ランダムフォレストやロジスティック回帰などの二項分類の予測モデルを使って新しいデータで予測をしたときの予測精度(AUC)の確認方法
Exploratoryではアナリティクス・ビューからランダムフォレストやロジスティック回帰を使って、例えば、「この人はコンバージョンするのかどうか」あるいは「離職するのかどうか」といった、「TRUE(はい)」や「FALSE(いいえ)」で答えられるような質問への答えを予測するモデルを構築できます。
こちらのノートでは、アナリティクスビューで作成したランダムフォレストやロジスティック回帰などの二項分類のモデルを使って、新しいデータに対して予測をしたときの予測精度の確認方法を紹介します。
利用データ
サンプルデータとして、従業員データを使用していきます。このデータは1行が1従業員のデータで、列には年齢や職種、離職など従業員の属性を表す列があります。

新しいデータに対して予測をする
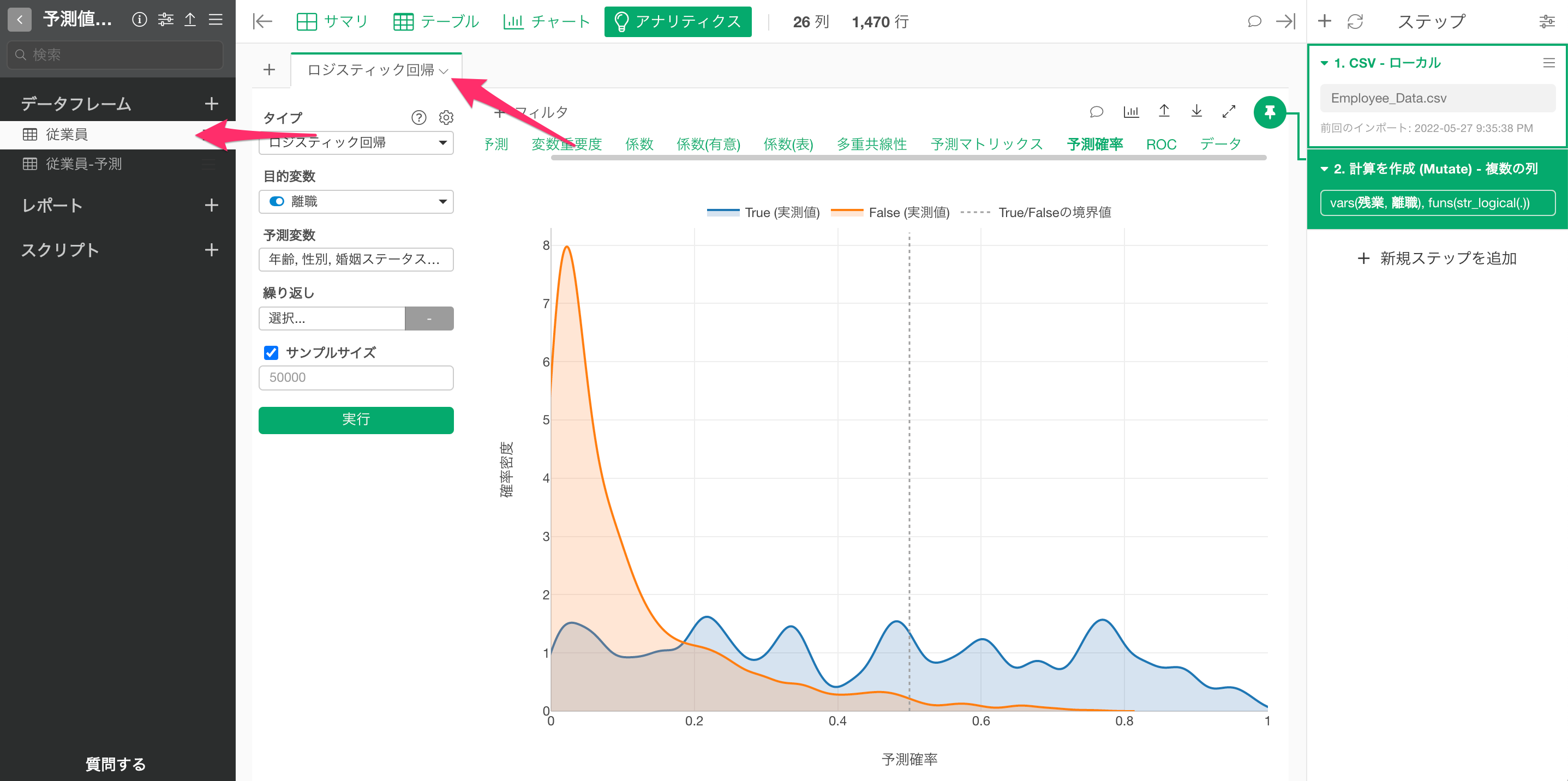
今回は、「従業員」というデータフレームで、従業員の「離職」を予測するロジスティック回帰のモデルを構築しており、まずは、そちらのモデルを使って、「従業員-予測」という新しいデータフレームで、従業員の離職を予測していきます。
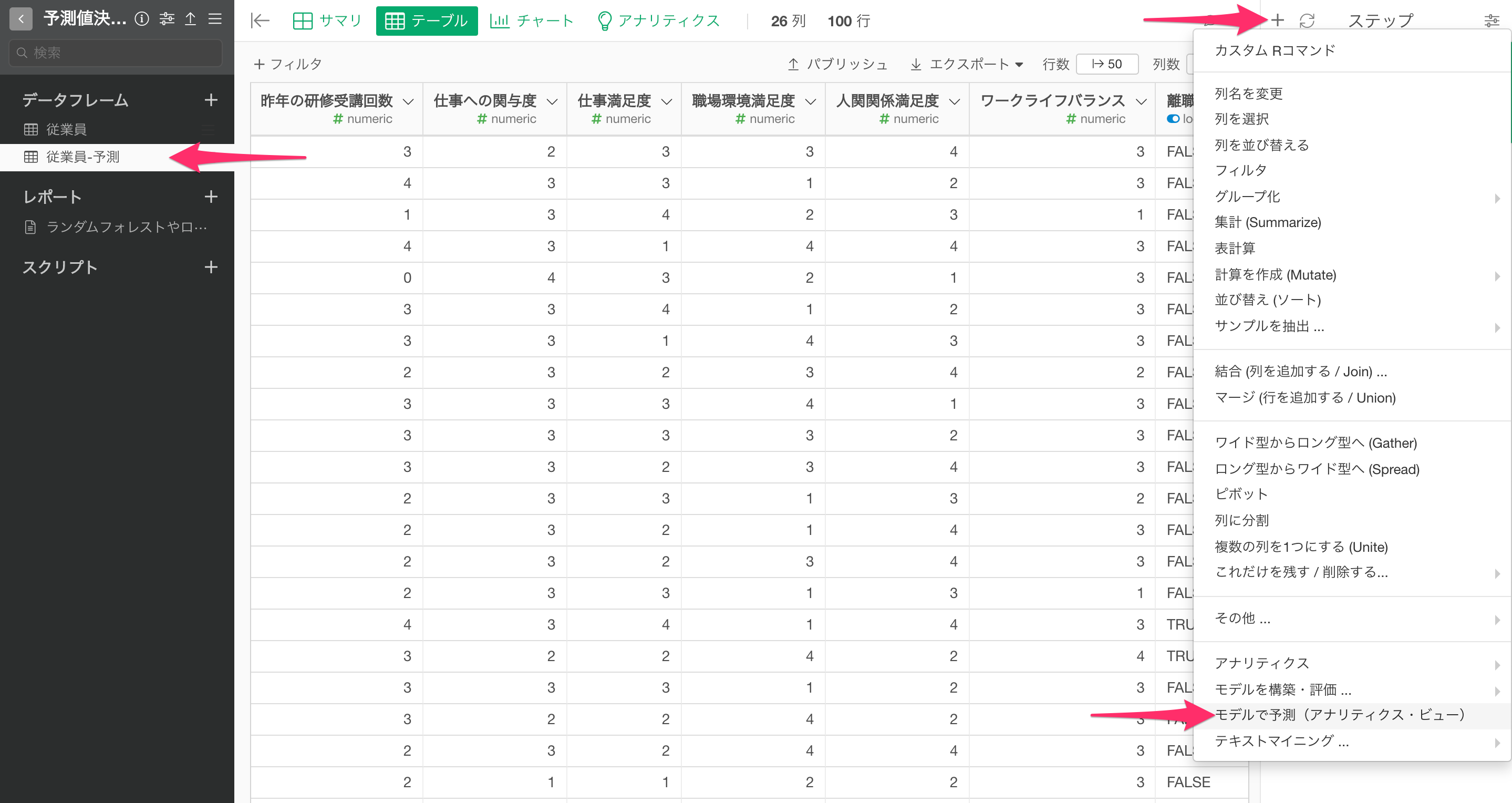
ステップメニューから、「モデルで予測(アナリティクス・ビュー)」を選択します。
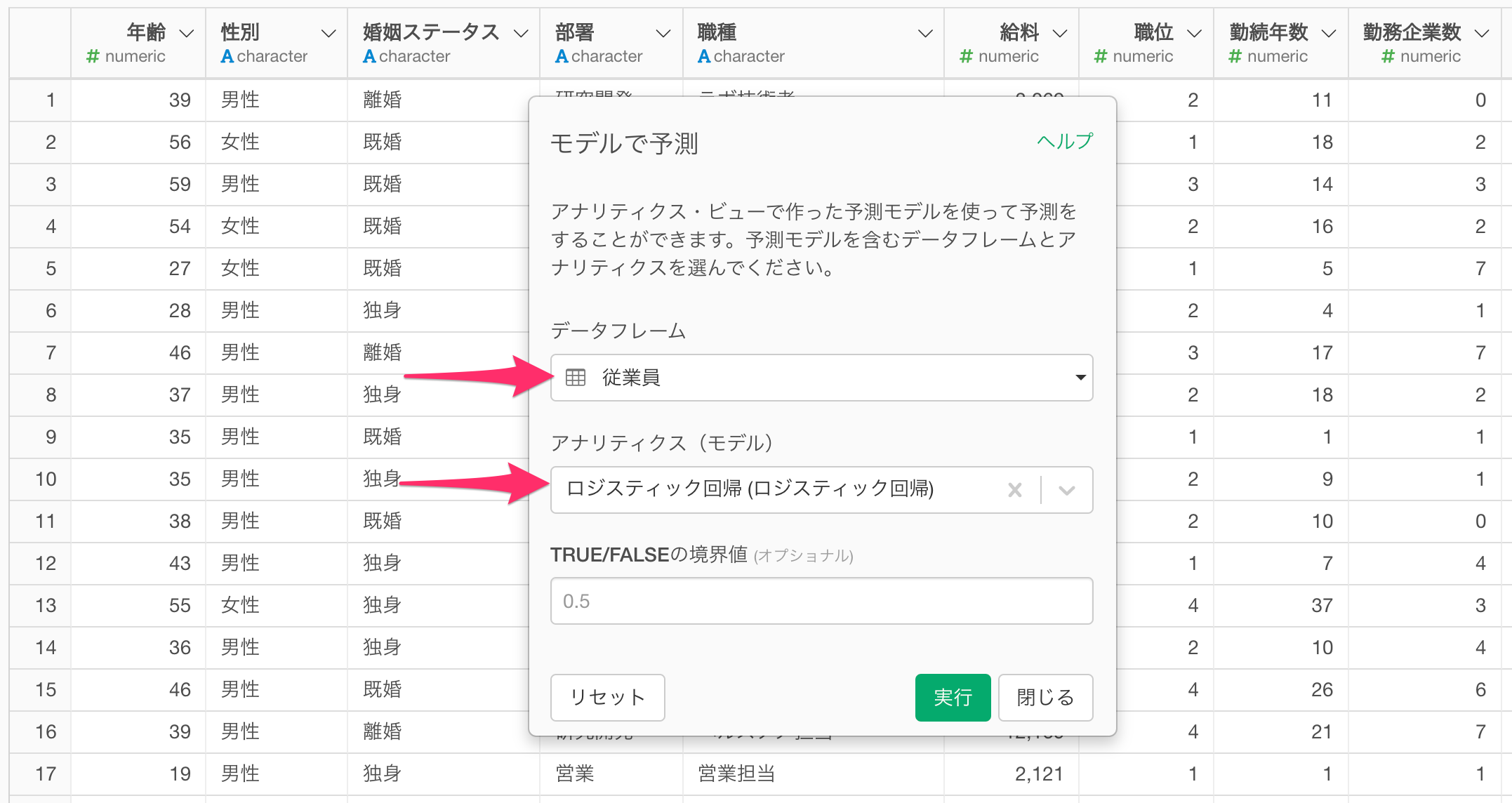
「モデルで予測」のダイアログが表示されたら、「データフレーム」に予測モデルを作成したデータフレームを選択して、「アナリティクス(モデル)」に予測に使いたいモデルを選択し、実行します。
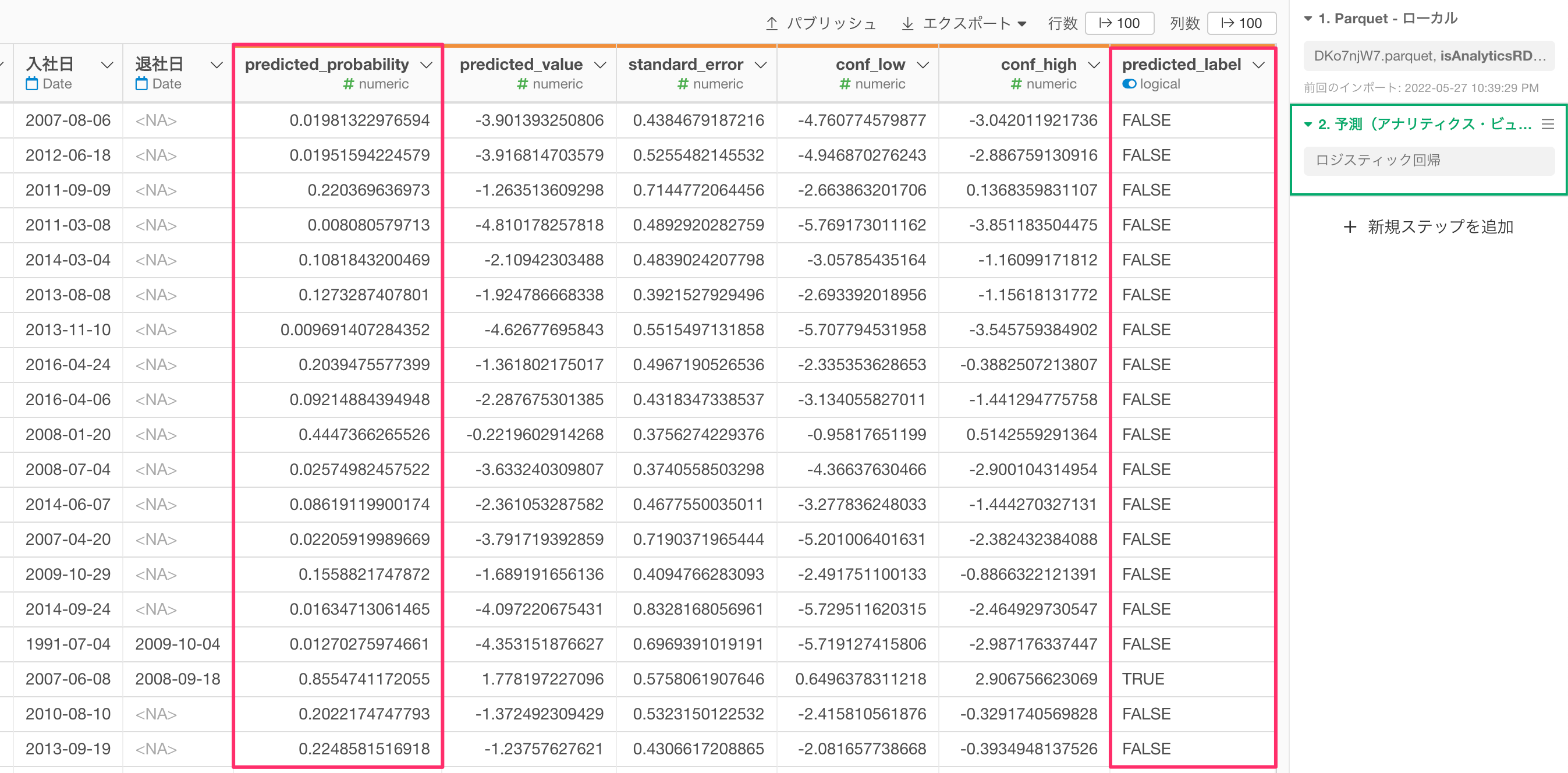
すると、予測のステップが追加され、「predicted_probability(TRUEの予測確率)」や、「predicted_label(予測結果)」の列が追加されました。
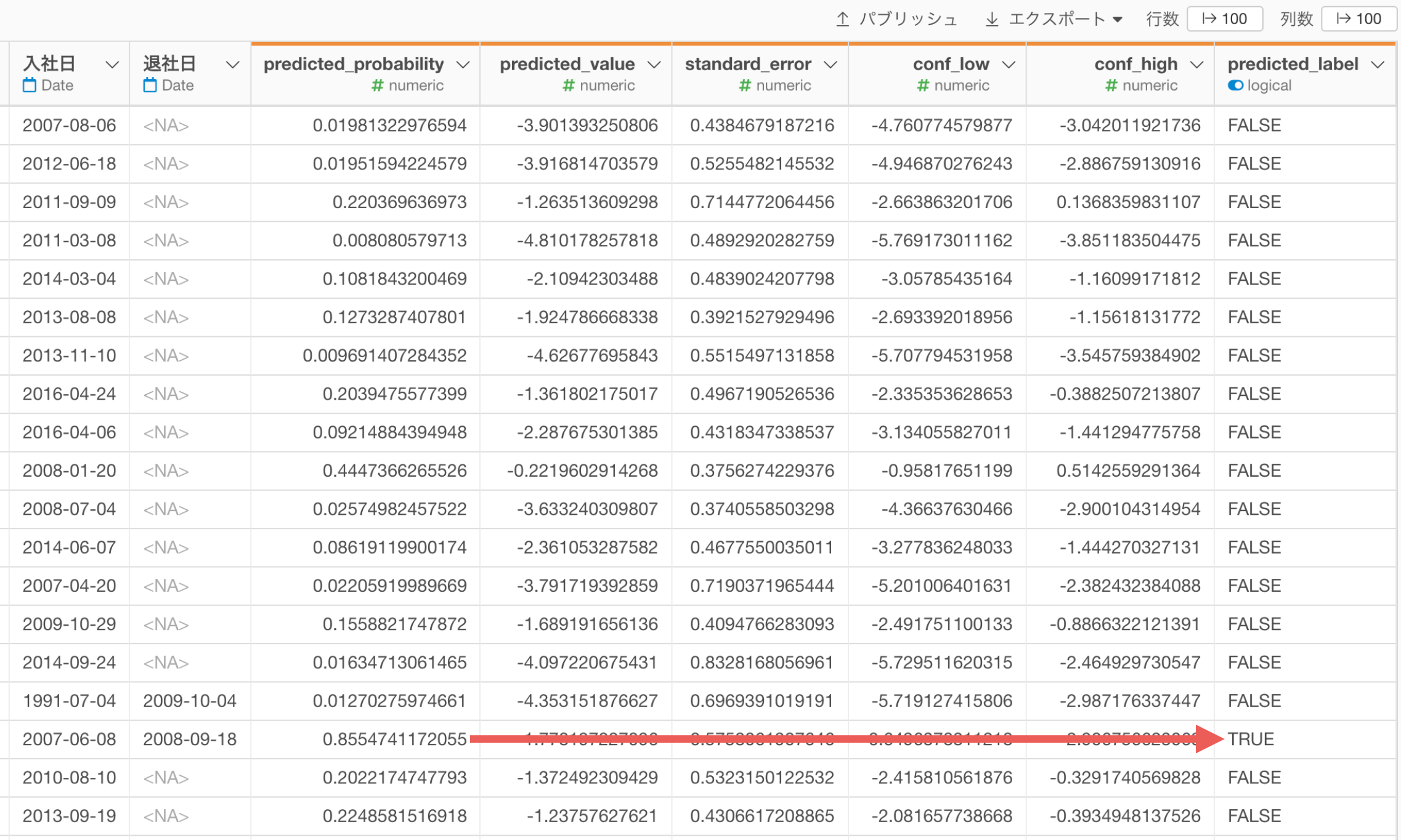
なお、TRUEという予測結果を返すしきい値である「TRUE/FALSEの境界値」のデフォルトの設定は0.5(50%)になるので、「predicted_probability」が0.5(50%)以上であれば、「predicted_label」はTRUEになっています。
予測精度の確認
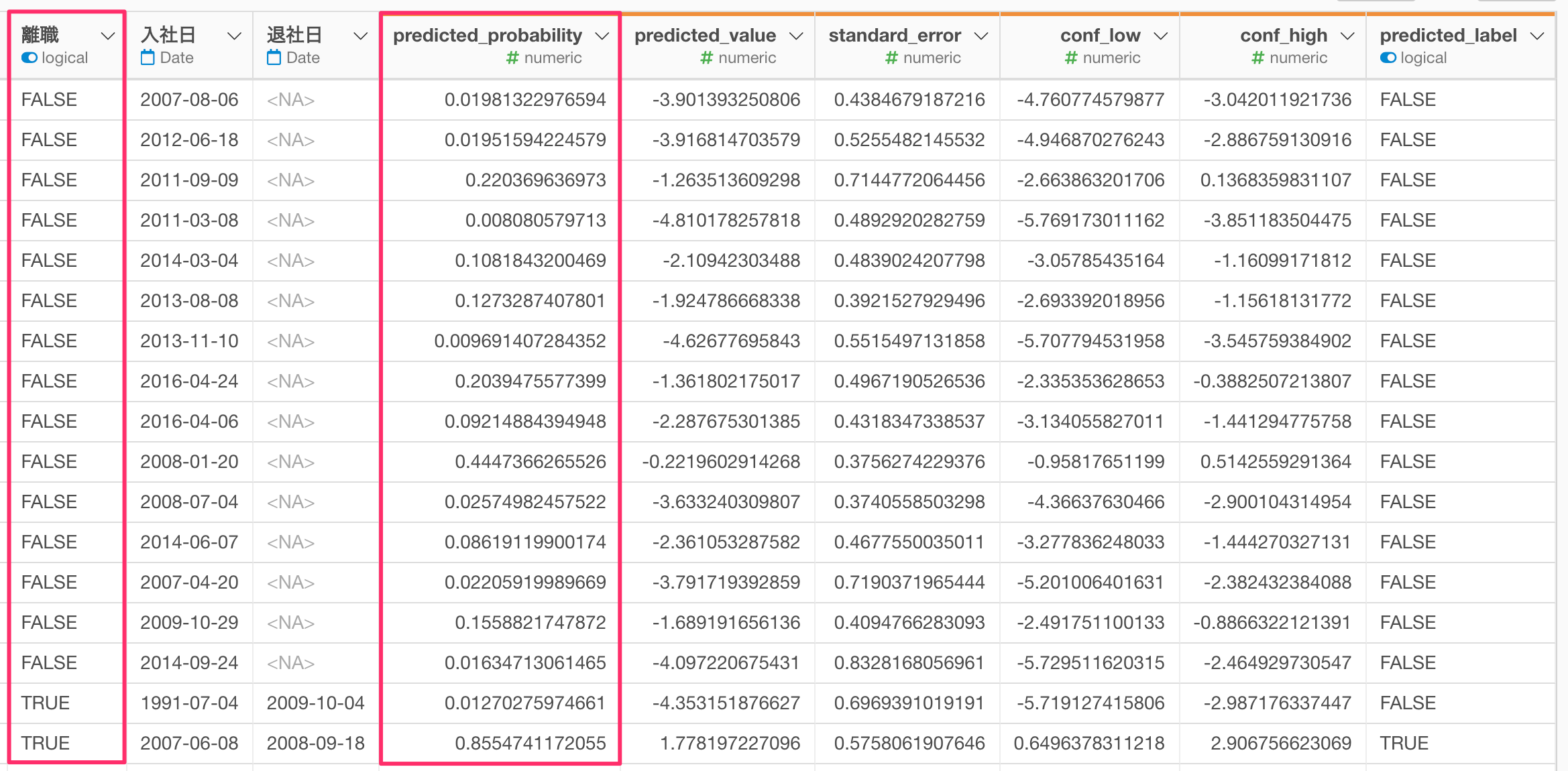
続いて、答えである「離職」の列と、「予測確率」の列を使ってこのモデルの精度を確認していきます。
なお、予測精度を確認するためには、予測をしたデータの中に答え(今回の例で言うと、実際に離職しているかどうかの列)が必要になりますので、ご注意ください。
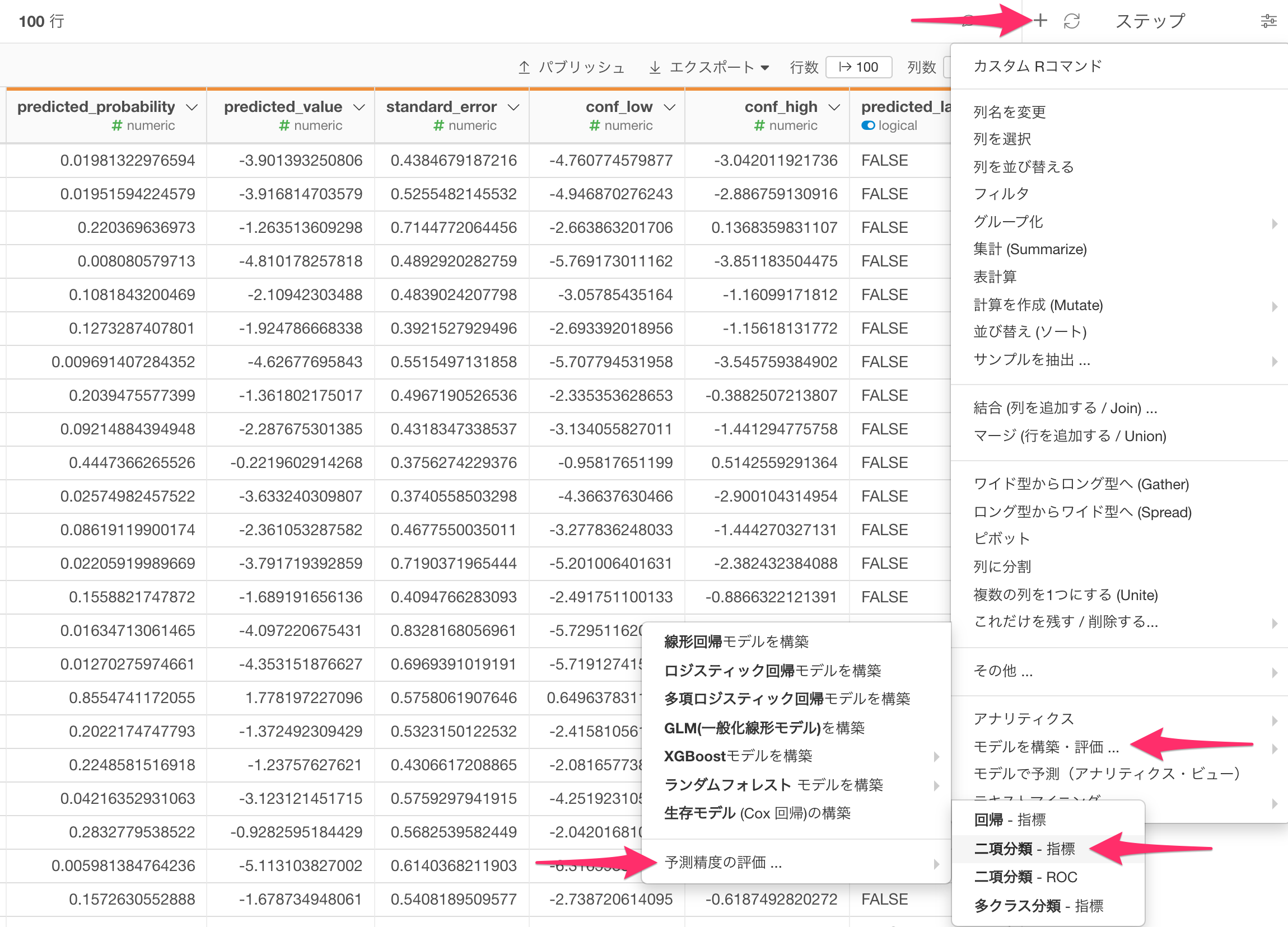
ステップメニューを開き、「モデルを構築・評価...」、「予測精度の評価...」、「二項分類 - 指標」を選択します。
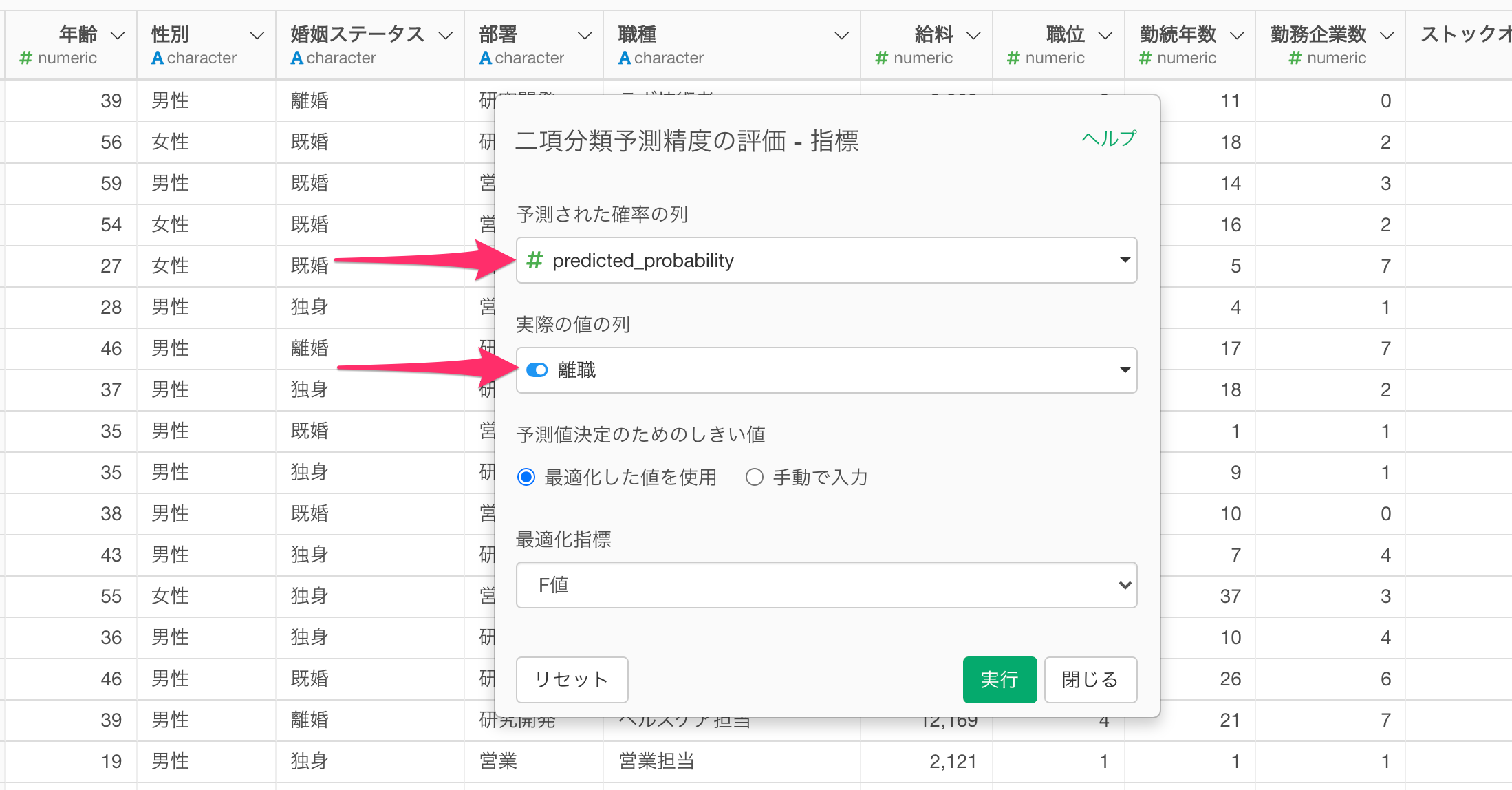
すると、「二項分類予測精度の評価 - 指標」のダイアログが表示され、「予測された確率の列」には自動でTRUEの予測確率である「predicted_probability」列が選択されますので、「実際の値の列」を選択し、実行します。

すると、「二項分類予測精度の評価」のステップが追加され、この予測モデルのサマリ情報が計算され、予測精度であるAUCを確認できます。