ランダムフォレストやロジスティック回帰などの二項分類の予測モデルで、予測値決定のための最適なしきい値を確認する方法
Exploratoryではアナリティクス・ビューからランダムフォレストやロジスティック回帰を使って、例えば、「この人はコンバージョンするのかどうか」あるいは「離職するのかどうか」といった、「TRUE(はい)」や「FALSE(いいえ)」で答えられるような質問への答えを予測するモデルを構築できます。
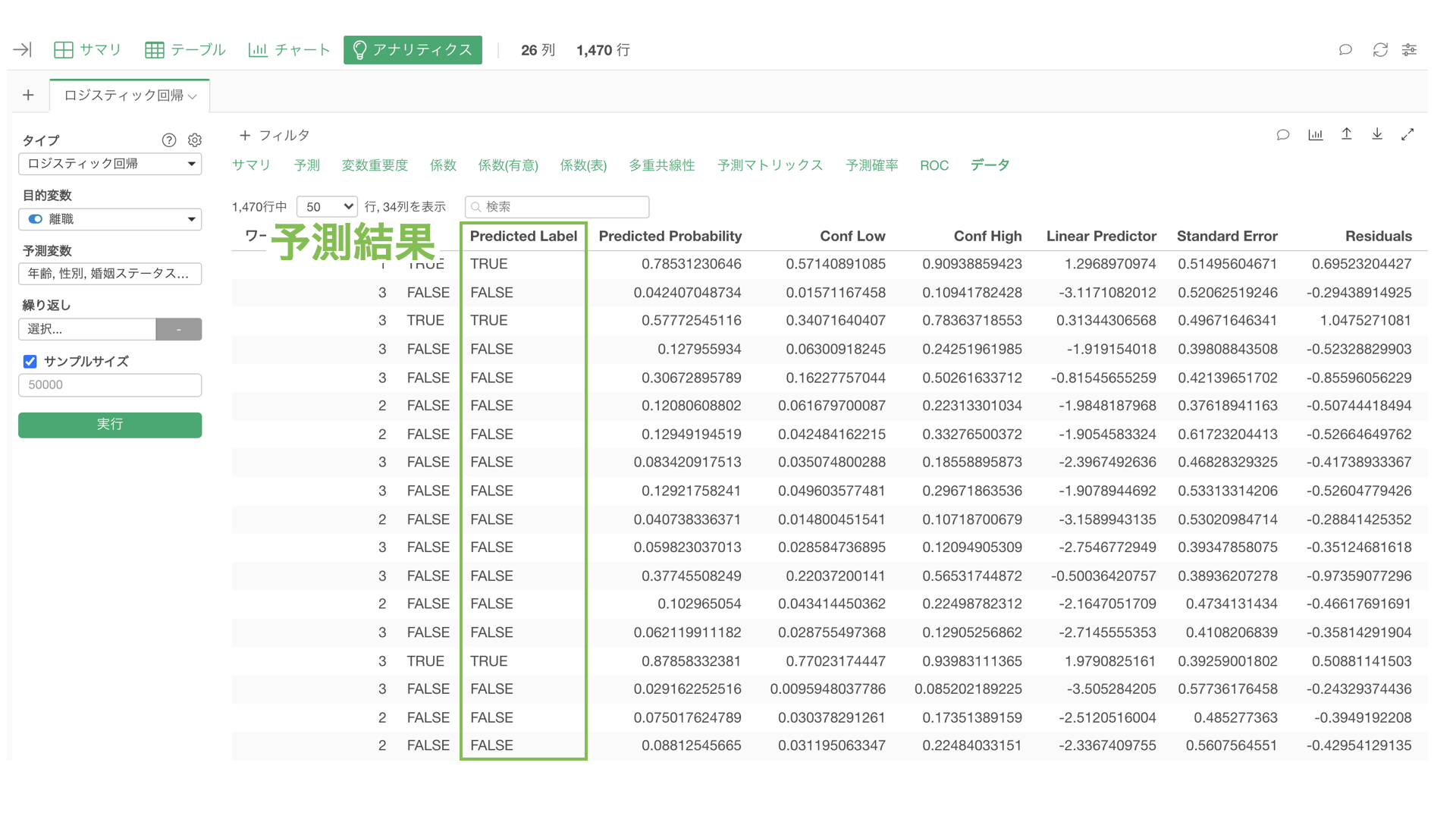
ただし、こういったモデルは、厳密には、TRUEになるかや、FALSEになるかを予測しているわけではなく、実際は「TRUEになる確率」を予測しています。
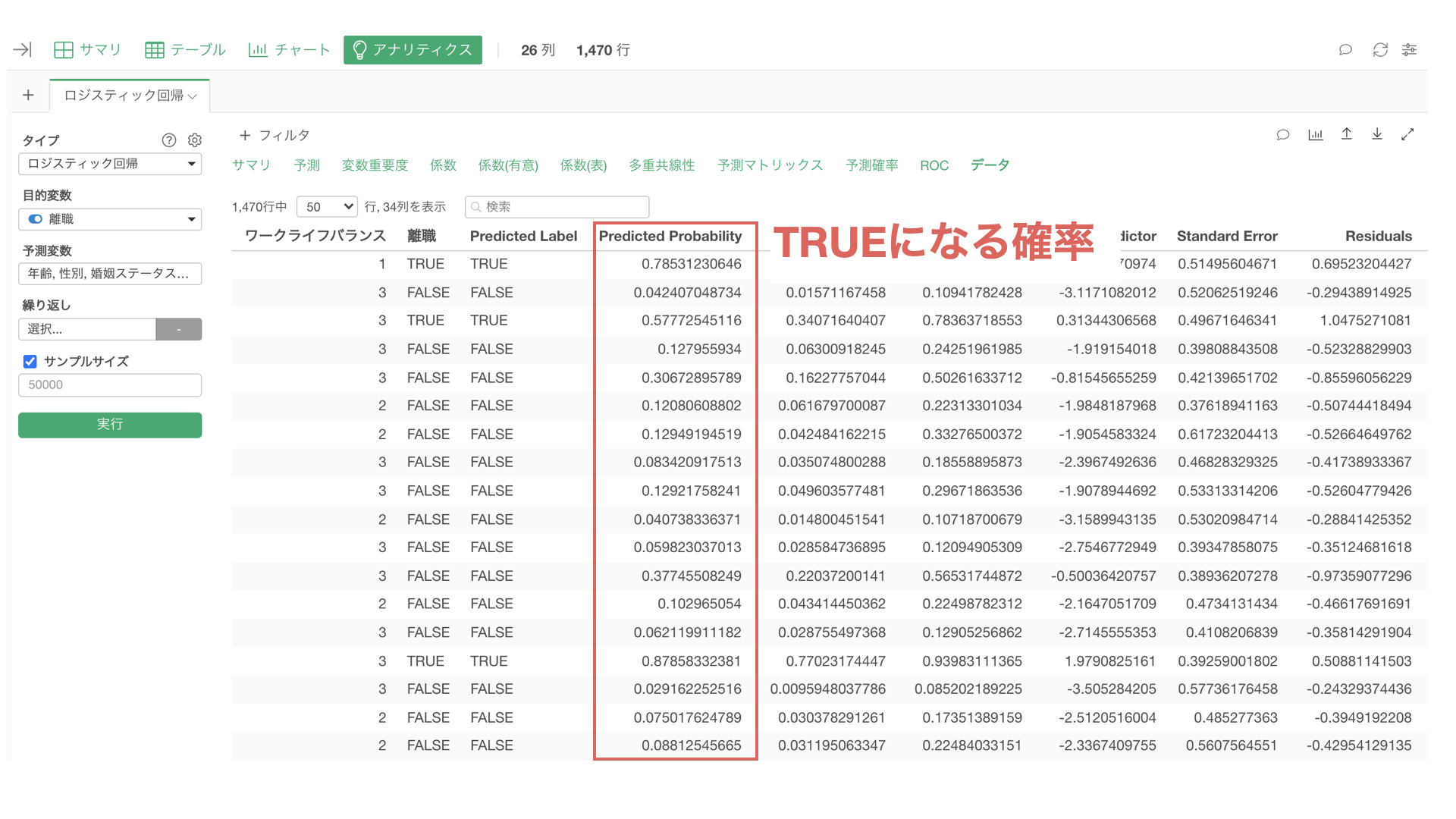
そこで、予測した「TRUEになる確率」をもとに最終的な予測結果をTRUEにするか、あるいはFALSEにするかを決めるために、「TRUEになる確率がどの程度であれば、TRUEという予測結果を返すか」を、「しきい値」として決める必要があります。
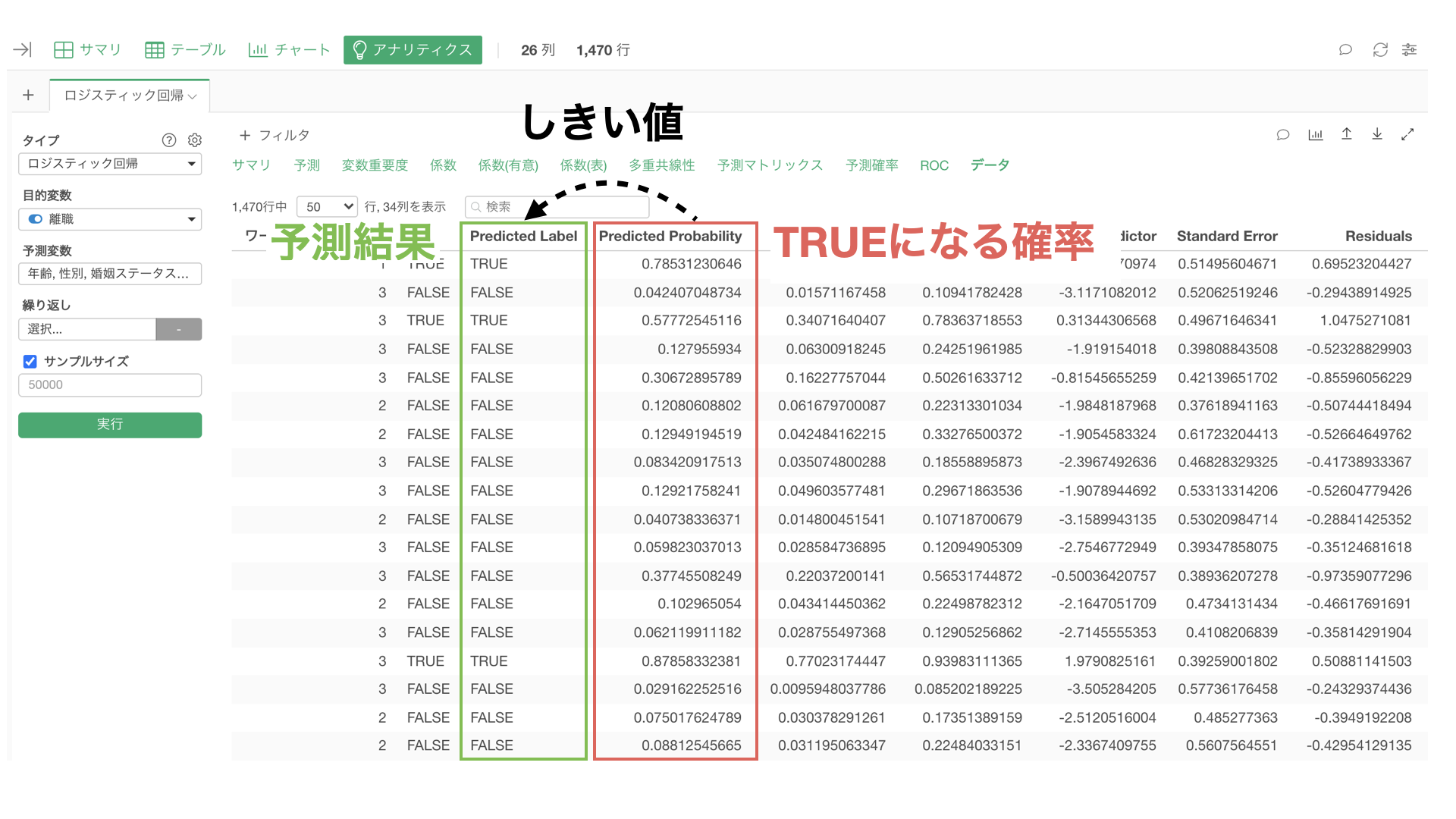
Exploratoryでは、TRUEになる確率が0.5(50%)を超えると、TRUEという予測結果が返るように、デフォルトのしきい値を設定していますが、実はデフォルトのしきい値が、「TRUE」や「FALSE」を予測するうえで、常に最適なしきい値であるとは限りません。
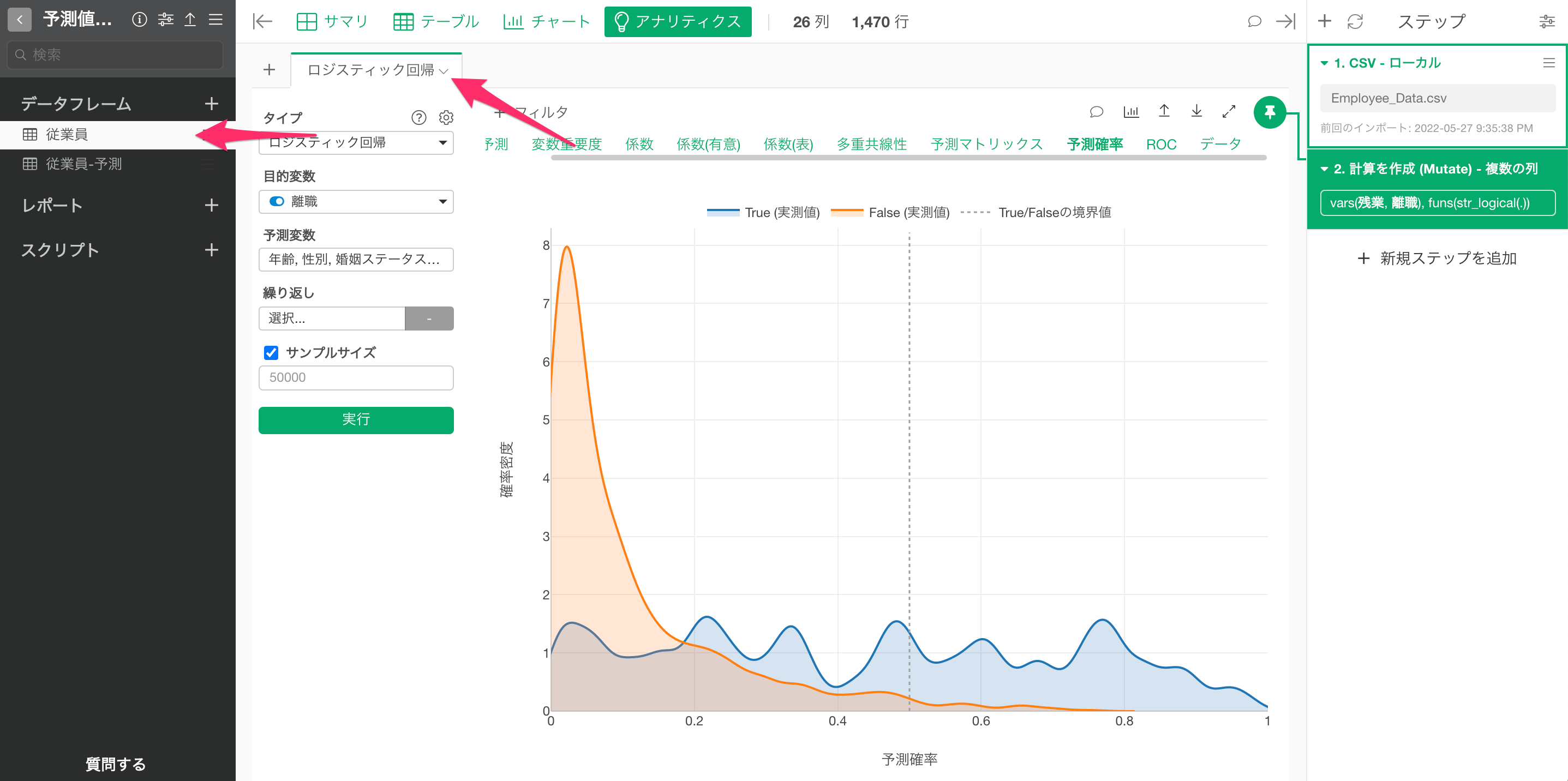
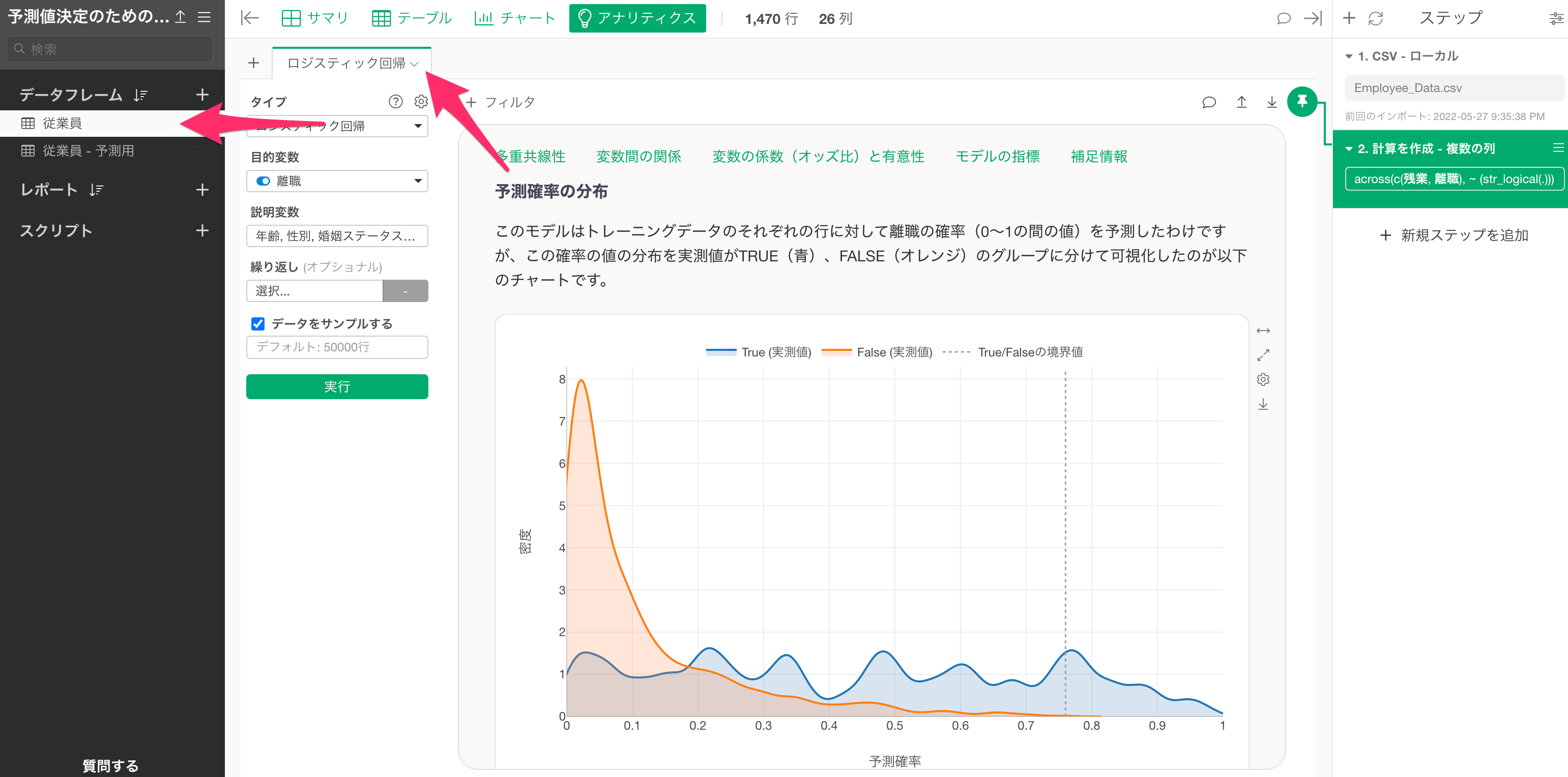
例えば、上記のチャートは、従業員の離職を予測するロジスティック回帰のモデルにおける離職の予測確率を、実際のデータでTRUEだったとき(青)と、FALSE(オレンジ)だったときに分けて、それぞれの分布を密度曲線として可視化したものになります。
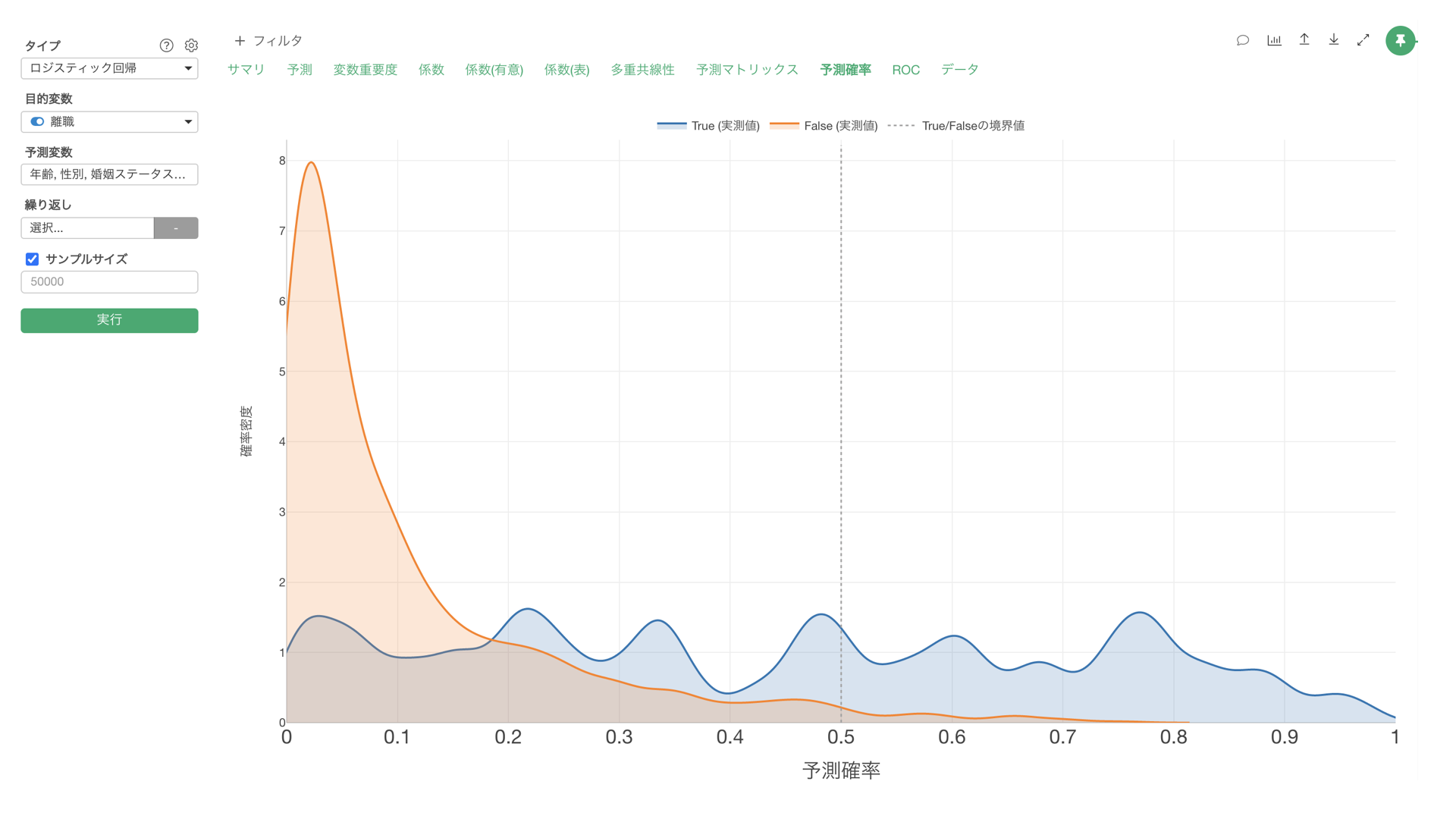
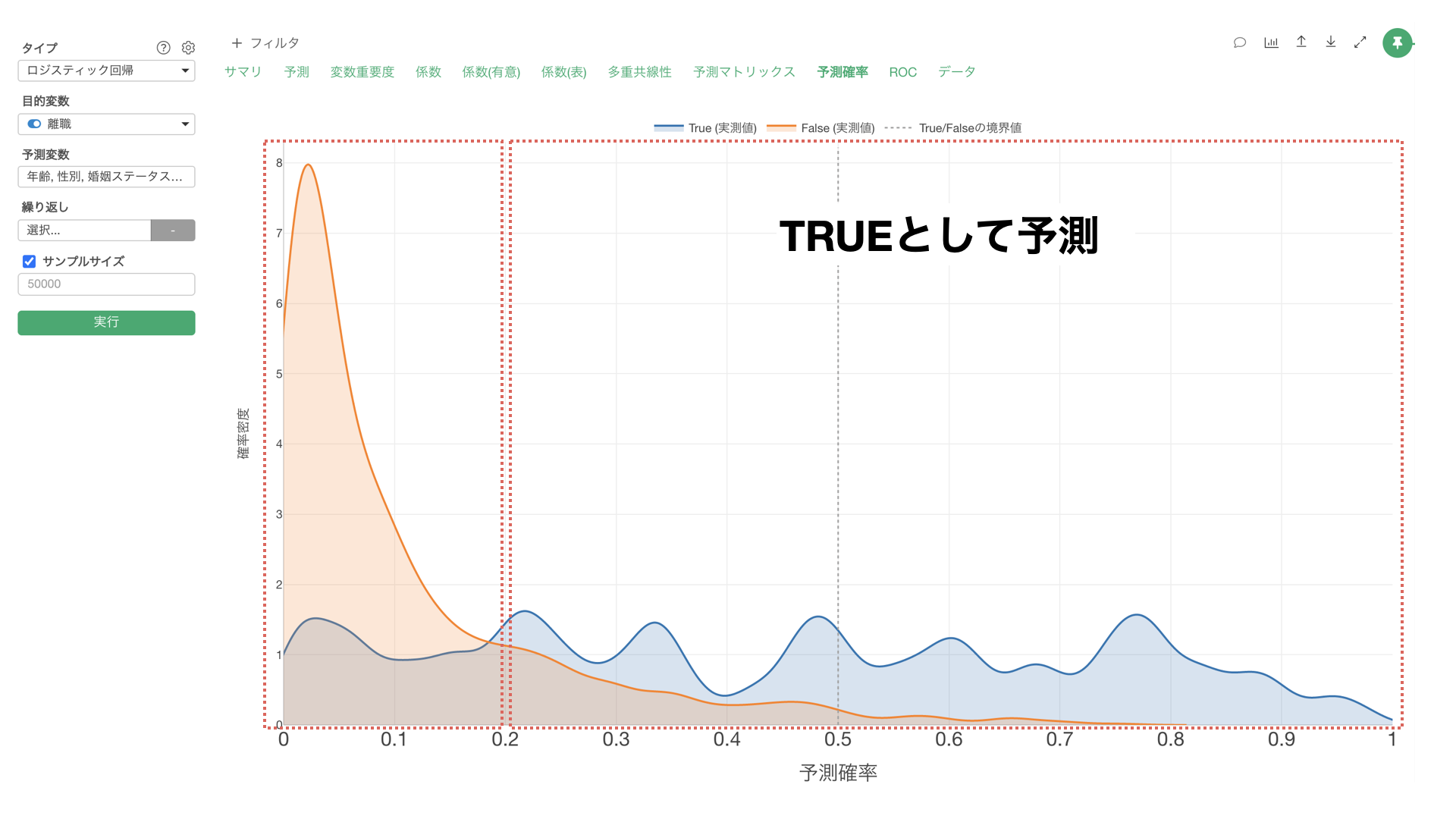
Exploratoryのデフォルトのしきい値は0.5(50%)となるため、「TRUEになる確率」が0.5(50%)の以上の データに対しては、実際に離職しているかどうかとは関係なく、TRUEとして予測することになります。
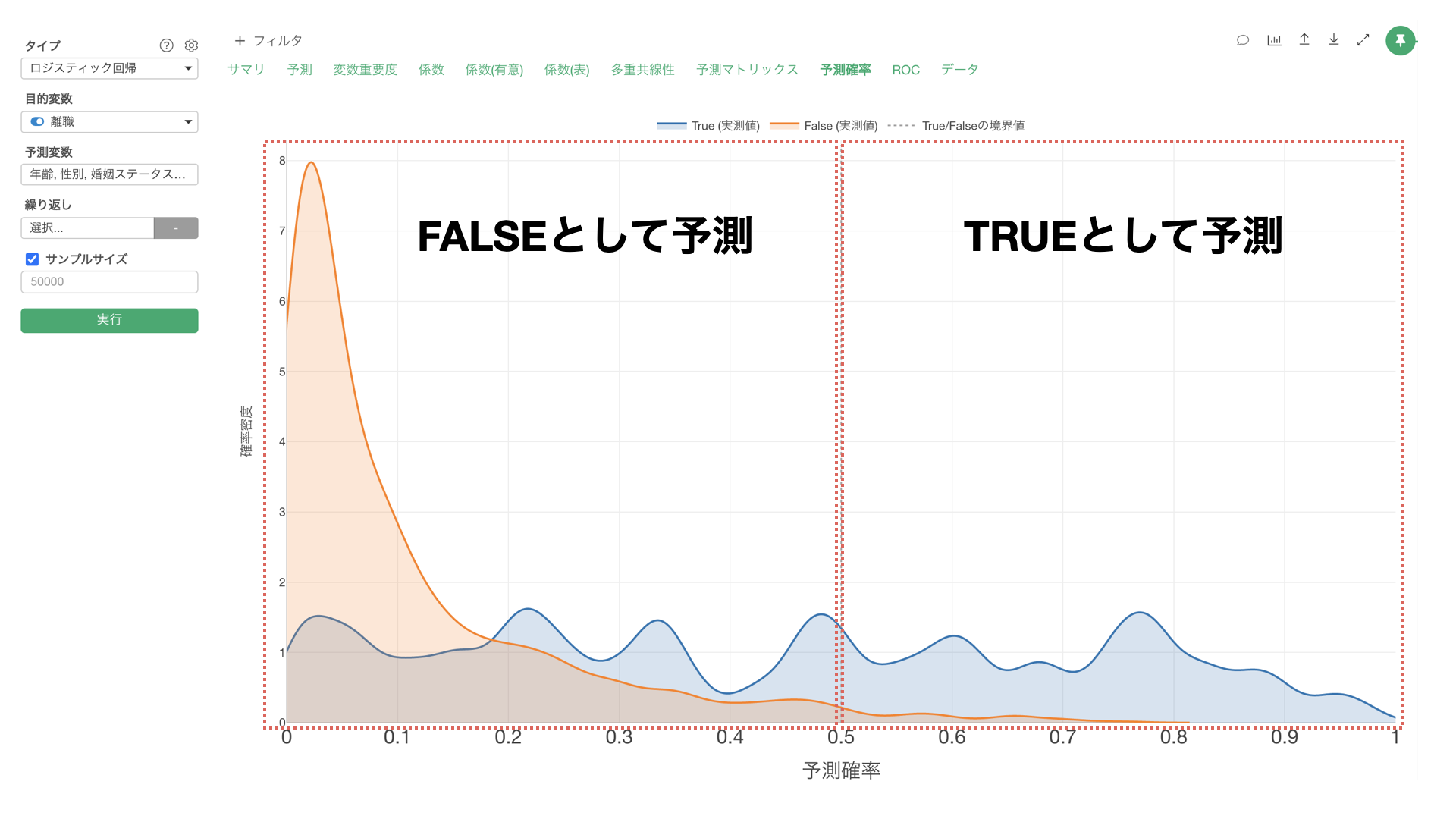
しかし実際には、TRUEになる確率が0.2(20%)から0.5(50%)の間、つまりはFALSEとして予測されるデータにも多くのTRUEのデータが含まれていることを確認できます。
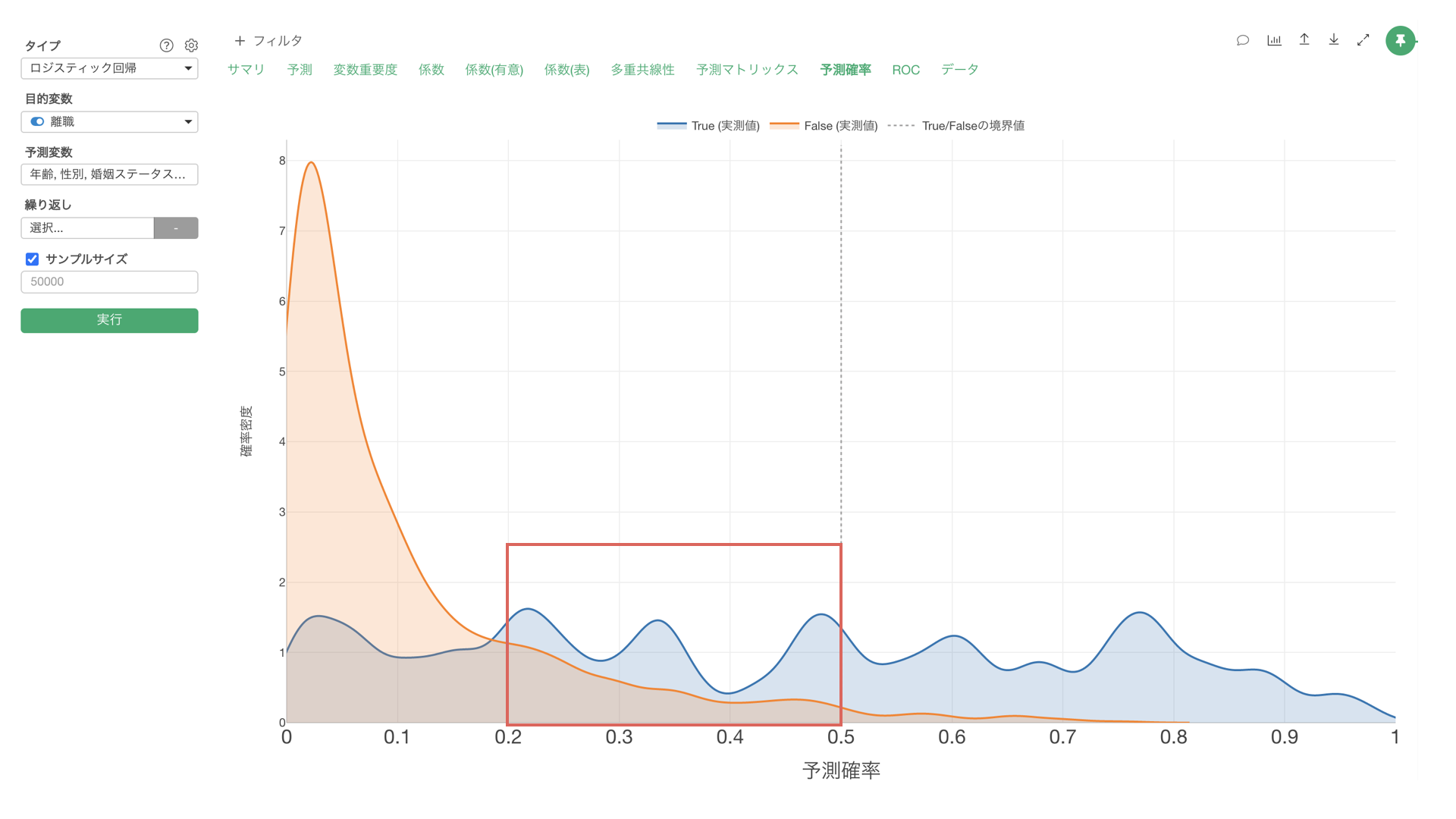 このようなモデルの場合、TRUEになるしきい値を0.5(50%)に設定するより、0.2(20%)あたりに設定した方が、TRUEとFALSEをよりバランスよく予測できていると考えることができます。
このようなモデルの場合、TRUEになるしきい値を0.5(50%)に設定するより、0.2(20%)あたりに設定した方が、TRUEとFALSEをよりバランスよく予測できていると考えることができます。
しかし、実際にしきい値を決めるときに、そのしきい値を0.2(20%)すべきなのか、あるいは0.3(30%)にすべきなのかを、目視で判断することは、難しくなっています。
そこで、このノートでは予測値決定のための最適なしきい値を確認する方法を紹介します。
前提:利用データとモデル
今回はサンプルデータとして、従業員データを使用していきます。このデータは1行が1従業員のデータで、列には年齢や職種、離職など従業員の属性を表す列があります。
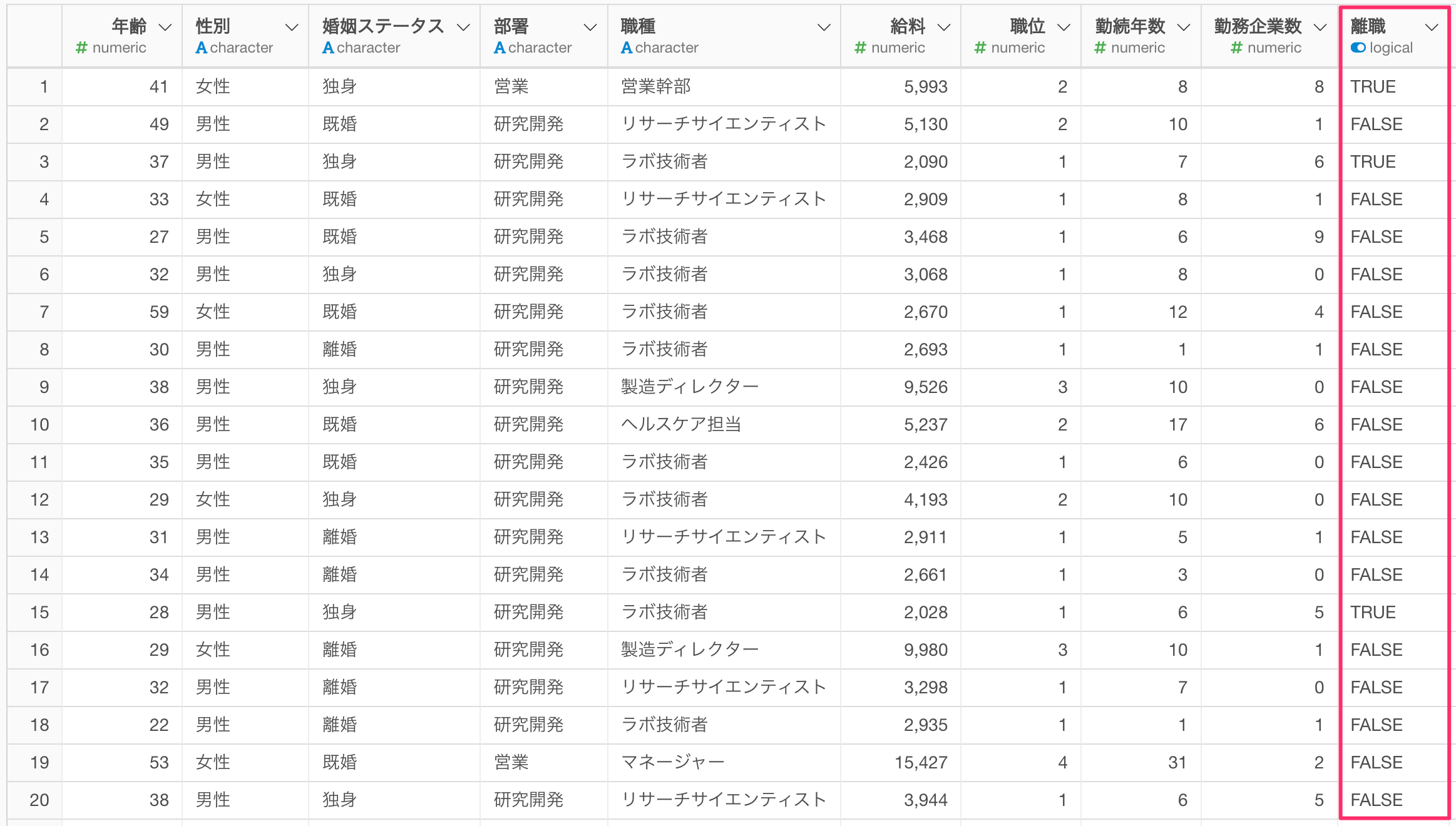
上記の「従業員」というデータフレームで、従業員の「離職」を予測するロジスティック回帰のモデルを構築しており、そちらのモデルを利用することを前提に、今回は、話を進めていきます。
構築済みのモデルに対する最適なしきい値を確認する
現在のExploratoryデスクトップ(v10.7時点)では、アナリティクス・ビューでモデルを構築することに利用したデータフレームを、最適なしきい値を確認することに使い回すことには対応していないため、以下の手順で最適なしきい値を確認します。
- ブランチを利用して、モデル構築に利用したデータフレームと同じ内容のデータフレームを用意する、
- 1で用意したデータフレームを使って、予測の「ステップ」を追加する。
- 最適なしきい値を確認する。
1. ブランチを利用して、モデル構築に利用したデータフレームと同じ内容のデータフレームを用意する
初めに、しきい値を確認したいモデルを構築したステップに移動します。
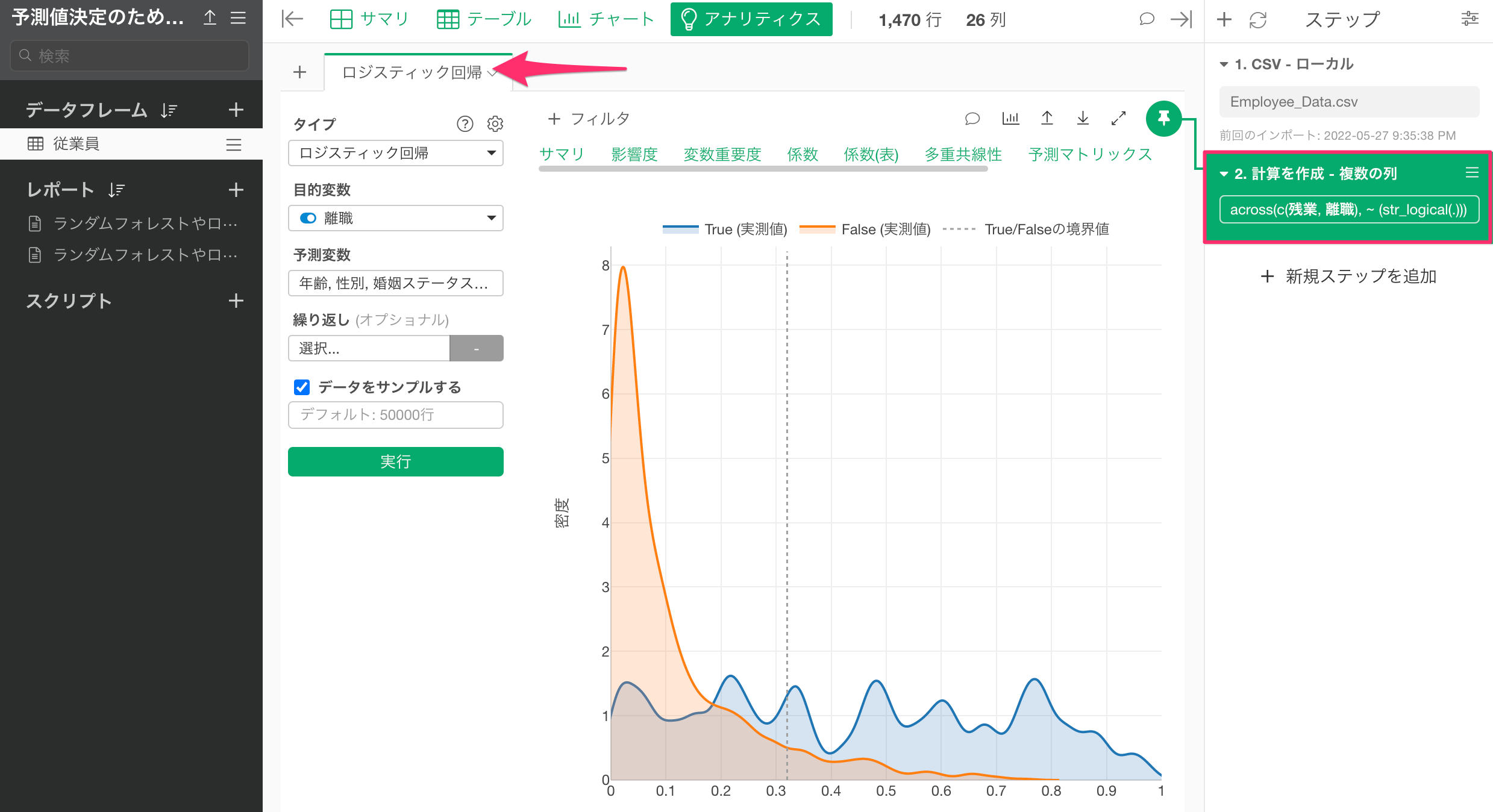
続いてステップのブランチアイコンをクリックして、ブランチを作成をボタンをクリックします。
任意のブランチ名を指定し、ブランチの作成を確認します。
2. 予測の「ステップ」を追加する
続いて、作成したブランチのステップメニューから、「モデルで予測(アナリティクス・ビュー)」を選択します。
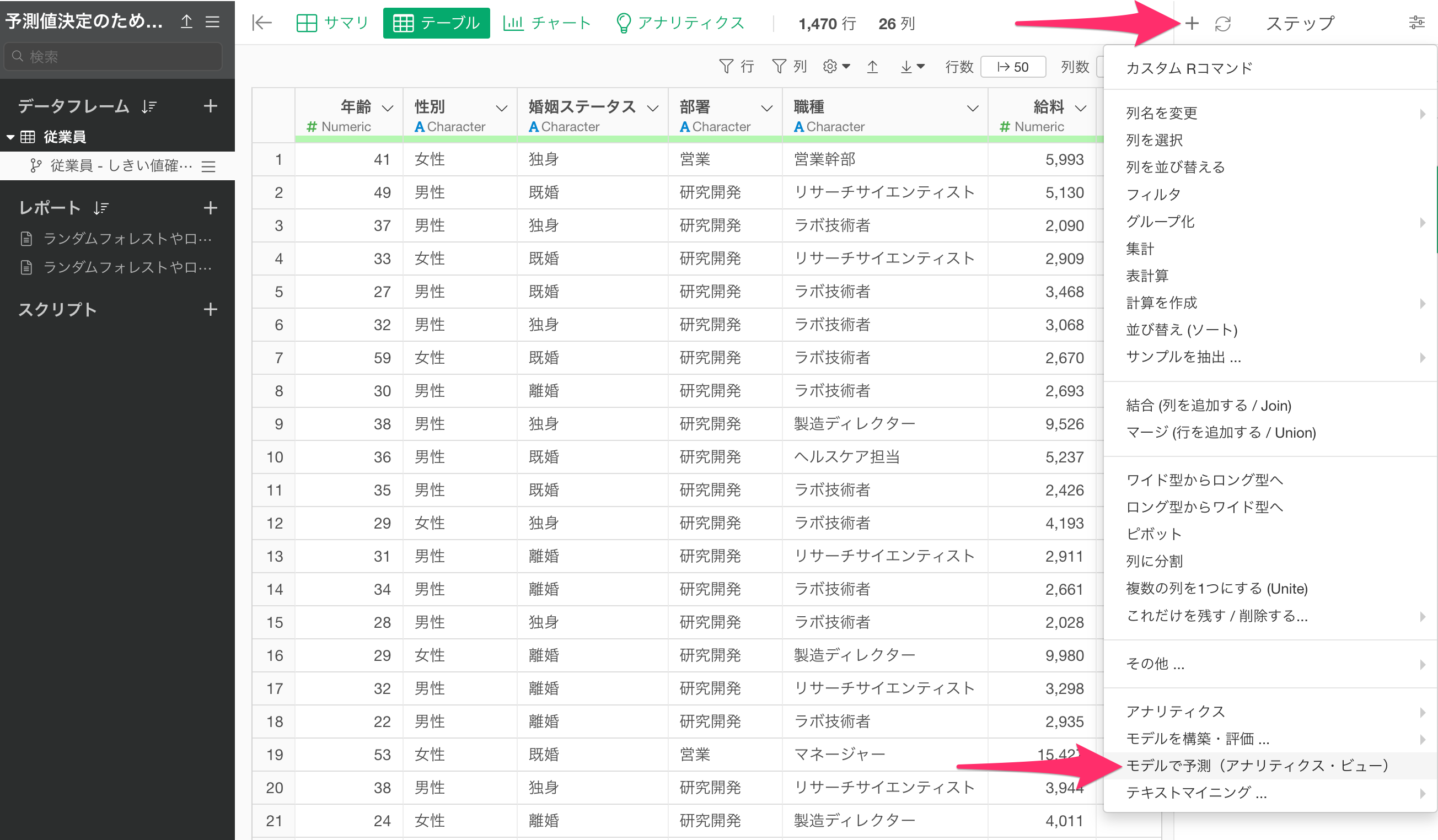
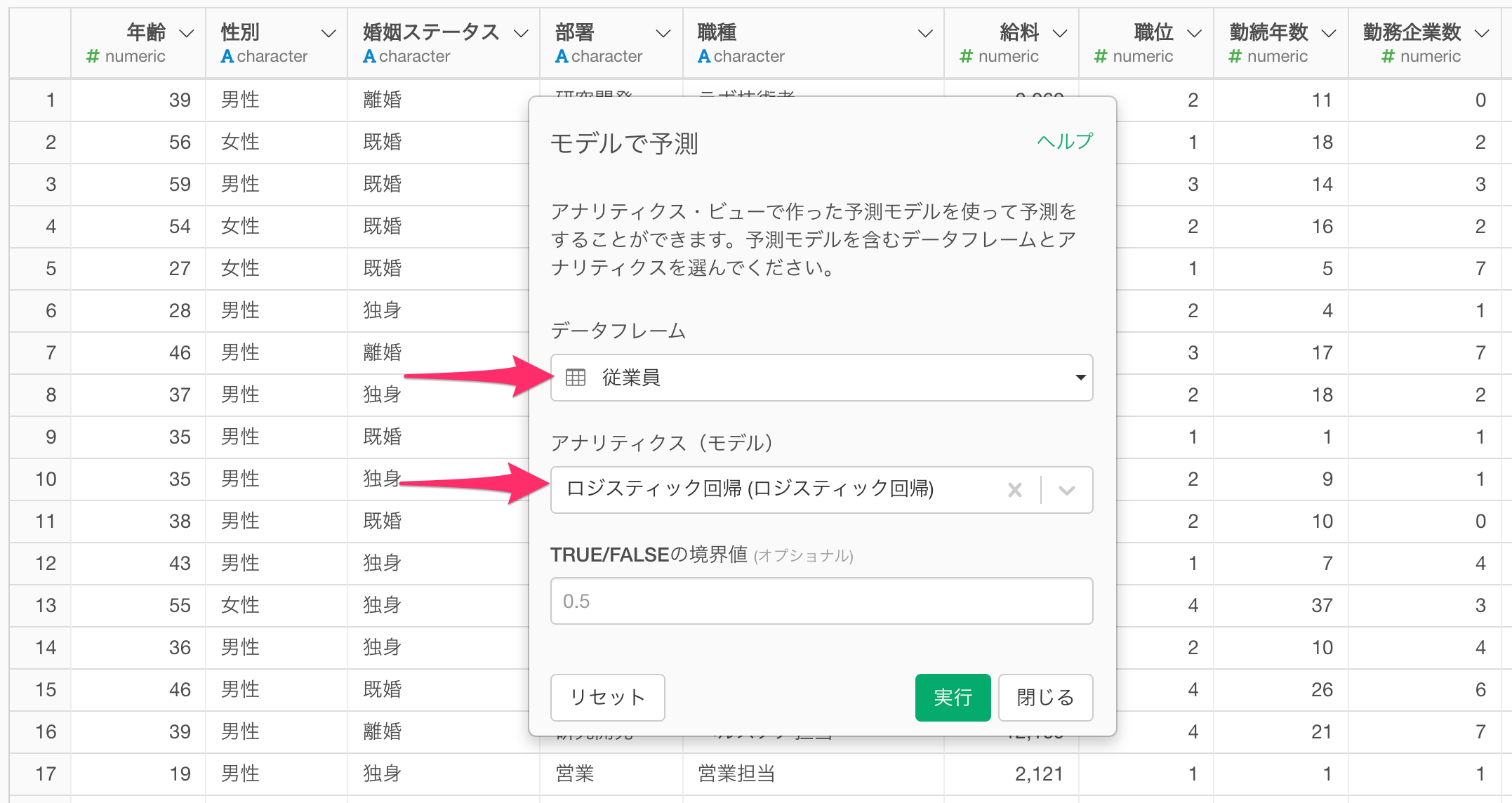
「モデルで予測」のダイアログが表示されたら、予測モデルを作成していたデータフレームを選択して、「アナリティクス(モデル)」に、予測に使いたいモデルを選択し、実行します。
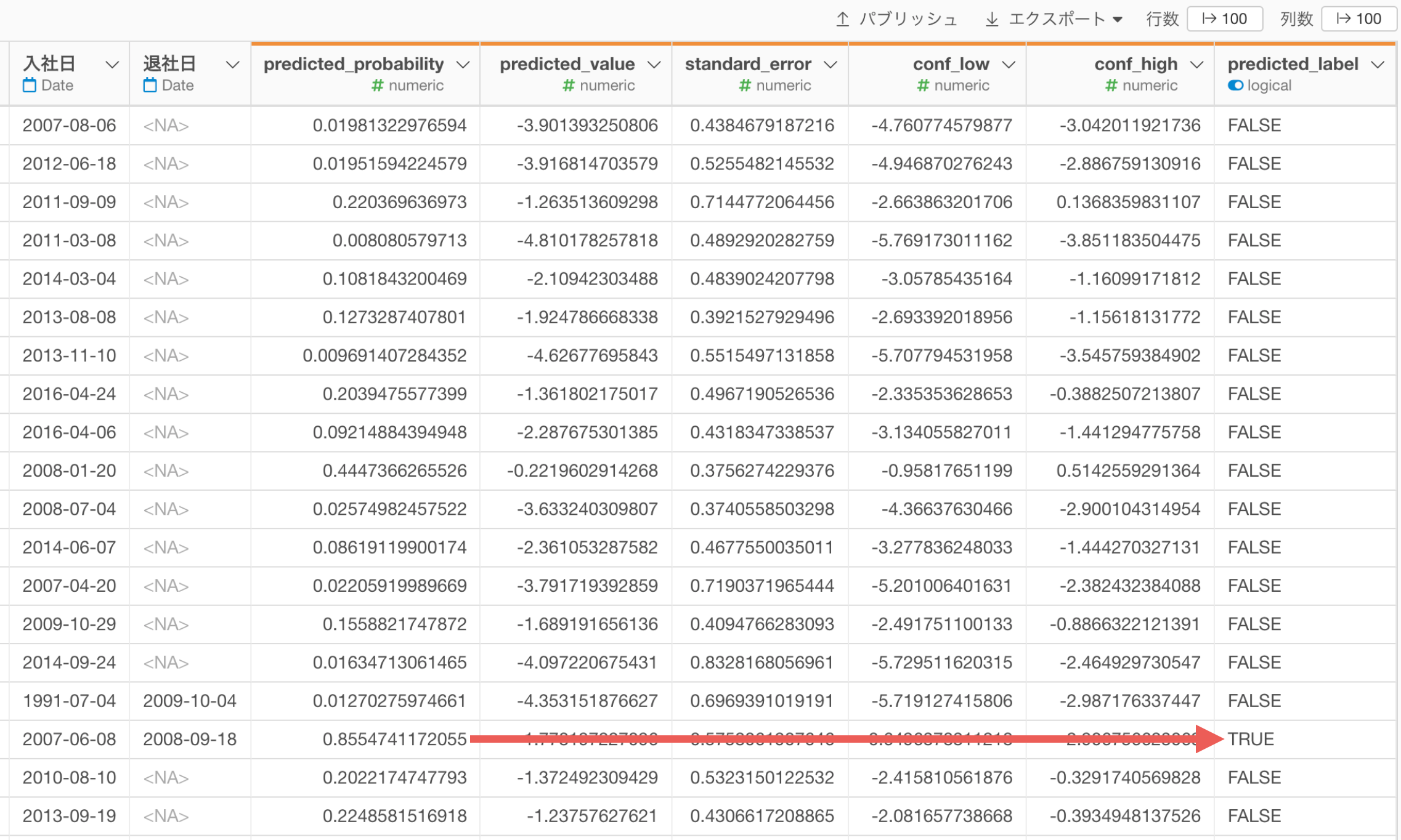
すると、予測のステップが追加され、「predicted_probability(TRUEの予測確率)」や、「predicted_label(予測結果)」の列が追加されます。
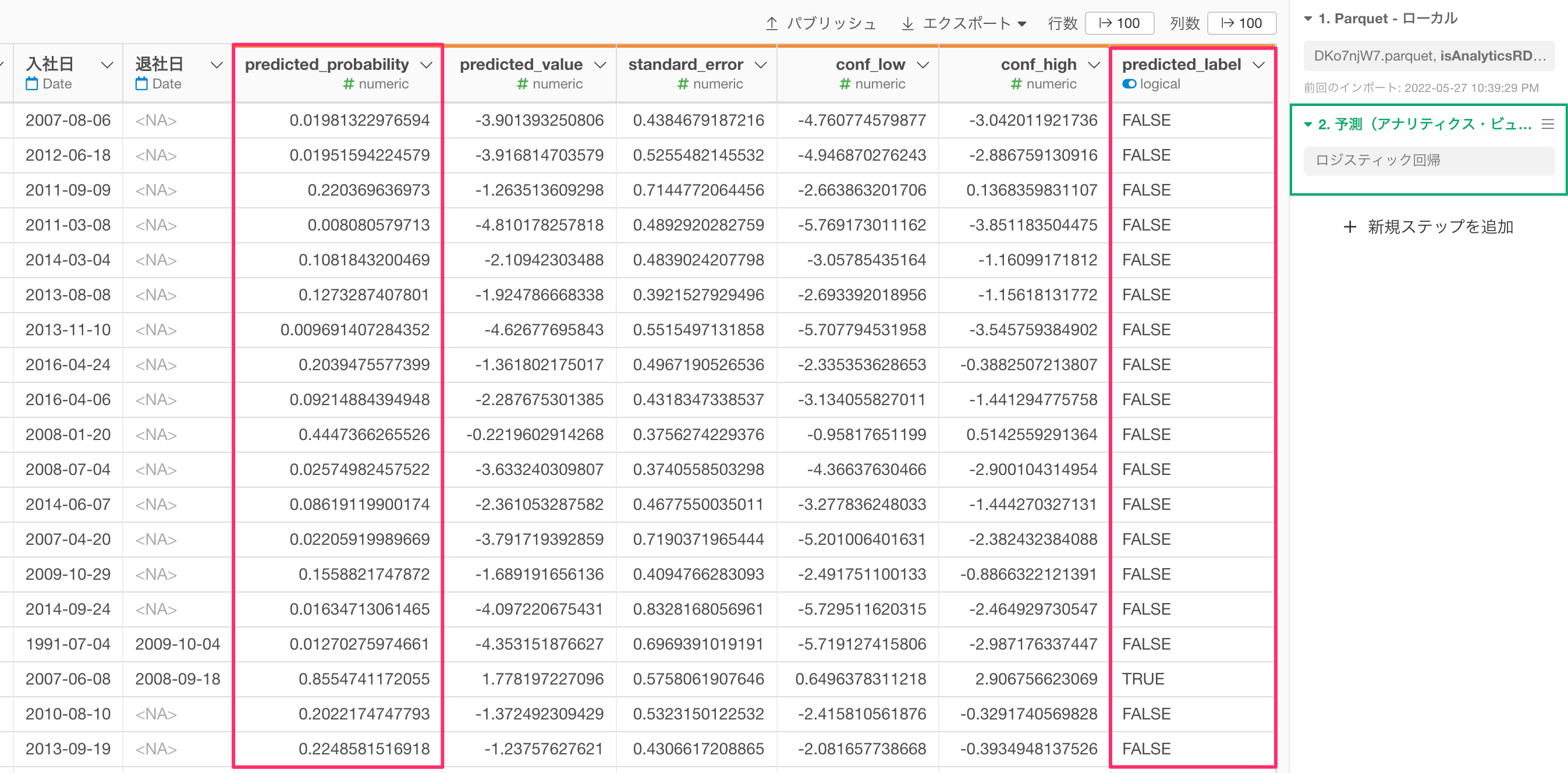
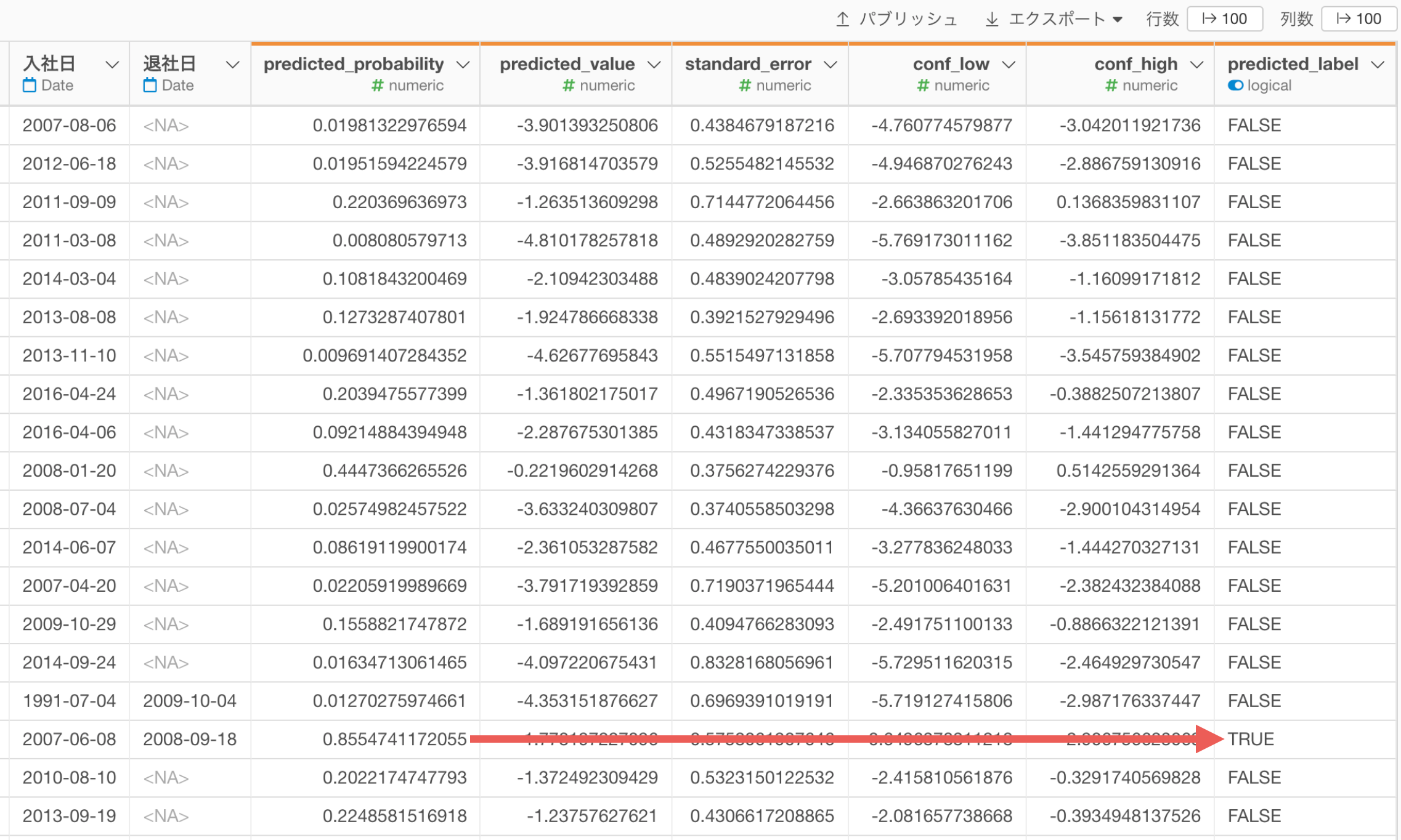
なお、TRUEという予測結果を返すしきい値である「TRUE/FALSEの境界値」のデフォルトの設定は0.5(50%)になるので、「predicted_probability」が0.5(50%)以上であれば、「predicted_label」はTRUEになっています。
3. 最適なしきい値を確認する
続いて、離職を予測するうえで、最適なしきい値を調べていきます。
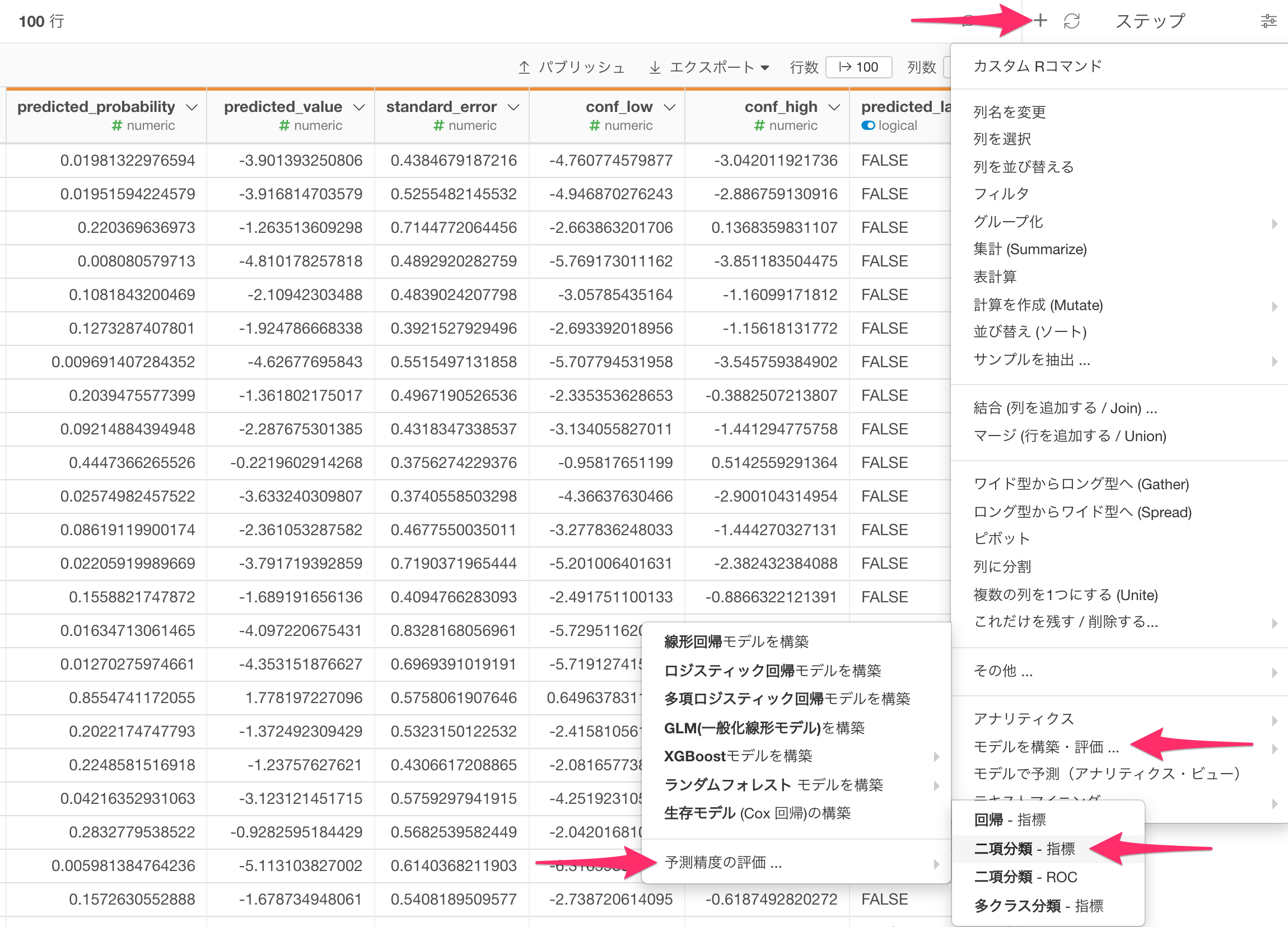
現在開いている(先程作成した)ブランチのデータフレームのステップメニューを開き、「モデルを構築・評価…」、「予測精度の評価…」、「二項分類 - 指標」を選択します。
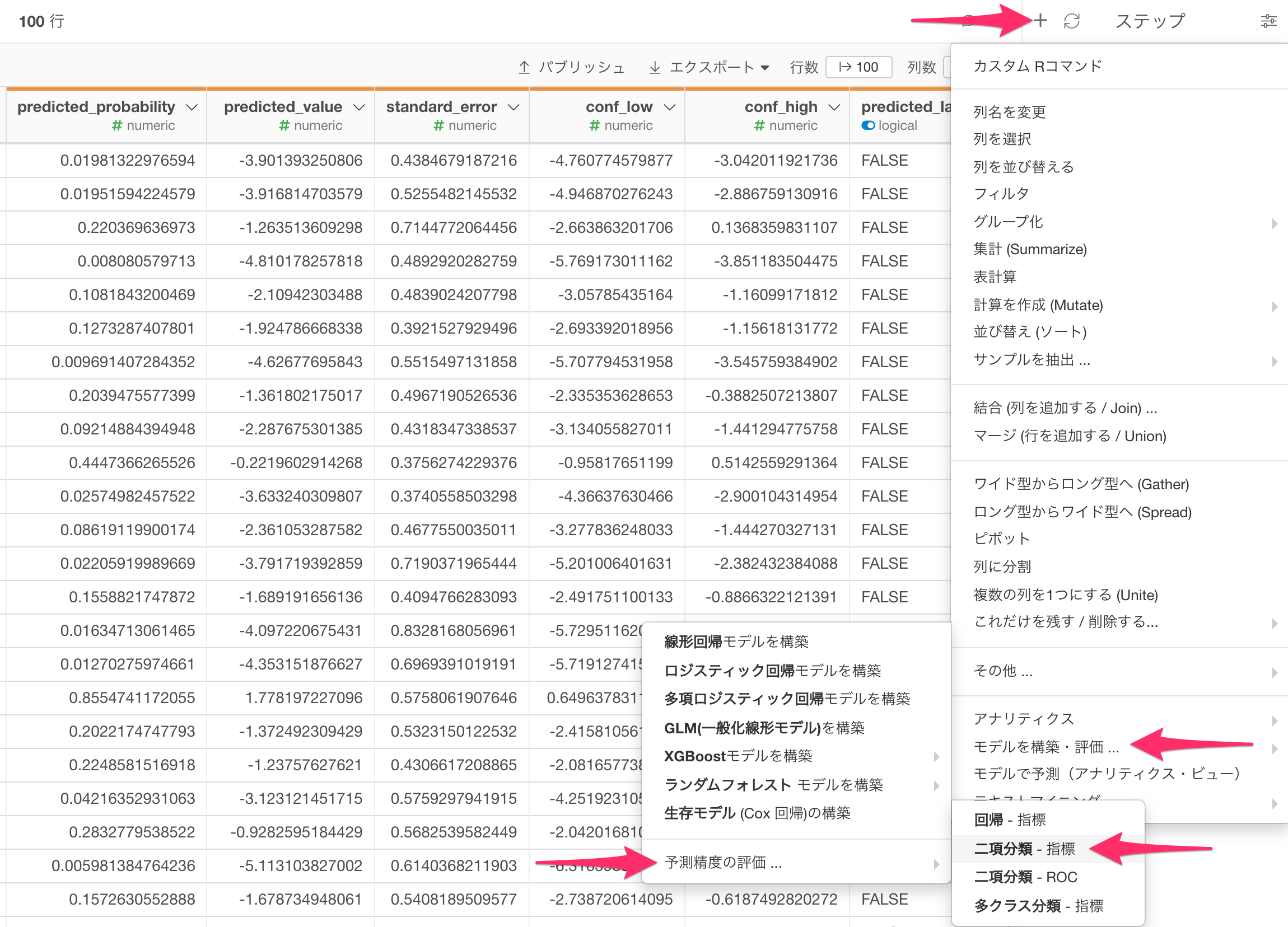
すると、「二項分類予測精度の評価 - 指標」のダイアログが表示され、「予測された確率の列」には自動でTRUEの予測確率である「predicted_probability」列が選択されますので、「実際の値の列」には、予測モデルにおける目的変数(今回の例では「離職」)を選択します。
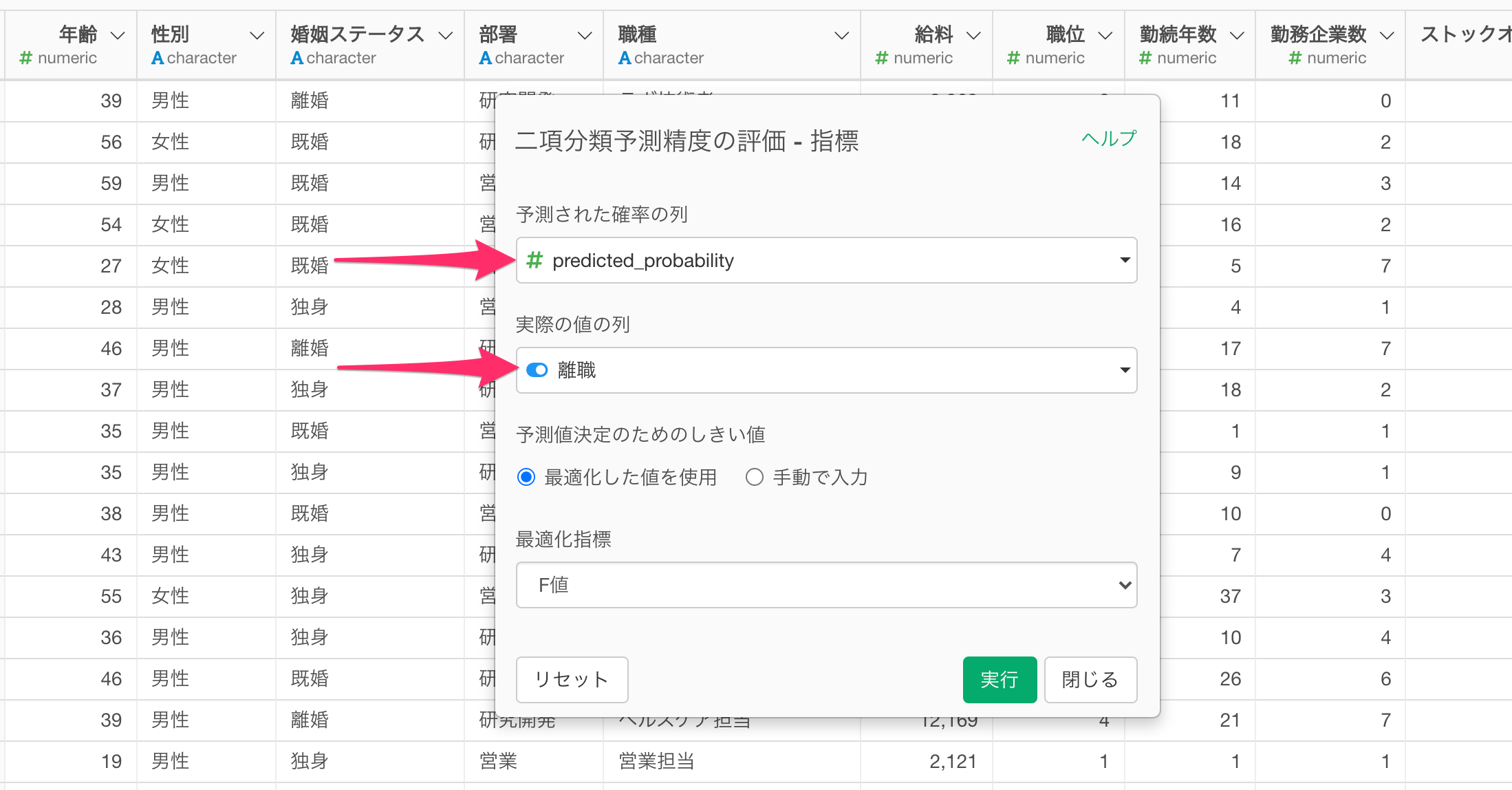
続いて、「予測値決定のためのしきい値」の「最適化した値を使用」にチェックを付けて、任意の指標を選択します。
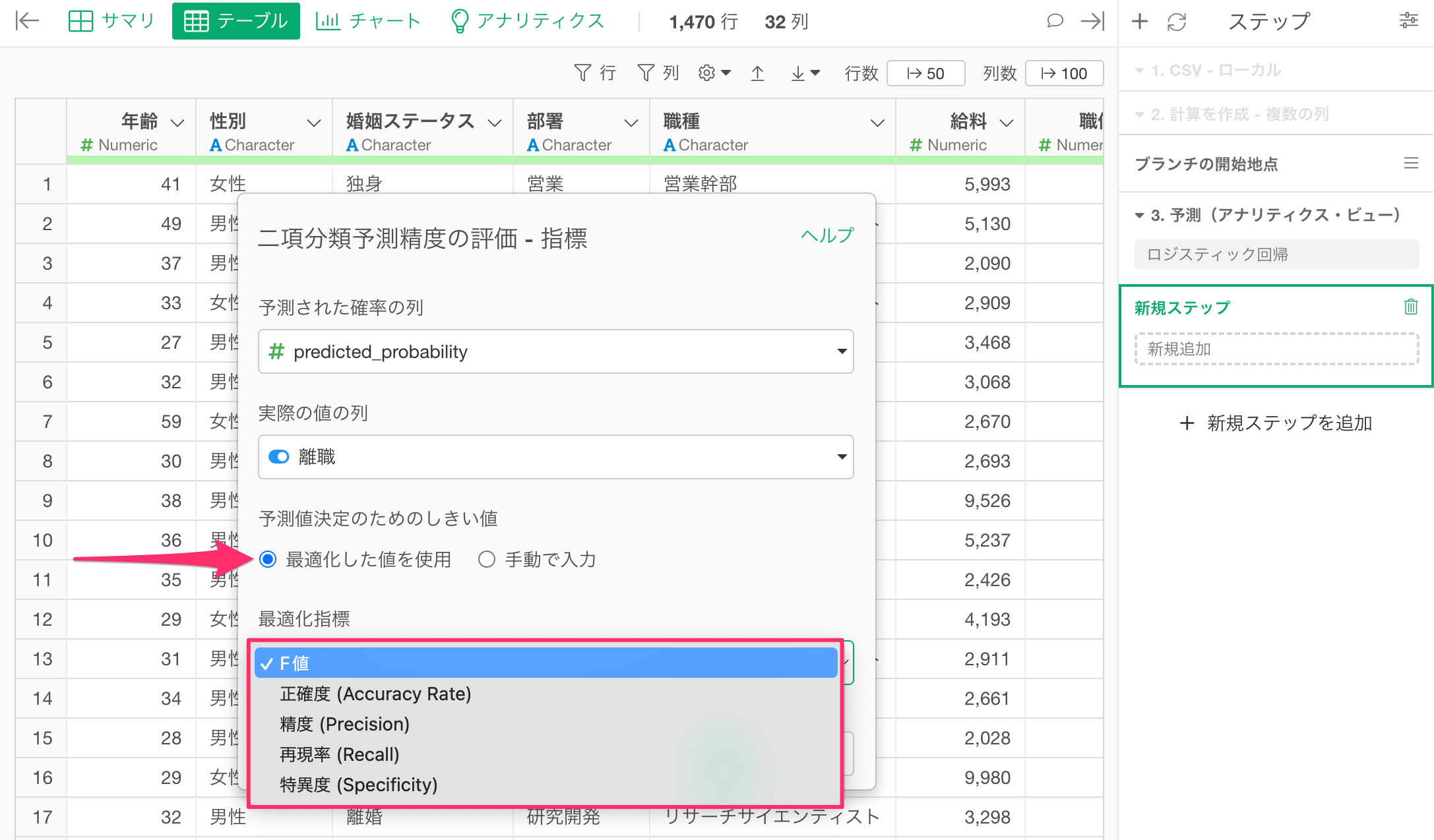
任意の指標を選択したら実行します。(今回の例ではTRUEとFALSEをバランス良く予測するために「F値」を選択していますが、TRUEと予測することに重きをおきたい場合は、再現率を選択することになります。)
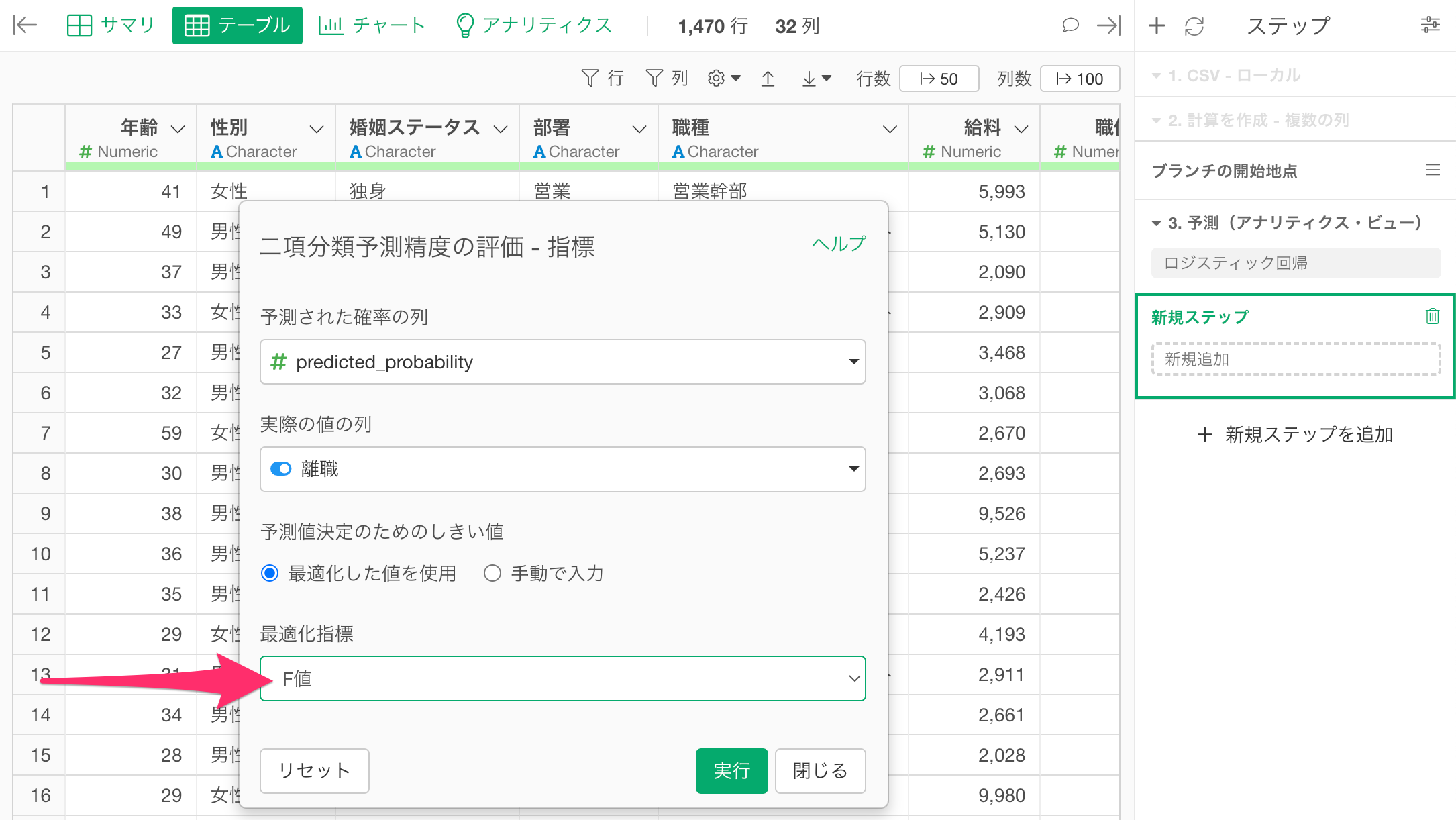
すると、「二項分類予測精度の評価」のステップが追加され、最後の列に、最適な「threshold(しきい値)」を確認することができます。
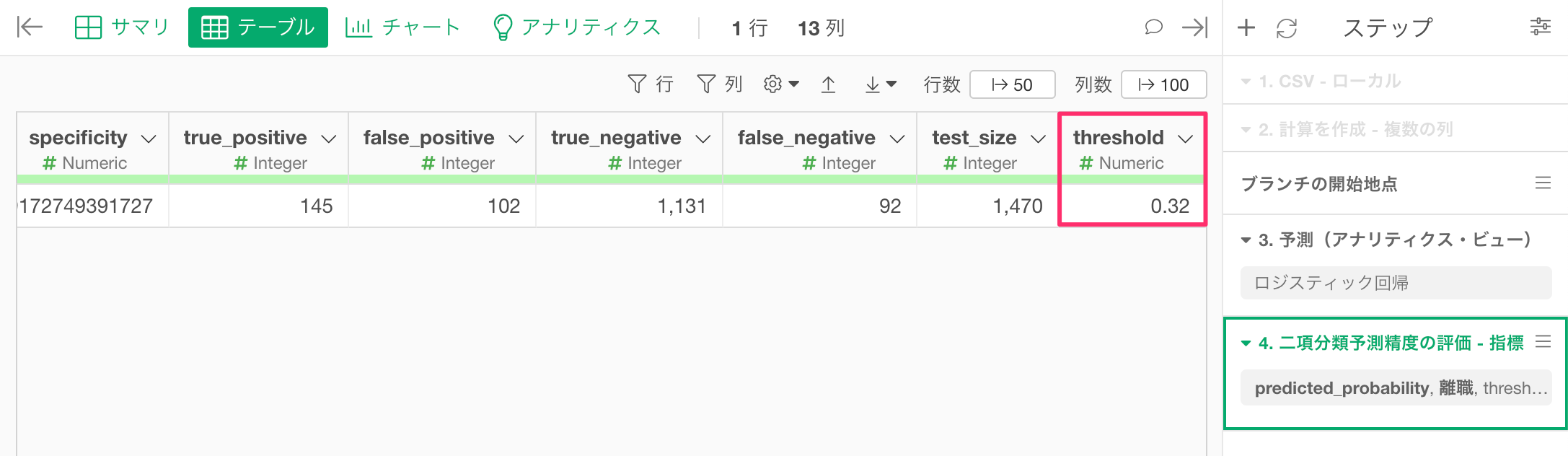
今回の例では、F値に最適化したTRUEという予測結果を返すためのしきい値は「0.32(32%)」ということが分かるわけです。
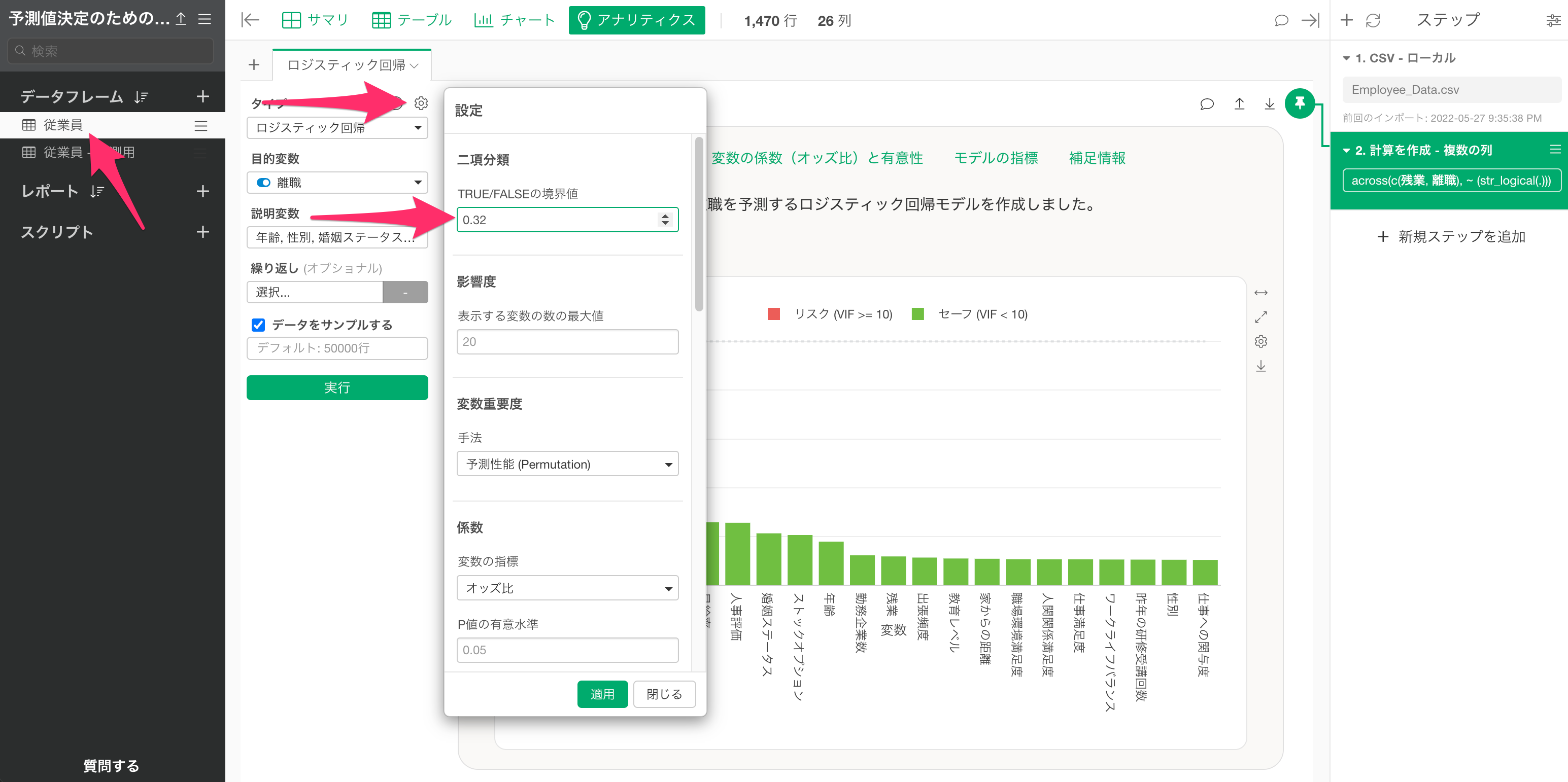
そのため、元のアナリティクスに戻り、アナリティクスの設定から、今回確認した、しきい値である「0.32」をTRUE/FALSEの境界値の設定することで、最適化しきい値での予測結果の詳細を確認します。
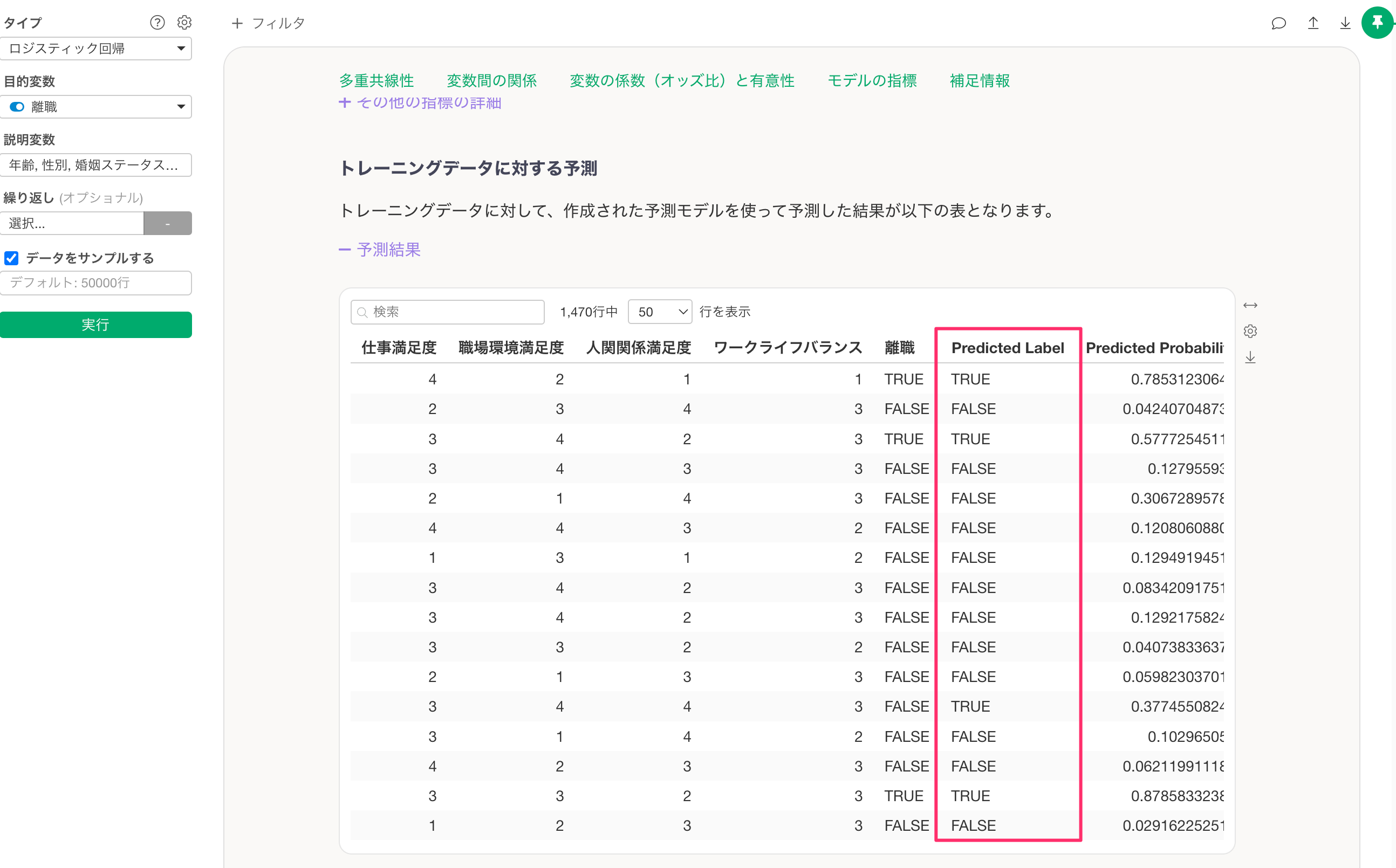
適用ボタンをクリックすると、入力した境界値をもとに、「トレーニングデータに対するよ予測」のセクションにおける「Predicted Label」の情報が更新されます。
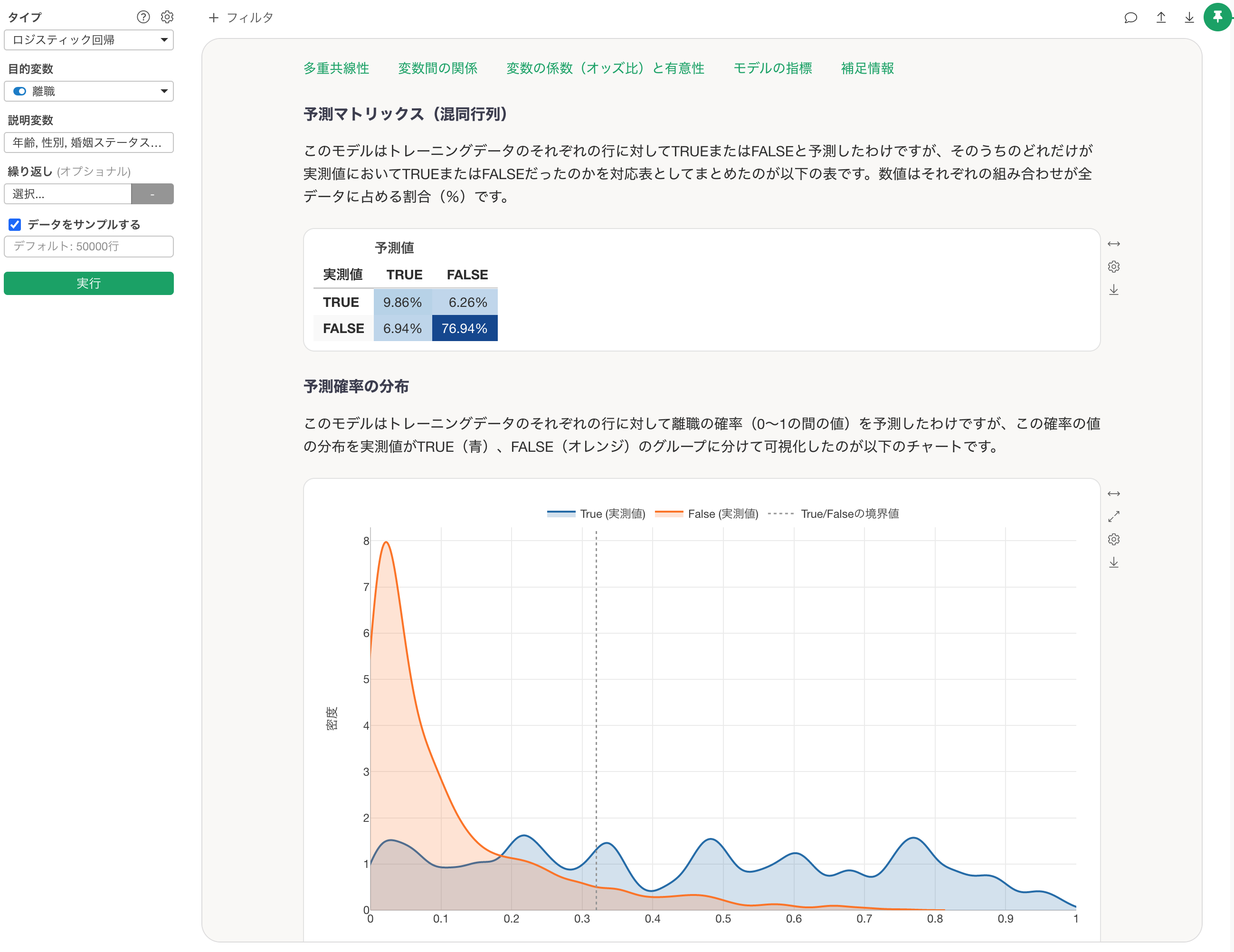
上記以外にも、「予測マトリックス」や「混同行列」の結果が更新されます。
新しいデータに対する最適なしきい値を確認する
1. 新しいデータに対して予測をする
今回は、「従業員」というデータフレームで、従業員の「離職」を予測するロジスティック回帰のモデルを構築しており、まずは、そちらのモデルを使って、「従業員 - 予測用」という新しいデータフレームで、従業員の離職を予測していきます。
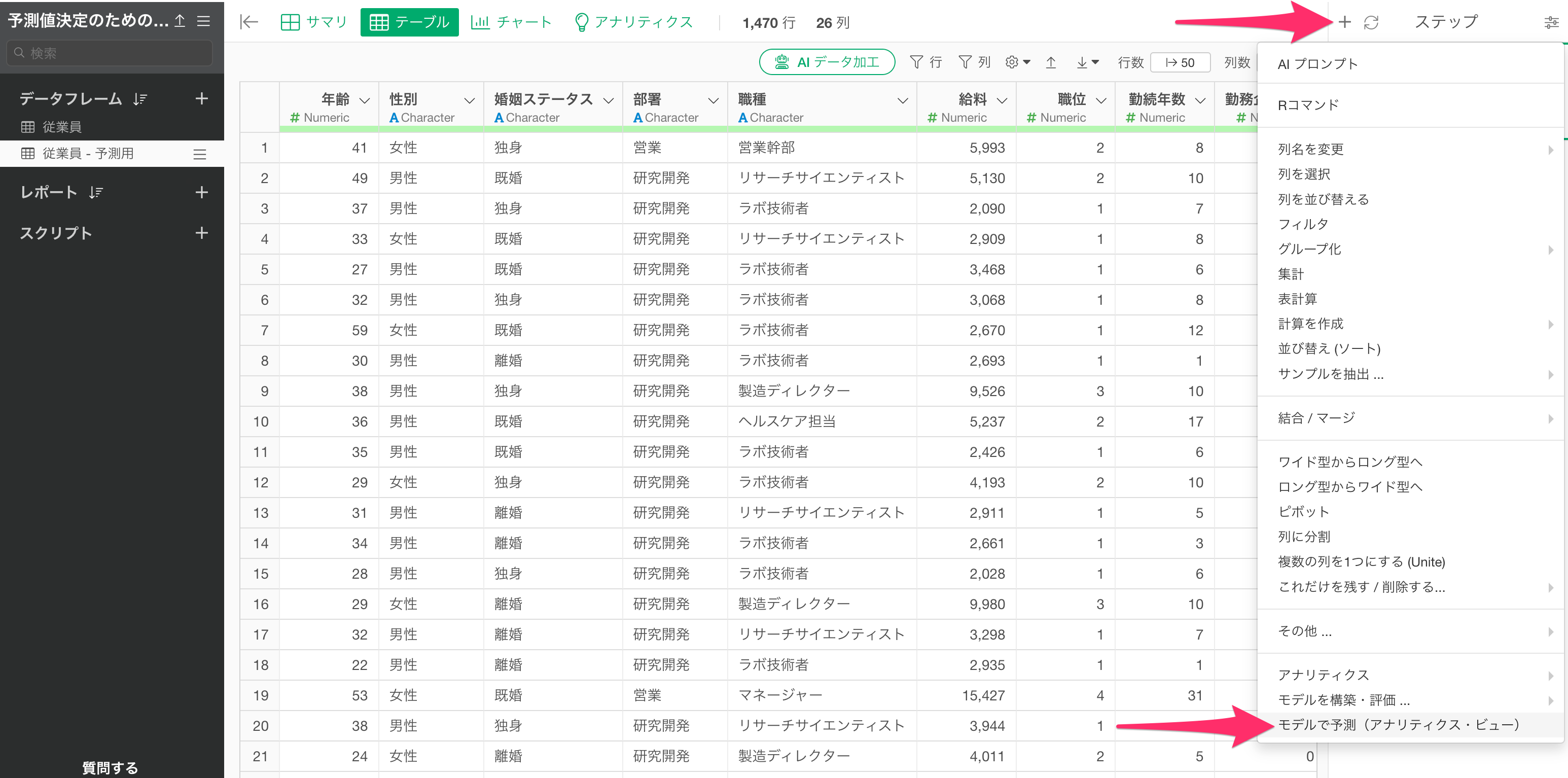
予測対象のデータフレームである「従業員 - 予測用」のステップメニューから、「モデルで予測(アナリティクス・ビュー)」を選択します。
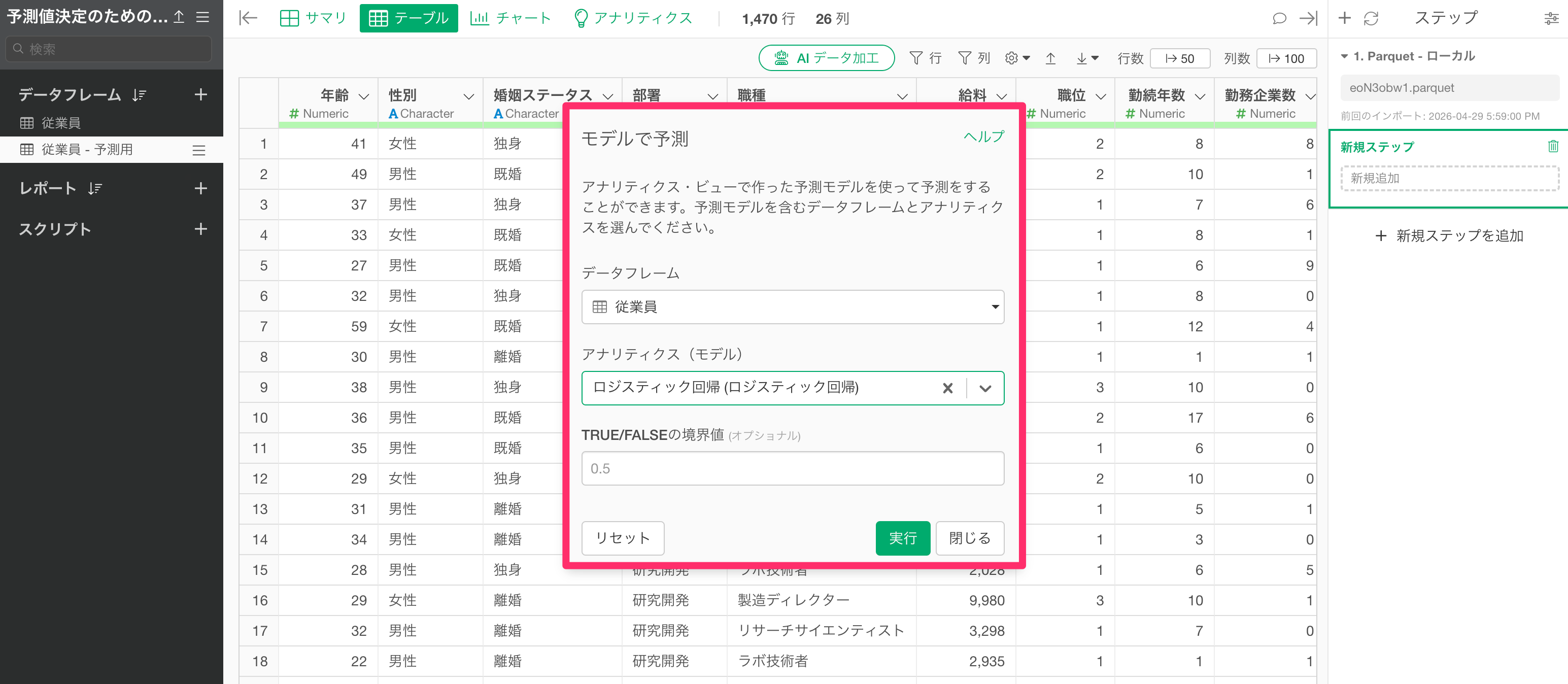
「モデルで予測」のダイアログが表示されたら、「データフレーム」に予測モデルを作成したデータフレームを選択して、「アナリティクス(モデル)」に予測に使いたいモデルを選択し、実行します。
すると、予測のステップが追加され、「predicted_probability(TRUEの予測確率)」や、「predicted_label(予測結果)」の列が追加されました。
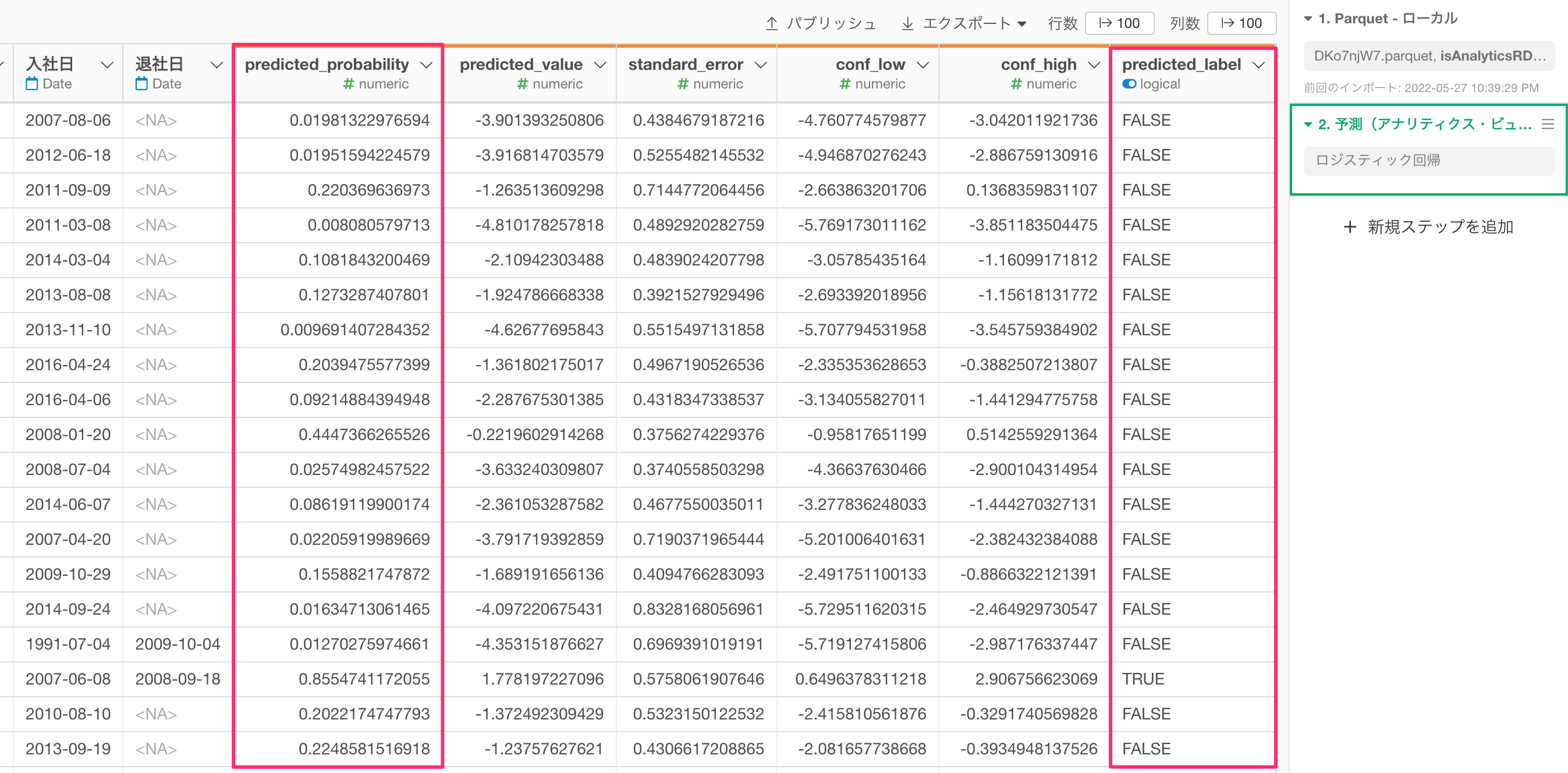
なお、TRUEという予測結果を返すしきい値である「TRUE/FALSEの境界値」のデフォルトの設定は0.5(50%)になるので、「predicted_probability」が0.5(50%)以上であれば、「predicted_label」はTRUEになっています。
2. 予測値決定のための最適なしきい値の確認
続いて、離職を予測するうえで、最適なしきい値を調べていきます。
ステップメニューを開き、「モデルを構築・評価…」、「予測精度の評価…」、「二項分類 - 指標」を選択します。
すると、「二項分類予測精度の評価 - 指標」のダイアログが表示され、「予測された確率の列」には自動でTRUEの予測確率である「predicted_probability」列が選択されますので、「実際の値の列」を選択します。
なお、予測値決定のための最適なしきい値を確認するためには、予測をするデータの中に答え(今回の例で言うと、実際に離職しているかどうか)が必要になりますので、ご注意ください。

続いて、「予測値決定のためのしきい値」の「最適化した値を使用」にチェックを付けて、「最適化指標」に「F値」を選択し、実行します。

すると、「二項分類予測精度の評価」のステップが追加され、最後の列に最適な「threshold(しきい値)」を確認することができます。
今回利用した予測モデルとデータの場合、TRUEという予測結果を返すための、最適なしきい値は「0.32(32%)」ということが分かりました。

最適なしきい値を確認することができたら、「モデルで予測(アナリティクス・ビュー)」のステップを実行するときに、この最適なしきい値を「TRUE/FALSEの境界値」の値に使って、予測結果を返すことが可能になります。

「TRUE/FALSEの境界値」の値を指定したしきい値に変更することで、そちらを元にした予測結果が得られることを確認できます。