どの変数が最も関係しているのか調べるときに便利なボルータの紹介
変数重要度
ここにそれぞれの顧客の属性とチャーン(解約)したかどうかを示すデータがあります。
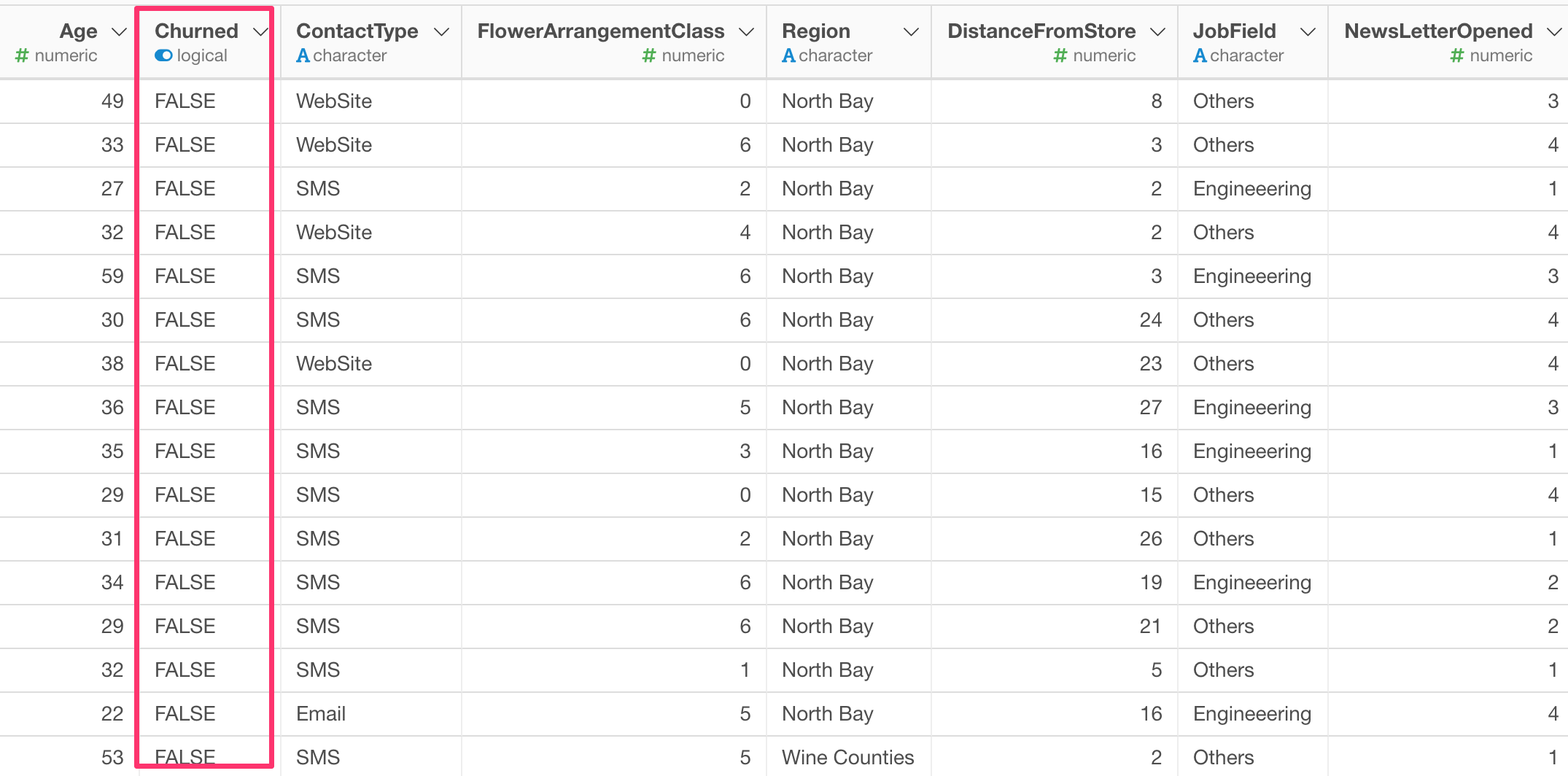
年齢や性別などの顧客のタイプを表す属性がいくつもありますが、結局どの属性がよりチャーンというイベントに影響しているのかを調べたいとします。
こんな時にデータサイエンスの世界でよく使われるのは、ランダムフォレストという機械学習のアルゴリズムです。
このアルゴリズムの良い点は、予測モデルを作るだけでなく、どの変数(列)が自分の知りたい「目的変数」に関係しているのかを調べることがを簡単にできるという点です。これは一般的には「変数重要度」と言われる機能です。
これを使うと、今回の場合だと、どの顧客の属性がチャーンというイベントに影響しているのかをサクッと調べることができます。
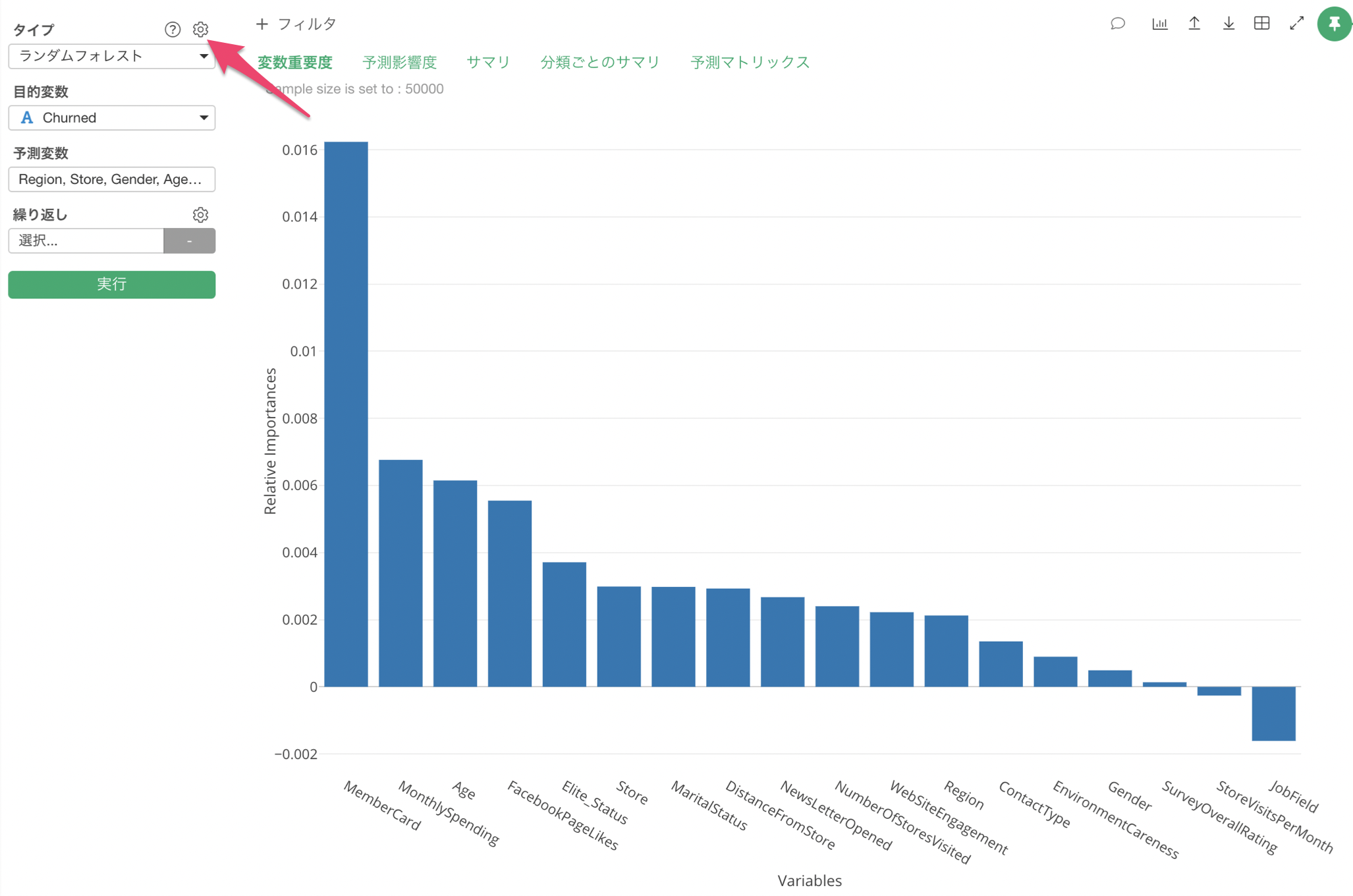
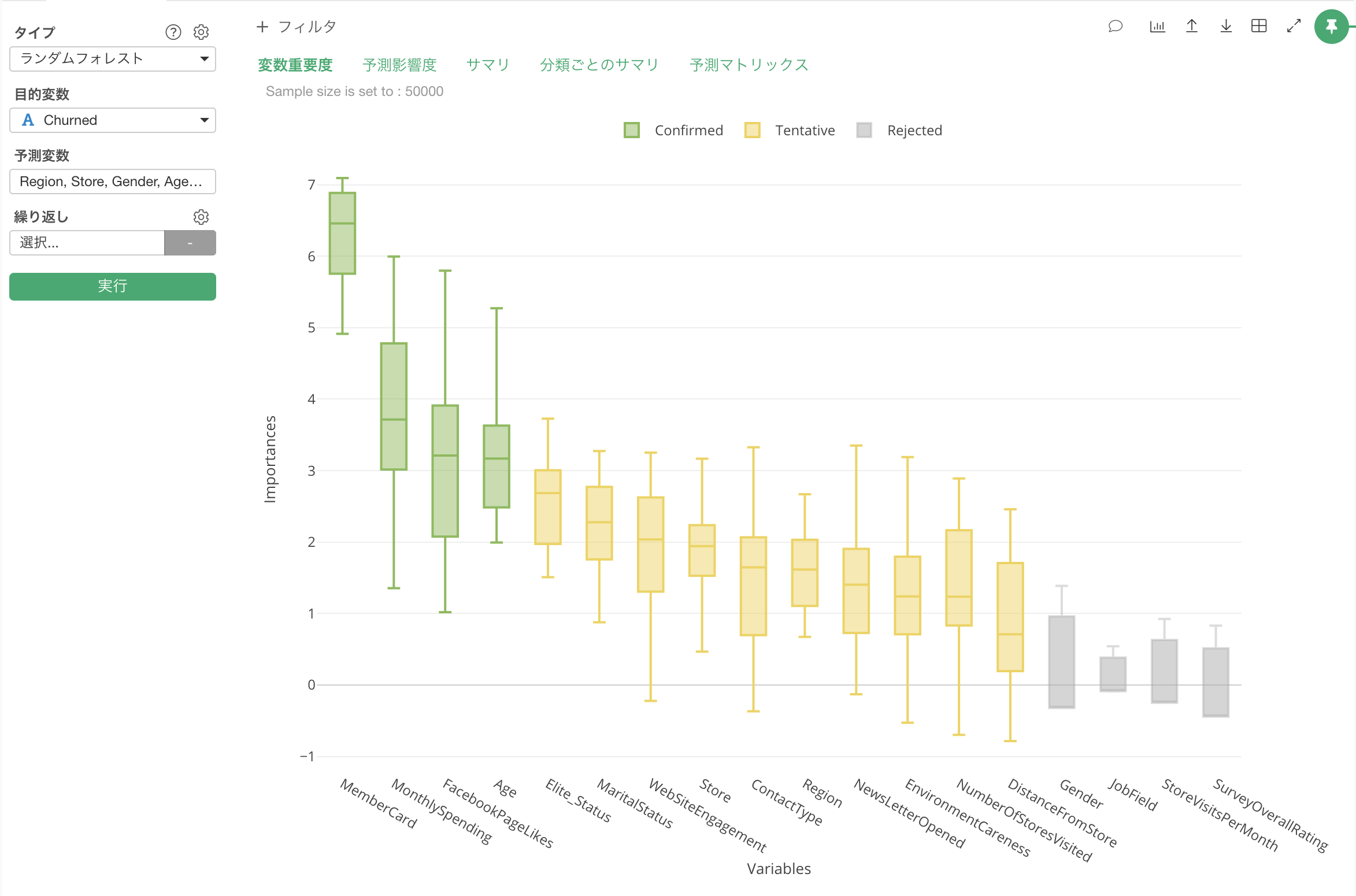
以下のバーチャートはそれぞれの属性(予測変数)のチャーンに与える影響の強さを相対的に表したものです。
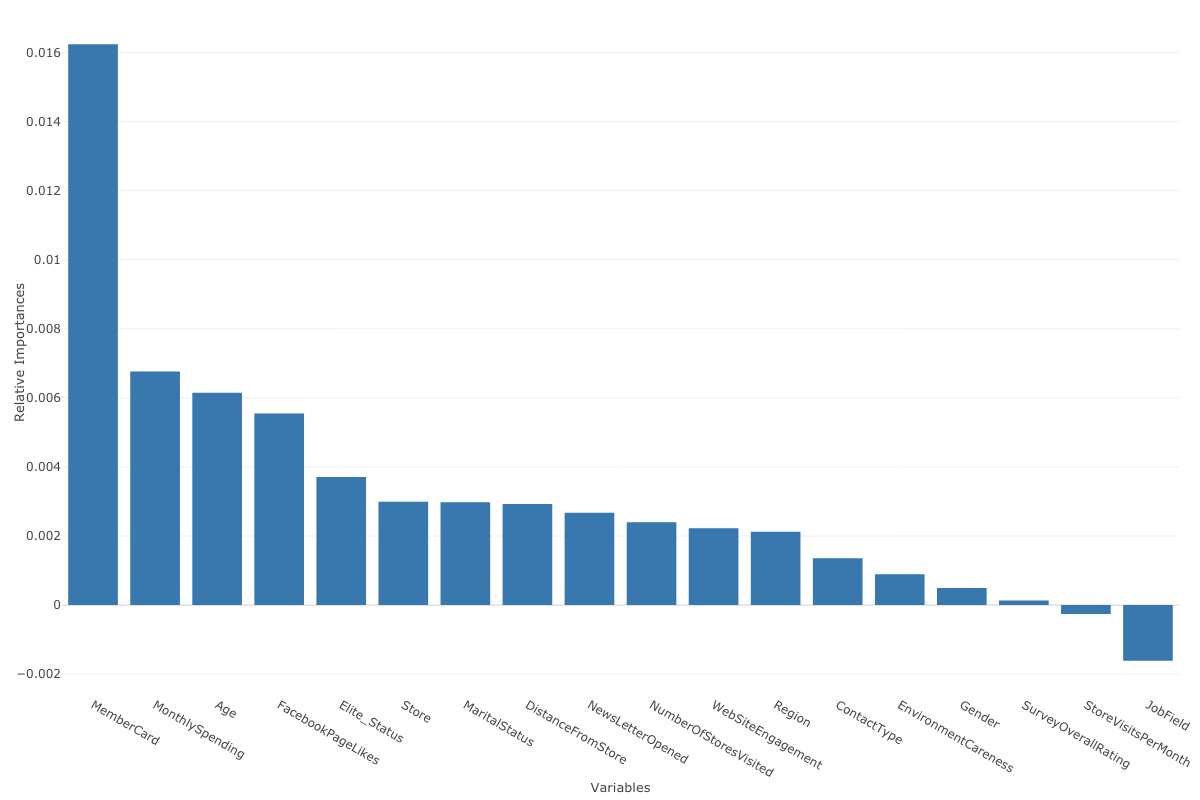
MenbarCardやMonthlySpendingといった変数がチャーンに対して、大きい影響を与えているということがわかります。
変数重要度の問題
しかし、このランダムフォレストの変数重要度の機能を使って出てきた情報を解釈する時に2つの問題に出くわします。
その名の通り、ランダムフォレストはモデルを構築する際にデータを「ランダム」にサンプルして、それを元のにたくさんの「決定木」を生成します。そしてこの、「ランダム性」のせいで、この変数重要度の結果が実行するたびに変わるということがよくあります。
もう一つの問題は、全ての変数が重要なものからそうでないものへと、相対的なランク付けがされるのはいいのですが、結局どの変数が重要でどの変数は意味がないのかという判断ができません。上記のバーチャートの場合、左から順に見ていった場合にどの変数までが重要なのか、それとも全ての変数が重要なのかといった判断に困ります。
そこで、このような問題を解決するために「ボルータ」という手法を使います。
ボルータとは
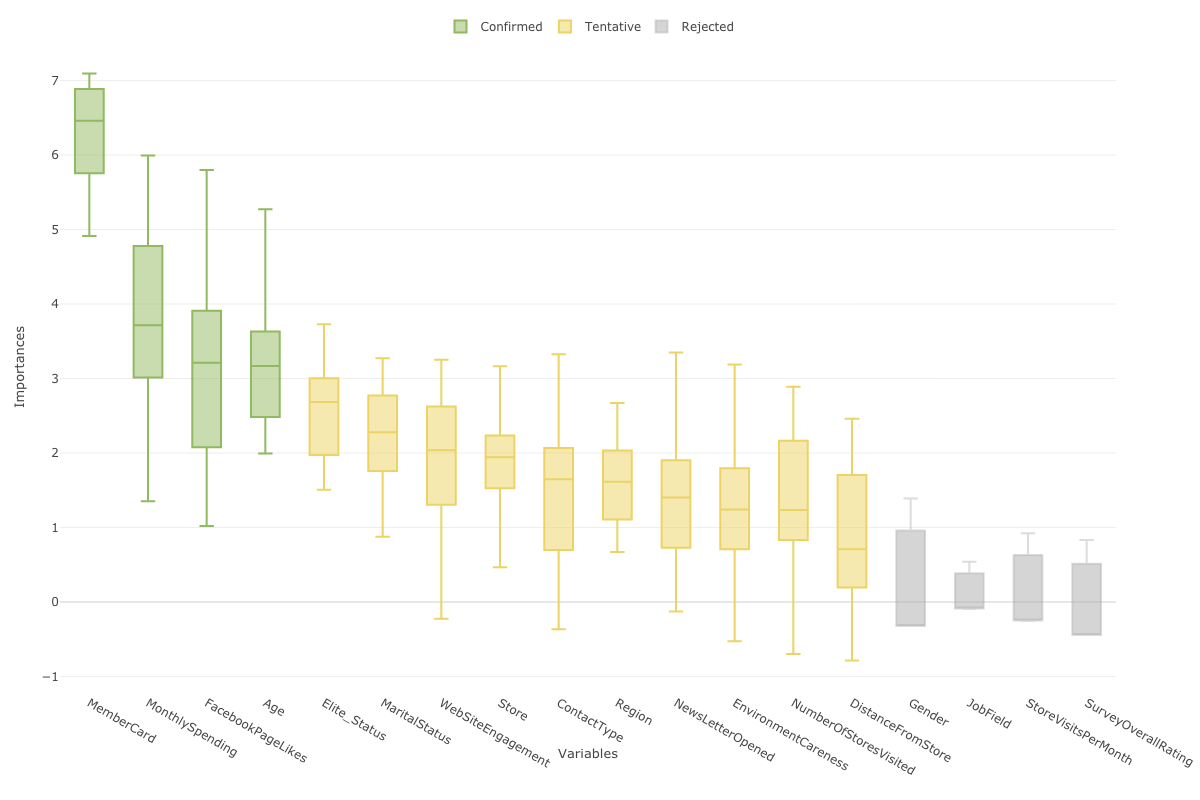
ボルータを使用すると、ランダムフォレストの変数重要度で出てきた結果に対して、重要度のスコアのばらつきを測定し、そのばらつきをもとに変数間の重要度を理解することができます。さらに、どの変数の重要度が統計的に有意と言えるのか、逆にどの変数が統計的に有意とは言えないのかといったことを教えてくれます。
こうしたことができるのは、ボルータは、ランダムフォレストを指定した回数(デフォルトは20回)の分だけ実行しているからです。例えば、20回実行しているのであれば、それぞれの変数の重要度のばらつきを箱ひげ図で表示することができます。
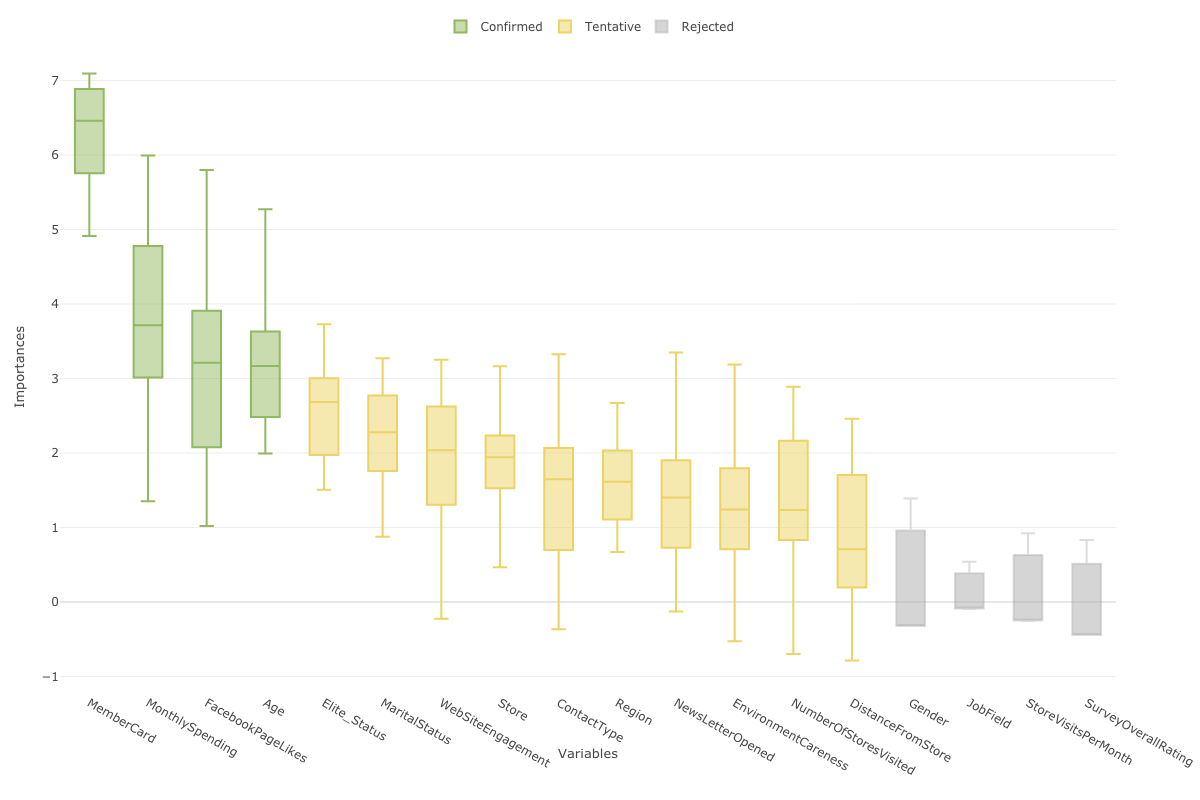
また、目的変数に影響を与えるはずのない、ランダムに生成された「シャドー変数」を使うことで、それぞれの変数に対して統計の仮説検定を行います。
それにより、それぞれの変数の重要度が、有意(Confirmed)なのか、有意であると言えない(Rejected)のか、もしくはどちらとも言えない(Tentative)ということを色を使って教えてくれます。
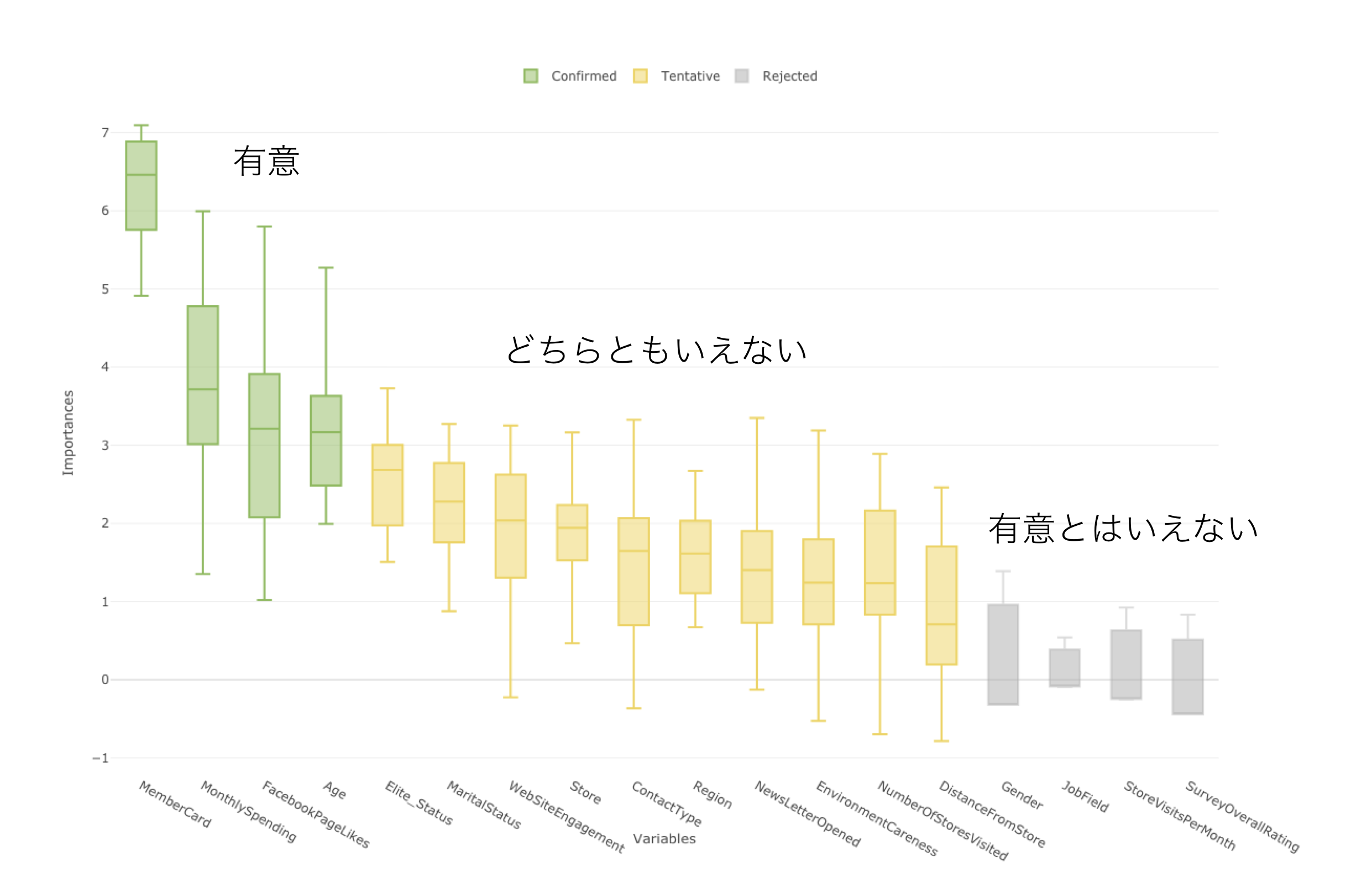
今回の結果では、MenberCardとMonthlySpendingの他に、FacebookPageLikesやAgeがチャーンに対して影響を与えているようです。また、GenderやJobFieldといった属性は統計的に影響があるとは言えないこともわかりました。
ボルータは、モデル構築が遅くなるのでデフォルトではオフになっていますが、アナリティクスのプロパティから簡単にオンにすることができます。
ボルータの使用方法
それでは、ボルータを有効にしていきましょう。
ランダムフォレストのプロパティをクリックします。
変数重要度の「ボルータを有効化」を " Yes " にします。
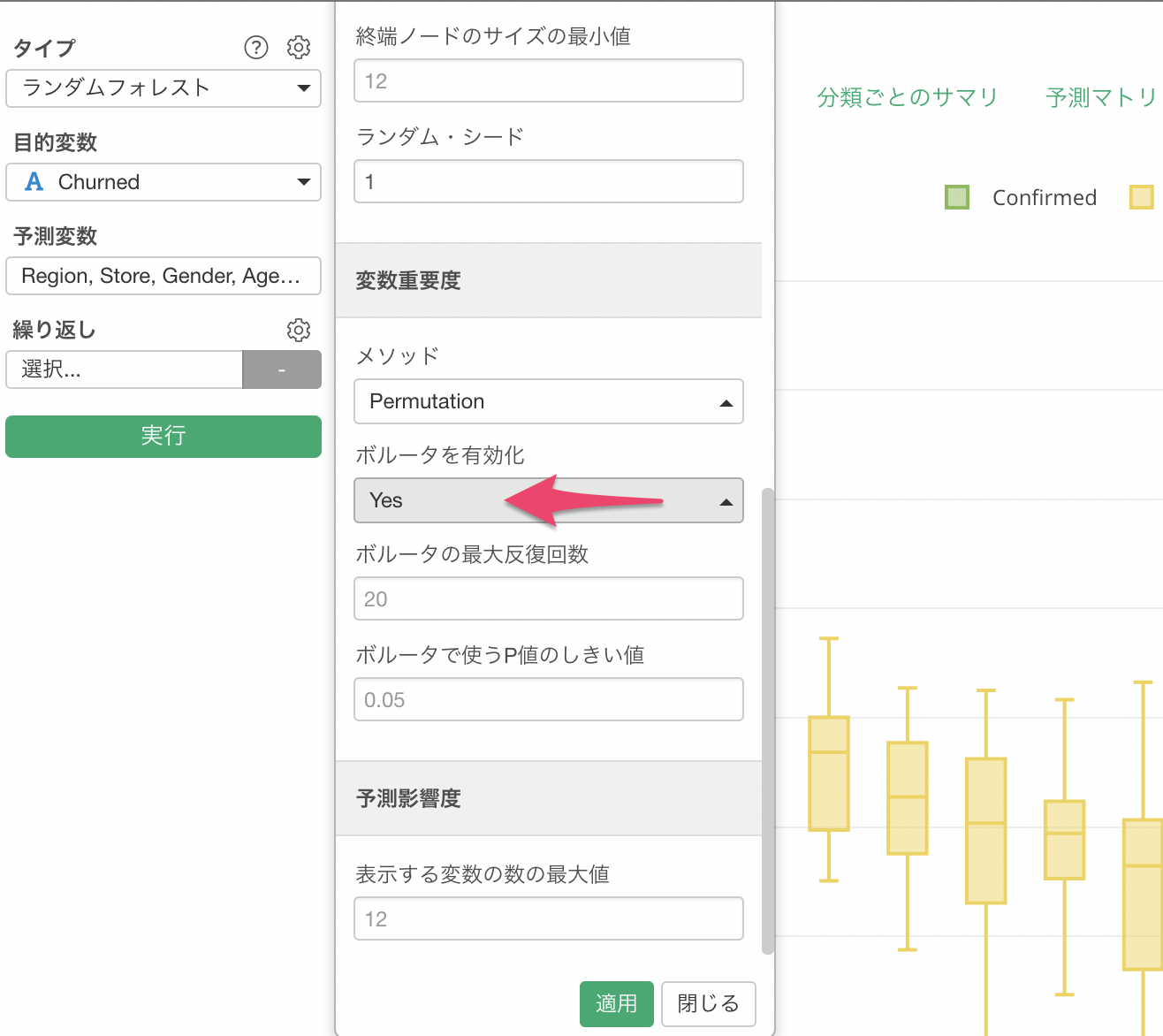
「ボルータの最大反復回数」と「ボルータで使うP値のしきい値」については、次回ボルータの理論編で紹介させていただきます。
ボルータを有効化することで、変数の重要度を統計的に検定することができました。
自分で試してみる
まだExploratoryをお持ちでない方は、この機会にぜひ試してみて下さい!
こちらのページよりサインアップ(無料)した後、Exploratoryをダウンロードし始めることができます!
データサイエンスを学ぶ

データサイエンスやデータ分析の手法を1から体系的に学び、現場で使えるレベルのスキルを身につけていただくためのトレーニングを定期的に開催しています。
データを使ってビジネスの問題を解決していくための、質問や仮説の構築の仕方などを含めたデータリテラシーも基礎から身につけていただくものとなっております。
ぜひこの機会に参加をご検討ください!