Exploratoryで共分散構造分析(SEM)を実行する方法
共分散構造分析(SEM: Structural Equation Modeling)は、直接測定できない「潜在変数」を導入し、変数間の複雑な因果関係をパス図として可視化・検証できる強力な統計手法です。
現在、Exploratoryの標準UI(アナリティクス・ビュー)には共分散構造分析のメニューは用意されていませんが、Exploratoryが持つ「ノート」機能にてRパッケージであるlavaanを使うことで、共分散構造分析を実行できます。
必要なパッケージのインストール
まず、SEMを実行するためのパッケージをインストールします。
プロジェクトメニューから「Rパッケージの管理」を選択します。
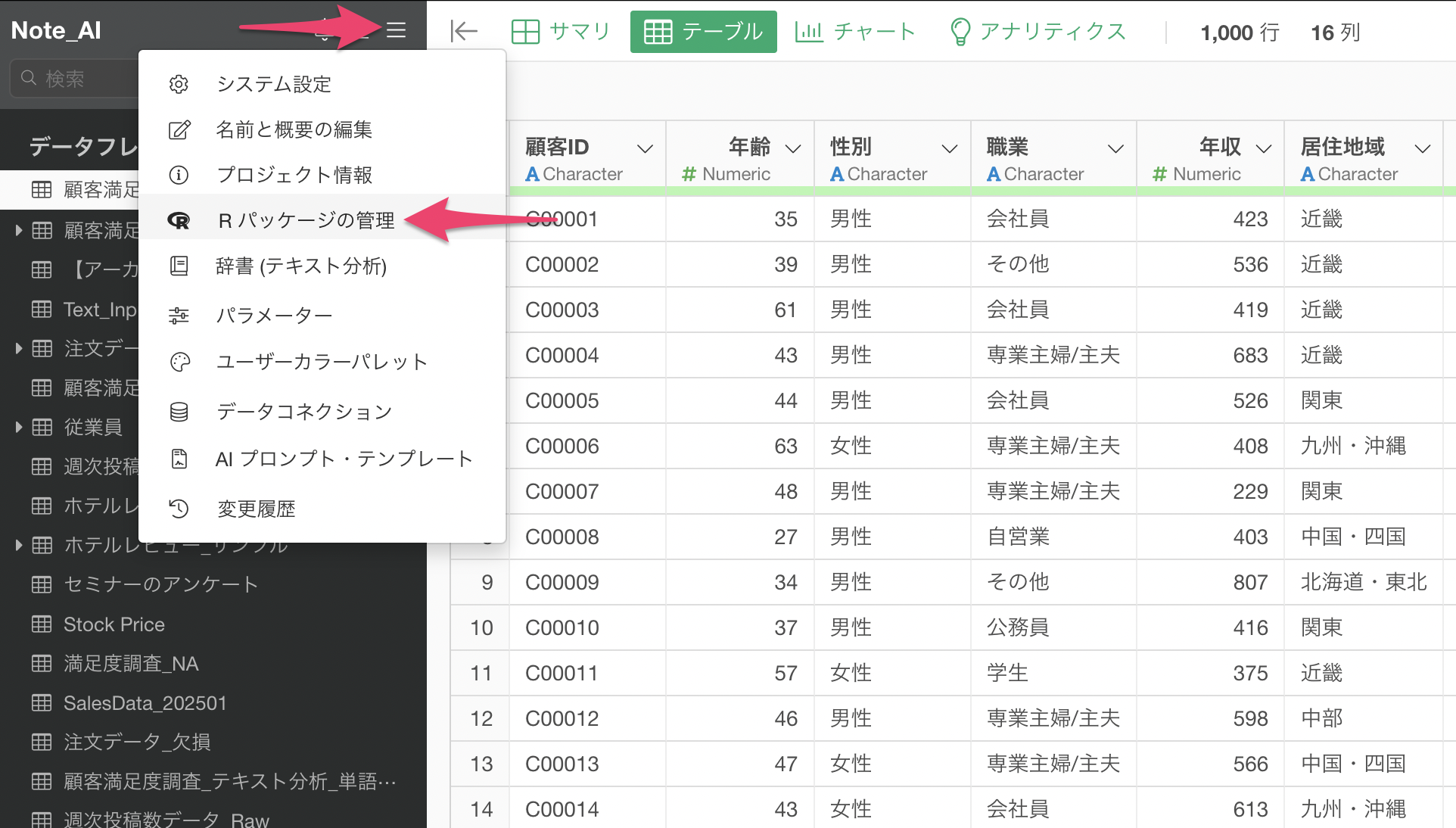
Rパッケージの管理のダイアログが表示されるため、パッケージをインストールをクリックしてから「lavaan」と「semPlot」パッケージをインストールしてください。
ノートの作成と共分散構造分析の実行
レポートのプラスボタンから「ノートを作成」を選択します。
ノートのウィンドウが開けたら、左上のプラスボタンから「Rコード」ボタンをクリックします。
 Rスクリプトを記述するためのコードブロックが追加されました。
Rスクリプトを記述するためのコードブロックが追加されました。
共分散構造分析の実行
lavaanパッケージでは、モデルをテキスト形式で定義します。以下の3つの記号を使い分けるのがポイントです。
=~: 潜在変数の定義(右辺の観測変数によって構成される)~: 回帰(因果関係)~~: 共分散(相関関係)
以下のRスクリプトを使用します。
library(lavaan)
library(semPlot)
# SEMモデル用に変数名を作成
顧客満足度調査$y1 <- 顧客満足度調査$製品品質満足度
顧客満足度調査$y2 <- 顧客満足度調査$サービス満足度
顧客満足度調査$y3 <- 顧客満足度調査$価格満足度
顧客満足度調査$y4 <- 顧客満足度調査$また利用したい
顧客満足度調査$y5 <- 顧客満足度調査$他人に推薦したい
顧客満足度調査$x1 <- 顧客満足度調査$購入回数
顧客満足度調査$x2 <- 顧客満足度調査$利用期間_月
顧客満足度調査$x3 <- 顧客満足度調査$年齢
# SEMモデルの定義
model <- '
# 測定モデル
f1 =~ y1 + y2 + y3
f2 =~ y4 + y5
# 構造モデル
f2 ~ f1 + x1 + x2
f1 ~ x3
'
# SEMモデルのフィット
fit <- sem(model, data = 顧客満足度調査)
# 結果の要約
summary(fit, fit.measures = TRUE, standardized = TRUE)
# 日本語フォントの設定
par(family = "HiraKakuProN-W3") # Macの場合
# par(family = "Yu Gothic") # Windowsの場合
# モデルの図示
if(requireNamespace("semPlot", quietly = TRUE)) {
semPaths(fit,
whatLabels = "est",
layout = "tree",
rotation = 2,
edge.label.cex = 0.7, # ラベルサイズを少し小さく
sizeMan = 8,
sizeLat = 10,
curve = 1.5, # 矢印を少し曲げる
edge.label.position = 0.55, # ラベル位置を調整
mar = c(3, 3, 3, 3), # マージンを広げる
nodeLabels = c("年齢", "価格満足", "サービス満足",
"品質満足", "購入回数", "利用期間",
"また利用", "推薦意向",
"顧客満足度", "再購入意向"))
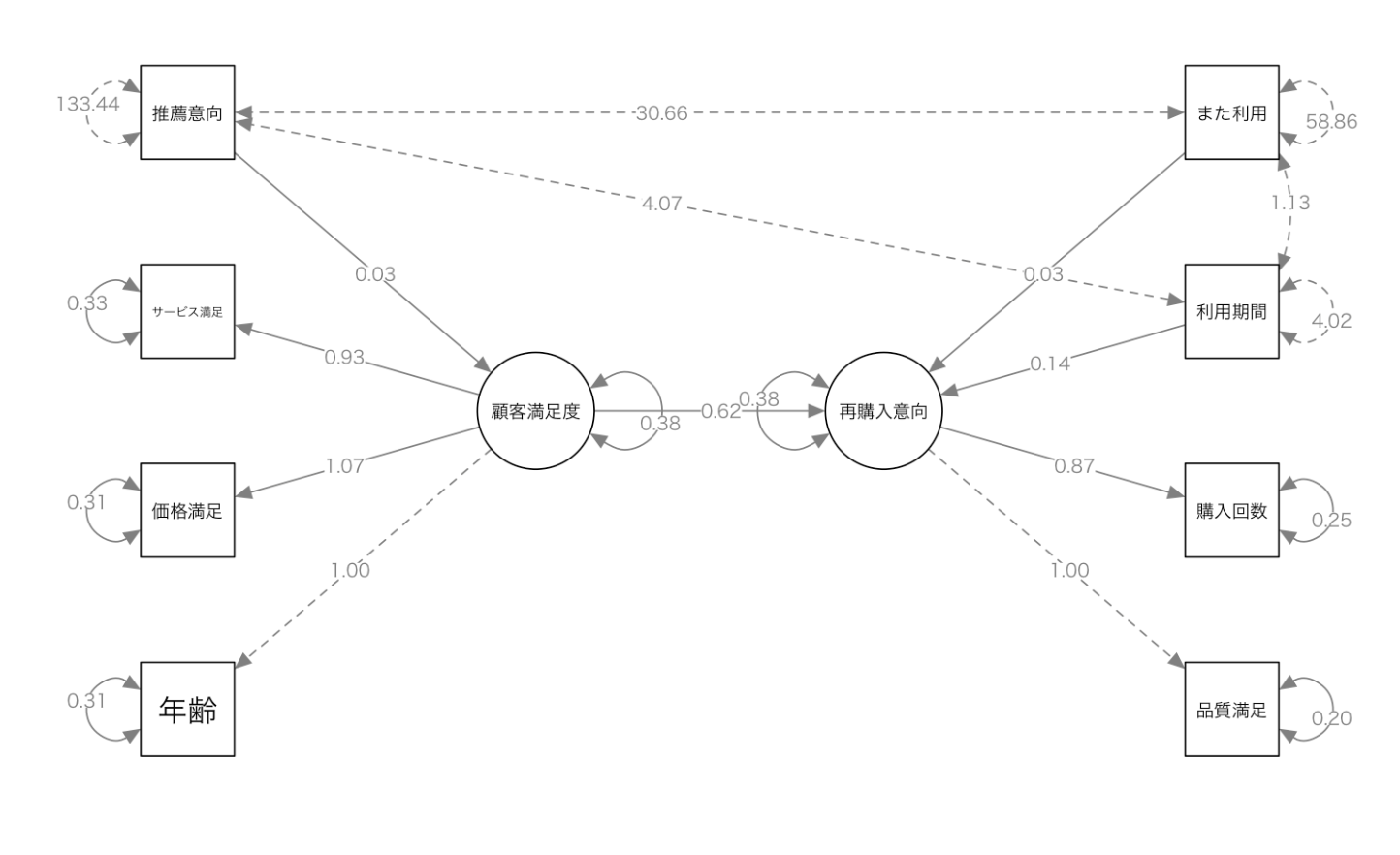
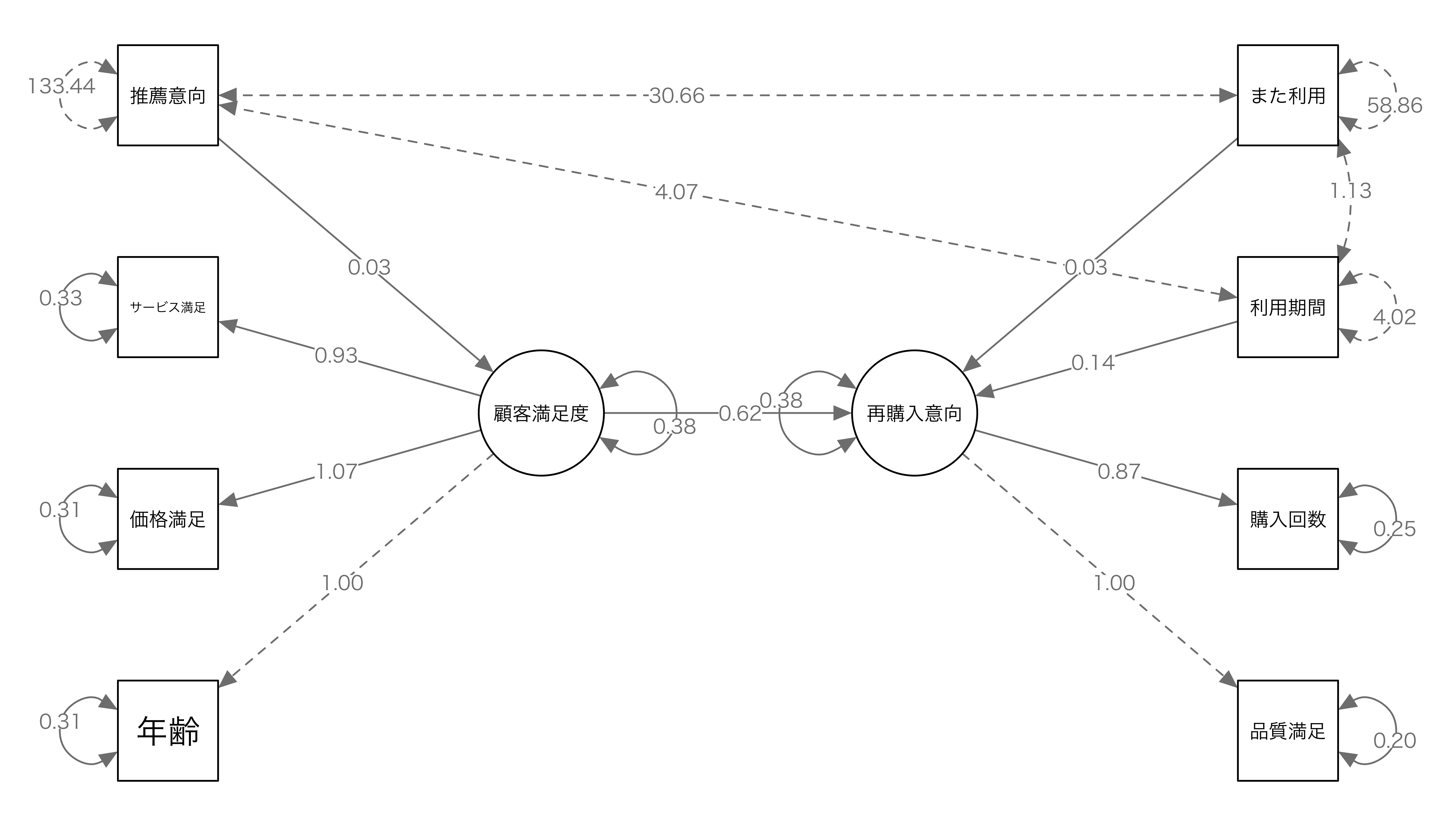
}このRスクリプトを実行した結果が以下となります。
自分のデータで分析する場合の変更箇所
上記のサンプルコードを自分のデータに適用する際は、以下の箇所を変更してください。
1. データフレーム名の指定
変更箇所:
sem()関数のdataパラメータ
# 例:データフレーム名が「顧客満足度調査」の場合
fit <- sem(model, data = 顧客満足度調査)
# 例:データフレーム名が「アンケート結果」の場合
fit <- sem(model, data = アンケート結果)
2. 列名(変数名)の対応付け
変更箇所: SEMモデル用の変数名作成部分
# 自分のデータの列名に合わせて変更してください
データフレーム名$y1 <- データフレーム名$実際の列名1
データフレーム名$y2 <- データフレーム名$実際の列名2
データフレーム名$y3 <- データフレーム名$実際の列名3
データフレーム名$y4 <- データフレーム名$実際の列名4
データフレーム名$y5 <- データフレーム名$実際の列名5
データフレーム名$x1 <- データフレーム名$実際の列名6
データフレーム名$x2 <- データフレーム名$実際の列名7
データフレーム名$x3 <- データフレーム名$実際の列名83. モデル定義の変更(必要に応じて)
変更箇所: model変数の定義部分
モデルの構造自体を変えたい場合(例:潜在変数を3つにする、パスを追加するなど)は、この部分を修正します。
# 基本のモデル構造はそのまま使用できます
model <- '
# 測定モデル
f1 =~ y1 + y2 + y3 # 潜在変数f1は y1, y2, y3 で測定
f2 =~ y4 + y5 # 潜在変数f2は y4, y5 で測定
# 構造モデル
f2 ~ f1 + x1 + x2 # f2 は f1, x1, x2 の影響を受ける
f1 ~ x3 # f1 は x3 の影響を受ける
'4. グラフのラベル変更
変更箇所:
semPaths()関数のnodeLabelsパラメータ
図に表示する日本語ラベルを自分のデータに合わせて変更します。ラベルの順序は、x3, y3, y2, y1, x1, x2, y4, y5, f1, f2 の順です。
nodeLabels = c("年齢", "価格満足", "サービス満足",
"品質満足", "購入回数", "利用期間",
"また利用", "推薦意向",
"顧客満足度", "再購入意向") パス図の読み方
SEMのパス図には様々な矢印と数値が表示されます。それぞれの意味を理解することが重要です。
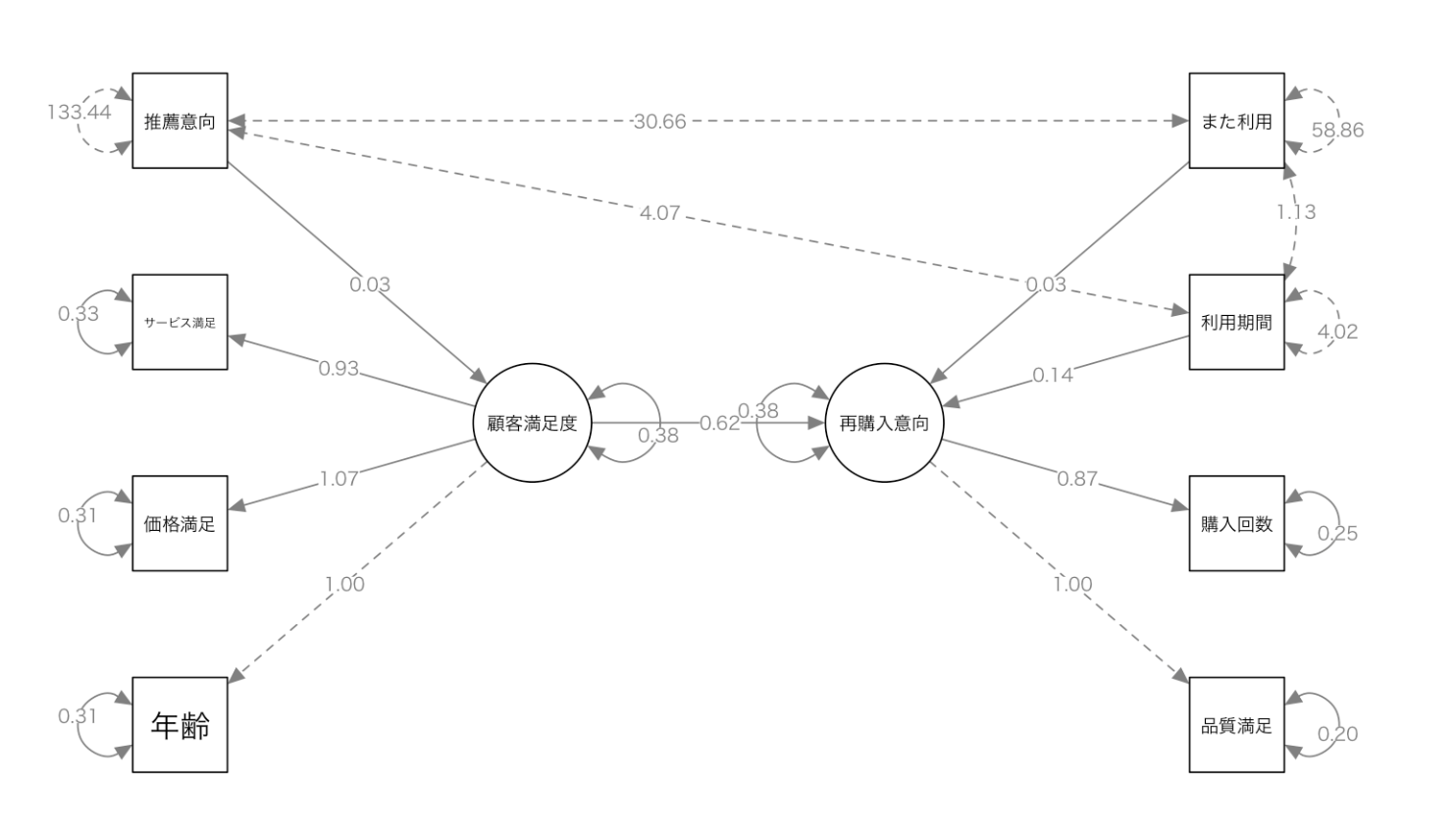
矢印の種類
- 実線の矢印:因果関係・影響関係を表します。
- 例:「顧客満足度 → 再購入意向」= 顧客満足度が再購入意向に影響を与える
- 点線の矢印:共分散(相関関係)を表します
- 例:年齢と他の変数間の点線 = これらは相関があるが、因果関係は仮定していない
数値の意味
潜在変数(楕円)から観測変数(四角)への矢印の数値:因子負荷量
- 例:顧客満足度 → サービス満足度:0.93
- 意味:サービス満足度は顧客満足度という潜在変数を強く反映している
潜在変数間・変数から潜在変数への矢印の数値:パス係数(標準化回帰係数)
- 例:顧客満足度 → 再購入意向:0.38
- 意味:顧客満足度が1単位増えると、再購入意向が0.38単位増える
観測変数の横の小さな円の数値:誤差分散(残差)
- 例:推薦意向:133.44
- 意味:この観測変数のうち、モデルで説明できない部分の大きさ
1.00という数値:測定の基準として固定された値(モデル識別のため)
よくあるエラーと対処法
Error: variable ‘xxx’ not found
- 原因: モデル式で指定した変数名がデータフレームに存在しない、または綴りが間違っている
Error in strrep(” “, pflen): invalid ‘times’ value
原因: 日本語の長い列名を直接モデル定義に使用している
対処: 短い変数名(y1, y2, x1など)を作成してモデル定義に使用してください
図の日本語が文字化けする
原因: Rのグラフィックデバイスが日本語フォントを認識していない
対処:
par(family = "HiraKakuProN-W3")(Mac)またはpar(family = "Yu Gothic")(Windows)を図の描画前に実行してください
図の数値ラベルが重なって読めない
原因: デフォルトのレイアウトでは矢印が直線的すぎて数値が重なる
対処:
curve = 1.5とedge.label.position = 0.55パラメータを追加して、矢印を曲げてラベル位置を調整してください
まとめ
共分散構造分析(SEM)は、直接測定できない潜在変数を使って、変数間の複雑な因果関係を可視化・検証できる統計手法です。アンケート調査などで得られた複数の質問項目から、背後にある概念(顧客満足度や再購入意向など)を抽出し、それらの関係性をパス図として表現できるため、ビジネスにおける意思決定の根拠を明確にするのに役立ちます。
Exploratoryでは、標準UIには共分散構造分析のメニューはありませんが、ノート機能でRのlavaanパッケージを使用することで、SEMの実行が可能です。この方法により、Exploratory上でデータ分析、結果の可視化までを一貫して行うことができます。