Amazon Redshiftのデータをインポートする方法
ExploratoryではAmazon Redshiftのデータベースからデータを素早くインポートできます。
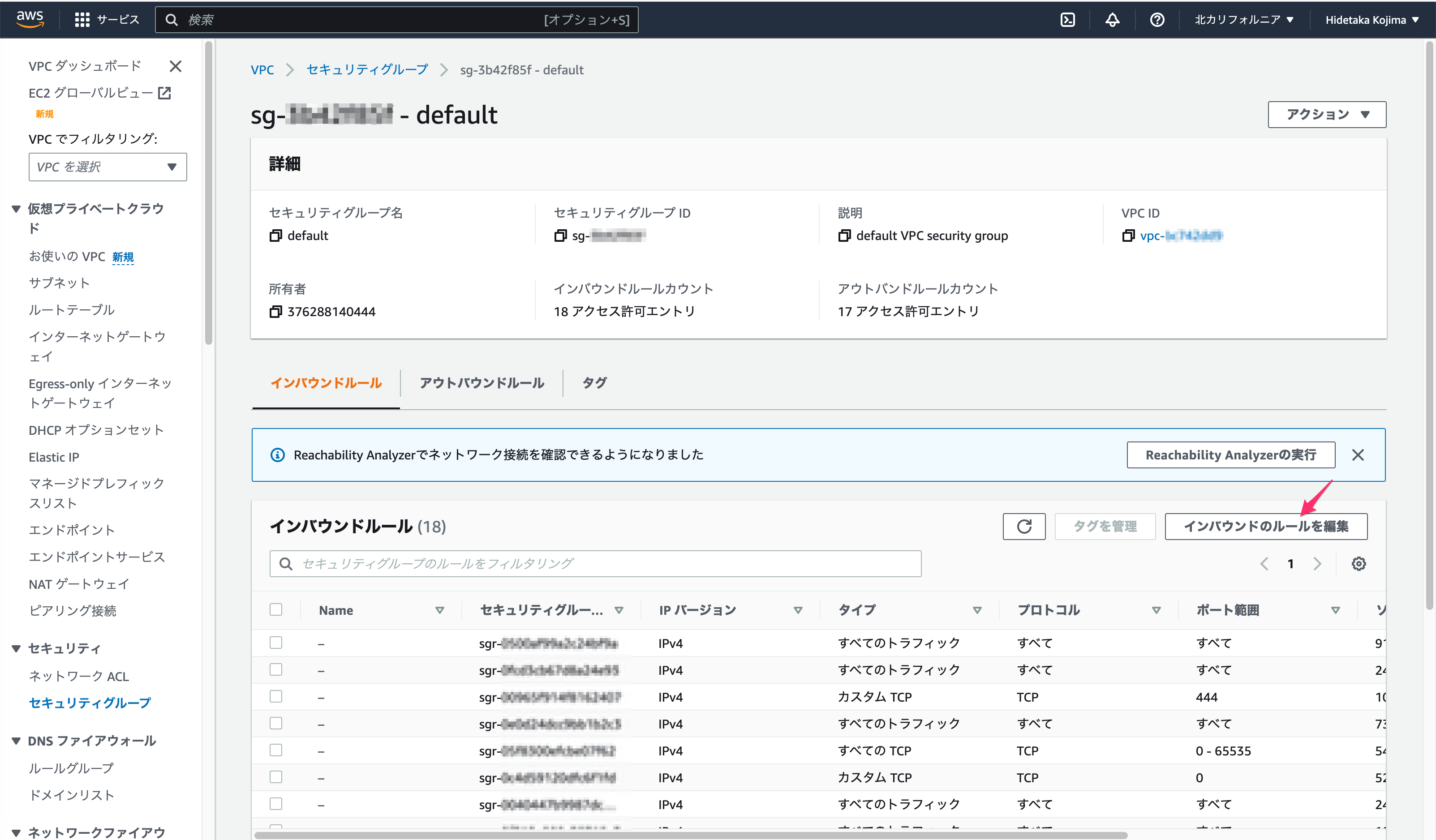
1. AWS セキュリティグループのセットアップ
Redshiftデータベースのインスタンスに関連付けられたDBセキュリティグループに、ご利用のクライアントPCのIPアドレスが追加されていることを確認してください。
3. Redshiftのインポートダイアログを開く
データフレームの横の「+」ボタンをクリックし、「データベース」を選択します。
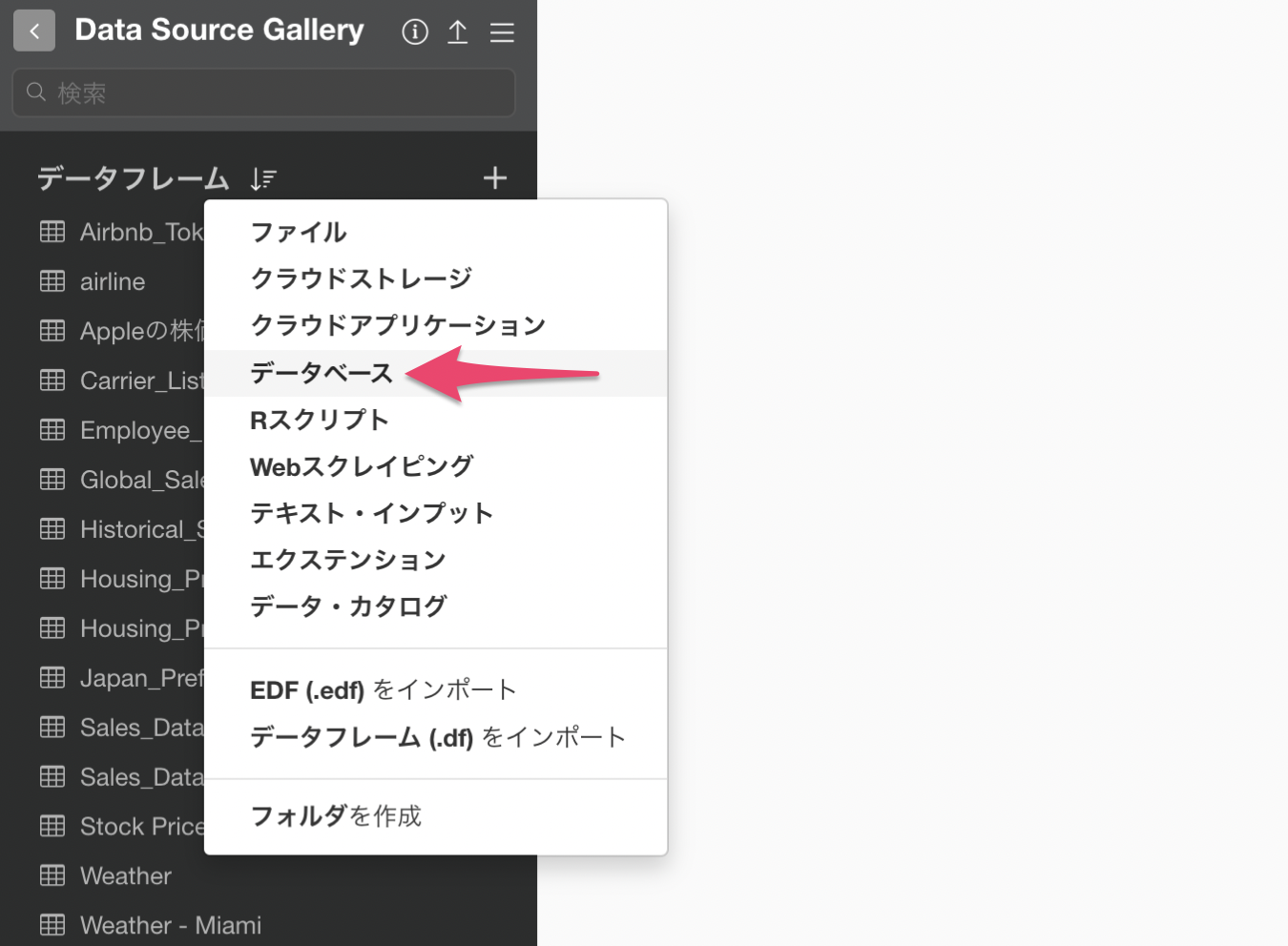
「Amazon Redshift」をクリックします。

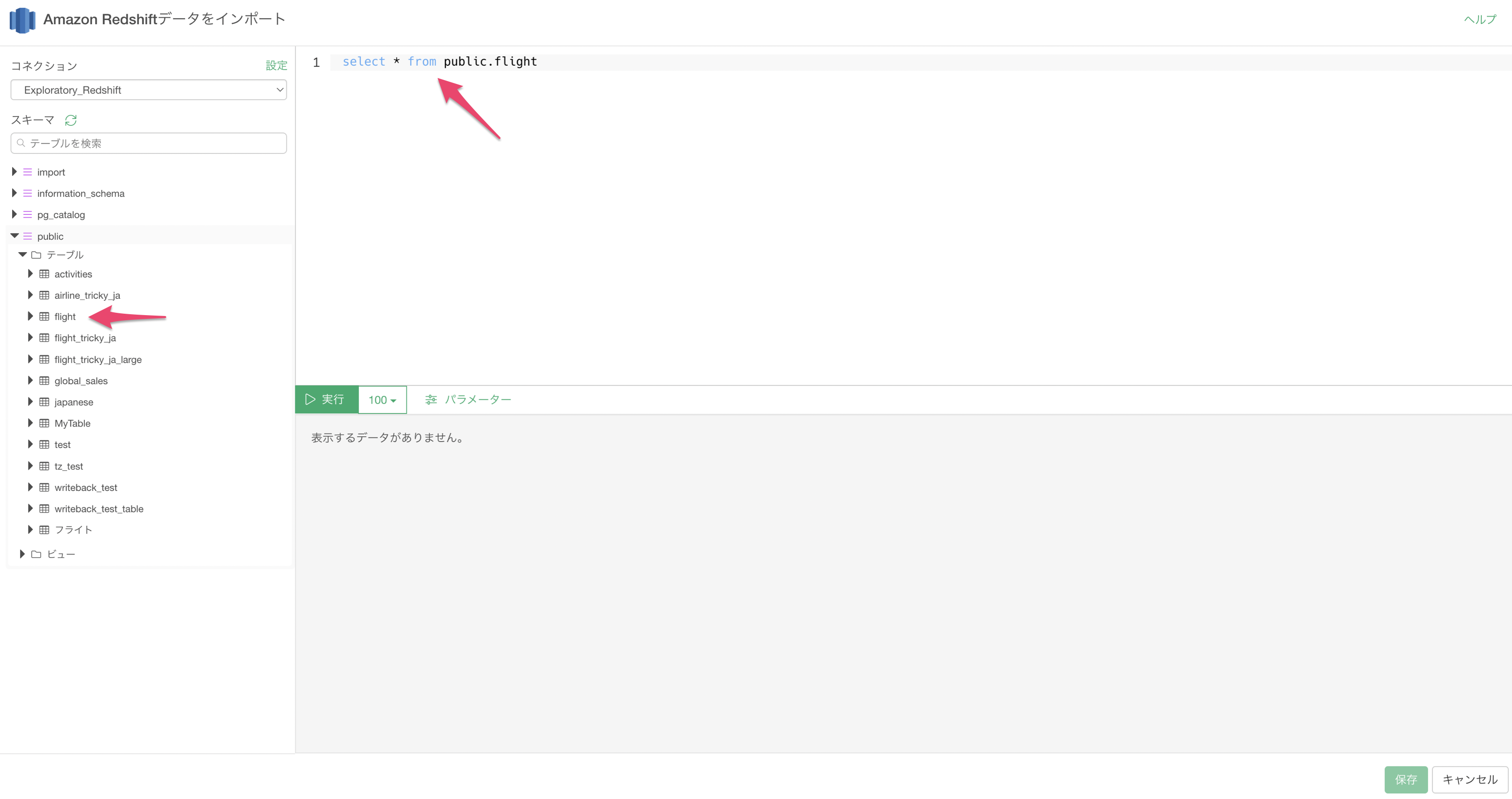
4. プレビューとインポート
左のダイアログからインポートするテーブルを選択すると、入力フィールドにクエリが追加されるため、取得したいデータに合わせてクエリを記述します。
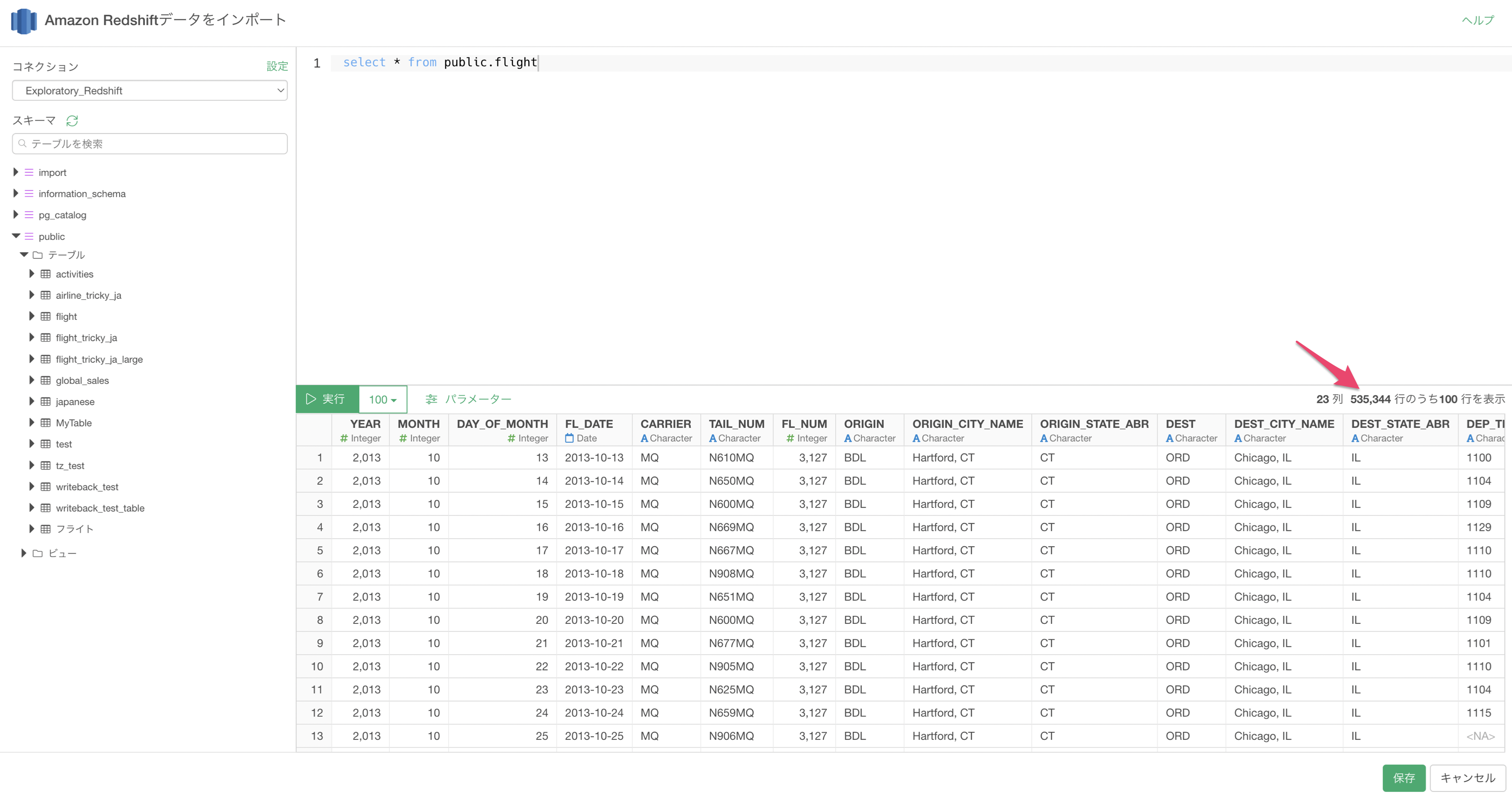
「実行」ボタンをクリックすると、データのプレビューが表示されます。
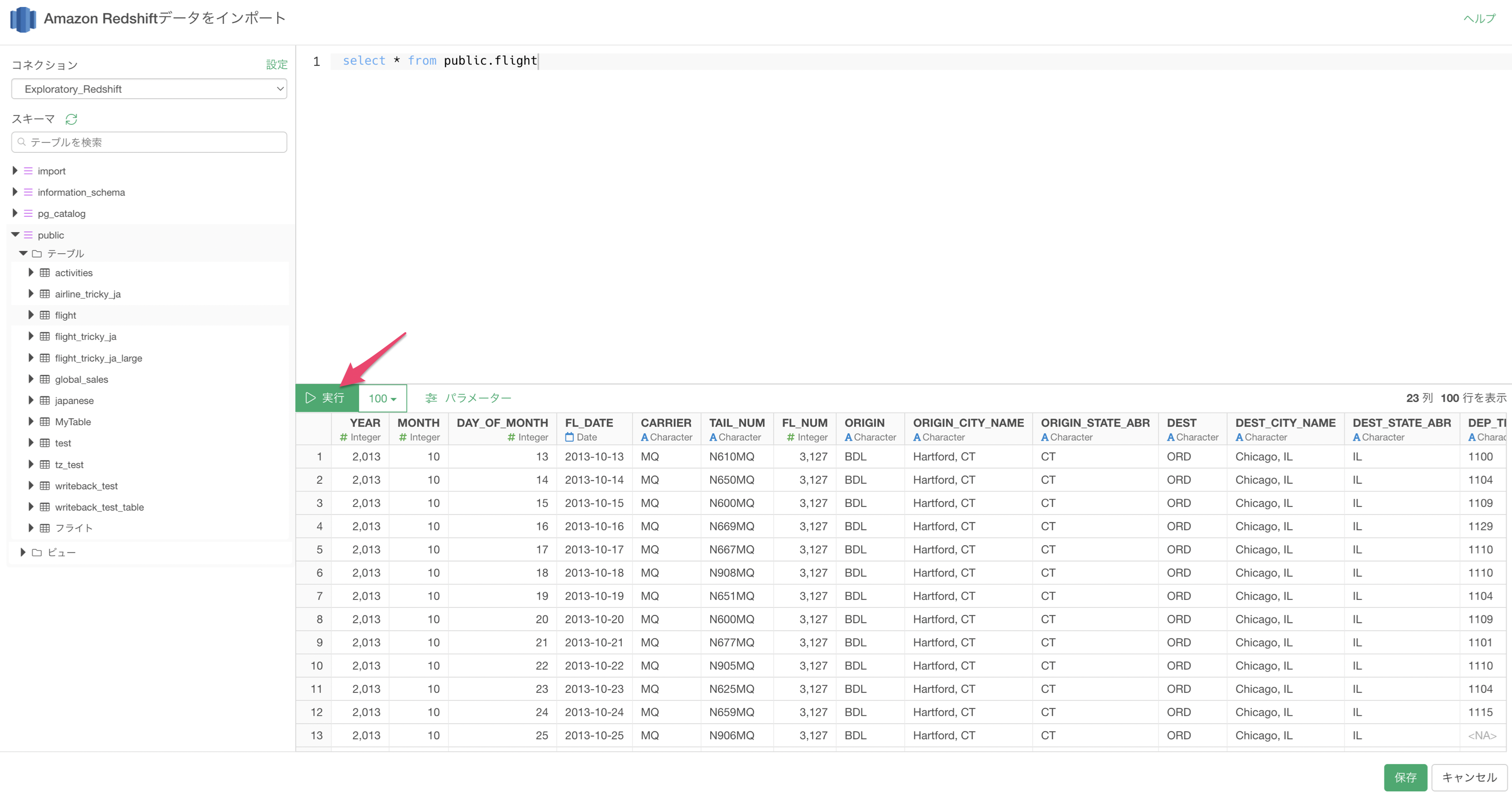
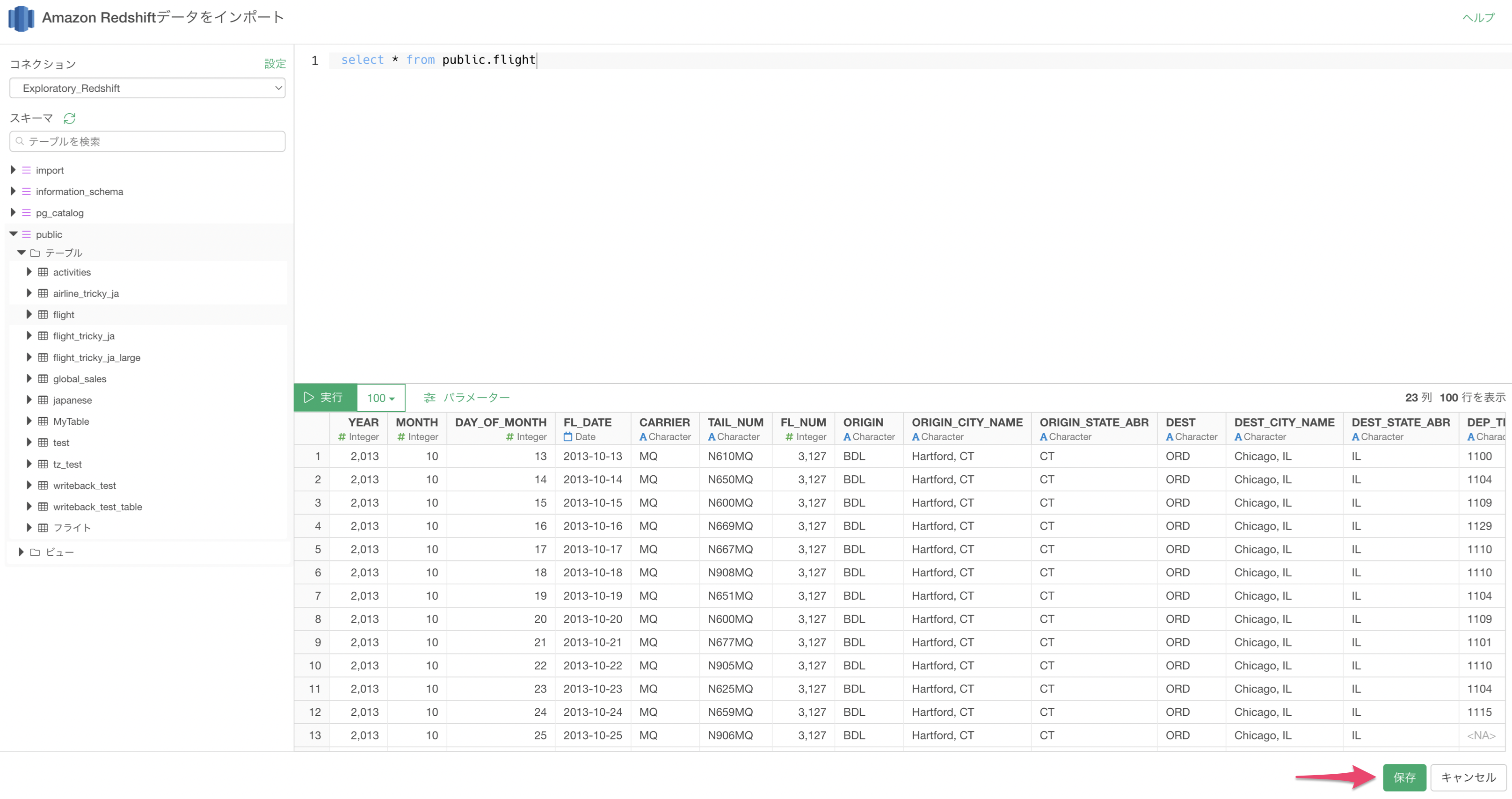
「保存」ボタンをクリックすると、データをインポートできます。
5. ランダムなサンプルデータを取得する
もしデータのサイズが大きい場合、分析に適切なサイズのデータをランダムにサンプルを取得することができます。
md5 関数を使用して生成された乱数を取得し、以下のようなクエリでランダムなサンプルデータを取得できます。
SELECT *
FROM airline_2016_01
ORDER BY md5('randomSeed' || flight_num)
LIMIT 1000006. SQLでパラメーターを使用する
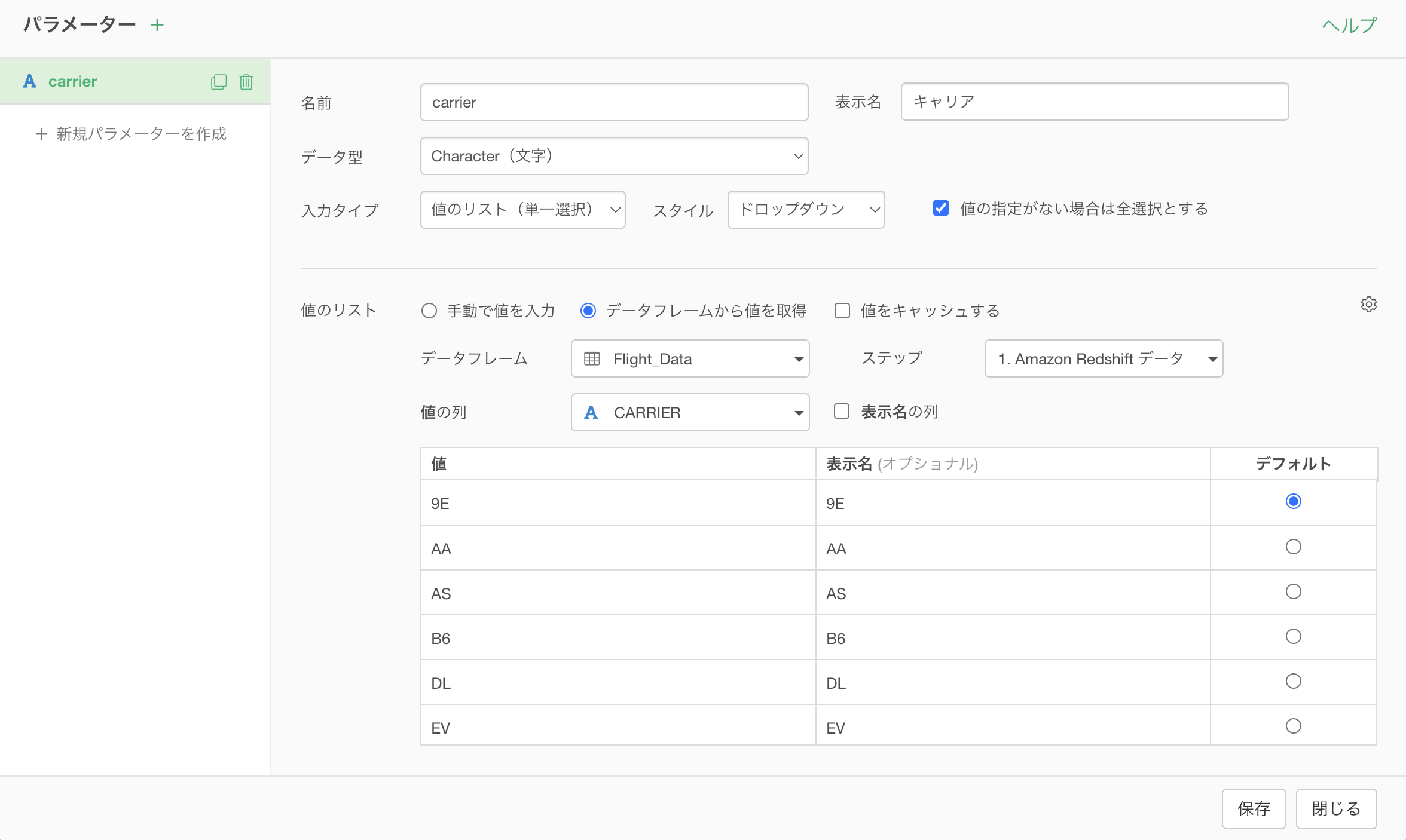
インポートダイアログの「パラメーター」ボタンをクリックします。
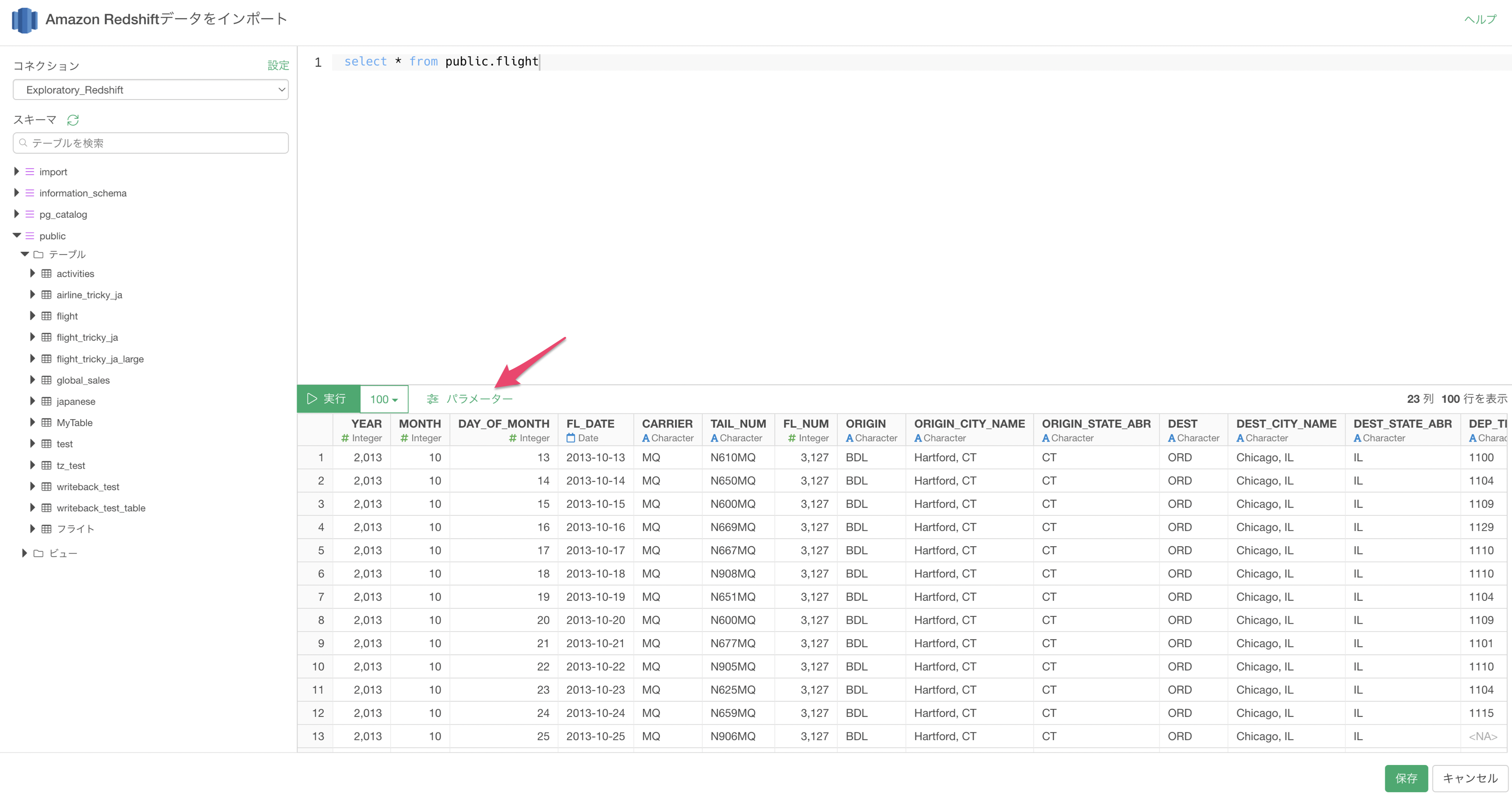
パラメーターペインが表示されたら「設定」ボタンをクリックします。
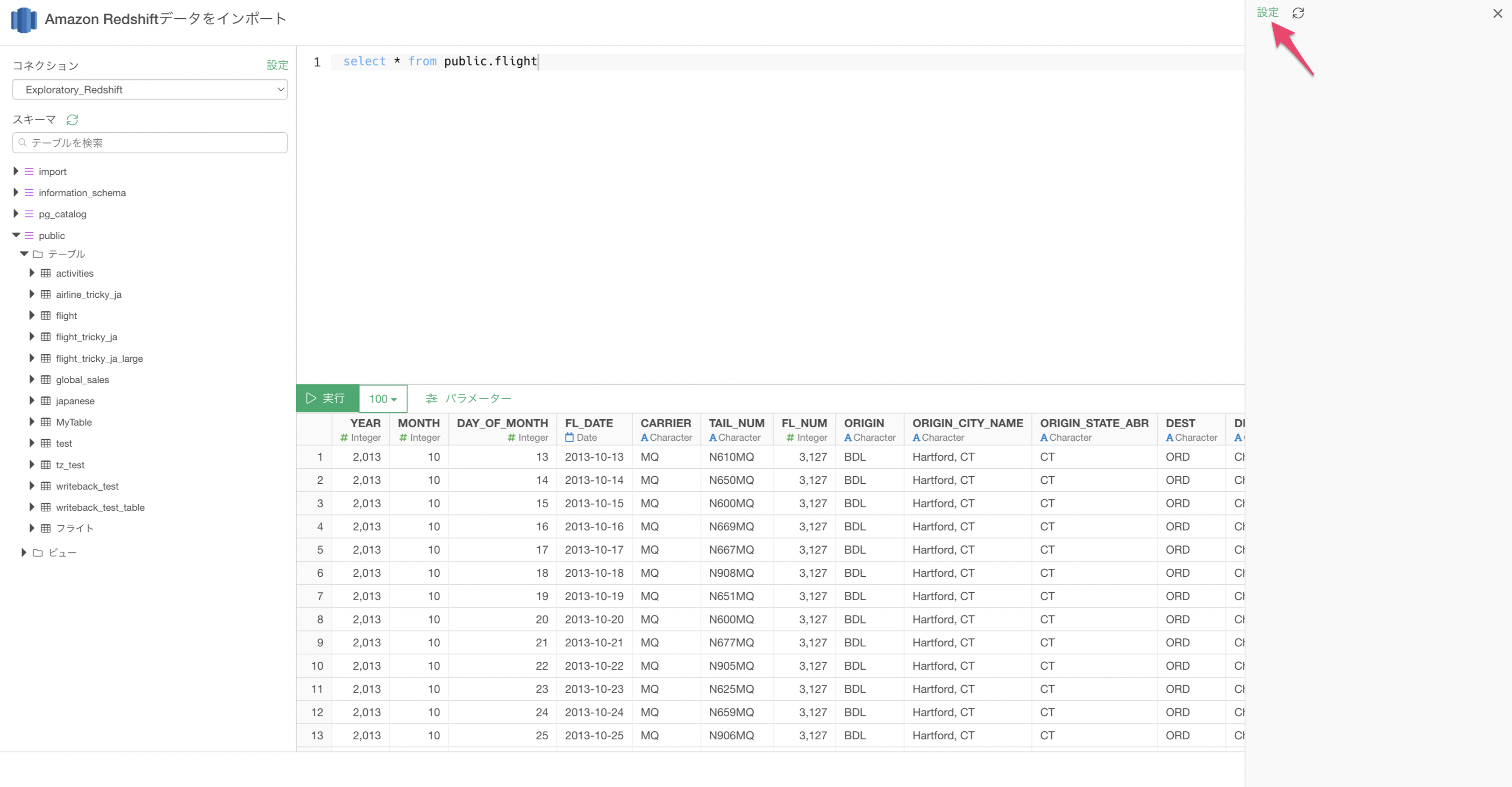
次に、パラメーターを定義し、保存ボタンをクリックします。
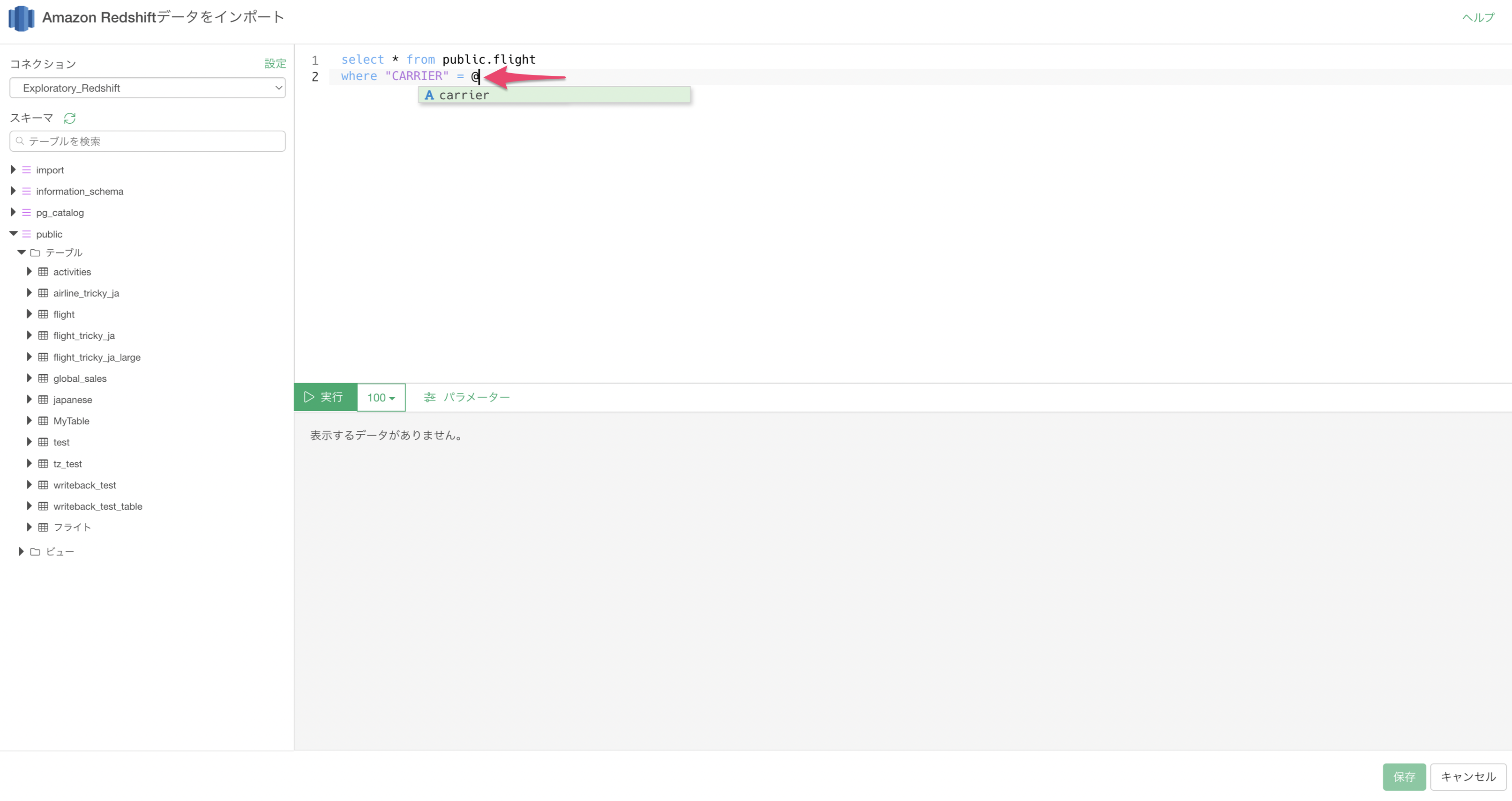
続いて、以下のように@{}と記述して、クエリ内の変数名を囲みます。
select * from testdb.flights
where "CARRIER" = @{carrier}このとき、@(アットーマーク)を入力すると、以下のようにパラメータの候補が表示されます。
パラメーターの詳細はこちらの記事をご覧ください。
7. 実際の行数
クエリを実行した際の行数は、クエリを再実行しないと取得できないため、パフォーマンスの観点から、デフォルトの設定では取得していません。
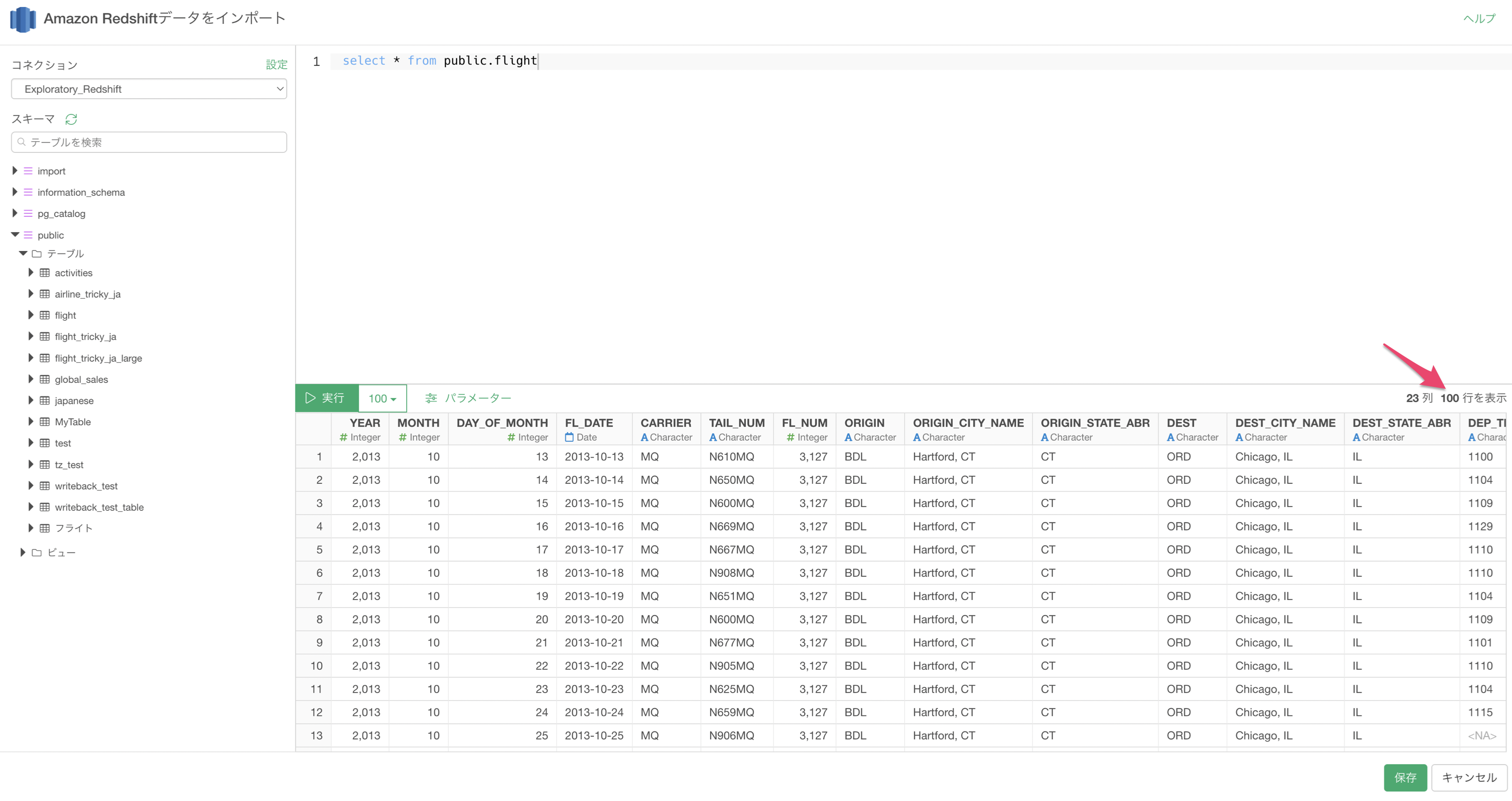
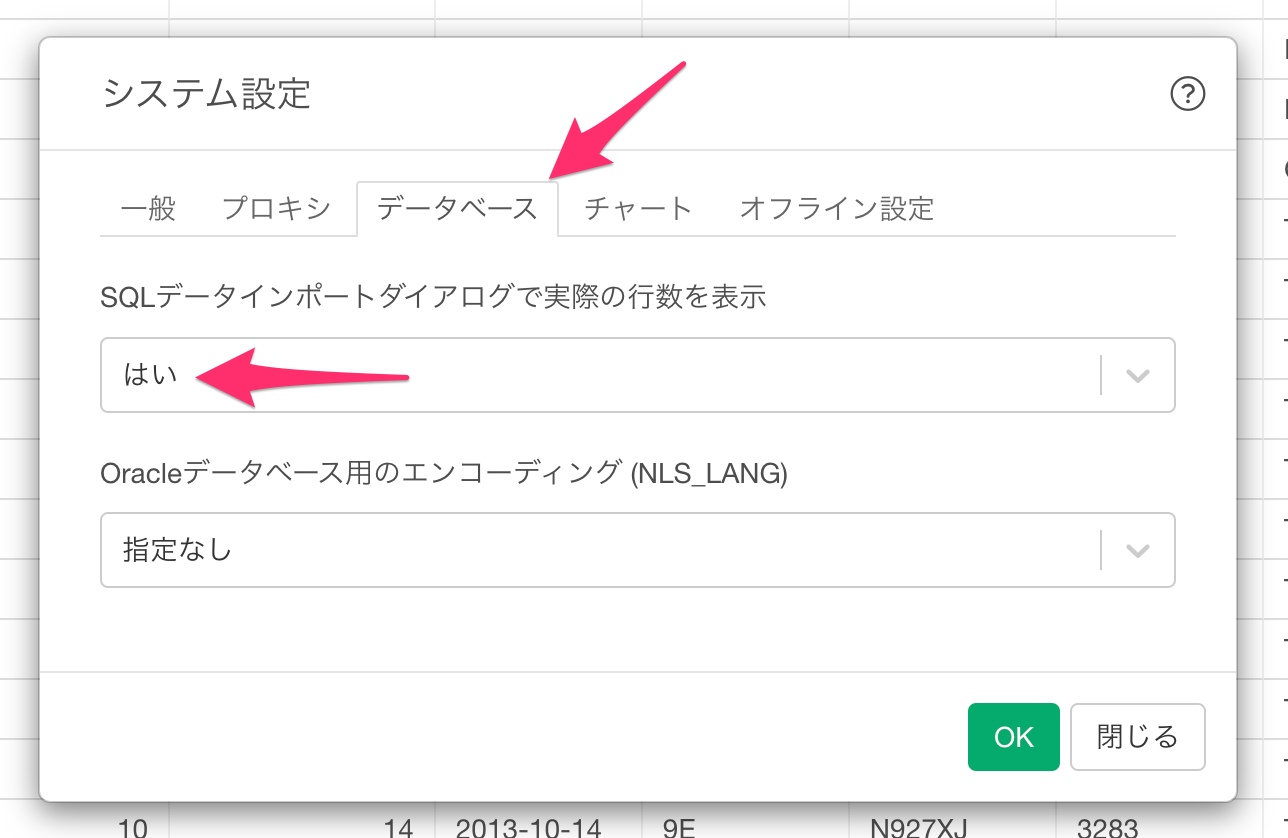
もし、クエリのプレビュー画面に実際の行数を表示させたい場合は、「システム設定」から設定します。
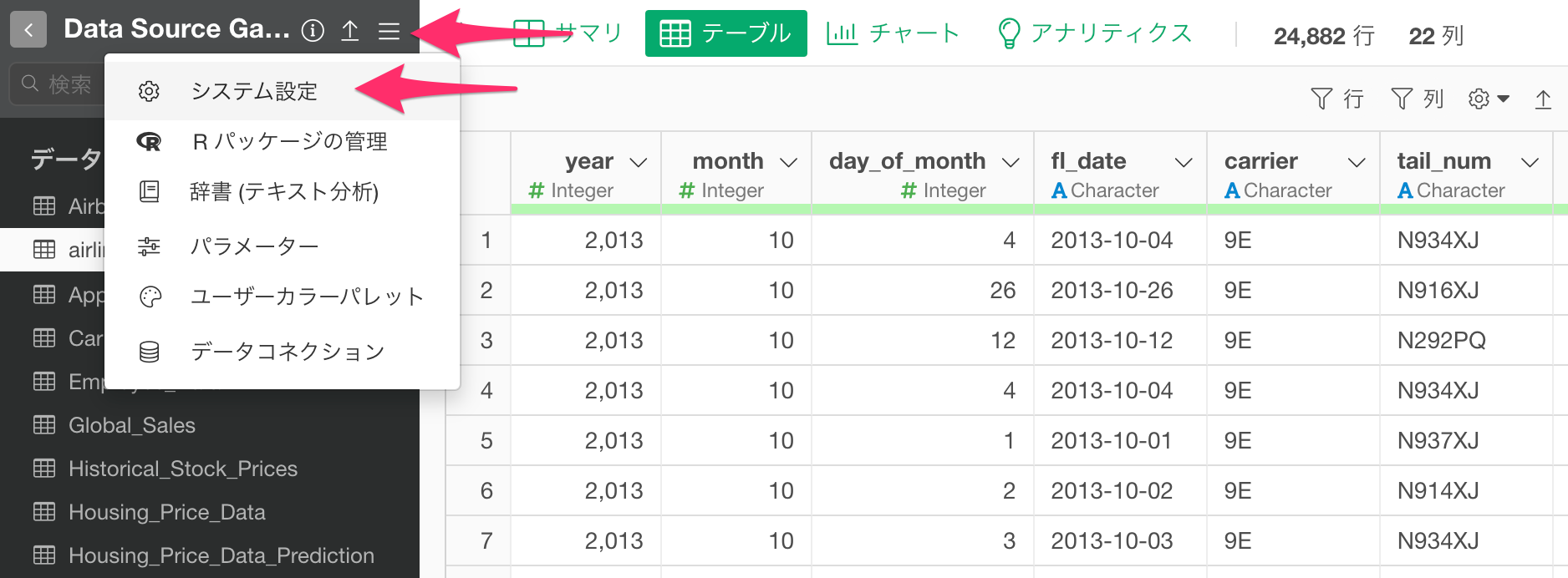
データベースタブに移動して、「SQLデータインポートダイアログで実際の行数を表示」を「はい」に設定します。
すると、以下のように「実行」ボタンをクリックした際、実際の行数が表示されるようになります。