Exploratory アワー #512 - 元のデータの比率を保持したままデータをサンプル(層化抽出)したい
大規模なデータセットを扱う際、パフォーマンスの問題を解決するためにデータのサンプリングが必要となることがあります。
今回は、Exploratoryを使用して元のデータの比率を保持したまま層化抽出(相加抽出)を行う方法について説明します。
この手法により、元のデータセットの特性を維持しながら、より小さなデータセットを作成することができます。
問題
- 大規模なデータセット(例:1000万行)を扱う際、パソコンのスペックによっては処理が重くなる。
- 単純なランダムサンプリングでは、元のデータの各グループ(例:国、顧客セグメント)の比率が崩れてしまう。
解決方法
今回はサンプルデータとしてECサイトの注文データを使用します。
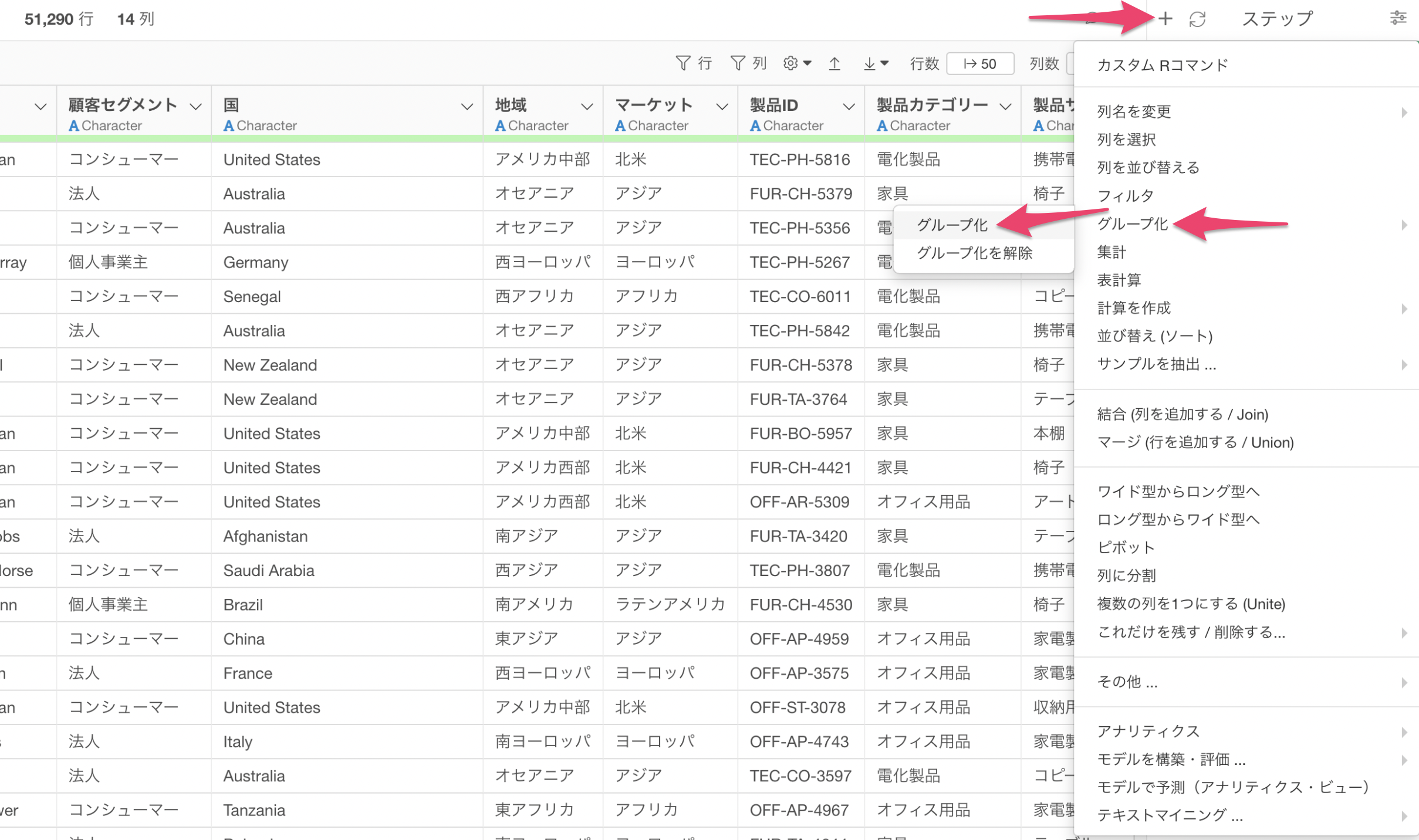
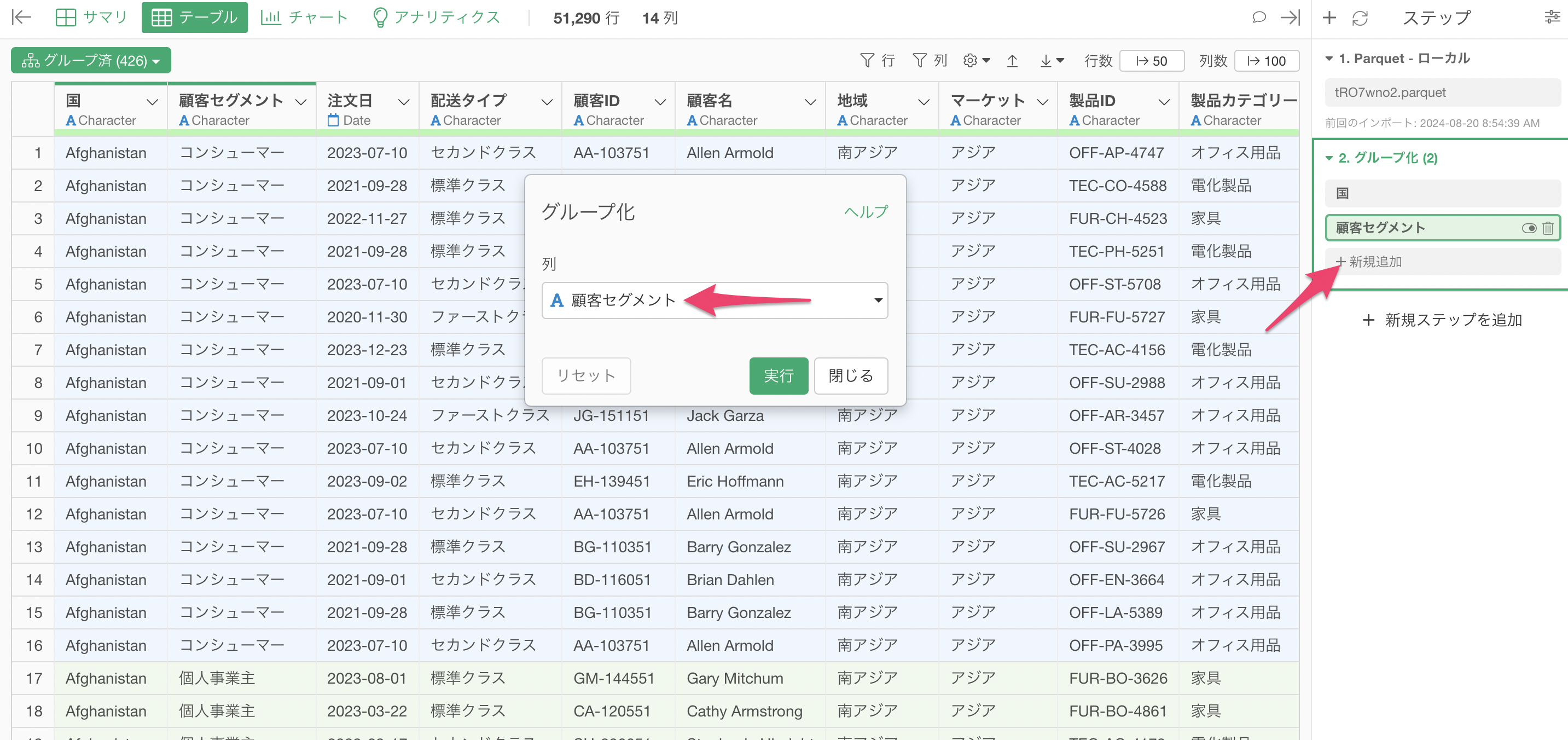
グループ化の設定
ステップメニューから「ステップを追加」を選び、「グループ化」を選択します。
グループ化する列(例:国、顧客セグメント)を指定します。
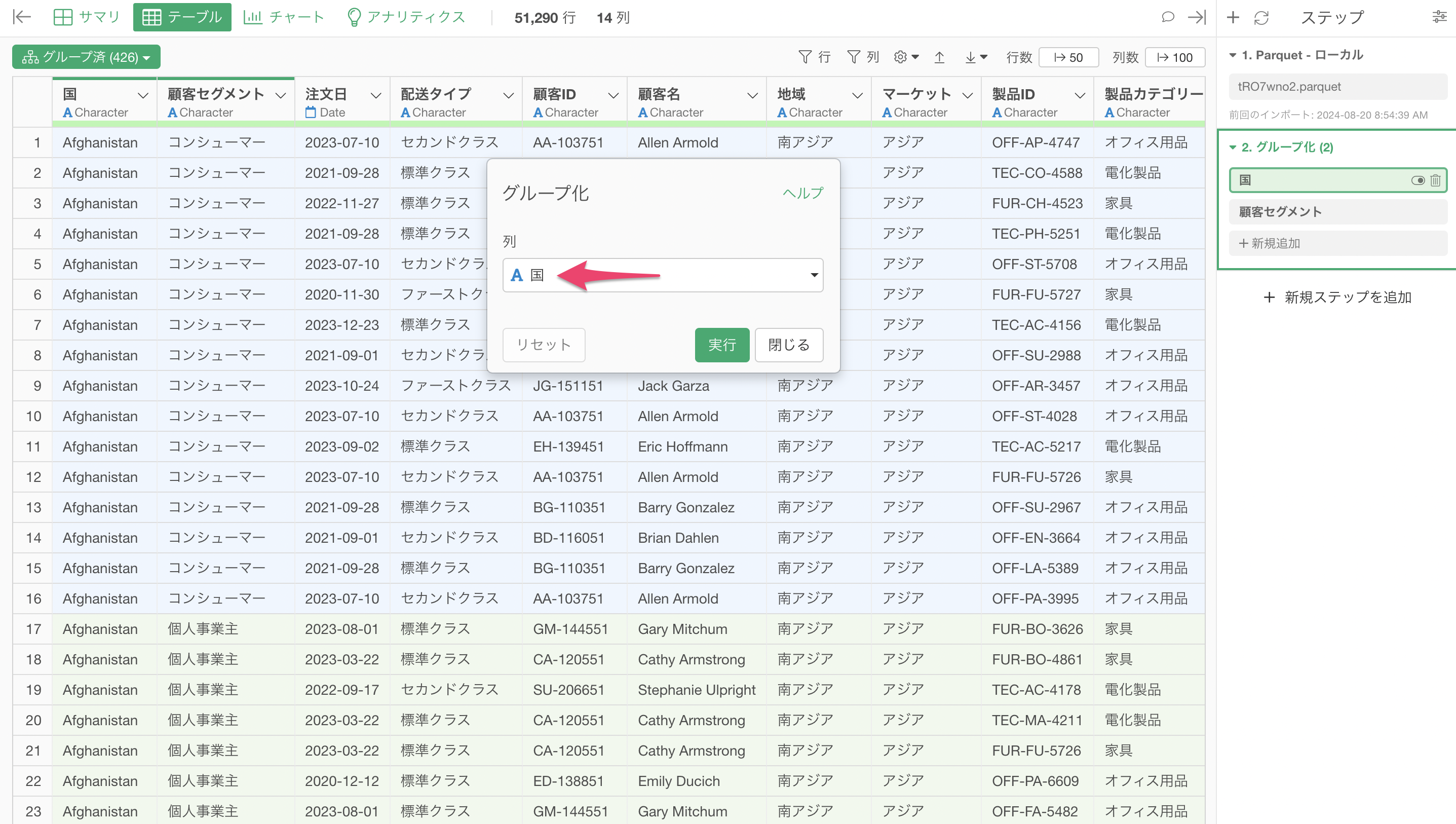 複数の列でグループ化を行いたい場合は、グループ化したステップでの「新規追加」から行います。
複数の列でグループ化を行いたい場合は、グループ化したステップでの「新規追加」から行います。
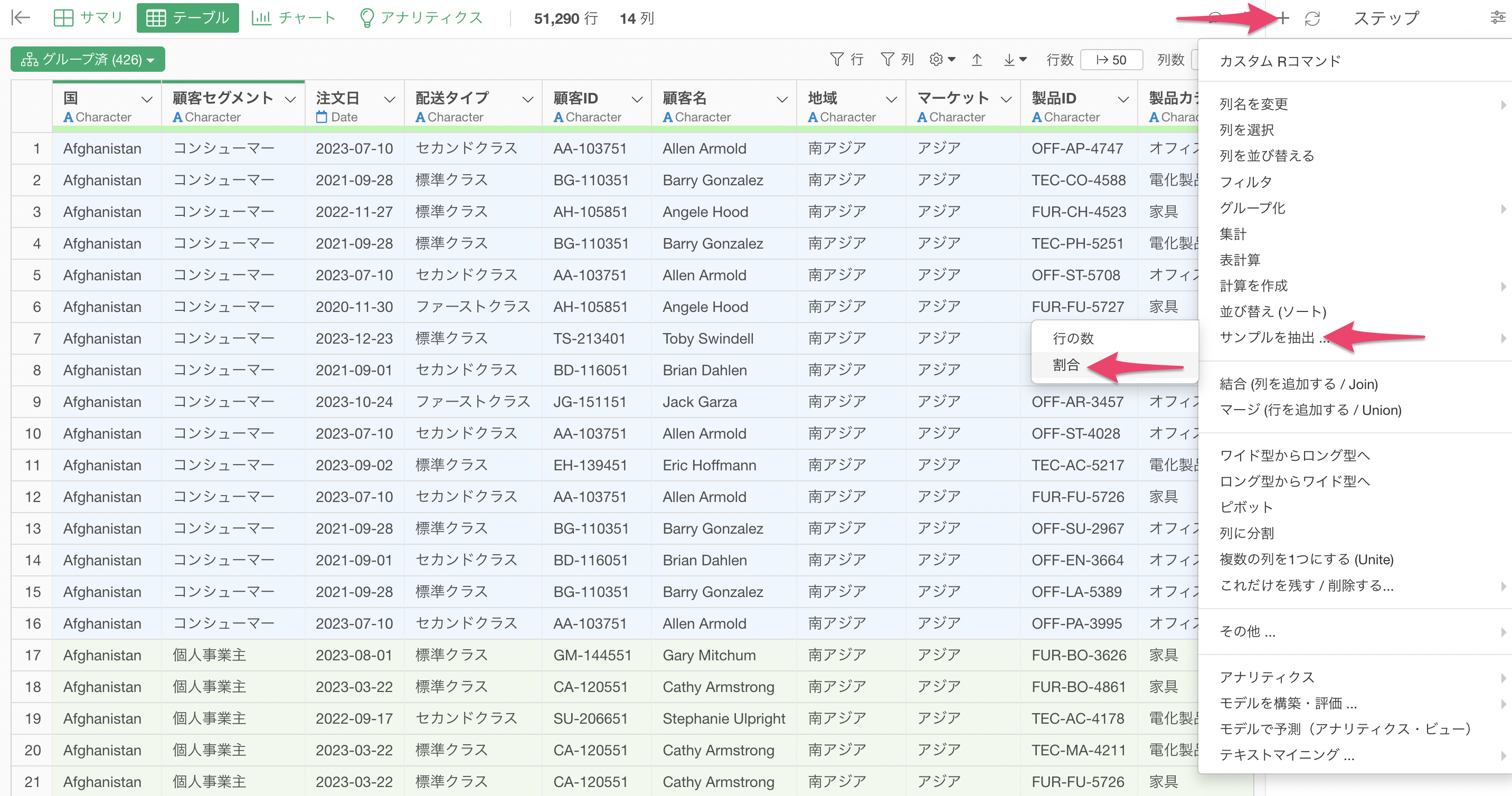
サンプル抽出の設定
ステップメニューから「ステップを追加」を選び、「サンプルを抽出」の「割合」を選択します。
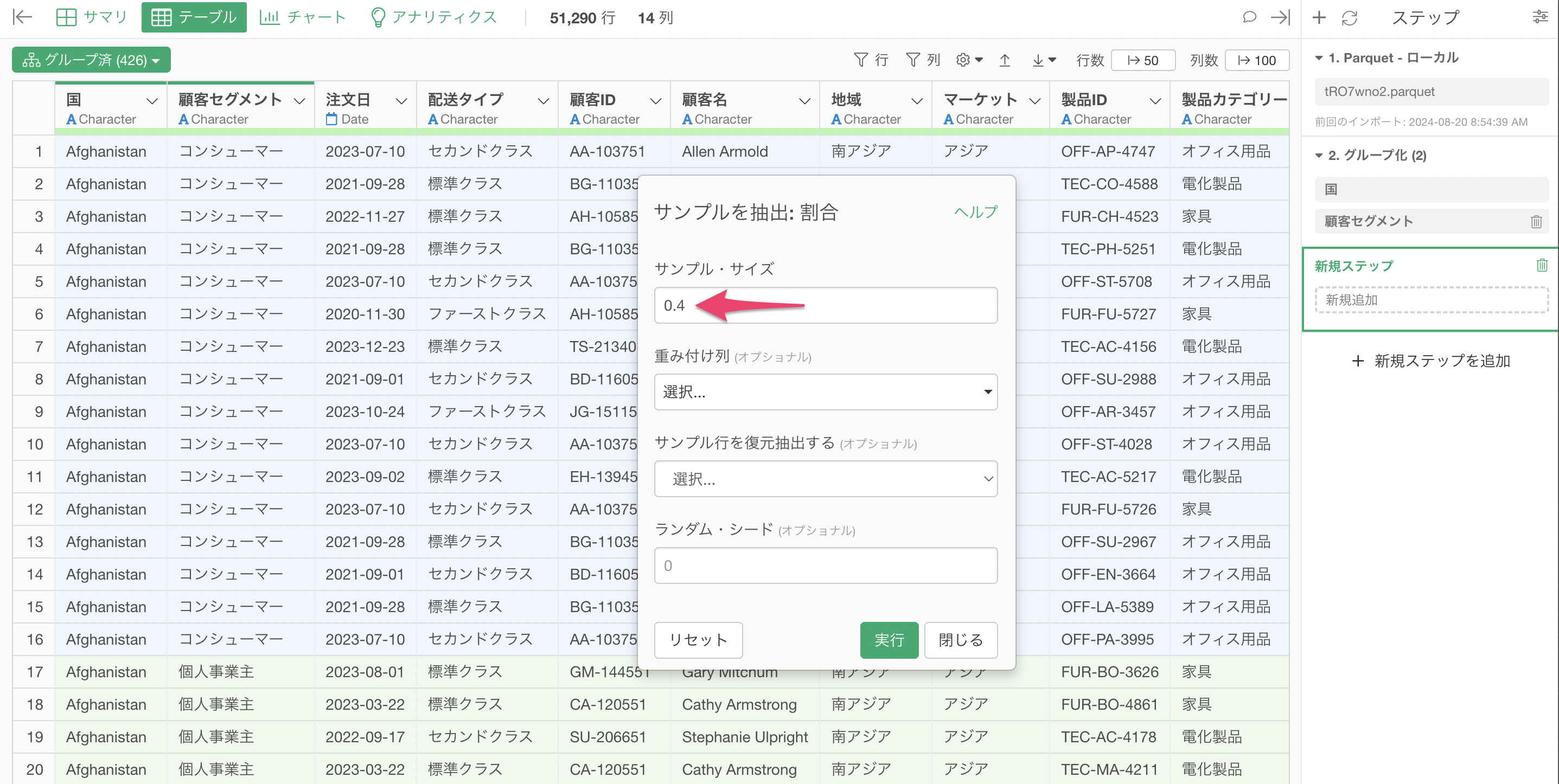
サンプル・サイズを指定します。例えば、0.4の場合は40%のデータをサンプル(残す)することとなります。
これにより、各グループ(国、顧客セグメントなど)の比率が元のデータと同じでありつつも、データをサンプルできました。
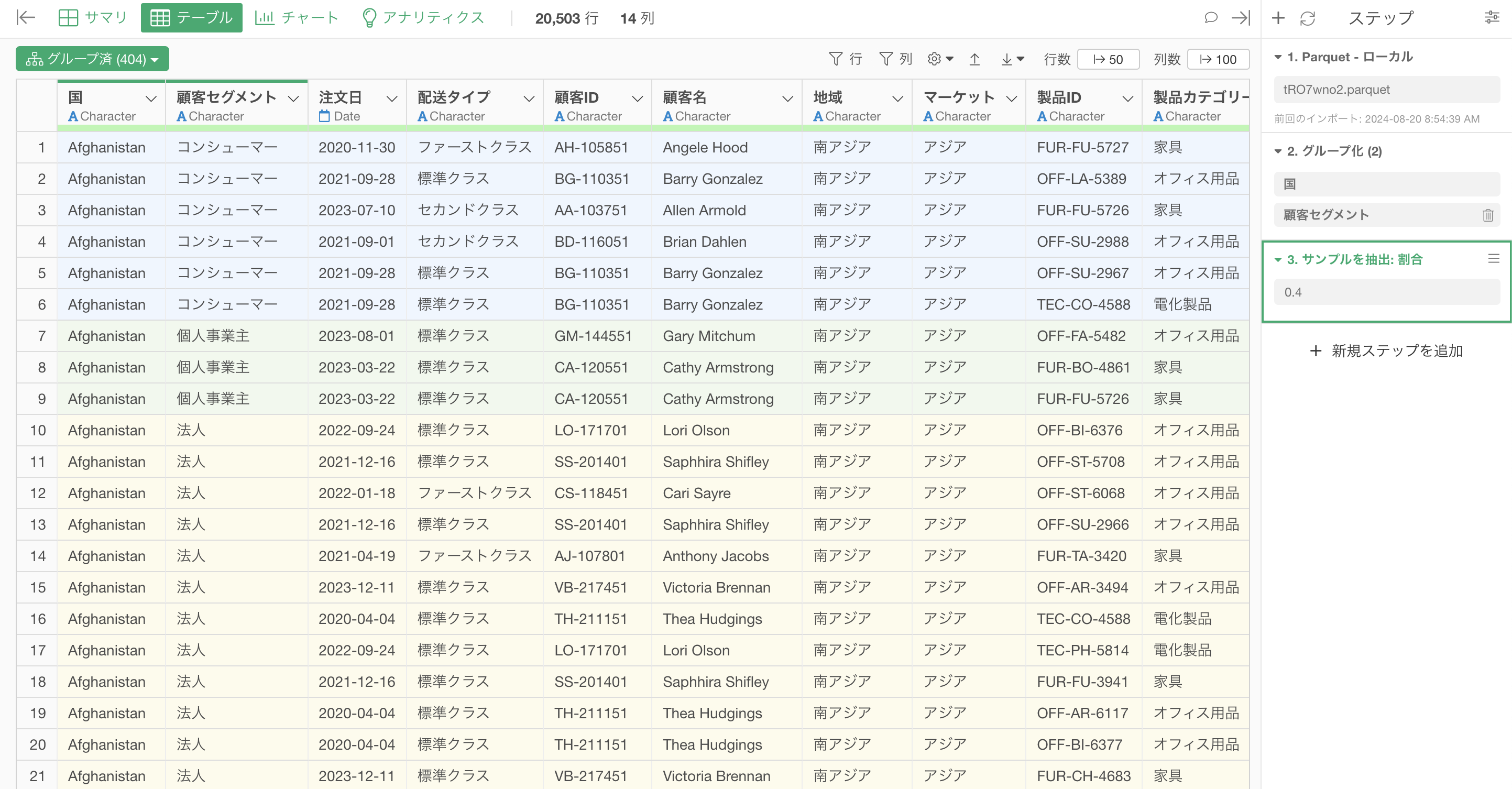
サンプルをする前は顧客セグメントの「コンシューマー」の比率は「51.7%」となっていました。
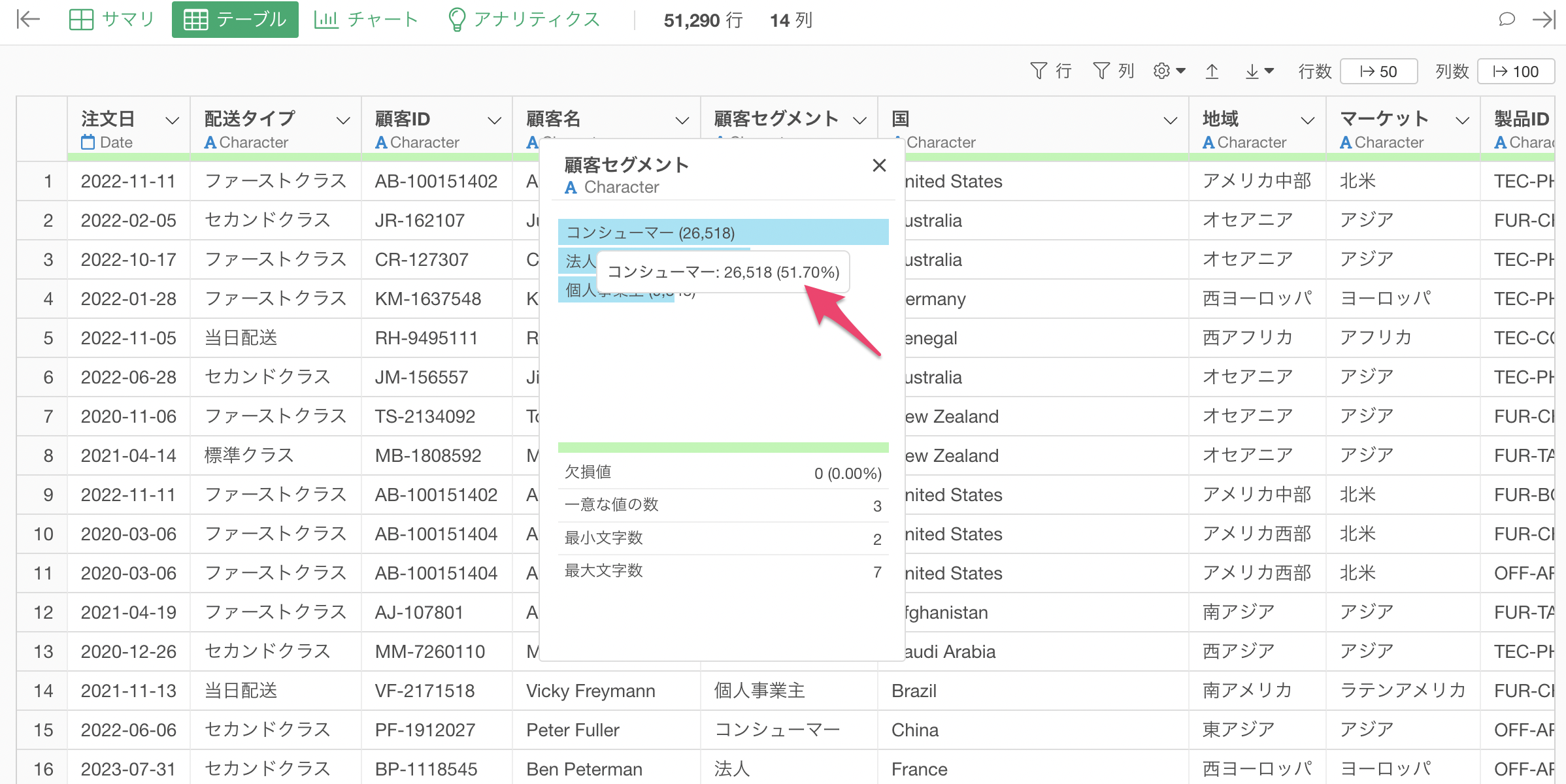
サンプル後も顧客セグメントの「コンシューマー」の比率は「51.71%」とほぼ同じ比率になっていることがわかります。
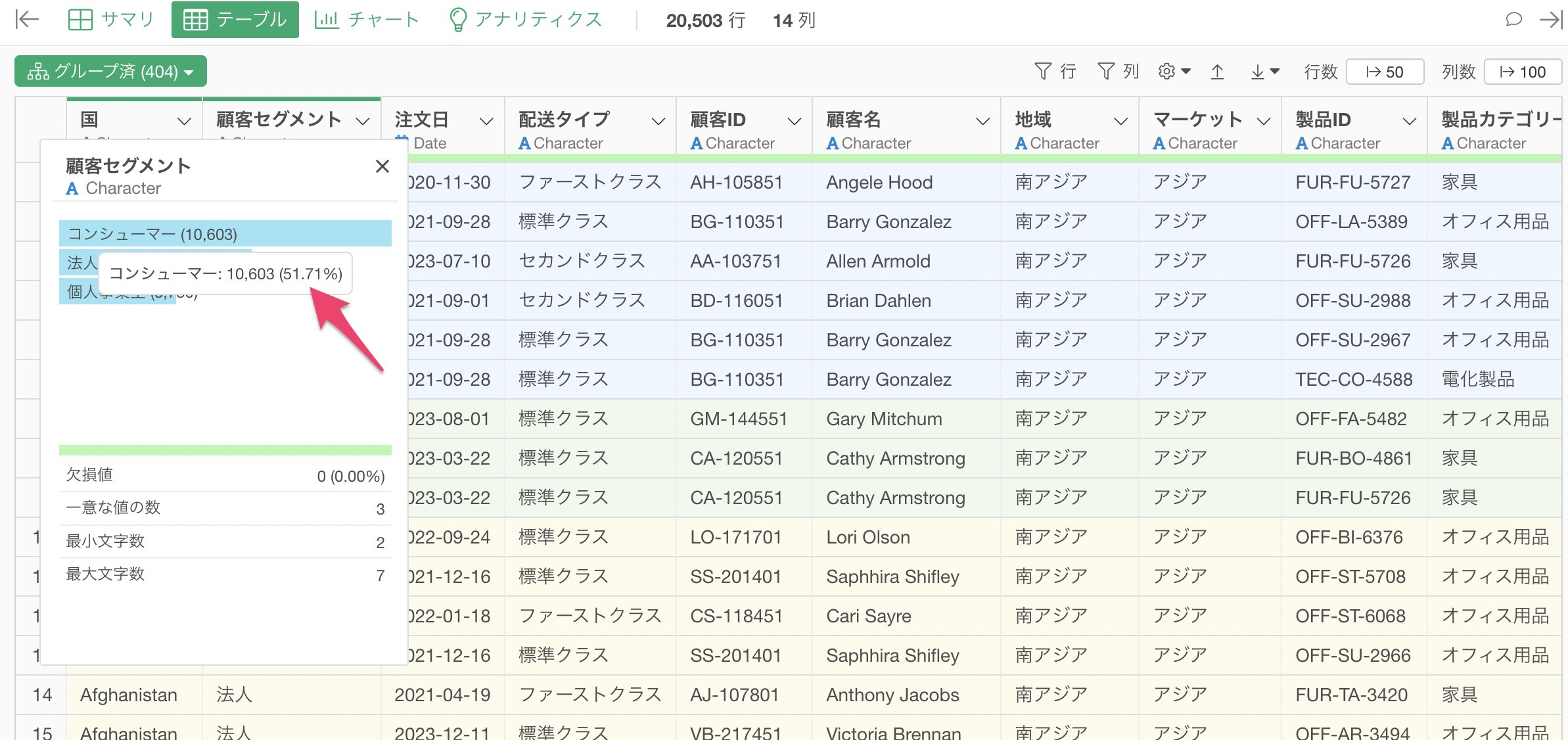
グループ化の解除
サンプリング完了後、「グループ済」と表示されているボタンから「グループの解除」を選択します。
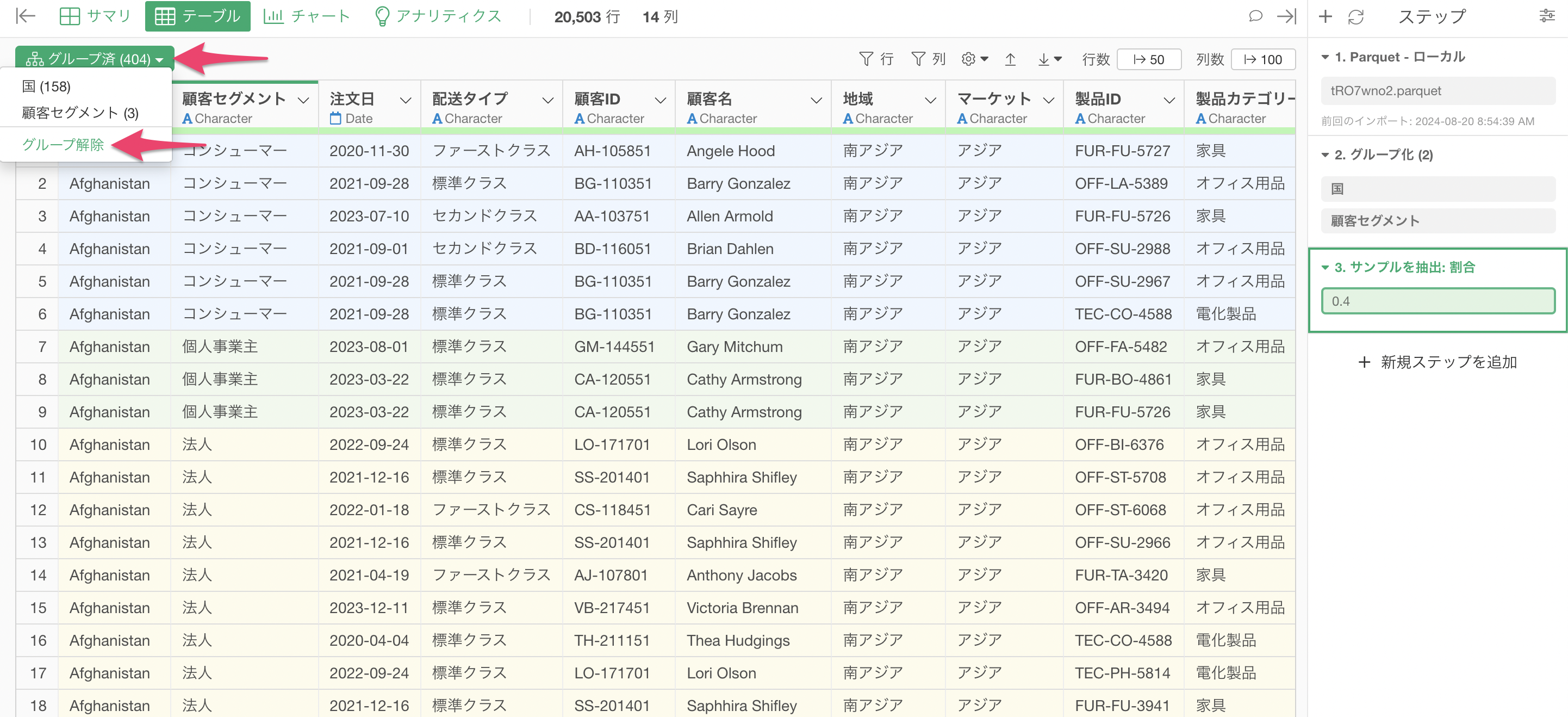
これにより、後続の処理が通常通り実行できるようになります。
ビデオ
参考情報
- セミナー #96 - サイズの大きいデータを扱うときのベストプラクティス - リンク