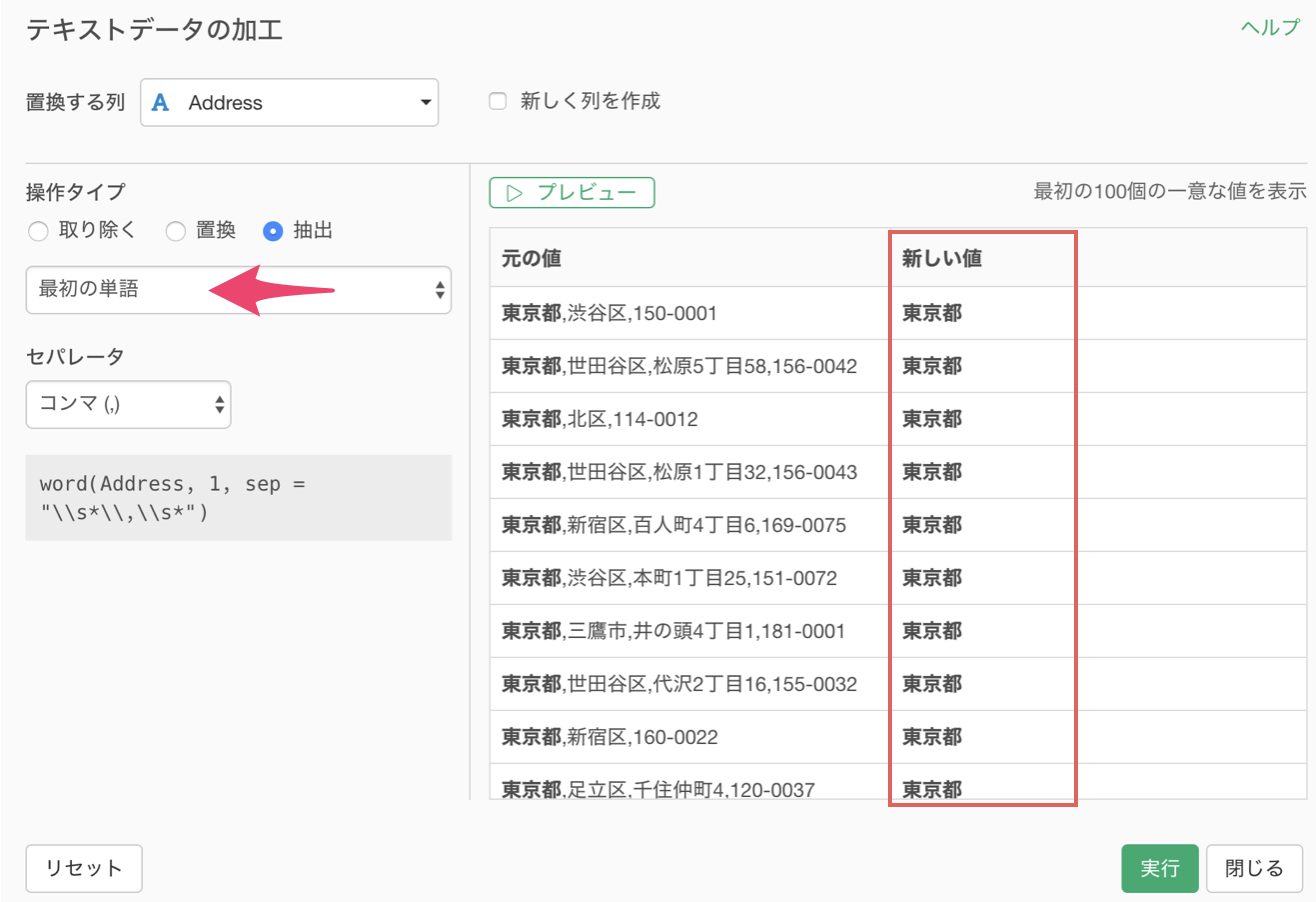
N番目の単語を抽出する方法
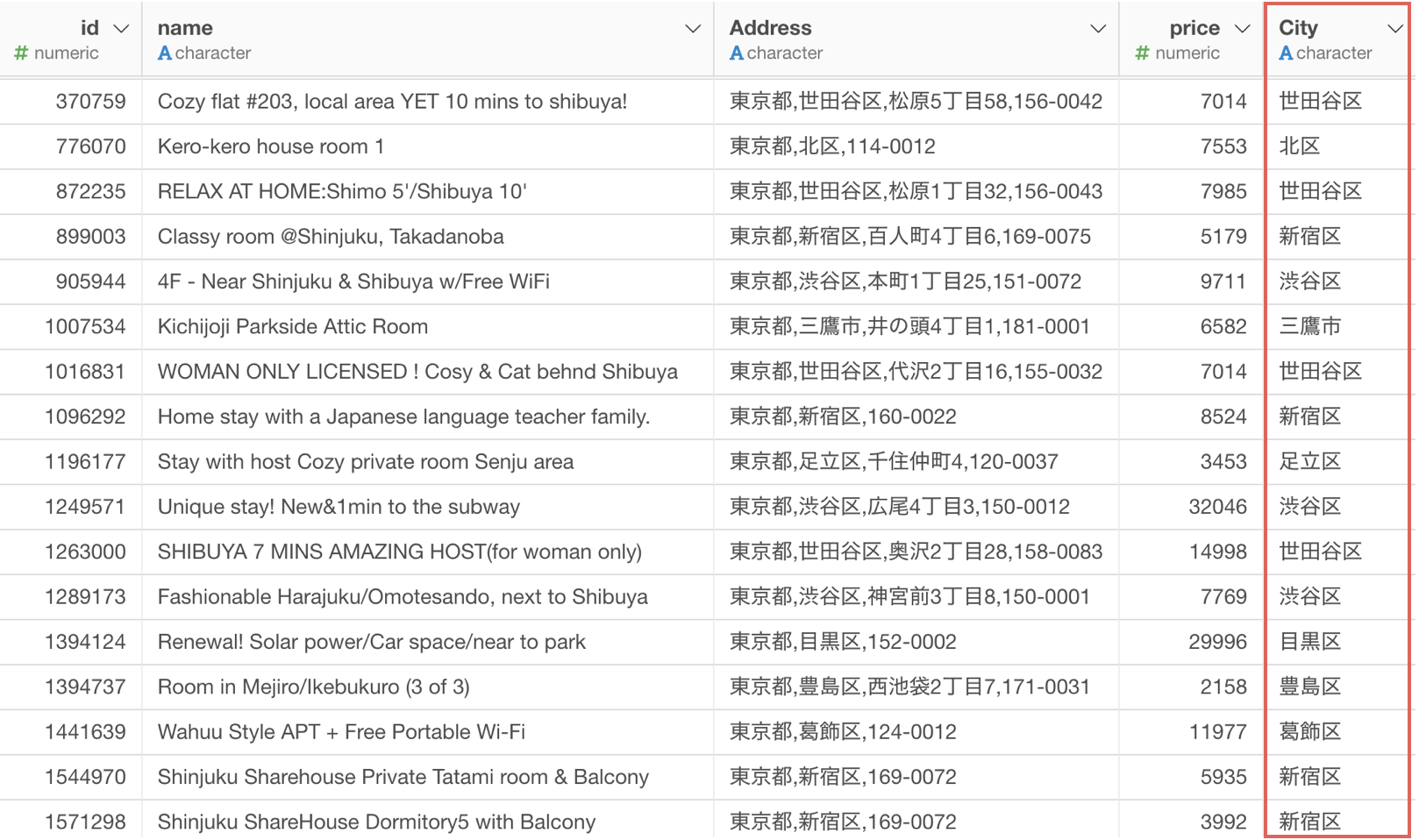
今回は、Airbnbの東京の宿泊施設データを使用します。

このデータには住所の列があります。

住所はコンマ(,) で区切られて情報が格納されています。

今回は2番目にある渋谷区の情報を抽出したいです。

住所の列の列ヘッダメニューからテキストデータの加工 (UI) を選び、抽出するを選択します。
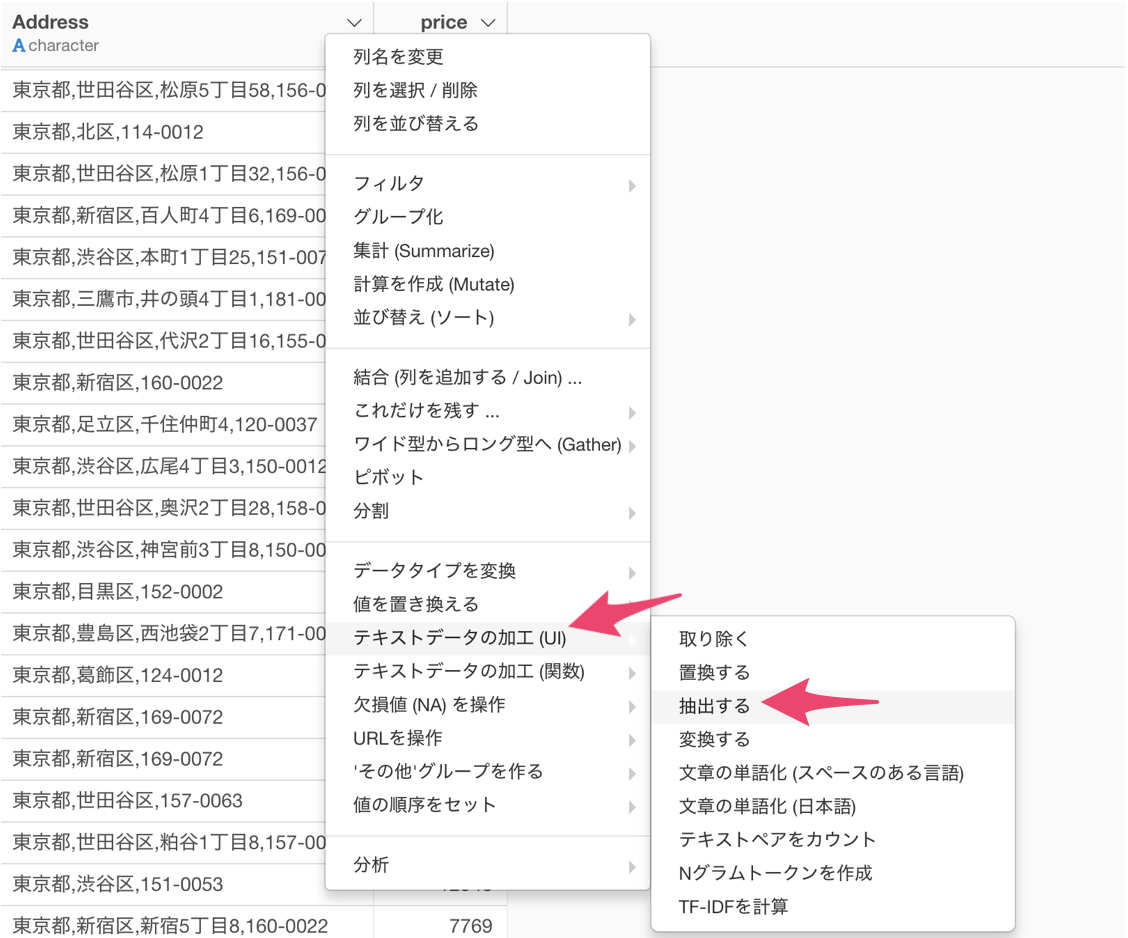
テキストデータの加工のダイアログが表示されます。
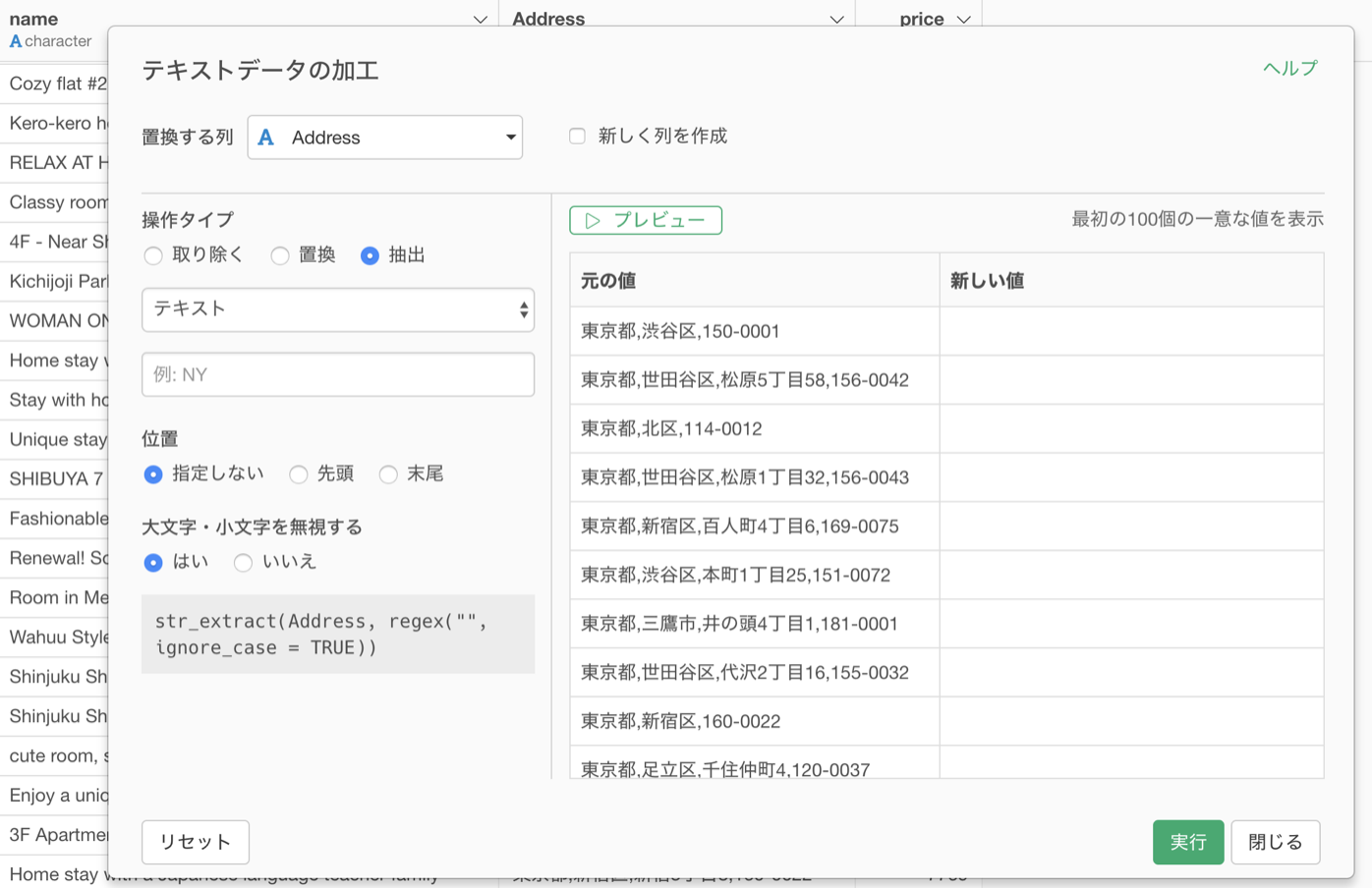
抽出のタイプにN番目の単語(2番目、3番目等) を選択します。
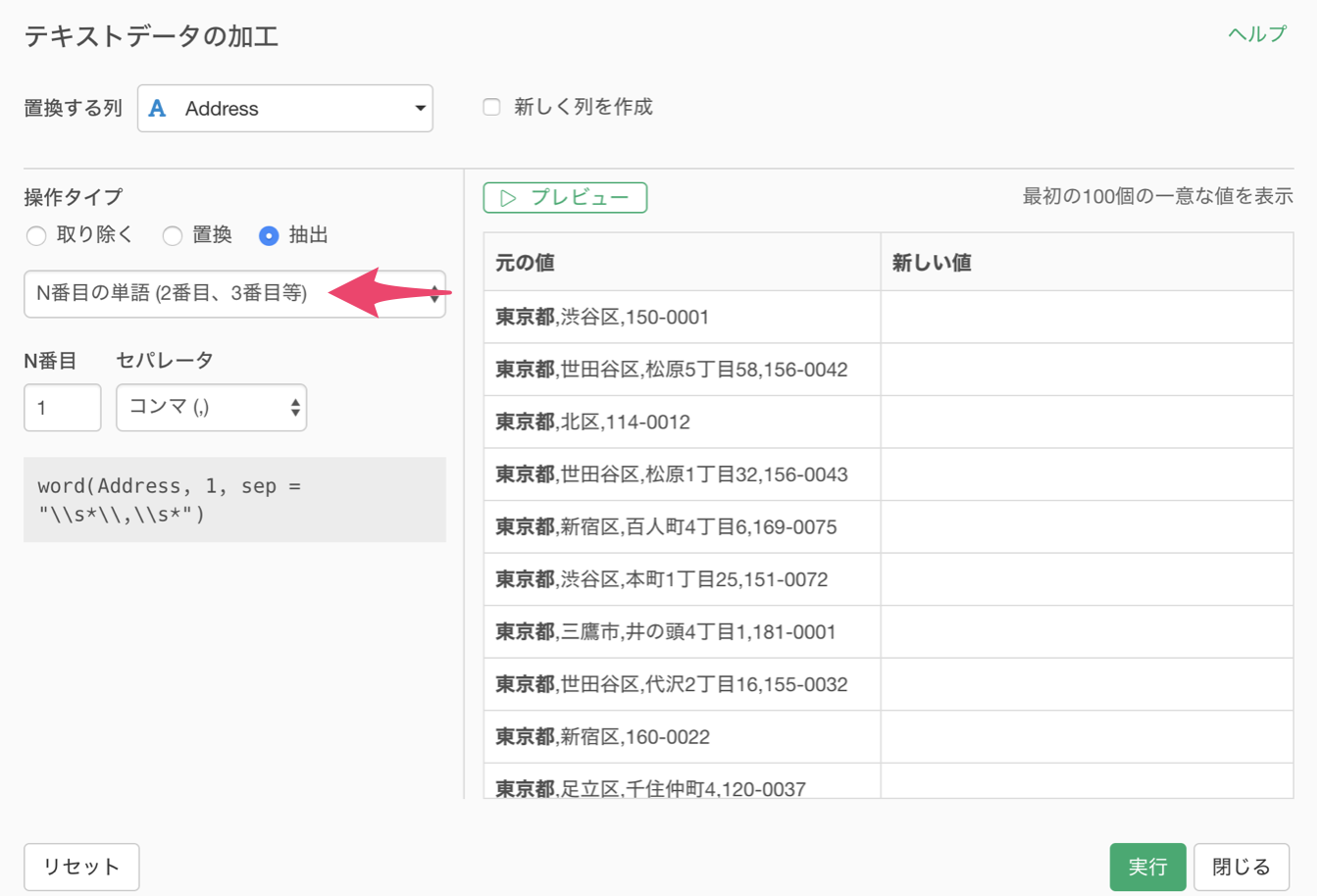
〇〇区の情報を抽出したいので、N番目に2を入力し、セパレータにコンマを選択します。
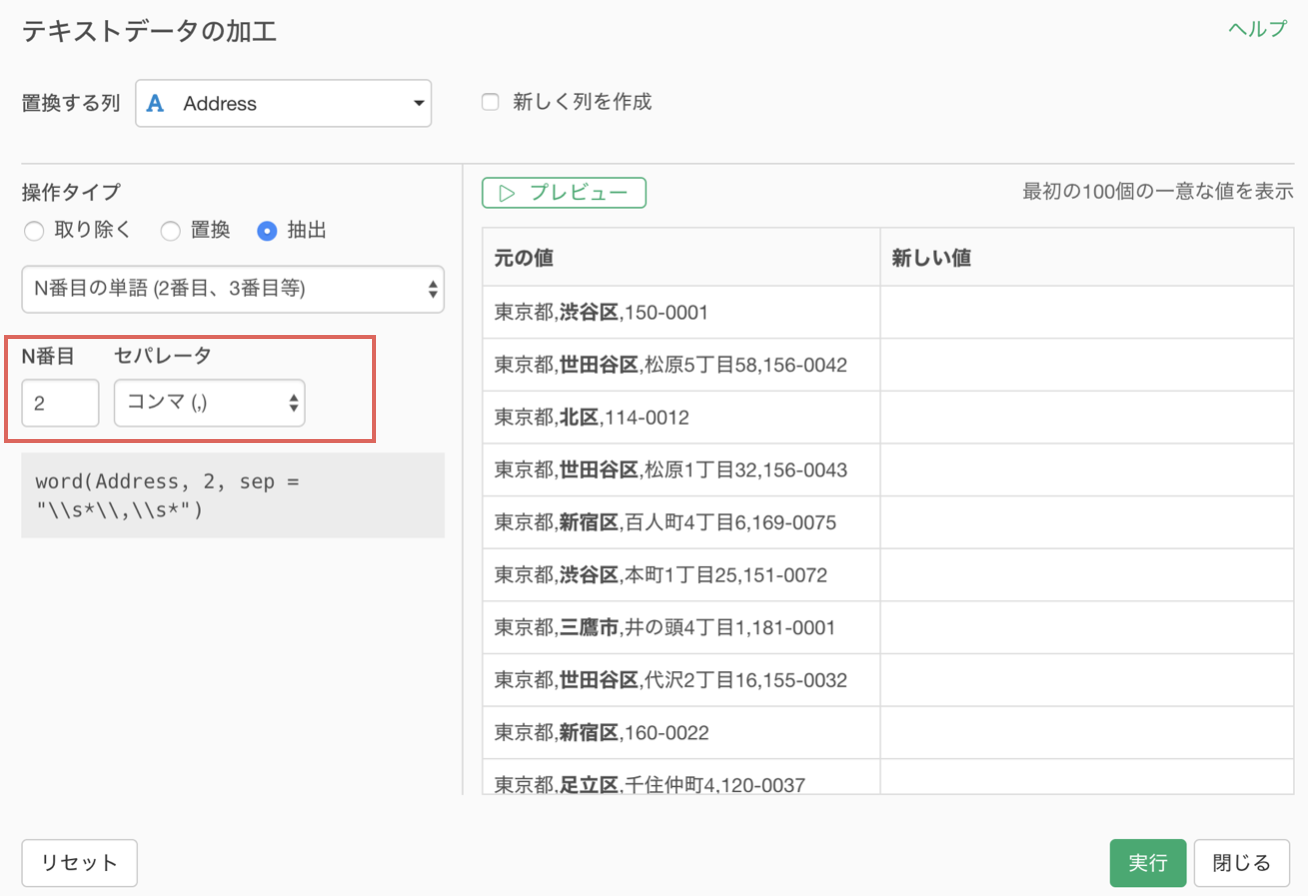
プレビュー画面にある元の値の列をみると、マッチする箇所が太文字で表示されています。これにより、抽出対象の単語がすぐに確認できますね!
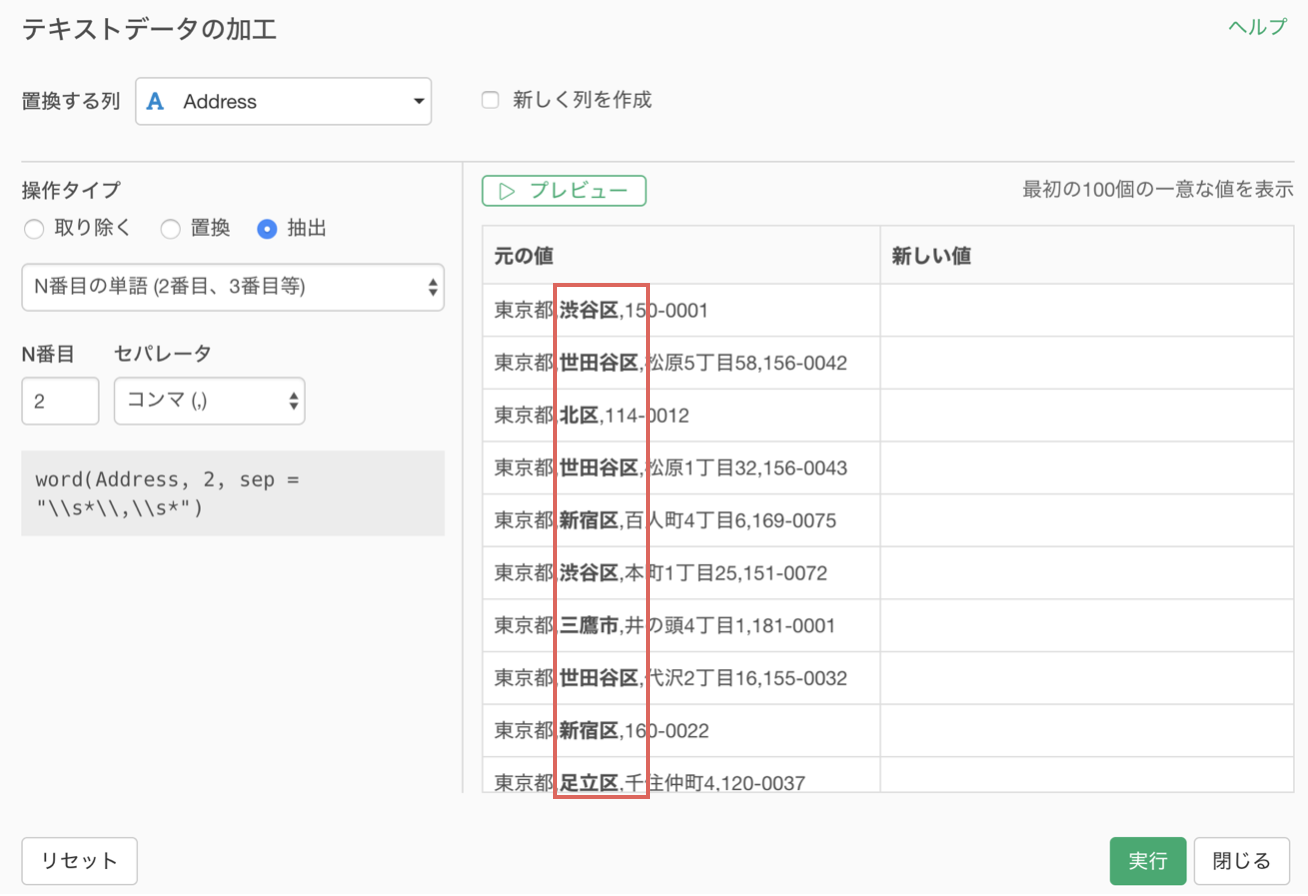
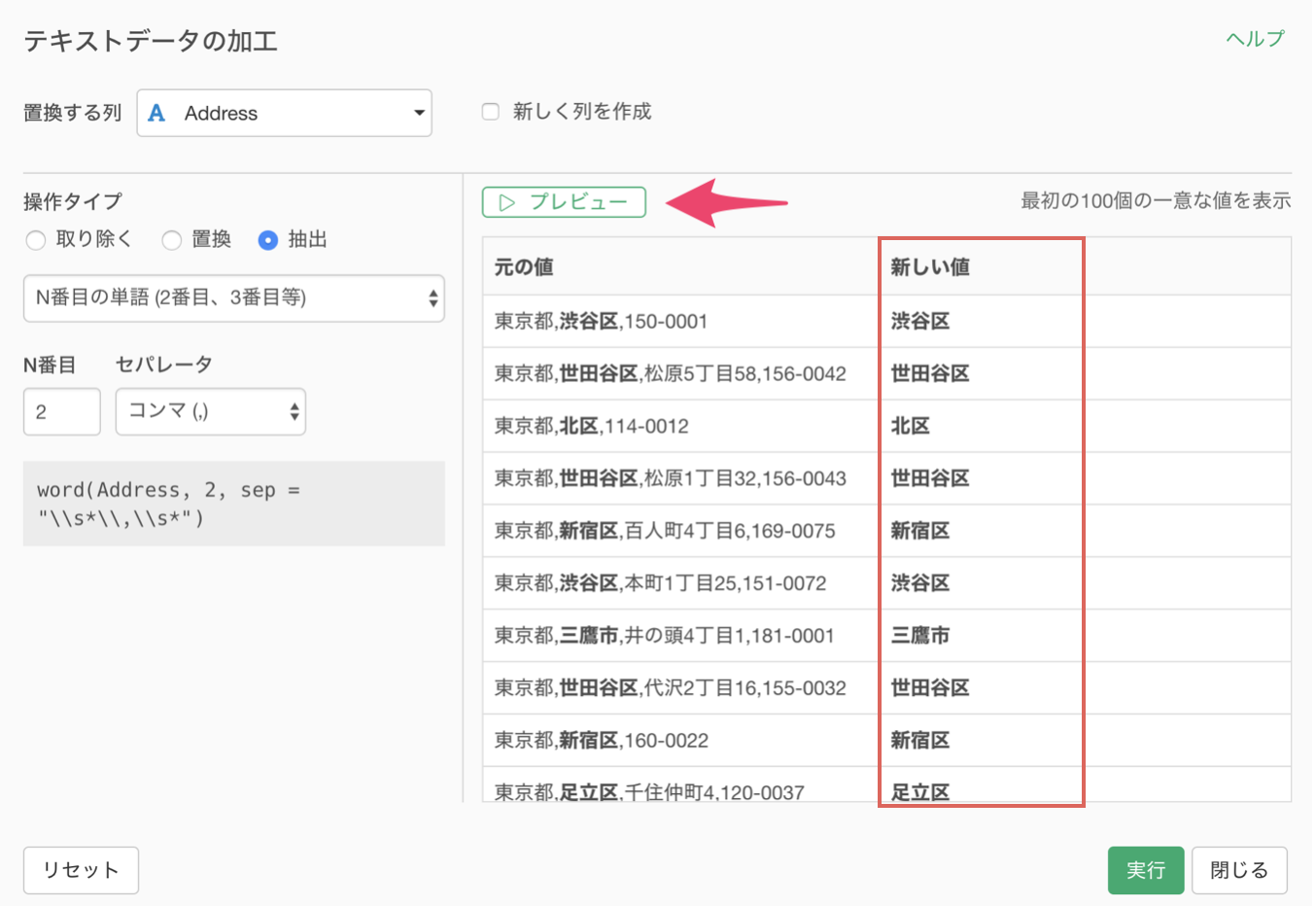
プレビューボタンをクリックすると、新しい値に2番目の単語である〇〇区が抽出されています。
新しく列を作成にチェックして列名を入力したら実行します。
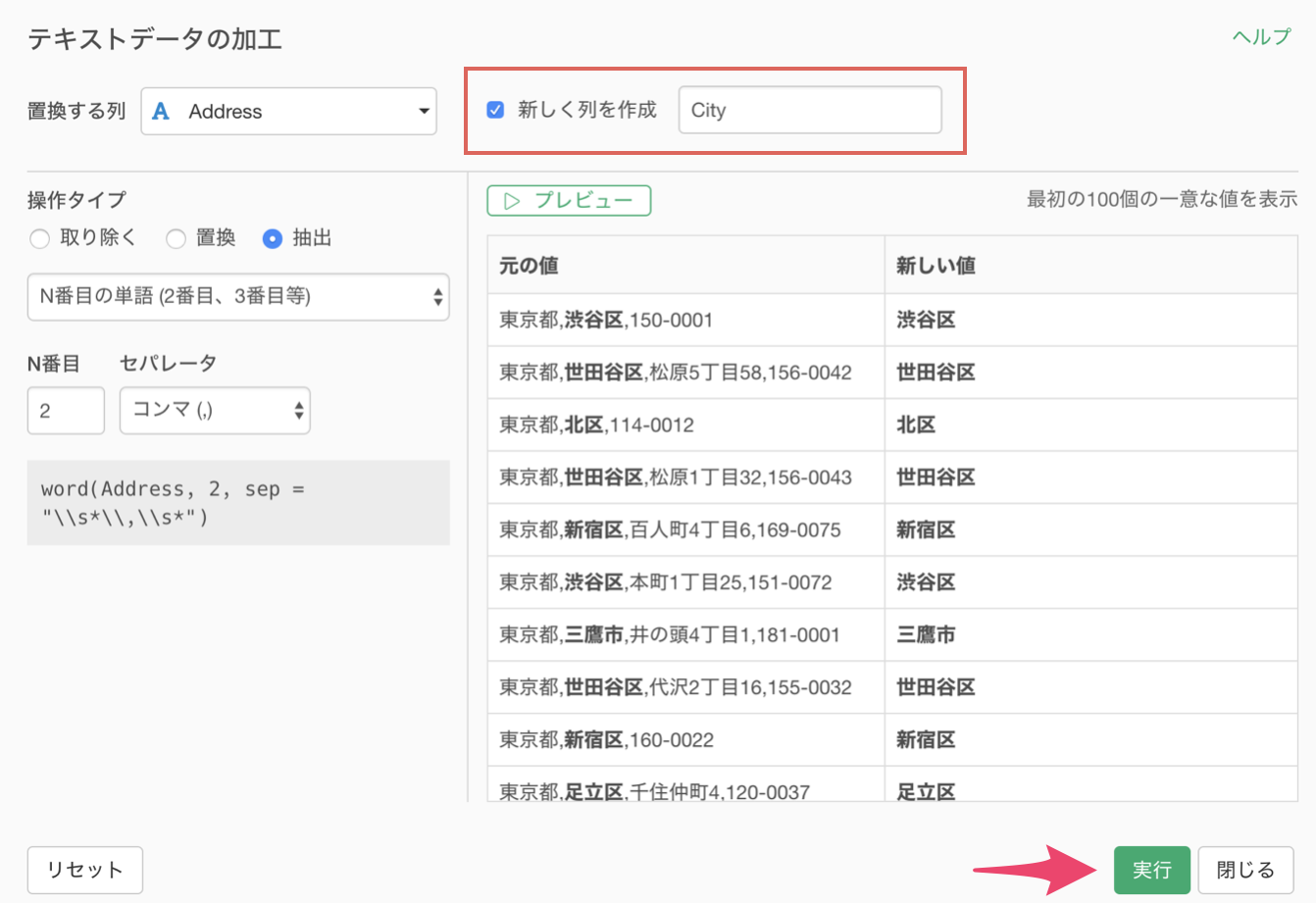
住所の列の2番目にある単語の〇〇区を抽出することができました。
最後(最初)の単語を抽出したい
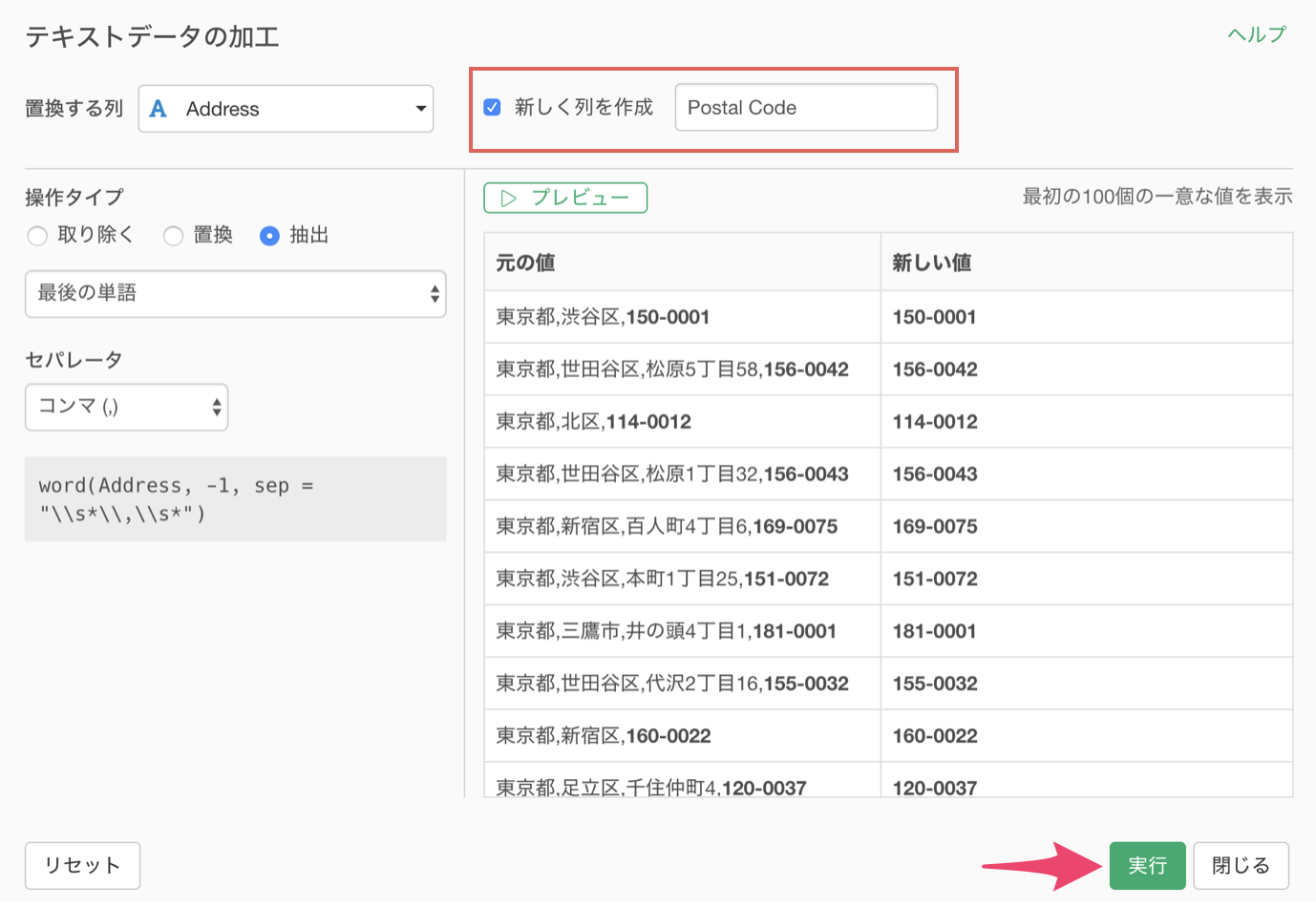
次に、住所の列から郵便番号を抽出したいとします。

しかし、今回のデータは区までのデータしかないものがあります。そのため、3番目か4番目のどちらを選べばいいのでしょうか。

その場合、最後の単語を選ぶことで郵便番号を抽出できます。

住所の列の列ヘッダメニューからテキストデータの加工(UI) を選び、抽出するを選択します。
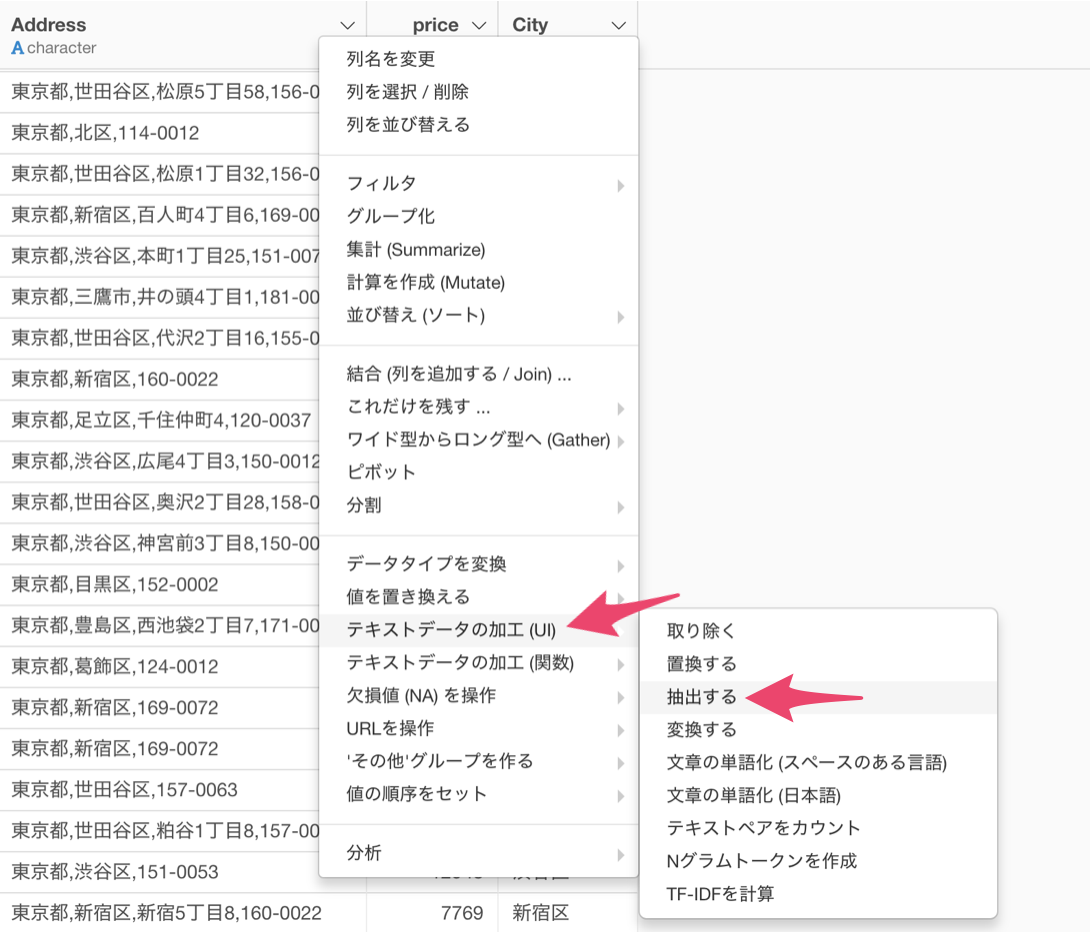
抽出する方法に最後の単語を選び、セパレータにコンマを選択します。
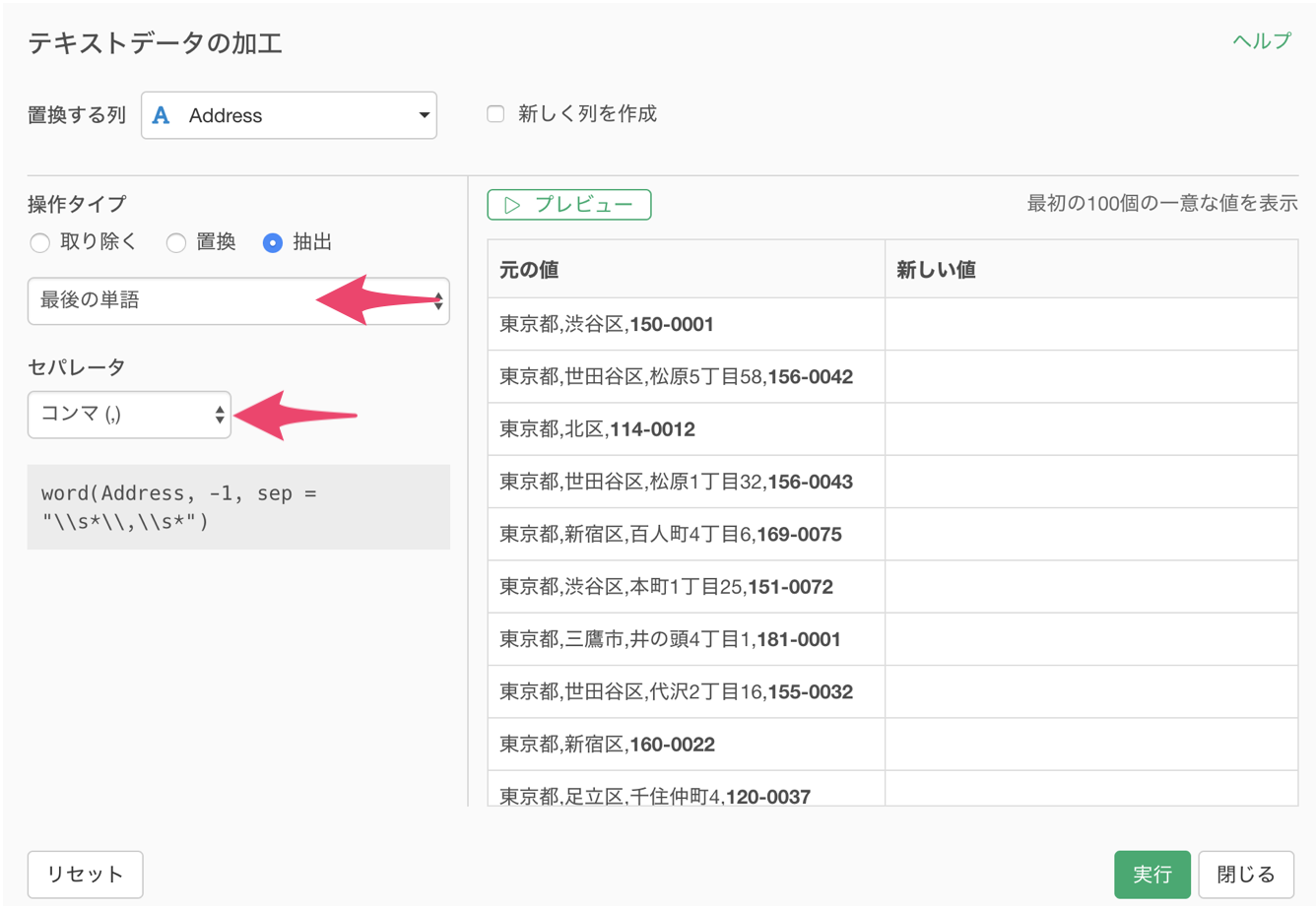
プレビューボタンをクリックして新しい値を確認すると、最後の単語である郵便番号を取得できています。
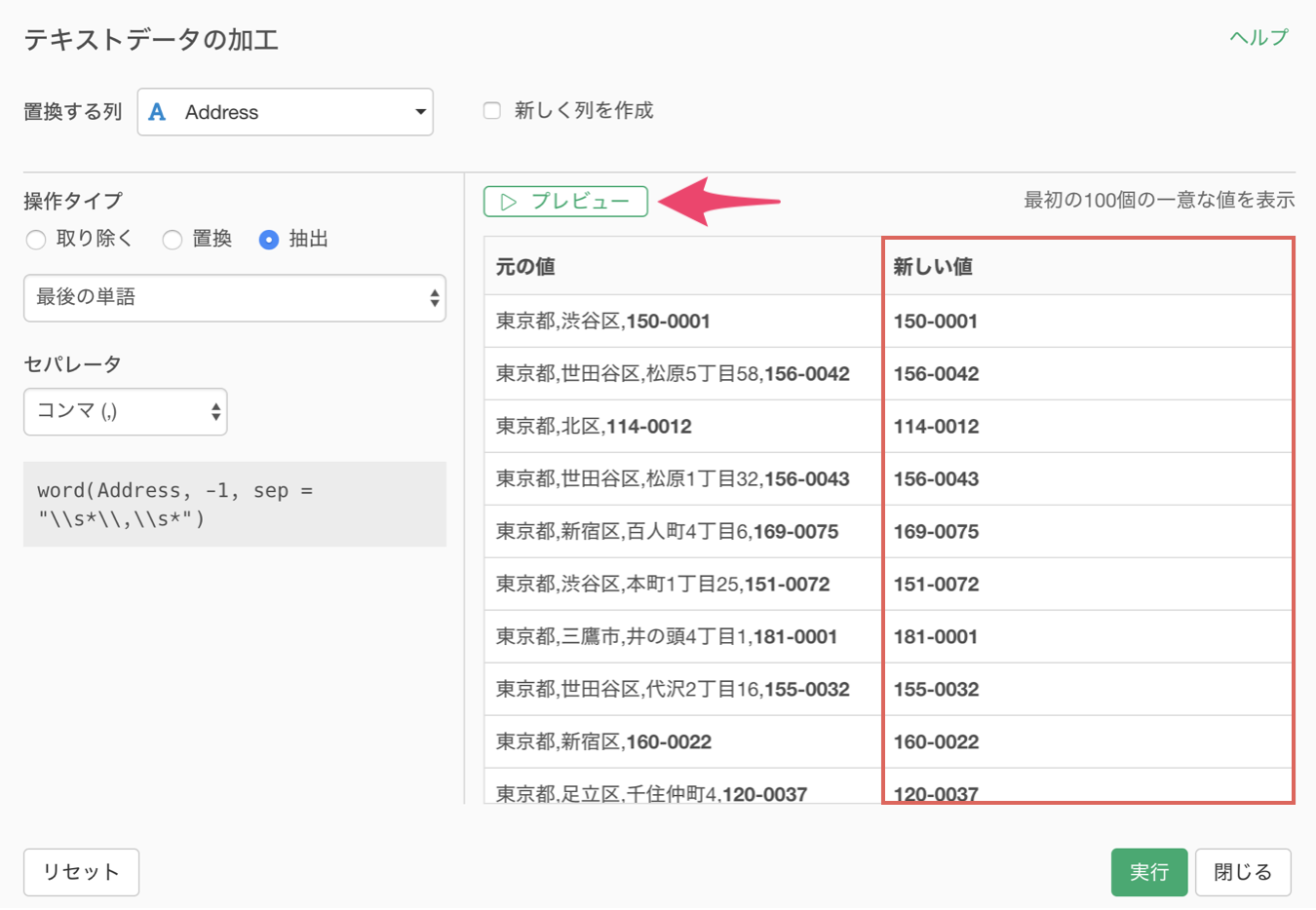
新しく列を作成にチェックをして列名を入力したら実行します。
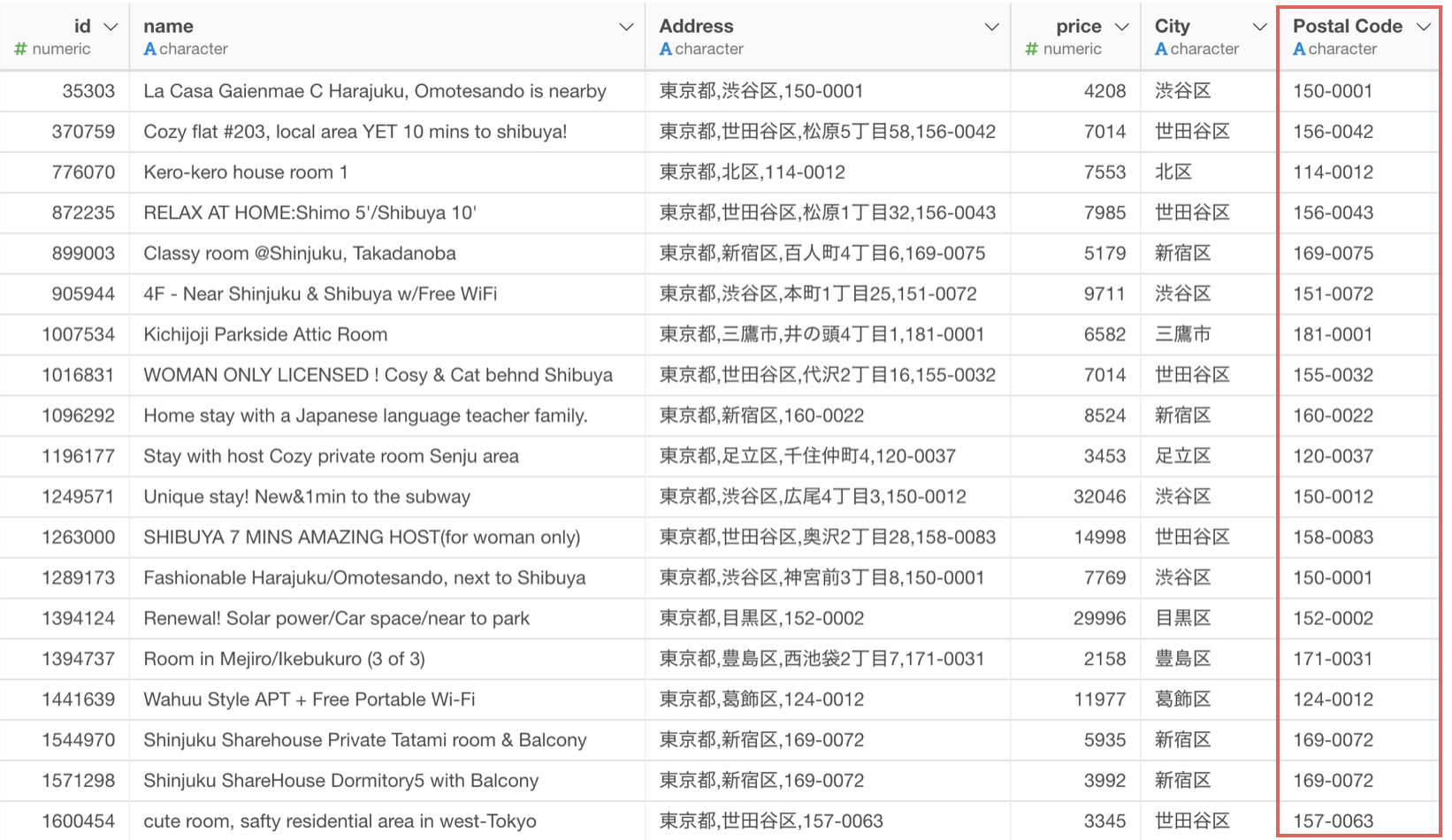
住所の列から最後の単語の郵便番号を抽出することができました。
ちなみに、最初の単語を抽出することもできます。