マーケティング領域におけるExploratoryの活用 Part 1 - t検定
このノートは、マーケティング領域でExploratoryを効率的に使い始めることができるように作られた「マーケティング領域におけるExploratoryの活用」の第1弾、「t検定」編です。
データをインポートする
今回はサンプルデータとして「Airbnbのベルギーの宿泊施設」のデータを使用します。このデータは1行が1物件になっており、それぞれの物件に関する価格や広さなどの情報が列として入っています。
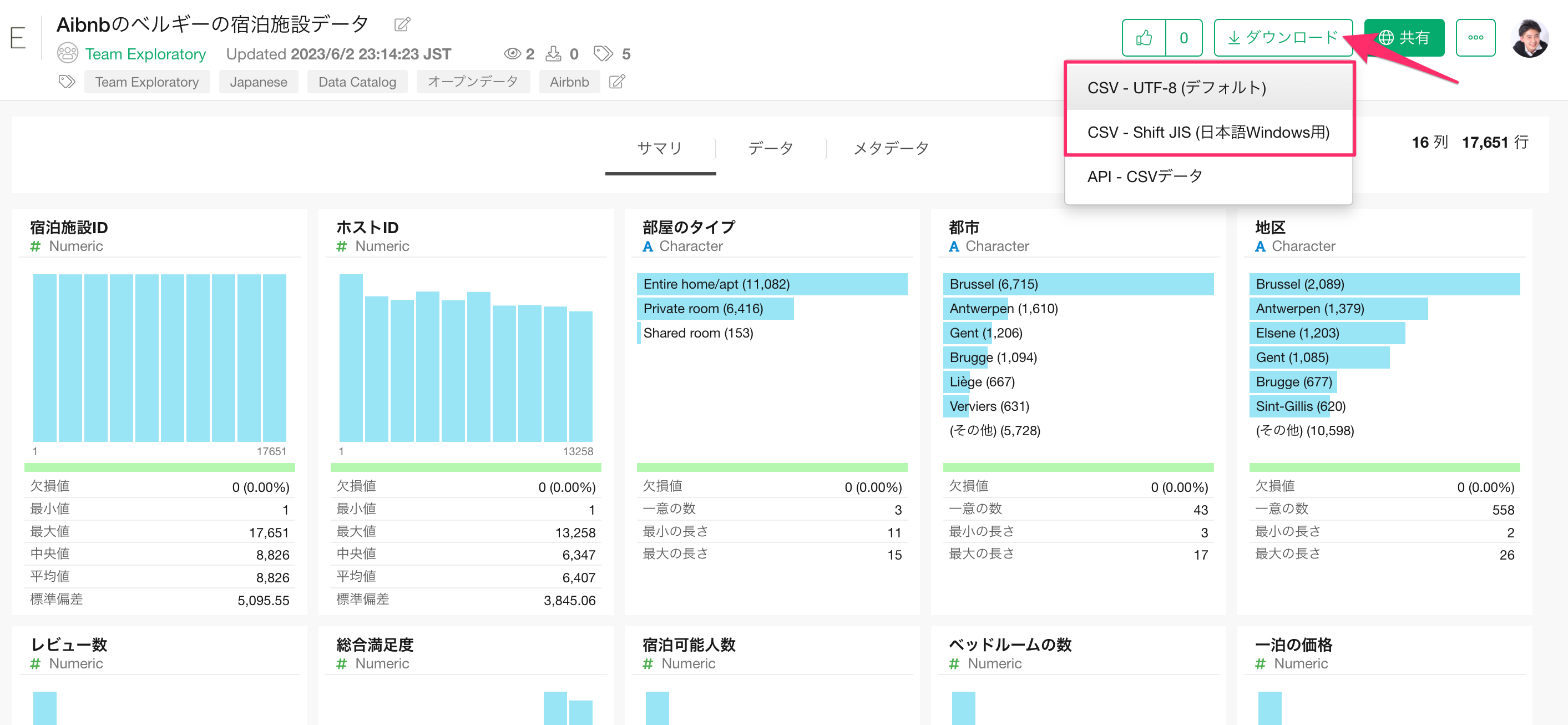
データはこちらのページからダウンロードできます。Macをお使いの方は「CSV-UTF8」を、Windowsをお使いの方は「CSV - Shift-JIS」をダウンロードしてください。
Airbnbのデータをダウンロードできたら、ダウンロードしたフォルダを開き、「Airbnbのベルギーの宿泊施設データ.csv」をExploratoryの画面にドラッグ&ドロップします。
インポートダイアログが表示されました。インポートダイアログの左側にある項目から、インポート時の設定を行うことが可能ですが、今回は設定は不要なため「インポート」ボタンをクリックします。
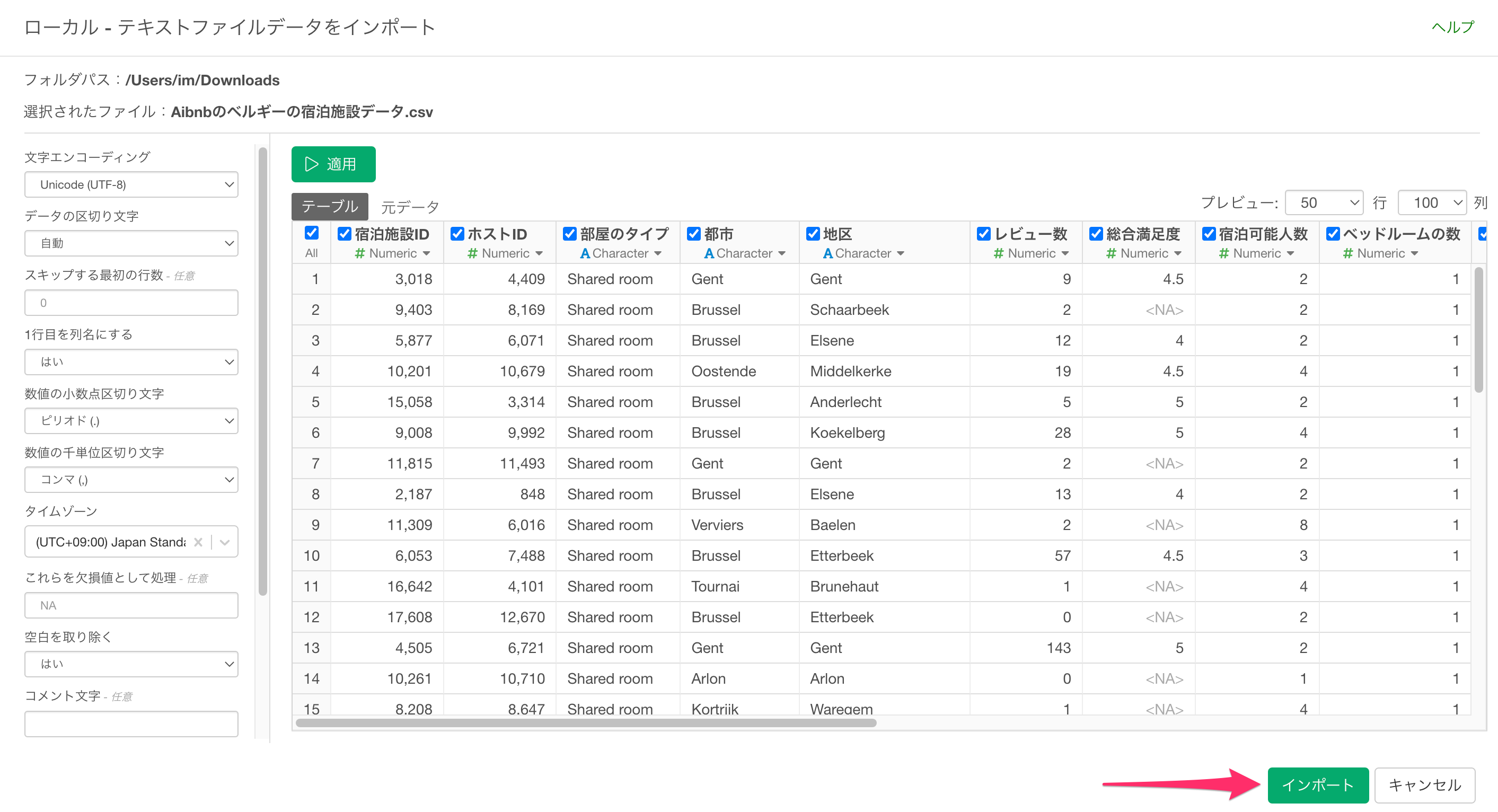
任意のデータフレーム名を指定して、「作成」ボタンをクリックします。
Airbnbのデータをインポートすることができました。
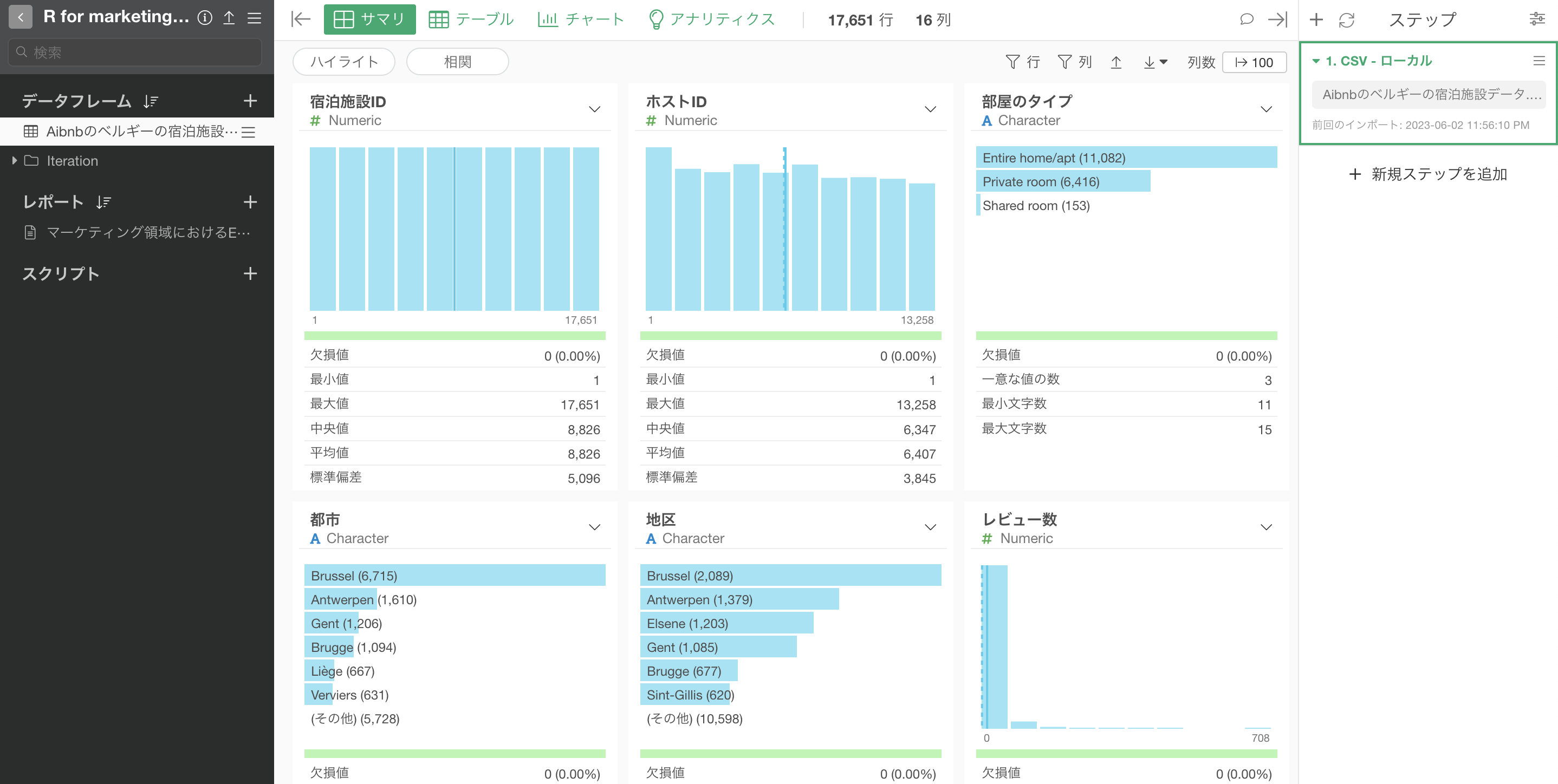
都市のサイズで価格に差があるか
今回は、「都市のサイズ」で、「一泊の価格」が異なるかどうかをt検定を使って調べます。
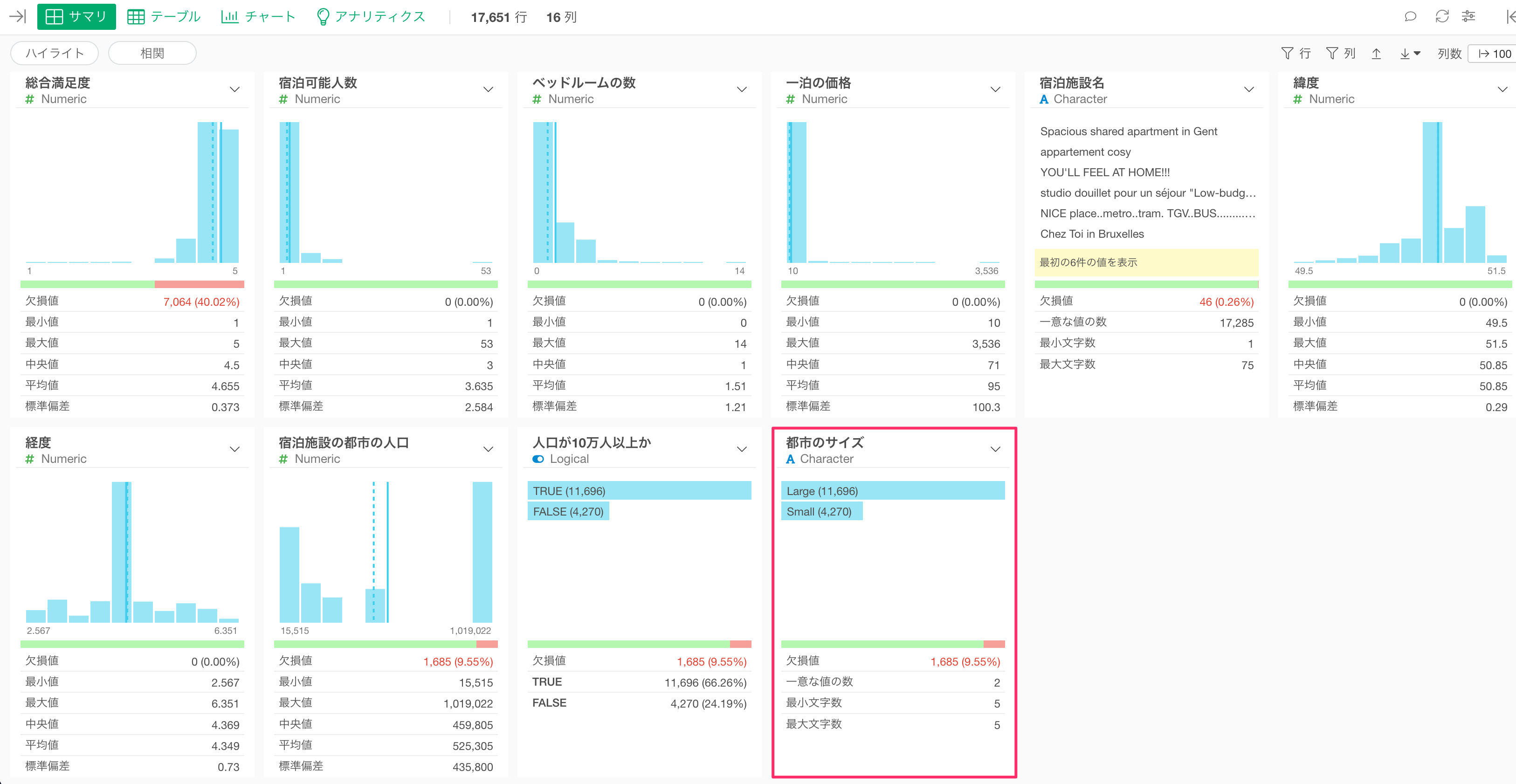
なお、今回のデータを確認すると、都市のサイズには欠損値が含まれています。
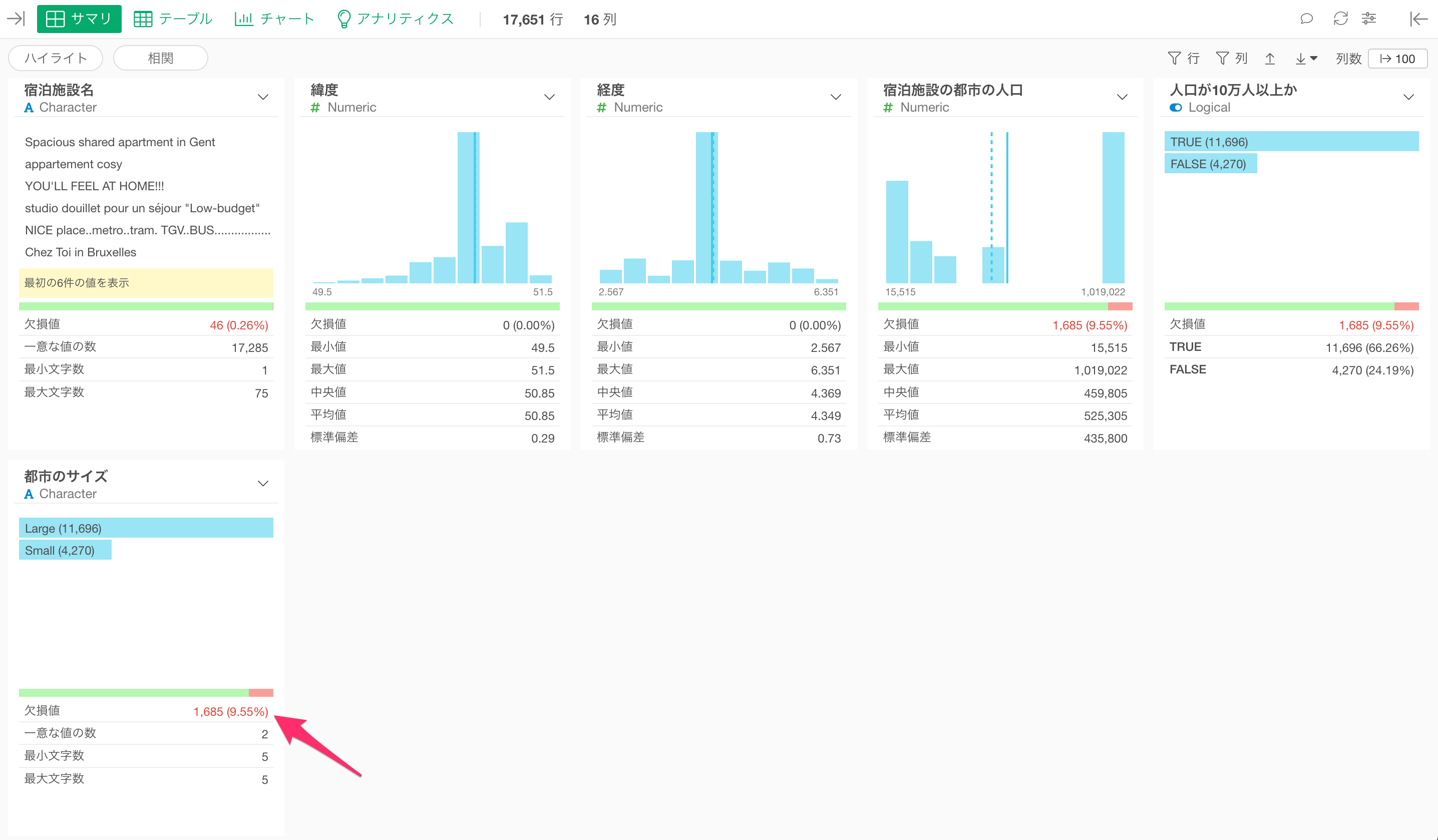
今回の検証には欠損値のデータは不要ですので、欠損値のデータをフィルタして取り除きます。
「都市のサイズ」の列ヘッダーメニューから「フィルタ」の「欠損値(NA)を除く」を選択します。
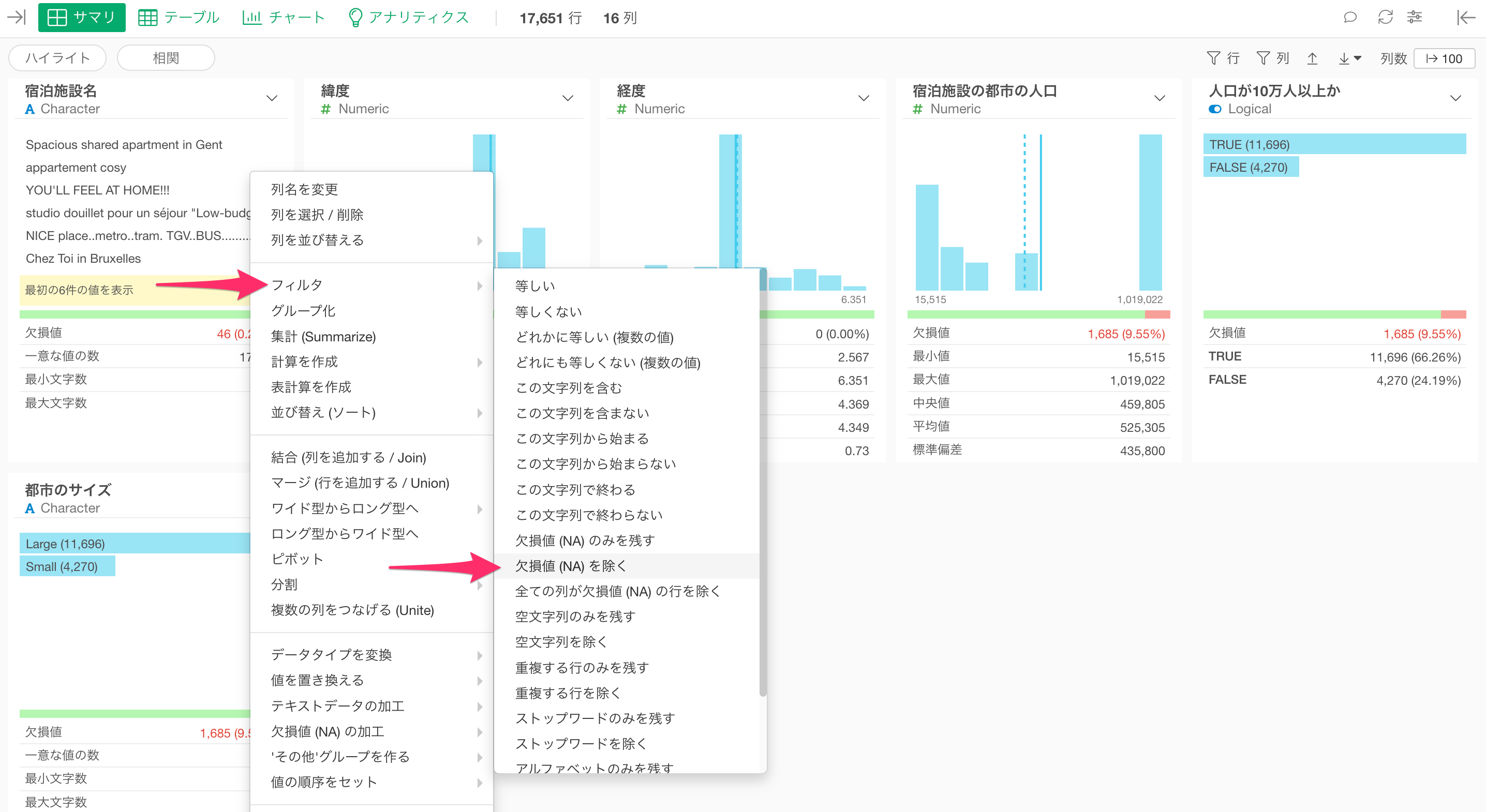
フィルタのダイアログが表示され、演算子が「欠損値(NA)を除く」になっていることを確認したら、そのまま「実行」ボタンをクリックします。
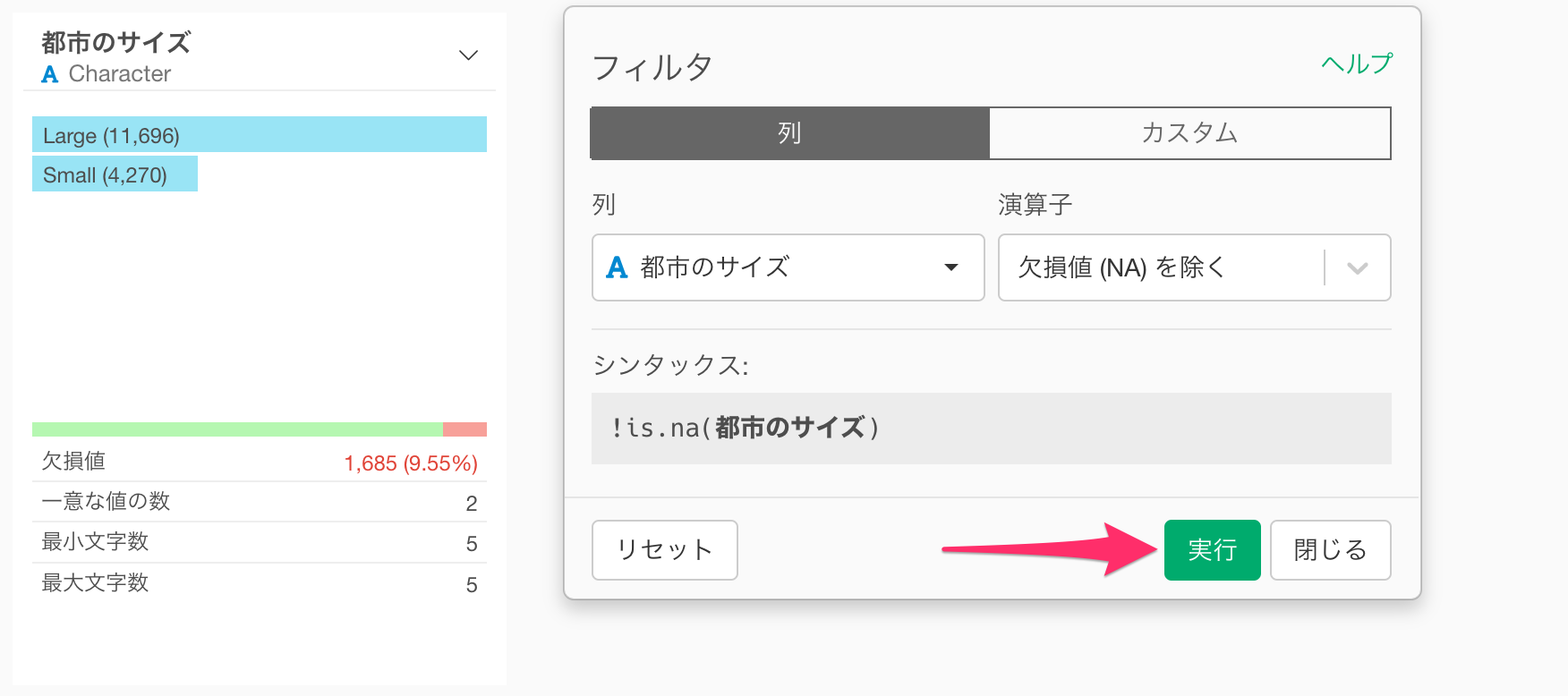
欠損値を取り除くステップが追加され、サマリ・ビューからも欠損値を取り除けたことがわかります。
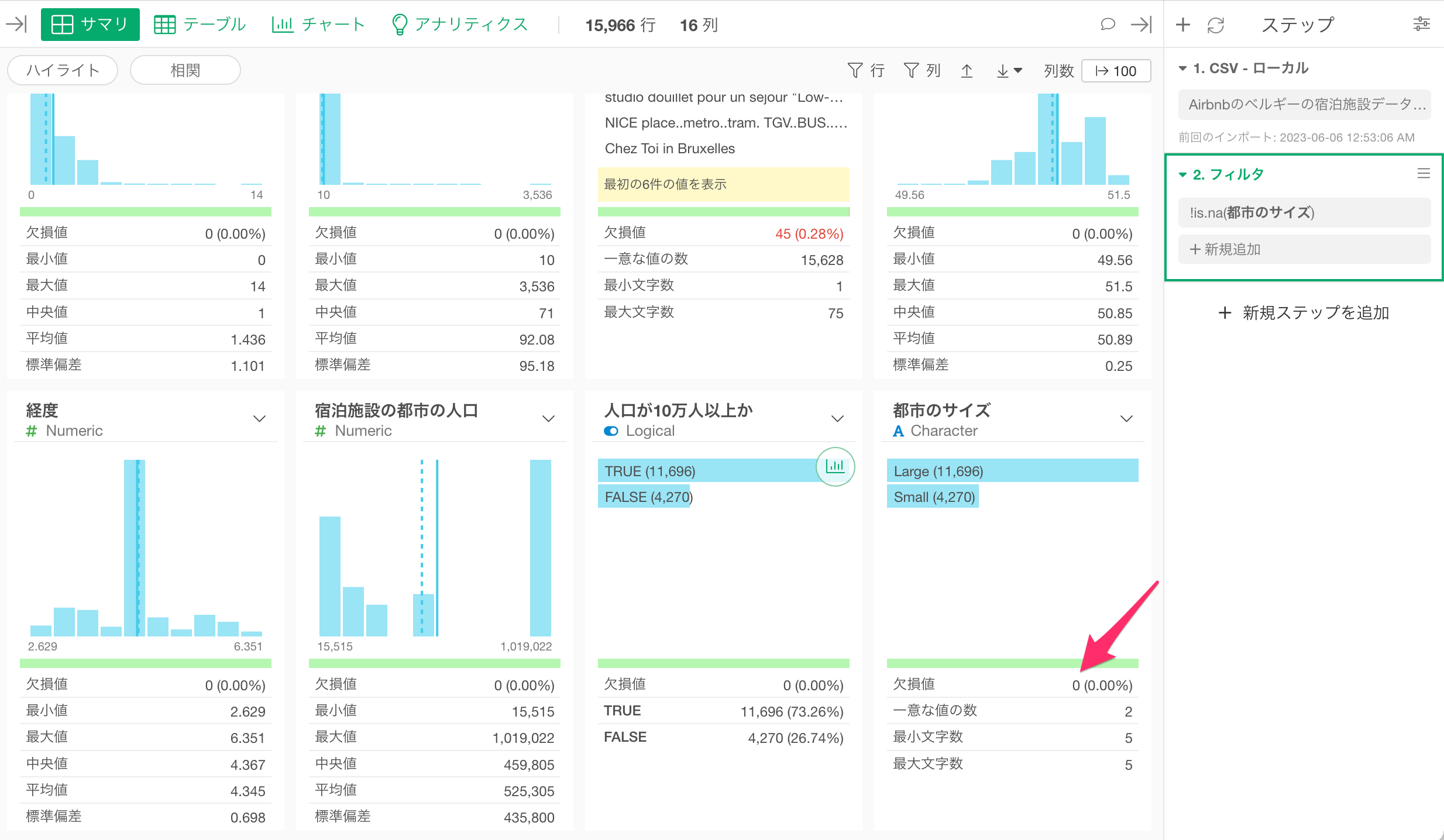
続いて、t検定を行う前に、チャートビューから都市のサイズのグループごとに「一泊の価格」の平均と、一泊の価格の平均的なばらつきを表す標準偏差を集計します。
チャート・ビューに移動し、タイプに「集計テーブル」、グループ化に「都市のサイズ」を選択します。
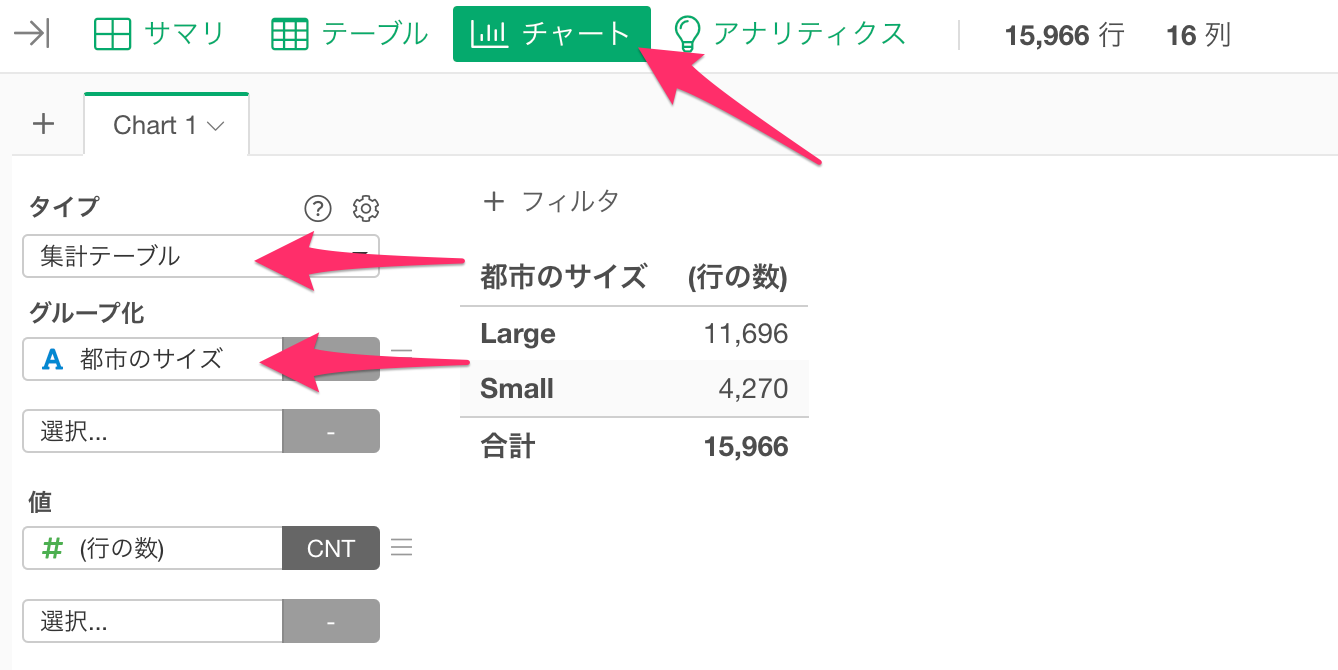
続いて、値に「一泊の価格」を選択して集計関数に「平均値(Mean)」を選択します。
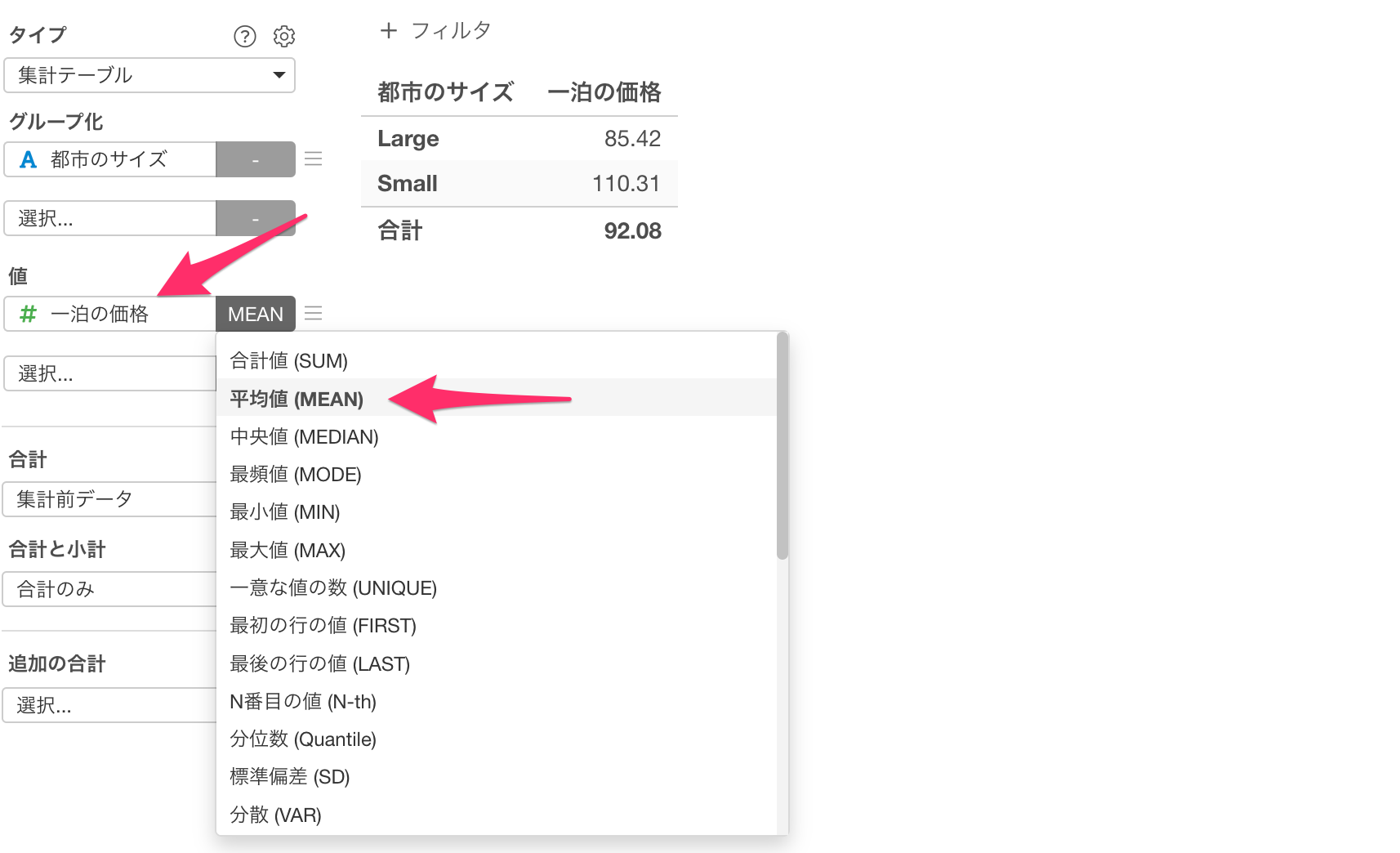
二番目の値に再び「一泊の価格」を選択して集計関数に「標準偏差」を選択します。
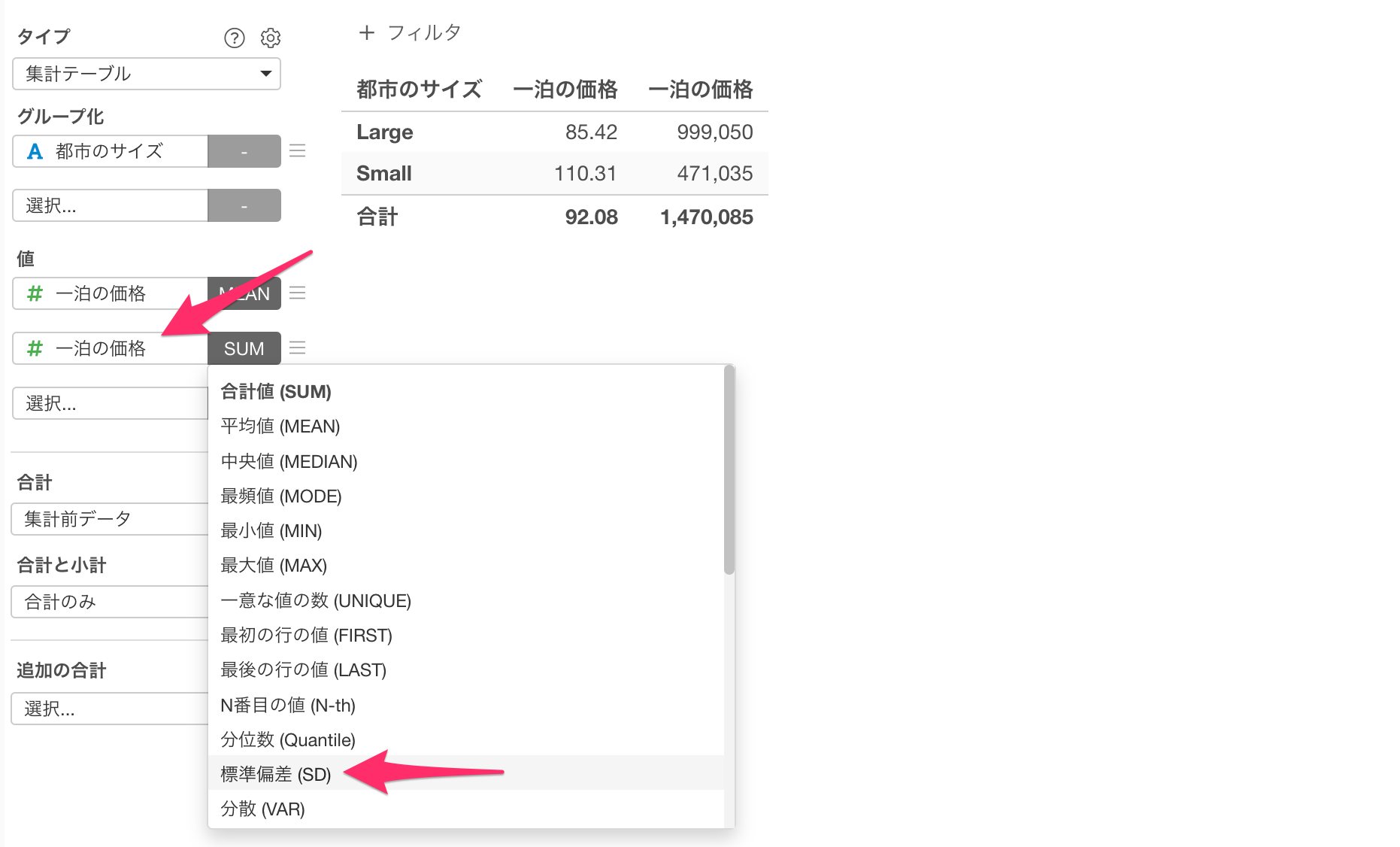
一泊の価格の平均と標準偏差を計算できましたが、列名が同じなので、各々の列の集計内容が分かるように列名に関数名を追加します。
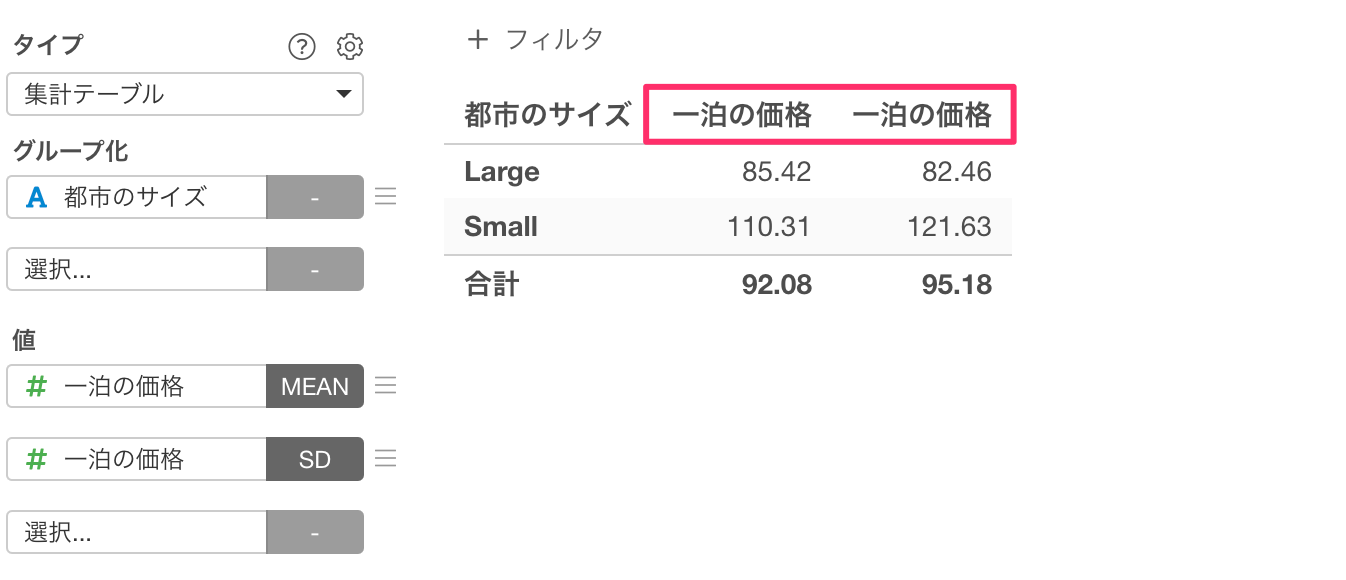
プロパティを開き、「値の列」の「関数名を表示する」にチェックをつけ、適用します。
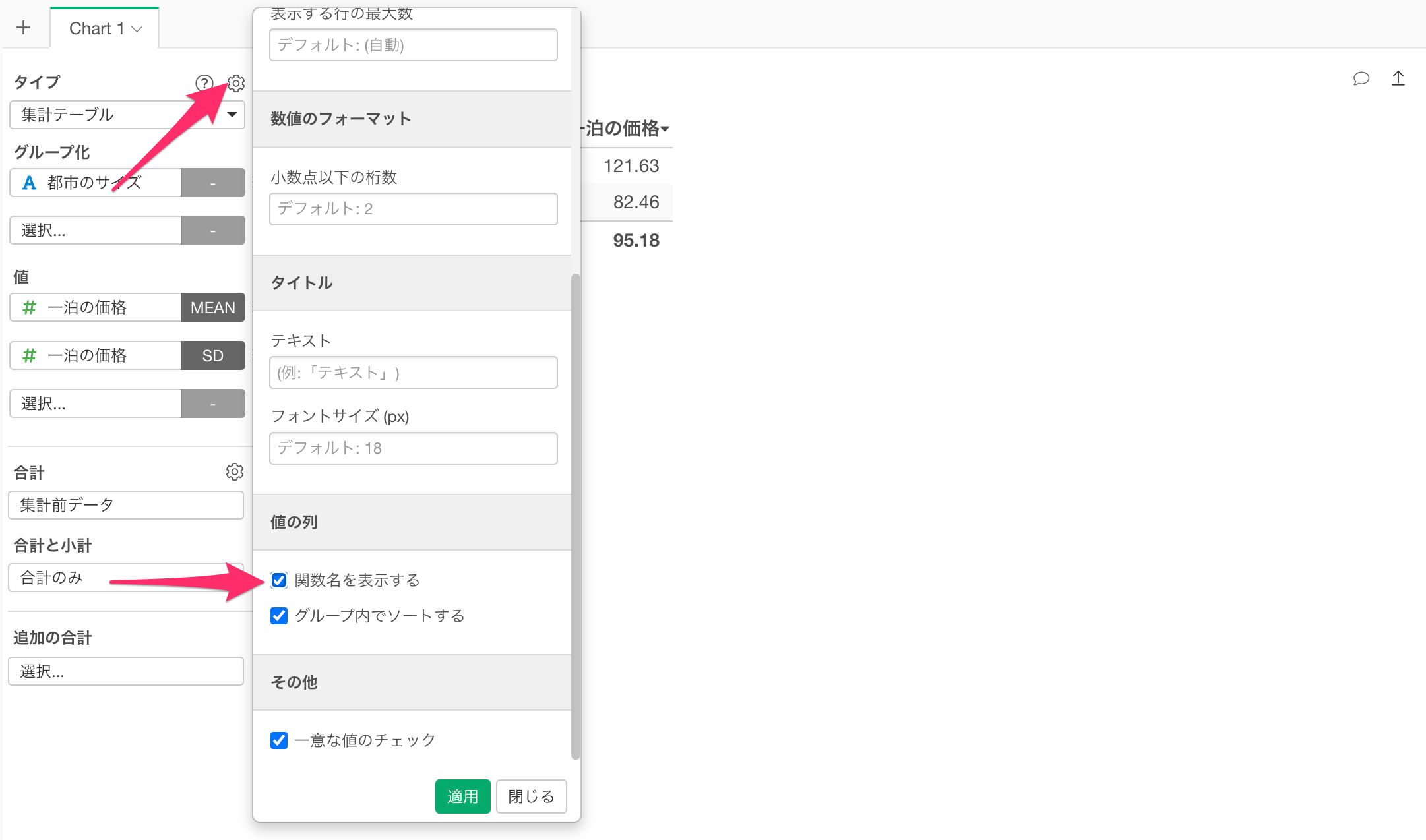
これで、値の末日に関数名を追加できました。
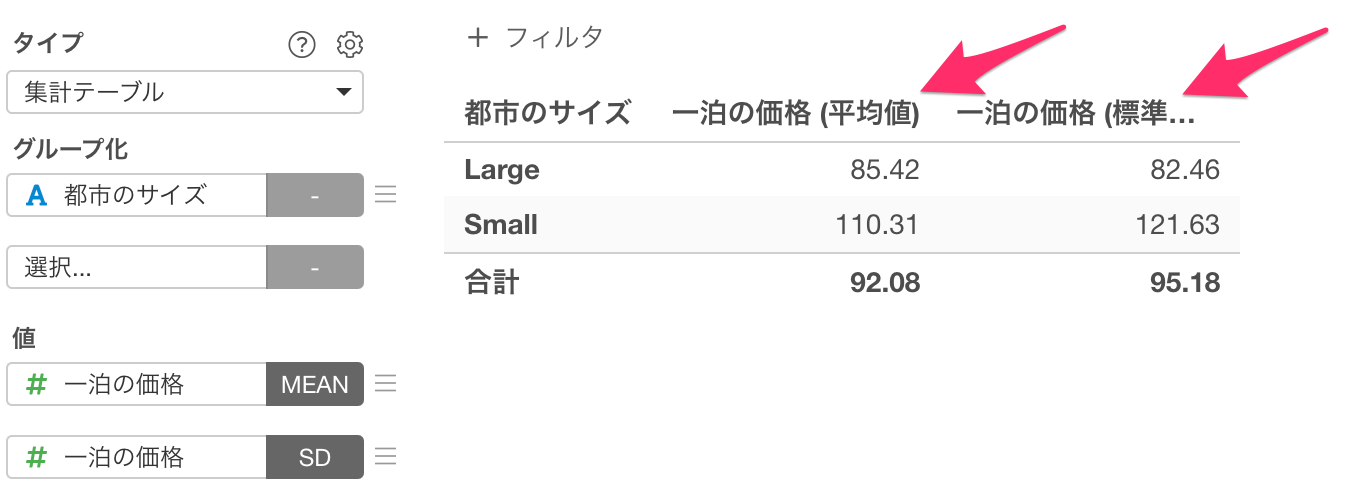 大都市よりも小都市のほうが一泊の価格が高いことがわかりました。
大都市よりも小都市のほうが一泊の価格が高いことがわかりました。
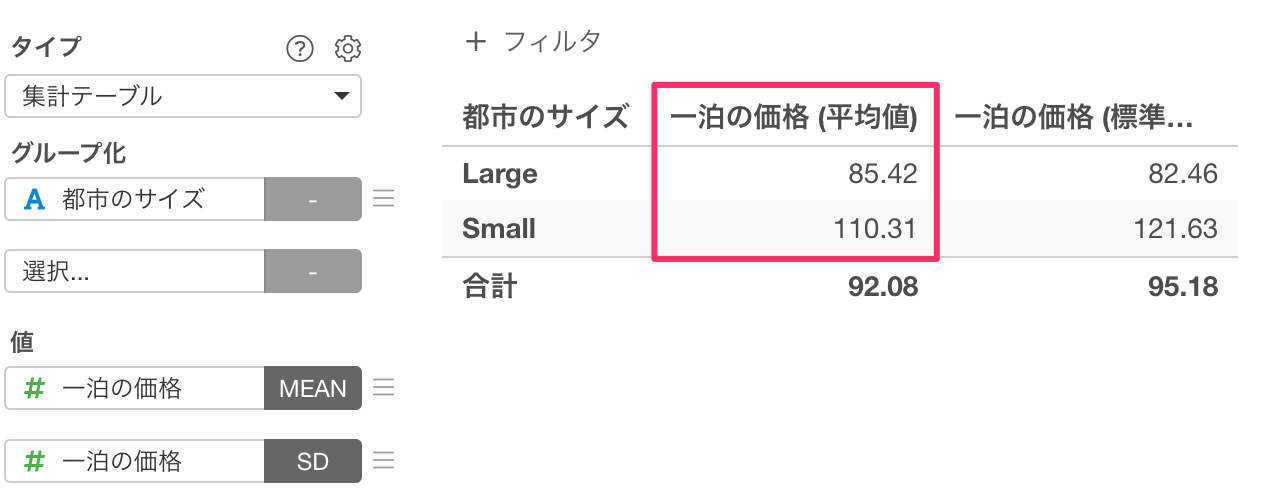
しかしこの価格の違いは意味のある、有意な違いと言えるのでしょうか。
そこで、「t検定」を使って2つのグループ間の数値の平均値の差が有意かどうかを検定していきます。
t検定の前提
t検定では、2つの独立したサンプル(今回のデータでは都市のサイズが「Large」のグループと「Small」のグループ)の分散が等しいことを前提にしているため、「ルビーン検定」を使って、等分散性を検定します。
なお、v7のExploratoryでは、アナリティクス・ビューで「ルビーン検定」をサポートしていませんので、今回はノートを使ってRスクリプトを記述して、「ルビーン検定」を行い、等分散性を検定します。
レポートの隣の「+」ボタンをクリックして、「ノートを作成」を選択します。
任意の名称を設定し、「作成」ボタンをクリックします。
空のノートが開いたら、「+」ボタンをクリックして、Rのコードを記述するための「Rのコード」を選択します。
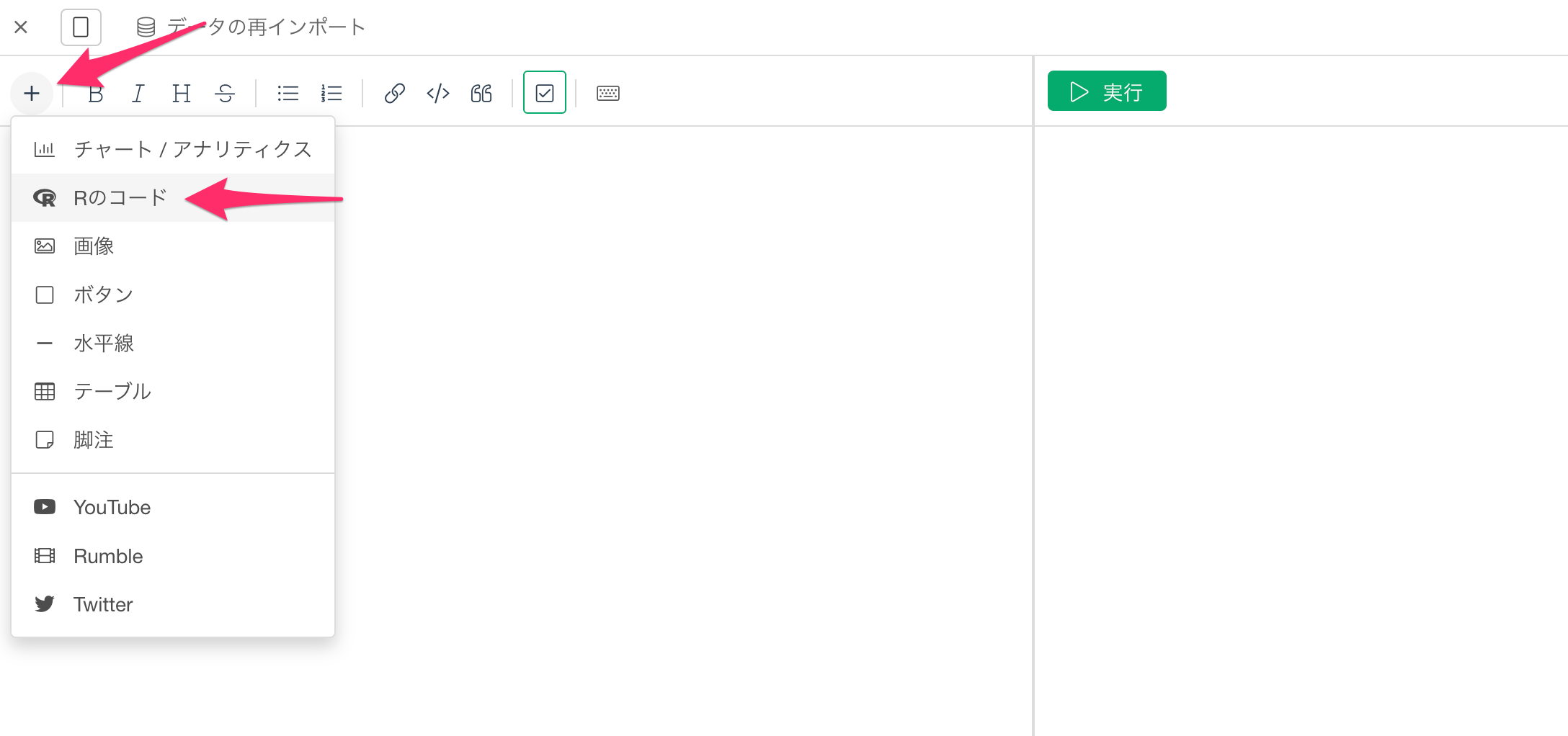
Rのコードを選択すると、Rを記述するためのコードブロックがノートに挿入されるので、コードブロック内にRのコードを記述します。
今回利用しているデータフレームは「Airbnbのベルギーの宿泊施設データ」という名称のため、コードブロック内に以下のように記述し実行します。
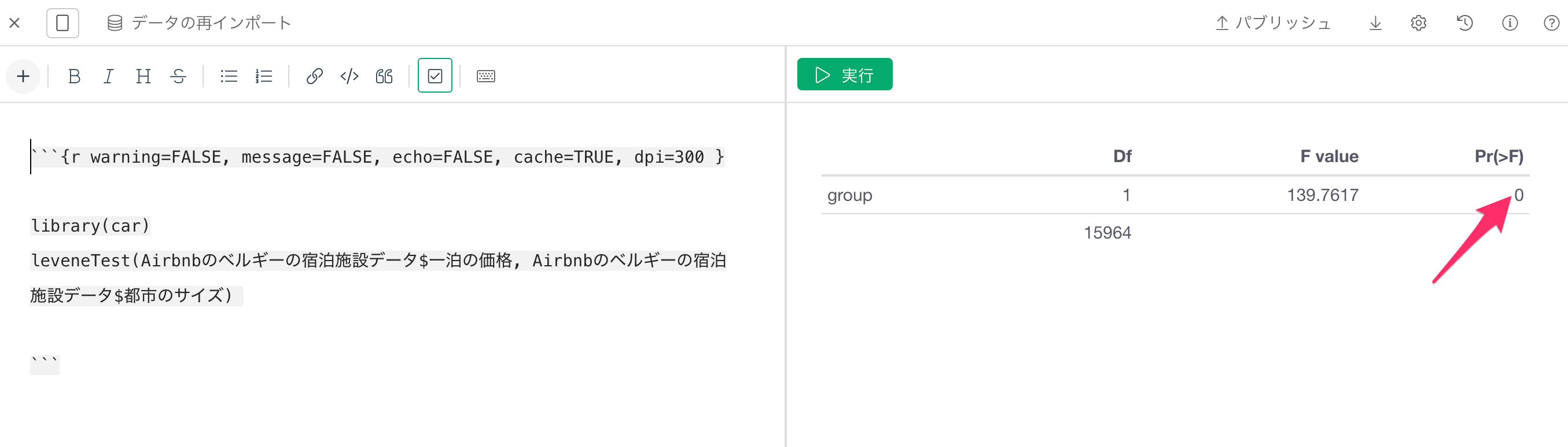
leveneTest(Airbnbのベルギーの宿泊施設データ$一泊の価格, Airbnbのベルギーの宿泊施設データ$都市のサイズ) 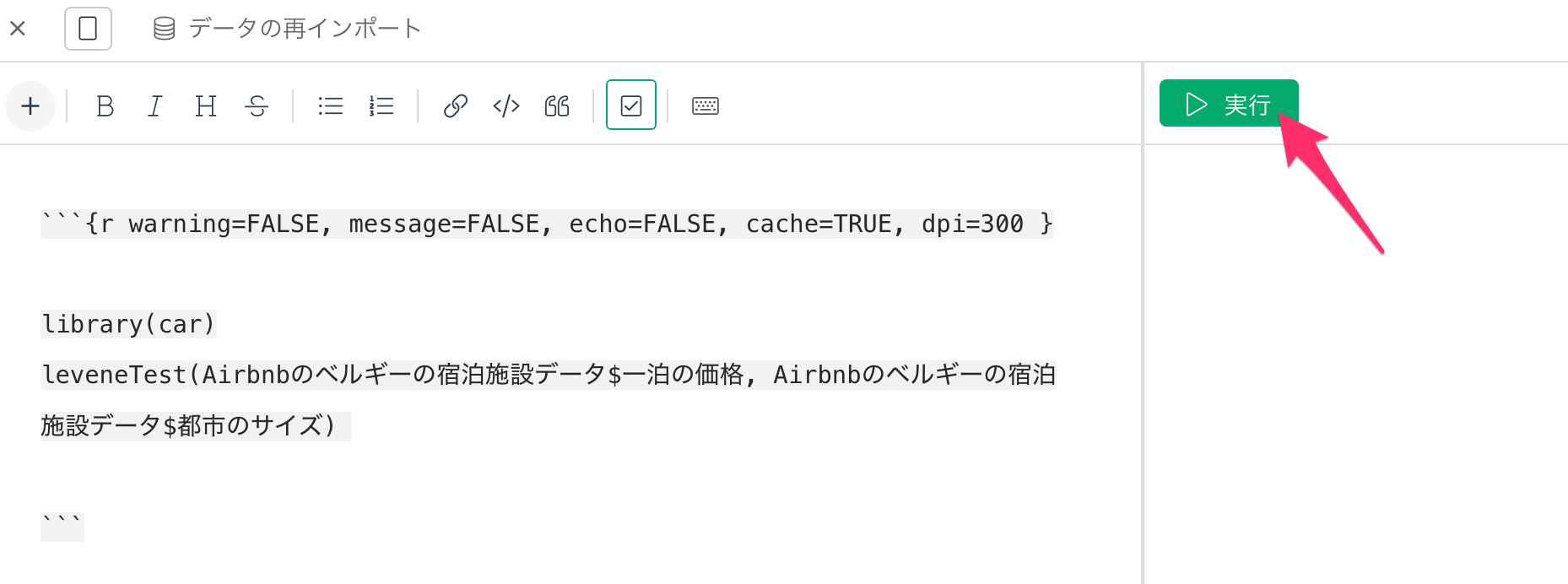
すると、ルビーン検定の結果が表示されます。
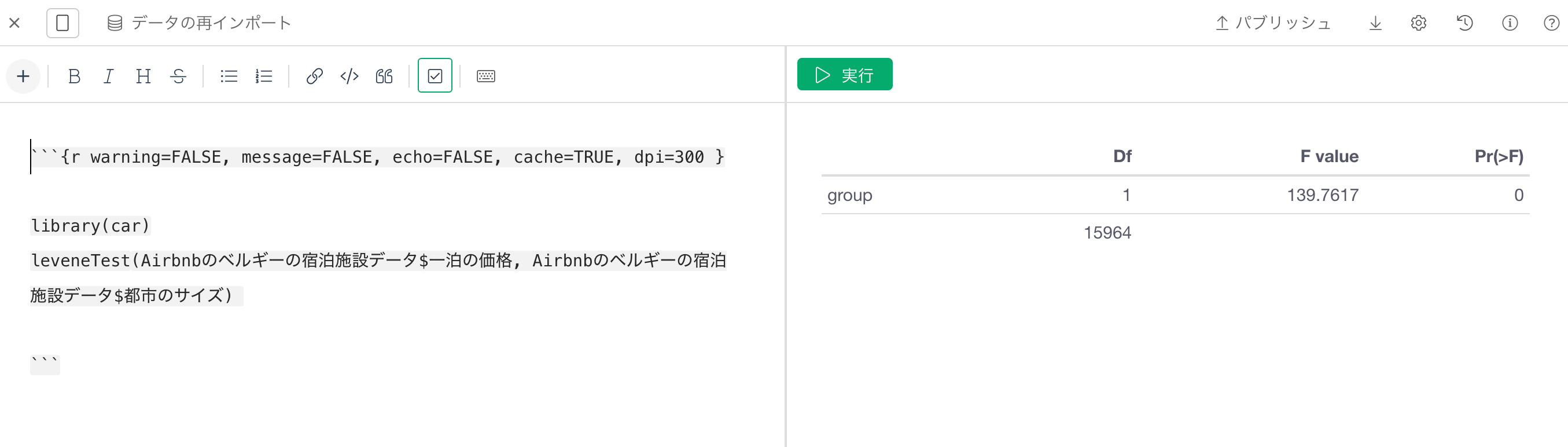
ルビーン検定における帰無仮説は、「各群の分散は等しい(等分散性)」となり、有意水準を5%とした場合、今回のP値は5%を下回ってるため、帰無仮説は棄却され、「各群の分散は等しいとは言えない」、つまり分散が等しい前提を持たないことがわかります。
t検定を使って、一泊の価格に有意な違いがあるかを調べる
それでは、 t検定を実行していきましょう。
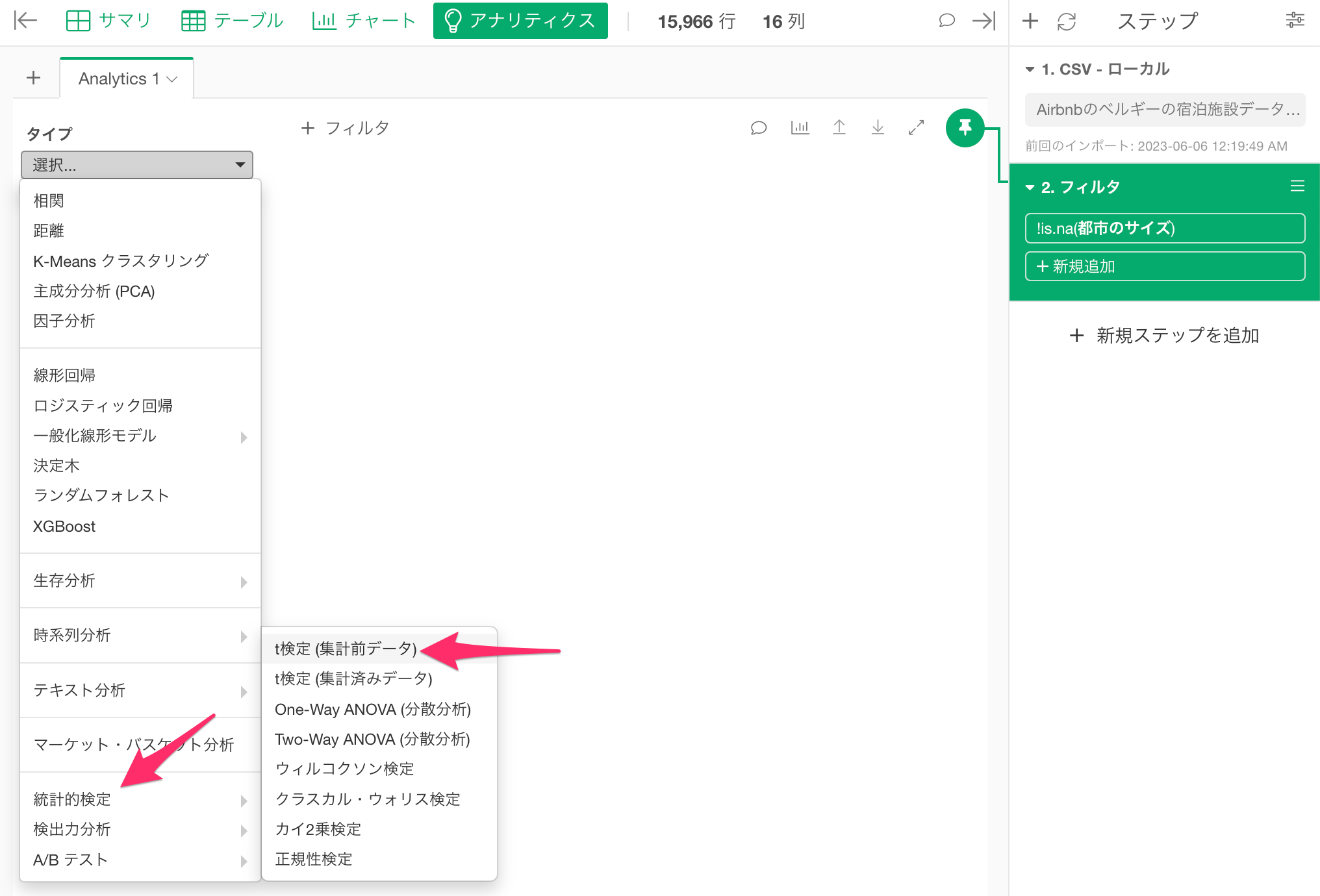
欠損値を除いた2番目のステップにピンが刺さっていることを確認したら、アナリティクス・ビューに移動し、タイプに「統計的検定」の「t検定(集計前データ)」を選択します。
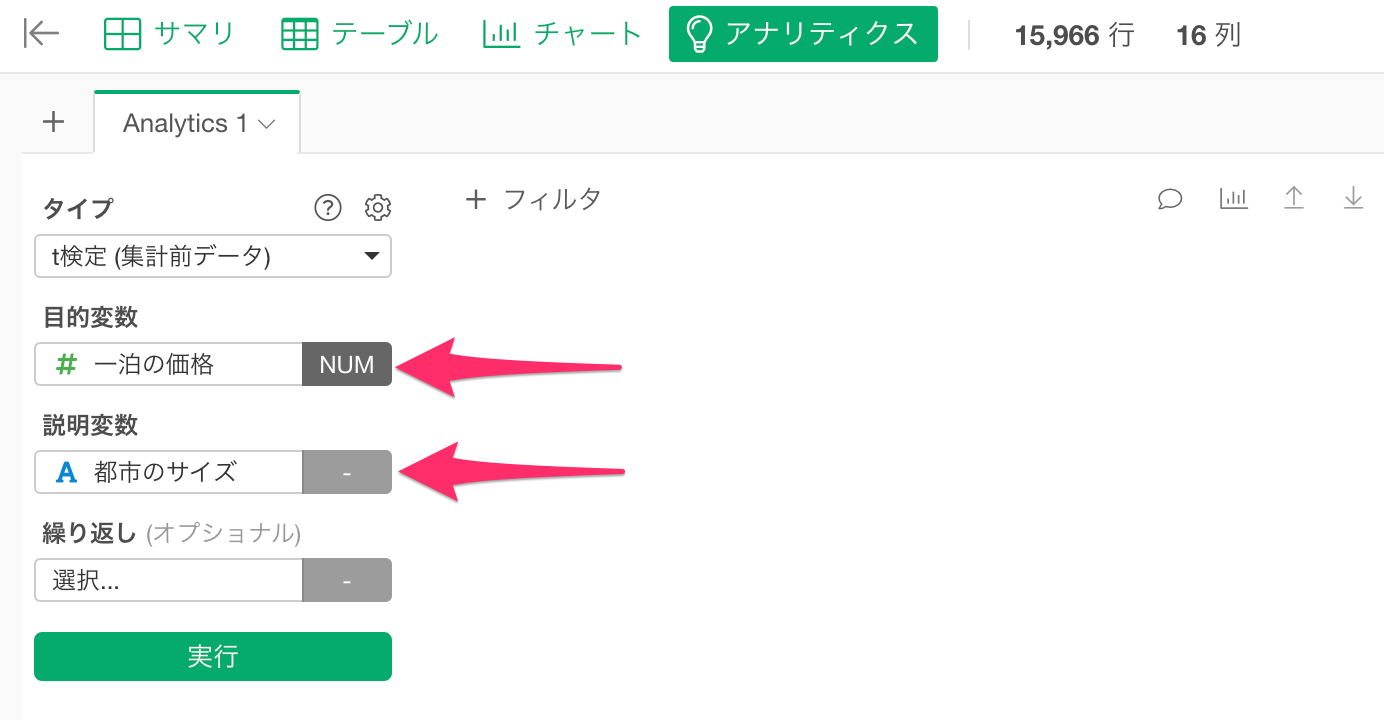
目的変数に「一泊の価格」、説明変数に「都市のサイズ」を選択し実行します。
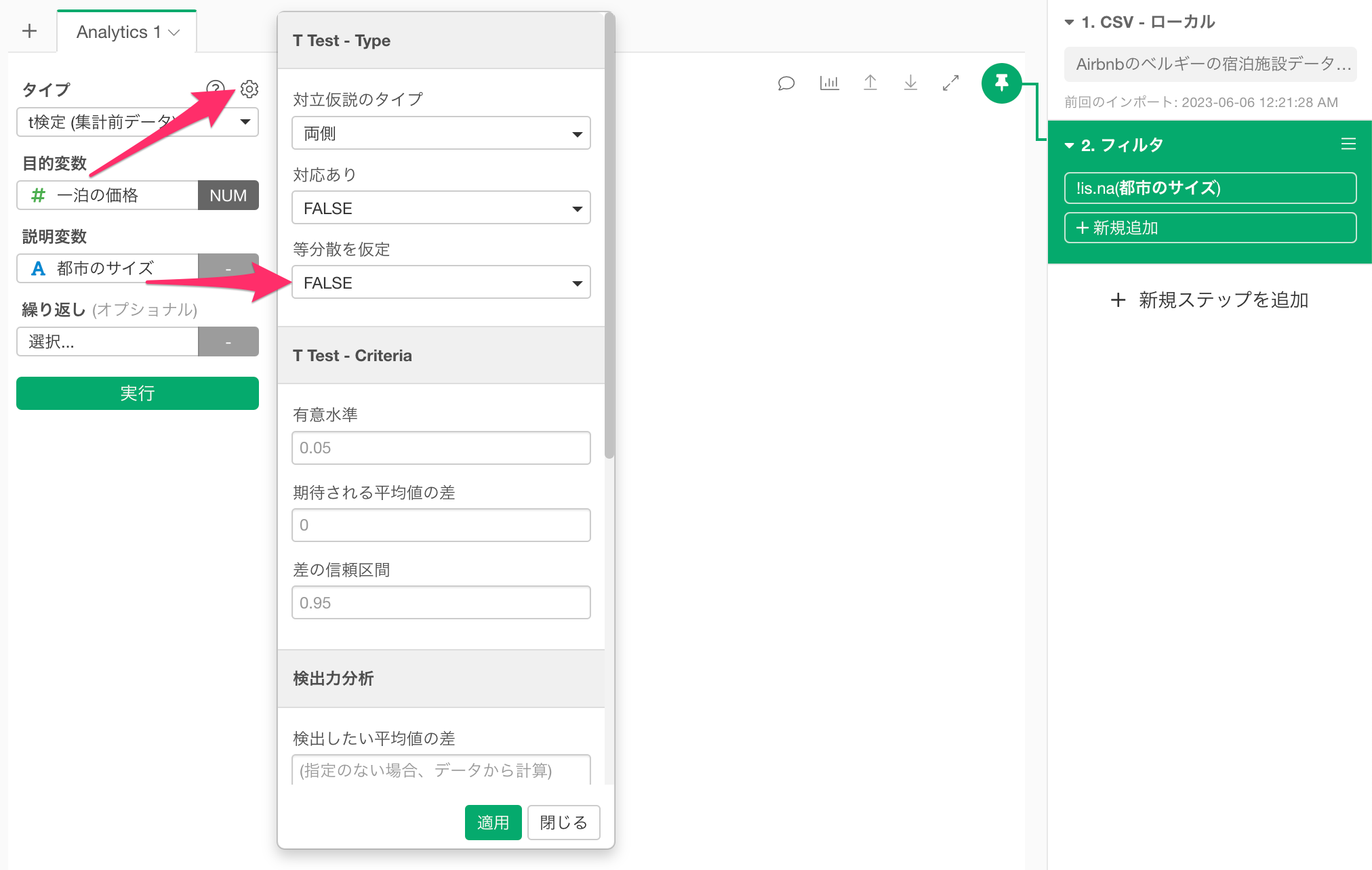
なお、t検定のデフォルトの設定では、「等分散を仮定」がFALSEになっていますが、仮に「ルビーン検定」の結果、分散が等しいことを確認できた場合、「等分散を仮定」を「TRUE」に設定して、t検定を実行できます。
t検定を実行すると、サマリタブにt検定のサマリ情報が表示されます。

有意水準を5%とした場合、P値が非常に小さい値になるため、「2つのグループの平均値には差はない」という帰無仮説が棄却され、2つのグループの平均値の間には有意な差があると判断できます。

なお、P値の詳細を確認したい場合は、指標の情報アイコンから詳細の確認が可能です。

「差」のタブでは、グループ間の平均値の差とその信頼区間がエラーバーとして可視化されます。
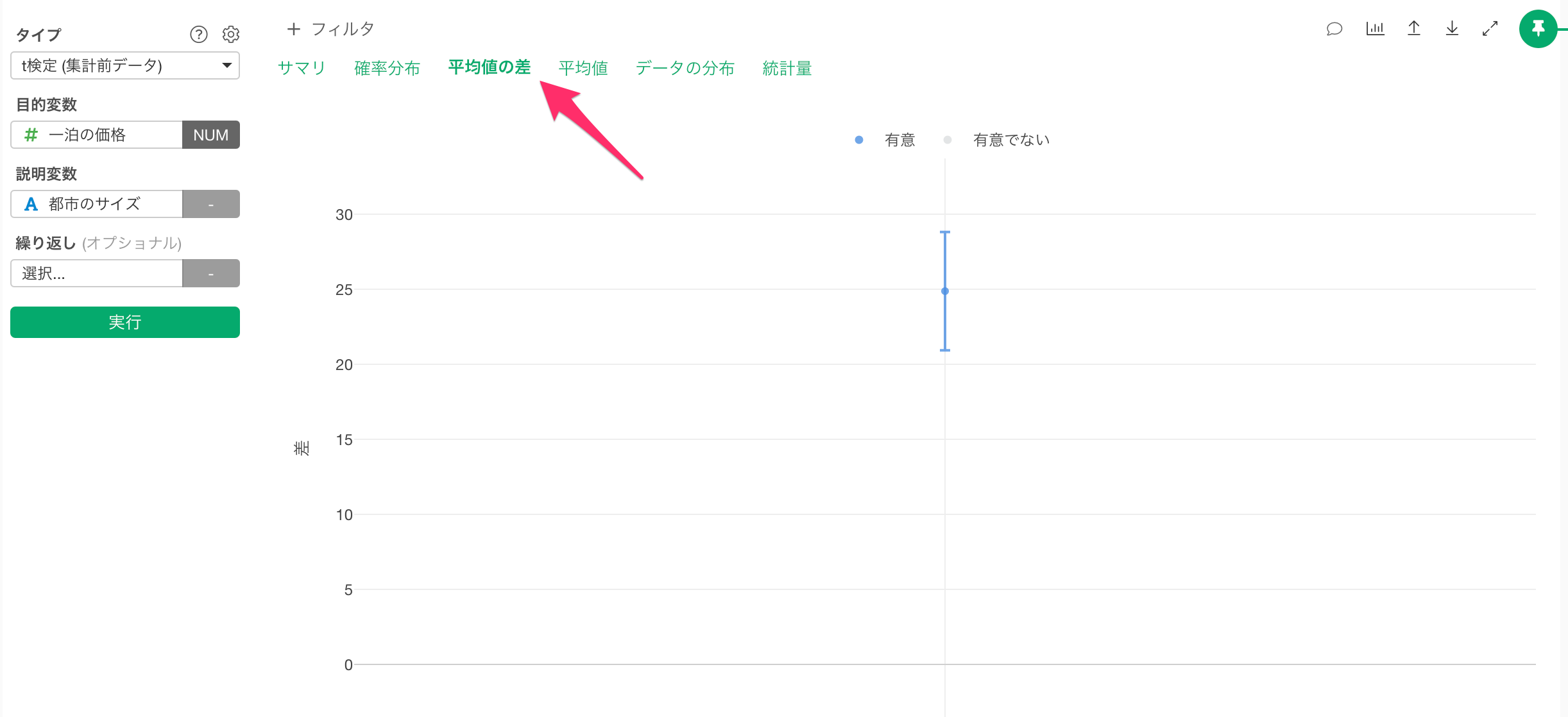
差はベースレベル(行数が最も多いカテゴリー値)と比べての差となります。
さらに、差の信頼区間が0を跨いでいるときは、「差が0であるかもしれない」と解釈でき、逆に差の信頼区間が0を跨いでいないときは、「差が0であることはない」と解釈できます。
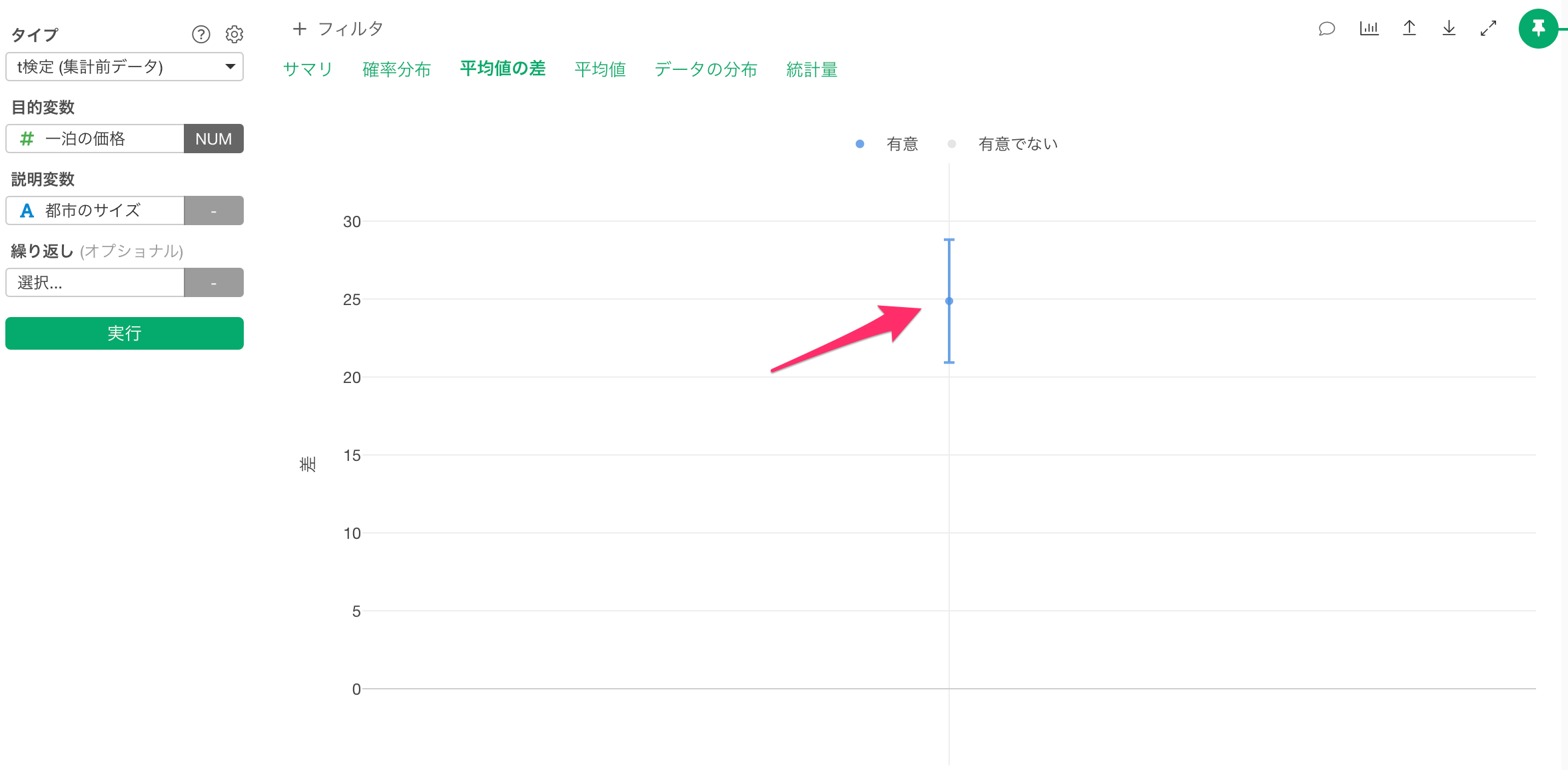
今回は、差の信頼区間が0を跨いでいないため、「差が0であることはない」と解釈できます。
マーケティング・アナリティクス・トレーニング

効果的なマーケティング活動を行うために必要なデータ分析手法を、見込みまたは既存顧客の購買、属性、行動に関するデータを使い、実際に手を動かしながら短期間で効率的に習得していただくためのトレーニングを開催しています。
データドリブンなマーケティング活動を行うために必要なデータサイエンスの手法を短期間で習得したい方は、ぜひこの機会に参加をご検討ください!