Exploratory アワー #756 - 2つのデータフレームを比較をしたい - Rスクリプト版
2つのデータフレームを比較する際、UI操作によるマージ(結合)以外にも、Rスクリプトを活用することでより詳細かつ効率的にデータの差異を特定する方法があります。
今回は、Exploratoryのノート機能とRスクリプトを組み合わせ、データ構造の比較や、全列を対象とした統計的な有意差の確認を一括で行う手順について紹介します。
問題
アンケートデータなどの比較において、列数が膨大になると、どの列が不足しているのか、あるいはデータの分布や平均値にどのような違いがあるのかを目視で確認するのは非常に困難です。
また、数値列だけでなくカテゴリー列も含めて、2つのデータ間で統計的に意味のある差(有意差)があるかどうかを、一つひとつの列に対して個別に検証していくには多大な時間がかかります。
解決方法
データ構造の比較
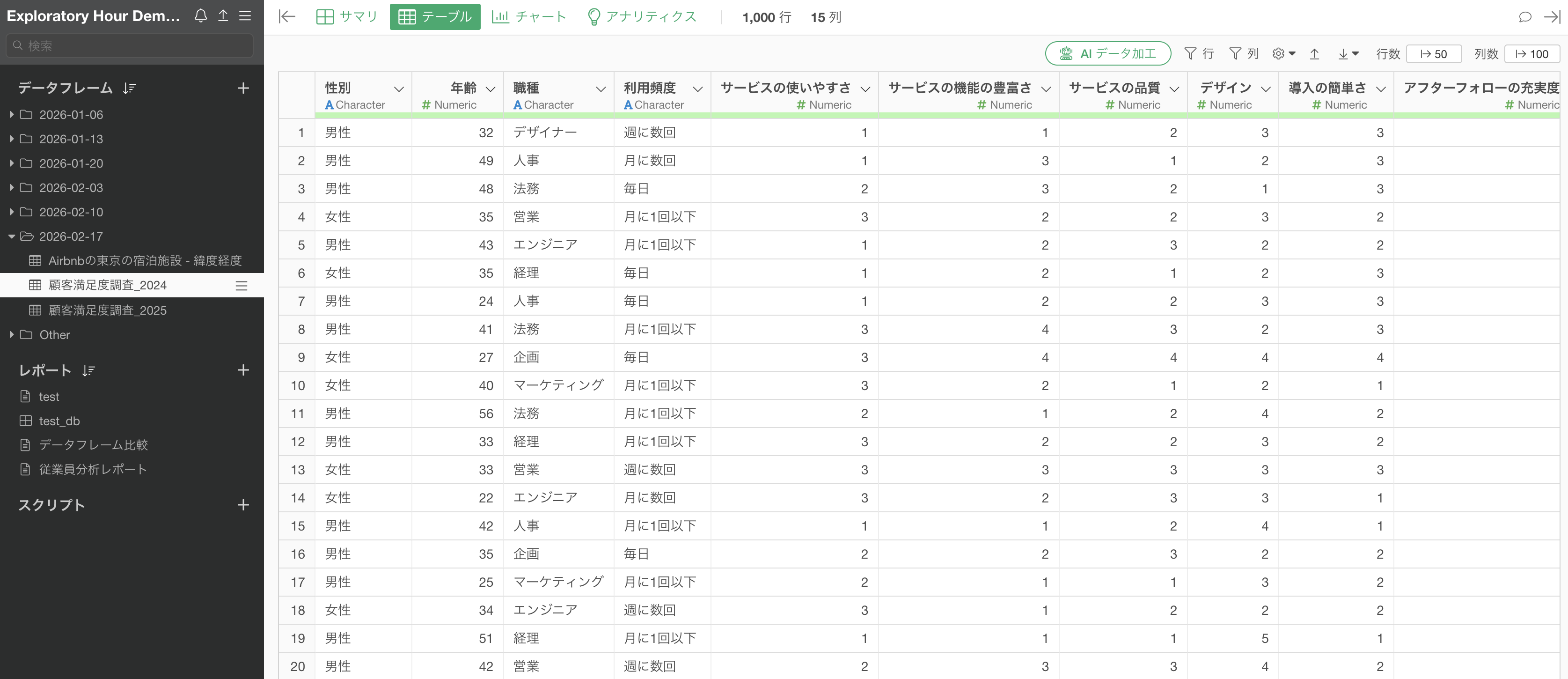
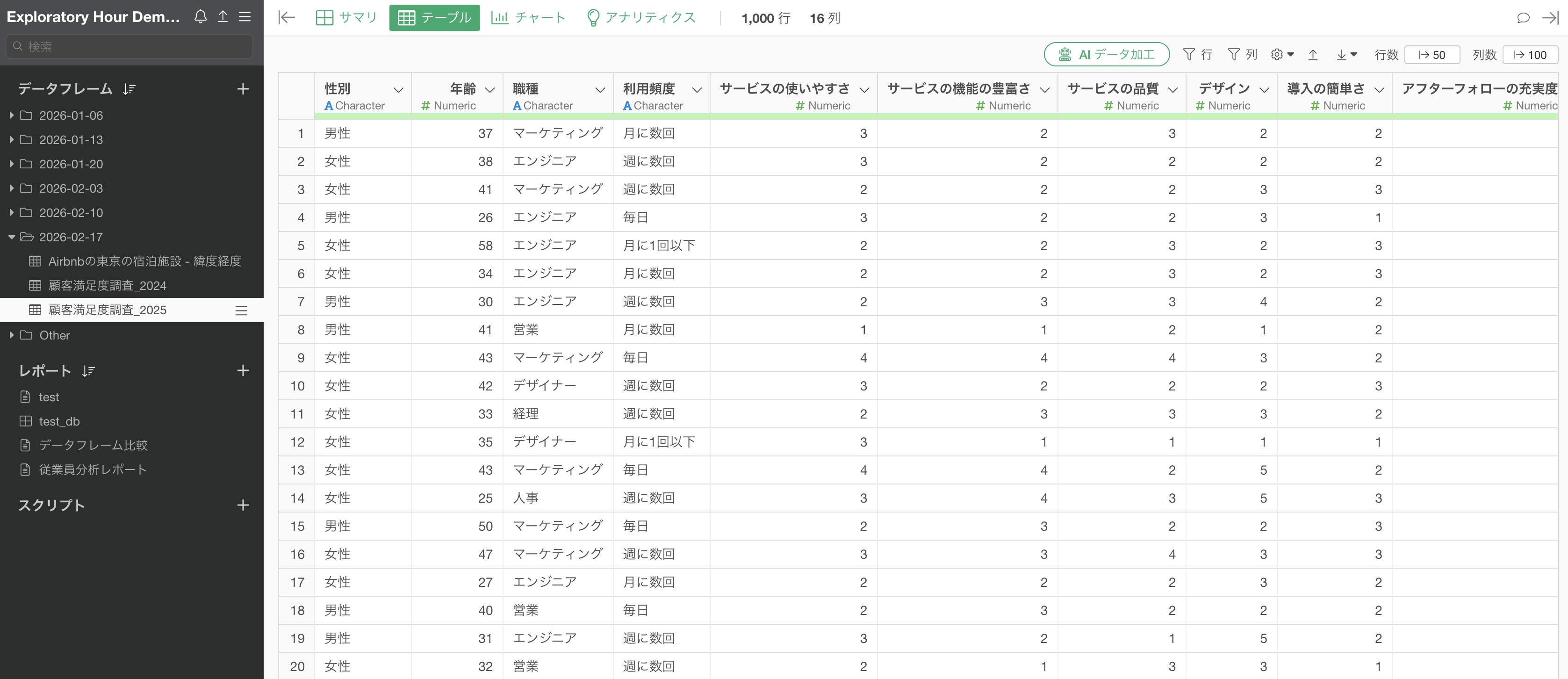
今回使用するサンプルデータは、2024年度と2025年度の顧客満足度調査データです。1行が1回答者を表し、性別や職種などの属性情報と、5段階評価の質問列が含まれています。
2024年度
2025年度
まず、2つのデータフレーム間で列数や行数、列名の違いを特定するために、arsenalパッケージのcompareDF関数を使用します。これにより、例えば2025年度に新しく追加された質問列などを即座に検出することが可能です。
具体的な操作として、まずプロジェクトメニューの「Rパッケージの管理」を選択します。
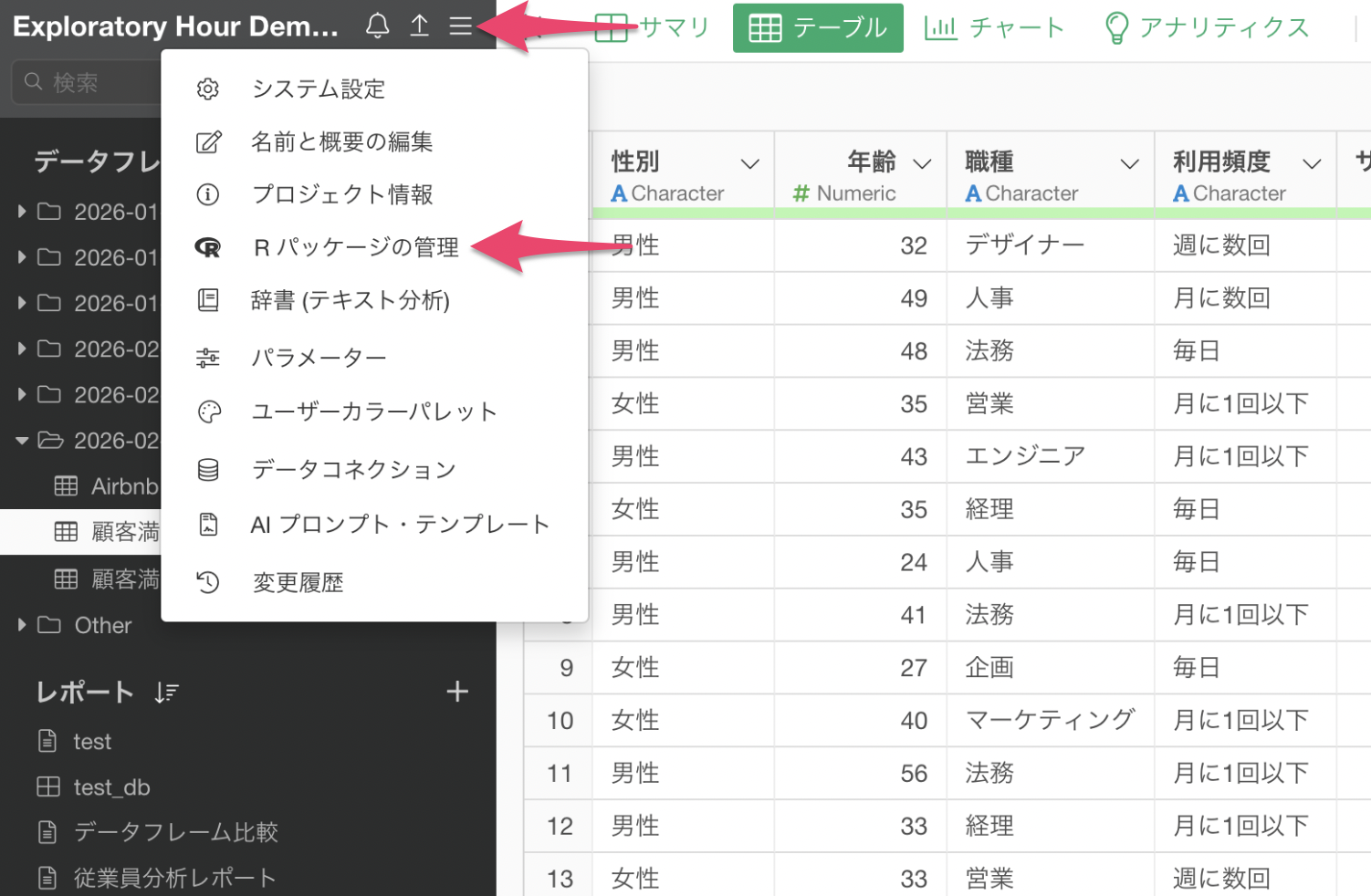
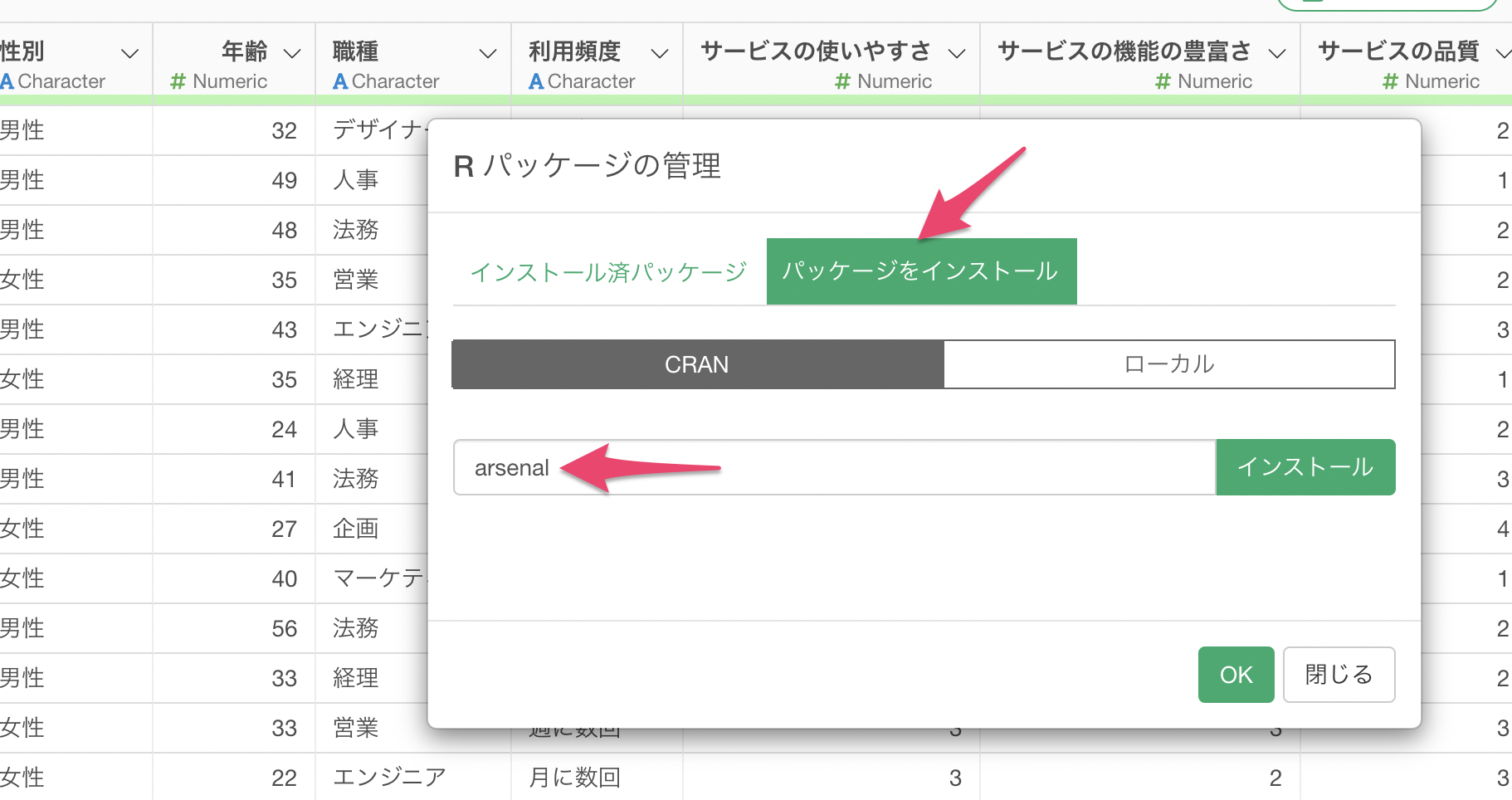
次にCRANからarsenalパッケージをインストールします。
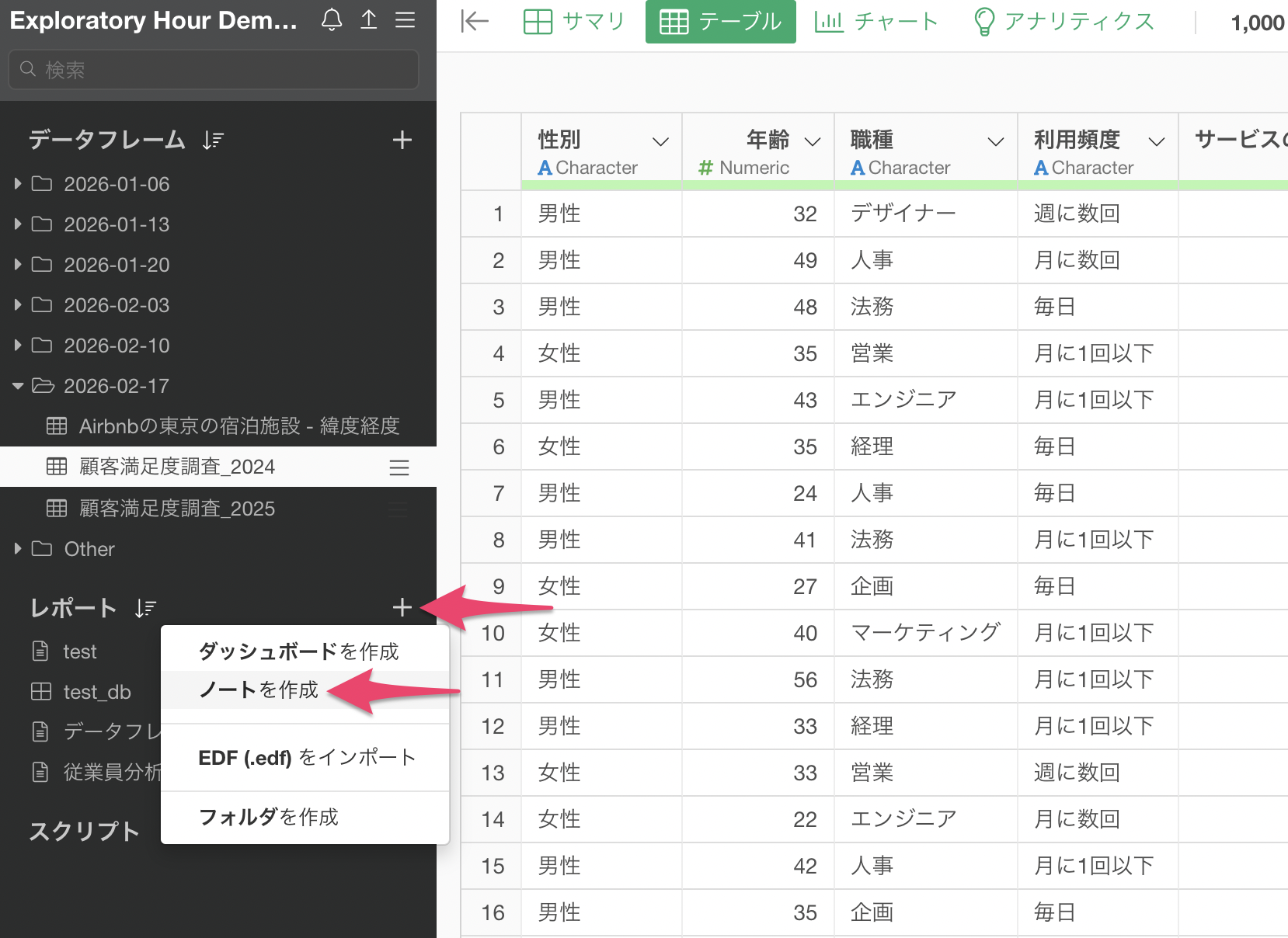
次に、ノートを作成します。レポートのプラスボタンから「ノートを作成」を選択します。
ノートが作成できたら、左上のプラスボタンからRスクリプトを選択します。
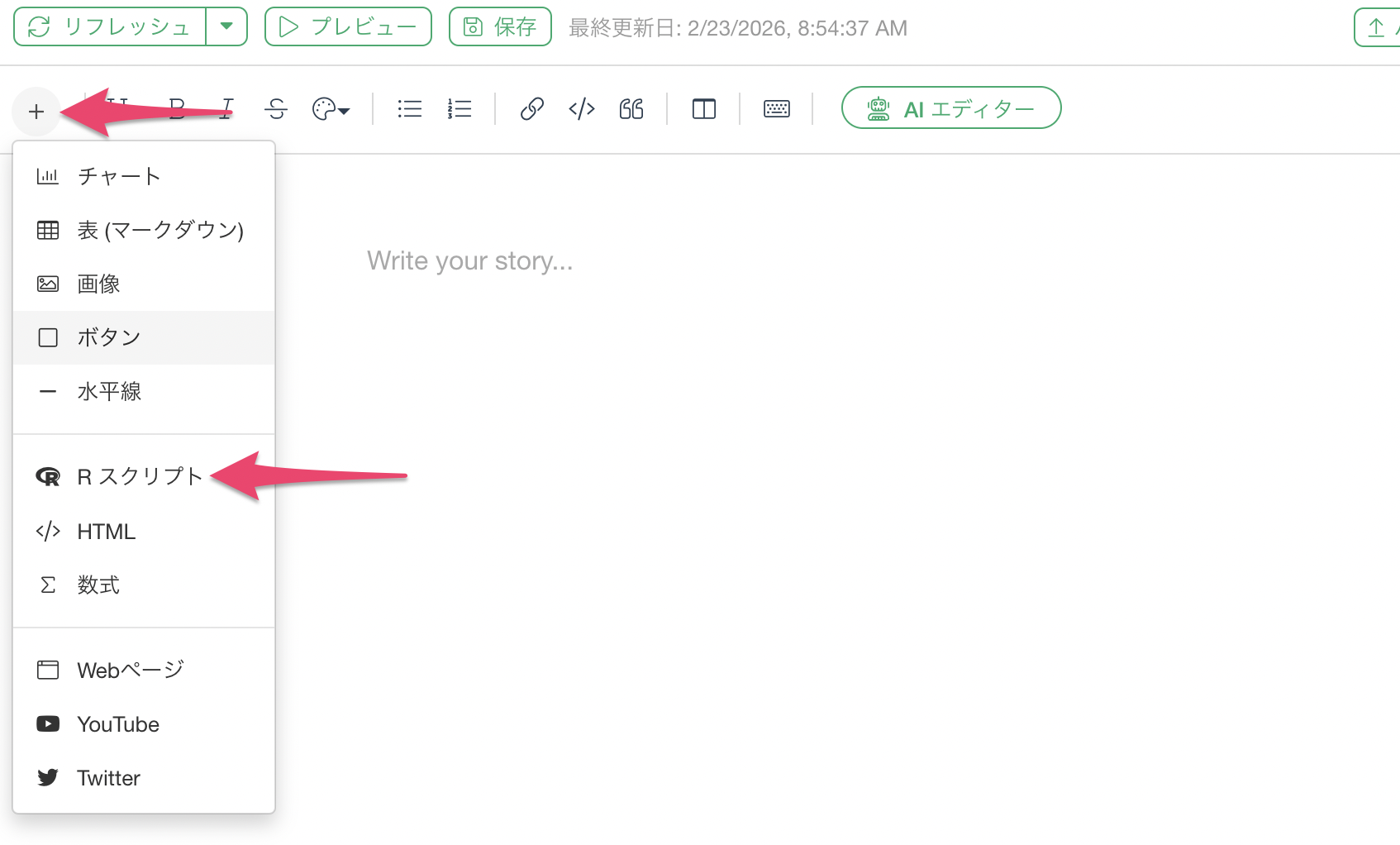
これによりRスクリプトのコードブロックが追加されます。
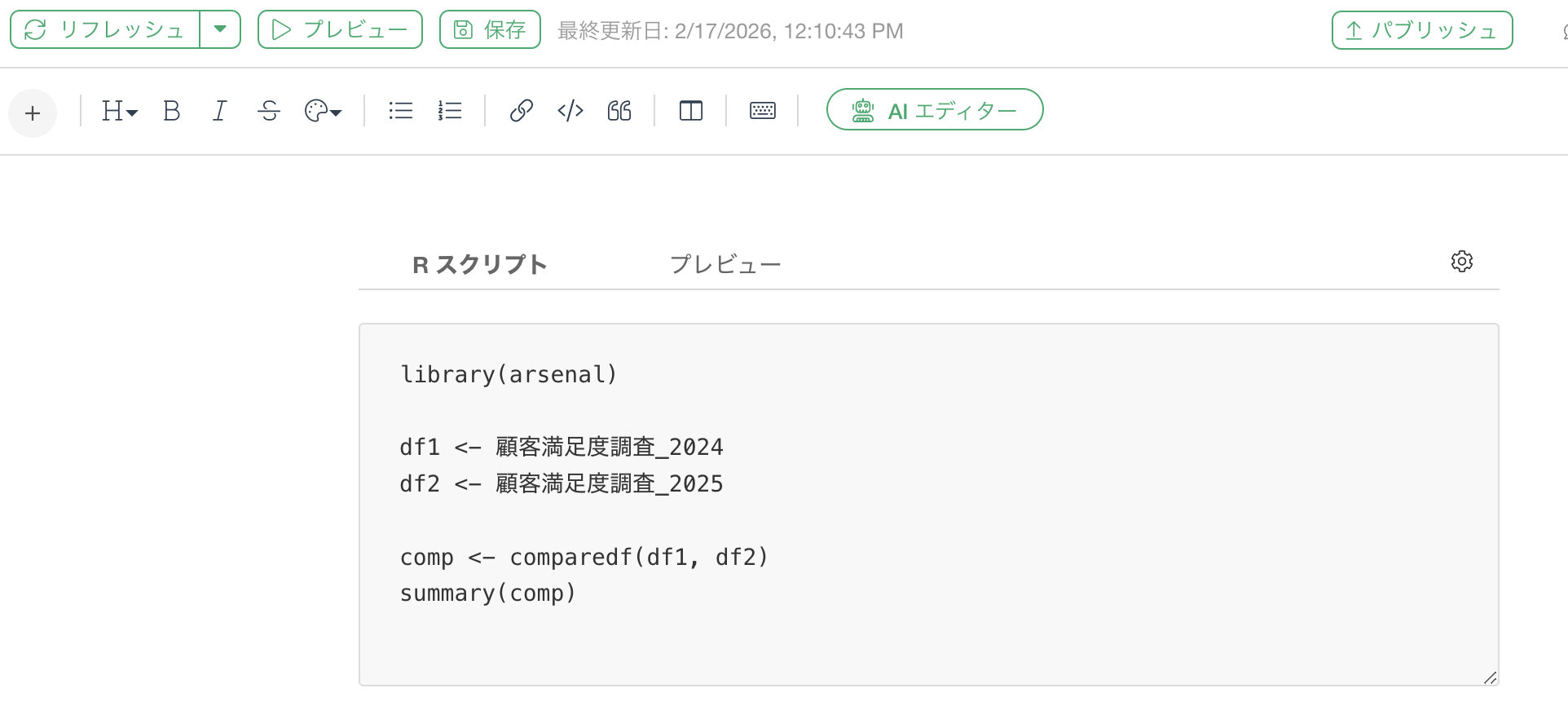
Rスクリプトとしては、以下のように指定します。
library(arsenal)
df1 <- 顧客満足度調査_2024
df2 <- 顧客満足度調査_2025
comp <- comparedf(df1, df2)
summary(comp)
比較したい2つのデータフレームを変数(DF1,
DF2)に格納した上で、compareDF(DF1, DF2)を実行しています。
実行すると、列数の違いや、特定のデータフレームにのみ存在する列名がサマリーとして表示されます。
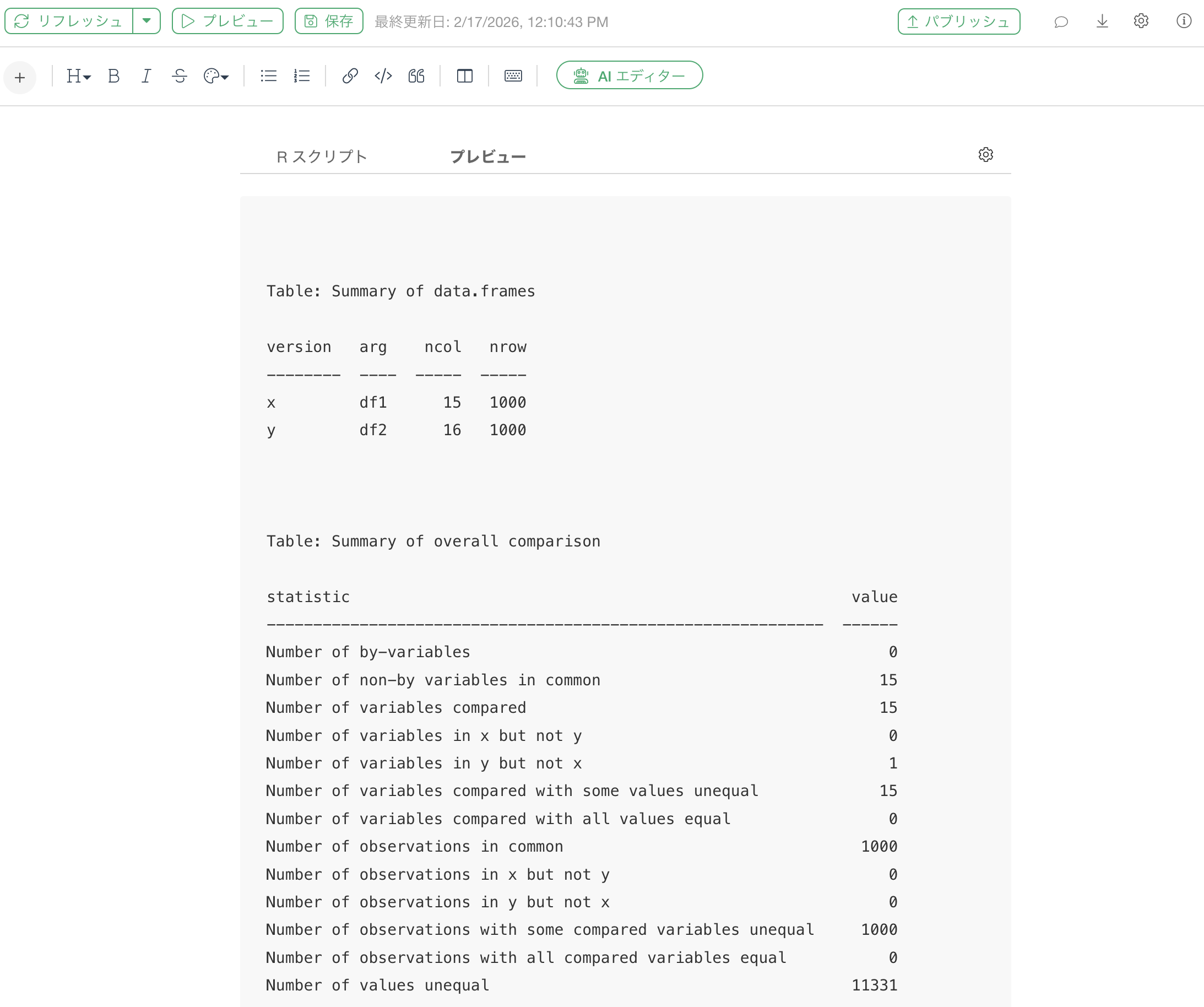
これにより、大規模なアンケートデータでも構造の不一致を瞬時に把握し、次の分析ステップへの橋渡しがスムーズになります。
全列の一括統計比較
次に、数値列の平均値の差やカテゴリー列の構成比の差を、全列一括で統計的に検証する方法として、tableoneパッケージを活用します。
この手順の目的は、2つの年度間で回答者の属性や評価傾向に「統計的に有意な差」がある箇所を素早く特定することにあります。UI版では数値列の信頼区間の比較が主でしたが、この方法ではカテゴリー列も含めた網羅的な分析が可能です。
Rスクリプトとしては、以下のように指定します。
library(tableone)
library(tibble)
# データ読み込み(ここだけ手動で指定)
df1 <- 顧客満足度調査_2024
df2 <- 顧客満足度調査_2025
group_name <- "データソース" # グループ列名
df1_label <- "2024" # ラベル
df2_label <- "2025"
# データ結合
df_combined <- bind_rows(
df1 %>% mutate(!!group_name := df1_label),
df2 %>% mutate(!!group_name := df2_label)
)
# 日付列を除外して変数を自動取得
vars <- df_combined %>%
select(-all_of(group_name)) %>%
select(where(~ !inherits(., c("Date", "POSIXct", "POSIXlt")))) %>%
names()
# カテゴリ変数を自動判別
cat_vars <- df_combined %>%
select(all_of(vars)) %>%
select(where(~ is.character(.) | is.factor(.) | is.logical(.))) %>%
names()
# テーブル作成
tab <- CreateTableOne(
vars = vars,
strata = group_name,
data = df_combined,
factorVars = cat_vars
)
tab_matrix <- print(tab, showAllLevels = TRUE, smd = TRUE, printToggle = FALSE)
# データフレーム整形
tab_df <- as.data.frame(tab_matrix) %>%
tibble::rownames_to_column("変数") %>%
mutate(
変数 = ifelse(grepl("^X\\.?[0-9]*$", 変数), "", 変数),
変数 = gsub("\\.\\.mean\\.\\.SD\\.\\.", " (mean (SD))", 変数),
変数 = gsub("\\.\\.\\.\\.", " (%)", 変数)
) %>%
select(-test)
tab_df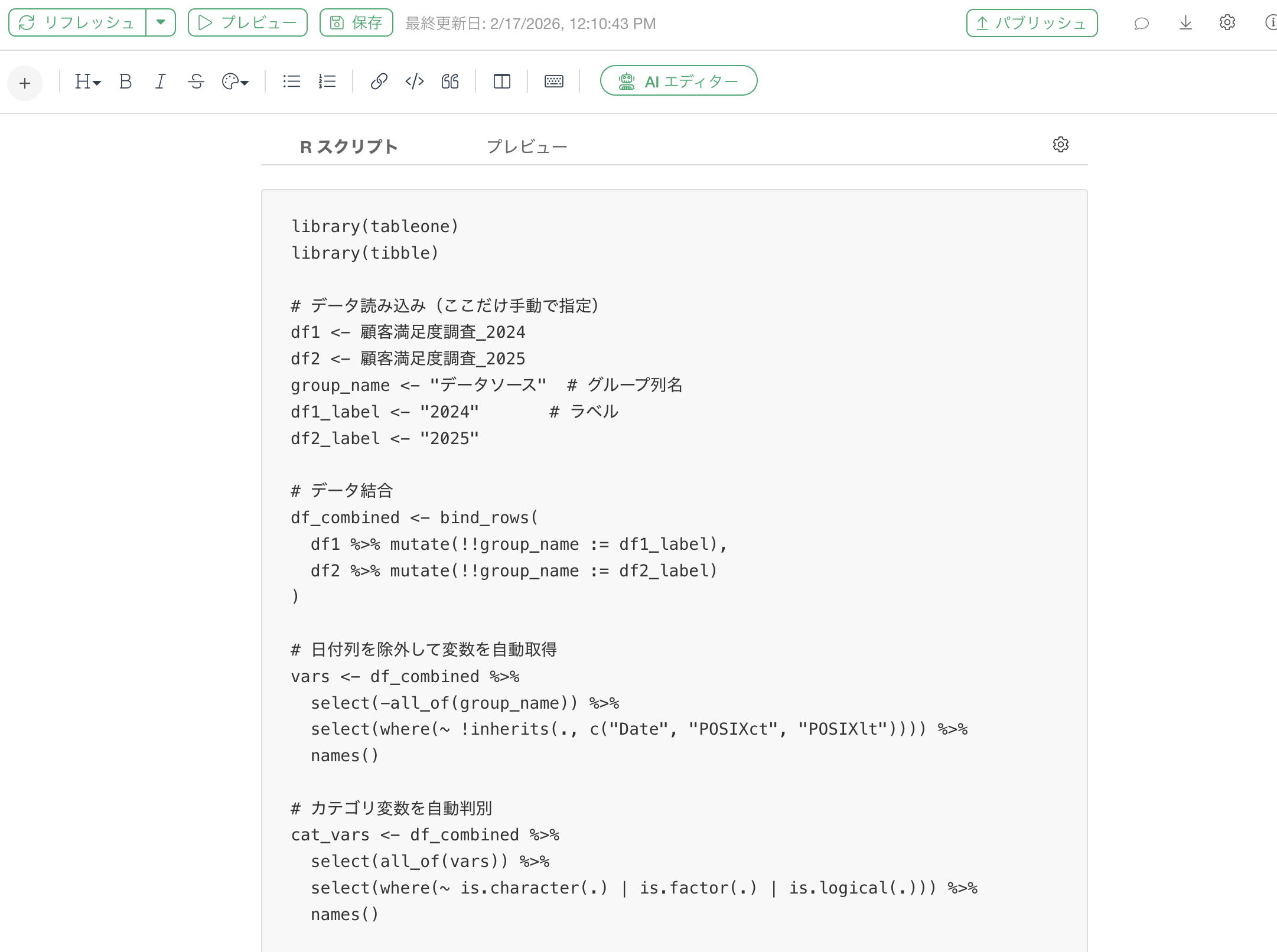
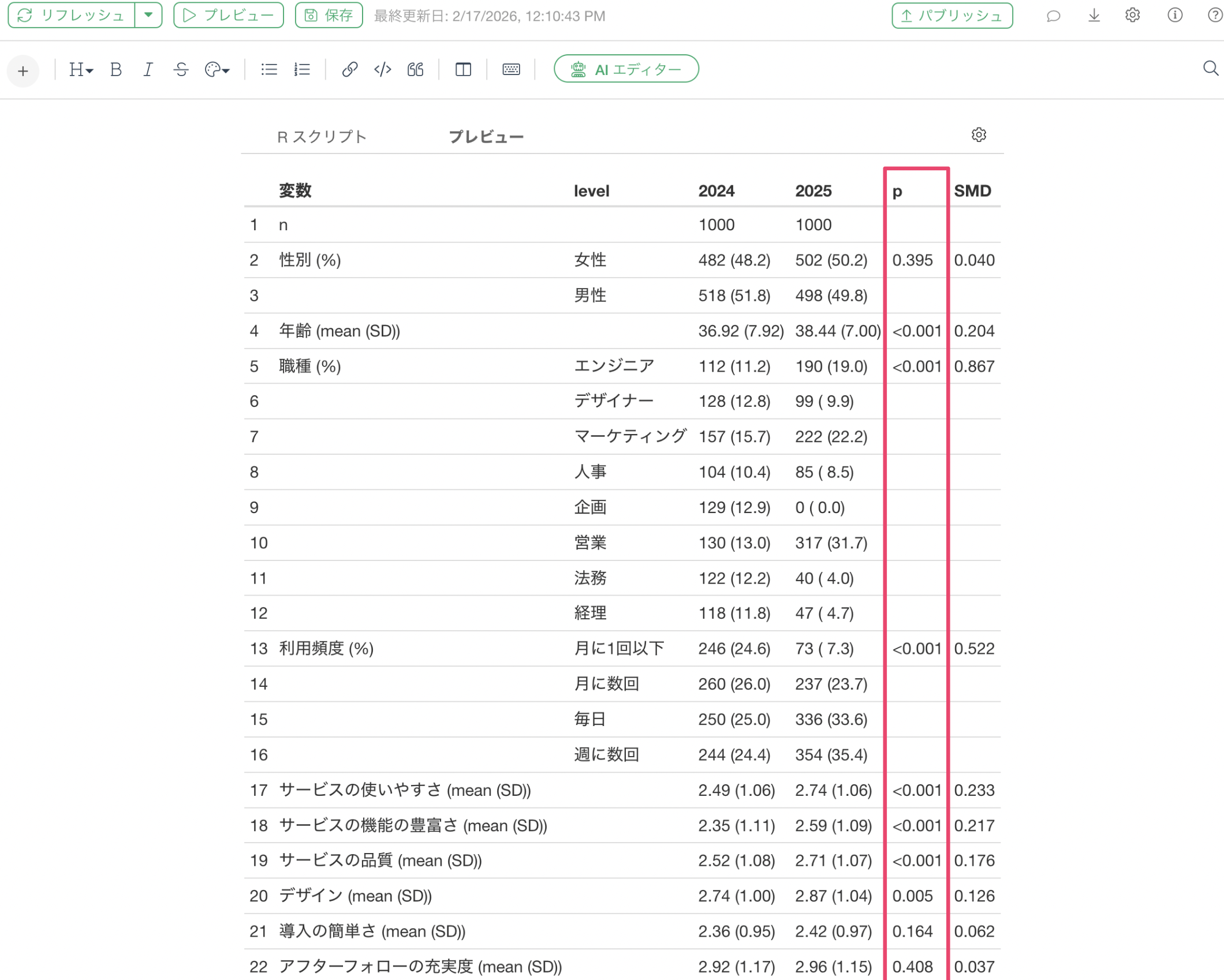
実行結果として、カテゴリー変数については件数と割合、数値変数については平均値と標準偏差が並べて表示されます。
さらに、右端に表示されるP値(5%未満)を確認することで、例えば「職種」や「利用頻度」において年度間で有意な違いがあるかどうかを、一目で判断できるようになります。