Exploratory アワー #528 - アンケートデータ: 全ての質問の答えが同じ人を除去する方法
アンケートデータの全ての質問に対して同じ回答をしている場合、適当に回答した可能性が高いため、データの質を向上させるためにそれらの回答者除外することが推奨されます。
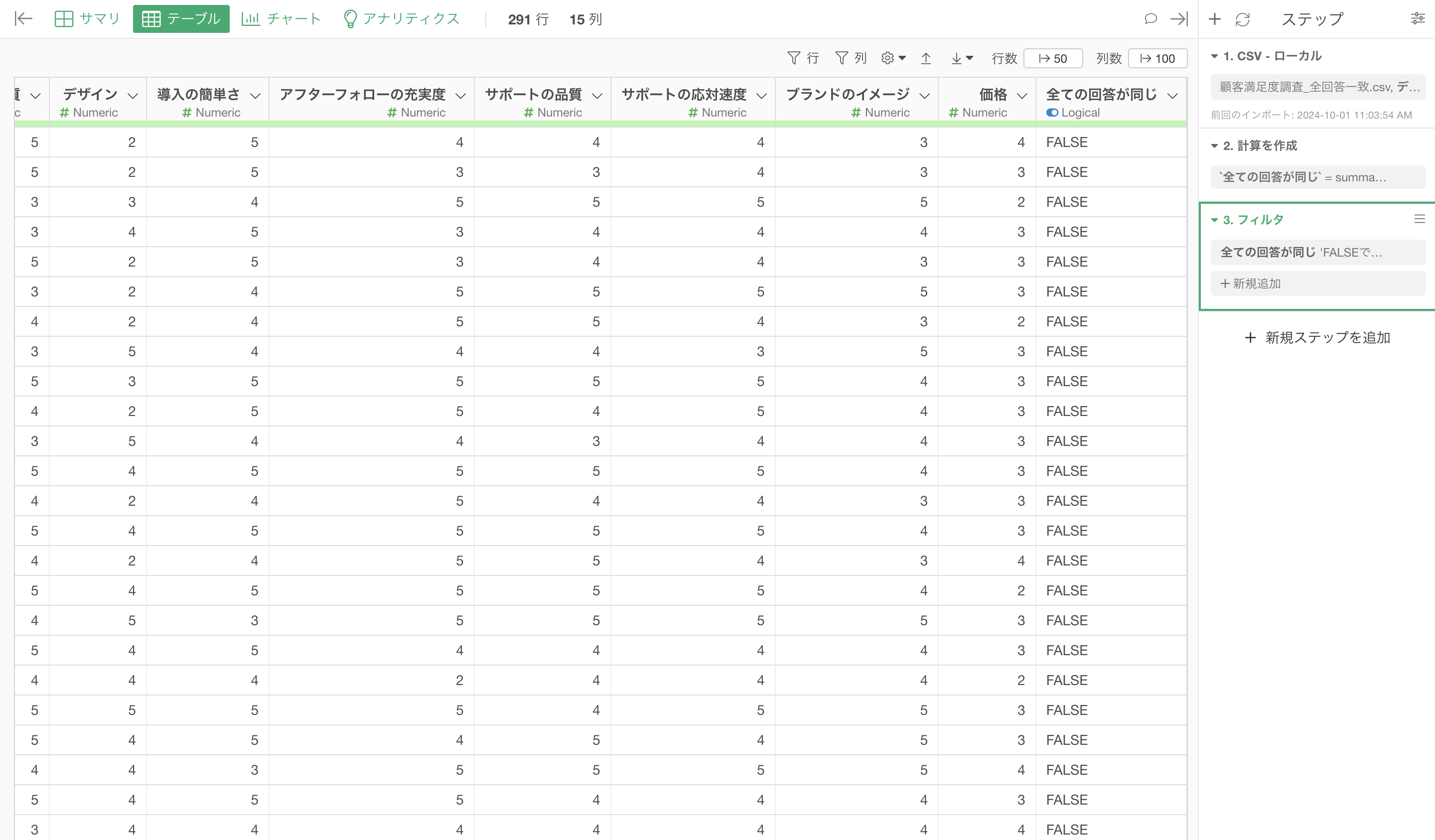
そこで今回はsummarize_row関数を使用して全ての回答が同じかどうかを識別し、フィルタを使ってその回答者を除外する手順を紹介していきます。
問題
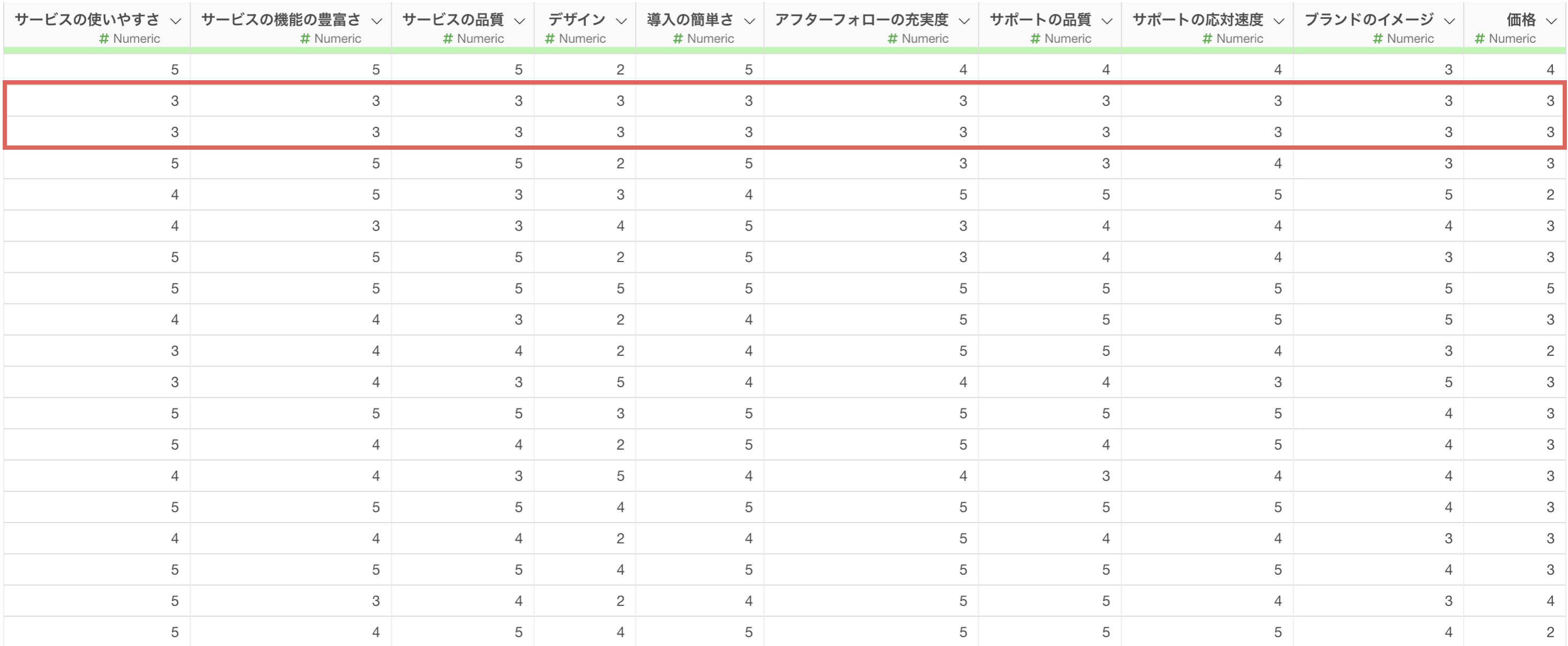
アンケートの全ての質問に対して、同じスコアを回答した人がいる場合、そのデータは信頼性に欠け、分析結果に悪影響を及ぼす可能性がある。
解決方法
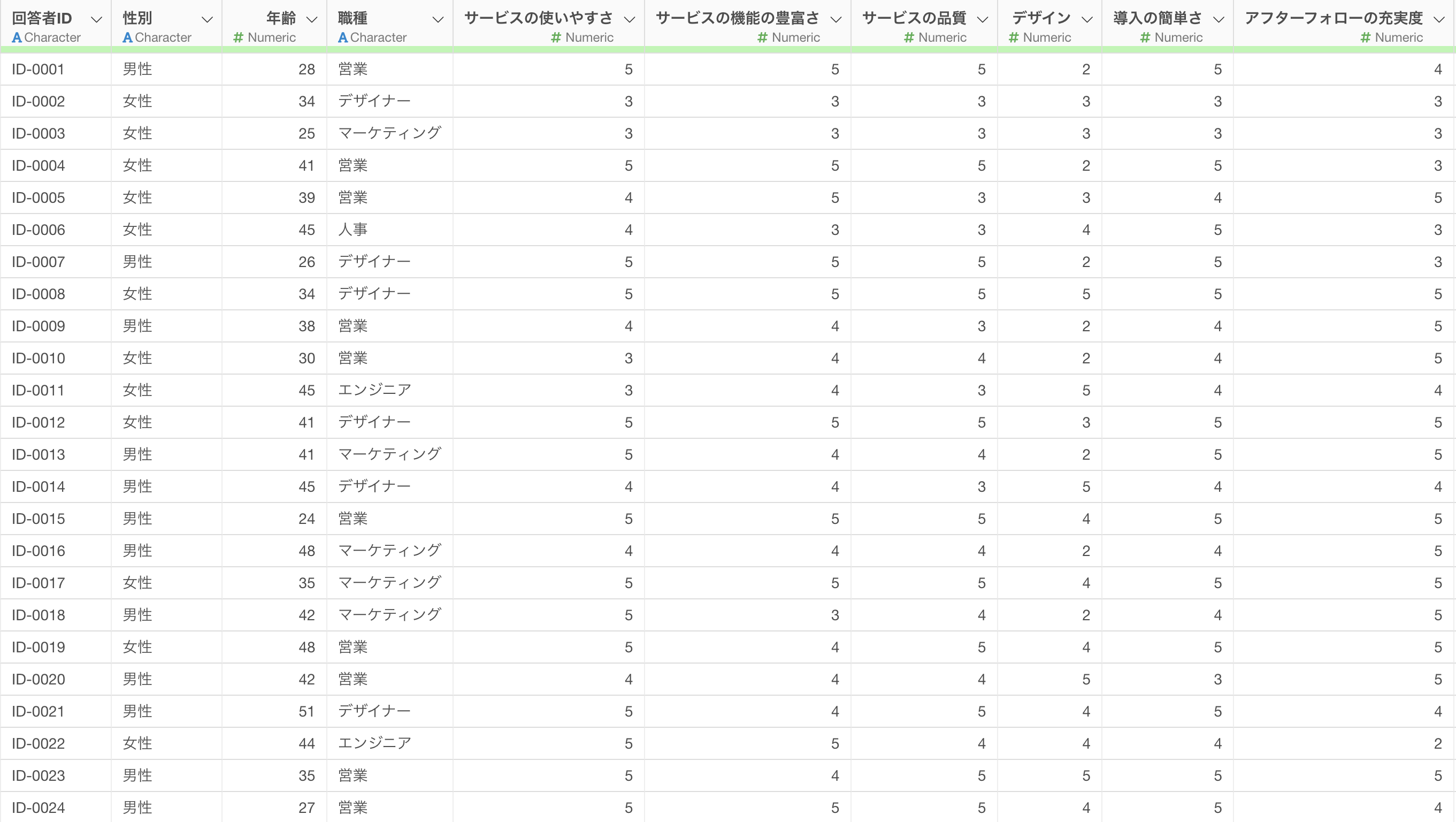
今回使用するアンケートデータは、1行が1回答者で各列にアンケートの質問が並んでいます。
まず、全ての質問に対する回答が同じ値であるかどうかを判定するフラグを作成します。
そこで、summarize_row関数を使用することで、全ての回答が同じかどうかを判別したフラグ列を作ることができます。
列ヘッダメニューから「計算を作成」の「標準」を選択します。
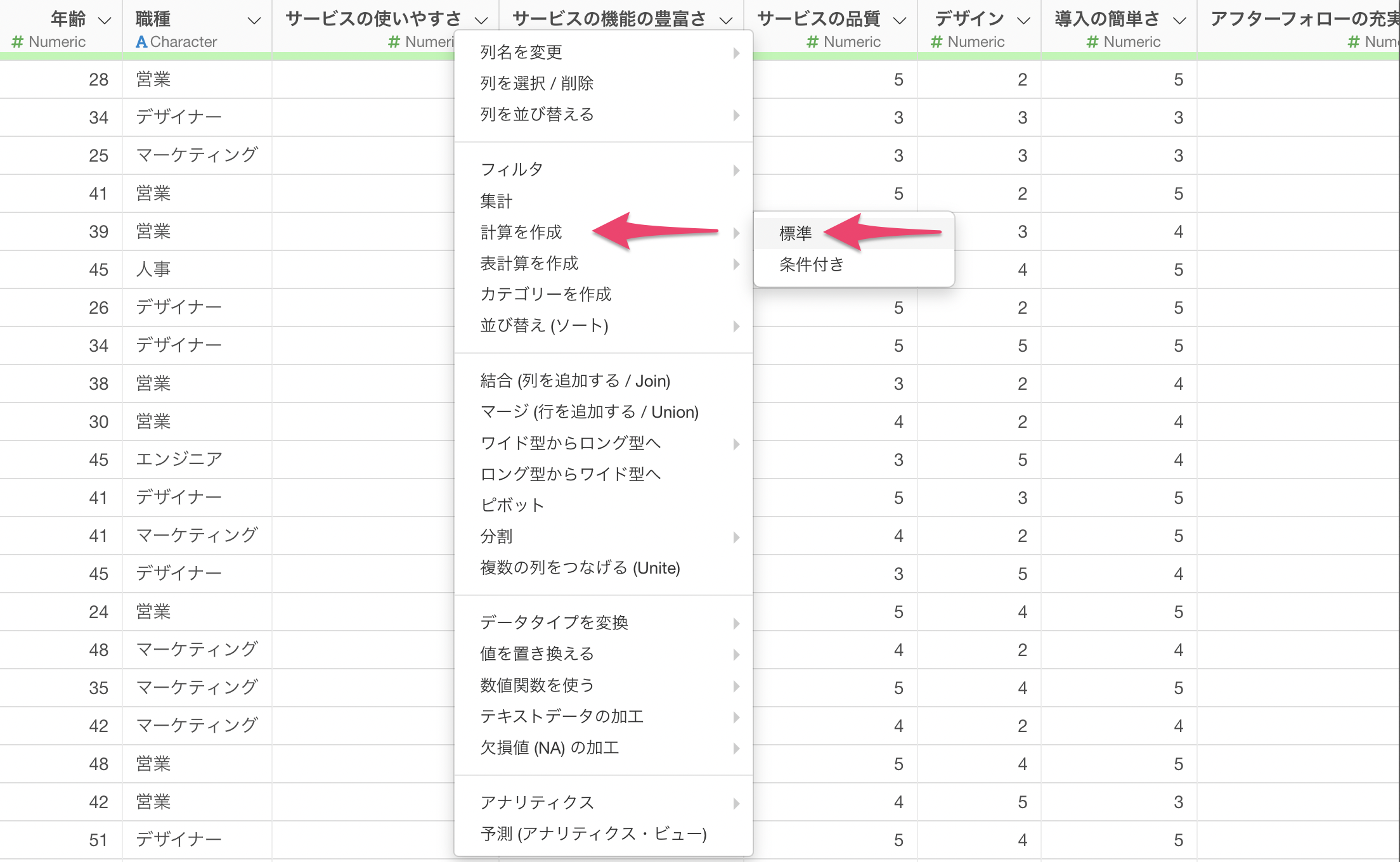
計算エディタには以下のように指定します。
summarize_row(across(c(サービスの使いやすさ:価格)) == サービスの使いやすさ, all, na.rm=TRUE)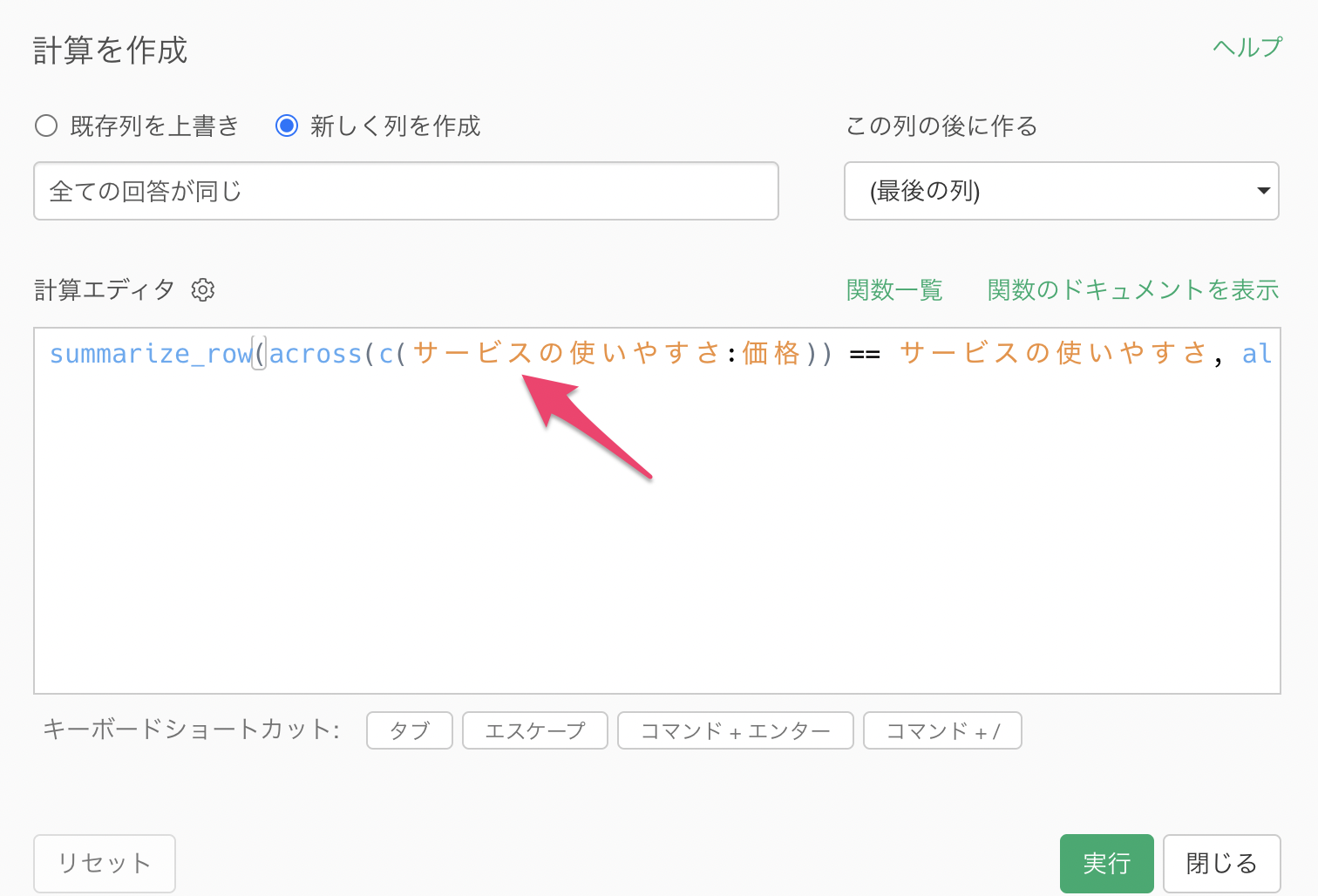
summarize_row関数で使用している引数としては以下となります。
across関数とc関数
個別に列を指定するか、範囲指定を利用して複数列を一括で選択することができますが、cの後の括弧の中にカンマ(,)区切りで書くことで個別の列選択、開始の列名、末尾の列名の間にコロン(:)を使うことで列の範囲指定が可能です。
列指定の後にはサービスの使いやすさといった特定の列との値と他の列の値が一致しているかの条件式を使います。
all
all関数を使用することで、全ての列の値が同じだった時にはTRUEを、1つでも値が異なるものがあればFALSEを返すようにフラグを立てることができます。
na.rm
欠損値(NA)が存在する場合、na.rm = TRUE を設定うることで、欠損値を除外して計算をすることができます。
これによって、すべての回答が同じかどうかを識別する列を作成することができます。
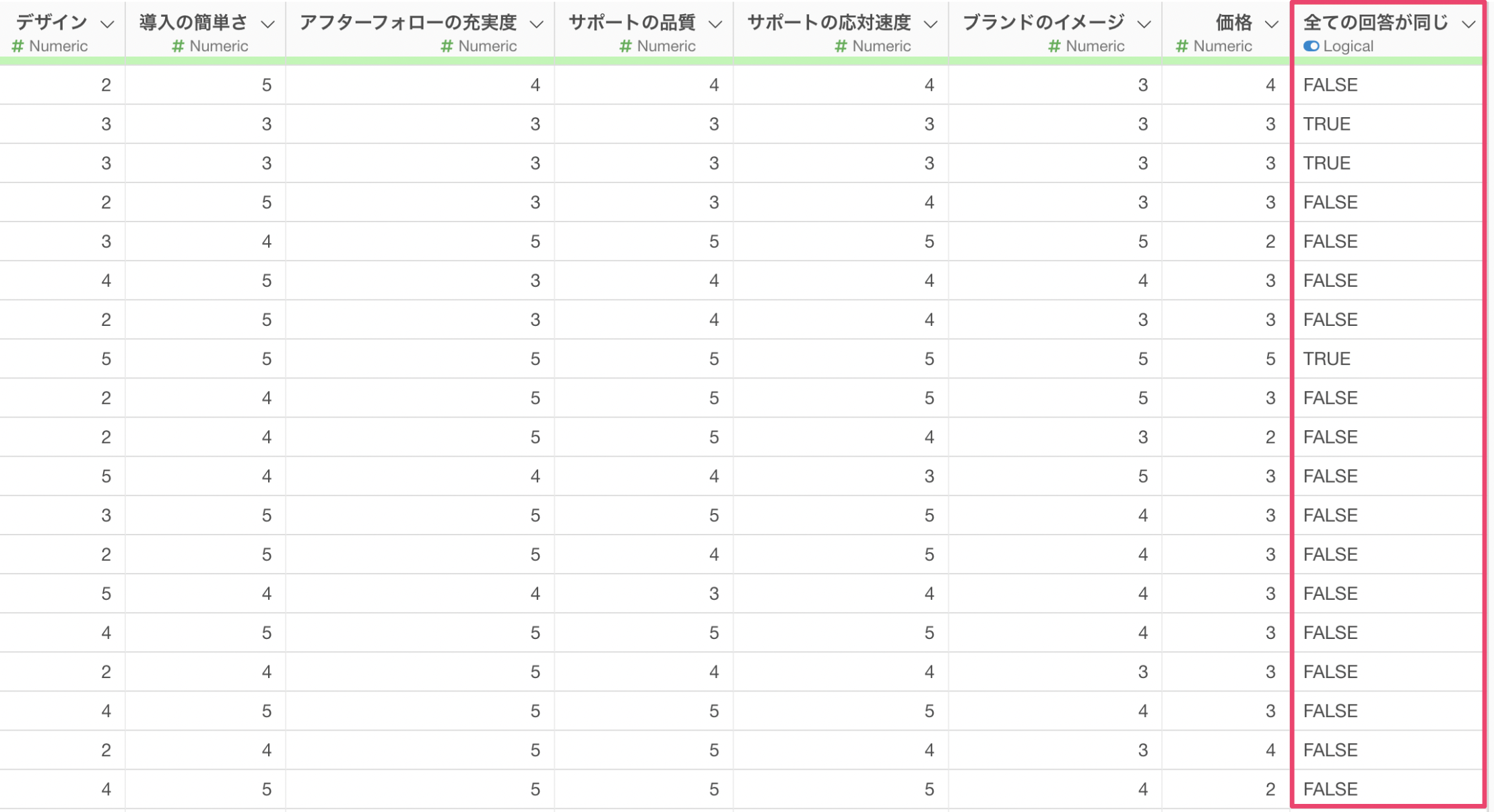
あとは、作成したフラグ列からTRUE となっている行(すべての回答が同じ人)を除去するために、フィルタの機能を使います。
全ての回答が同じの列ヘッダメニューから「フィルタ」を選び、「FALSE」であるを選択して実行します。
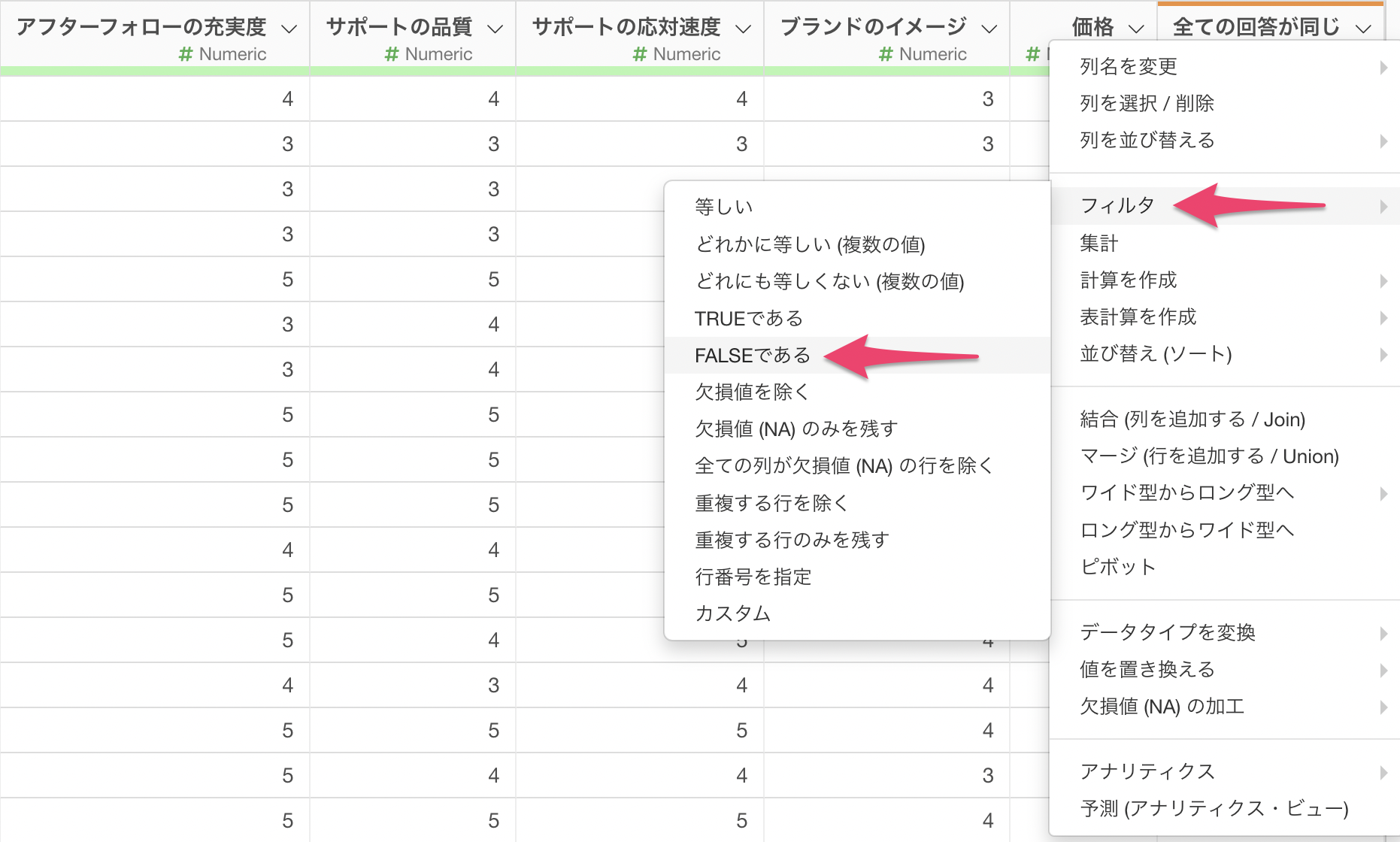
これによって、全ての質問に対して同じ回答をした人を取り除くことができました。