文字列にある1番目の単語と2番目の単語(数値のみ)をくっつけたい
例えば下記のような文字列があったとします。
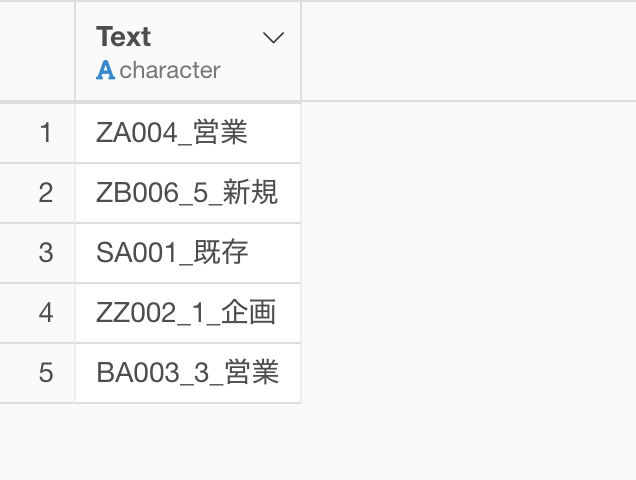
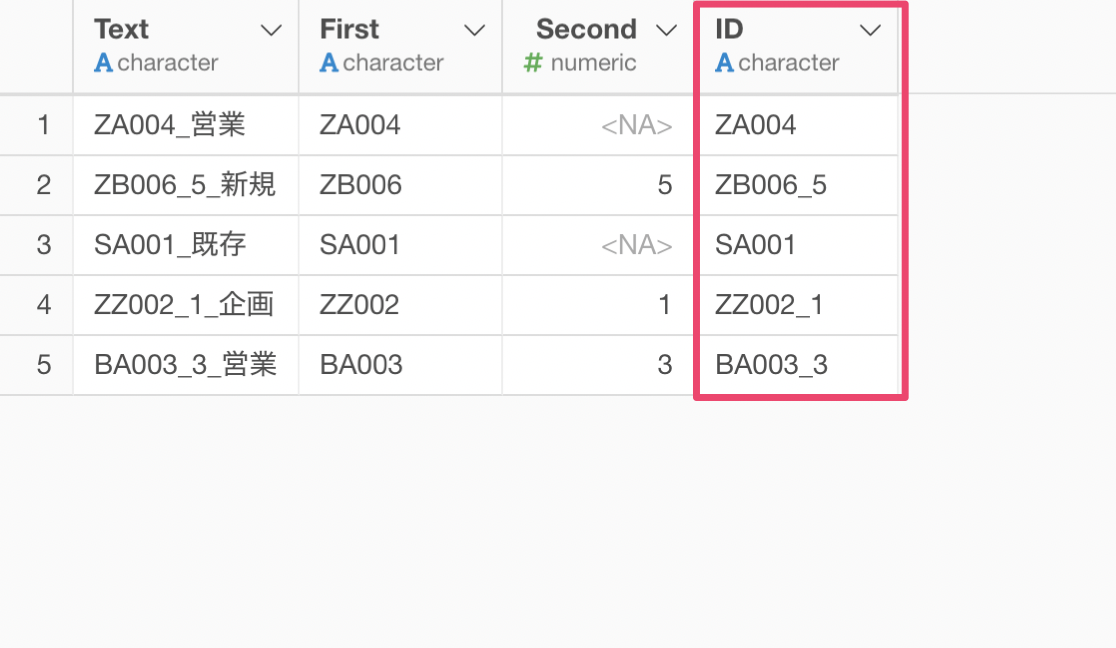
この文字列は区切り文字にアンダースコアー( _ )が使用されていますが、この中にある1番目の単語(ZA004)と2番目の単語を取り出して、数値の場合は1番目の単語にくっつけたいとします。
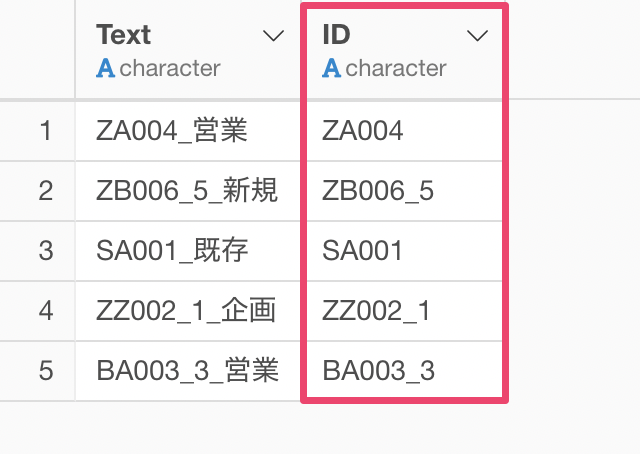
これをするには、下記のステップで可能です。
- 1番目と2番目の単語を抽出する
- 2番目の単語を数値のみにする
- 1番目の単語と2番目の単語の列をくっつける
1番目と2番目の単語を抽出する
列ヘッダメニューからテキストデータの加工 (UI) を選び、抽出するを選択します。
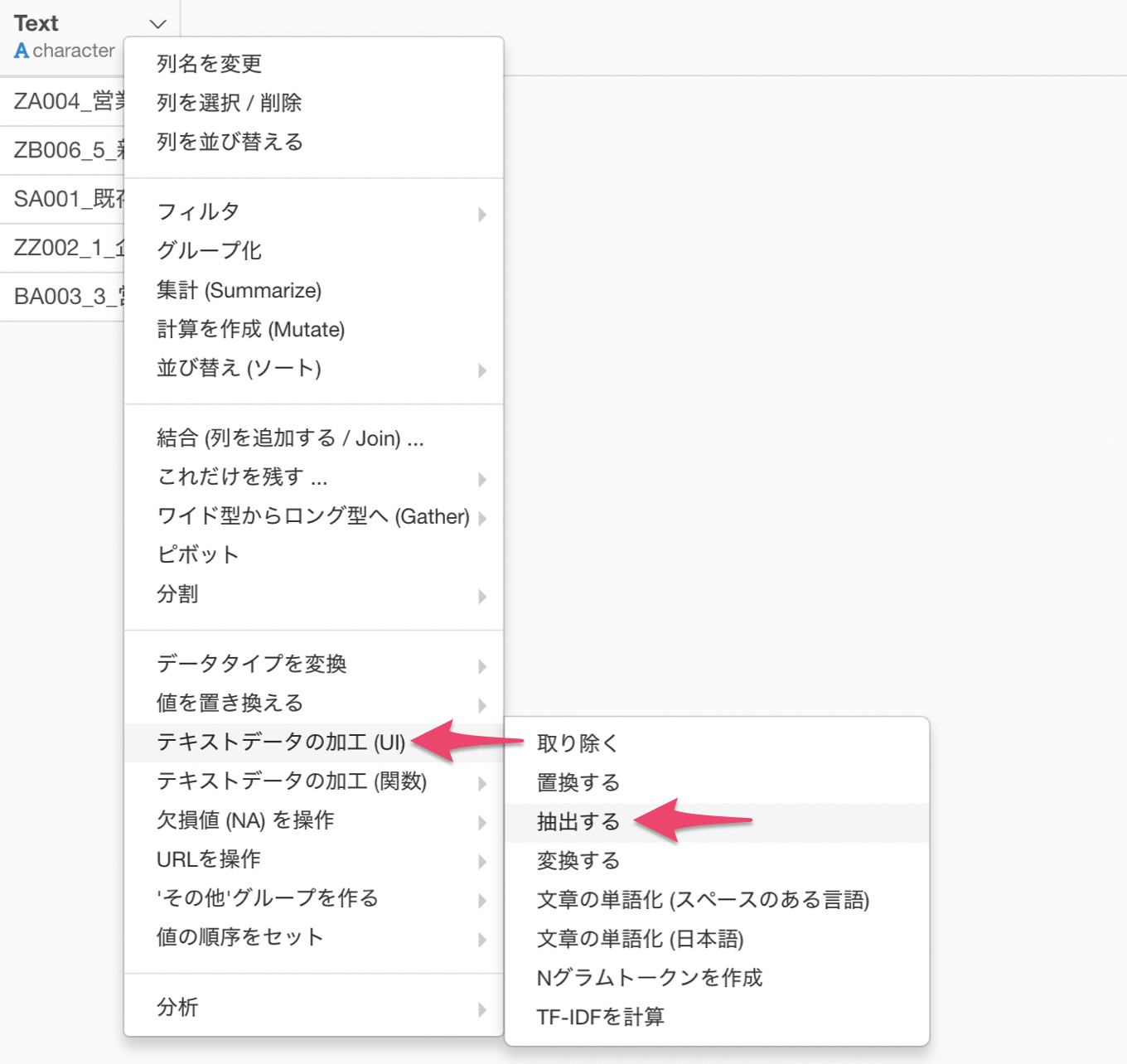
テキストデータの加工のダイアログが表示されます。
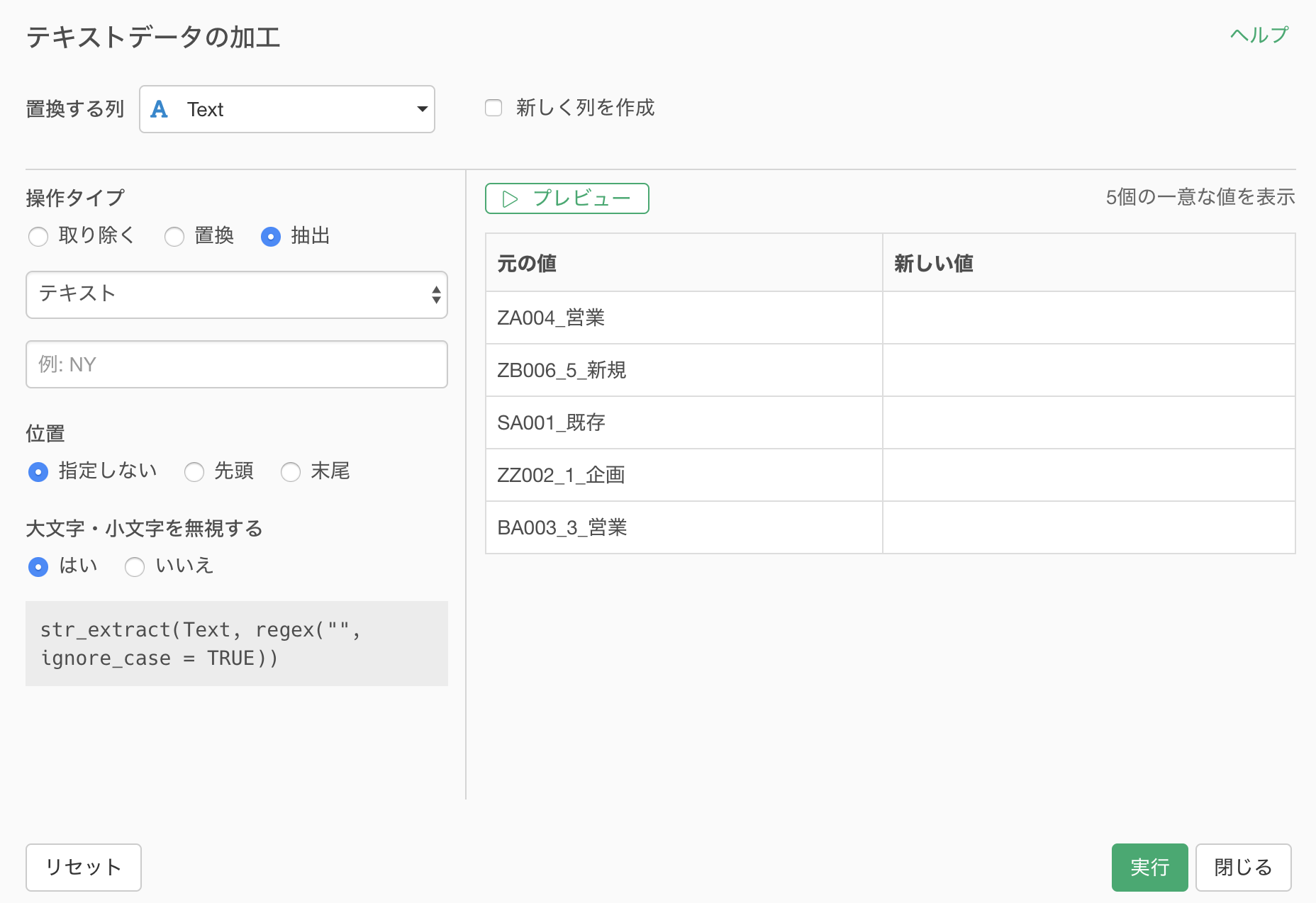
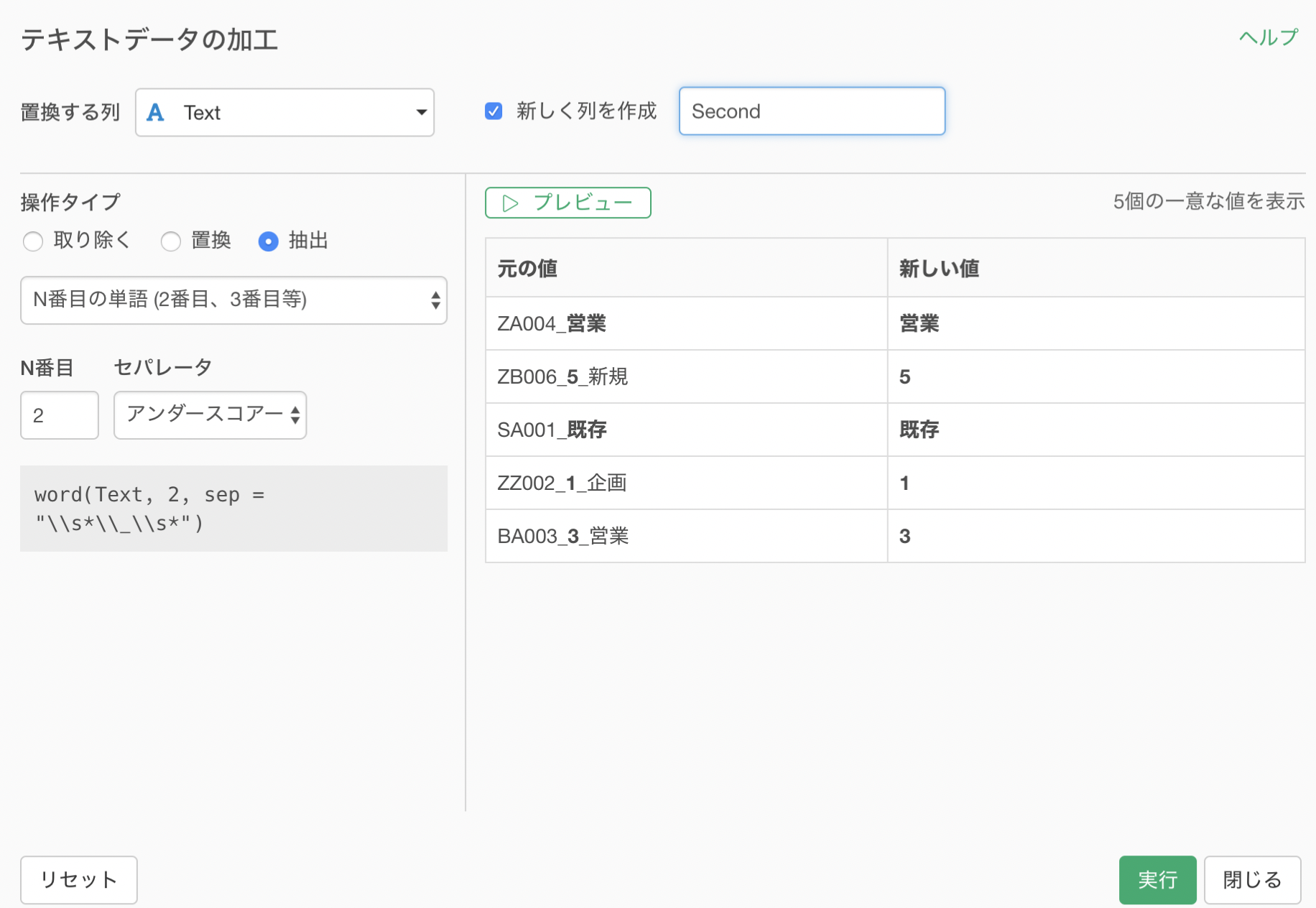
抽出のタイプにN番目の単語を選択します。
まずは1番目の単語を取り出したいので、N番目に1を指定して、セパレータ(区切り文字)にはアンダースコアー( _ ) を選択します。
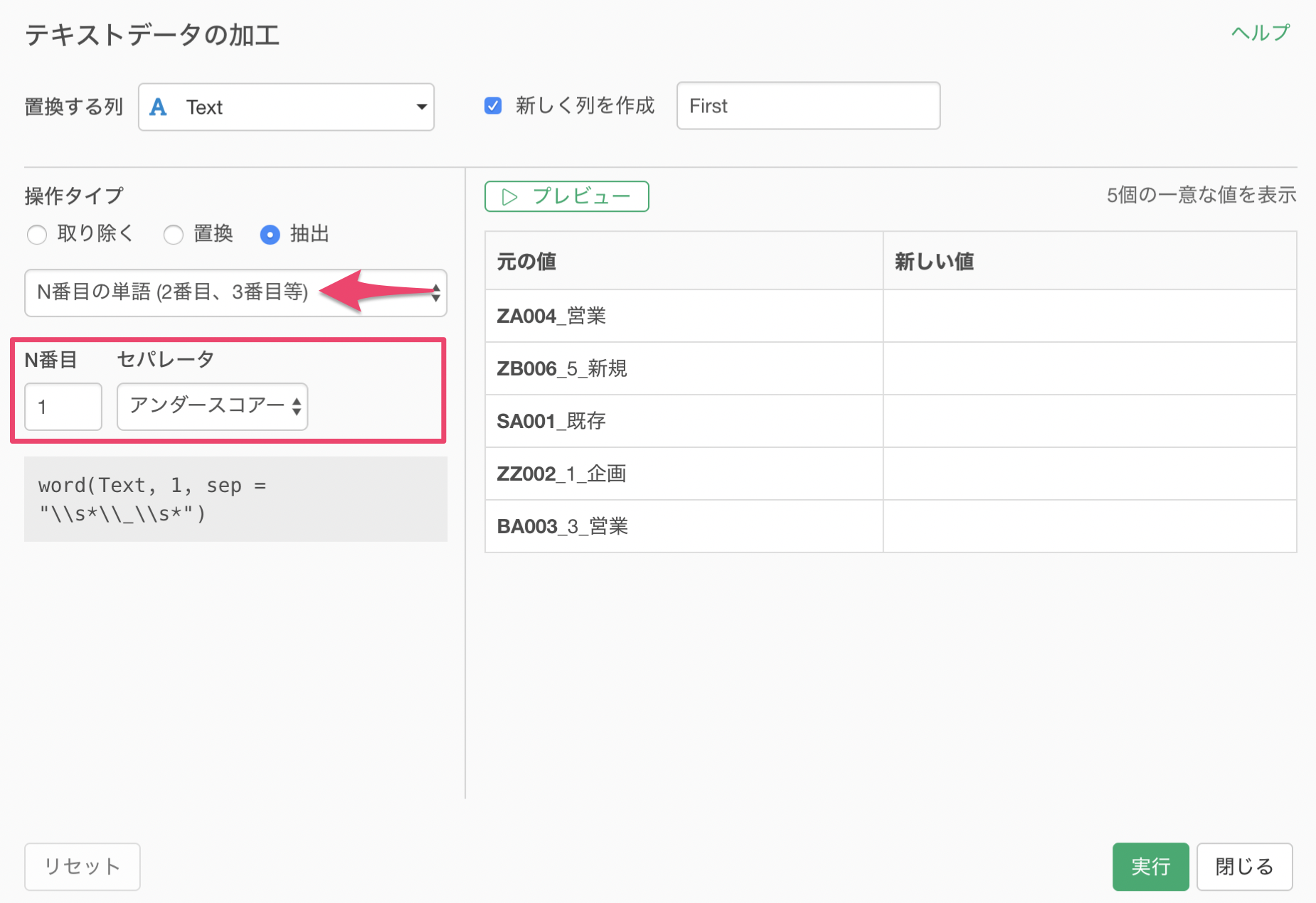
プレビューをクリックすると、新しい値に1番目の単語が取り出せていることが確認できます。
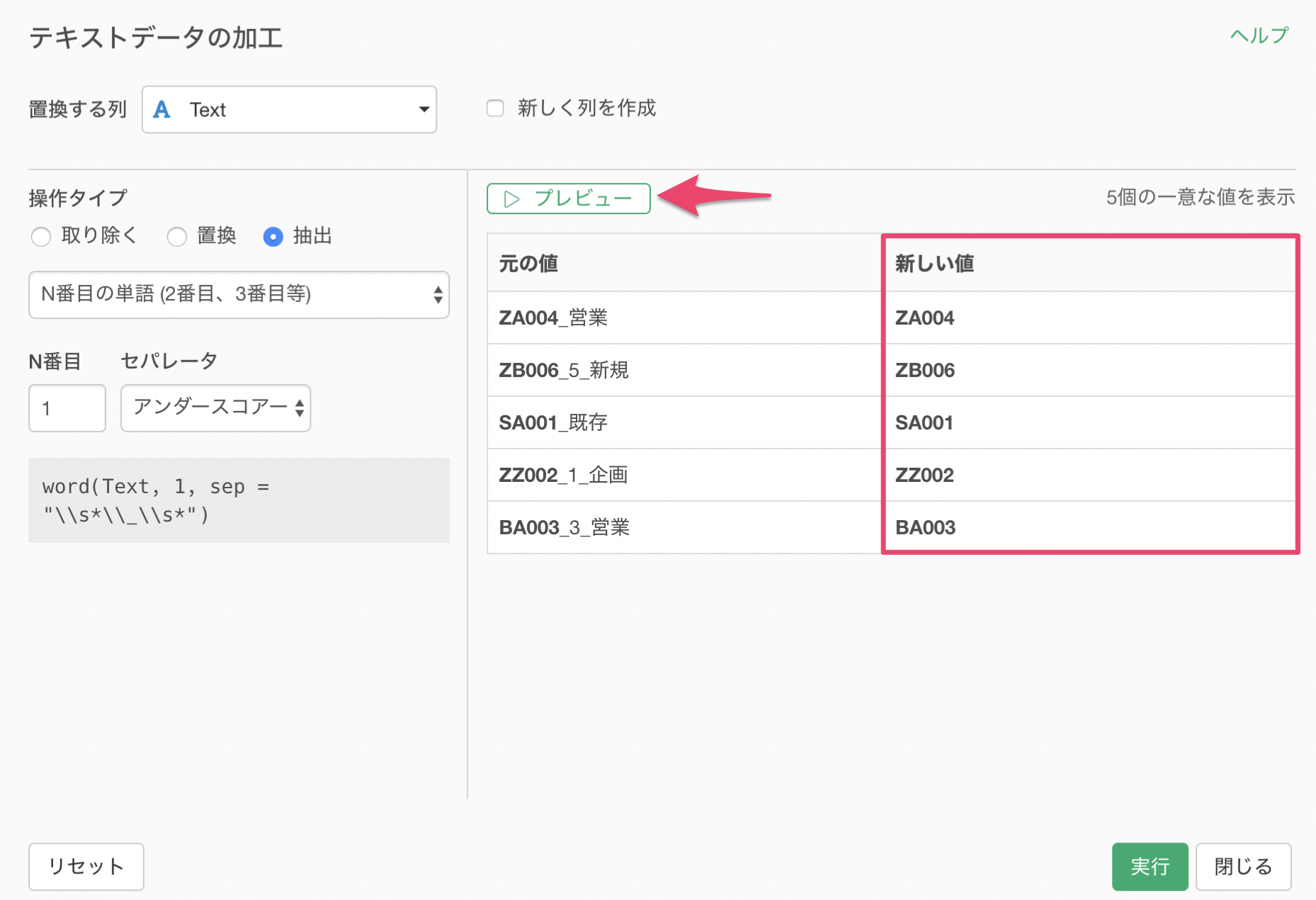
新しく列を作成にチェックをして、列名をつけたら実行します。
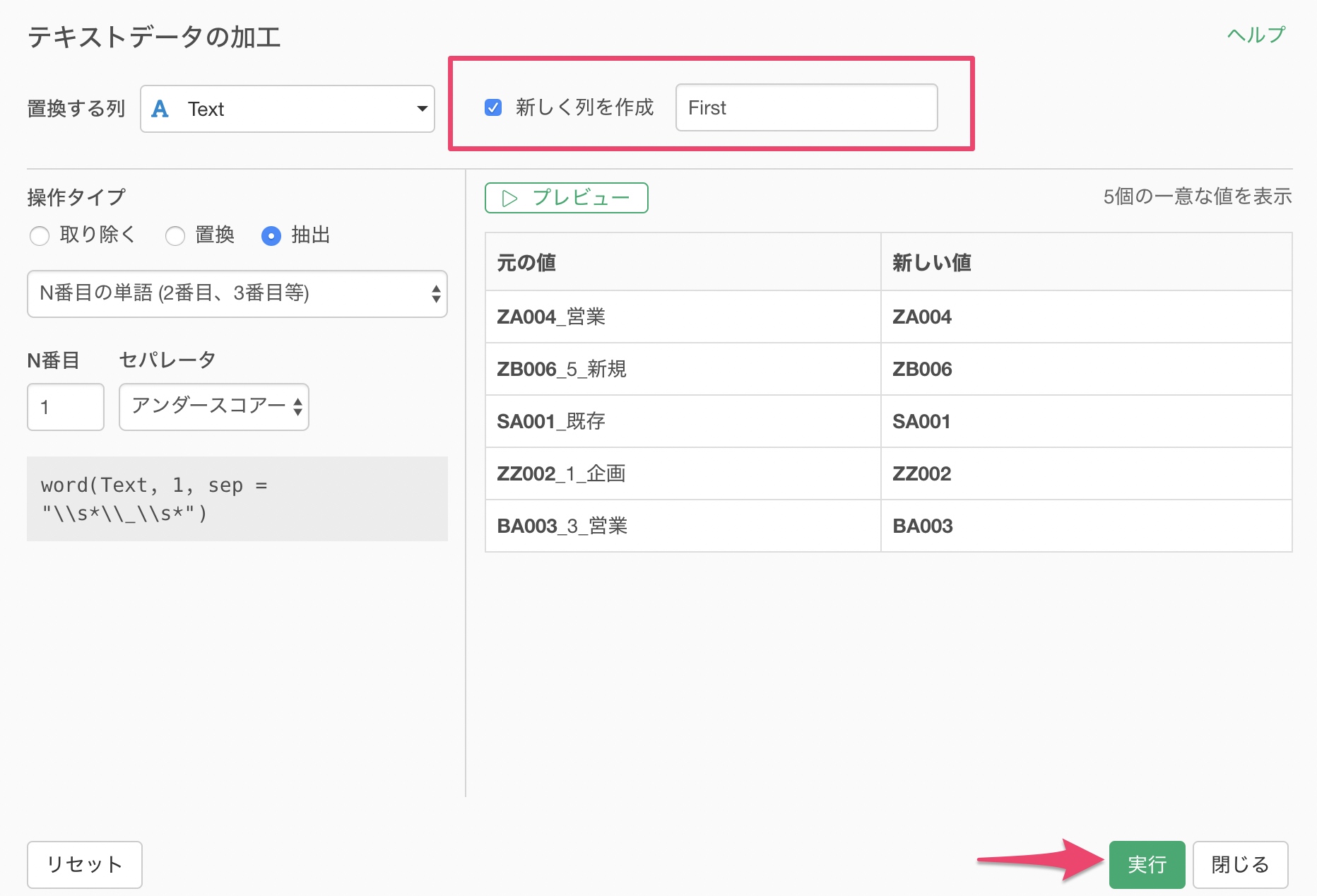
文字列の1番目の単語を取り出すことができました。
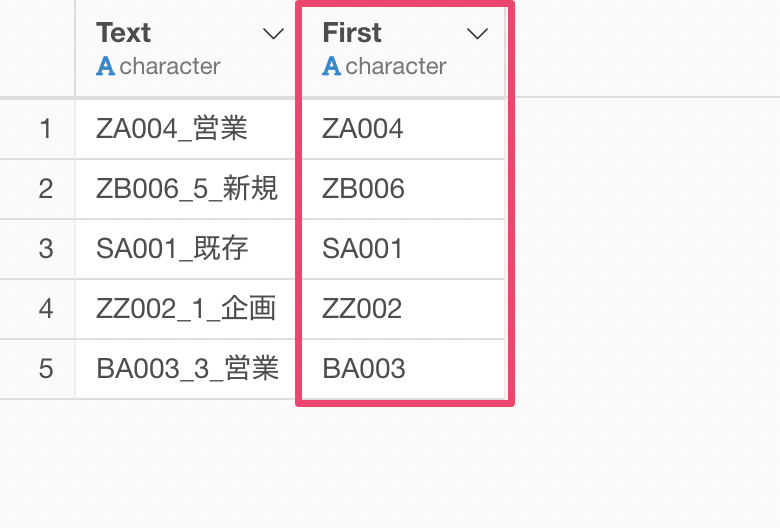
同様にして、2番目の単語も取り出します。
1番目と2番目の単語を取り出すことができました。
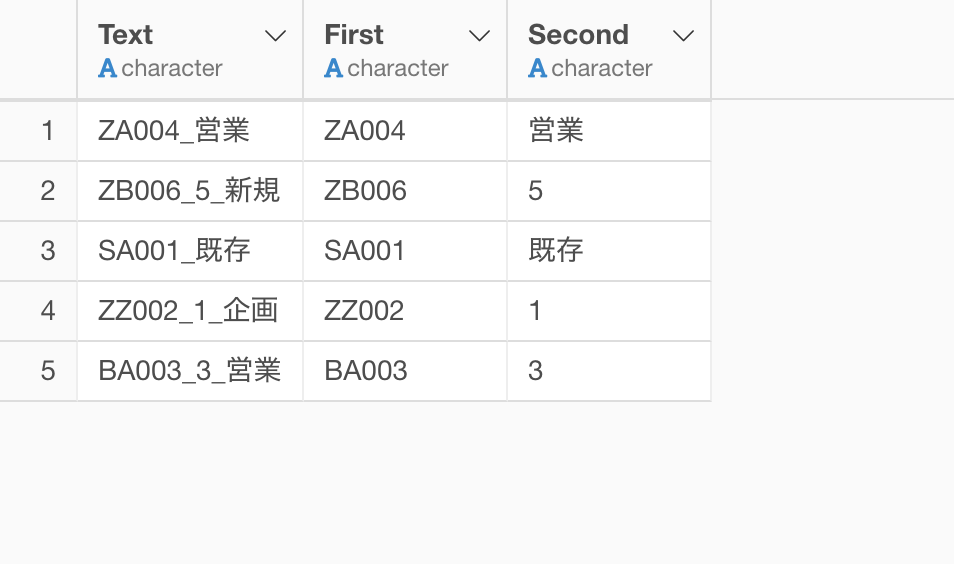
2番目の単語を数値のみにする
次に、2番目の単語は数値のみを使用したいため、データタイプを数値型に変えていきます。
列ヘッダメニューからデータタイプを変換を選び、Numeric (数値)タイプに変換を選択します。
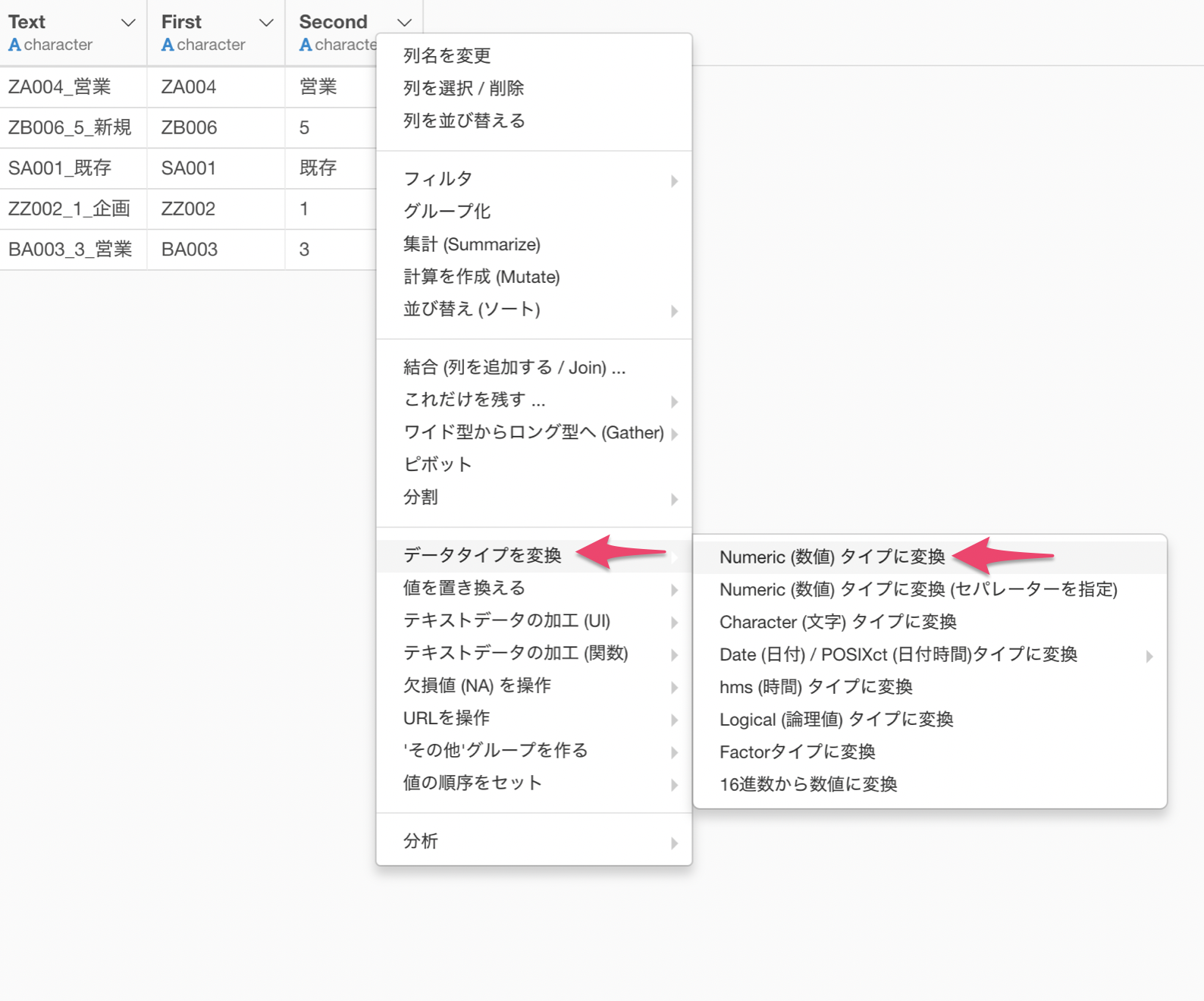
計算を作成のダイアログが表示され、計算エディタには既に関数と引数が入力されているのでそのまま実行します。
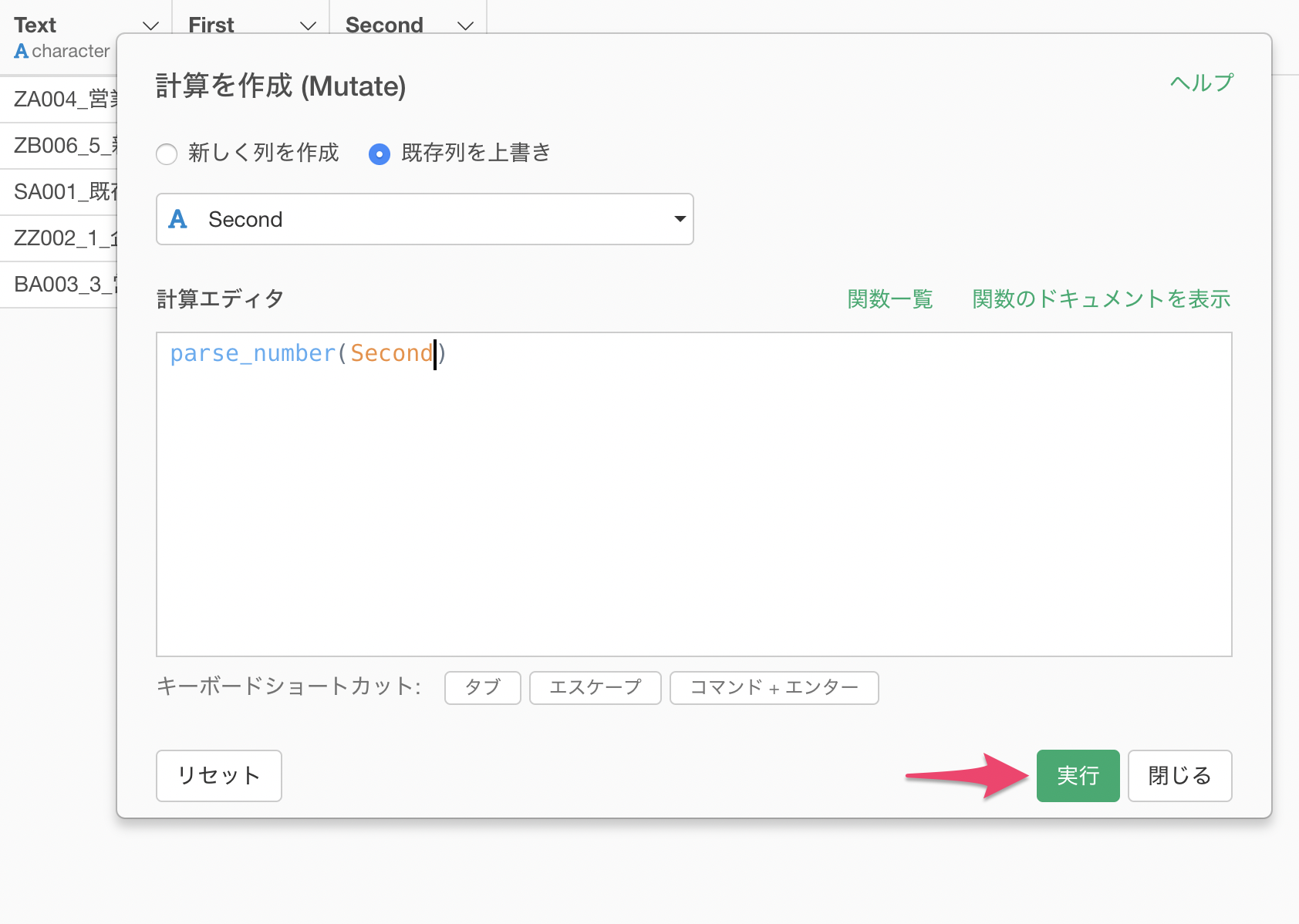
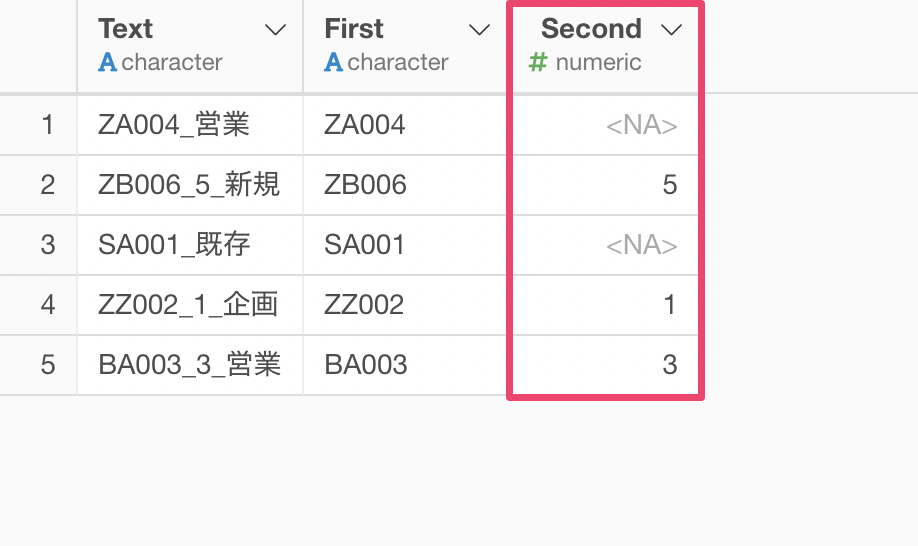
2番目の単語の列を数値のみにすることができました。
もし文字列の場合は今回の数値型への変換で欠損値 (<NA>)になります。
1番目の単語と2番目の単語の列をくっつける
最後に、文字列をくっつけていきます。
列ヘッダメニューから計算を作成 (Mutate) を選択します。
計算を作成のダイアログが表示され、計算エディタには列名が入力されています。
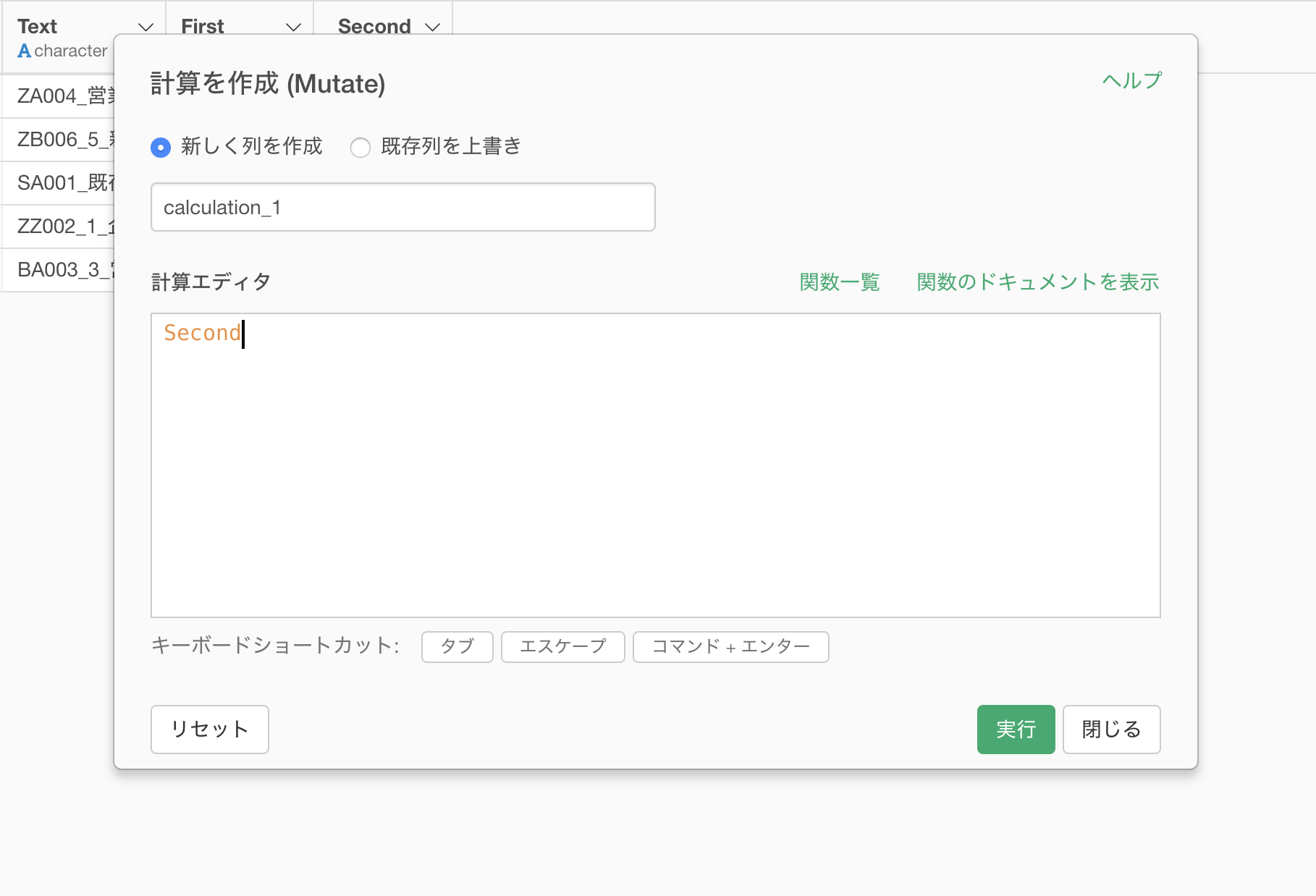
次に、下記のコードを計算エディタに入力します。
ifelse(!is.na(Second), str_c(First, Second, sep="_"), First)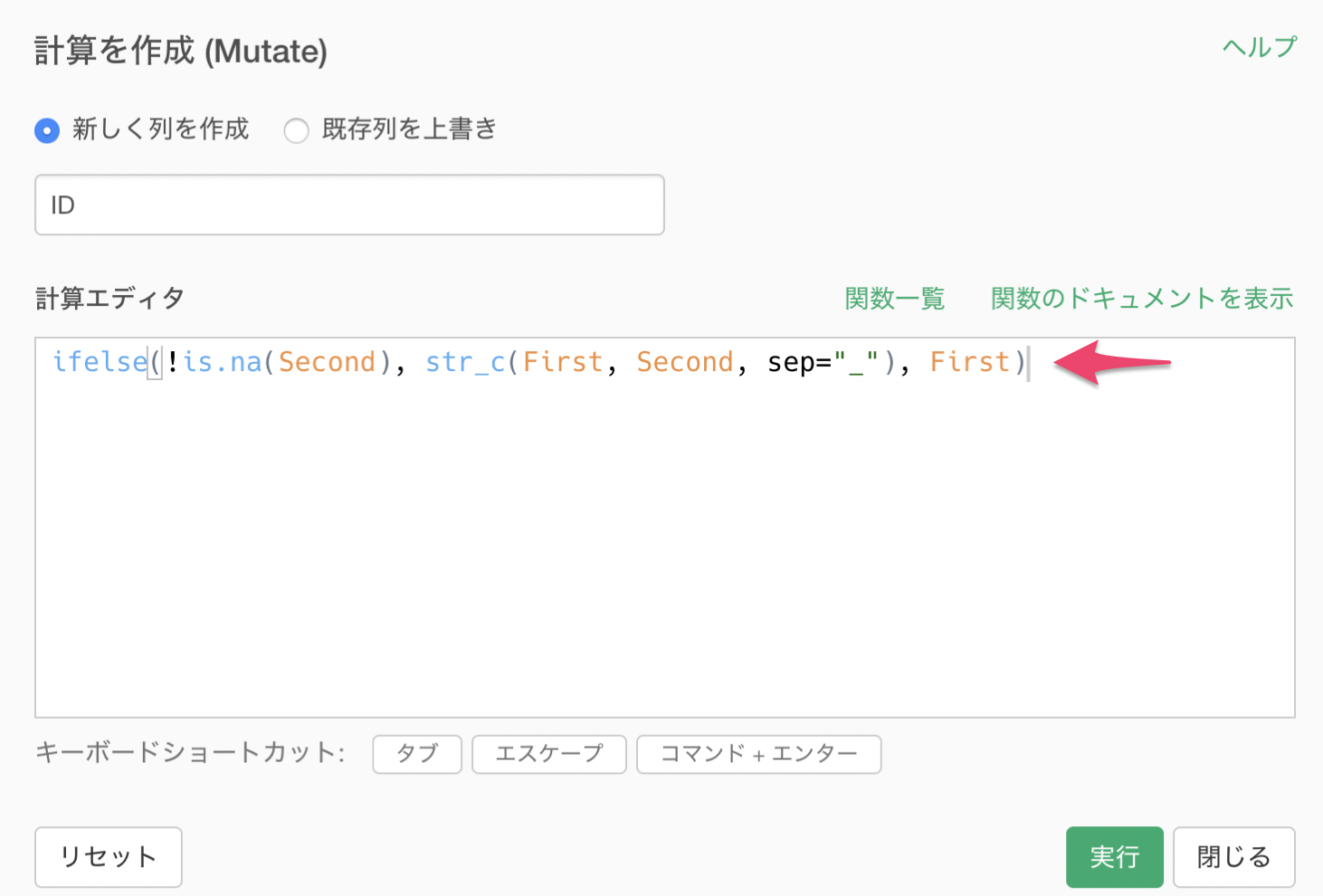
ここでは、ifelseを使った条件式により、もし2番目の単語の値が欠損値じゃなければ、1番目の単語と2番目の単語の列をくっつけるという処理をしています。
もし、2番目の単語が欠損値の場合は、1番目の単語のみでいいので、1番目の単語の列の値を返すように指定しています。
これにより、文字列にある1番目の単語と2番目の単語(数値のみ)をくっつけることができました。