Exploratory アワー #466 - アナリティクスで作成した予測モデルを使って別のデータに対して予測をしたい
アナリティクス・ビューで作成した予測モデルを使って別のデータに対して予測をする方法を紹介しています。
役立つ人
アナリティクス・ビューで構築した予測モデルを使って別のデータに対して予測をしたい方に役立つ機能です。
問題
アナリティクス・ビューでモデルを構築したときに、アナリティクス・ビューからは新しいデータに対する予測はできない。
解決方法
Exploratoryのアナリティクス・ビュー機能では、線形回帰、ランダムフォレスト、決定木、ランダムフォレスト、XGBoostなど、様々な予測モデルを作成することができます。
これらのモデルは、数値型データの予測やロジカル型データの予測に対応しています。
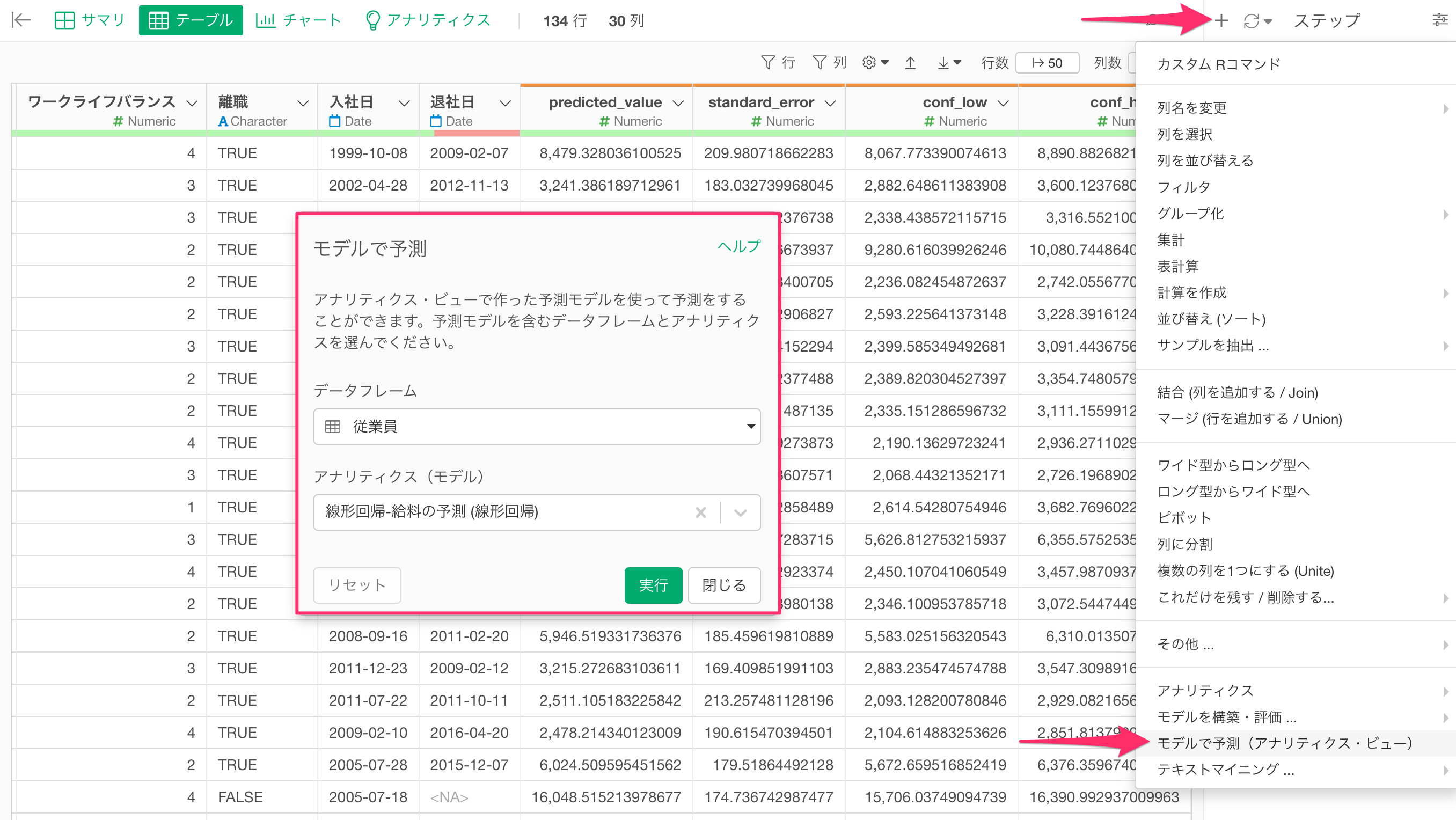
作成した予測モデルを新しいデータに適用する際は、予測モデルを適用したいデータフレームで「モデルで予測(アナリティクスビュー)」機能を使用します。
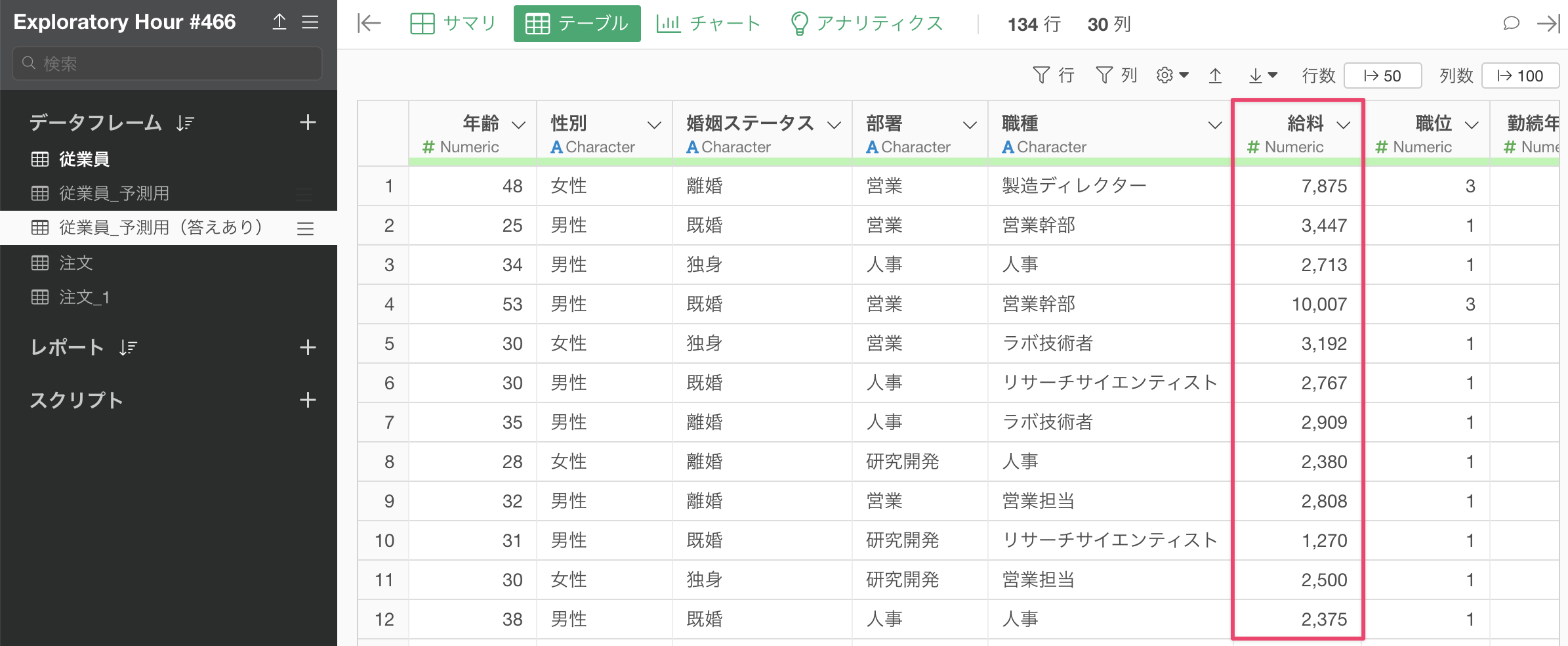
今回は1行が1人の従業員を表し、給料や離職状況などの情報を列に持つデータを利用します。
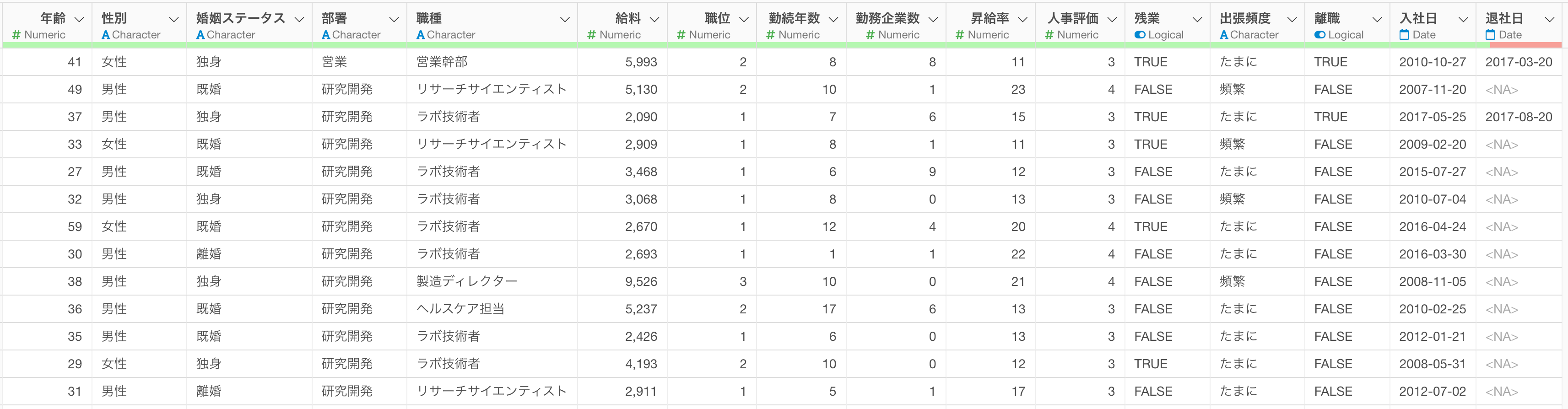
このデータを使って作成した、給料を予測する線形回帰モデルを、給料情報のない新しい従業員データに対して適用し、給料の予測を行います。
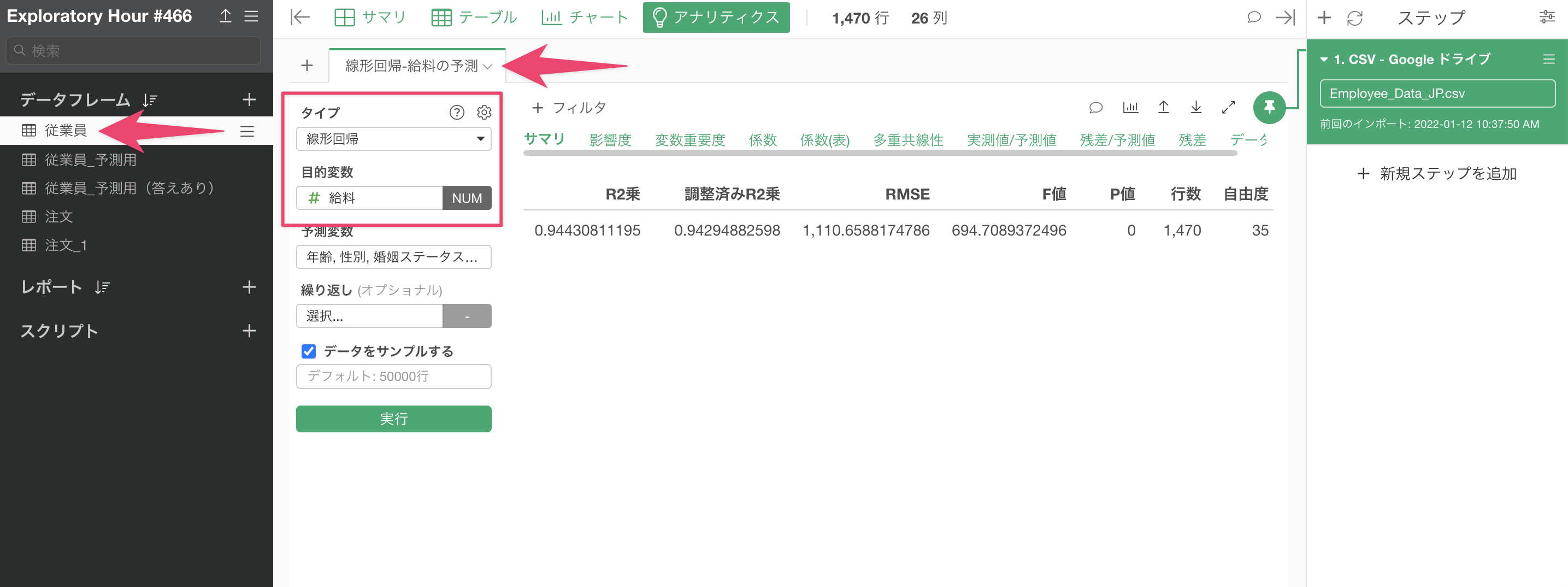
今回は、以下のように「従業員」というデータフレームにおいて既に給料を予測する線形回帰のモデルを前提に話を進めていきます。
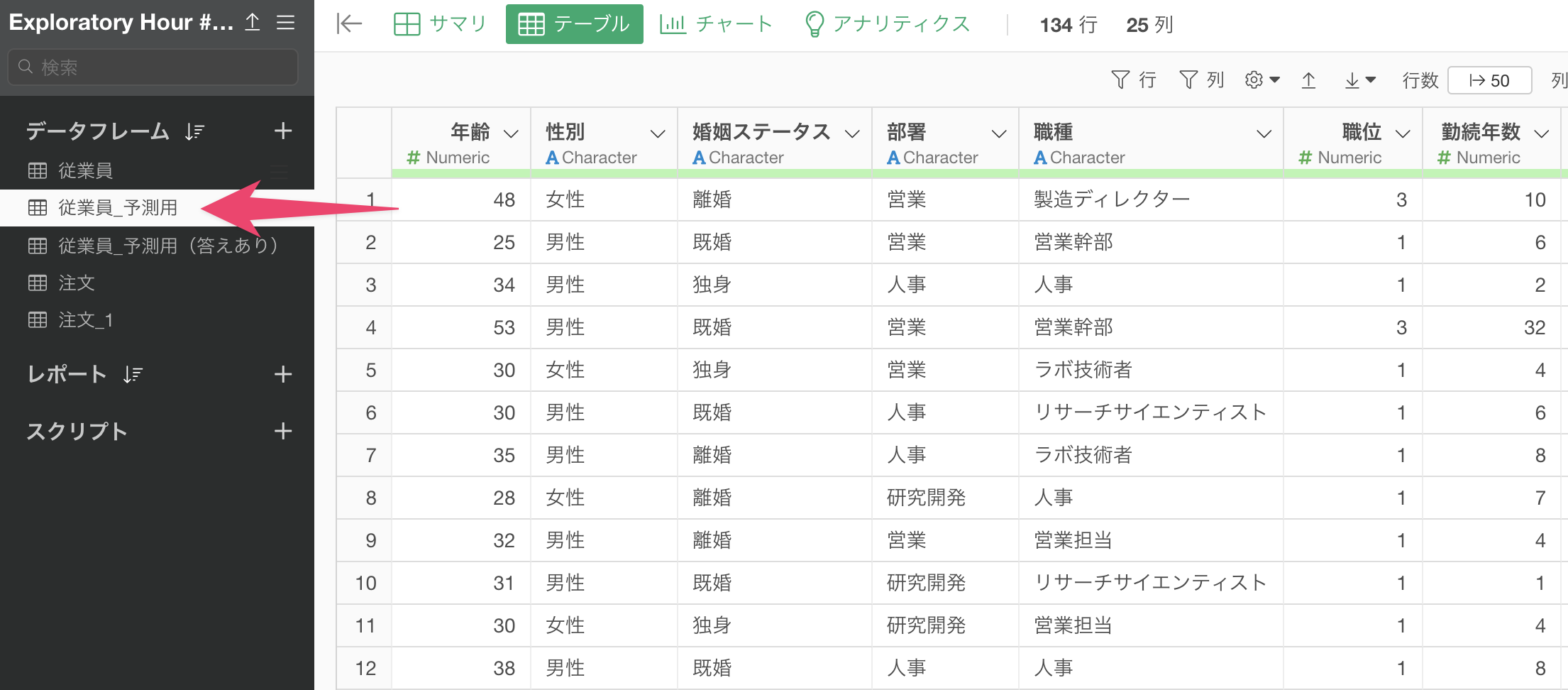
この予測モデルを使って、新しいデータに対して予測モデルを適用して予測を行いたい場合、予測をしたい対象のデータフレームに移動します。(今回は、「従業員_予測用」が予測をしたい対象のデータフレームです)
予測をしたい対象のデータフレームに移動します。ステップメニューの「+」ボタンをクリックし、「モデルで予測(アナリティクスビュー)」を選択します。
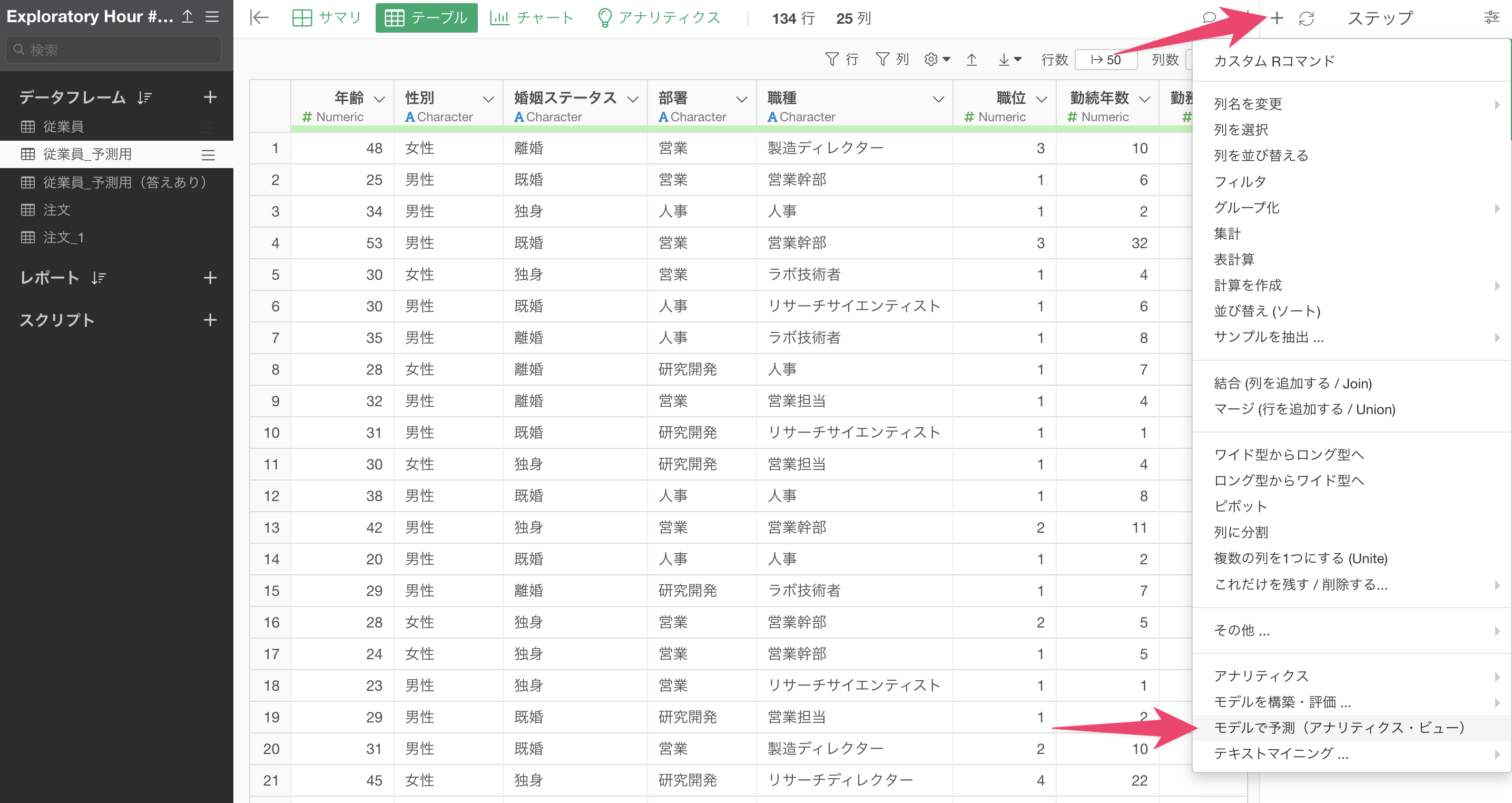
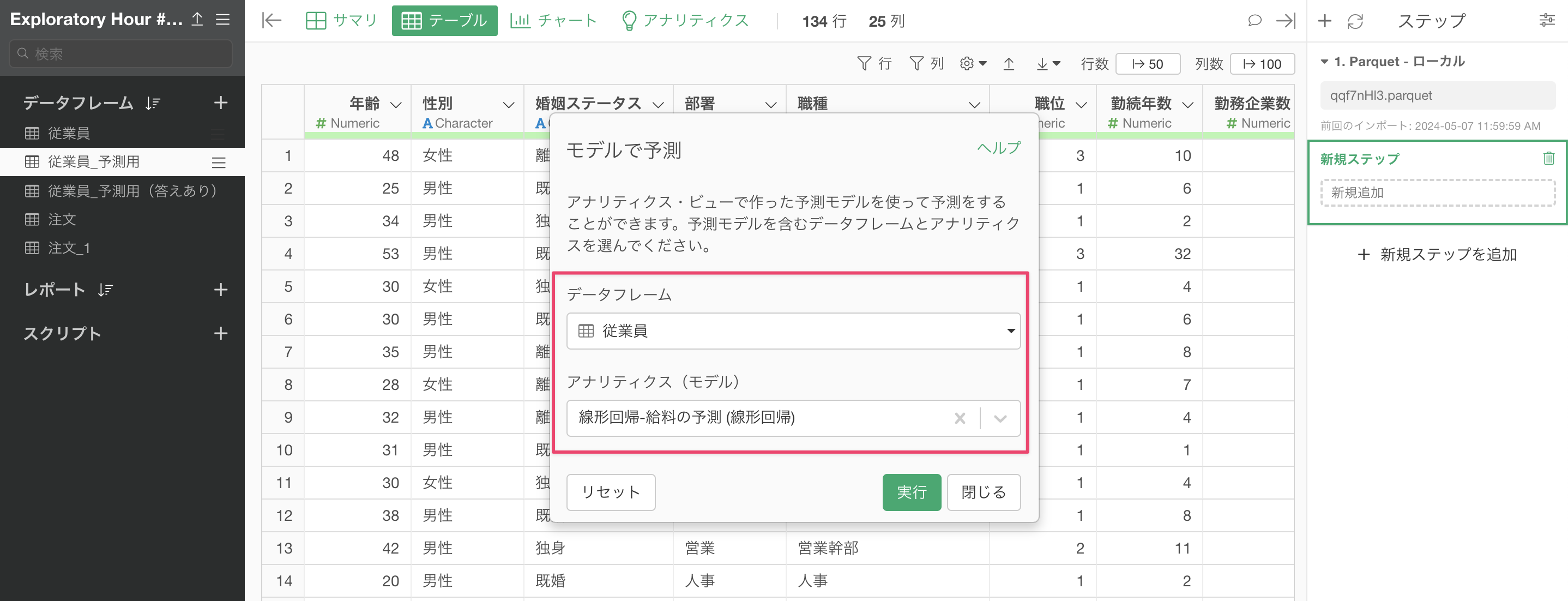
「モデルで予測」のダイアログが開いたら、予測モデルを作成したデータフレームと使用するモデルを選択します。
実行ボタンをクリックすると、新しいステップが追加され、予測結果を含む新しい列が追加されます。予測結果の列には、predicted_value(予測値)、conf_high(信頼区間の上限)、conf_log(下限)、starndard_error(標準誤差)などの情報が含まれます。
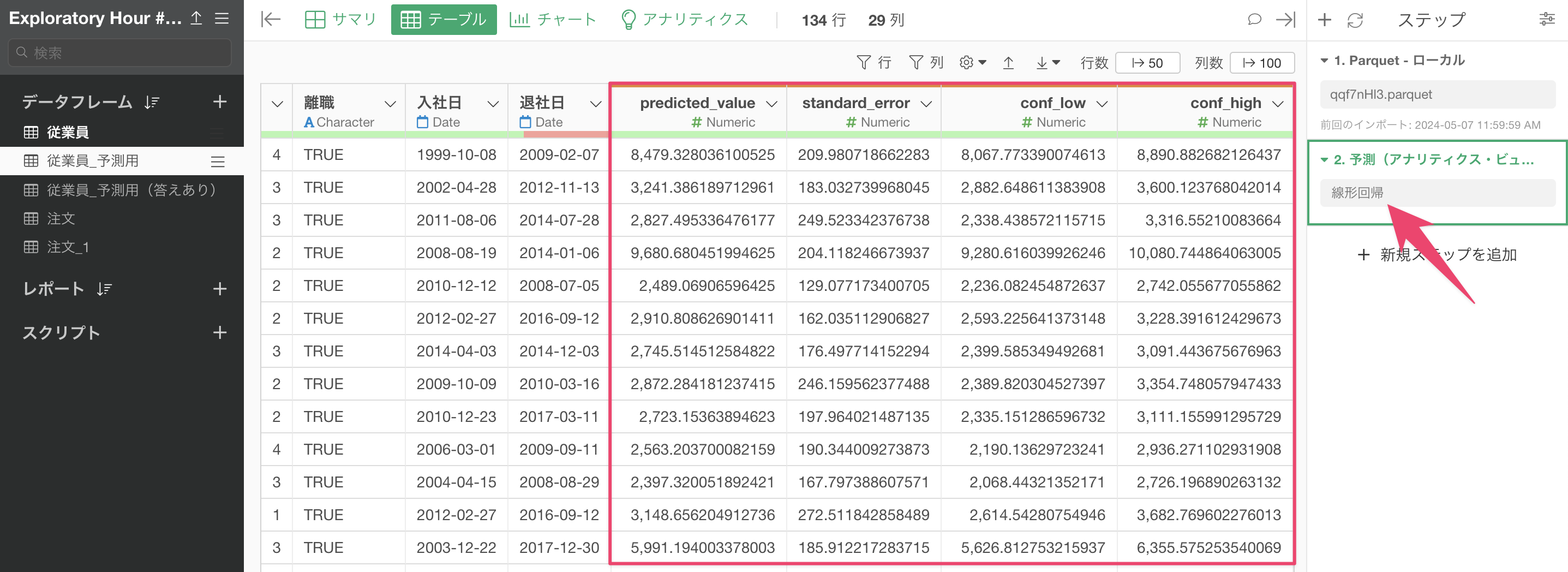
なお、このとき、表示される指標は、予測に利用するモデルによって異なります。
なお、予測対象のデータに実測の値があった場合、予測結果と実際の値を比較して、新しいデータに対する予測モデルの精度の評価が可能です。
前述した予測のステップを追加した後に、ステップメニューから「モデルを構築・評価」>「予測精度の評価」>「回帰」を選択します。
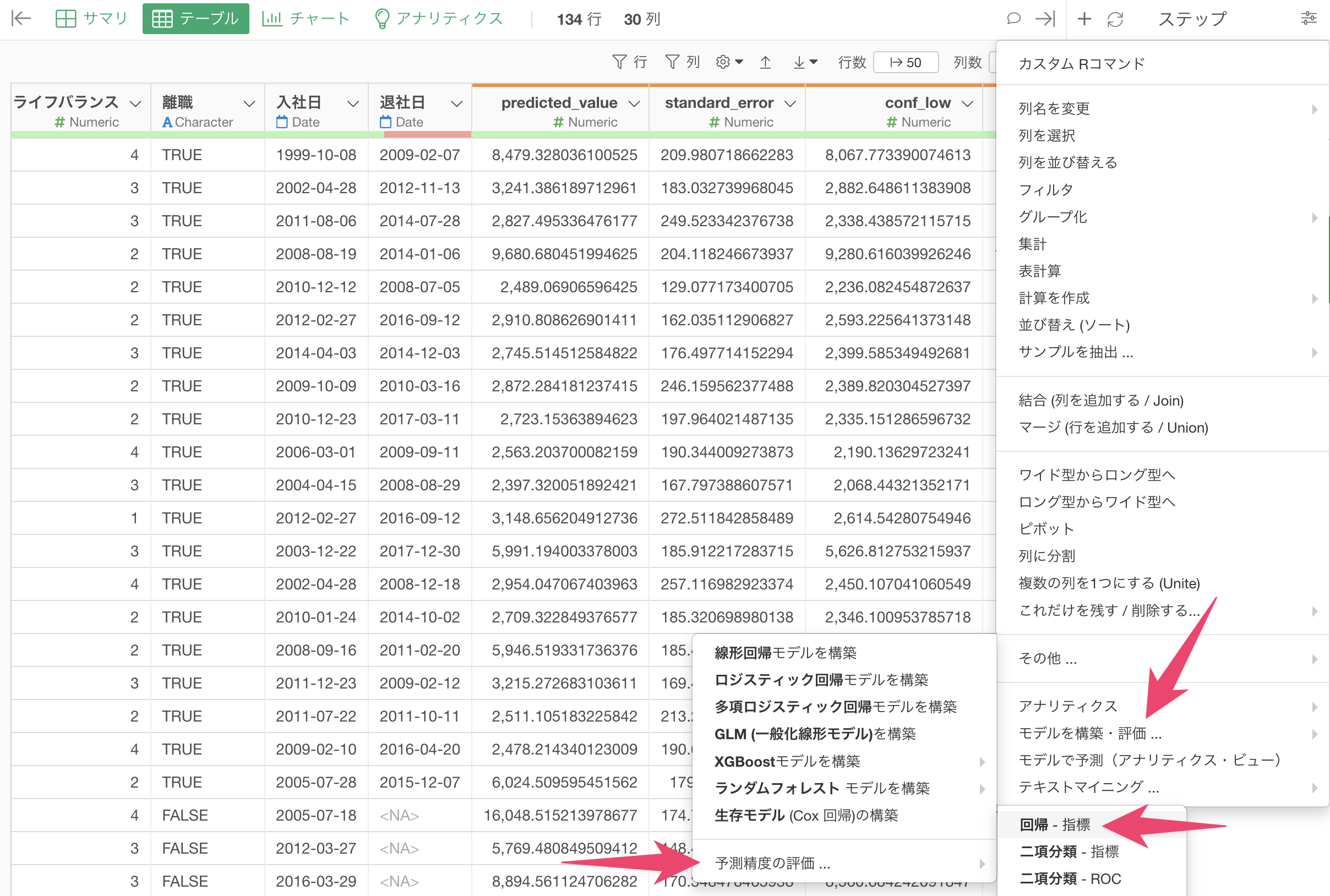
予測精度の評価ダイアログが開いたら、予測値の列と実際の値の列を選択します。
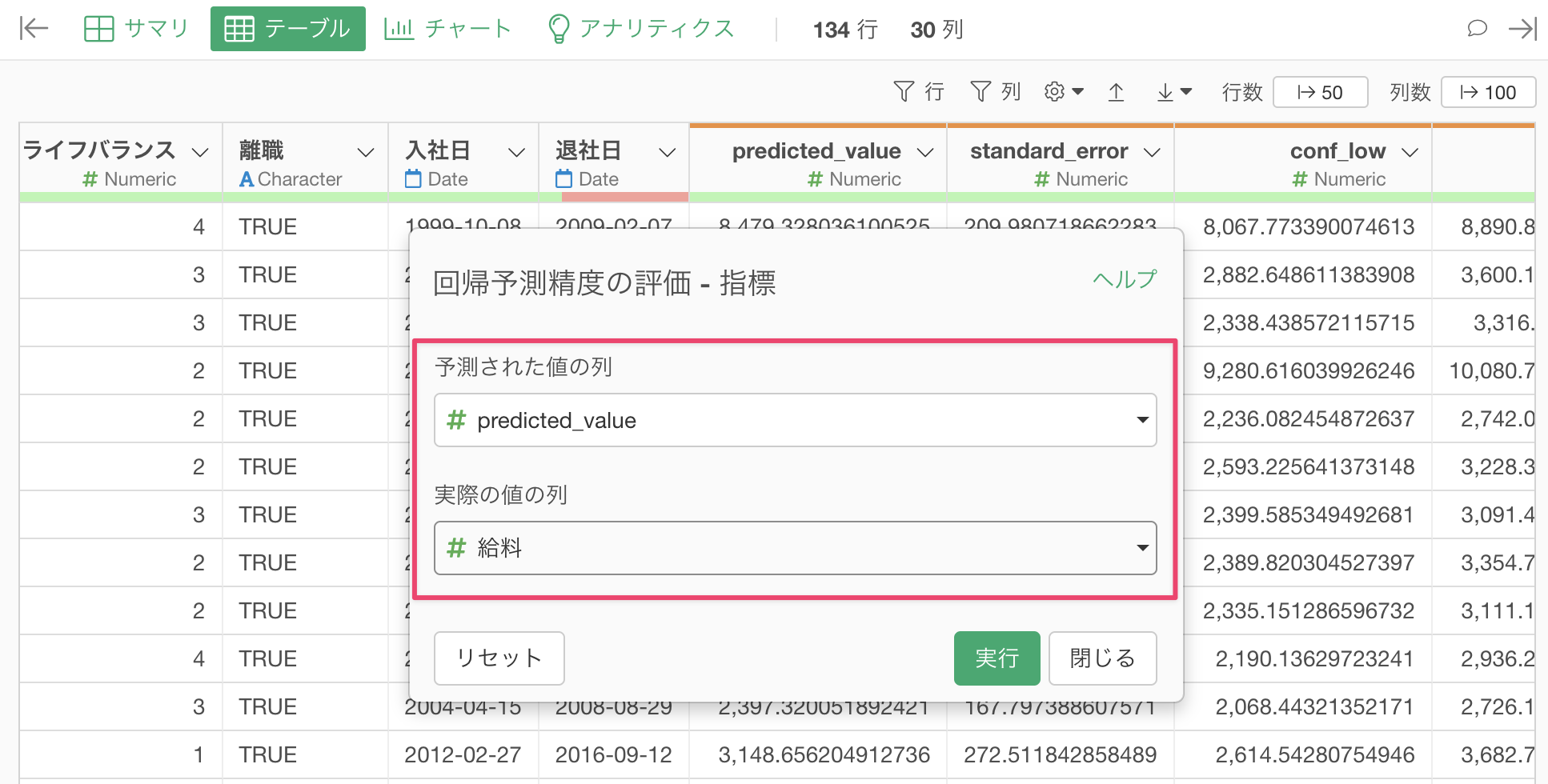
実行ボタンをクリックすると、予測モデルの精度を評価するための各種指標が表示されます。
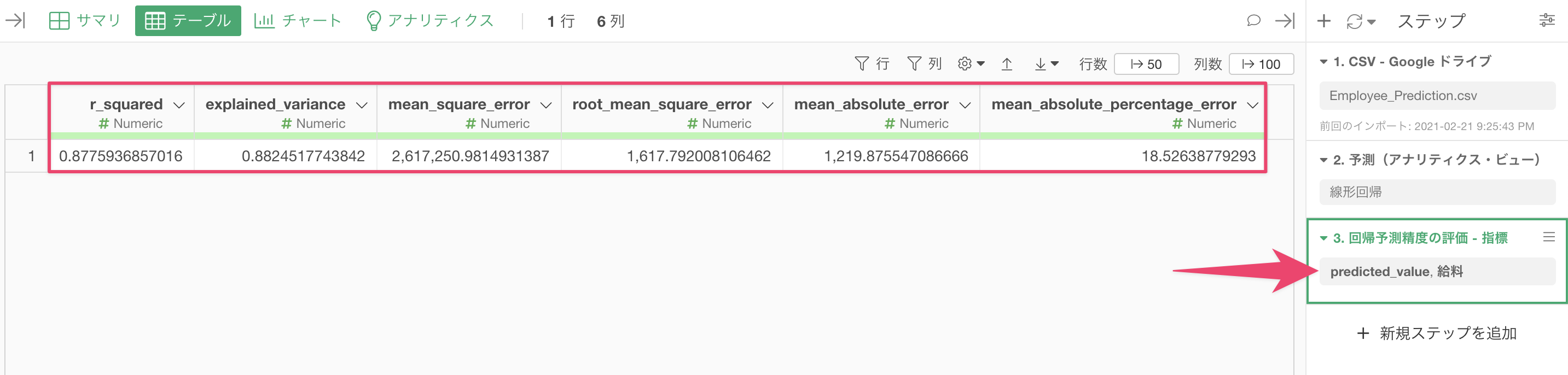
なお、予測モデルのタイプ(回帰、2項分類など)によって、表示される評価指標は異なります。
ビデオ
参考情報
- アナリティクス・ギャラリー - リンク