前書き
このNoteは、株式会社ネオキャリアの分析啓蒙活動の一環として行った EDA Salon のレポートをパブリッシュしたものになります。
はじめに
こんにちは、株式会社ネオキャリアの松村です。 EDA Salon 第8回 のデータを使ったデータ分析をやってみます。
分析の概要
YouTubeのとレンディングデータということで、「トレンドに入る動画タイトルの特徴」を掘り下げてみたいと思います。
なお、鈴木さんの投稿にて、「視聴数とタイトルのネガポジが関係しているかも」という知見は得られているので、別の観点から見てみることにします。
今回は、「タイトルのテキストマイニング」として「トピックモデル」を使った分析をやってみようと思います。
分析の目論見として、
- 動画タイトルをクラスタリングすることでサブカテゴリのようなものを作れないか
- トレンド入りする動画タイトルの傾向(どういうワードを入れればいいか)をもう少し詳細に知りたい
といったことがあります。
注意: 分析結果そのものよりも、テキストの前処理の説明が多めです。ですので、「YouTubeデータの探索」というよりは「Exploratoryでトピックモデルを実行する方法の解説」みたいになってしまいました。。。
今回行うテキストの処理について
日本語のような単語と単語の間にスペースがない言語でテキスト分析、特に単語に着目した分析をやりたい場合、文章を単語に分割し、それが名詞なのか動詞なのかを判別する作業が必要です。この作業では内部で辞書の参照が行われています。
「文章の単語化」を使う
Exploratory Desktop 5.5から、「ステップの追加→テキストマイニング」の項目に「文章の単語化(日本語)」という項目が追加されました。この作業を 分かち書き と呼びます。この機能を使うことで、日本語の文章を単語に分け、それぞれの文章にその単語が何回現れたかを数えることができます。さらに、ストップワードのオプションを「日本語」にすることで、「て」「に」「を」「は」などの分析に使いそうもない単語を自動で除去することができます。
以下は、「Comedy」カテゴリーに絞って「文章の単語化(日本語)」を実行した例です(カテゴリによるフィルタを行わないと、メモリエラーになりました)。document_idは、文書ID(ここでは1ビデオに該当)、countはその単語が何回現れたかを示しています。
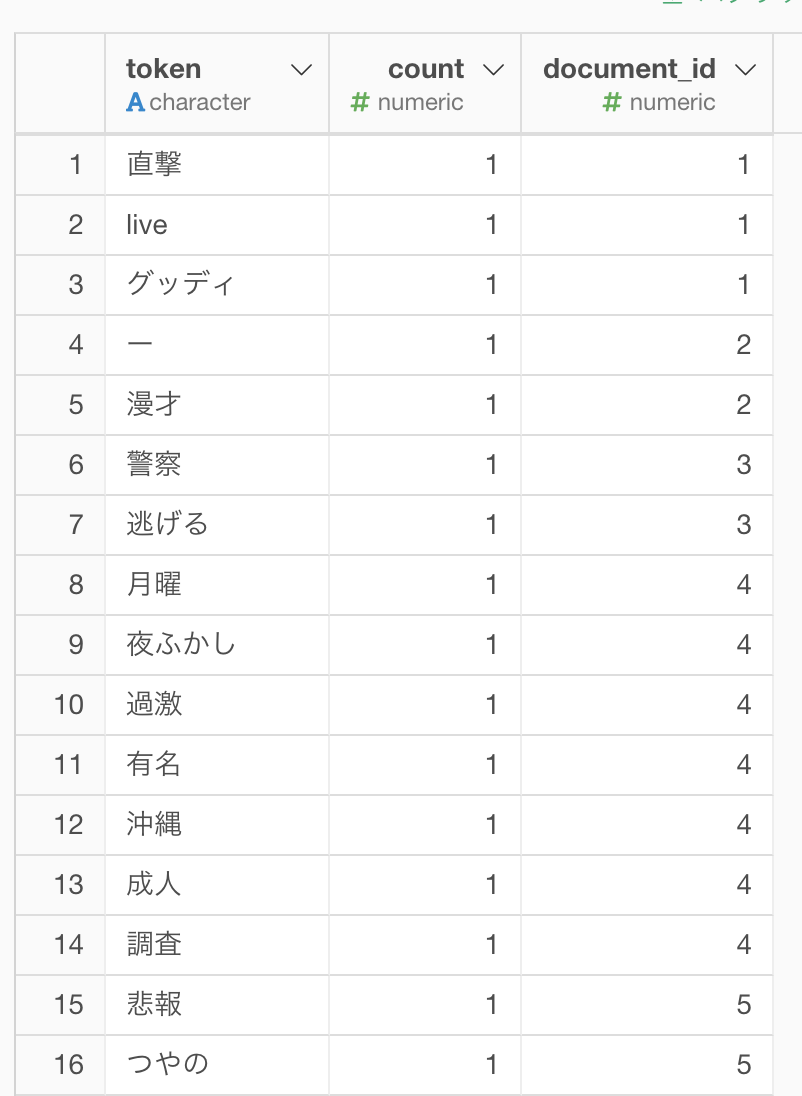
しかしながら、この結果をそのまま分析に使えるかというと、ちょっと不十分に思えます。理由として、
- 番組名(と思われる単語)などの固有名詞が分割されてしまっている
- 品詞の指定がやりにくい
といったことが挙げられます。
RMeCab + neologd を使う
そこで、別の方法として、カスタムスクリプトを使う方法を紹介します。Exploratoryはバックグラウンドで プログラミング言語Rが動いているのですが、ExploratoryではRのコマンドを直接使うことができます。そこで、Rで日本語の形態素解析をする際に非常によく使われるRMeCabパッケージと、固有名詞などの判別に強い辞書ツールのneologdを利用して、スクリプトを書いてみました。
MeCab, RMeCabパッケージ、neologdの導入については付録に回しました。
なお、RMeCabをExploratory上から使った例として、安倍首相に関するTwitterデータをテキストマイニングして可視化してみた(Part1) がありますが、今回は以下の理由で上記のスクリプトを使わず、独自でスクリプトを書いてみました。
- 形態素解析後のテーブルデータで品詞のフィルタをする方法だと、今回はそもそもの行数が多いため形態素解析の結果が膨大になる可能性が高い →品詞はテーブルにする前に絞っておきたい
- トピックモデルを実行することを考えて、相性のいいtidytextパッケージで後の処理を書きたい
- 活用がある品詞(動詞、形容詞など)は原型を使うなど、RMeCabのオプションを使いたい
以下、RMeCab パッケージとneologd がインストールされている前提でのスクリプトになります。
Rスクリプト
まず、分かち書きのためのスクリプトを作成します。以下のスクリプトを「スクリプト→スクリプト」からmecab_wakatiといった適当な名前をつけて保存します。このとき 名詞|形容詞|動詞 の箇所を変更することで、任意の品詞を抽出することができます。また、 dic = の箇所は環境によって異なるため注意が必要です(詳細は付録を参照)。
library(rlang)
#' MeCab を用いた分かち書き
@param ... RMeCabC() 関数と同じ
@param pos 品詞の文字列。複数あるときは | で区切る
mecab_wakati <- function(..., pos = "") {
res <- RMeCab::RMeCabC(...) %>%
unlist() %>%
.[stringr::str_detect(names(.), pos) == TRUE] %>%
stringr::str_c(collapse = " ")
if(length(res) == 0) {
res <- NA_character_
}
return(res)
}
#' mecab_wakatiを用いてmutateする
#' @param col カラム名(文字列)
wakati_df <- function(df, col) {
vec <- df %>% dplyr::pull(col)
df_wakati <- df %>%
dplyr::mutate(
wakati = purrr::map_chr(
vec,
~mecab_wakati(.x, mypref = 1,
dic = "~/mecab-ipadic-neologd/build/mecab-ipadic-2.7.0-20070801-neologd-20200130/mecab-user-dict-seed.20200130.csv.dic",
pos = "名詞|形容詞|動詞"))
) %>%
dplyr::select(-col)
return(df_wakati)
}続いて、トピックモデルのためのスクリプトを作成します。 以下のスクリプトを「スクリプト→スクリプト」からtopic_modelといった適当な名前をつけて保存します。
library(rlang)
library(magrittr)
build_topic_model <- function(data, document, term, value, k) {
doc <- rlang::sym(document)
ter <- rlang::sym(term)
val <- rlang::sym(value)
dtm <- data %>%
tidytext::cast_dtm(document = !!doc, term = !!ter, value = !!val)
lda <- topicmodels::LDA(dtm, k = k, control = list(seed = 1234))
res <- lda %>%
broom::tidy() %>%
tibble::as_tibble()
return(res)
}分析
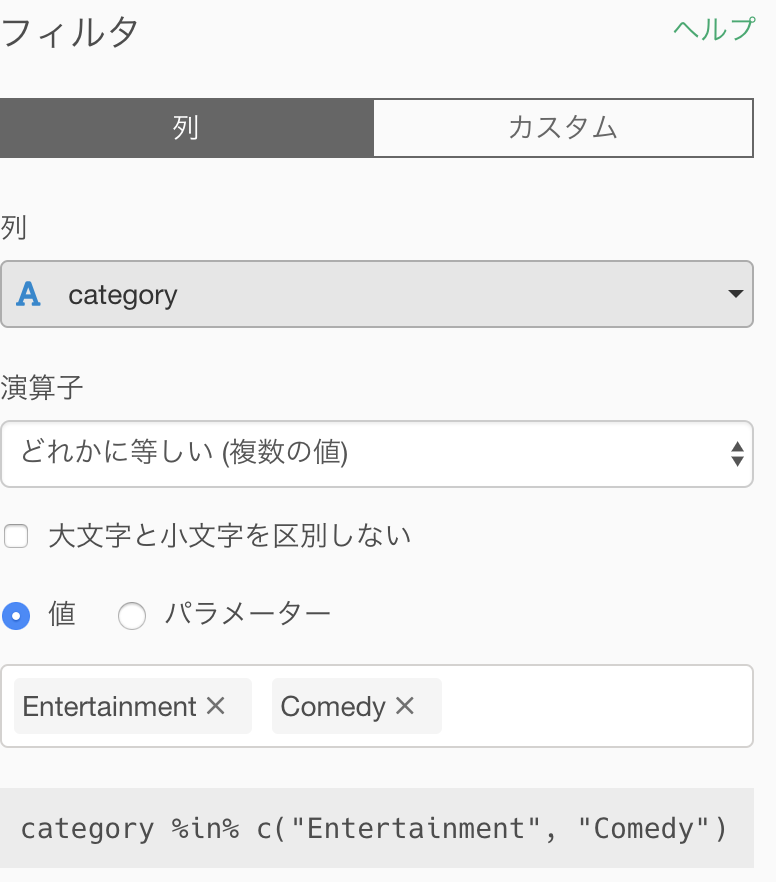
長かったですが、準備ができたので実際のテキスト処理&分析に移ります。今回は、日本の「ComedyまたはEnterrainment」のカテゴリーで分析を行ってみます。
テキストの処理
まず、分かち書きを実行します。新規ステップのカスタムRコマンドから、以下を実行します。

続いて、新規ステップのカスタムRコマンドから、以下を実行します。

この時点で、テーブルは以下のようになります。

行数は、ビデオ数×単語数(名詞、動詞、形容詞のみ)です。また、neologdを利用したことで「直撃live」「百田尚樹」などの固有名詞を抽出できていることが分かります。
次に、トピックモデルで分析を行うため、各ビデオタイトルにその単語がいくつ含まれているのかを集計します。ここでは普通にステップで「集計」を選択します。
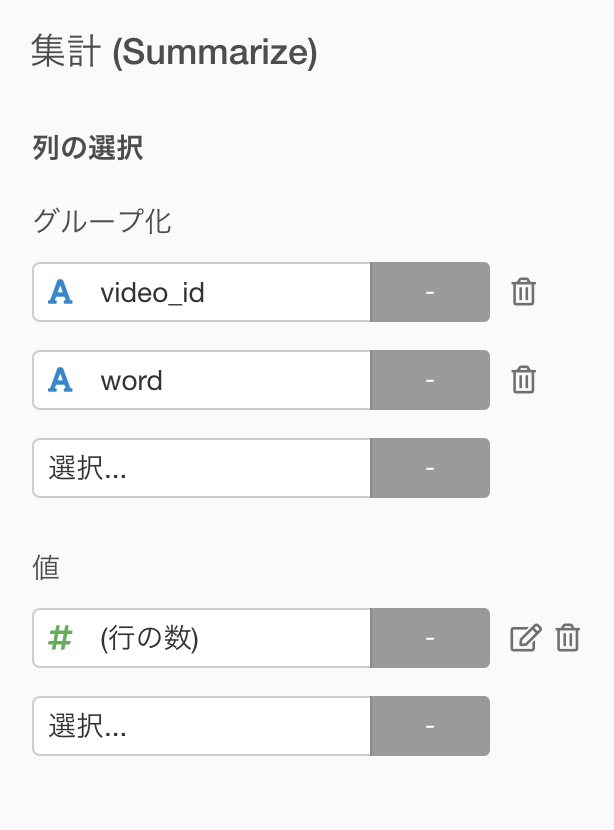
この時点での出力は以下です。
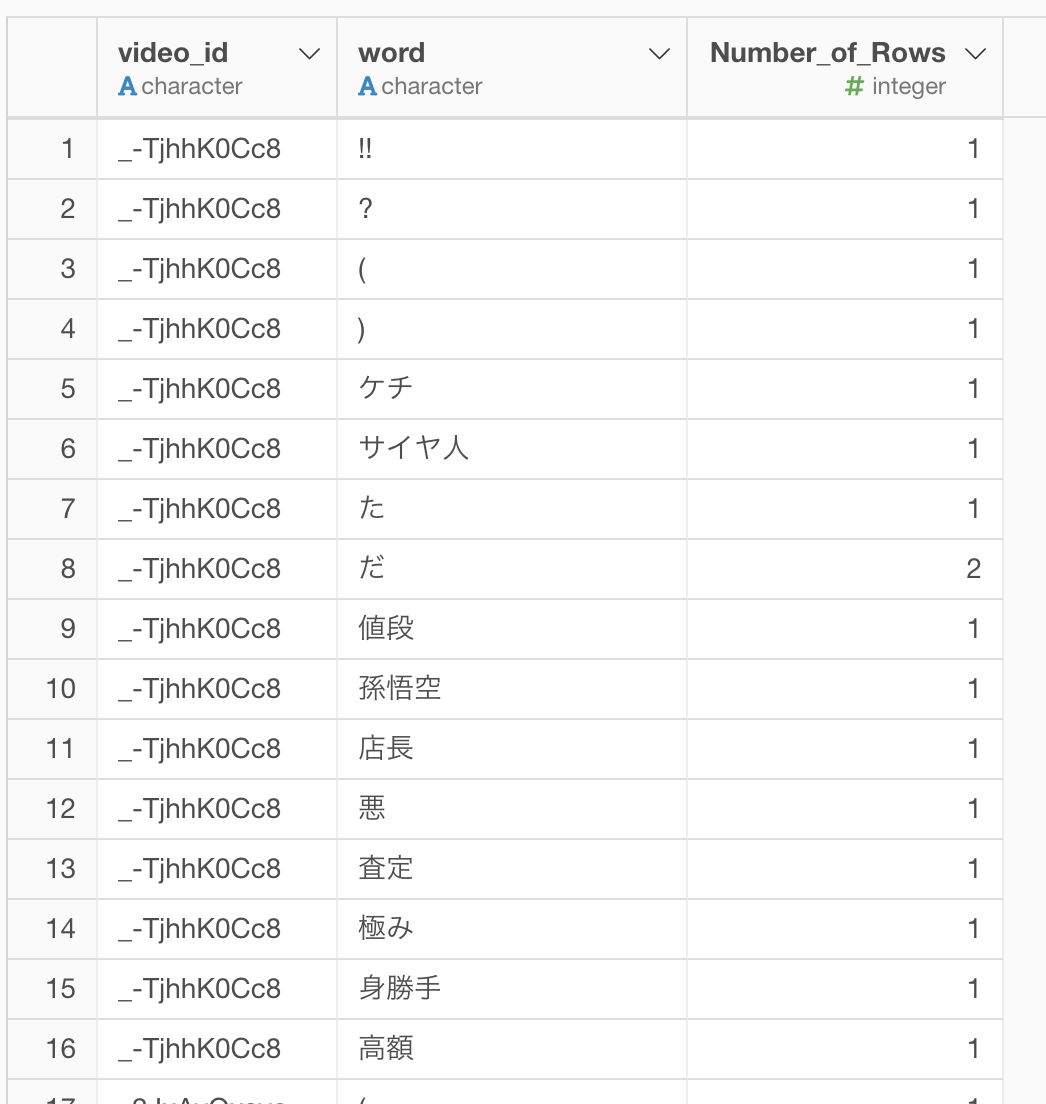
ビデオIDと単語による集計ができましたが、「!!」や「?」、「だ」などのいわゆるゴミが残ってしまっているので、これを以下の順序で取り除きます。
- ストップワードの除去
- 記号や半角カタカナなどを除去
1については、こちらを参考にしました。
2は、ステップのフィルタで以下のように入力をしました。
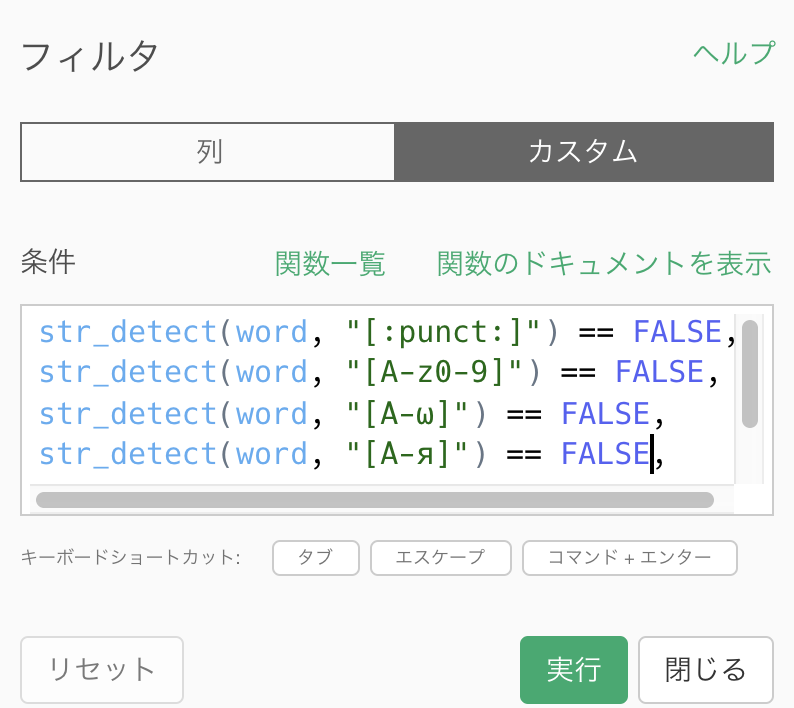
str_detect(word, "[:punct:]") == FALSE,
str_detect(word, "[A-z0-9]") == FALSE,
str_detect(word, "[Α-ω]") == FALSE,
str_detect(word, "[А-я]") == FALSE,
str_detect(word, "[ヲ-ン]") == FALSE,
str_count(word) > 1こうすることで、以下の出力が得られました。

割ときれいに分割できたのではと思います。
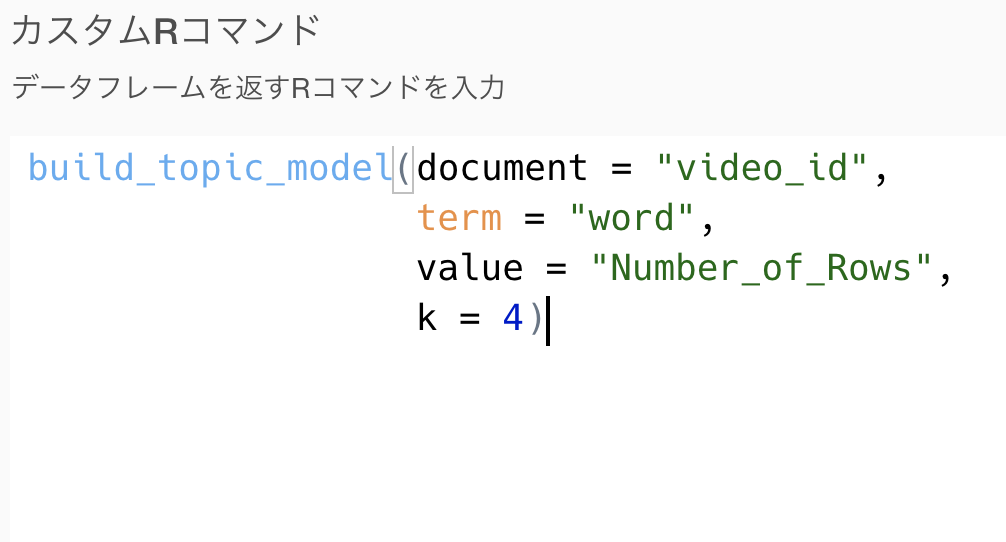
トピックモデルを使った分析
続いて、トピックモデルによる分析と考察を行います。 新規ステップのカスタムRコマンドから、以下を実行します。 今回は、トピック数4で実行してみます。
各トピックに対して上位10単語を可視化してみると以下のようになりました。
- トピック1: 芸能的な時事ニュース?
- トピック2: 大食い系
- トピック3: 虎ノ門ニュース(YouTube番組名)と特定の芸能人
- トピック4: 対決や検証系
といった感じでしょうか….? 実データでトピックモデルを実行するときは、解釈に困ることが結構多いです。
当初の目論見に対して
- サブカテゴリのようなものを作れないか→ 大食い、検証といったものはサブカテゴリ化できそうな印象です。
- トレンド入りする動画タイトルの傾向をもう少し詳細に知りたい→「Comdey」や「Entertainment」ジャンルにおいては、タイトルよりもチャンネルそのものや出演人物の影響でトレンド入りする可能性もありそうな雰囲気です。
課題
動画のタイトルがあまり長くない(単語数が少ない)ため、あまりきれいな結果にはならなかった
トピックモデルはトピック数の選び方にいつも迷う。
→今回はスクリプトを書いたけど、Exploratory上でいろいろオプションを選べて実行できるようになると嬉しいです!(トピックモデルの実装を求む!)
- 動画タイトルをやるなら共起ネットワークのような「どういう単語を組み合わせればいいか」のような探索のほうが向いている気もする
→ネットワーク分析(テキストでは、共起ネットワーク)の実装を求む!
- コメントのデータがもしあれば、それを分析するのも面白いかも。
付録
RMeCab のセットアップ
MeCabとRMeCabのインストール方法
https://exploratory.io/note/2ac8ae888097/Mecab-RMeCab-0944283373151109
neologd のインストールとRで使う方法について
Rスクリプトについて
wakati_df について
Exploratoryのステップに使うカスタムコマンドの制限として、データフレームを返さなければいけないという制限があります。今回はその制約上、文字列を入力として分かち書きを実行する関数と、dplyr::mutate を用いてデータフレームの列にする関数を分けました。
また、本当はステップのRコマンド入力時に辞書や原型を返すかなどのオプションを入力できるようにしたかったのですが、時間の都合上、関数の中にそのオプションを入れてしまいました。