Exploratory アワー #508 - 日本語の文字列のみをデータとして残したい
大量のデータから日本語の文字列のみを抽出することは、データ分析や顧客管理において重要な作業です。
今回は、Exploratoryを使用して、ひらがな、カタカナ、漢字を含む日本語文字列を効果的にフィルタリングする方法を紹介します。正規表現を活用することで、複雑な文字列パターンにも対応できる柔軟なフィルタリング手法を説明します。
問題
データセットに日本語と外国語の文字列が混在しているが、日本語の文字列のみを抽出したい。
日本語の場合、ひらがな、カタカナ、漢字それぞれに対応した正規表現を書く必要があるが、どのように書けばいいかわからない。
解決方法
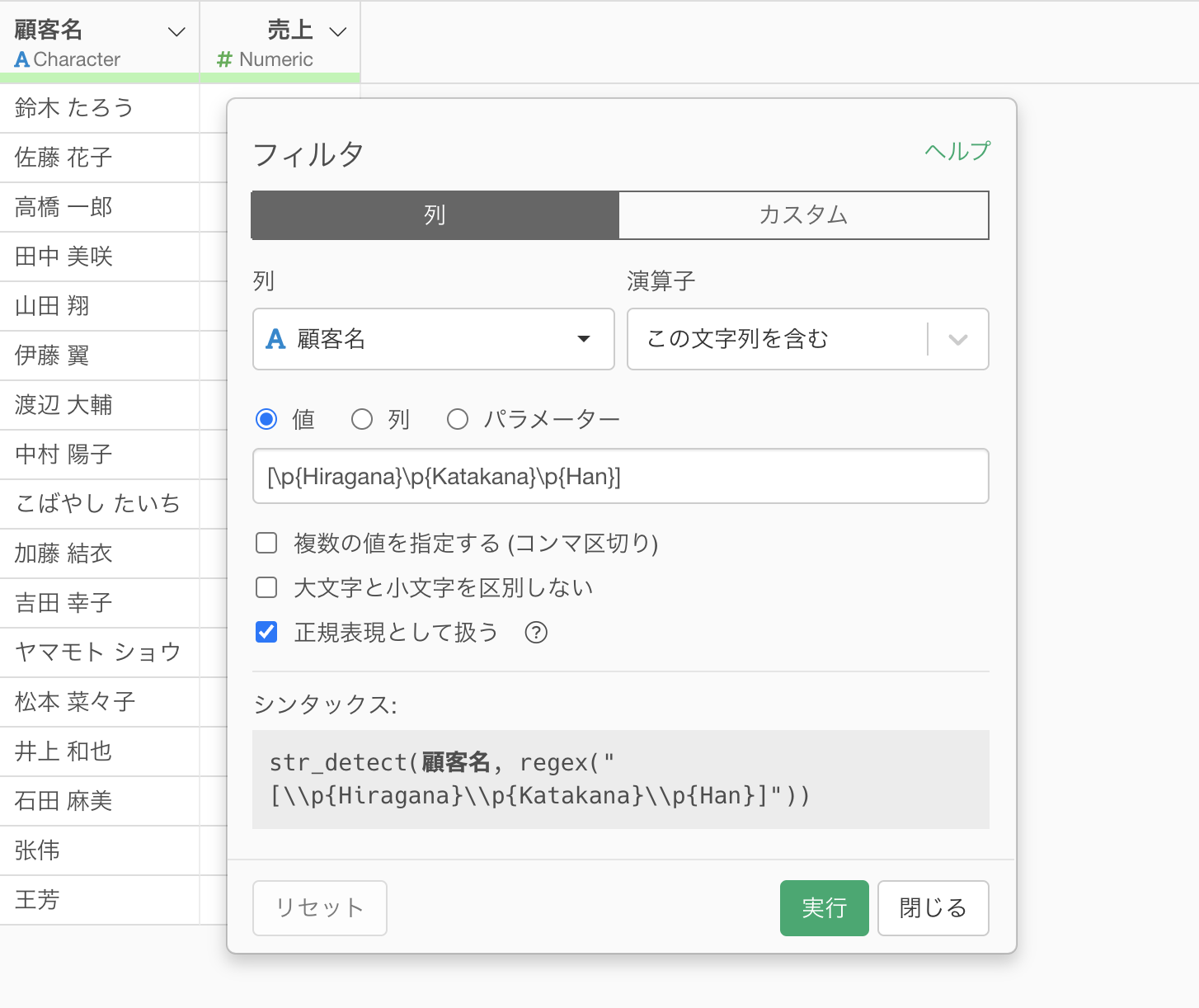
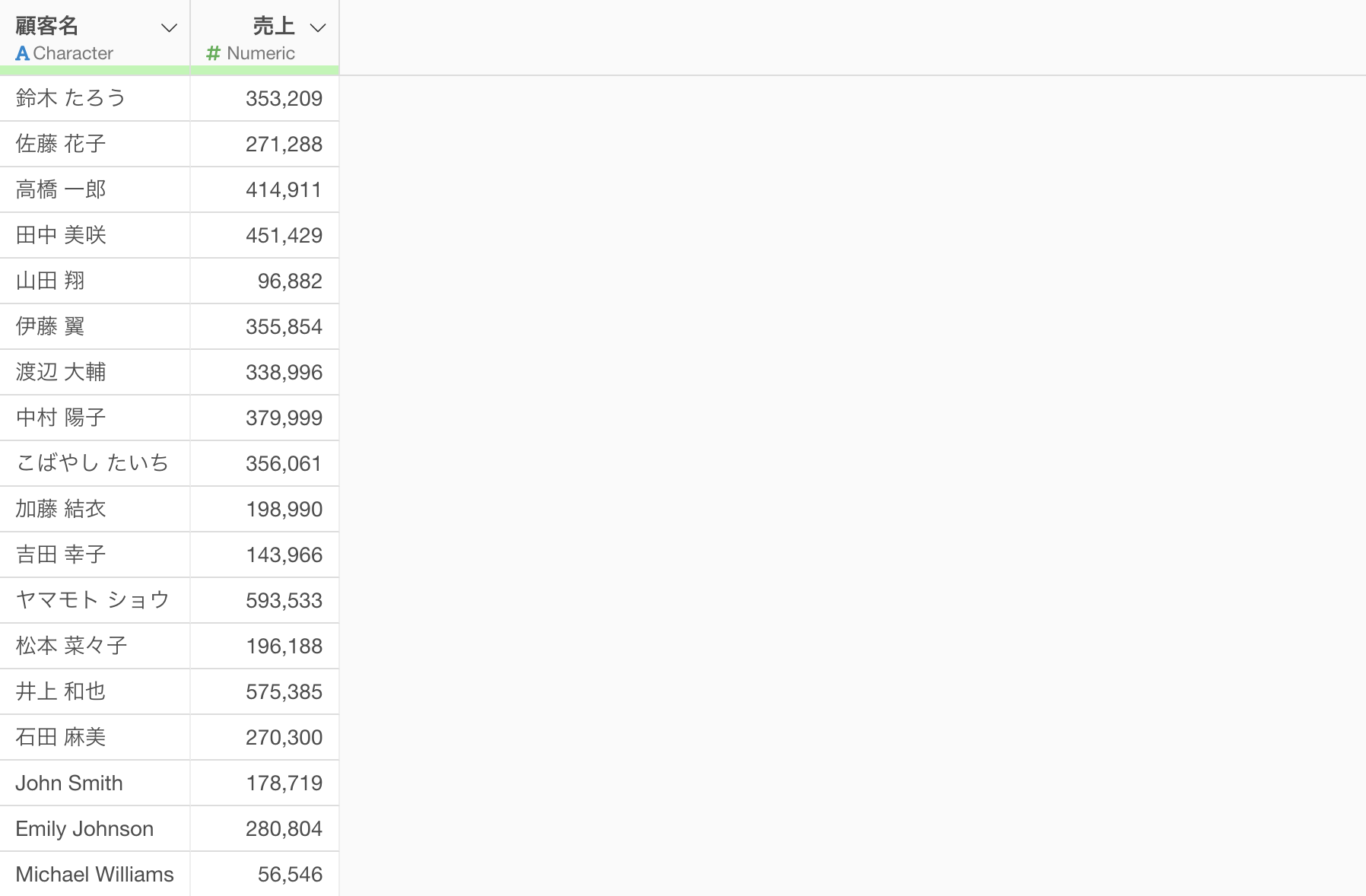
今回は以下のような顧客ごとの売上のデータを使用します。
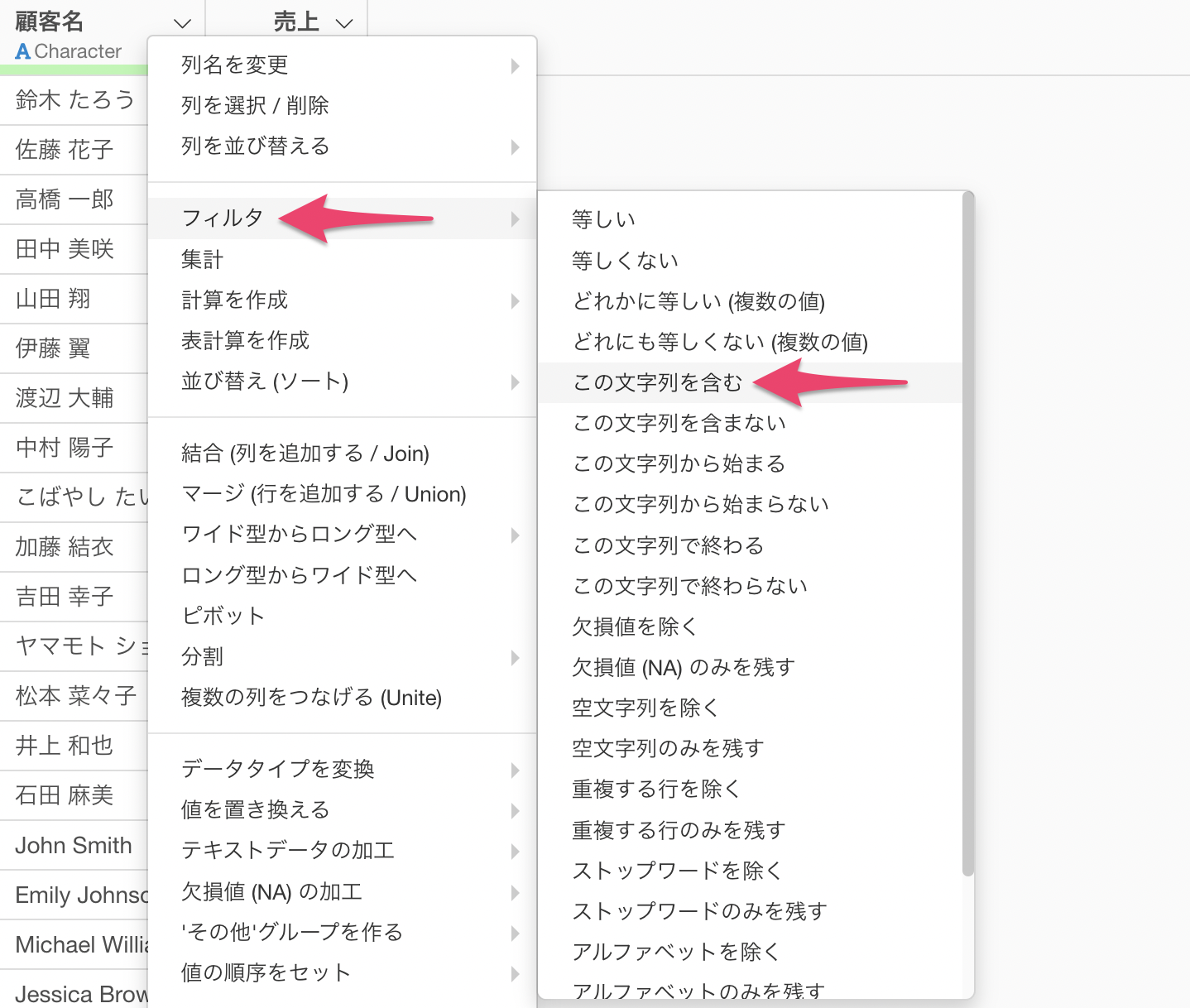
顧客名の列ヘッダメニューから「フィルタ」を選び、「この文字列を含む」を選択します。
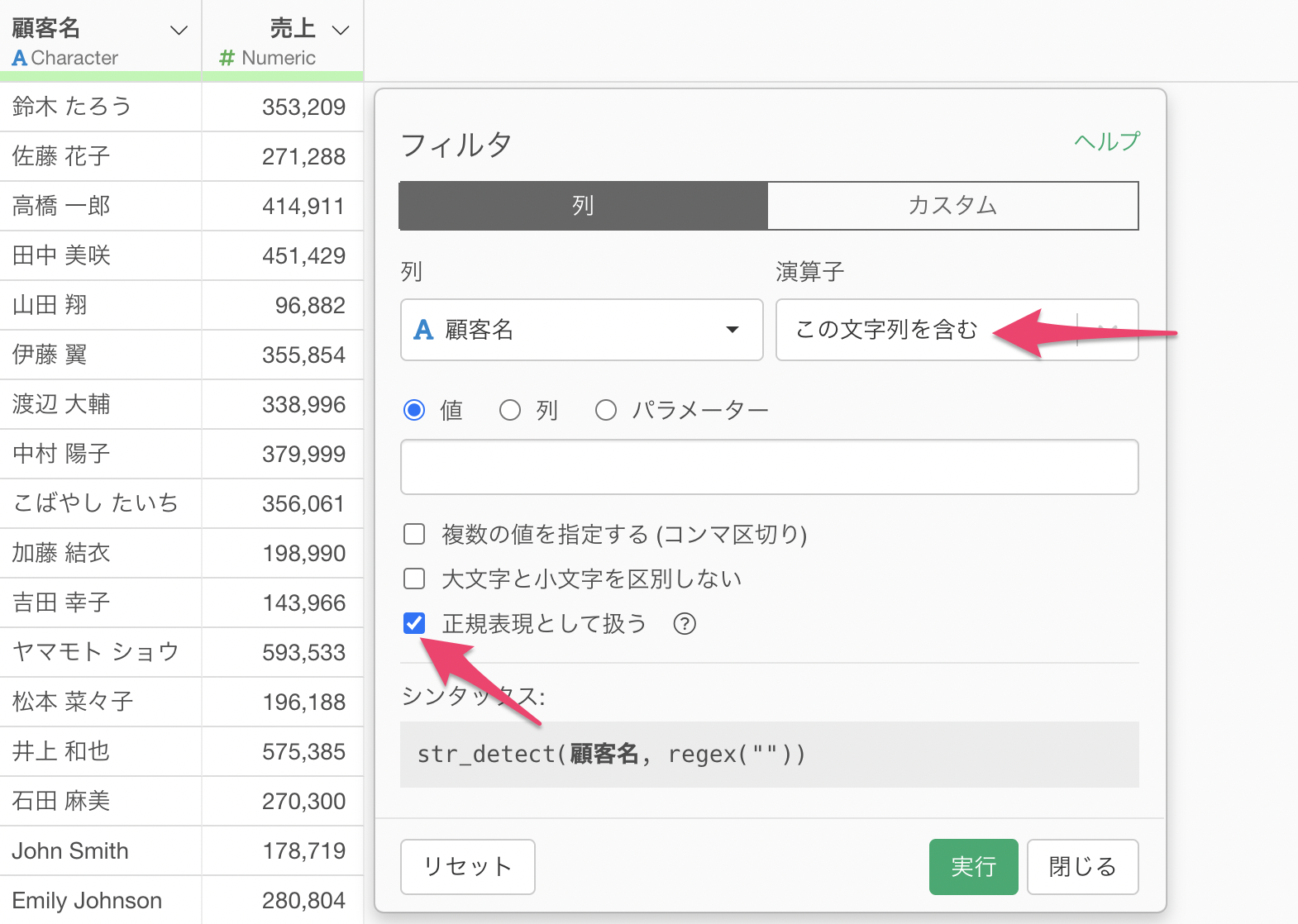
フィルターダイアログが表示されるため、「正規表現として扱う」にチェックを入れます。
ひらがなのフィルタリング
ひらがなを含む値のみを残す場合の正規表現では、以下を値に入力します。
[\p{Hiragana}]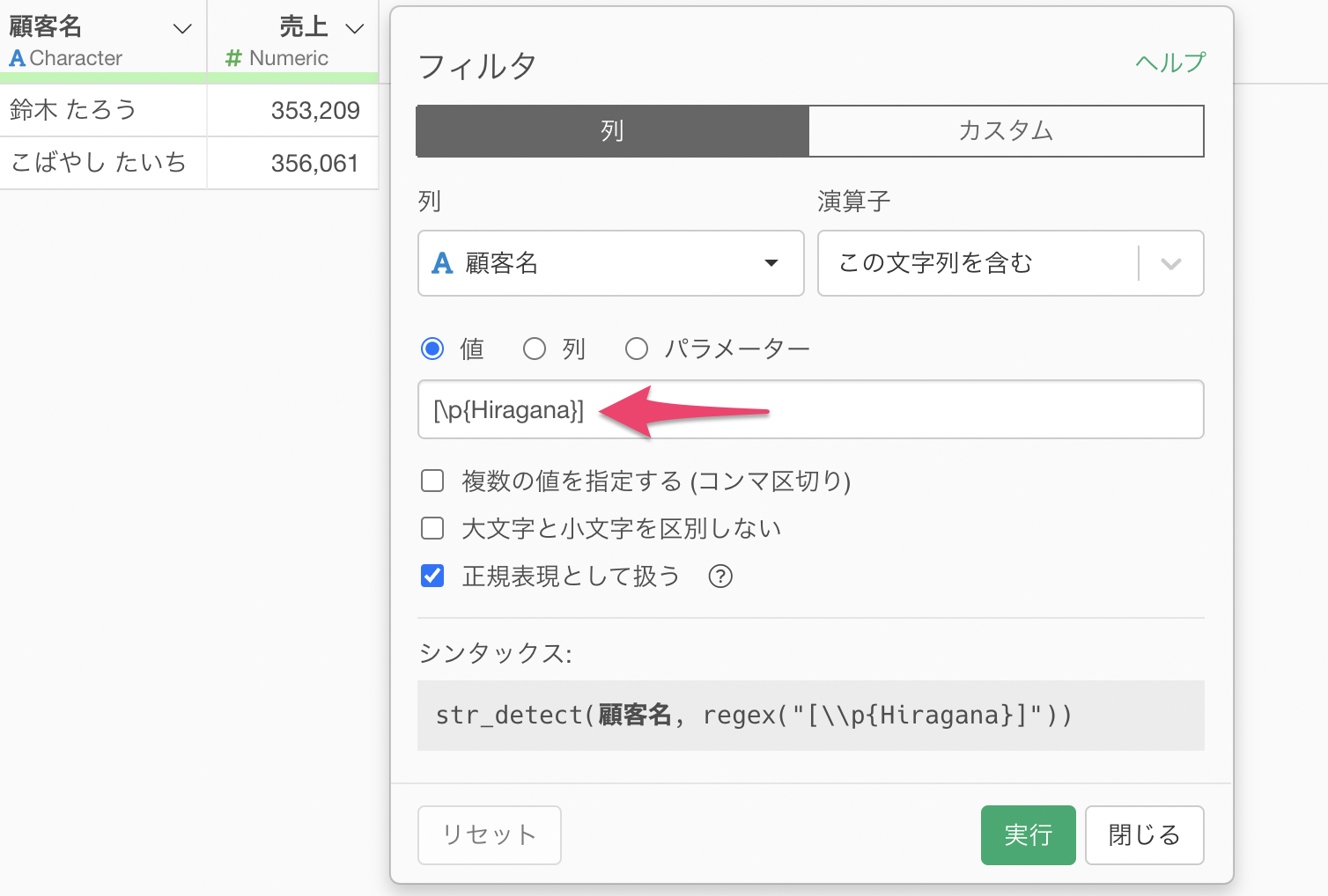
カタカナのフィルタリング
カタカナを含む値のみを残す場合の正規表現では、以下を値に入力します。
[\p{Katakana}]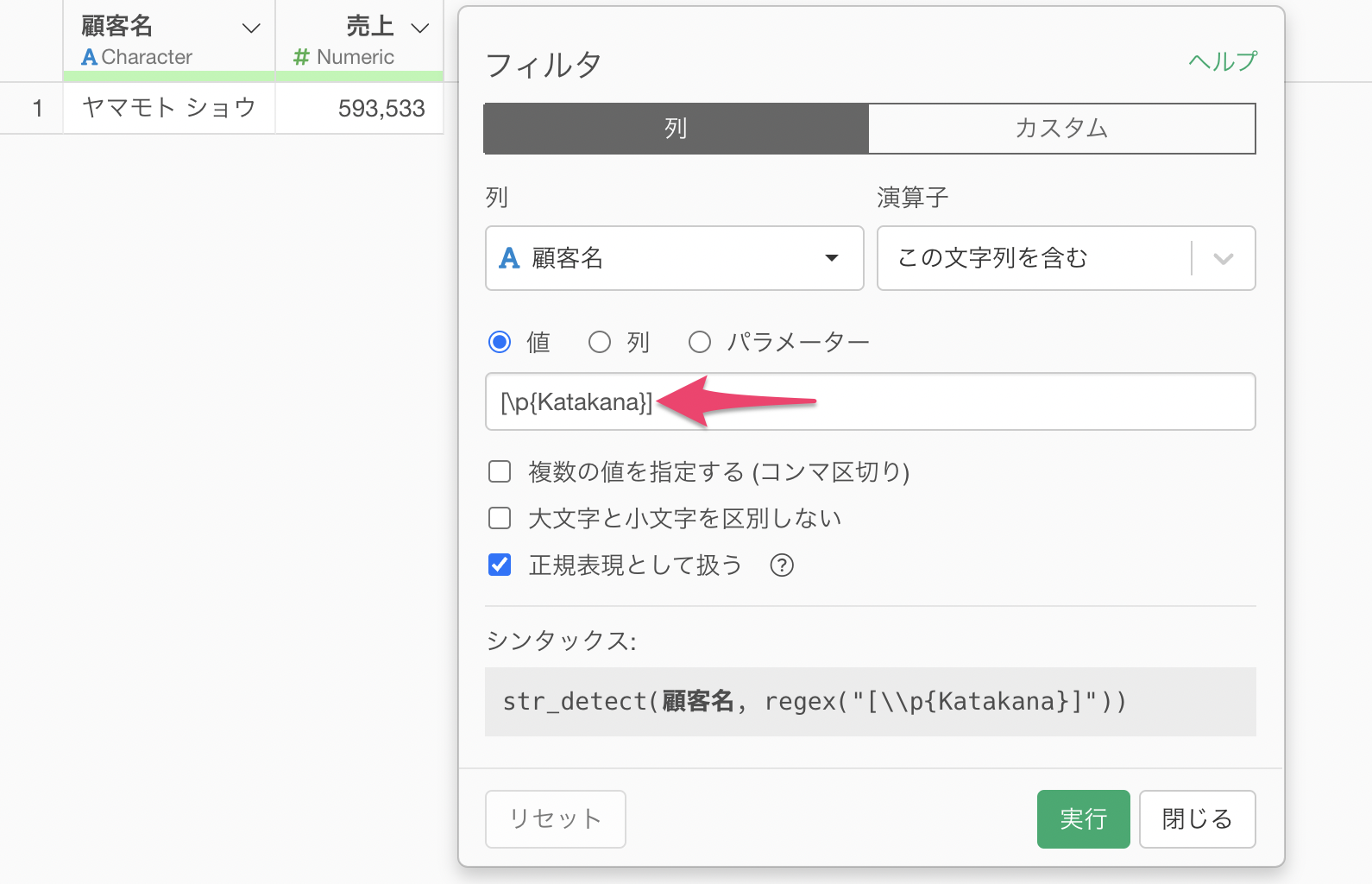
漢字のフィルタリング
漢字を含む値のみを残す場合の正規表現では、以下を値に入力します。
[\p{Han}]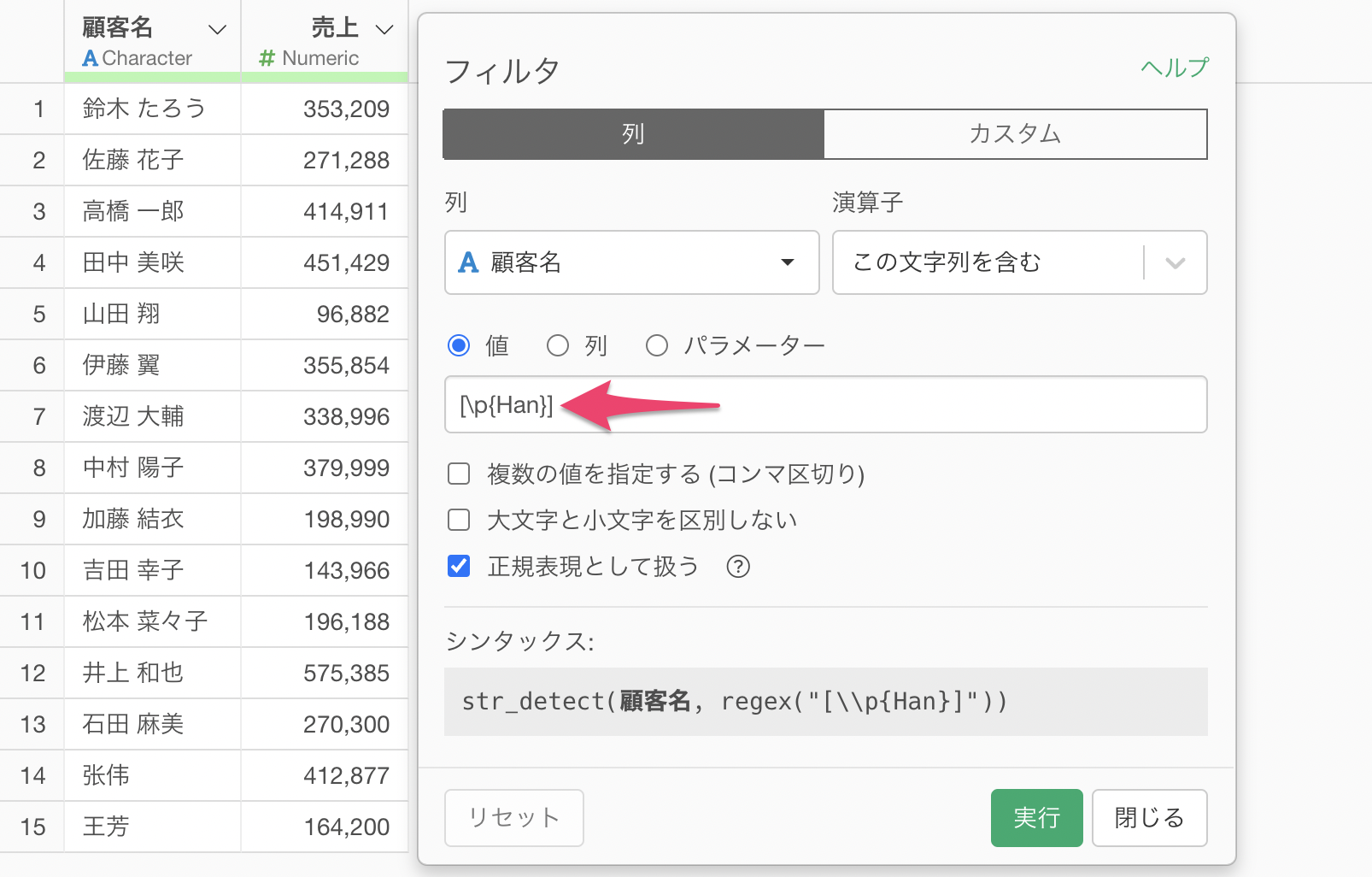
漢字のフィルタリングは中国語の文字も含んでしまう可能性があるため、完全に中国語を除外したい場合は、個別の対処が必要になることがあります。
日本語(ひらがな、カタカナ、漢字)を全て含むフィルタリング
日本語を含む値のみを残す場合の正規表現では、以下を値に入力します。
[\p{Hiragana}\p{Katakana}\p{Han}]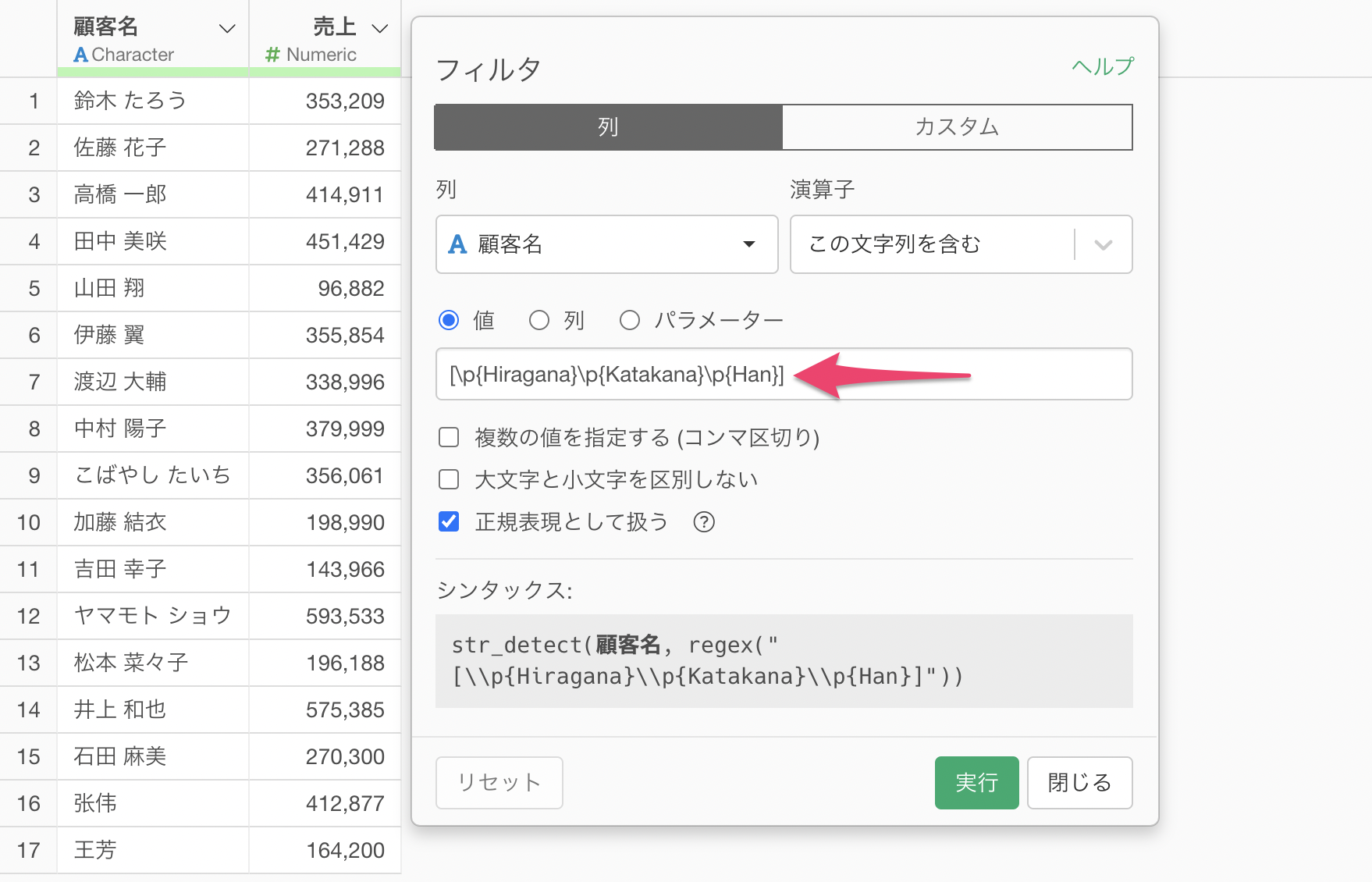
これらの手順に従うことで、Exploratoryを使用して効果的に日本語文字列をフィルタリングすることができます。
ビデオ
参考情報
- 日本語の文字列のみをデータとして残す方法 - リンク