Exploratory アワー #581 - 正規表現: マッチングした文字列を再利用できる「後方参照」の使い方
正規表現を使用してパターンマッチングを行う際、マッチした文字列を再利用したいケースが頻繁にあります。このような場合に有効なのが後方参照という機能です。
後方参照を使用することで、正規表現でマッチした特定のグループを保持し、それを同じパターン内で再利用したり、置換後の文字列で活用したりすることができます。この機能は、テキストデータの構造を変更する際に特に有用です。
今回は、Exploratoryの正規表現機能における後方参照の使い方について、名前の順序変更を例に説明していきます。
問題
- 正規表現でマッチした文字列の一部を保持し、別の場所で再利用する必要がある
- パターンマッチングした文字列の順序を入れ替えたい
- 複数のグループにマッチした文字列を、特定の順序で組み合わせて新しい文字列を生成する必要がある
解決方法
例えば、「Hello World」というテキストを「World Hello」に変換する場合を考えてみましょう。
正規表現「([^ ]+) ([^ ]+)」を使うと、ハイフンの前後の文字列をそれぞれグループとして捉えることができます。そして、後方参照「\2 \1」を使用することで、捉えたグループを逆順に組み替えて、「World Hello」にすることができます。
ちなみに、([^ ]+)について解説をすると、以下のような構成要素となっており、これを使うことでスペース以外の任意の文字列が連続するグループとなっています。
- ( ) - グループを作成
- [^ ] - スペース以外の任意の1文字にマッチ
- + - 直前のパターンの1回以上の繰り返しにマッチ
では、これを使って顧客のデータで試してみましょう。
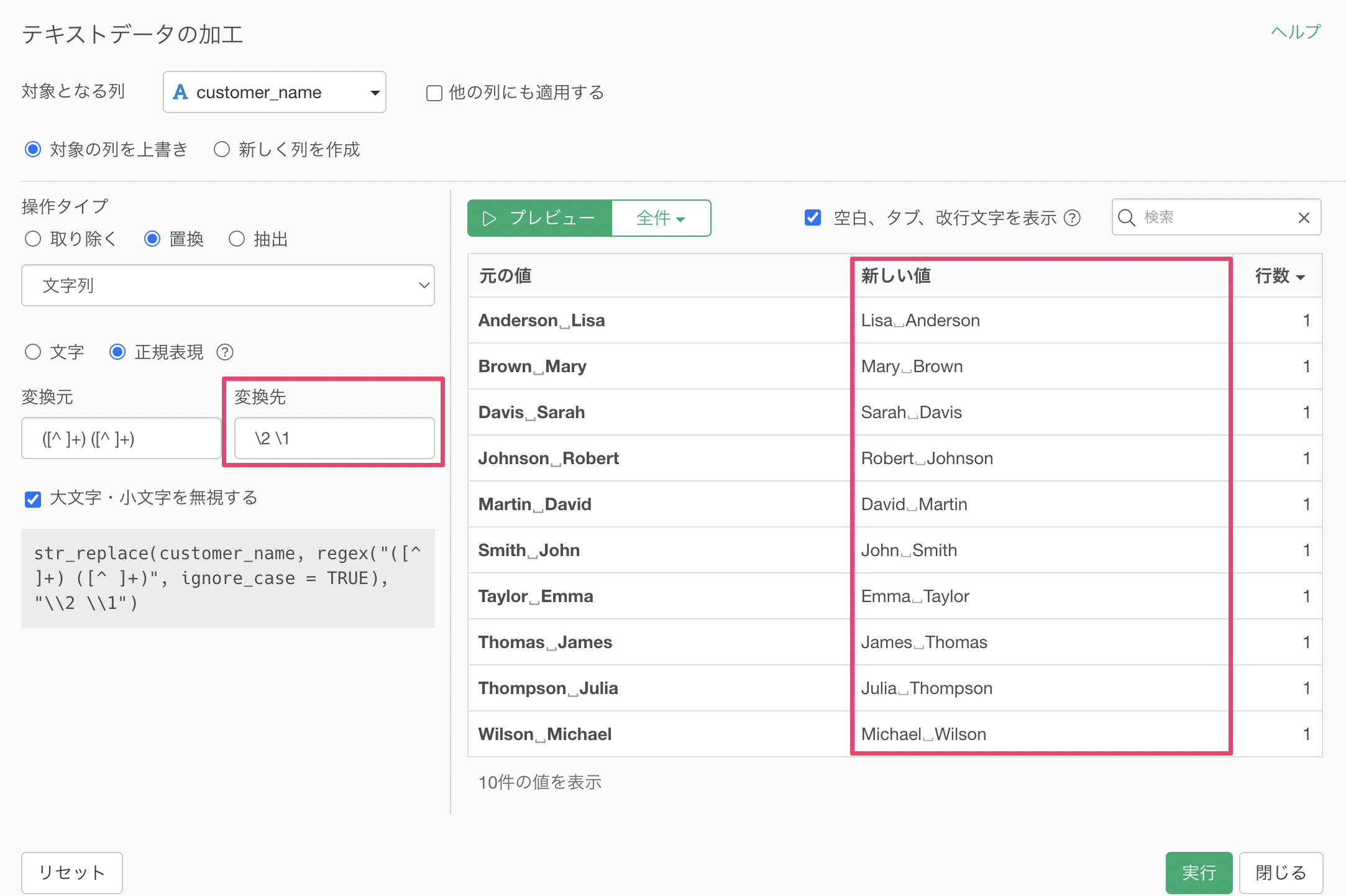
例えば、以下のような顧客名のデータがあったときに、「Last Name, First Name」の形式になっているため「First Name, Last Name」の形式に変換をしたいとします。

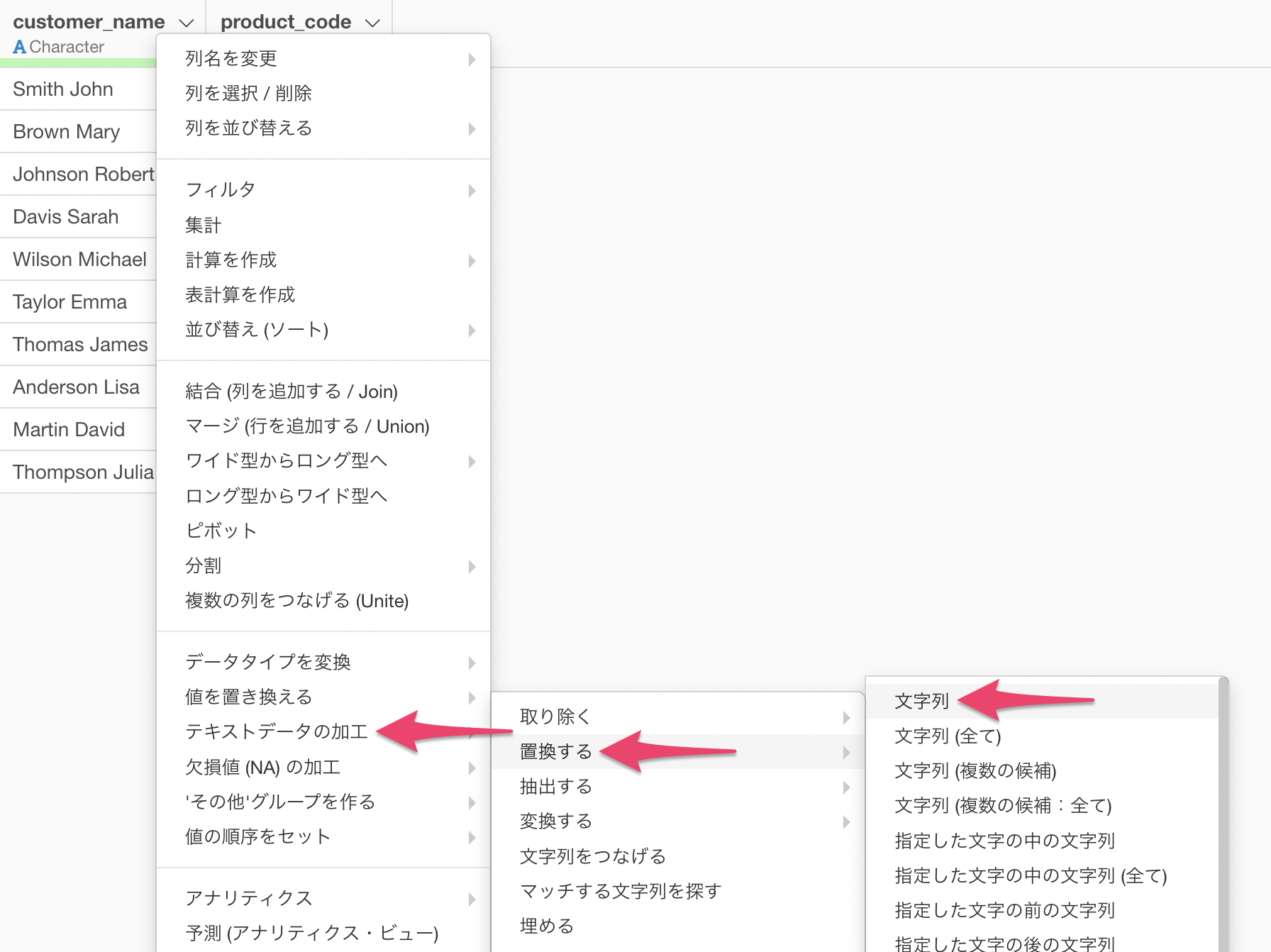
customer_nameの列ヘッダメニューから「テキストデータの加工」の「置換する」の「文字列」を選択します。
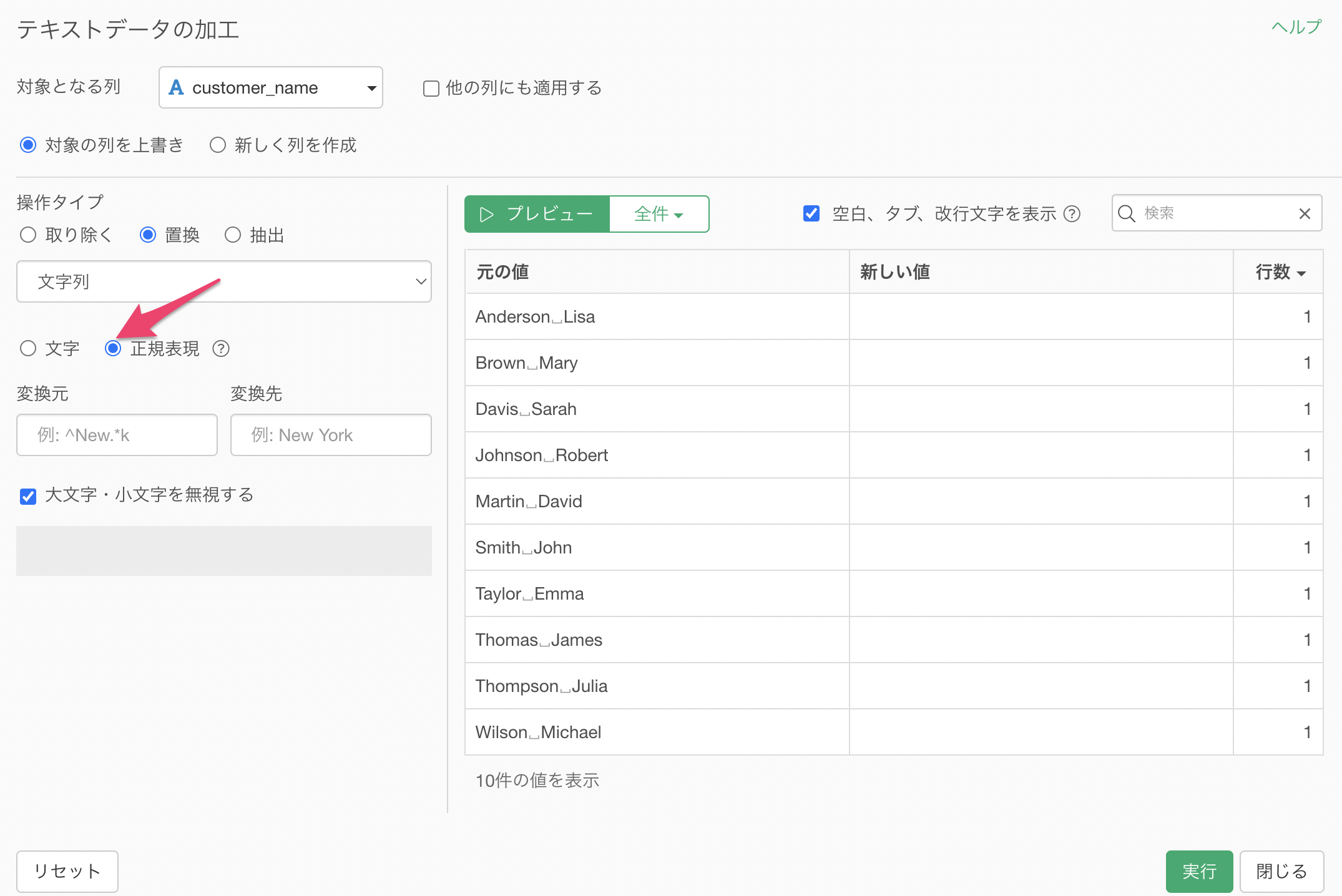
テキストデータの加工のダイアログが表示されるため、「正規表現」にチェックをつけます。
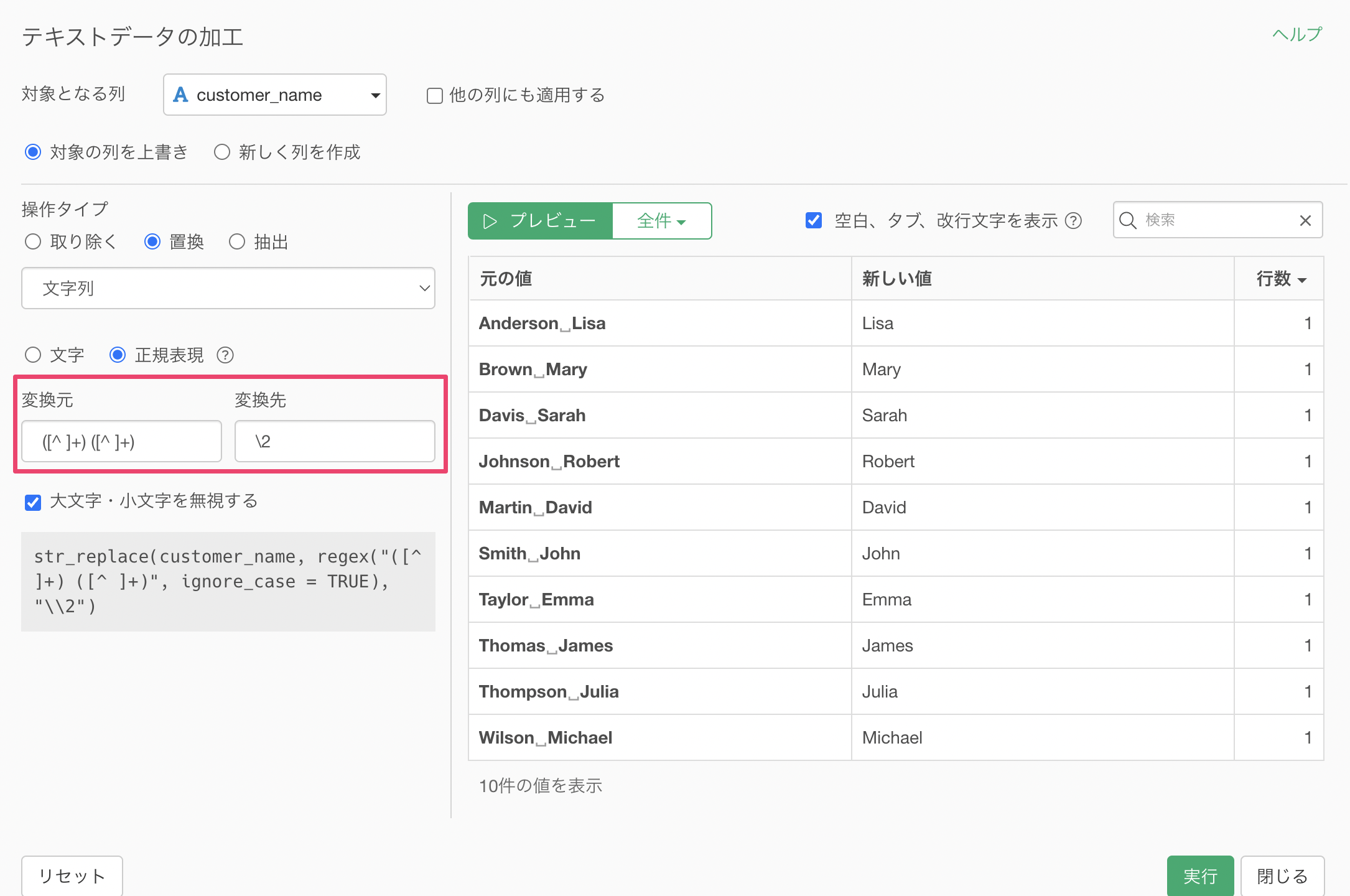
変換元に「([^ ]+) ([^ ]+)」を指定し、変換先に「\2」を指定してみます。これによって「Last Name, First Name」といったグループの順番のうち2番目の「First Name」を取り出すことができています。
変換先に「\2 \1」を指定することで、「First Name, Last Name」の順番に入れ替えることができていることがわかります。
実行することで「Last Name, First Name」の形式になっているデータを「First Name, Last Name」の形式に変換することができました。
ビデオ
参考情報
- Exploratoryでの正規表現の使い方 - リンク