Airbnbに東京で部屋を出すならどこ良い?
自分が東京でAirbnbに部屋を出すと仮定し、その場合にどのエリアに出すのが良いのか?という視点でデータを分析してみた。
仮説
需要より供給が少ないと思われるエリアをみつけられれば、稼働率が高く、プライシングも高めに設定できて収益性も良いのでは?
需要をどのように推定するか?
Airbnbのサイトでの検索履歴のデータが欲しいといころだが、入手できないのでGoogle検索数が需要に相当するだろうという仮定で分析してみる。
Google検索数と宿泊施設数の概要
airbnb tokyo の Google Trends
host_since が 2010-06-25 〜 2019-09-26 なのでその間の Google Trends の airbnb tokyo の確認。 https://trends.google.co.jp/trends/explore?date=2010-06-25%202019-09-26&q=airbnb%20tokyo
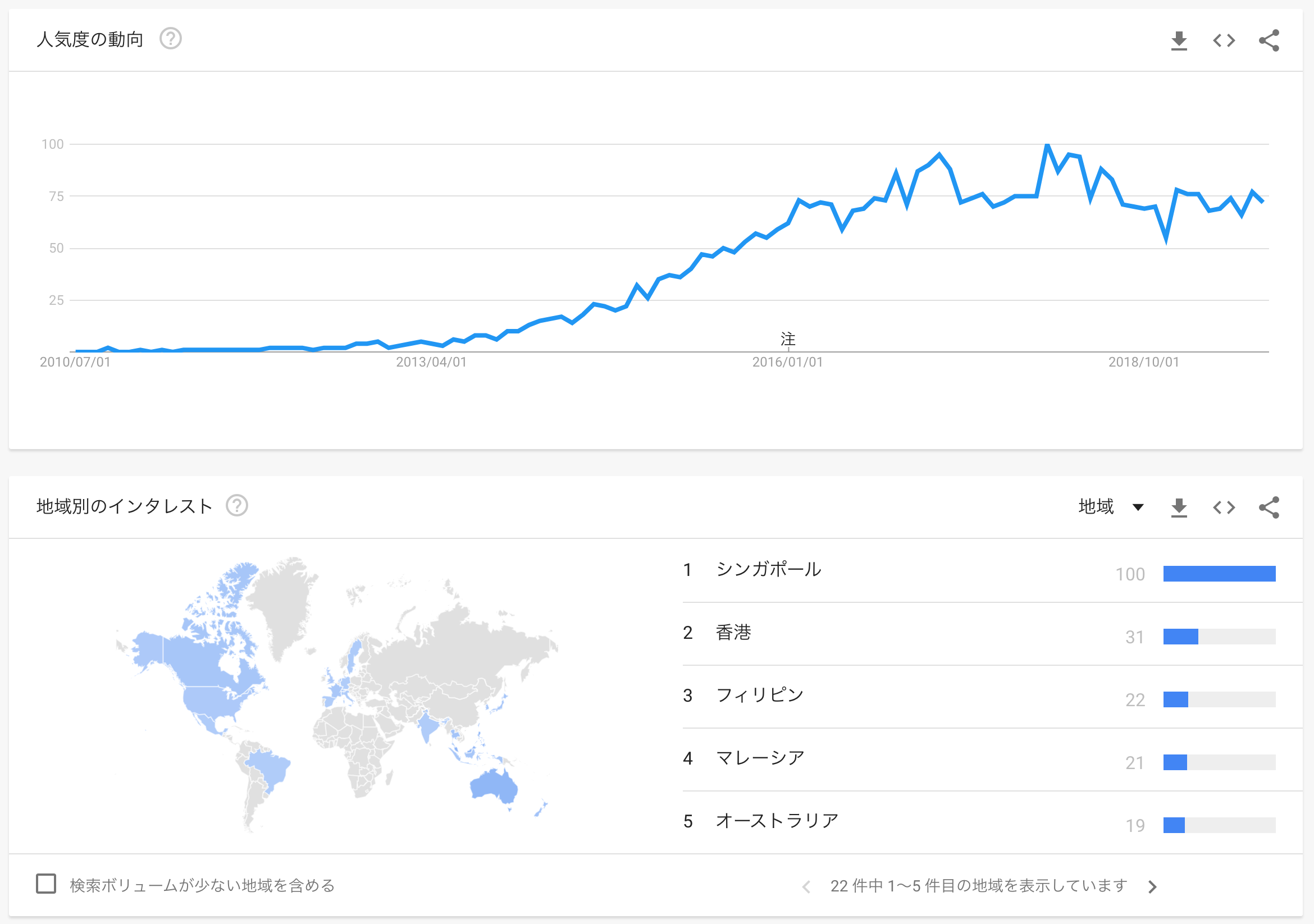
地域別にみるとシンガポールが一番多かったのは意外。
東京の宿泊施設数の時系列推移と比較
airbnb tokyo の検索トレンドと宿泊施設数の時系列推移をまずは確認。 Google Trends からデータをダウンロード& データフレームにインポート。
まずはラインチャートで確認。宿泊施設数は右肩あがりだが、検索数は2018年1月をピークにトレンドが変わってのびていない。
宿泊施設数は右肩あがりに延びているように見える。 次に散布図で確認。色を年、ラベルに月を表示してみた。
2018年8月以降に明らかにトレンドがかわっている。宿泊施設数は伸びているが、検索数がのびていない。
2018年6月に旅館業法などの許可がない宿泊施設を一括削除 したらしいが、この宿泊施設数には影響がみられない。これはデータが現在の宿泊施設数のリストのようなので、過去存在していてなくなったという情報が取れていないからだろうか。あるいは、削除後に各宿泊施設が法的対応して復活したからかもしれない。
ただ、削除騒動の前後から検索数の上昇トレンドが止まっているようだ。 全体のトレンドとしては競争が厳しくなってきていそうだが、エリアによっては狙い目があるかもしれないのでエリア別に見てみよう。
エリア別の Google検索数
続いてはエリア別の検索数を取得してみる。Googleトレンドでは検索数の相対値なので、今回は Google Ads のキーワードプランナーで、 airbnb tokyo の関連ワードと検索ボリュームを取得。 地域はGoogle Trends の上位20地域、言語は英語を指定。期間は Google Ads で取得できる最古が2015年11月からだったので、そこから取得。
キーワードプランナーからダウンロードしてインポートしたデータはこんな感じ。
月毎に横持ちのデータ(ワイド型)になっているので、ロング型に変換。Exploratory だとこれをGUIで簡単できるのは便利。検索キーワードをエリア別にグルーピング化してみた結果がこちら。
tokyo が圧倒的に多いので tokyo を除外するとこんな感じ。
次に時系列での変化を可視化。(Y軸がエリア毎に大きくことなる点注意。)
右肩上がりのエリアが多いが、ginza, haneda, ikebukuro, meguro, nakano, odaiba, setagaya あたりはのびていない。
とりあえずこのエリア別の検索ボリュームをエリア別の需要と仮定して分析することとする。
エリア別の 宿泊施設数
次に供給側として、エリア別の宿泊施設数を確認。
Airbnb のエリア別宿泊施設数
neighbourhood があったので、こちらが使えるか確認。 宿泊施設数の上位20はこんな感じ。
Shinjukuに次いで多いのが Toshima なのが意外。NAも結構あるな。Google検索数では Toshima は上位に来ないのはなぜだろうか?他のワードで検索されているんじゃないかと思って、Toshimaのホテルがどの辺なのかを地図チャートで確認。
エリアと検索キーワードにはズレがありそうだ。エリア別にどの検索ワードで検索されているかをどう推定しようかとデータを眺めていたら、name に大抵地名が入ってそうなことが分かったので、形態素解析してワードを抽出してみよう。
name を形態素解析して検索ワードを推定
こちらの記事を参考にMeCabとRMeCabをインストールして形態素解析実行。英小文字にそろえて、フィルタにstopwordでないという条件が指定できたので、英語と日本語のstopwordを除外。それでも地名に関係ないワードが結構あったので、数値除外、1文字除外して、あとはがんばってざっと目検で地名以外のワードをフィルタし、ワードクラウドで可視化。
Toshima の name のワード上位に想定どおり ikebukuro がきていた。でも otsuka も あるんだな。同じ意味のワードでの言語違いはまとめた方が良いが今回は省略。
ワードクラウドはエリアで繰り返しができないようなので、エリア別に集計してワード数上位5つを確認。
neighbourhood 別のワードは結構かぶってるな・・・
しかも neighbourhood を良くみると、Ikebukuro と Toshima、Ueno/Asakusa と Taito があり、設定値が適切なのか疑問がでてきたので、エリア別に色分けして地図にプロット。shiroto さんがサンプル分析でしていたように zipcodeでグループ化している。
Ikebukuro は 池袋駅周辺に限定されてはいるものの、Toshimaと若干かぶってる、Ueno/Asakusa は Taito とおもいっきりかぶってる。
name のワードクラウドを全体で見ると、特定の地名に集中してるので、最寄りの有名な地名を name にいれる傾向があるようだ。
neighbourhood をそのまま使うのはちょっと厳しそう。city の値も表記揺れ等がありそうなのでそのままでは使えなさそう。郵便番号か緯度経度あたりが一番精度高そうだけどそうしようかと思っていたところ、 wasabi_ さんが緯度経度から Yahoo!リバースジオコーダAPI で住所を取得したデータを共有していただいていたので、ありがたくそちらを拝借。
市区町村(city)単位の現在の宿泊施設数はこんな感じ。
地図にプロットしてみるとこんな感じ。
市区町村単位の月別の推移はこんな感じ。
2018年3月頃から、新宿区、台東区、豊島区、墨田区が急増していて、墨田区が渋谷区を抜いたのは最近といったことが見てとれる。
次に、この市区町村を Google 検索数の検索キーワードをグルーピングしたものとマッピングできるようにグルーピングしてみる。線引が結構難しいが、とりあえず以下でマッピングすることにした。
- akihabara → 千代田区
- asakusa/ueno → 台東区、墨田区
- disneyland → 江戸川区
- ginza → 中央区
- haneda → 大田区
- shibuya/harajuku → 渋谷区
- shinjuku/ikebukuro → 新宿区、豊島区
- meguro → 目黒区
- shinagawa → 品川区
- shinjuku → 新宿区
Google 検索ボリュームが少ない kichijoji, meguro, nakano, odaiba, setagaya は対象外に。また、tokyo station も東京駅周辺の定義が難しく、宿泊施設数もあまりないので今回対象外とした。
asakusa, ueno と harajuku, shibuya はエリア分割が難しいので、検索キーワードのグループも合算してみることにする。また宿泊施設数が豊島区(池袋)が多いが、ikebukuro の検索数がやけに少なく、新宿と同一エリアと捉えられている可能性があるので、shinjuku/ikebukuro でまとめることにした。
需要と供給の視覚化
最後に需要(Google Trends)と供給(宿泊施設数)を視覚化。
まずは対象としたエリアの合計を確認。検索数の伸びよりも宿泊施設数の伸びの方が大きい。
次にエリア別に見るとこのようなかたち。
1宿泊施設あたりの検索数で見るとこのようになる。
どこ右肩下がり傾向であるが、比較的多いのは
- shibuya/harajuku
- shinjuku/ikebukuro
- disneyland
であった。
結論
私が東京でAirbnbに宿泊施設を出すなら以下の3つのエリアが良いと考える。
1. 下北沢・明大前
検索数が多く、検索数に対する宿泊施設数は多くない、渋谷/原宿、新宿/池袋のエリアがまず候補にあがる。
池袋は検索数が少なく、渋谷が比較的宿泊施設数が少ないので、新宿と渋谷の中間あたりが狙い目。
地価の比較的低い山手線の外側で探すと、「外国人に人気の二大観光スポット新宿・渋谷に電車1本で数分でいける!」という訴求ができる点で下北沢・明大前を選定。
2. 越中島・潮見・新木場
ディスニーランドの検索数はまだ少ないが成長しており、宿泊施設数も比較的少ないので狙い目。「東京駅、ディスニーランドに電車1本で数分でいける!」という訴求できて、地価も安そうなところとして、京葉線の越中島・潮見・新木場を選定。
3. 錦糸町・両国・浅草橋
「東京駅、秋葉原、浅草に電車で10分程度でいける!」という点を訴求できる地域で、地価の高い山手線内ではないところだとこの辺かな。相撲も訴求できる。しかし上野・浅草エリアは検索数に対する宿泊施設数が多い点が懸念。
今回の分析の限界
需要の推定
需要の推定をGoogle Trends および Google Ads のキーワードプランナーで今回行ったが、思ったよりも検索数が少なかったので、Airbnbユーザーは Google で検索する数より、 Airbnb内で検索する数が圧倒的に多い可能性がある。従って、Google検索数による需要の想定という前提がそもそも無理があった可能性が結構ある。
供給過剰なエリアは、稼働率(成約率)が高いかプライシングが高め、供給不足なエリアはその逆なことが想定されるので、それが確認できれば、Google検索数が需要と相関するという仮説の補強になるかとも思ったが、availability_365 は貸し出している日数で、その中で成約した日数ではなさそうだったこと、プライシングの高低を判断する基準(相場)のデータを作成するのに時間がかかりそうなので断念。
http://www.analyze-world.com/entry/2017/11/09/061023 みたいにお得な物件情報とかもあわせたら面白そうだったが時間の関係で断念。
また、availability_365 が貸し出しされている日数なら、供給量はそこも加味した方が良さそうだが、全期間で平均化された値と思われるので、availability_365 の値は供給量に加味しなかった。
エリアの推定
Google検索ワードに対応するエリアを区単位で分けてしまったが、実際はきれいに線引きできるものではないため、どこで分けるかによって結果が変わってしまう。この分け方の妥当なロジック検討まで今回はできなかった。
時系列分析
Google検索数と宿泊施設数は時系列データなので、時系列分析を時間があれば学習してやりたかったが、今回は時間が取れず。