どの単語の組み合わせがよく使われるかを分析する方法
今回は、Twitter searchから「データサイエンス」のキーワードで取得したツイート(文章)を単語化したデータを使用します。
前回のノートにて、文章を単語化してどの単語がよく使われるかを可視化していきました。
ここでもう一度、前回のあらすじをおさらいしましょう。
ステップ1: 文章(ツイート)を単語化する

ステップ2: 単語化したデータをワードクラウドを使って可視化する

しかし、Twitterから「データサイエンス」のキーワードでデータを取得しているため、必然と「データ」と「サイエンス」が多くなってしまい、どの単語がよく使われるのかが区別つきません。
ステップ3: 「データ」と「サイエンス」という単語をフィルタを使って取り除く
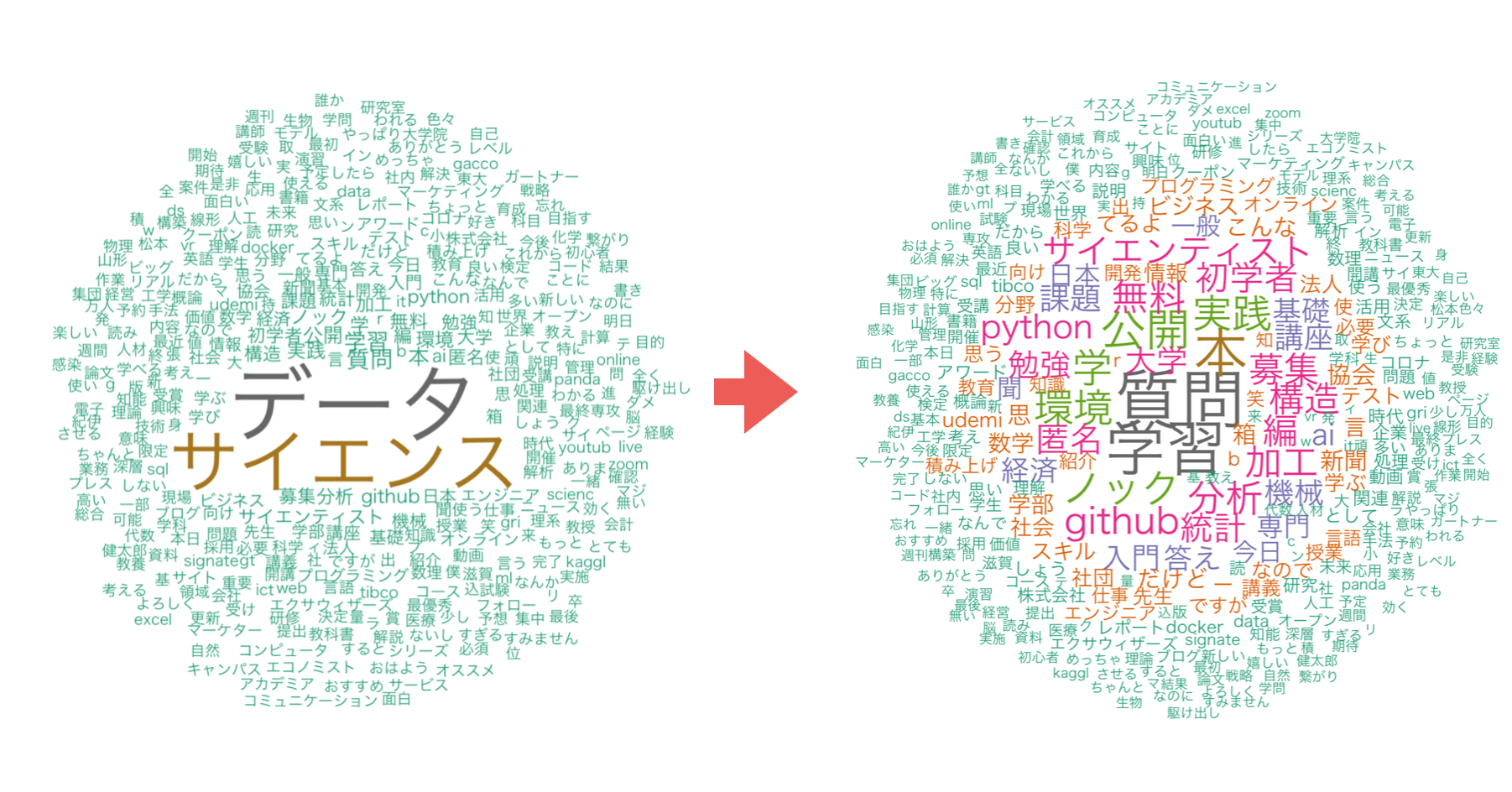
「データ」と「サイエンス」を取り除くことで、どの単語がよく使われているのかをワードクラウドを使って可視化していくことができました。
詳しくは下記のノートをご覧ください。
前回行った、文章を単語化してワードクラウドで可視化する方法では、よく使われる単語は可視化できますが、一緒に使われている単語はわかりません。
例えば、機械と学習は一緒に使われているかもしれません。
それとも、pythonとAIが一緒に使われているかもしれないです。
実際にツイートを見てみると、pythonとAIが同じ文章に使われるケースがあるようです。

よく一緒に使われている単語がわかれば、アクションに繋げていくことができます。
例えば、ツイッターのハッシュタグに一緒に使われる単語を追加することで、他の人がツイートを見つけやすくなったりします。

そのため、よく一緒に使われている単語の組み合わせは何かを分析したいです。
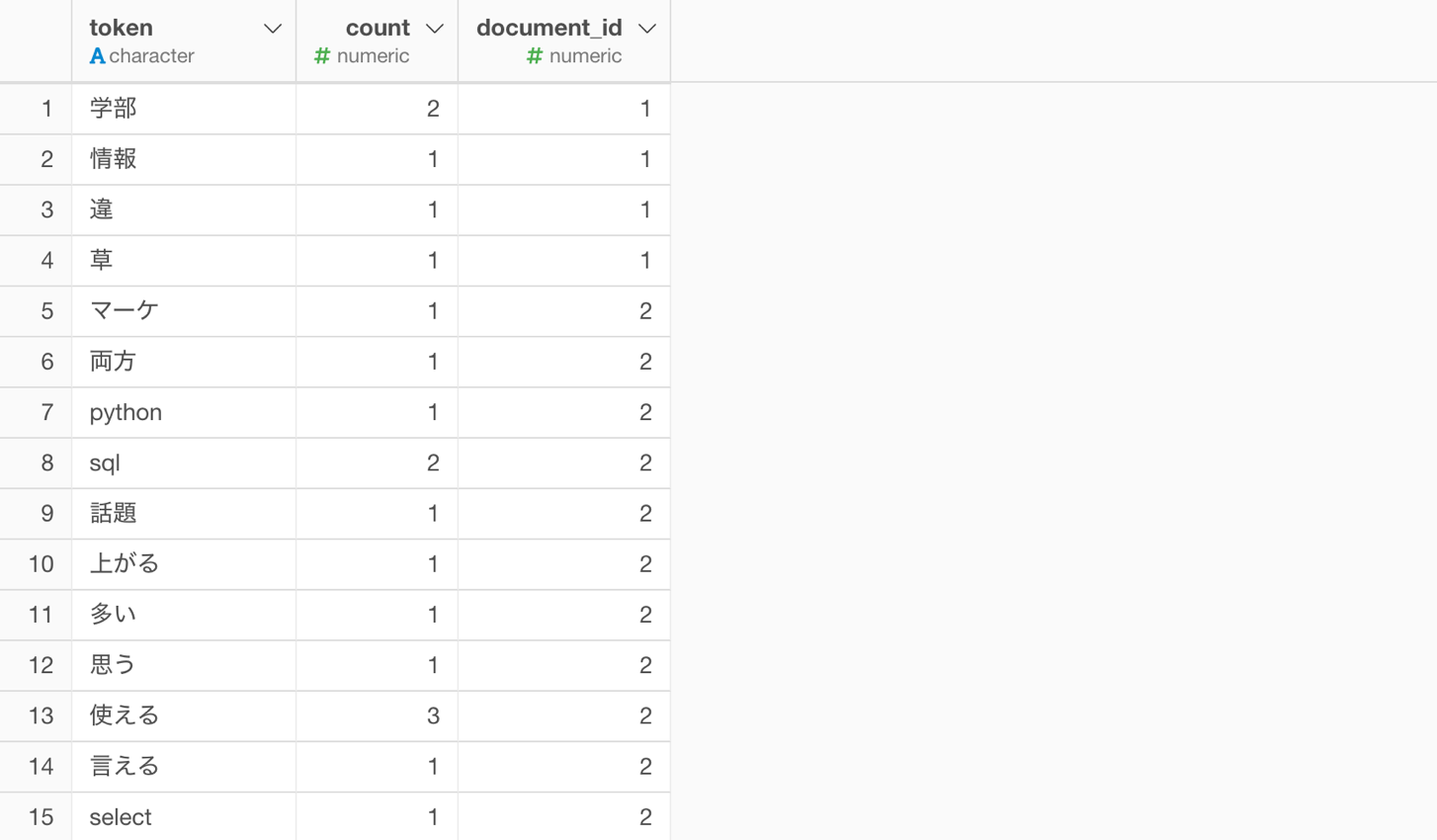
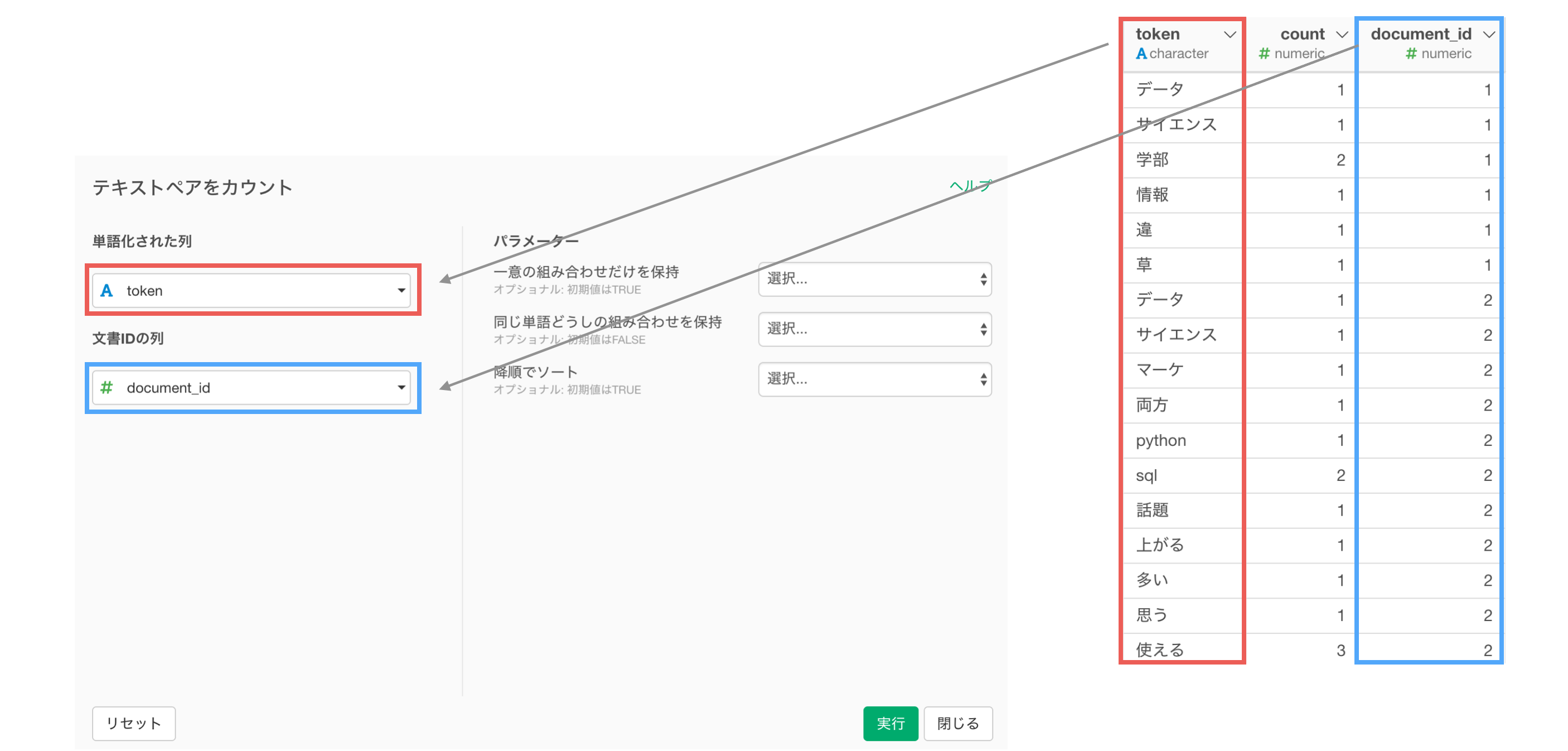
下記のように、文章を単語化したデータがあります。
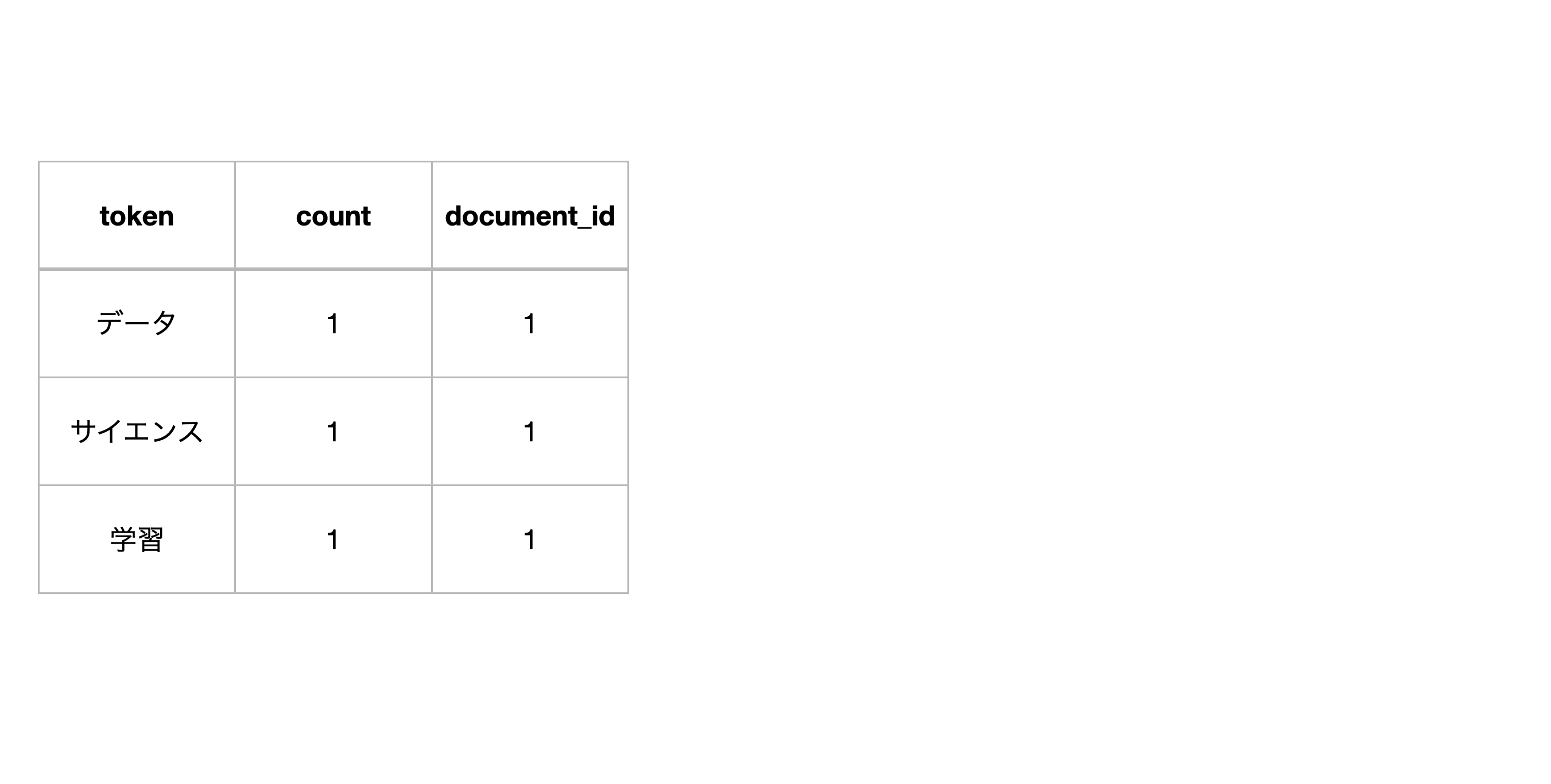
この単語化されたデータから、それぞれの単語の組み合わせを作ります。
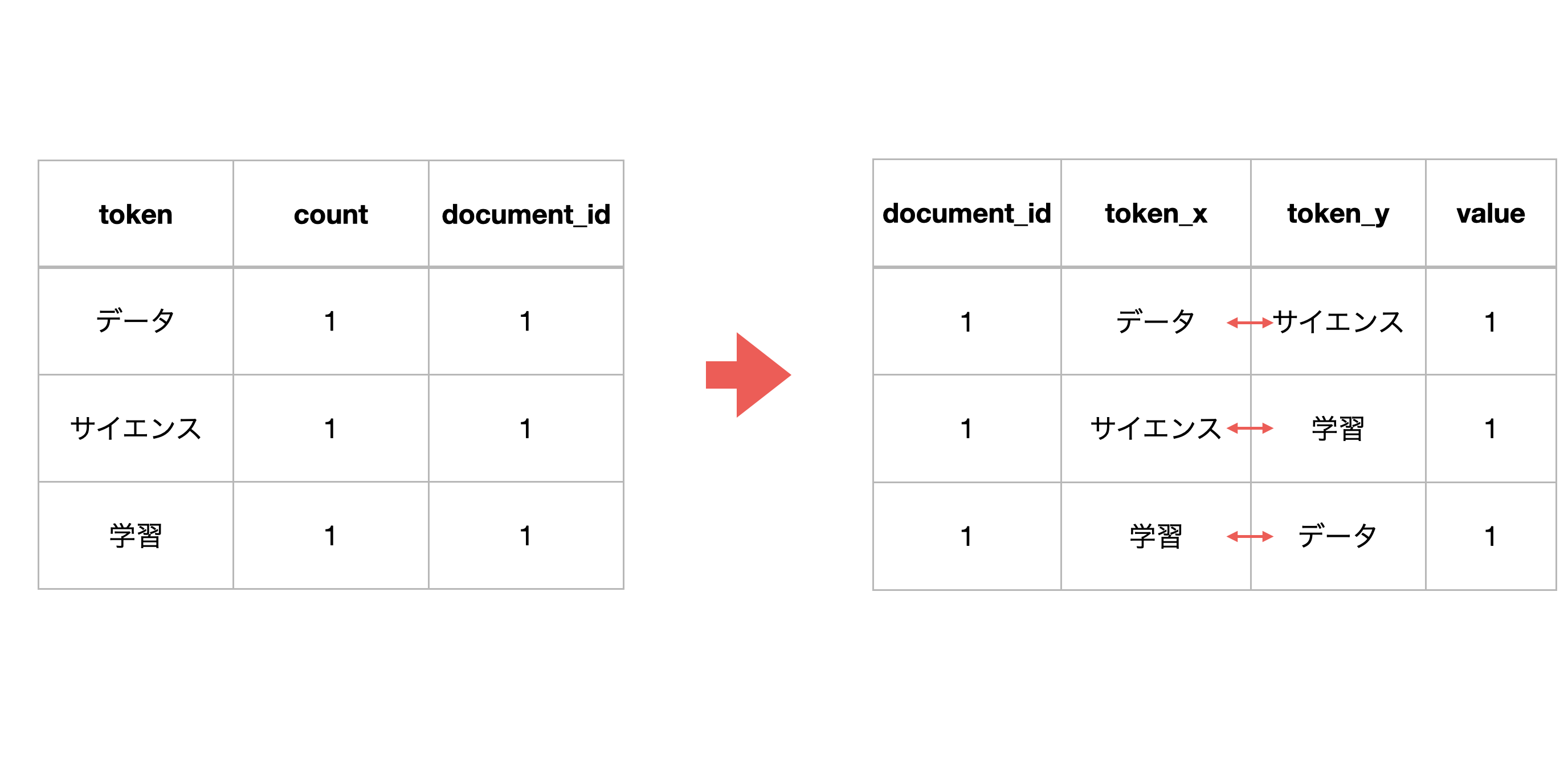
しかし、データにはより多くのドキュメント(document_id)が存在します。
ドキュメントとは文章のことで、元々の1ツイートが1ドキュメントに該当します。
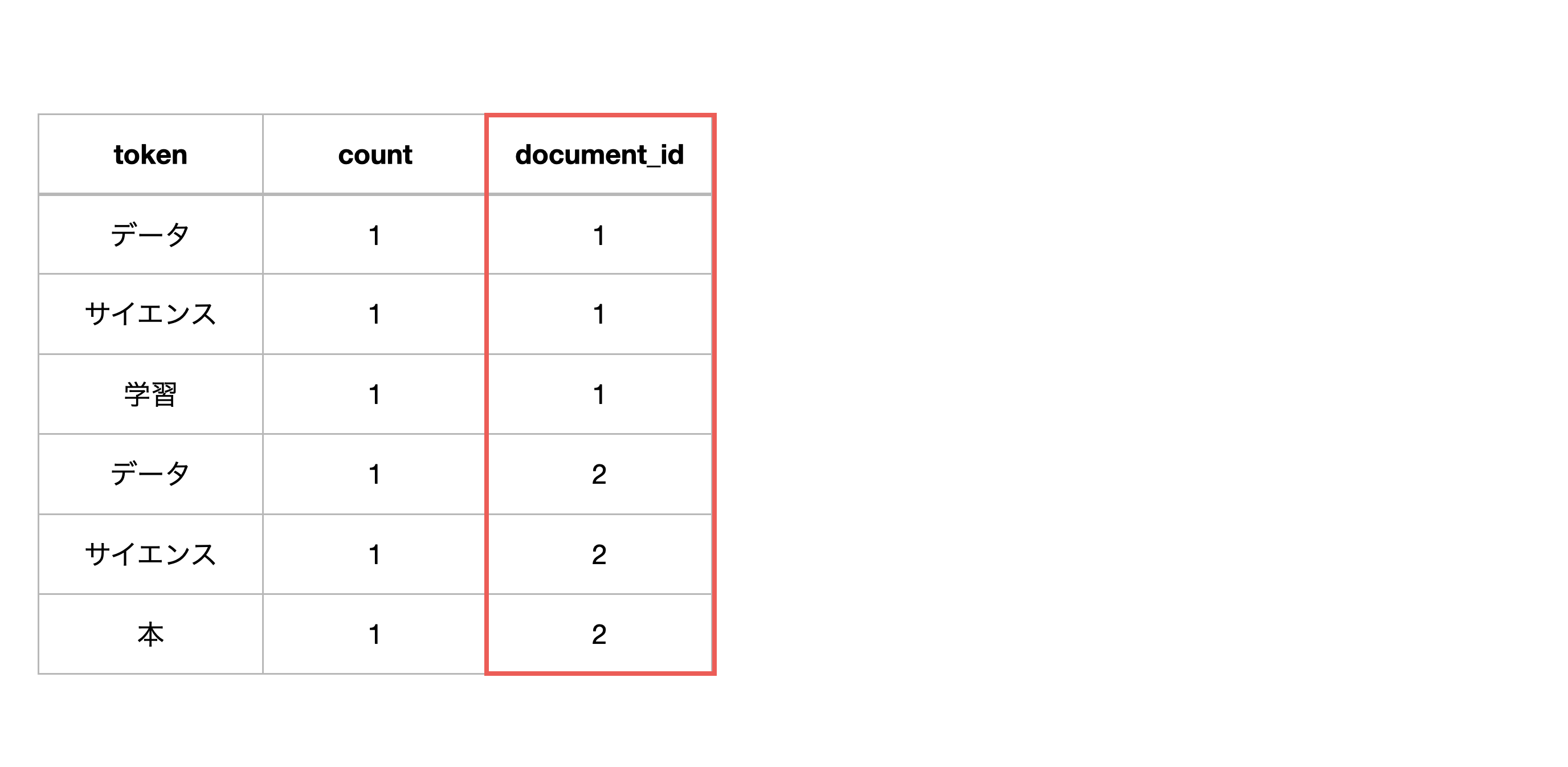
そのため、ドキュメント(document_id)ごとに、グループを分けます。
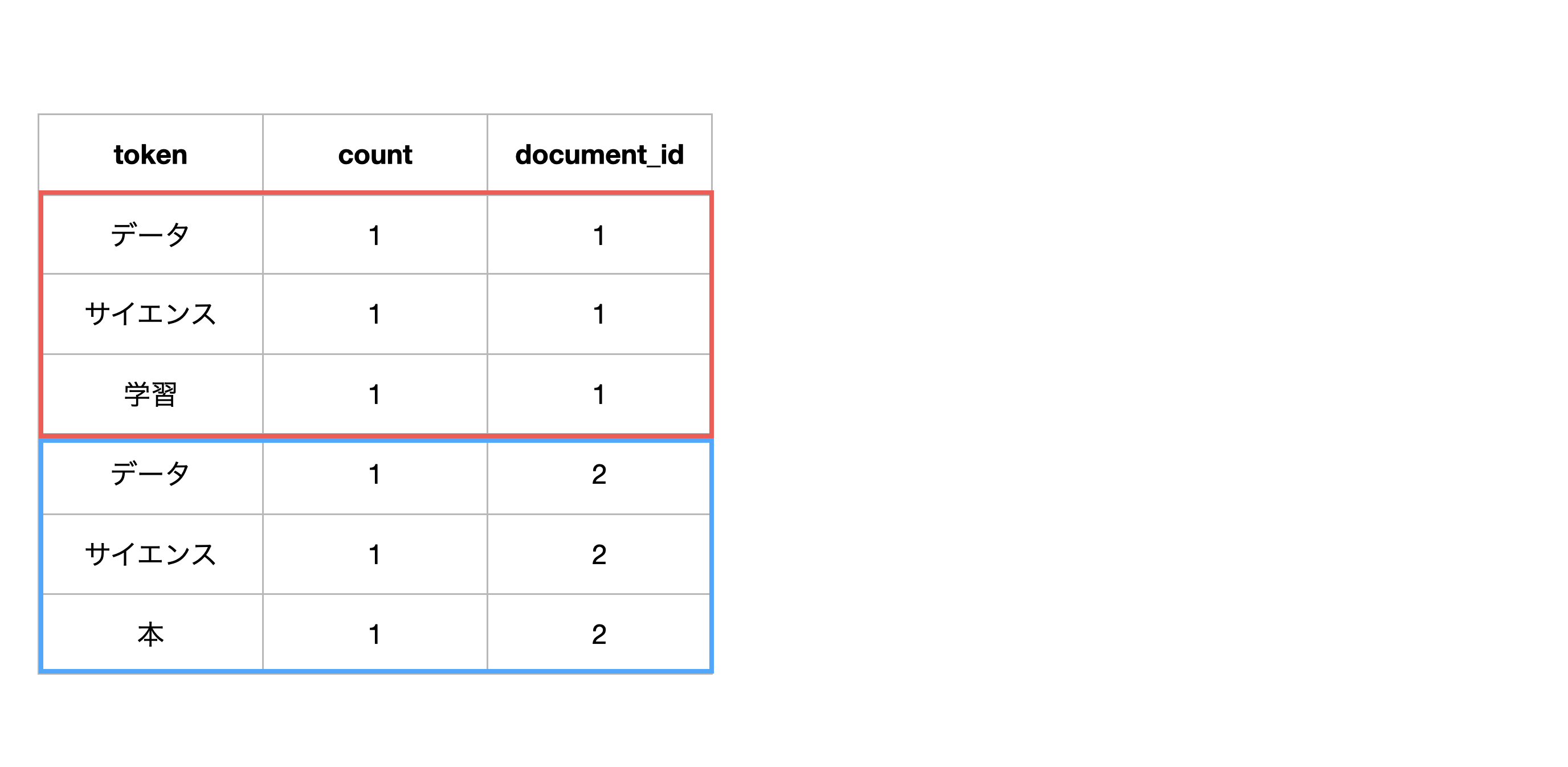
次に、ドキュメントごとに、単語の組み合わせを作ります。
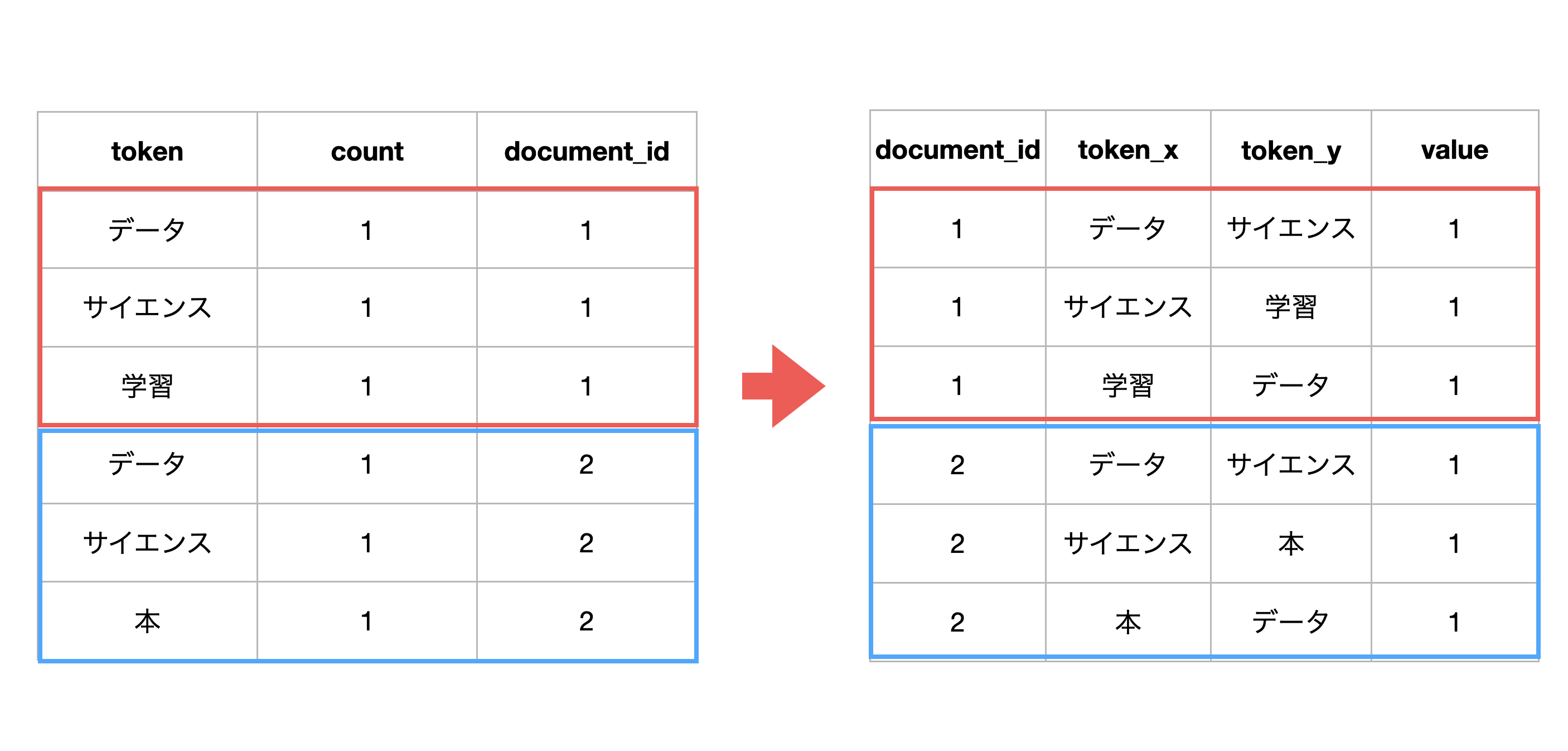
最後に、ドキュメントは関係なしに、単語の組み合わせごとに値を集計します。
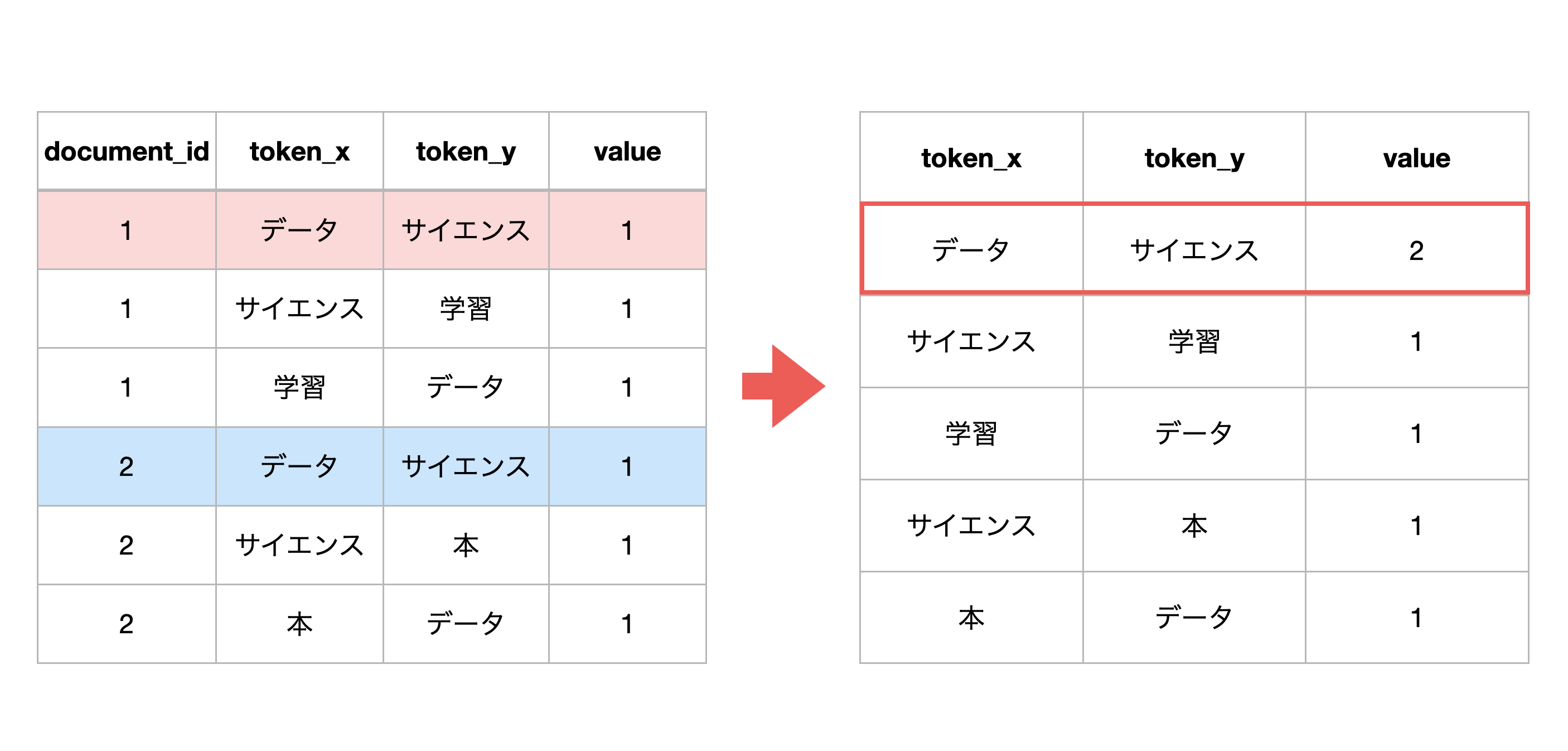
今回の例で言うと、document_idが1と2の時に、「データ」と「サイエンス」の組み合わせが存在し、行が分かれていますが、これを一つの行にまとめます。そして、単語の組み合わせが存在するドキュメントの数がvalueの値になります。
単語の組み合わせを数えるための手順を紹介しましたが、実際にこの処理をしていくわけではありません。
Exploratoryでは、UIで簡単に単語の組み合わせを数えていくことができます。
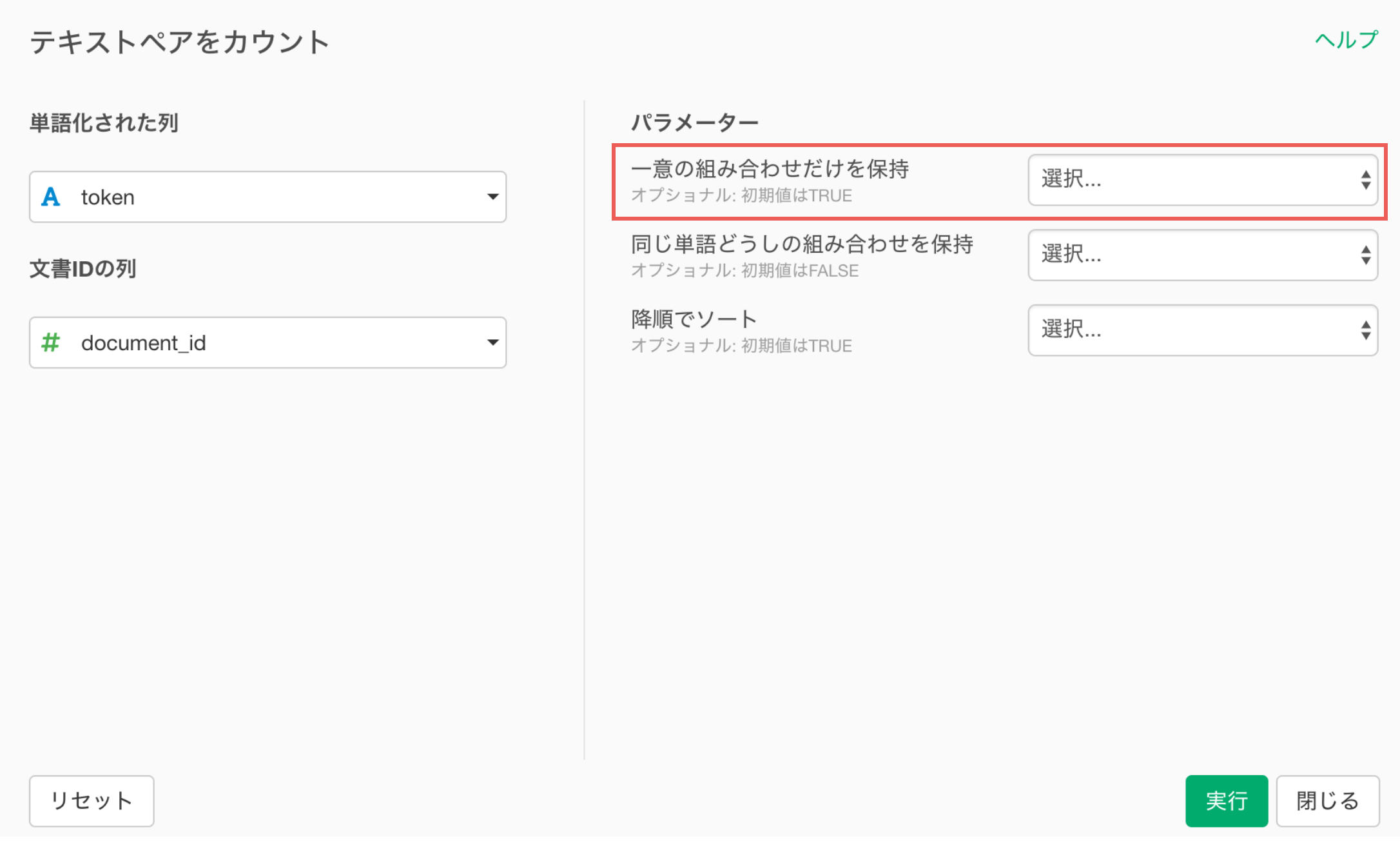
token(単語)の列ヘッダメニューからテキストデータの加工(UI)のテキストペアをカウントを選択します。
テキストペアをカウントのダイアログが表示されます。
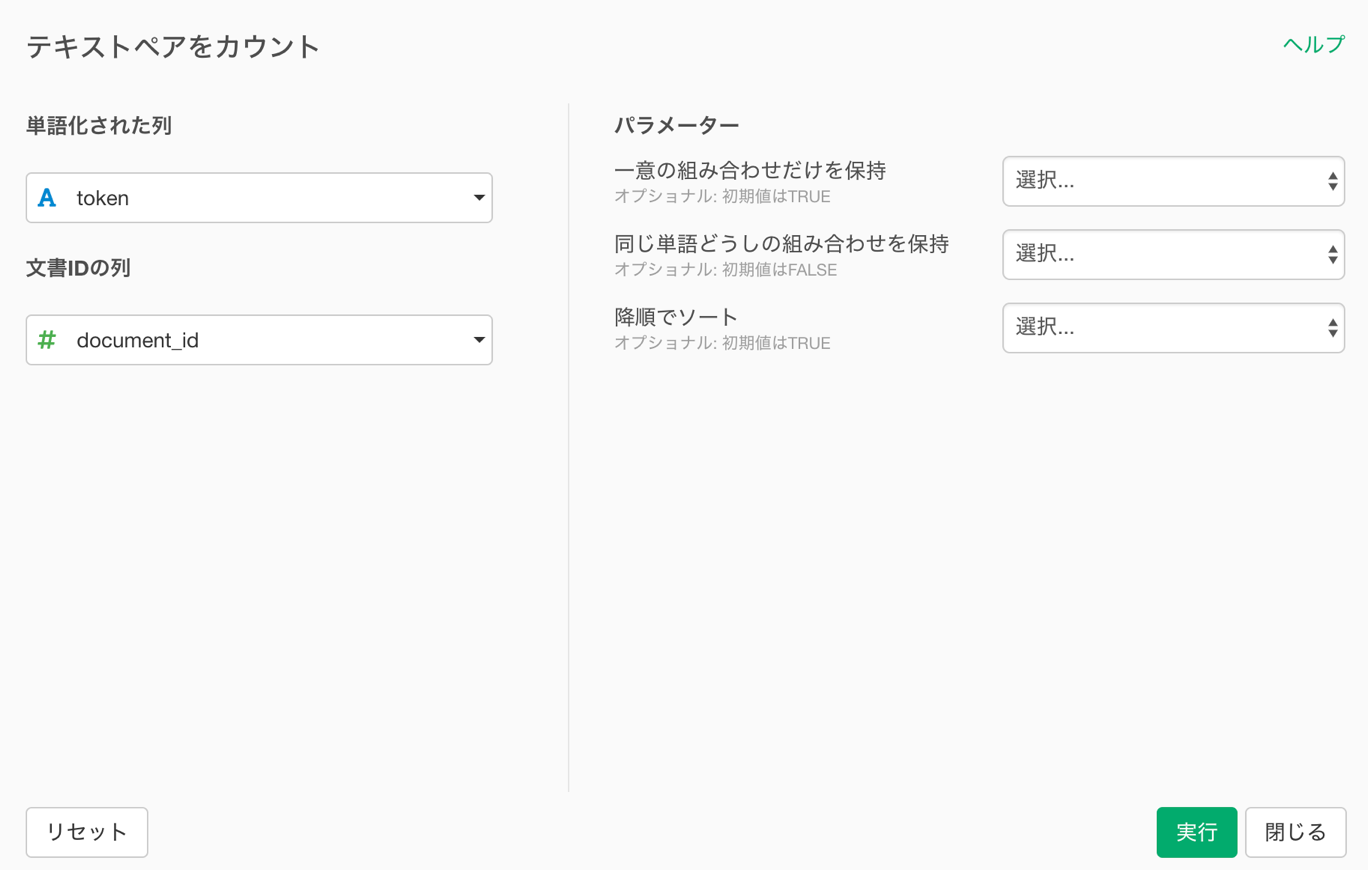
単語化された列にはtokenが選択され、文書IDの列にはdocument_idが選択されているので、このまま実行します。
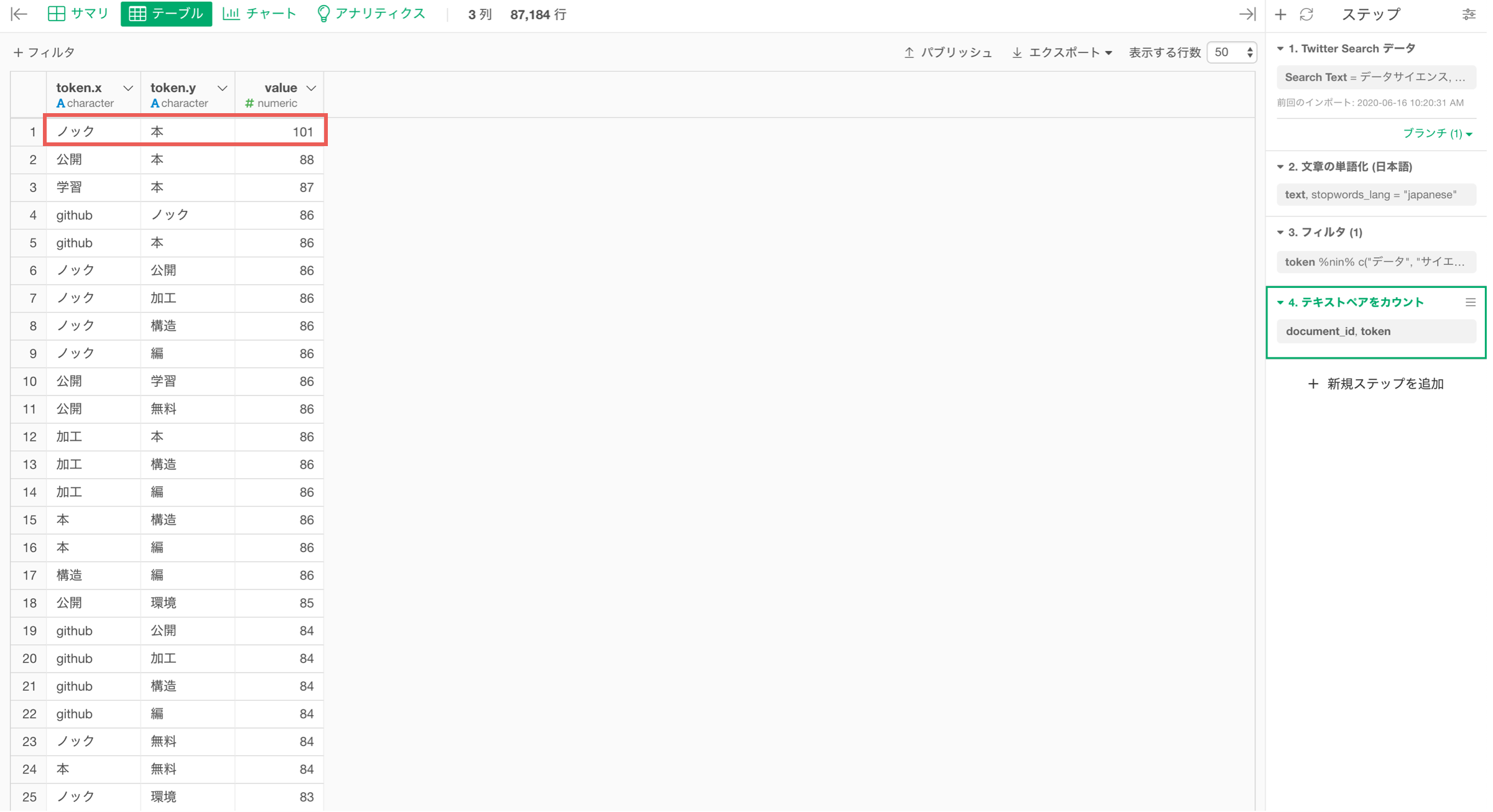
これで、単語の組み合わせを数えることができました。
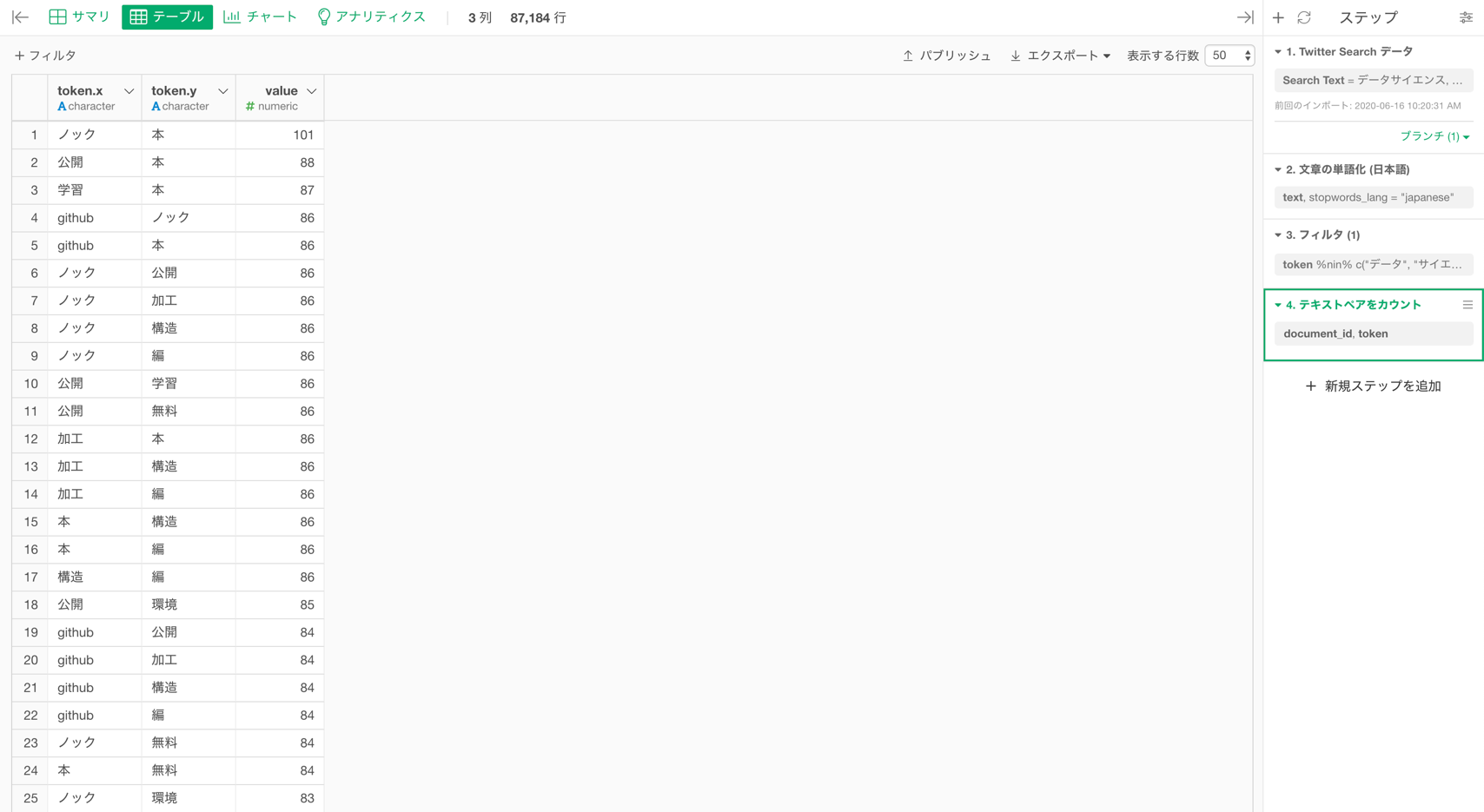
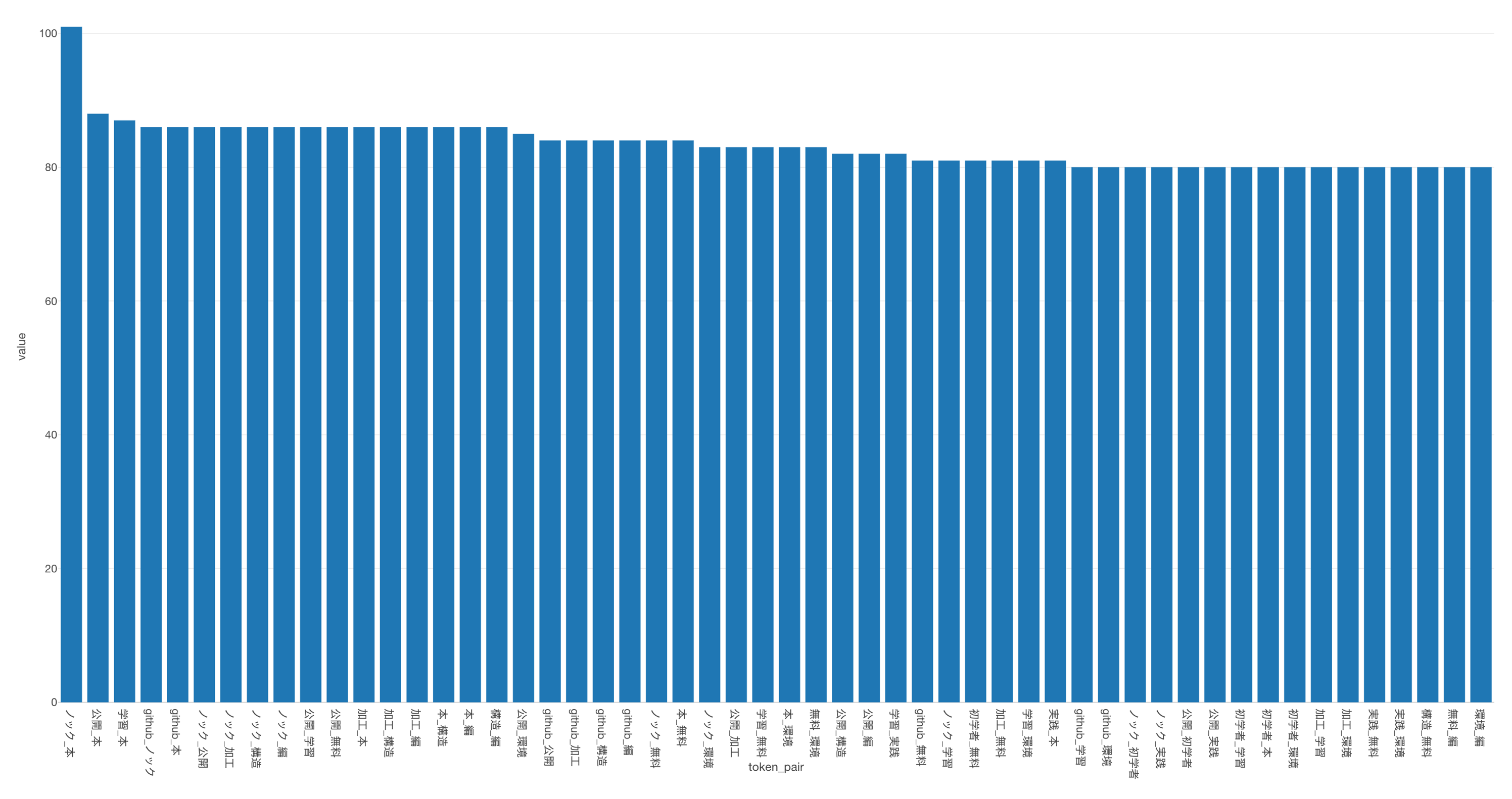
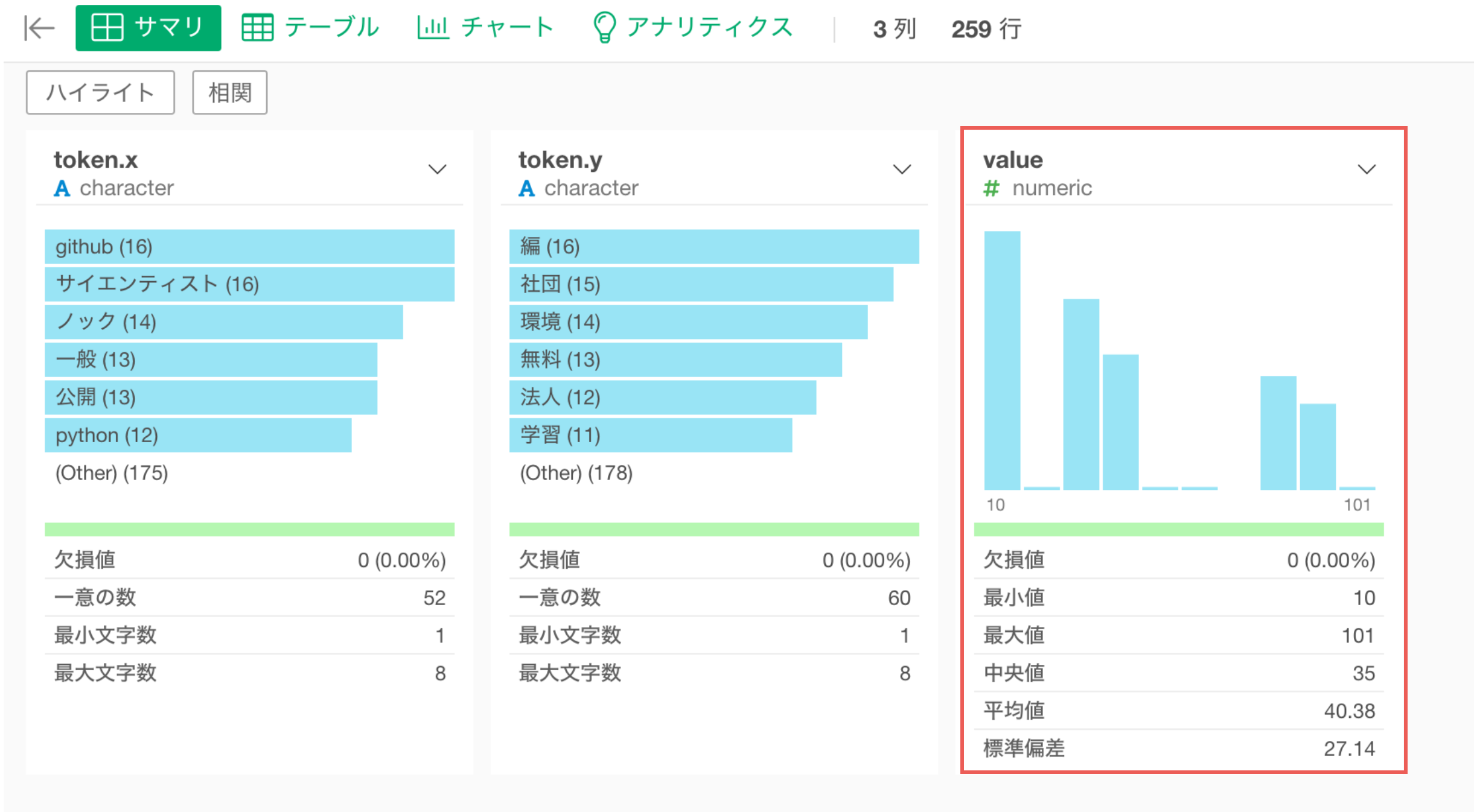
「ノック」と「本」の組み合わせが最も使われており、valueは101なので、101個のドキュメントで出現していることになります。
サマリ・ビューから単語の組み合わせの値(value)の列を見ると、1から11の間にデータが集まっているようです。
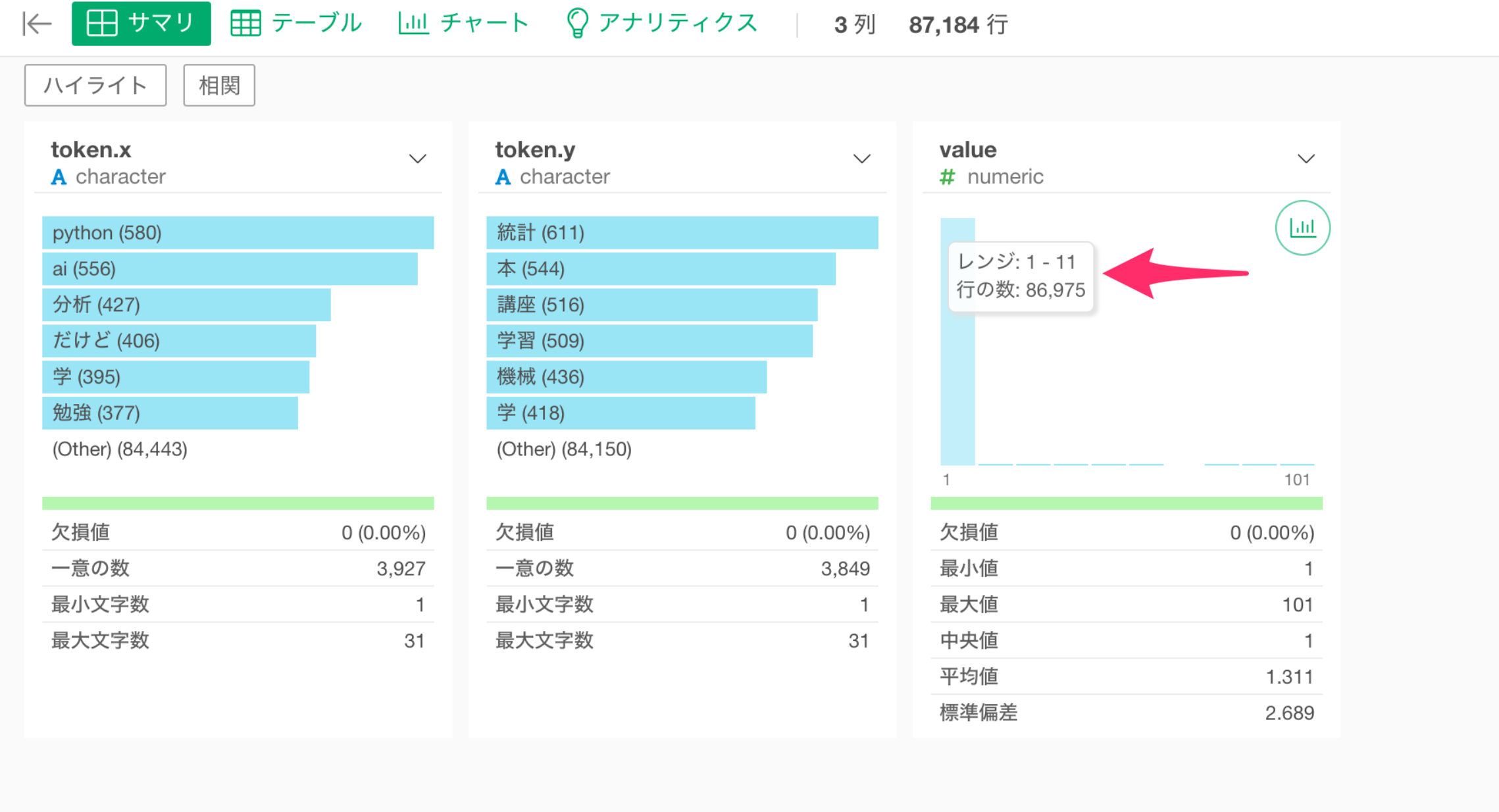
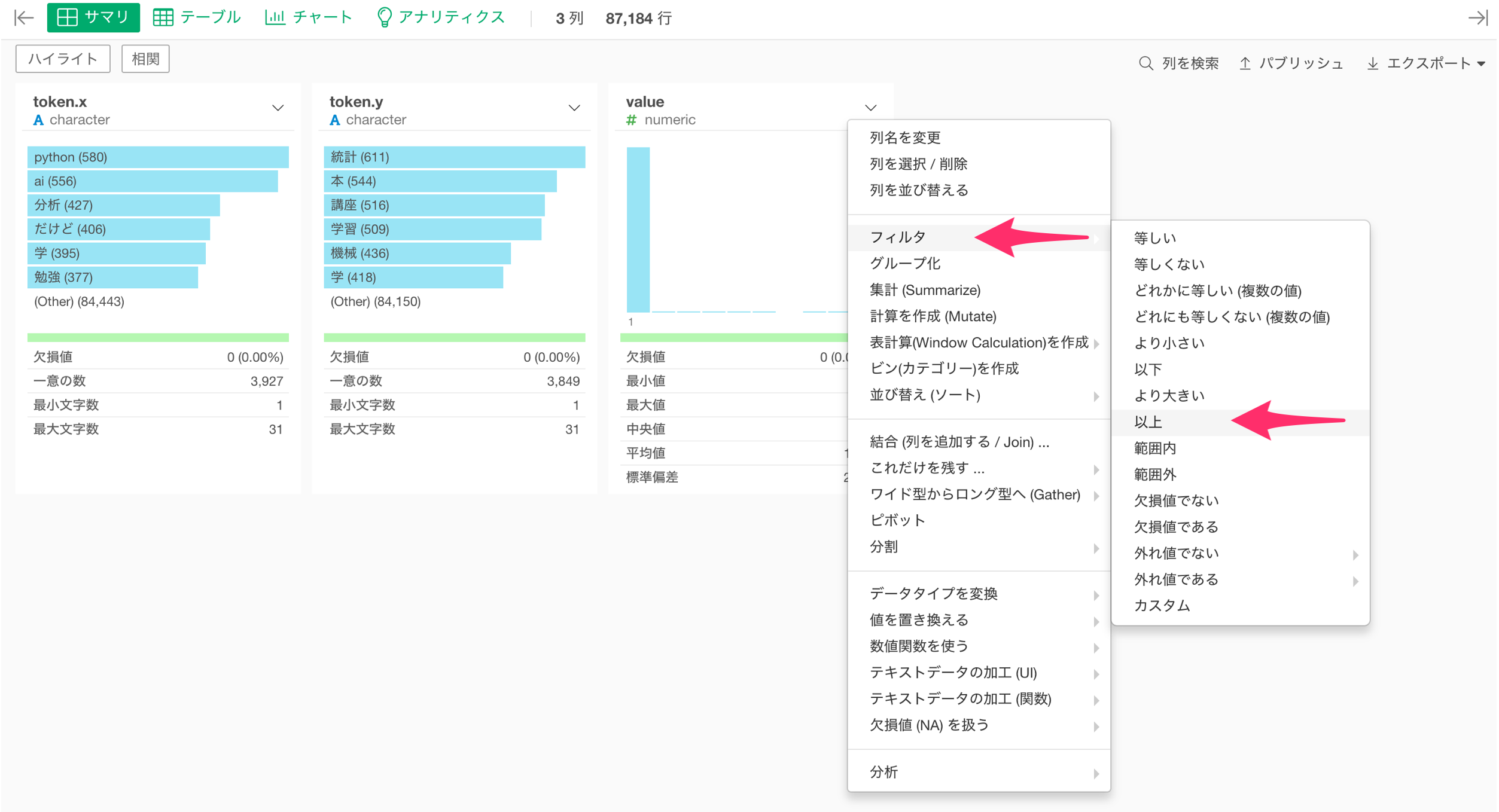
このままでは、あまり使われない単語の組み合わせも可視化されてしまうため、フィルタを使って値が10以上の組み合わせだけを残したいです。
valueの列ヘッダメニューからフィルタの以上を選択します。
値に10を入力して、実行します。
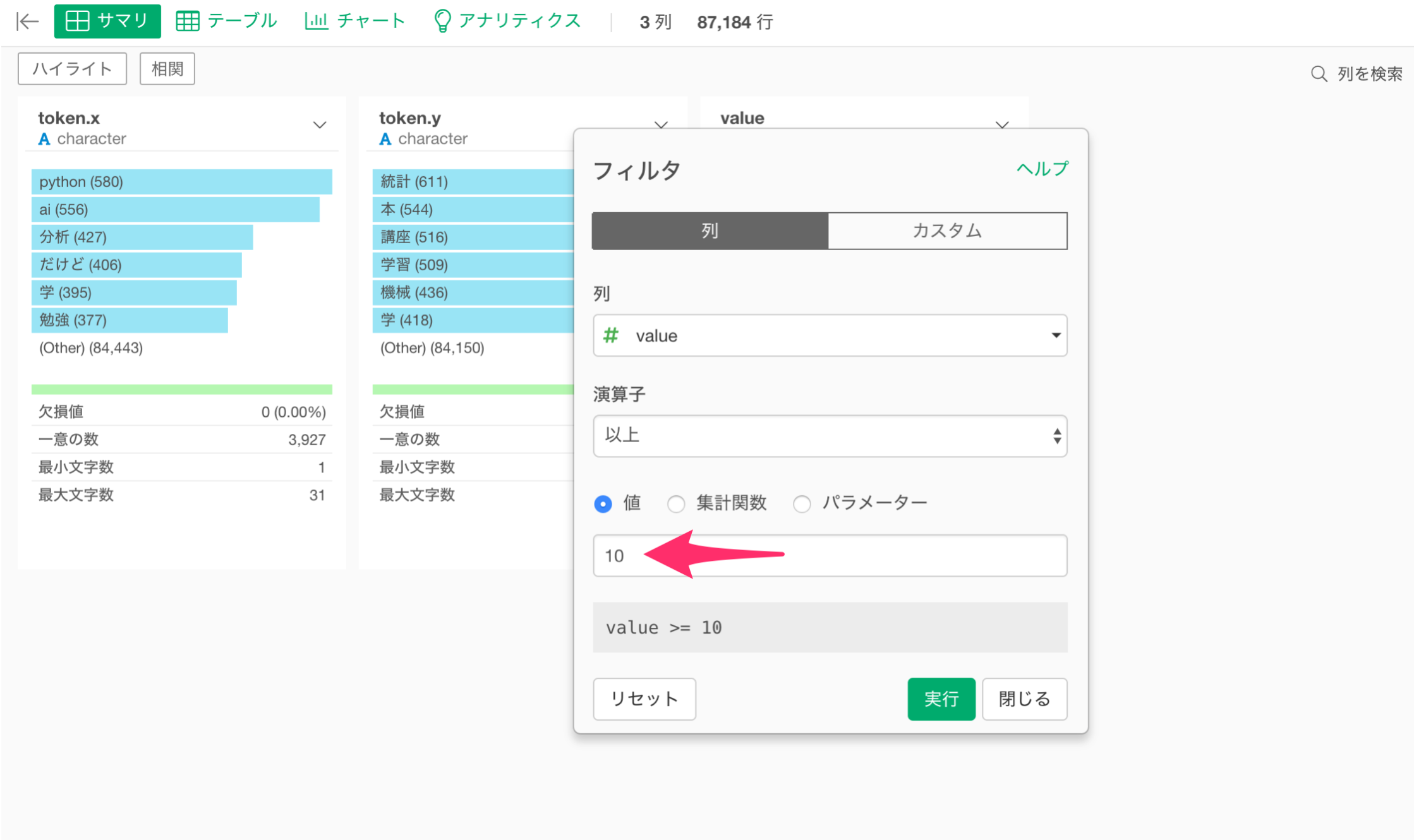
単語の組み合わせの値が10以上のデータのみにすることができました。
では、さっそく単語の組み合わせを可視化していきましょう!
チャートタイプにバーを選択します。X軸にはtoken.xを選び、Y軸にはvalueの合計値(sum)を選択します。
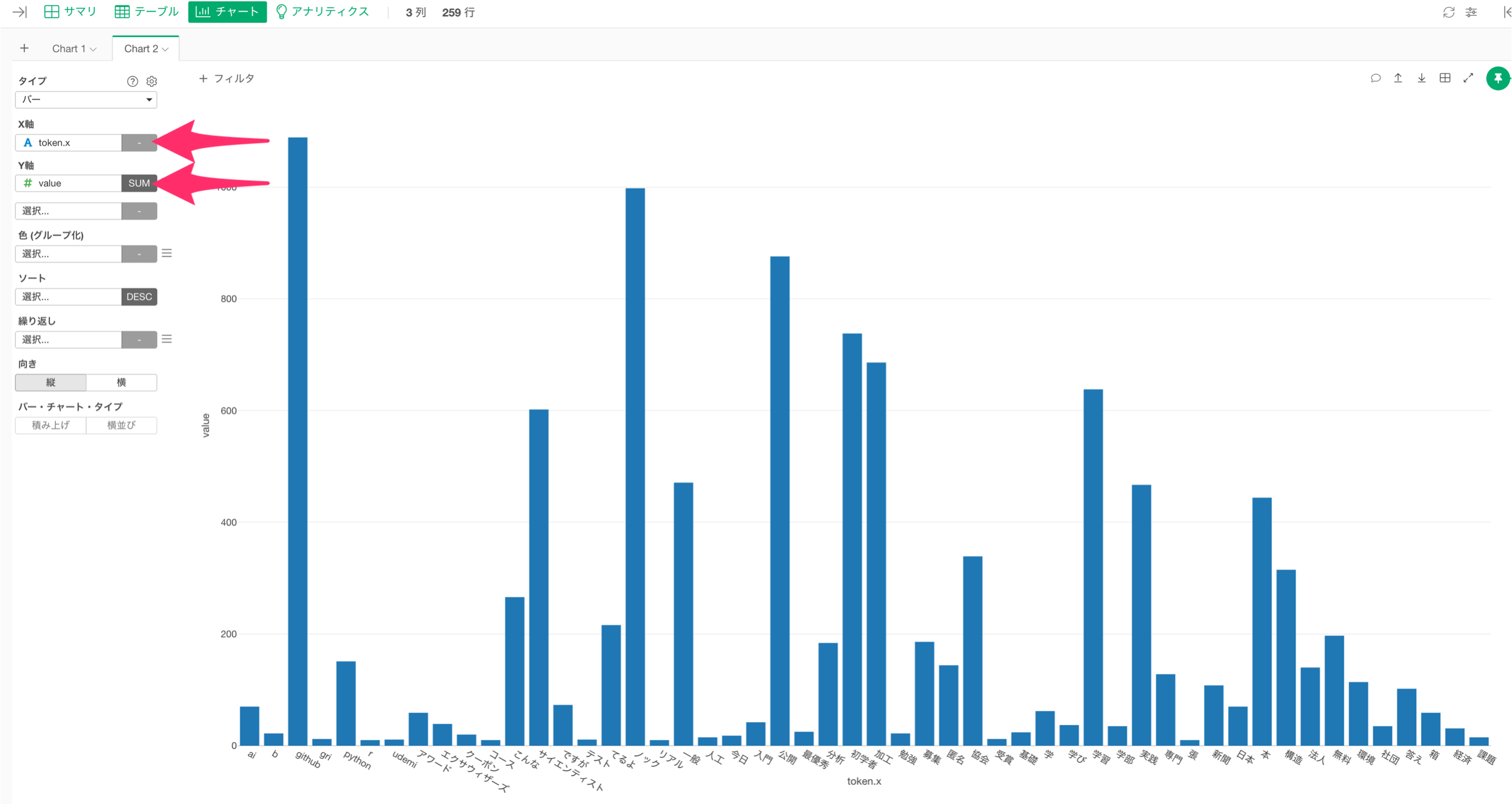
このままでは、一つの単語のみが可視化されていて、組み合わせがわかりません。
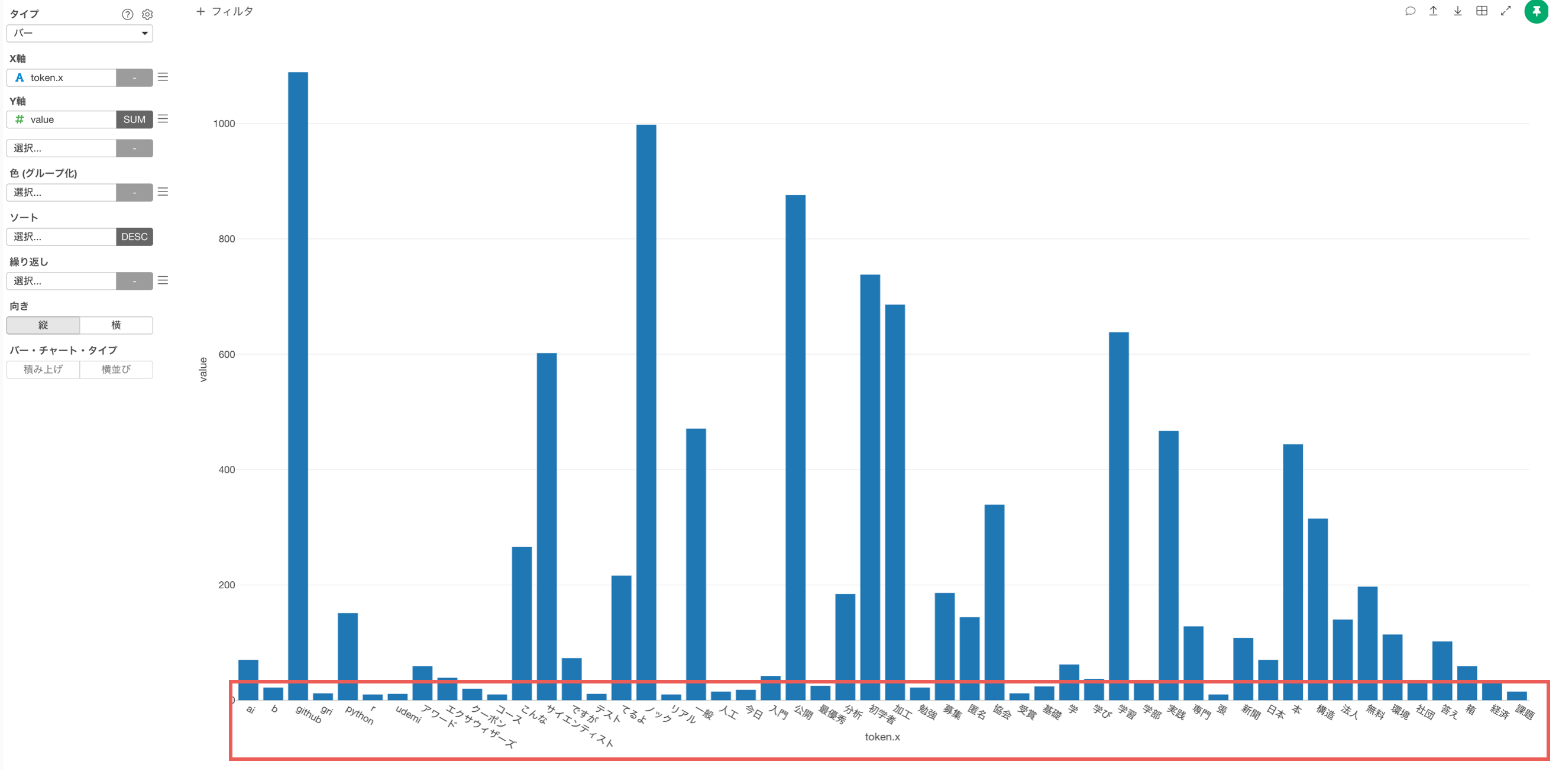
なぜなら、X軸には一つの列(一つの単語)しか選択できないからです。
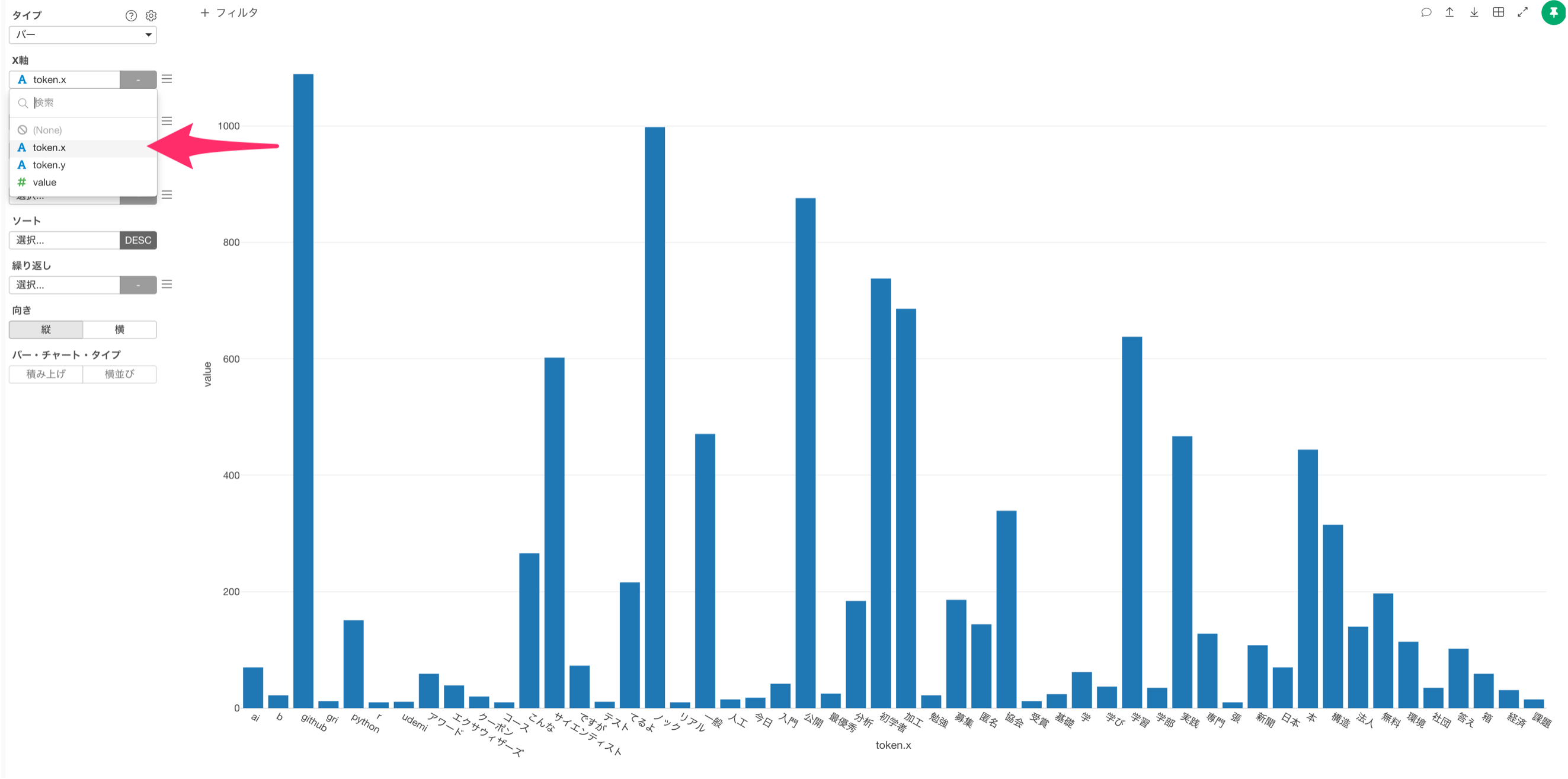
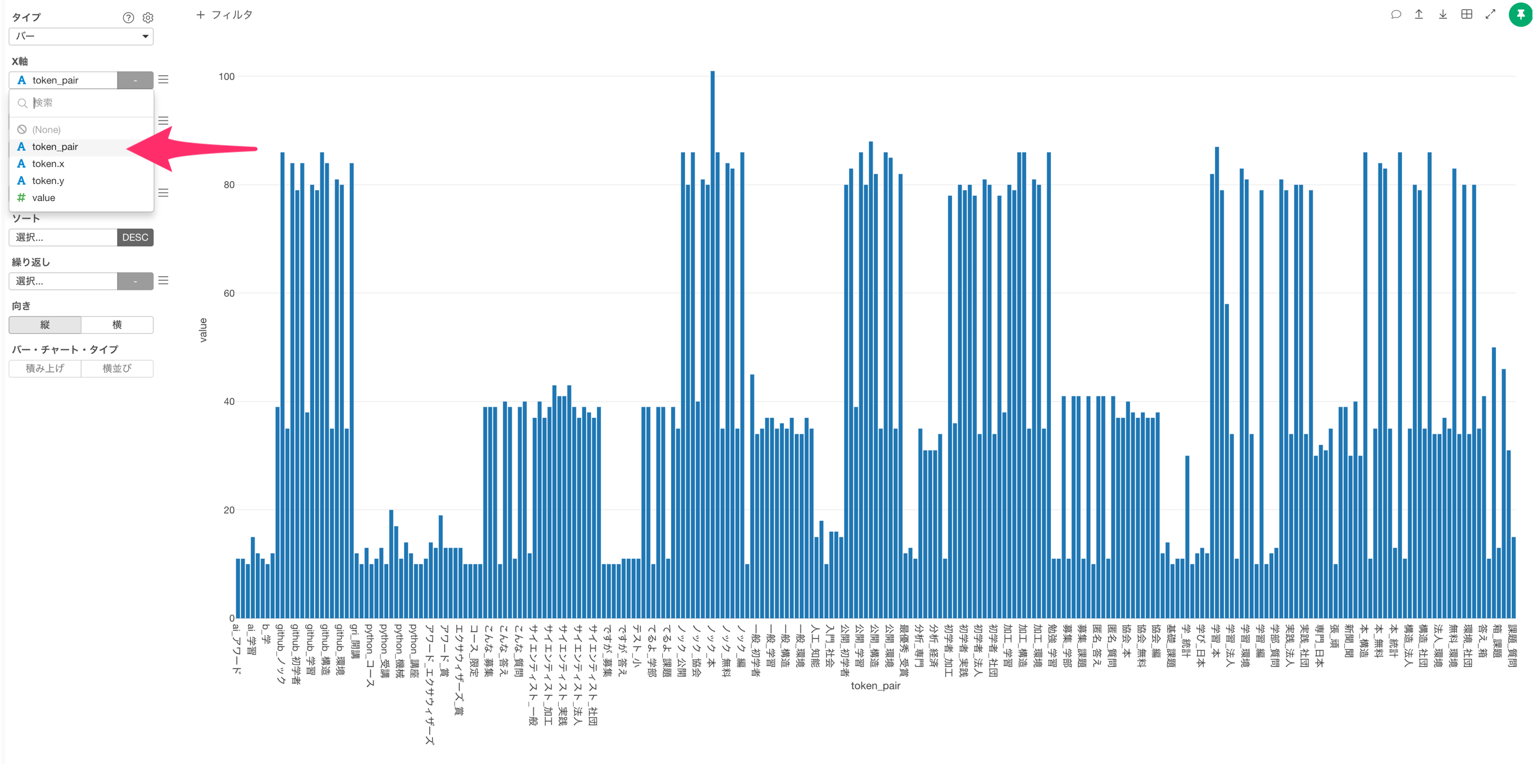
そのため、単語どうしを組み合わせた列を作りましょう!
token.xとtoken.yをShiftキーを使って選び、列ヘッダメニューから複数の列をつなげるを選択します。
複数の列をつなげるのダイアログが表示されます。
新しい列名に任意の名前を入力して実行します。
単語どうしを組み合わせた列を作ることができました。
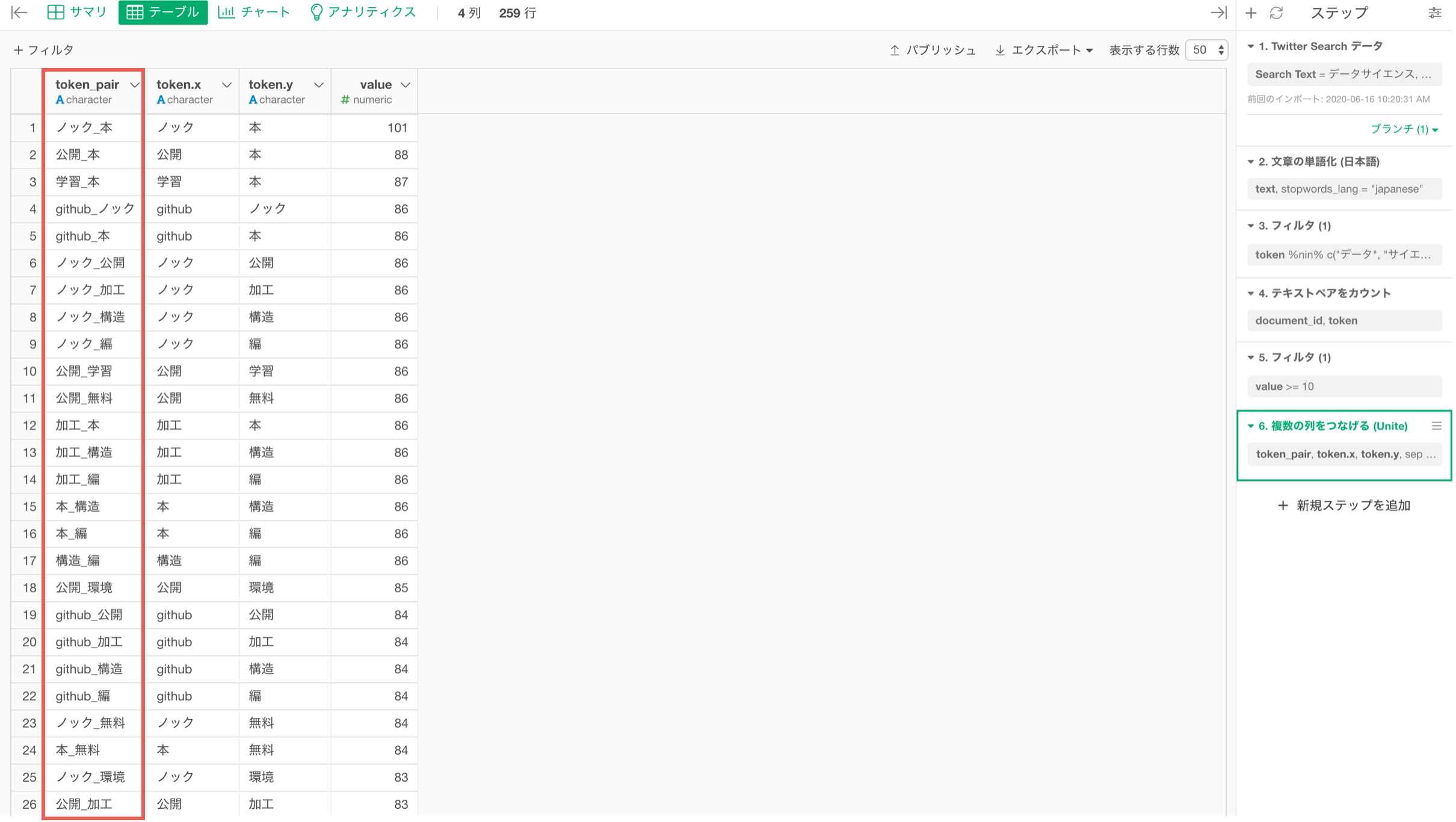
チャートに戻り、チャートピンを最新のステップに紐づけます。
X軸に単語の組み合わせ(token_pair)の列を選択します。
ソートにY1軸の降順を選択します。
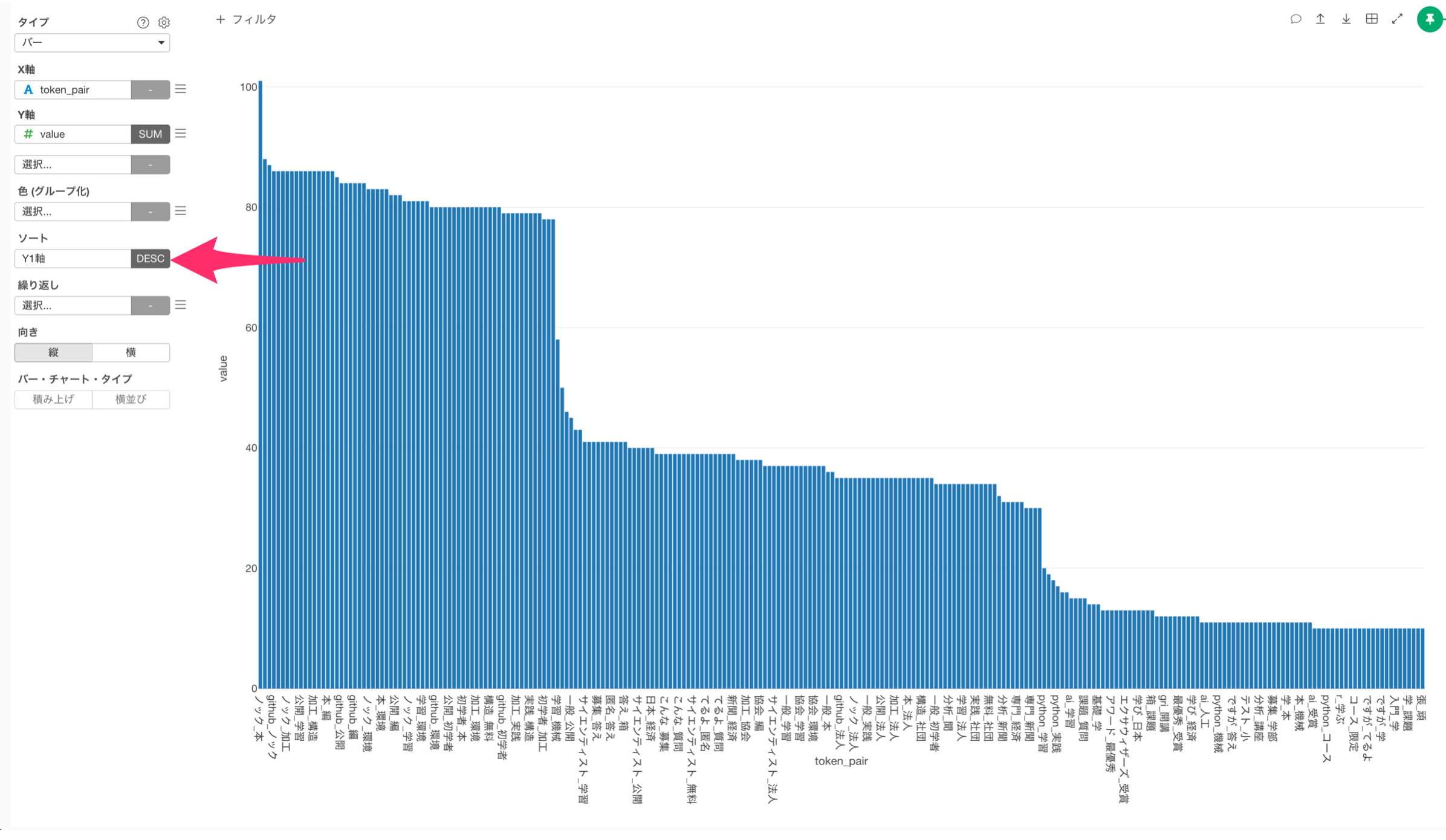
単語の組み合わせを可視化することができました!
しかし、可視化されている単語の組み合わせの数が多いため、上位50のみにしたいです。
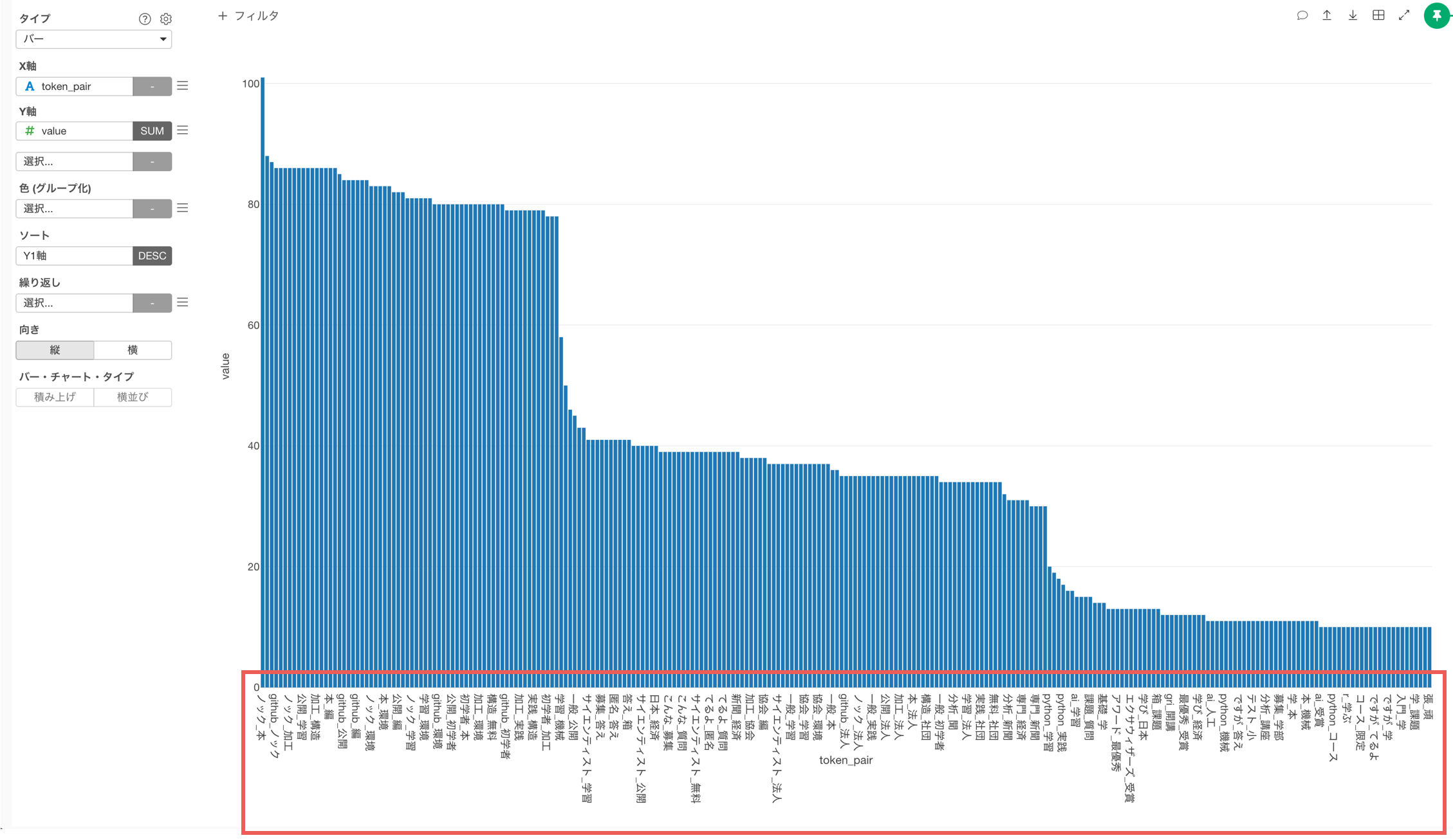
X軸のメニューから表示する値の制限を選択します。
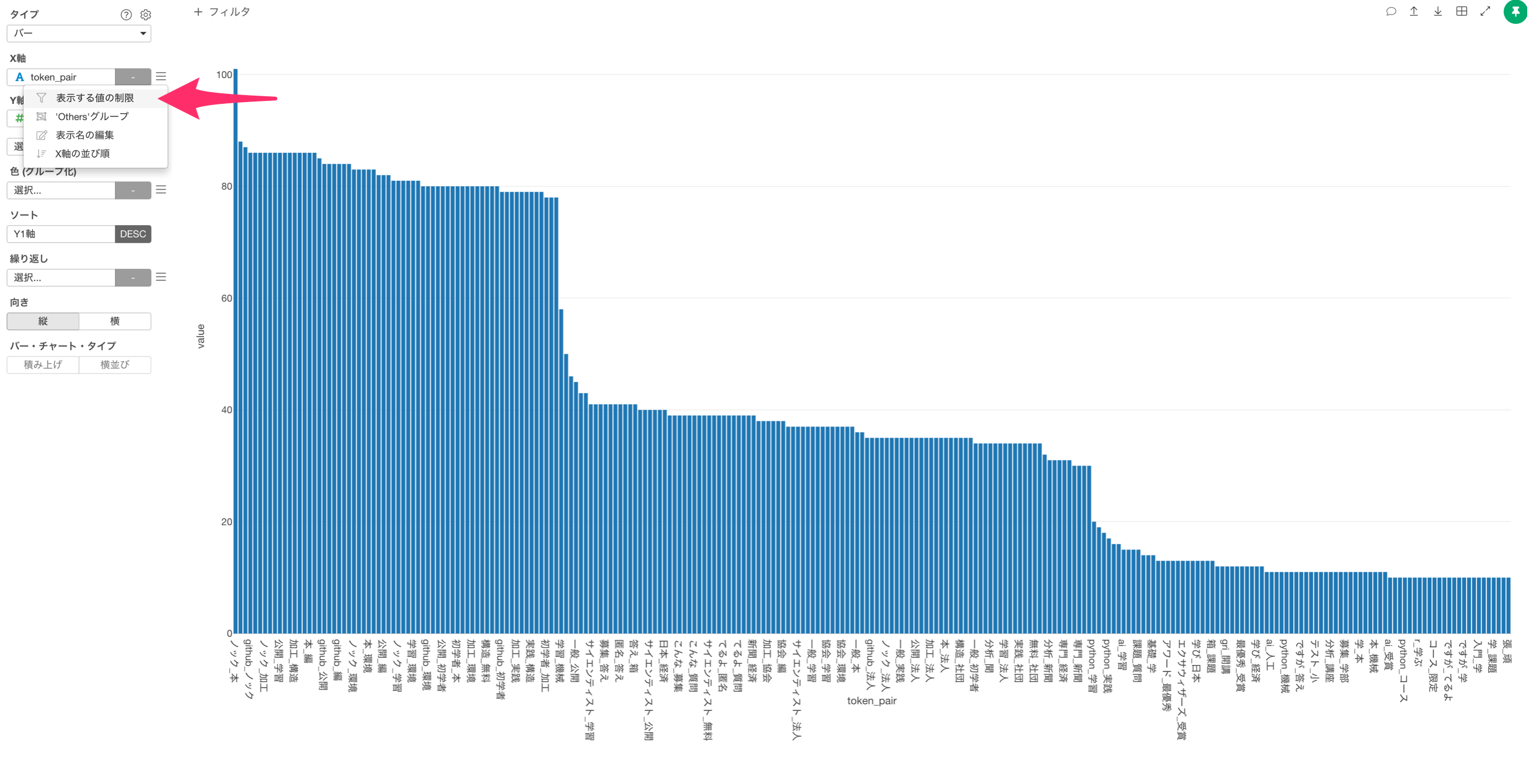
タイプに上位を選択選び、結果の数に50を指定して実行します。
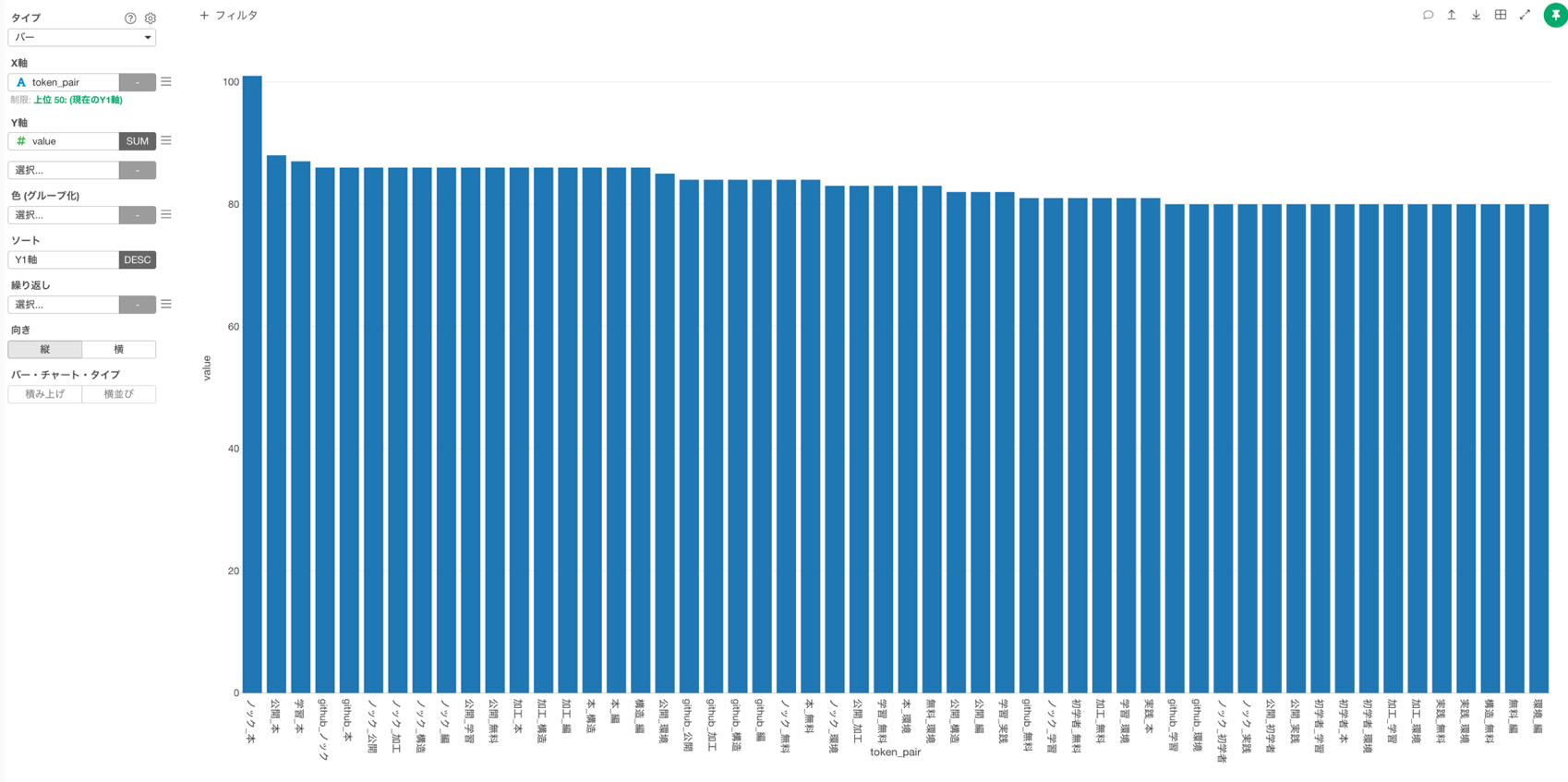
よく使われる単語の組み合わせの上位50を可視化することができました。
「ノック」と「本」や「ノック」と「github」、「ノック」と「公開」といった単語の組み合わせがよく使われているようです。
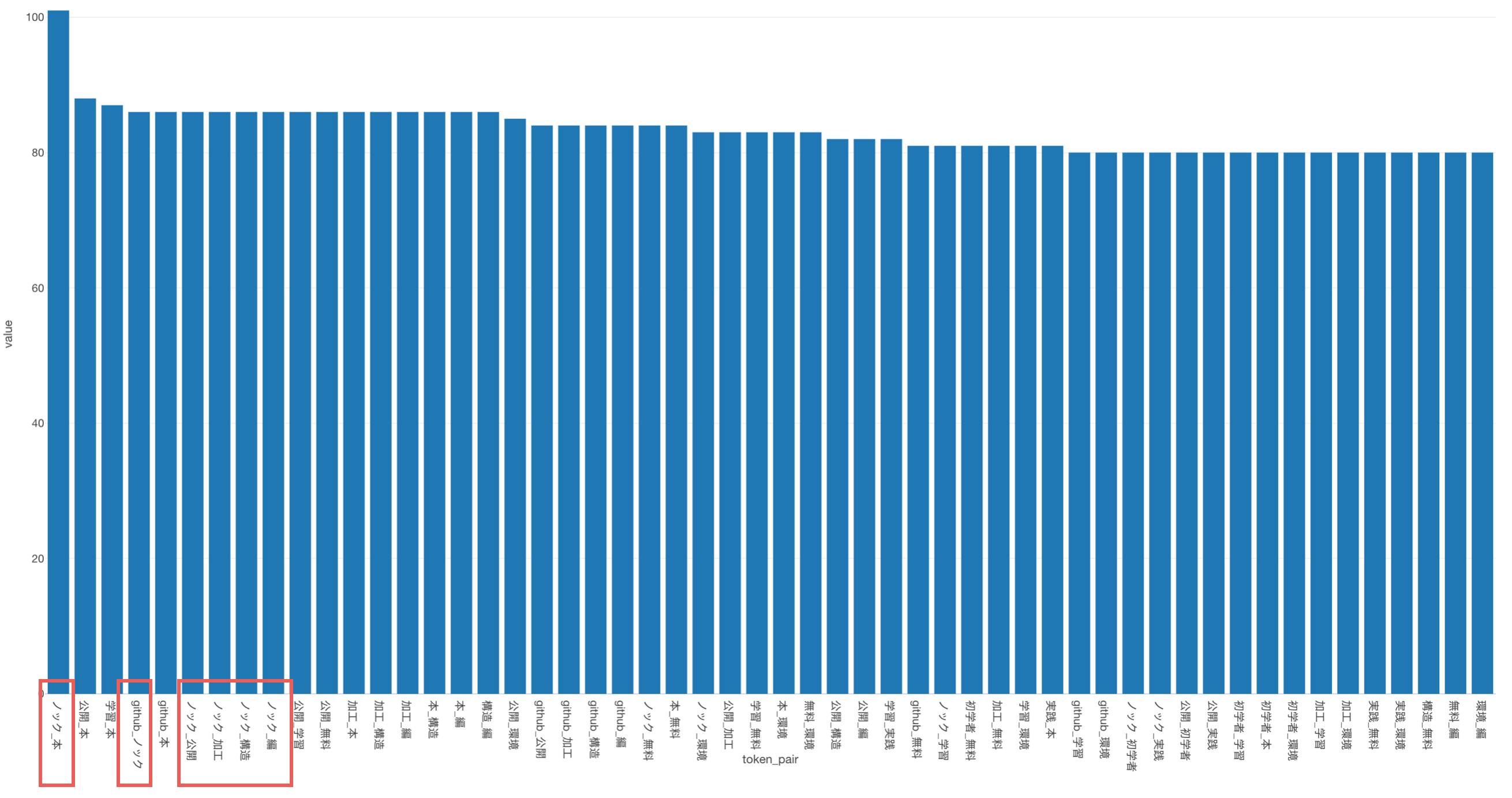
Twitterを見てみると、データサイエンティスト協会から、「データサイエンス100本ノック」というコンテンツがgithubで公開されていたため、関連したツイートがあったことが予想されます。

テキストペアをカウントのパラメータについて
テキストペアをカウントにある一意の組み合わせだけを保持はデフォルトでは、TRUEとなっています。
一意の組み合わせだけを保持がTRUEの場合、同じ単語の組み合わせが一つ取り除かれます。
FALSEの場合は、「ノック」と「本」、「本」と「ノック」のように同じ単語の組み合わせを残すことができます。
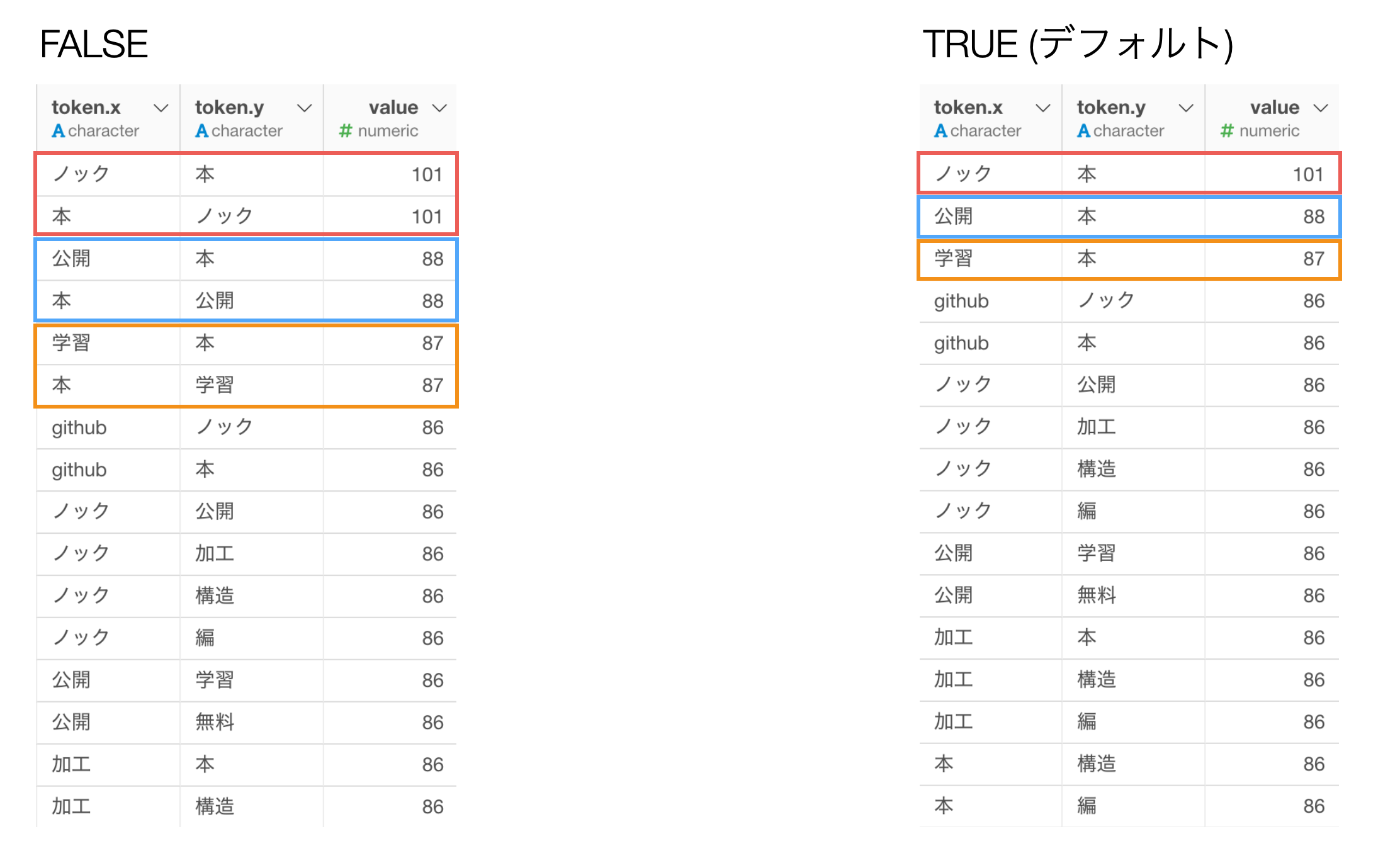
もし両方残して確認したい場合は、こちらの設定をFALSEにすると良いでしょう。