Exploratory アワー #777 - 行数を指定してCSV/Excelファイルをインポートしてデータの概要を理解したい
Exploratoryのインポート機能では、バージョン14から追加された「最大行数」オプションを使用することで、大容量のファイルの一部だけを先に読み込み、データの全体像を素早く把握することができます。これにより、不要な列を事前に特定してからインポートを行うことができ、インポートにかかる時間を短縮することが可能です。
役立つ人
大容量のCSVやExcelファイルを扱う方、データの内容を効率的に確認してからインポートしたい方にお役立ていただける機能です。
問題
手元にある大容量のCSVやExcelファイルをそのままExploratoryにインポートしようとすると、インポートに非常に長い時間がかかることがあります。あらかじめデータの概要を確認できれば、必要な列だけを選択して効率よくデータをインポートできます。
解決方法
例えば、100列・数百万行にのぼる1GB超の注文データを受け取ったとします。
仮にこのファイルがどのようなものかよく分からない状態で、そのままインポートすると、インポートに時間がかかります。
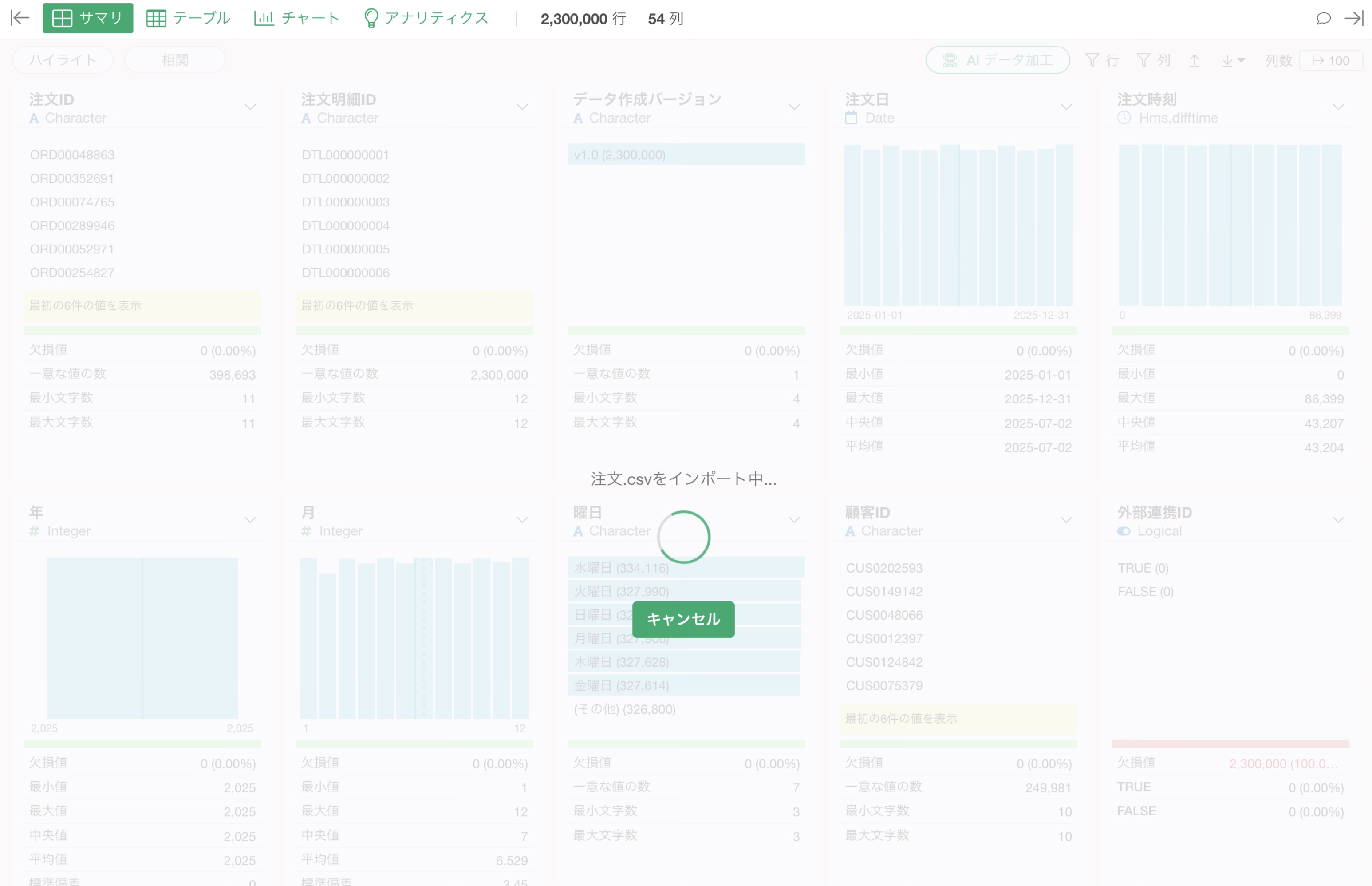
この課題を解決するために、Exploratoryのインポートダイアログにある「最大行数」オプションを活用します。
このオプションを使うと、ファイルの先頭から指定した行数分のデータだけを取り込むことができます。少量のデータで列の内容や値の分布を確認したうえで、本番のインポートに必要な列を絞り込むことができます。
今回は1行が1つの注文を表し、列には注文日、返品フラグ、返品理由など多数の情報が含まれている1GB超のCSVファイルを使用します。
Exploratoryの操作方法
まずはCSVファイルをExploratoryにインポートします。
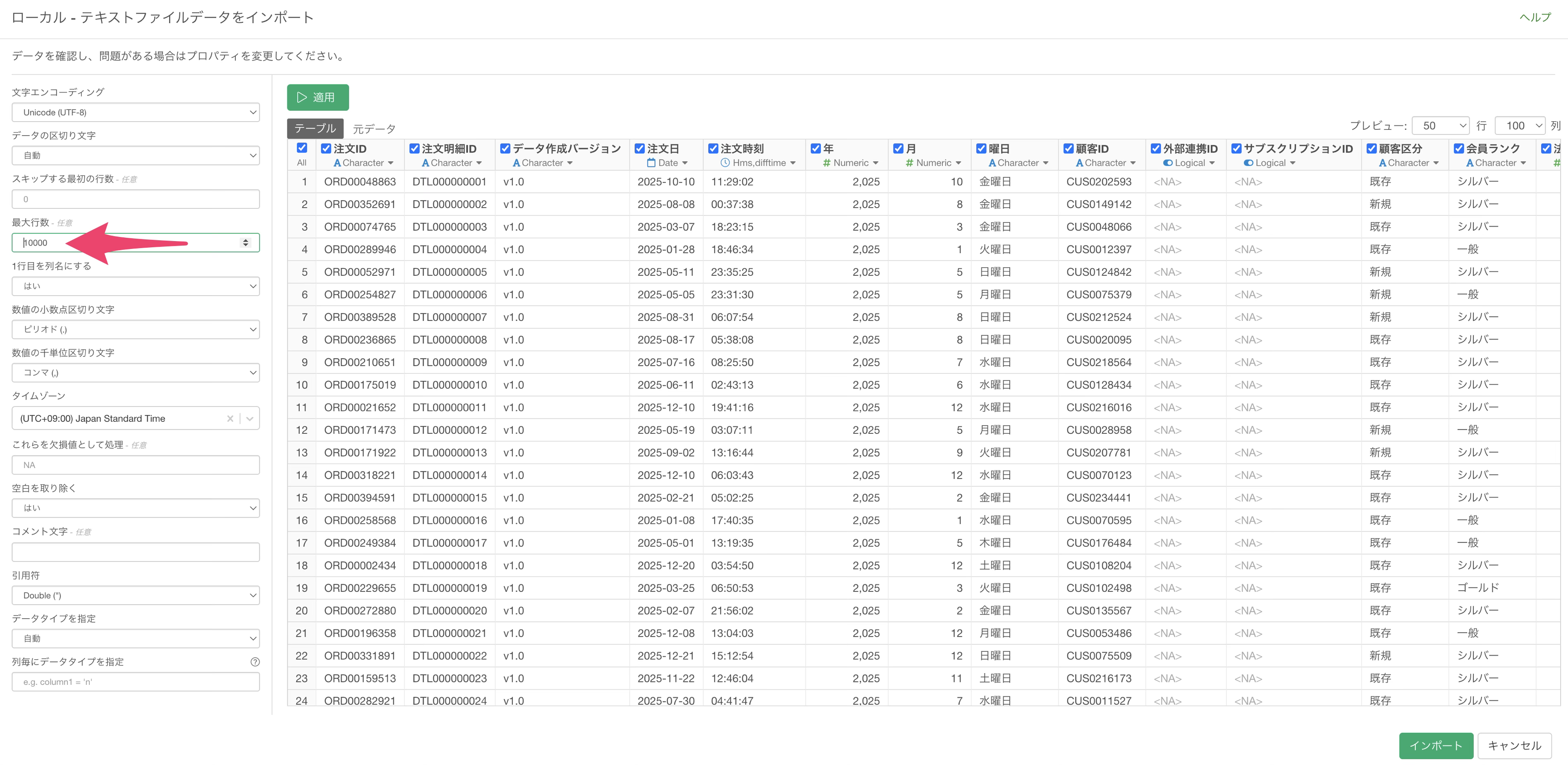
インポートダイアログが開いたら、バージョン14から追加された「最大行数」オプションを確認します。デフォルトでは全件のデータを取り込む設定になっていますが、ここに行数を指定することで、ファイルの先頭から指定した行数分のデータのみを取り込む挙動に変わります。
今回はデータの概要確認が目的のため、最大行数に「10000」(1万行)を入力し、「適用」ボタンをクリックしてインポートします。
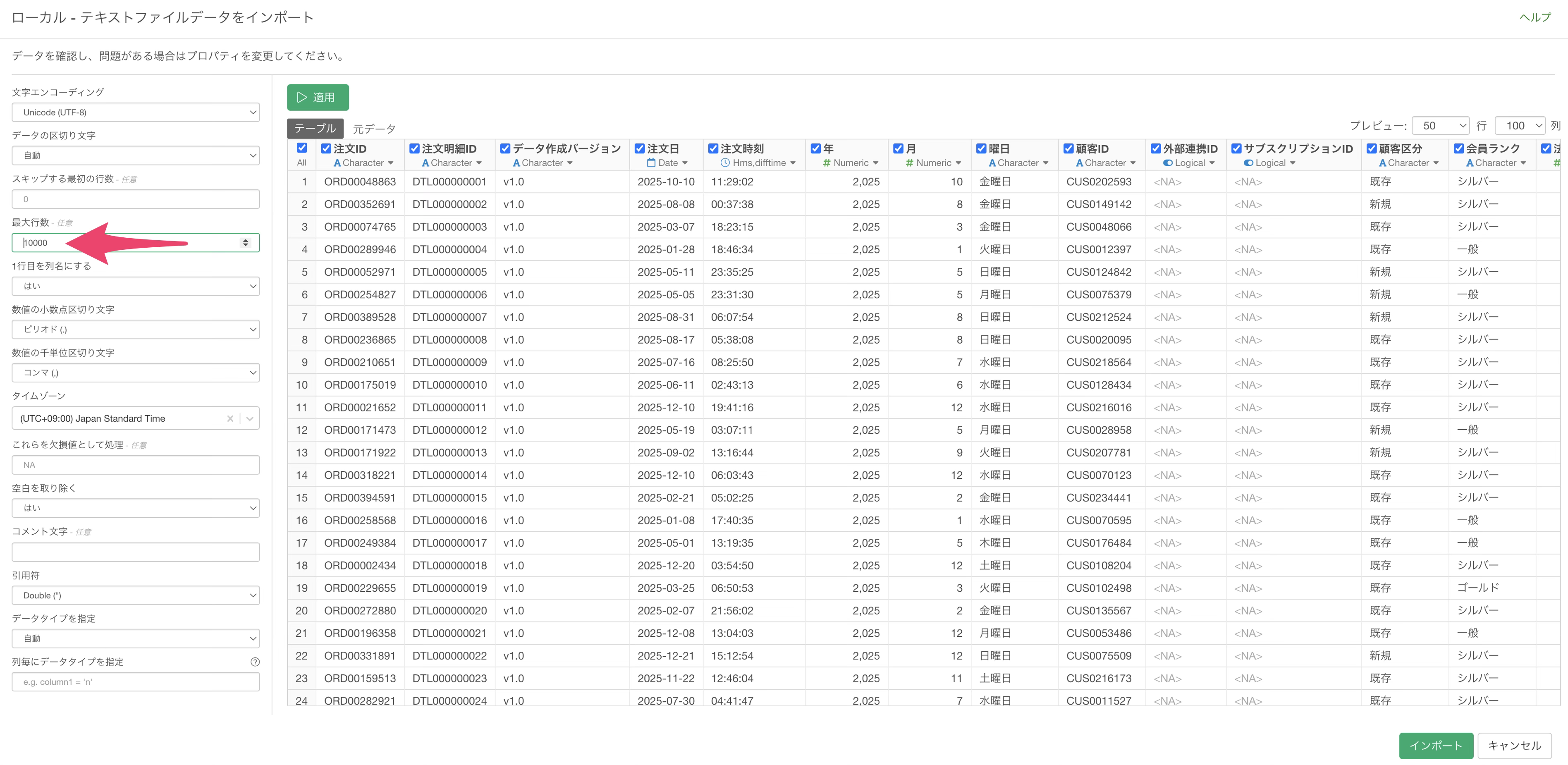
1GBを超えるファイルでも1万行の指定をすることで、ほぼ一瞬でインポートが完了します。
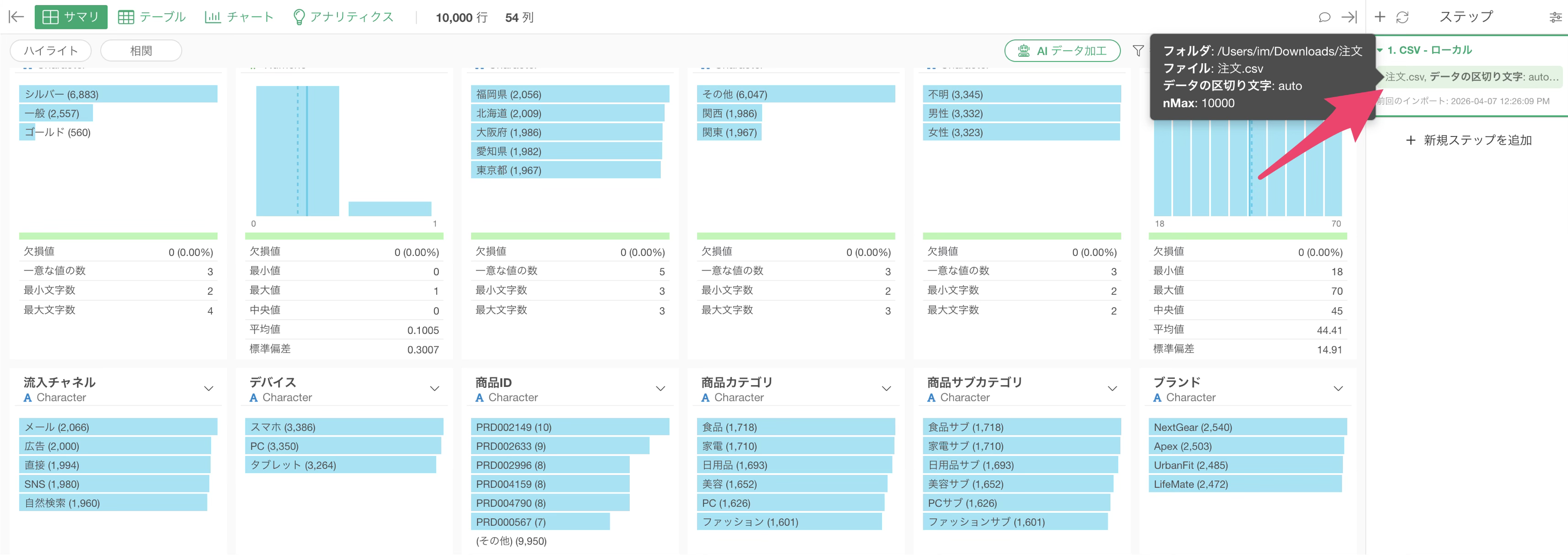
取り込まれたデータのサマリを確認すると、例えば「外部連携ID」や「サブスクリプションID」のような列が全て欠損値になっていることや、
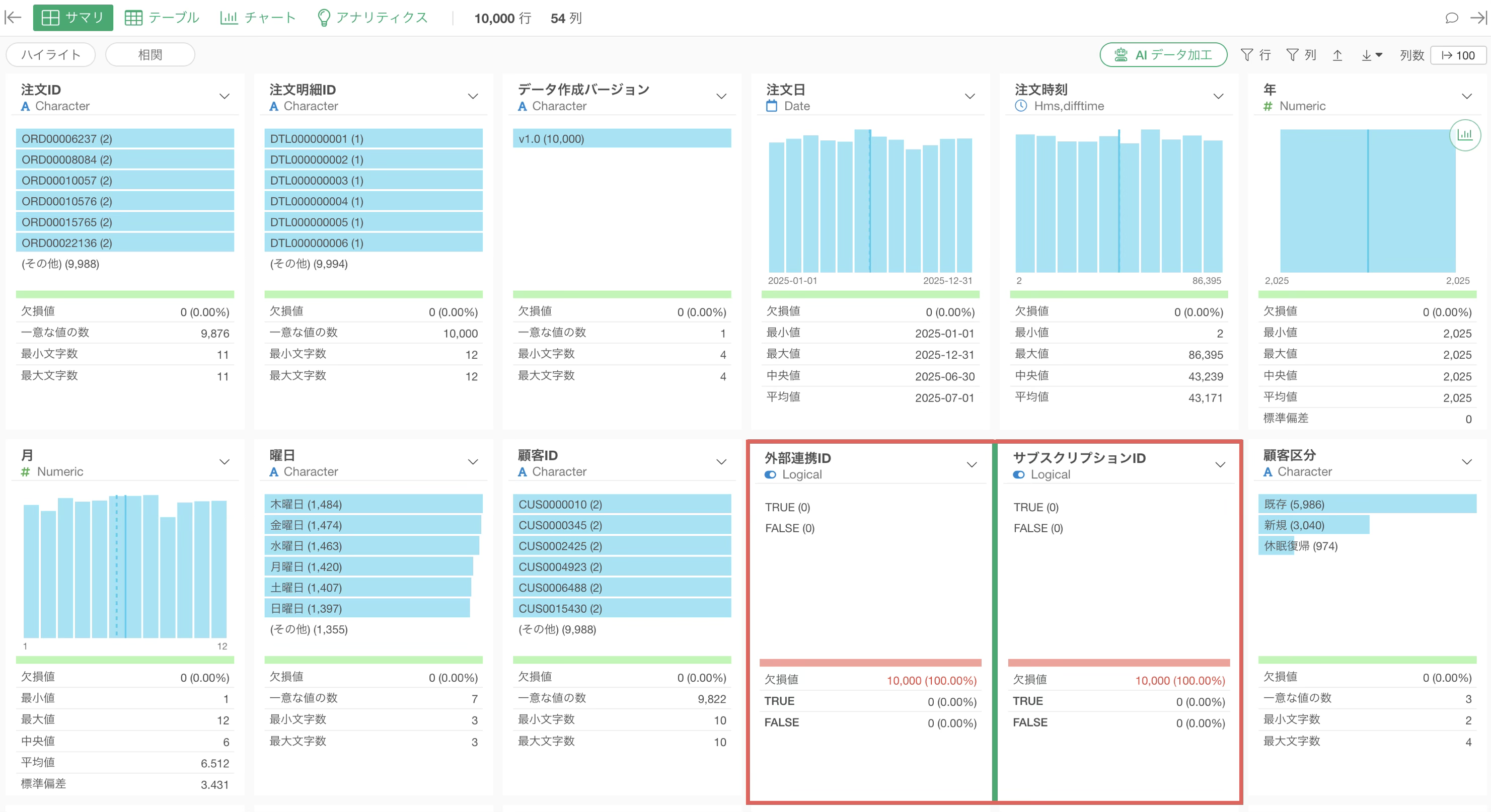
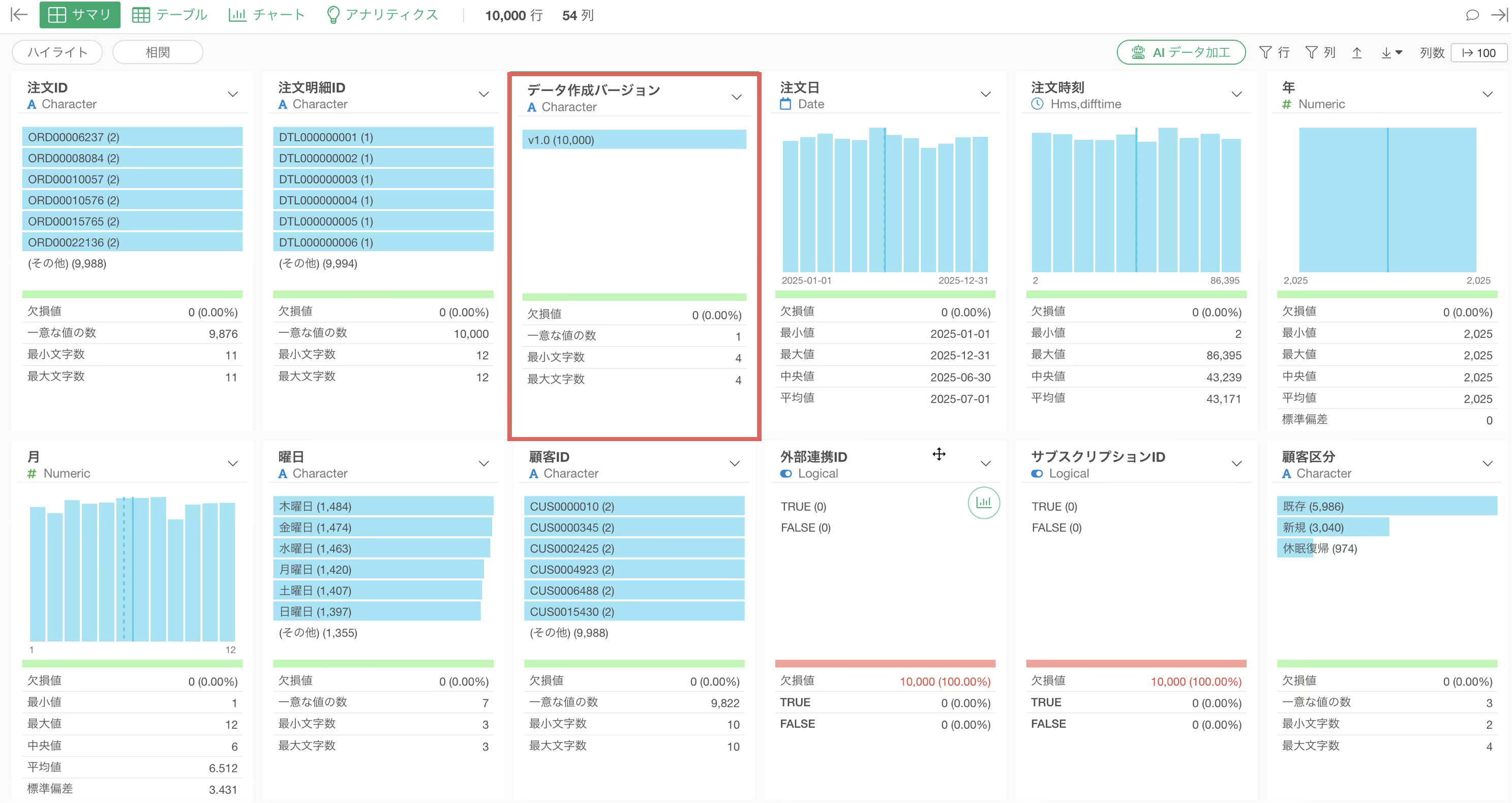
「データ作成バージョン」のように全行で同じ値しか入っていない列が見つかります。
また、「返品フラグ」と「返品理由」のように、どちらか一方だけで情報が足りる列の組み合わせも把握することができます。
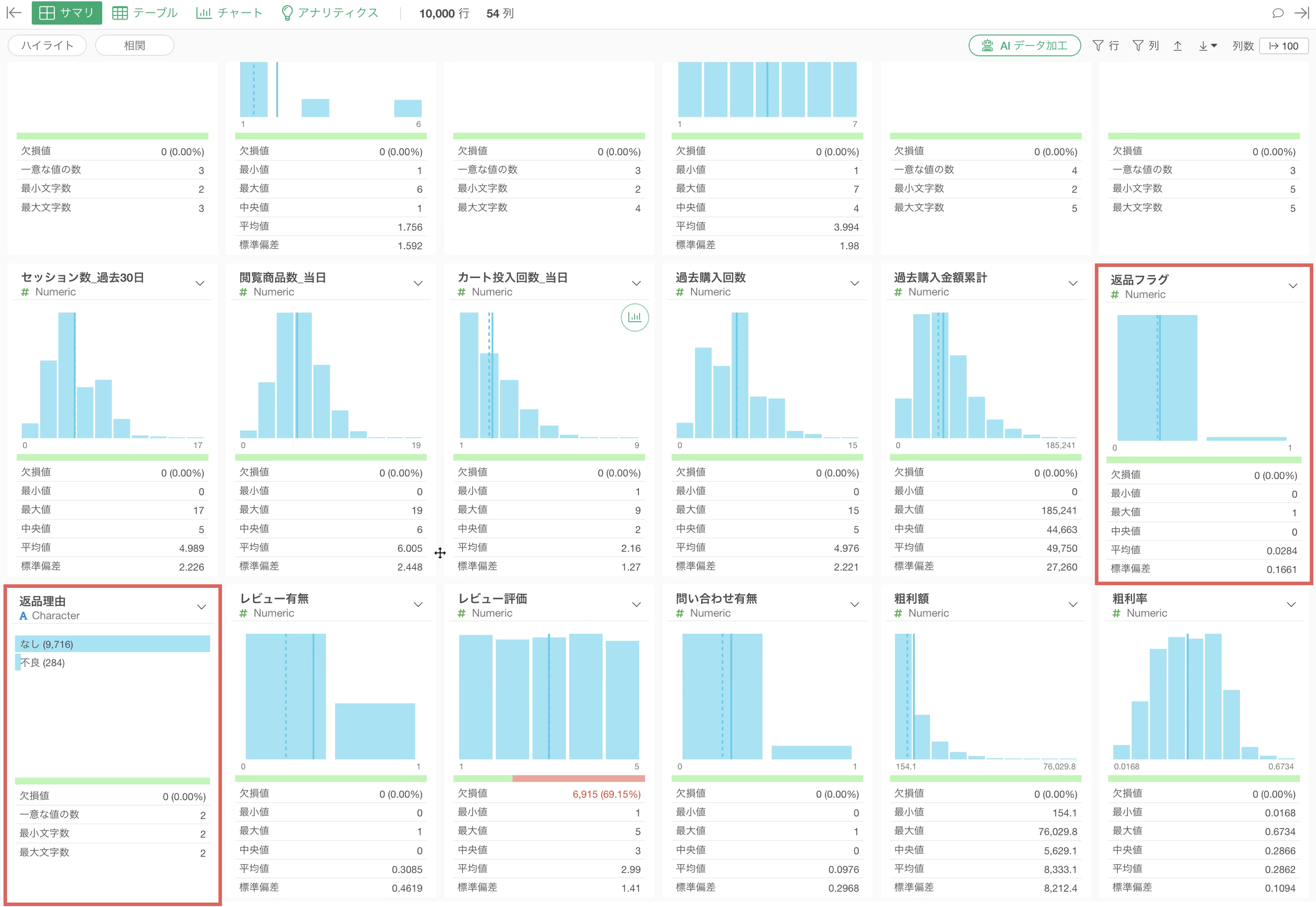
これで必要な列と不要な列の当たりをつけることができました。
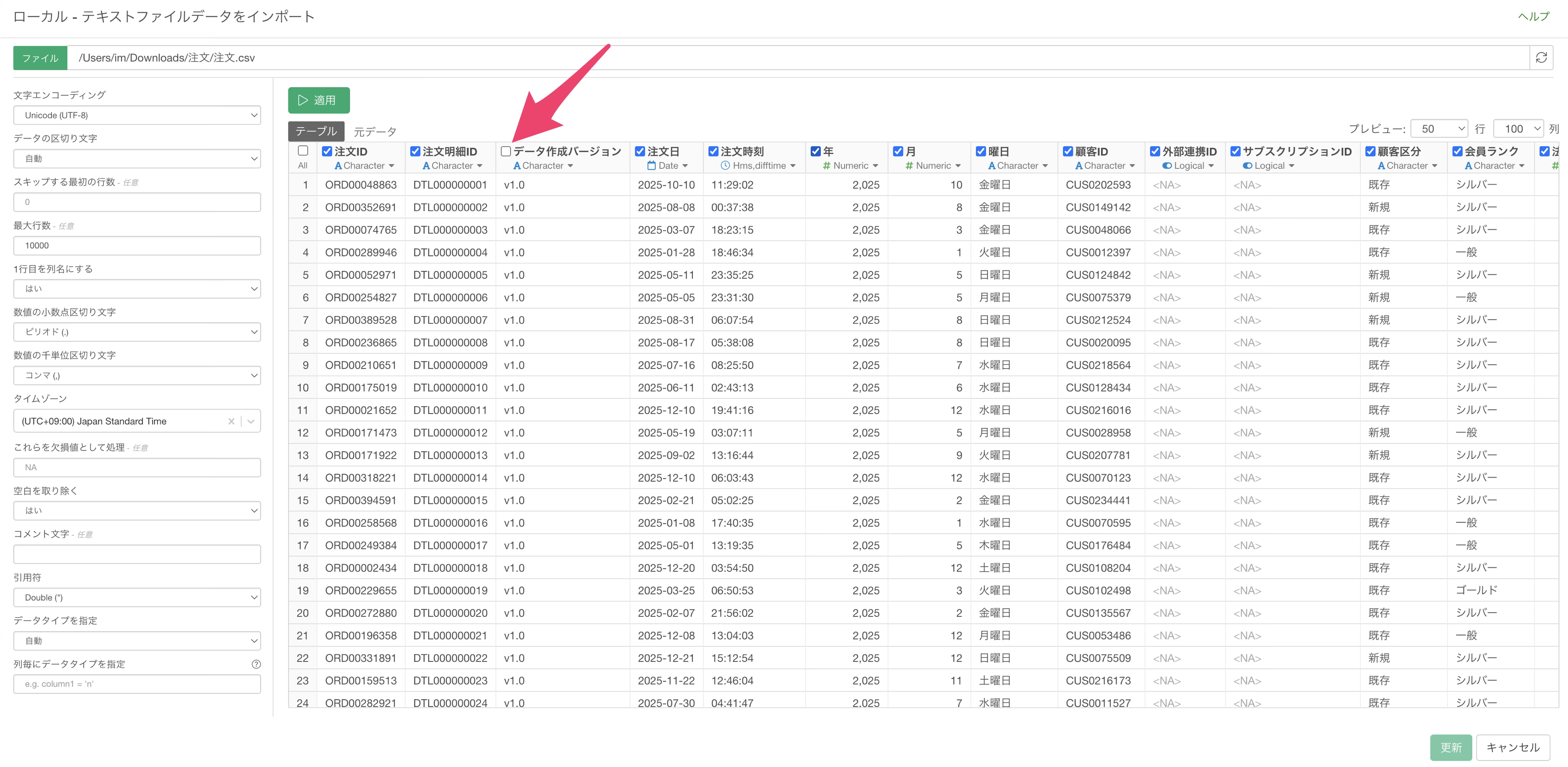
概要確認の結果をもとに、インポートが不要な列を特定したら、再度インポートダイアログを開きます。
インポートダイアログが開いたら、不要と判断した列のチェックを外していきます。
必要な列だけを選択できたら、「最大行数」の入力欄をクリアして全件取り込みの状態に戻し、「適用」ボタンをクリックしてデータを更新します。
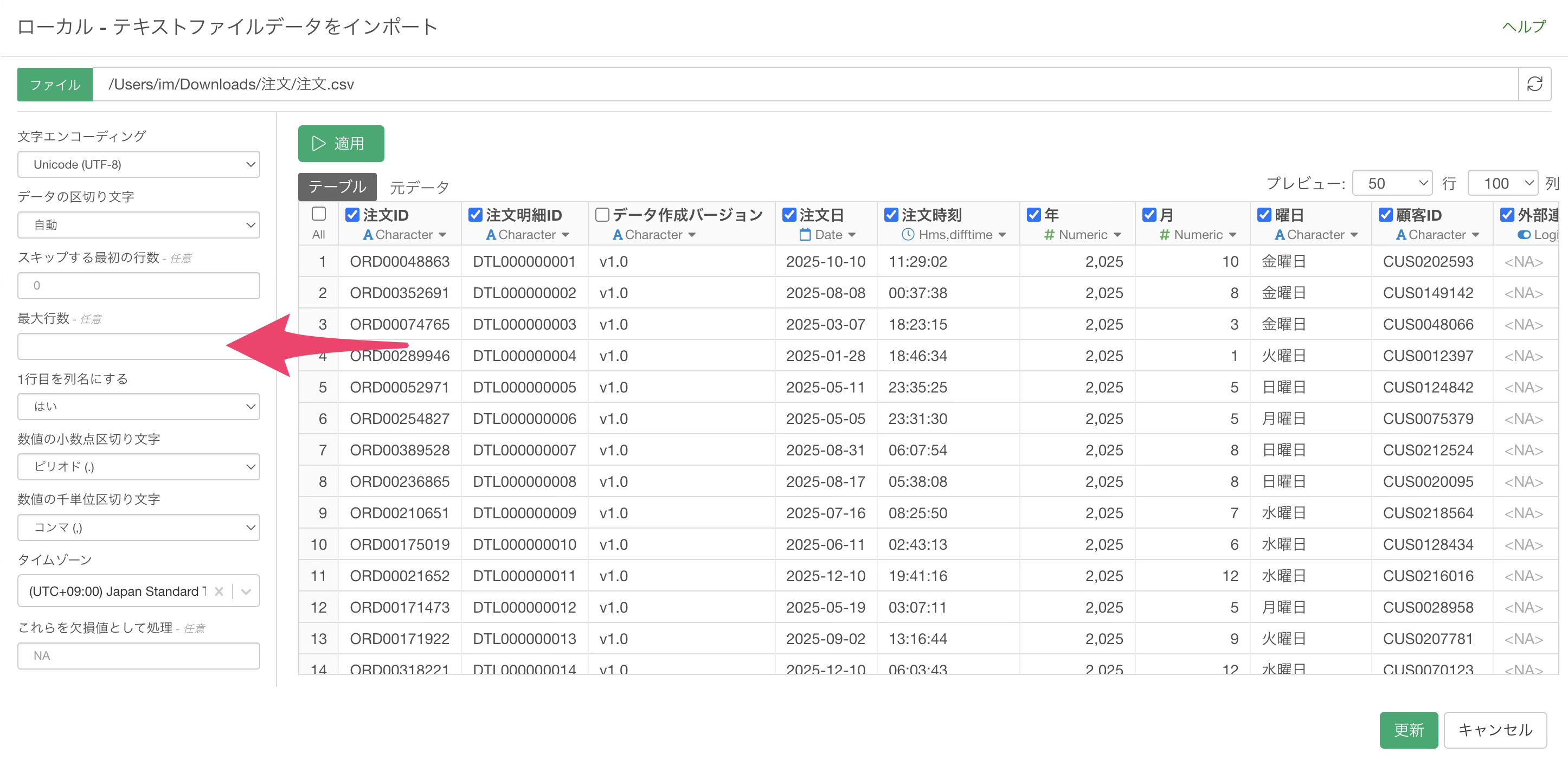 インポートする列数を削減した状態でインポートすることで、全列をそのままインポートする場合と比べてインポートにかかる時間を大幅に短縮することができます。
インポートする列数を削減した状態でインポートすることで、全列をそのままインポートする場合と比べてインポートにかかる時間を大幅に短縮することができます。
これで大容量ファイルから必要なデータだけを効率よくインポートする一連の操作が完了しました。
ビデオ
参考情報
- CSVのデータソースでデータのインポート時に最大行数を指定する方法 - リンク