テキストをハッシュ化(匿名化)したい
個人情報を含むデータを扱う際、プライバシー保護のために特定の個人を識別できないよう形式にテキストを変換する必要があり場合があります。
Exploratoryでは、匿名化機能を使用することで、顧客名などの個人情報を識別不可能な文字列に変換しながら、同一人物のデータに対しては常に同じ変換結果を得ることができます。
役立つ人
個人情報を含むデータを分析する方、データを第三者と共有する必要がある方、プライバシー保護が必要なデータを扱う方にお役立ていただける機能です。
問題
顧客名などの個人情報を含むデータを分析や共有する際、個人を特定できないようにデータを加工する必要があります。しかし、該当列の情報削除してしまうと同一人物のデータを追跡できなくなってしまい、分析に支障をきたします。個人を特定できない形式でありながら、同じ人物には常に同じ値が割り当てられる仕組みが必要です。
解決方法
ハッシュ化・匿名化について
個人情報を扱う際、データを見る時や他の人に渡す時に、特定の個人を識別できないような形で文字列を変換したいケースがよくあります。
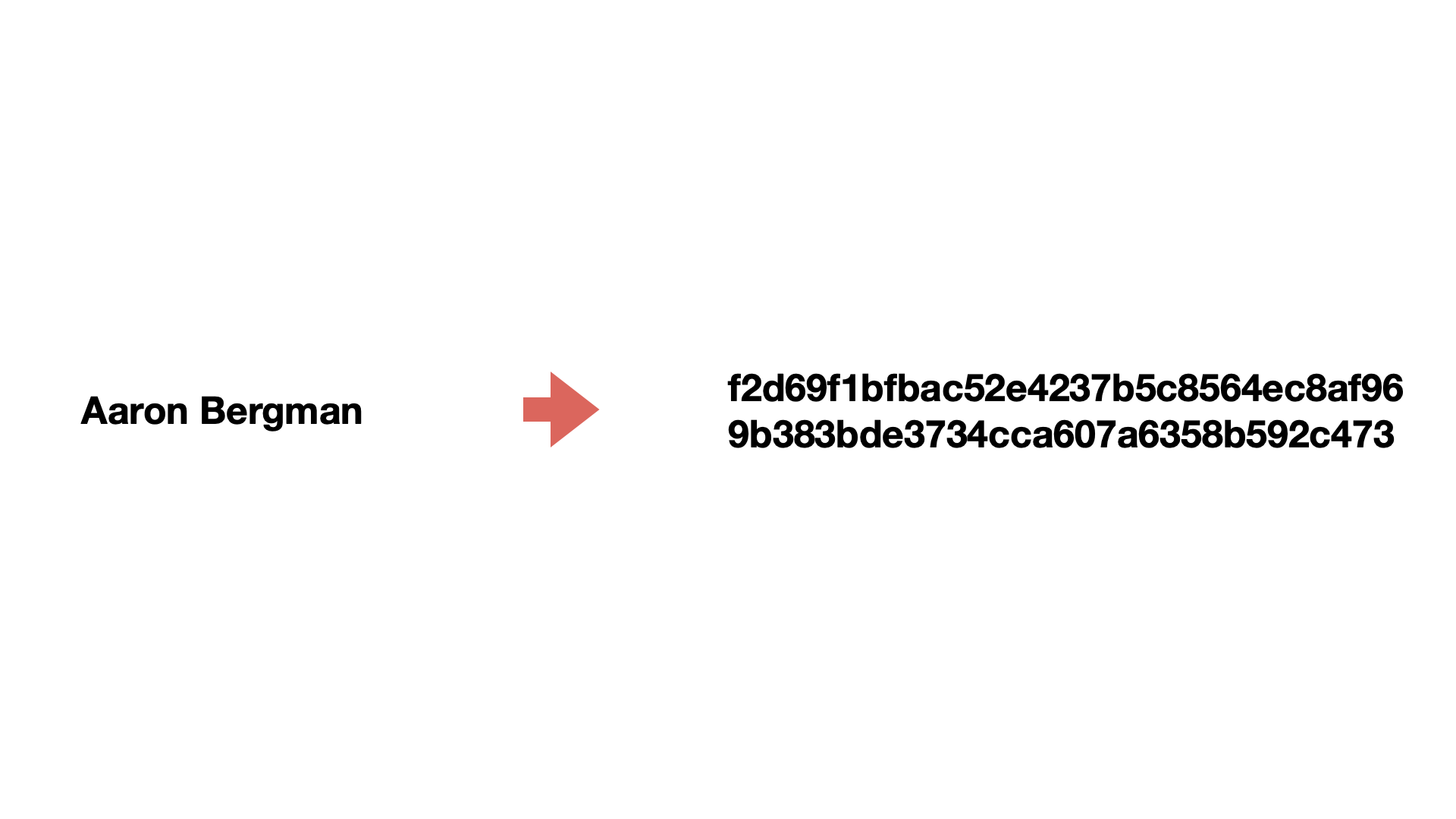
例えば、「Aaron Bergman」という顧客名がある場合、この名前は個人情報に該当するため、Aaron Bergmanという人だと特定できないような文字列に変換する必要があります。

このような処理のことを「ハッシュ化」や「匿名化」と呼びます。
ハッシュ化・匿名化のメリットは、Aaron Bergmanは常に同じ文字列に変換されるという点です。誰なのかは認識できないけれども、同じ値があった時には同じ匿名化された結果が返ってくるため、文字列自体に意味はないものの、一意なデータとして扱いたい時に非常に便利です。
Exploratoryのテキストデータの加工における匿名化機能では、SHA-256というアルゴリズムを使用して匿名化の実施が可能です。
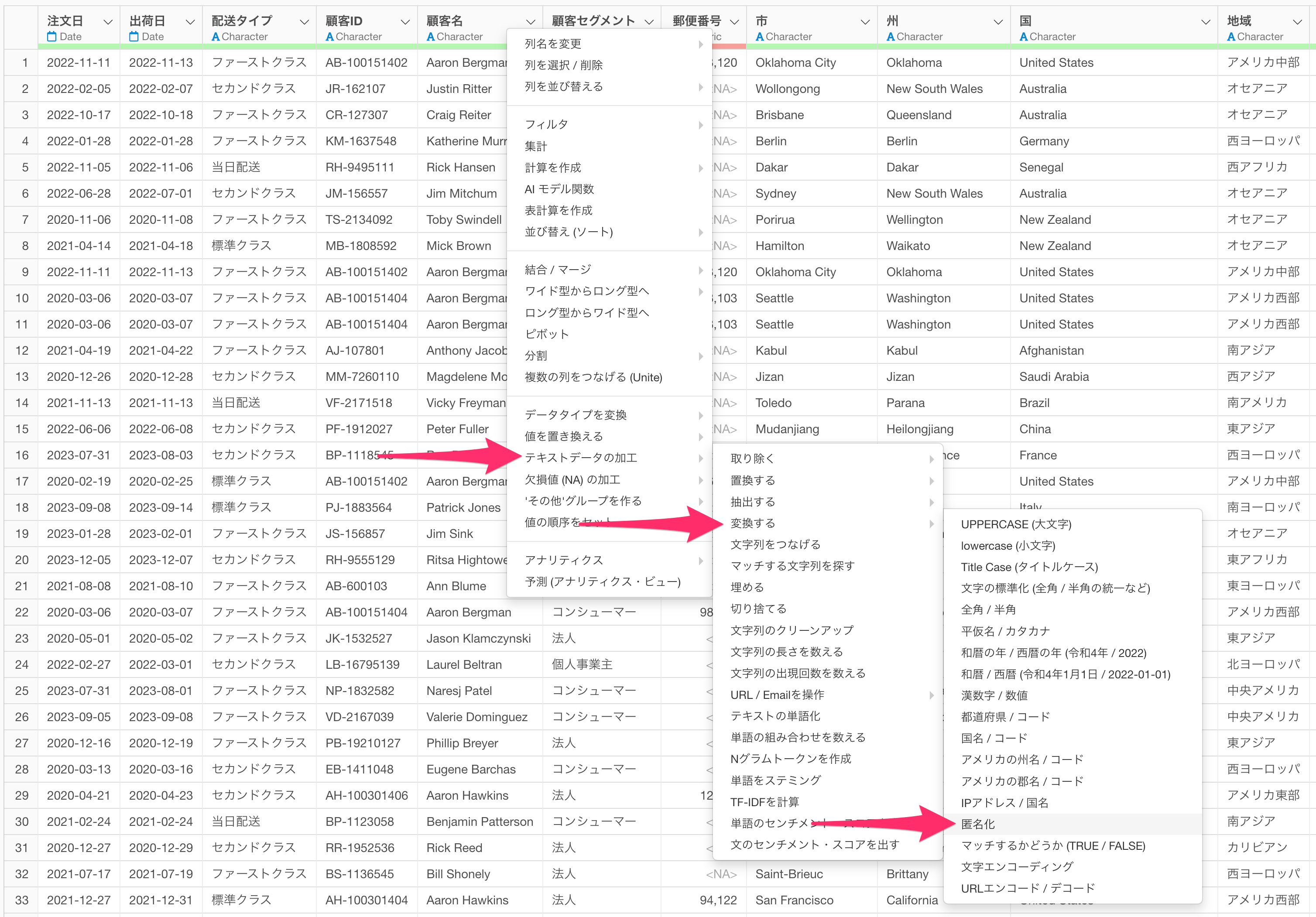
なお、同じ文字列に対しては常に同じ匿名化結果が返されますが、さらにセキュリティを高めるために、「キー」や「ソルト」と呼ばれる任意の文字列を組み合わせることで、一意な文字列を特定できないようにし、異なる結果を生成することができます。
上記の処理はExploratoryがデフォルトでインストールしているopensslパッケージに以下のような関数によってサポートされています。
- sha1
- sha224
- sha256
- sha384
- sha512
- keccak
- sha2
- sha3
- md4
- md5
- blake2b
- blake2s
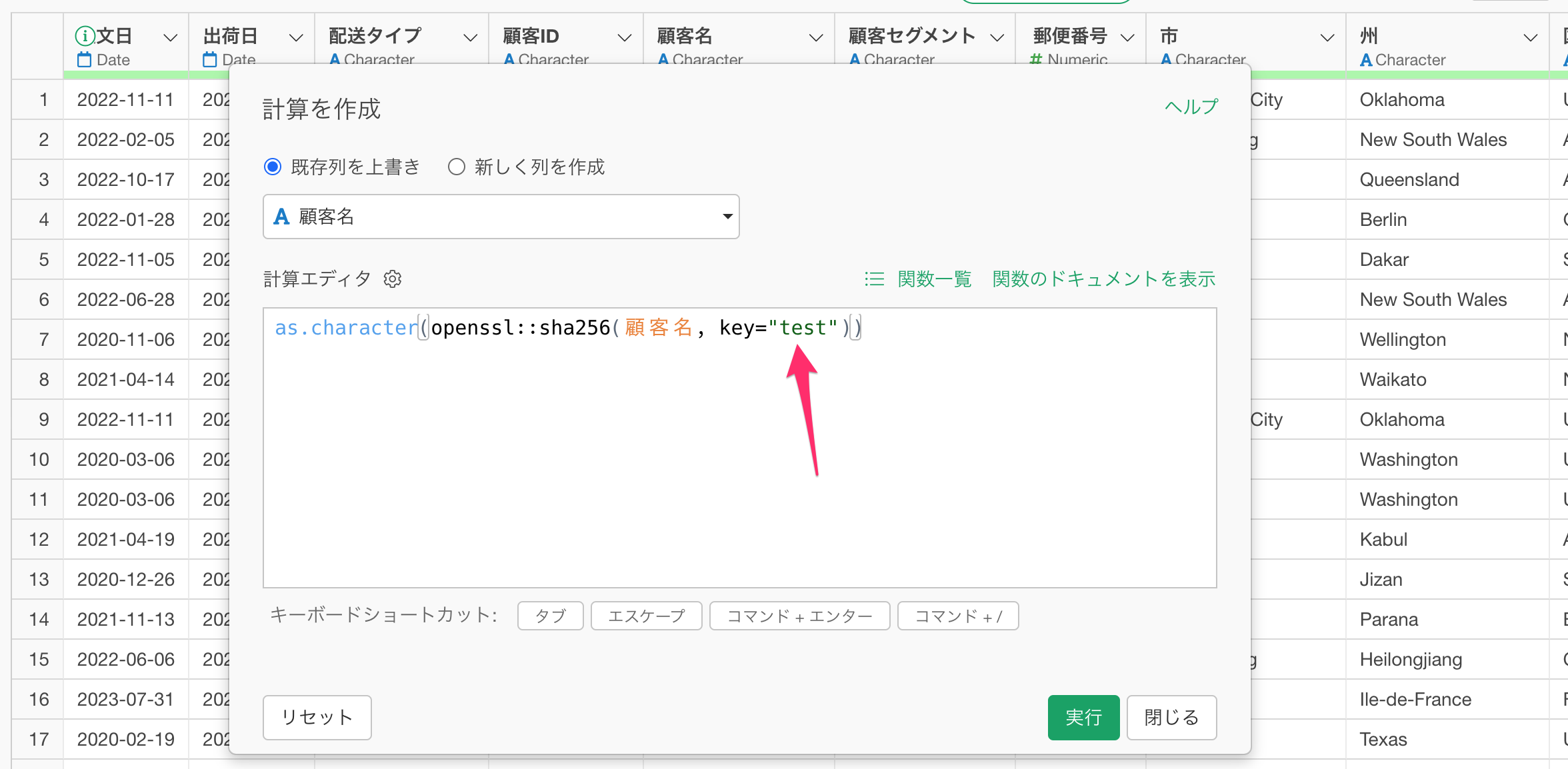
例えば、sha256を使って、顧客名の列を”test”というキーを使ってハッシュ化したい場合、計算を作成のダイアログの中で、as.character(openssl::sha256(顧客名, key="test"))と記述することで対応が可能です。
ノート形式で詳しいやり方を知りたい方はこちらのノートをご参考ください。
ビデオ
参考情報
- 数値または文字列をハッシュ化(匿名化)する方法 - リンク