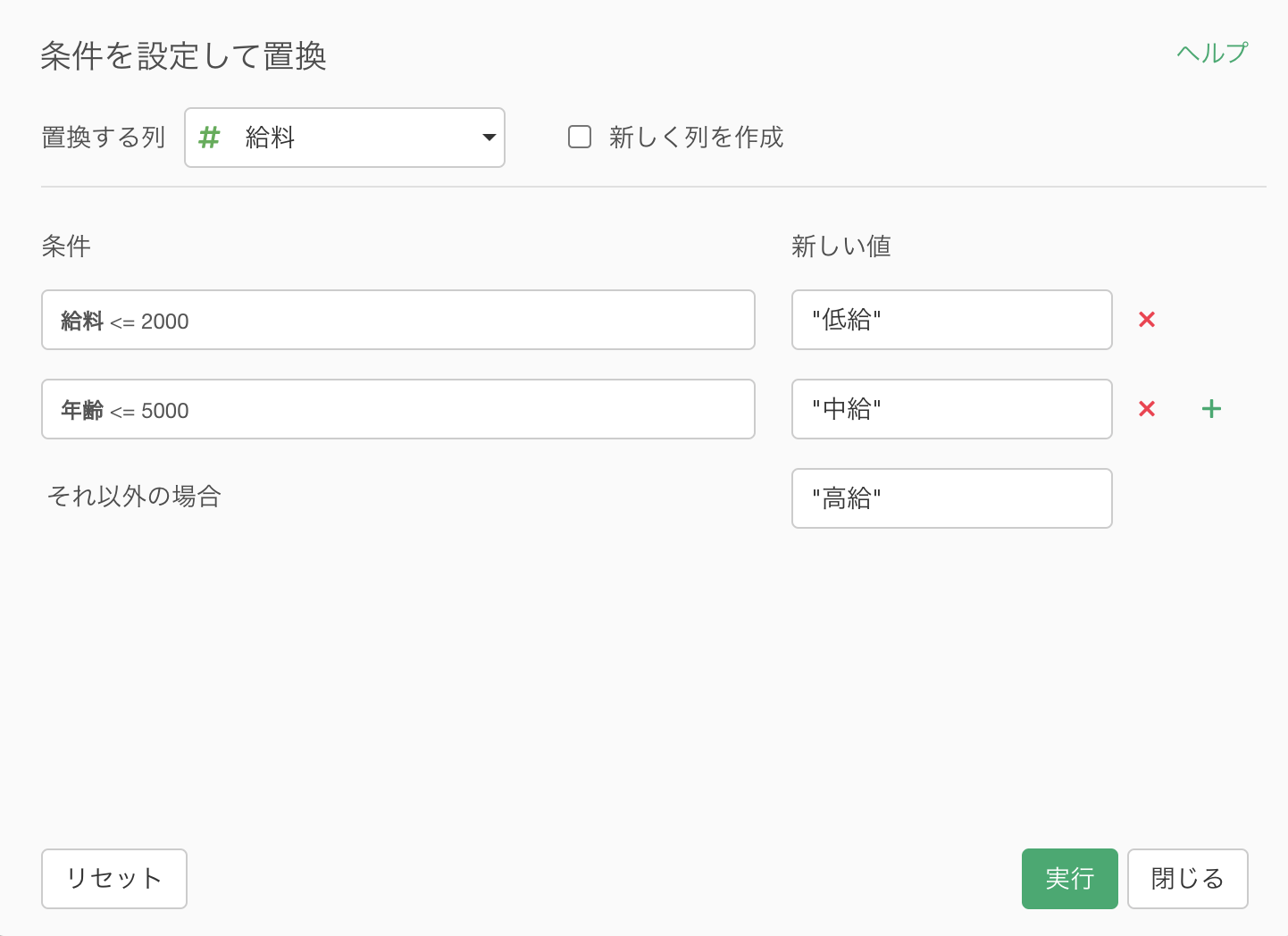
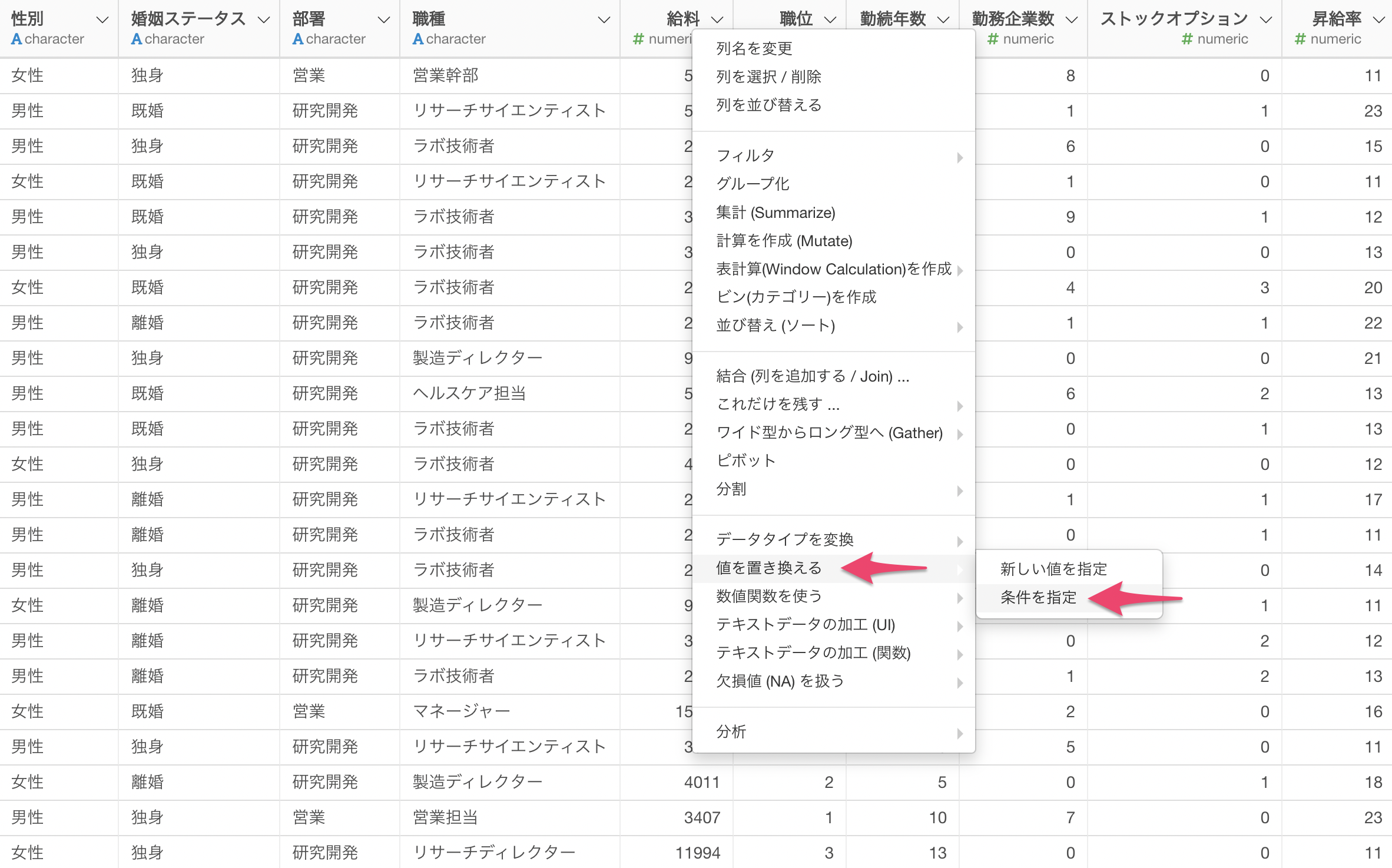
複数の条件に基づいて値を置き換える
条件に基づいて値を置き換えたいことがあります。これまでは、計算を作成の中でcase_when関数を使用して実行していましたが、構文が少し複雑に見え、初めての人にとってはわかりにくいことがありました。
そこで、新しいUIを構築しました。
列ヘッダメニューから値を置き換えるを選び、条件を指定を選択します。
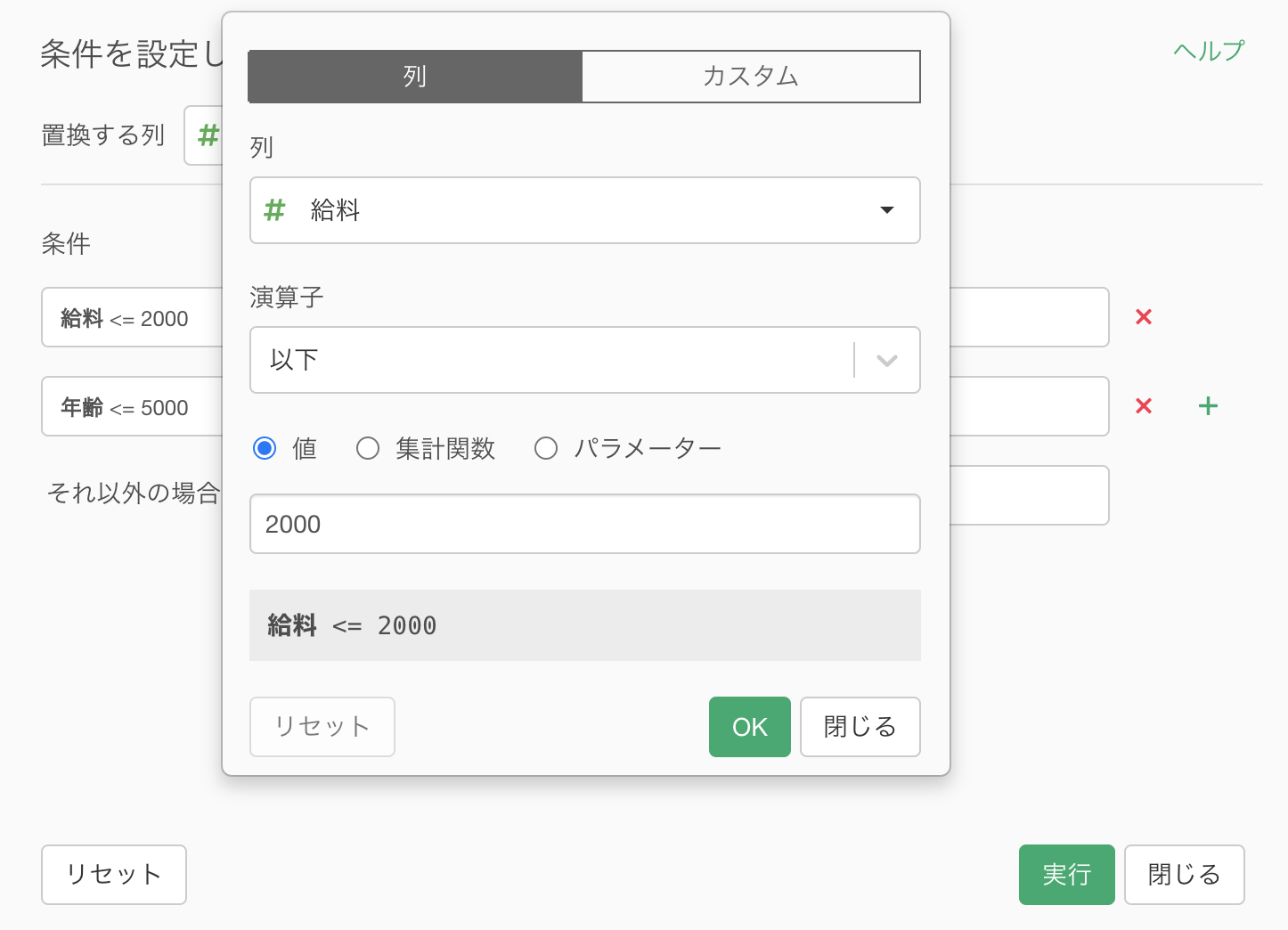
次に、条件と新しい値を割り当てます。
ボタンをクリックして、フィルターに使用されているのと同じダイアログが開かれるので条件を指定することができます。
使い方を詳しく知りたい方はこちらのノートをご覧ください。
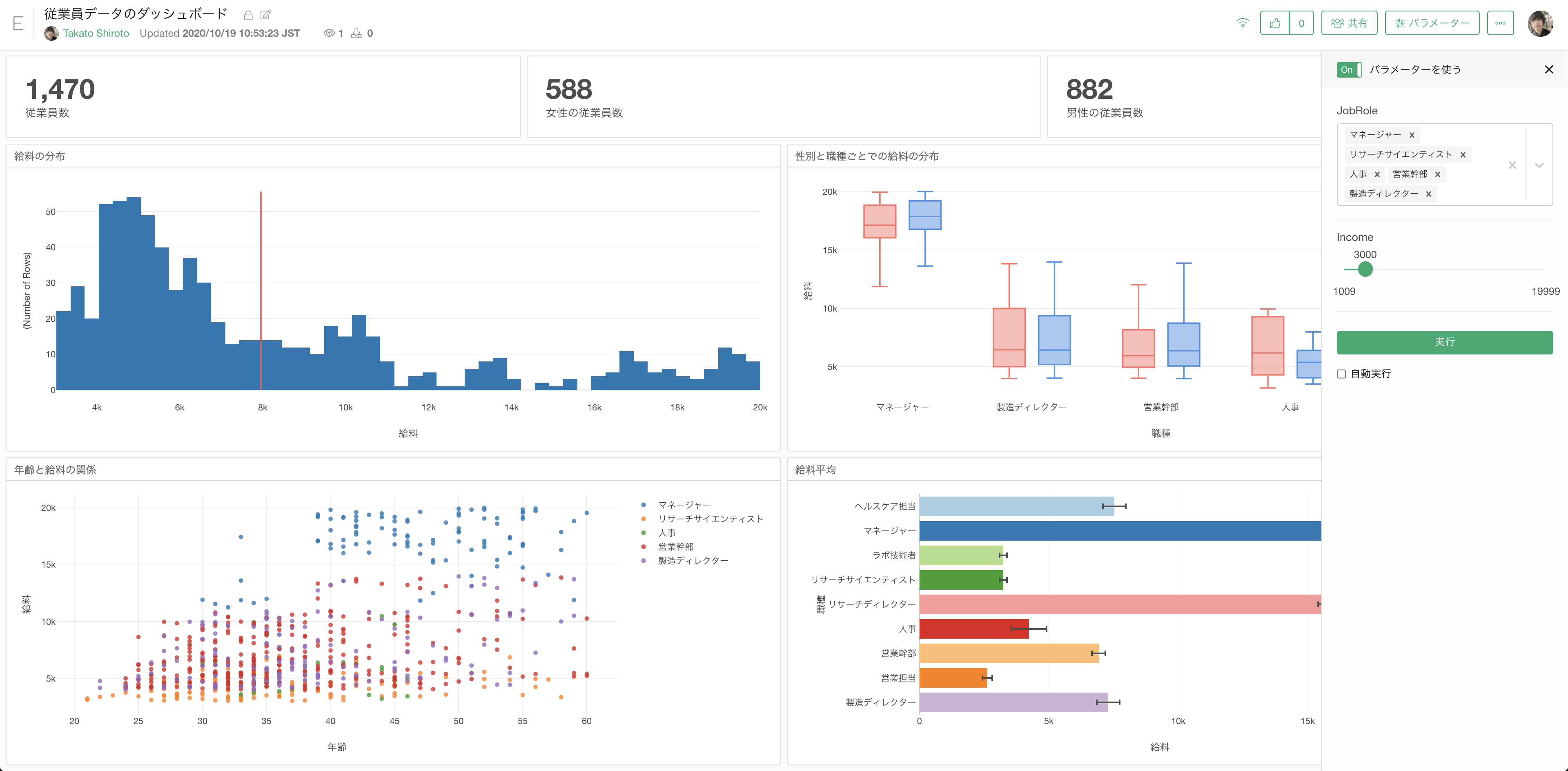
ダッシュボード
画面内に収めるがオフの場合、各行セクションの高さを調整できるようになりました。
例えば、ダッシュボードの2行目にテキストを表示していますが、デフォルトの高さがテキストの量に対して高すぎます。
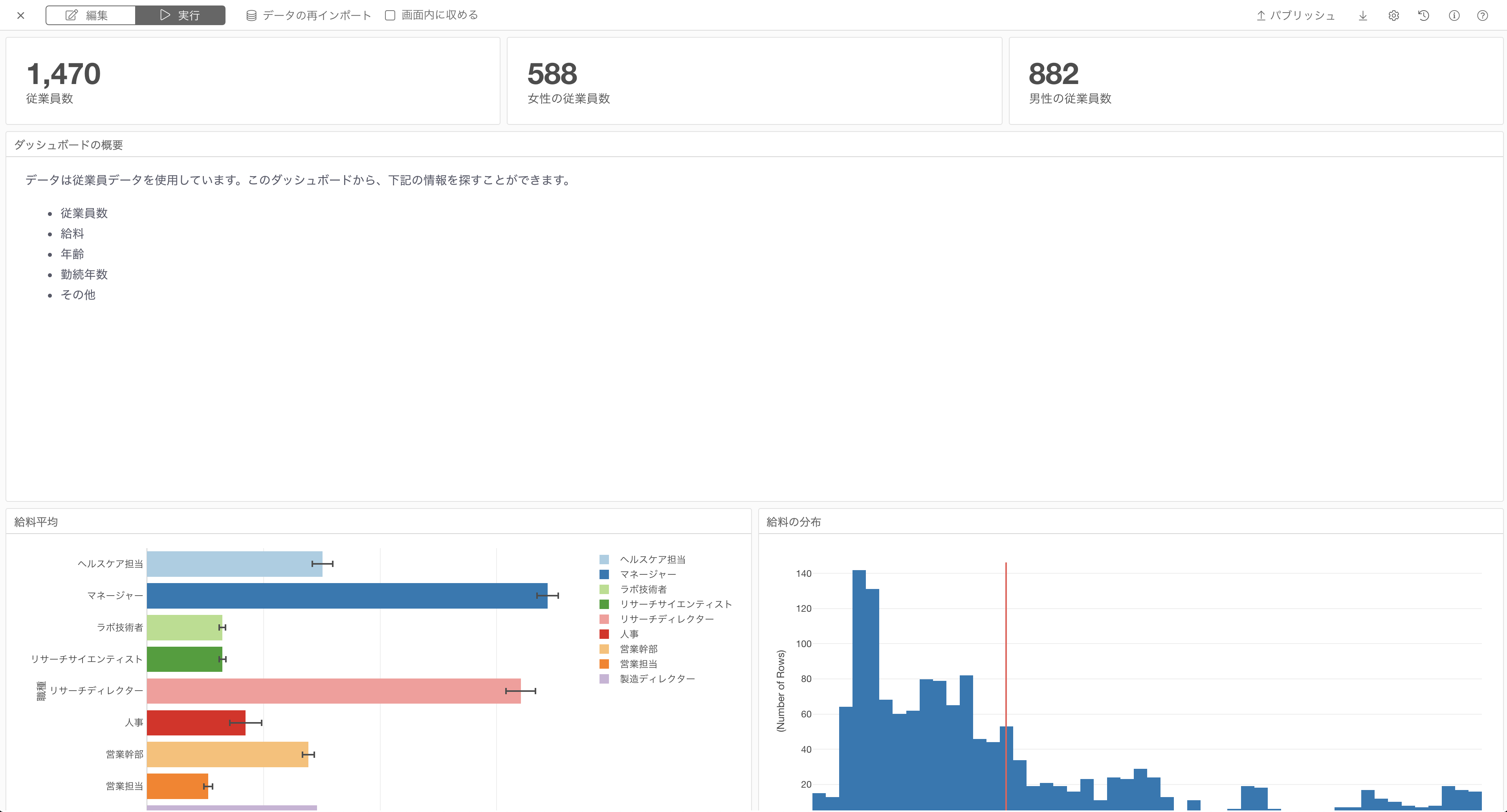
ギアアイコンから行の高さを変更できます。
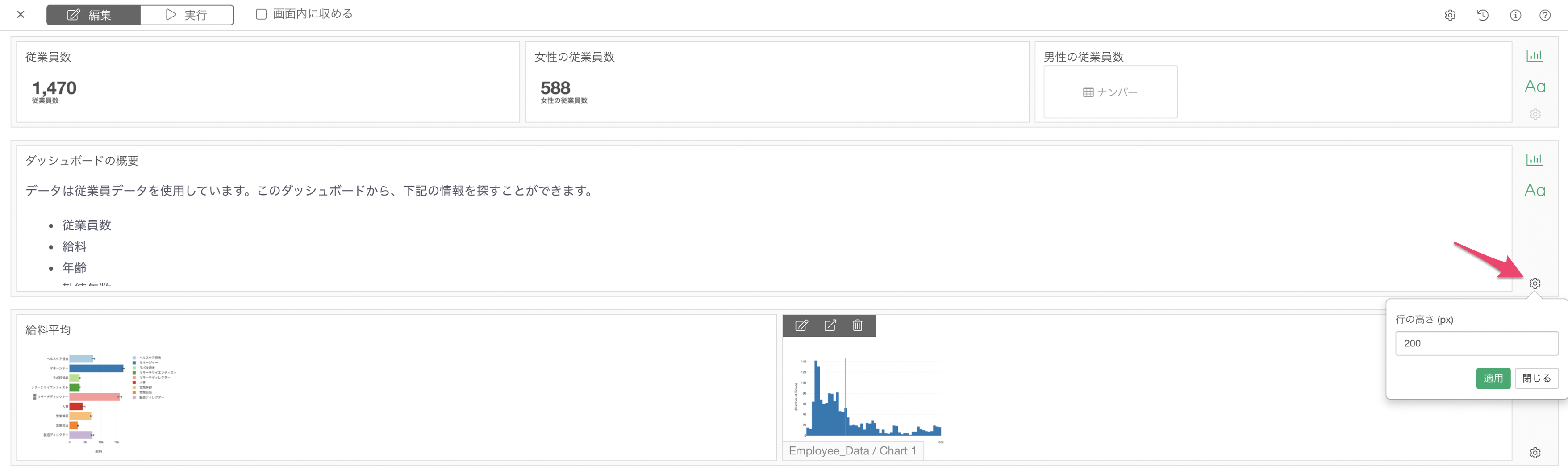
また、行ごとに異なる高さを設定することができます。
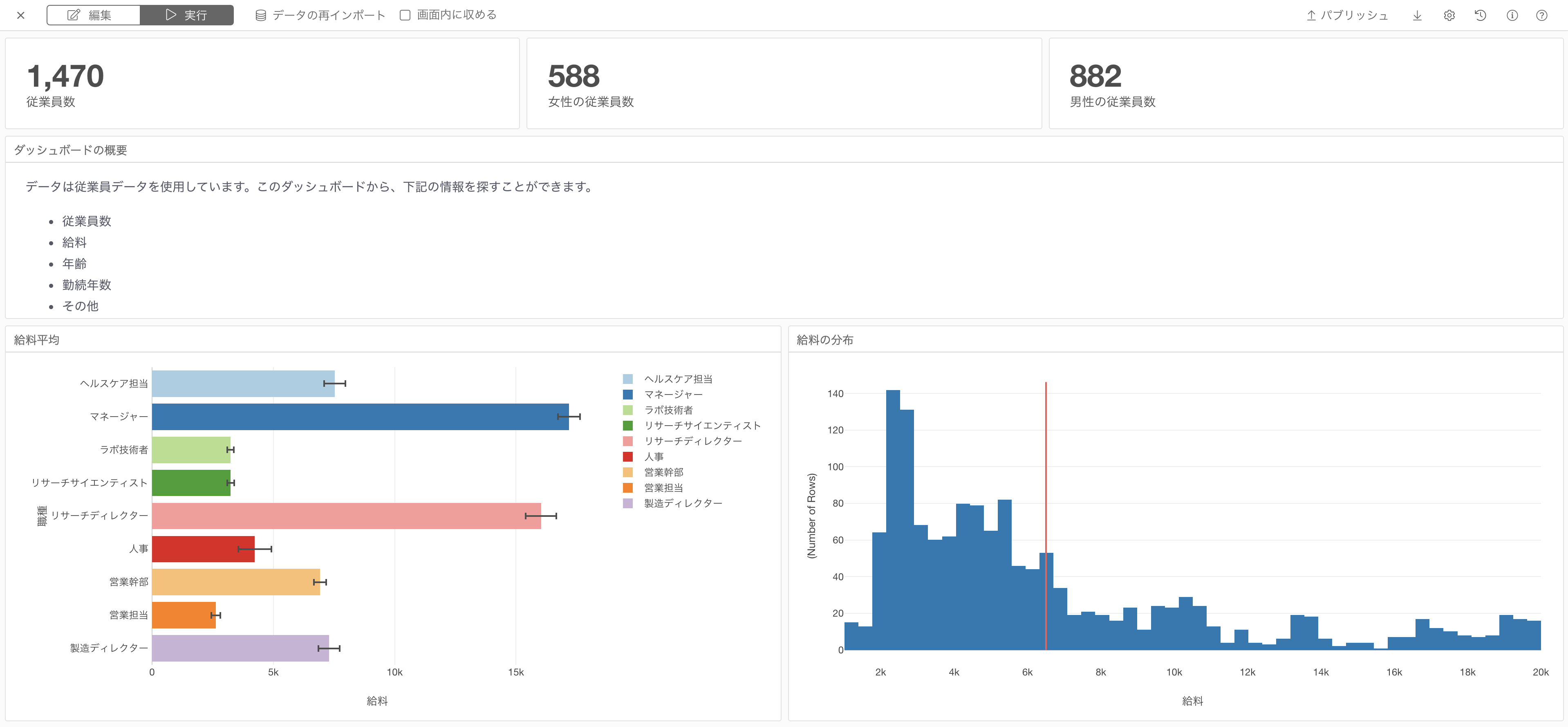
パラメーター
ドロップダウンとスライダーのダイナミックパラメーター
値のリスト(ドロップダウン)とスライダータイプの値を任意のデータフレームからダイナミック(動的)に取得できるようになりました。
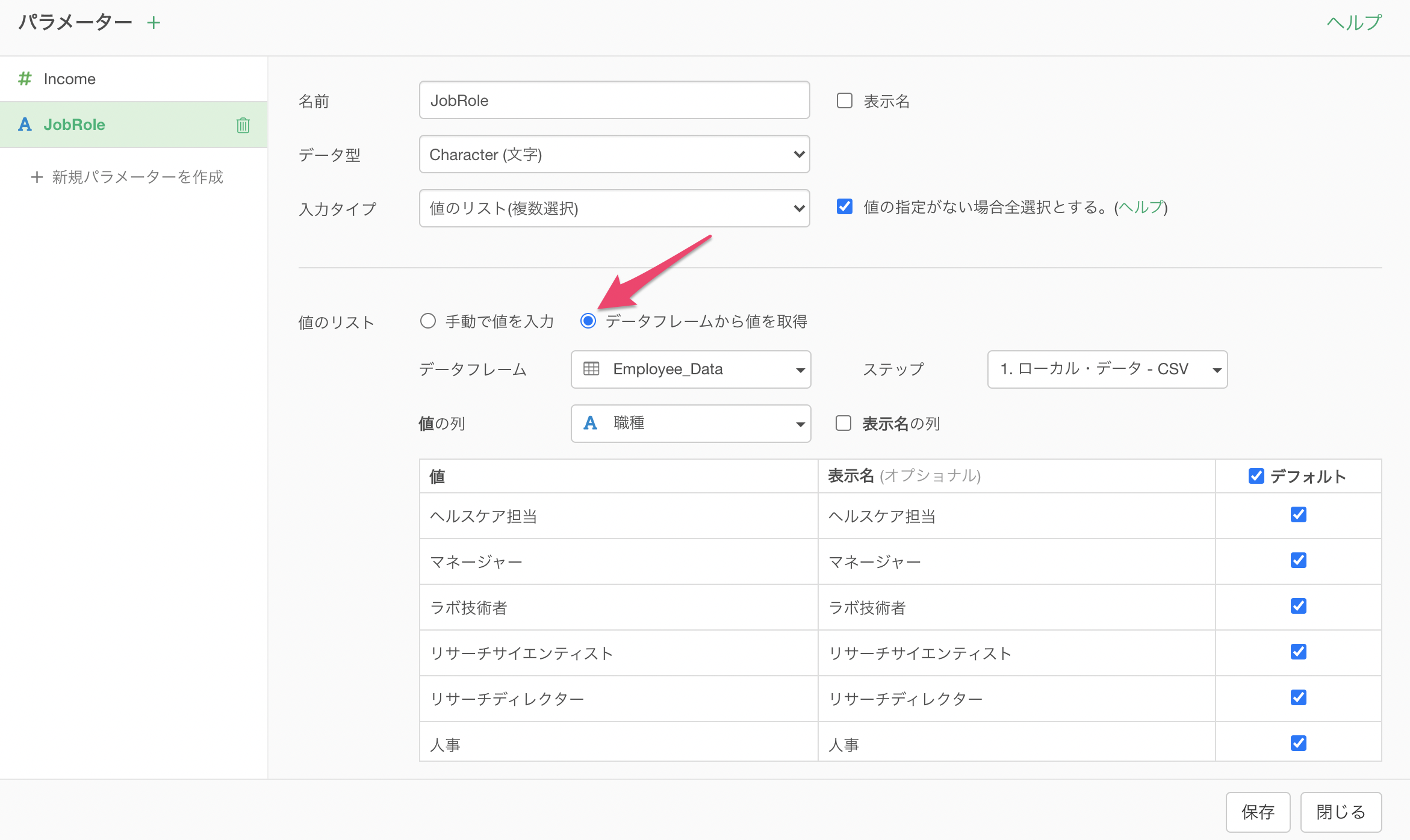
これまでのパラメーターではパラメーターの値を「コピー」することしかできませんでした。つまり、値をコピーするということは、データ自体が更新されたとしてもパラメーターの値は同じままになります。
この新しい「データフレームから値を取得」を使用すると、指定したデータフレームから値がダイナミックに抽出されます。
また、値のリストだけでなく、数値を使用して最小値と最大値を設定するスライダーもサポートしています。
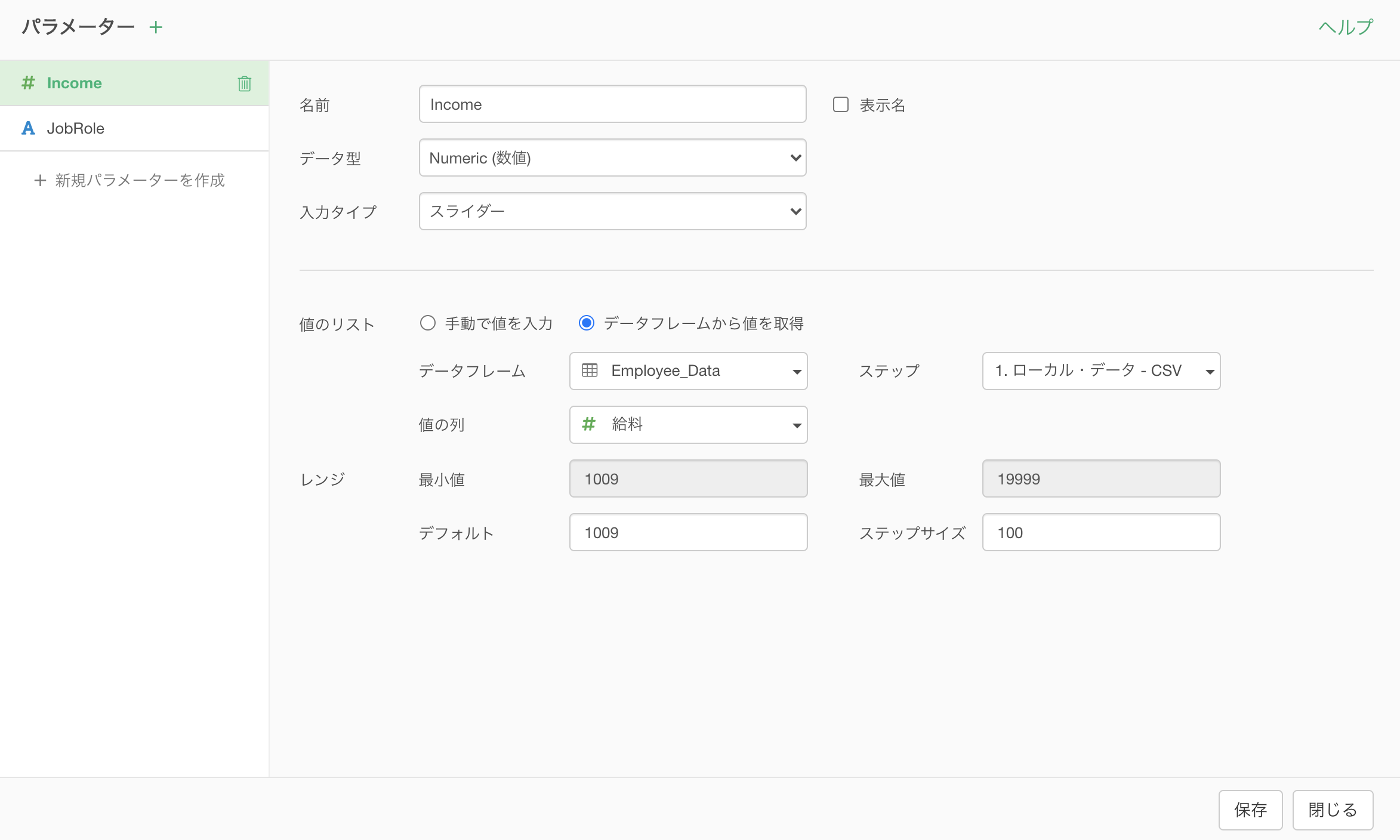
ダイナミックに値を取得する方法の優れている点は、新しいデータを再インポートして基になるデータが更新されたとしても、パラメーターの値もそれに伴い常に最新のものが反映されます。

つまり、サーバーにダッシュボード(またはデータ、チャート、アナリティクスなど)を公開してスケジュールすると、データが更新されていきますが、値のリストやスライダーでデータからダイナミックに値を取得している場合、パラメーターの値もサーバー側で更新されていきます。
以上になります!
しかし、このリリースには、さらに多くの機能拡張とバグ修正があります。確認したい場合は、リリースノートをご覧ください!
そして、ダウンロードページからExploratory v6.2をダウンロードして、ぜひ新しい機能を体験してみてください!