
文章を単語化してどの単語がよく使われるのか可視化する方法
今回はサンプルデータとして、Twitter searchから「データサイエンス」のキーワードで取得したデータを使用します。

Twitter Searchからツイートを取得する方法は下記のノートをご覧ください。

今回の流れとしては、まずは文章を単語化します。
次に、どの単語がよく使われるのかをワードクラウドを使って可視化していきます。
Twitter Searchからデータを取得すると、文章のデータ(ツイート)があります。

この文章のデータのままでは、一つの文章(一行)がそれぞれ別の値として認識されるため、どういった単語が使われているのかの傾向を掴むことはできません。

そのため、文章を単語化すると、単語ごとに出現回数を可視化することができるようになります。
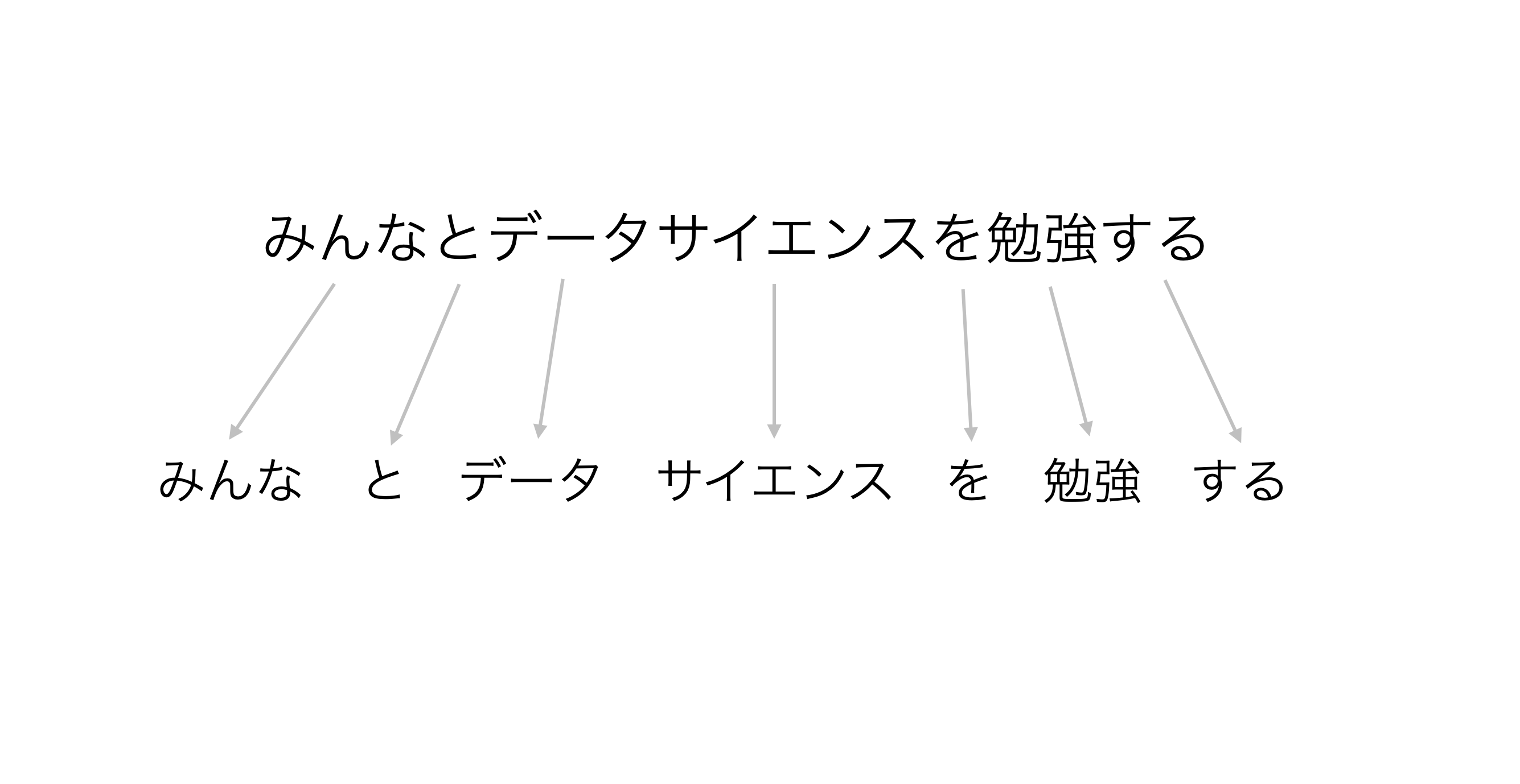
例えば、下記の「みんなとデータサイエンスを勉強する」という文章があったとします。

文章を単語化することで、文章を「単語ごと」に分けることができます。
Exploratoryでは、UIから簡単に文章を単語化することができるので、やってみましょう!
文章(text)の列ヘッダメニューからテキストデータの加工(UI) の文章の単語化(日本語) を選択します。

文章の単語化のダイアログが表示されました。
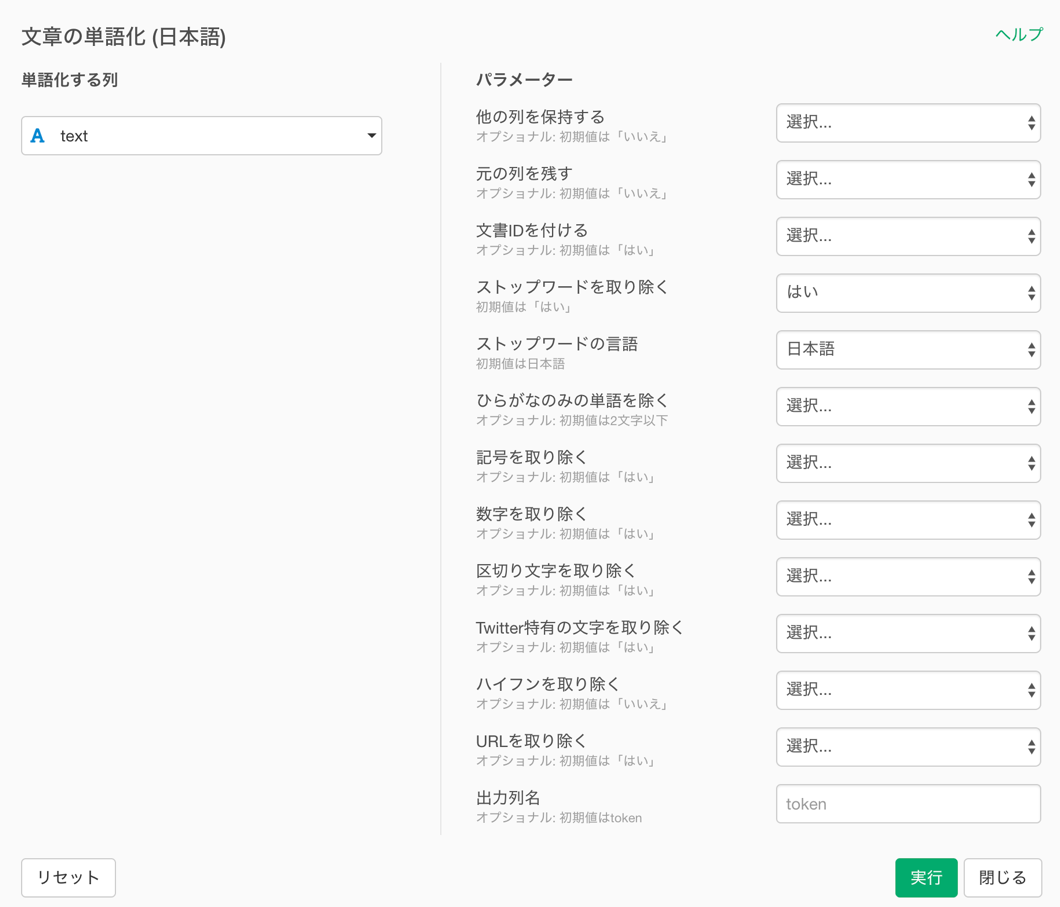
パラメーターには大きく分けて「列の設定」と「残す単語を厳選する」といった2つの種類があります。
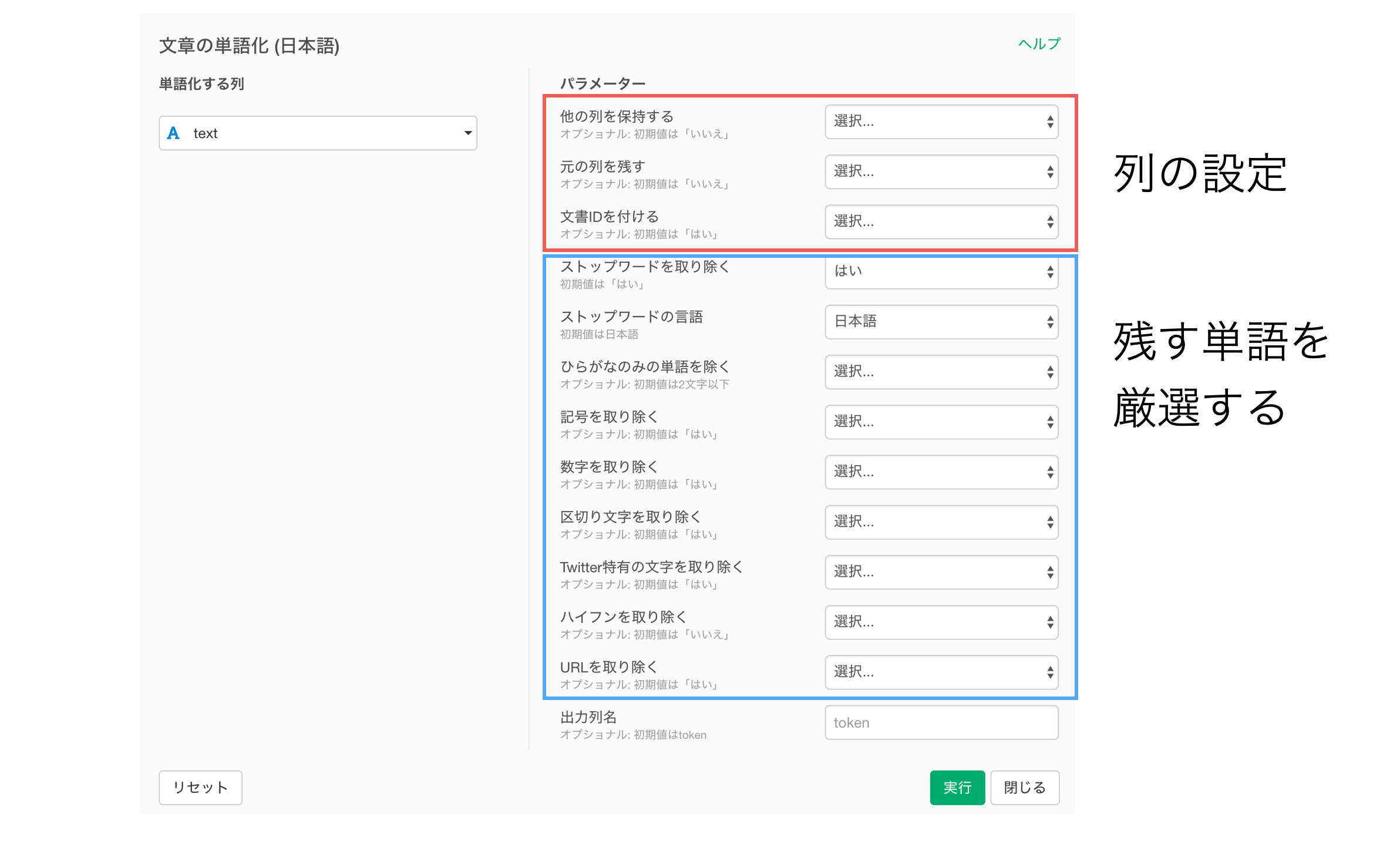
列の設定
まずは、列の設定のパラメーターについて解説していきます。
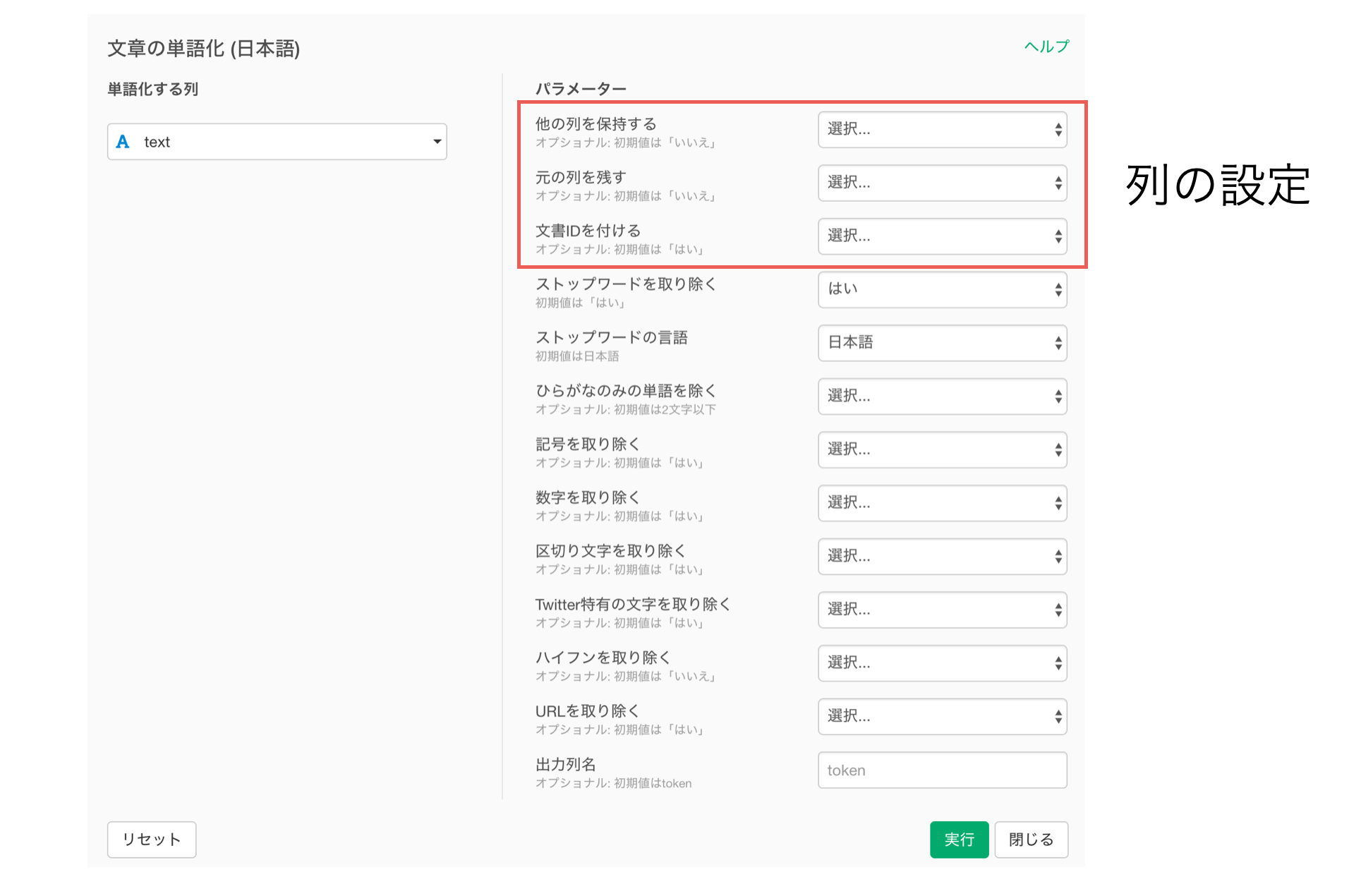
文章の単語化で列の設定に全て「いいえ」を選択して実行すると、下記の2つの列のみが残ります。
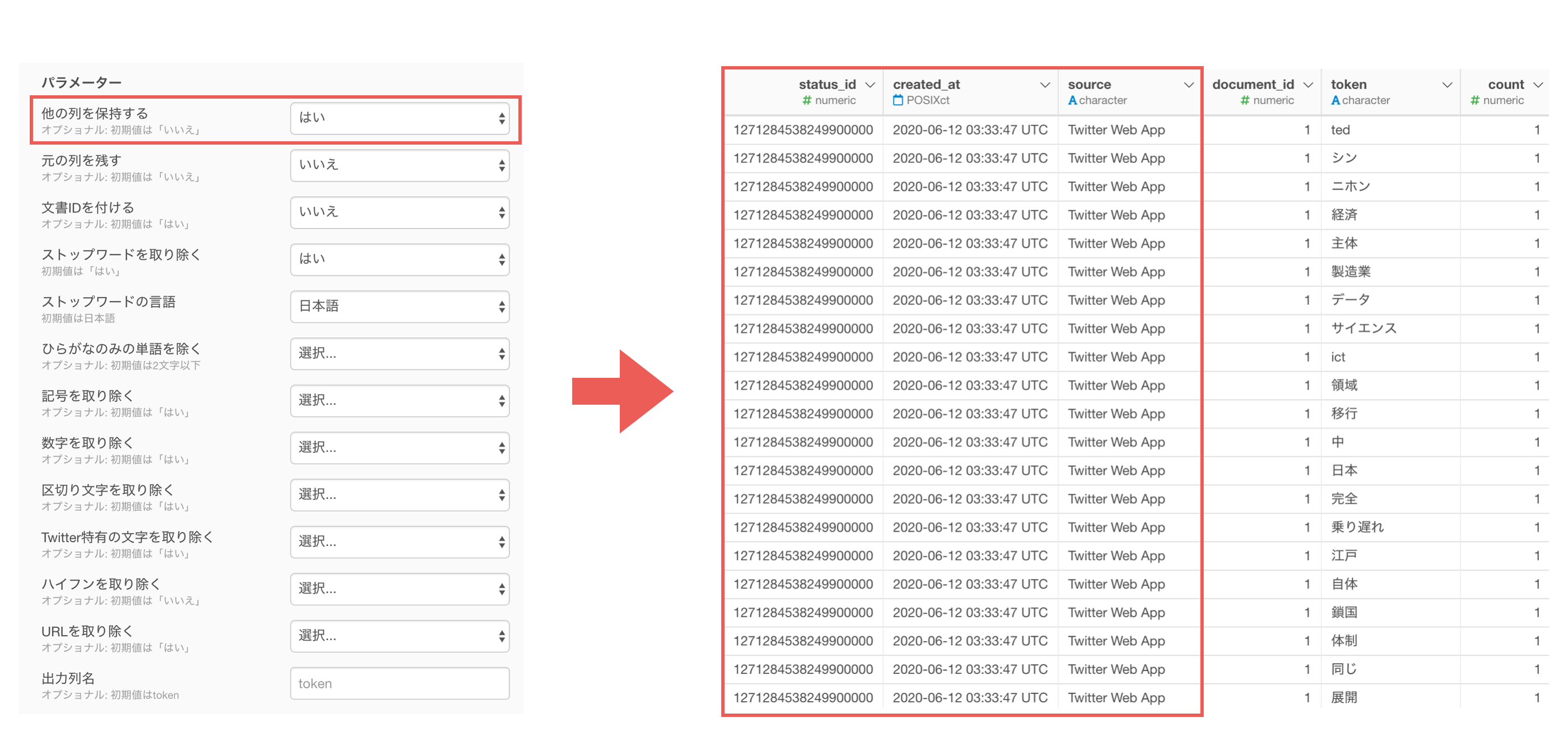
他の列を保持するに「はい」を選択すると、単語化する前にあった列をそのまま残すことができます。
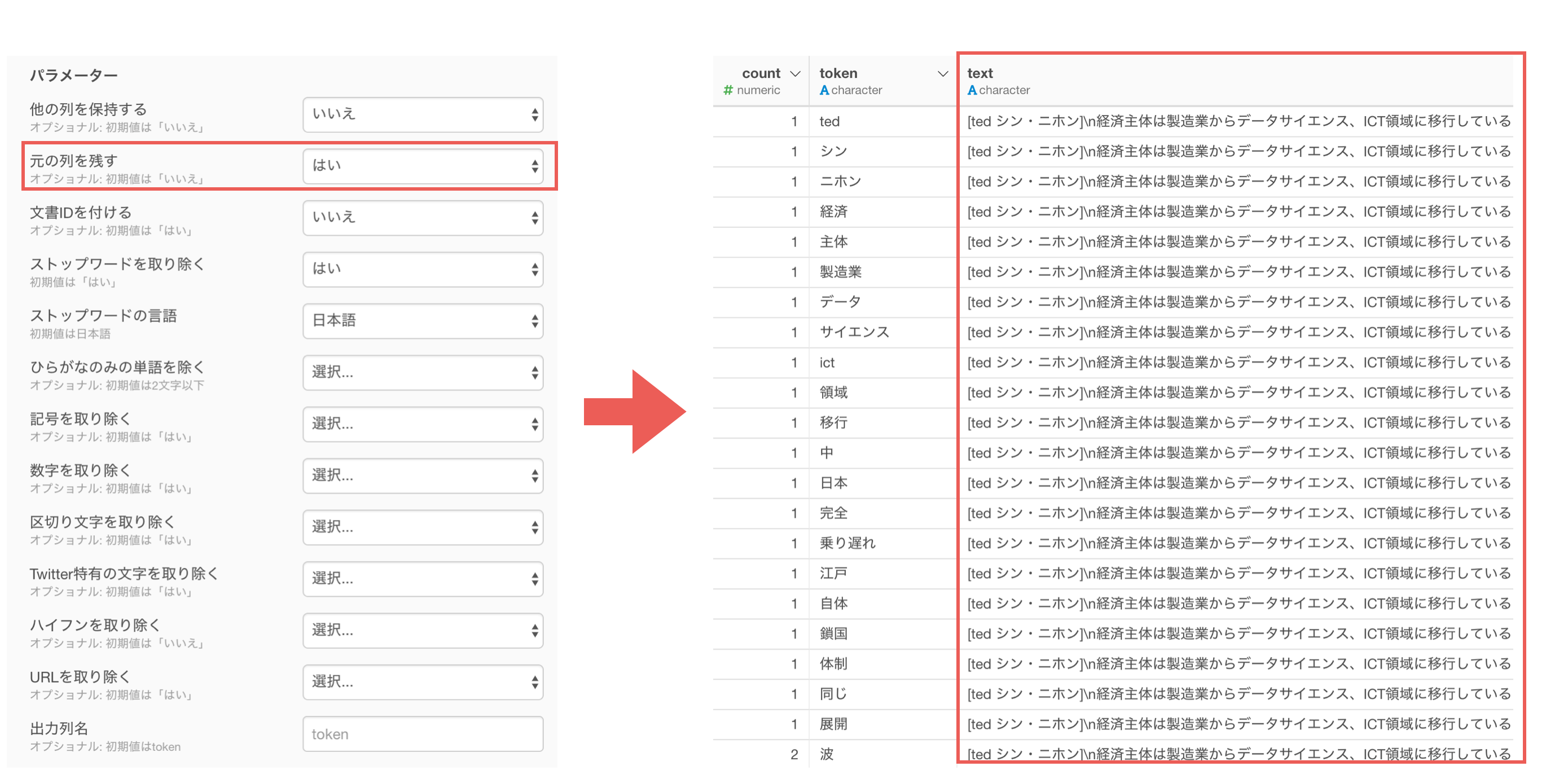
元の列を残すに「はい」を選択すると、単語化した列の元の文章を残すことができます。元の文章がどういう文章だったのかを確認したい場合は、こちらの設定を「はい」にすることをオススメします。
最後に、文書IDをつけるでは、文章(ドキュメント)ごとに一意なIDをつけることができます。

列の設定で唯一、文書IDをつけるはデフォルトで「はい」になっています。
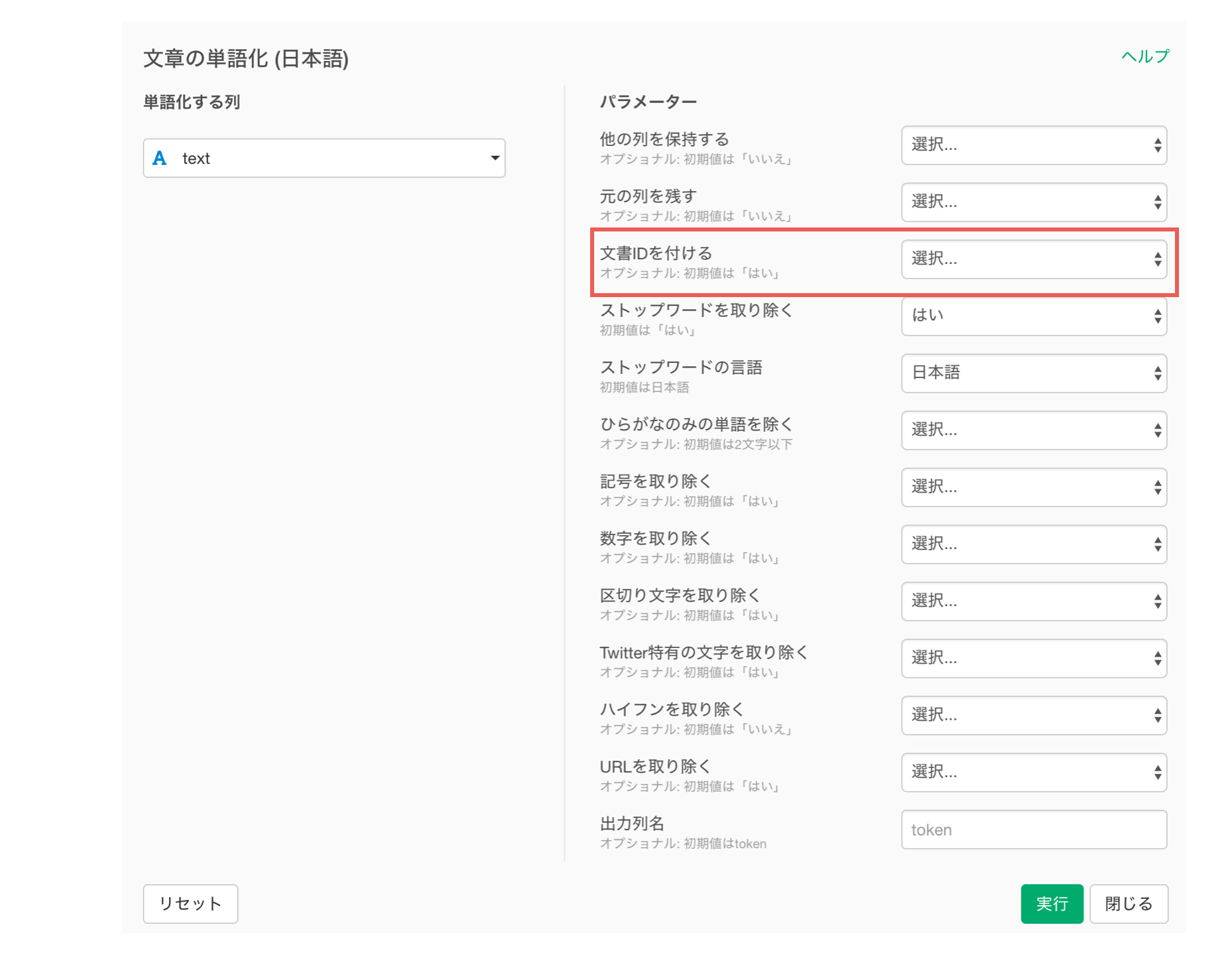
この文書IDを使うことで、「テキストペアをカウント」という機能を使って単語の組み合わせをカウントすることができます。
残す単語を厳選する
次に、残す単語を厳選することができるパラメーターについて解説していきます。

しかし、数が多すぎるため、こちらも厳選して下記の2つを紹介します。
- ストップワードを取り除く
- ひらがなのみの単語を除く
「ストップワード」という言葉は普段はあまり触れる機械がない言葉ですが、テキストを分析していく際にかなり重要になります。
先ほどの「みんなとデータサイエンスを勉強する」という文章を思い出してください。
これらの赤文字の単語はあまりにも一般的すぎるため、テキスト分析していく中では意味の無い単語になります。このことをストップワードと呼びます。
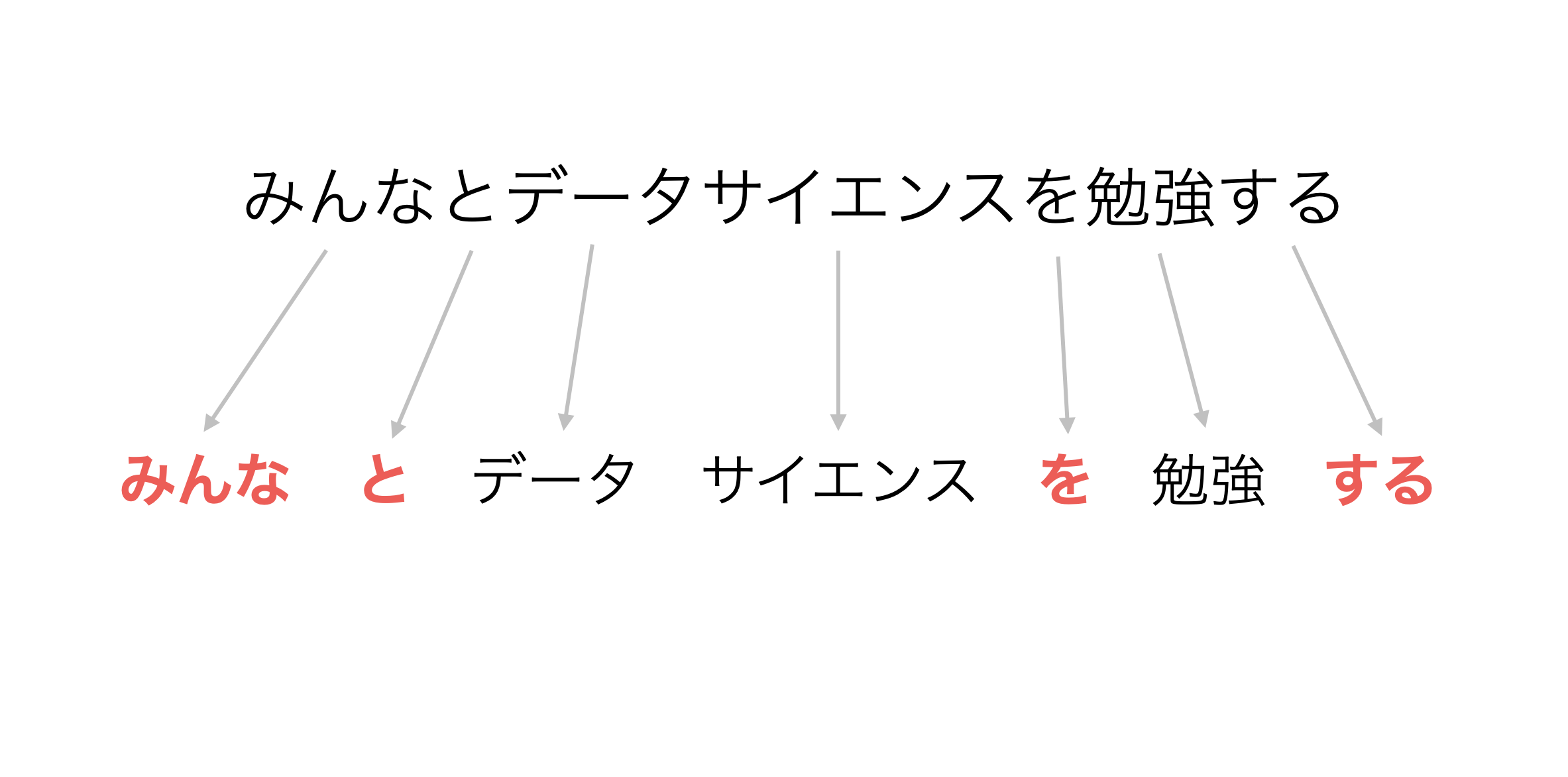
そのため、ストップワードを取り除くと、一般的に使用される単語が取り除かれ、重要な単語のみを残すことができます。
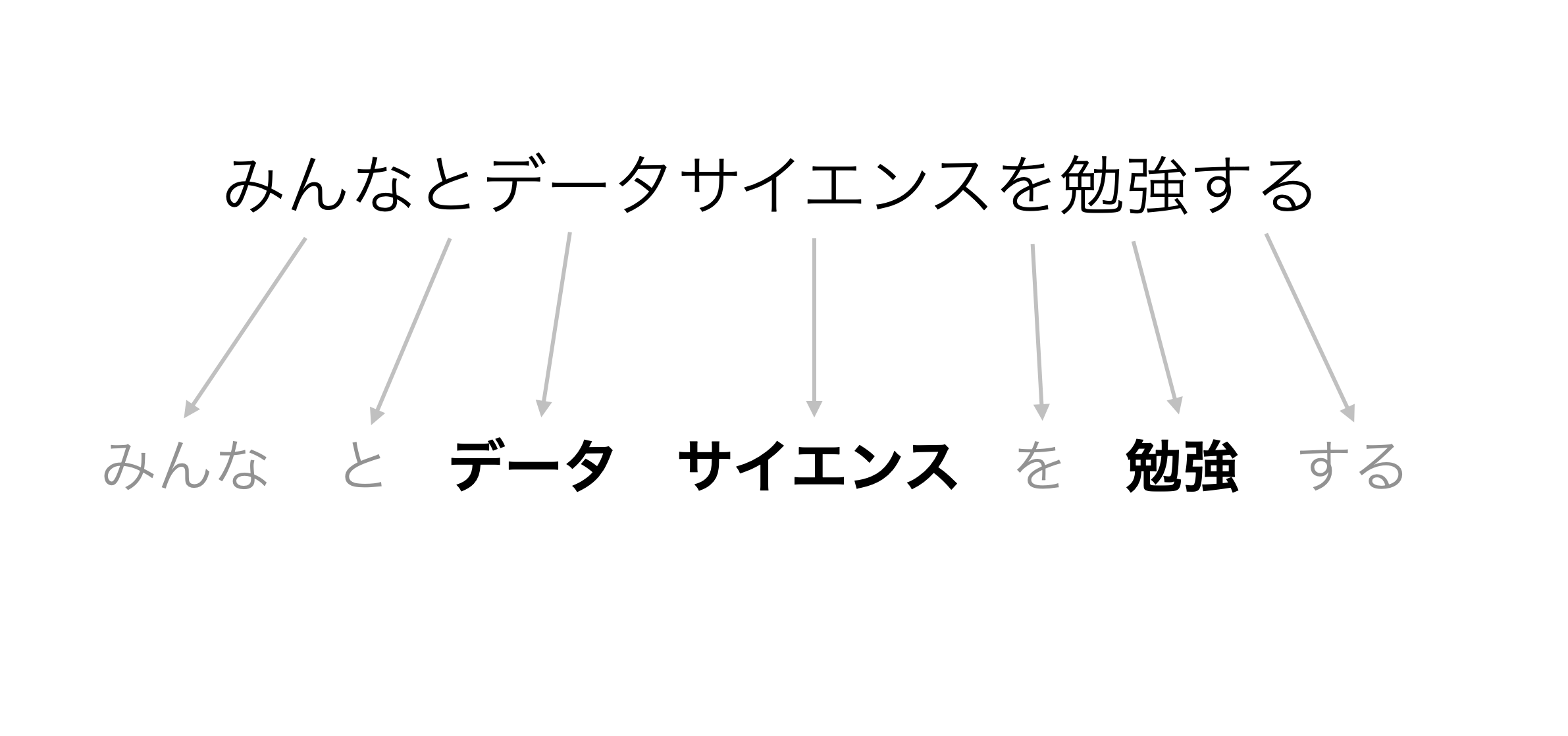
今回のデータで試してみると、ストップワードを取り除くことで、「という」や「みんな」、「中」といった単語が取り除かれています。

次に、ひらがなのみの単語を取り除くについて紹介します。
2文字以下(文字数は指定可能)のひらがなはストップワードと同じく、テキスト分析をしていく中で意味の無いデータになることがあります。

そのため、2文字以下のひらがなを取り除くと、不要な単語が取り除かれ、重要な単語のみを残すことができます。

ひらがなのみの単語を取り除くと「の」や「が」、「ない」といった不要な単語が取り除かれています。

デフォルトでは、ストップワードやひらがなのオプションが適用されているので、そのまま実行すると、残す単語を厳選して単語化することができます。

文章を単語化することができましたが、これらのデータはどのように解釈すれば良いのでしょうか。

単語化した後のデータの解釈
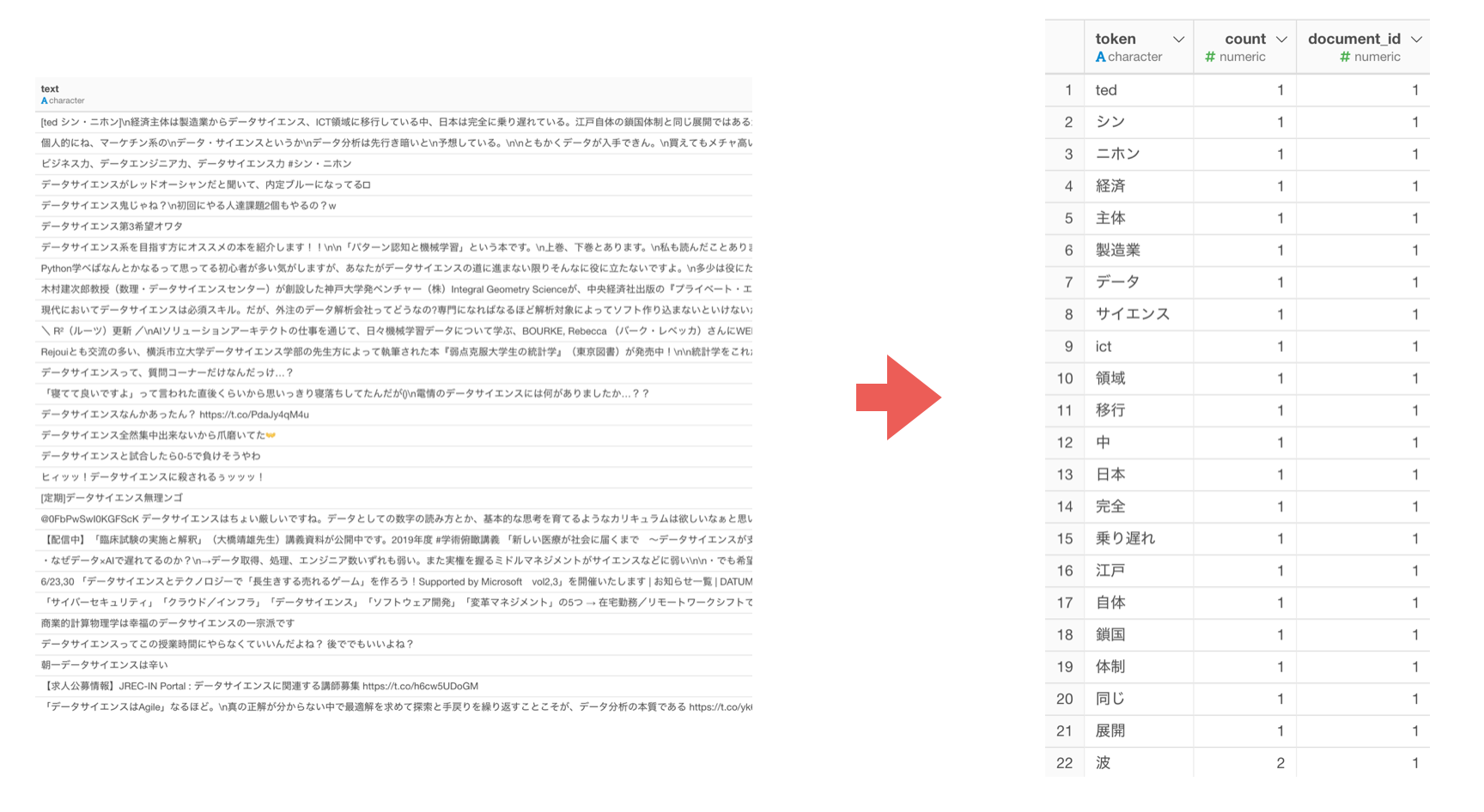
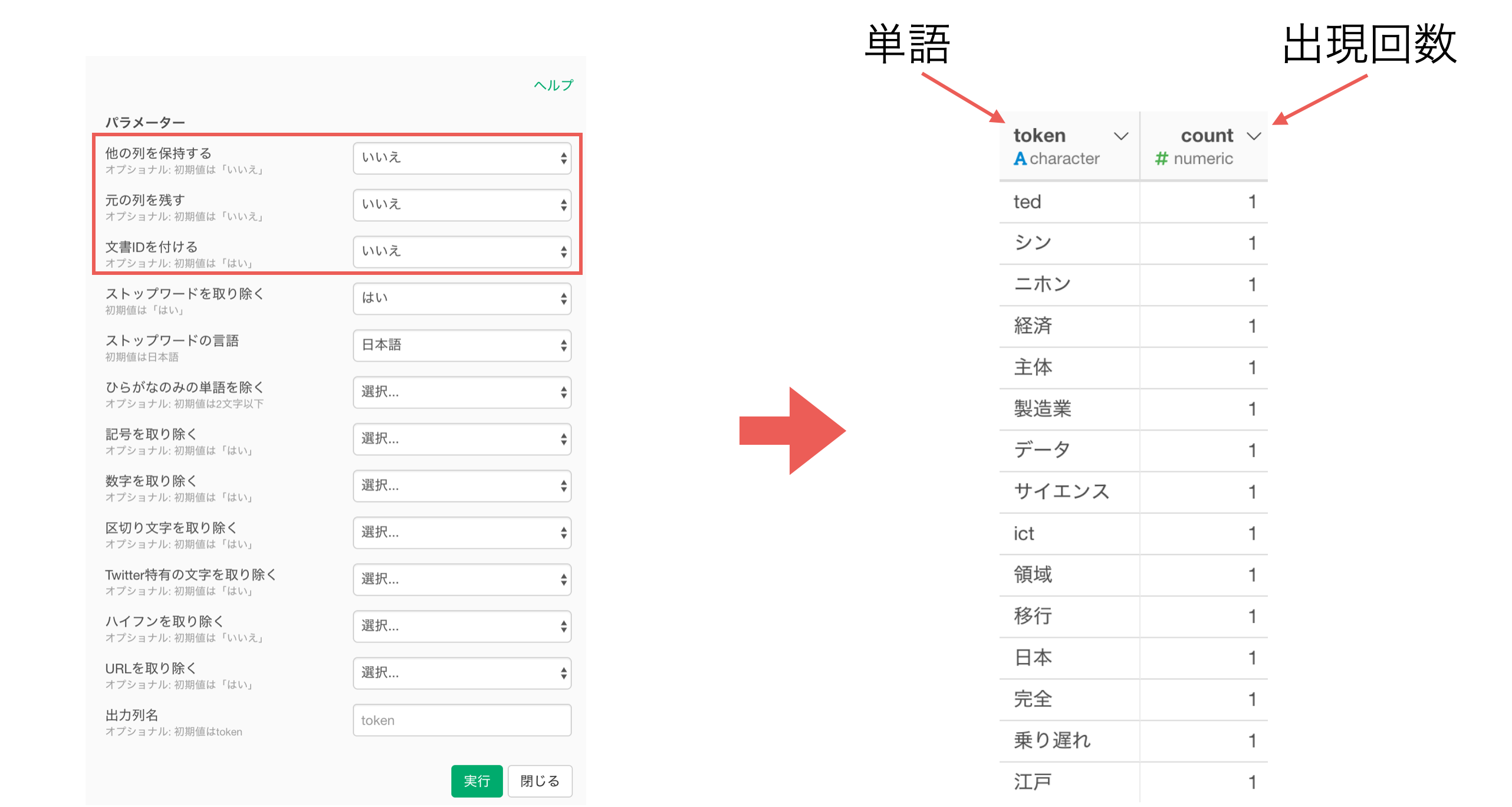
例えば、下記の2つの文章を単語化したとします。
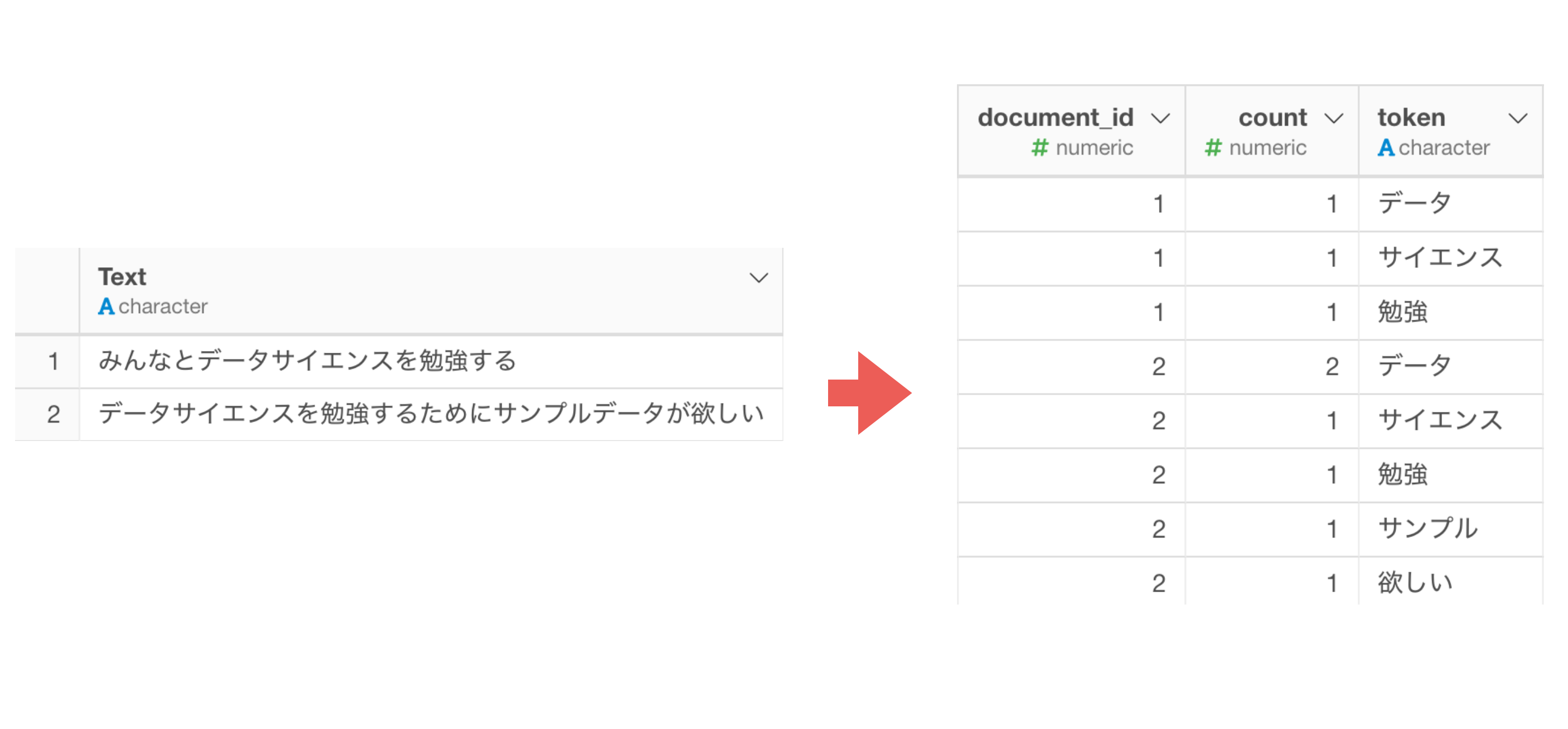
元の文章のデータでの1行が1ドキュメント(document)として考えます。
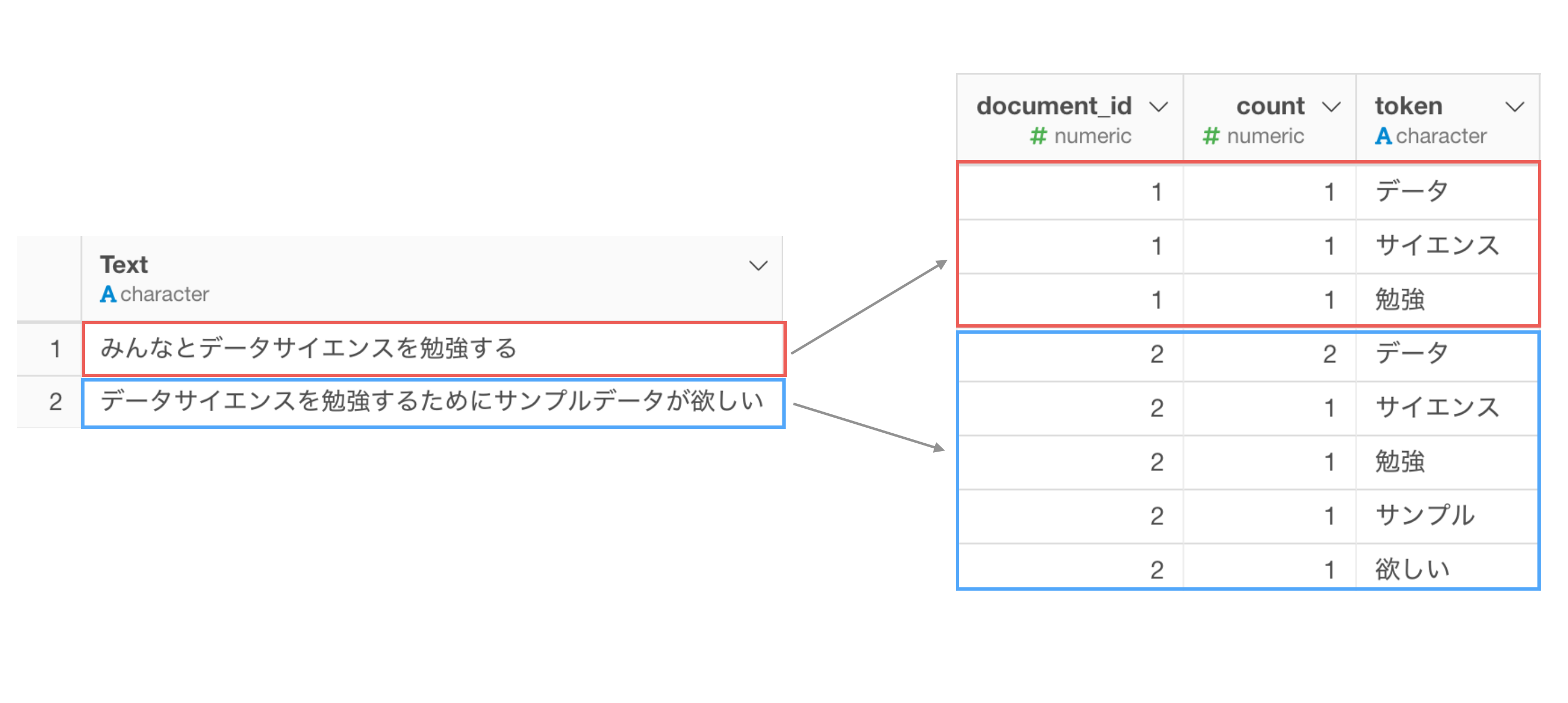
単語(token)はドキュメント(document_id)ごとに分けられます。
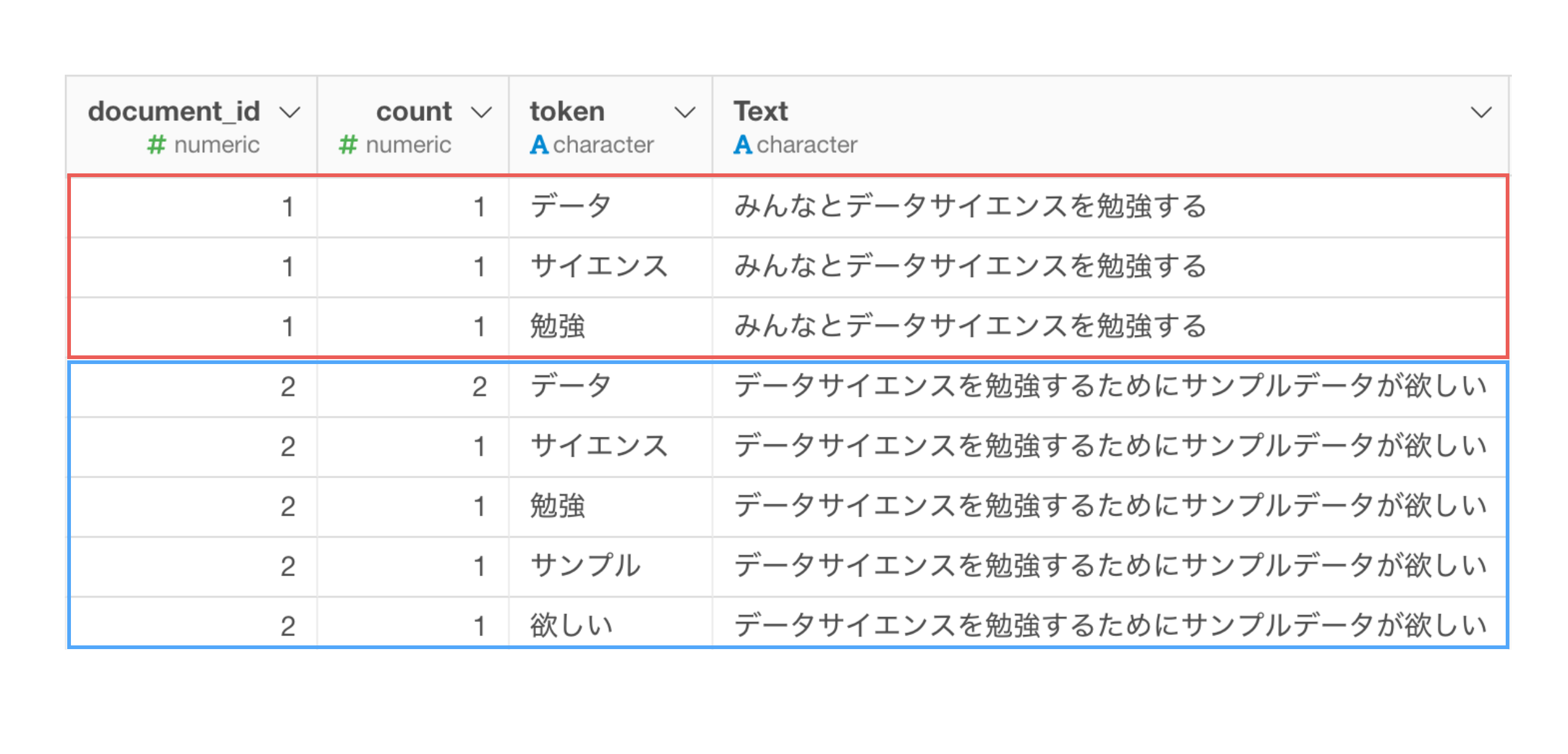
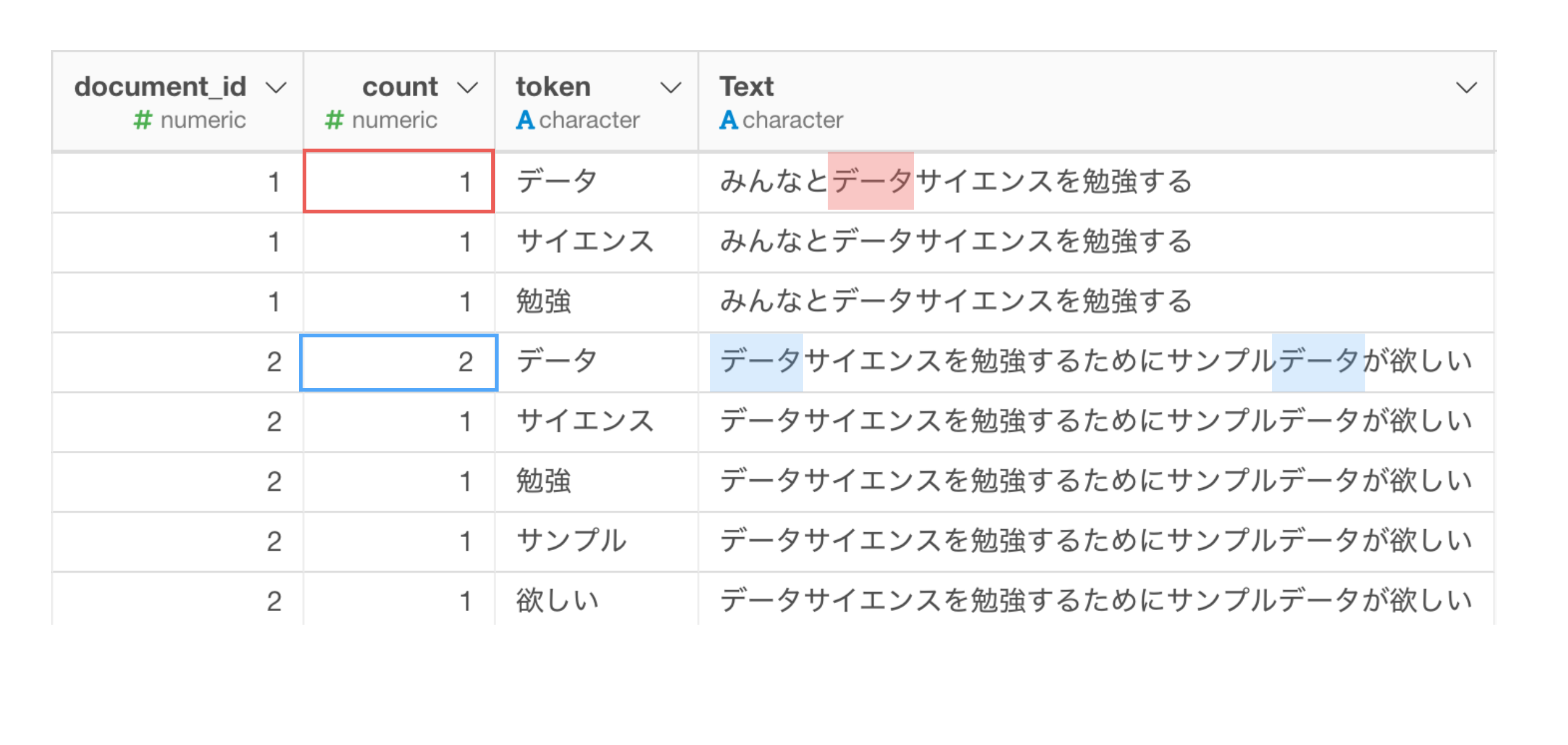
単語のそれぞれのドキュメント内での出現回数がcount列の値になります。
ワードクラウドを使ってよく使われる単語を可視化する
では、単語化した後のデータの解釈ができたところで、早速チャートからワードクラウドを使ってよく使われる単語を可視化していきましょう。

チャートタイプにワードクラウドを選択し、単語にtokenを選択します。

色で分割には、countの合計値(sum)を選択します。

ワードクラウドを使ってよく使われる単語を可視化できましたが、Twitterからデータを取得する際にキーワードに「データサイエンス」を使ったためか、他のどの単語がよく使われているのか区別がつきません。

チャートフィルタをクリックします。

列にtokenを選び、演算子にどれにも等しくないを選択します。
値には、「データ」と「サイエンス」を選び実行します。

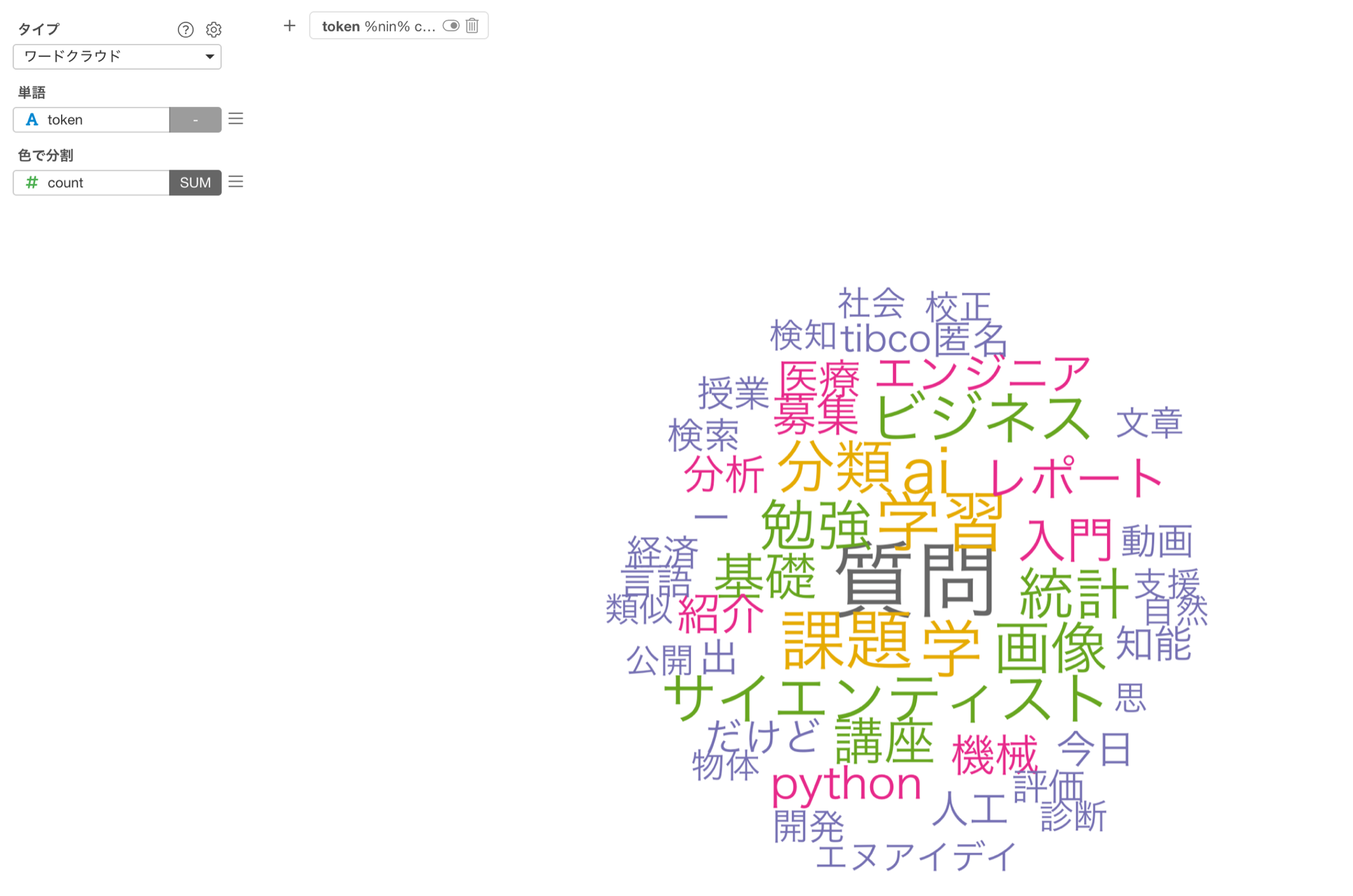
どの単語がよく使われるかをワードクラウドを使って可視化することができました。

単語のサイズが大きければ、色で分割にしてしている出現回数が多いということになります。
よく使われる単語には「質問」や「学習」、「勉強」などが多いようです。
単語の出現回数が少ない場合
ワードクラウドを使って可視化した際に、単語の出現回数が少ないデータでは、表示される単語の数が少なくなってしまいます。
より多くの単語を表示したい場合は、チャートプロパティから単語の最小頻度を変えることで表示する単語の数を調整することができます。
今回の場合は、単語の最小頻度に2を指定します。
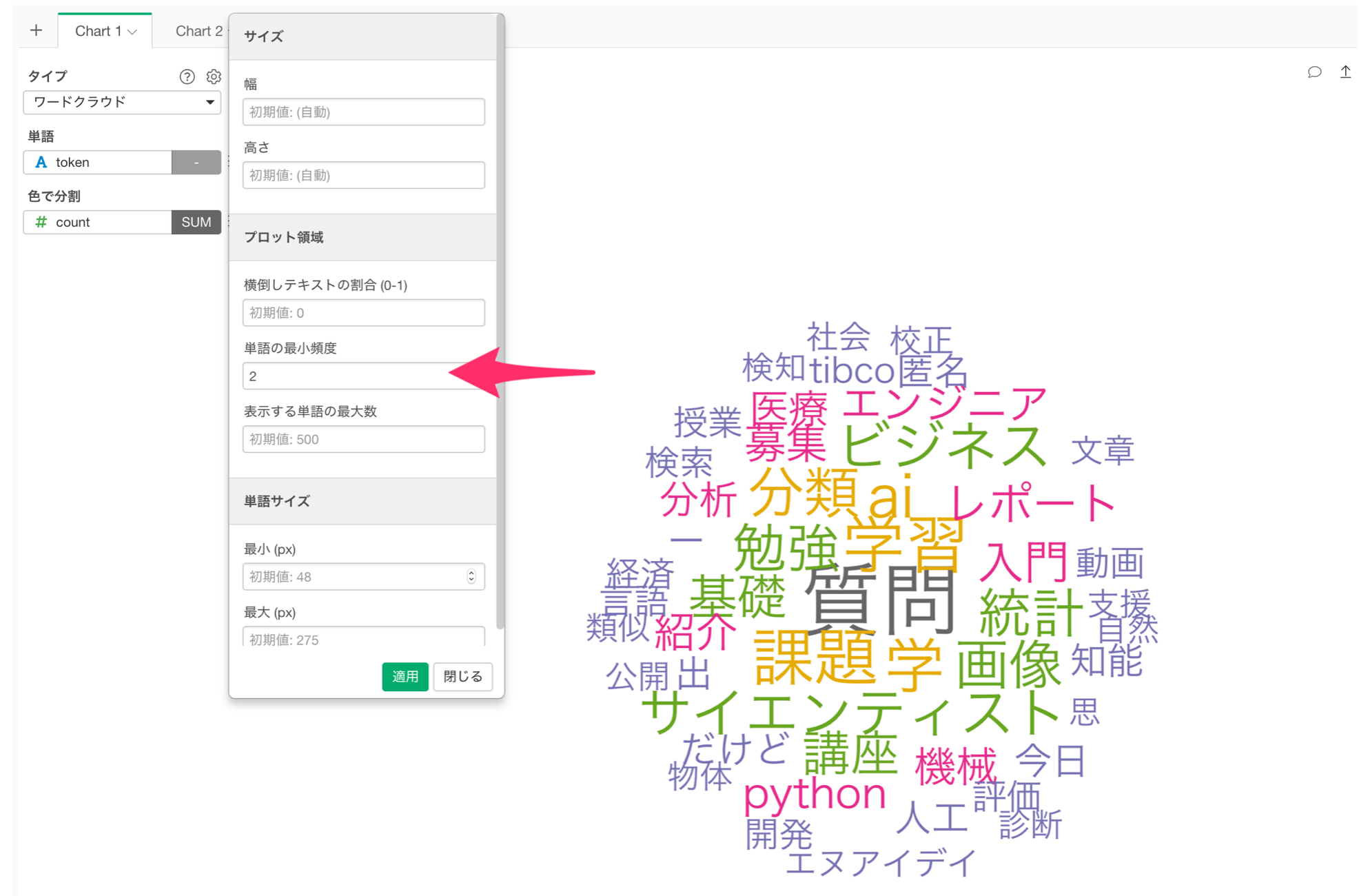
これにより、2回以上出現した単語をワードクラウドで可視化することができました。
