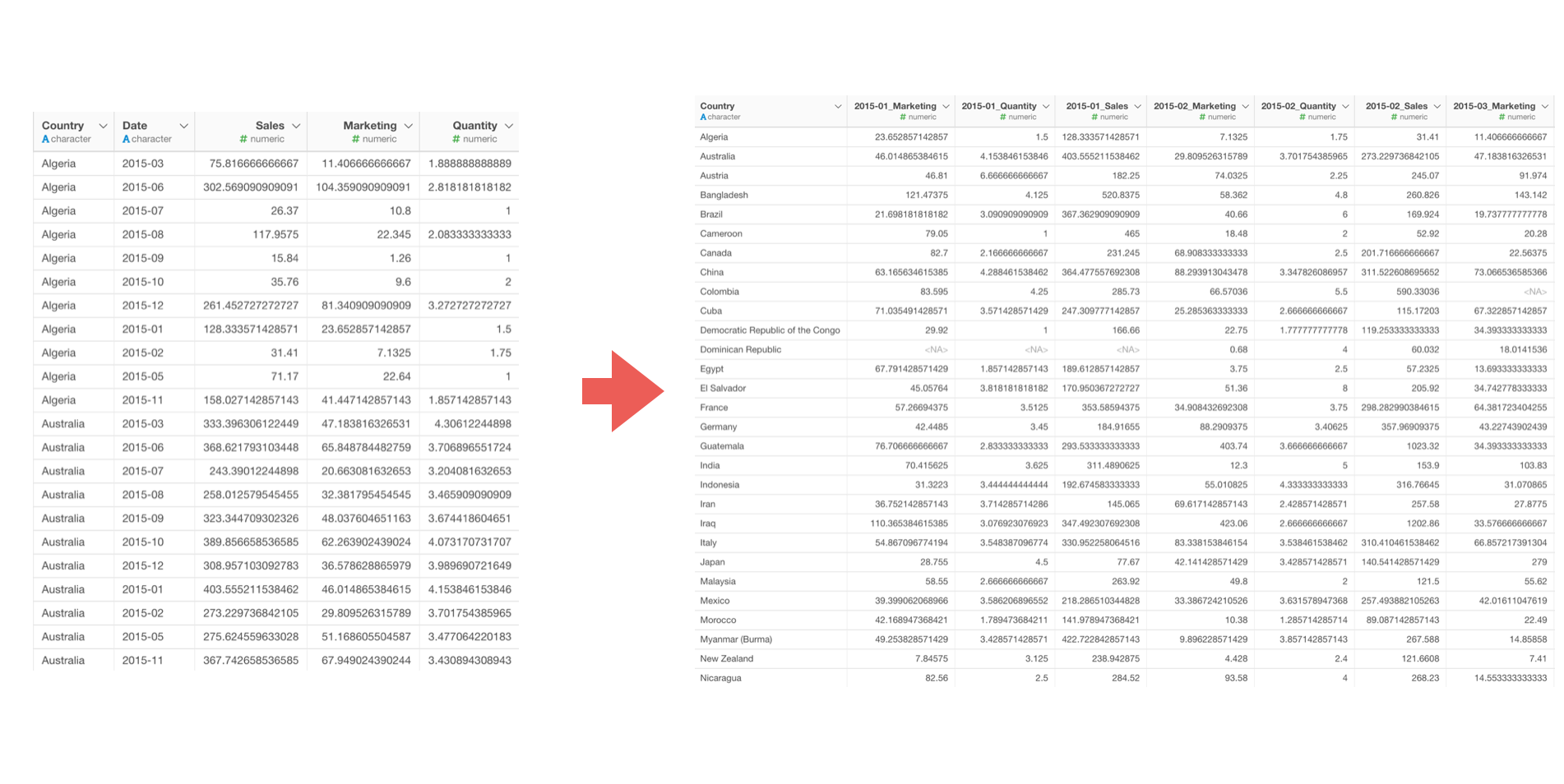
複数の指標がある縦長のデータを月と指標の組み合わせごとに列がある横長のデータにする方法
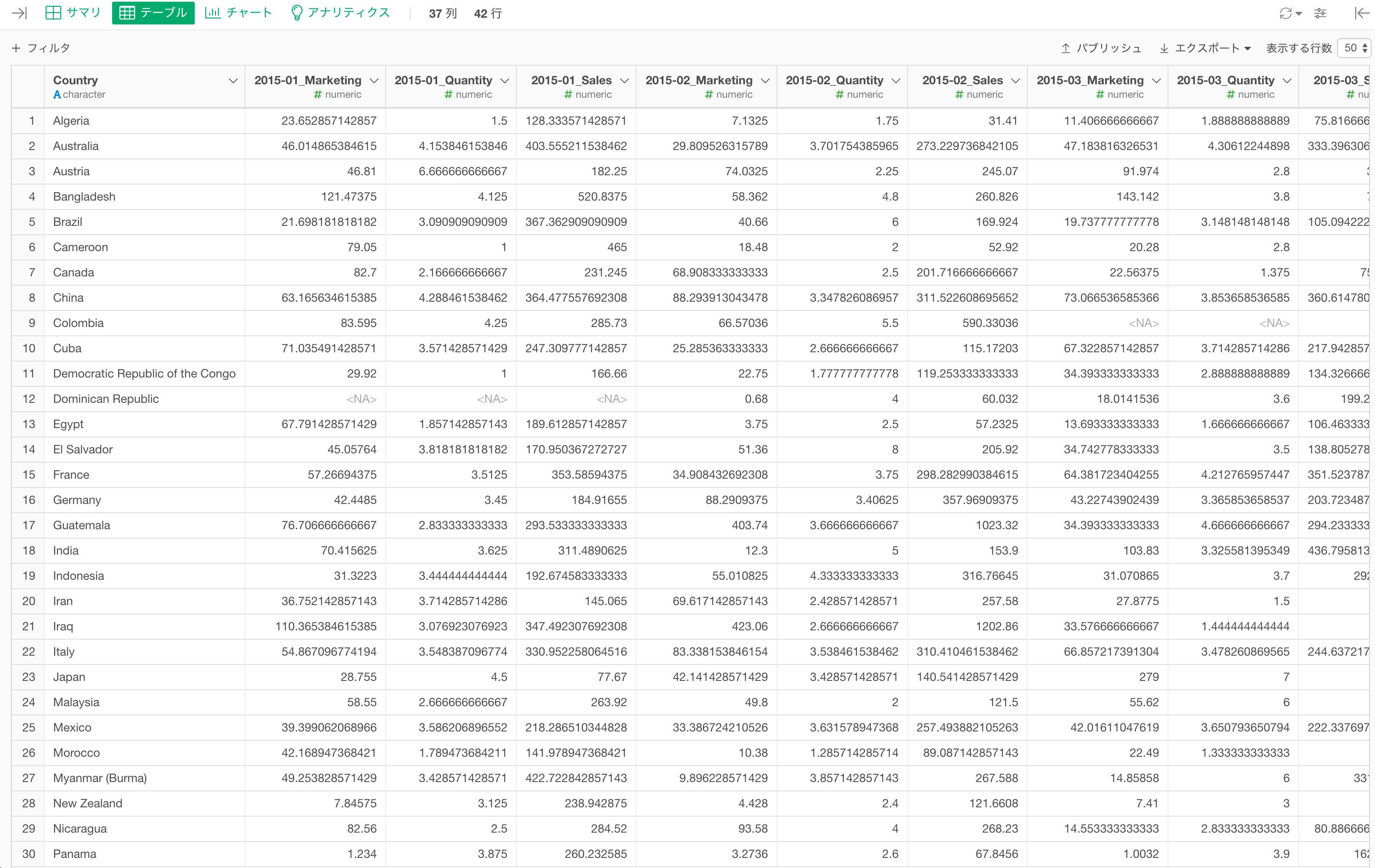
今回は国ごとの売上データを使用していきます。
このデータは一行が月ごとに分かれていて、売上(Sales)やマーケティング費用(Marketing)、購買数(Quantity)の列があります。
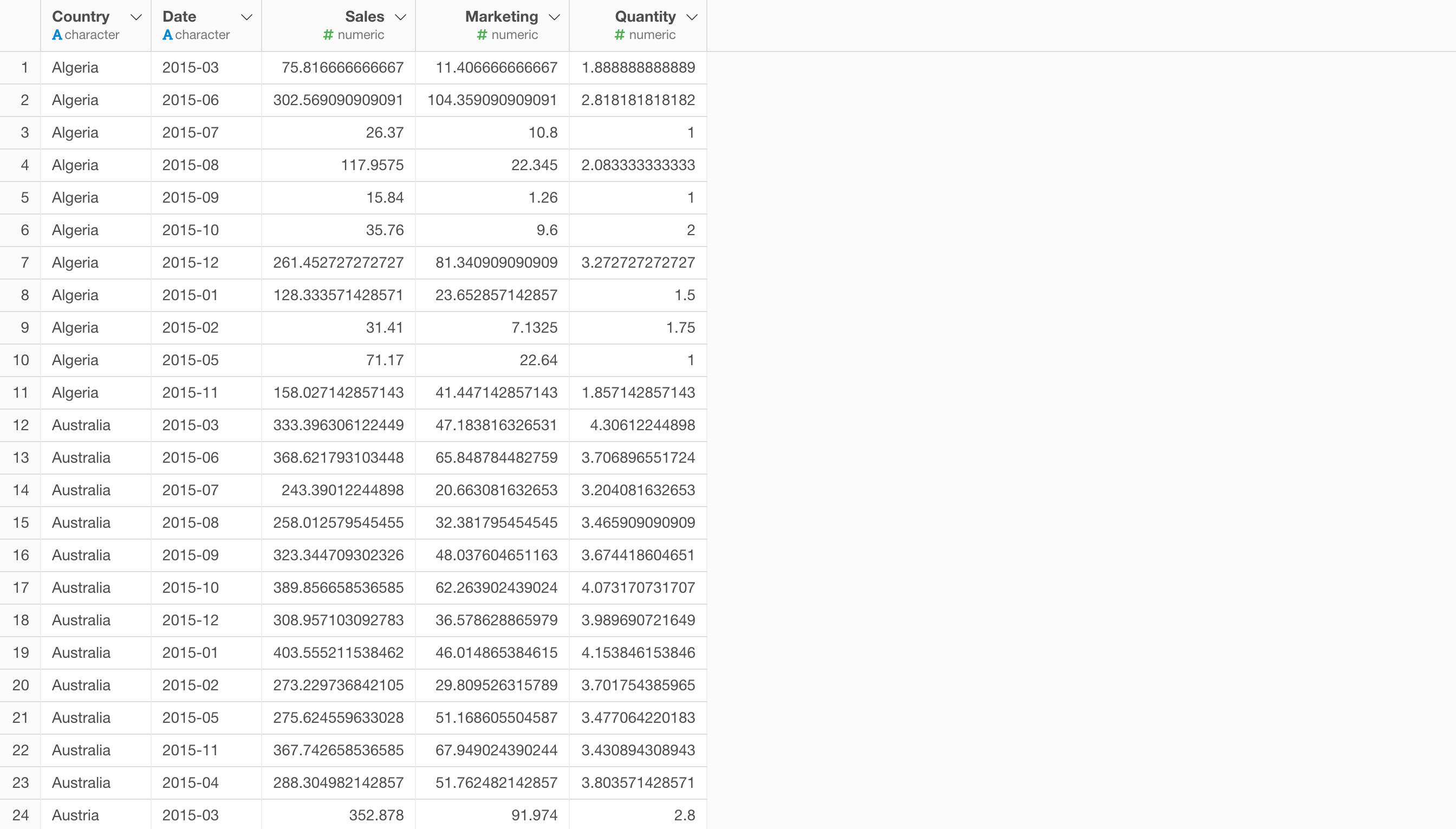
チャートなどで可視化する際には、このロング型のデータは便利ですが、K-meansのようなクラスタリングをする際には一行が1比較対象が望ましい形になります。
例えば、このデータでそのままK-meansを実行すると、一つのデータポイントが日本の2015年11月のようになります。
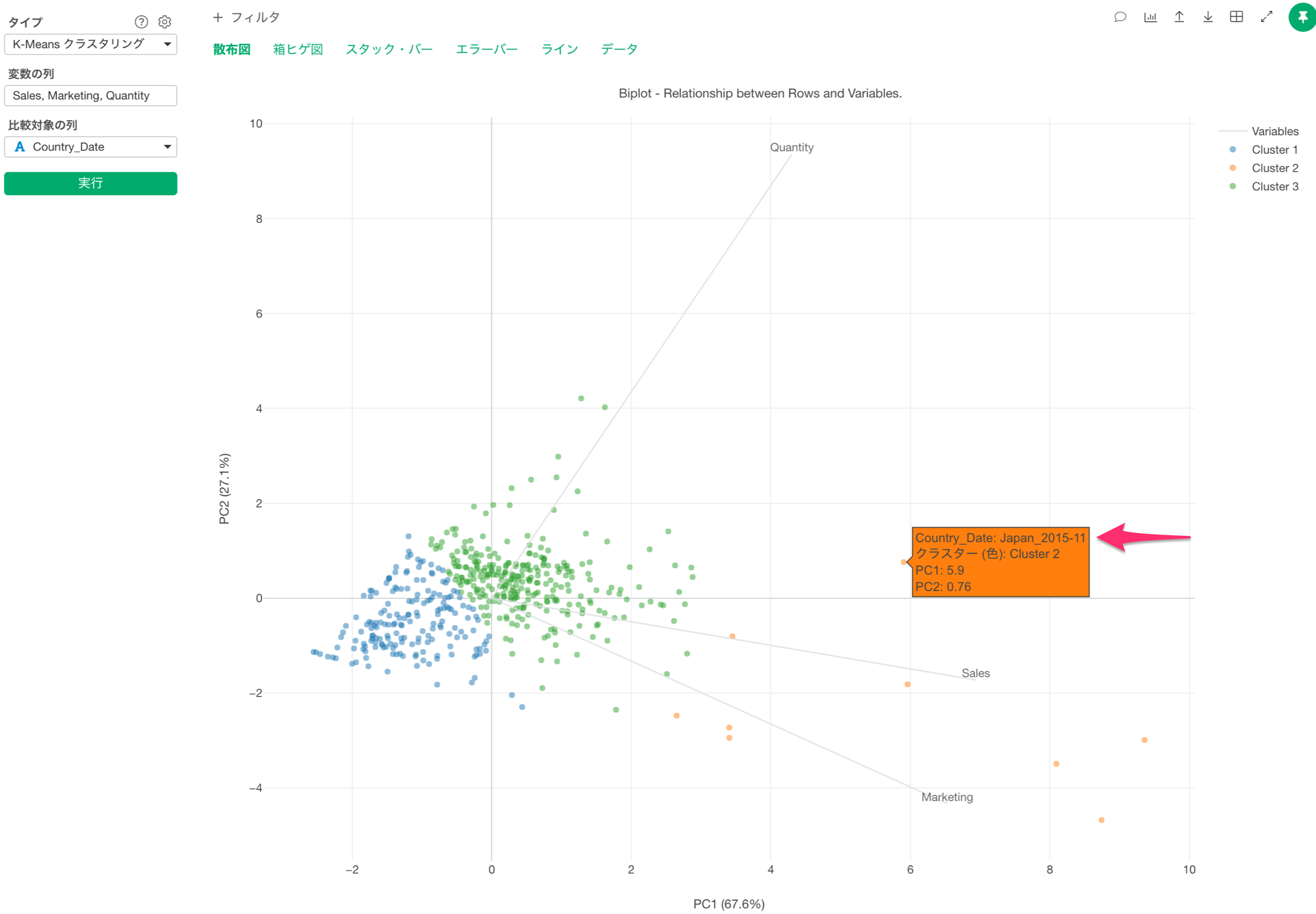
そのため、1行が1カ国(比較対象の列)にしたいです。
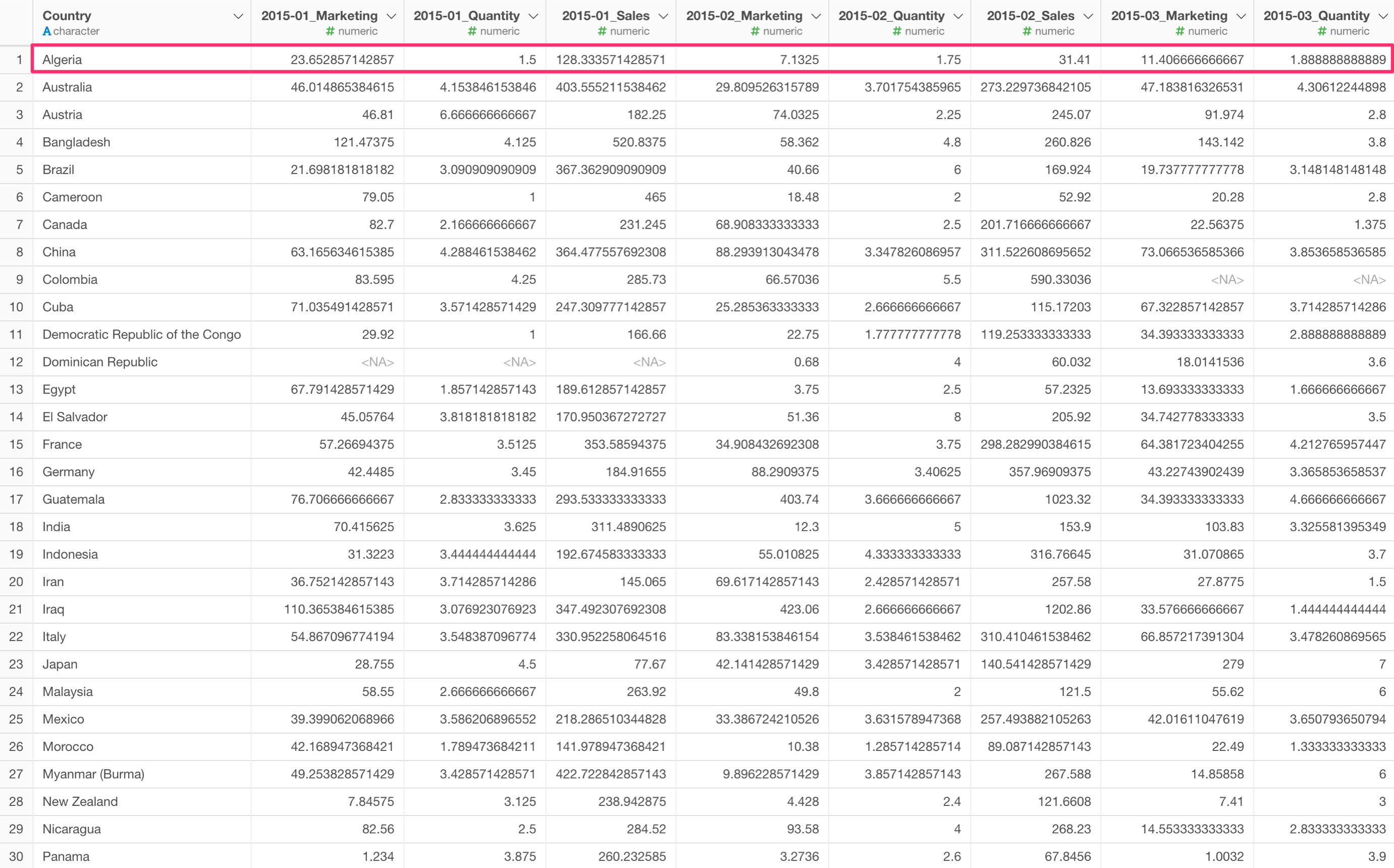
集計を使って一行が1ヵ国にもできますが、それでは値がまとめられてしまい、月ごとの特徴が見えなくなってしまいます。
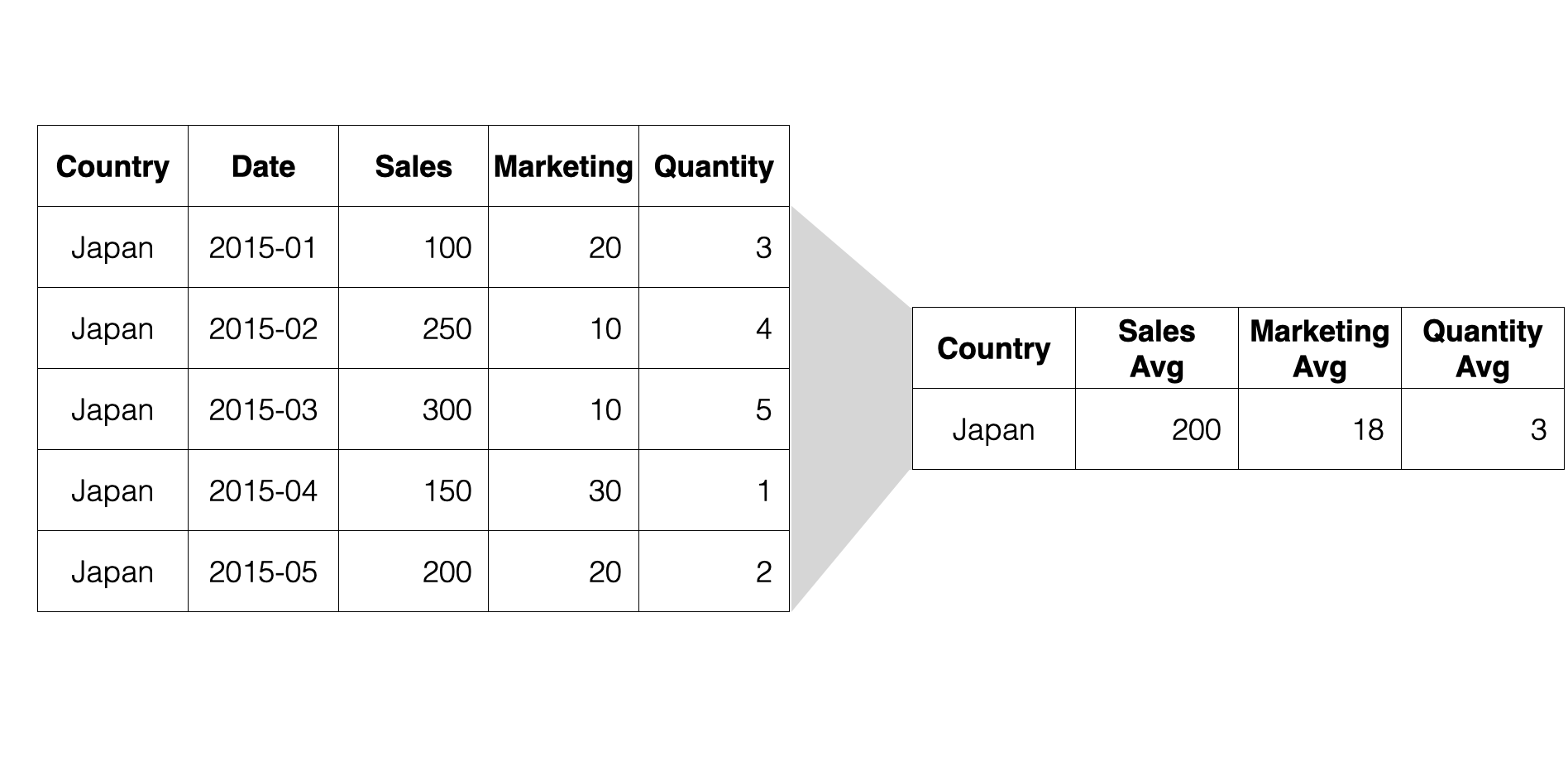
そのため、一列が月ごとの売上やマーケティング費用になるようにします。
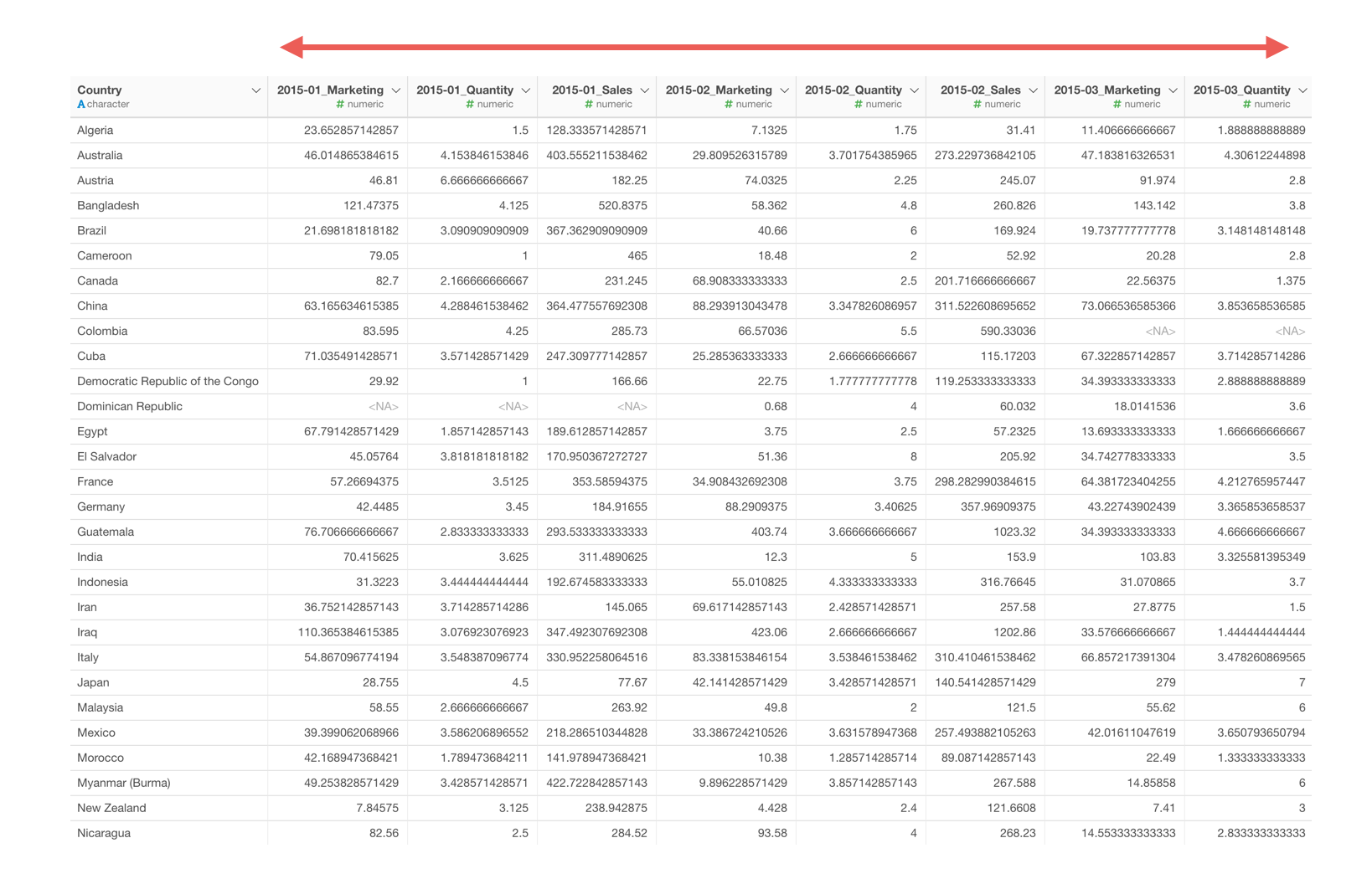
つまり複数の値があるロング型のデータを、それぞれをワイド型に変換していきます。
まずは売上やマーケティング費用、購買数の列をShiftキーを使って選び、列ヘッダメニューからワイド型からロング型へ(Gather) の選択された範囲を選びます。
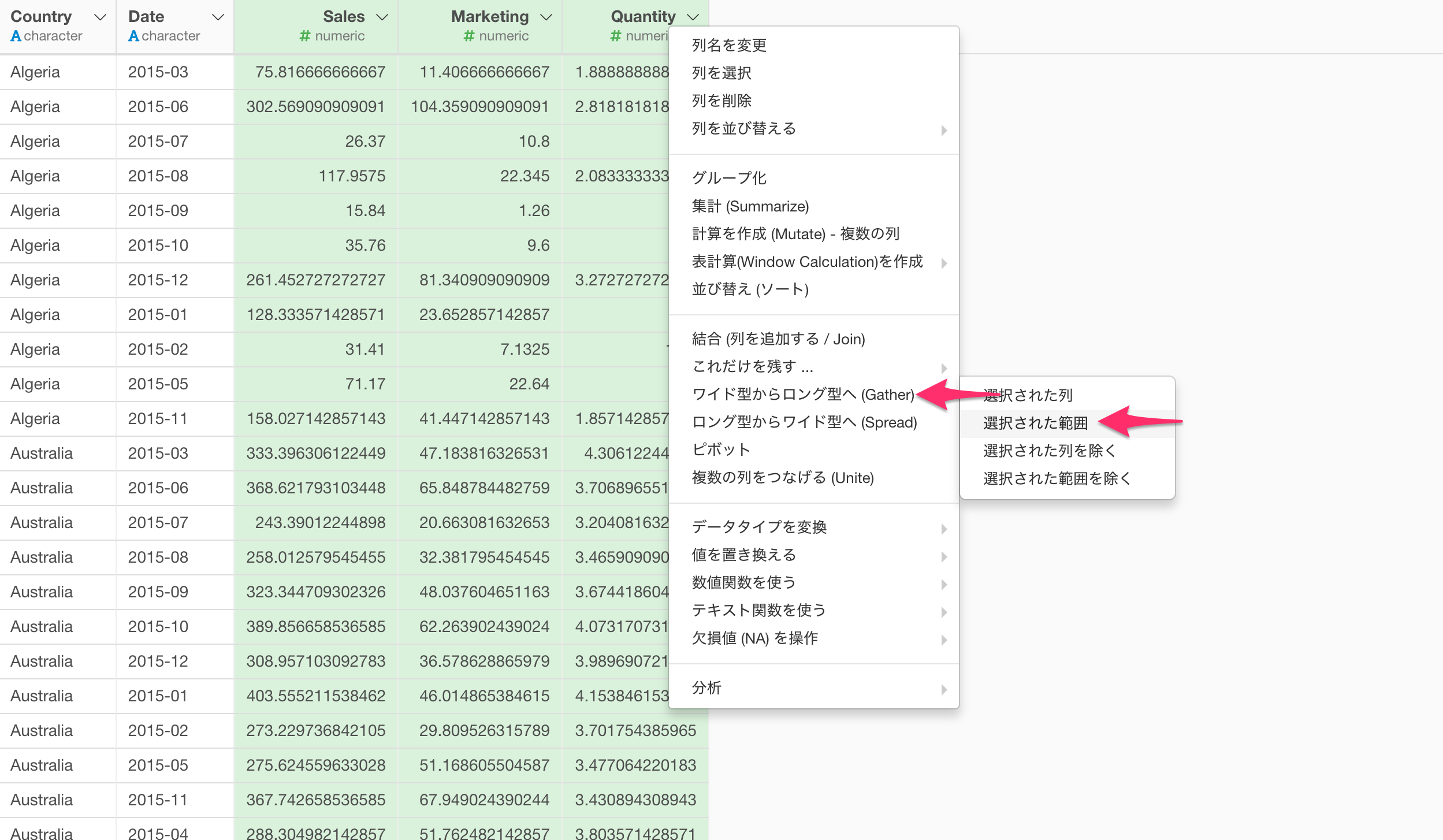
ワイド型からロング型へのダイアログが表示されるため、そのまま実行します。
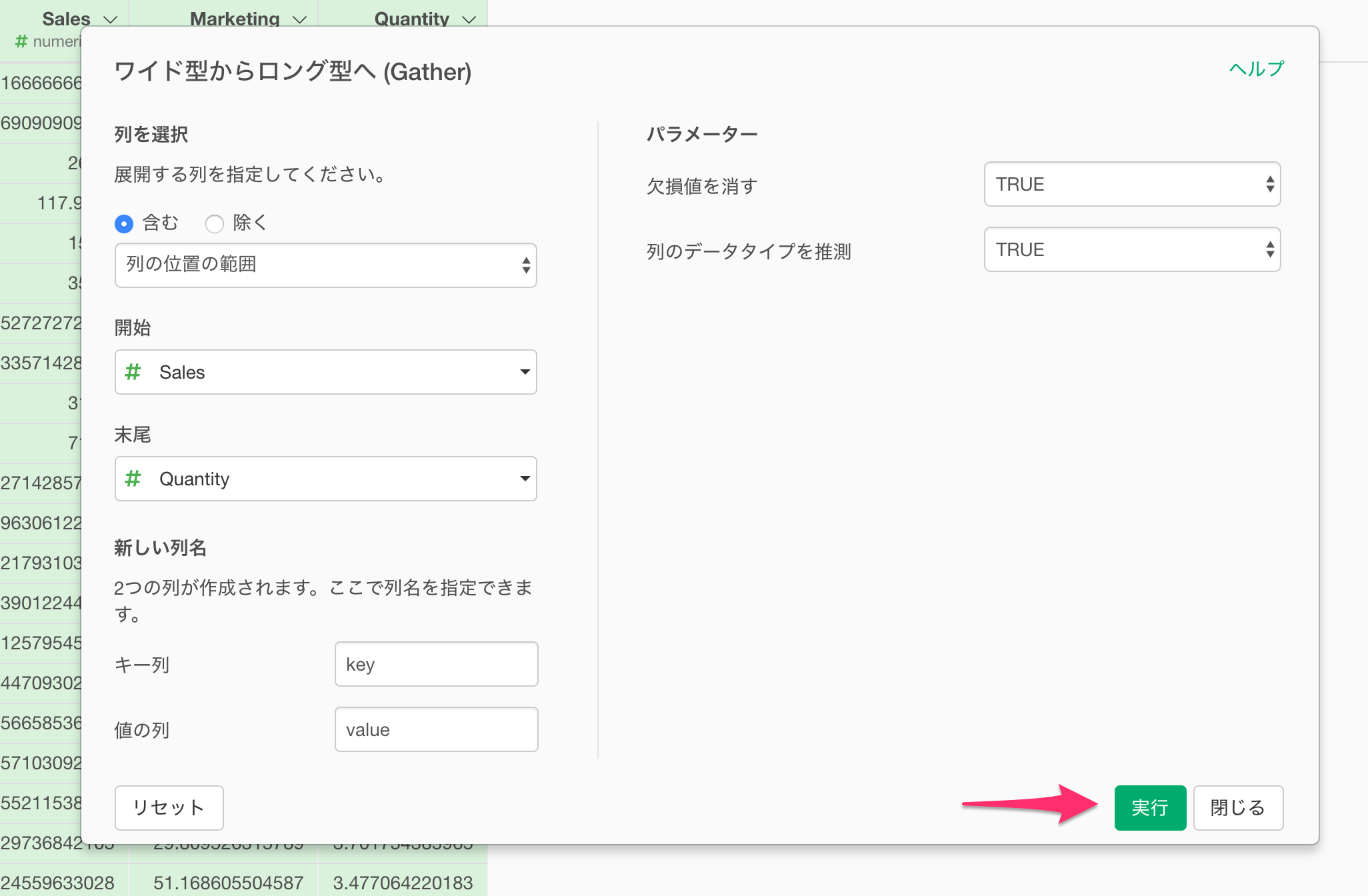
数値列を一つの列にまとめたロング型のデータになりました。
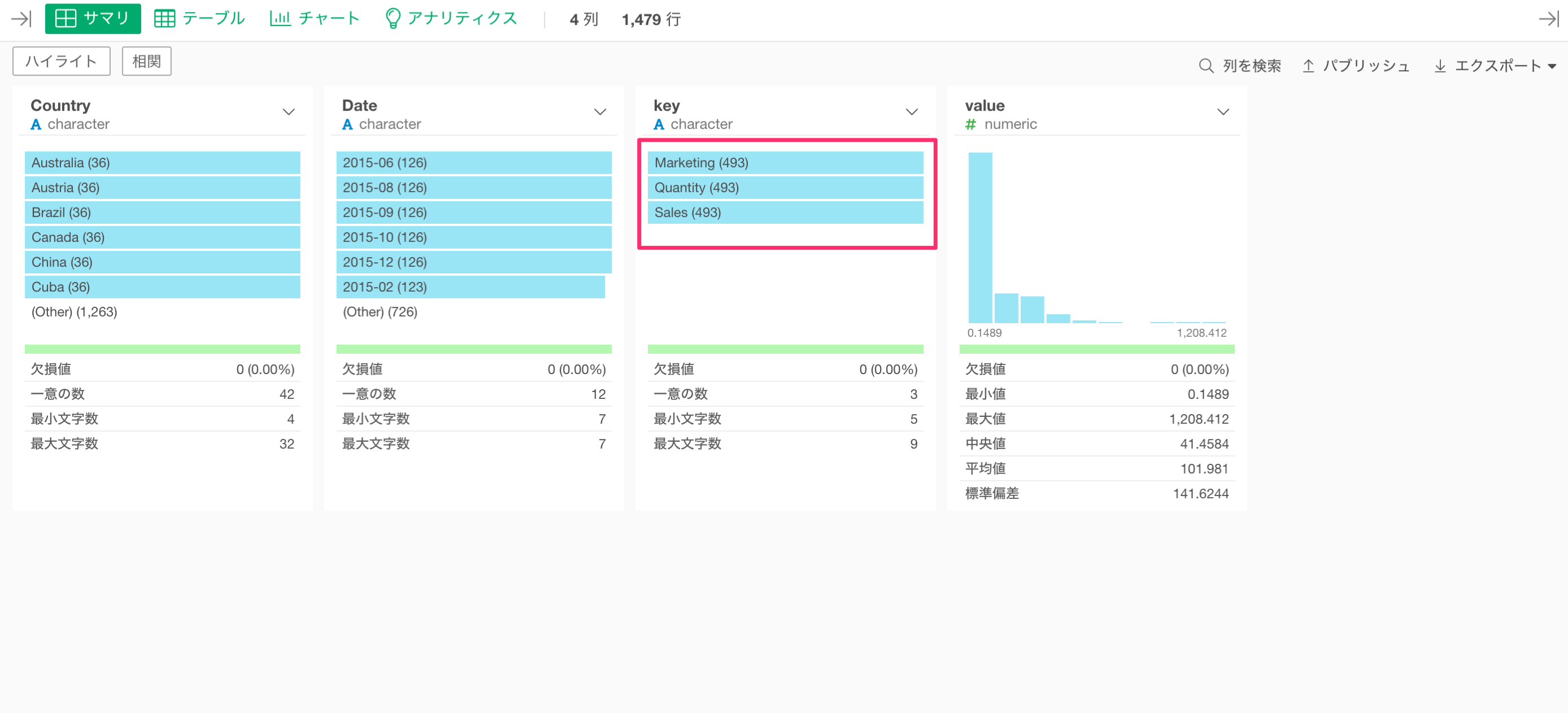
サマリ・ビューからkeyの列をみると、元の列名が値となっていることがわかります。
次に、DateとkeyをShiftキーを使って選び、列ヘッダメニューから複数の列をつなげる(Unite) を選択します。
複数の列をつなげるのダイアログが表示されました。
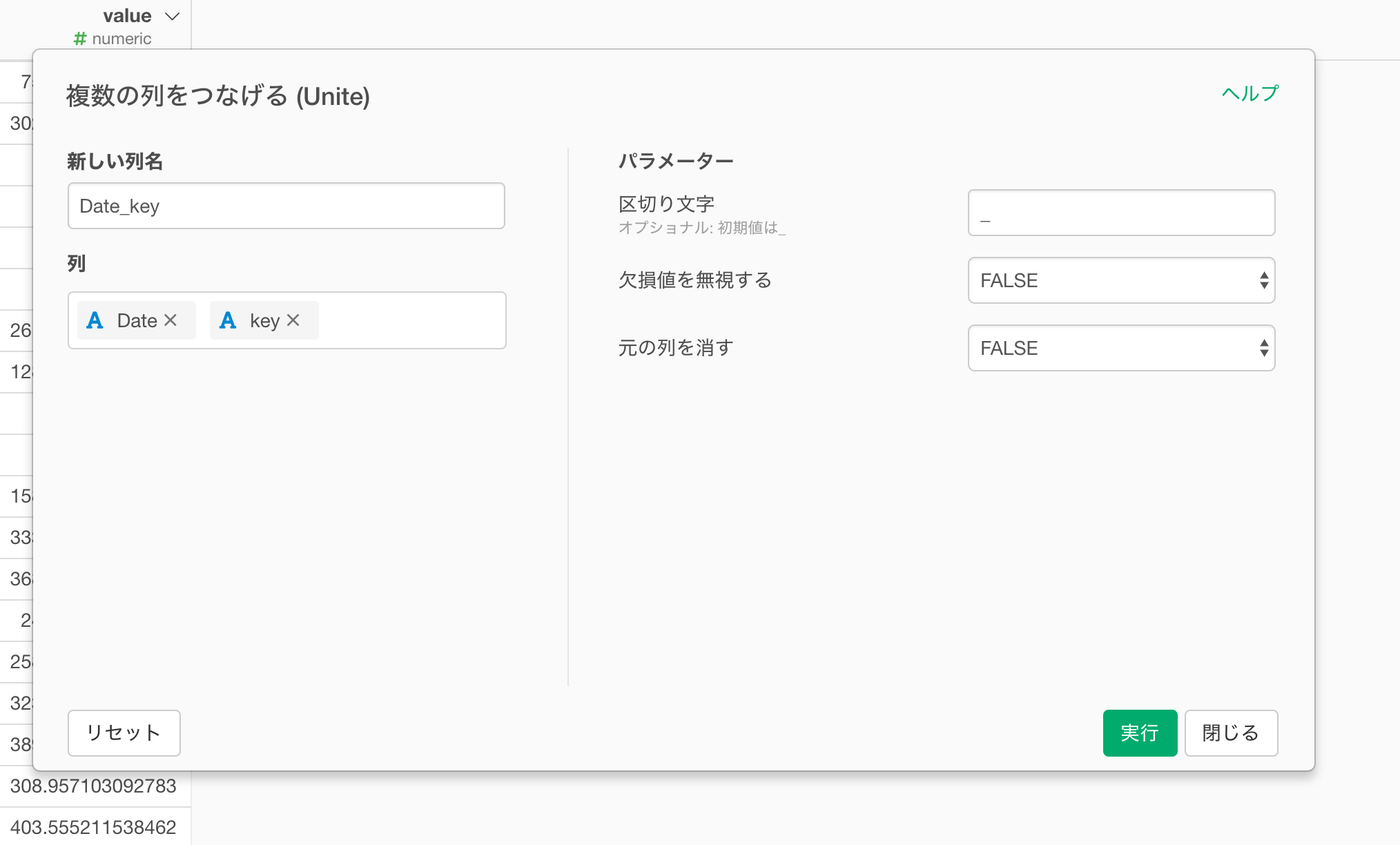
元の列を消すにTRUEを選ぶことで、Dateやkeyの列を取り除くことができます。
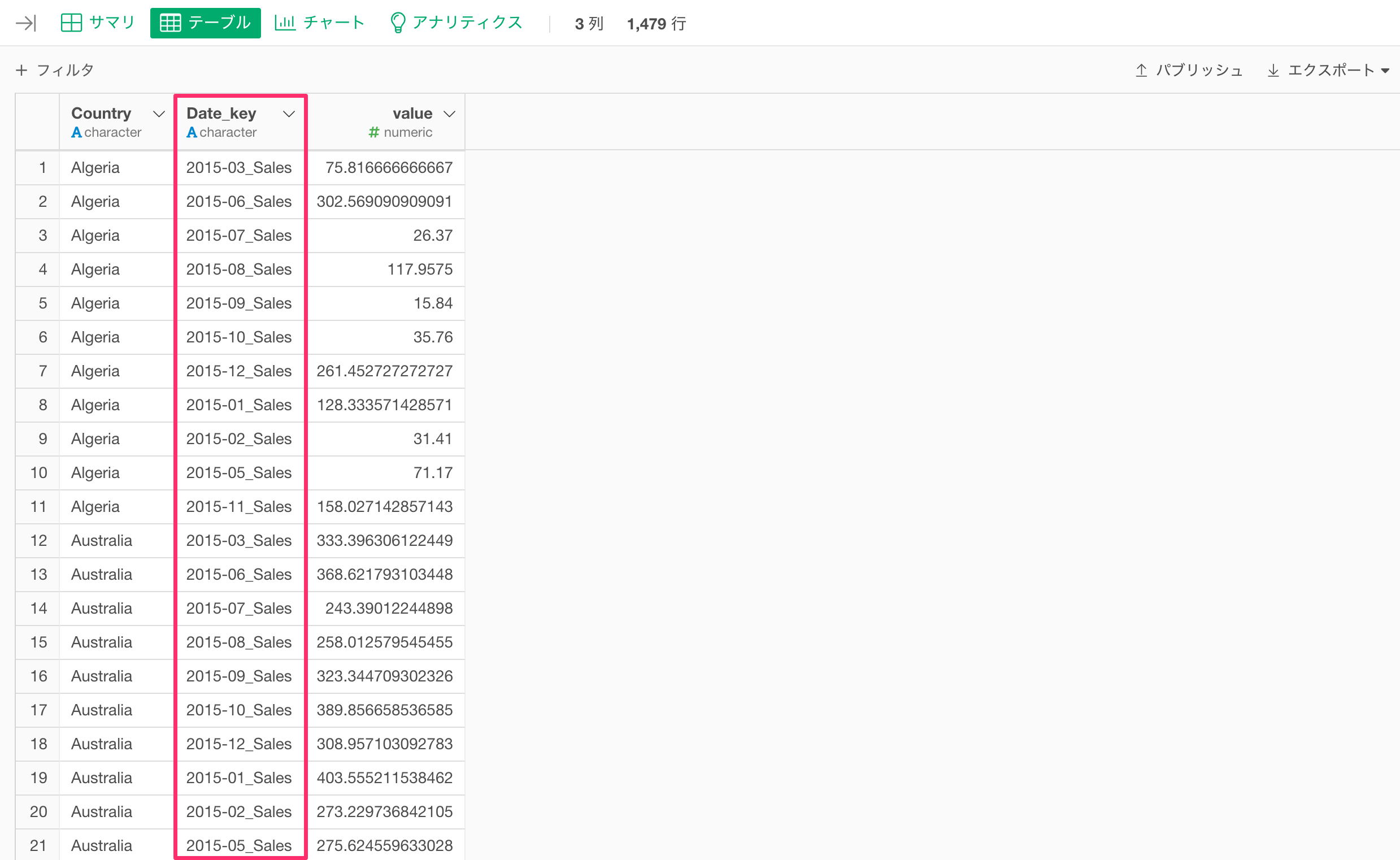
実行すると、Date列とkey列がつながっていることが確認できます。
最後に、列同士をつなげたDate_key列とvalueの列をShiftキーを使って選んだ状態で、ロング型からワイド型へ(Spread) を選択します。
ロング型からワイド型へのダイアログが表示されるので、そのまま実行します。
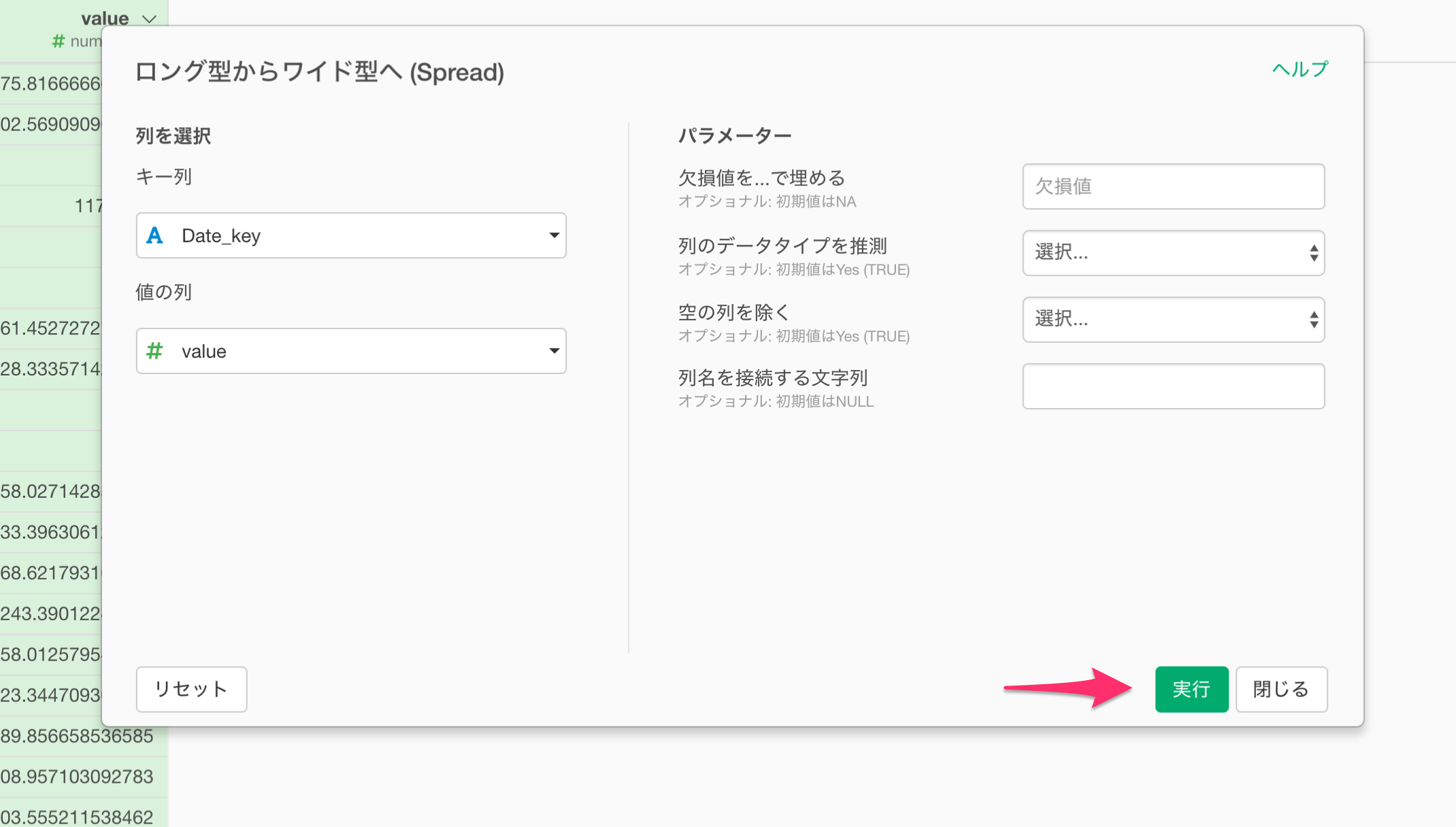
2015年1月の売上、2015年2月の売上、2015年1月のマーケティング費用…のように、複数の値があるロング型のデータを、それぞれの値ごとにワイド型に変換することができました。
ワイド型への変換でエラーが出る場合の対処法
ロング型からワイド型への変換で下記のようなエラーが出た場合、データに重複している行が存在しています。
Error : Each row of output must be identified by a unique combination of keys. Keys are shared for 600 rows: * 671, 676 * 727, 734 * 788, 793 * 815, 820 * 891, 896 * 1093, 1098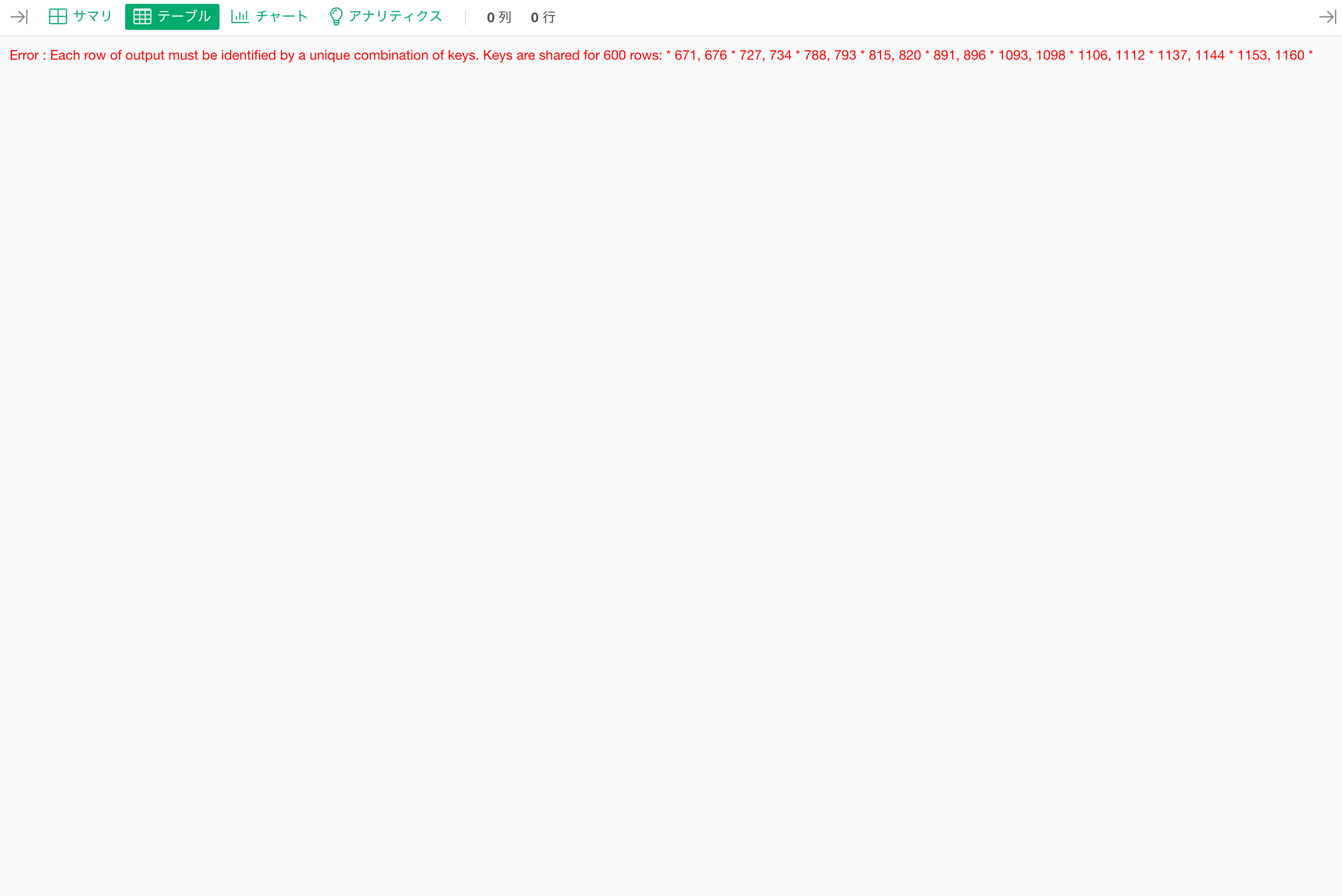
ワイド型への変換の際は重複している行があるとエラーになるため、重複している行を取り除く必要があります。
重複している行を取り除く方法は、下記のノートをご参考ください。