ブランチを作成する方法
Exploratoryでブランチを作成する方法を説明します。
ブランチとは
データを探索していると、様々な疑問が浮かんできます。そして同じデータ・セットに対して異なる加工、集計の処理をしたり、分析したいと思うことは良くあることです。
そういった時に便利な「ブランチ」という機能があります。以下どんな時にブランチが使えるか説明していきます。
複数の試行のためにブランチを作成する
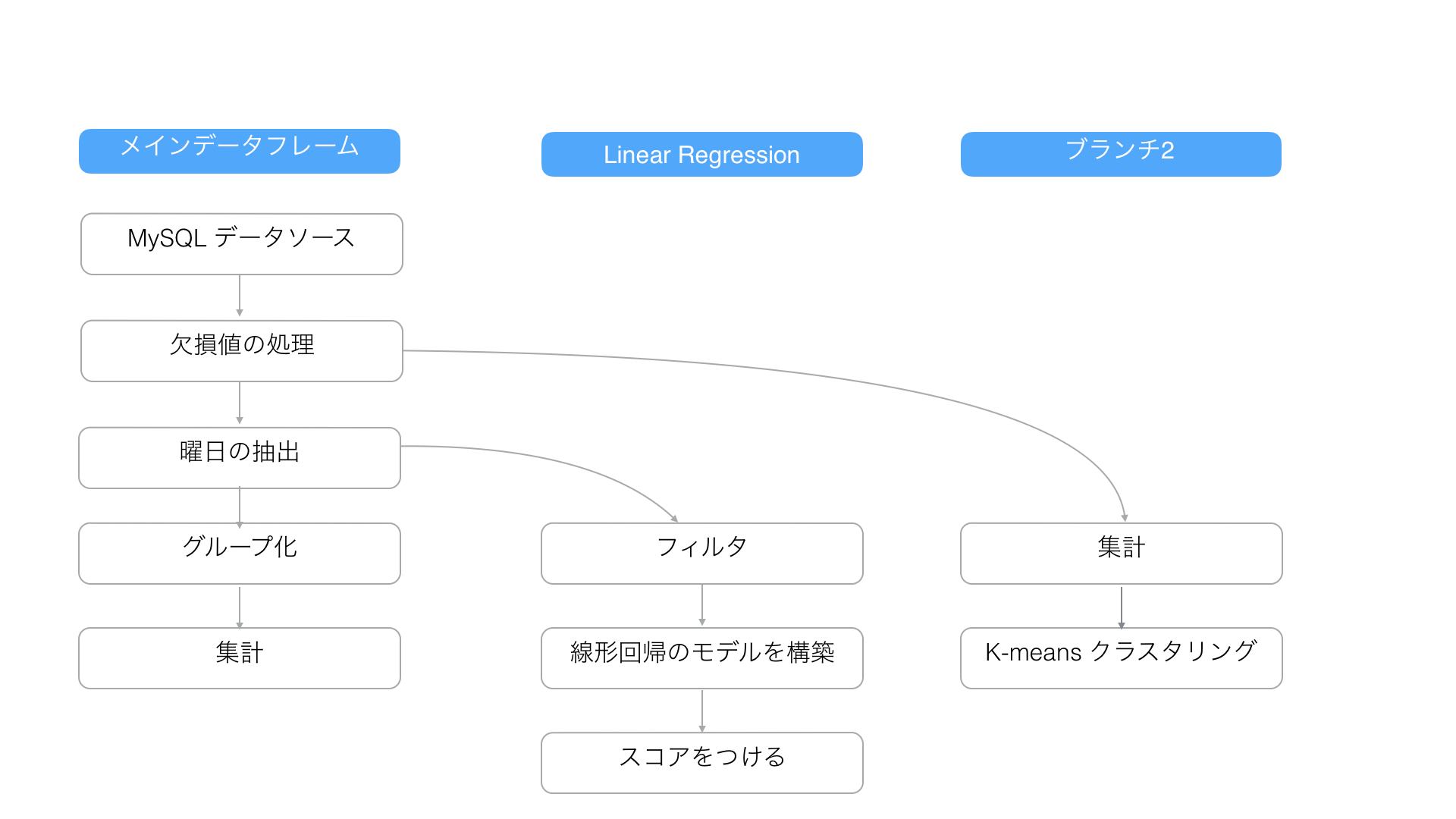
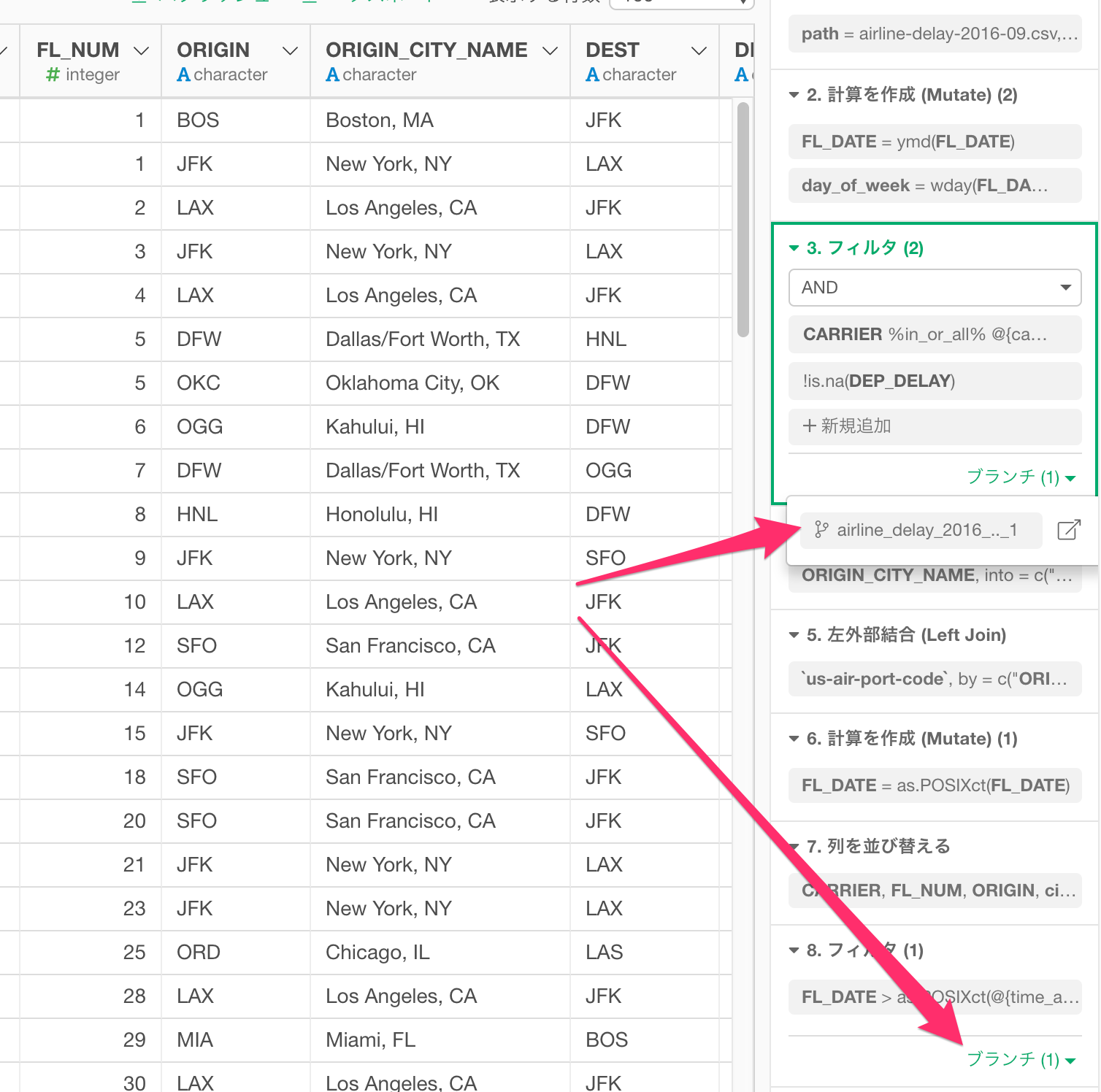
例えば以下のように欠損値の処理をしたり、日付から曜日の情報を抽出して、集計をしたデータがあったとします。
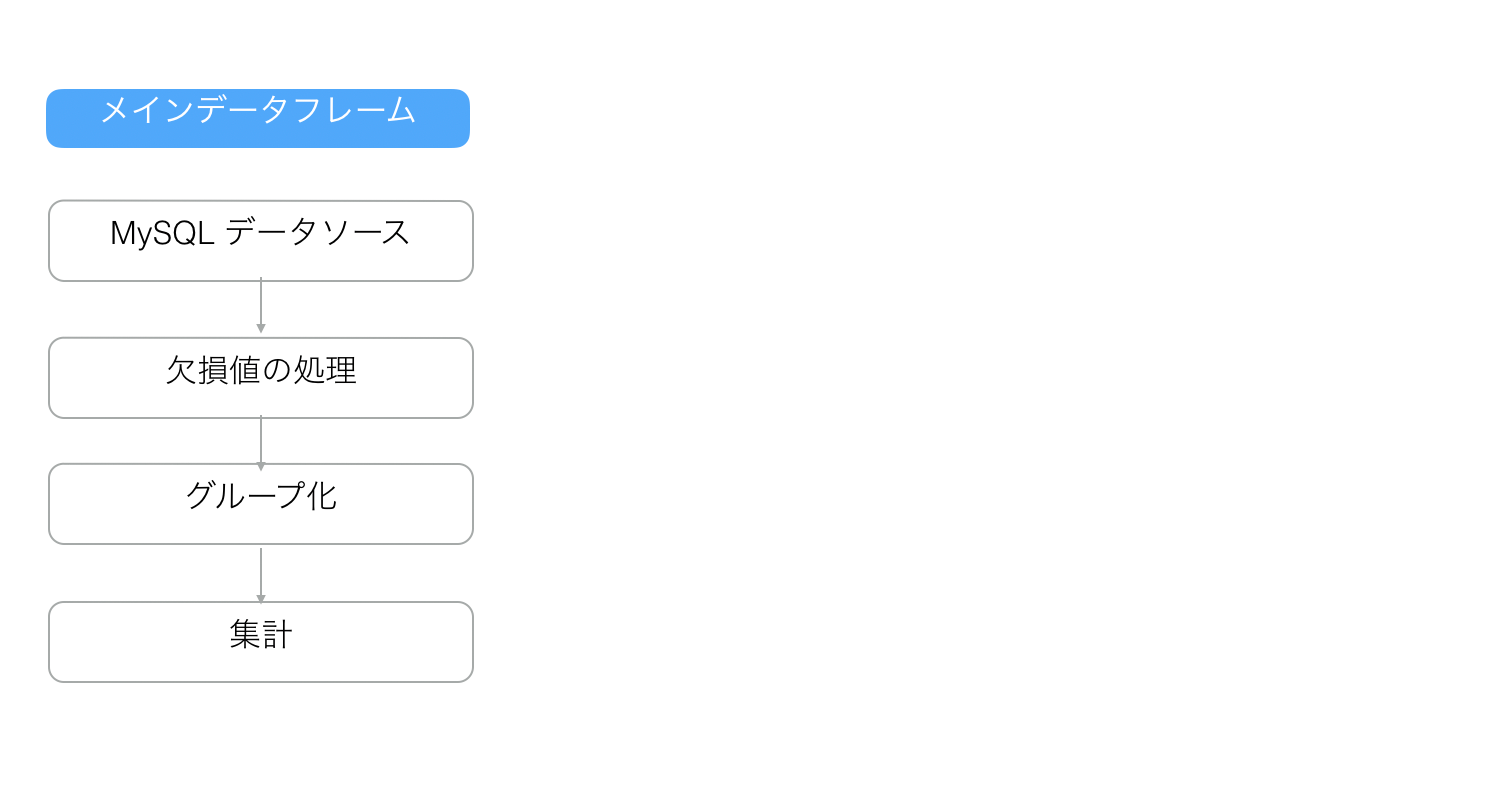
以下のようなイメージです。
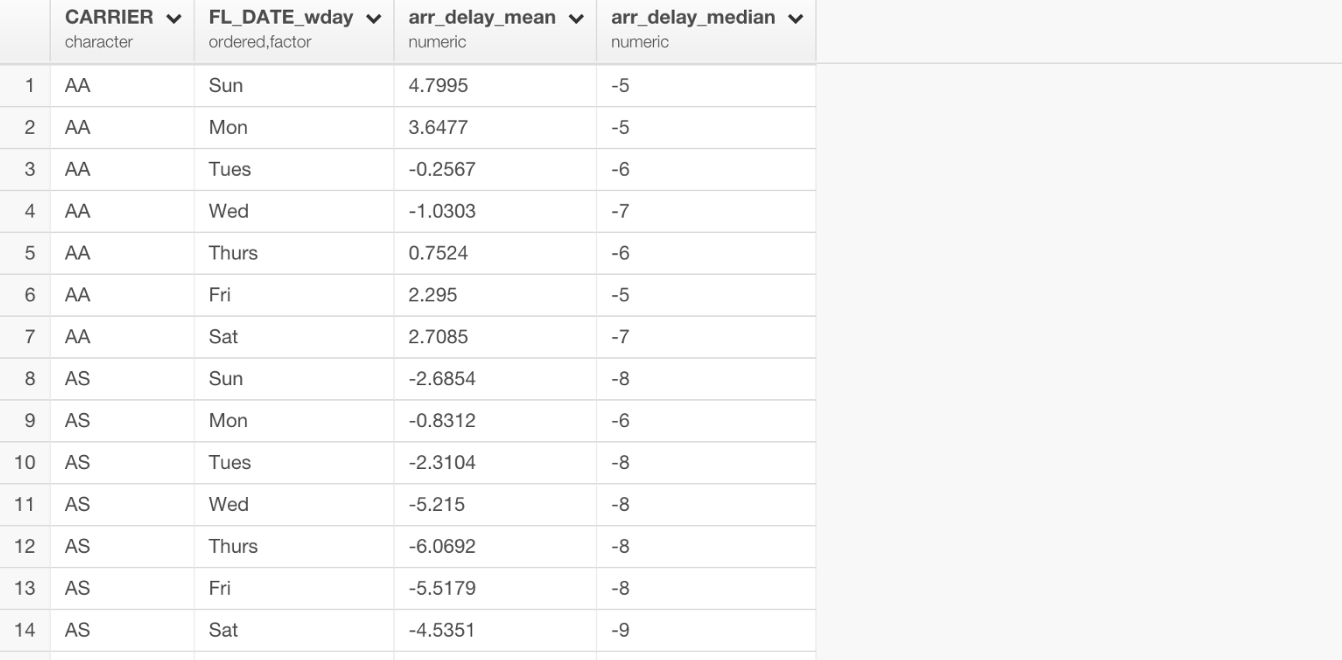
続いて、この「フライトの遅延」に関するデータを使って「Arrival Delay Time(到着遅延時間)」と「Departure Delay Time (出発遅延時間)」の2変数の相関を確認するために、手早く線形回帰のモデルを構築するとします。
しかし、上の図を見る限り、最新のステップのデータフレームには回帰のモデルを構築するために必要な全てのデータがありません。データを集計したことで、集計の計算に含まれない詳細データの列がなくなってしまったからです。
データをもう一度インポートしたり、データフーレムを複製することで、異なるデータフーレムは作成できますが、その場合、欠損値の処理など、同じ処理をもう一度とやり直す必要が出てきます。こういった時に「ブランチ」機能を便利に使うことができます。
「Linier Regression」という名前のブランチを以下のように「曜日の抽出」ステップから簡単につくることができます。
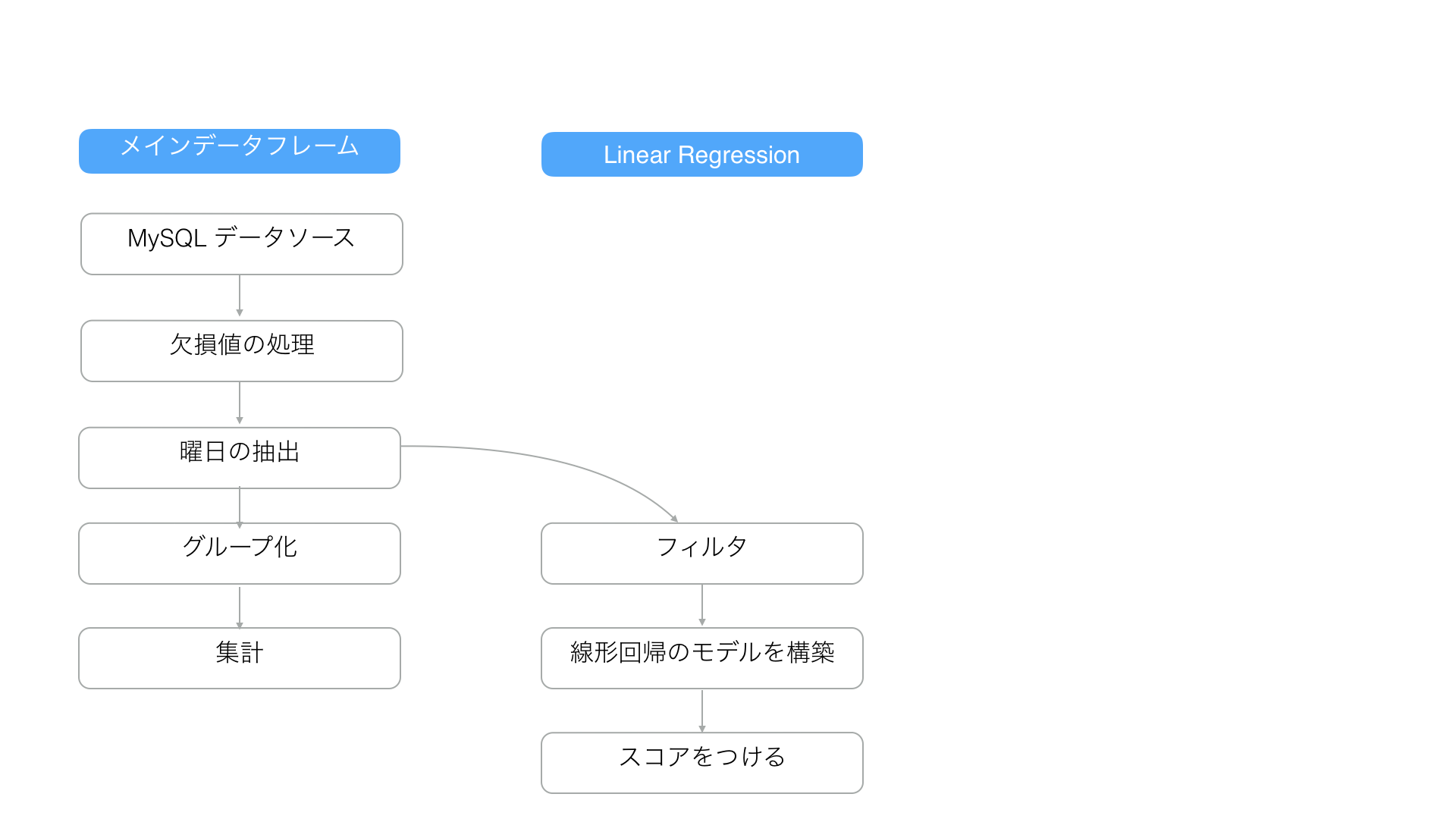
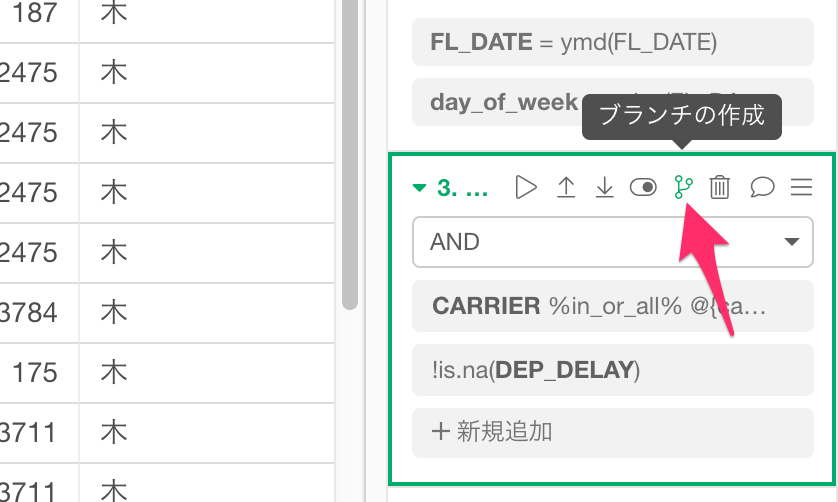
ステップメニューの「ブランチ」アイコンをクリックすることで、全てのステップから「ブランチ」の作成ができます。
ブランチを作成すると、メインのデータフレームの下にブランチのデータフレームが並びます。
そして、それぞれのブランチごとに加工・集計のステップが追加できます。
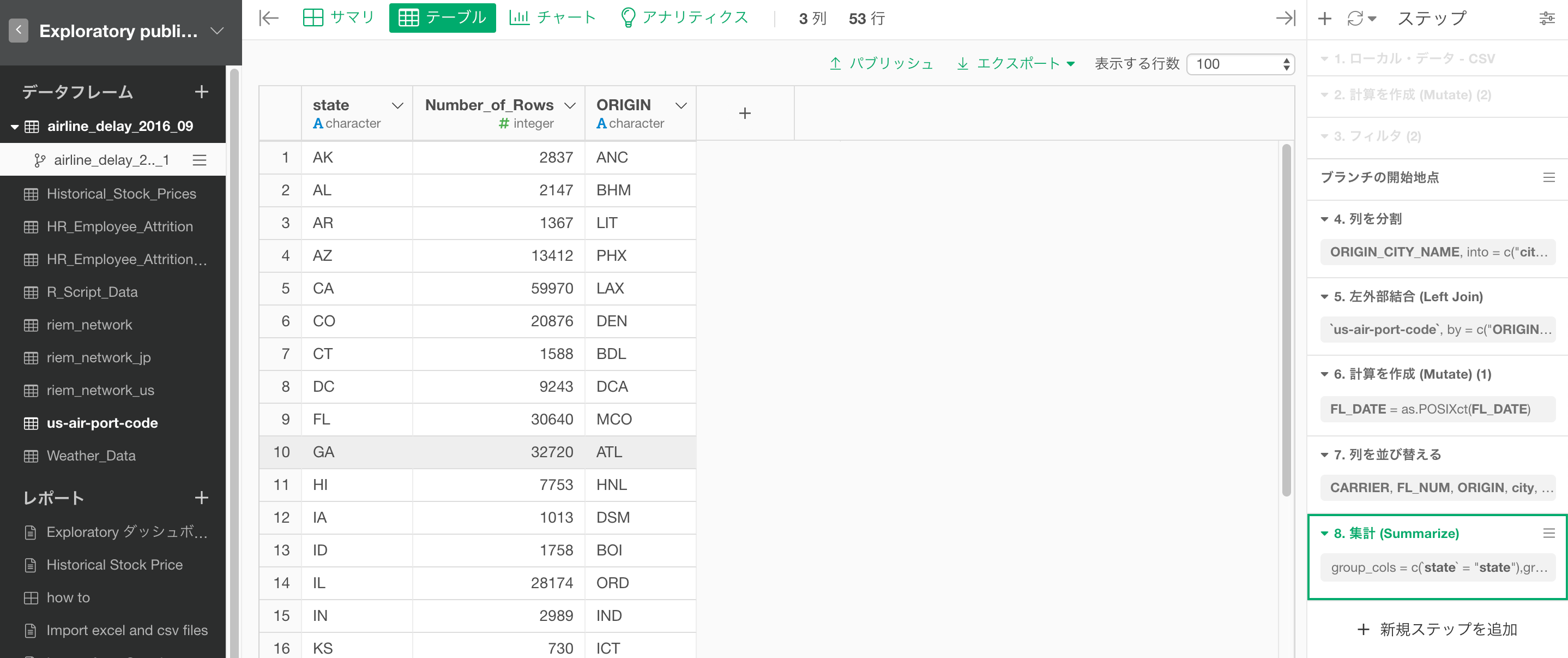
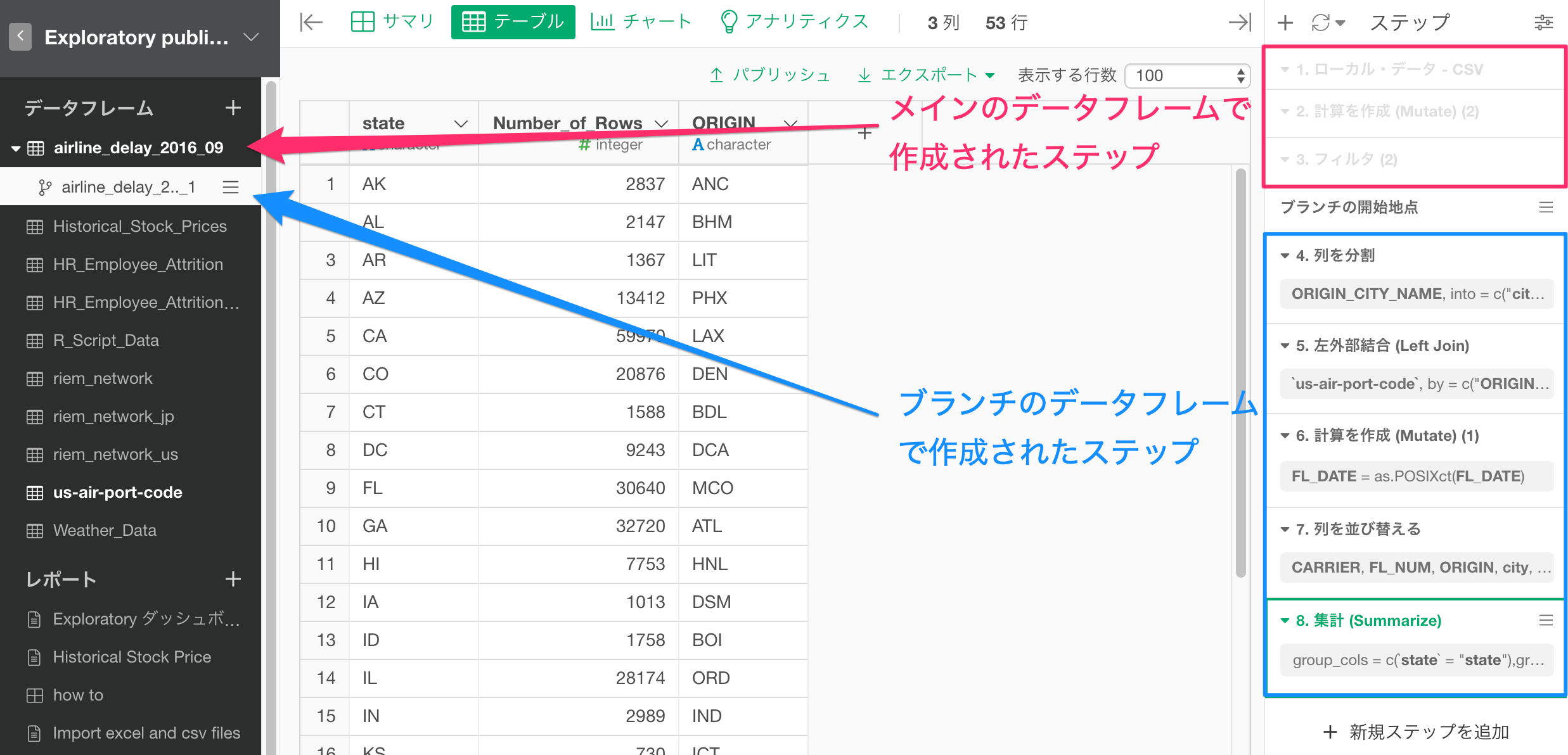
メインのデータフレームで作成されたステップはぼやけた背景色で表示され、「ブランチの開始地点」のステップの後にラングリングのステップの追加されていきます。
ブランチはメインデータフレームのいかなるステップでも作成できます。
またメインのデータフレームでは、どのステップでブランチが作成されたかを確認できます。
ブランチの開始地点を変更する
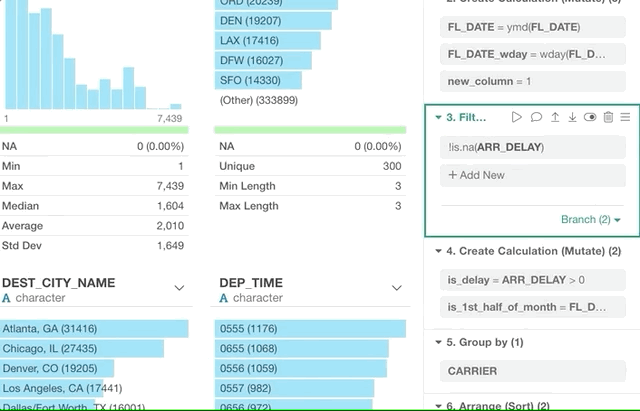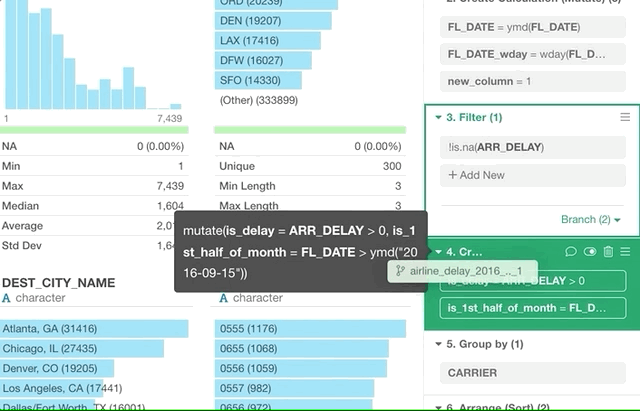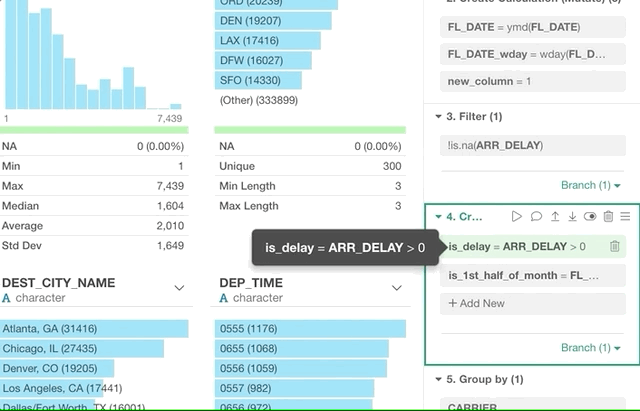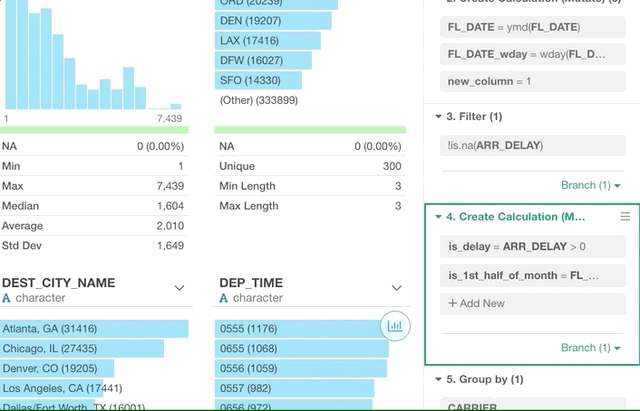
ブランチの作成後にブランチの開始地点を変更したい場合があります。
そういった時はドラッグアンドドロップで簡単に可能です!
ブランチボタンをクリックして変更したいステップにブランチのデータフレーム・トークンをドラッグします。
データの独立性と再現性を担保するExploragory のDAGエンジン
「ブランチ」機能は、ゼロから構築したExploratory DAG(Directed Acyclic Graph / 有向非巡回グラフ)エンジンの上で構築されています。データ・ラングリングの任意のステップからブランチを作成できるだけでなく、データフレームとデータラングリングステップ間の依存関係もすべて自動的に管理されます。
例えばメインのデータフレームのステップに変更があった時に何が起こると思いますか?メインのデータフレームのステップから新しいブランチを作成するのが最も簡単なやり方です。
ご存知かもしれませんが、実はデータラングリングの各ステップでは、パフォーマンスを向上させるために内部的にデータをキャッシュしています。
そしてメインデータフレームのデータラングリングステップの1つを更新すると、関連するブランチのデータフレームはどうなると思いますか?
メインのデータフレームの、データソースをクエリするステップを含む、いずれかのステップで変更があった際は関連するブランチの全てのデータフレームで自動的にその変更が反映されます。
実例
ブランチが効果を発揮するいくつかの例を見てみましょう。
1. データソースをからデータを再読み込みする
例えば、ステップの上部にある「データをデータソースから再インポート」ボタンをクリックすることでリモート・データベースのデータを再読み込みしたとします。
こういった時はメインのデータフレームだけでなく、ブランチのデータフレームを含む全てのステップは更新されます。
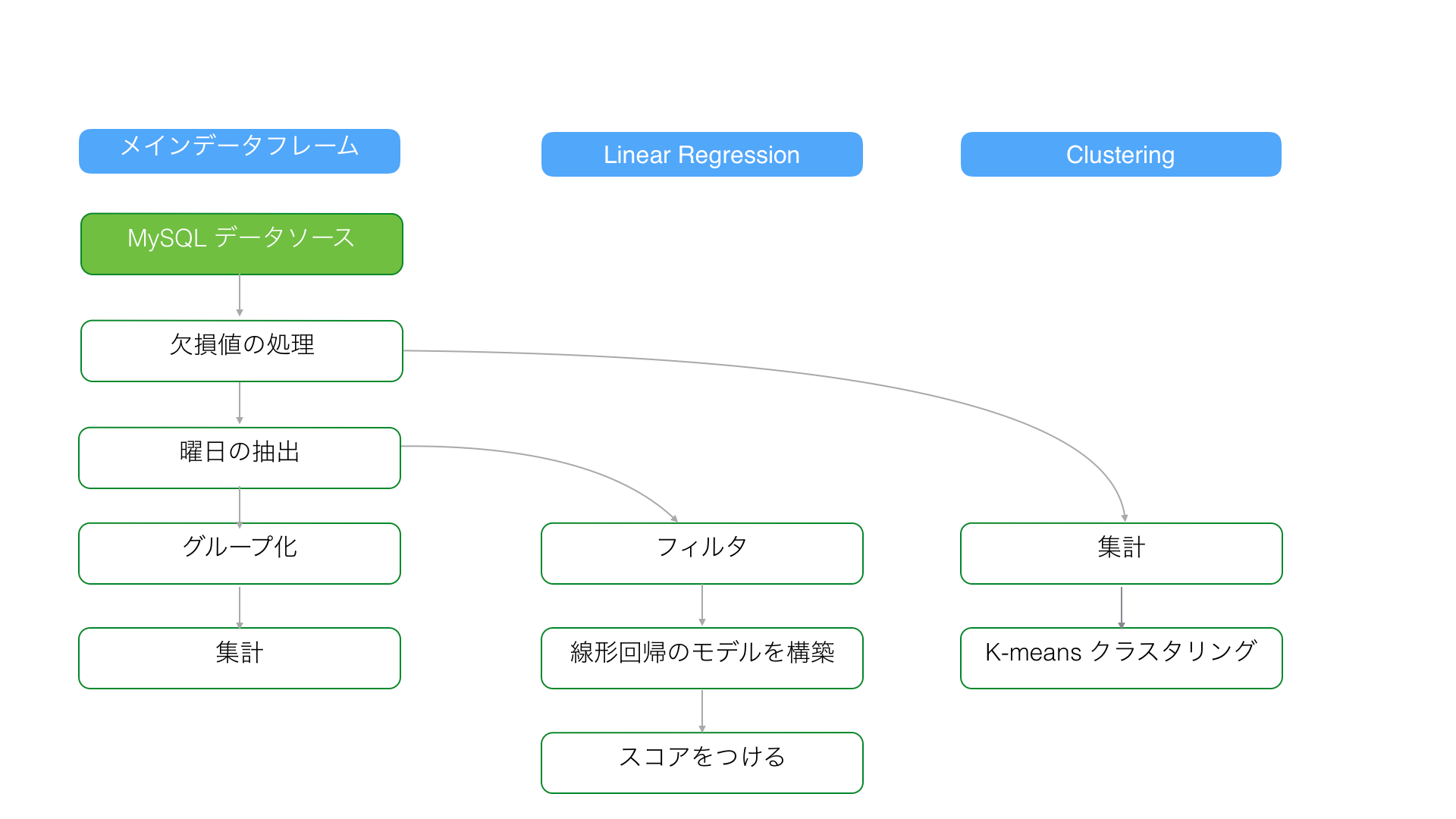
緑で塗りつぶされているボックスは、ユーザーが更新したステップを表しています。緑の枠線が付いた白い背景のボックスは、それらのステップが自動的に更新されることを表しています。
2. メインのデータフレームのステップを更新する
例えば、メインのデータフレーム内の「月の日の抽出」ステップを更新したとします。
これによって、「月の日の抽出」ステップと依存関係があるメインのデータフレームだけでなく、ブランチのデータフレームの全てのステップが更新されます。
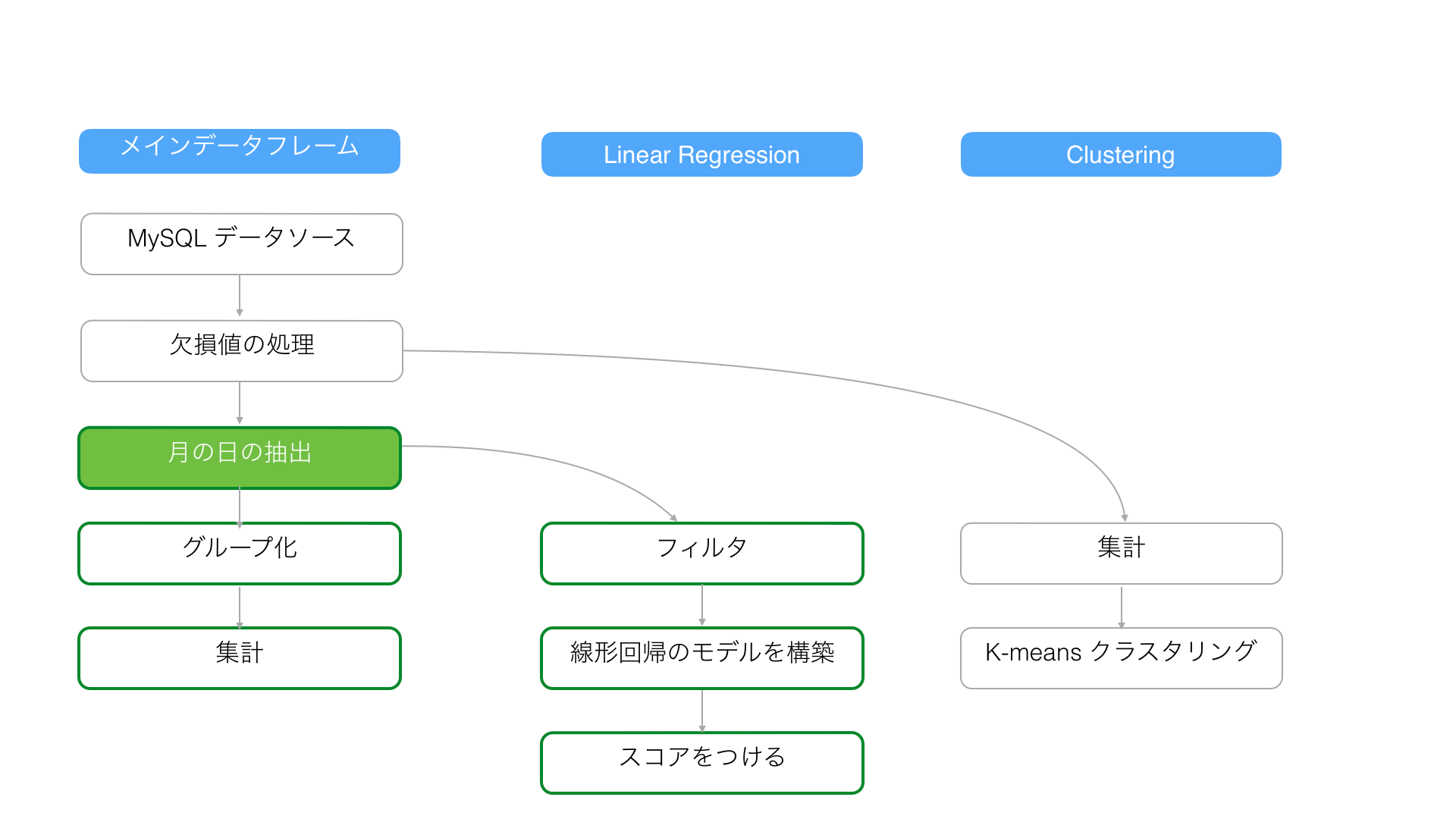
上記のシナリオでは、「Clustering Experiment」のブランチデータフレームは「月の抽出」ステップに依存しないため、更新されません。
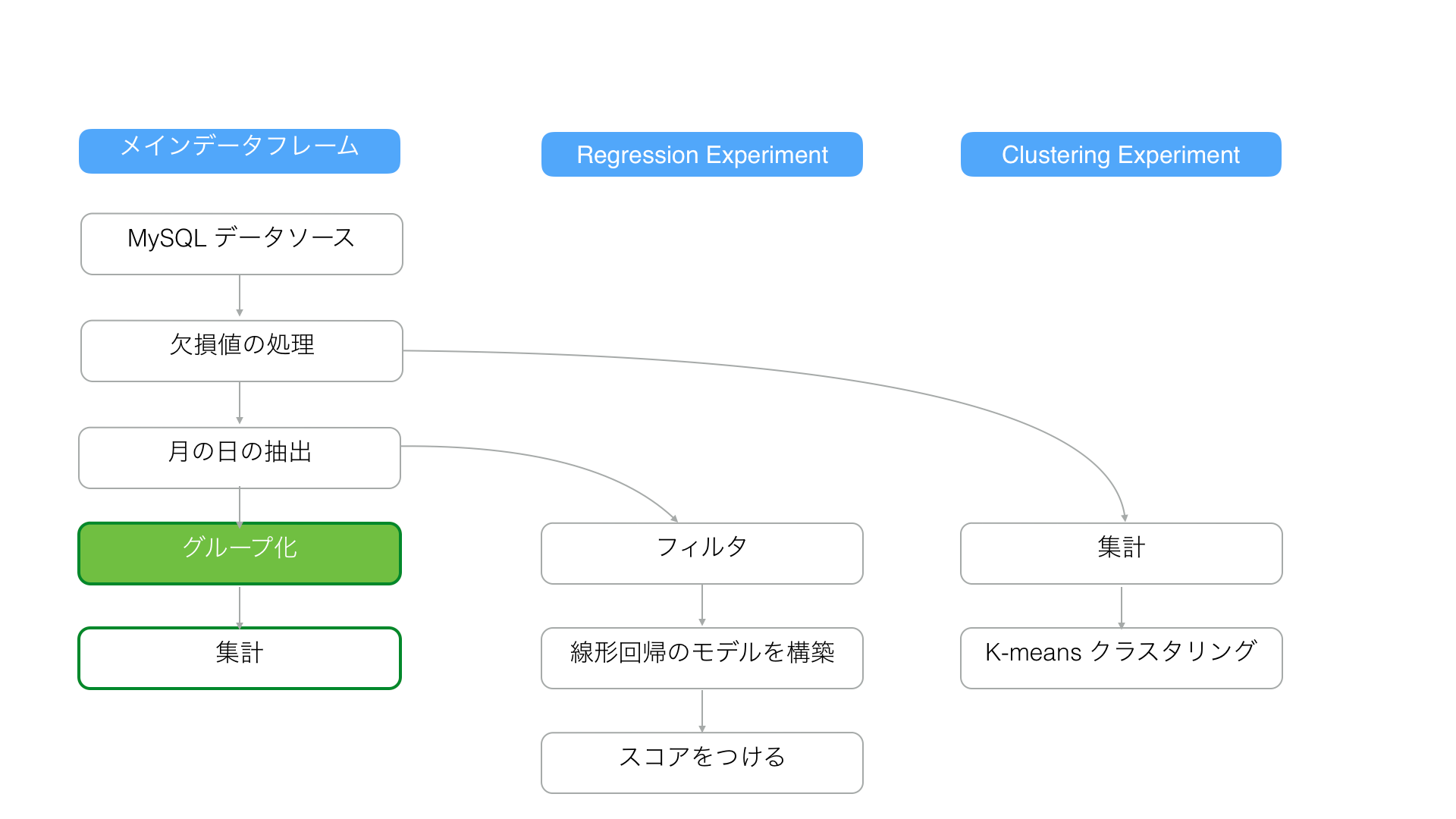
また以下のように、メインデータフレームの「グループ化」ステップを更新した場合、ブランチデータフレームは更新されません。
3. ブランチの開始地点のステップを削除する
メインのデータフレームのステップを削除したときに、そのステップに依存するブランチがあった場合、削除されたステップの前のステップからブランチが始まるように調整されます。
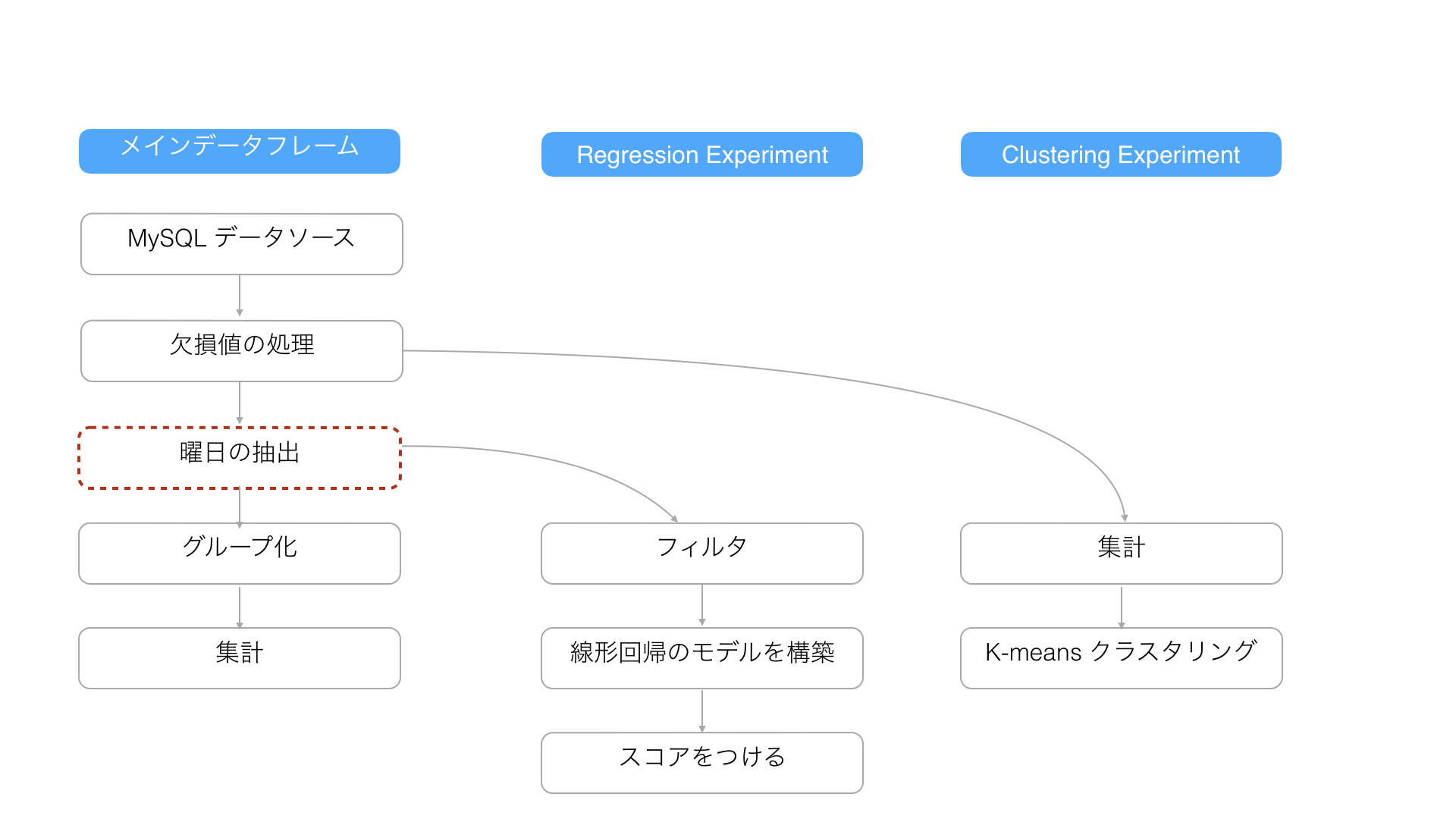
次のようなケースがあったとします。
「Regresssion Experiment」ブランチの開始地点の「曜日の抽出」のステップを削除したとします。「Regresssion Experiment」のブランチは開始地点のステップが削除されると、宙に浮いてしまうように思うかもしれませんが、Exploratory DAGエンジンは自動的に削除されたステップの前のステップに再接続します。
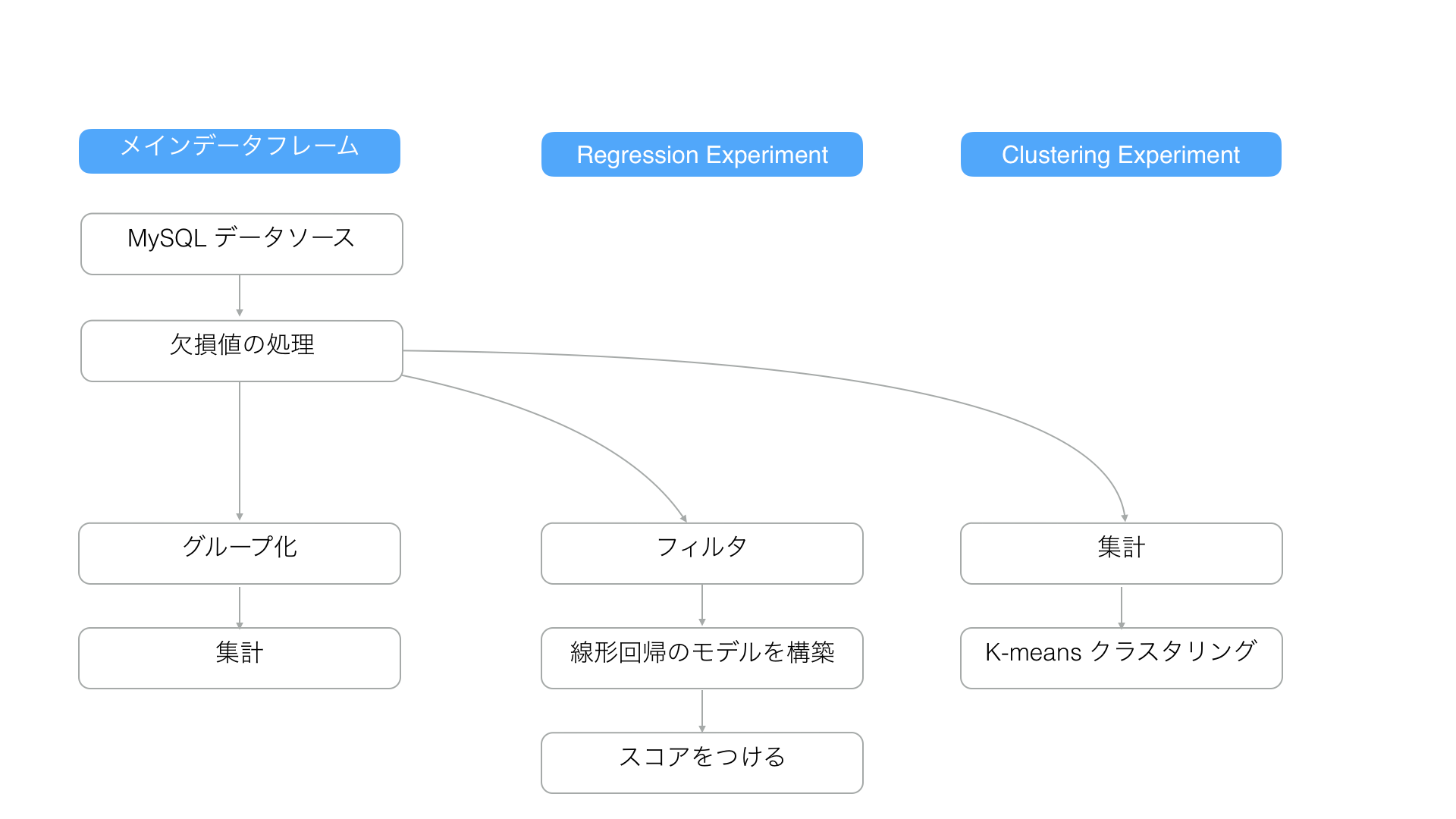
そして、メインのデータフレームとブランチのデータフレーム全てのステップでキャッシュされたデータは更新されます。
4. メインのデータフレームと依存関係のある別のデータフレームが更新された場合
例えばメインのデータフレームが他のデータフレームとJoinなどで結合しているとします。
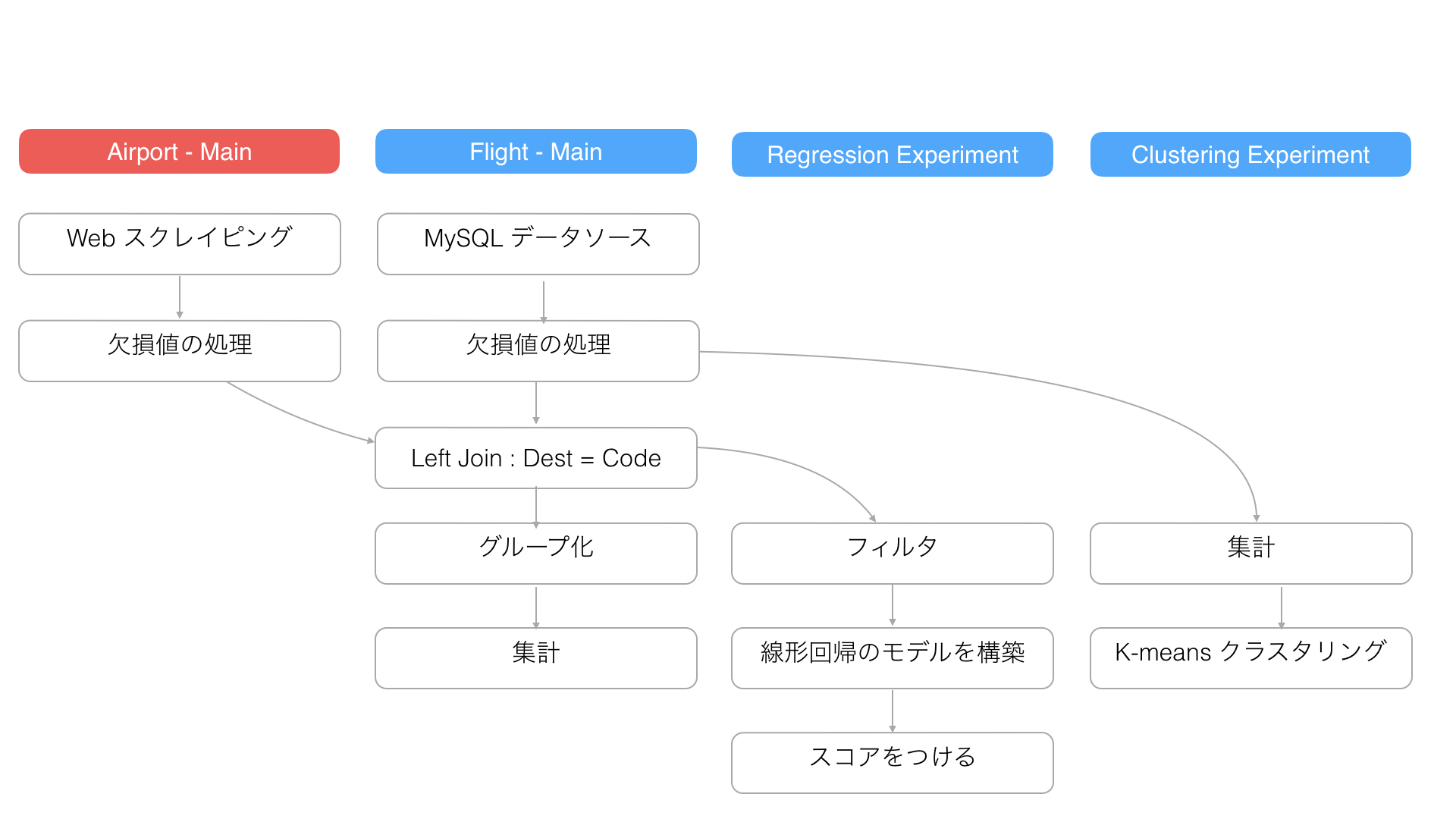
上記の図で赤く塗りつぶされている「Airport - Main」は今まで使ってきた「Flight - Main」データとは異なるデータを表しており、「Flight - Main」の3番目のステップで結合されています。
例えば、Webスクレイピングして、抽出されている「Airport - Main」のデータをリロードしたとします。
すると「Airport -Main」のデータフレームにある、「欠損値の処理」というステップだけでなく、後続のLeft Join(左外部結合)および、それ以降のステップも更新されるわけです。
またこれにより、「Regression Experiment」というブランチのステップも全て更新されます。
しかし、例えば「Clusttering Experiment」のブランチ・データフレームは更新されたステップと依存関係がないので、特にデータは更新はされません。
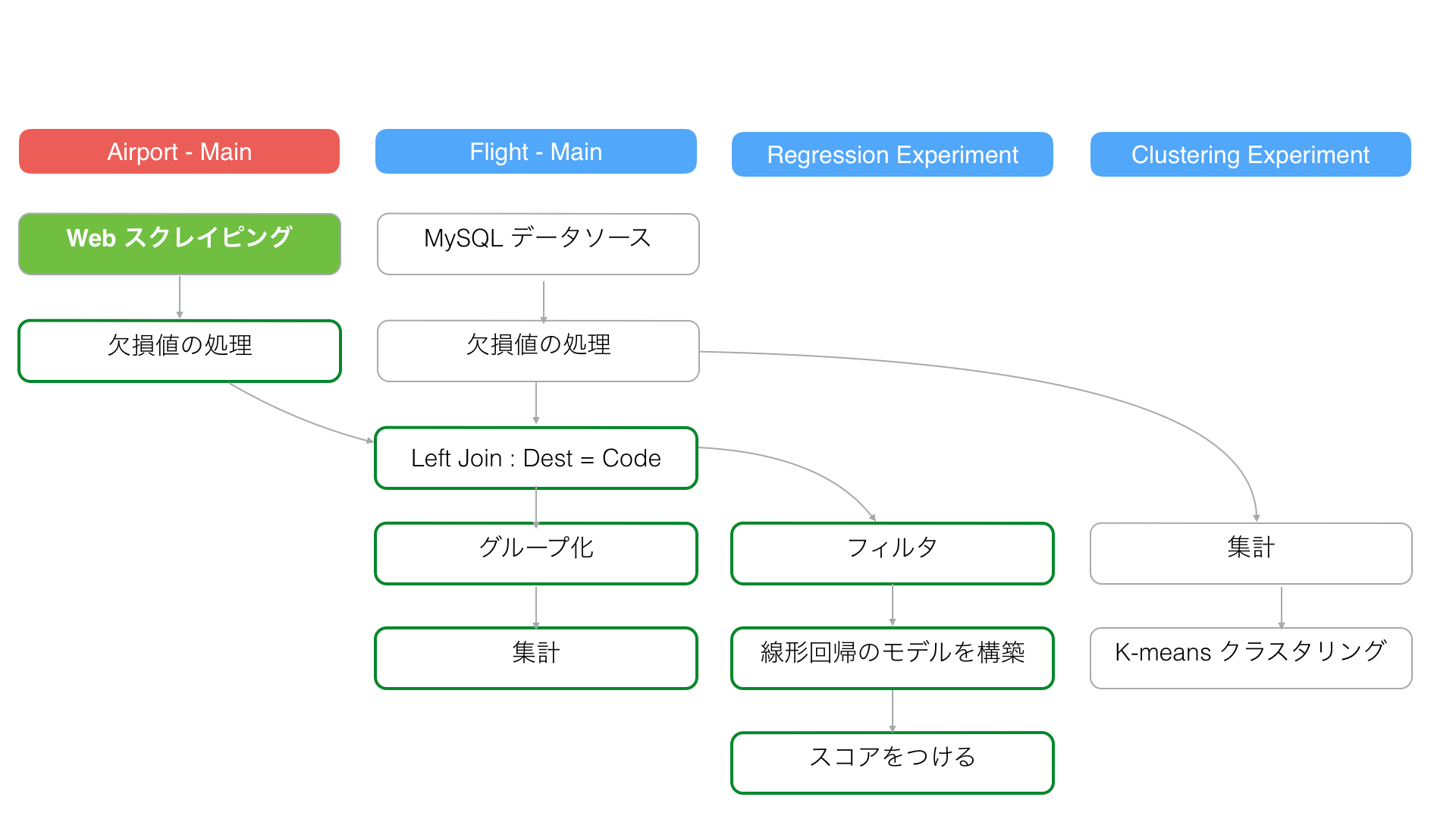
遅延データ・キャッシング
ちなみに、データ・ラングリングのステップ毎のデータ・キャッシュは必要なタイミングでのみ生じます。
従って、ブランチデータフレームを開くまで、メインのデータフレームが更新されたとしても、ブランチデータフレームでは何も起こらないということです。
終わりに
我々は皆が独創的な発想力をもっています。そして常に身の回りのことに多くの興味や疑問をいただきます。
我々の目的は素早く、インタラクティグにデータの探索を実現してもらうことです。
この「ブランチ」機能を利用することで、データの独立性と再現性を維持した状態で、より多くの質問をいだき、またデータを探索して回答を見つけることに時間を使えるようになります。
是非「ブランチ」機能を楽しんでください。