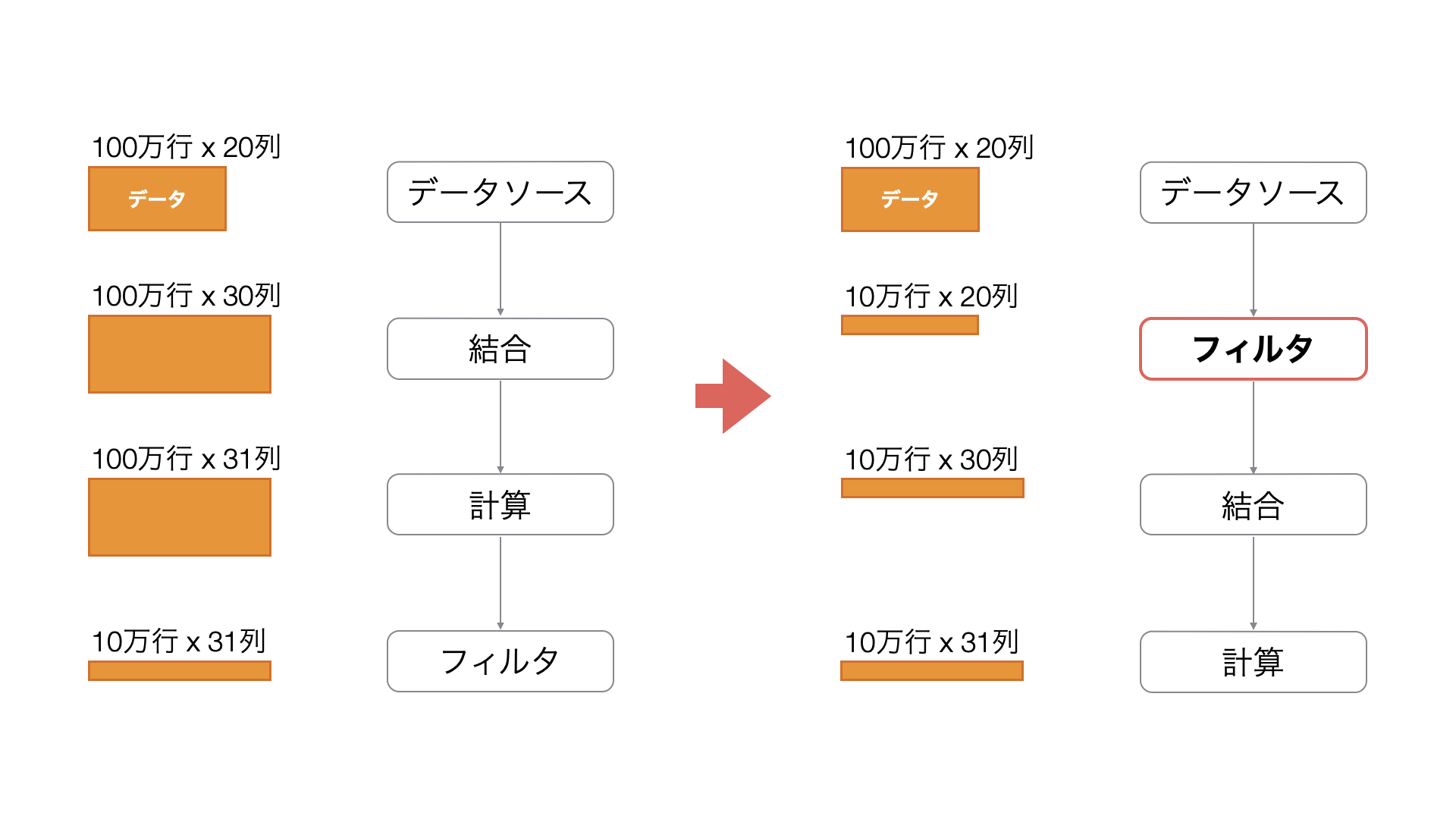
パフォーマンスチューニング: フィルタの改善
データ加工のパフォーマンスを向上させる上で、特に行数の多いデータを扱う際には、データ処理の順序が重要になります。特にフィルター処理を適切なタイミングで実行することで、不要なデータ処理を削減し、処理速度を大幅に改善することが可能です。
問題
大規模データの処理において、フィルター処理を後の工程で実行すると、不要なデータに対しても結合や計算などの処理が実行されてしまい、メモリ使用量の増加やパフォーマンスの低下を引き起こします。
例えば、100万行のデータに対して結合や計算を行った後に、結合や計算の影響を受けない条件で、フィルター処理を実行した結果、データの行数が10万行になったとします。
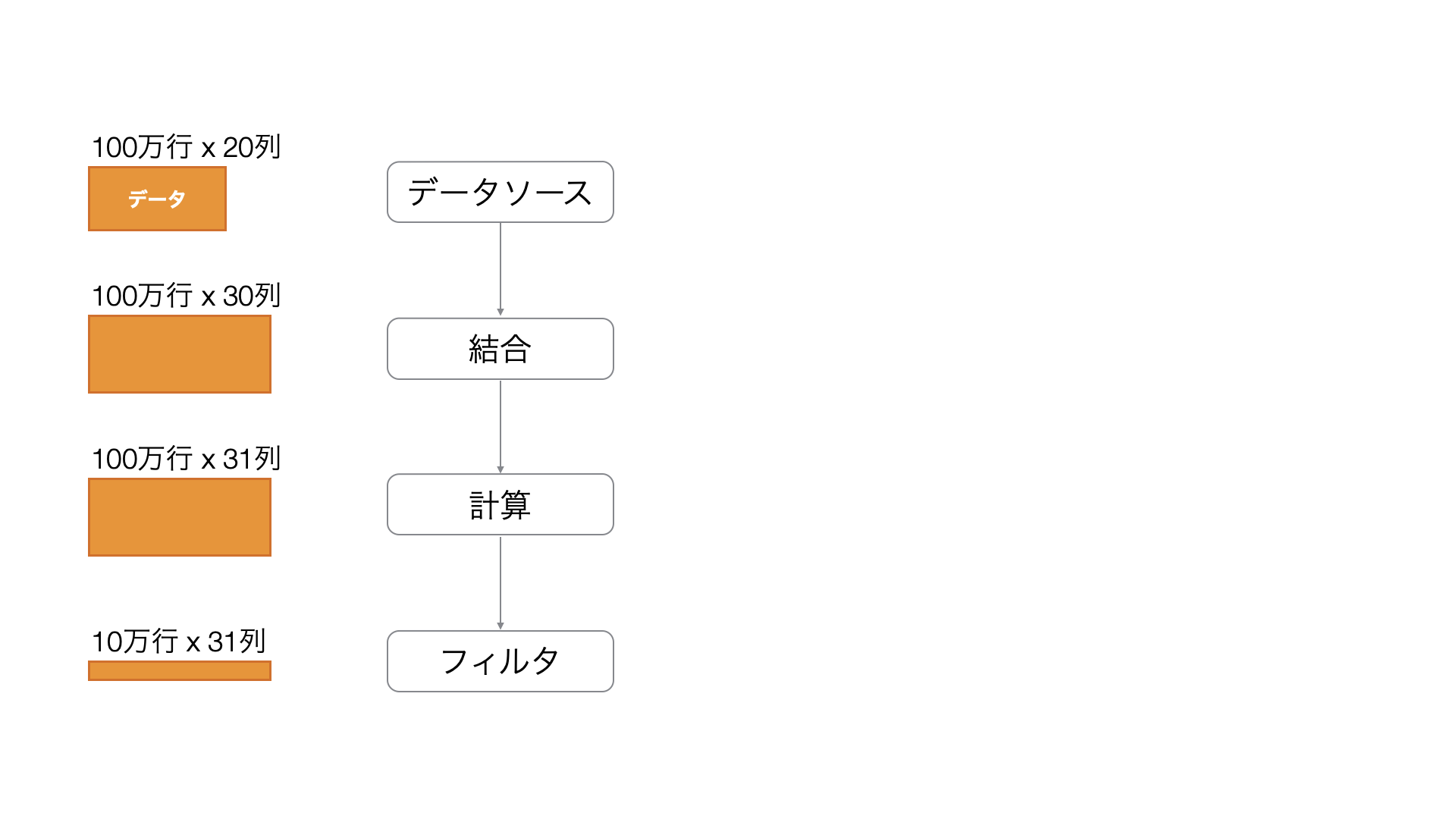
その場合、最終的に不要となる90万行のデータに対しても、無用な処理が実行されることになります。
解決方法
フィルター処理を早い段階で実行することで、後続の処理対象となるデータ量を削減し、パフォーマンスを改善します。特に、グループ化や表計算など、処理負荷の高い操作を行う前にフィルター処理を実行することで、効率的なデータ処理が可能になります。
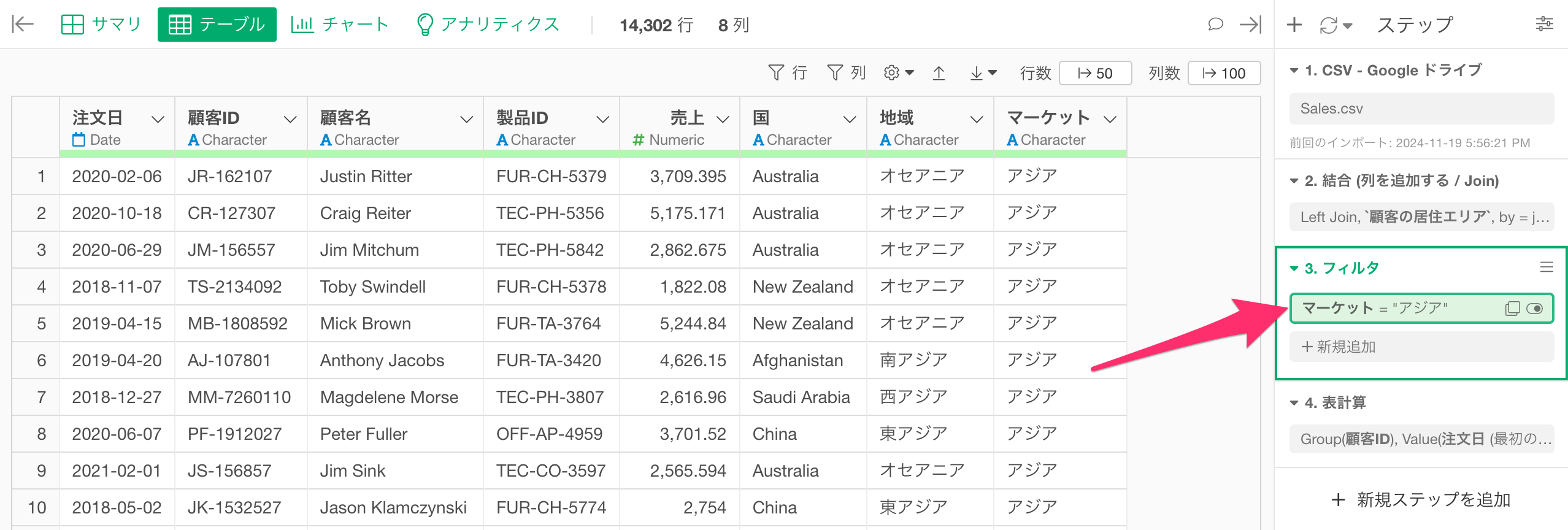
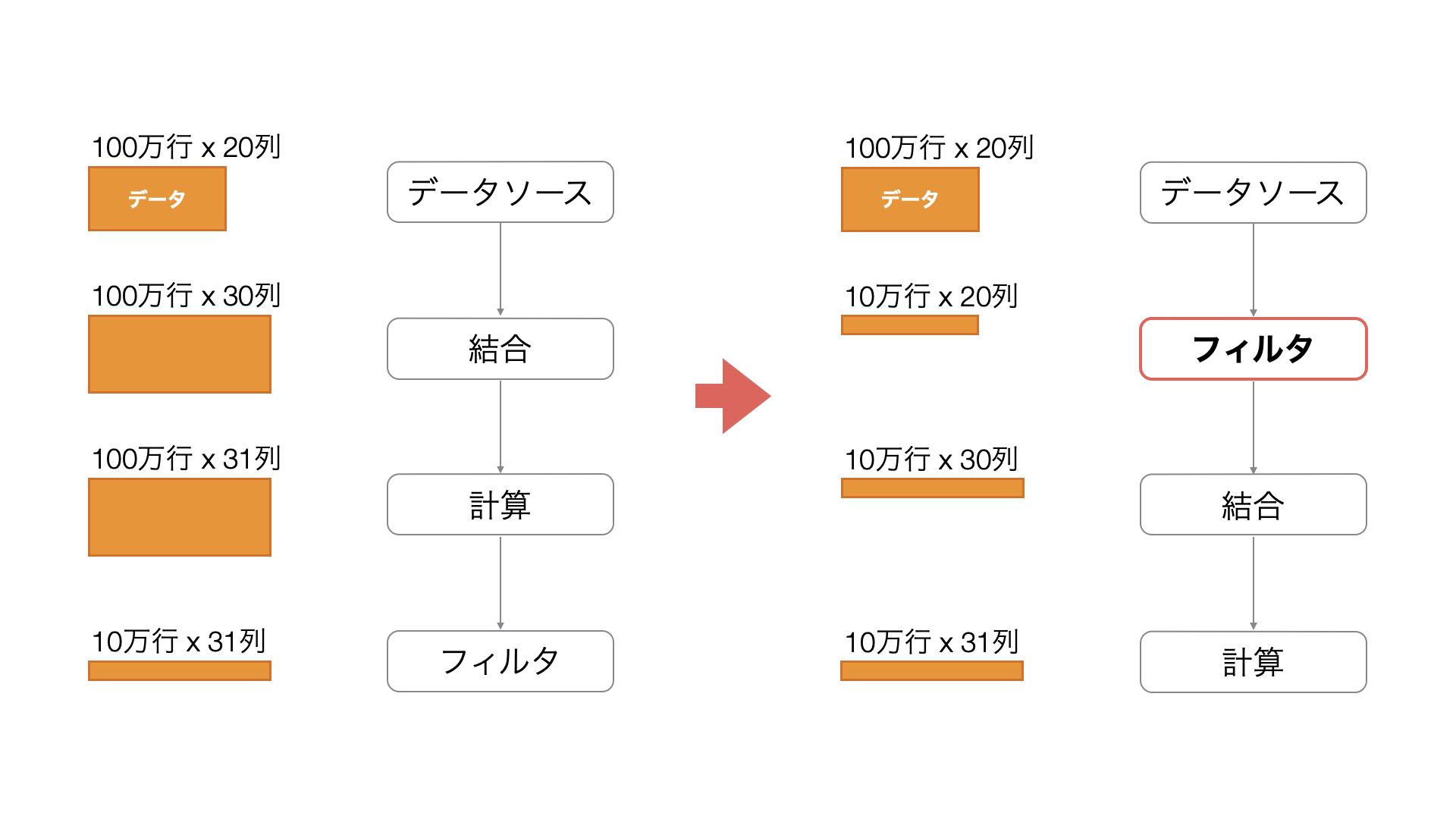 以下のデータフレームでは2番目のステップで結合の処理を行い、3番目のステップで、表計算を行ってします。仮に2番目のステップで結合された列を使って、アジアのデータにフィルタしたい場合、処理が重くなりがちなグループごとの表計算の処理の後ではなく、前にフィルタのステップを追加することで、パフォーマンスを最適化できます。
以下のデータフレームでは2番目のステップで結合の処理を行い、3番目のステップで、表計算を行ってします。仮に2番目のステップで結合された列を使って、アジアのデータにフィルタしたい場合、処理が重くなりがちなグループごとの表計算の処理の後ではなく、前にフィルタのステップを追加することで、パフォーマンスを最適化できます。
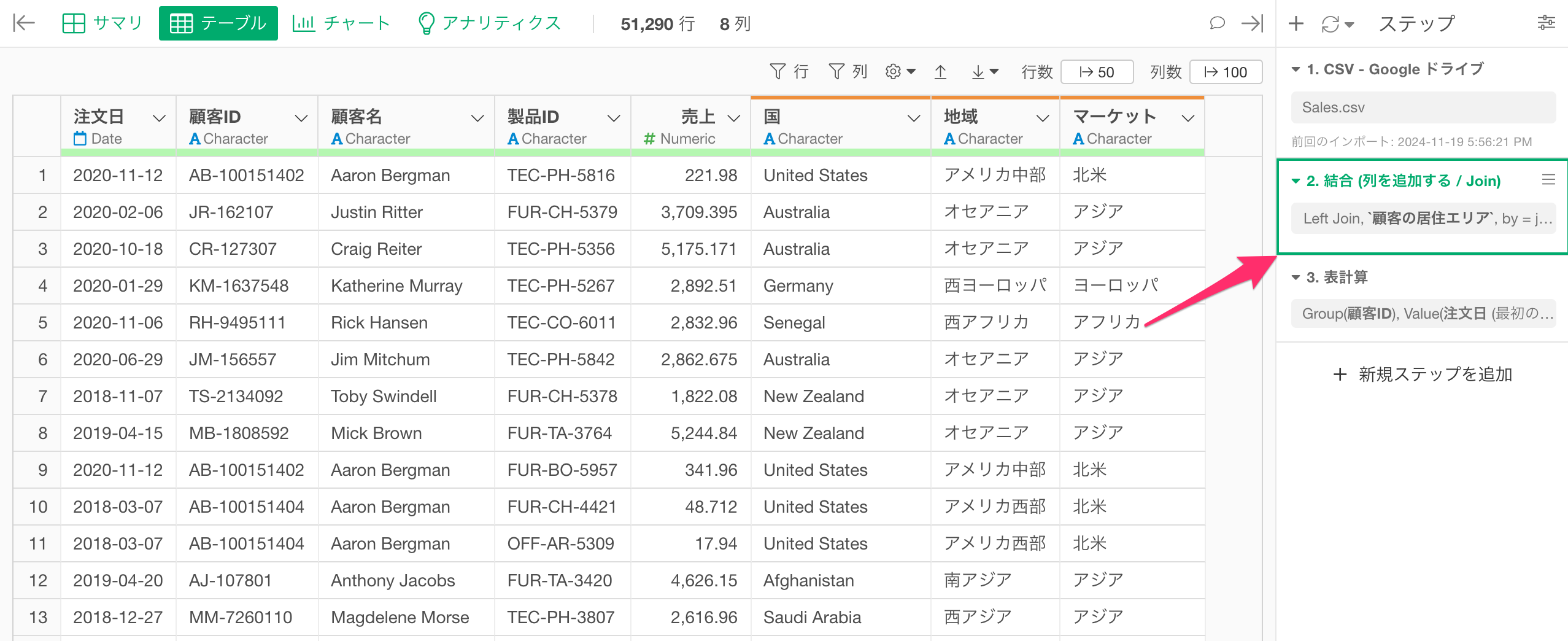
なお、複数のステップの間にステップを追加したい場合、ステップを追加したいステップの直前のステップに移動して、データ加工のメニューを選択することで、該当のステップの直後にステップを追加することが可能です。
ビデオ
参考情報
- パフォーマンスを向上させるためのベストプラクティス - リンク