値が欠損値かどうかラベルをつける方法
今回はAirbnbの東京の宿泊施設データを使用します。
このデータには宿泊施設のレビュー評価の列があります。
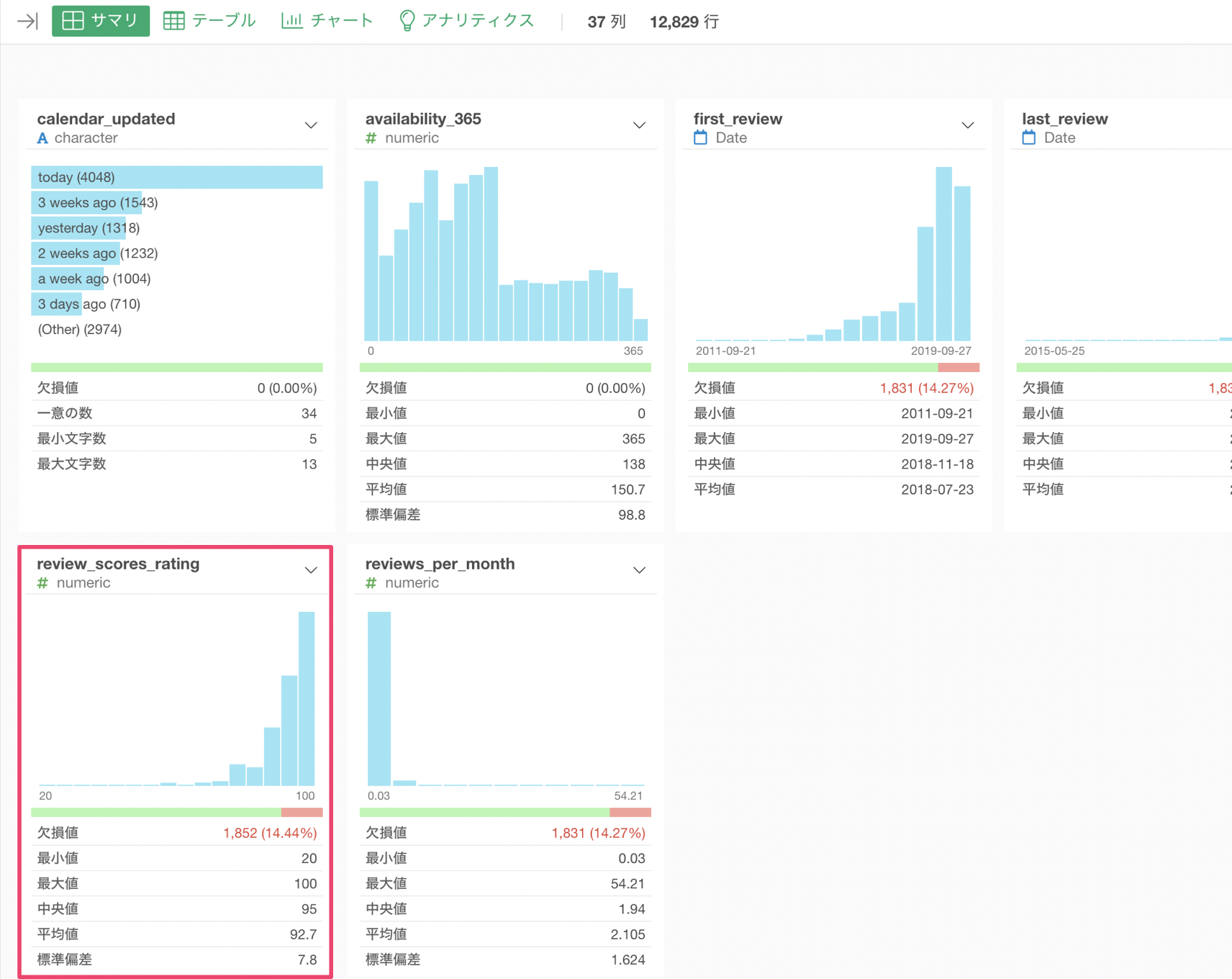
しかしこの列には欠損値が1,852行もあり、全体の14.44%もあることがわかります。
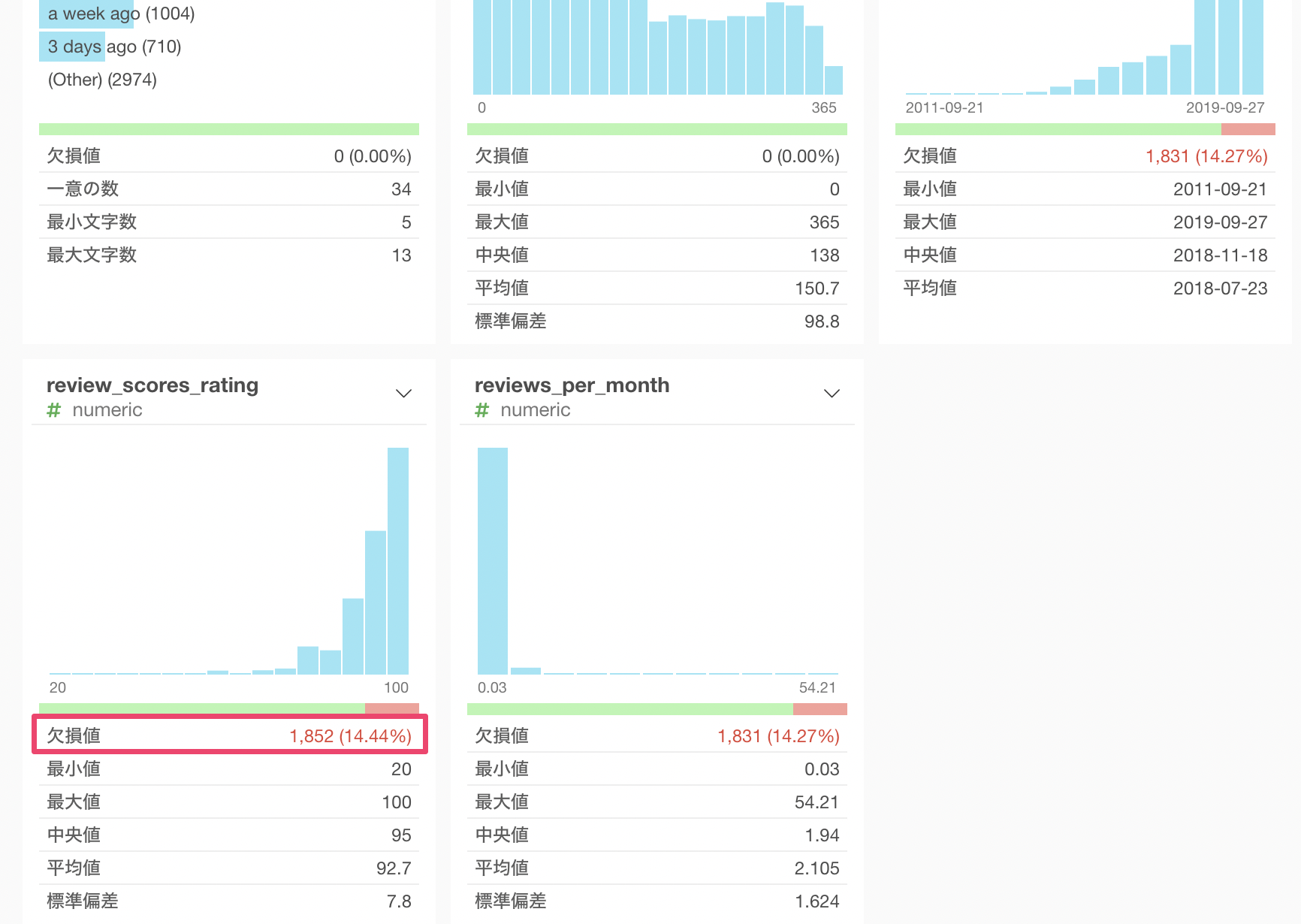
これらのレビュー評価のない宿泊施設にはどのような特徴があるのか調べたい時に、レビュー評価がある宿泊施設とない宿泊施設(欠損値)でラベルをつけたいことがあります。
review_scores_rating(レビュー評価)の列ヘッダメニューから、「計算を作成 (Mutate)」を選択します。
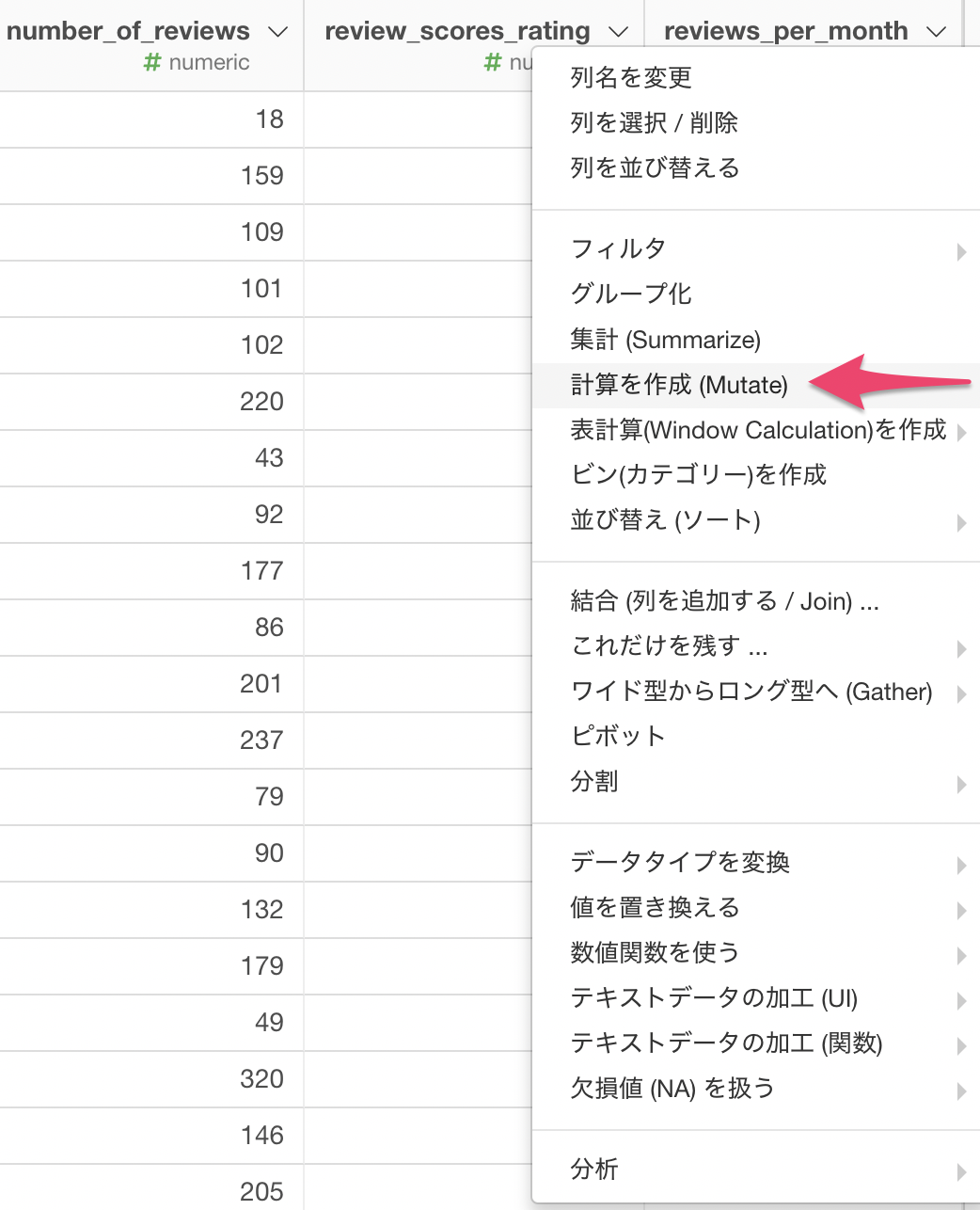
ここで欠損値の場合にTRUEを返すことができる便利なis.naという関数があります。is.na関数は下記のように記述されます。
is.na(<列名>)上記の列名には、実際の列名を指定してください。
今回の場合、計算を作成のエディタにはis.na(review_scores_rating)を入力して実行します。
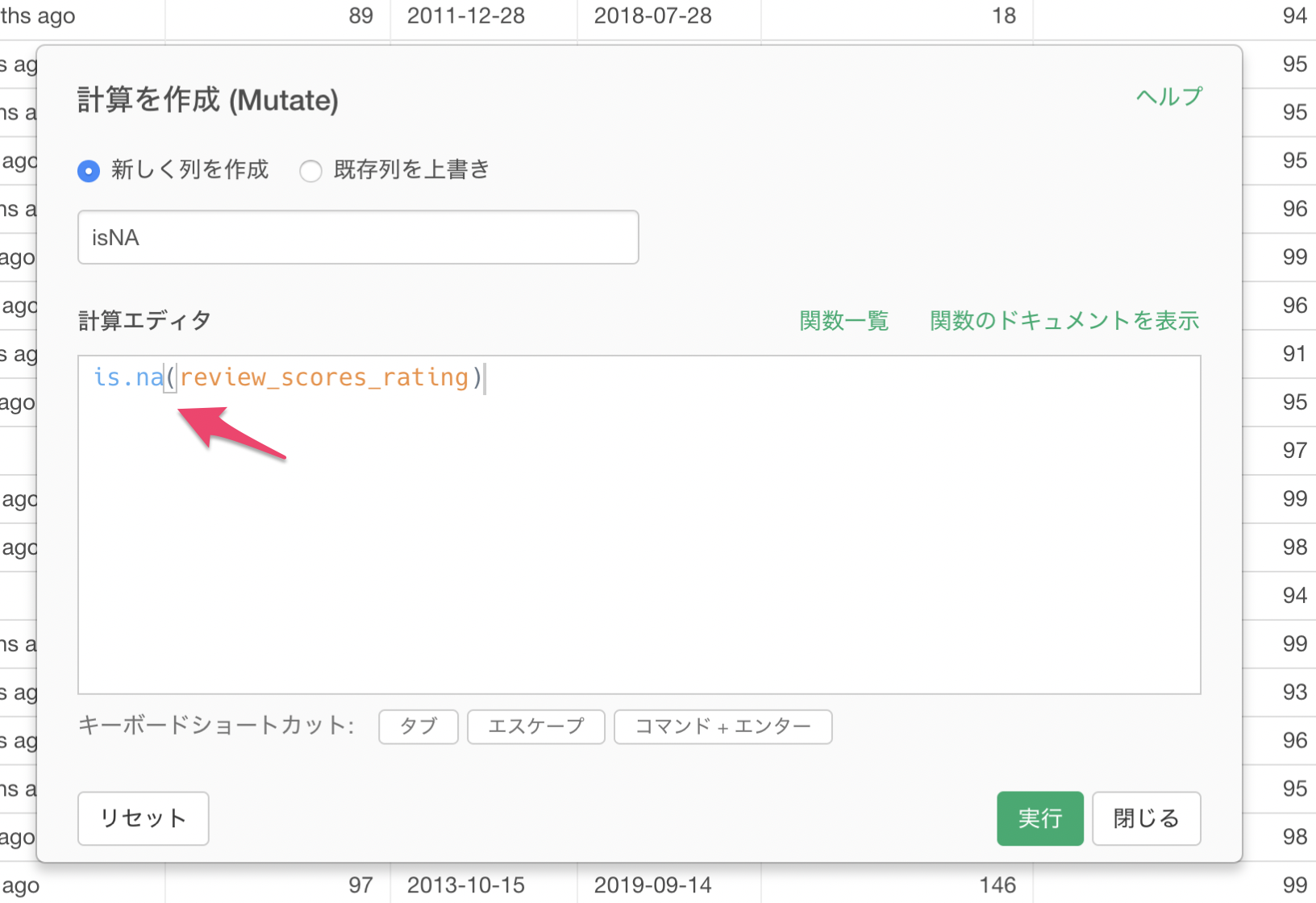
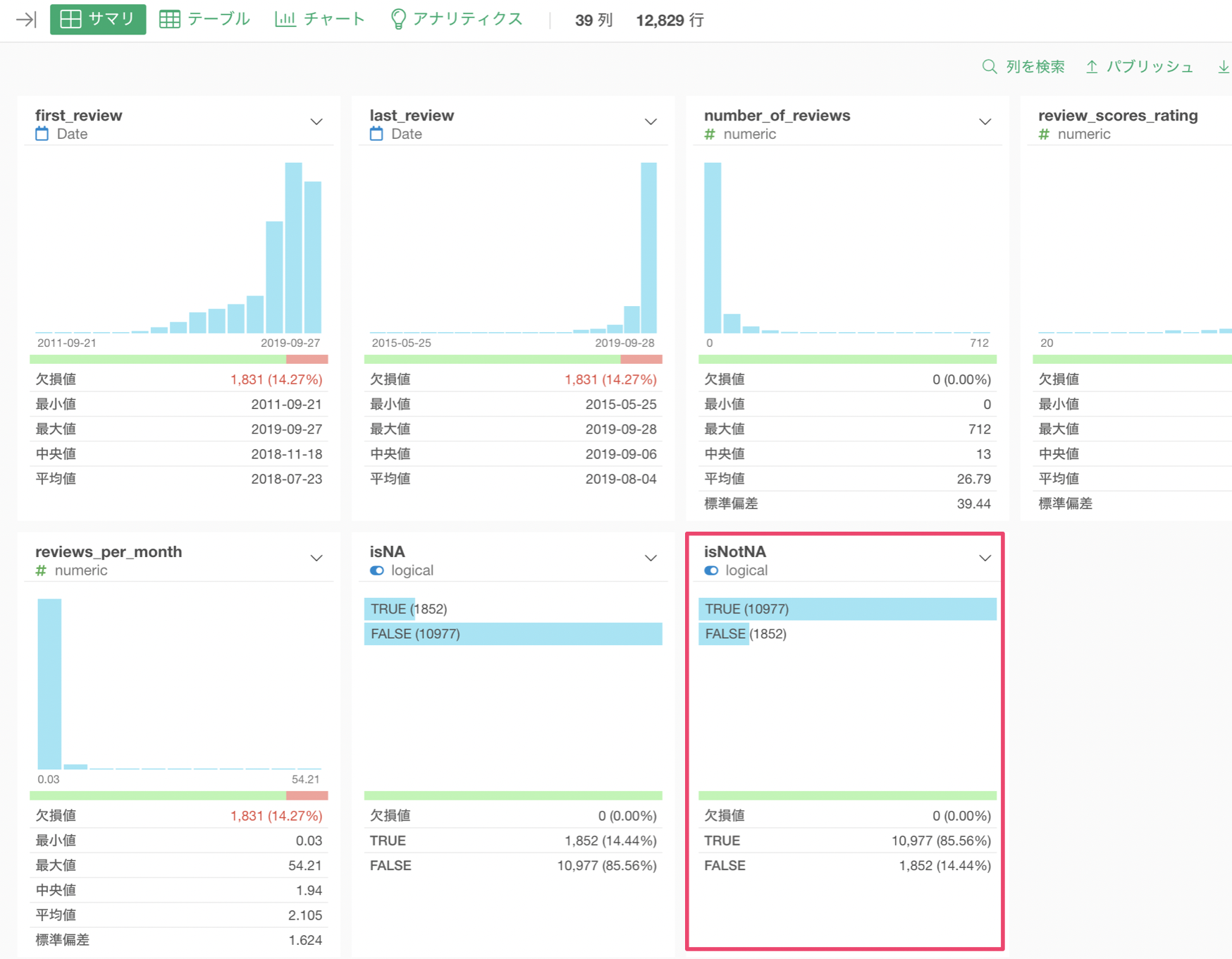
これでレビュー評価の列が欠損値の場合にTRUEを、欠損値じゃない場合にFALSEを返す列を作成できました。
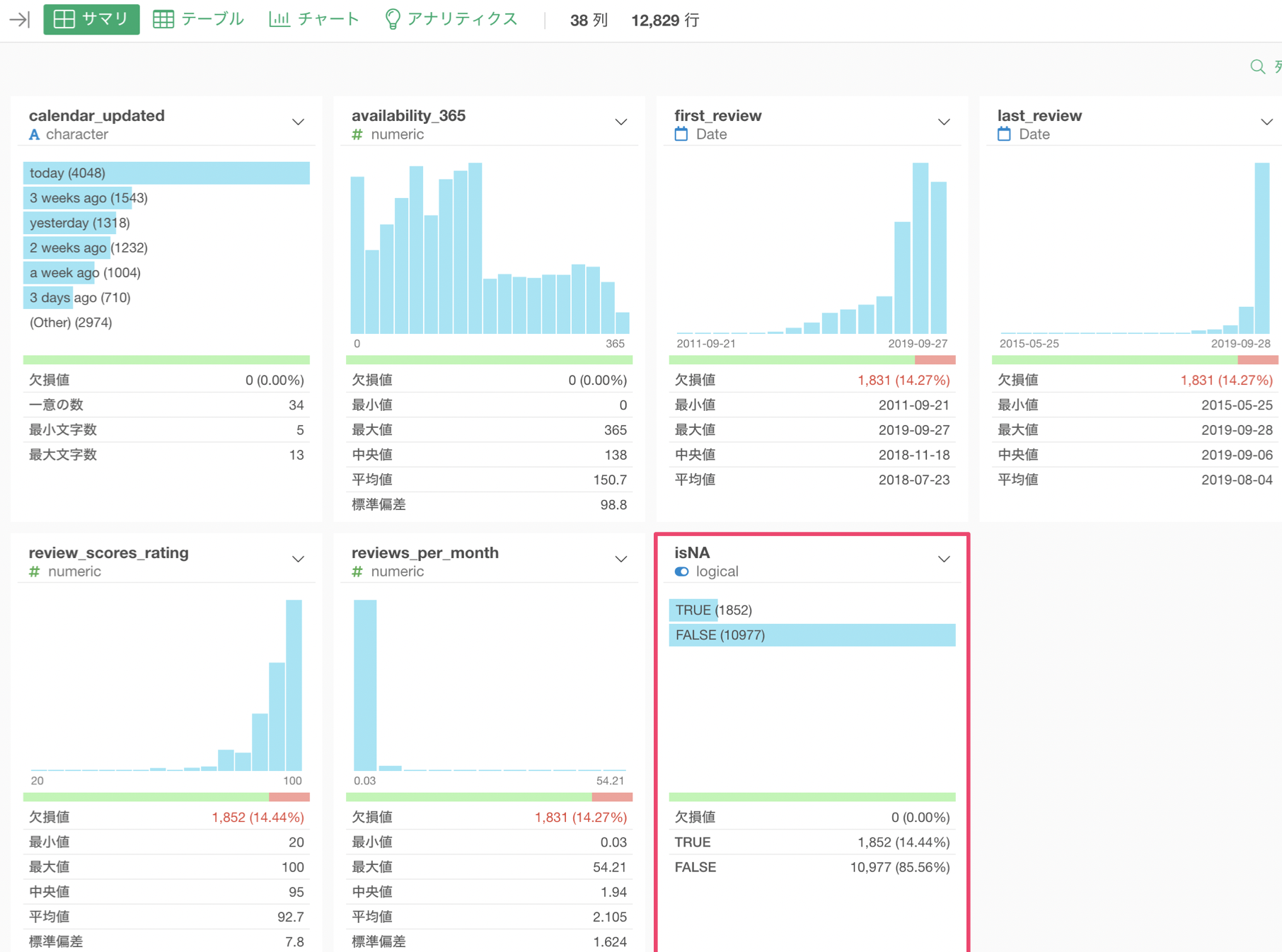
サマリ・ビューから先程の作成した列を見てみると、レビュー評価の欠損値1,852行を全てTRUEにすることができているのがわかります。
値がある場合にTRUEを返したい
欠損値じゃない場合、つまり行に値がある場合にTRUEのラベルをつけたいことがあります。
その場合は下記のように、is.naの関数の前に否定を表す ! を付けることで、欠損値じゃない場合にTRUEを値として返すことができます。
!is.na(<列名>)上記の列名には、実際の列名を指定してください。
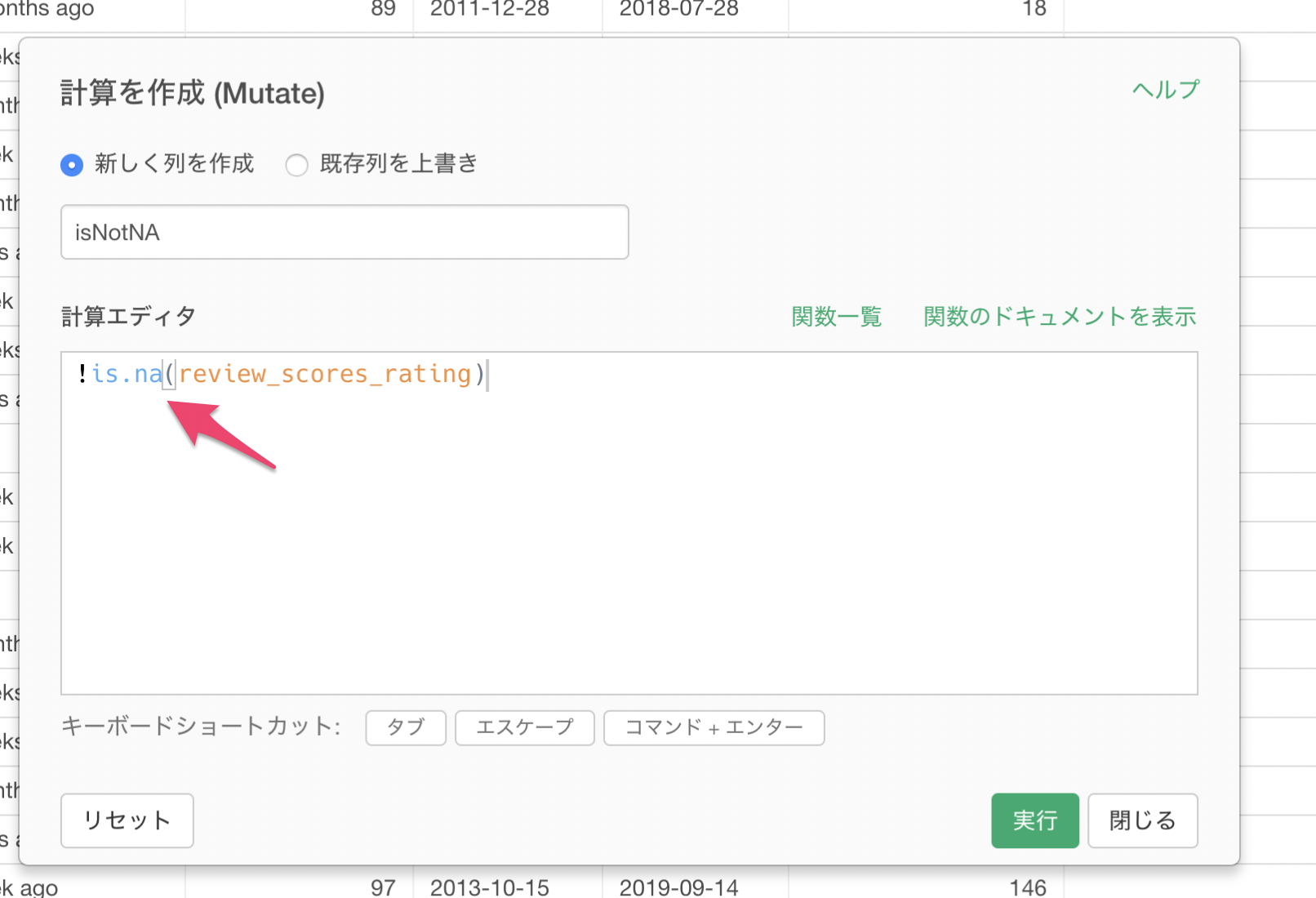
これにより、値がある場合はTRUEとなっていることがわかります。
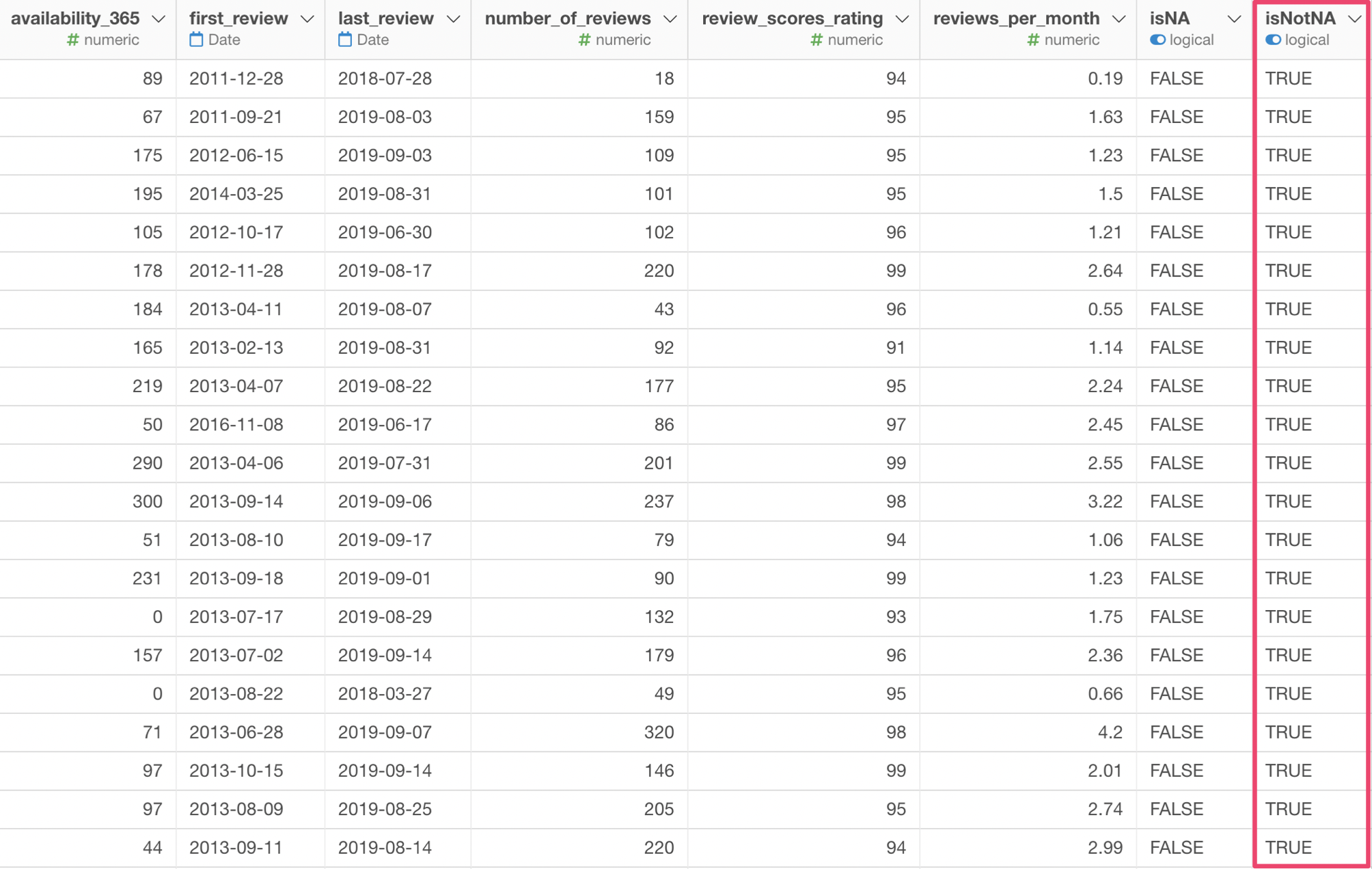
サマリ・ビューをみると、レビュー評価の値がある場合にTRUEとなっていることがわかります。