複数の数値列の値を集計して新しい列として追加する方法
行ごとに、複数の数値列の値を集計(例えば合計値や平均値など)した結果を新しい列として追加したい場合は、「計算の作成」のステップの中でsummarize_rowという関数を使うことで実現できます。
これは合計値や平均値だけでなく、以下の集計関数がサポートされています。
- sum: 合計値
- mean: 平均値
- median: 中央値
- mode: 最頻値
- max: 最大値
- min: 最小値
今回は顧客満足度調査のデータを使用していきます。
1行が1回答者のデータで、列にはアンケートの5段階評価に対する回答の列があります。
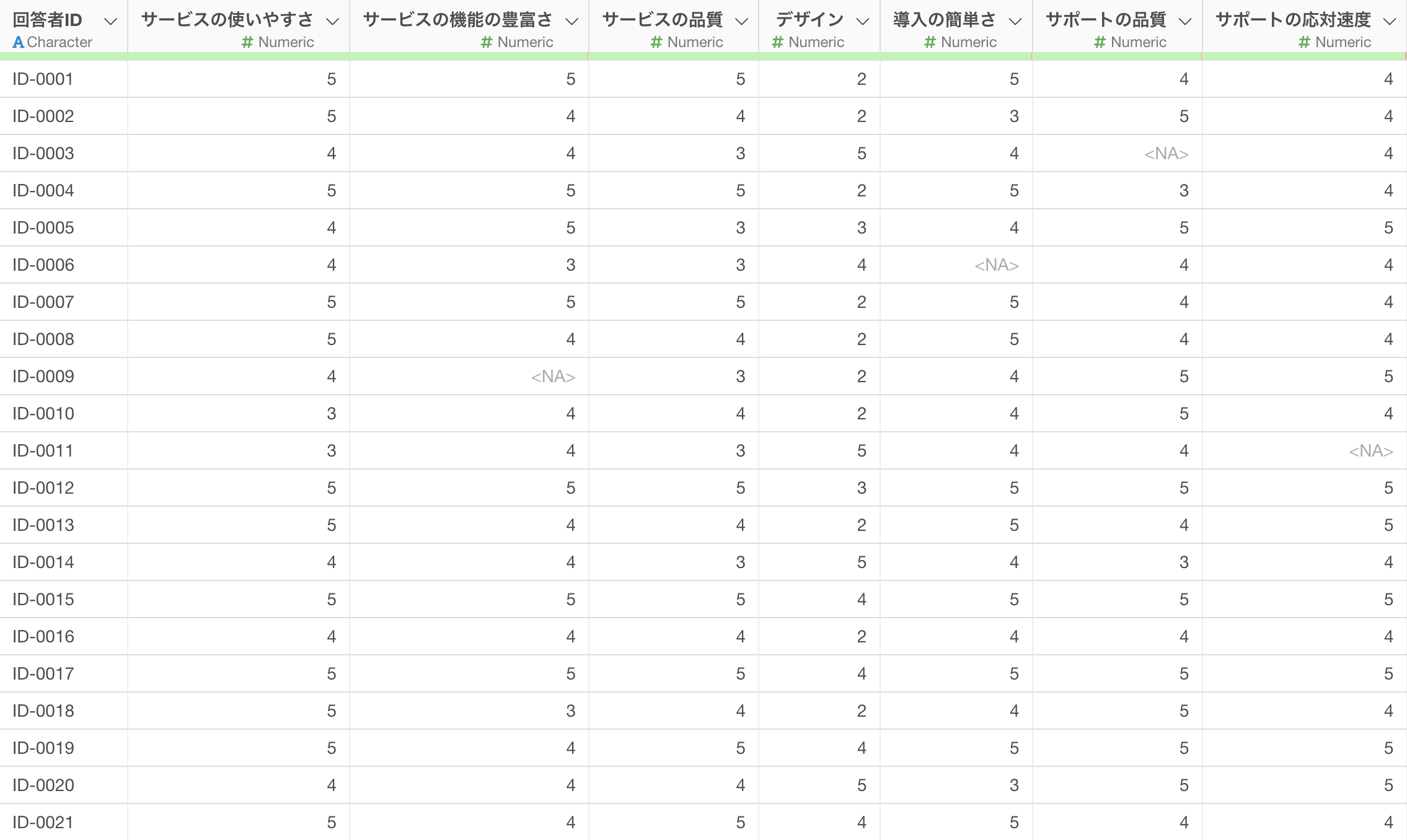
やりたいこととしては、回答者ごと、つまり行ごとにアンケートの質問に対する回答の平均値を求めたいです。
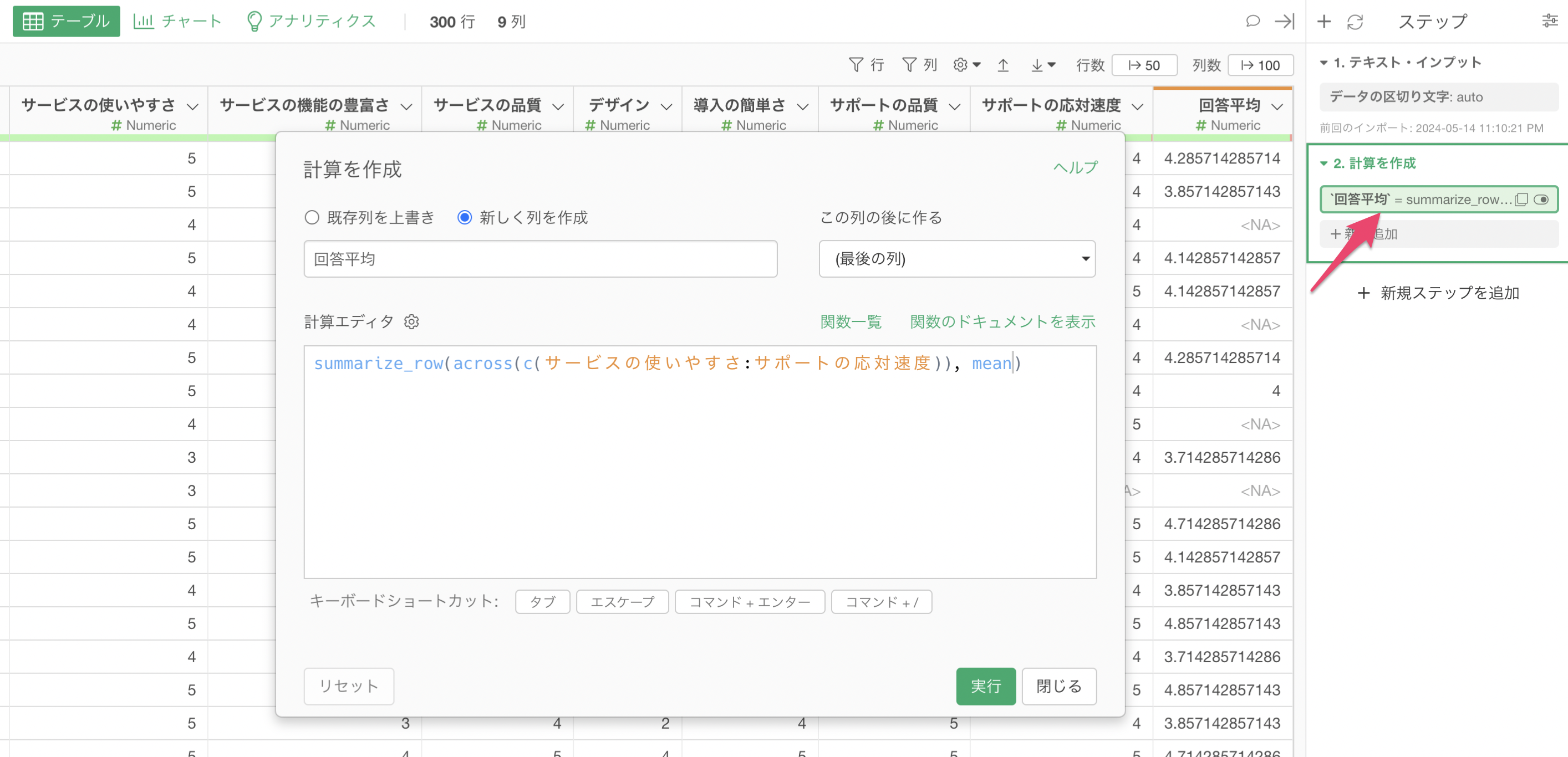
列ヘッダメニューから「計算を作成」の「標準」を選択します。
計算を作成のダイアログが表示されるため、計算エディタの中身は削除します。
次に、下記のようにsummarize_row関数を使います。across関数の中にc関数を使うことで列を指定することができ、カンマ(,)区切りで1列ずつ指定が可能です。
summarize_row(across(c(サービスの使いやすさ, サービスの機能の豊富さ)))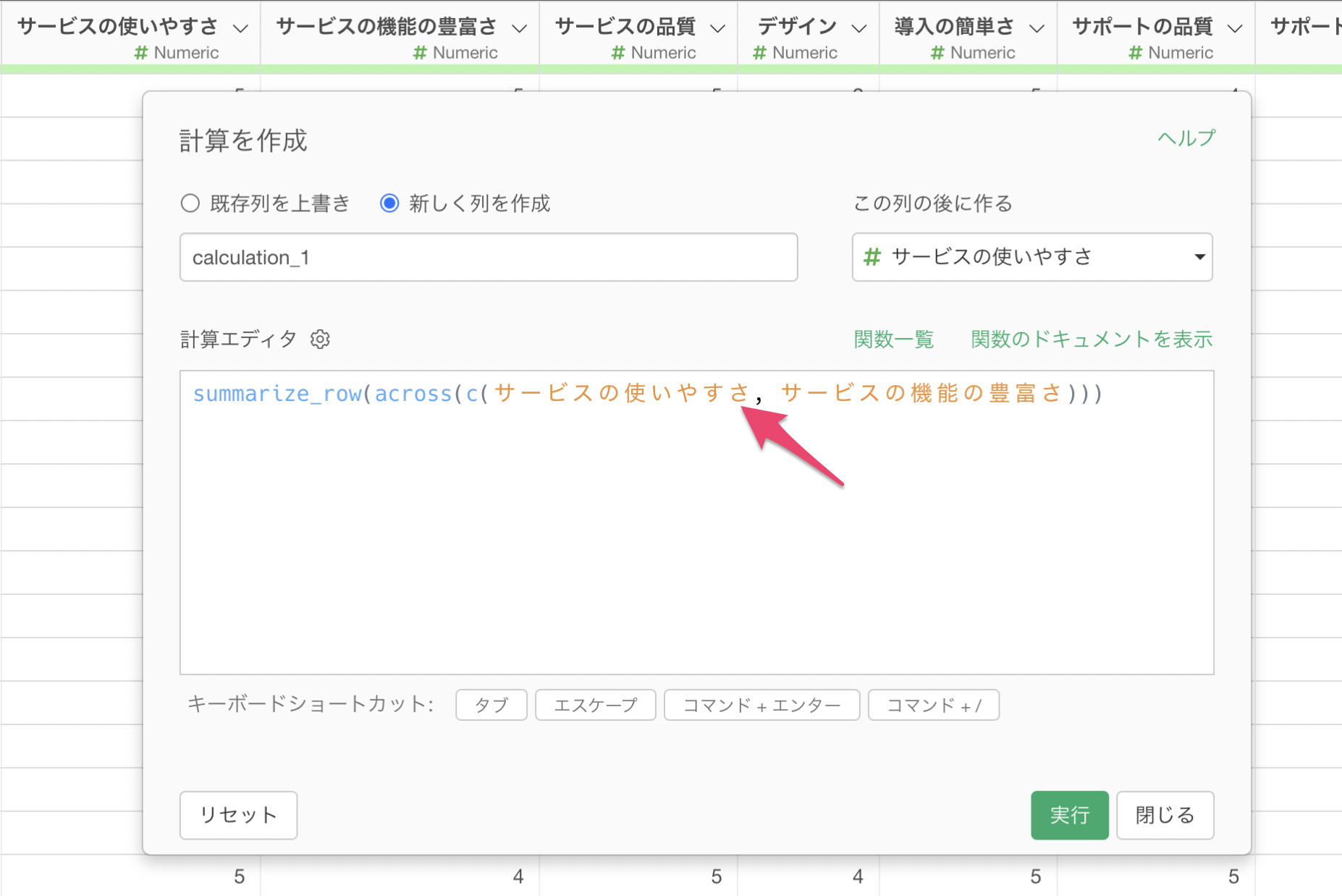
しかし、今回は7列分質問に対する回答の列があるため、1つずつ列を指定するのは大変な作業となります。
そこで、以下のようにc関数の中に列の範囲をコロン(:)使って指定ができます。今回は「サービスの使いやすさ」から「サポートの応対速度」までの列を指定しています。
summarize_row(across(c(サービスの使いやすさ:サポートの応対速度)))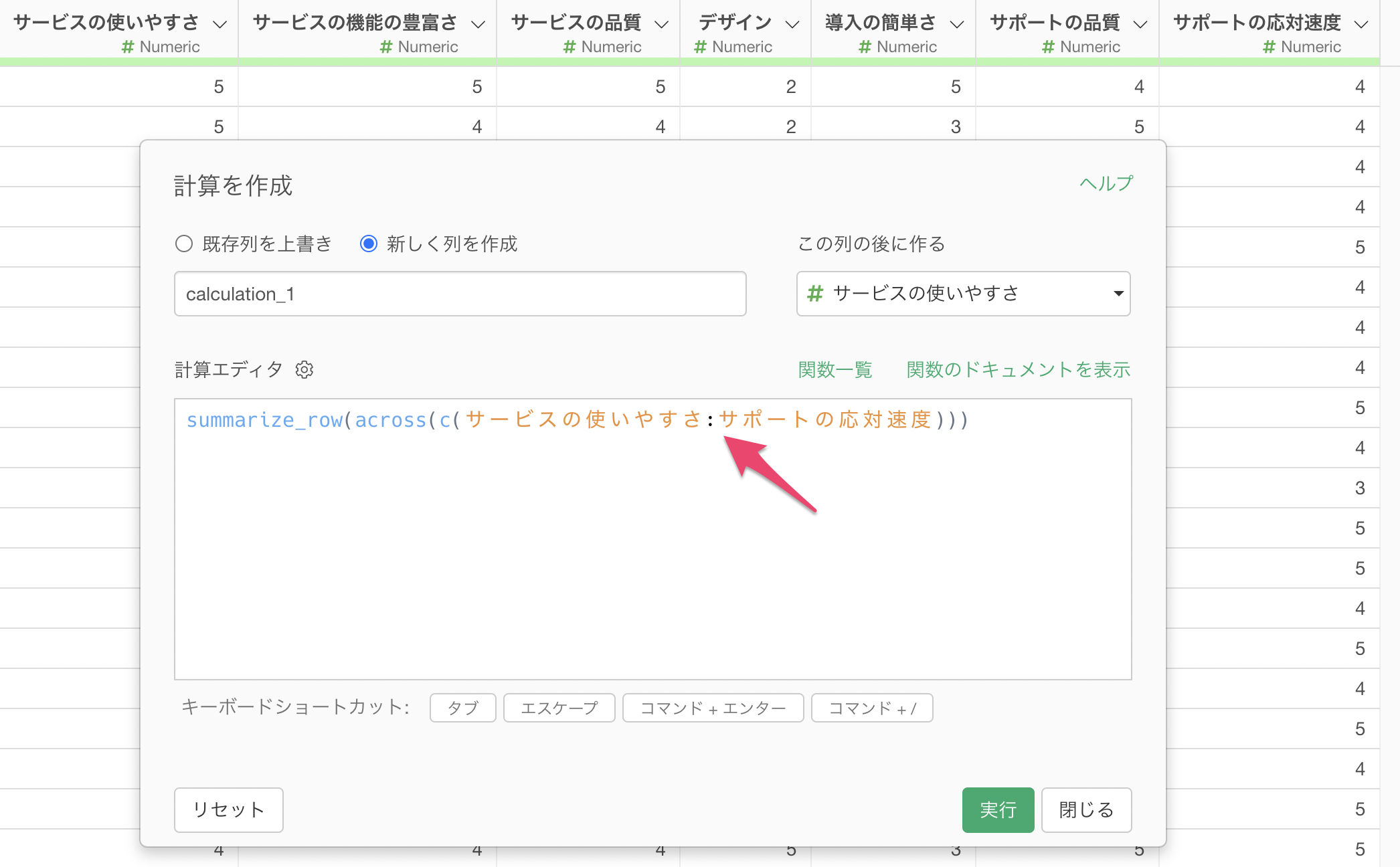
列の指定ができたら、指定した列に対して集計関数を指定します。平均値の場合は、mean関数を使うこととなります。
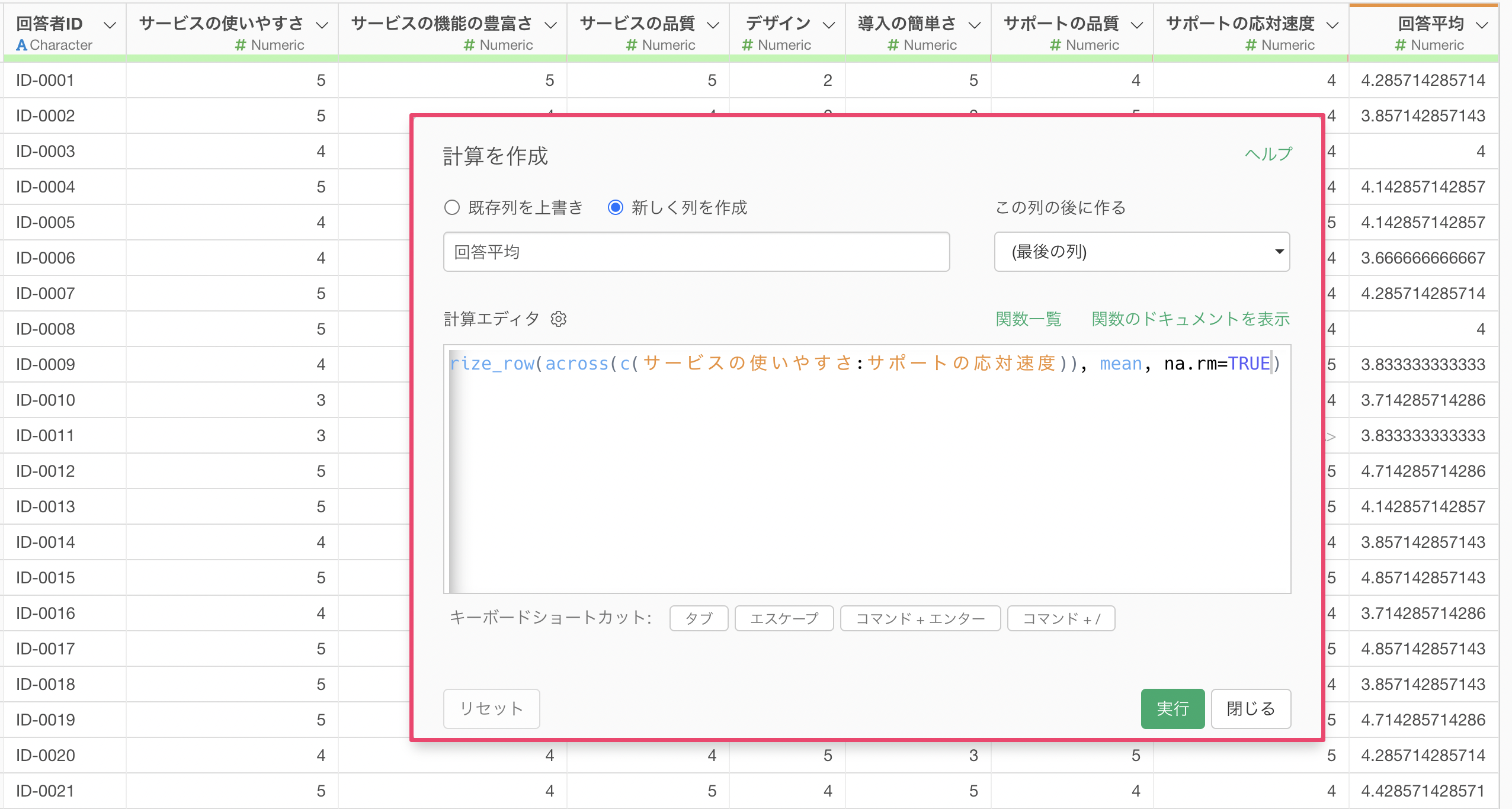
summarize_row(across(c(サービスの使いやすさ:サポートの応対速度)), mean)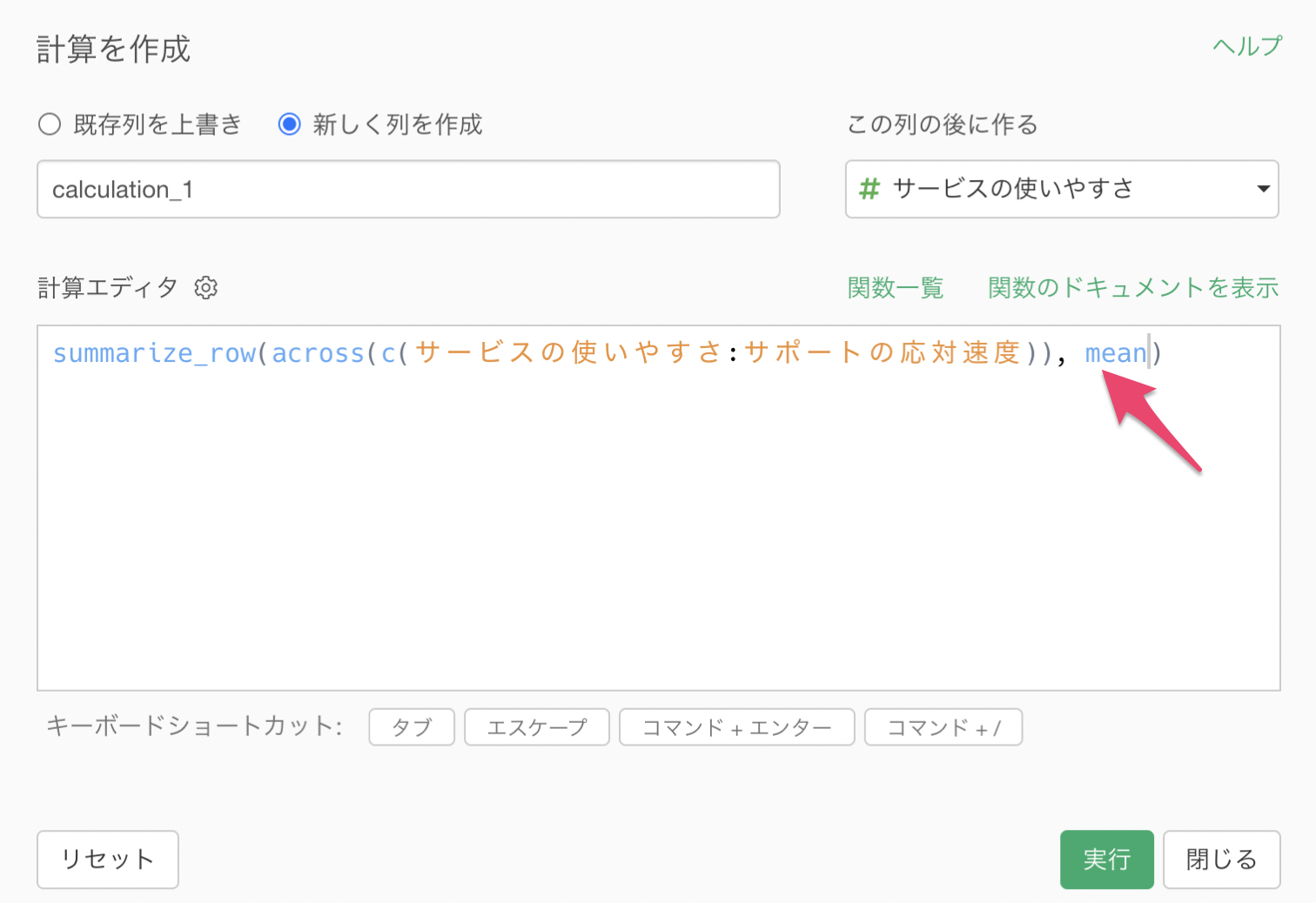
新しく列を作成にチェックをつけ、列名には「回答平均」、この列の後に作るには「最後の列」を選択して実行します。
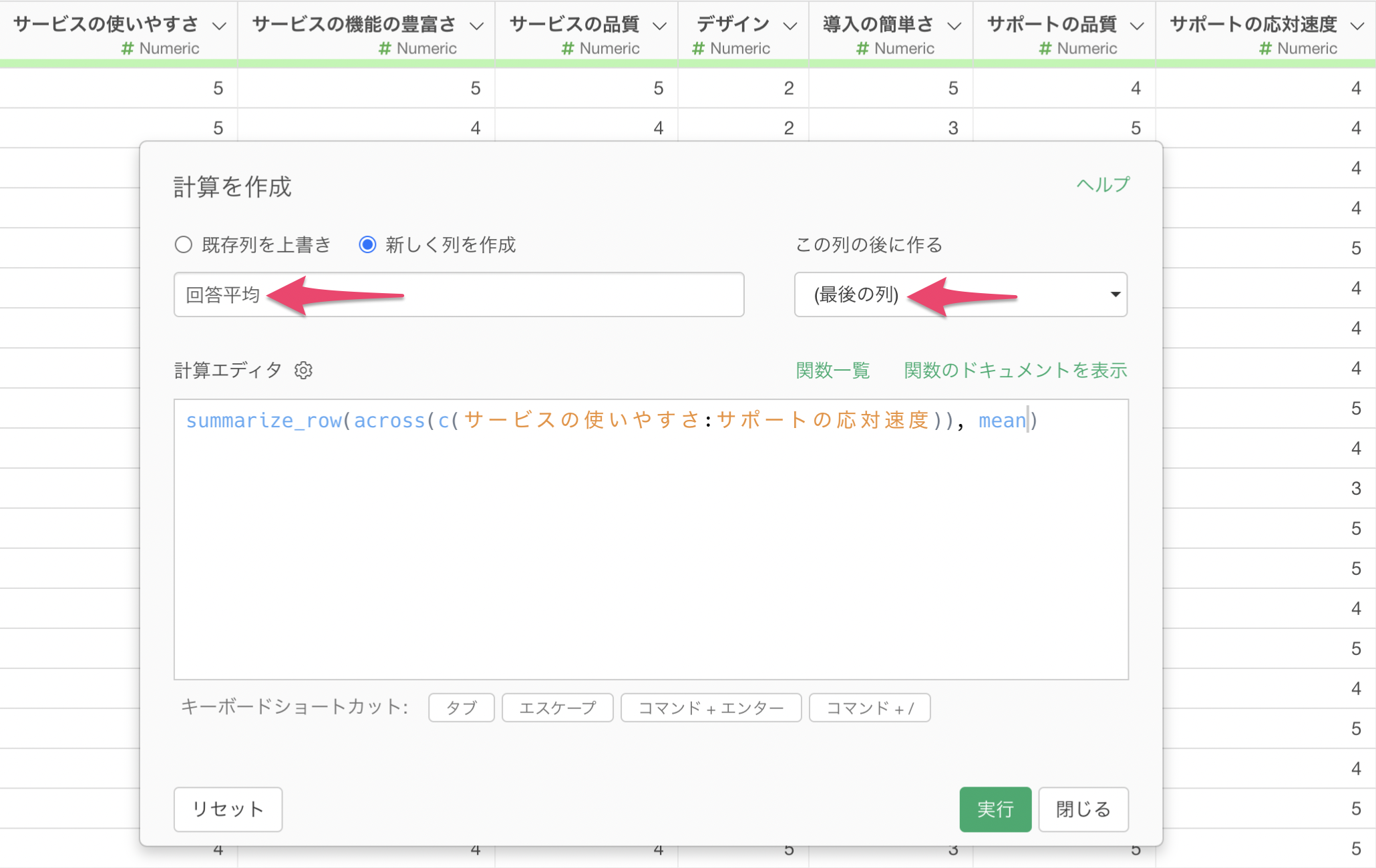
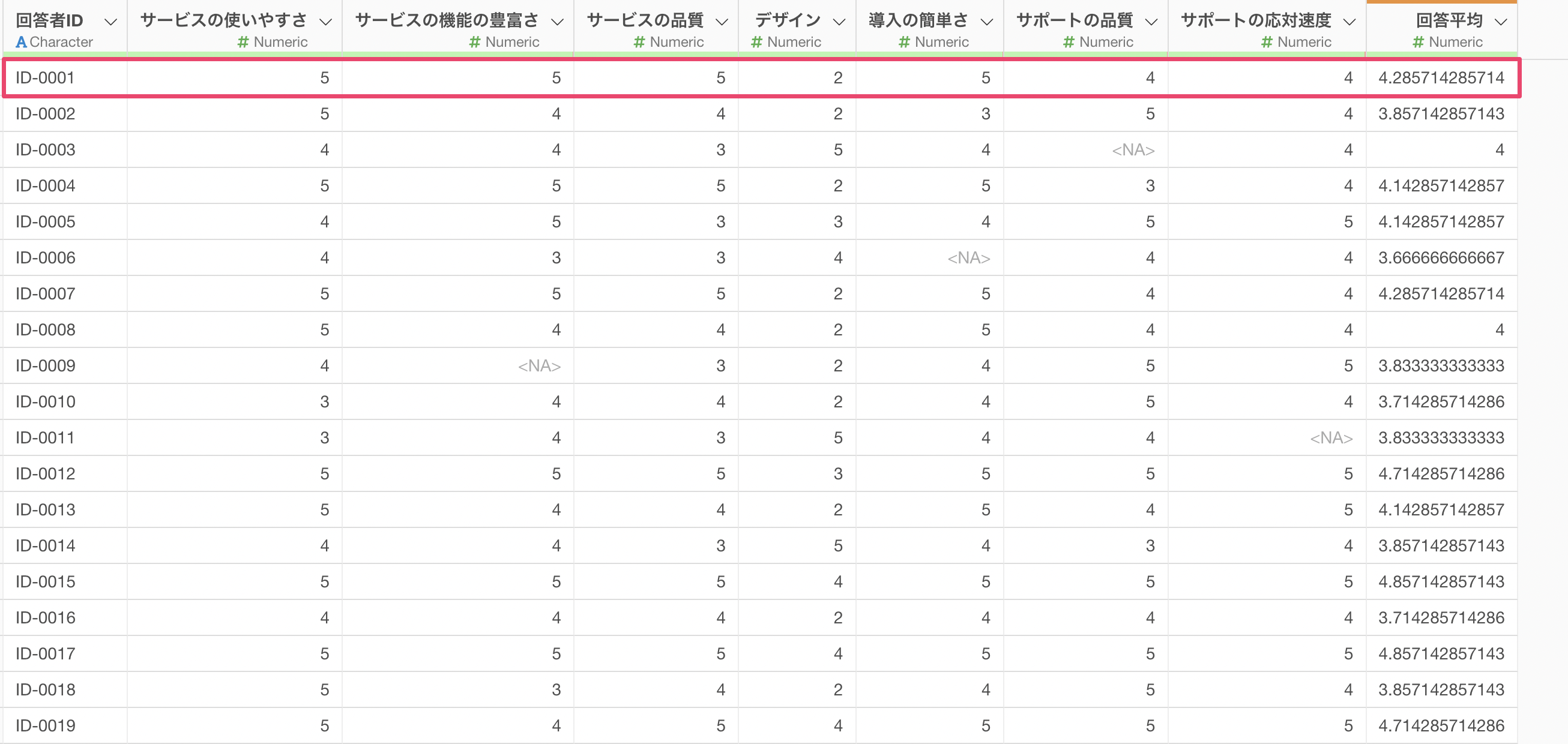
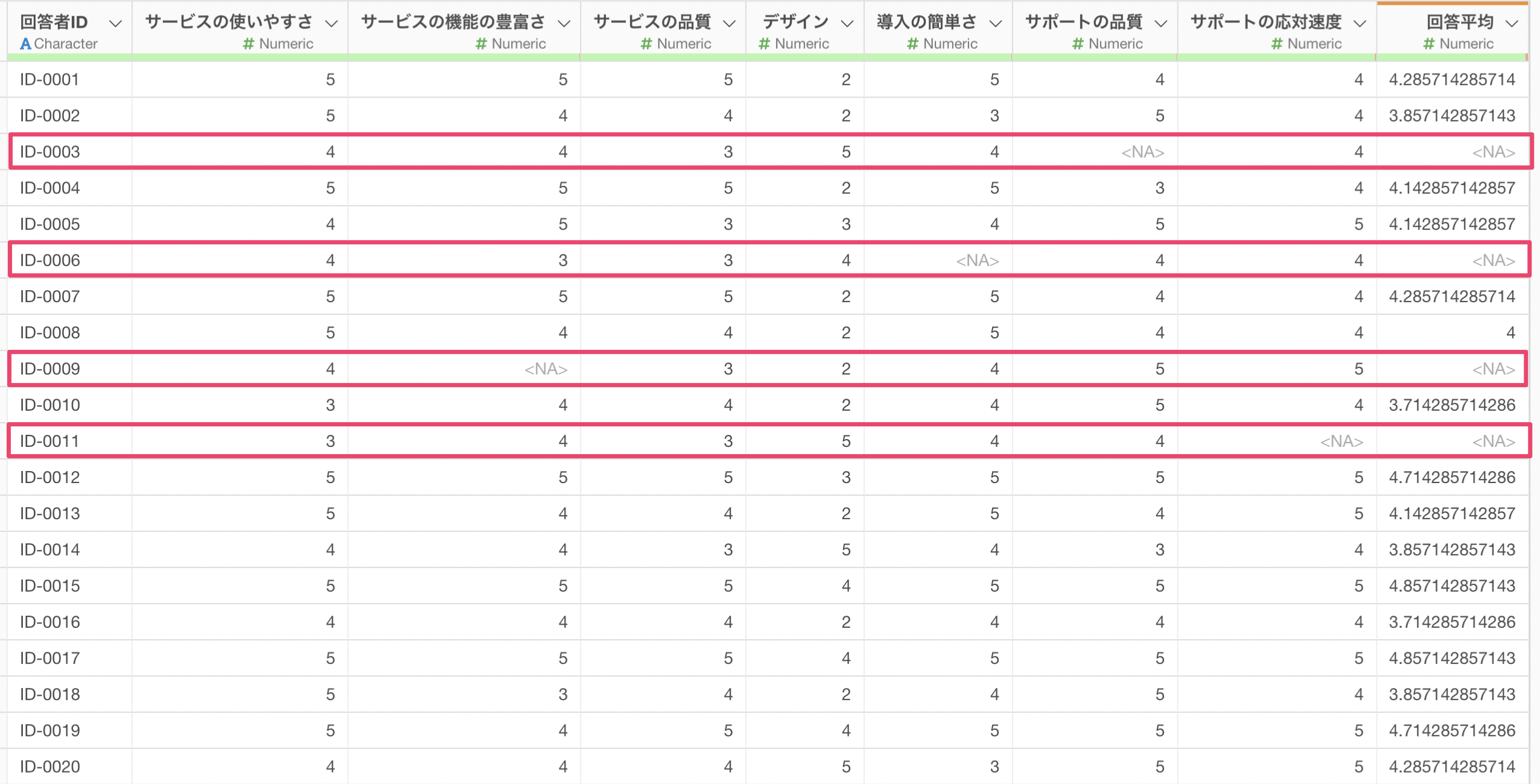
これによって、回答者ごと(行ごと)にアンケートの質問に対する回答平均を求めることができました。
しかし、いくつかの値は欠損値(NA)となっています。理由としては、計算対象の「サービスの使いやすさ」から「サポートの応対速度」の列のなかで一つでも欠損値があると、計算結果も欠損値として返してしまうためです。
そこで、計算を作成のステップのトークンをクリックして計算式を修正します。
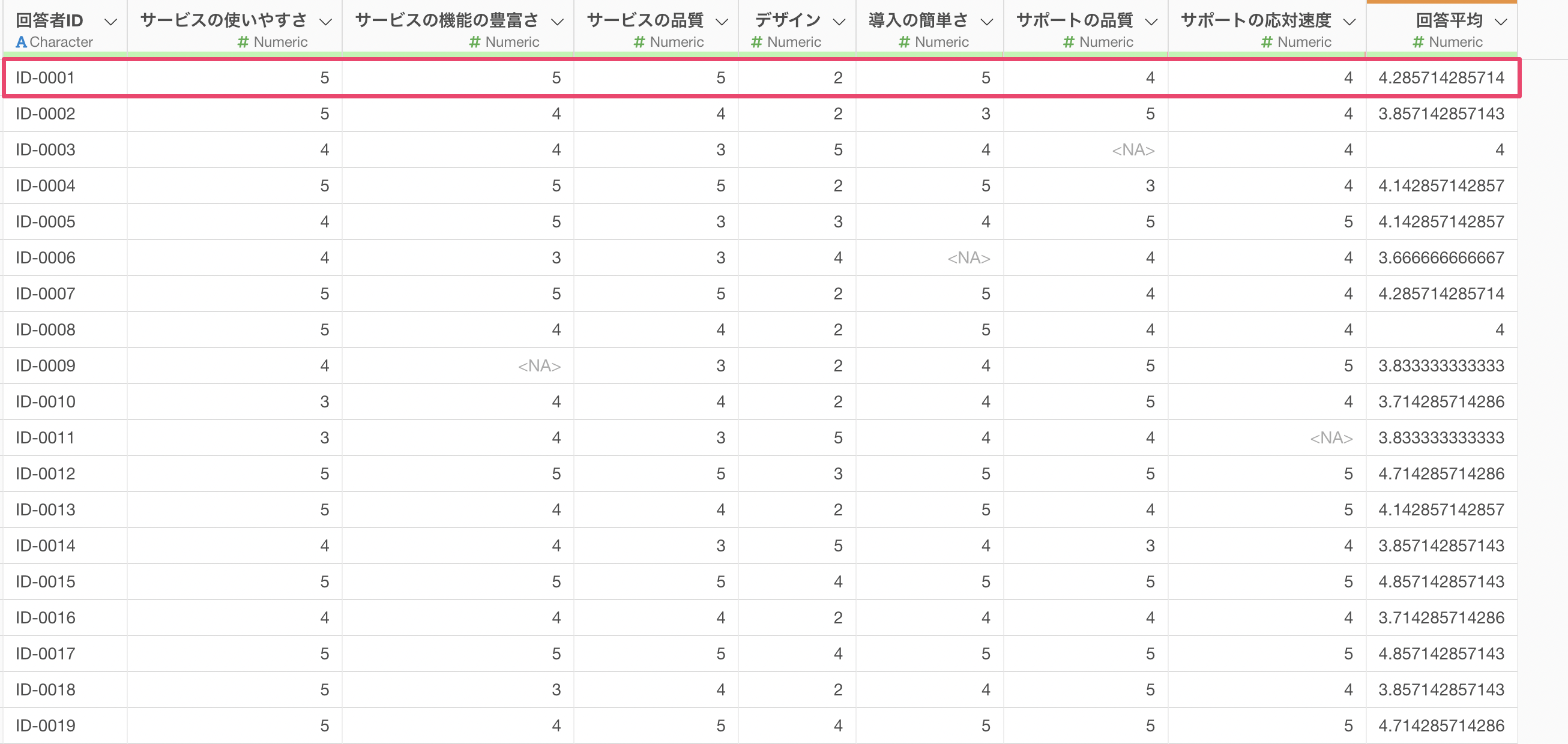
summarize_row関数の最後の引数として、na.rm = TRUE を追加します。
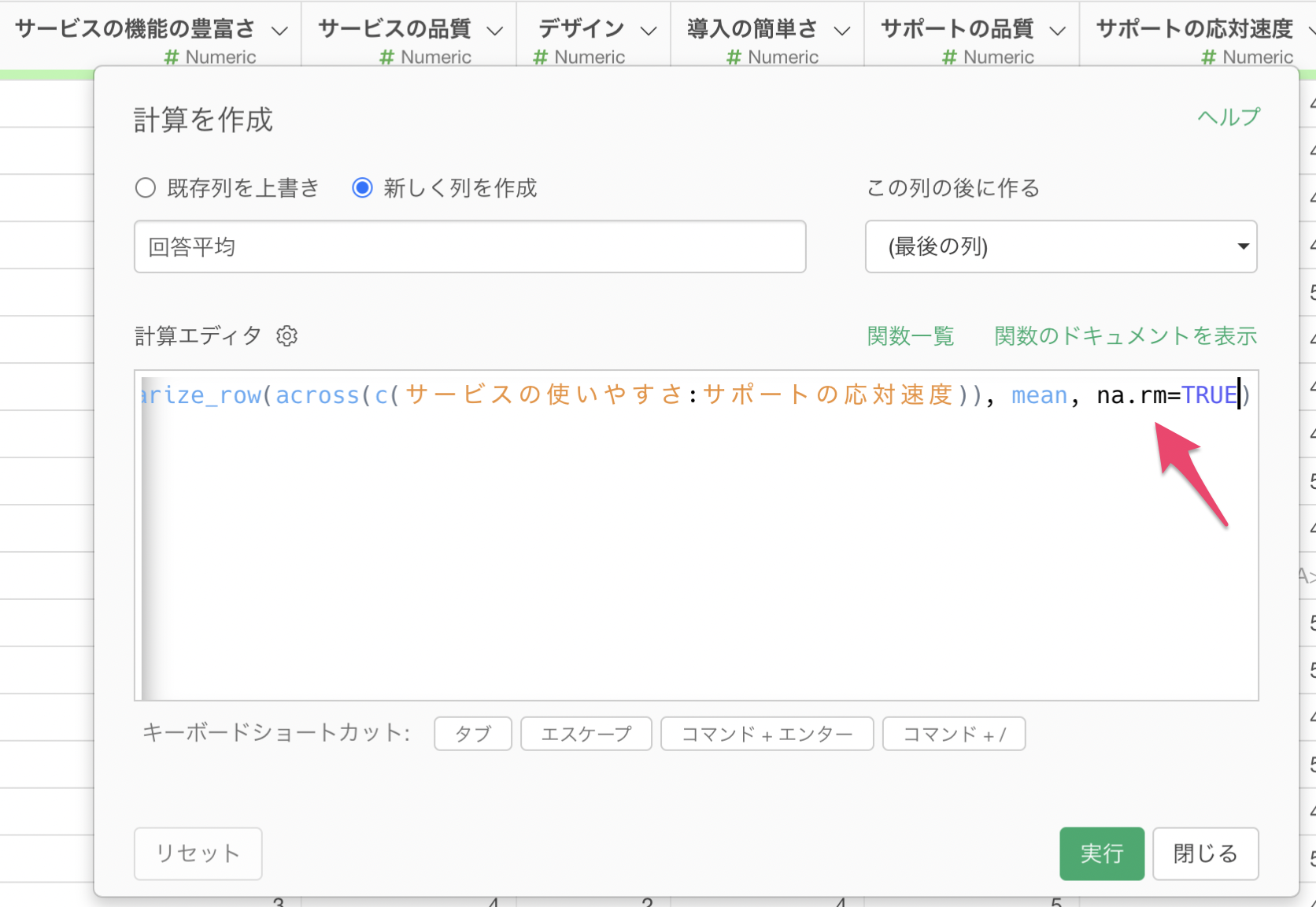
この引数は、計算対象の列に欠損値があったとしても、欠損値を除いた上で計算をしてくれるものとなっています。
実行することで、計算対象の列に欠損値があっても、回答平均の値が求められていることがわかります。
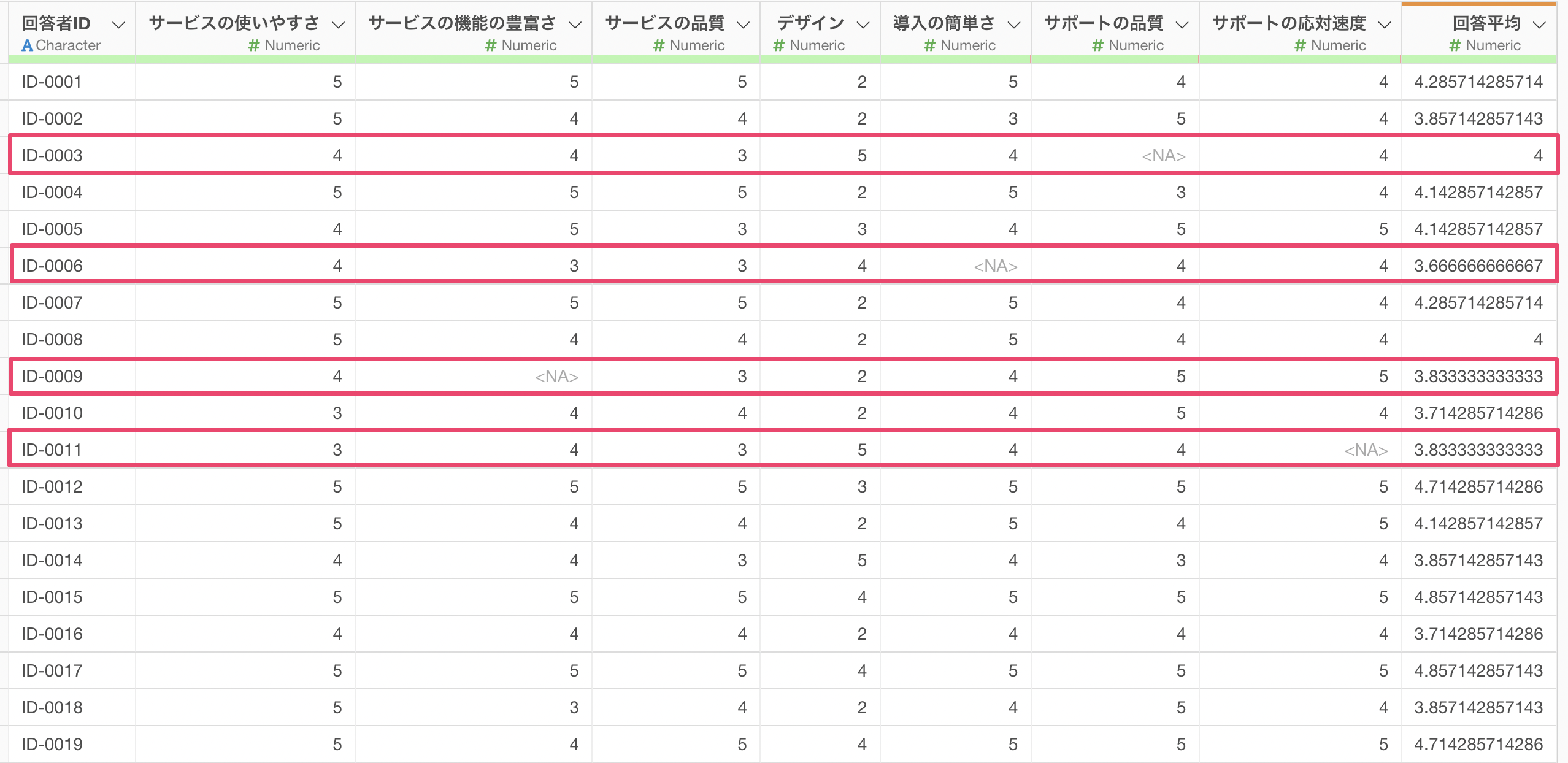
今回紹介したように、行ごとに集計した値を求めたい場合はsummarize_row関数を使用してみてください!
参考資料
今回は、「行ごとに値を集計する方法」について紹介していきました。
行ごとに値を集計する方法については他にも参考資料がありますので、ご興味がありましたらぜひご覧ください。