Exploratory アワー #734 - AI 関数: 文章をいくつかのグループに分類する
ExploratoryのAI関数を活用することで、アンケートの自由回答のようなテキストデータを効率的にグループ分けし、分析の質を向上させることができます。特に、文脈を理解した上でテキストを分類できるため、従来のトピックモデルでは難しかった精度の高い分析が期待できます。
問題
アンケートの自由回答データは、回答者によって表現が多様であるため、そのままでは傾向を把握することが困難です。従来のテキスト分析手法であるトピックモデルでは、文脈を十分に理解できず、同じ意味合いの文章が異なるグループに分類されてしまうなど、分析結果の精度に課題がありました。
解決方法
AI関数を用いた文章のグループ分け
まず、ExploratoryのAI関数を使用して、アンケートの自由回答を文脈に基づいてグループ分けします。
今回使用するデータは、1行が1回答者に対応し、各列にアンケートの質問が並んでいます。特に「推奨度の理由」という自由回答の列に注目します。

この「推奨度の理由」列のヘッダーメニューから「AI 関数を作成」を選択します。

プロンプトには以下のように指定して実行します。
提供された文章に対して適切なラベルをつけて文章をグループ分けしてください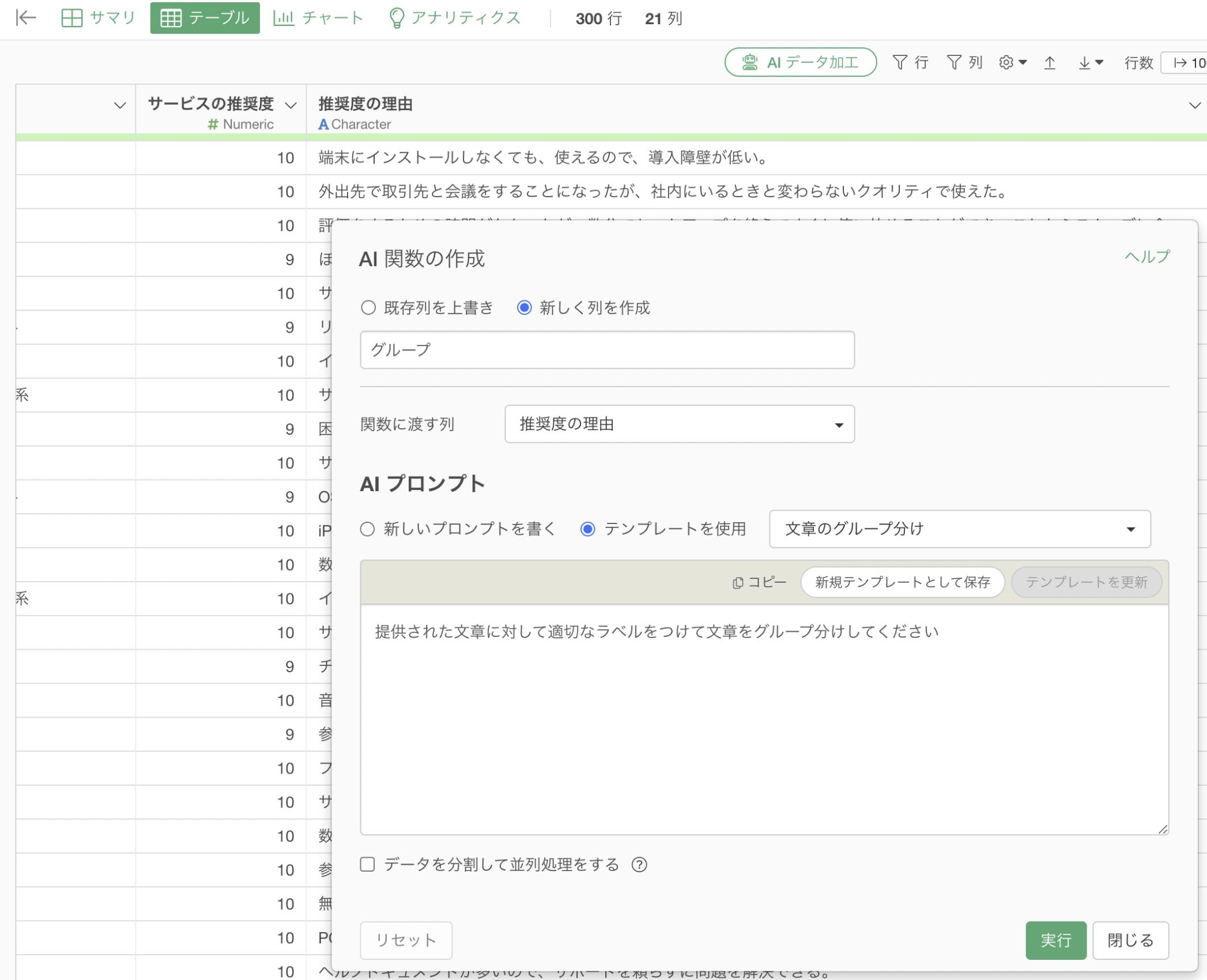
事前にラベルを定義せずにAIに対してグループを自由に作成してもらう時には、「データを分割して並列処理をする」のチェックは外して実行してください。
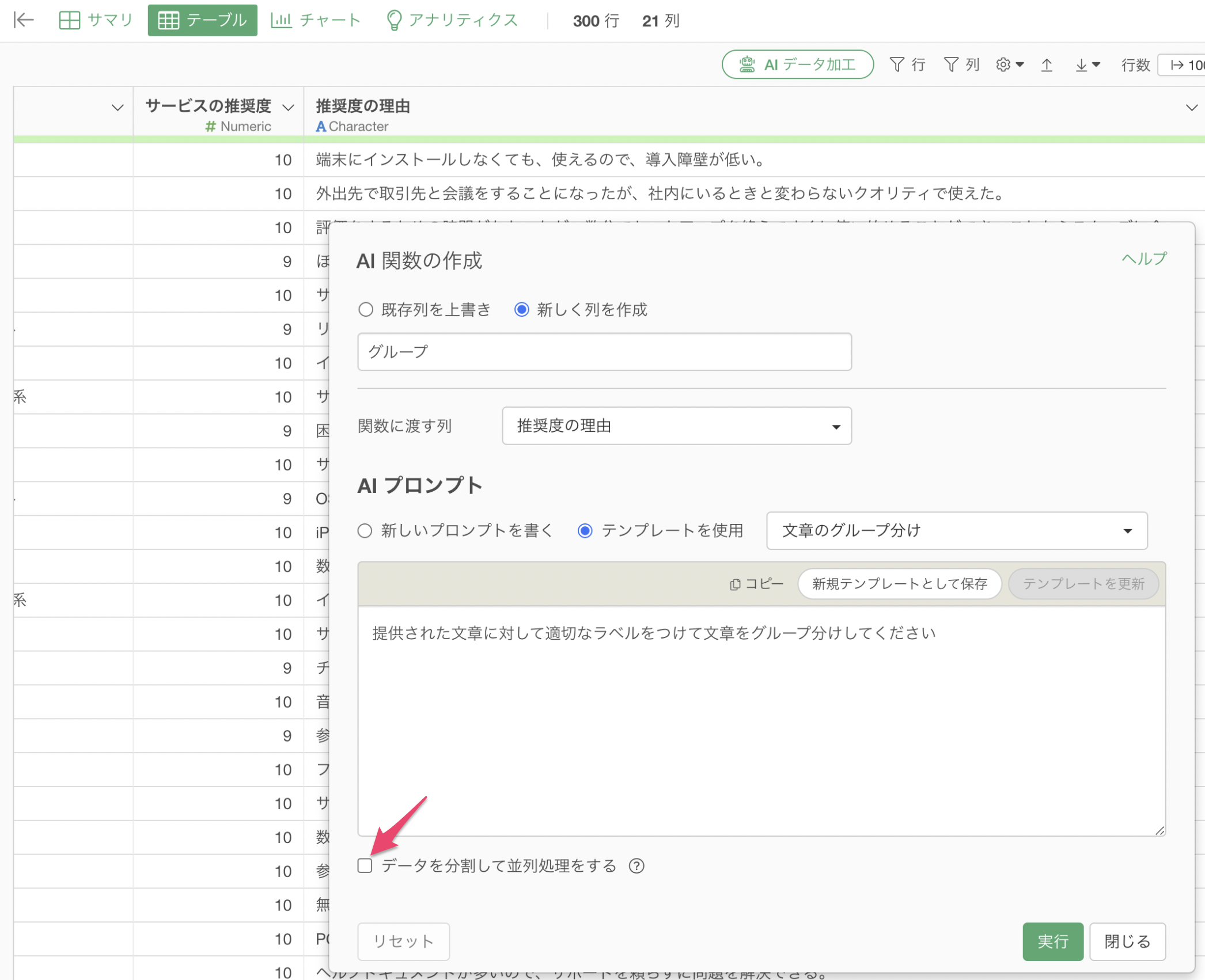
このオプションがオンの場合、データは複数のチャンクに分割され、それぞれ並列で処理されます。例えば、300行のデータであれば100行ずつに分割して処理されます。
この設定をオンにしたまま「AIによる自由なグループ分け」を指示すると、分割されたデータごとに異なるラベルが生成され、表記の揺れが生じる可能性があります。例えば、「導入」と「導入のしやすさ」のように、意味合いが近いにもかかわらず異なるラベルが付与されることがあります。
そのため、AIに「自由にグループ分け」をさせる時には「データを分割して並列処理する」のチェックを外してください。
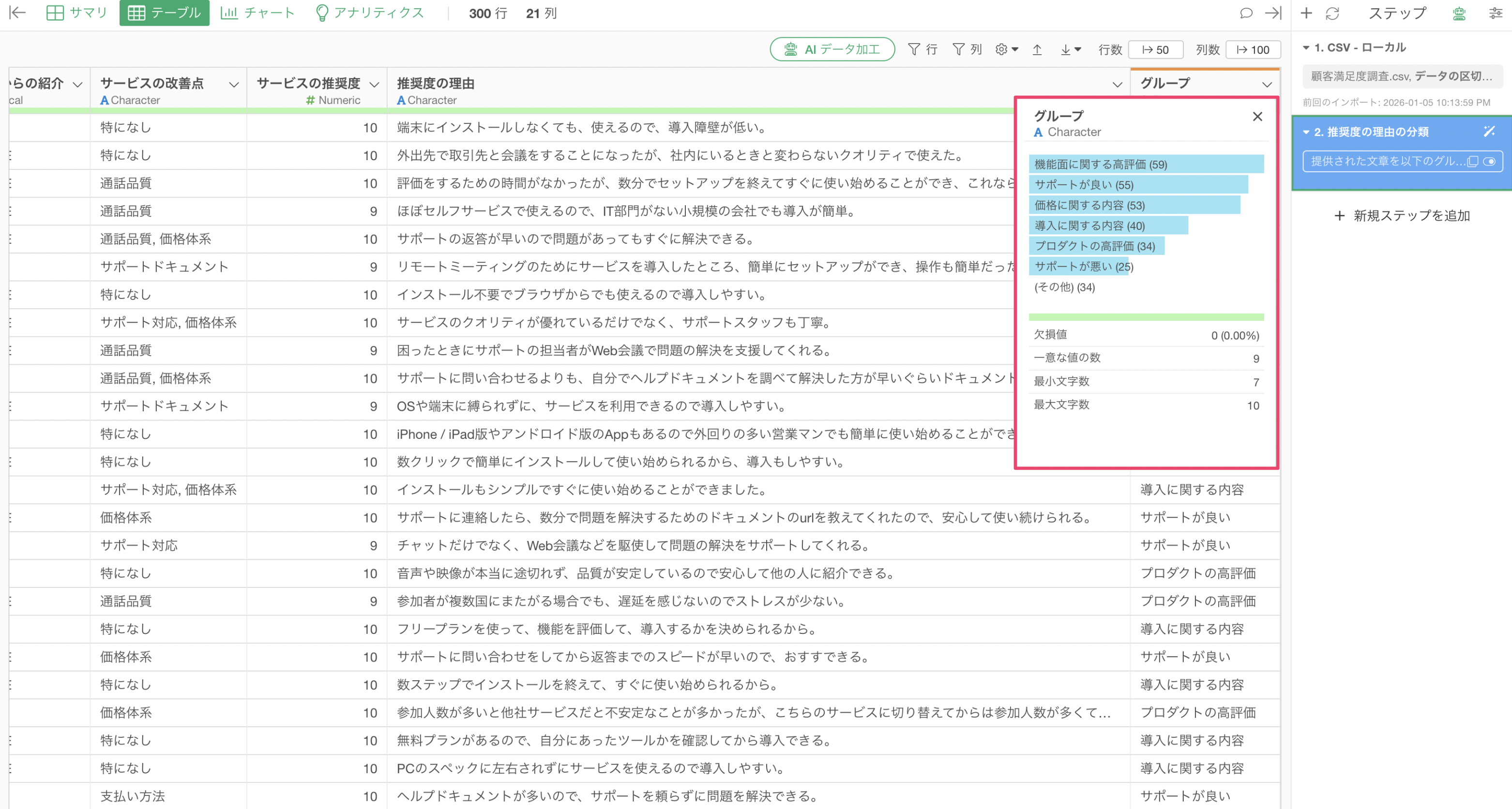
実行することで、AI によって自由にグループ分けをして、「サポート」、「機能」などの5つのグループを作成できていることが確認できます。
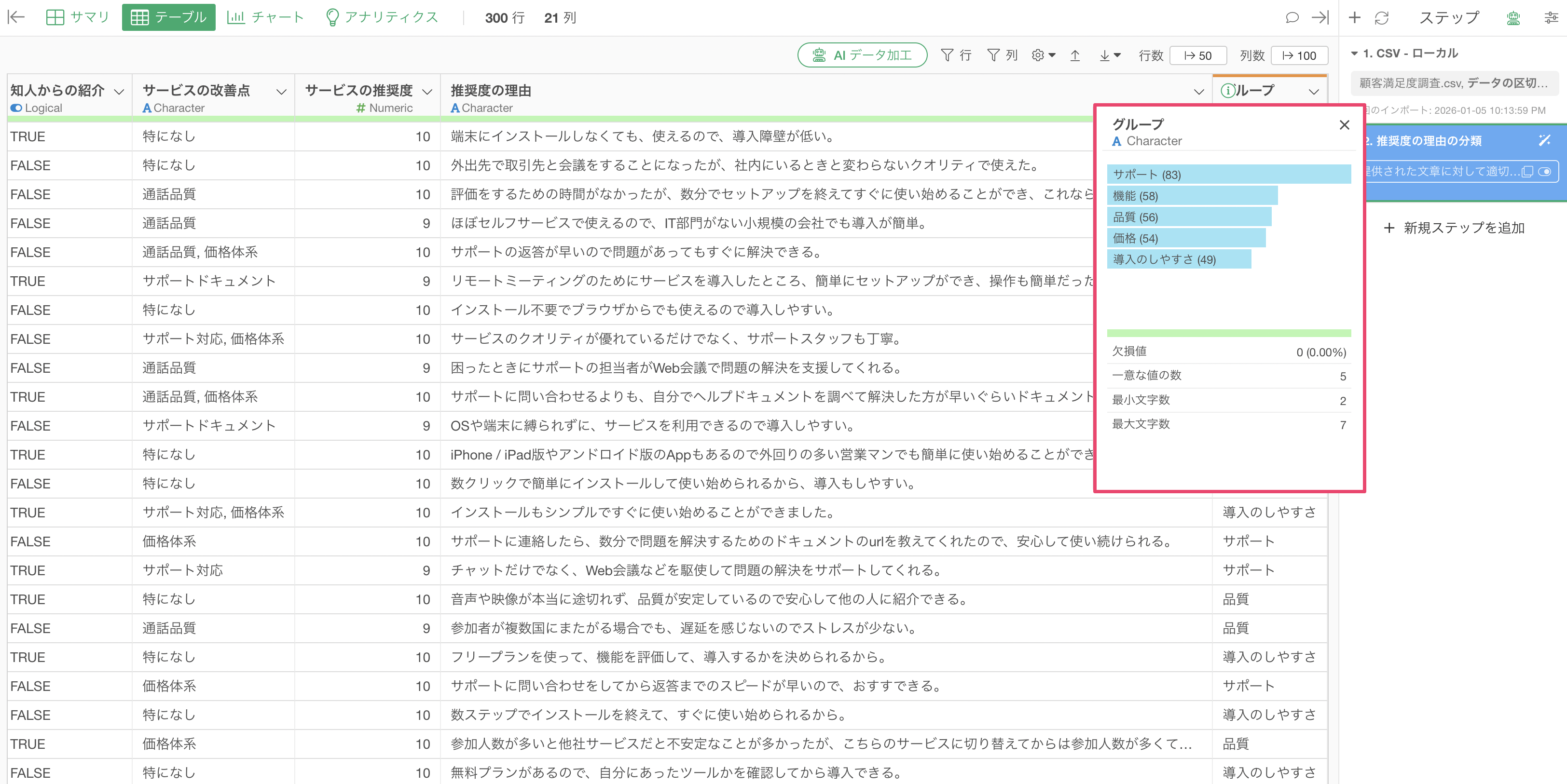
事前定義されたラベルを用いた文章の分類
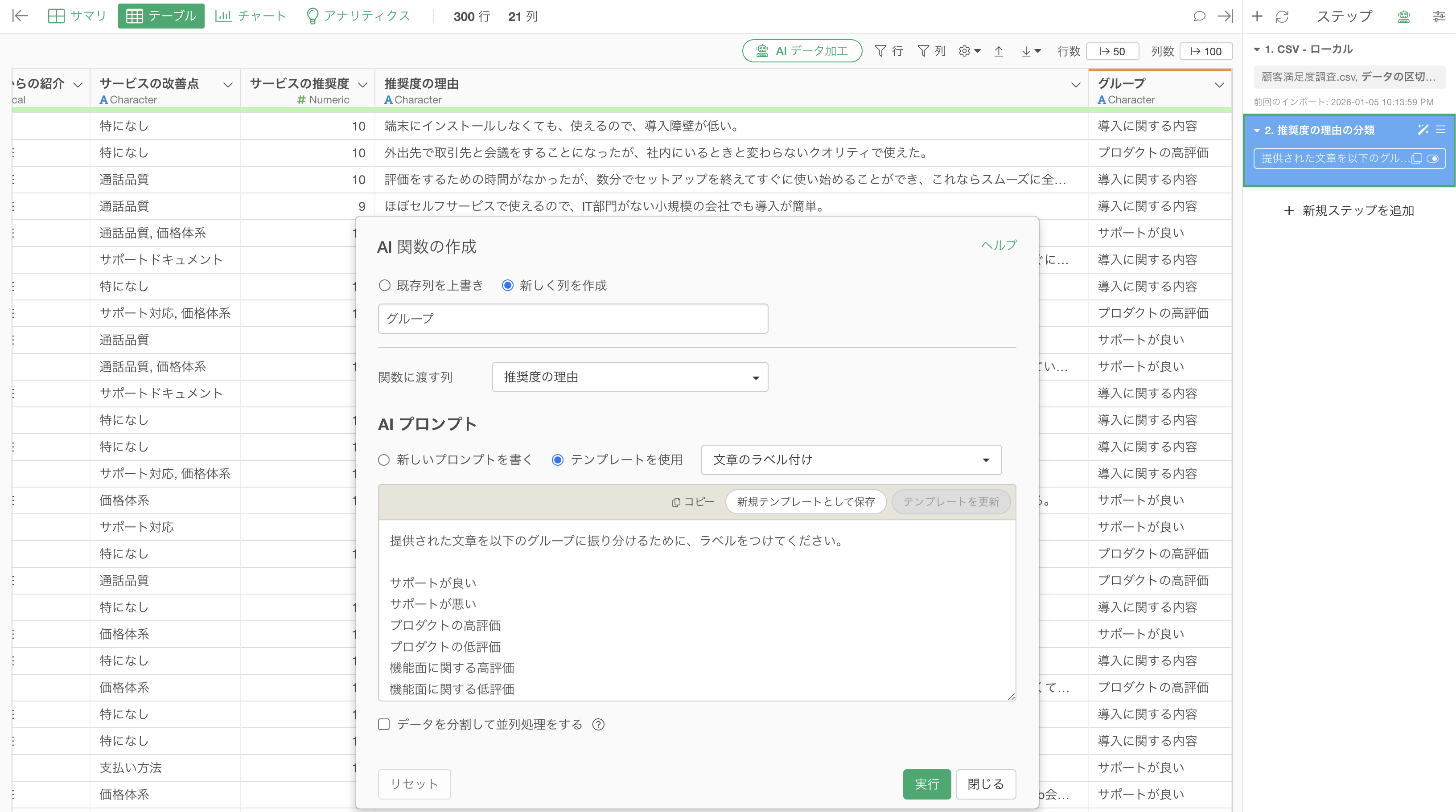
AI関数では、事前に定義したラベルに基づいて文章を分類することも可能です。
まず、プロンプトには以下のように、事前にラベルを定義します。
提供された文章を以下のグループに振り分けるために、ラベルをつけてください。
サポートが良い
サポートが悪い
プロダクトの高評価
プロダクトの低評価
機能面に関する高評価
機能面に関する低評価
競合サービスとの比較
導入に関する内容
価格に関する内容
その他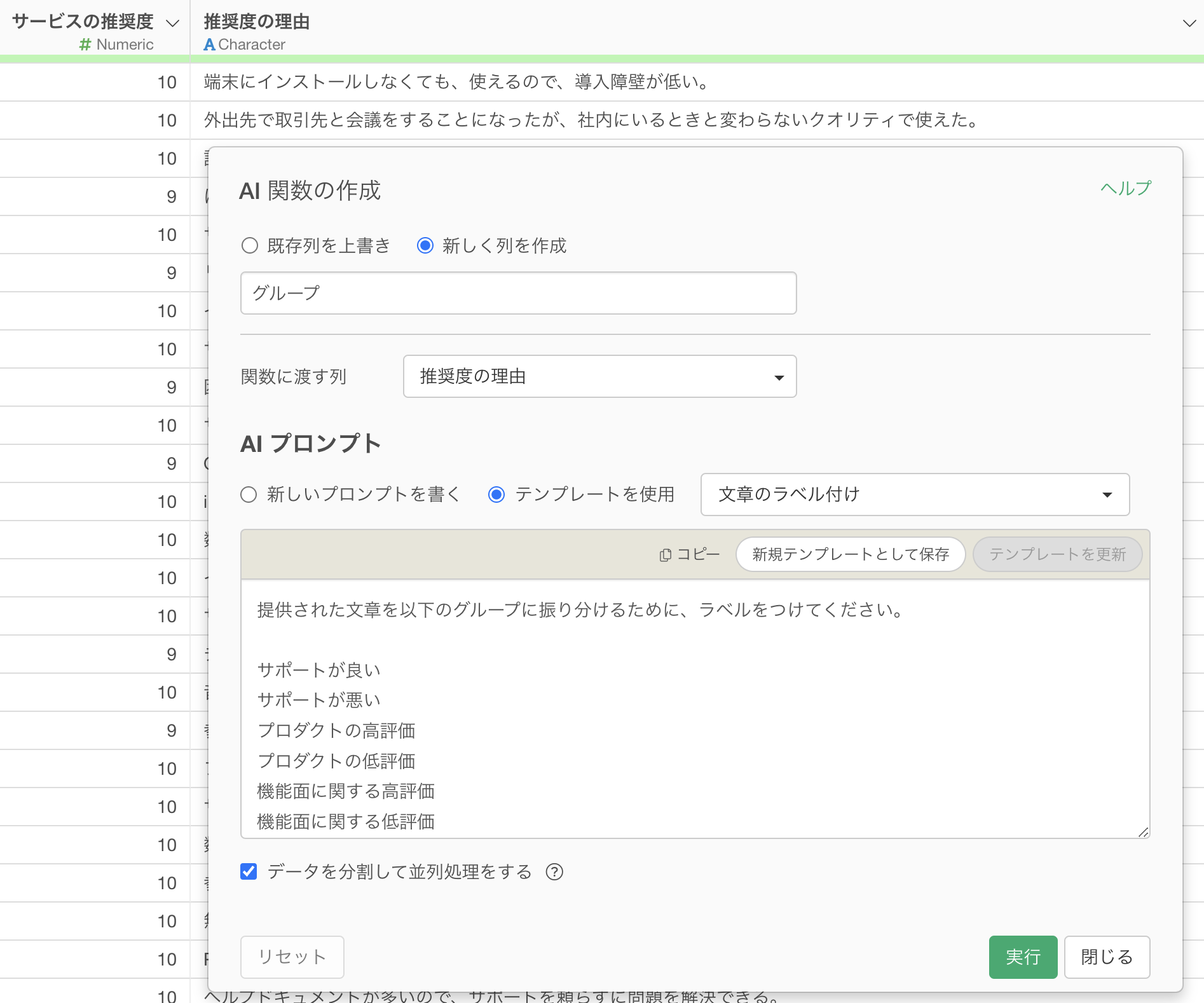
このように事前にラベルを定義している場合、AIは定義されたラベルの中から最適なものを選択して文章に付与するため、出力されるラベルに表記の揺れが生じることはありません。
そのため、事前にラベルを定義している場合は、「データを分割して並列処理する」のチェックをオンにしたままでも問題なく実行できます。
実行することで、指定されたグループの中から最も適切だと判断されるラベルを各行に付与します。