Loading and Understanding the Data
There are a number of variables included in this dataset:
- Last name - the last name or last initial of the student
- First name - the first name of the student
- Student ID - the student’s ID number
- Submission - the text content of the post that was submitted
- Type - label indicating if the submission was a comment or question
- Score - the automatically assigned score by Perusall from 0-2
- Created - the date and time of the submission
- Last edited at - the data and time of the last edit of the submission
- Number of replies - the number of submissions in the same thread after the submission
- Number of upvoters - the number of times the submission received a check mark or upvote
- Status - if the submission was submitted before the deadline or not, on-time or invalid
- Page number - the page number of the paper where the submission can be found
- Range - the highlighted portion connected with the submission, from the start of the highlight to the end
- Paper - which paper the submission is for
Examining the Data Distribution
Within this data set, there is some missing data such as Student ID in a few instances. There are also inconsistencies in the formatting of Student ID (eg. jz1220 vs N19945522). There were also inconsistencies in the formatting of Last name where it was sometimes the initial, the full last name, or even a middle initial with the full last name. Fortunately, much of what we did with the data did not require these elements so there should be little detrimental effect.
According to the data set, we completed 11 readings all together with McNamara having the most submissions and Saqr having the fewest. Interestingly, the Saqr was the reading due before Easter weekend and the McNamara was the reading due after Easter weekend.
Not surprisingly, more discussion took place beyond the questions being asked. Out of the 830 submissions, 654 of them were comments while 176 of them were questions.
The submissions would consistently occur most frequently in the first seven pages of the reading and dropped off significantly after.
Tokenizing the Text
After tokenizing the text per the instructions, we found some additional columns, specifically document_id, Token, and sentence_id. After completing this operation, the data became exceedingly longer, now providing an individual data entry for each word in each submission. If it came to rebuilding those submissions, you would mostly be able to aside from information such as punctuation and capitalization that is removed during the operation.
After this operation, the most frequent words which many of the filler words such as “the”, “to”, “of”, “and”, “a”, etc.
Cleaning the Bag of Words
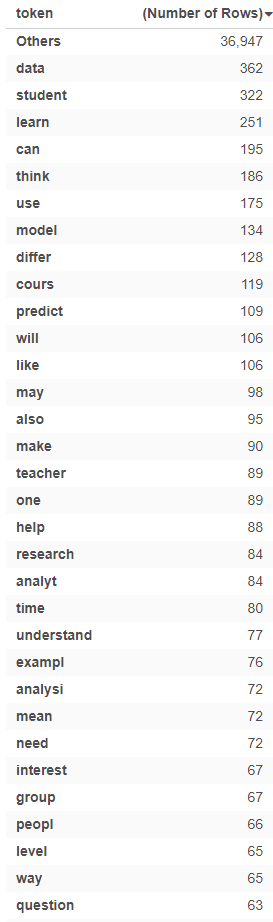
After cleaning the bag of words further with the next operation, many of those filler words had since been removed. The left many of words that dealt with the content for the course including “data”, “student”, and “learn”. This is not surprising given a course of “Learning Analytics” where we specifically discuss students, data, and learning. Without seeing exactly words were removed, I assume that we didn’t lose significant information from this process. However, if there was significant content related to one of those removed words, it would be much more problematic. (What if it were a course about language with an emphasis on prepositions?)
Creating Bi-grams and Tri-grams
By processing the data for bi-grams and tri-grams, we see some changes in the table. Specifically, the Token column has been replaced by token with the different permutations of monograms, bi-grams, tri-grams. There is also a new gram column to indicated the number of “grams” in the token for each data entry.
We now see that the the most common bi-grams are learn_analyt, predict_model, and make,sens.
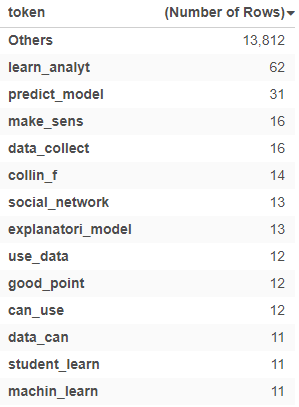
We also find that the most common tri-grams are design_base_research, use_predict_model, and educ_data_mine.
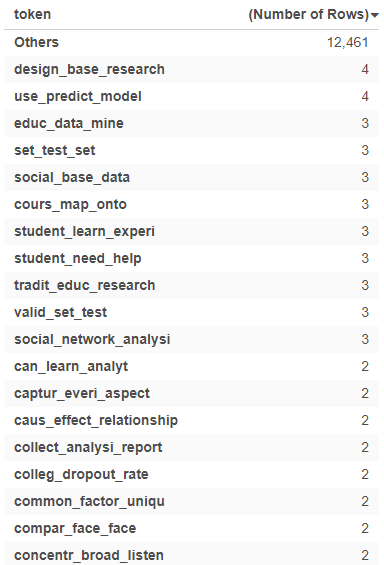
Bi-grams and tri-grams are significantly less common than monograms with the largest monogram having 362 entries, the largest bi-gram having 62 entries, and the largest tri-gram having only 4 entries.
“Student”, a common word encountered in our course has a wide range of bi-grams and tri-grams associated with it throughout the papers. 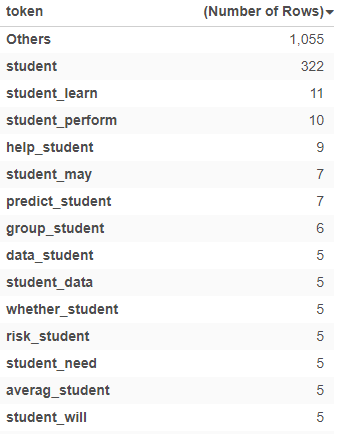
Sentiment Analysis
I ran sentiment analysis on the data set as well and found some interesting things. Firstly, our distribution trended positive as a class overall.
The most positive submission across all students and papers was Ruby in the Ochoa writing: > I think that having a personalized prediction to guide a student’s learning could be efficient in the way that the student’s learning are tailored to their individual needs and not comparing with others. Doing so presents a more “efficient” way of learning when comparing the student without personalized learning to the same student with personalized learning.
The most negative submission across all students and papers was Ana in the Selwyn writing: > It is also possible that data become an excuse or scapegoat for police failures.
Given these examples, I could see how the calculation would determine that a submission was positive (“efficient”, “not comparing”, “personalized”) or negative (“excuse”, “scapegoat”, “failures”). I think that this analysis doesn’t go further than determining the positivity or negativity of a message, but does not determine the author’s positivity, negativity, or anything else meaningful. It’s just the language being used.