AI 関数を使った名寄せ、表記揺れの解決
「田中さん、顧客リストなんだけど、『トヨタ』『トヨタ自動車』『トヨタ自動車(株)』って全部同じ会社だよね?これ、集計する前に手作業で直さないと…」
画面に表示された顧客リストには、同じ企業を指しているはずなのに、入力者によって表記が異なる「表記揺れ」が無数に存在しています。
あなたは知っています。この作業に何時間かかるかを。そして、これが本来やるべき分析業務ではないことも。
データ分析の現場では、こうした「表記揺れ」が、あなたの時間を奪い続けています。
分析精度の低下: 同一のものが別物としてカウントされ、正確な実態を把握できない
膨大な時間の浪費: 本来なら戦略立案に使えるはずの時間が、データ修正に消えていく
機会損失: 不正確なデータに基づく意思決定により、ビジネスチャンスを逃してしまう
従来、この問題を解決するには、専門の担当者がルールベースのプログラムを書いたり、あるいはあなた自身が延々と手作業で修正したりする必要がありました。
しかし、Exploratory v14で追加されたAI 関数が、この状況を根底から変えようとしています。
あなたの分析を阻む、4つの「よくある表記揺れ」問題
「表記揺れ」と一言で言っても、そのパターンは様々です。あなたの目の前にあるデータにも、こんな問題が潜んでいませんか?
問題1: 企業名・組織名の表記揺れ
同じ会社を指しているはずなのに、「トヨタ」「トヨタ自動車」「トヨタ自動車(株)」のように、法人格の有無、略称・通称が混在するケースです。さらに厄介なのが、「ユニクロ」や「無印良品」のように店舗名の通称が使われてしまうことです。
| 具体例(統一前) | 統一後の例 |
|---|---|
| トヨタ | トヨタ自動車株式会社 |
| トヨタ自動車 | トヨタ自動車株式会社 |
| トヨタ自動車(株) | トヨタ自動車株式会社 |
| ホンダ | 本田技研工業株式会社 |
| 本田 | 本田技研工業株式会社 |
| 本田技研工業(株) | 本田技研工業株式会社 |
| ファーストリテイリング | 株式会社ファーストリテイリング |
| ユニクロ | 株式会社ファーストリテイリング |
| 良品計画 | 株式会社良品計画 |
| 無印良品 | 株式会社良品計画 |
人間が見れば、同じ企業であると理解できます。しかし、コンピュータは単なる「文字列」として認識するため、同じ企業でも表記方法が違うだけで「全くの別物」であると判断してしまうのです。それにより、正確な顧客数や取引社数の集計が困難になります。
問題2: 固有名詞の表記揺れ(表記法の違い)
全く同じものを指しているにもかかわらず、「Excel」「excel」「エクセル」のように、大文字・小文字、カタカナ・アルファベットといった純粋な表記法の違いで別々の値になってしまう問題です。
| 具体例(統一前) | 統一後の例 |
|---|---|
| Excel | Excel |
| excel | Excel |
| エクセル | Excel |
| Google Spread Sheets | Google Sheets |
| Sheets | Google Sheets |
| Google スプレッドシート | Google Sheets |
社内ツールの利用実態調査や特定の製品に関する自由回答の分析などで起こりがちですが、表記方法の違いによって別々な値として認識されてしまうため、正確な件数を把握したい場合に大きな妨げとなります。
問題3: 商品名・サービス名の表記揺れ(属性情報の混在)
「iphone 15 256GB」と「iphone 15 128GB 白」のように、本来は同じ製品シリーズなのに、色・容量・サイズといった属性(バリエーション)情報が付加されているために、別々の商品として扱われてしまう問題です。
| 具体例(統一前) | 統一後の例 |
|---|---|
| iphone 15 256GB | iPhone 15 |
| アイフォン 15 128GB | iPhone 15 |
| iphone 15 128GB 白 | iPhone 15 |
| IPHONE 15 256 GB 白 | iPhone 15 |
| Xperia 5 V 256GB | Xperia 5 V |
| XPERIA 5V 黒 128GB | Xperia 5 V |
| エクスペリア5 V 256GB | Xperia 5 V |
| Xperia 5 V 128GB ブルー | Xperia 5 V |
売上分析で「iPhone 15シリーズ」全体の動向を見たい時に、これらのバリエーションの違いがノイズになってしまいます。
問題4: 住所の表記揺れ
「東京都港区」と「港区」のような都道府県名の省略、「三丁目」と「3丁目」のような漢数字とアラビア数字の混在、全角・半角スペースの不統一など、住所データは特に表記揺れが発生しやすい項目です。
| 種類 | 具体例(統一前) | 統一後の例 |
|---|---|---|
| 全角/半角 | 東京都中央区銀座3 − 8 − 3 8 | 東京都中央区銀座3-8-38 |
| 漢数字/アラビア数字 | 東京都中央区銀座三丁目八番三十八号 | 東京都中央区銀座3丁目8-38 |
| 丁目番地表記 | 東京都中央区銀座3丁目8番地38 | 東京都中央区銀座3-8-38 |
| カタカナ表記 | 東京都渋谷区千駄ケ谷1-2-3 | 東京都渋谷区千駄ヶ谷1-2-3 |
| 都道府県の省略 | 港区南青山3-8-38 | 東京都港区南青山3-8-38 |
| 市区町村の省略 | 南青山3-8-38 | 東京都港区南青山3-8-38 |
| 大字の省略 | 長野市南長野県町 | 長野市大字南長野県町 |
| 複合的な表記揺れ | 博多区博多駅前三ー五ー七 | 福岡県福岡市博多区博多駅前3-5-7 |
住所の表記揺れが起きてしまうことで、顧客データの統合や配送管理の現場で大きな混乱を招くことにつながってしまいます。
そして、誰もが「手作業」という沼に沈んでいく
これほど多くの現場で問題になっているにもかかわらず、なぜ表記揺れは解決されないのでしょうか。それは、従来の解決策があまりにも高く、険しい壁だったからです。
まず試すのは「ルールを作って自動化」です。しかし、すぐに挫折します。
企業名の「前株/後株/株式会社なし」、ツール名の「大文字/小文字/カタカナ」、商品名の「容量/色/サイズ」、住所の「都道府県の有無/漢数字」など、一つのルールを作れば、必ず新たな例外が見つかります。気づけば、メンテナンス不能な「秘伝のタレ」のような複雑なルールが出来上がっているだけで、完璧な統一にはほど遠いのが現実でした。
次に考えるのは「専門家への依頼」です。しかし、見積もりを見て愕然とします。
「システム開発には数百万円、さらに月々の保守費用も…」「独自のAIモデルを構築するには、データサイエンティストの雇用と高価なインフラが…」。表記揺れの修正という「守り」の作業に、それほどの投資はできない。ほとんどの企業で、そう判断されてきました。
複雑すぎるルール、高すぎるコスト。この二つの壁を前に、多くの人が同じ結論にたどり着きます。
「今回は、手作業でお願いできる?」
その一言で、分析担当者の貴重な数時間、あるいは数日間が、単純なデータ修正作業に消えていくのです。本来やるべき分析や戦略立案の時間は奪われ、ただただ疲弊していく。
これが、データ分析の現場で繰り返されてきた、静かなる「地獄」の正体です。
でも、もう大丈夫です。
複雑なルールも、専門知識も不要。AI 関数が実現する表記の統一
ExploratoryのAI 関数は、最先端の大規模言語モデルの力を、あなたに届けます。
複雑なパターンマッチングも、ルール構築も、プログラミングも不要。必要なのは、たった一つ。あなたの言葉で、やりたいことを伝えるだけ。
使い方も驚くほど簡単です。
列ヘッダメニューから「AI 関数を作成」を選択します。
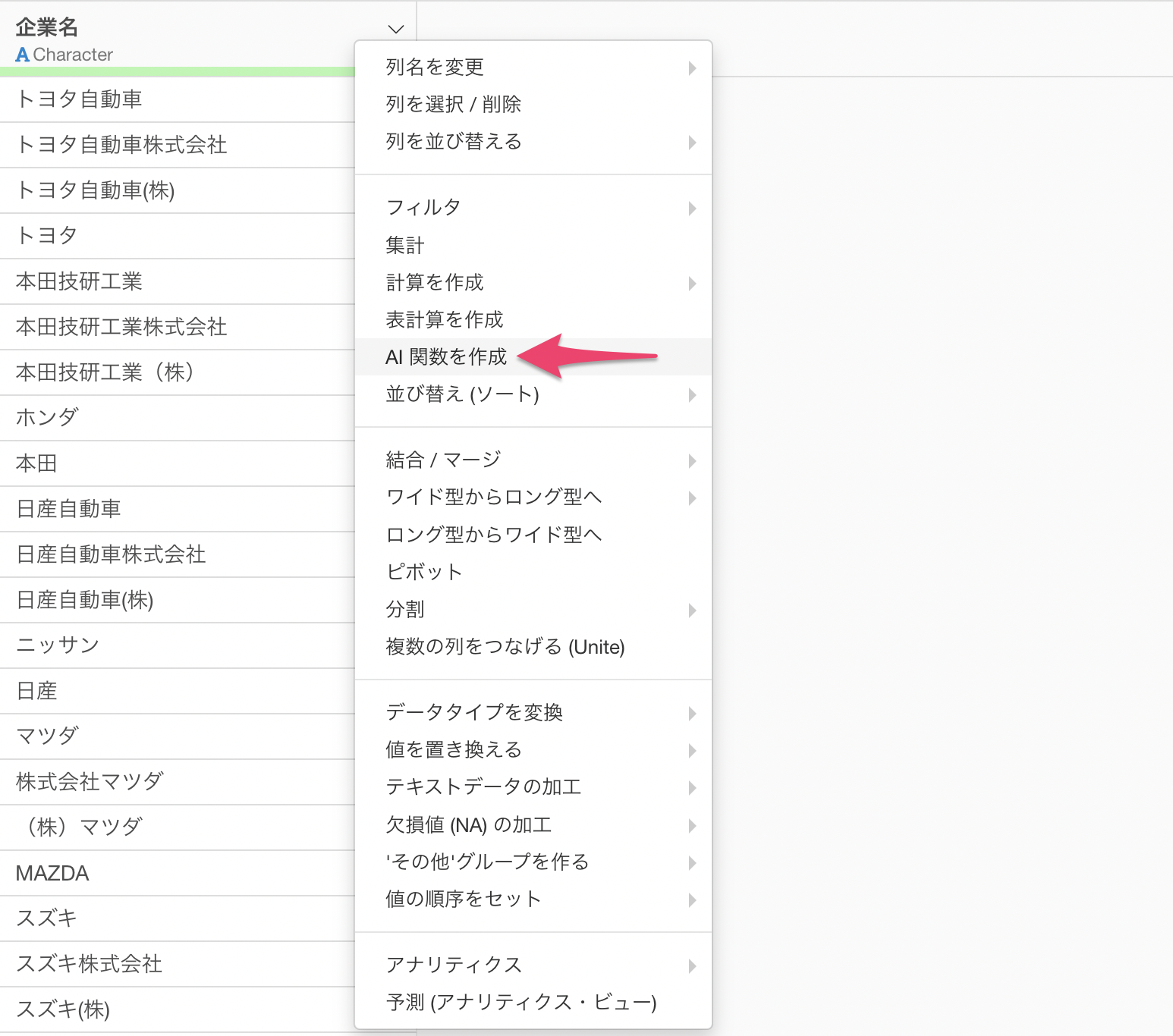
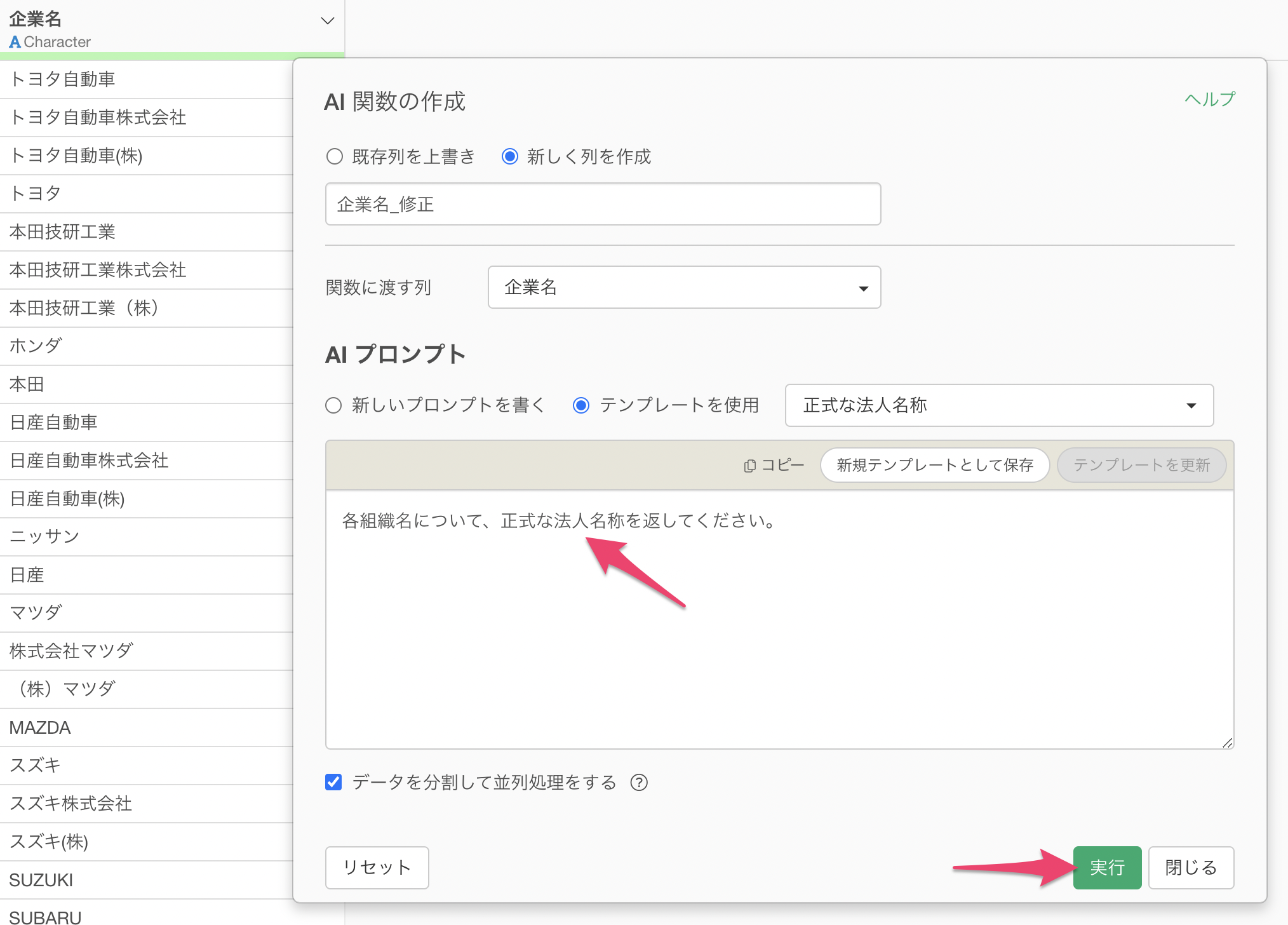
プロンプト入力欄にAIに実施して欲しい指示を書いて、実行するだけです。
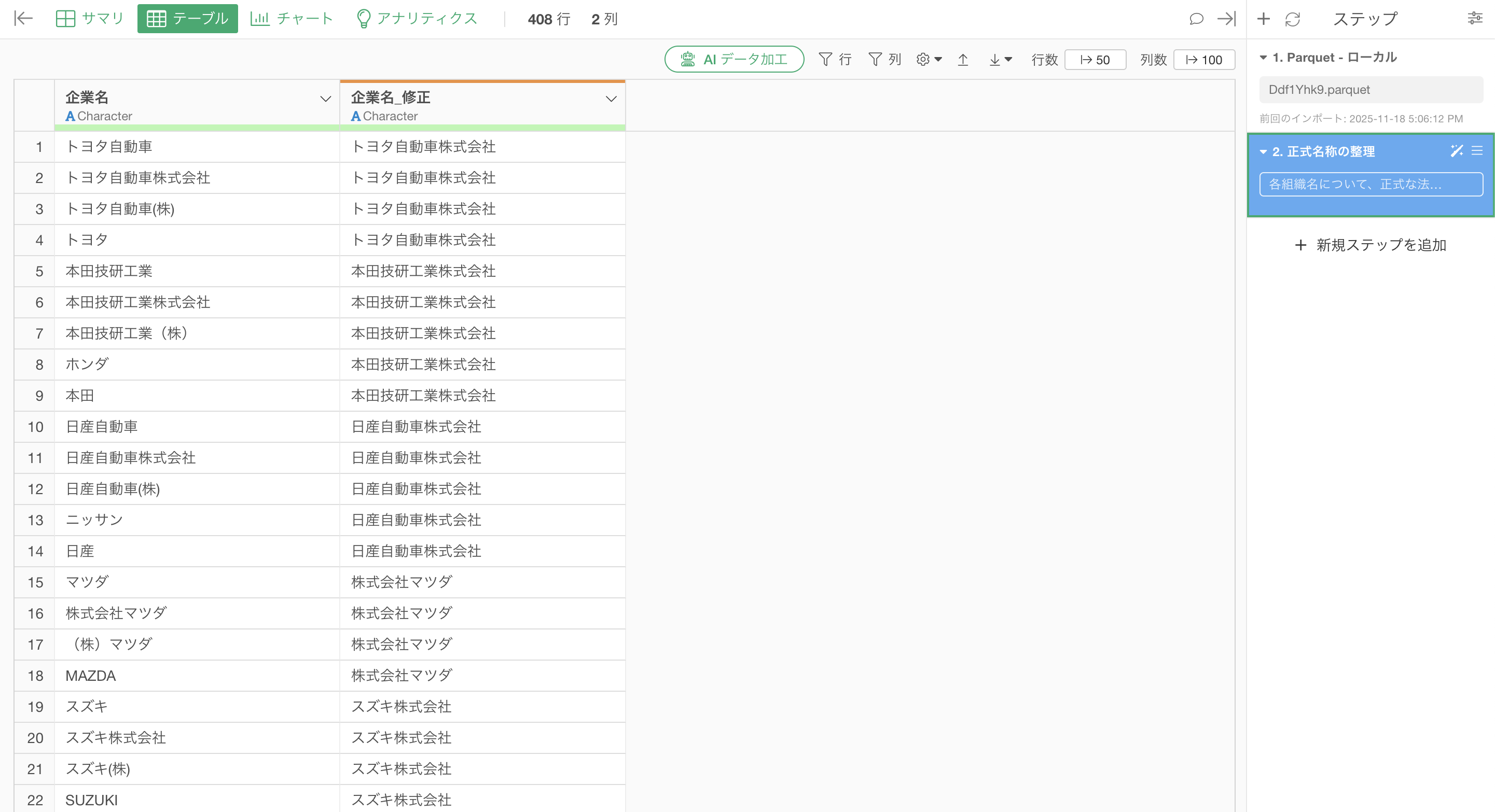
それだけで、数千行のデータに対する表記揺れ修正も、数十秒〜数分で完了します。
4つの典型的な表記揺れ解決ストーリー
それでは、実際の現場で起きている4つの典型的な問題を、AI 関数がどのように解決するのか見ていきましょう。
使用しているプロジェクトについては、こちらからダウンロードいただけます。
プロジェクトのインポート方法についてはこちらのノートをご覧ください。
1. 企業名・組織名の表記揺れ
営業企画部に異動して3ヶ月のあなた。部長から「取引先企業数を正確に把握したい」という指示が下りました。しかし、CRMデータを開いてみると…
同じトヨタ自動車が「トヨタ」「トヨタ自動車」「トヨタ自動車(株)」「トヨタ自動車株式会社」と4つの別企業としてカウントされています。本田技研工業も「ホンダ」「本田」「本田技研工業(株)」とバラバラ。このままでは正確な企業数すら出せません。
AI 関数による解決:
プロンプト入力欄に、以下のように書くだけです。
各組織名について、正式な法人名称を返してください。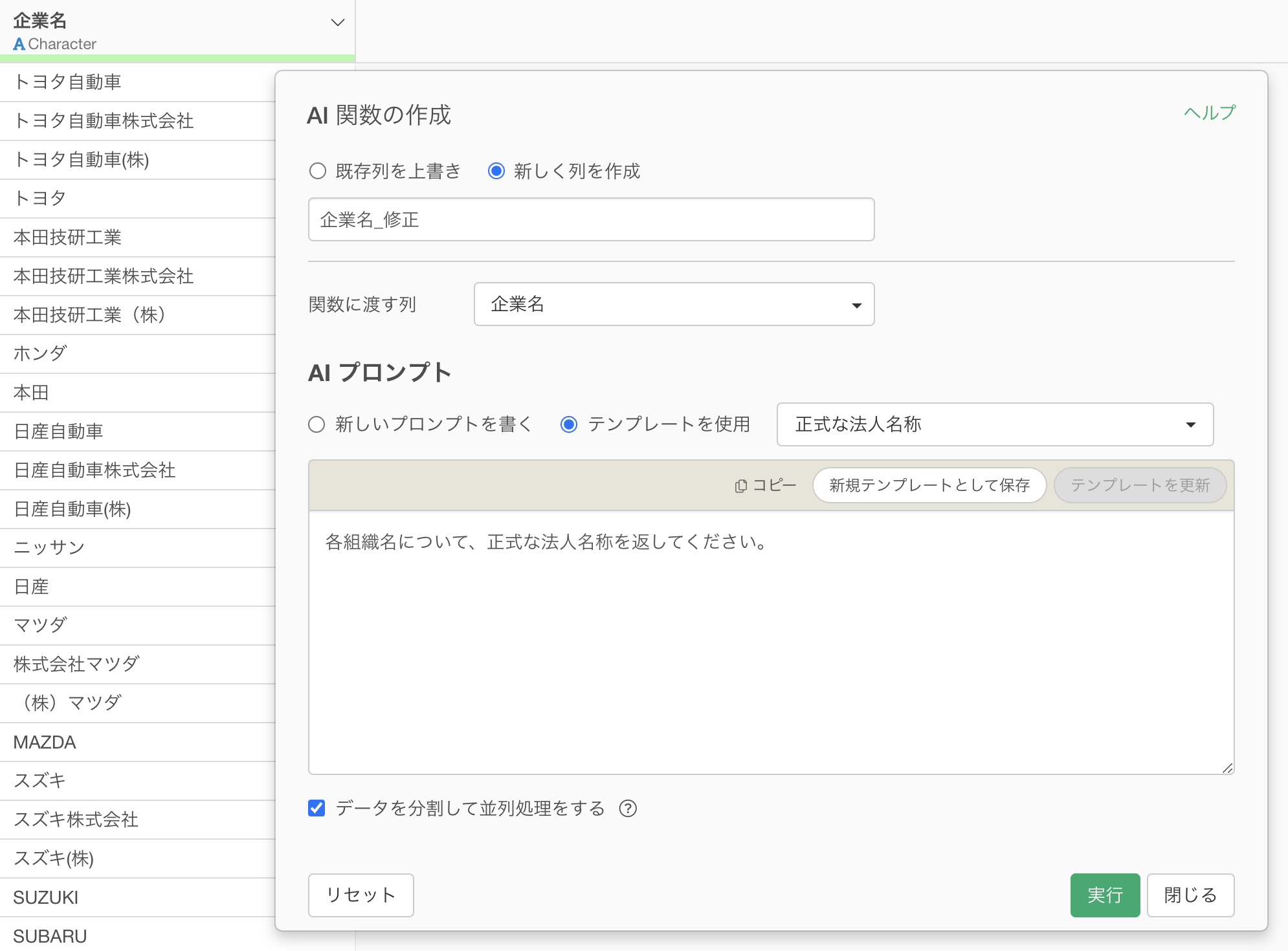
実行することで、以下のように表記揺れの修正ができています。
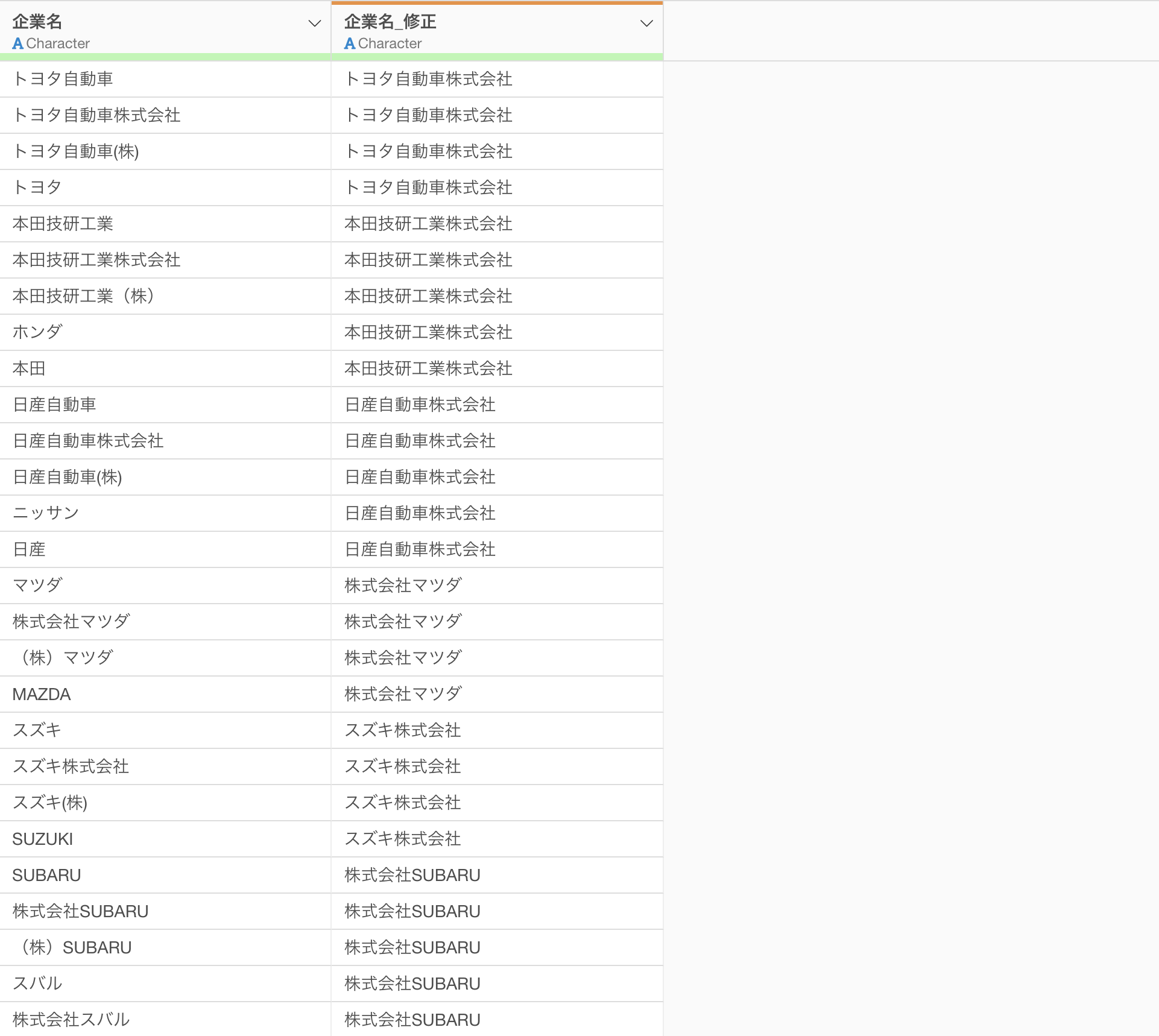
さらには、「ユニクロ」を「株式会社ファーストリテイリング」に、「無印良品」を「株式会社良品計画」にしてくれています。
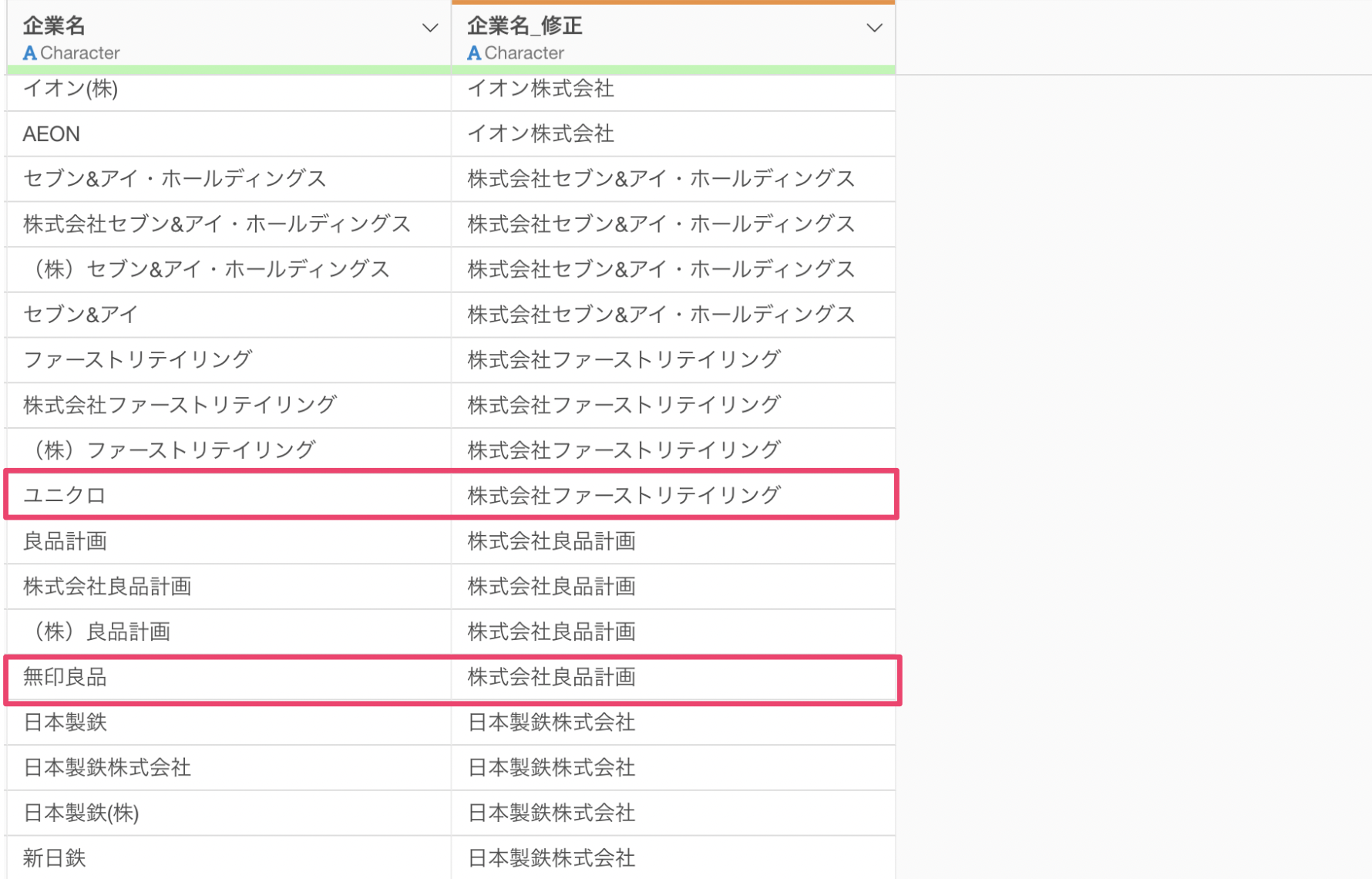
プログラムを書く必要も、一つひとつ手作業で直す必要もありませんでした。AIが通称から正式名称へ、略称から完全な法人名へ、そして前株・後株まで正確に変換してくれたのです。
2. 固有名詞の表記揺れ(表記法の違い)
あなたは情報システム部門で、社内のITツール利用状況を調査するアンケートを実施しました。しかし、回収した回答データを見て愕然としました。
同じExcelが「excel」「EXCEL」「エクセル」とバラバラ。さらに「excel colab」のように、複数のツールがスペース区切りで一つのセルに入力されているケースも。
これでは正確な利用状況が把握できません。
AI 関数による解決:
AI 関数に、期待する動作を明確に伝えます。
提供するツールの名称のデータで正式名称を返し、表記揺れを修正してください。不明な場合は結果は空で返してください。
例:
- Excel, excel, エクセル -> Excel
- Power BI, power bi, PowerBI -> Power BI
- Google スプレッドシート, Google Spreadsheets, Google Sheets -> Google Sheets
Power BIやTableauに対して、Excelと誤ったツールを返すことはしないでください。
同じツールに対しては、同じ正式名称を全く同じ文字として返すようにして下さい。(先頭や末尾に半角スペースはつけない)
また、一つのセルに複数の値が含まれている場合は、カンマ区切りで分けて結果を返して下さい。
Excel Power BI -> Excel, Power BI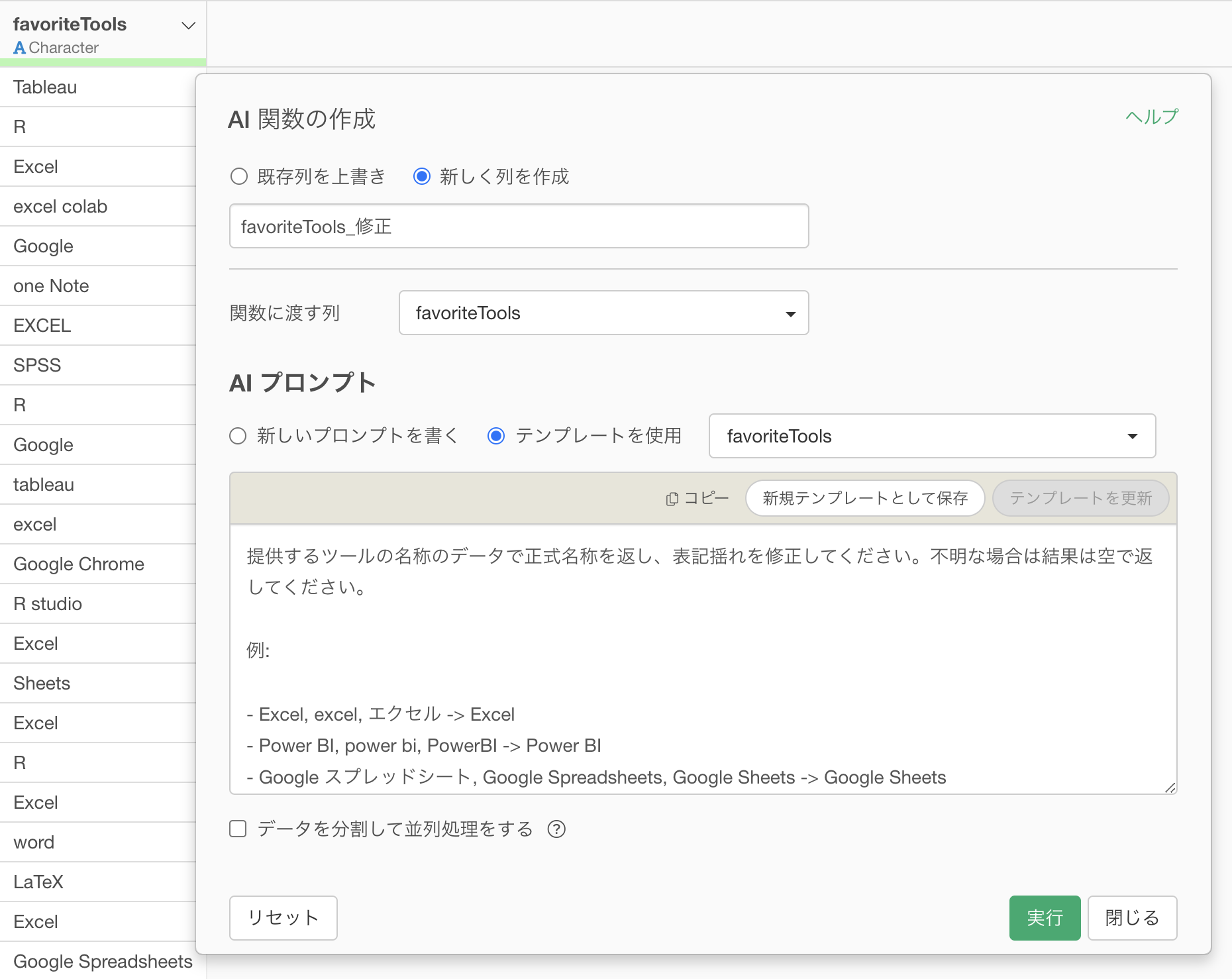
大文字小文字の統一、スペースの正規化、複数ツールの適切な分離などを通して、正しいツールの名称に統一されました。
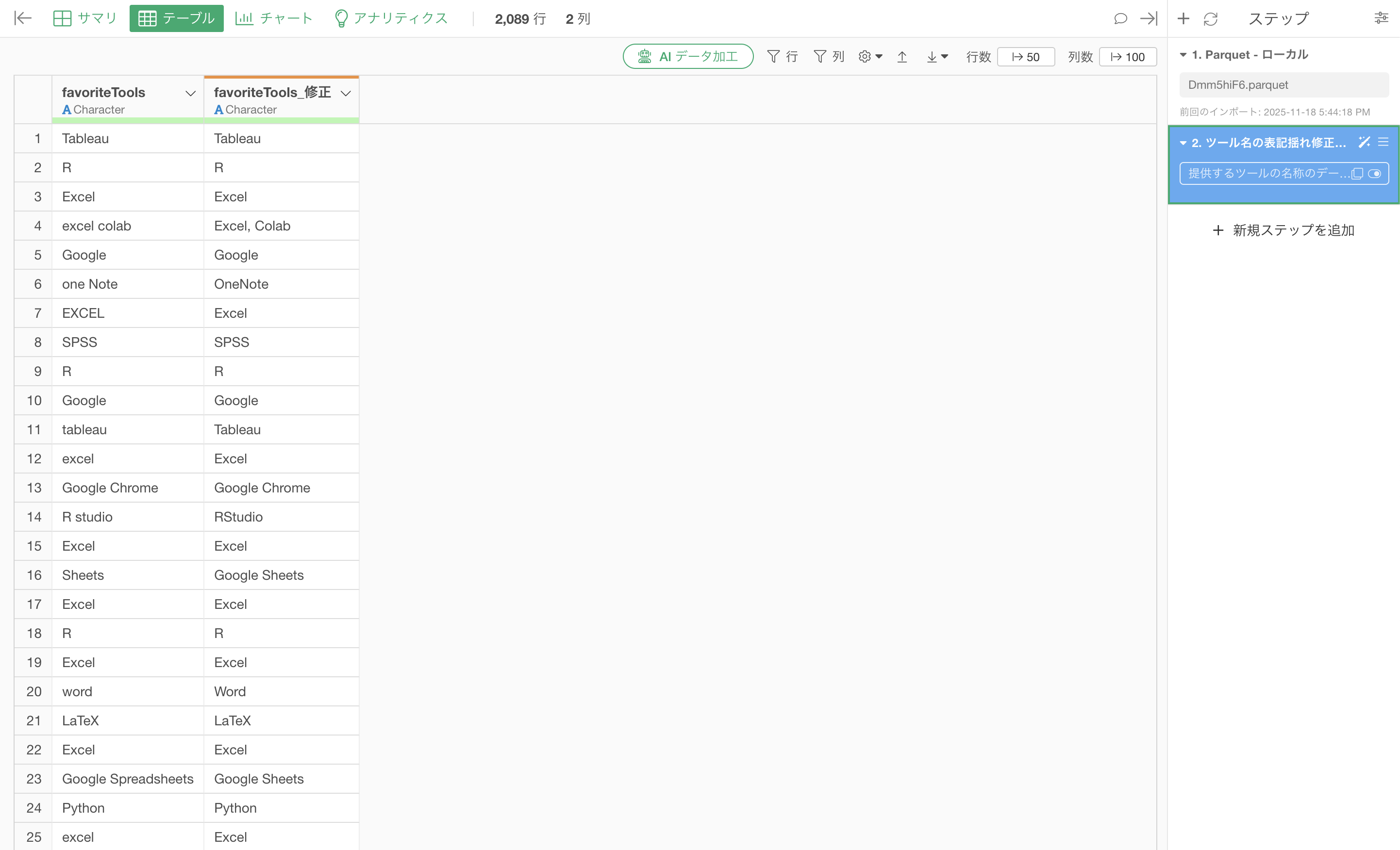 これにより、Excelの表記揺れも統一されていることが確認できます。
これにより、Excelの表記揺れも統一されていることが確認できます。
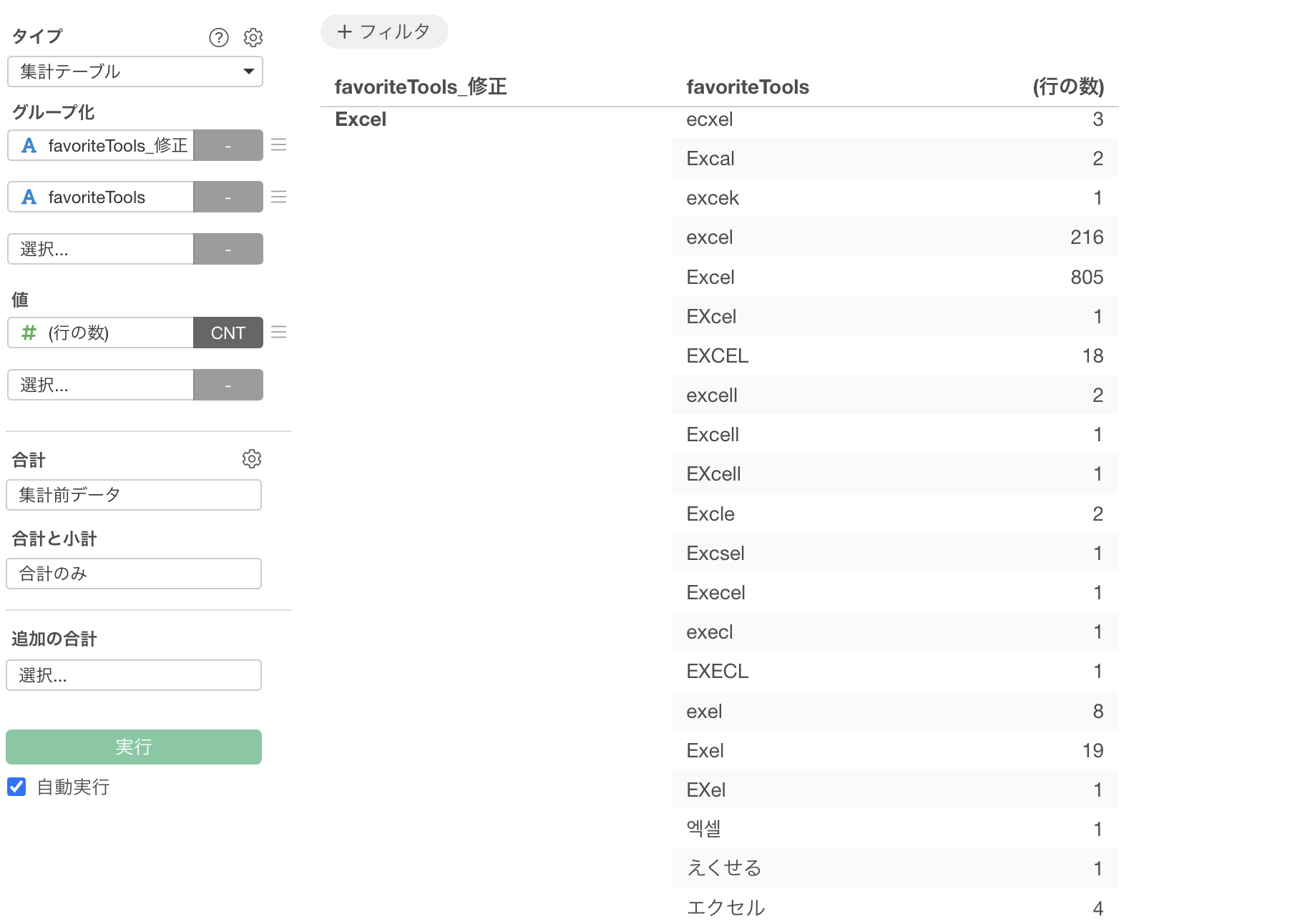
大文字・小文字の統一、スペースの正規化、複数ツールの適切な分離。すべてが正確に処理されることでようやく「本当に社内で使われているツール」が見えてきます。ExcelとGoogle Sheetsのどちらが主流なのか。正確なデータがあってこそ、適切なライセンス契約ができ、必要な研修計画が立てられ、IT投資の優先順位が決められます。そして、その基盤となるデータ整備が、プロンプト一つで完了したのです。
3. 商品名・サービス名の表記揺れ(属性情報の混在)
あなたはECサイトの在庫管理を担当しています。月次レポート作成のため、売上データを商品別に集計しようとしたところ、大きな問題に気づきました。
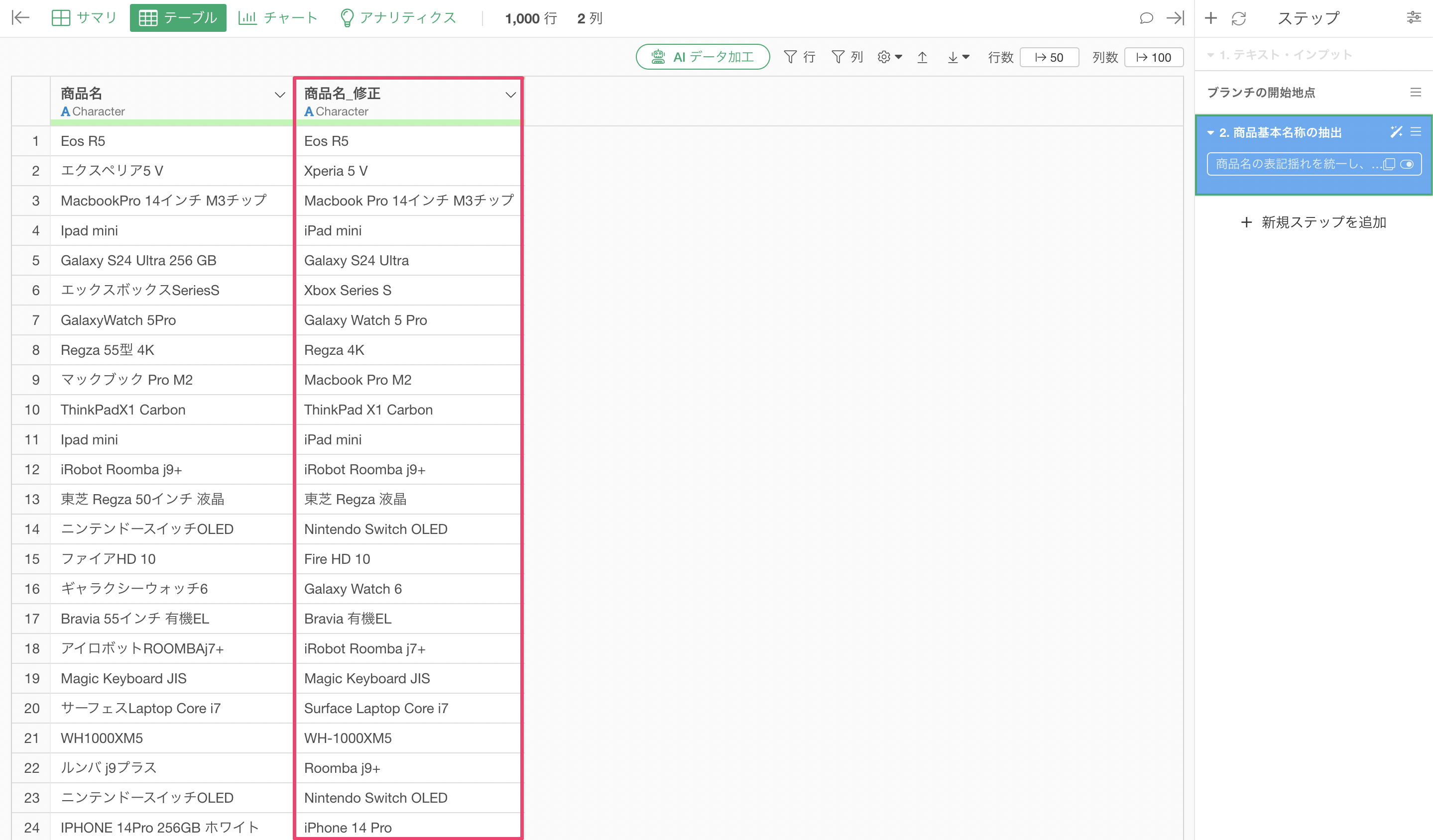
「iphone 15」という商品が、容量違いや色違いで、まるで別商品のように記録されているのです。
「iphone 15 256GB」
「アイフォン 15 128GB」
「IPHONE 15 256 GB 白」
「iphone 15 128GB ホワイト」
カタカナ表記もバラバラ。スペースの有無も統一されていない。これでは「本当はどの商品が一番売れているのか」が見えてきません。
AI 関数による解決:
複雑なルールを定義する必要はなく、AI 関数に以下のように伝えるだけです。
商品名から容量・色などのバリエーション情報を削除し、正式な基本商品名に統一してください。
# 削除対象
- 容量: GB、TBなどの記憶容量
- サイズ: インチ、型などの画面サイズ
- 色: ブラック、ホワイト、黒、白などの色情報
- メモリ: RAMのサイズ(16GB、32GBなど)
- その他バリエーション: WiFiモデル、セルラーモデルなど
# 保持・標準化対象
- メーカー名(正式な表記で統一)
- 商品シリーズ名(正式な表記で統一)
- モデル名・型番(正式な表記で統一)
- 世代情報(第10世代、Series 9など)
# 標準化ルール
- 大文字・小文字は公式の商品名に統一する(例: 「AirPods」であり「Airpods」や「airpods」ではない)
- スペースは公式の商品名に統一する(例: 「AirPods Pro」であり「AirpodsPro」ではない)
- 同一商品は常に同一の標準化された名称を返すこと
# 例
- Amazon Fire HD 10 Plus 64GB → Amazon Fire HD 10 Plus
- iPhone 15 Pro 256GB ブラック → iPhone 15 Pro
- MacBook Pro 14インチ M3 16GB 512GB → MacBook Pro 14インチ M3
- Airpods Max → AirPods Max
- AirpodsPro 2 → AirPods Pro 2
- IPHONE 15 Pro Max 128GB ホワイト → iPhone 15 Pro Max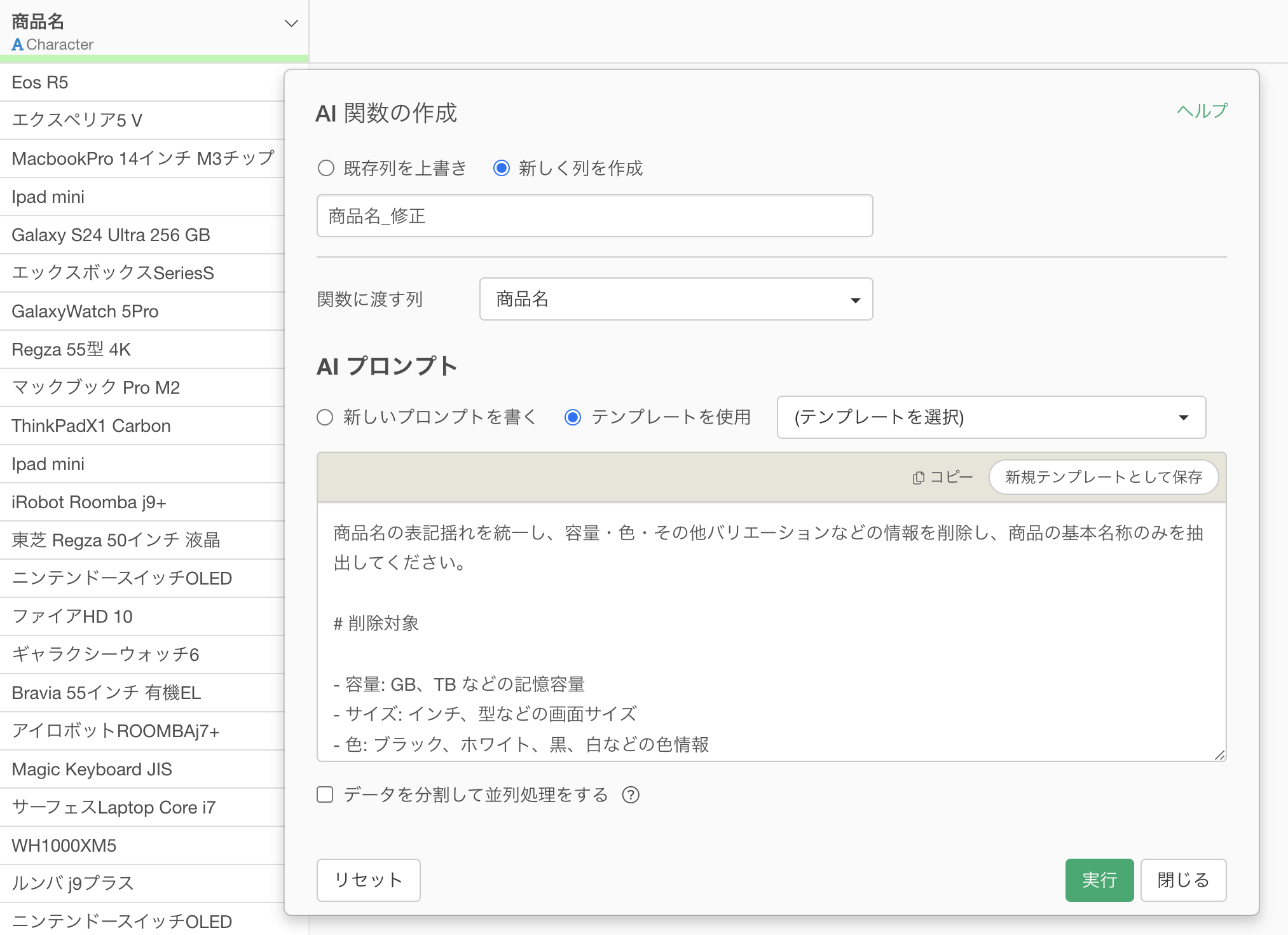
これにより、カタカナ表記の統一、不要な容量情報の削除、正式な商品名への変換。すべてが一度に完了しました。
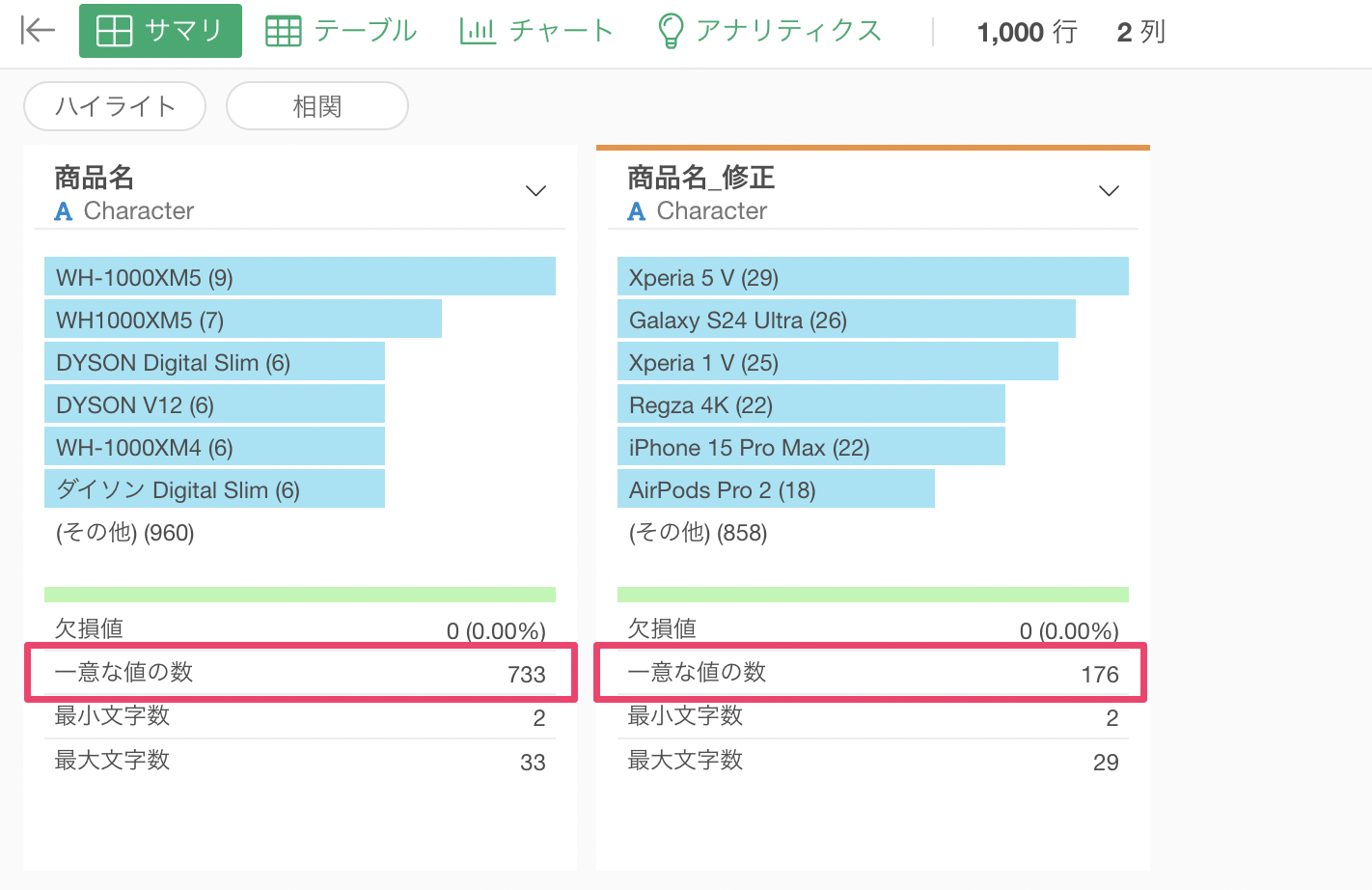
実行前と比べてみると一意な値の数(ユニークな件数)は「733」から「176」へと大幅に減っています。いかに多くの表記揺れが発生していたかがわかります。
修正された結果を見てみると、同じiPhoneの型番を表している場合は、色や容量に違いがあったとして一つのiPhoneの型番を返していることがわかります。
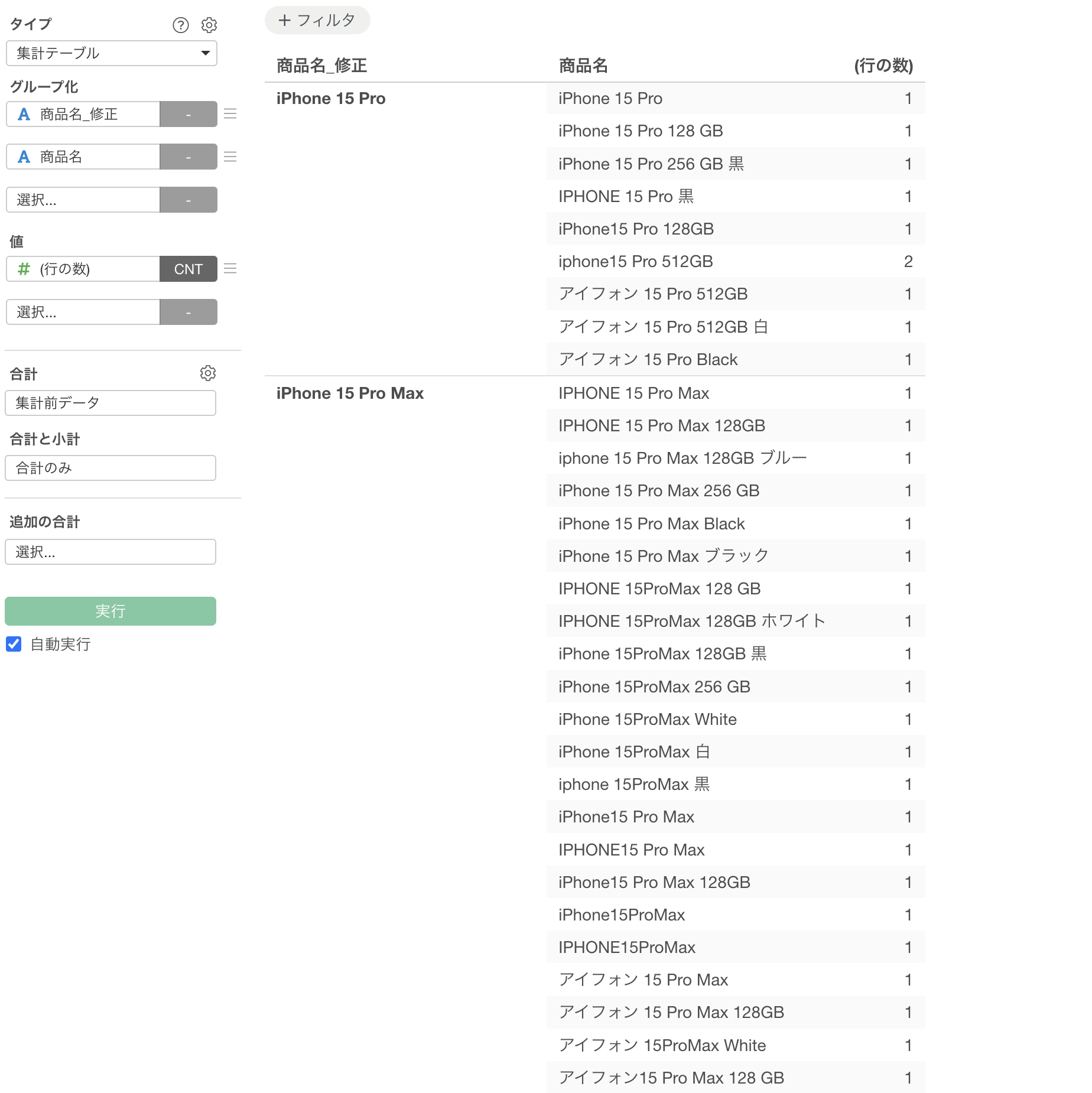
表記揺れの多さでいうと「Xperia 5 V」の方が多いのですが、これも異なる表記があったとしても正しい製品名である「Xperia 5 V」として返してくれています。
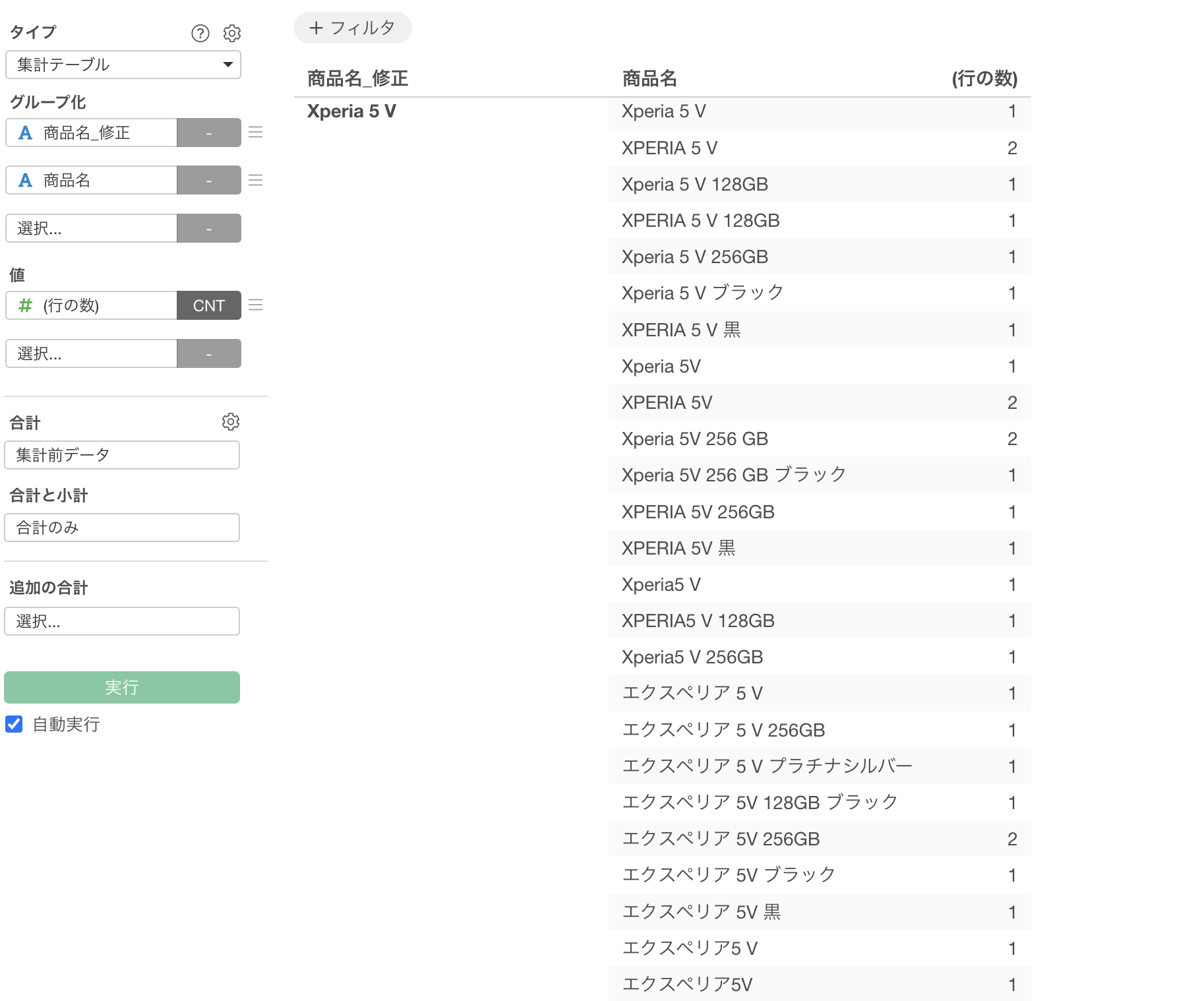
このように、商品名を統一していく時にも、AIの力を使うことで簡単に修正ができてしまいます。在庫戦略も、マーケティング施策も、すべてがこの「正確なデータ」から始まります。そして、その第一歩が、わずか数十秒で完了したのです。
4. 住所の表記揺れ
あなたは物流システムの管理を担当しています。最近、配送ミスが増えているという報告が上がってきました。原因を調査すると、配送先住所のデータ品質に問題があることが判明。
同じ住所のはずなのに、入力者によって表記が異なるため、システムが別の住所と認識してしまいます。
「東京都 渋谷区 道玄坂 1-2-3」(余計なスペース)
「北九州市小倉北区魚町1-1-1」(都道府県名が省略)
「福岡県福岡市博多区博多駅前三ー五ー七」(漢数字が混在)
「広島県福山市東桜町1丁目1番地」(番地表記)
AI 関数による解決:
住所の標準化も、AI 関数なら明確なルールを伝えるだけです。
以下の住所を標準的な表記に統一してください。
【統一ルール】
- 数字は半角のアラビア数字
- ハイフンは半角「-」
- 都道府県名を必ず含める
- カタカナの「ヶ」は「ケ」に統一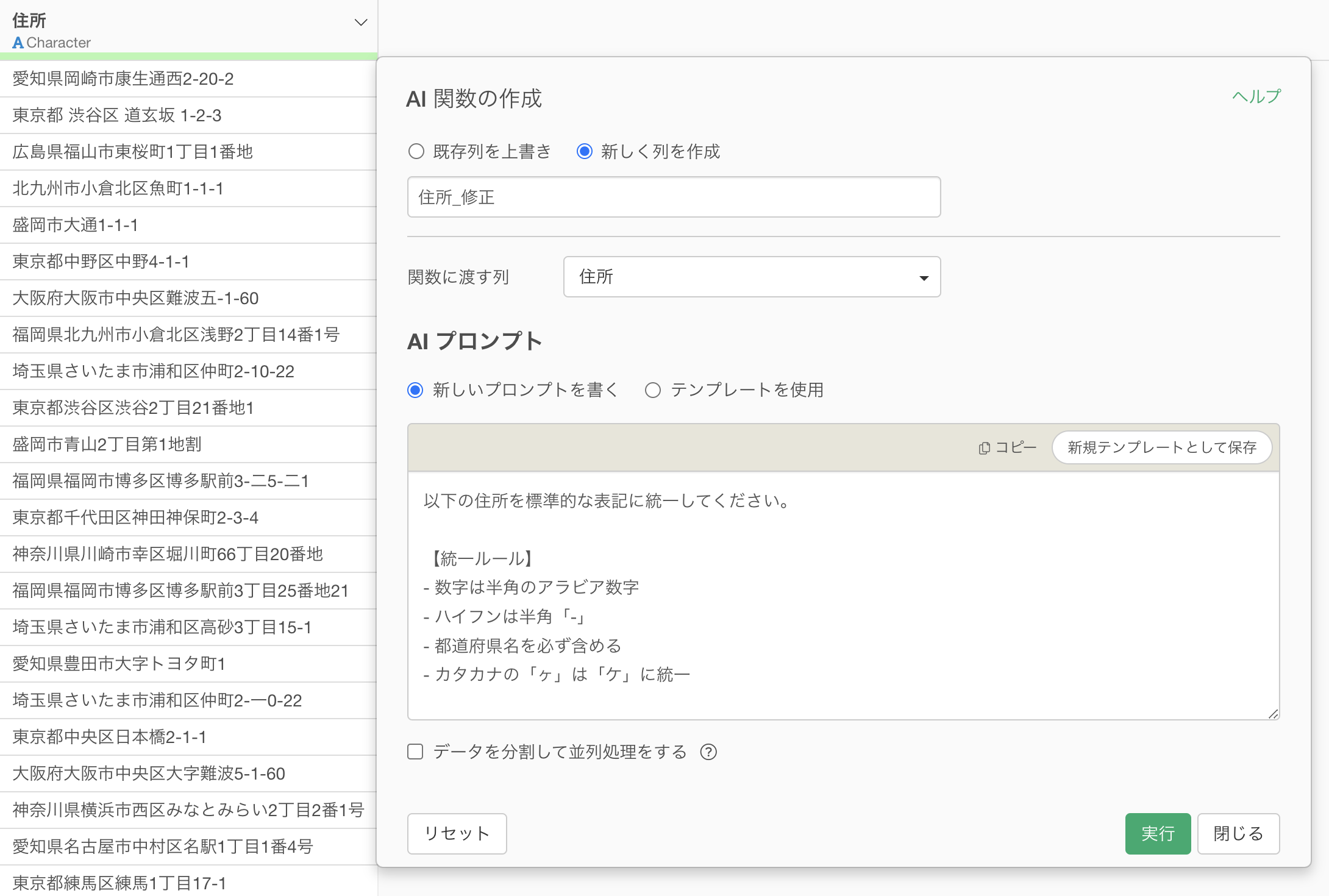
省略された都道府県名の補完、漢数字からアラビア数字への変換、全角・半角の統一が処理されました。
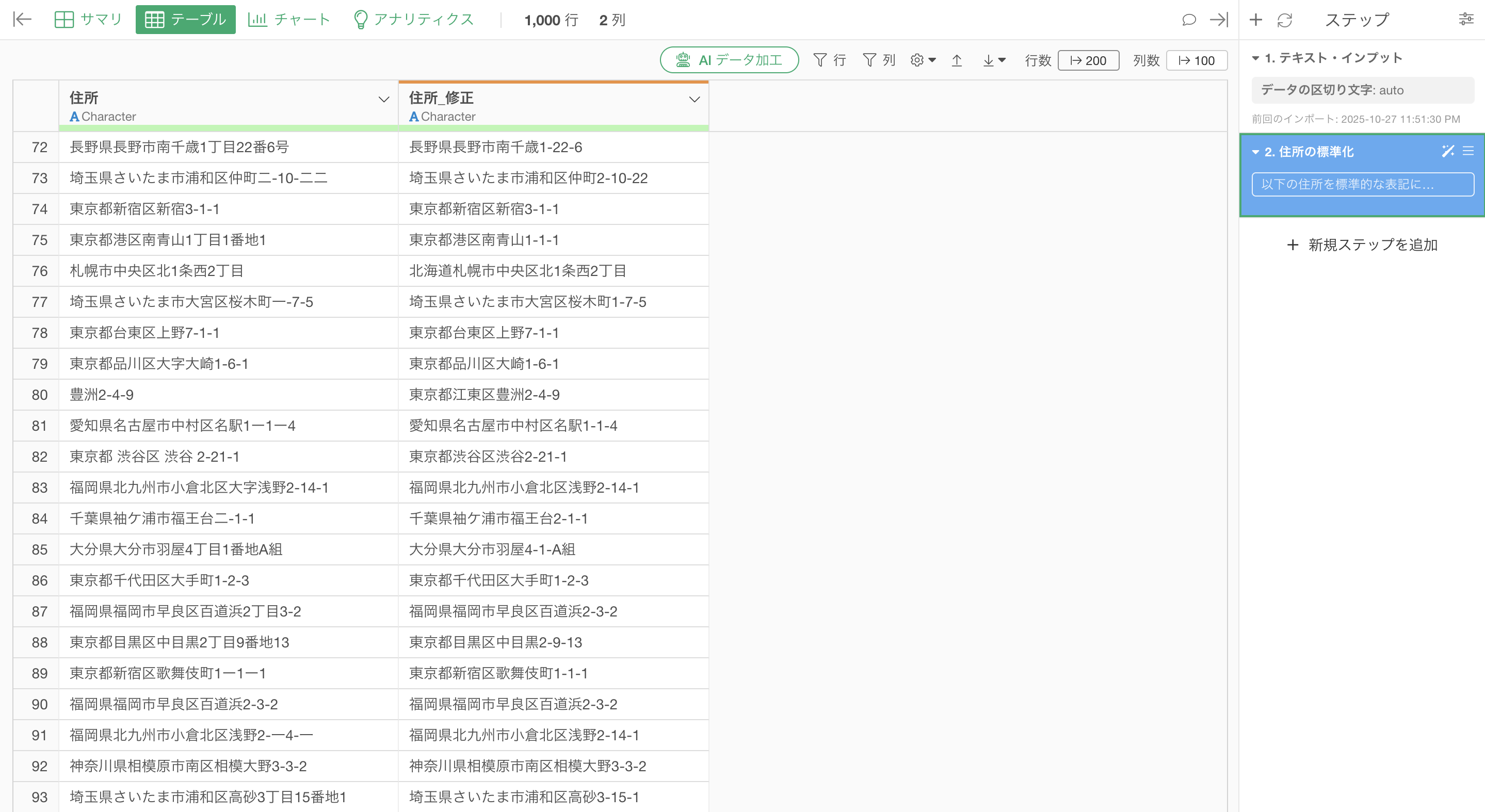
これにより、省略された都道府県名の補完、漢数字がアラビア数字に統一、バラバラだった区切り文字も標準化されました。 そして何より、物流チーム全体が、データ修正ではなく、本来の業務であるルート最適化や配送効率化に集中できるようになったのです。
まとめ: 表記揺れ修正の新時代が、ここから始まる
Exploratory v14で追加された「AI 関数」は、プログラミングスキルがないユーザーでも、最先端のAIを活用して表記揺れを自動修正できる革新的な機能です。
この記事でご紹介した4つの事例である企業名の正式名称への統一、商品名からのバリエーション情報除去、住所の標準化、ツール名の統一は、どれも多くの企業で日常的に発生している課題です。
これまで、こうした課題を解決するには
専門のエンジニアを雇うか
外部委託に数百万円を投じるか
あなた自身が何時間も手作業で修正するか
という選択肢しかありませんでした。
しかし、AI 関数を使えば、プロンプトを書くだけで、数千行のデータに対する表記揺れ修正が数分で完了します。専門知識も、プログラミングスキルも、高額な予算も不要です。
データ修正に費やしていた時間を、本来やるべき分析業務や戦略立案に使えるようになる。それが、AI 関数がもたらす未来です。
今すぐ、その威力を体験してみませんか?
言葉で説明するより、実際に体験していただくのが一番です。
Exploratoryは30日間の無料トライアルをご用意しています。クレジットカードの登録も不要です。
AI 関数を実際に使って、あなたのデータで表記揺れ修正を試してみてください。数クリックで完了する驚きを、ぜひご自身で体感してください。
導入について相談したい方へ
「自社のデータでどう活用できるか知りたい」
「具体的な導入ステップを相談したい」
「チームでの利用を検討している」
そんな方は、お気軽にお問い合わせください。Exploratoryのチームが、あなたのデータ活用を全力でサポートします。