アンケートデータ分析 Part 3 - 因子分析
このノートは、アンケートデータを有効活用して、ビジネスやサービスの改善につなげるための使い方を効率よく学ぶために作られた「アンケートデータ分析」のトライアルツアーの第3弾「因子分析」です。
因子分析はアンケートの回答データから、質問に答えた背景や、モチベーションをつかむことなどに利用される統計のアルゴリズムです。
因子分析を行うと、アンケートの回答の背後にある共通性である**「因子」**を見つけられ、因子分析の結果を、商品開発に役立てたり、マーケティング活動の際のターゲティングやコミュニケーションに役立てられます。
所要時間は20分ほどです。
それでは、さっそく始めていきましょう!!
因子分析とは?
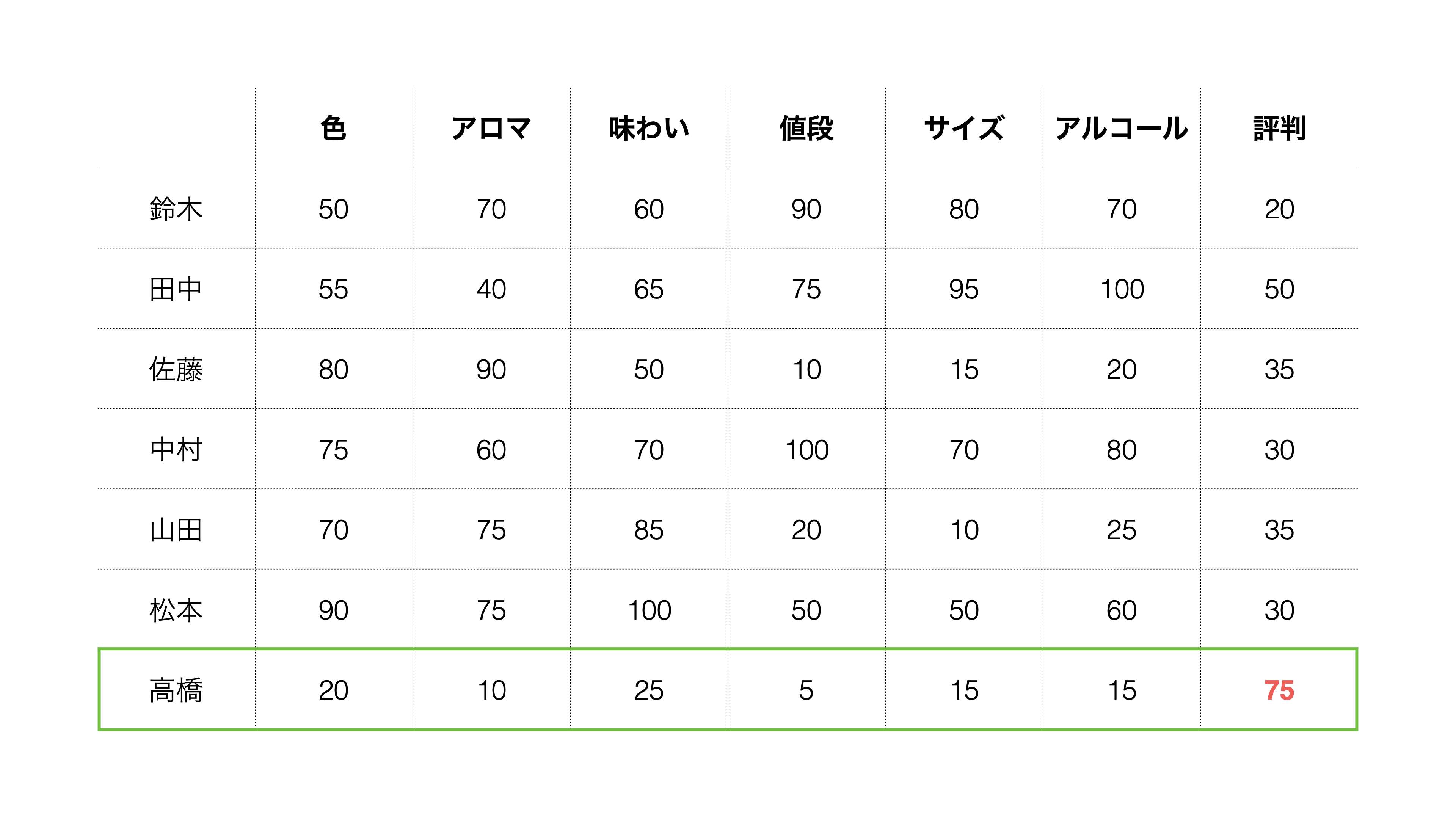
例えば「ビールに求めるもの」に関するアンケートを実施し、以下の結果を得られました。
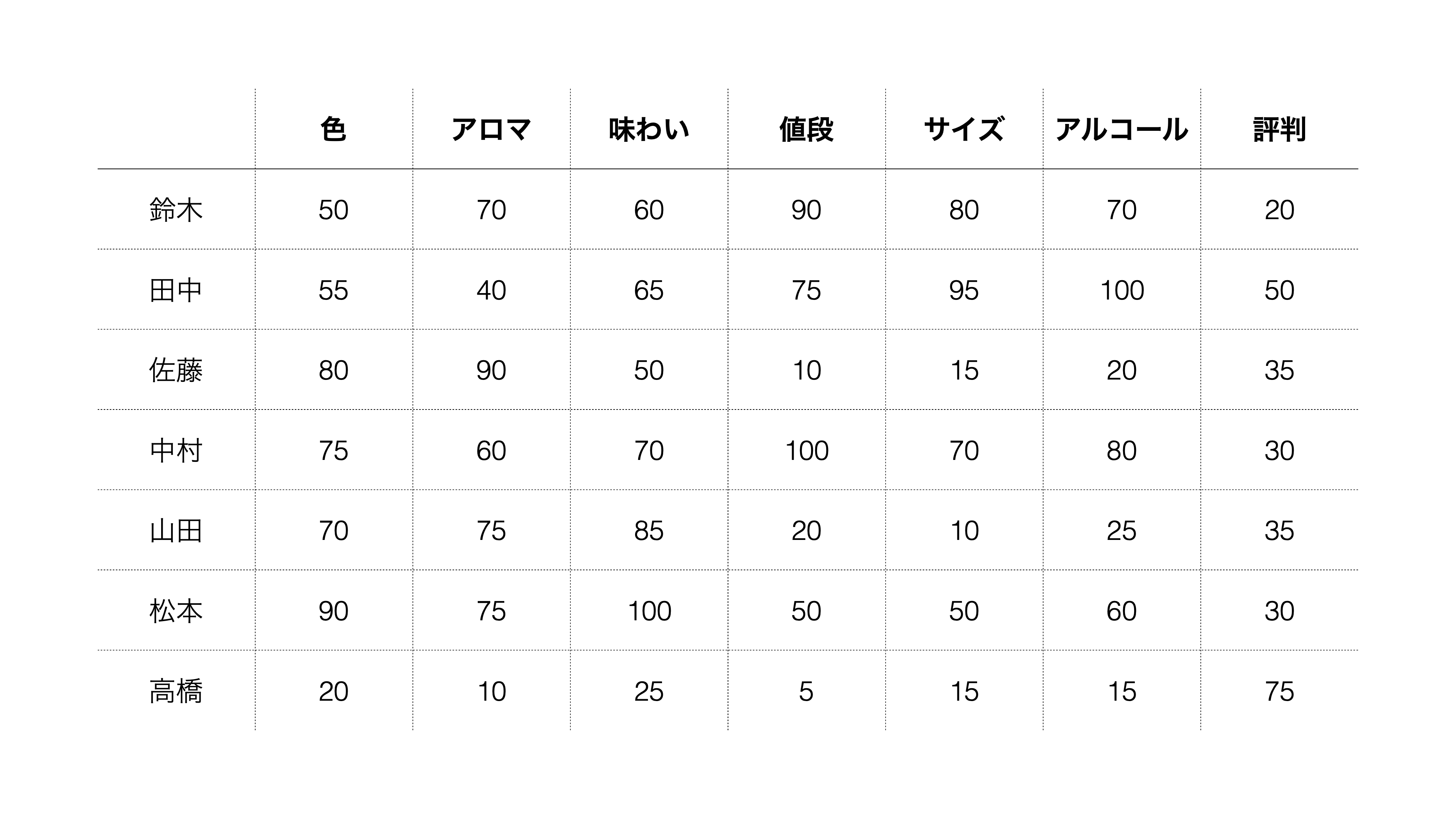
このデータは1行が1人の回答者を表しており、各列は重要度のスコアを表しています。数値が大きくなるほど、その項目の重要度が高くなります。
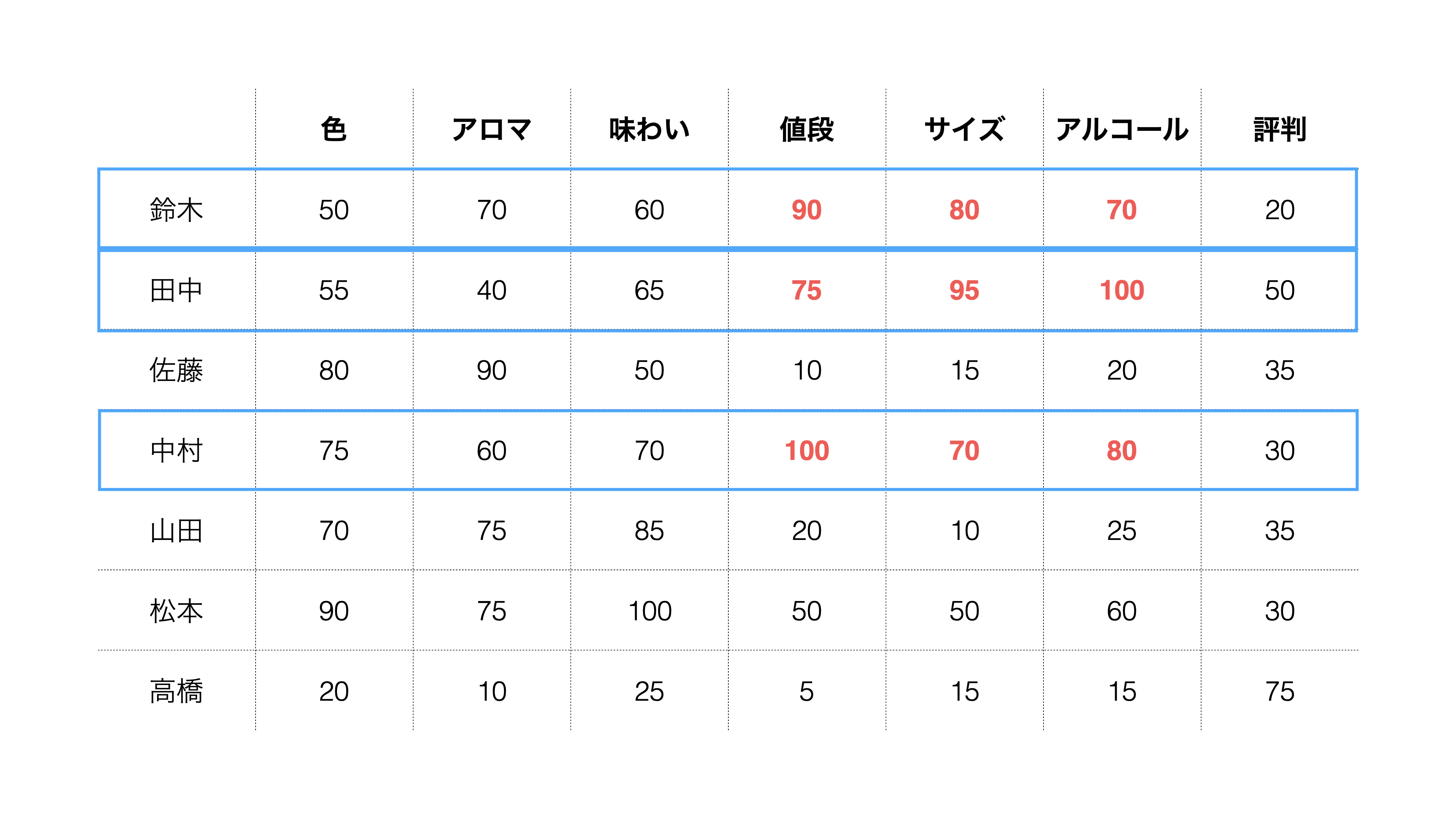
回答を見てみると「値段」、「サイズ」、「アルコール」を重視する人がいるようです。
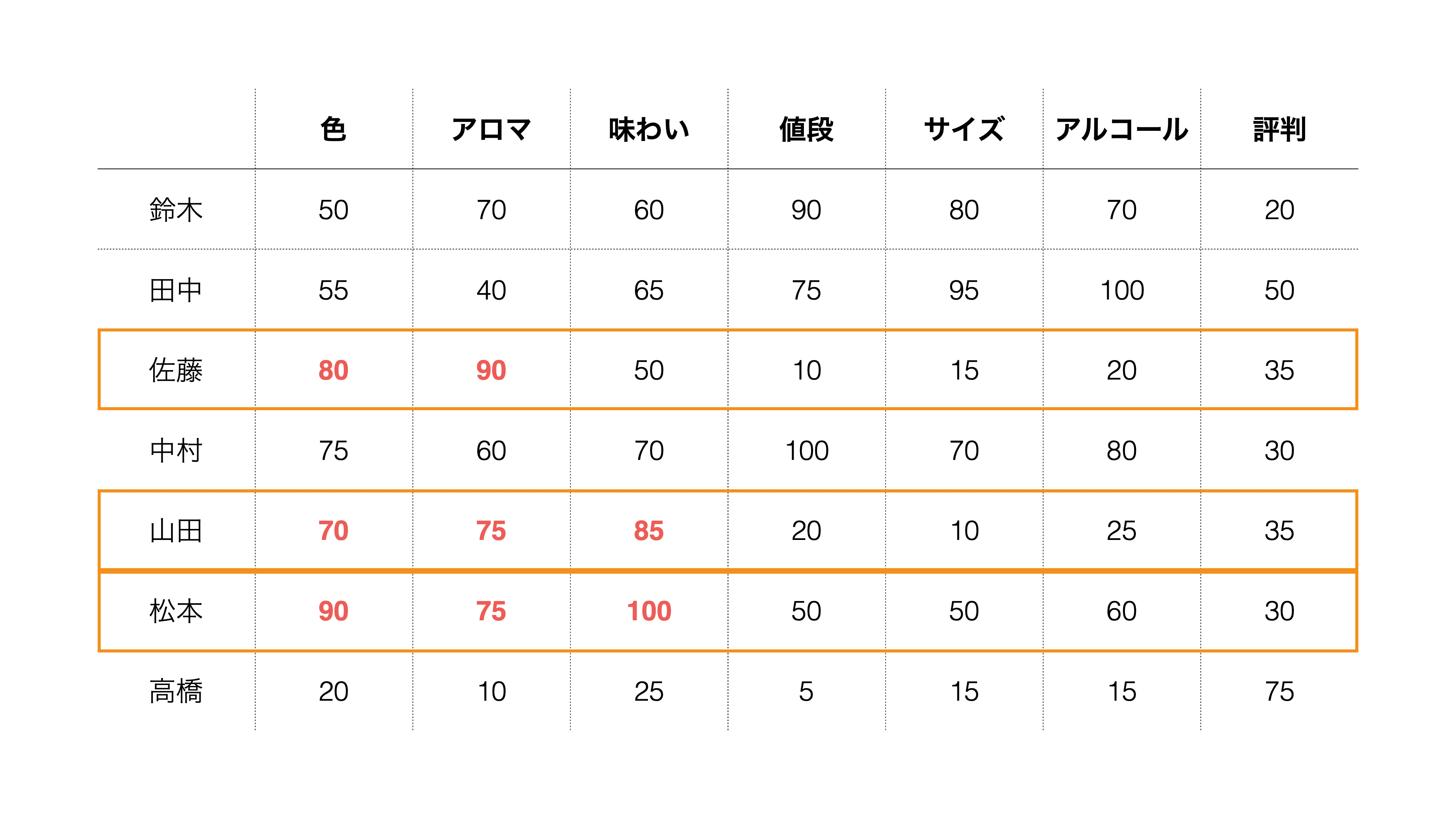
また、「色」、「アロマ」、「味わい」を重視する人もいるようです。
さらに「評判」を重視する人もいるようです。
各々のグループは、重要と考える項目が異なるわけです。
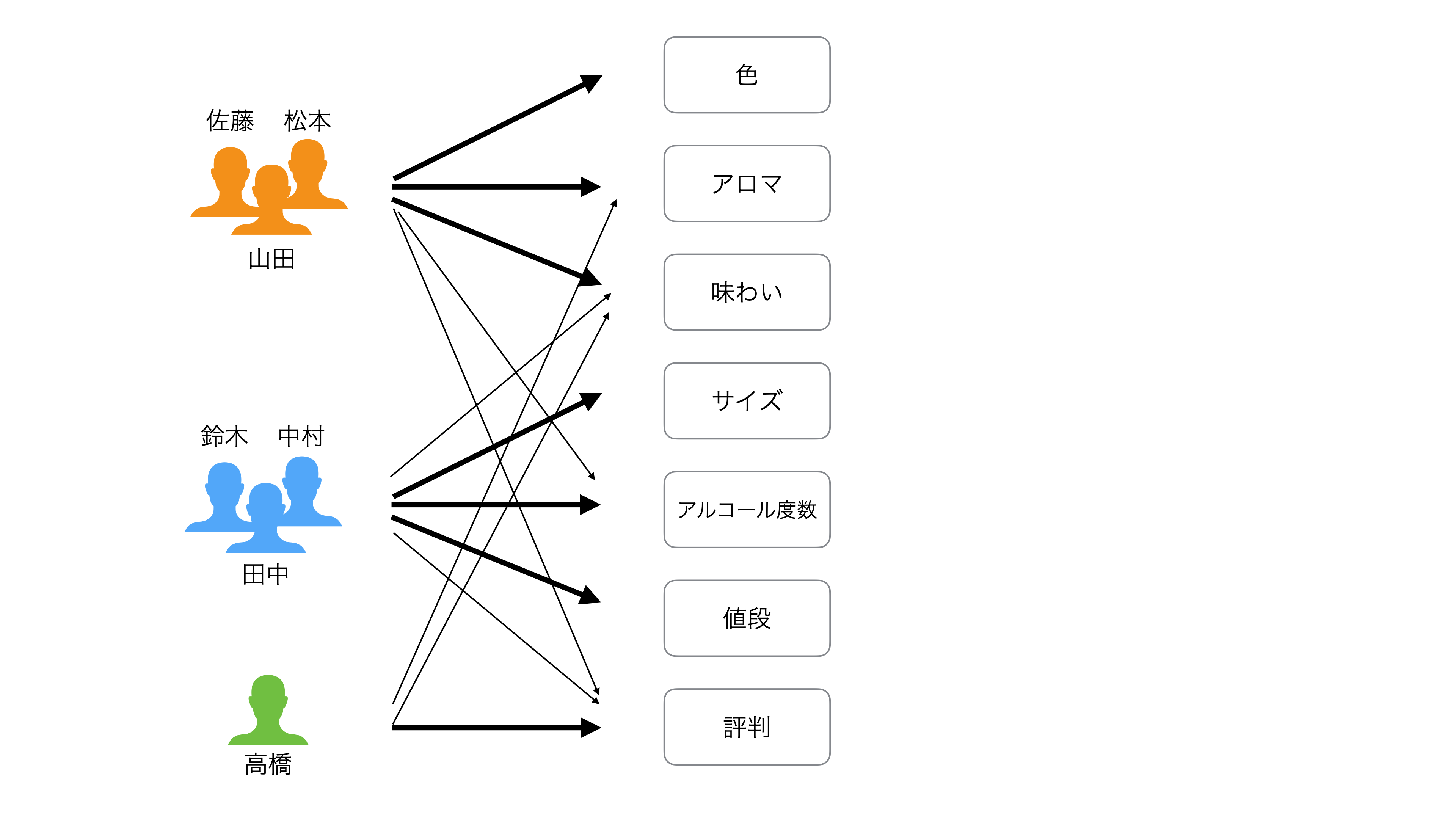
見方を変えると「ビールに求めるもの」に対して、以下を重要に考えるモチベーション(因子)があるとも言えます。
- オレンジの人: 「クオリティ」
- 水色の人: 「コスト」
- 緑色の人「評判」

因子分析では、上記のようなモチベーションのラベル付けをできるように、アンケートの背後にあるモチベーションを「因子」として抽出し、各因子と各変数(質問)の相関の強さを「因子負荷量」として、計算します。
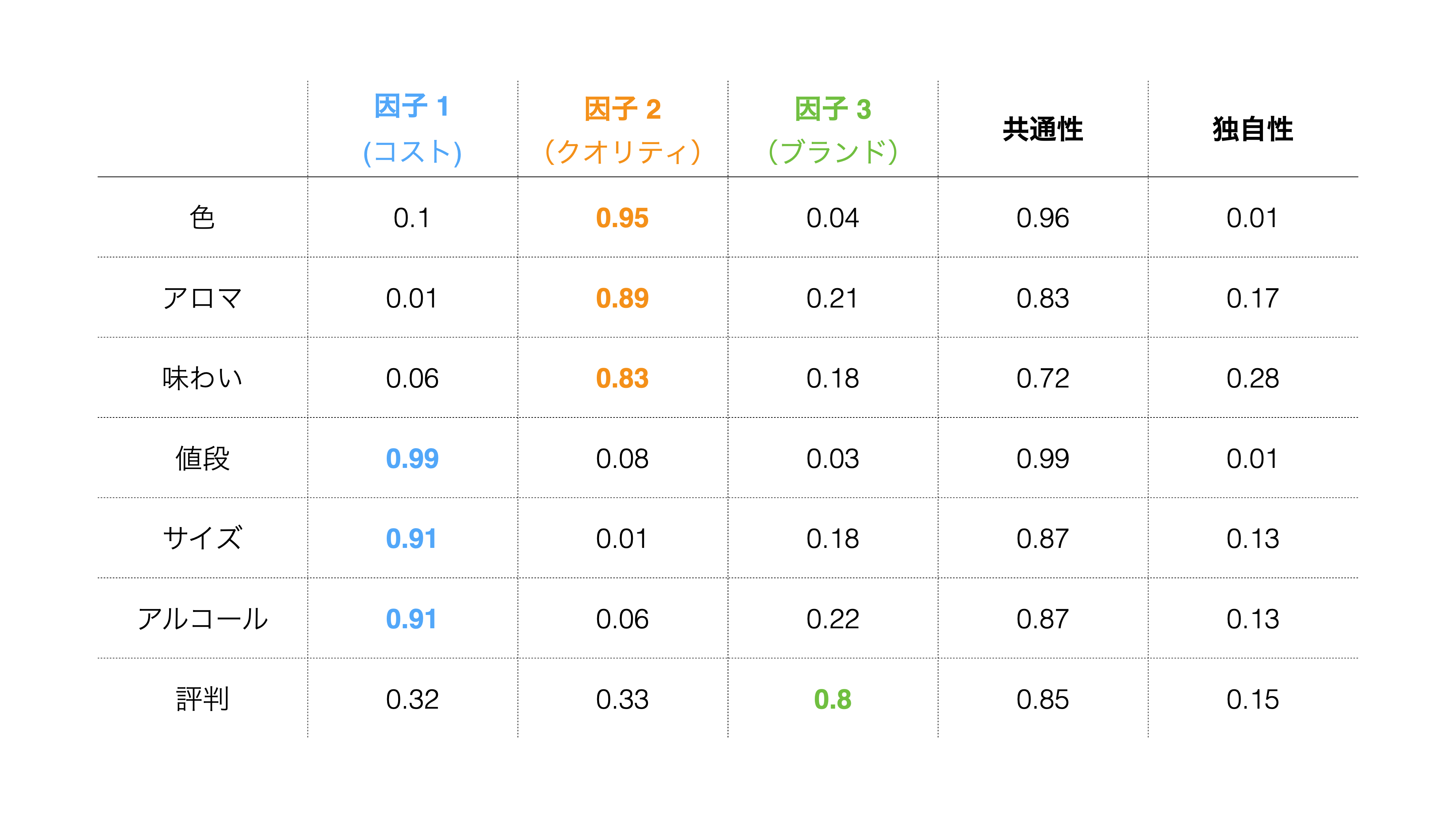
因子負荷量は−1から1の間の値をとり、−1または1に近づくほど、各因子がそれぞれの変数に与える影響が強いと言えます。
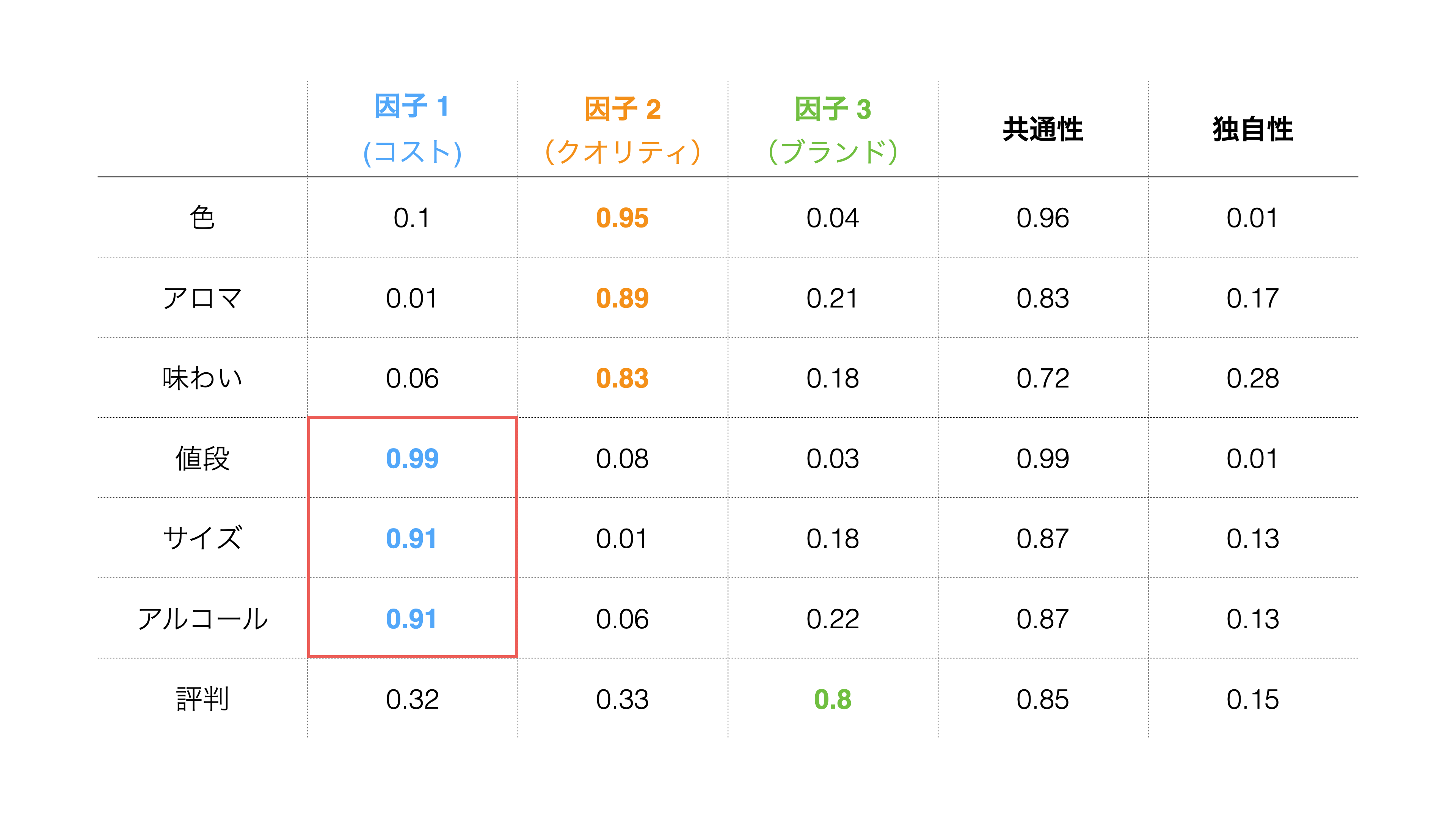
そのため、例えば「因子1」は「値段」、「サイズ」、「アルコール」の「因子負荷量」が高いため「因子1」との関係が強く、因子1には「コスト」という名前を設定できます。
必要なデータ
因子分析には、1行が1観測対象(例: 回答者)のデータが必要で、因子の抽出にあたっては、数値型の列が必要です。
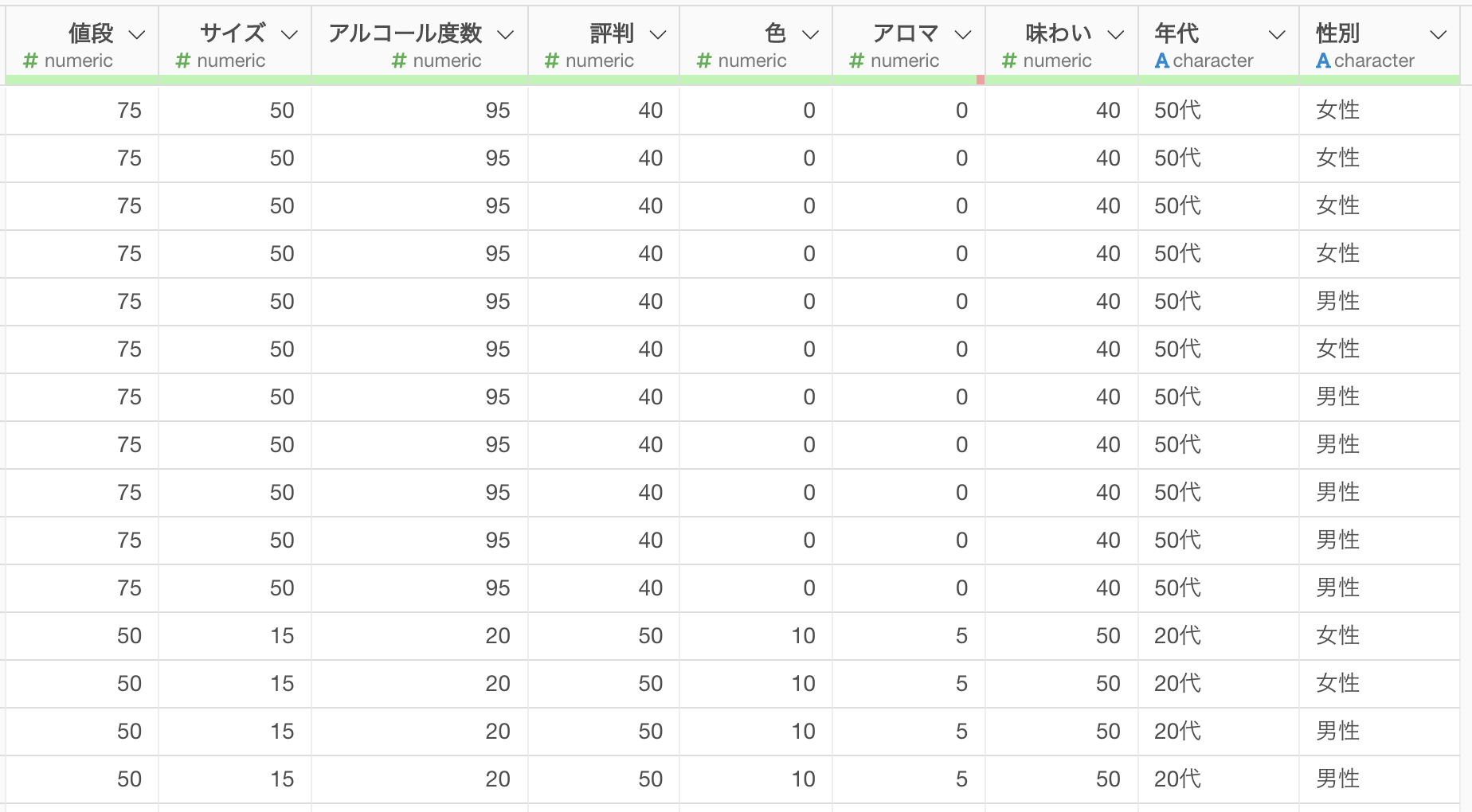
データの概要
今回はサンプルデータとして、「ビールに求めるもの」に関するアンケートのデータを使用します。データはこちらのページからダウンロードできます。
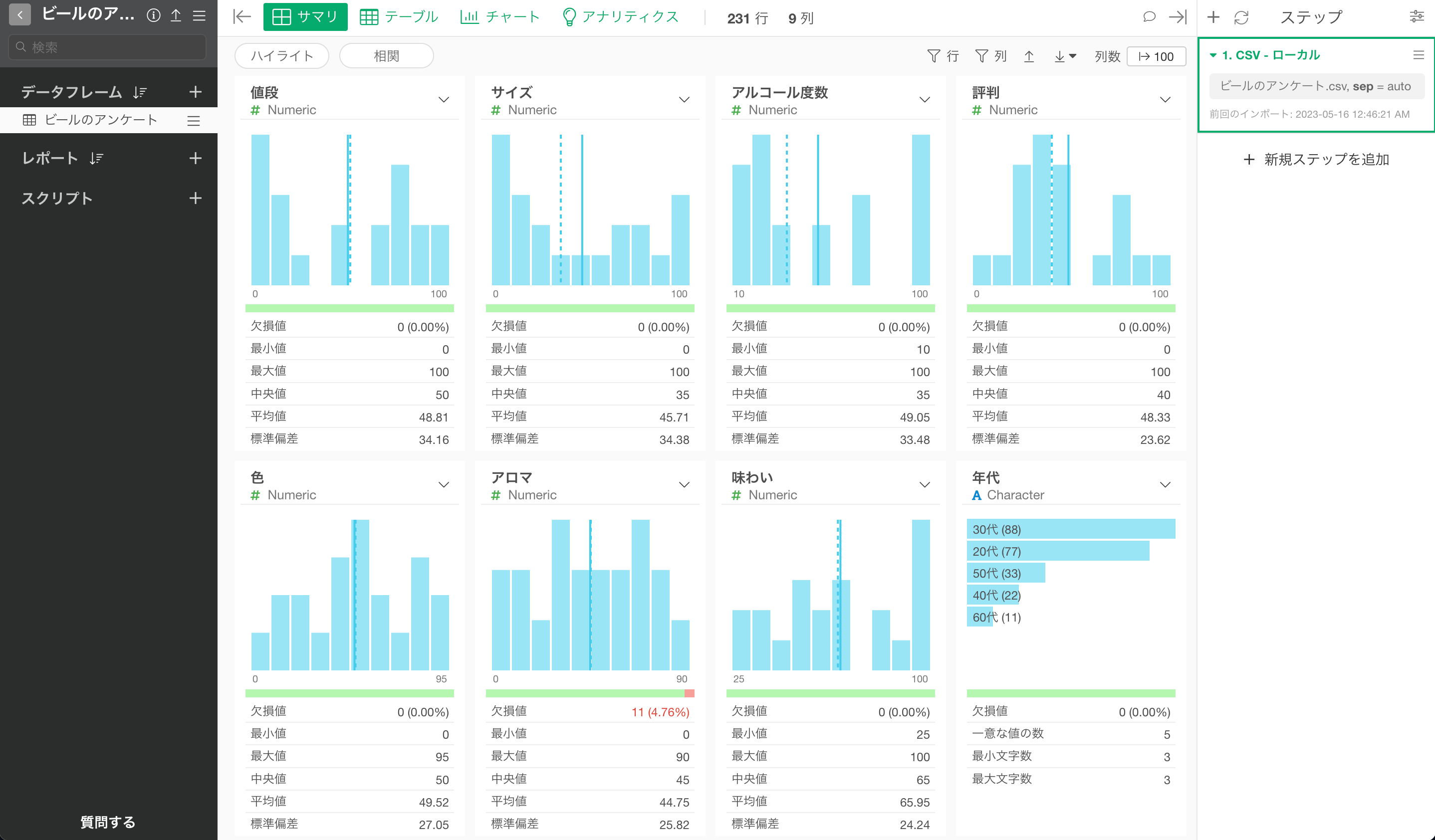
このデータは、1行が1人の回答者を表していて、列には値段やサイズに関する質問の回答スコアや、回答者の属性(年代、性別)があります。
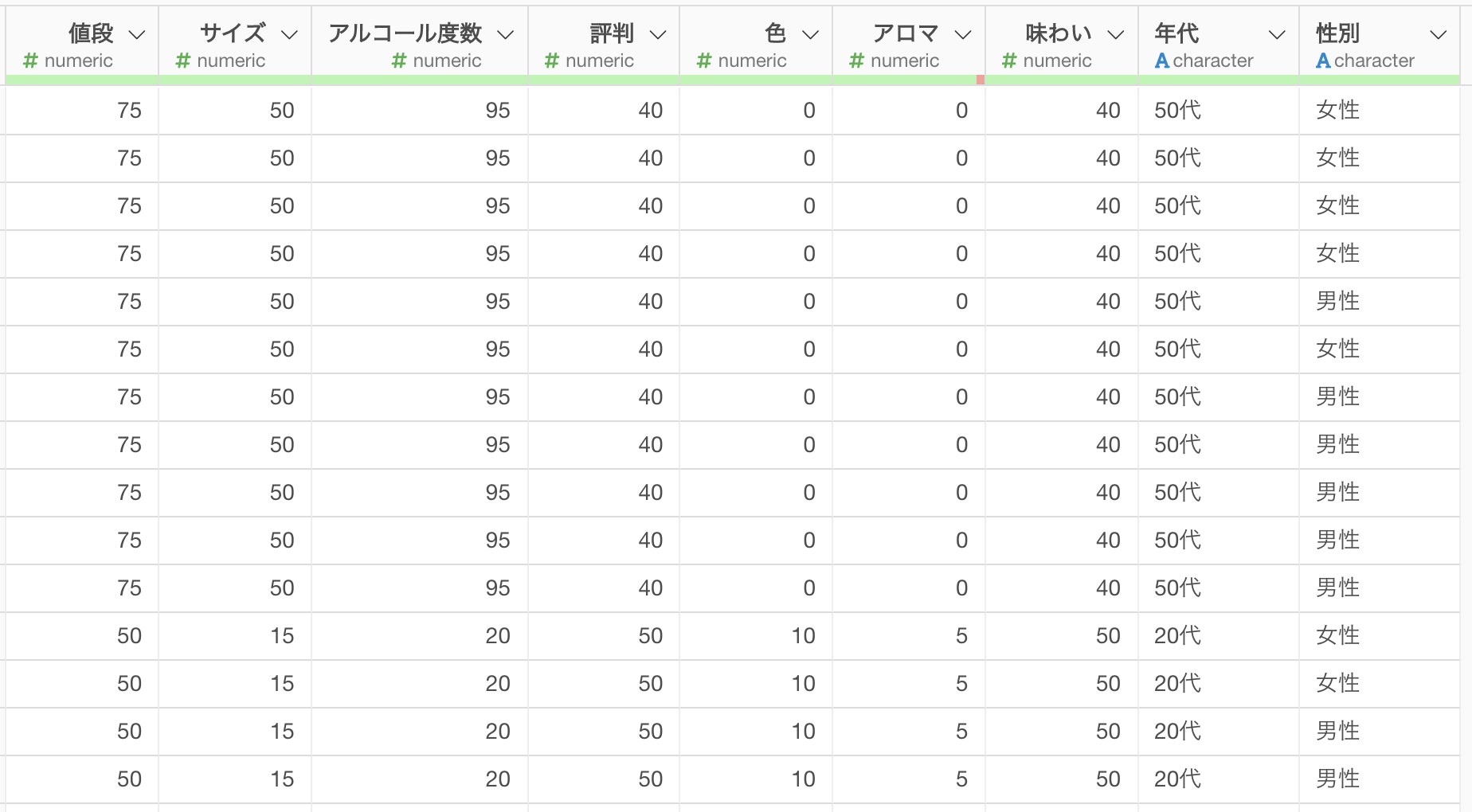
なお、質問の回答スコアは100段階で、数値が大きくなるほど重要度が高くなります。
データのインポート
Exploratoryを起動したら、プロジェクト「新規作成」ボタンをクリックします。

プロジェクトを作成するためのダイアログが表示されるので、任意の名前をつけて、作成ボタンをクリックします。
プロジェクトを作成できました。

プロジェクトを作成することができたら、次はデータをインポートします。データはこちらのページからダウンロードできます。
顧客のトライアルの状況のデータをダウンロードできたら、ダウンロードしたフォルダを開き、「顧客のトライアルの状況.csv」をExploratoryの画面にドラッグ&ドロップします。
すると、インポートダイアログが表示されます。
インポートダイアログでは左側にある項目から、データをインポートする際の設定を指定できますが、今回は設定は不要なため「保存」ボタンをクリックします。
するとデータフレームの設定ダイアログが表示されるので、「保存」ボタンをクリックします。
ビールのアンケートデータをインポートできました。
因子分析を実行する
因子分析をしたいときには、「アナリティクスビュー」に移動します。
タイプに「因子分析」を選択します。

変数の列をクリックして、因子分析に使用する列を選択します。シフトキーを押すことで、複数の列を一気に選択できます。
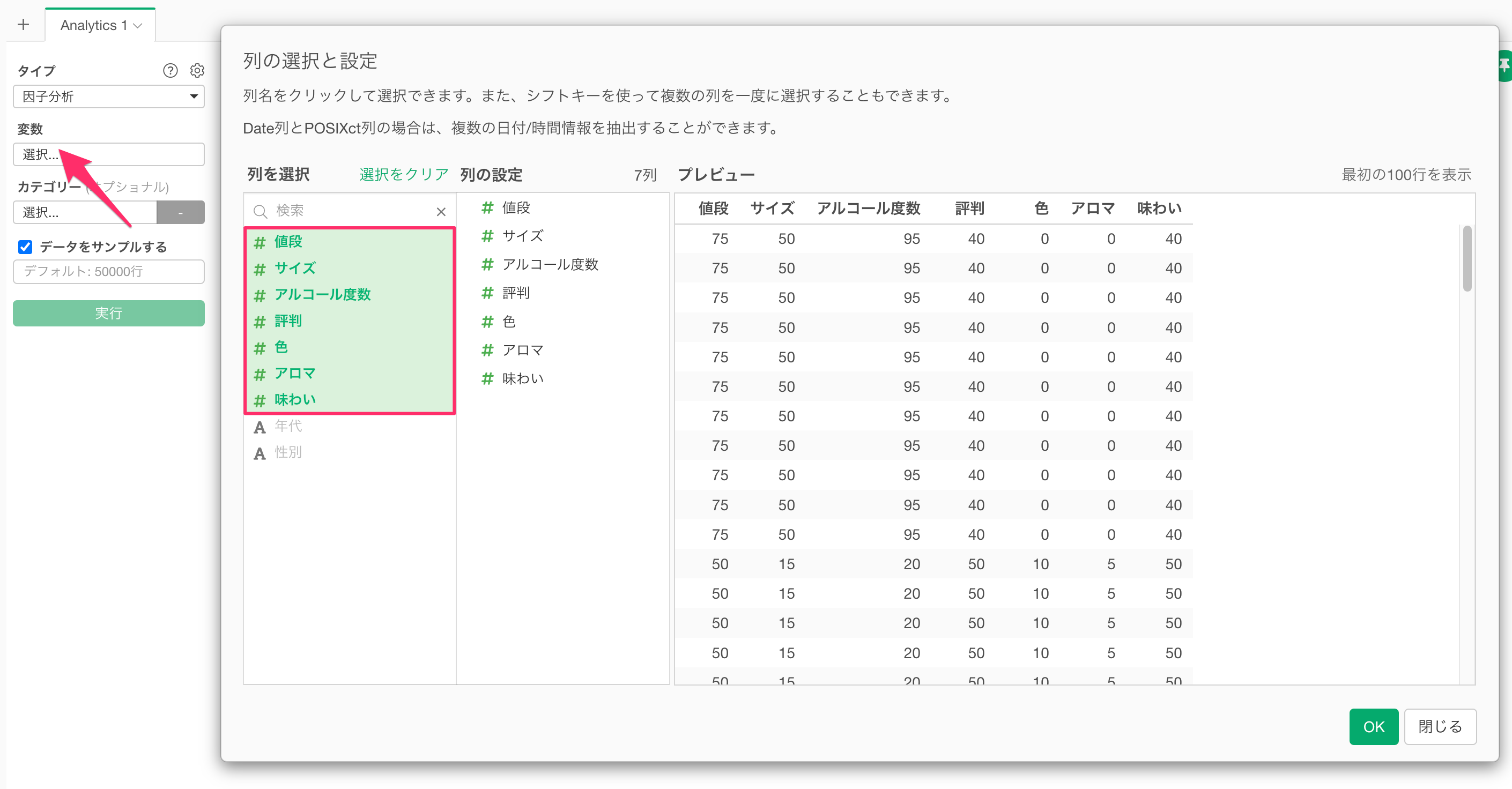
列の指定が完了したら実行することで、因子分析の結果が表示されます。
結果の解釈
因子分析を実行すると、結果を解釈するための複数のタブが表示されます。

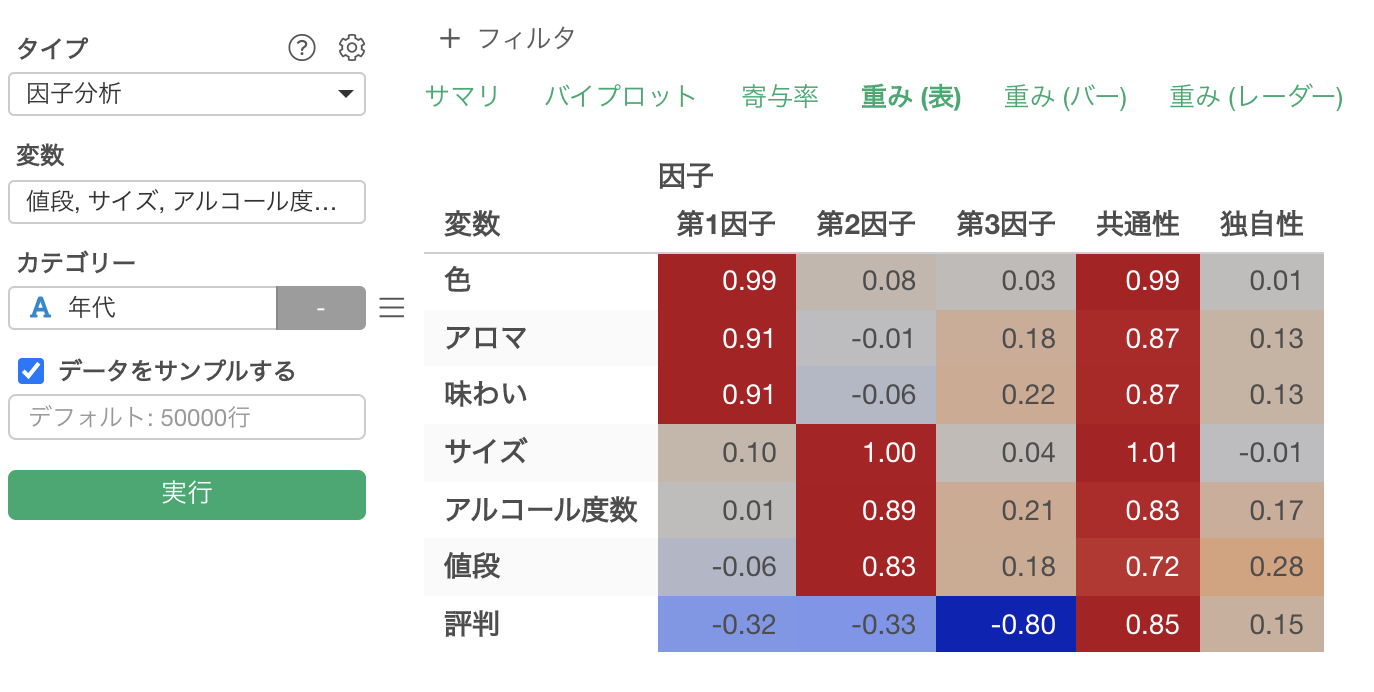
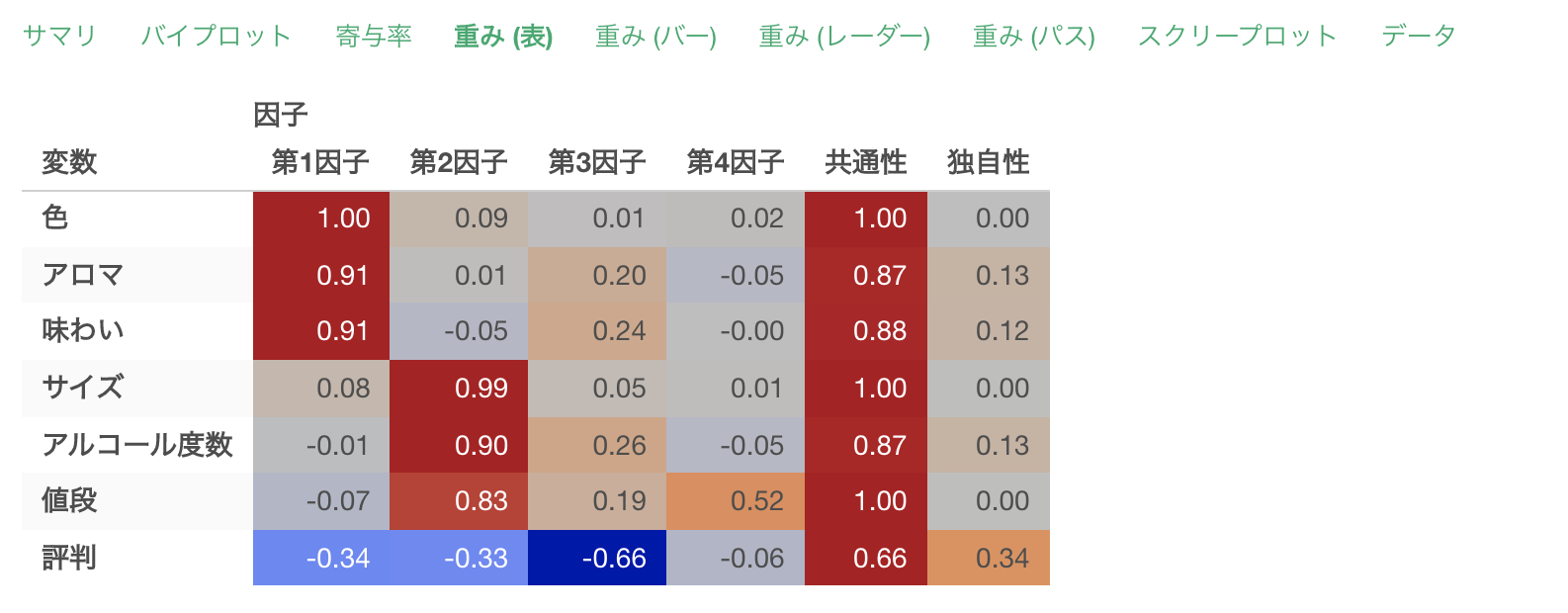
重み(表)
重み(表)のタブでは、抽出した因子ごとに、各変数(質問)の因子が変数に与える影響の強さの指標として、**「因子負荷量」**が表示されます。
因子負荷量は−1から1の間の値をとり、−1または1に近づくほど、各因子がそれぞれの変数に与える影響は大きくなります。

例えば、因子負荷量が高い変数を考慮して、「色」「アロマ」「味わい」の因子負荷量が1に近い、第1因子には「クオリティ」といった共通性を見出せます。
同じように各因子には以下に名前をつけられそうです。
- 第1因子: クオリティ
- 第2因子: コスト
- 第3因子: 評判
同様の情報は、重み(バー)のタブや、
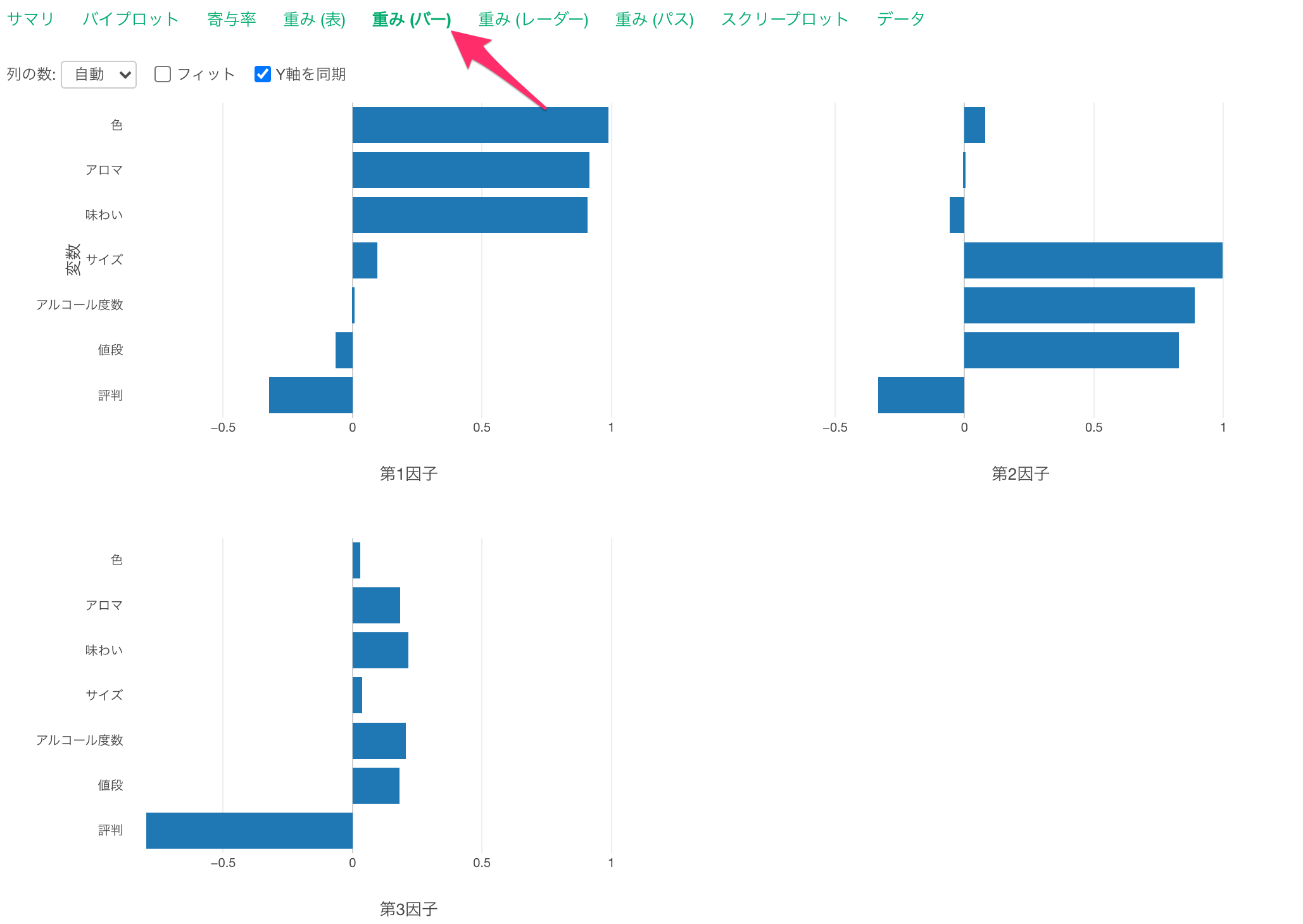
重み(レーダー)のタブでも確認できます。
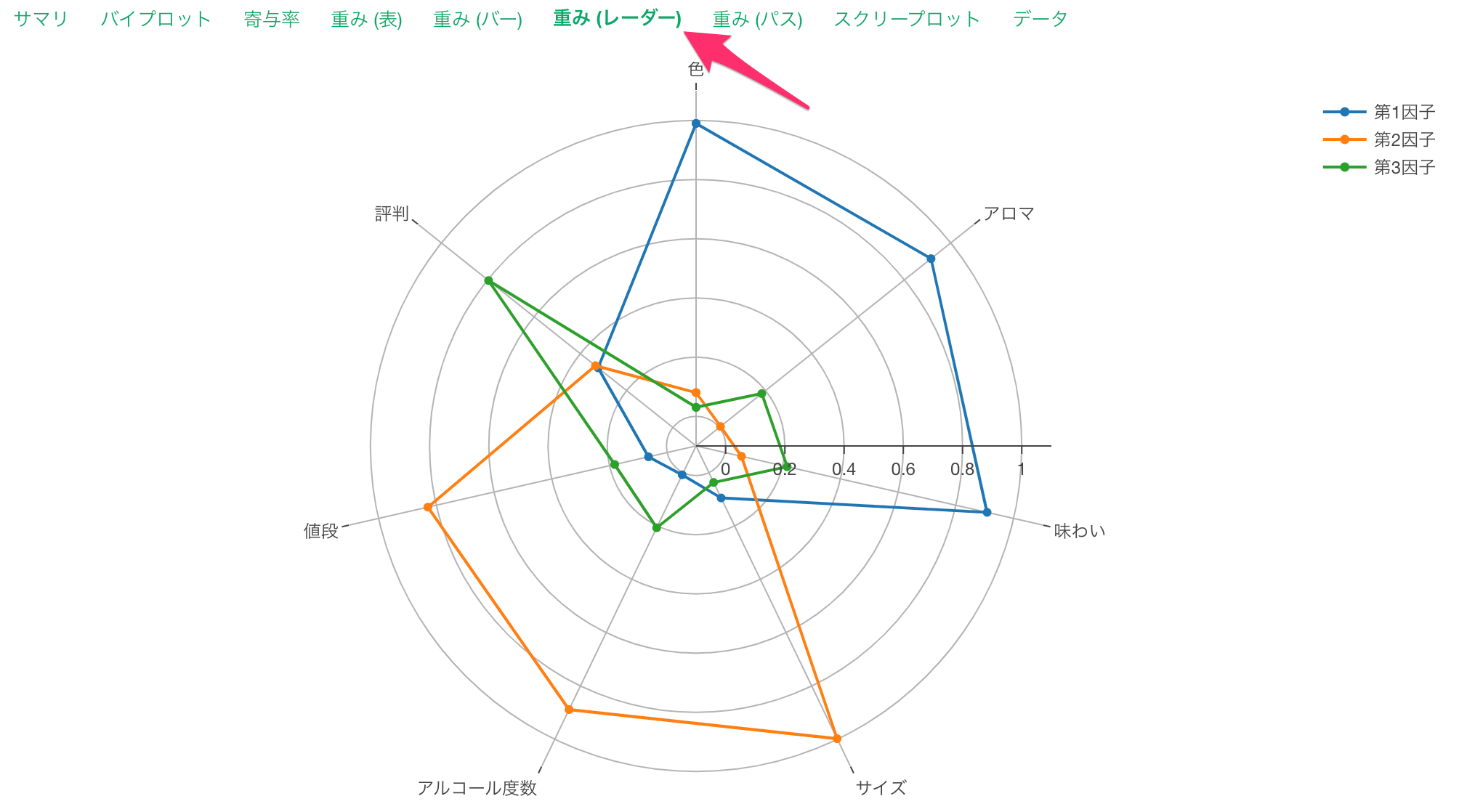
なお、レーダーチャートで表示される因子負荷量は、因子負荷量の絶対値です。
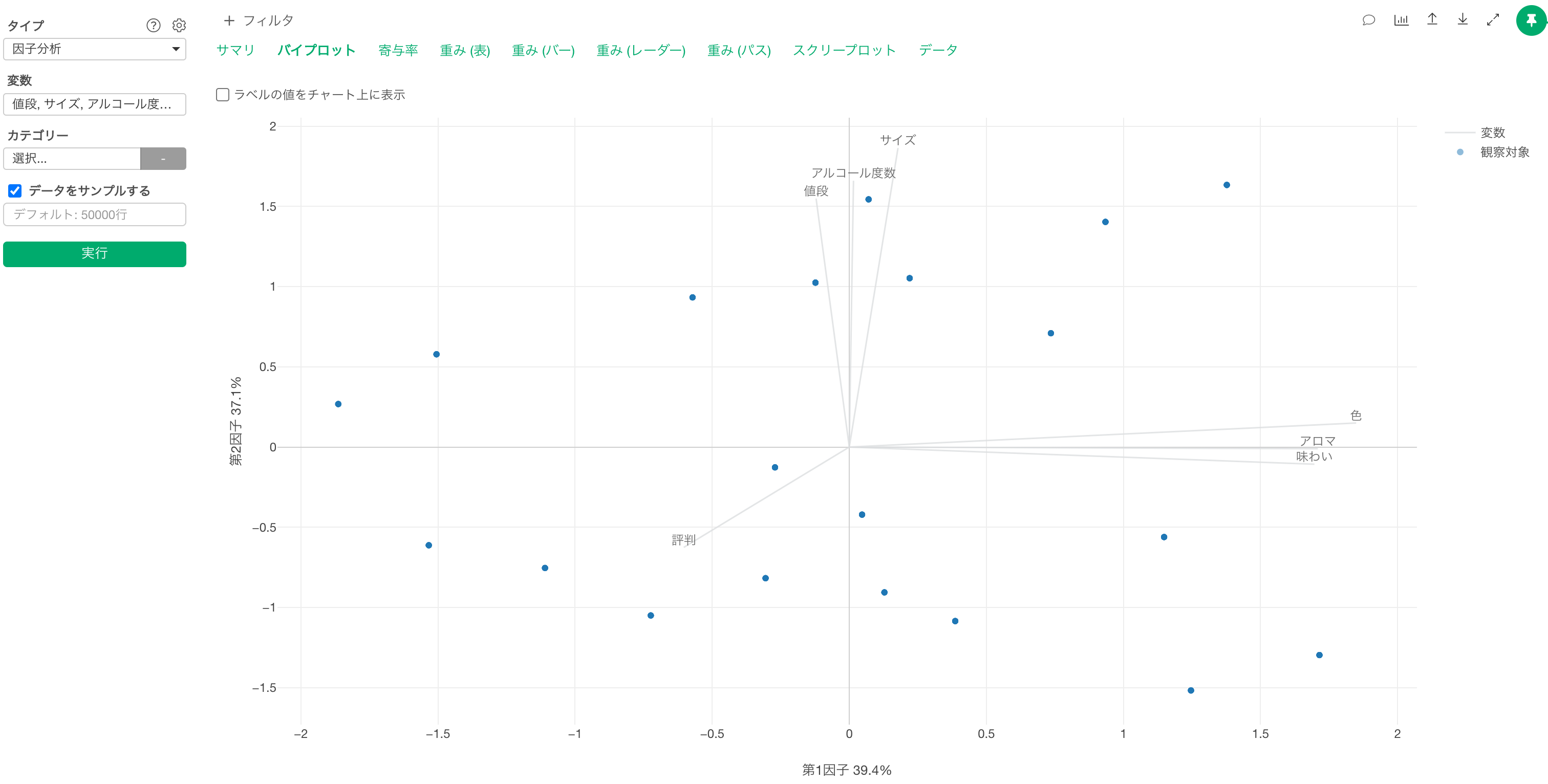
バイプロット
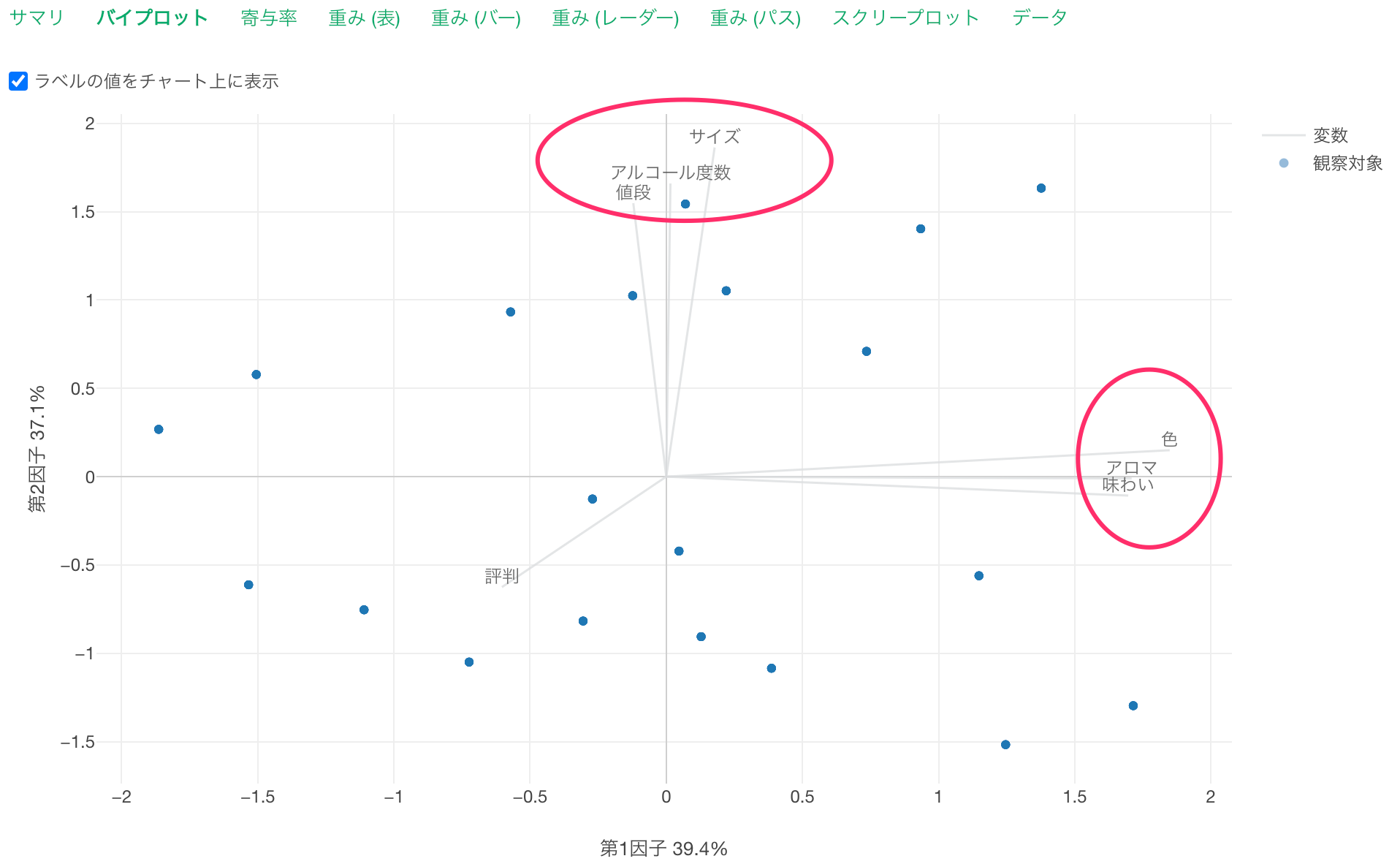
「バイプロット」のタブでは、最初の2つの因子(X軸の第1因子と、Y軸の第2因子)によって、もとの変数間の関係を可視化したチャートが表示されます。

バイプロットで表示される線は、それぞれの変数(質問)を表しており、**点はデータの1行(回答者)**を表します。また、相関の強い変数の線は同じ方向に伸びます。
そのため、「サイズ」、「アルコール度数」、「値段」に関する回答の相関と、「色」、「アロマ」、「味わいと」に関する回答の相関を確認できます。
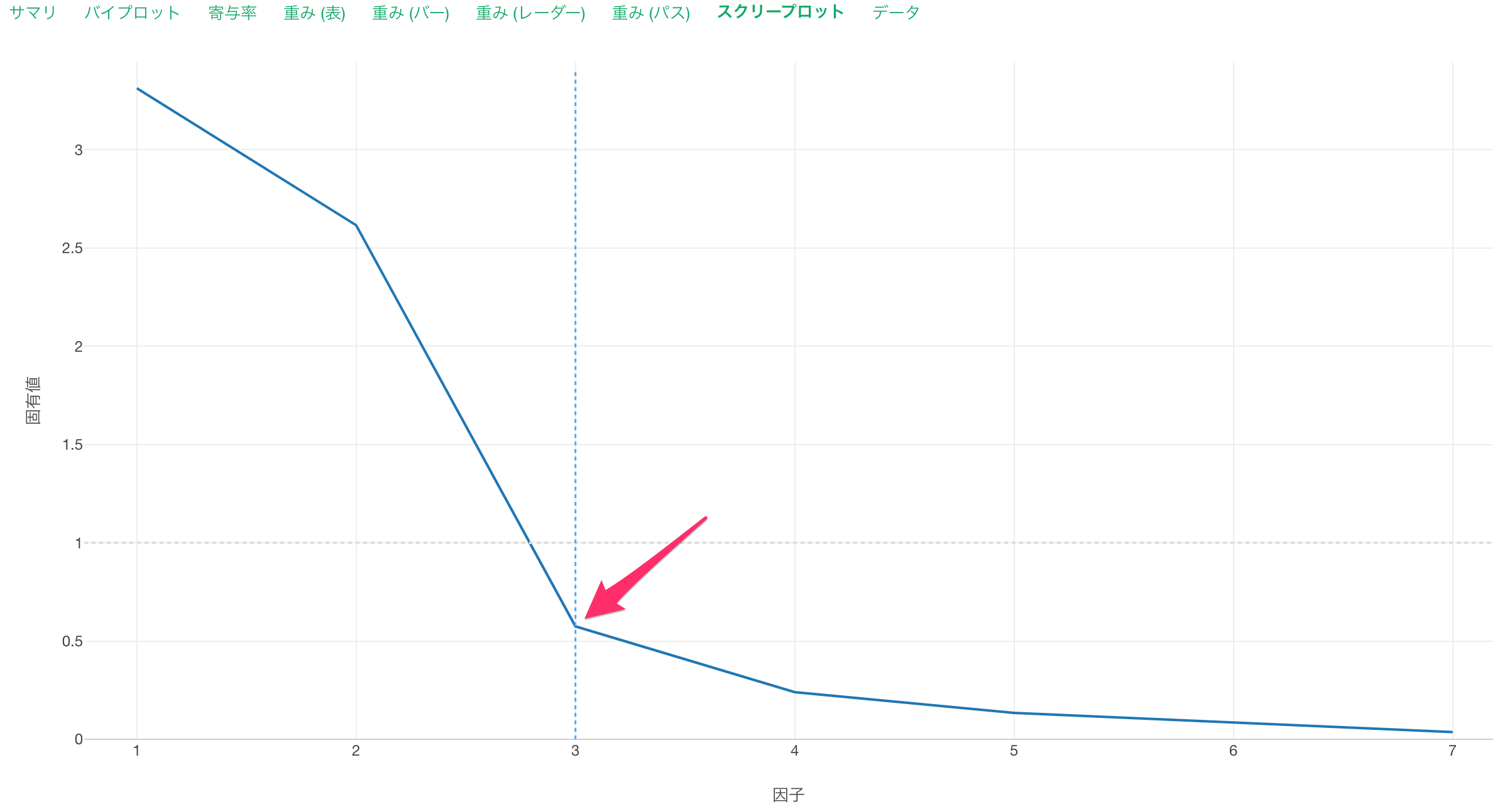
スクリープロット
スクリープロットでは、因子の数を増やしていったときの誤差のばらつき(固有値)を可視化しています。誤差のばらつきの減少が収束するあたりが最適な因子の数となります。固有値が基準値である「1」を下回った時が最適な因子の数になることが多くなっています。

今回は、3あたりで固有値が収束しているので、最適な因子の数は3と考えられます。
なお、スクリープロットで探索した最適な因子の数を使って、設定から「因子の数」を変更できます。
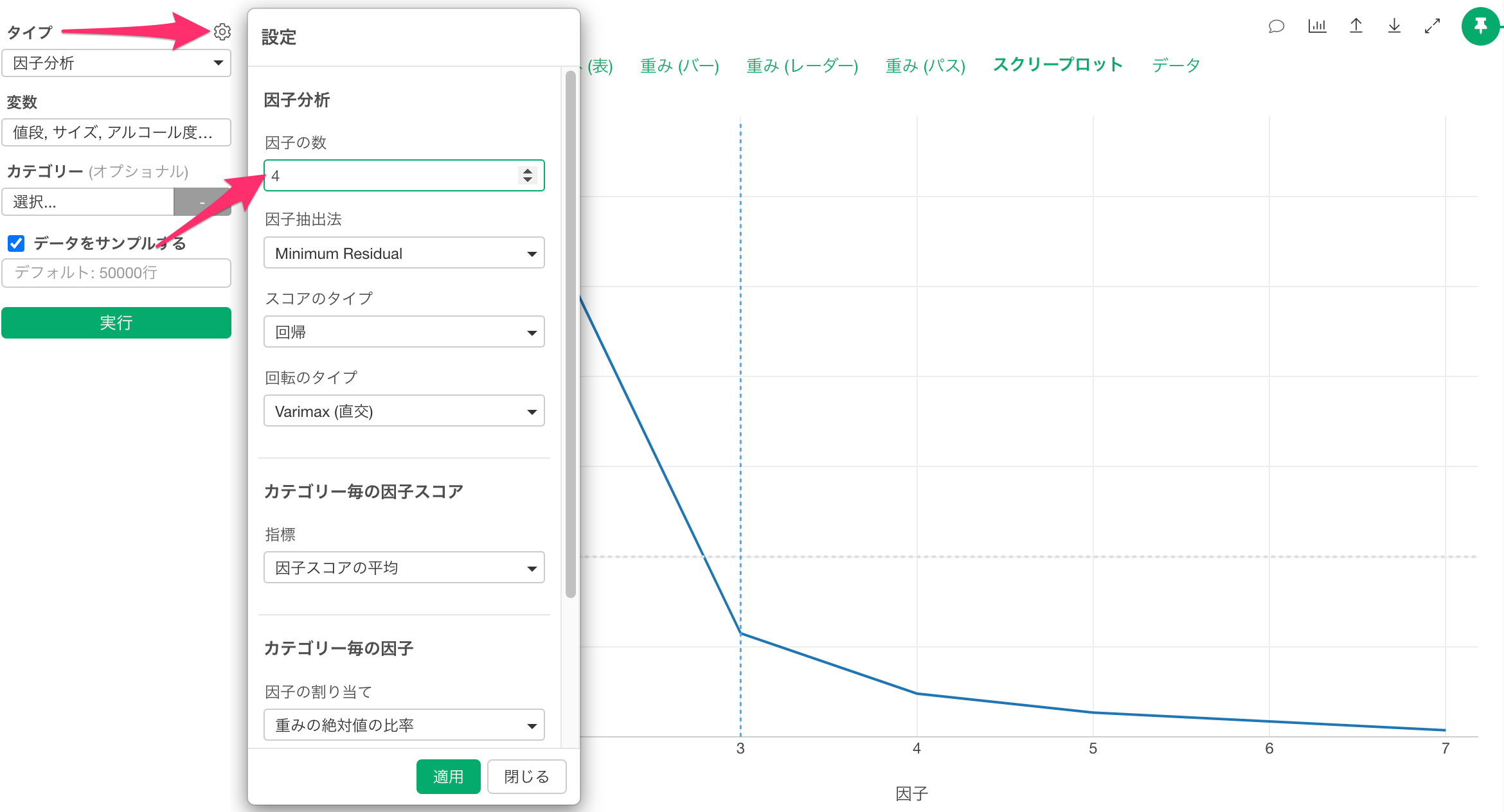
因子の数を指定すると、指定した因子数での実行結果が表示されます。
アンケートデータ分析 - トライアルツアー
アンケートデータ分析の他のパートには下記のリンクからご確認いただけます。ぜひ次の「集計」のパートも実施してみてください。
参考資料
- アンケートデータ分析 - リンク