Exploratoryで傾向スコアマッチングを行う方法
マーケティング施策やキャンペーンの効果を検証する際、「施策を受けたグループと受けていないグループを単純に比較するだけでは正しい結論を導けない」という問題に直面することがあります。たとえば、特定のページを見た人の購入率が高かったとしても、もともとそのページを見るような人はサイトへの訪問頻度が高く、購入意欲も高い傾向があるかもしれません。このような属性の偏り(セレクションバイアス)を取り除いた上で公平な比較を行うための統計手法が「傾向スコアマッチング」です。
本記事では、傾向スコアマッチングの考え方を紹介し、ExploratoryのRコマンド機能を使って実際に実行する方法を解説します。今回はECサイトの特集ページの効果検証を例として取り上げますが、傾向スコアマッチングはメール配信、広告接触、機能利用など、さまざまな施策の効果検証に応用できます。
傾向スコアマッチングとは
傾向スコアマッチングは、2つのグループ(例:施策を受けた人と受けていない人)の属性を揃えた上で比較を行うための統計手法です。Rosenbaum & Rubin (1983) によって提唱されました。
ランダム化比較試験(RCT)のようにランダムにグループを割り当てることができれば、2つのグループの属性は平均的に揃うため、結果の差を施策の効果として解釈できます。しかし、実際のビジネスデータの多くは観察データであり、誰が施策を受けるかはランダムではありません。その結果、施策を受けたグループと受けていないグループの間に属性の偏り(セレクションバイアス)が生じ、単純な比較では施策の効果を正しく測定できなくなります。
傾向スコアマッチングでは、まず各ユーザーについて「施策を受ける確率(傾向スコア)」をロジスティック回帰などで算出します。次に、施策を受けたグループ(処置群)と受けていないグループ(対照群)の中から、傾向スコアが近い者同士をペアとしてマッチングします。これにより、属性が似通った者同士での比較が可能になり、セレクションバイアスを軽減した上で施策の効果を検証できるようになります。
使用するデータ
今回は、ECサイトのユーザー行動データを使って、特集ページの閲覧が購入や売上に与える影響を検証します。
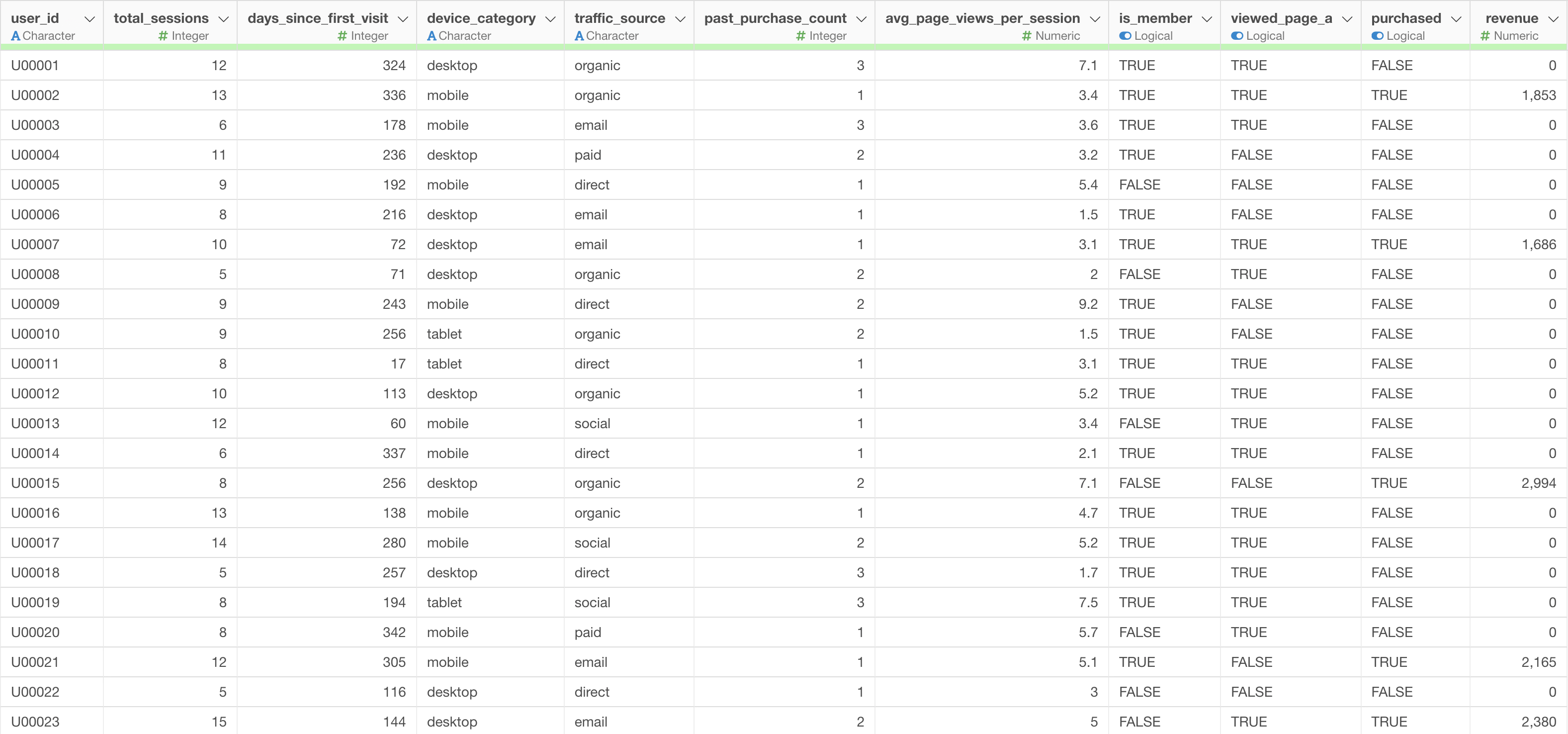
傾向スコアマッチングの用語で言えば、viewed_page_a(特集ページの閲覧)が処置変数、purchased
や revenue
が目的変数、total_sessions や
device_category
などがマッチングで揃えたい属性に相当します。
MatchItパッケージのインストール
傾向スコアマッチングには MatchIt
というRパッケージを使用します。Exploratoryにはデフォルトでインストールされていないため、最初にインストールする必要があります。
Rパッケージのインストールは、プロジェクトメニューの「Rパッケージの管理」から行えます。
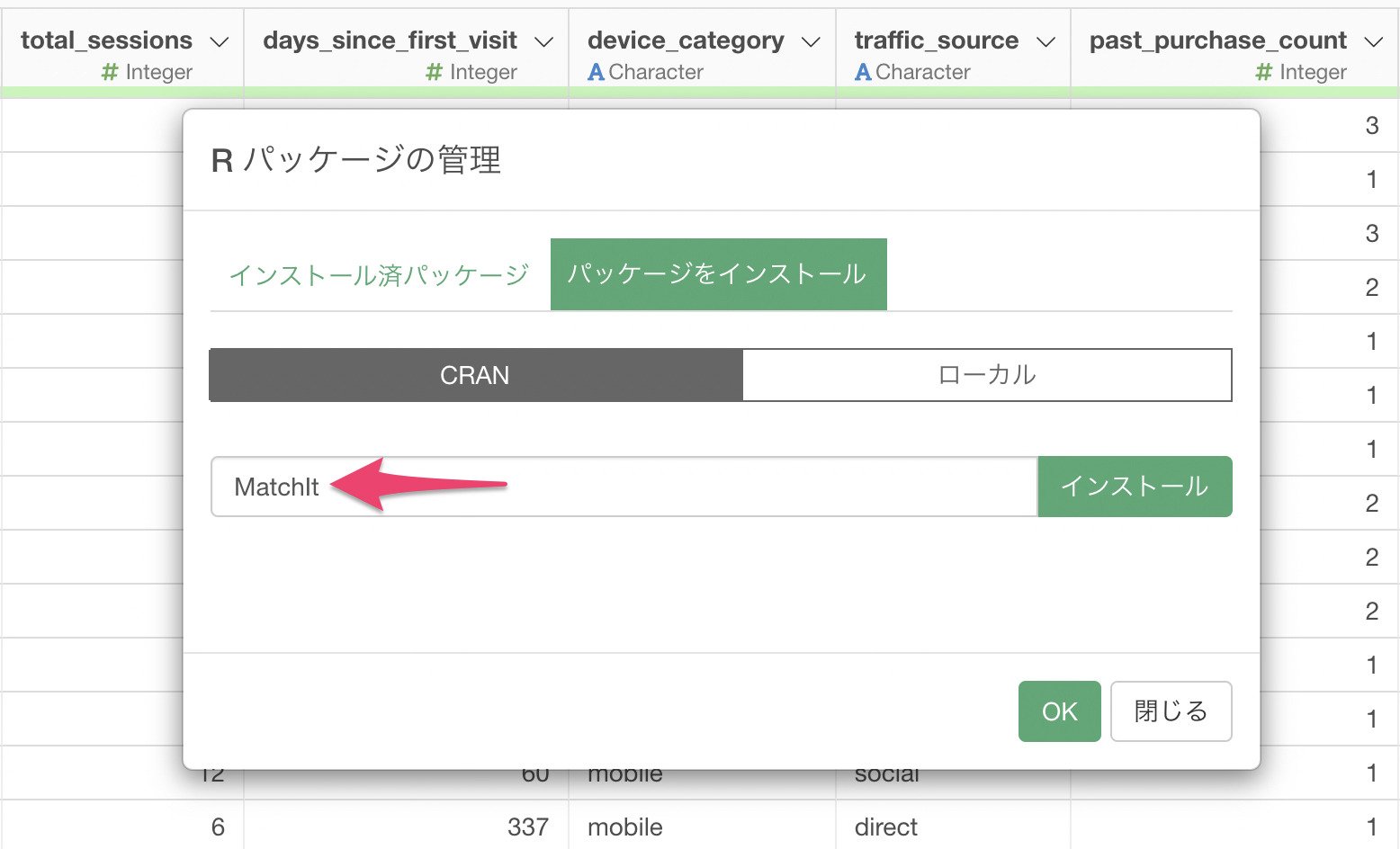
パッケージインストール画面で MatchIt
と入力し、インストールボタンをクリックします。
Rパッケージのインストールの詳しい手順は「Rパッケージのインストール方法」を参照してください。
傾向スコアマッチングの実行
ステップメニューにある「Rコマンド」を選択します。
以下のRスクリプトを入力して実行します。
MatchIt::matchit(
viewed_page_a ~ total_sessions + days_since_first_visit +
device_category + traffic_source + past_purchase_count +
avg_page_views_per_session + is_member,
data = .,
method = "nearest",
distance = "glm",
caliper = 0.1, # キャリパーを設定してマッチの質を向上
std.caliper = TRUE,
ratio = 1,
replace = FALSE
) %>%
MatchIt::match.data()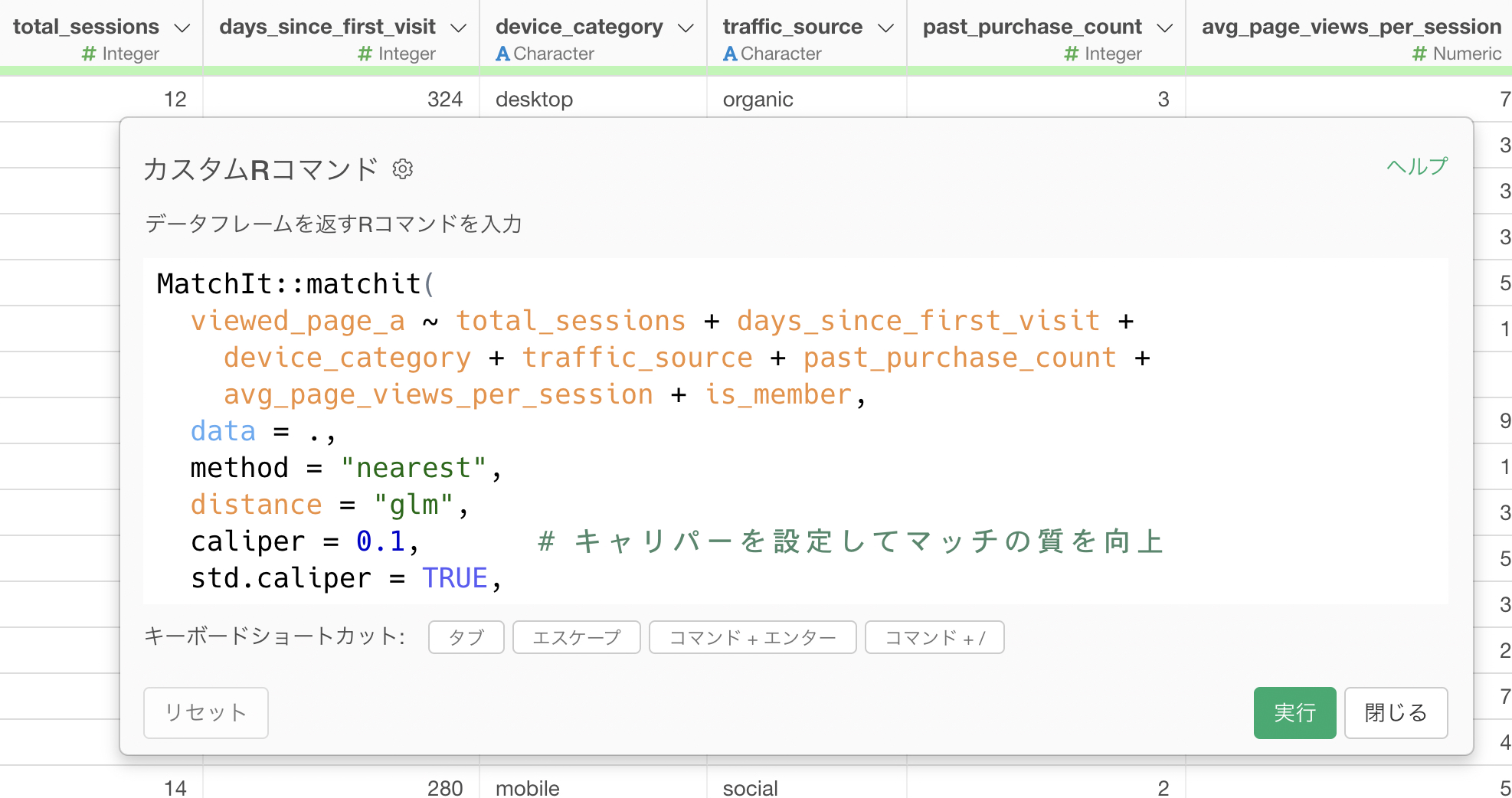
viewed_page_a ~ total_sessions + days_since_first_visit + ...
の部分が、傾向スコアを算出するためのモデルの式です。~
の左側が処置変数(どのグループに属するかを示す列)で、右側がマッチングの際に揃えたい属性の列です。ご自身のデータに合わせて、列名を変更してください。
主要なパラメータ
| パラメータ | 値 | 説明 |
|---|---|---|
method |
"nearest" |
最近傍マッチング。傾向スコアが最も近い相手とペアにする、最も一般的な手法 |
distance |
"glm" |
傾向スコアの算出にロジスティック回帰(一般化線形モデル)を使用する。標準的な選択肢 |
caliper |
0.1 |
マッチングを許容する傾向スコアの差の上限。Austin (2011) では傾向スコアの標準偏差の0.2倍が推奨されている。値を小さくするとマッチの質が上がるが、マッチできないユーザーが増える |
std.caliper |
TRUE |
caliper
の値を傾向スコアの標準偏差単位として扱う。TRUE
にすることで、データのスケールに依存しない閾値設定が可能になる |
ratio |
1 |
1対1マッチング。処置群1人に対して対照群1人をマッチさせる |
replace |
FALSE |
復元なしマッチング。一度マッチした対照群のユーザーは再利用しない |
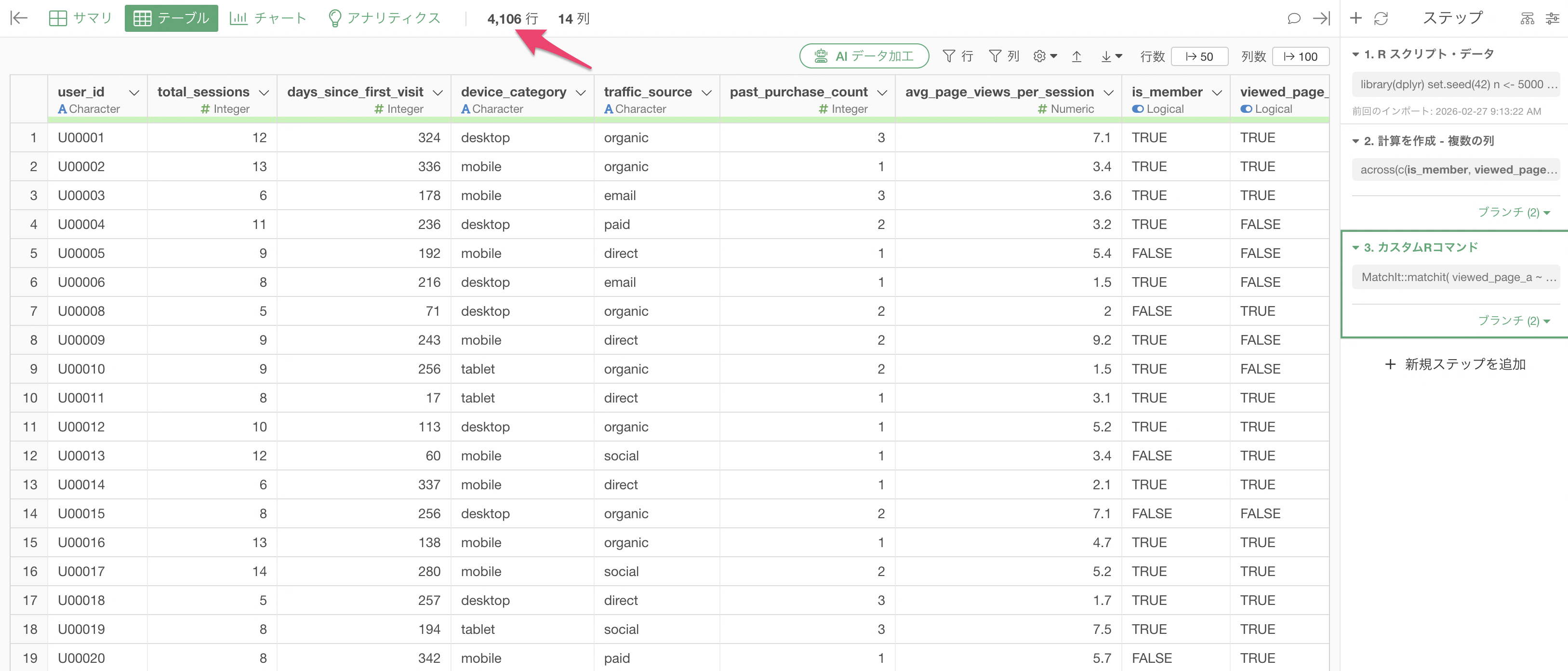
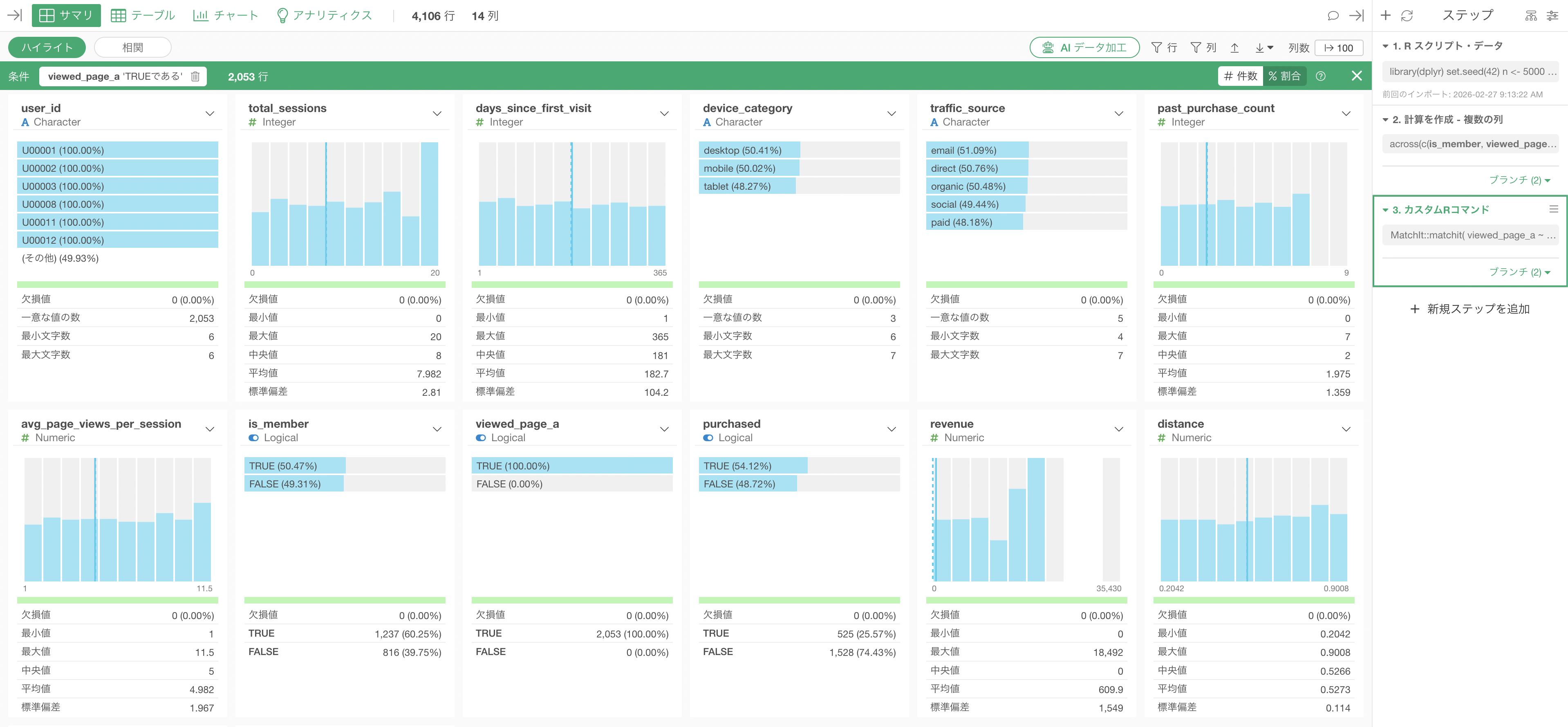
実行することで、元々5,000行あったデータが4,106行と少なくなっていることが確認できます。
マッチング前後の比較検証(バランスチェック)
傾向スコアマッチングが適切に機能したかどうかを確認するには、マッチング前後で各共変量のグループ間の差を比較します。マッチングによって処置群と対照群の属性が揃ったかどうかを検証するこのステップを「バランスチェック」と呼びます。
今回は、サマリビューにある「ハイライト」の機能を使ってバランスチェックを行います。
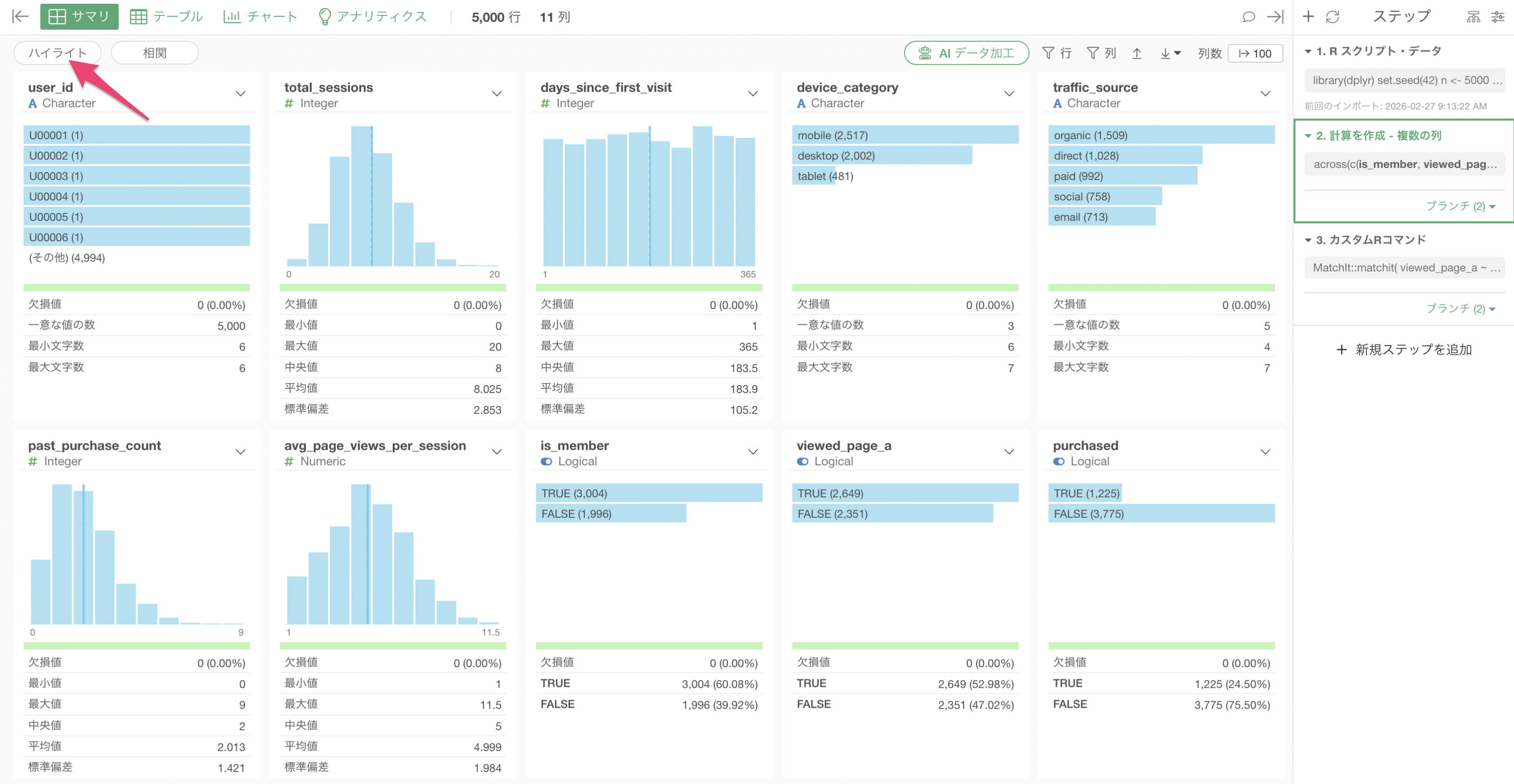
ハイライトする条件には「viewed_page_a」がTRUEであるという条件を設定します。
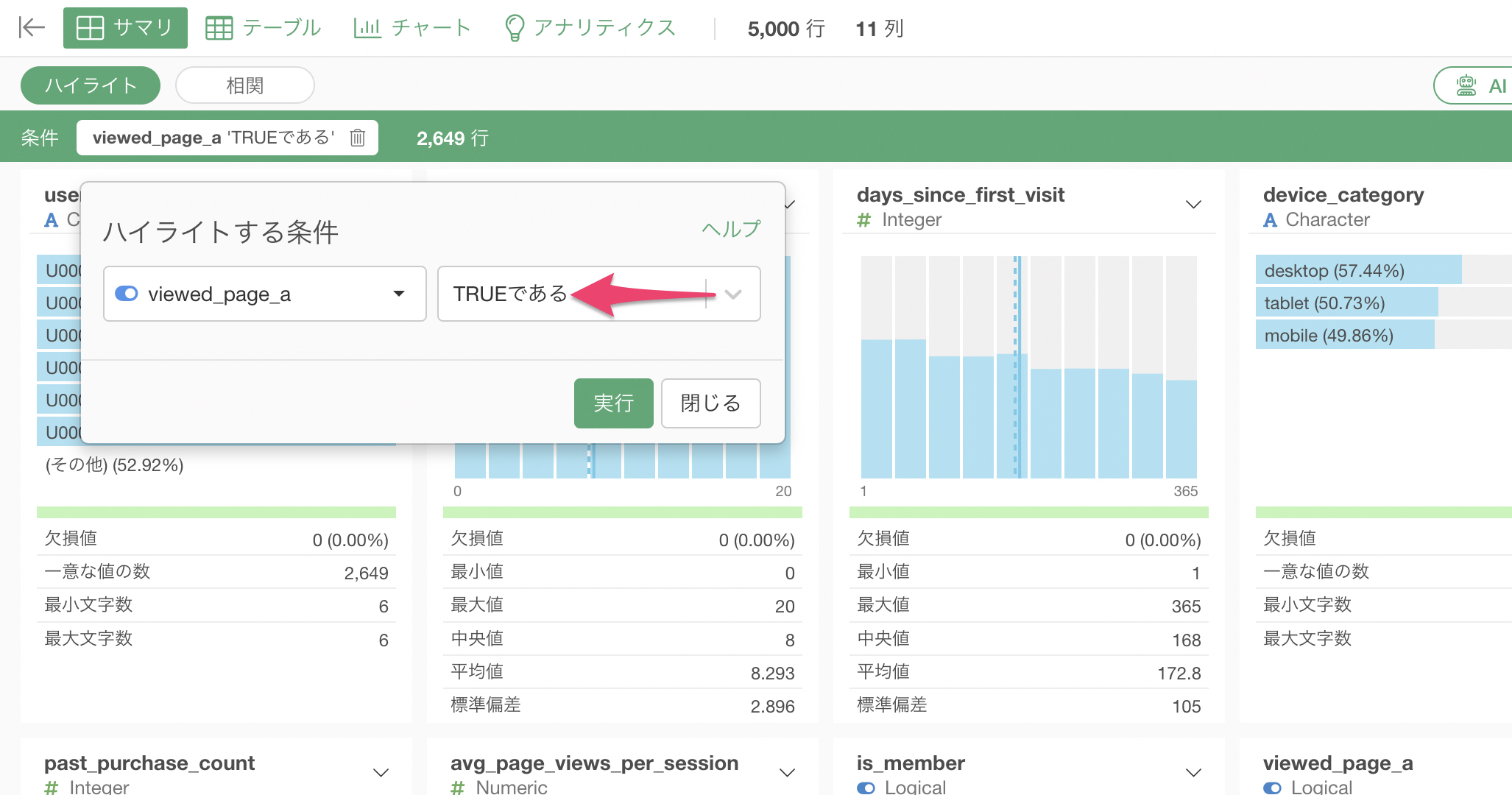
傾向スコアマッチングを行う前は、属性を揃えたい列であるdevice_categoryやtrafic_sourceなどの列でviewed_page_aのTRUEの割合に偏りがあります。
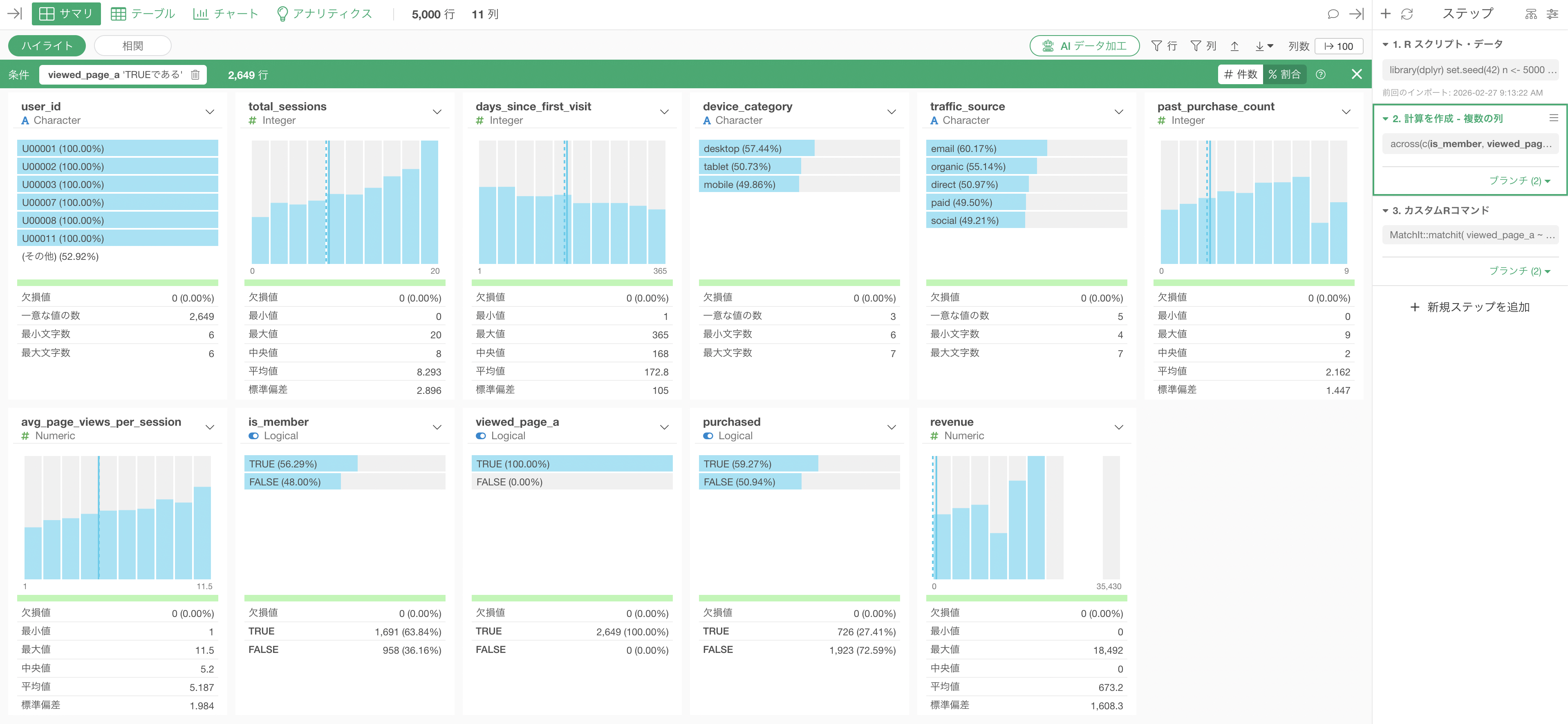
一方で、傾向スコアマッチングを行なったあとは、device_categoryやtrafic_sourceなどの列もviewed_page_aのTRUEの割合は50%前後になっていることがわかります。
効果の検証
バランスチェックで属性の偏りが解消されたことを確認できたら、マッチング後のデータを使って施策の効果を検証します。
今回はエラーバーの95%信頼区間を使って比較をします。
チャートビューを選択し、チャートのタイプには「エラーバー」を選択します。
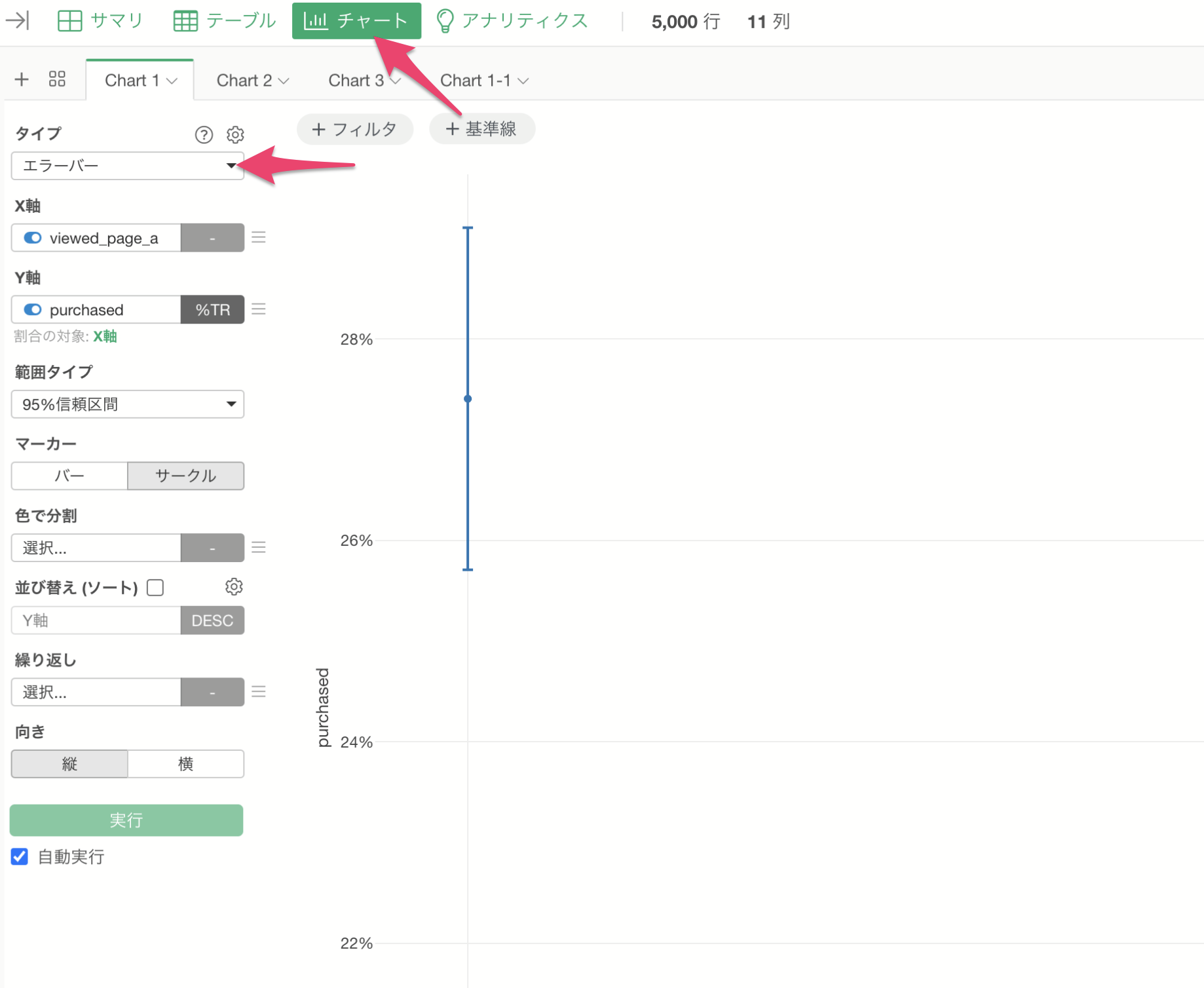
次に、X軸には「viewe_page_a」を、Y軸には「purchased」を選択します。
以下は傾向スコアマッチング前の結果となり、信頼区間は重なっていないことがわかりますが、これは特集ページ(viewed_page_a)を閲覧する人自体にバイアスがあるかもしれません。
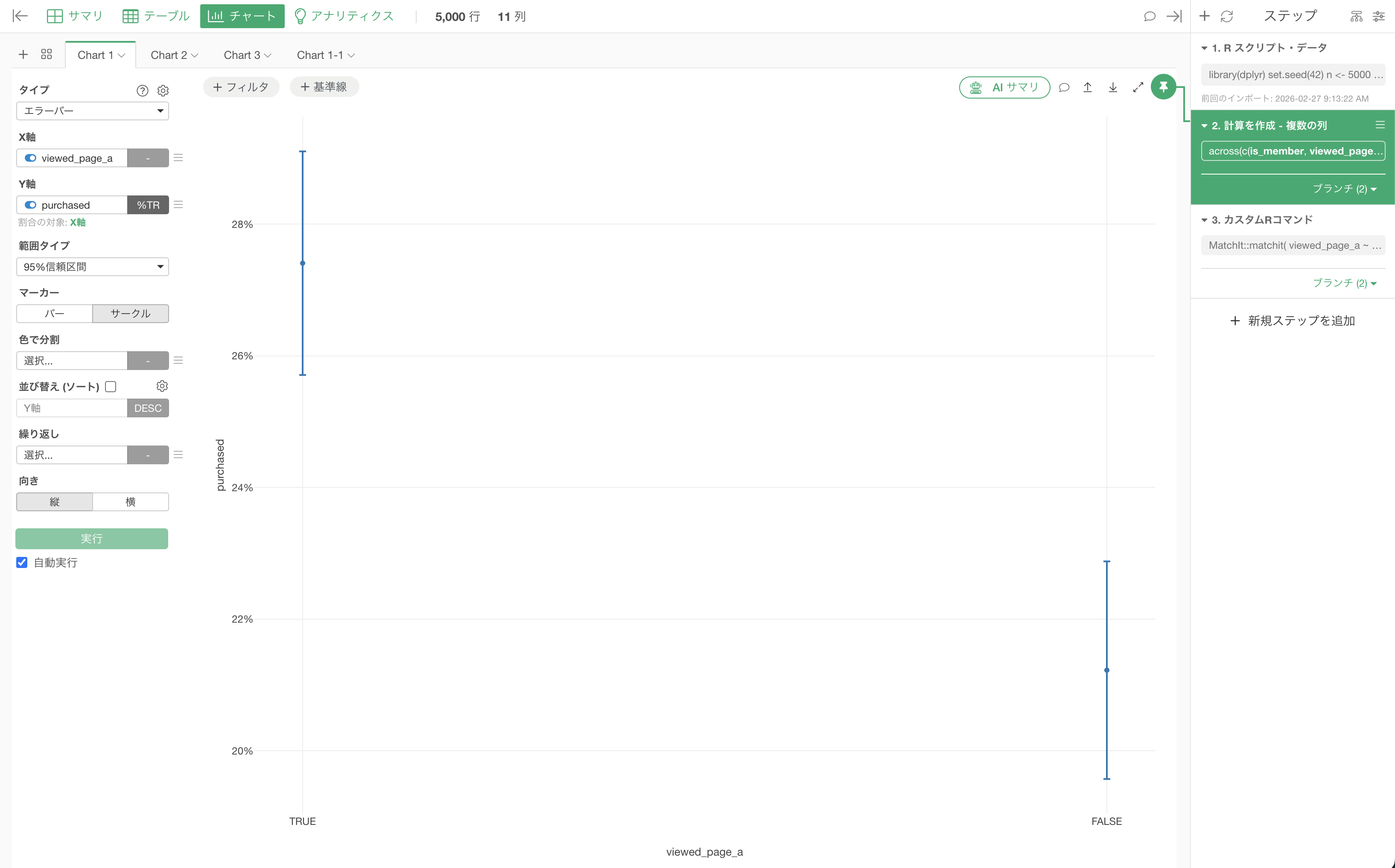
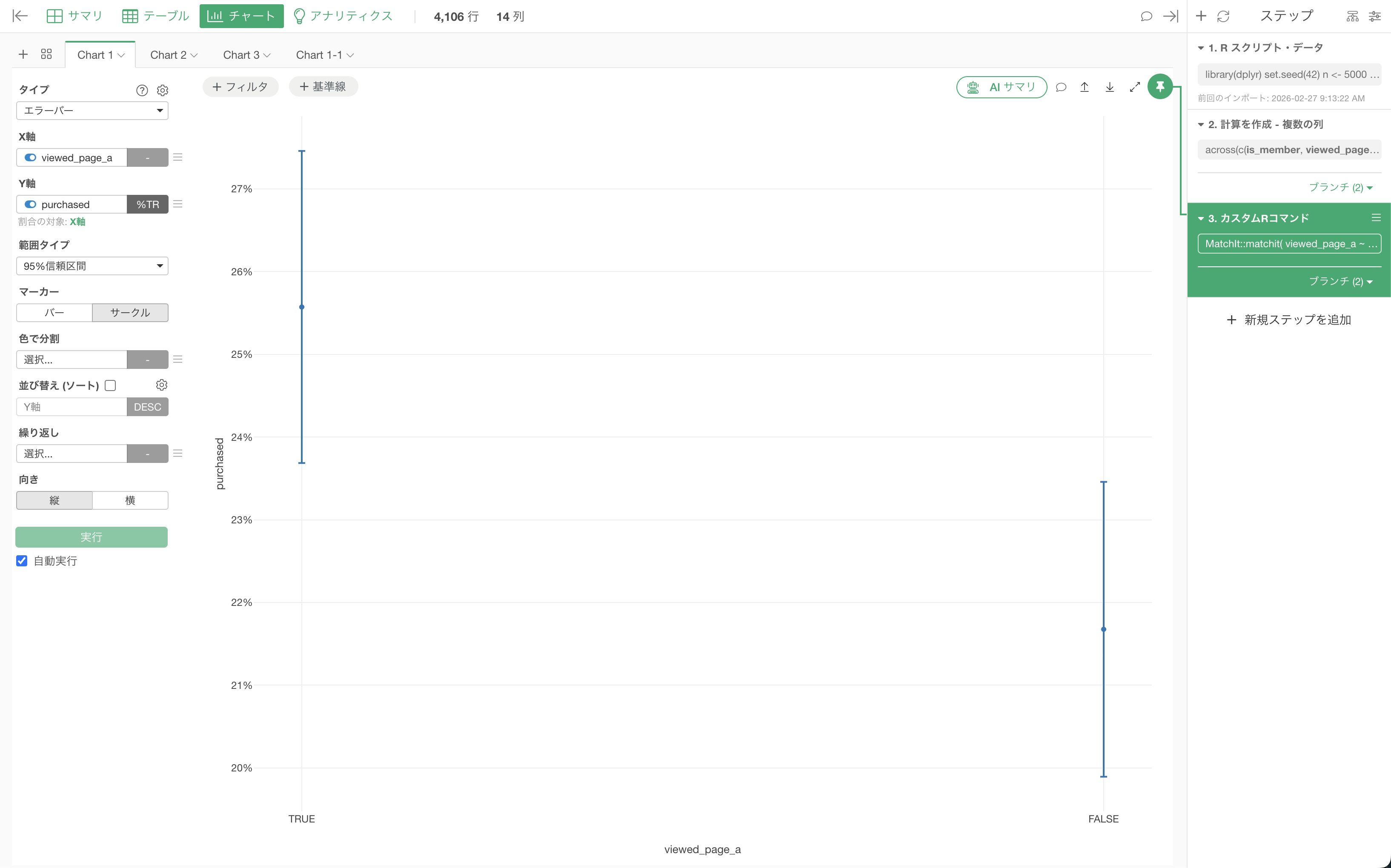
そこで、傾向スコアマッチングを行なった結果でも同様に95%信頼区間で確認しましょう。
この傾向スコアマッチング後でも信頼区間が重なっていないことから、統計的に有意な違いがあると言えます。つまり、同じような属性の人だったとしても特集ページ(viewed_page_a)を閲覧する人の方が購買する確率が高くなっていると考えられます。
まとめ
傾向スコアマッチングは、施策を受けた人と受けていない人を比較する際に、属性の偏りを取り除いた上で公平な比較を行うための統計手法です。ランダム化比較試験が実施できない観察データにおいて、施策の効果をより正確に推定するために広く使われています。
Exploratoryではデフォルトのアナリティクス機能として提供されていませんが、MatchIt
パッケージをインストールし、「Rコマンド」を実行するだけで傾向スコアマッチングを実行できます。
これにより、施策が本当に効果を持っているのかを、より信頼性の高い形で検証することが可能になります。