サブスクデータ分析 #3 - コンバージョンの要因分析と予測
このノートはサブスクリプション型のビジネスに特有な指標の作成・可視化や分析方法を効率的に学んでいただける「サブスクデータ分析」のトライアルツアーの第3弾、「コンバージョンの要因分析と予測」です。
サブスクリプション型のビジネスでは、新規顧客のコンバージョン(獲得)がビジネスの成長には欠かせません。
そして、コンバートしやすい顧客セグメントや行動がわかれば、そういった情報を顧客のターゲティングに活かして、コンバートする顧客を増やすための打ち手につなげられます。
さらに、見込み顧客ごとにコンバージョンが発生する確率を予測できれば、コンバートする確率が高い顧客を重点的にサポートして、顧客の獲得効率を高める打ち手につなげられます。
そこで、こちらのノートではデータサイエンティストが最も頻繁に利用する機械学習のアルゴリズムの「ランダムフォレスト」を使って、見込み顧客のコンバージョンを予測するモデルを作成し、コンバートしやすい顧客の特徴を分析します。
さらに、作成した予測モデルを使って、トライアル中の見込み顧客がコンバートする確率を予測します。
所要時間は20分ほどです。それでは、さっそく始めていきましょう!!
予測モデルとは?
例えば、Netflixのような動画視聴サービスを例に考えてみましょう。
以下のように1行が1人の顧客を表していて、過去に誰が有料顧客としてコンバートしたかというデータが手元にあり、顧客の属性情報もあったとします。
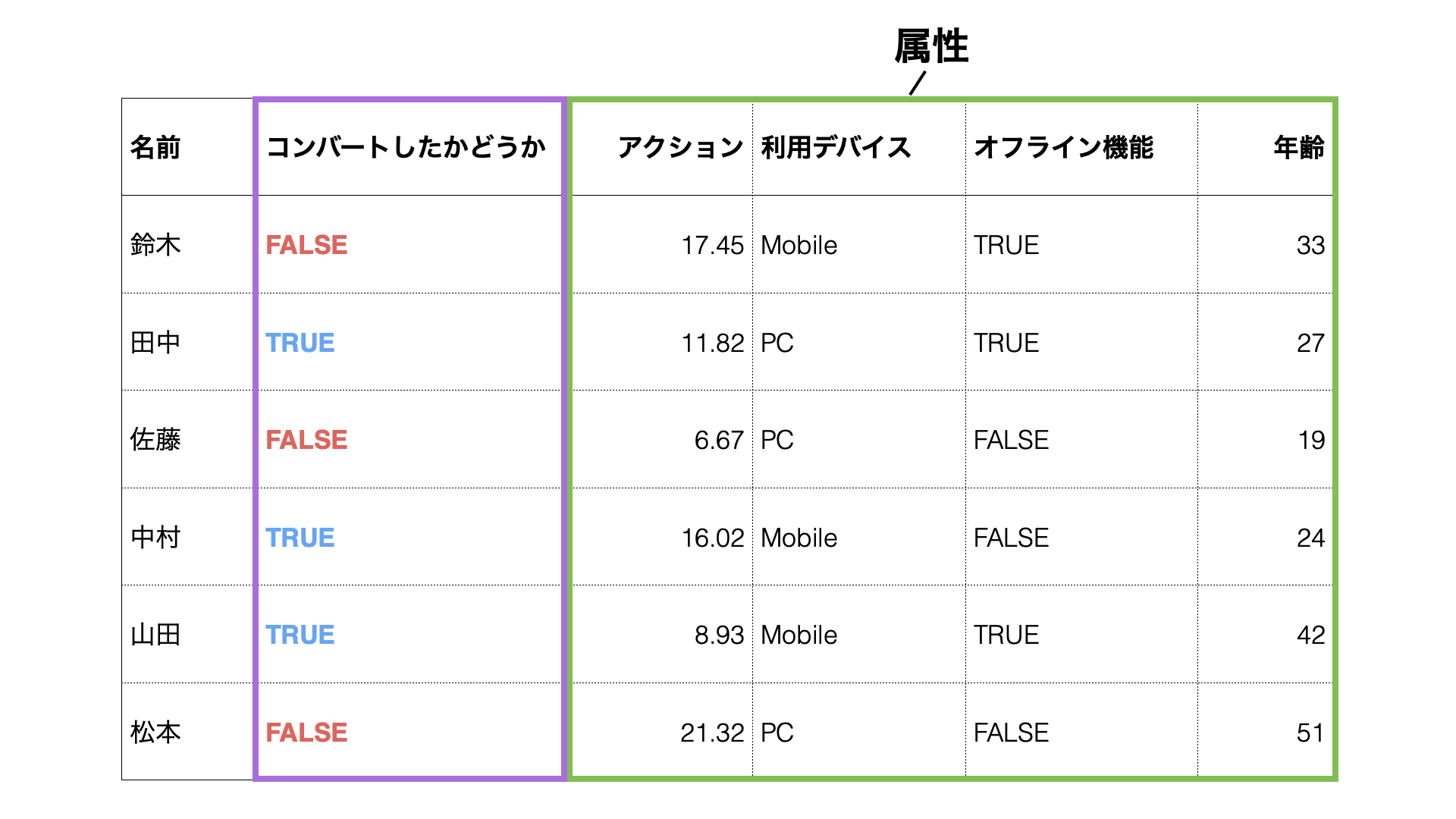
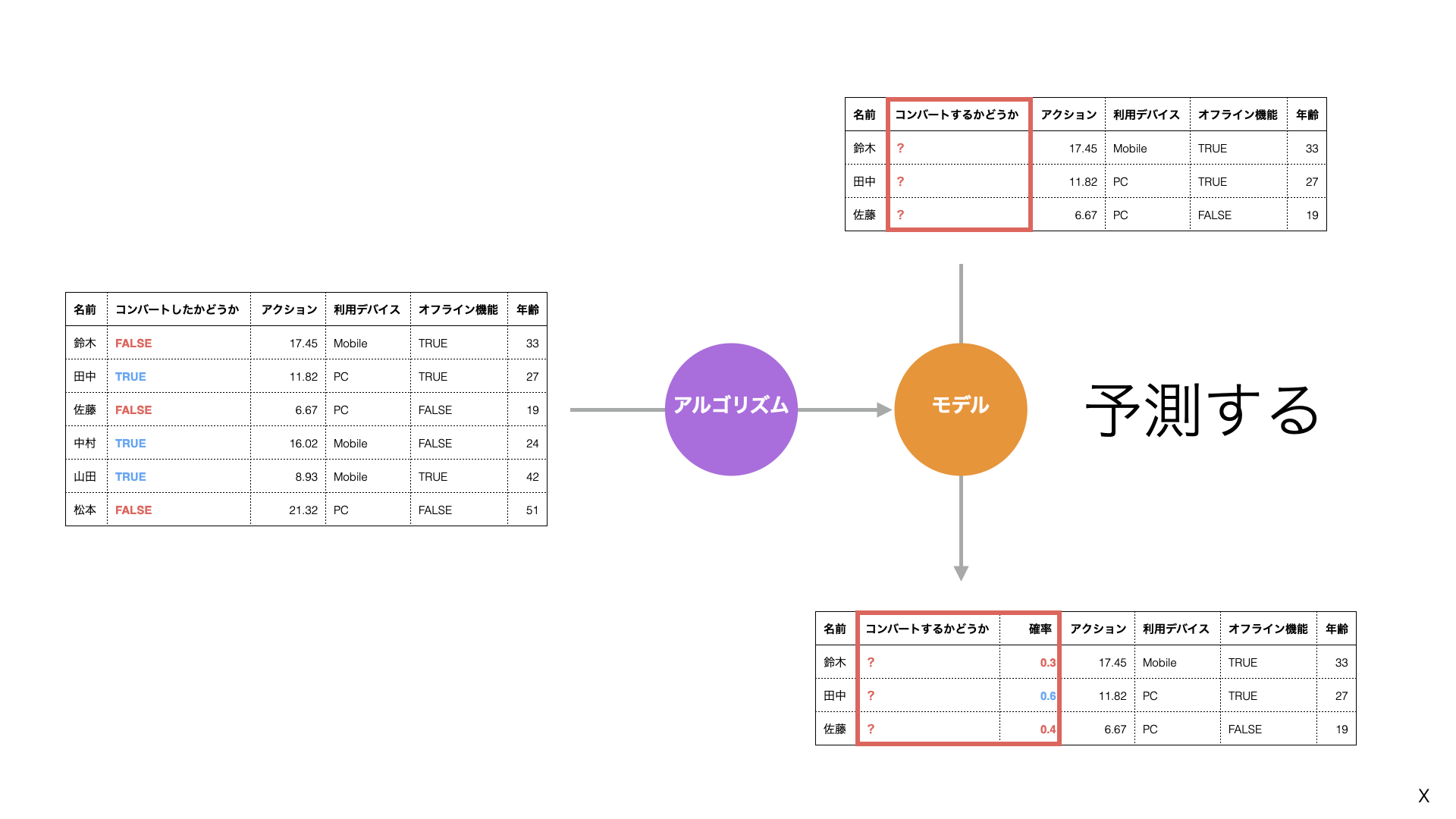
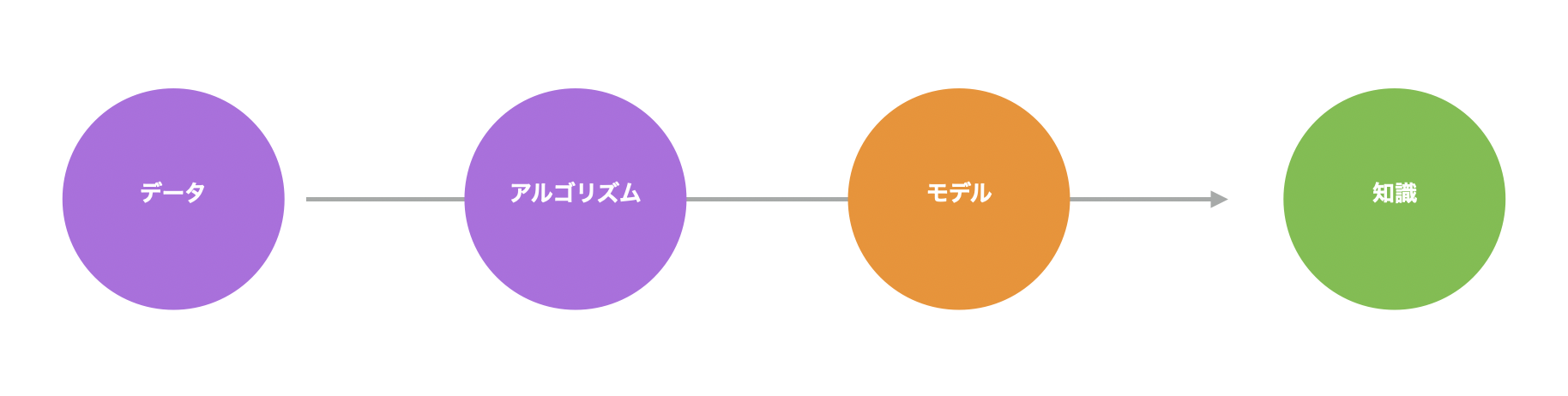
こういったデータがあれば、統計や機械学習の「アルゴリズム」を使って、顧客の属性とコンバージョンの関係をもとに、将来を予測するために、過去のデータの中にあるパターンを数式化またはルール化できます。
このように、アルゴリズムが検出したデータの中にあるパターンを表現したものを「予測モデル」と呼びます。

予測モデルを使うと、新しい見込み顧客の中から誰がコンバートするかを予測できます。
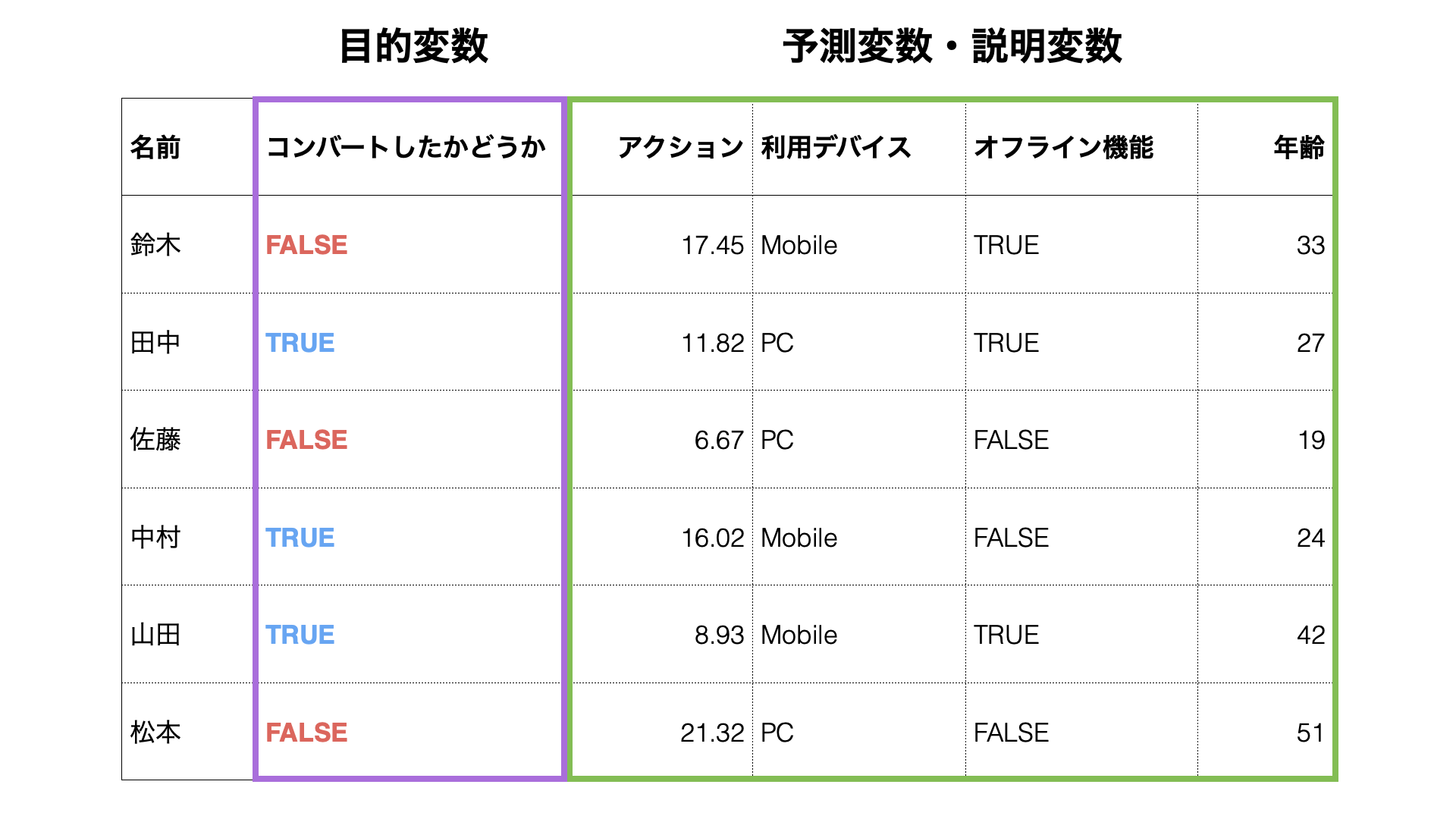
なお、データサイエンスの世界では、予測する対象(「コンバートしたかどうか」)のことを「目的変数」と呼び、予測をするために利用する情報のことを「予測変数」または「説明変数」と呼びます。
また、予測モデルを作ると、データの中にあるパターンに関して、例えば以下のことも理解できます。
- 目的変数(コンバージョン)と関係の強い変数はどれか
- それはどういった関係なのか
- それは有意な関係なのか
- このモデルでは目的変数の動きのどれくらいを説明できるのか
データの概要
今回のサンプルデータはNetflixのような動画配信サービスの、トライアル期間中のサービスの利用状況のデータです。データはこちらのページからダウンロードできます。
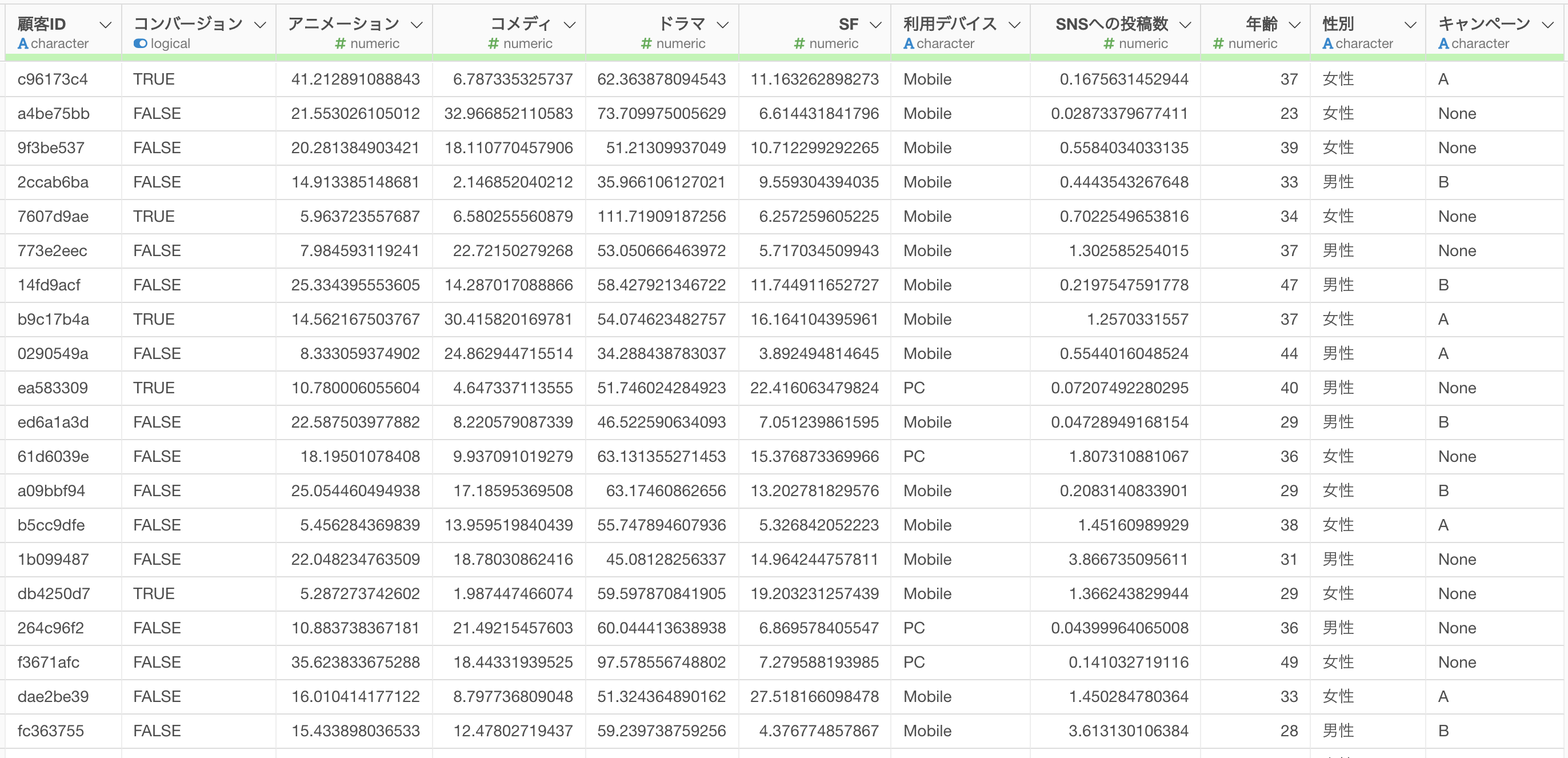
このデータは、1行がトライアルに申し込んだ1人の見込み顧客を表していて、列には以下の情報があります。
- コンバートしたかどうか
- コンテンツごとの視聴時間
- 主な利用デバイス
- 年齢
- 性別
- サインアップに至ったキャンペーン
データのインポート
Exploratoryを起動したら、プロジェクト「新規作成」ボタンをクリックします。
プロジェクトを作成するためのダイアログが表示されるので、任意の名前をつけて、作成ボタンをクリックします。
プロジェクトを作成できました。

プロジェクトを作成することができたら、次はデータをインポートします。データはこちらのページからダウンロードできます。
顧客のトライアルの状況のデータをダウンロードできたら、ダウンロードしたフォルダを開き、「顧客のトライアルの状況.csv」をExploratoryの画面にドラッグ&ドロップします。
すると、インポートダイアログが表示されます。
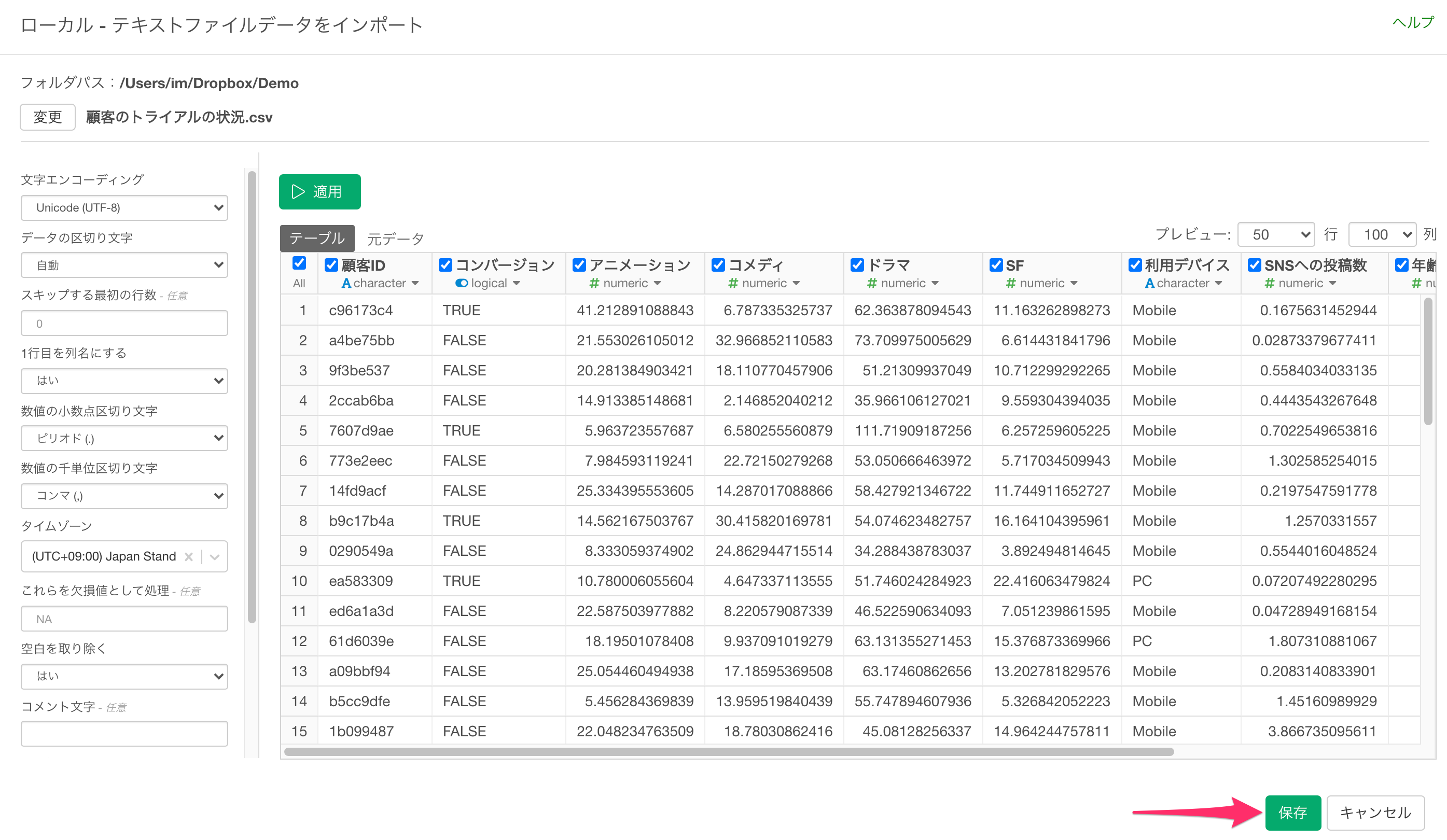
インポートダイアログでは左側にある項目から、データをインポートする際の設定を指定できますが、今回は設定は不要なため「保存」ボタンをクリックします。
するとデータフレームの設定ダイアログが表示されるので、「保存」ボタンをクリックします。
顧客のトライアルの状況のデータをインポートできました。
ランダムフォレストを使ってコンバージョンを予測するモデルを作る
予測モデルを作りたいときには、「アナリティクスビュー」に移動します。
今回は、データサイエンティストが最も頻繁に利用する機械学習のアルゴリズムの「ランダムフォレスト」を使って、見込み顧客のコンバージョンを予測するモデルを作成したいので、タイプに「ランダムフォレスト」を選択します。
ランダムフォレストの使い方に関する詳細はこちらのノートをご参照ください。
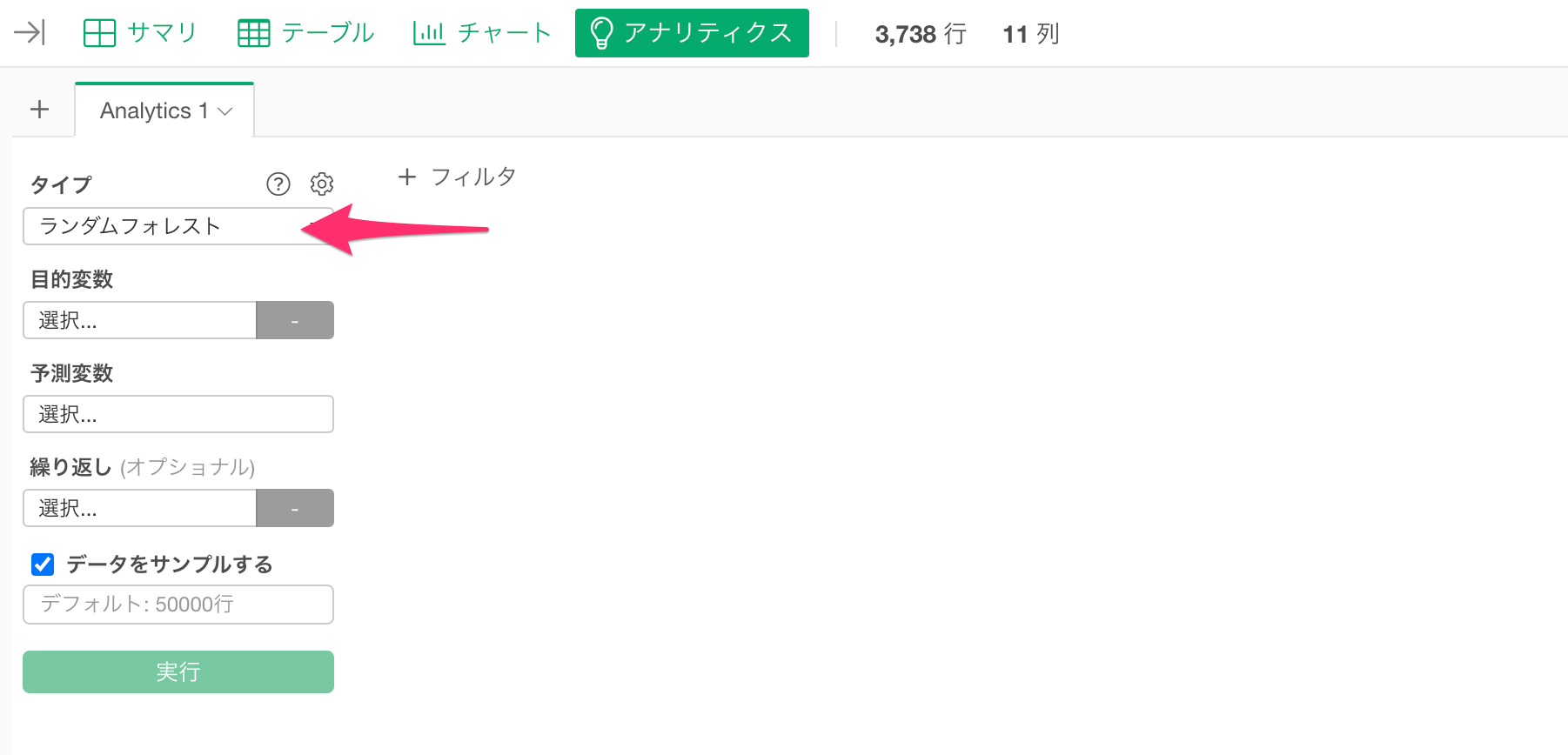
続いて、予測対象の列である「目的変数」に「コンバージョン」を選択します。

続いて予測変数を選択します。

予測変数の選択ダイアログが表示されたら、Shiftキーを押しながら、「アニメーション」と「キャンペーン」をクリックして、「顧客ID」以外の全ての列を選択し、「OK」ボタンをクリックします。
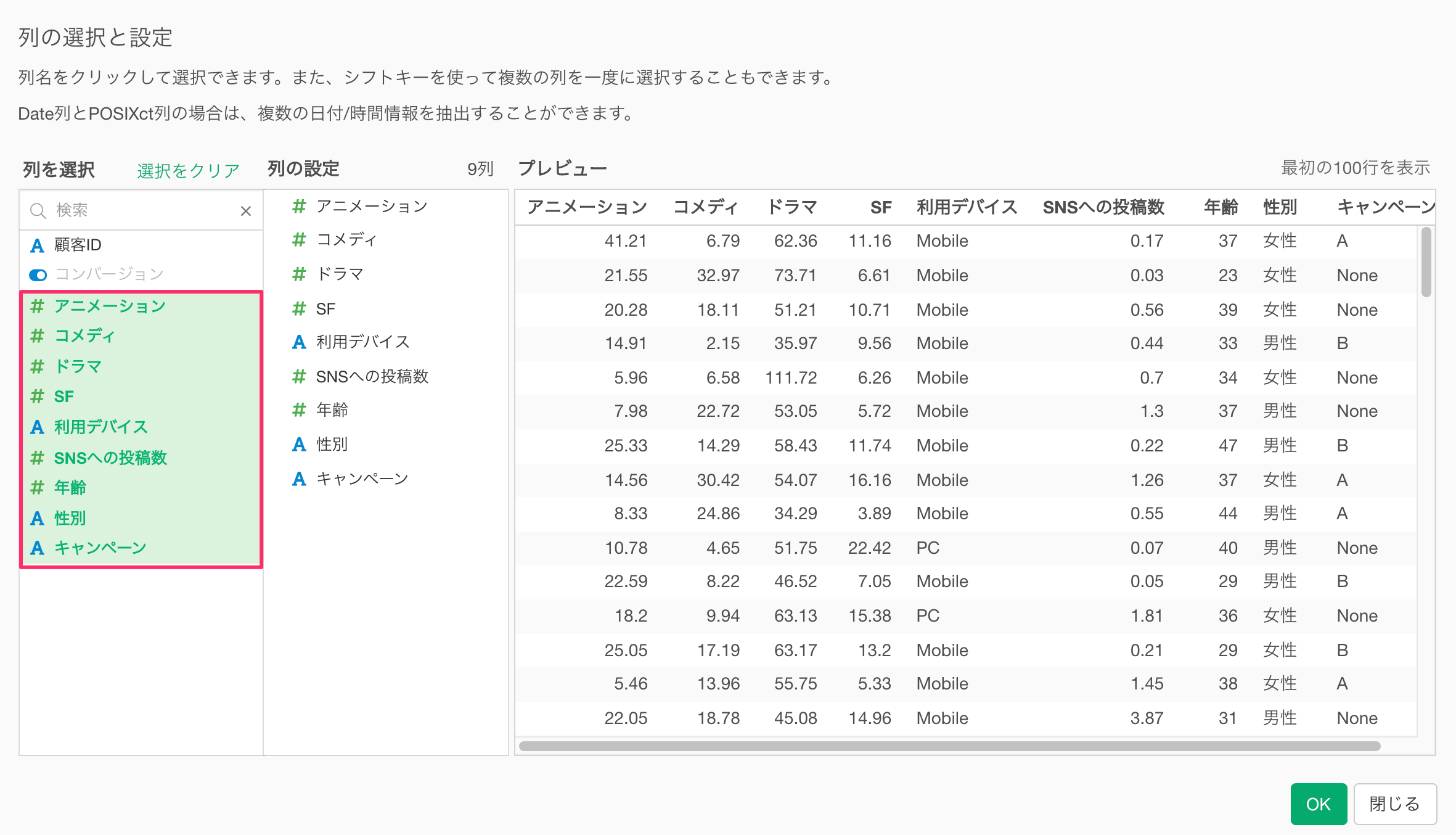
「実行」ボタンをクリックします。

コンバージョンを予測するモデルが作成されました。
予測モデルの解釈
予測モデルを実行すると、予測モデルを解釈するための複数のタブが表示されます。
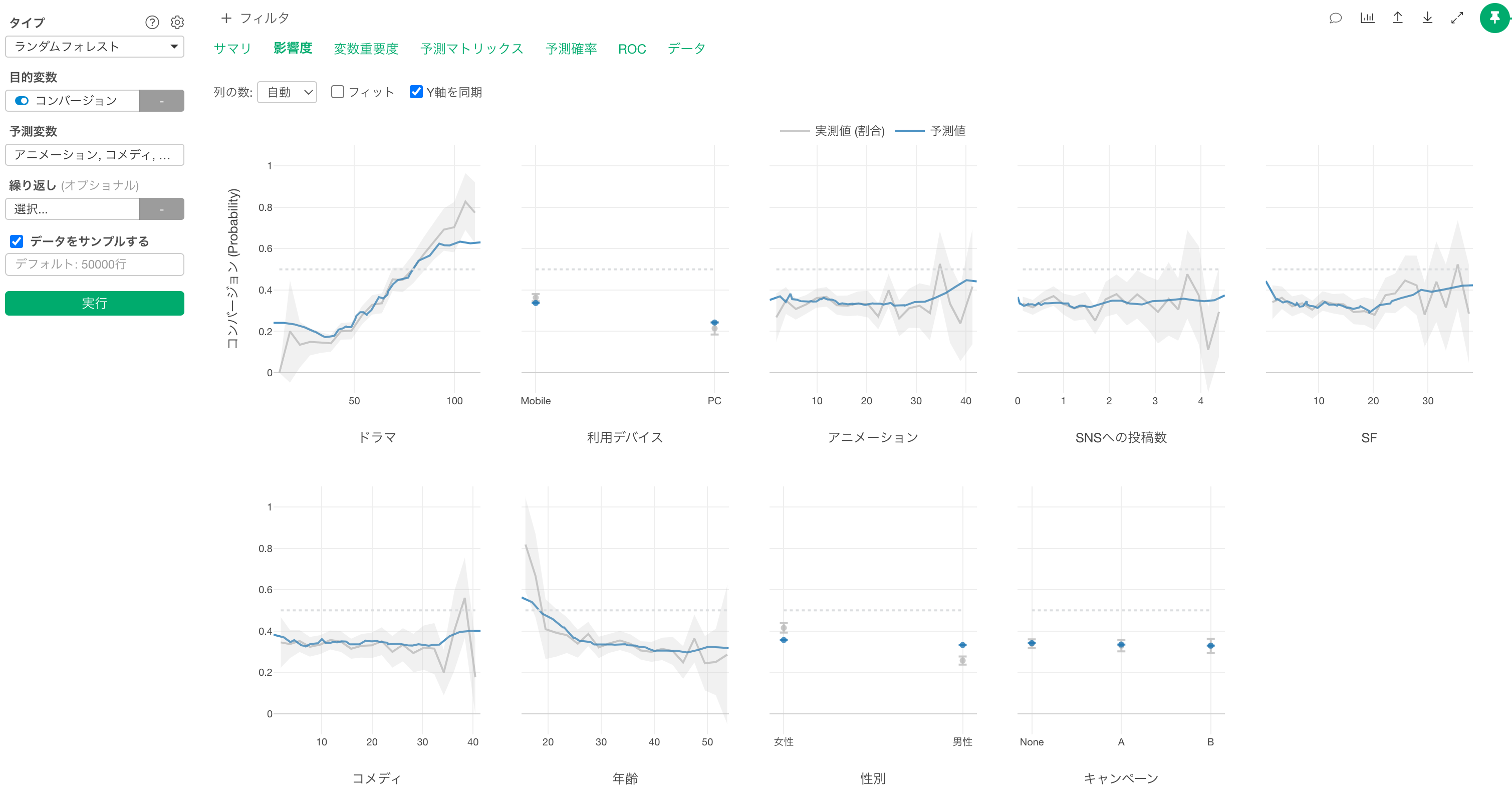
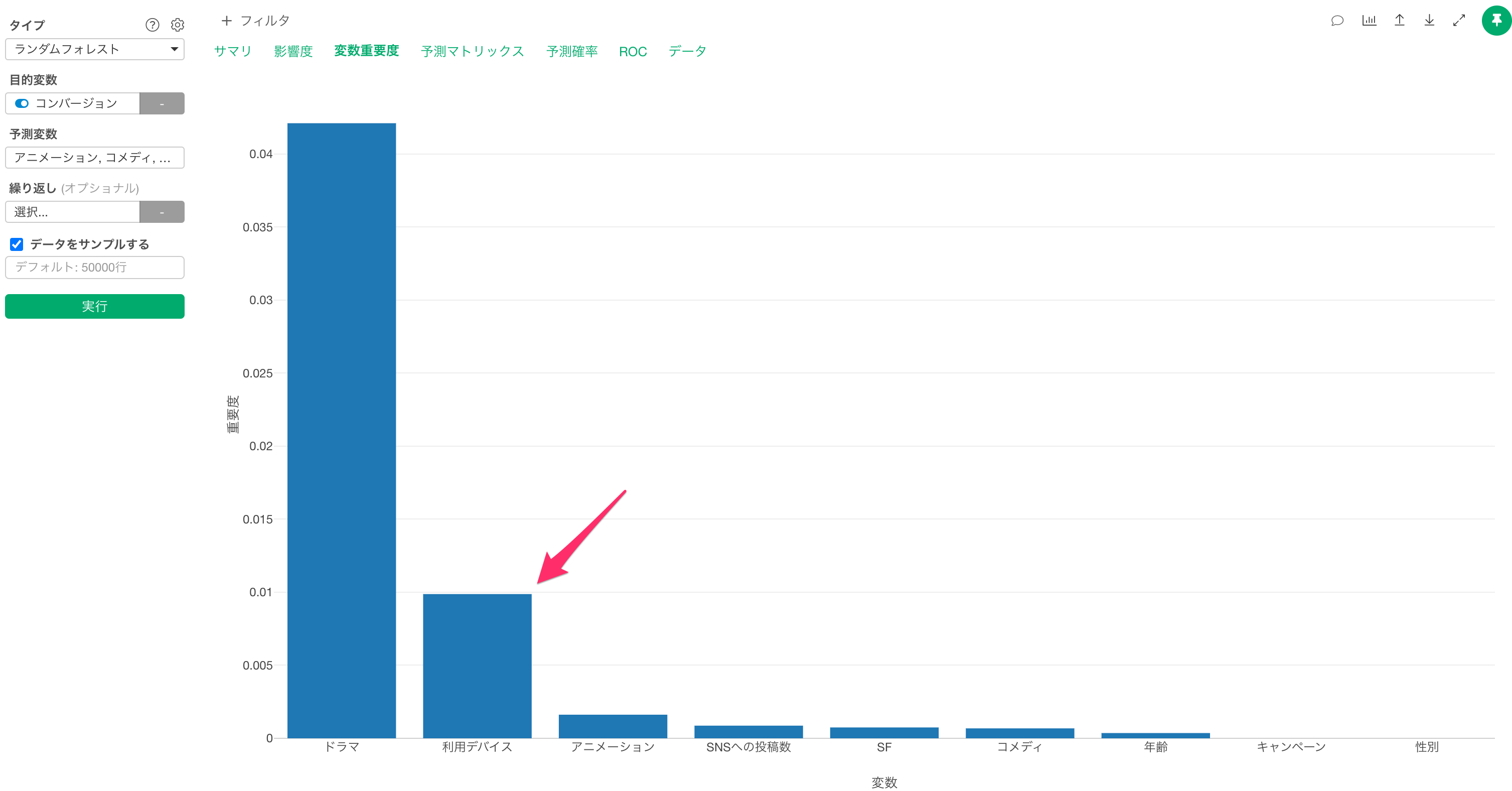
変数重要度
変数重要度タブでは、どの変数が目的変数(コンバージョン)とより相関が強いのかや、予測をする時に、より重要なのかを調べられます。
バーの高さが高いほど、目的変数との相関が強いことを示しています。
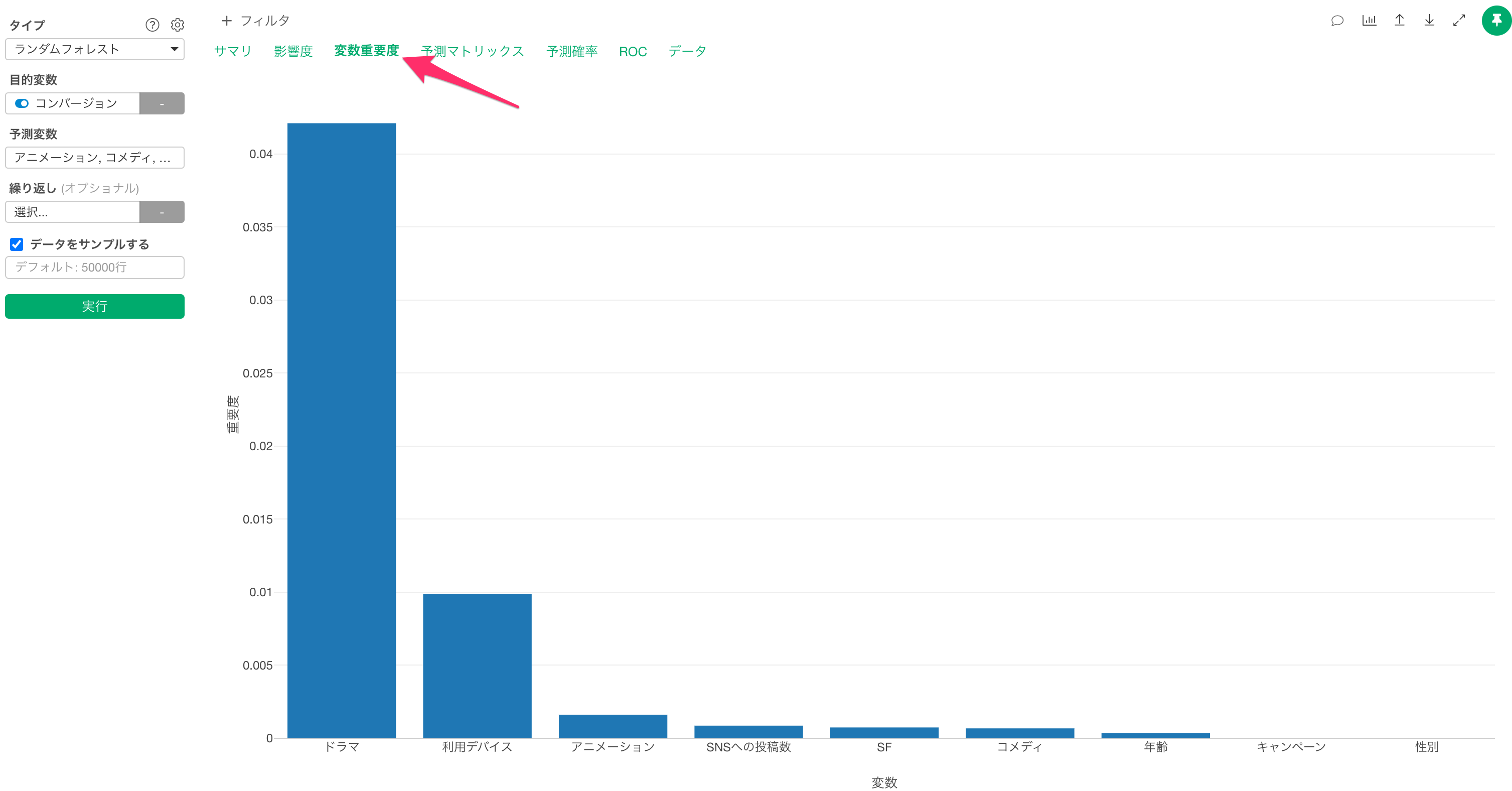
今回のデータでは、「ドラマ」の視聴時間がコンバージョンを予測するうえで最も重要な変数なようです。
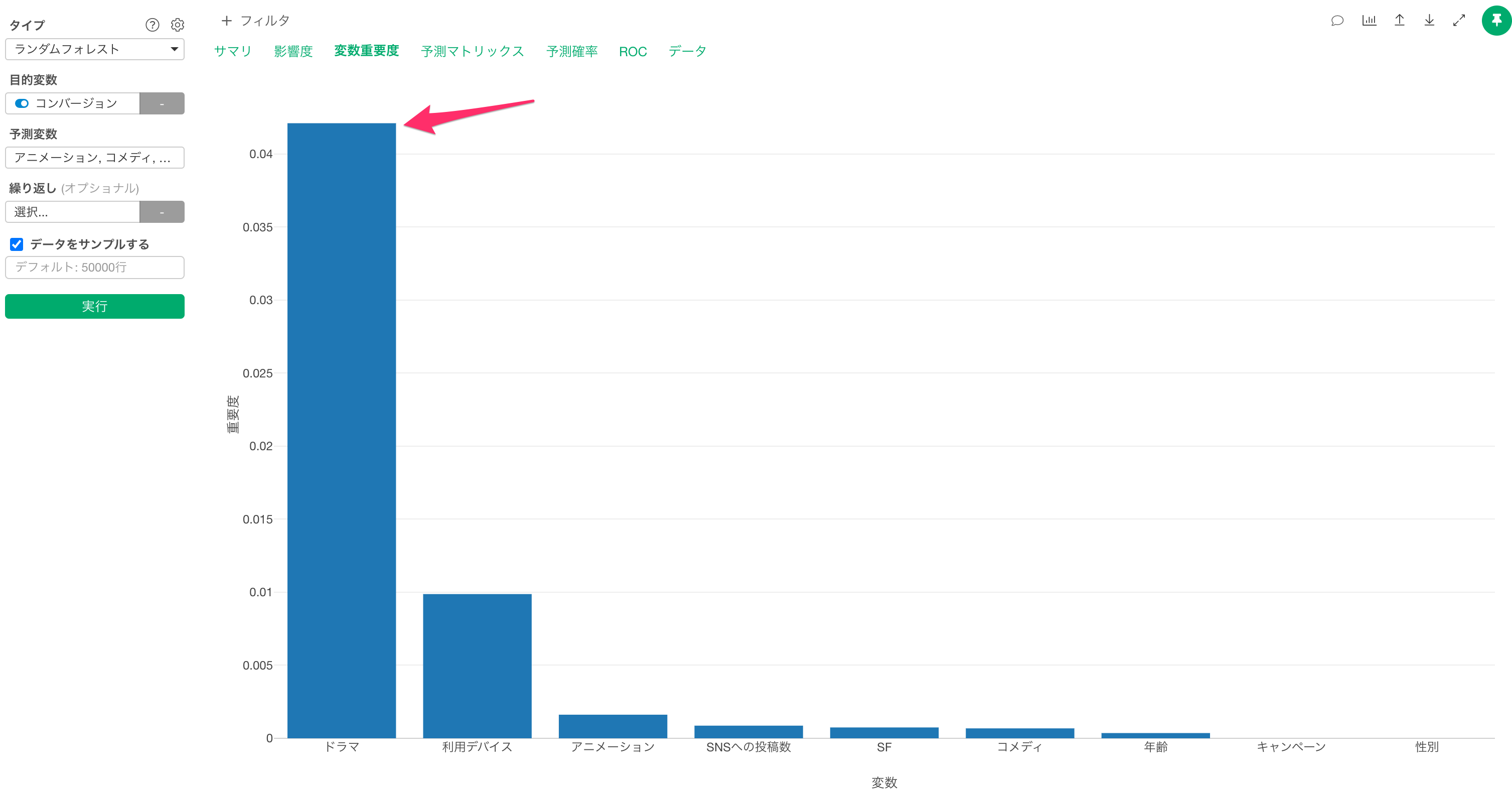
また「ドラマ」の視聴時間にも、主な「利用デバイス」も、コンバージョンを予測するうえで重要だとわかります。
なお、変数重要度に関する詳細は、こちらのノートをご参照ください。
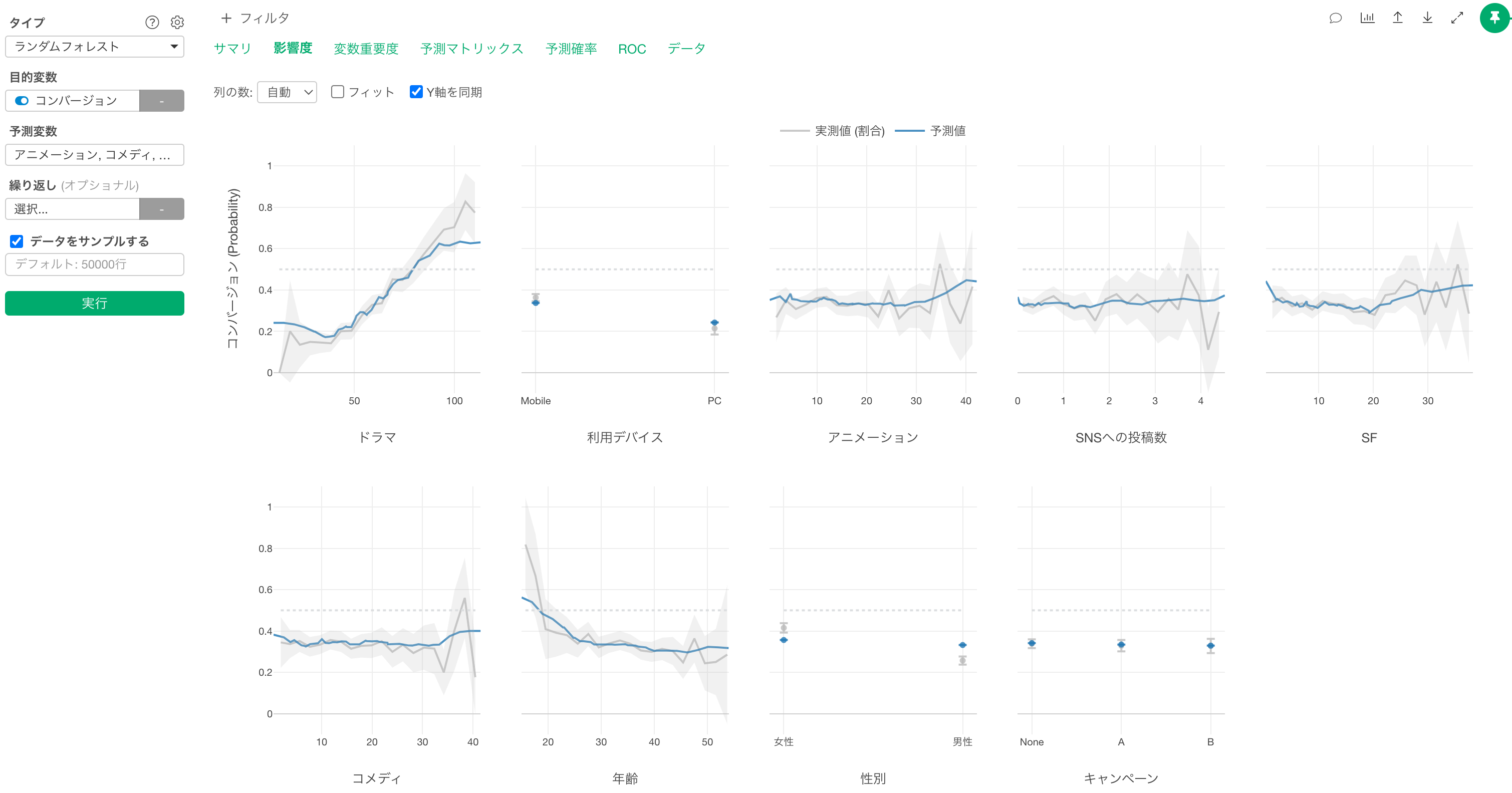
影響度
影響度タブでは、それぞれの変数の値が変わると、目的変数の値がどのように変わるのかがわかります。
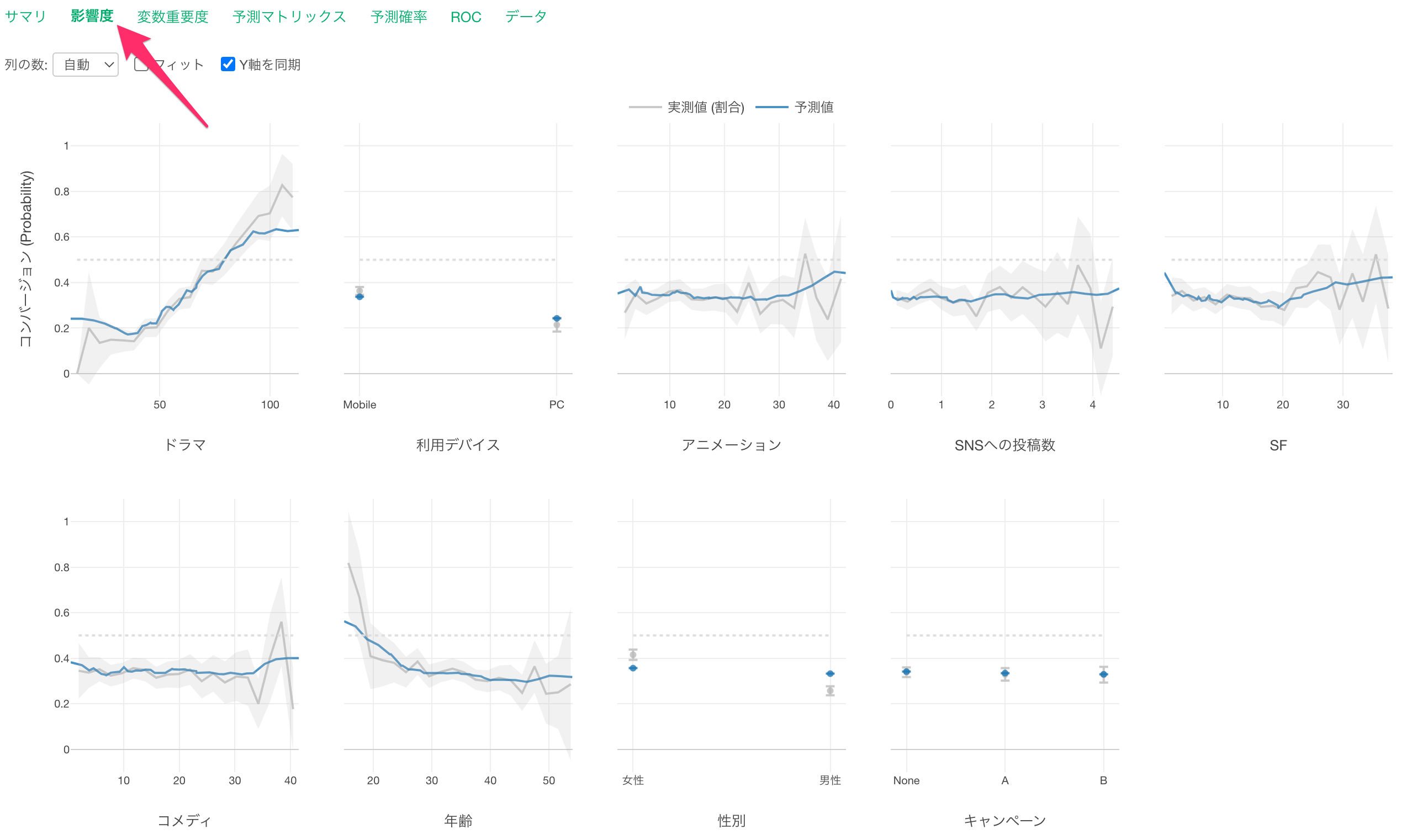
X軸は各「予測変数」の値を表しており、Y軸は「目的変数」に選択した変数(コンバージョン)のTRUEの割合なので、今回のデータでは「コンバージョン率」を表しています。
各予測変数は変数重要度が高い順に並んでいます。
グレーの線は実測値を表しています。
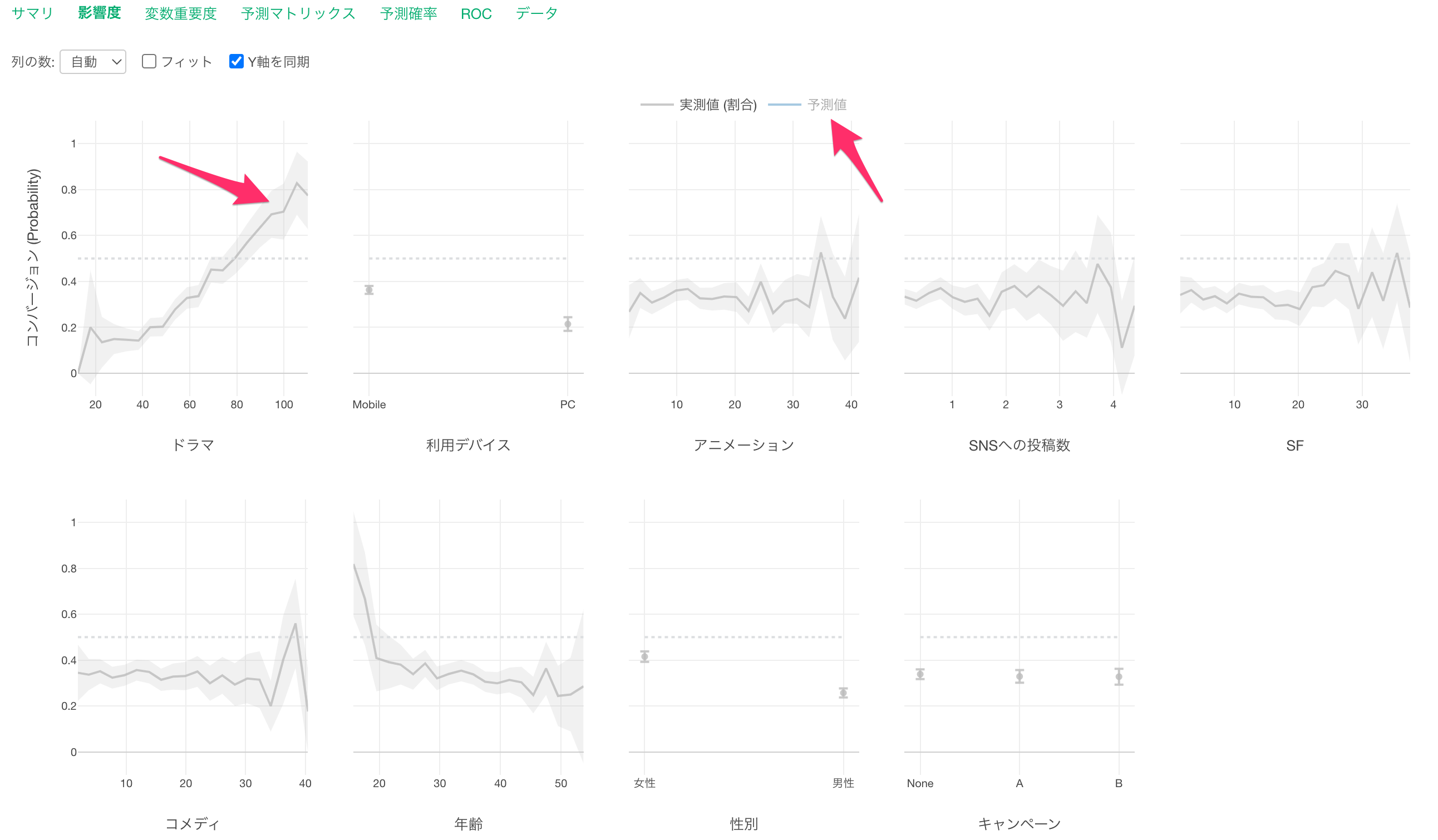
また、青い線は予測値を表します。
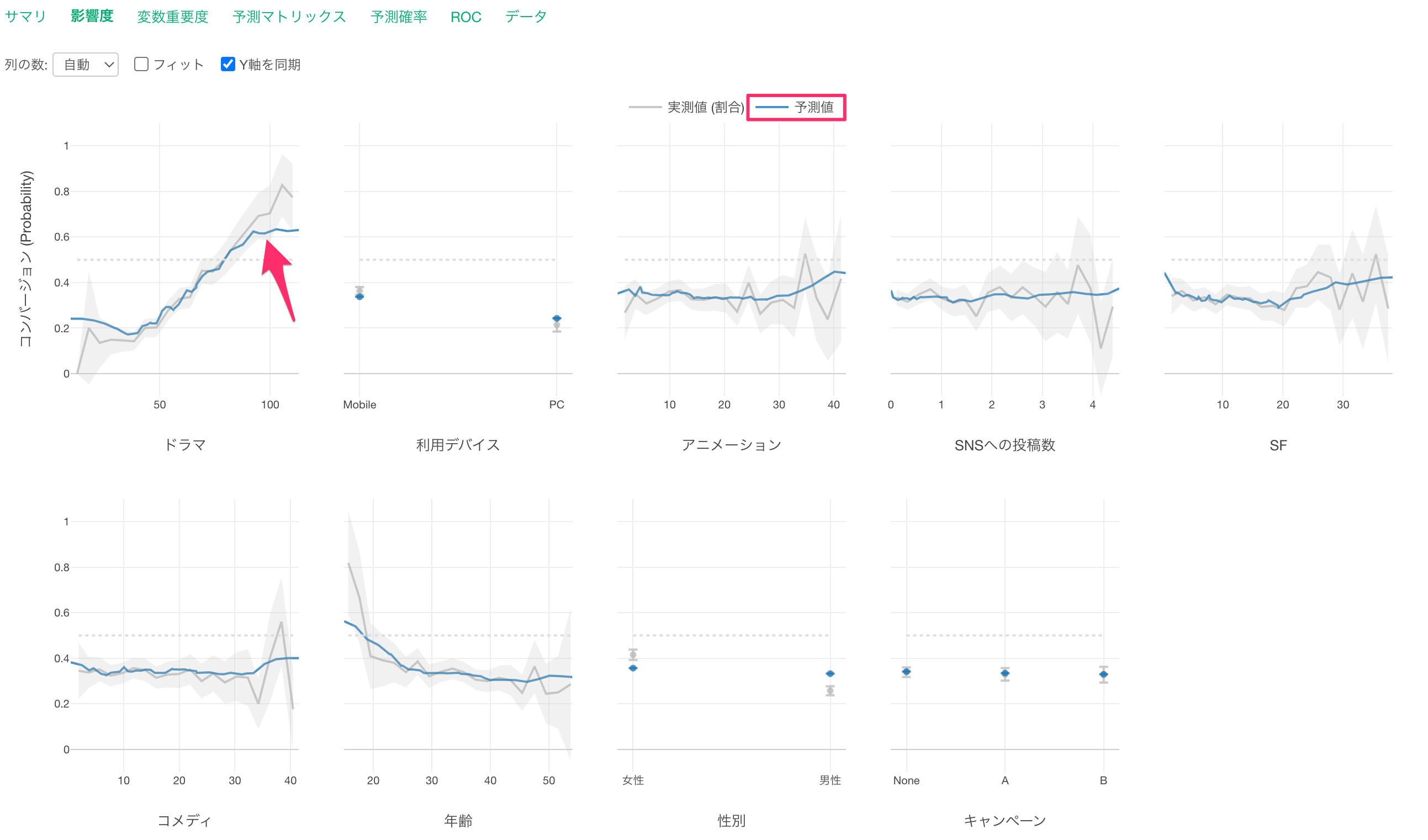
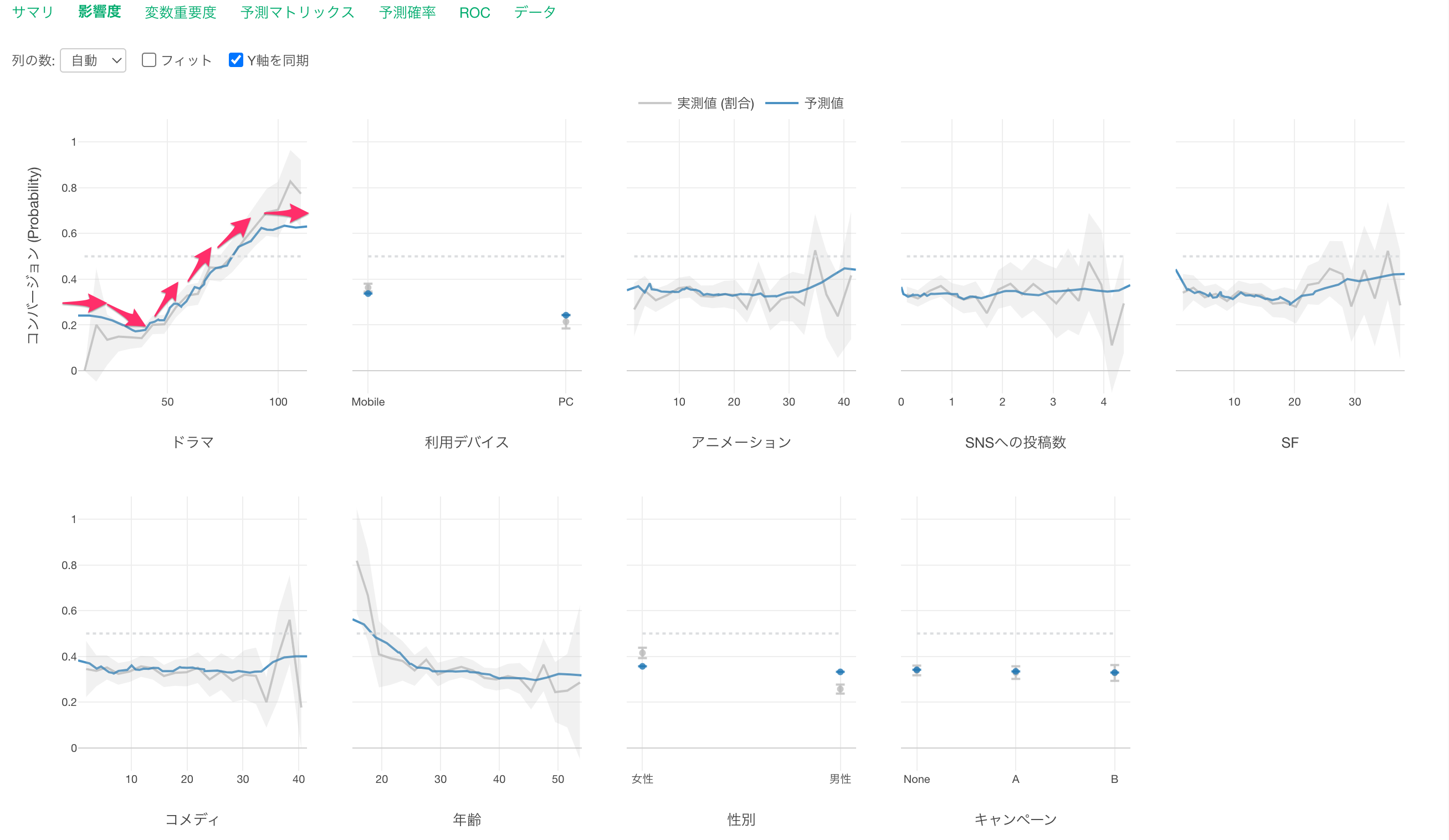
「ドラマ」に注目すると、視聴時間が増えるほど、コンバージョン率が高くなることがわかります。
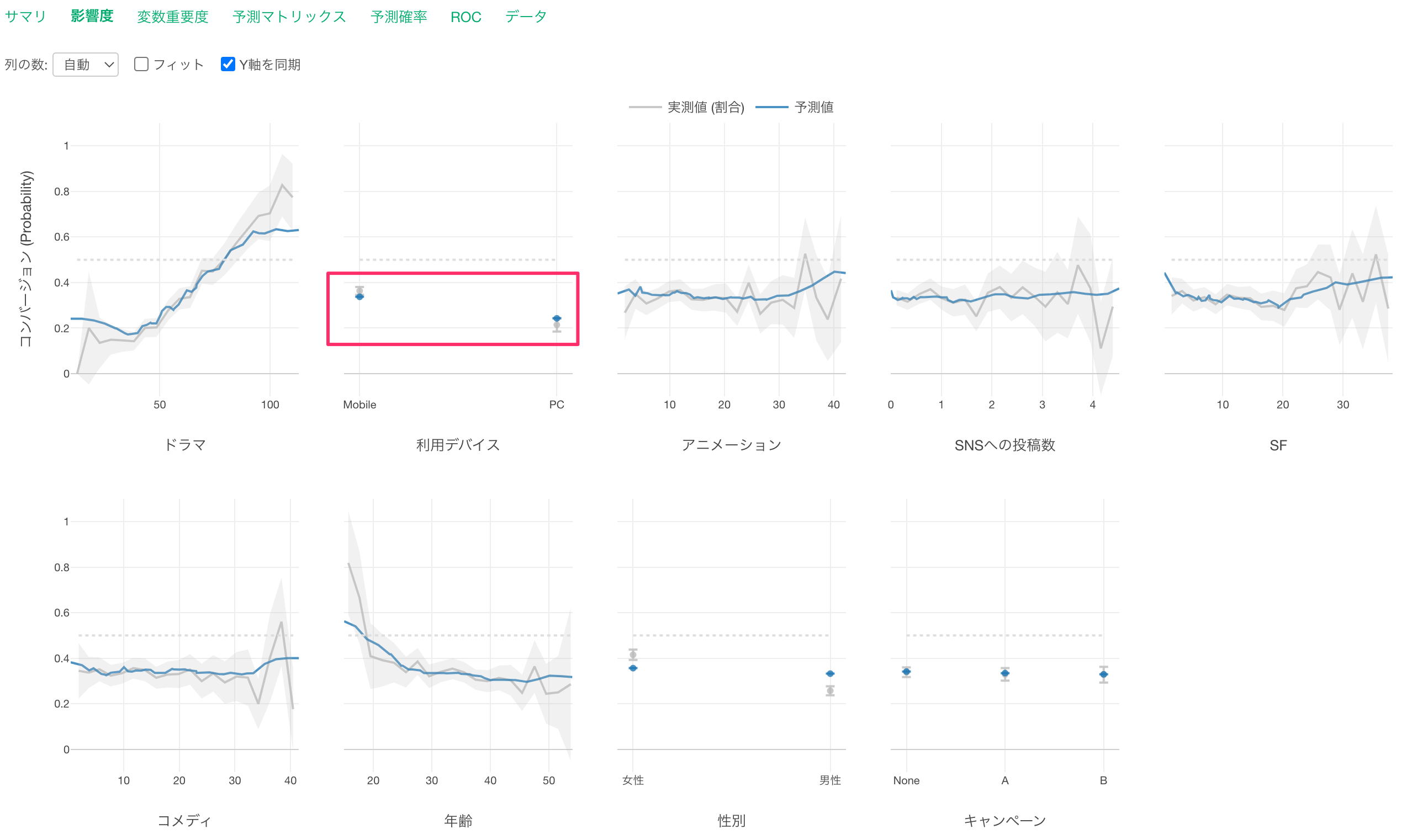
「デバイス」に注目をすると、主な利用デバイスが「Mobile」の方が「PC」と比べてコンバージョン率が高いことがわかります。
サマリ
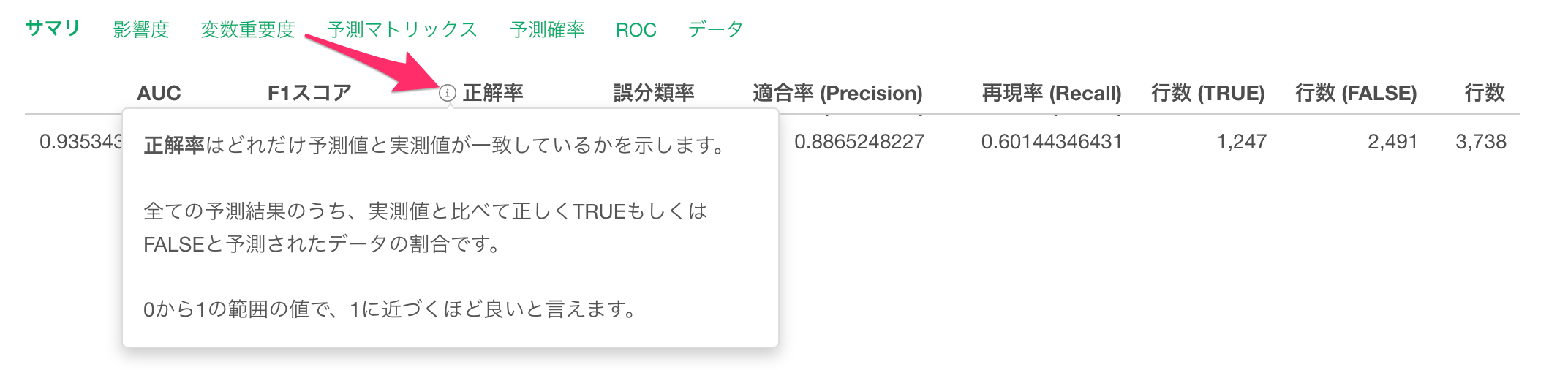
サマリタブでは、この予測モデルの評価を確認できます。

コンバージョンのTRUEとFALSEを、このモデルでどれだけ上手く分けられているかは「AUC」という指標で表されていて、AUCの情報アイコンからAUCの指標の細かい定義を確認いただけます。
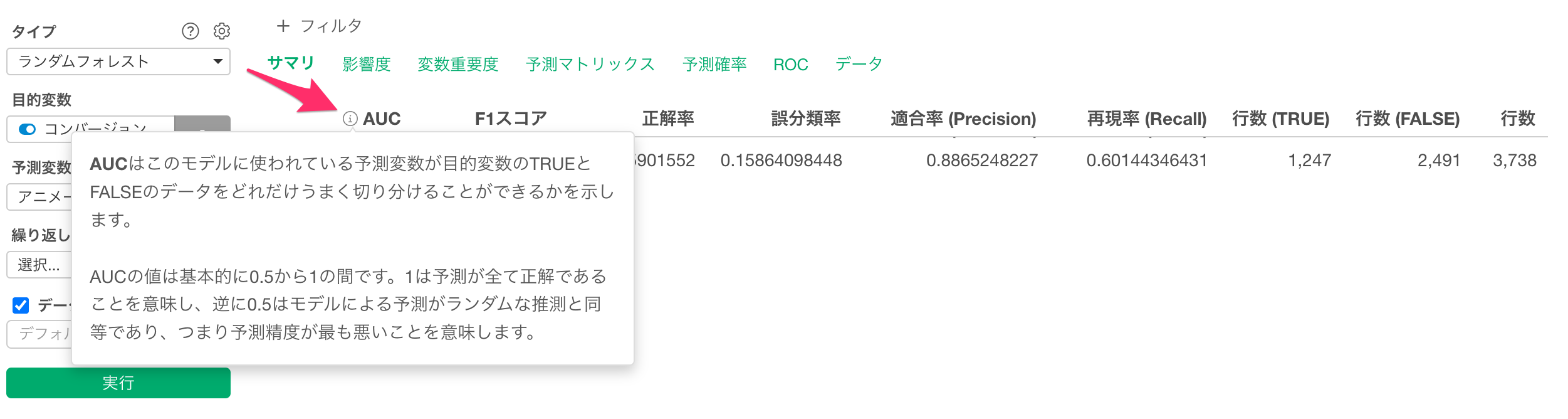
AUCはポップアップに表示されているように、0.5から1の間の値を取ります。1に近ければ近いほど、モデルが「TRUE/FALSE」を上手く分けられていることを示します。
今回は、AUCが0.93と1に近いため、このモデルを使うとTRUEとFALSEを上手く分けられているようです。

なお、サマリタブで表示されている指標のいくつかは同じように、指標の定義を確認いただけます。
こちらのトライアルツアーでは、ランダムフォレストの解釈方法を紹介しましたが、Exploratoryではどのタイプの予測モデルを作っても、「アナリティクスの文法」という仕組みをもとにモデルの解釈が可能です。
アナリティクスの文法に関する詳細はこちらのノートをご参照ください。
トライアル中の見込み顧客のコンバージョンを予測する
続いて、コンバージョンを予測するモデルを使って、まだコンバートするかどうかわからない顧客がコンバートする確率を予測します。
なお、作成した予測モデルを使って新しいデータに対して予測をするためには、作成した予測モデルの予測変数と同一の列を持ったデータが必要です。
予測用の新しいサンプルデータは、こちらのページからダウンロードできます。 
新規見込み客のトライアル状況のデータをダウンロードできたら、ダウンロードしたフォルダを開き、「新規見込み客のトライアルの状況.csv」をExploratoryの画面にドラッグ&ドロップします。
インポートダイアログが表示されるので、保存します。
データフレームの設定ダイアログが表示されるので、「保存」ボタンをクリックします。
新規見込み客のトライアルの状況のデータを新たにインポートできました。
いよいよ作成した予測モデルを使って、インポートした新しいデータに対して、コンバージョンを予測します。
テーブルビューに移動します。
ステップメニューから「モデルで予測(アナリティクス・ビュー)」を選択します。
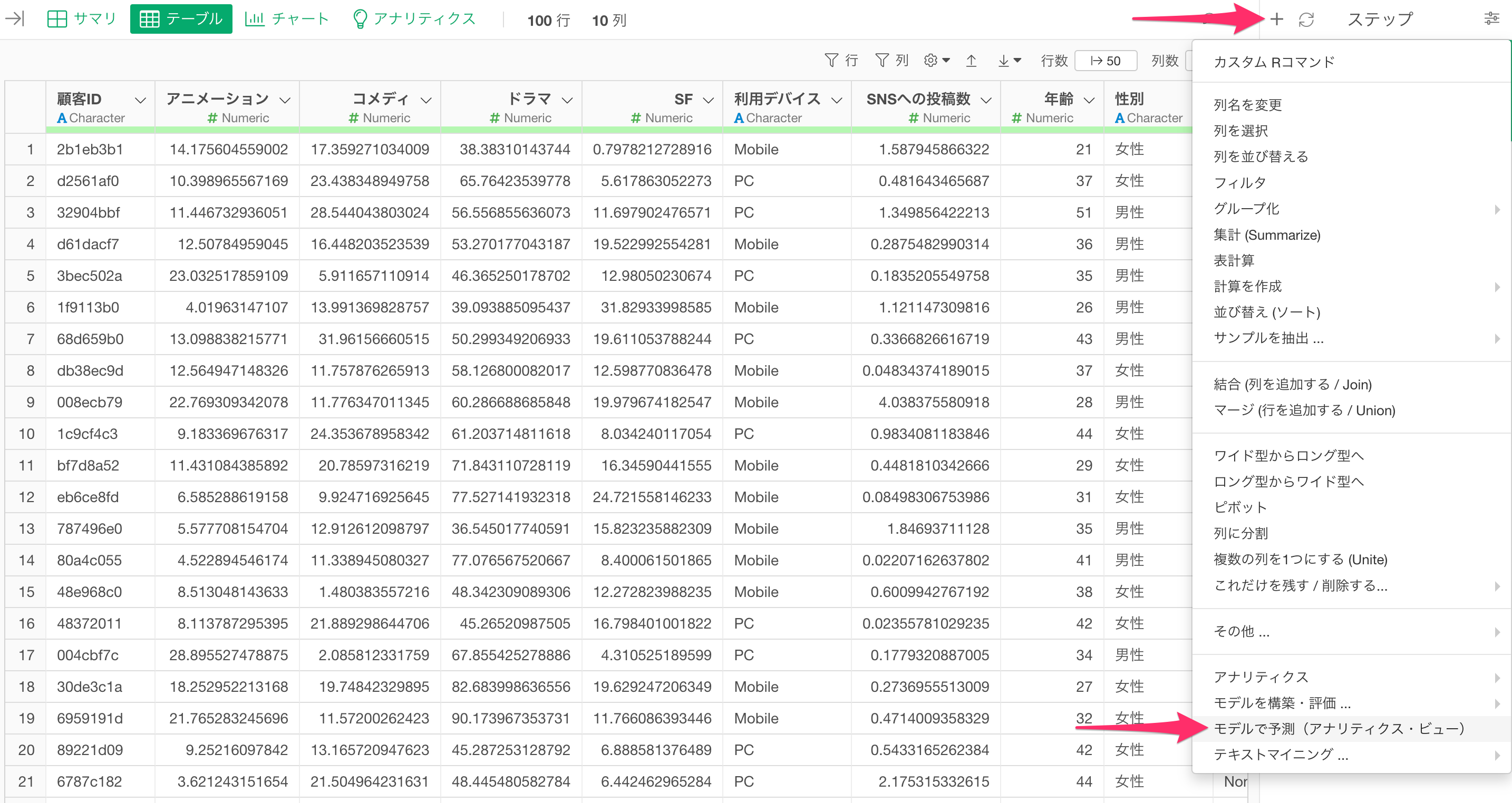
このメニューを選択すると、別のデータフレームで作成した予測モデルを使って、現在開いているデータフレームに対して予測ができます。
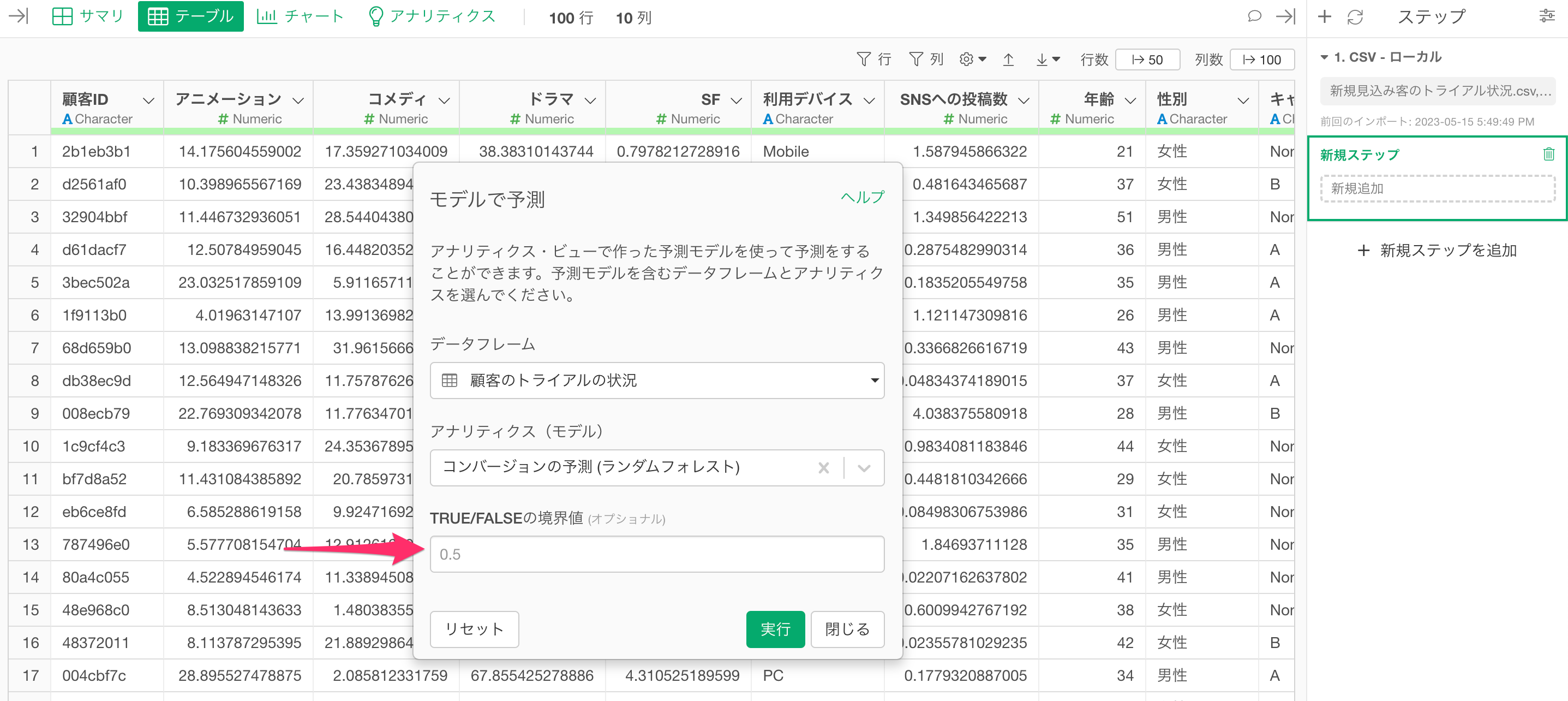
「モデルで予測」のダイアログが表示されるので、予測に使いたいデータフレームを選択します。
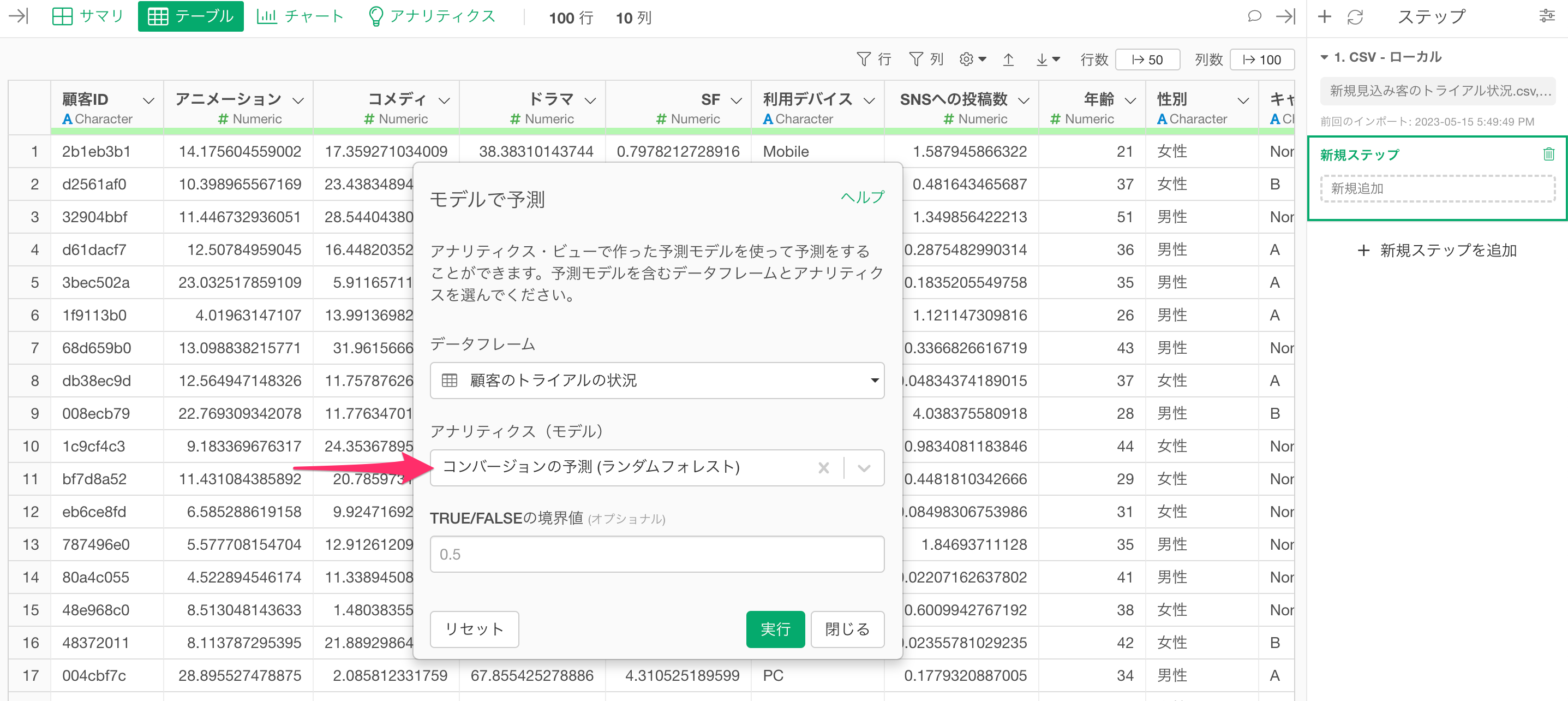
今回は「顧客のトライアルの状況」というデータフレームで作成した予測モデルを使って予測をしたいので、「データフレーム」に「顧客のトライアルの状況」を選択します。
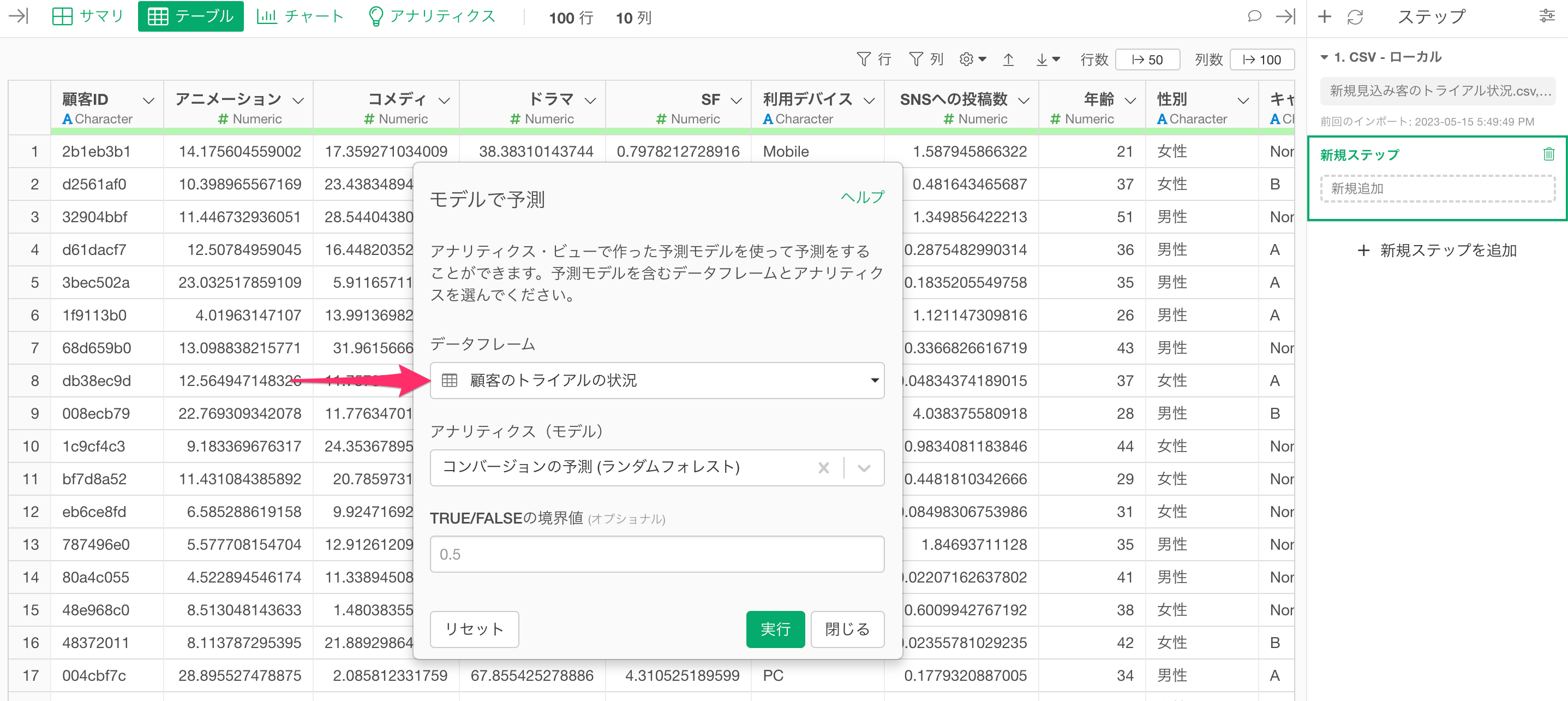
続いて、「アナリティクス(モデル)」から予測に使いたいモデルを選択します。
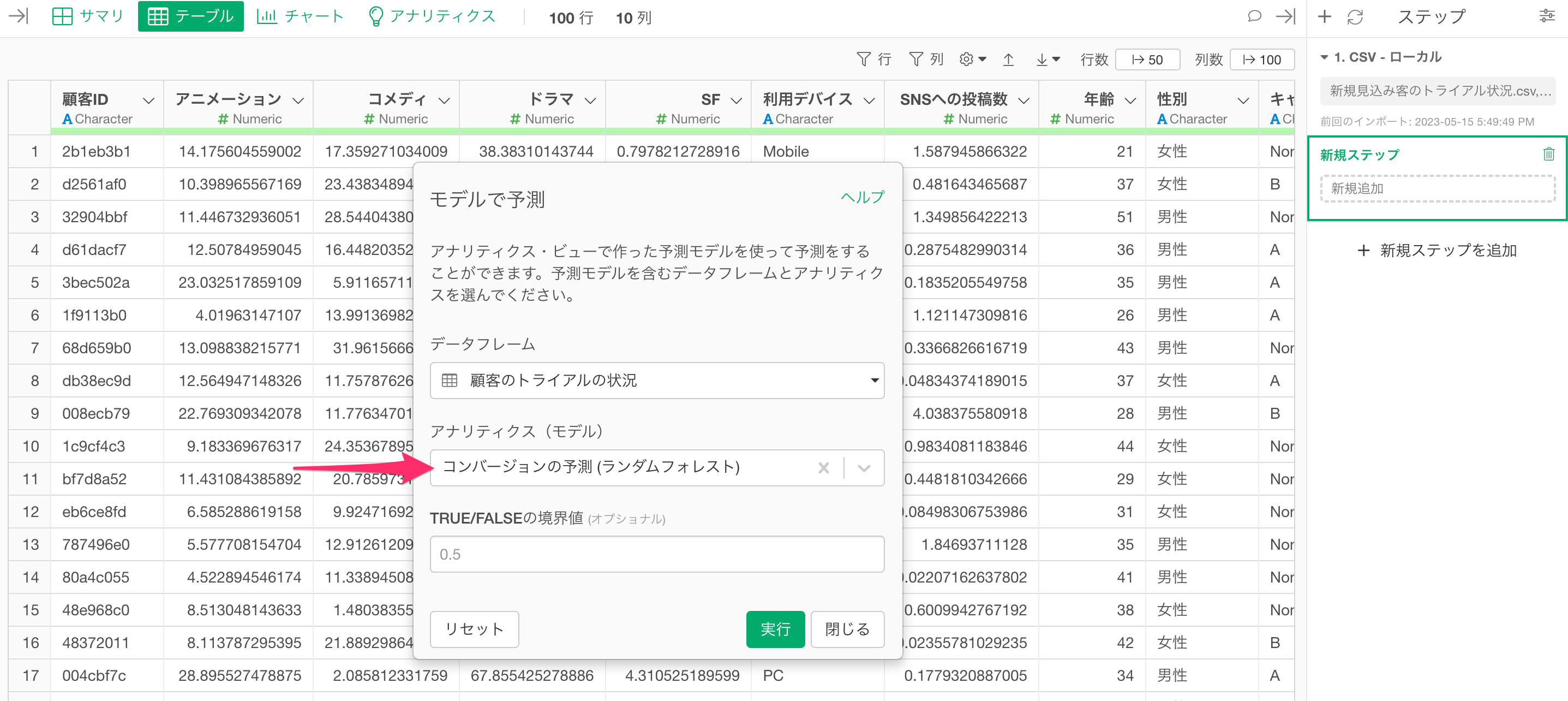
今回は「TRUE/FALSEの境界値」はデフォルトの0.5のままにして実行します。これによって予測モデルによって返される確率が0.5 (50%) 以上であれば「TRUE」、それ未満であれば「FALSE」という列が追加されます。
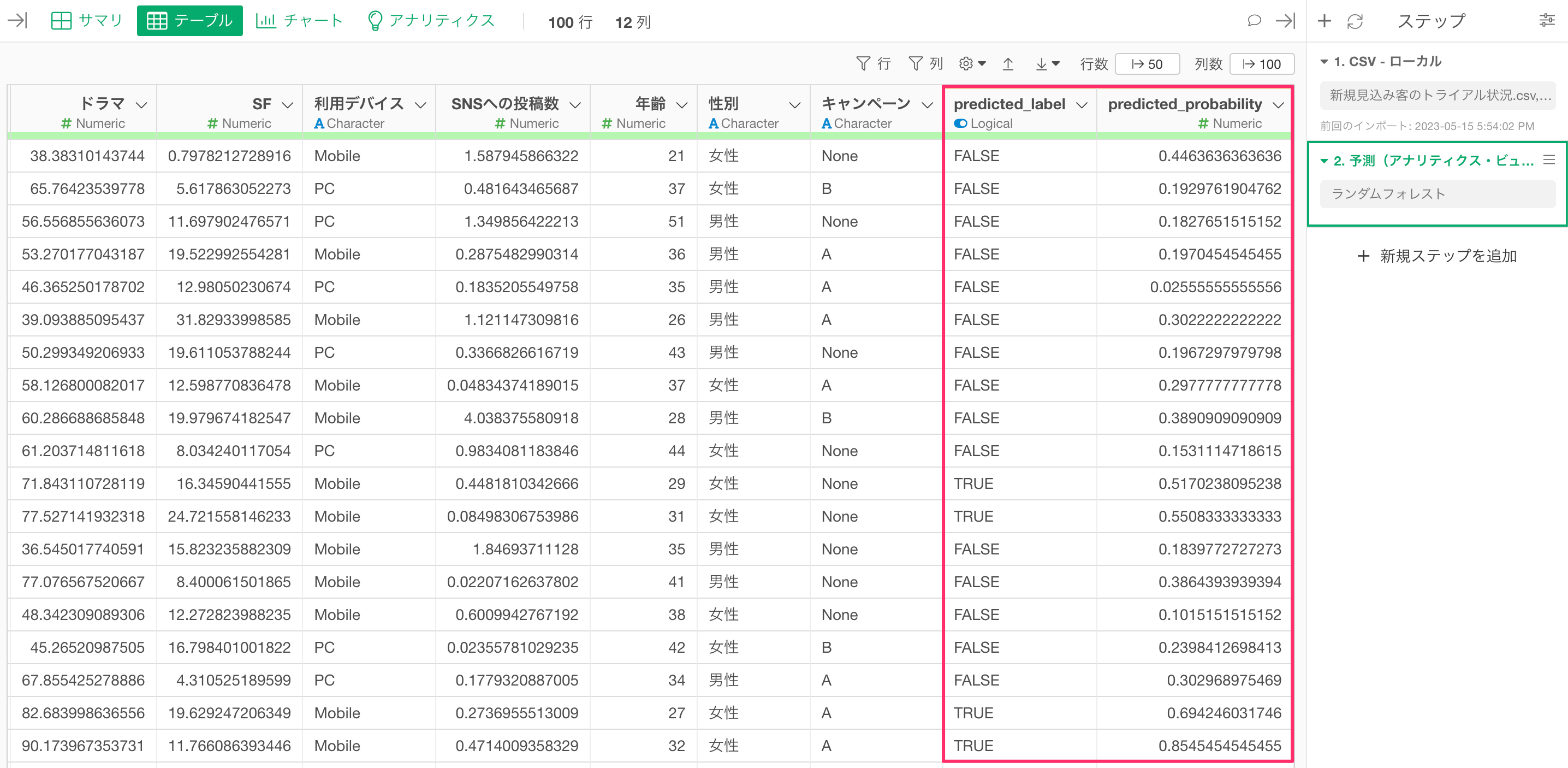
コンバージョンを予測するステップが追加され、コンバートする確率の列「predicted_probability」と、その確率と設定した境界値を元に、コンバートするかどうかの列「predicted_label」の列がデータに追加されました。
サブスクデータ分析
サブスクリプション型ビジネスユーザー様向けのトライアルツアーの他のパートは下記のリンクからご確認いただけます。
次回はリテンションが改善しているかを調べられる「コホート分析」を行います。
今回と同じく、20分程度終えていただける内容になっていますので、是非、お試しください!
サブスク型ビジネスデータ分析のためのページ
SaaSなどを始めとするサブスクリプション型ビジネスにとって重要なKPI、データの加工、可視化、統計・機械学習といった様々なデータサイエンスの手法やシリコンバレーなどでの事例を1つのページにまとめて紹介しています。
ぜひ、ご覧ください!