ANCOVAをExploratoryで行う
この記事では、ExploratoryでANCOVAを行ってみます。
データ
Rに付属のmtcarsデータ(自動車のデータ)から、燃費の良さ(mpg)、1/4マイルのタイム(qsec)、オートマティックかマニュアルか (am、オートマティックは0、マニュアルは1) をこちらに抜き出しました。
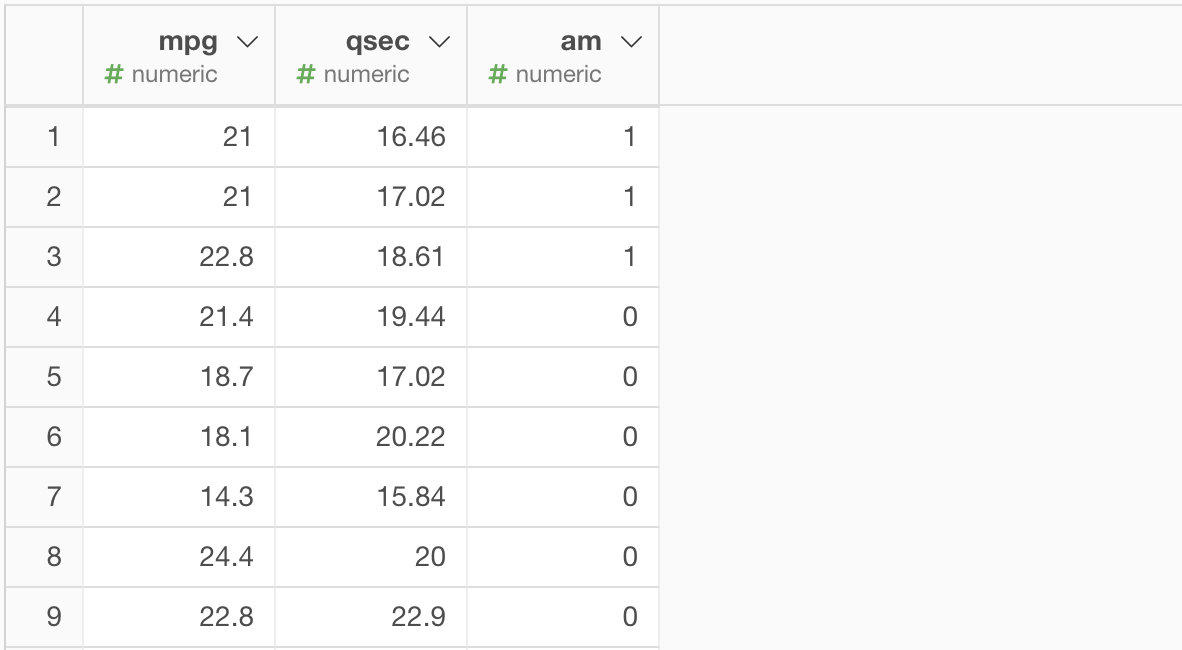
ANCOVAで検定したい問題
速い最大スピードを出せる車は普段走るには燃費が悪いだろうというのは想像に難くないですが、ここで興味があるのは、その度合いが、オートマ車とマニュアル車で違うのかどうかという点です。これをANCOVAで検定してみます。
am列をカテゴリーとして扱う
am列を数値ではなくカテゴリーとして扱うために、factorに変換します。
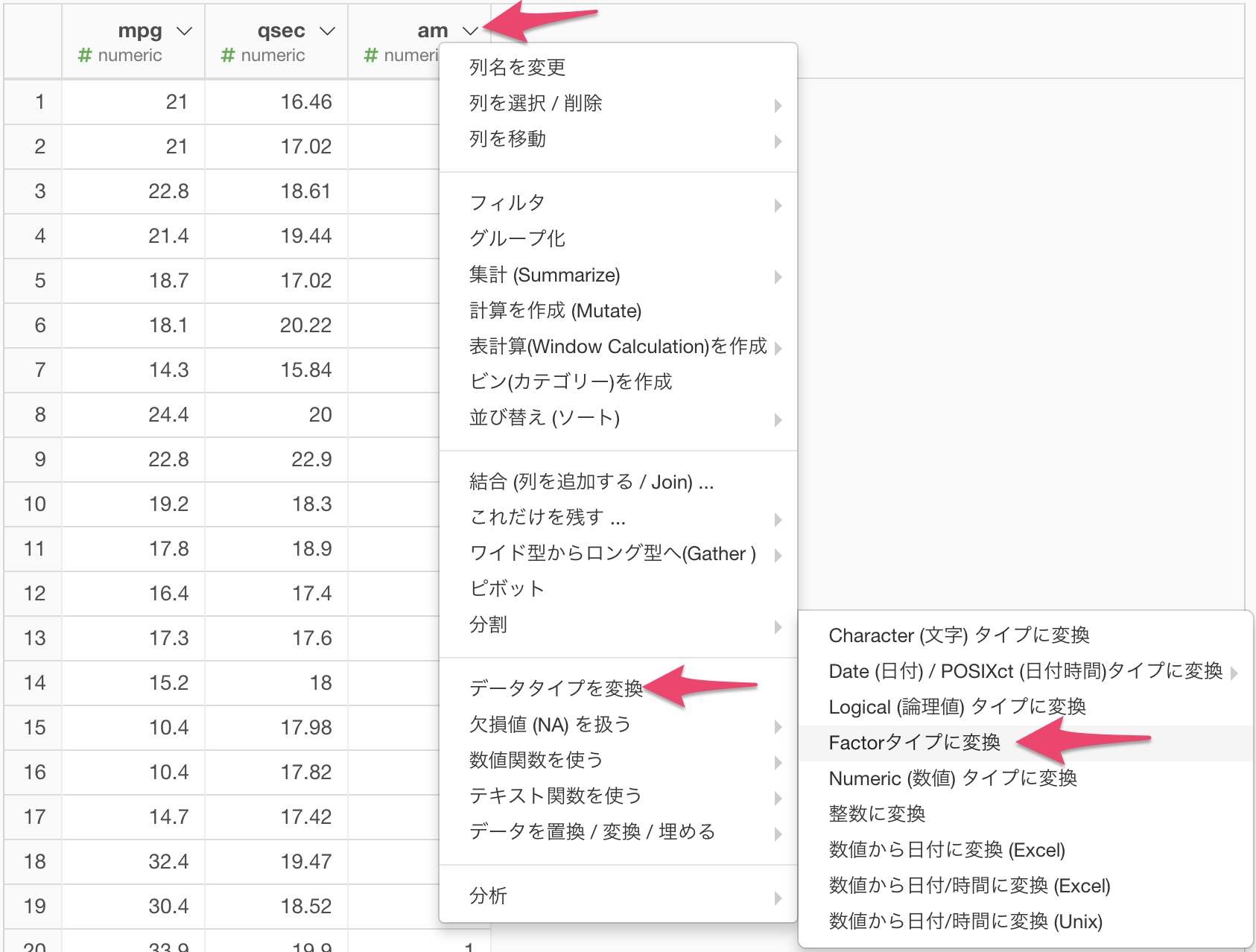
以下のようなコマンドが自動的に入ったmutateダイアログが現れるので、実行します。
factor(am)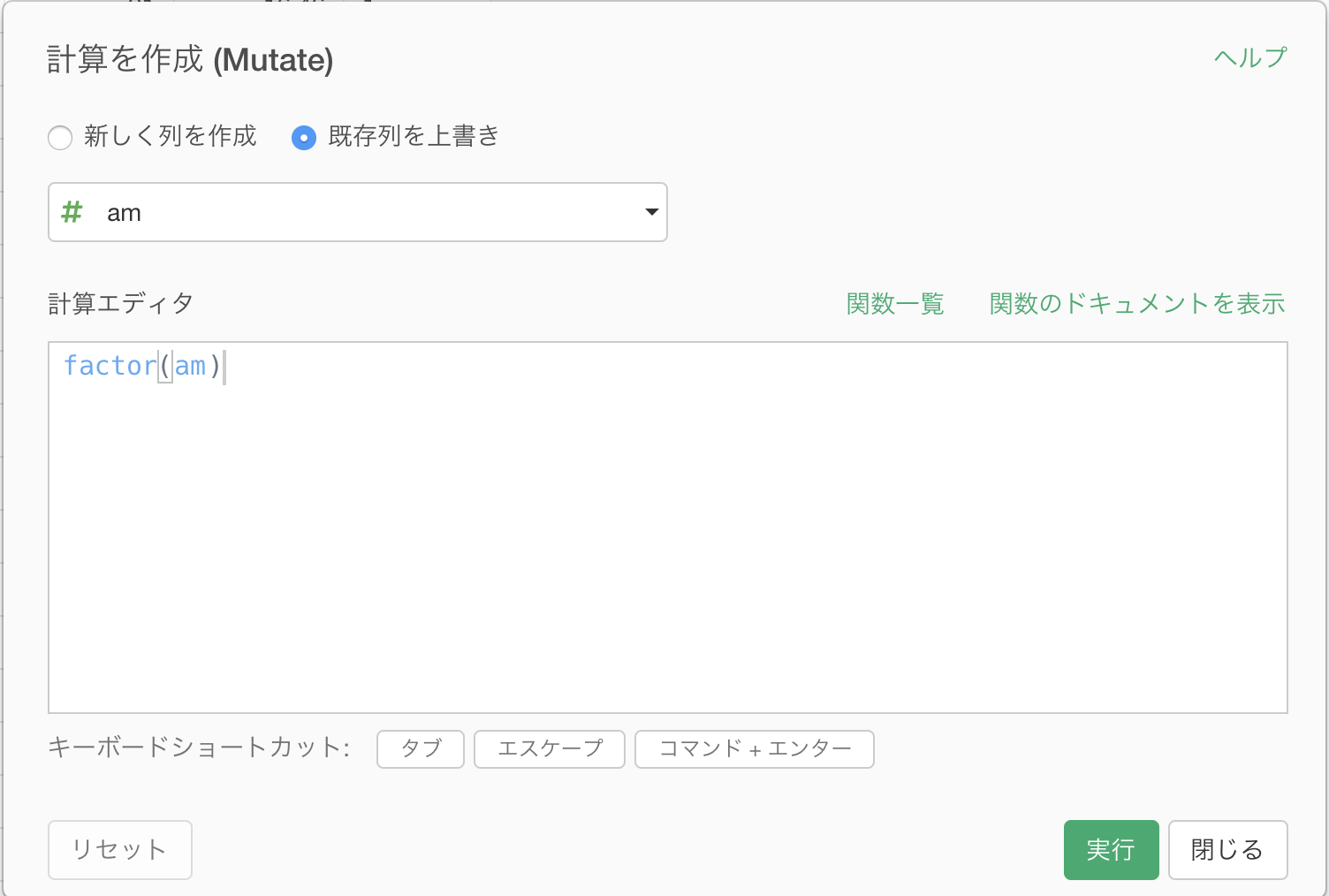
ANCOVAを実行
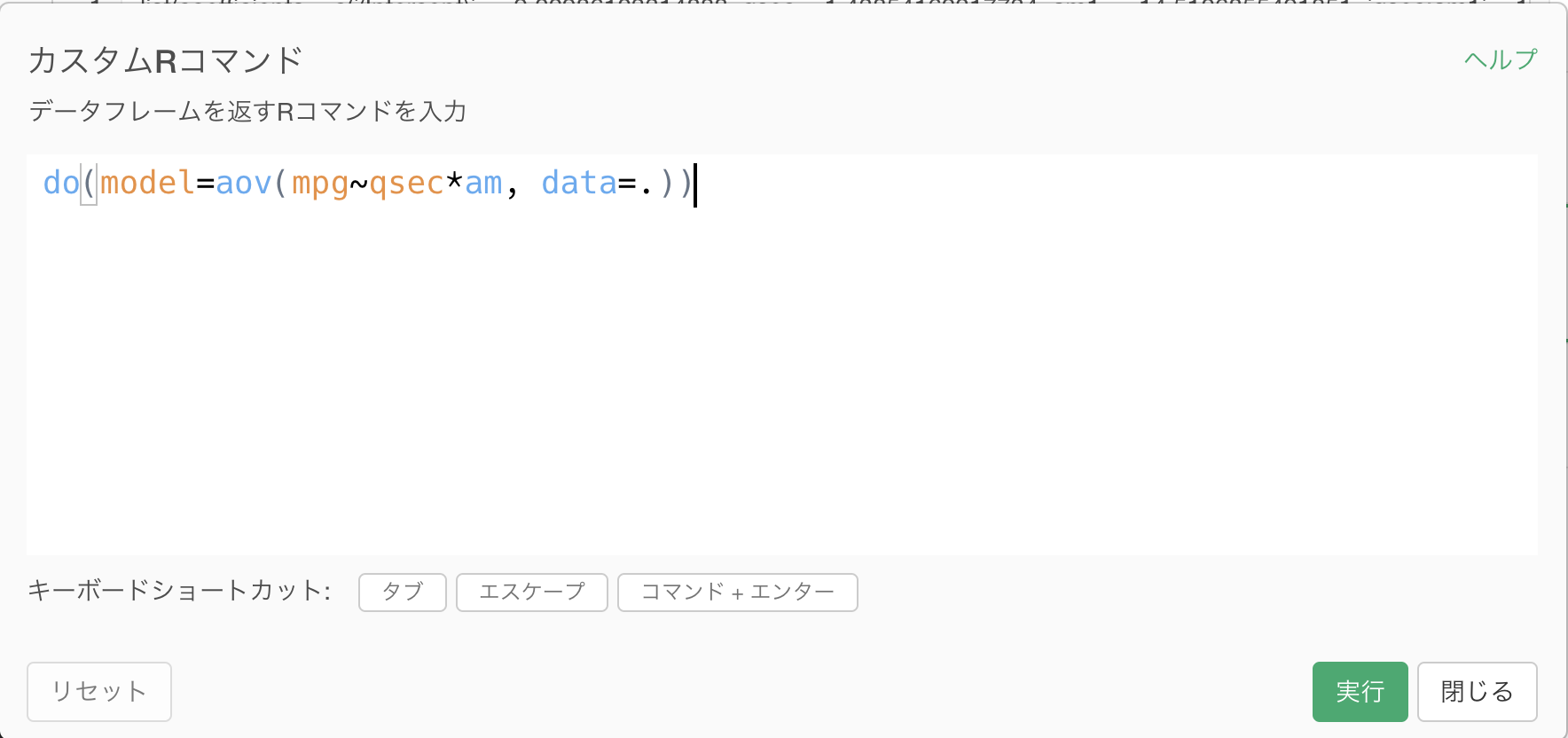
mpgへのqsecの影響度合いがamのカテゴリーによって影響されるのかを見るANCOVAを行うには、以下のようなRコマンドをカスタムRコマンドステップとして実行します。
do(model=aov(mpg~qsec*am, data=.))メニューをたどって、カスタムRコマンド・ダイアログを開きます。
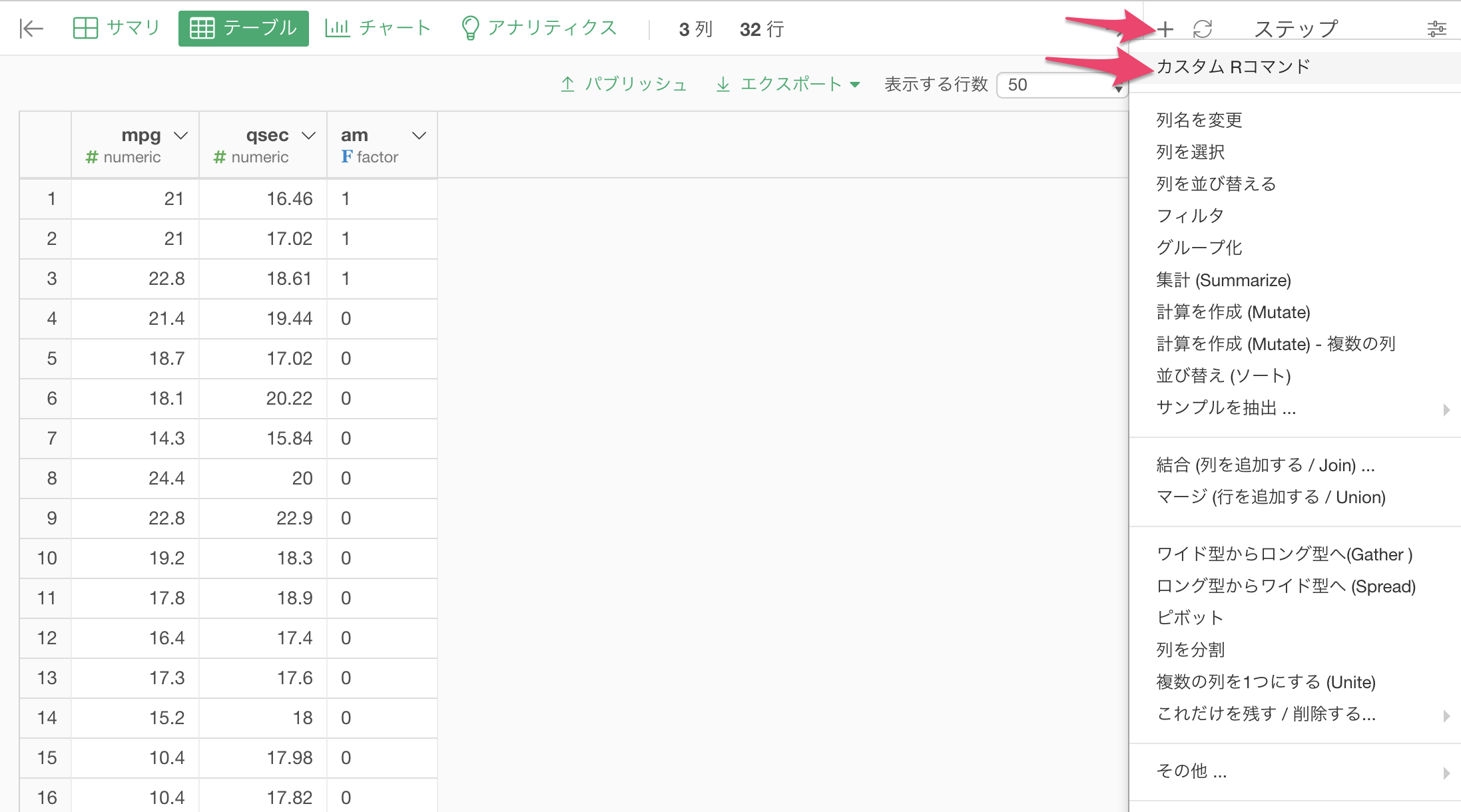
ここに、先ほどのコマンドを入力して実行します。
ANCOVAの分析結果をデータフレームとして取り出す
ここまでで、ANOVAの分析結果がmodel列に入っていますので、これをデータフレームとして取り出すために、以下のコマンドを、これもカスタムRステップとして実行します。
model_info(model, output="variables")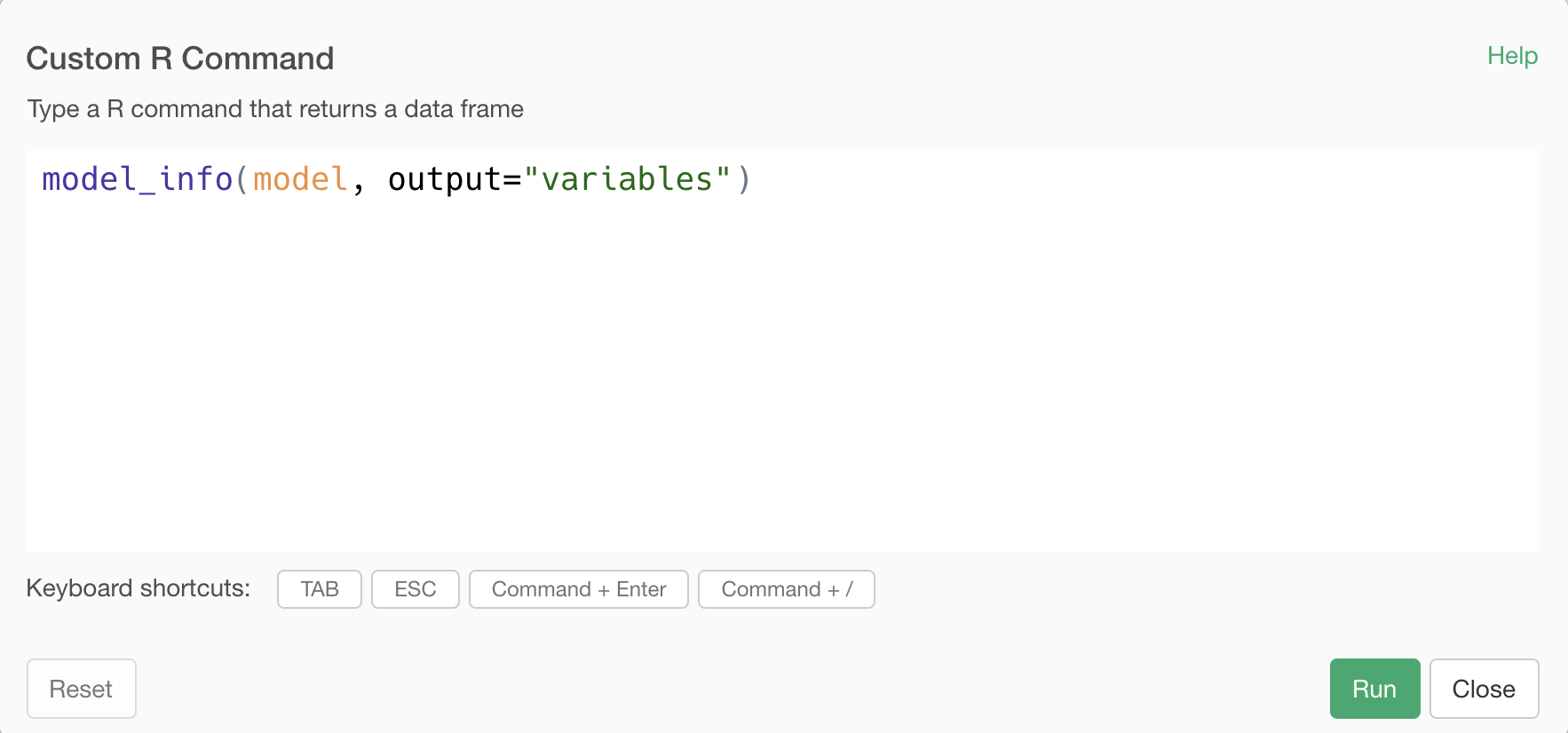
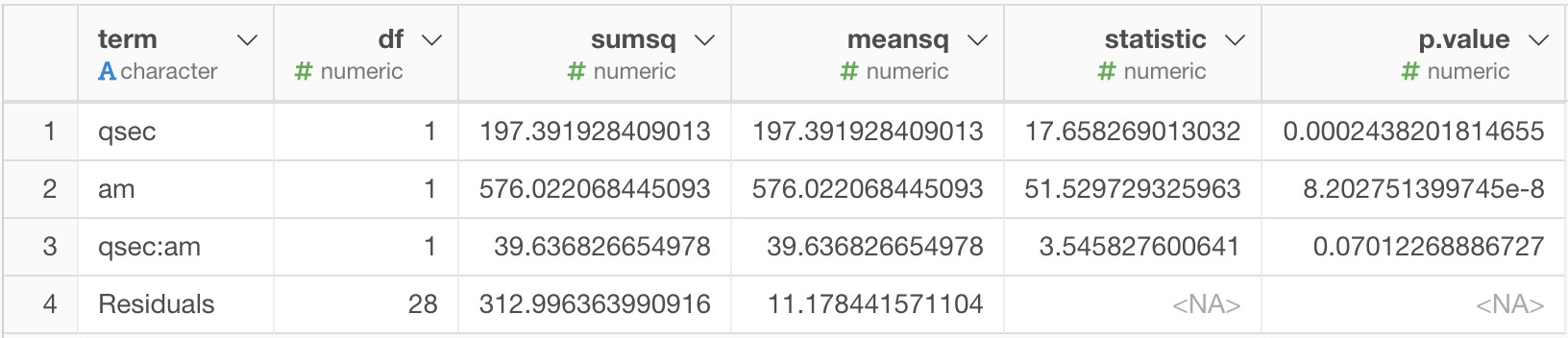
結果がデータフレームとして出力されました。
ANCOVAの原理
こちらの結果の読み方の前に、ANCOVAでやっていることを少し解説します。
今回のANCOVA分析では、mpgへのqsecの影響度合いがamのカテゴリーによって影響されるのかを見るために、以下の二つの線形回帰モデルの性能を較べています。
モデル1: mpgをqsecとamから予測するモデル。
モデル2: mpgをqsecとamに加えて、qsecとam(0または1)の積から予測するモデル。
qsecとamの積が、amが変わったときのqsecの影響力の差分を表現しています。これをモデルに組み込んだときにモデルの性能が上がる、つまりモデル2の性能がモデル1の性能よりよいのであれば、amの違いはqsecのmpgへの影響力に影響があるのだろう、という判断をします。
結果の読み方
結果の表の1行目から3行目は、一つずつtermを追加していくときに、上の行のモデルと較べてその行のモデルが意味のある性能向上をしているかの検定になっています。
つまり、1行目は、qsecだけでmpgを予測するモデルにそもそも意味があるかを検定しており、これは非常に小さなP値となっているので、意味がある、という結果を示しています。
2行目は、qsecだけでmpgを予測するモデルと、qsecとamの二つの情報をもとに予測するモデルの比較で、これも非常に小さなP値となっているので、amを予測に追加することは意味がある、という結果を示しています。
3行目が、今回の分析のメインとなるモデル比較ですが、qsecとamをもとに予測するモデルと、それに加えてqsecとamの積も予測のための情報としてつかうモデルの比較です。

ここではP値が0.07となっていますので、0.05をしきい値とするのであれば、惜しいですが、有意な差があるとは言えない、ということになります。
つまり、このデータからでは、オートマ車とマニュアル車で、最高スピードと燃費の関連度合いに違いがあるとは言えない、というのが今回の結果となります。