AI プロンプトのベストプラクティス
自然言語でデータを加工・整形ができる「AI プロンプト」機能を使うと、データの整形、計算、集計、結合、文字列の加工など、データラングリングに関してやりたいことをプロンプトに入力するだけで、データを自由自在に素早く加工できるようになります。
このノートでは、このAI プロンプトの機能を使いこなして、より望む結果を得やすくするために、効果的なプロンプトの書き方やお役立ちいただける情報を解説していきます。
基本的なプロンプトの書き方
基本的なプロンプトの構文は次のとおりです。
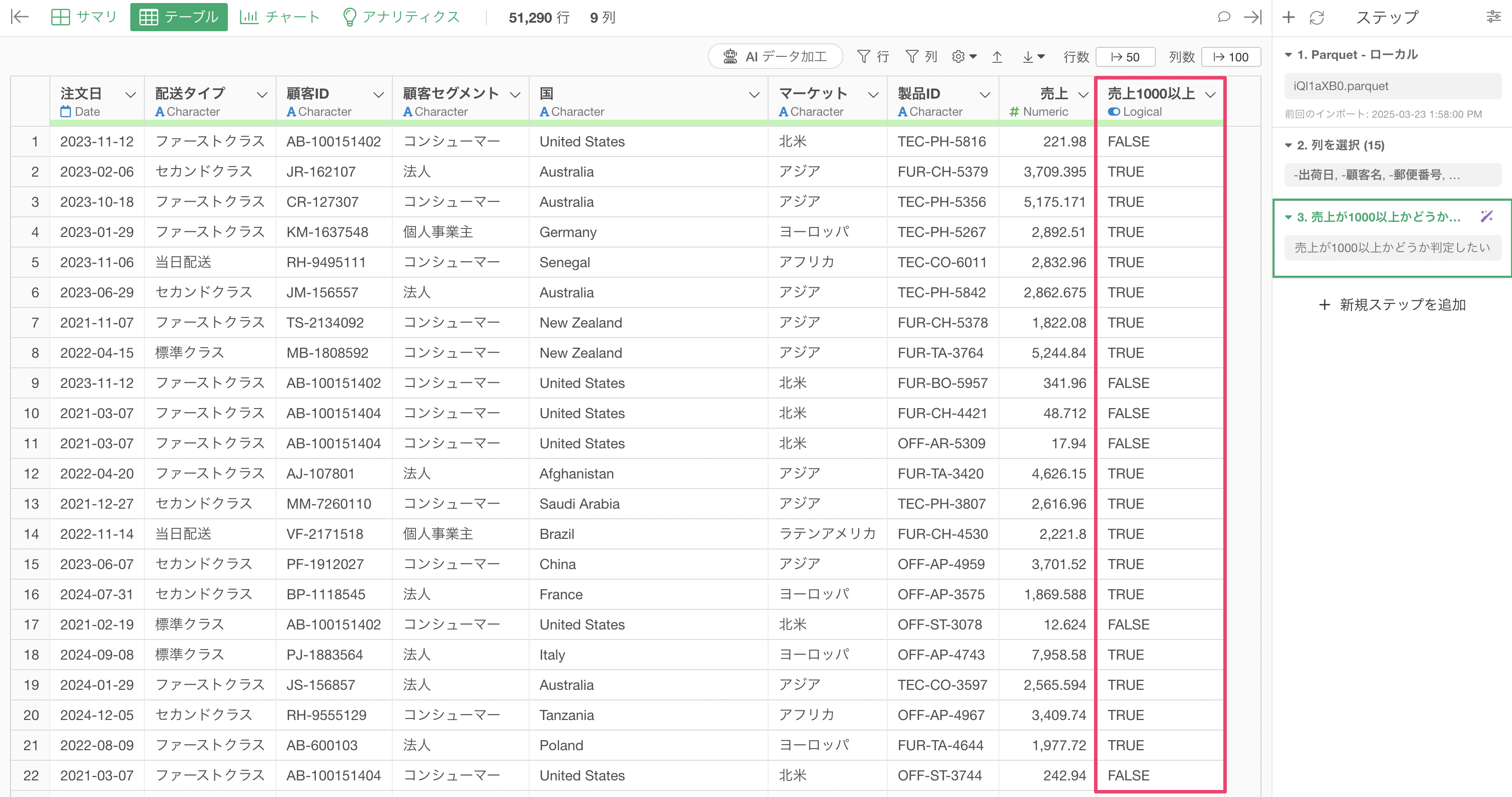
<列名>に<処理内容>をしたい例えば、 1行が1購買商品のECサイトの売上データを使用していたとします。
売上が1000以上かどうか判定した列を作りたいため、プロンプトに「売上が1000以上かどうか判定したい」と入力します。
プロンプトを実行することで、売上を1000以上かどうか判定するためのRコマンドの結果が返ってきました。そのため、「ステップとして実行」のボタンをクリックします。
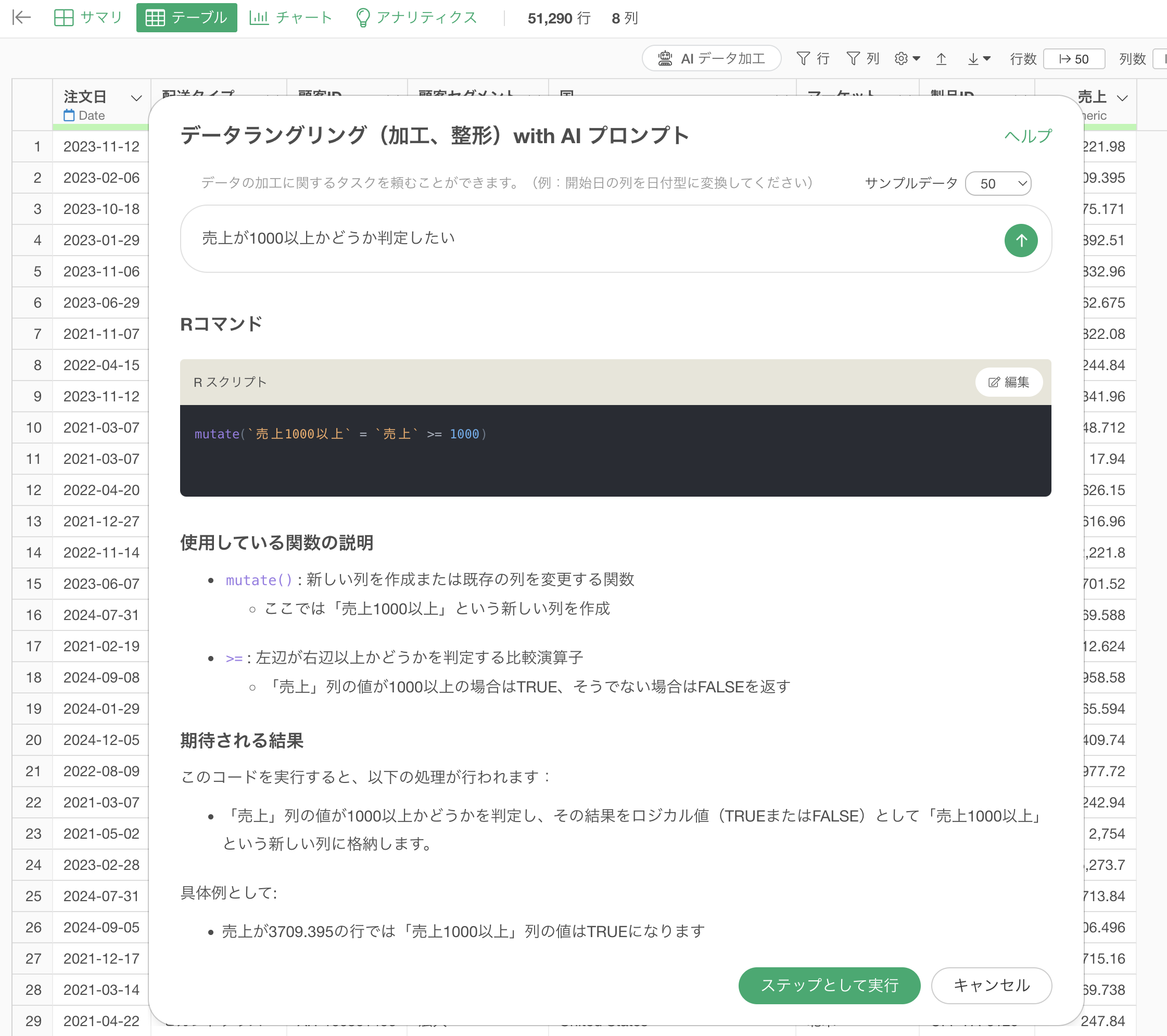
これによって「売上1000以上」といった列が作成されています。
上記の例のように、プロンプト機能を使う際には、以下を意識してプロンプトを書くことで、より実現したい処理に沿った結果を返してくれるようになります。
- シンプルな一文で表現する:「〜したい」で終わる簡潔な一文が理解されやすい
- 具体的な列名を使う:処理を行いたい対象の列名をプロンプトに含める
グループ単位に分けて計算・集計をする
集計
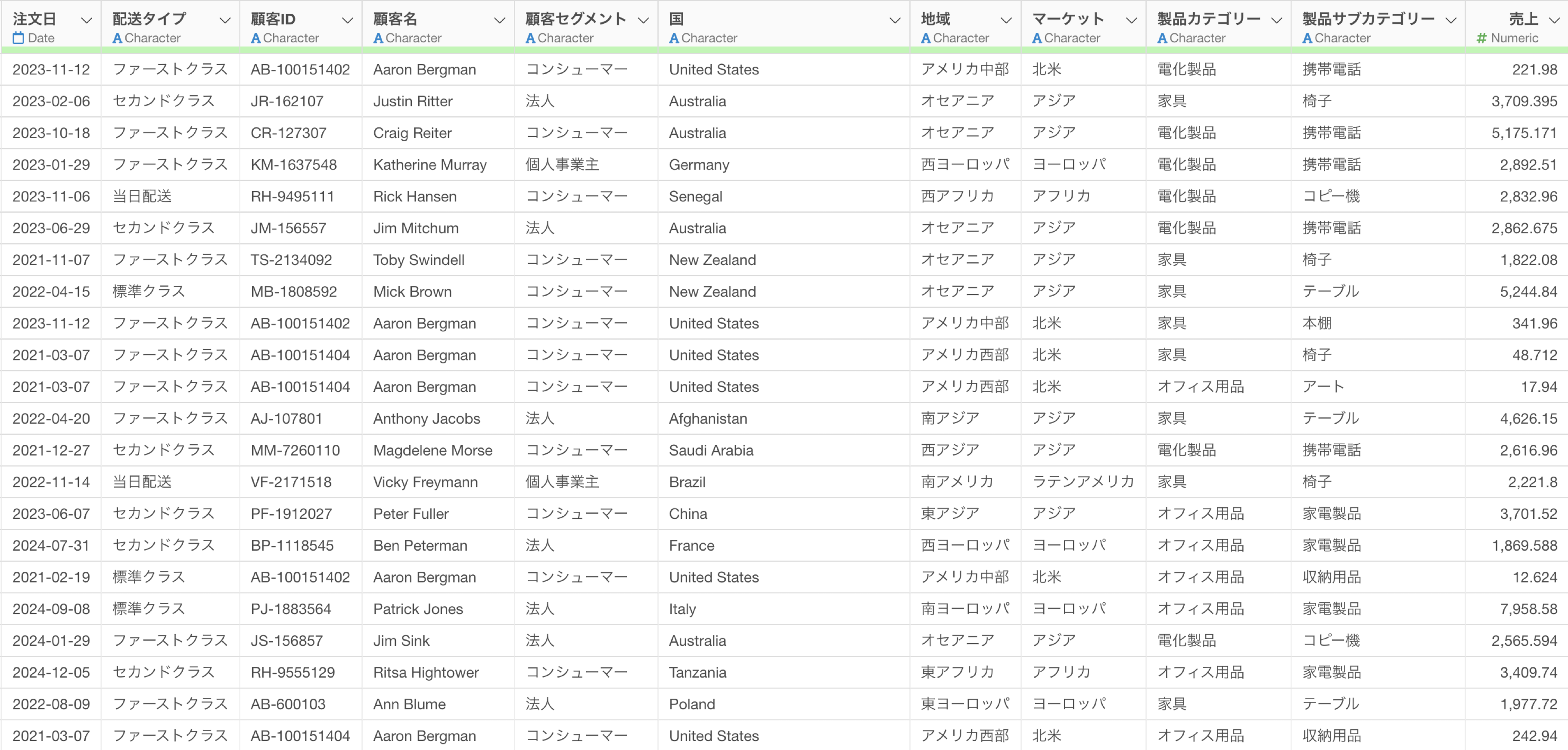
1行が1購買商品ごとにある売上データを使用します。
プロンプトで以下のように顧客数と売上合計の集計をするように指示をしたとします。
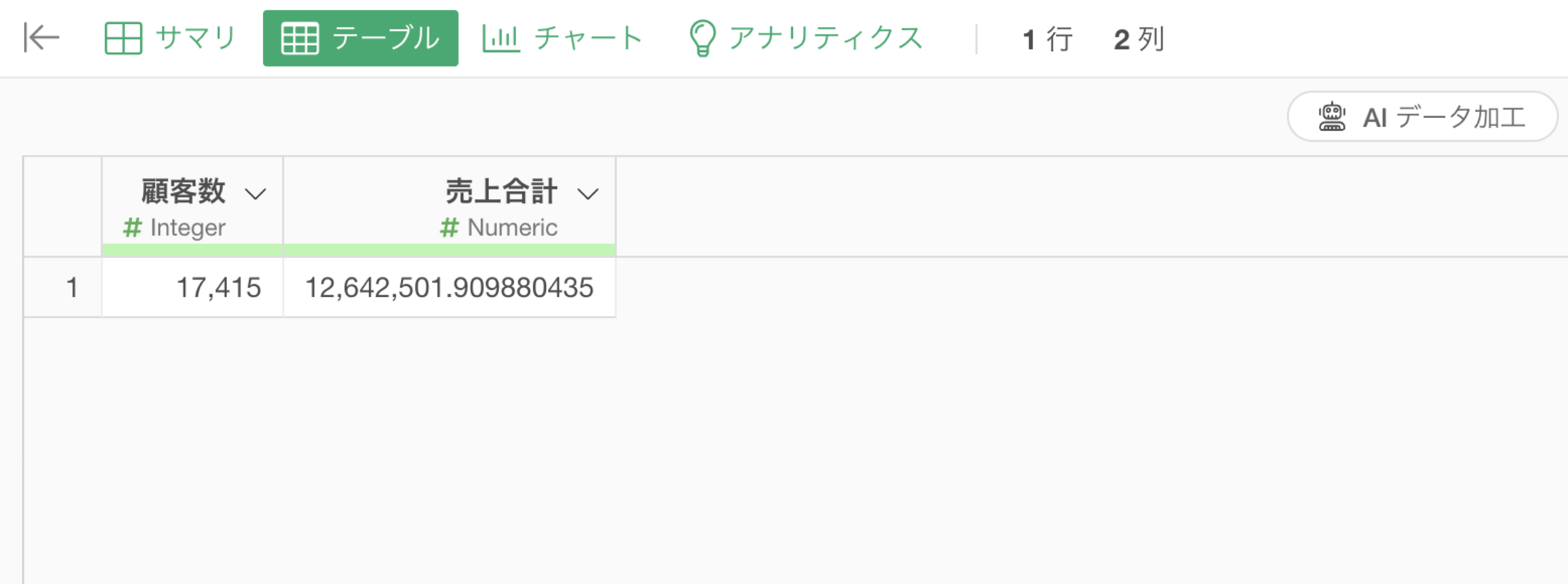
顧客数と売上合計を集計したい
この場合、どういった単位で実行するのかの指定がないために、全体での結果が返ってくることがあります。
このデータにはアジアやアフリカなどの値を持った「マーケット」の列があるために、マーケットごとに顧客数や売上合計を求めたいです。
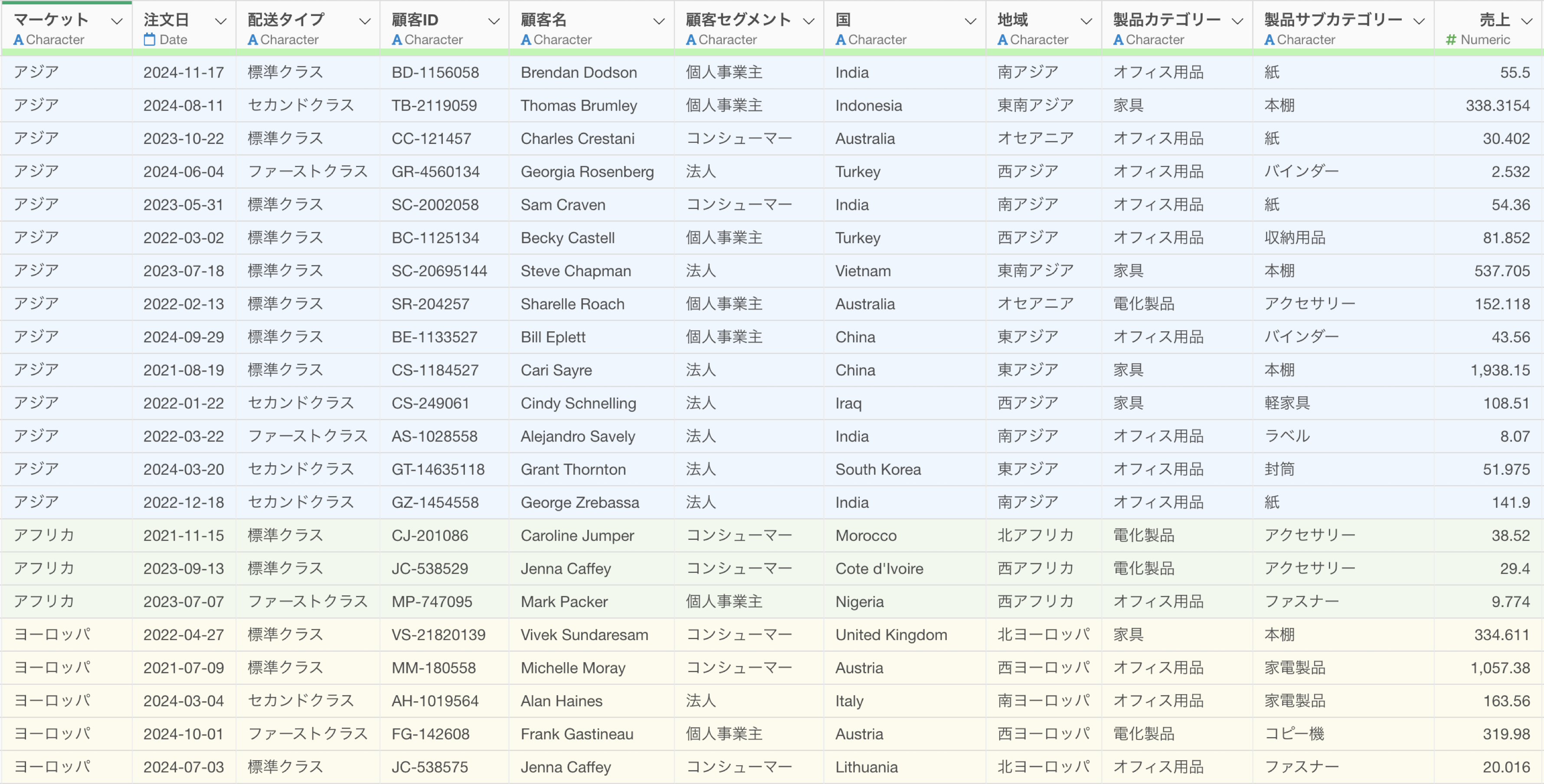
集計や計算などでグループ単位で分けたい時には、「グループごと」をプロンプトの冒頭につけます。この「ごと」や「毎」はどちらを使用していただいても構いません。
マーケットごとに顧客数と売上合計を集計したい
マーケット毎に顧客数と売上合計を集計したいプロンプトを「マーケットごとに顧客数と売上合計を集計したい」といった指示に変更します。
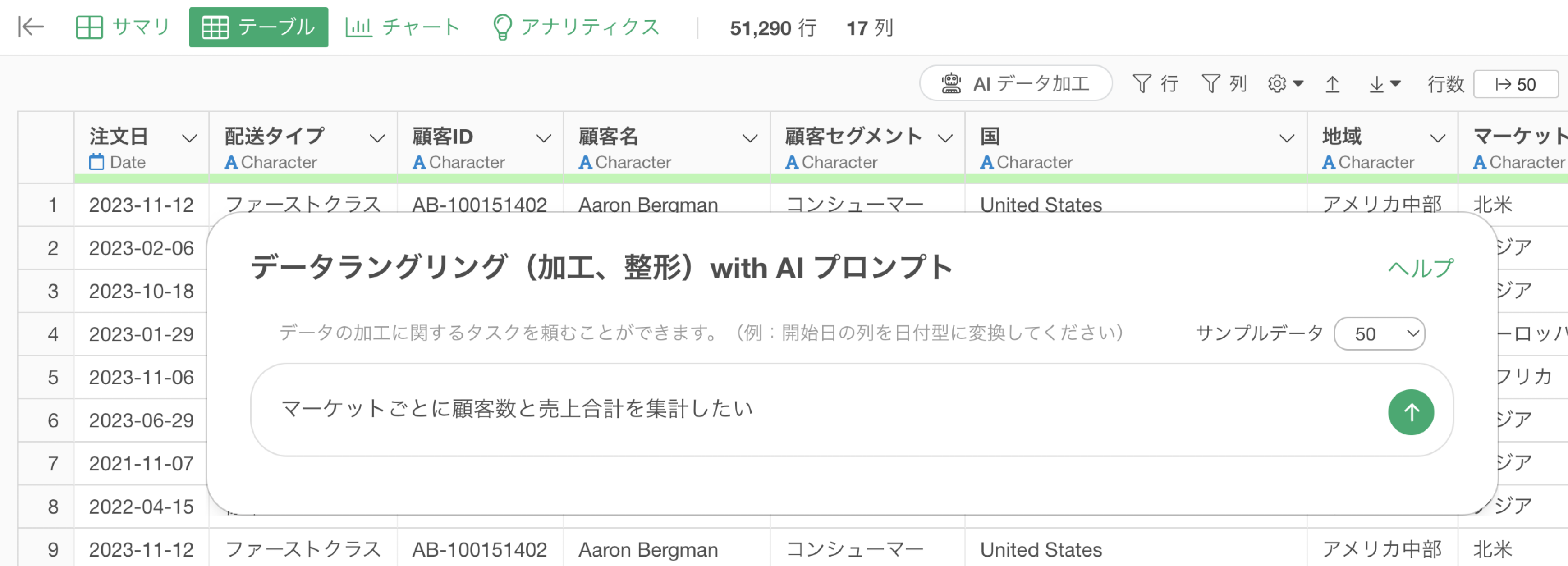
これによって集計をする時にグループ化処理であるgroup_byといった関数を使用して、マーケットごとに顧客数や売上を集計してくれていることがわかります。
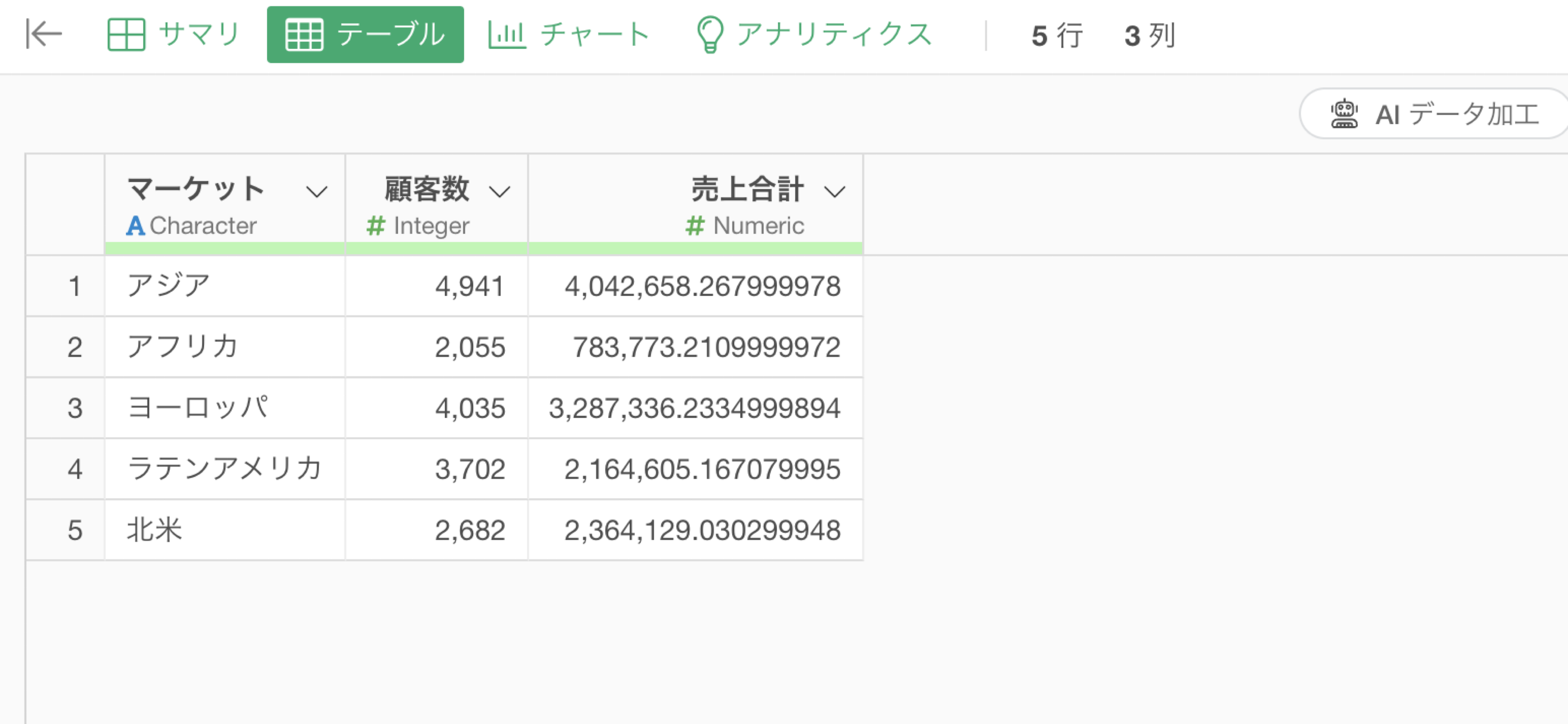
ステップとして実行をすることで、マーケットごとに顧客数や売上を集計できていることが確認できます。
このグループは複数指定いただくことも可能です。例えば、「月ごと」と「マーケット」ごとに集計をしたい場合であれば、プロンプトには以下のように指定します。
月ごと、マーケットごとに顧客数と売上合計を集計したい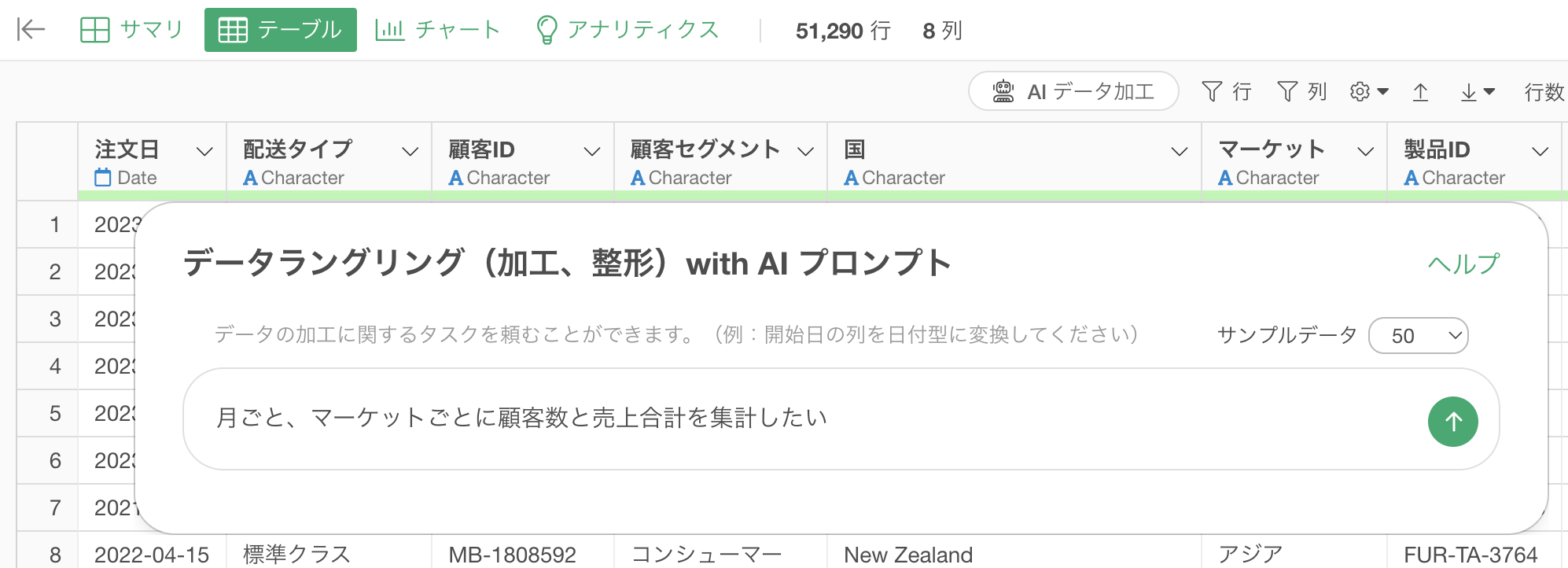
これによってグループ化では日付列である注文日の情報も使って、月ごと、マーケットごとに集計されるように変わっています。
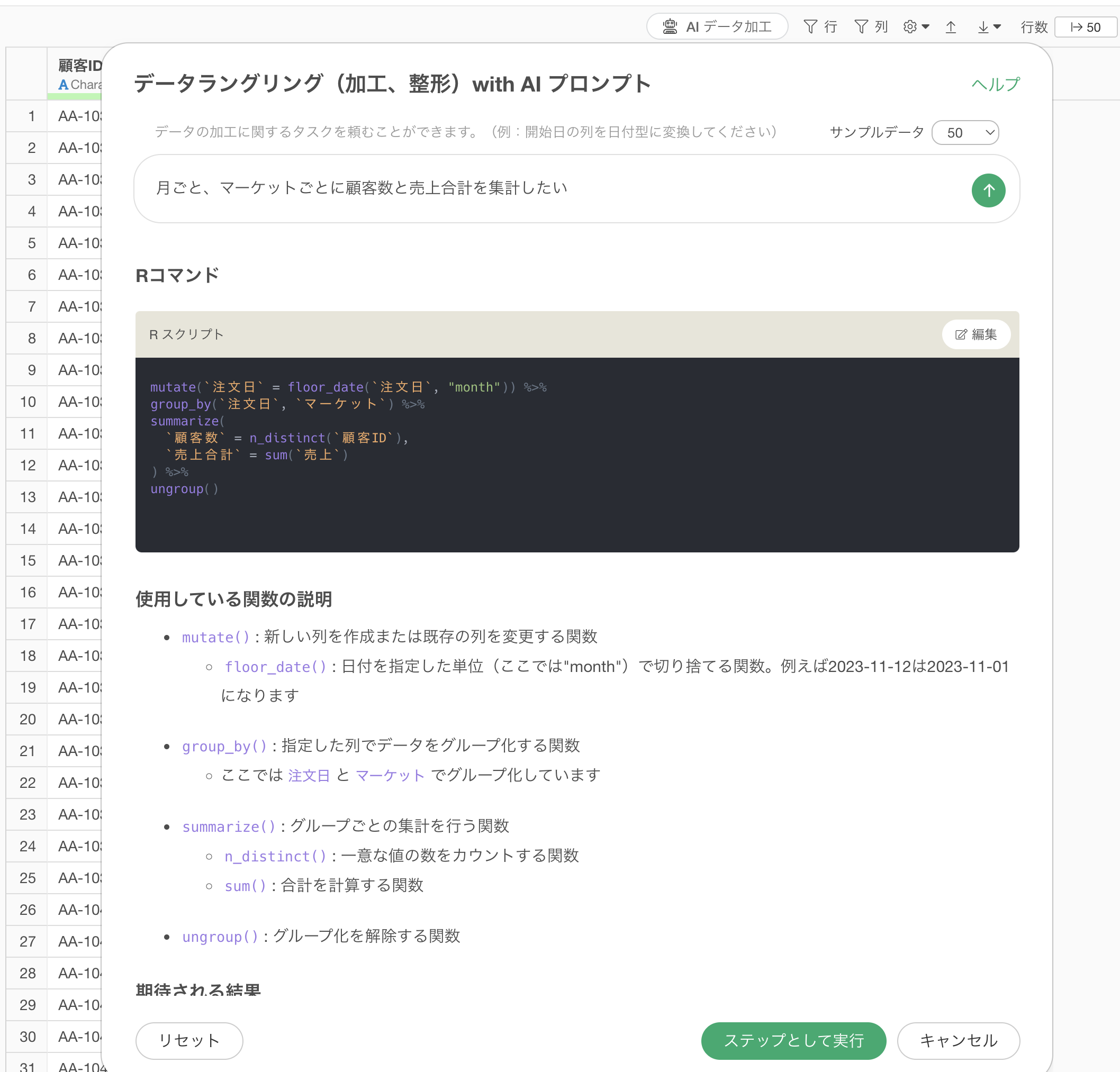
ステップとして実行をすることで、月ごと、マーケットごとに顧客数や売上を集計できていることが確認できます。
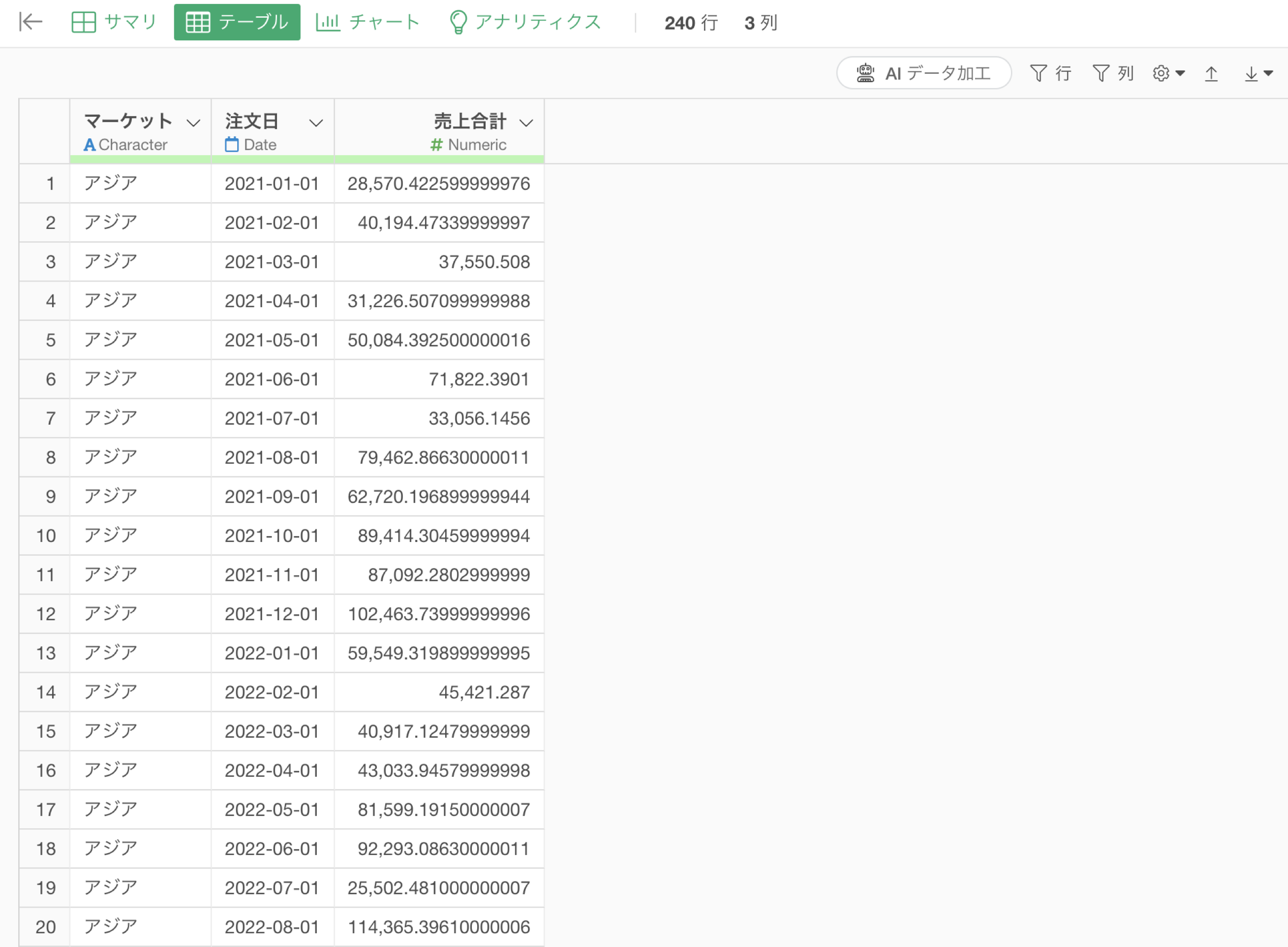
計算
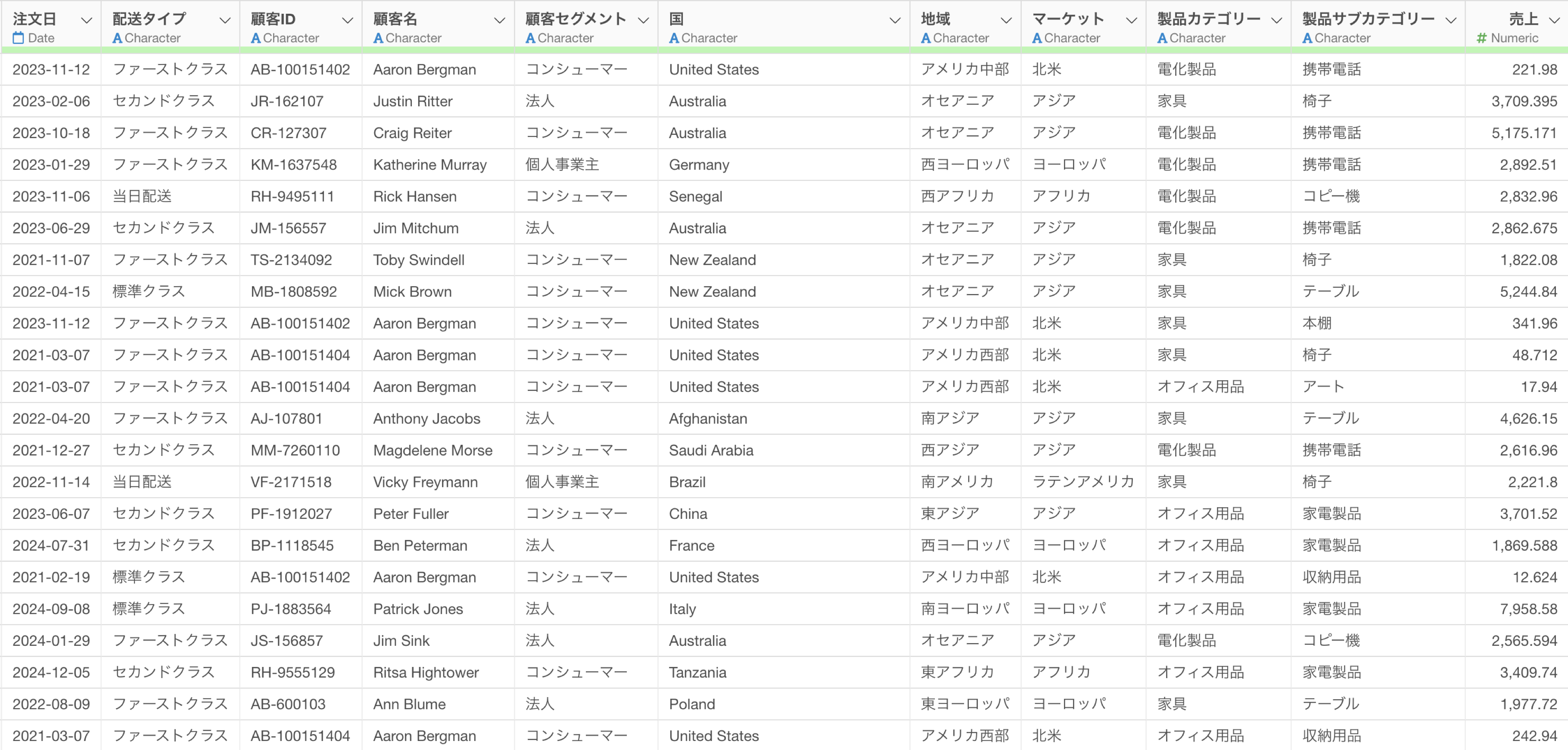
これまで紹介してきたのは、データの集計処理になりますが、例えば以下のように1行が1人の従業員を表すデータを集計するのではなく、部署ごとに従業員数(行数)を計算(集計)した列を追加したいこともあります。
そのようなときには、意図せずAIが集計のコードを生成をしないようにするためには、以下のように、計算した結果を列として追加するプロンプトを記述します。
部署と職種ごとに行の数を計算した「従業員数」の列を追加して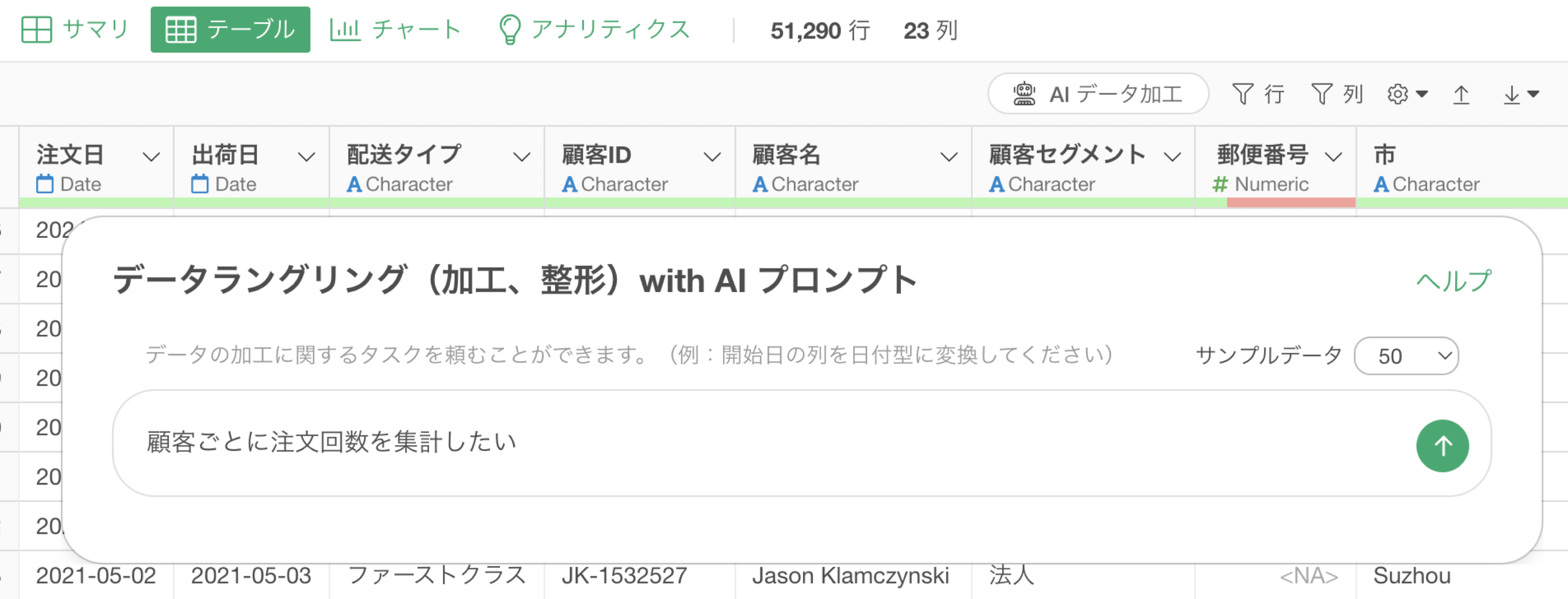
すると、AIが集計処理を行うコードを生成せずに列を計算するコードを生成します。
 ステップとして実行をすることで、集計した結果を列として追加できていることを確認できます。
ステップとして実行をすることで、集計した結果を列として追加できていることを確認できます。
集計の際に計算がうまくいかなかった時のTips
ここでも1行1購買商品のECサイトの購買データを使って説明をしていきます。

例えば、顧客ごとに注文回数を集計するために、以下のプロンプトを指示したとします。
顧客ごとに注文回数を集計したい
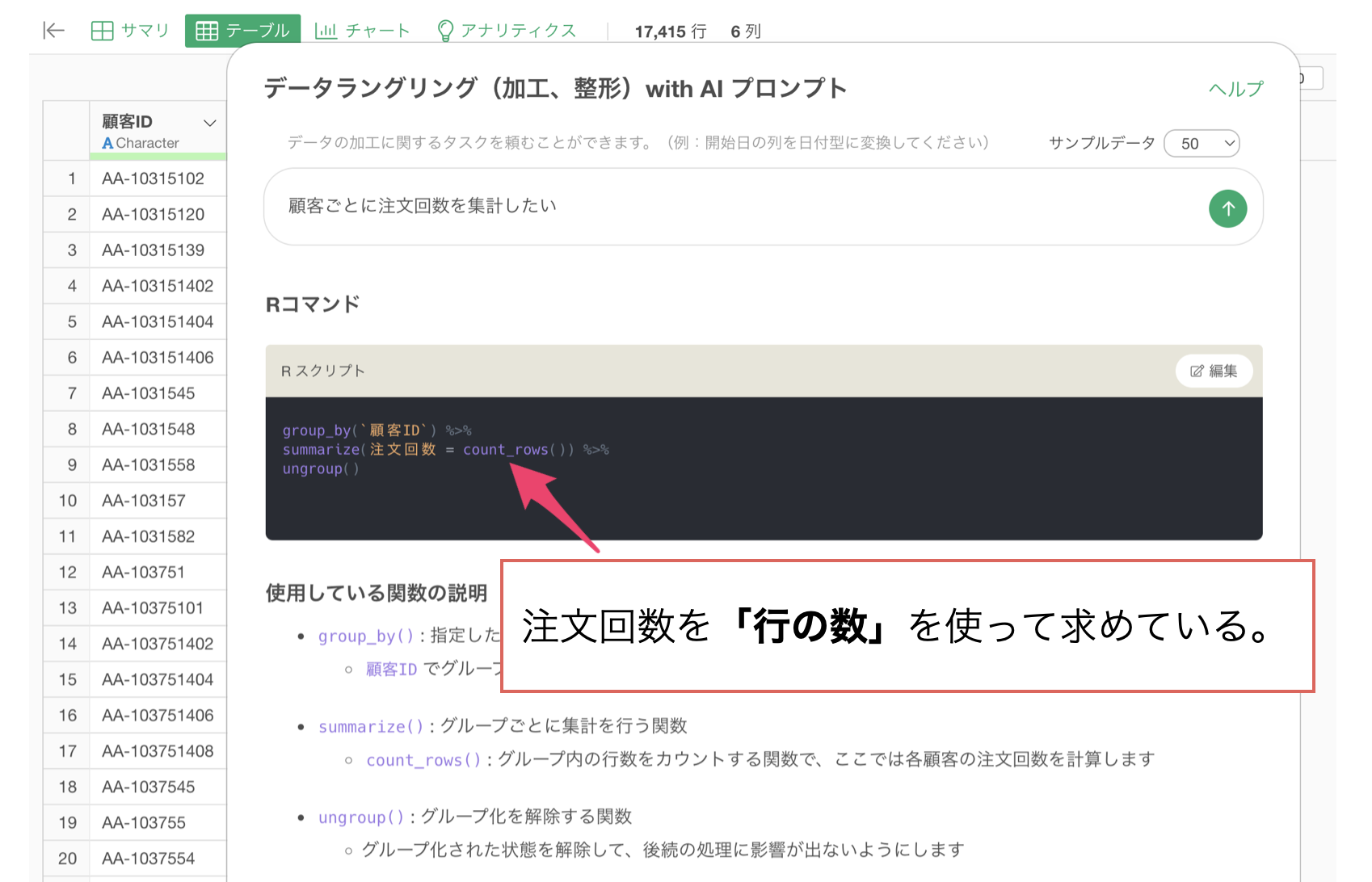
顧客ごとに注文回数を計算しようとしていますが、行の数を求める関数を使用していることがわかります。
ただ、このデータの1行は1注文ではなく、1購買商品のデータです。従って、購買された商品ごとに行が分かれ、注文した商品の種類の分だけ行を持っています。
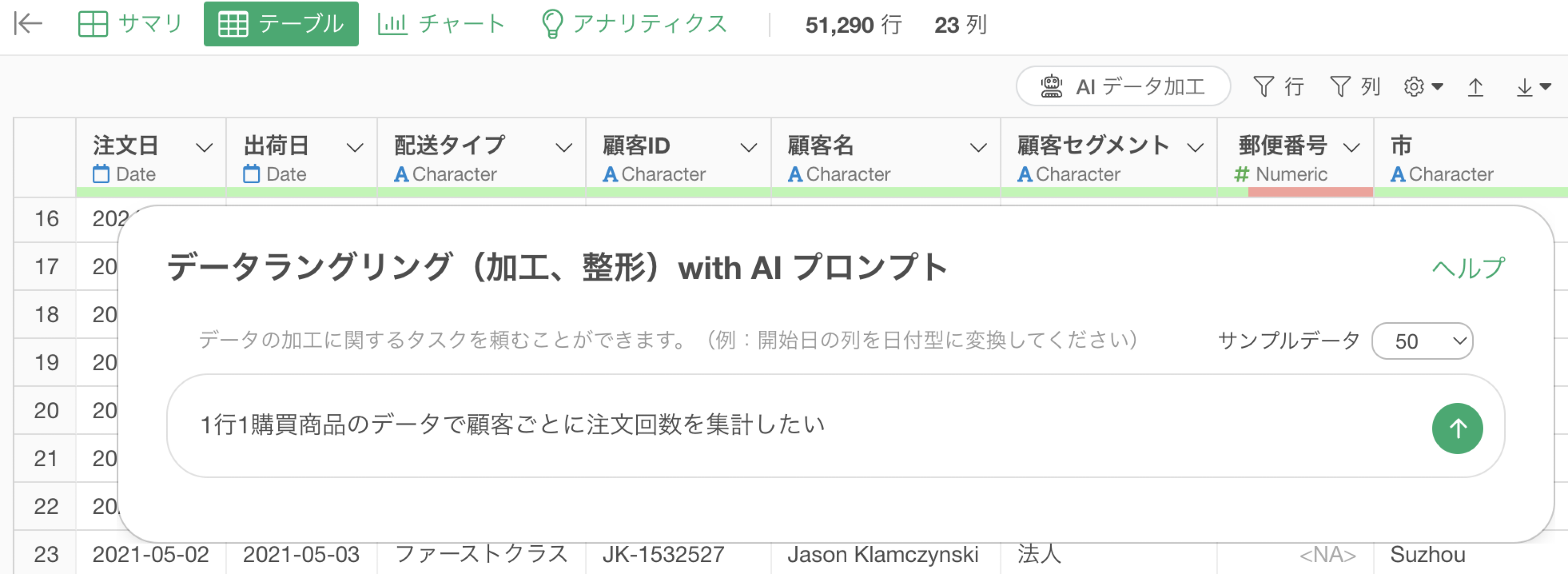
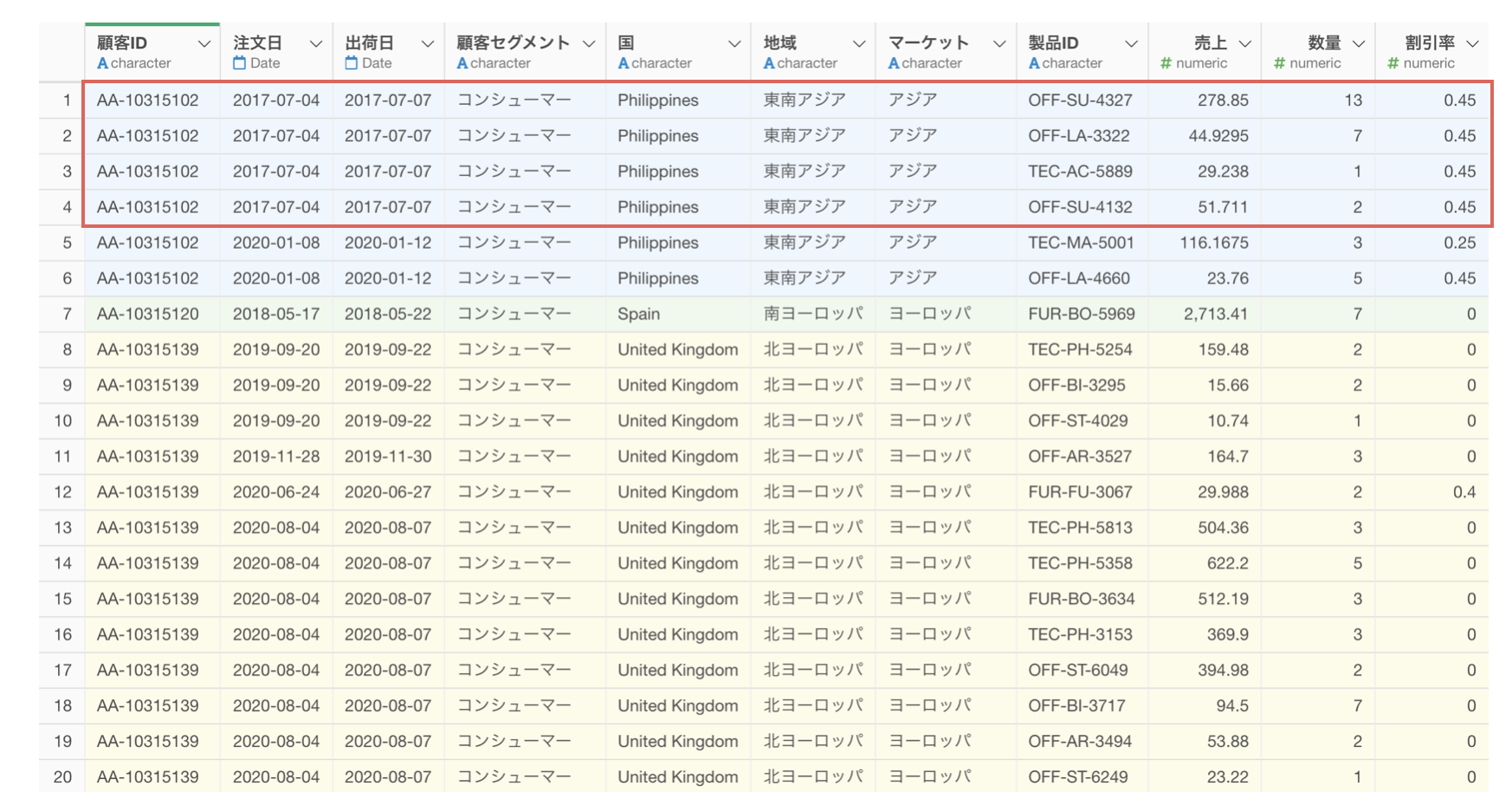
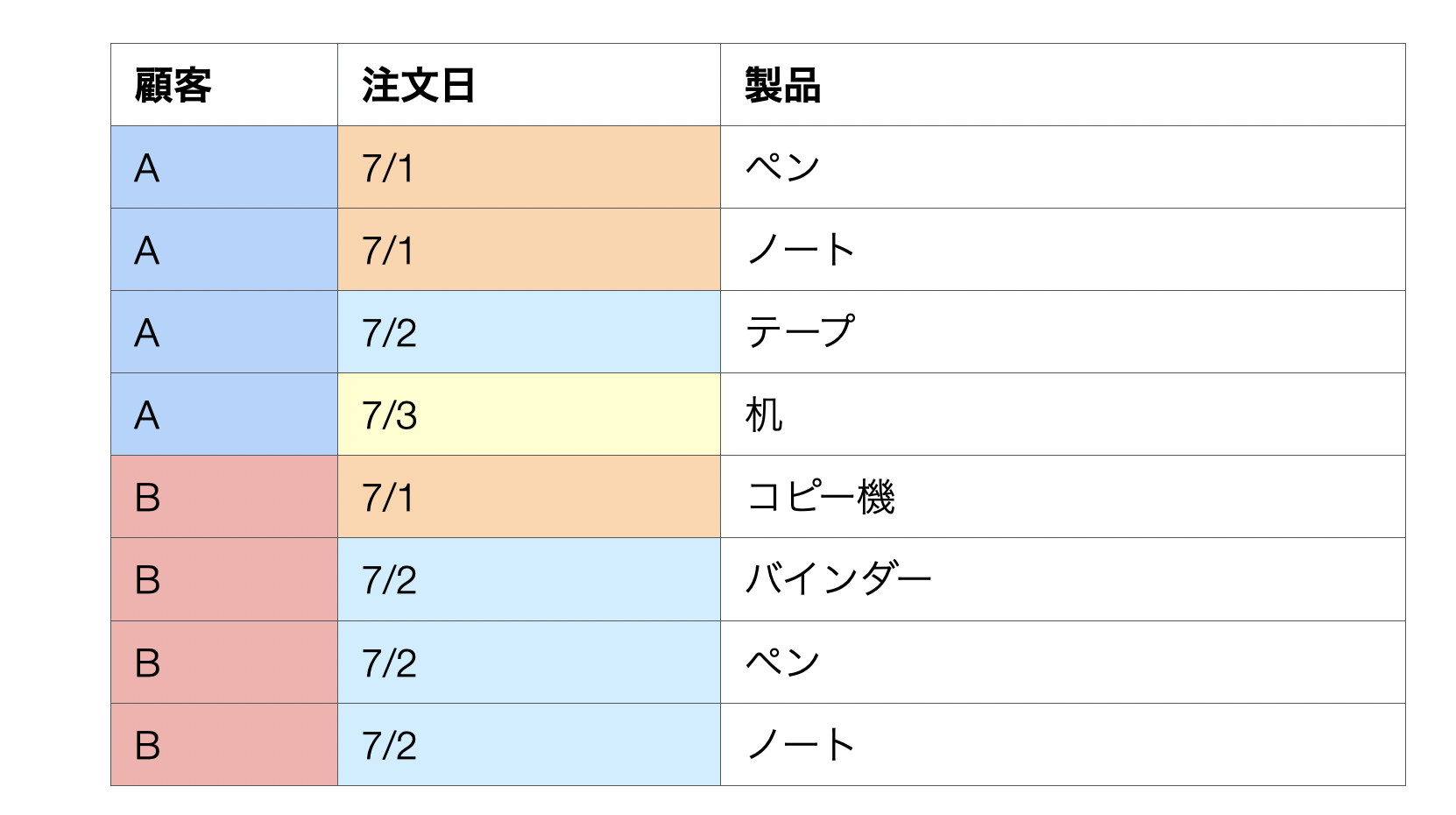
例えば、以下のような1行が1購買商品のデータがあったとします。
行の数を数えるとそれぞれの顧客から4件の注文があったように見えますが、果たして顧客Aは実際には何件の注文があるのでしょうか。
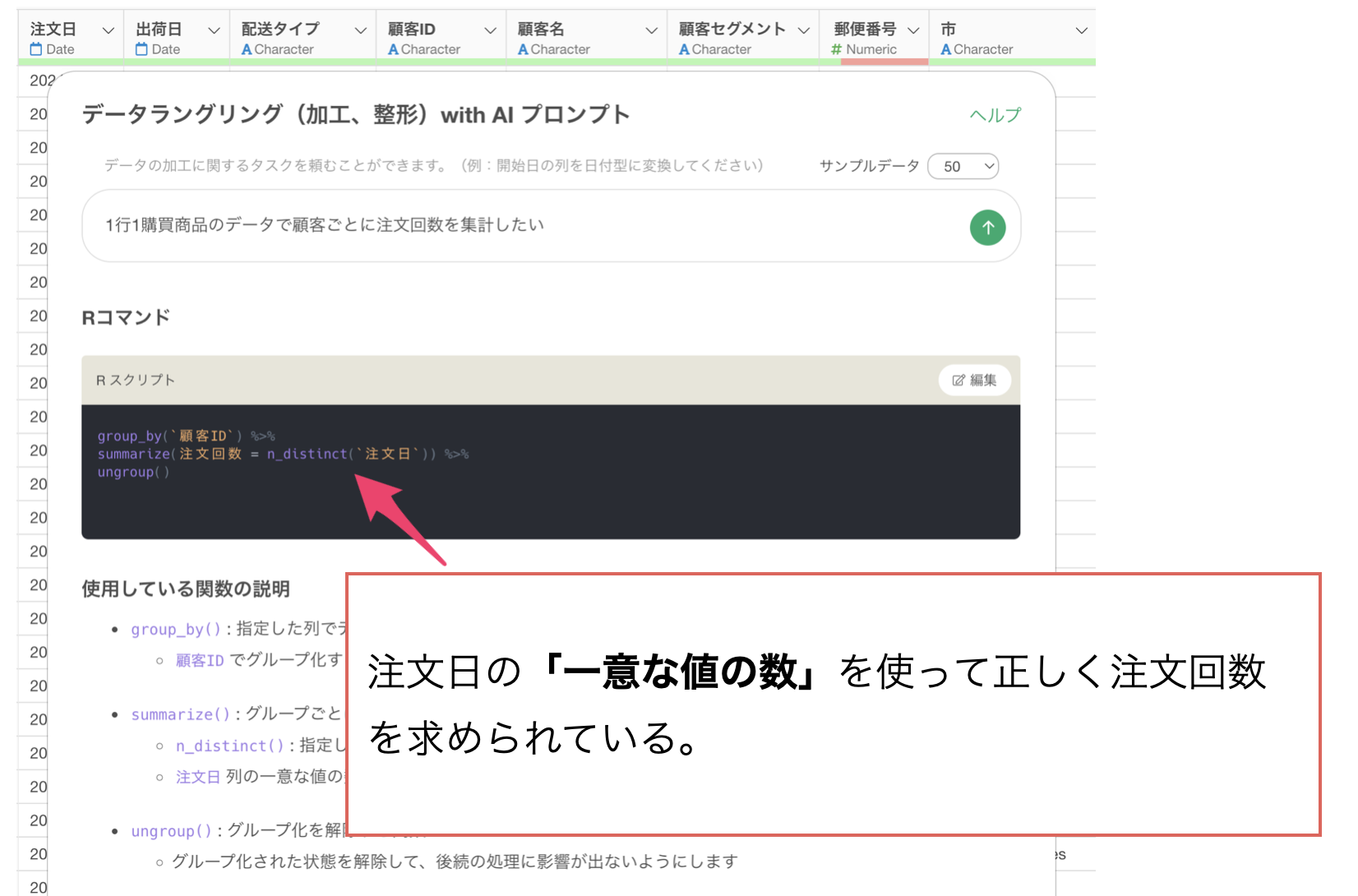
注文日を見ると実際には顧客Aは3件の注文、顧客Bは2件の注文であることがわかります。顧客ごとに注文の回数を数えるためには、注文日の一意(ユニーク)な数を顧客ごとに数えなければいけません。
そこで、データの1行の単位をプロンプトの冒頭に追加します。今回の場合は「1行1購買商品のデータ」を追加をすることになります。
1行1購買商品のデータで顧客ごとに注文回数を集計したい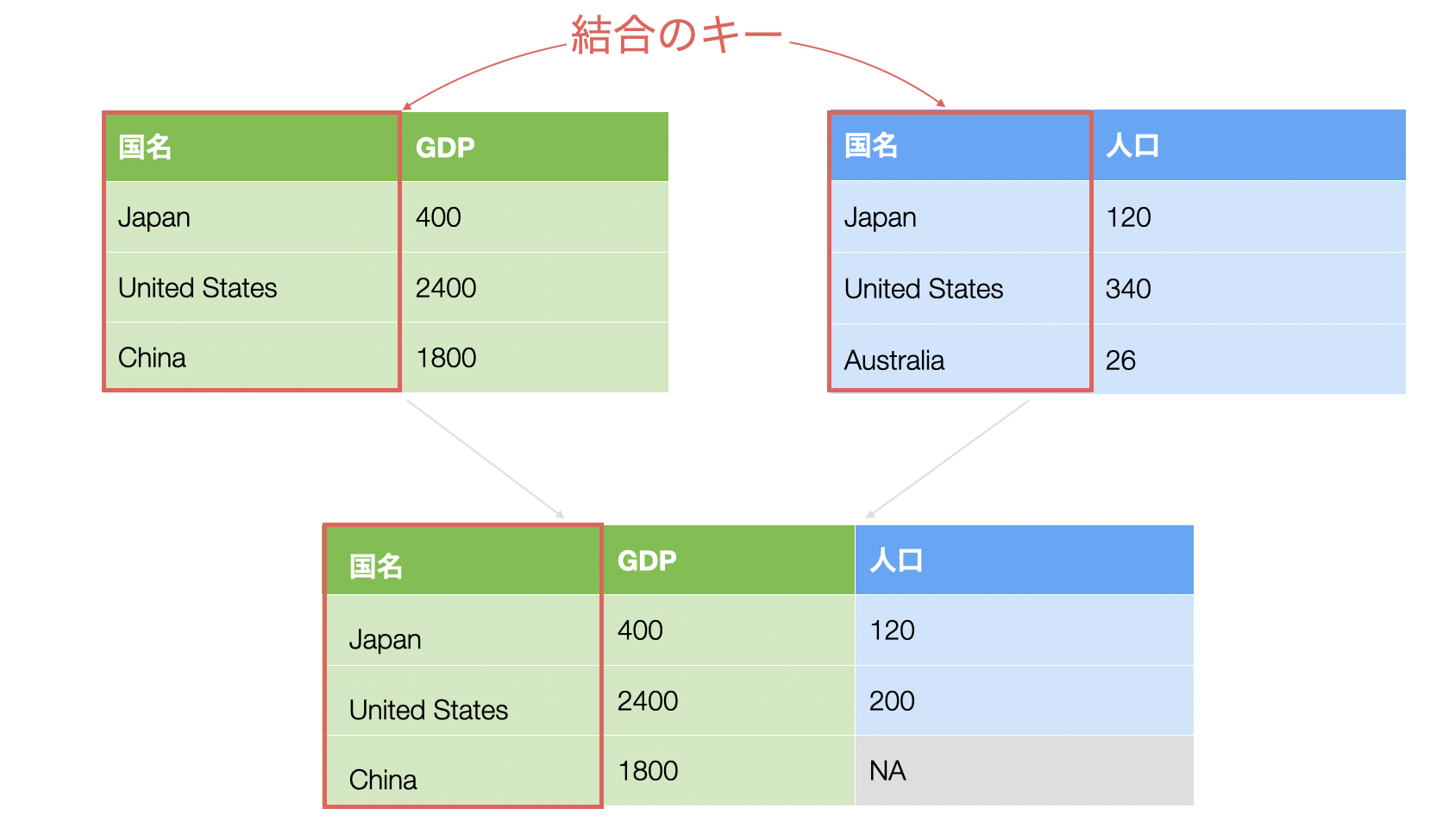
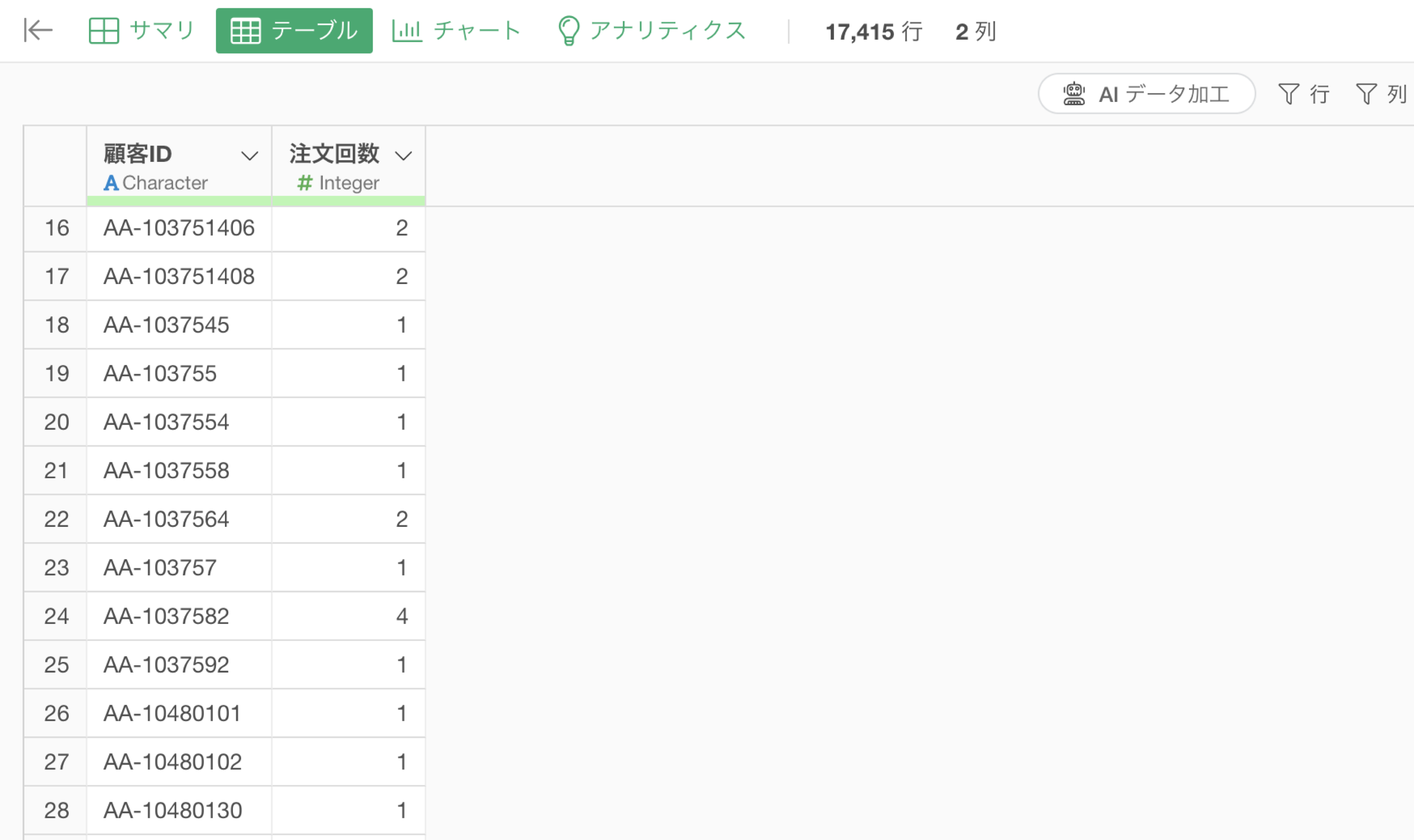
これによって、行の数ではなく注文日の一意な値の数を使って注文回数を計算するように変わっています。
ステップとして実行をすることで、顧客ごとに注文回数を正しく計算できていることが確認できます。
他のデータと結合をする
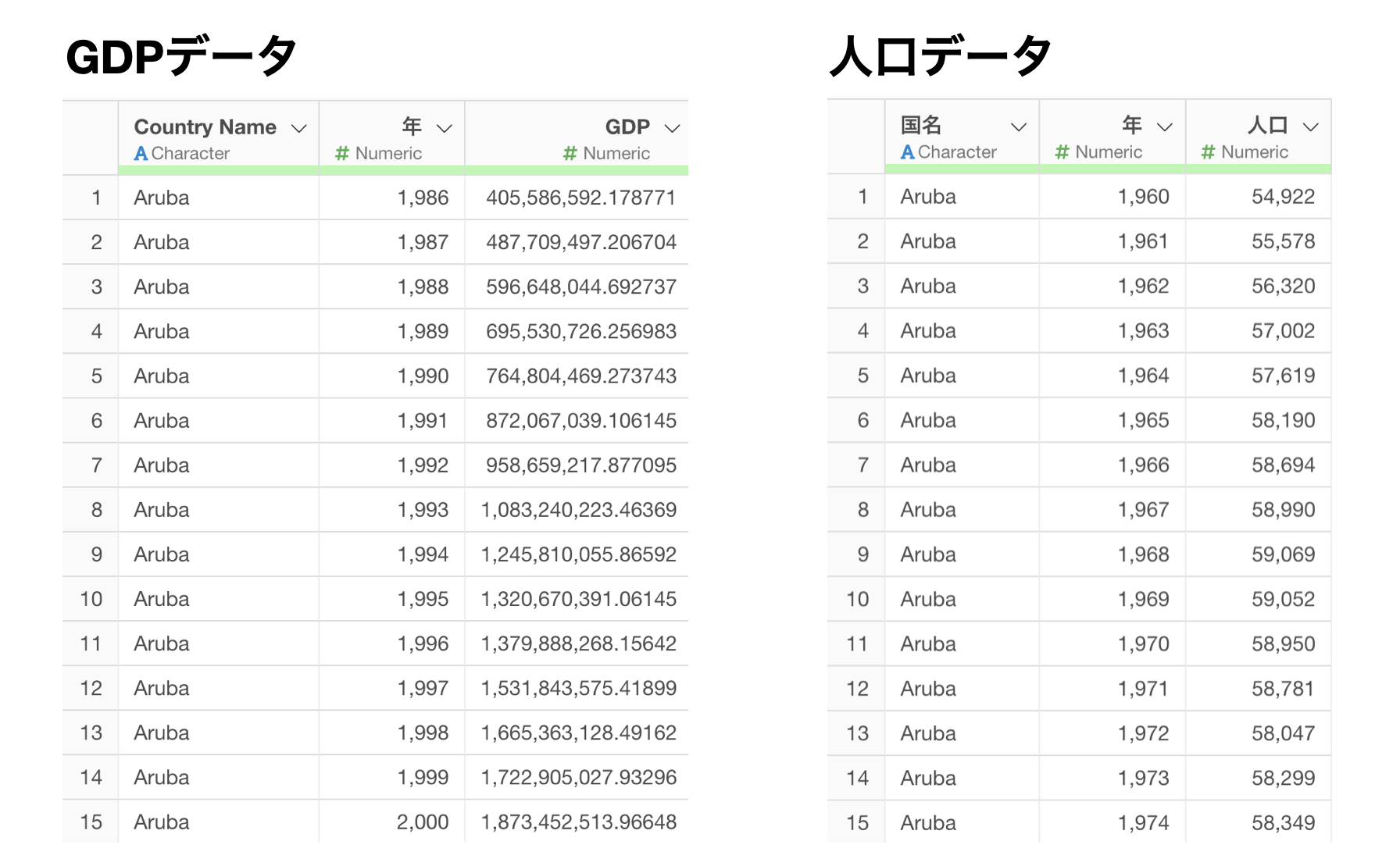
例えば、GDPと人口といった2つのデータがあったとします。
この「GDP」と「人口」の2つのデータフレームを結合をしていきたいとします。その場合、結合する際には結合のキーというものが必要になります。
以下は結合キーが1つのシンプルな例となります。
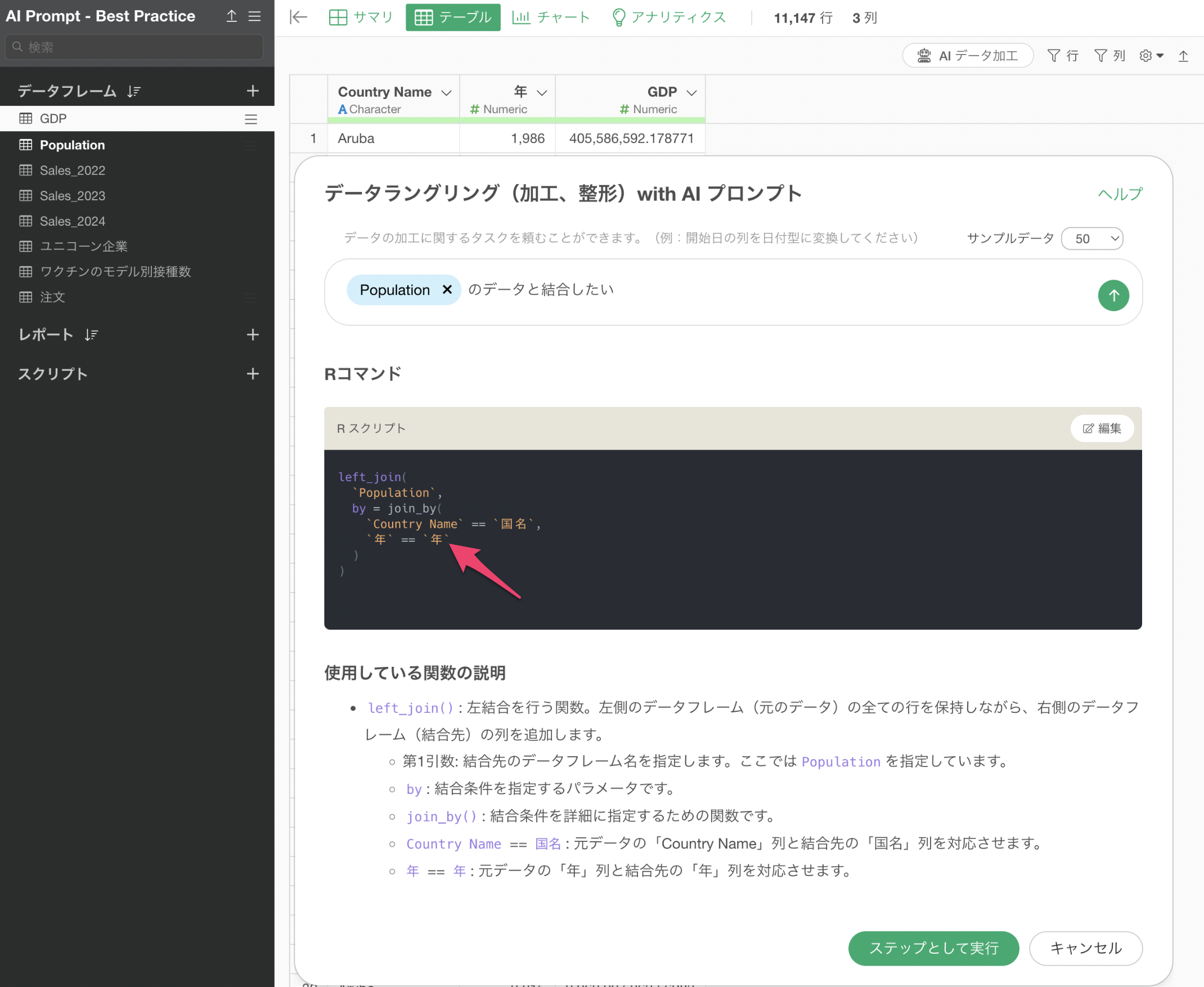
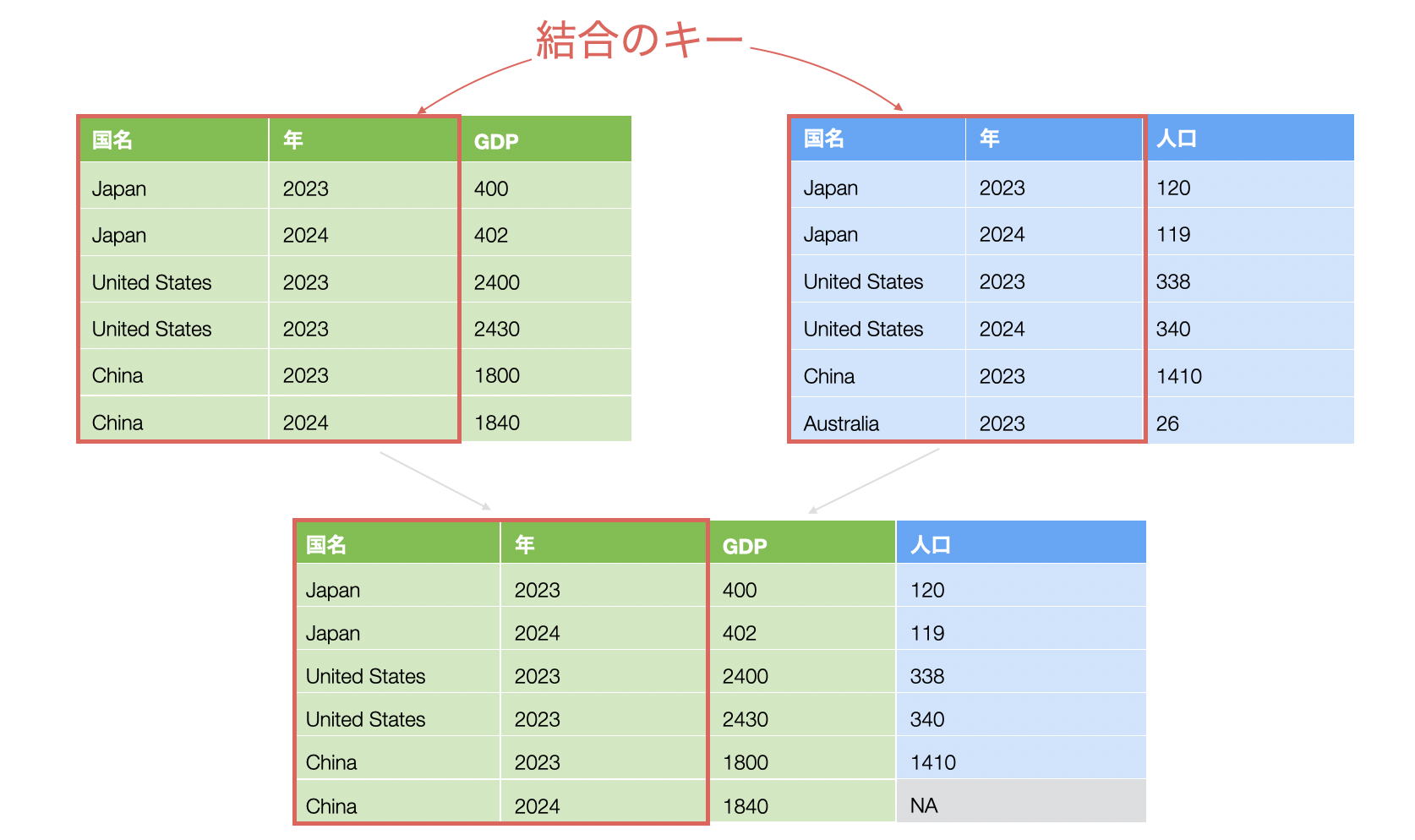
結合したいデータによっては、結合のキーは2つや3つなど、複数になることもあります。
これまでのUIベースでの結合では、それぞれのデータで何がキー列になるのかを、お互いのデータを見ながら確認をしていく必要がありましたが、AI プロンプトの機能では、データを元に推測をして結合のキーを勝手に設定をしてくれます。
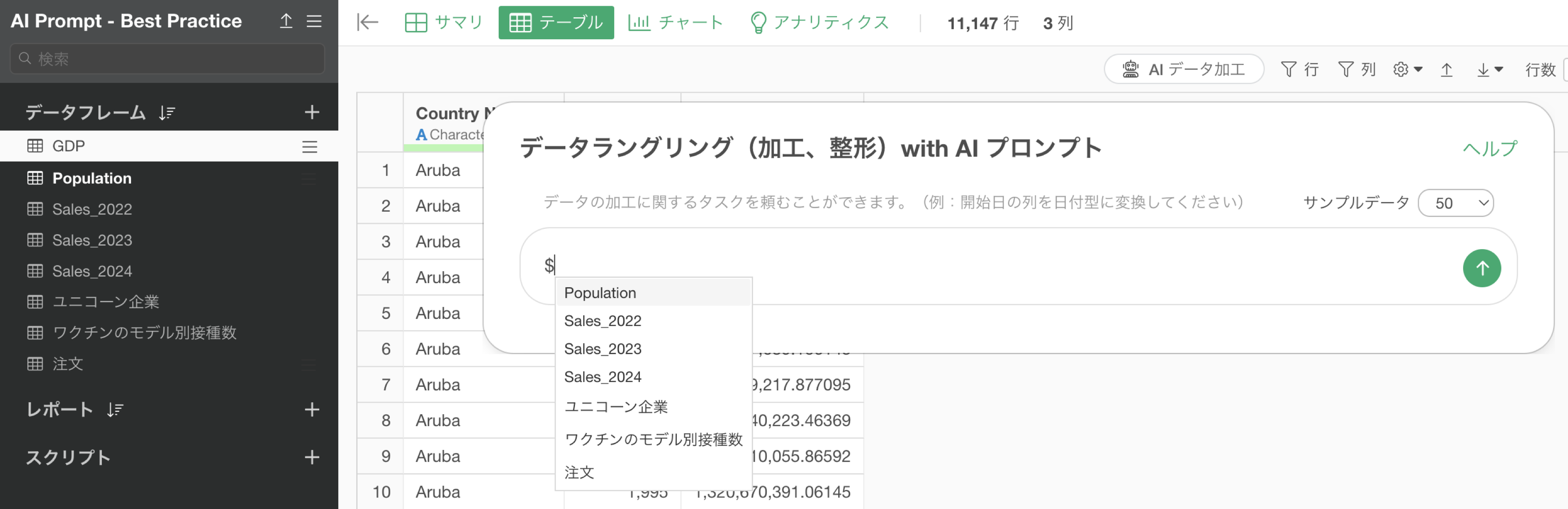
結合などの他のデータフレームを参照させるためには、「$」を入力します。これによってそのプロジェクトにあるデータフレームを指定することができるようになります。
結合をする場合には、プロンプトとして以下のように指定をします。
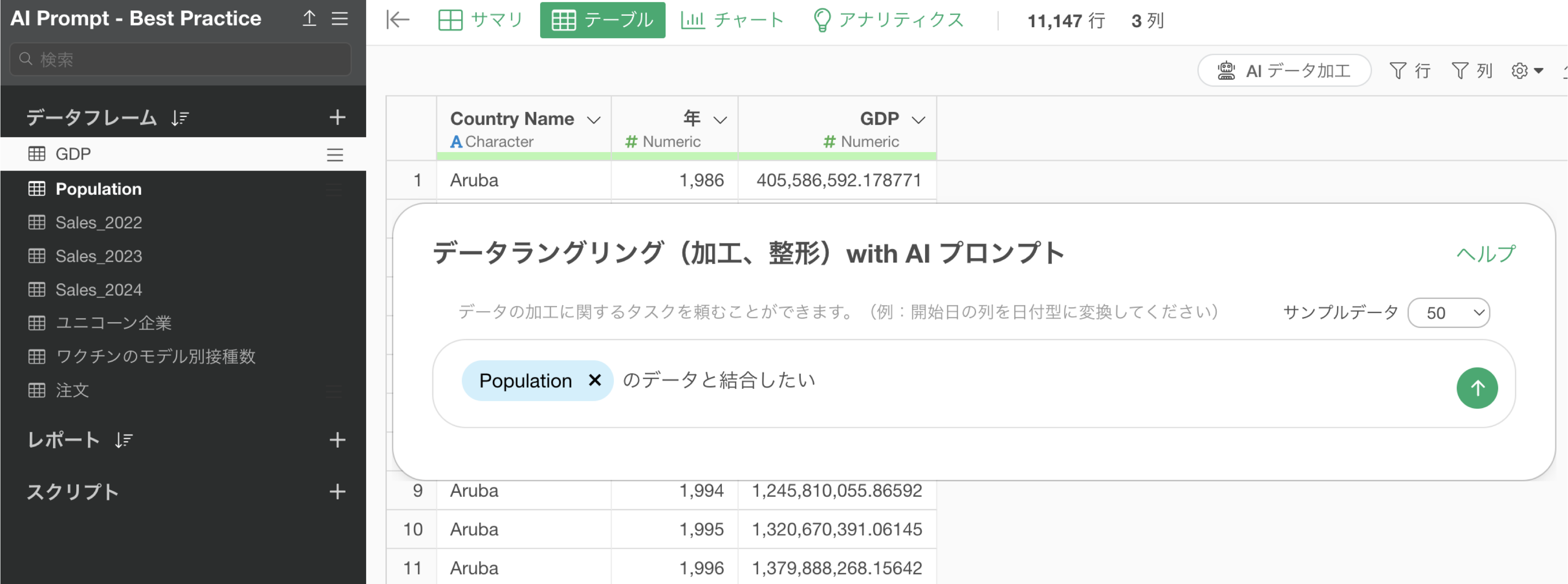
$Population のデータと結合したい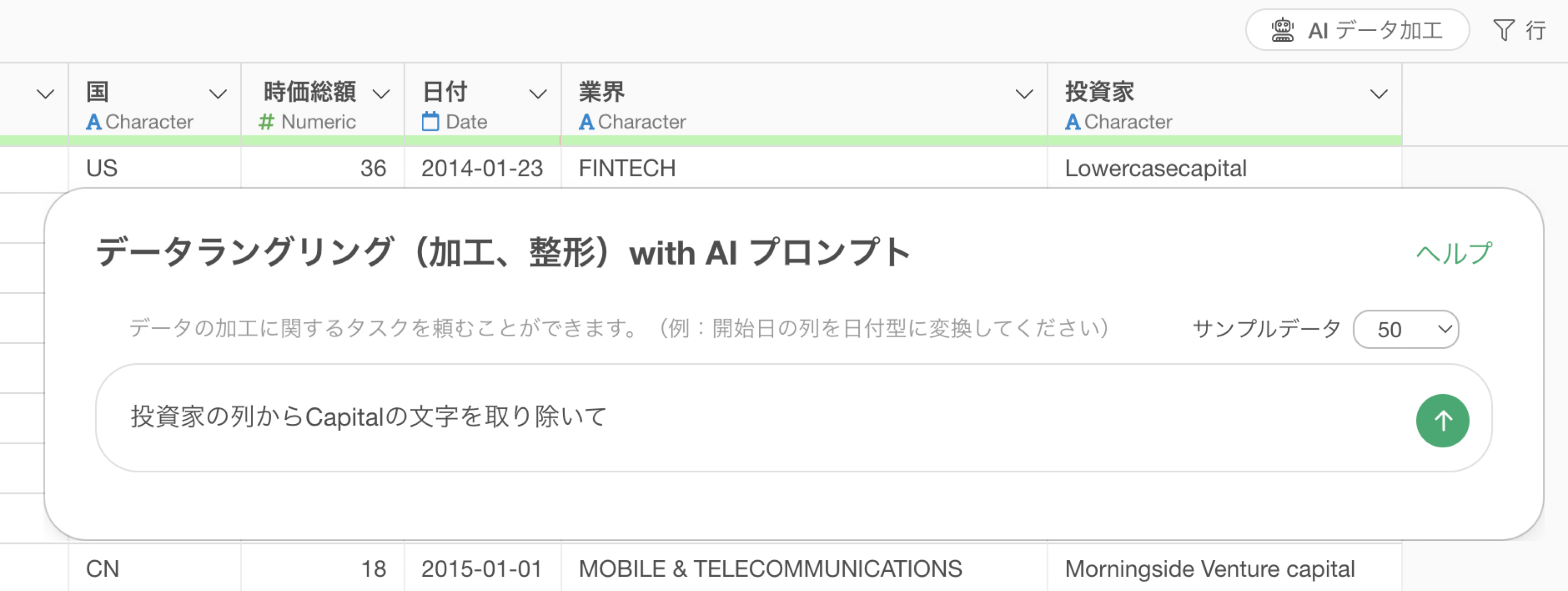
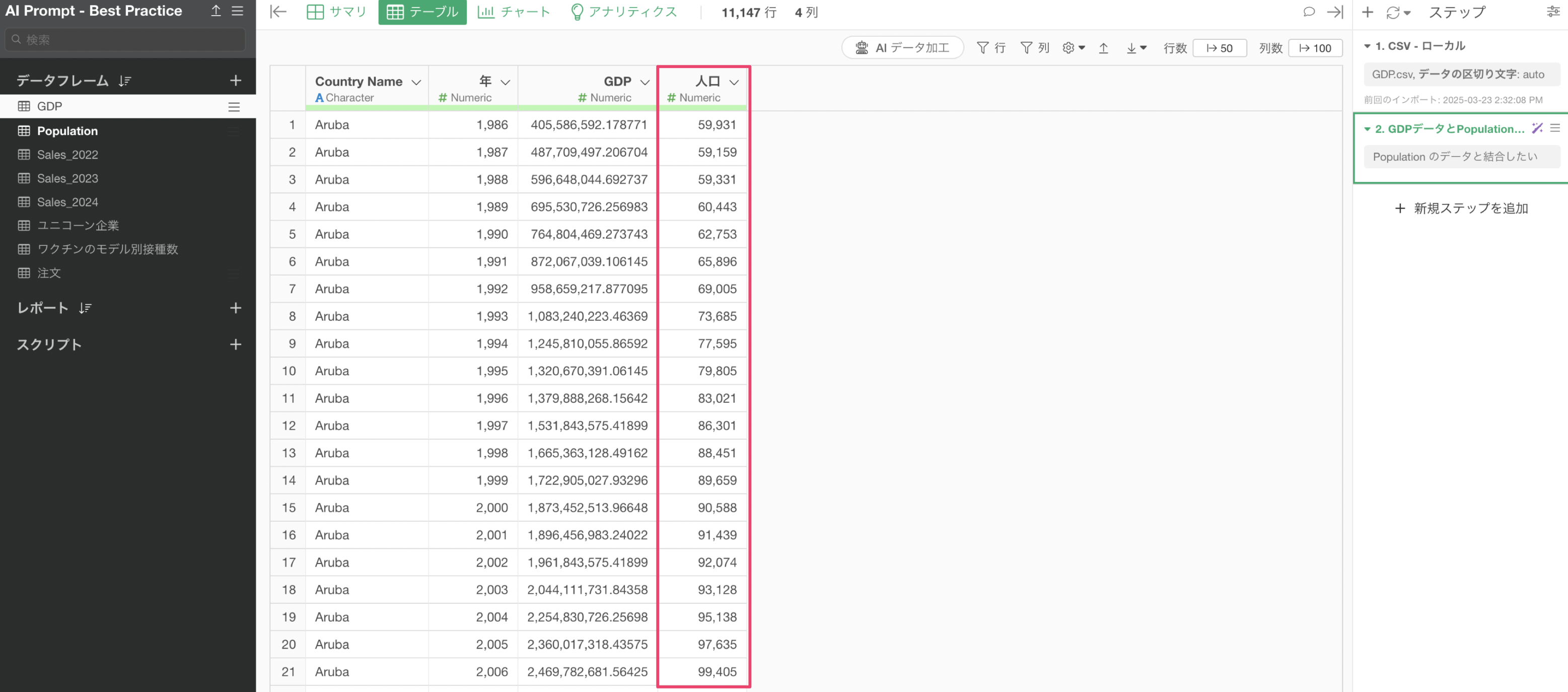
プロンプトを実行することで、Population(人口)のデータと結合するためのRコマンドが返ってきます。この際に列名が異なっていたとしても、同じ列だと推測されるものを自動的に識別して結合のキーに設定をしてくれています。
ステップとして実行をすることで、GDPのデータに対して人口のデータを結合することができました。
テキストデータの加工などの処理でうまくいかない時のTips
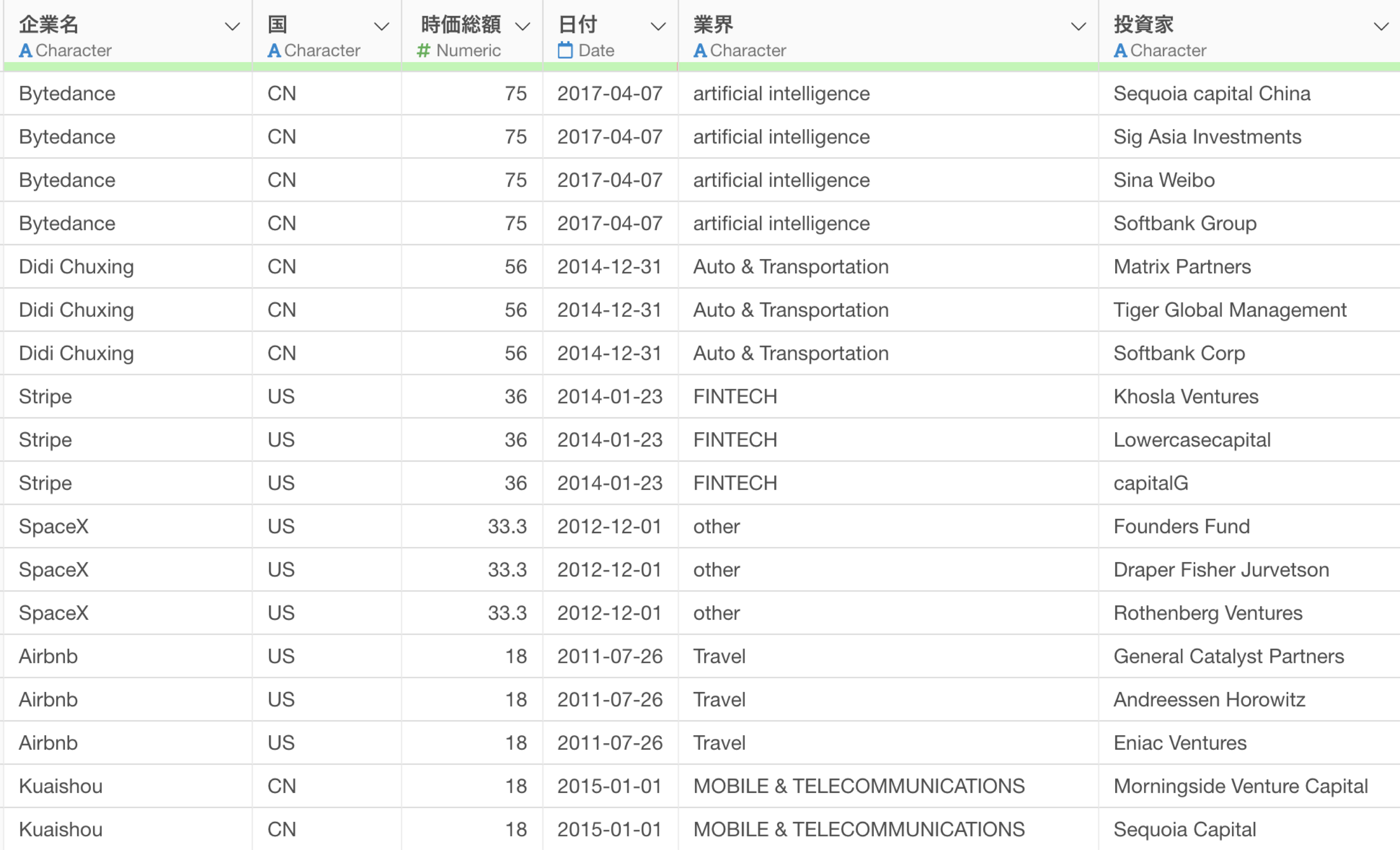
1行が1企業かつ投資家ごとに分かれているユニコーン企業のデータを使用します。
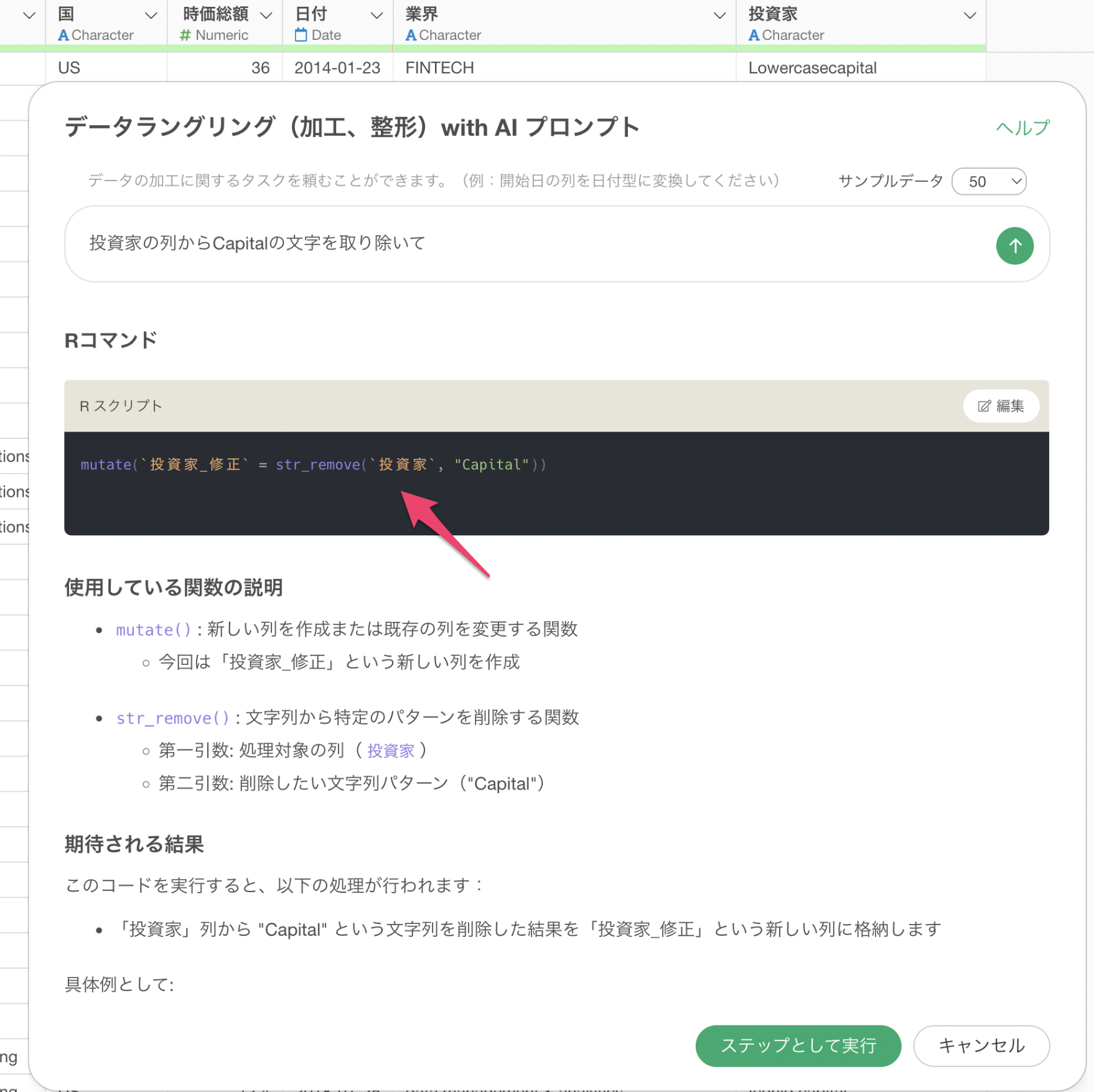
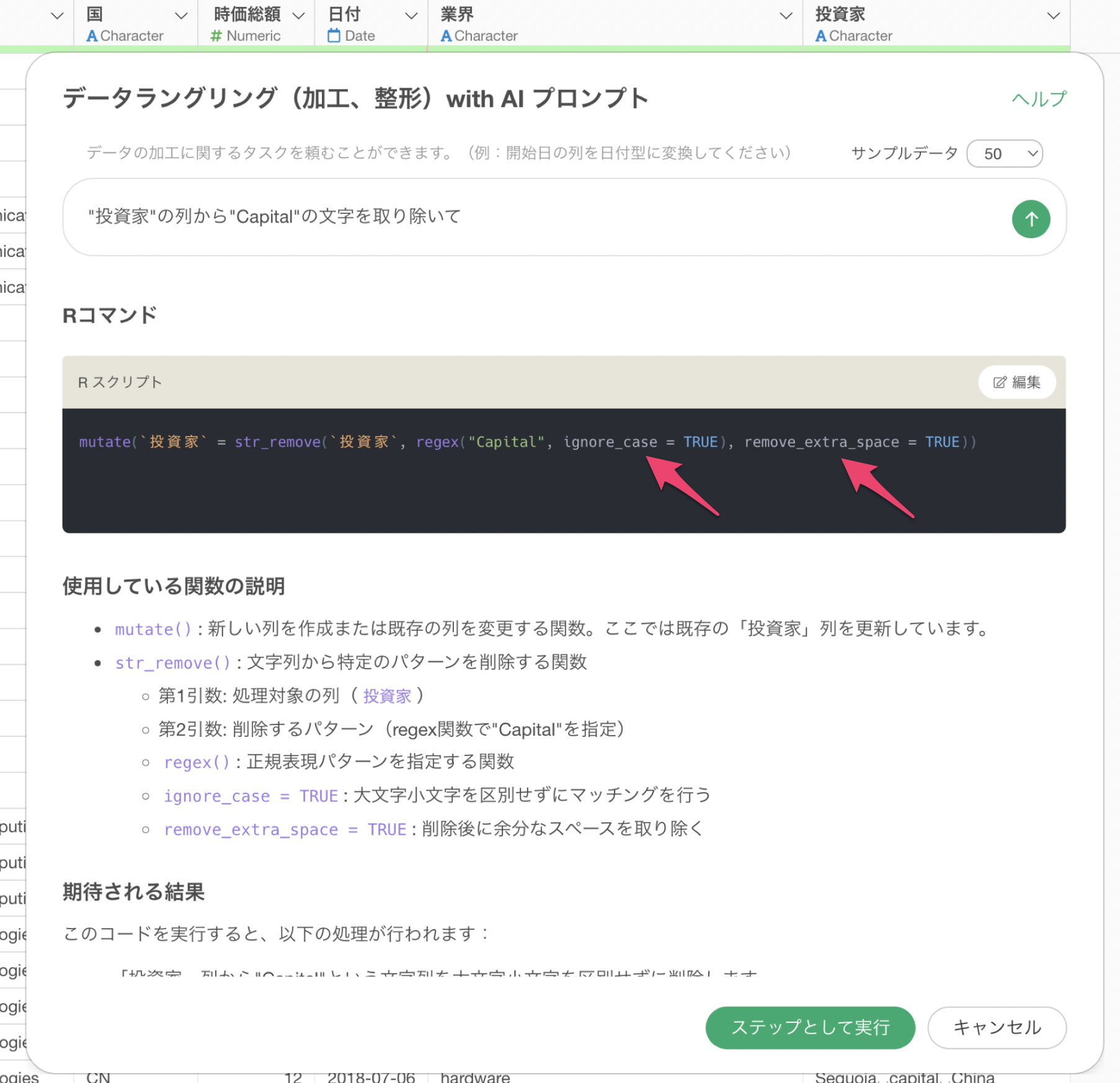
例えば、投資家の列から「Capital」といった文字を取り除きたいとします。そのため、以下のプロンプトを指示します。
投資家の列からCapitalの文字を取り除いて
これによって投資家の列から”Capital”といった文字を取り除くためのRコマンドが返ってきているため、ステップとして実行してみましょう。
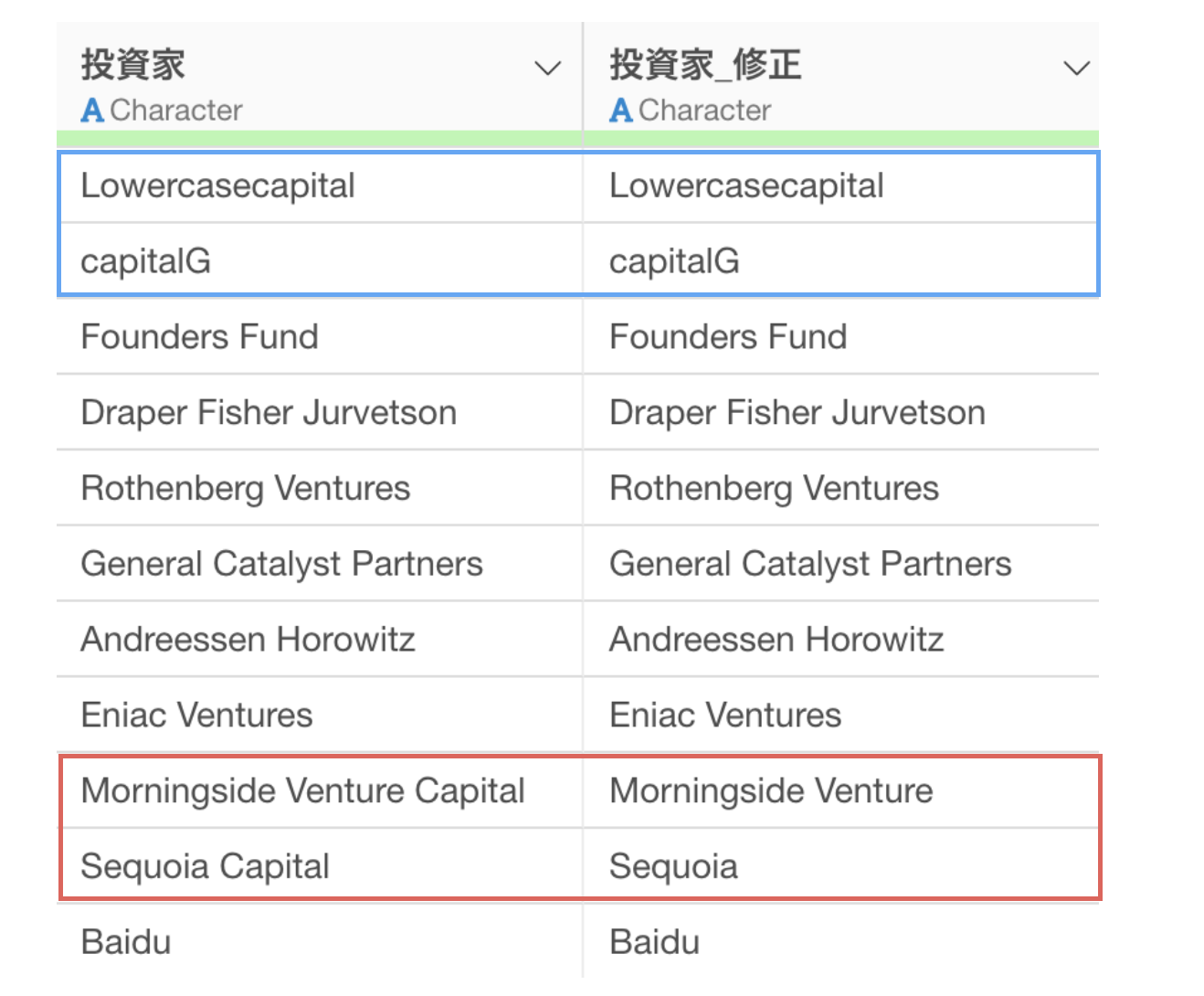
そうすることで、“Capital”の文字は取り除かれているのですが、いくつか問題があります。
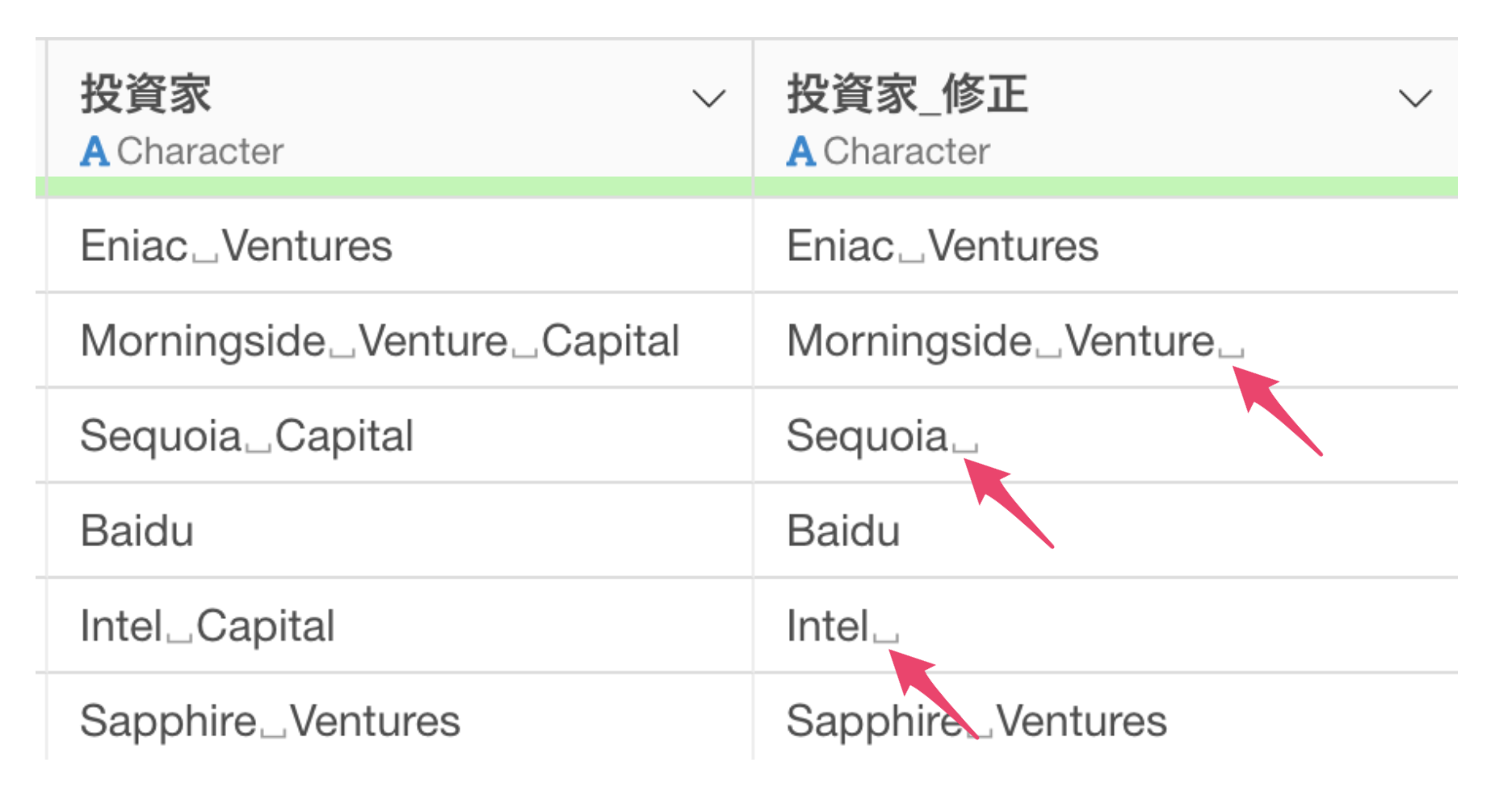
というのも、“Capital”といった先頭が大文字の場合は除かれていますが、“capital”のように全てが小文字の場合は取り除かれていません。
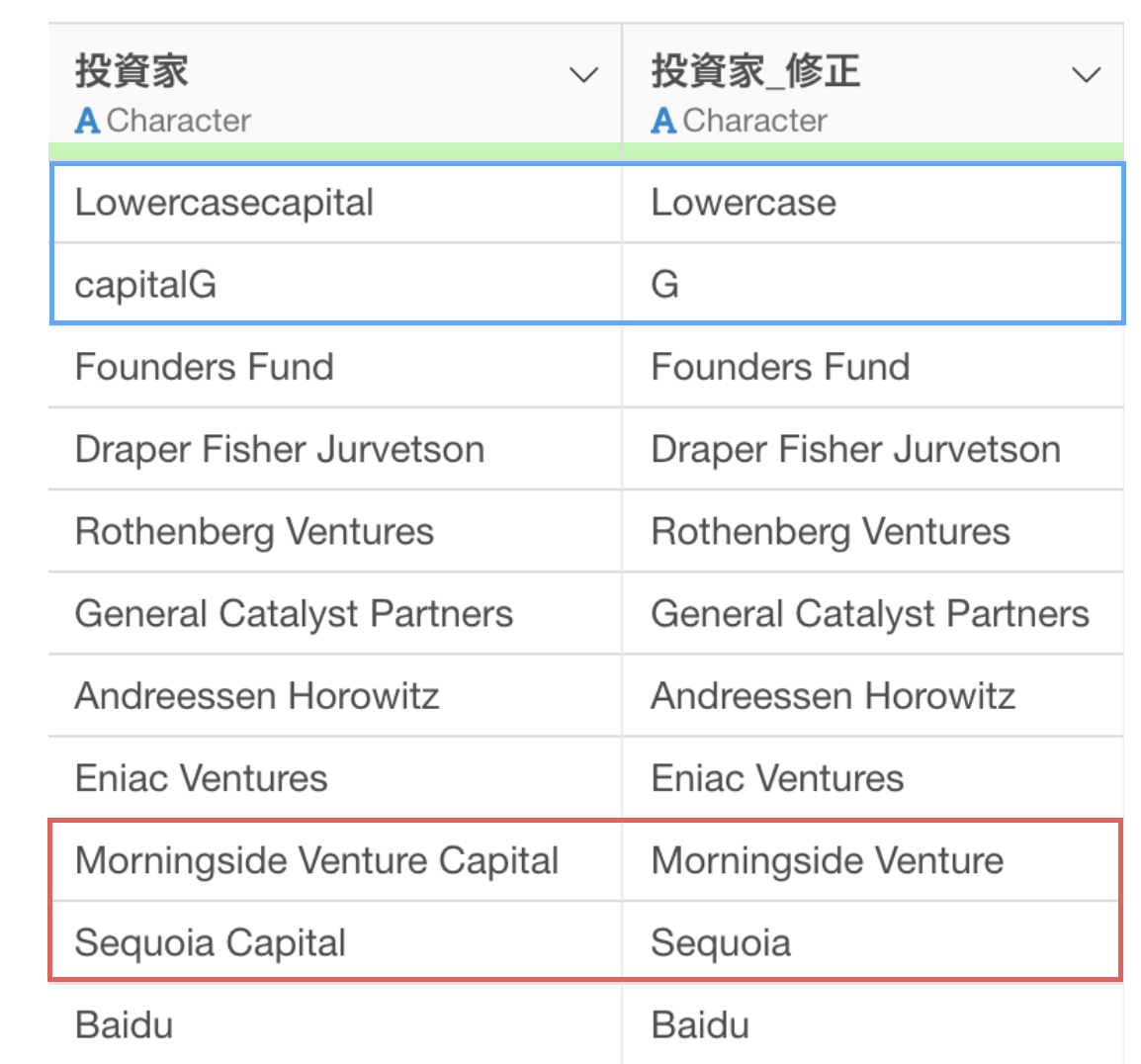
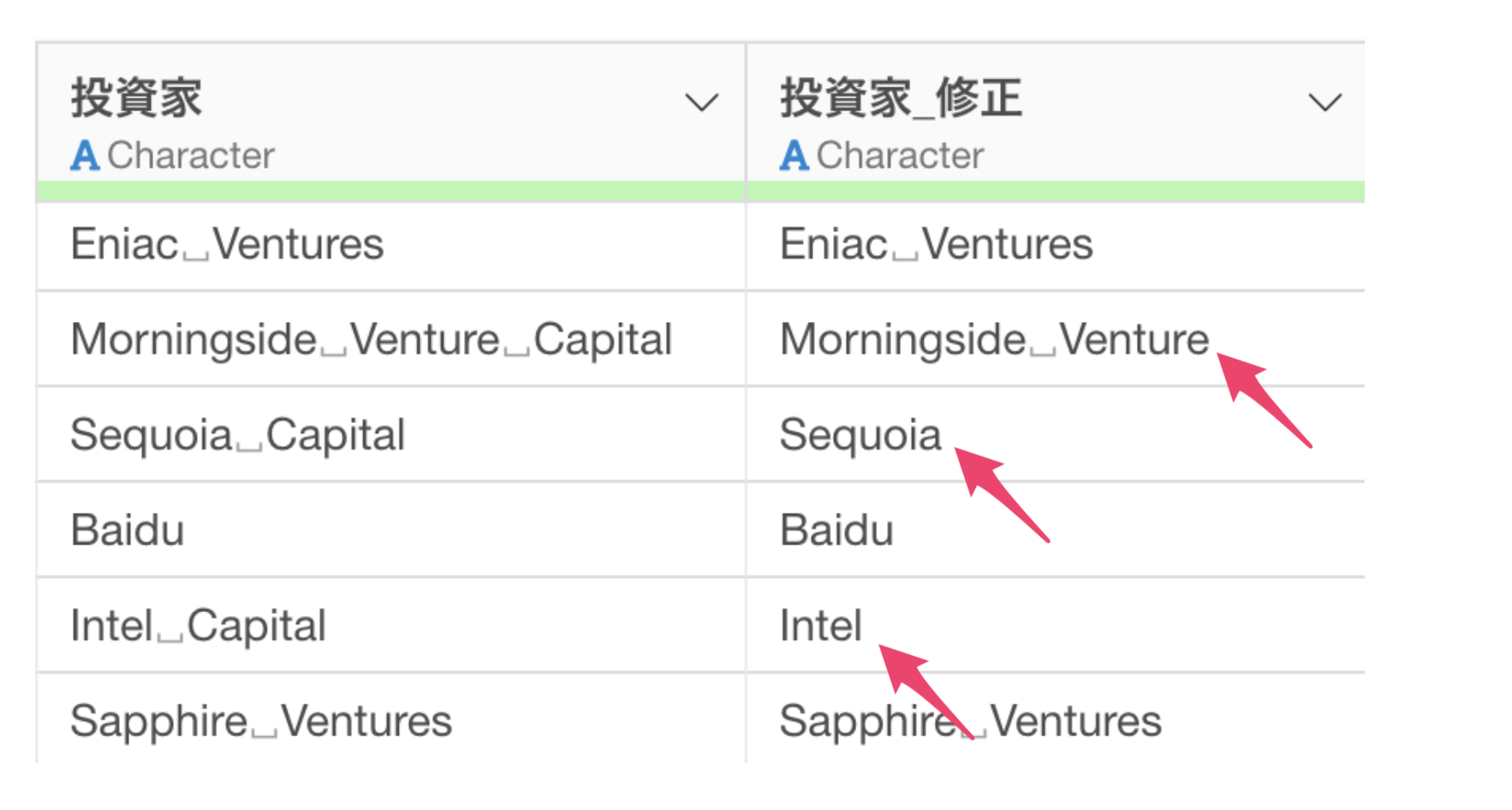
さらに、“Capital”の文字を取り除けたはいいものの、“Capital”の前にあったスペースがそのまま残ってしまっています。
そこで、列名である”投資家”や指定している文字である”Capital”に対してダブルクォート(“)で囲ってみます。
“投資家”の列から”Capital”の文字を取り除いて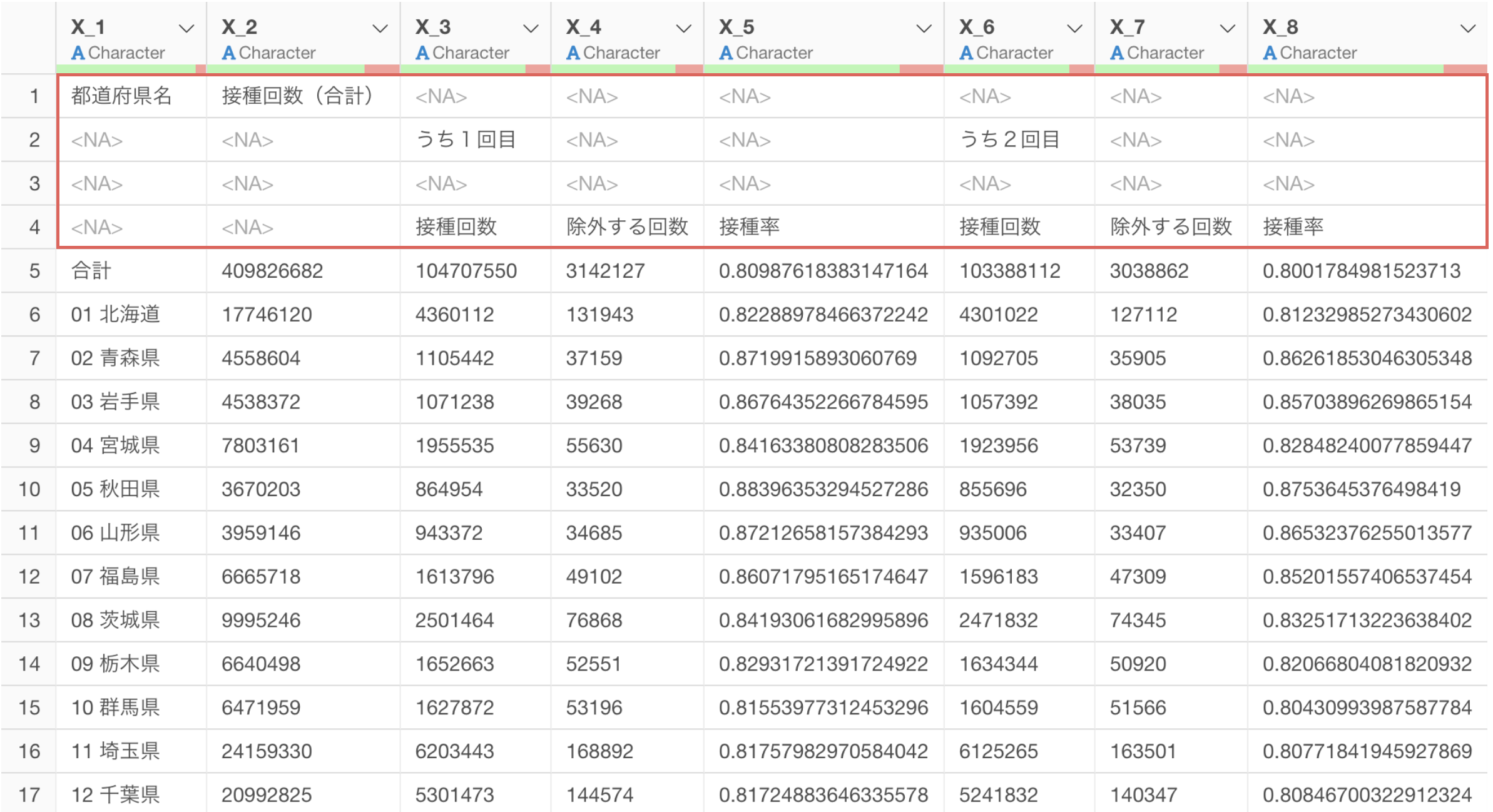
これは、AI Promptの機能の特徴として、RAG(Retrieval Augmented Generation)といってプロンプトを元にExploratoryで持っているコンテンツに対して検索をかけて、返ってきた結果を元に適切な処理内容を見つけるといった仕組みをとっています。
その際に、“投資家”や”Capital”といった特定の単語が含まれていると、その単語に検索結果が左右されることがあるために、それを抑制するためにダブルクォートで囲うといったことをしています。
これによって、Exploratoryが持っているコンテンツから正しく情報を参照し、Rコマンドが返す結果にも違いがあることが確認できます。
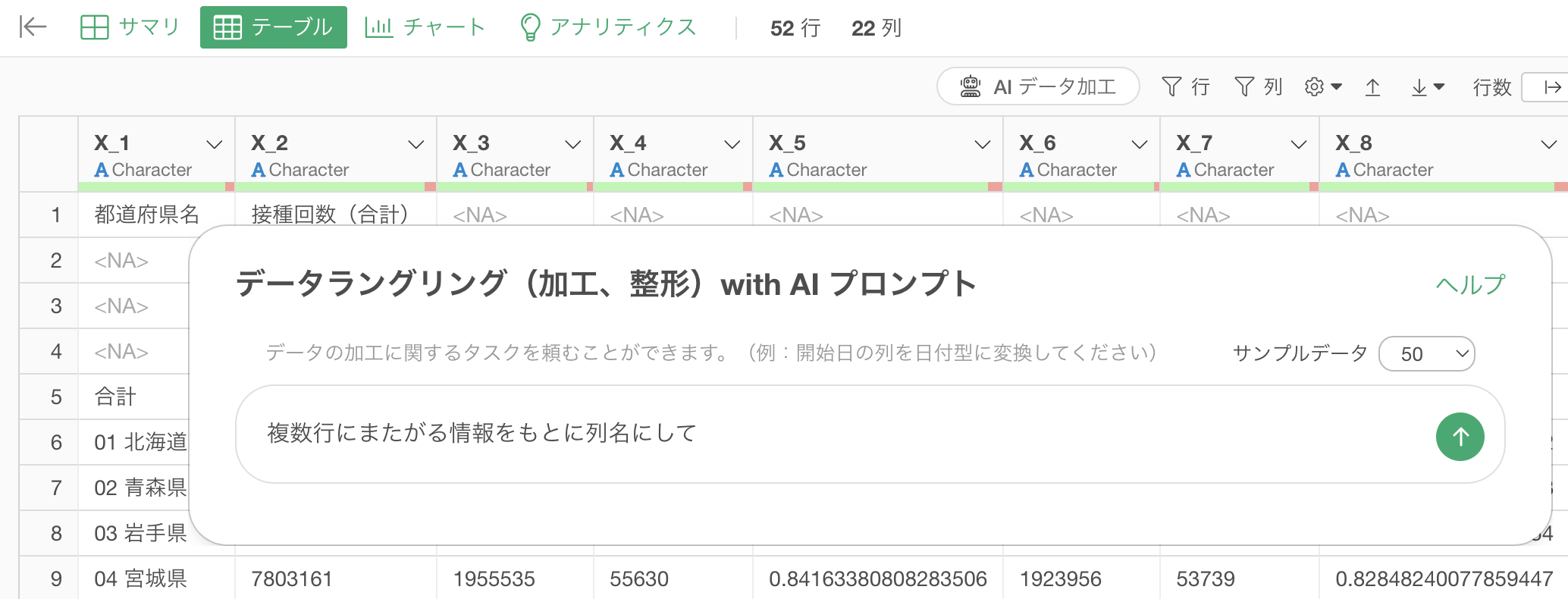
元のプロンプトで返ってくる結果:
mutate(`投資家` = str_remove(`投資家`, ”Capital”))ダブルクォートをつけたプロンプトで返ってくる結果:
mutate(`投資家` = str_remove(`投資家`,regex("Capital", ignore_case = TRUE), remove_extra_space = TRUE))このダブルクォートをつけた時に返ってくる結果での大きなポイントはignore_caseとremove_extra_spaceといった引数になります。
ignore_case = TRUEは「大文字・小文字」を無視して処理することができる引数になります。そのため、もともと取り除かれていなかった小文字の”capital”も取り除かれていることが確認できます。
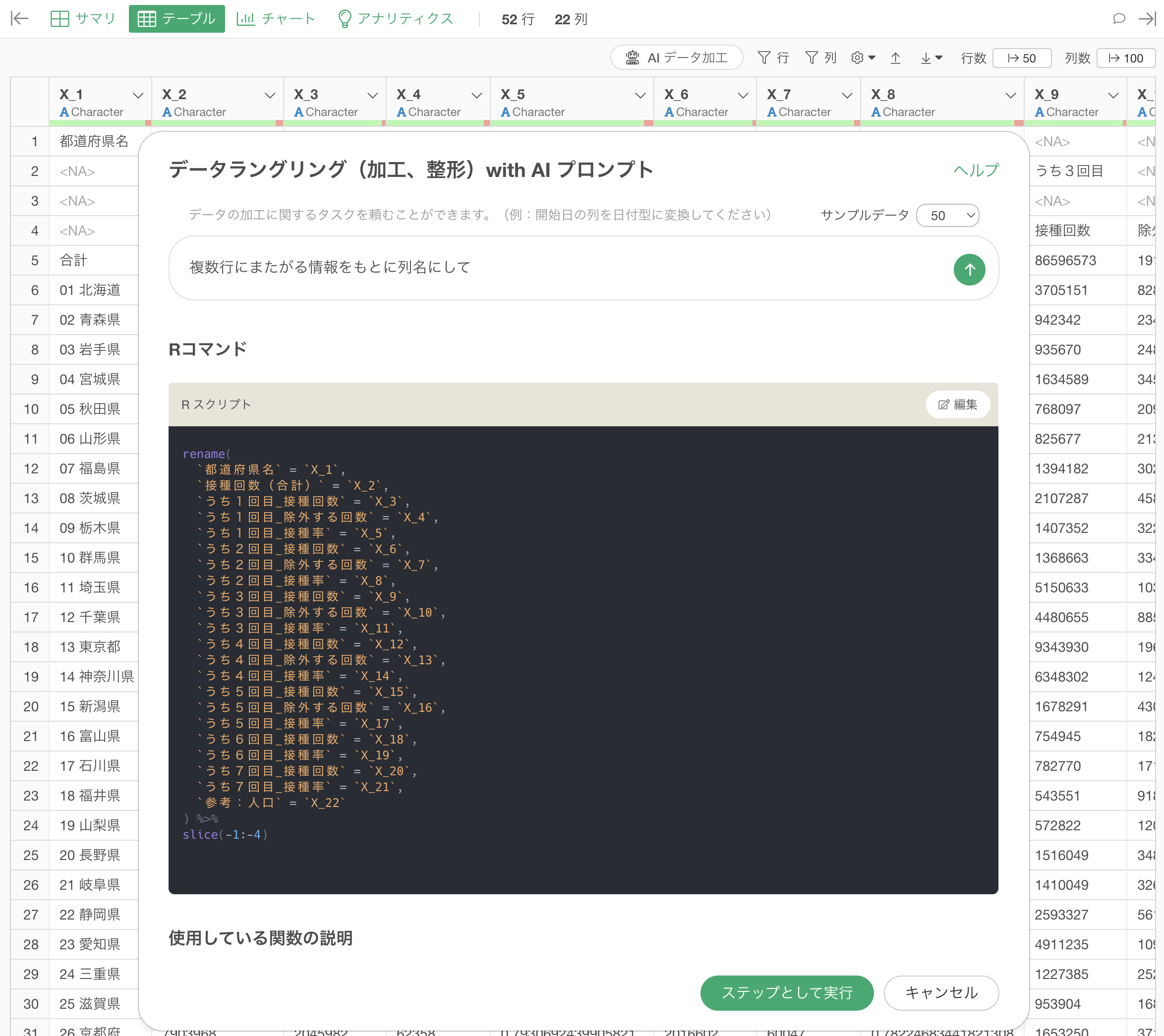
次にremove_extra_space = TRUEは、処理の後に不要な空白があった場合は削除するための引数です。これによってCapitalを消した際に元々あった空白が取り除かれていることが確認できます。
このようにテキストデータの加工でうまく結果が返ってこない場合は、列名や指定した文字に対してダブルクォートをつけてみてください!
列名をきれいにする
Excelなどのデータを扱っていると、汚い列名のデータとよく遭遇することがあります。
汚い列名のデータをきれいにする場合には、それぞれのシーンに合わせて以下のプロンプトを使うことで簡単に列名をきれいにすることができます。
- 列名が長すぎるので列名を短縮して
- 複数行にまたがる情報をもとに列名にして
- N行目を列名にして
- 列名にあるXXXの文字列を取り除いて
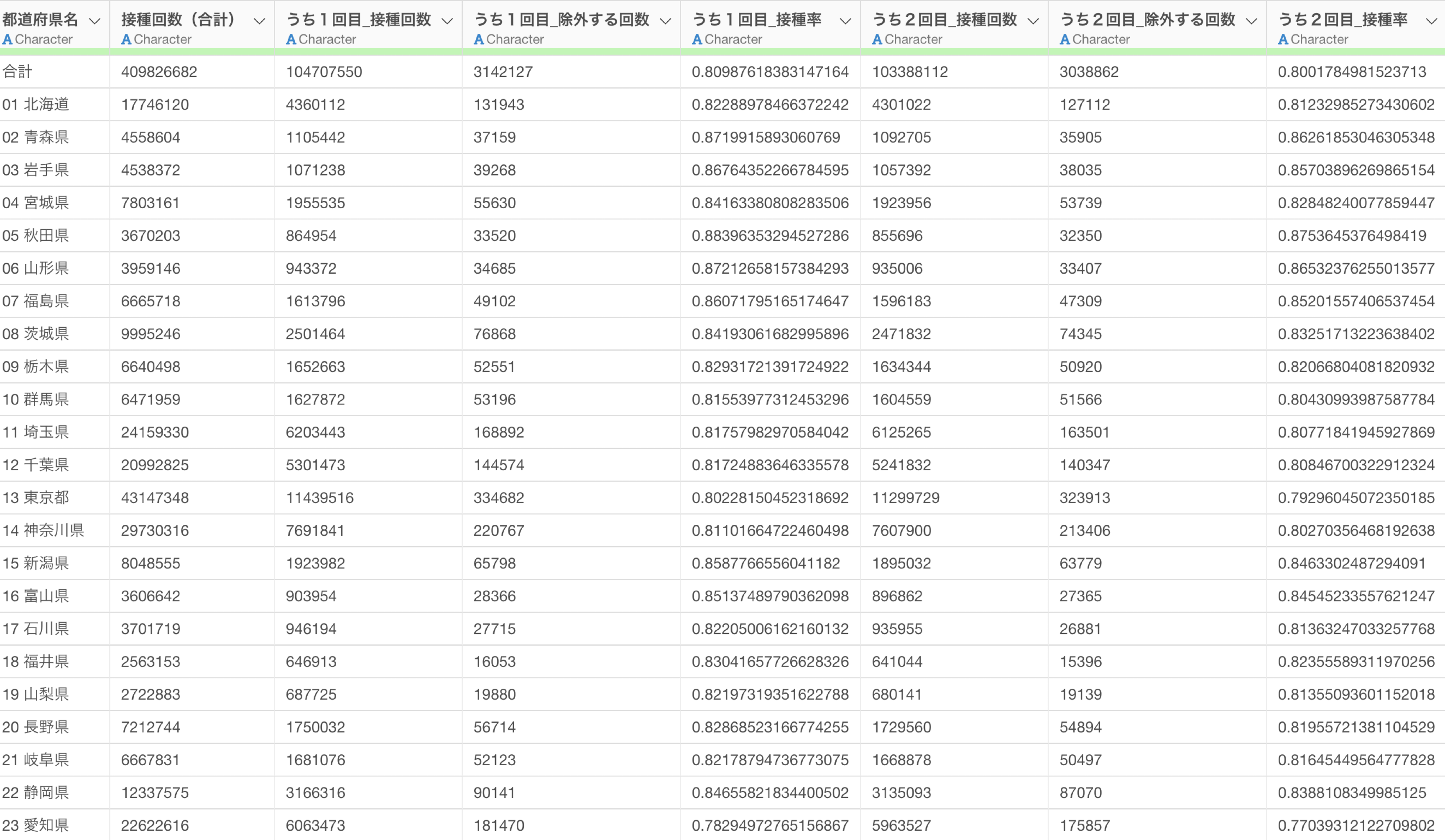
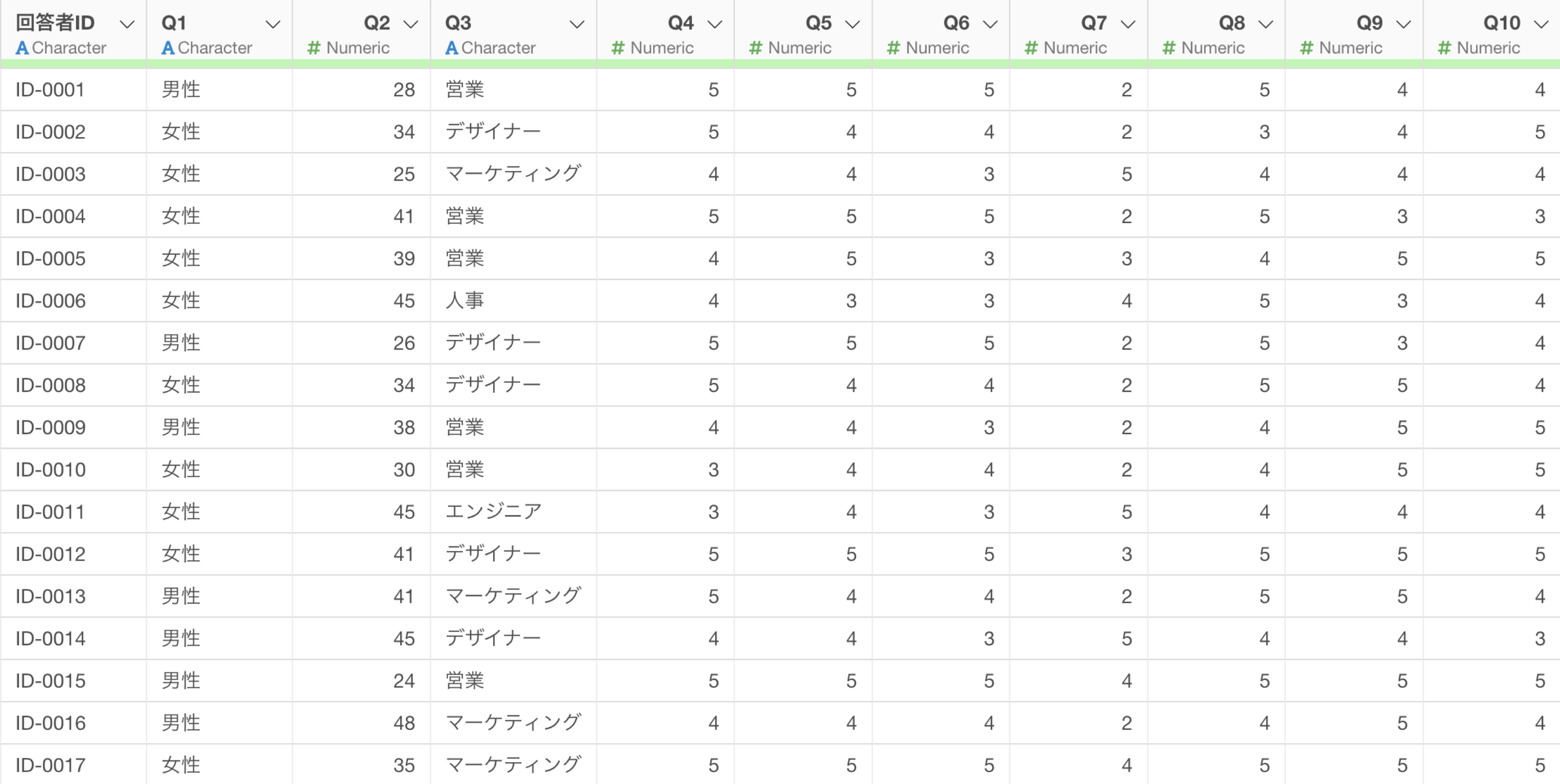
例えば、以下はワクチンの接種回数のデータですが、列名が驚くほど汚いです。列名が複数行、複数列に跨っているため、これを1つずつ修正しようとするのはやりたくない作業のひとつです。
そこで、以下のプロンプトを実行します。
複数行にまたがる情報をもとに列名にして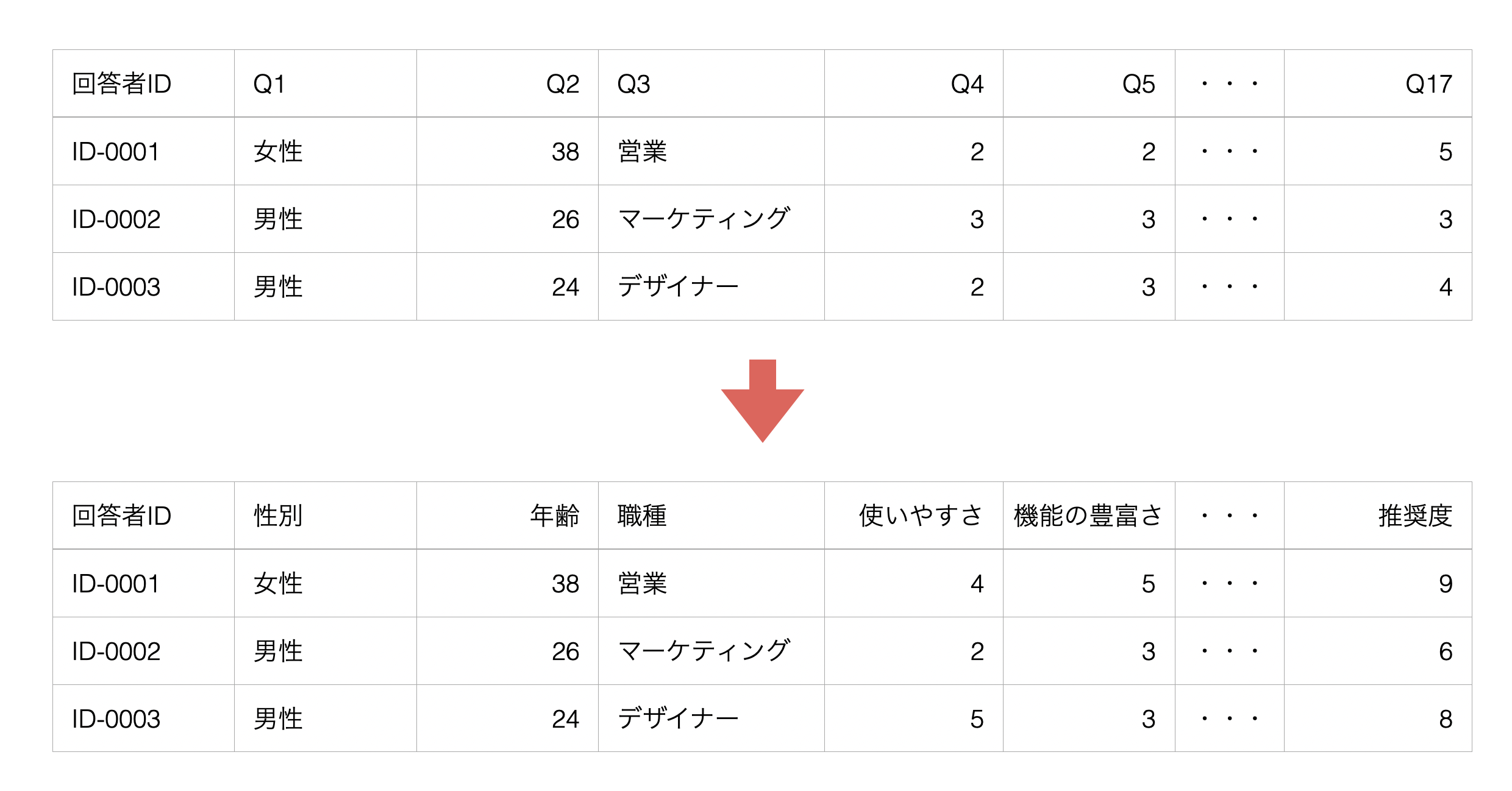
複数行、複数列にまたがる列名を、データを元に判断をして一括で変更をしていることがわかります。
ステップとして実行することで、複数行、複数列にまたがる列名を綺麗にすることができました。
Appendix
このAI プロンプトの機能は、これまでのExploratoryのUIでサポートされていたデータ加工を遥かに超える、よりエキサイティングな使い方ができます。そこで、いくつかの活用例をご紹介していきます。
列名の一括置換
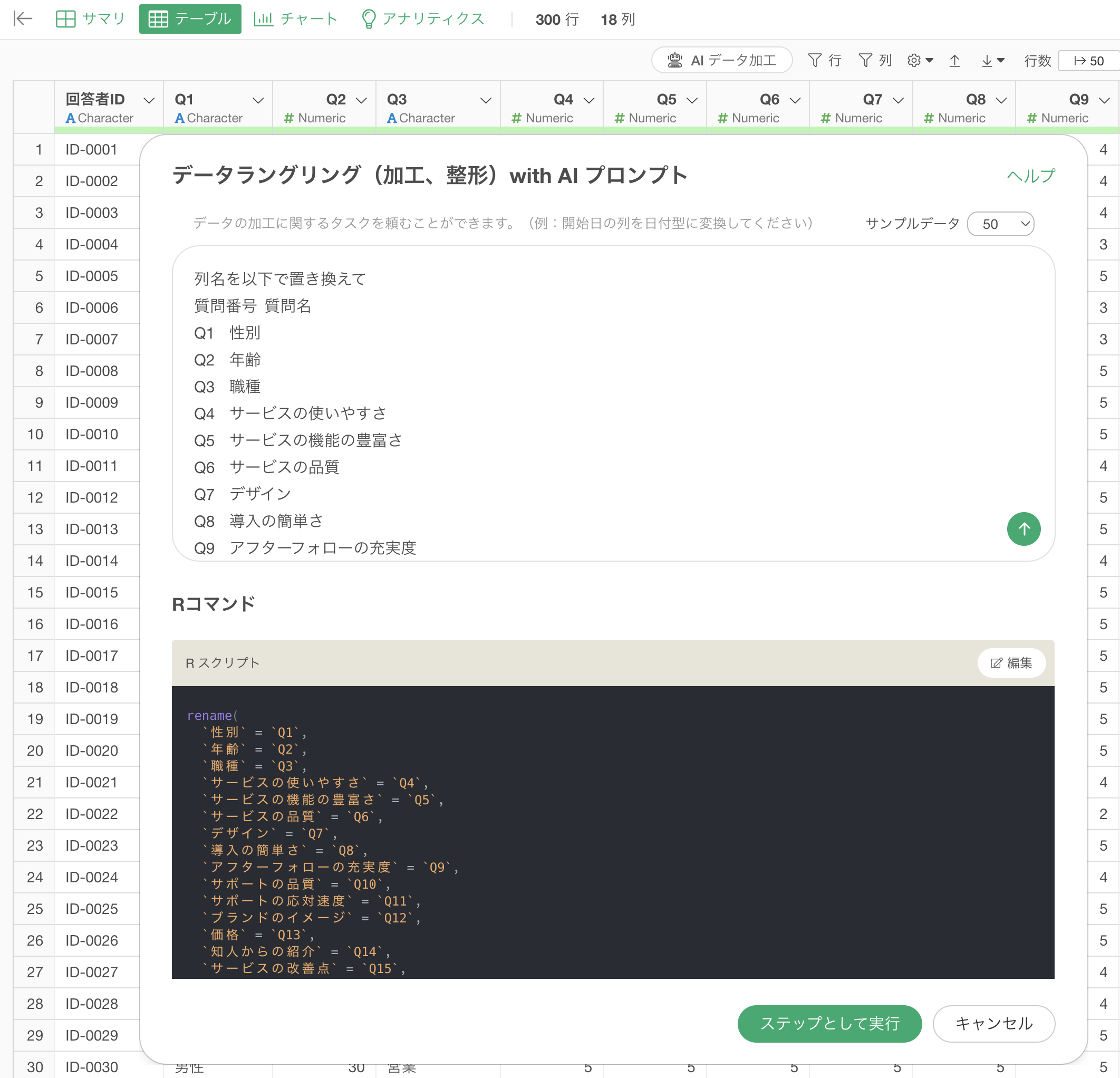
例えば、アンケートデータなどでよくあるのが、列名に「Q1」や「Q2」といった質問番号が使われるといったことがあります。
こういったデータだと分析をしようとしてもその質問番号自体が何を表すのかわからないために、それぞれの質問番号に対応する質問名を紐づけるといった作業が必要になります。そのため、以下のようにQ1であれば性別、Q2であれば年齢のように置き換えていきたいです。
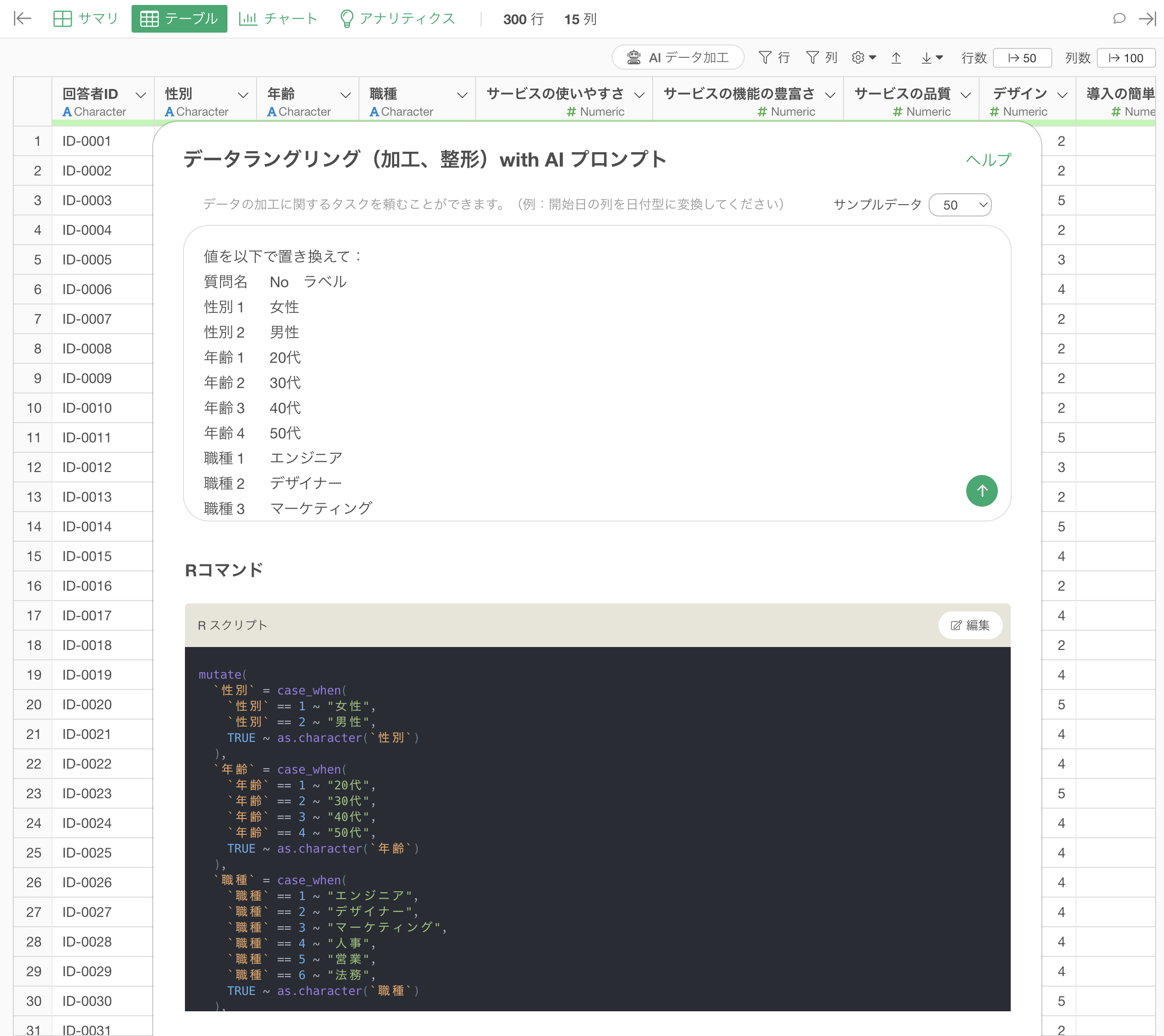 そこで、プロンプトに以下のように指定をして実行をします。
そこで、プロンプトに以下のように指定をして実行をします。
列名を以下で置き換えて
質問番号 質問名
Q1 性別
Q2 年齢
Q3 職種
Q4 サービスの使いやすさ
Q5 サービスの機能の豊富さ
Q6 サービスの品質
Q7 デザイン
・・・
Q17 推奨度の理由これによって、質問番号になっていた列名を一気に質問名で置き換えるためのRコマンドを結果として返してくれます。
実行することで、列名を一気に置換することができました!このように、今までなら面倒だった列名の置換作業も、このAI プロンプトの機能を使うことで、簡単に、そして素早く解決することができます。
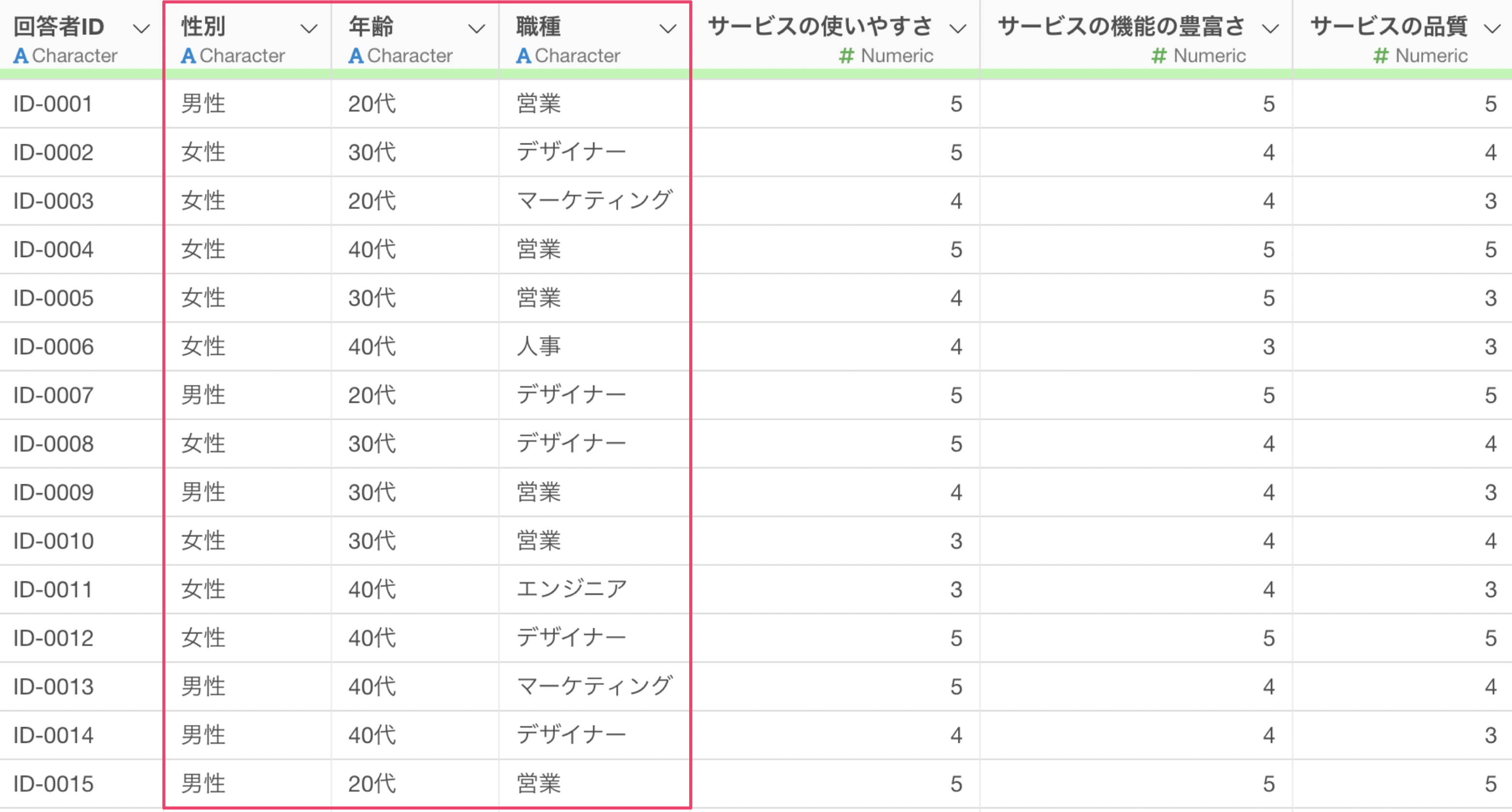
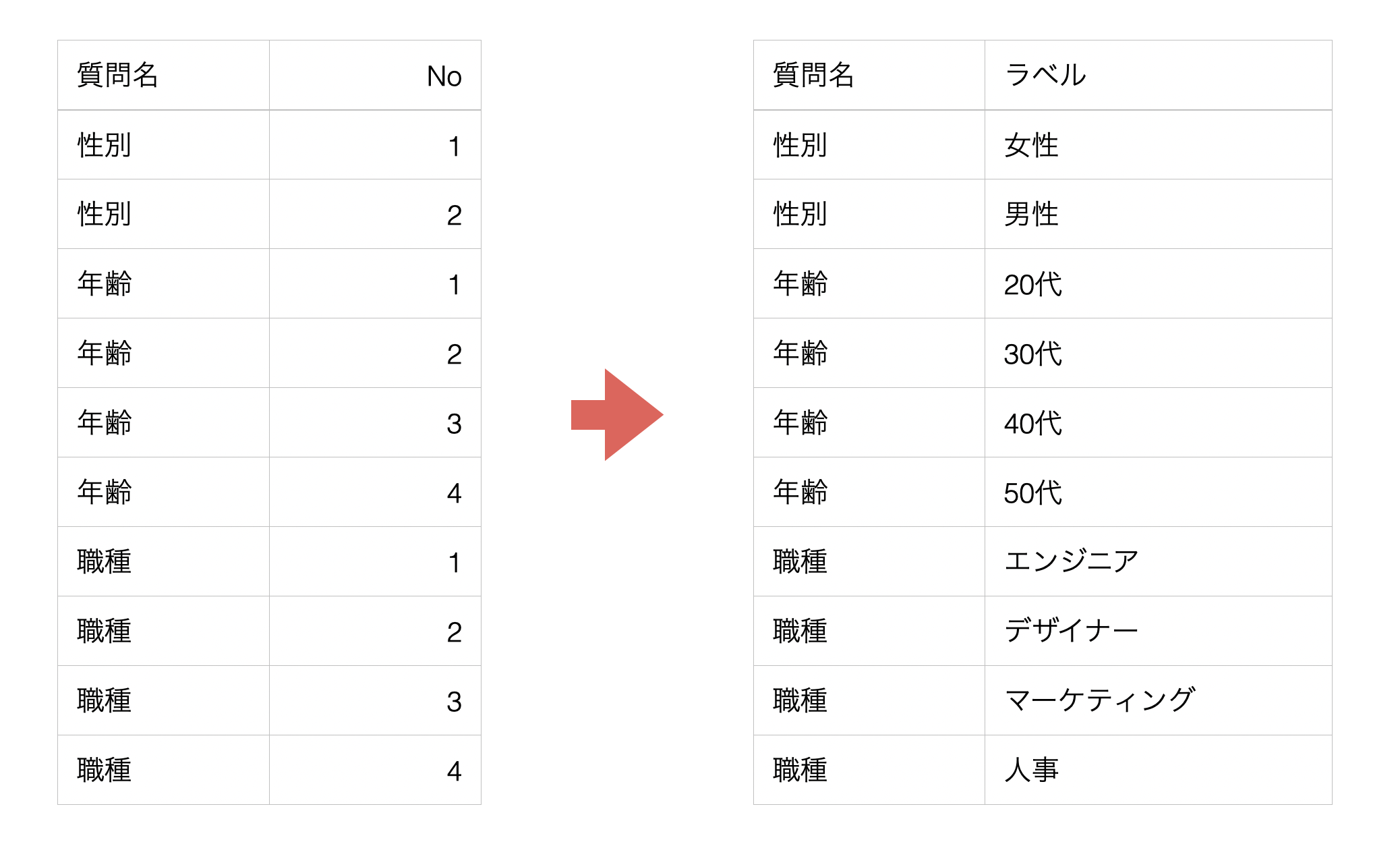
値の一括置換
先程は列名の質問番号を質問名で置き換えるといった例を紹介しましたが、値の方も一括で置換をすることが可能です。アンケートデータの例になりますが、性別や年齢、職種なども数値としてローデータを持っているということがあります。
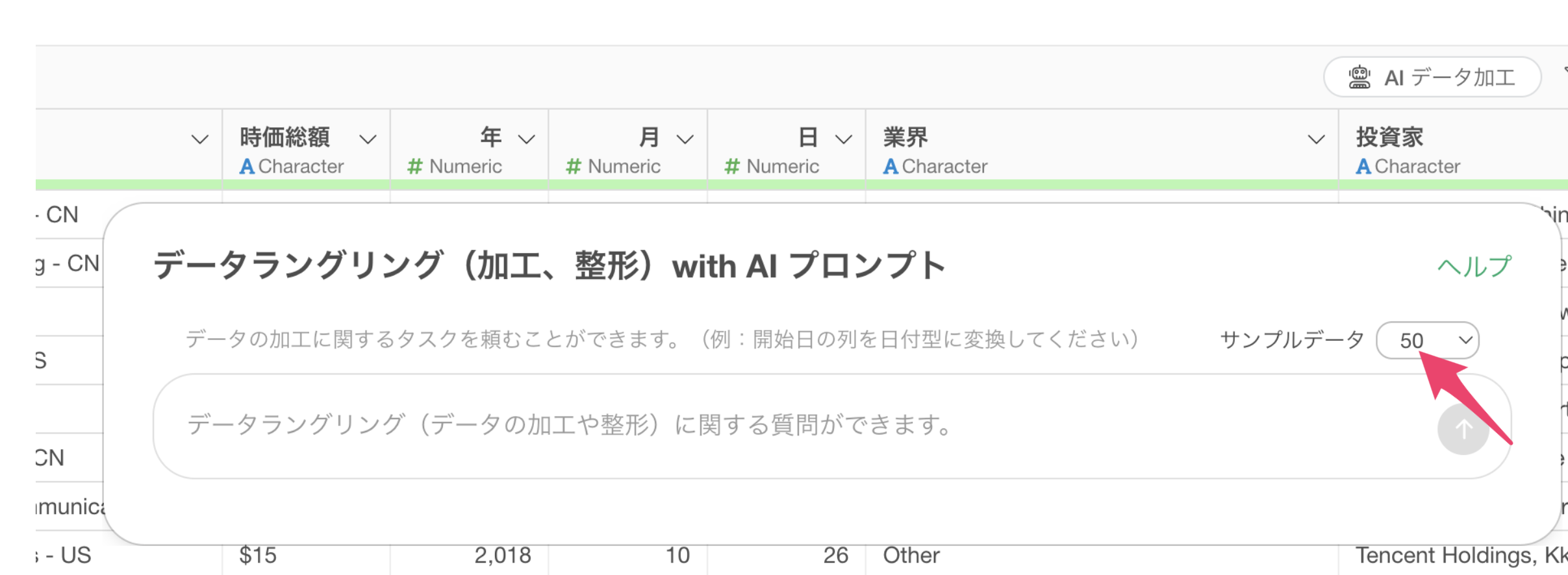
そこで、それぞれの質問名と回答番号に紐づく回答ラベルに一括で置換をしたいとします。この例では性別の1といった値は女性といったラベル、年齢の1は20代といったラベルに変更をしたいです。
そこで、プロンプトに以下のように指定をして実行をします。
値を以下で置き換えて
質問名 No ラベル
性別 1 女性
性別 2 男性
年齢 1 20代
年齢 2 30代
年齢 3 40代
・・・これによって、回答番号に紐づくラベルで一気に置き換えるためのRコマンドを結果として返してくれます。
実行することで、値を一気に置換することができました!値の置換作業も、元の値と新しい値を指定するだけで、一気に変更をしていくことが可能です!
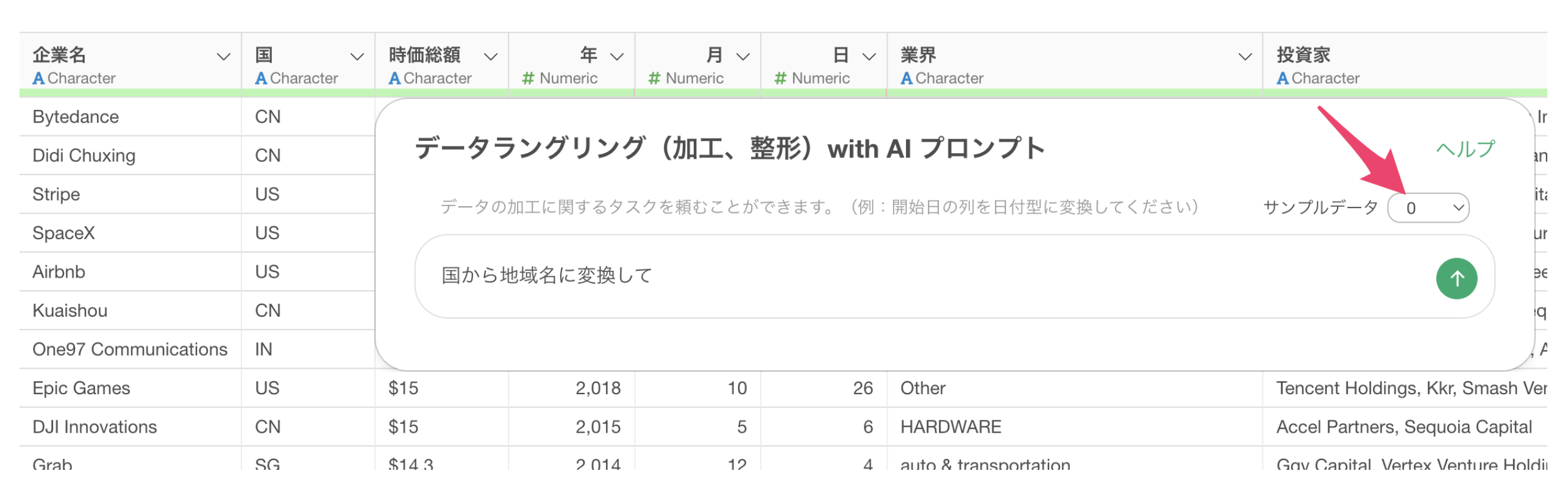
サンプルデータの行数について
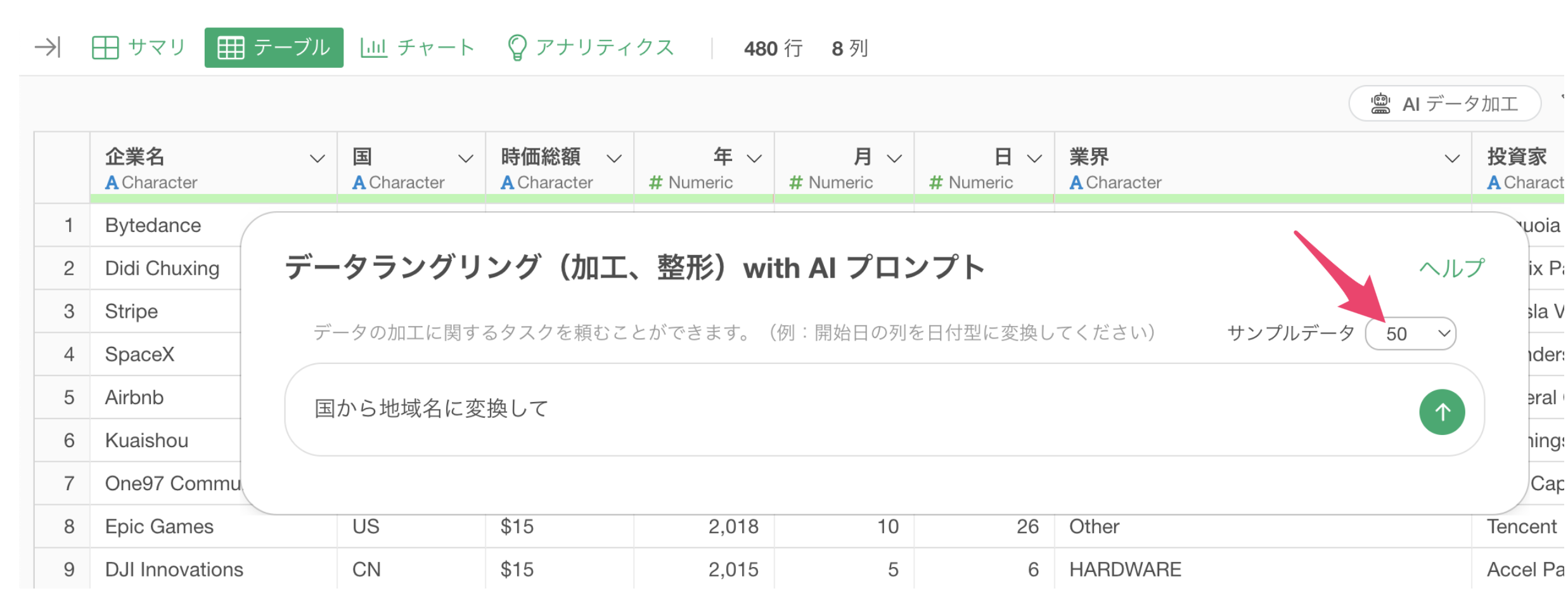
AI プロンプトの機能では、プロンプトを実行していい結果を返すために、データをサンプルしてLLMに提供しています。ただ、学習データとして使用しているわけではなく、より良い提案をさせるために、サンプルデータの指定があります。
デフォルトは50行ですが、もしサンプルデータを渡したくない場合は0行にすることが可能です。
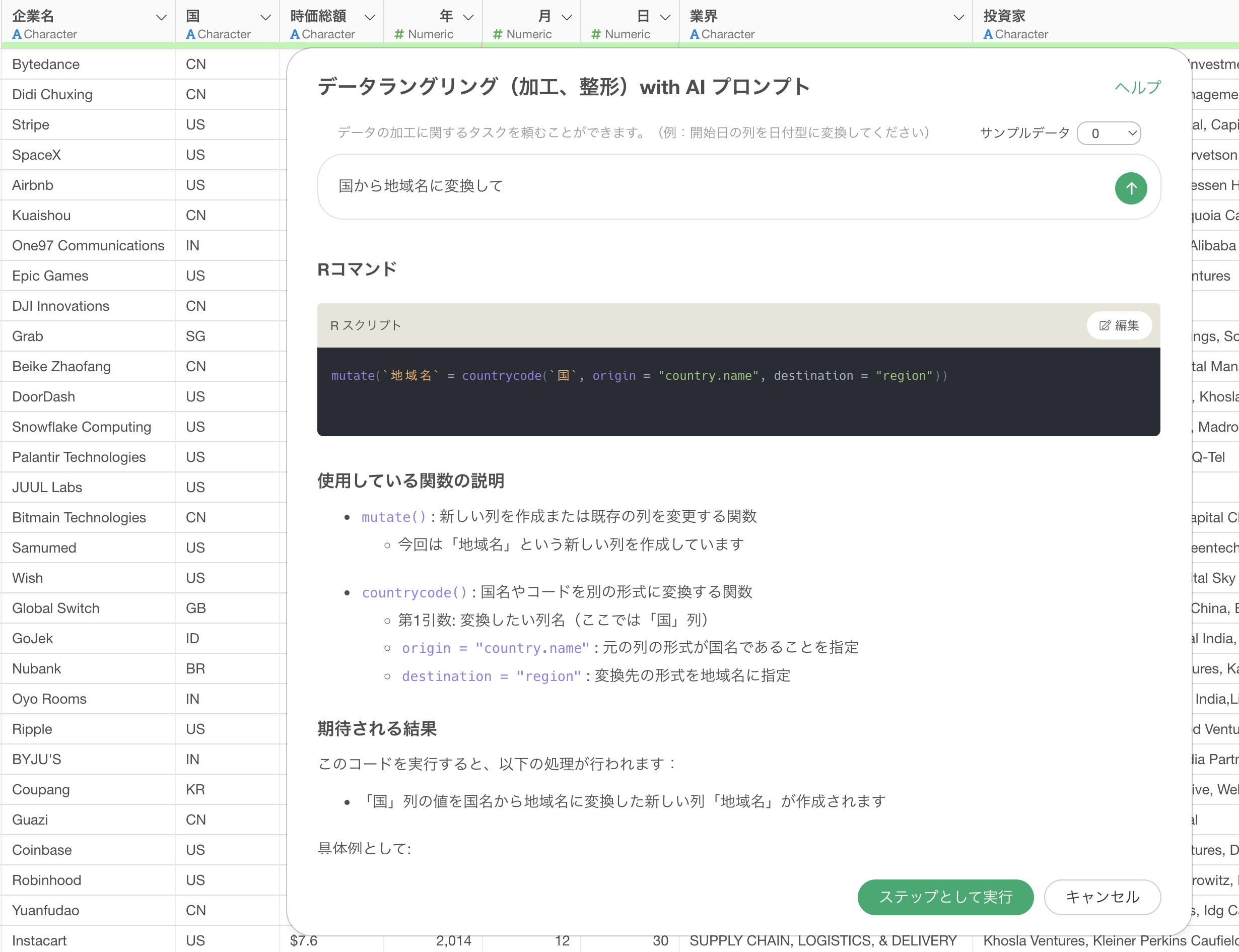
では、このサンプルデータがどのように影響をするのかについてみていきましょう。
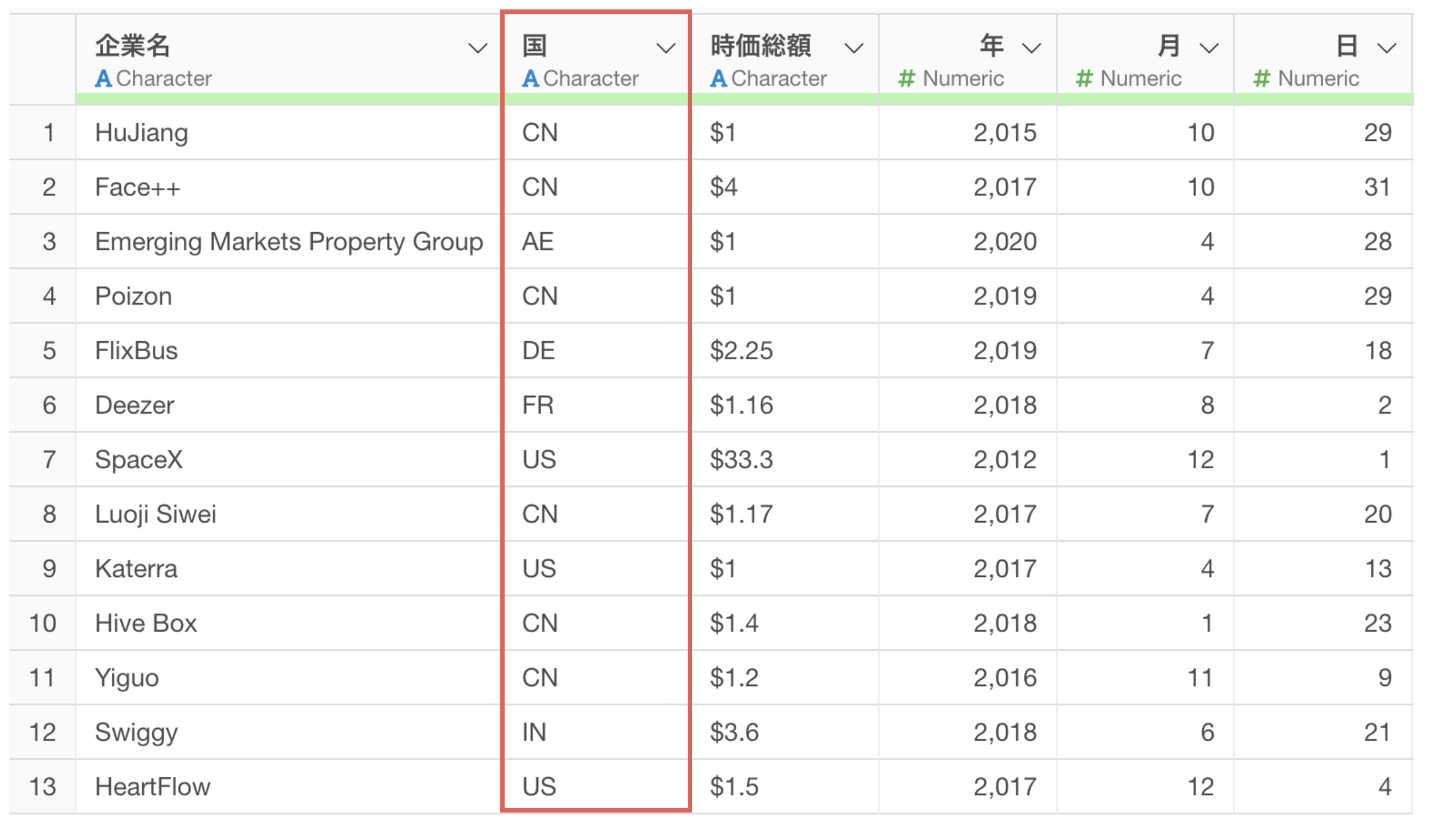
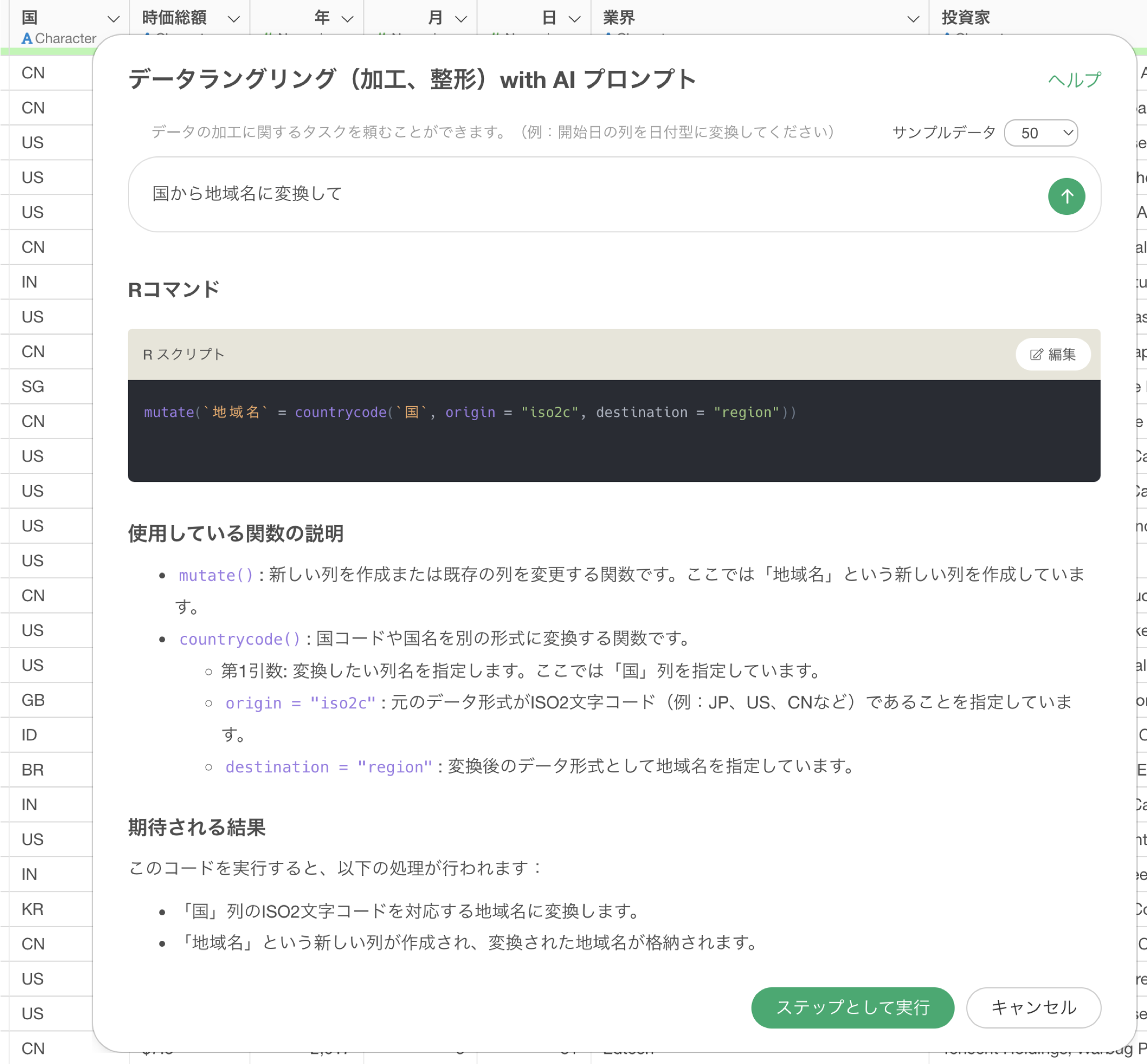
1行が1ユニコーン企業のデータで「国」といった列があります。この国の列は2文字の国コードを値として持っています。今回はこの国の列から地域名の列を作成していきたいです。
サンプルデータを「0行」にして、国から地域名に変換するために以下のプロンプトを指示します。
国から地域名に変換して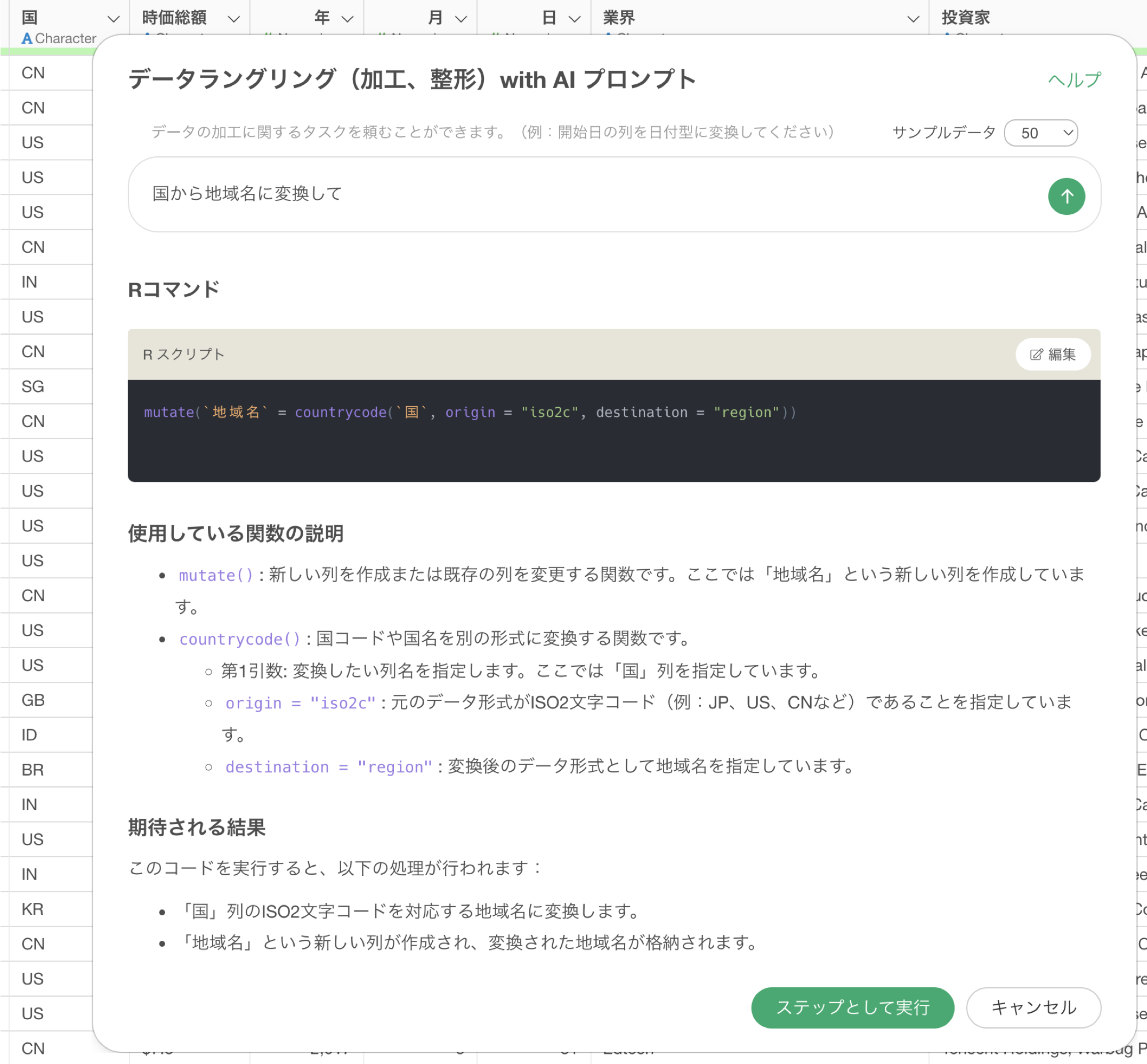
これで実行をした時に、「2文字の国コード」ではなく、「国名」から「地域名」に変換するためのRコマンドが結果として返っています。
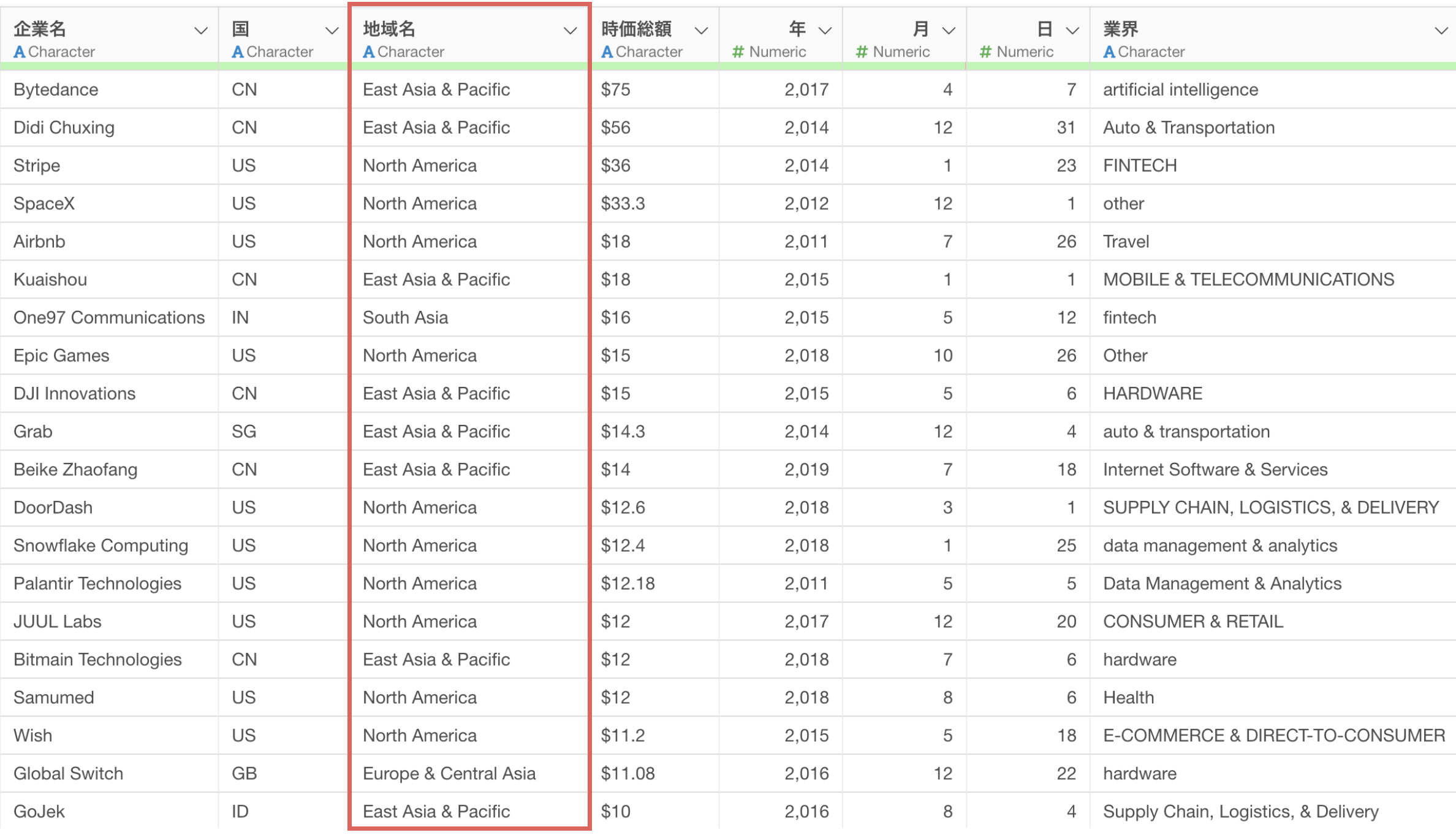
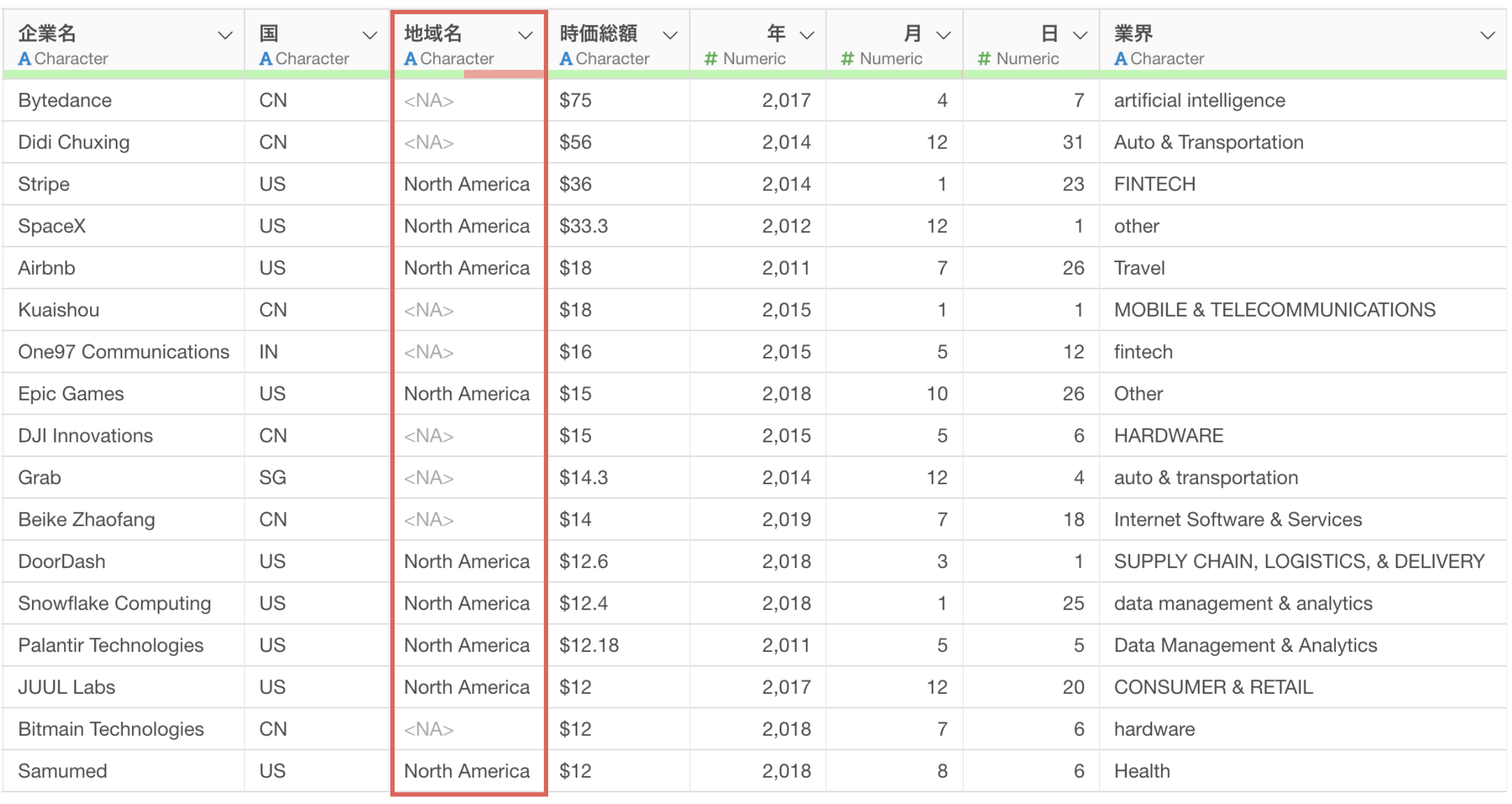
地域名の列は作成できましたが、国コードから地域名に変換するという正しい処理ができていないために、欠損値が非常に多い結果になっています。
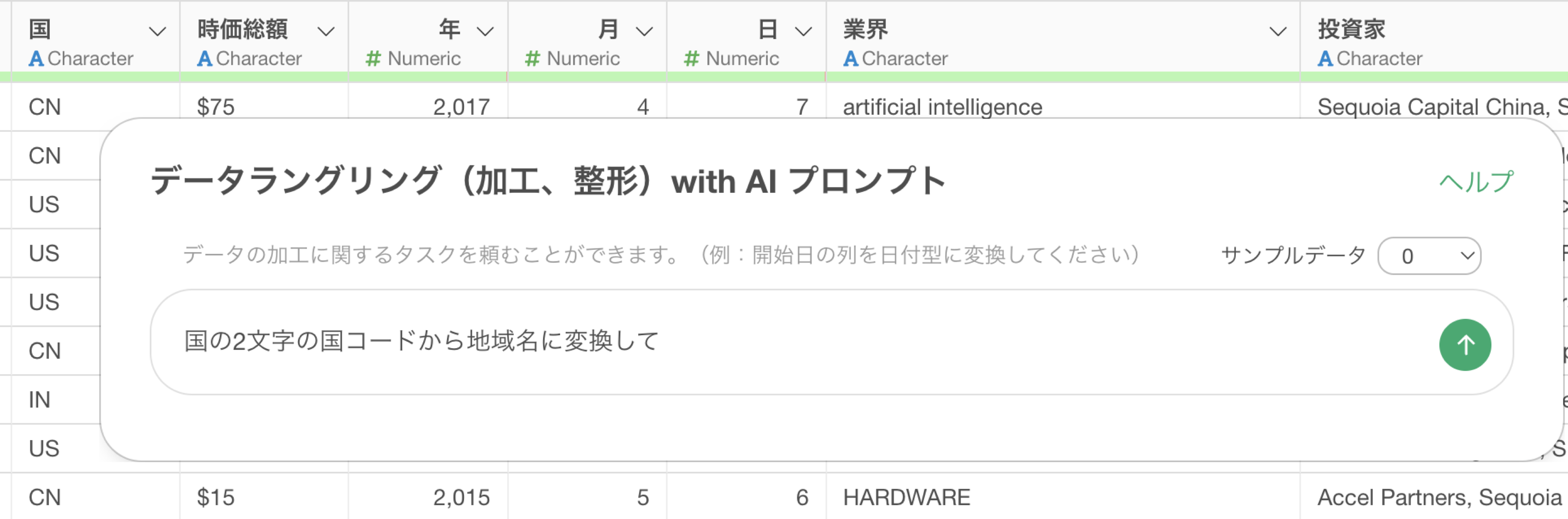
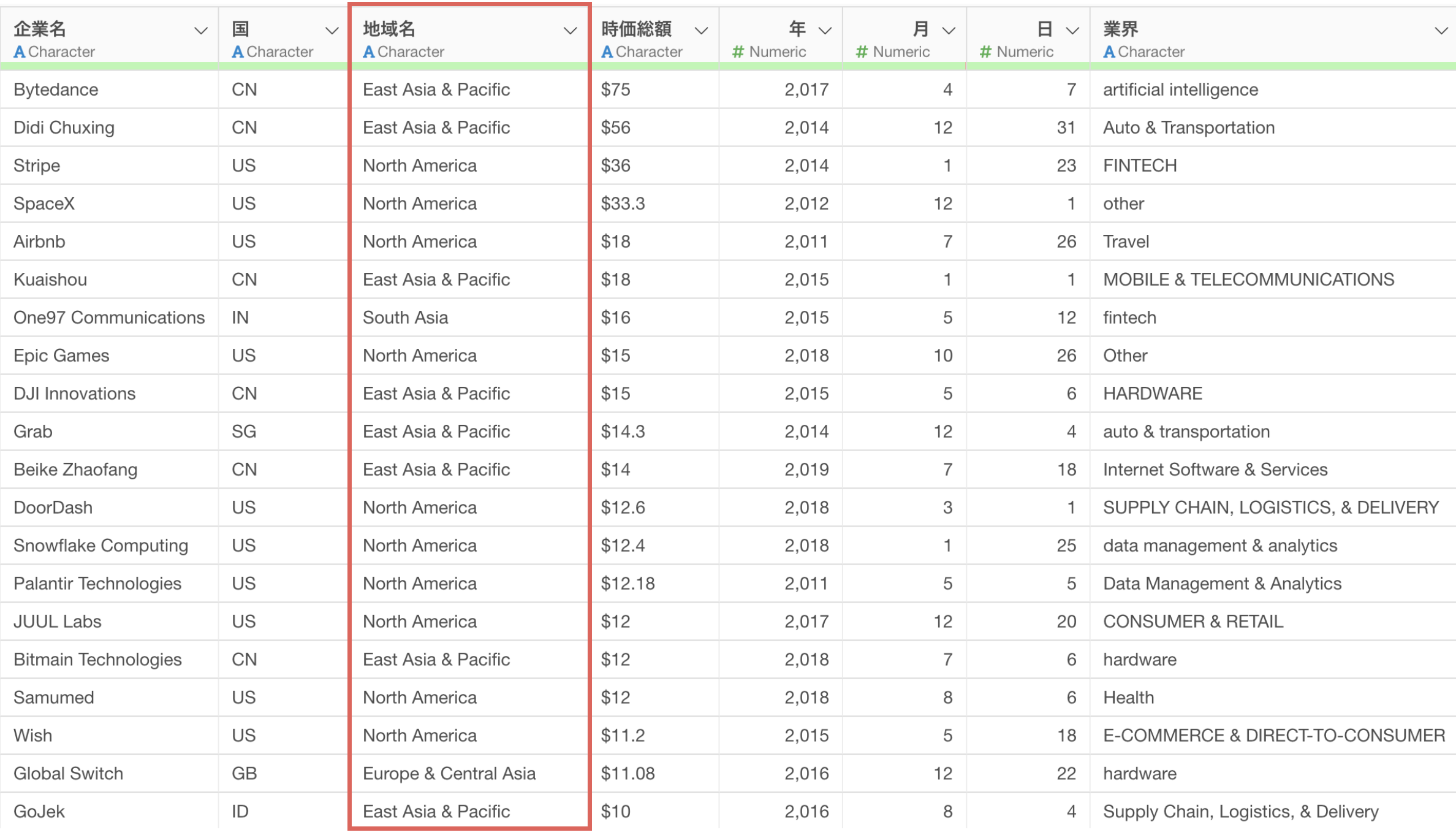
では、サンプルデータの行数をデフォルトの「50行」として同じプロンプトを指示したとします。
そうすることで「国コード」から「地域名」に変換するためのRのコマンドが返ってきています。
ステップとして実行することで、今度は地域名の列に欠損値がなく、正しく国コードから国名に変換されていることがわかります。
このように、データの値を元に処理の判断をする場合は、サンプルデータを渡すことで提案内容がより正しいものが返ってくる確率が上がります。また曖昧なプロンプトだったとしても推測をして結果を返してくれるといった利点があります。
もし、サンプルデータを渡せないといった時にも使えないわけではありません。データの値を見なくてもいい処理は、サンプルデータを渡さなくても同程度の結果を期待できます。
もしサンプルデータを渡さない時にうまくいかない場合は、実施したい処理内容を明確に記載する必要があります。
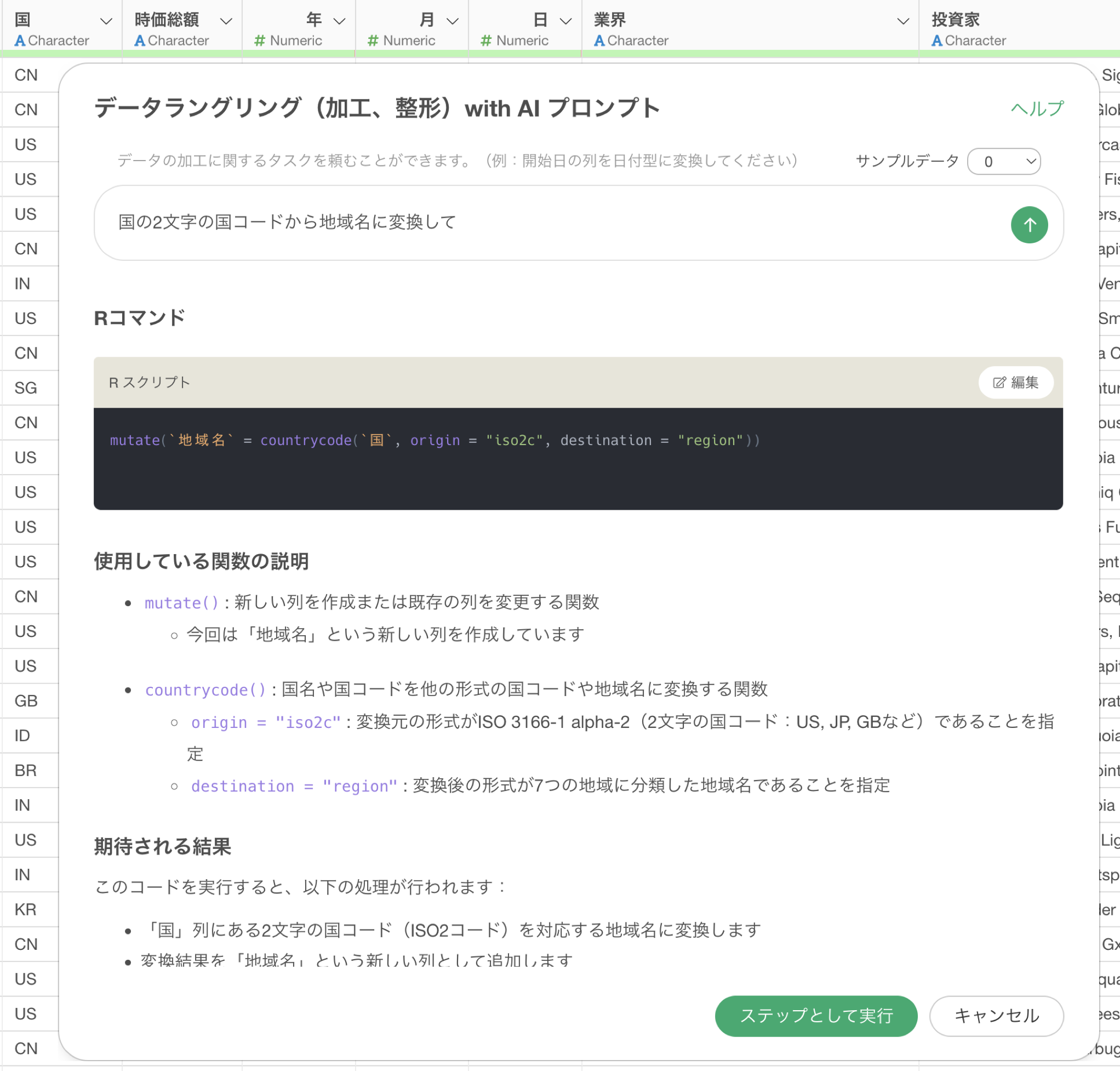
先ほどの例では「国から地域名に変換して」といったプロンプトを使っていましたが、これをより具体的にして以下のプロンプトに変更をします。
国の2文字の国コードから地域名に変換して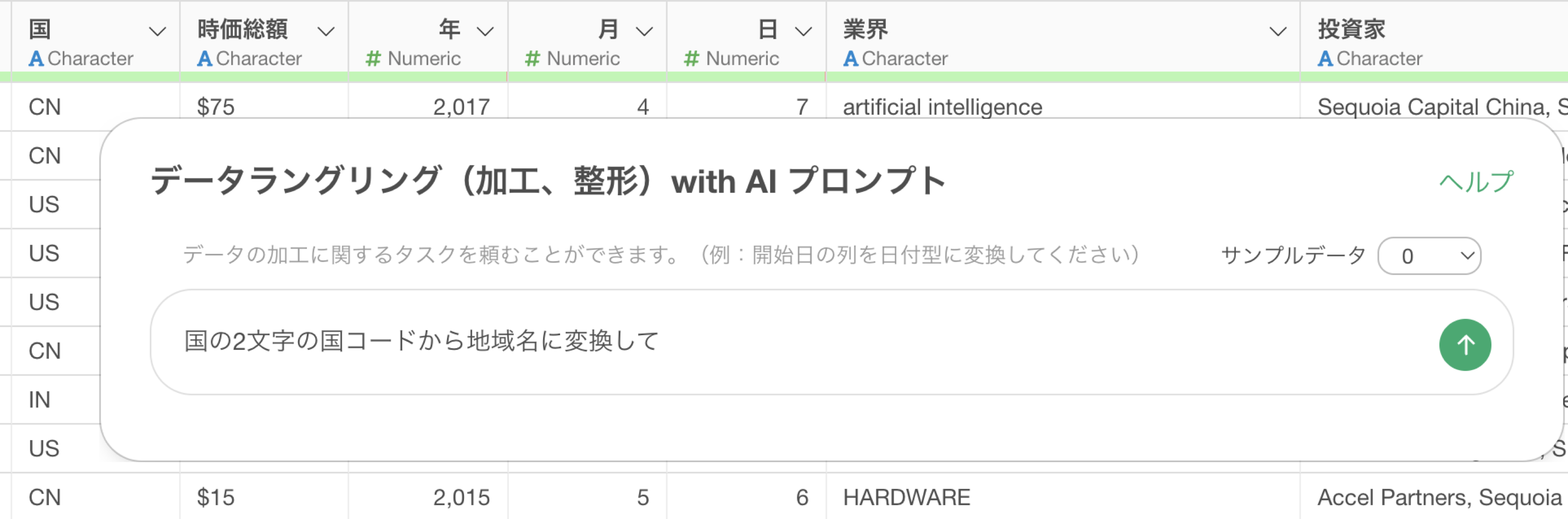
これによって国コードから地域名に変換するための正しいRコマンドを提案してくれるようになります。
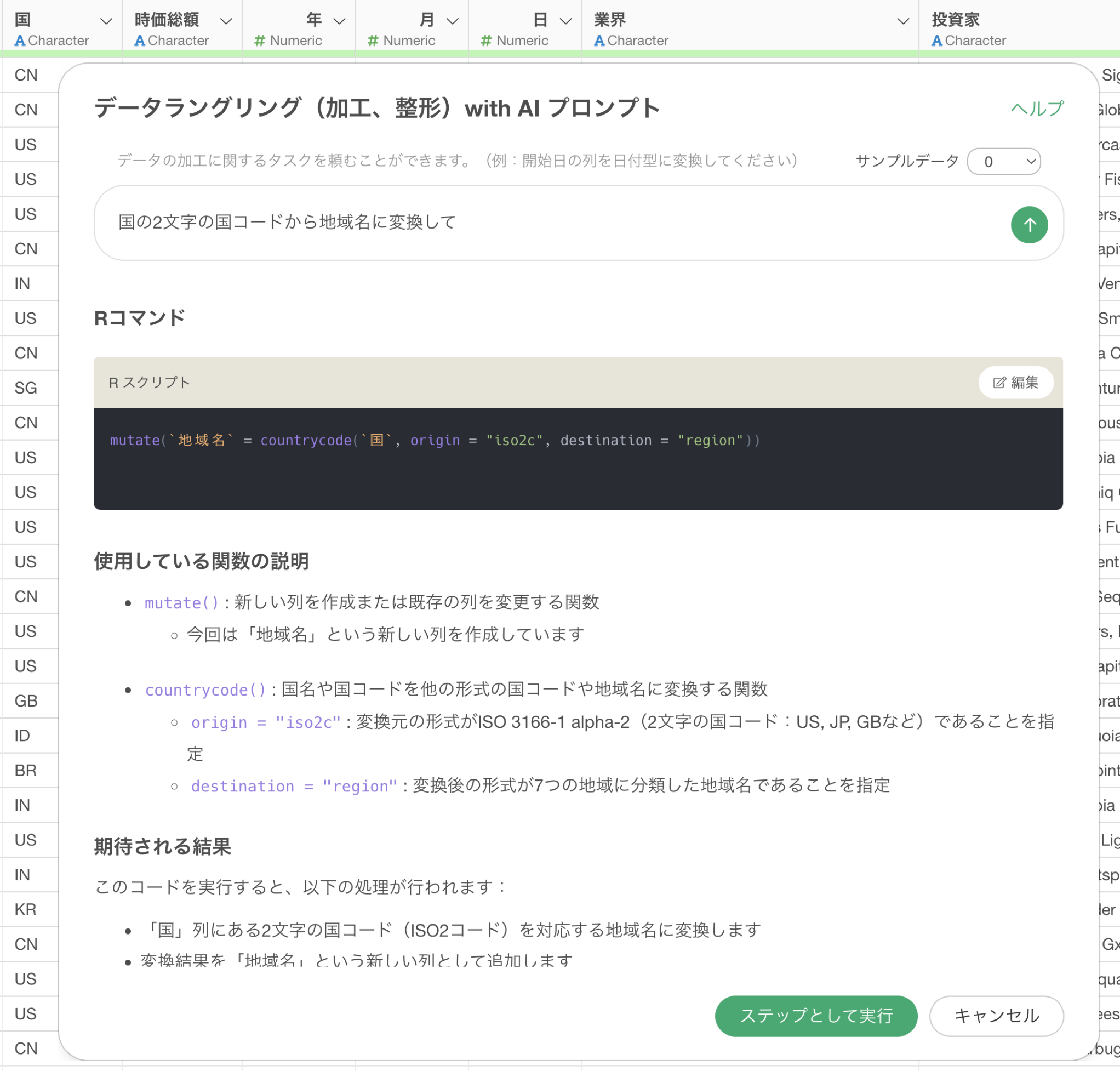
そのため、サンプルデータを提供ができない場合は、データの特徴をプロンプトに付け足してあげることで、よりいい精度での結果を返せるようになります。
AI 関数を使った方がいいケース
AI プロンプトは条件式や計算式に基づいた処理に適していますが、文脈の理解や判断が必要な処理では、AI 関数を使った方が適切な結果が得られます。
AI 関数が得意な処理
AI 関数は、1行ごとにAIが内容を理解して判断を行うため、以下のような処理に適しています。
文章の内容に基づく分類
アンケートの自由記述回答など、文章の内容を理解してグループ分けする場合はAI 関数が適しています。
AI 関数のプロンプト例:
提供された文章を以下のグループに振り分けるために、ラベルをつけてください。
サポートが良い
サポートが悪い
プロダクトの高評価
プロダクトの低評価
機能面に関する高評価
機能面に関する低評価
競合サービスとの比較
導入に関する内容
価格に関する内容
その他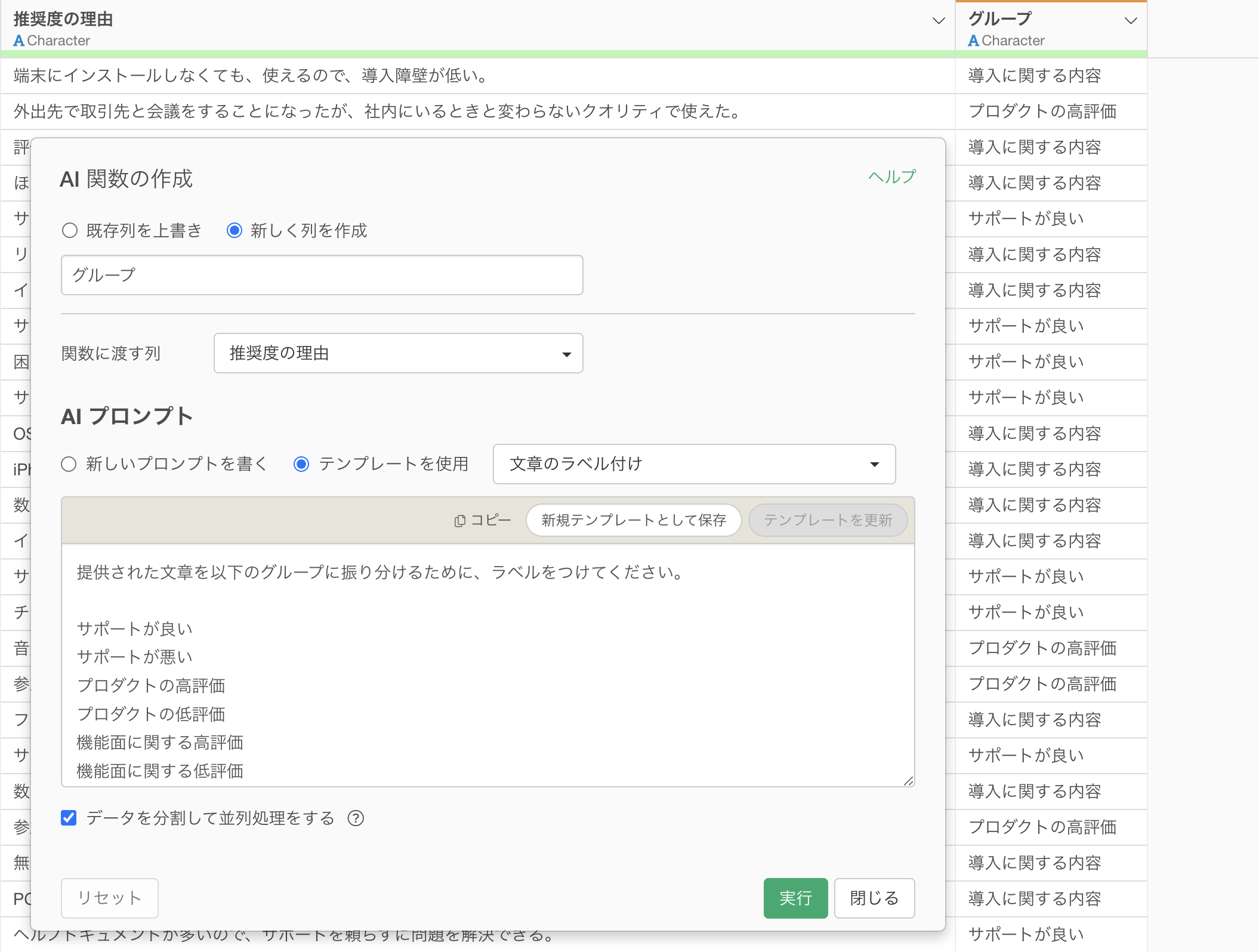
このような分類は、文章の意味を理解する必要があるため、条件式では表現できません。
感情分析・センチメントスコア
文章から感情を読み取ってスコア化する処理も、AI 関数の得意分野です。
AI 関数のプロンプト例:
提供された各文章に対して、-1.0から+1.0の範囲で極性スコアを算出してください。
スコアの基準:
極めてポジティブ(+0.8 ~ +1.0)
- 強い満足や称賛を表す表現
- 問題が完全に解決された状況
- 卓越した性能や品質の言及
ポジティブ(+0.4 ~ +0.7)
- 明確な利点や長所の言及
- 良好な体験や結果の報告
- 期待以上の成果
軽度のポジティブ(+0.1 ~ +0.3)
- 小さな改善や利点
- 基本的な機能の充足
- 一般的な満足感
中立(-0.1 ~ +0.1)
- 事実の叙述
- 感情を含まない説明
- 単なる状況説明
軽度のネガティブ(-0.3 ~ -0.1)
- 小さな不便や課題
- 軽微な問題点
- 改善の余地がある点
ネガティブ(-0.7 ~ -0.4)
- 明確な問題や不満
- 期待はずれの結果
- 重要な機能の欠如
極めてネガティブ(-1.0 ~ -0.8)
- 深刻な問題や不具合
- 強い不満や否定的感情
- 重大な支障や障害
判定の考慮要素:
- 表現の強さ(「とても」「非常に」等の程度副詞)
- 問題解決の程度(完全解決、部分解決等)
- 期待と結果の関係(期待以上、期待通り、期待以下)
- メリット・デメリットの具体性と重要度
- 全体的な文脈や意図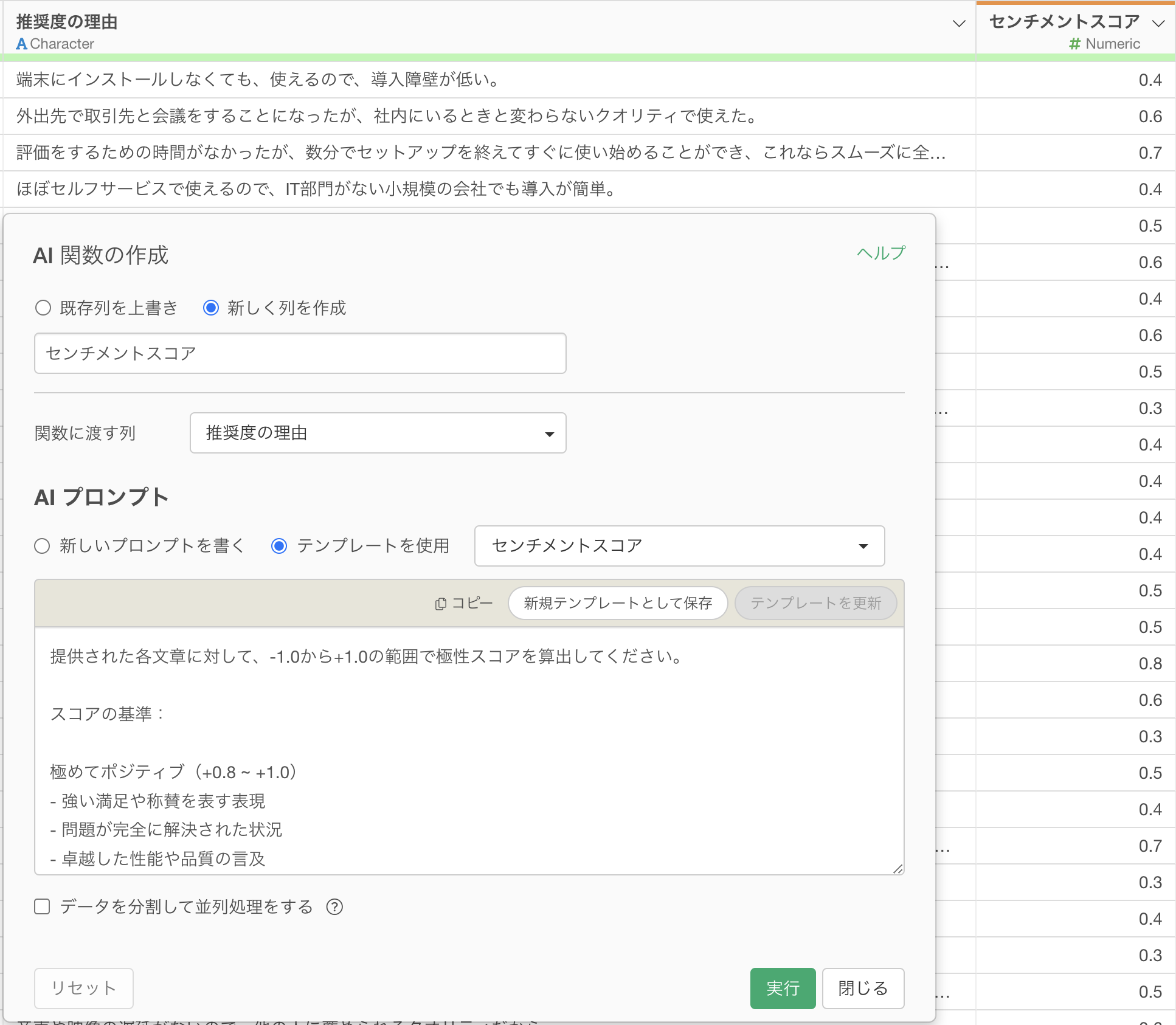
センチメントスコアは、単語の出現だけでなく、文章全体の文脈や表現の強さを考慮する必要があるため、AI 関数が適しています。
表記揺れの修正
企業名や製品名など、一般知識が必要な表記揺れの修正もAI 関数が得意です。
AI 関数のプロンプト例:
各組織名について、正式な法人名称を返してください。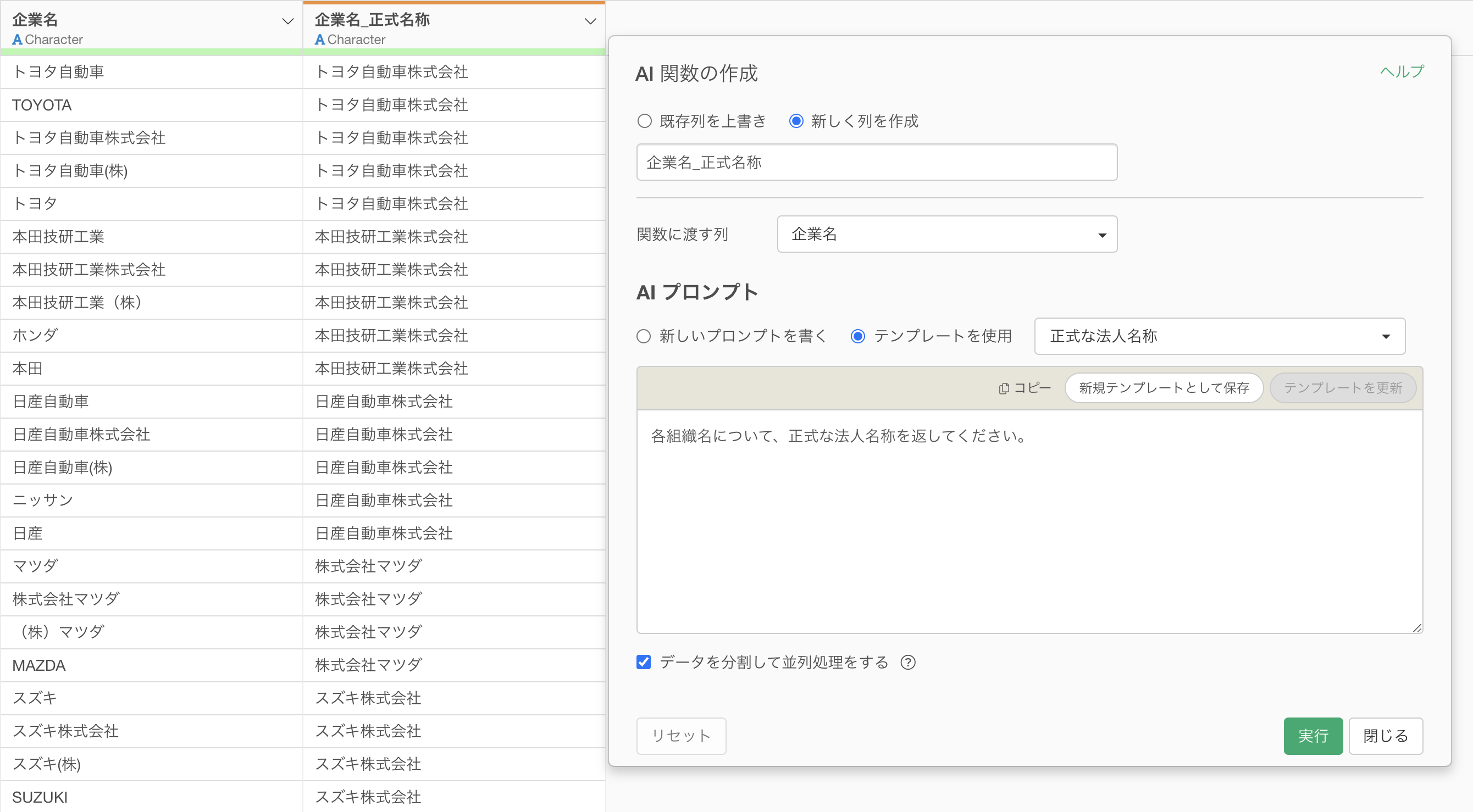
例えば、「ユニクロ」→「株式会社ファーストリテイリング」のように、店舗名から正式な企業名を推定する処理は、AIの持つ一般知識が必要になります。
その他のAI 関数が適した処理
- 翻訳: 文脈を考慮した自然な翻訳
- 要約: 文章の要点を抽出して短くまとめる
- 判定: 企業名から業種を判定、電話番号から国を判定、など
AI 関数の詳しい使い方については、こちらをご覧ください。