パフォーマンスを向上させるためのベストプラクティス
このノートでは、Exploratoryでの処理のパフォーマンスを向上させるための方法を紹介します。
Exploratoryのデータ処理の仕組み
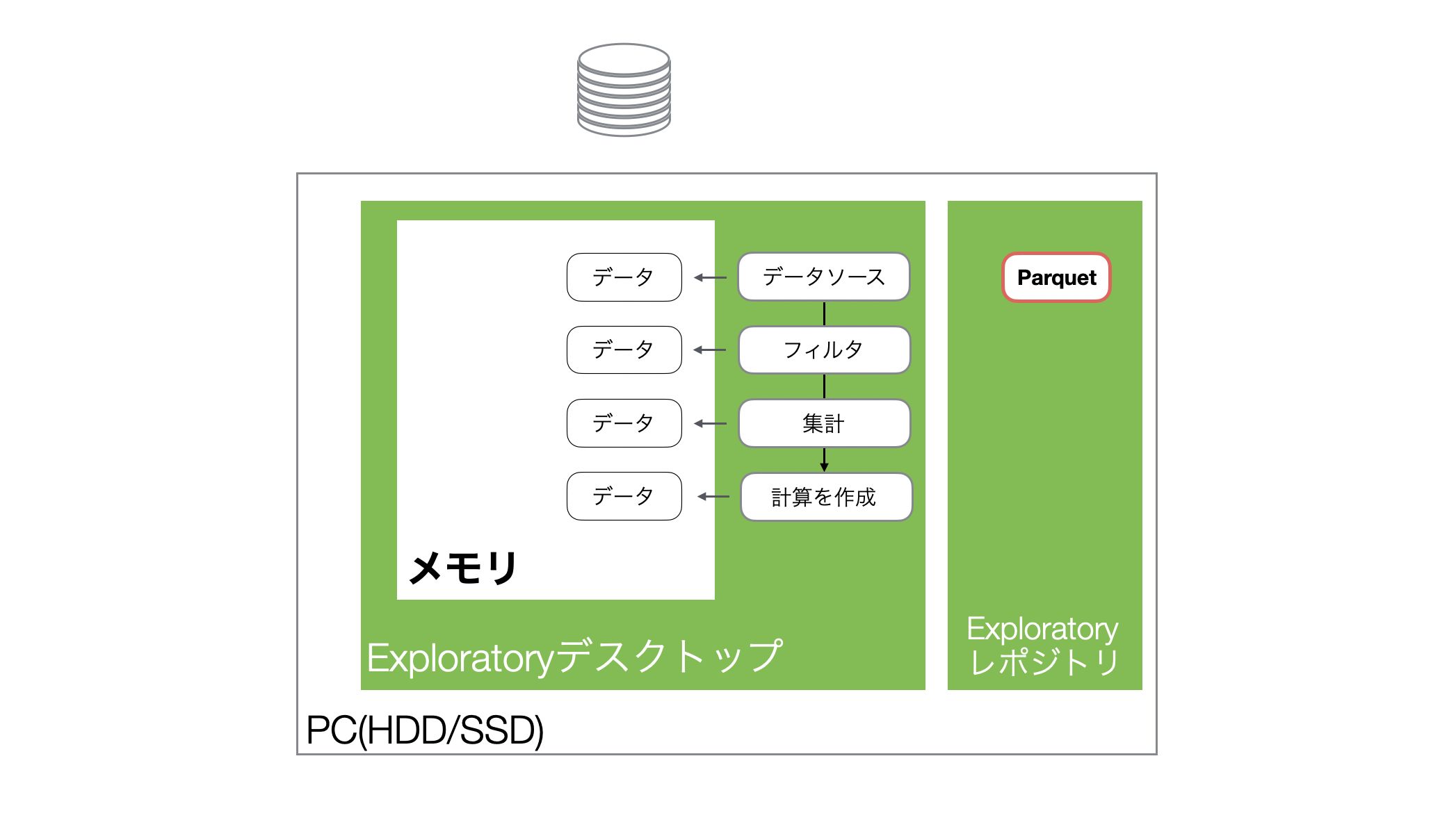
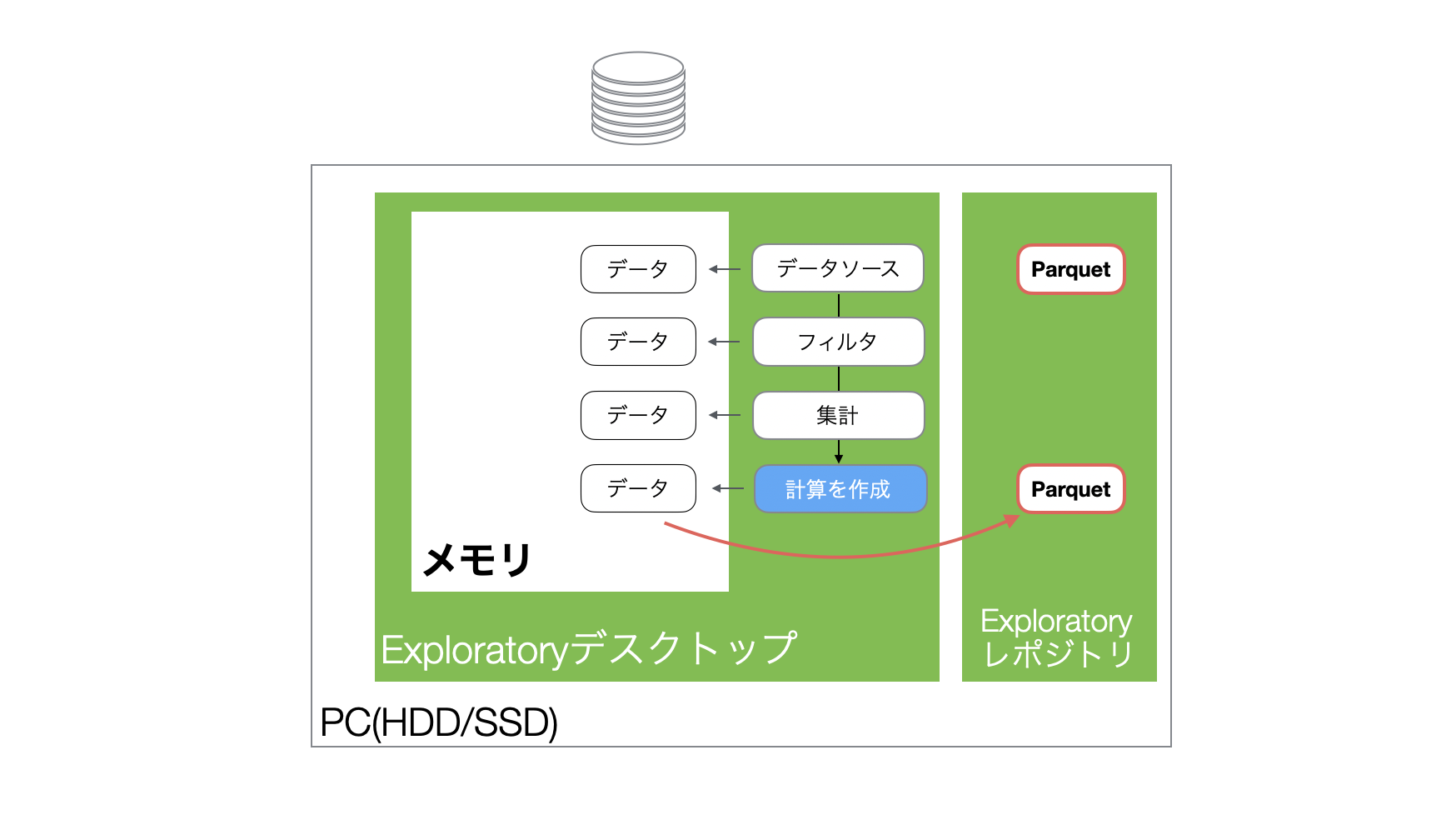
Exploratoryではデータをインポートすると、データをメモリに読み込み、メモリ上のデータに対して様々な処理を実行することになります。
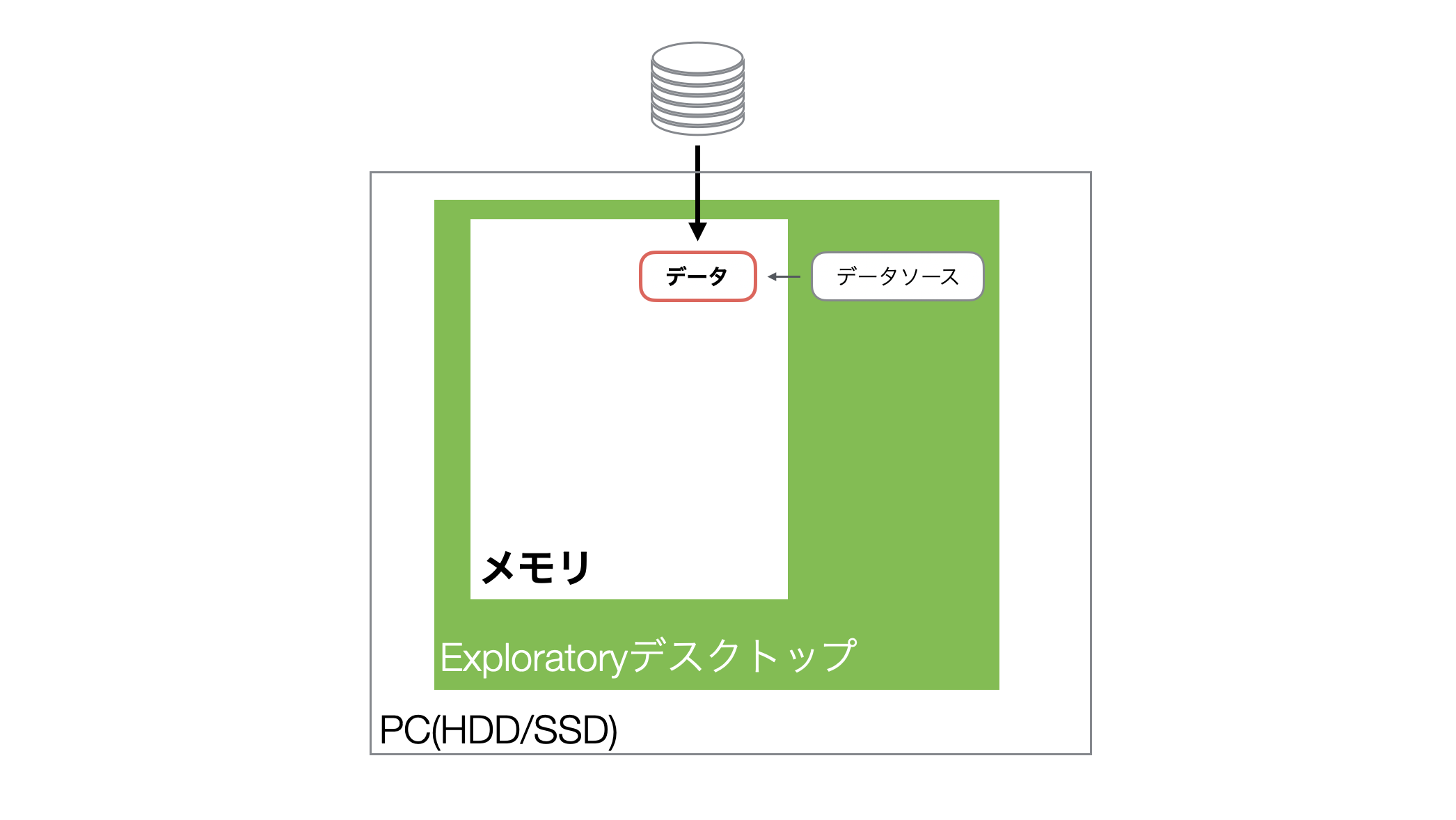
またExploratoryは、データをインポートした際、軽量・高速に扱えるParquetファイルも自動で生成します。
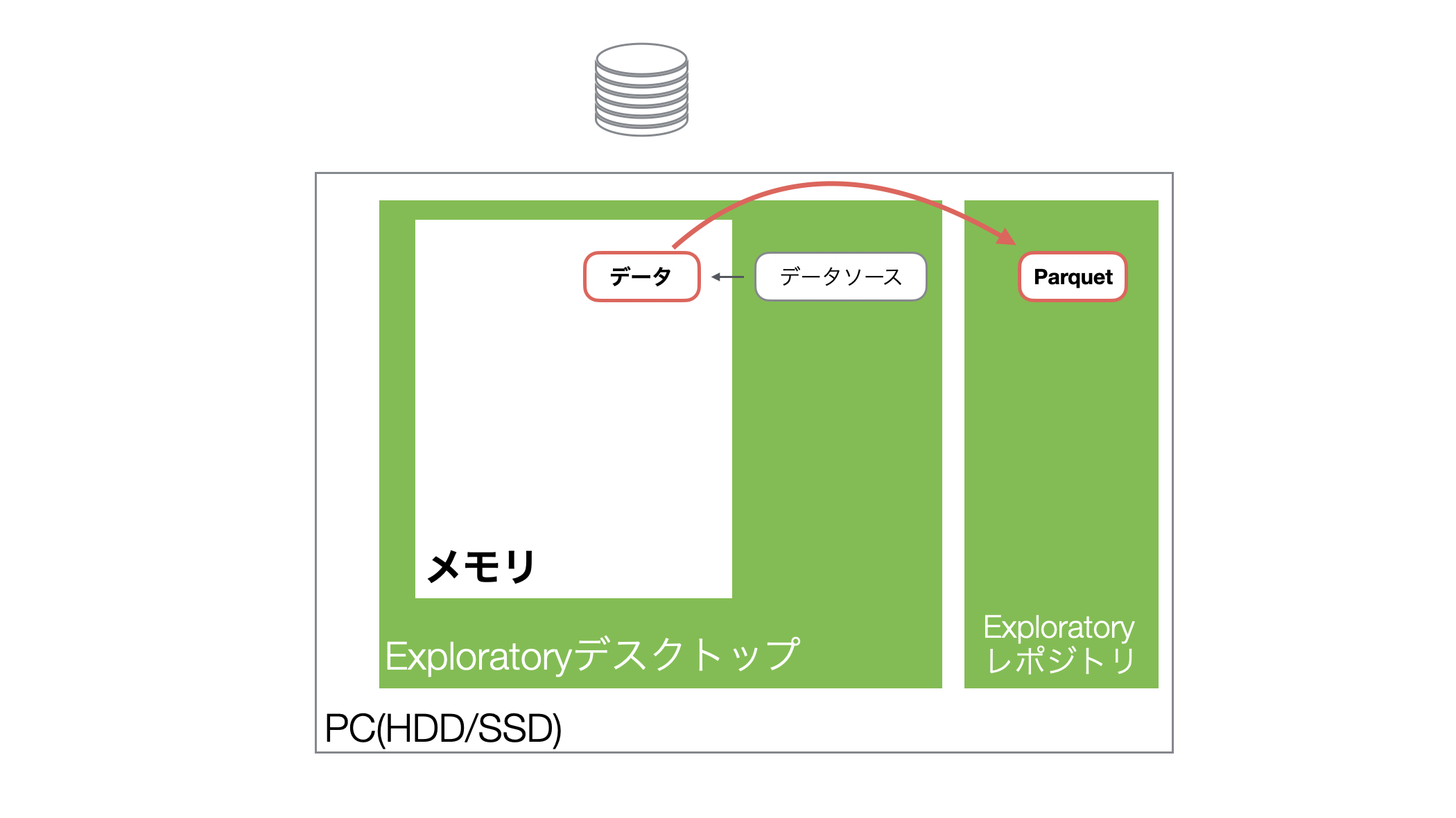
そして、プロジェクトを開き直し、同じデータフレームを開くとハードディスク上に保存されていたParquetファイルからデータがメモリに読み込まれます。
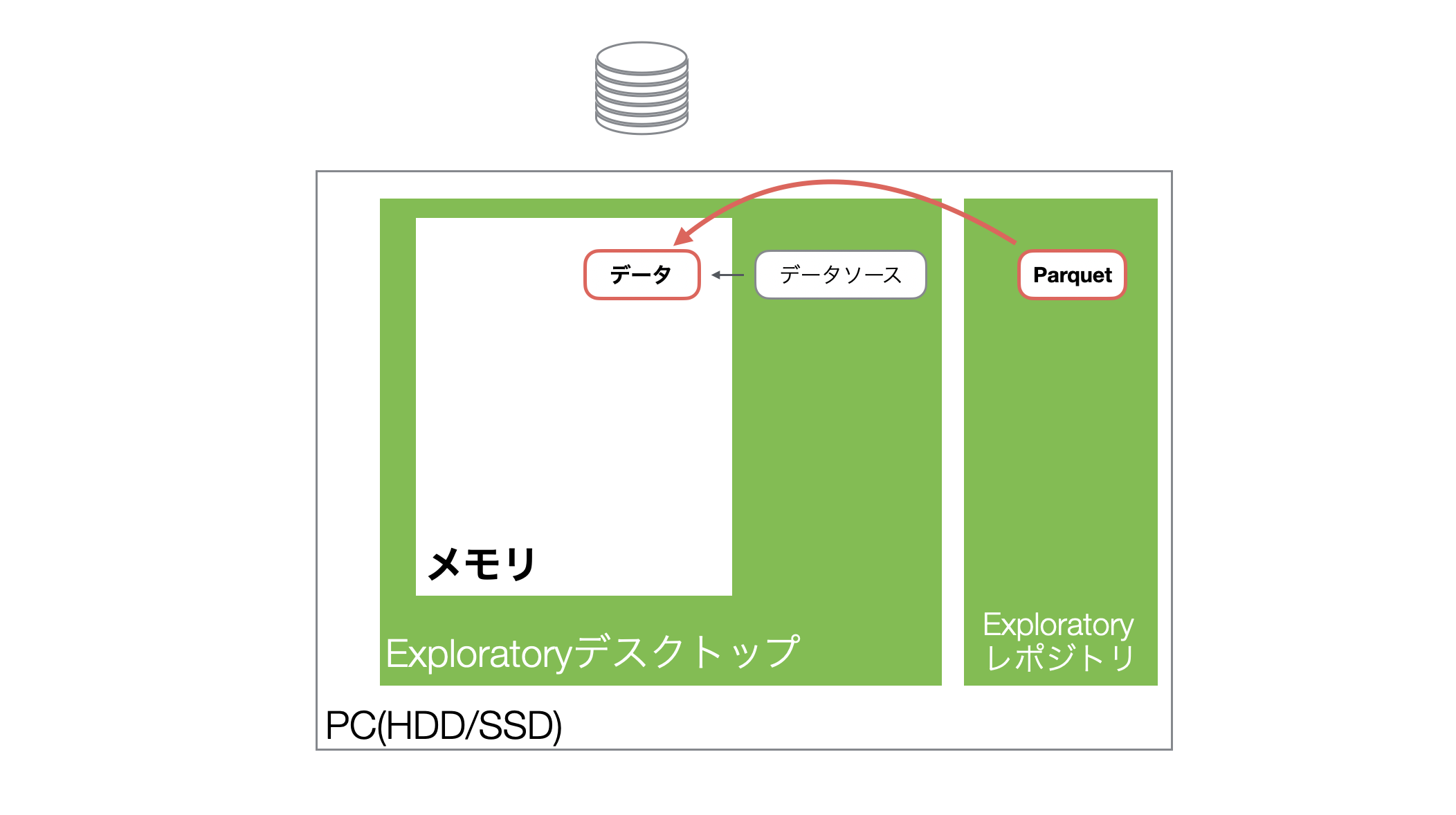
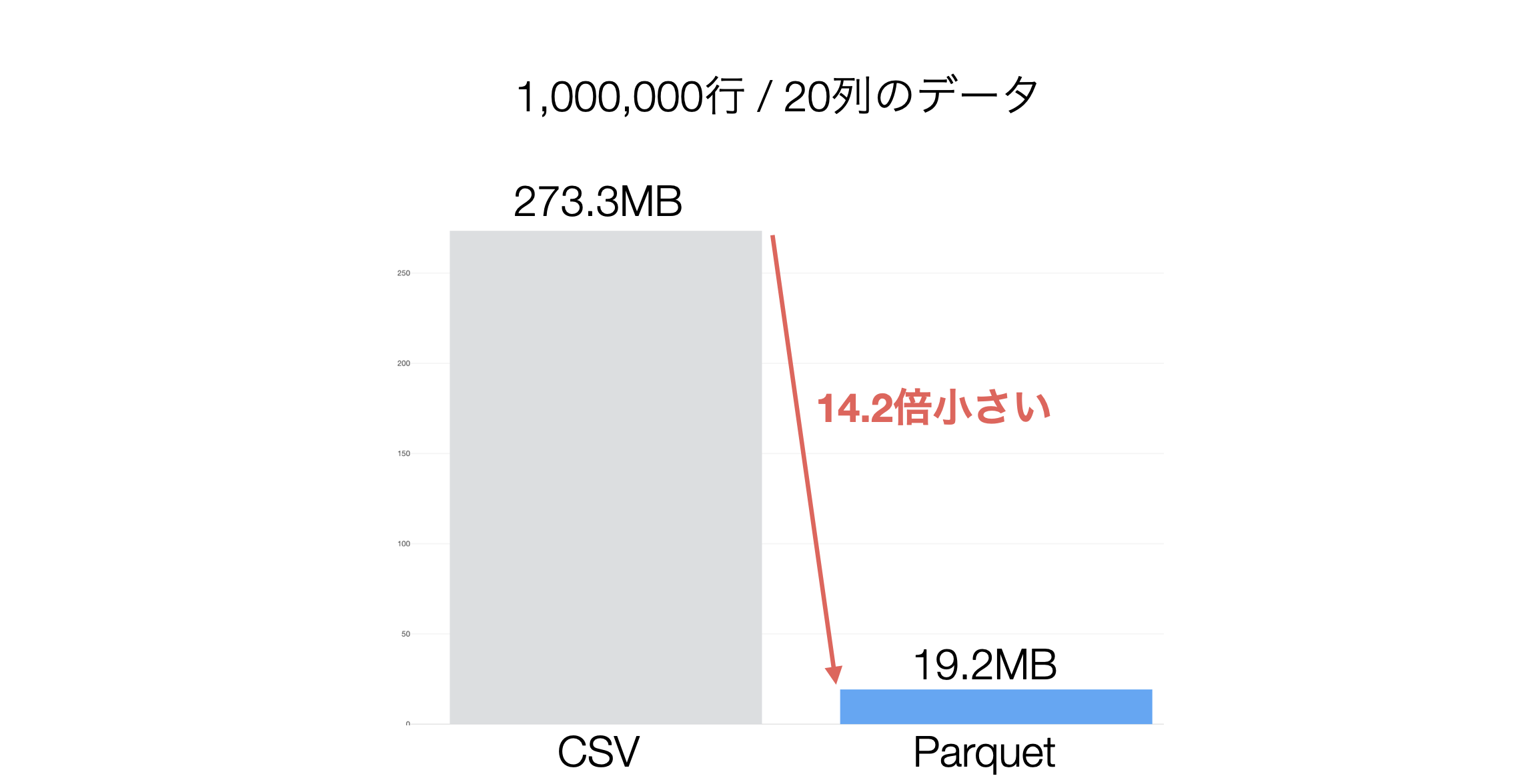
なおさ、生成されるParquetファイルはCSVと比べて、圧倒的にサイズが小さいため、データを読み込む際に優れたパフォーマンスを発揮します。
そして、データ加工のステップを追加すると、そのステップごとにメモリ上にデータフレームが作られることになります。なお、このとき、データが丸々コピーされるわけではなく、最適化された差分のみが付け加えられていくことになります。
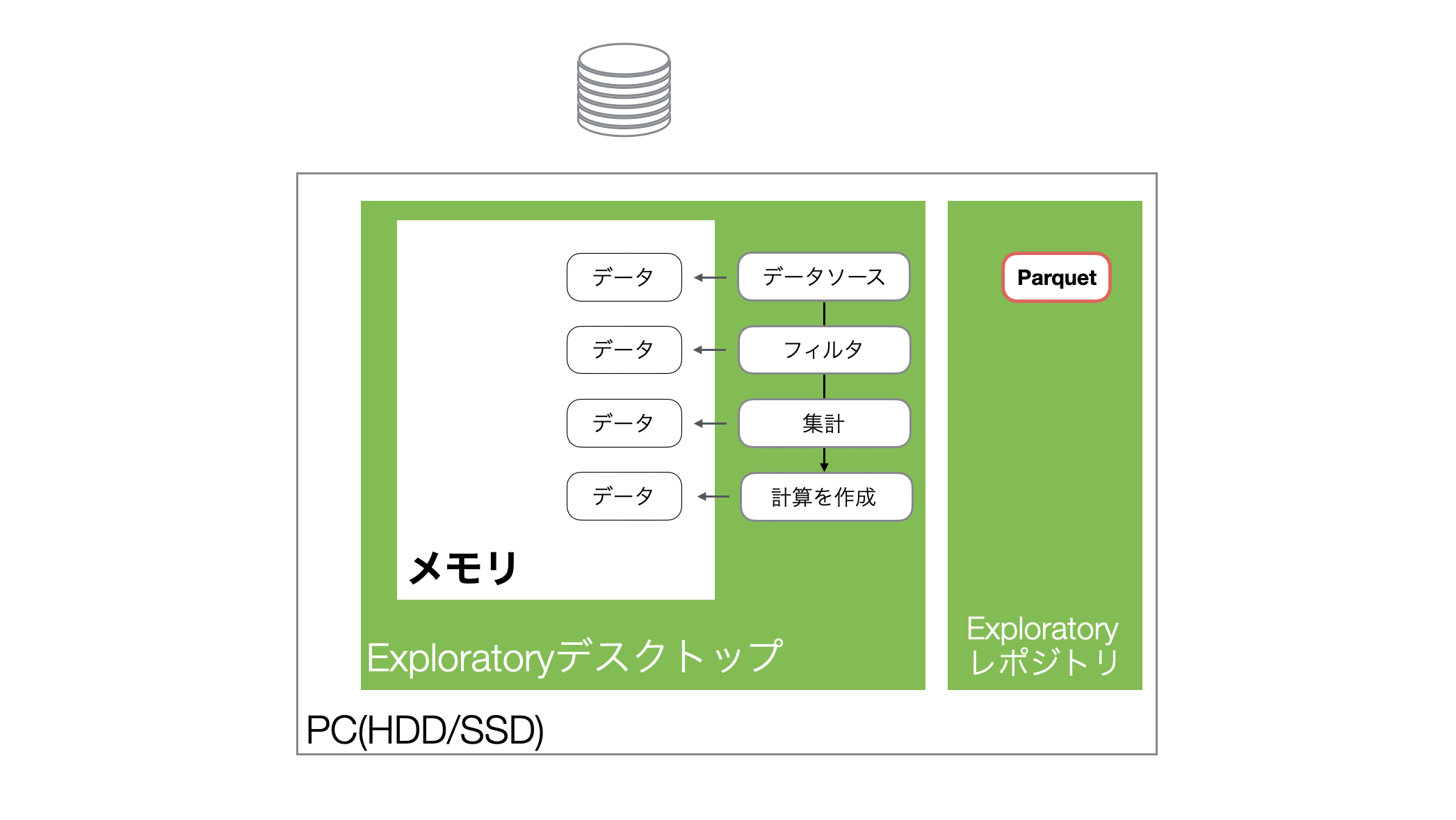
Exploratoryは上記のような仕組みでデータを扱っているため、サイズが大きい(列数や行数が多い)データを処理するときや、ステップの数ガ増えるとメモリの使用量が増えるわけです。
メモリの使用量を確認し解放する方法
Exploratoryでは、メモリの使用量が増え、メモリの量が足りなくなると、以下の2つの問題が発生します。
- メモリーが足りないというエラーが出る。
- 動作が遅くなる。
そして、メモリはExploratory以外のアプリケーションも使用するため、別のアプリケーションのメモリの使用量が大きければ、そちらを調べて、終了させることで、メモリを解放して、メモリの容量を確保することが可能です。
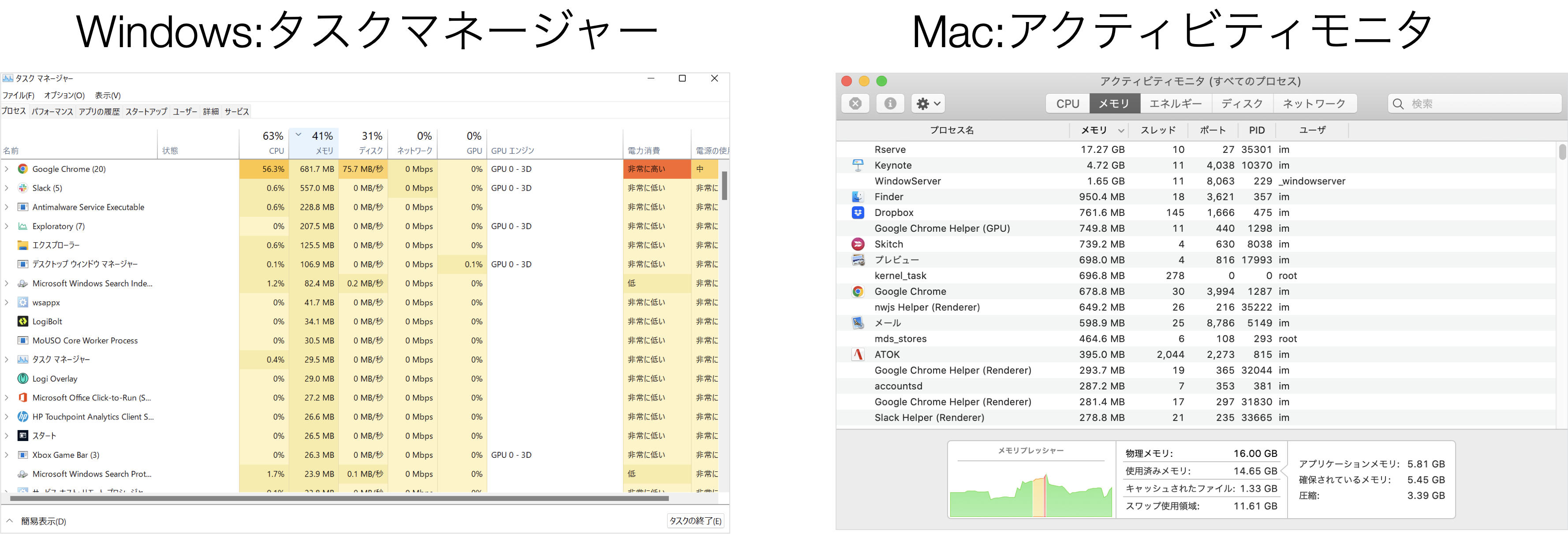
また、Exploratoryの各プロジェクトが利用しているメモリ量は、プロジェクトの中から確認して、不要なプロジェクトを閉じることで、利用されていたメモリ空間を解放することが可能です。
Rの最大メモリの割り当てサイズを変更する
なお、Rの最大メモリの割り当てサイズを大きくすることで、メモリ不足によるエラーを発生しづらくすることも可能です。
ver 15.3以降のExploratoryをご利用の場合
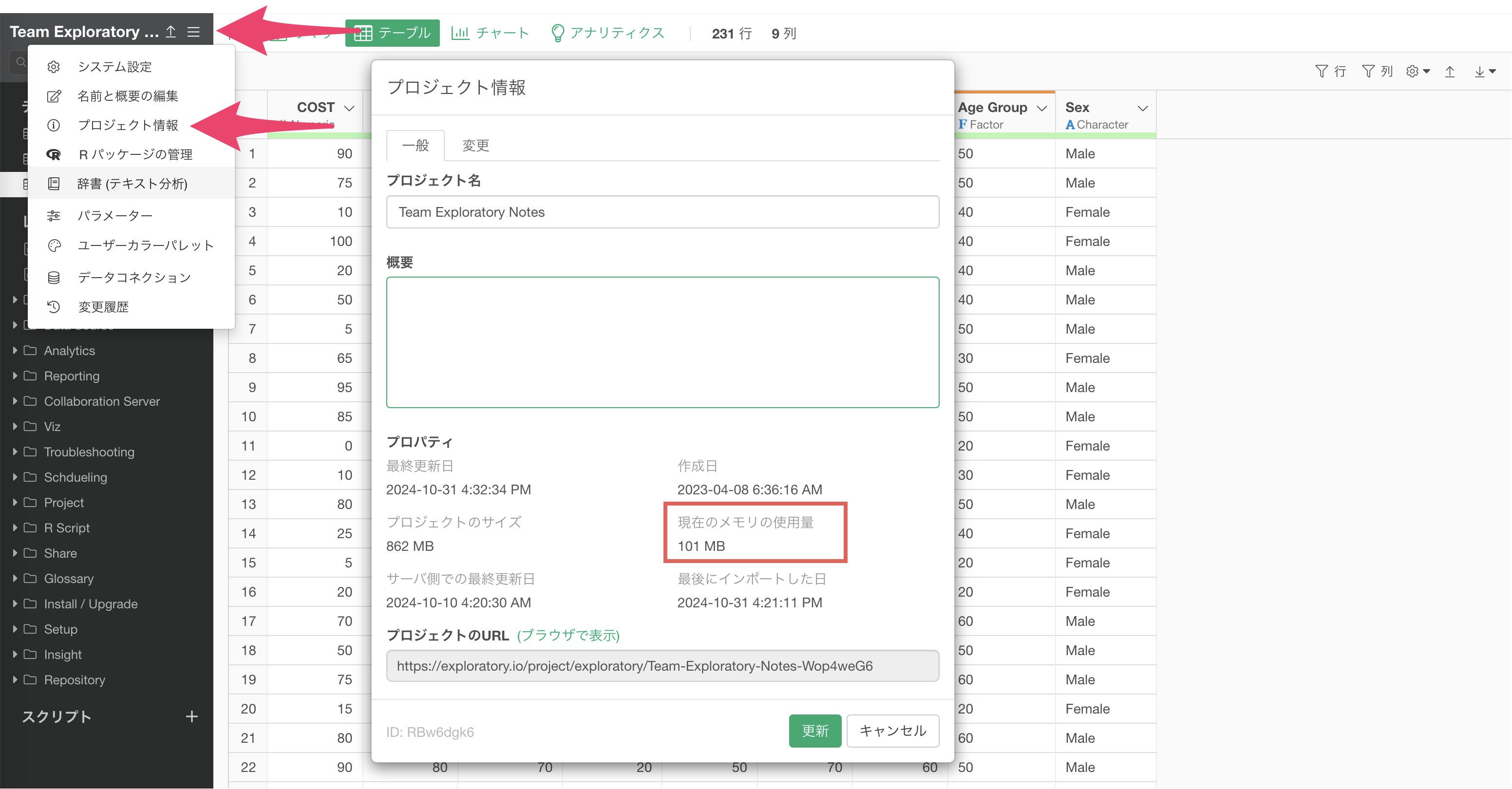
Rに割り当てる最大メモリサイズは、システム設定から変更します。
システム設定には、プロジェクトの一覧からアクセスが可能です。
またプロジェクトを開いた状態で、左上のプロジェクトメニューから「システム設定」をクリックすることでもアクセスが可能です。
続いて、「一般」タブの「Rの最大メモリサイズ」にご利用マシンのメモリサイズに合わせて、任意の値(GB)を入力してください。
何も指定しない場合は、お使いのマシンのメモリ状況に合わせて自動的に適切な値が設定されます。
なお、設定できる上限はお使いのマシンの物理メモリに依存します。たとえば16GBしかないマシンに32GBを設定しても、最大メモリサイズは16GBになります。
ver 15.3より前のExploratoryをご利用の場合
画像のようにプロジェクト内で「スクリプト」の横の「+」ボタンをクリックして、新しいスクリプトを作成し、以下のコマンドを入力します。
Sys.setenv('R_MAX_VSIZE'=32000000000)
このとき、「プロジェクトを開く際にこのスクリプトを読み込む」チェックボックスがオンになっていることを確認し、「実行」をクリックすることで、「Rの最大メモリサイズ」を指定することが可能です。
なお、こちらの結果も、Exploratoryデスクトップを利用しているマシンスペックに依存することにご注意ください。
お使いのマシンに16GBまでしかメモリを割り当てられない場合、32GBを設定しても最大メモリサイズは16GBになります。
5つの領域におけるベストプラクティス
ここからは、以下の5つの切り口で、Exploratoryでの処理のパフォーマンスを向上させるための具体的な方法を紹介していきます。
- データのインポート
- データラングリング
- チャート/アナリティクス
- ダッシュボード
- パラメーター
1. データのインポート
Exploratoryでは、ファイルやデータベースから様々なデータをインポートすることができます。特にデータベースから大量のデータを取得すると、以下のようなパフォーマンスに関わる問題が発生する可能性があります。
- データのダウンロードに時間がかかる。
- メモリを圧迫する。
- その後のデータラングリングなどの処理に時間がかかる。
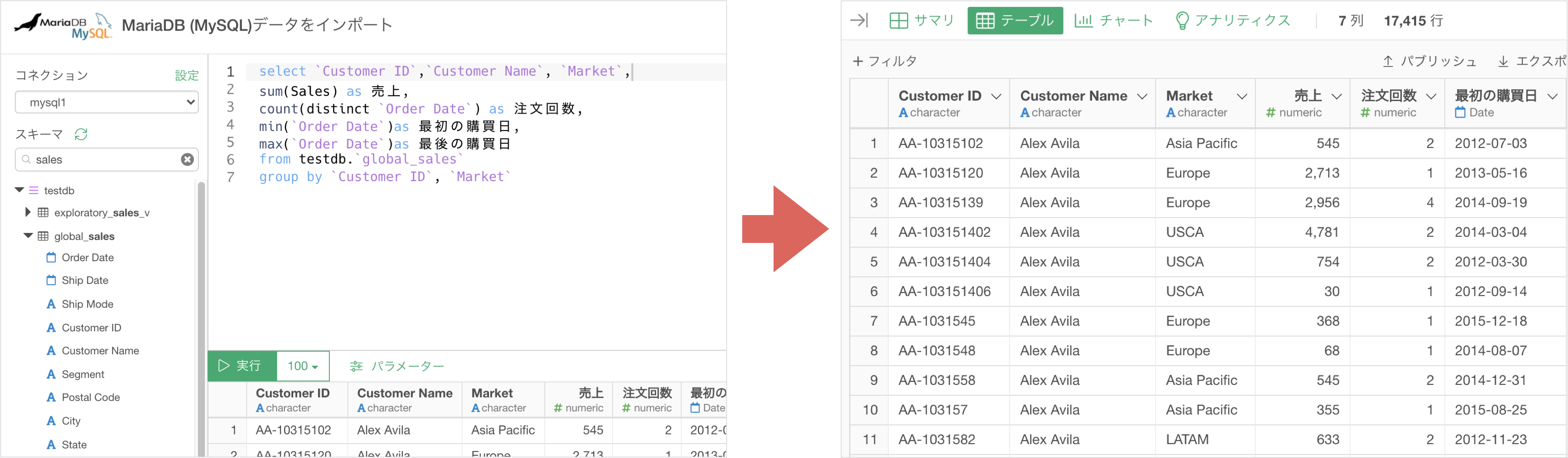
そこで、データベースからデータを取得する際は、以下の2つの方法で効率化を図ることができます。
- SELECT文を使って必要な列だけをインポートする。
- SQLを書いて、データベース側で集計処理を実行し、集計済みのデータをインポートする。
Oracle データベースからのデータのインポート
オラクルデータベースからデータのインポートの場合、「フェッチ・バッファ・サイズ」を変更することで、データのインポート速度を改善できる場合があります。
詳細につきましては、以下のリンクをご参考ください。
- Oracleのデータソースからのデータインポート時のパフォーマンスを高める方法 - リンク
2. データラングリング
データラングリングの領域では、より多くのベストプラクティスが存在しており、こちらのセクションでは、1つ1つそれらを紹介していきます。
前述したように、Exploratoryでデータを加工すると、ステップが追加され、各ステップごとにメモリにデータが読み込まれます。
そのため、このことを押さえて効率的なデータ加工を行うことで、メモリ使用量を抑え、パフォーマンスを向上させることができます。
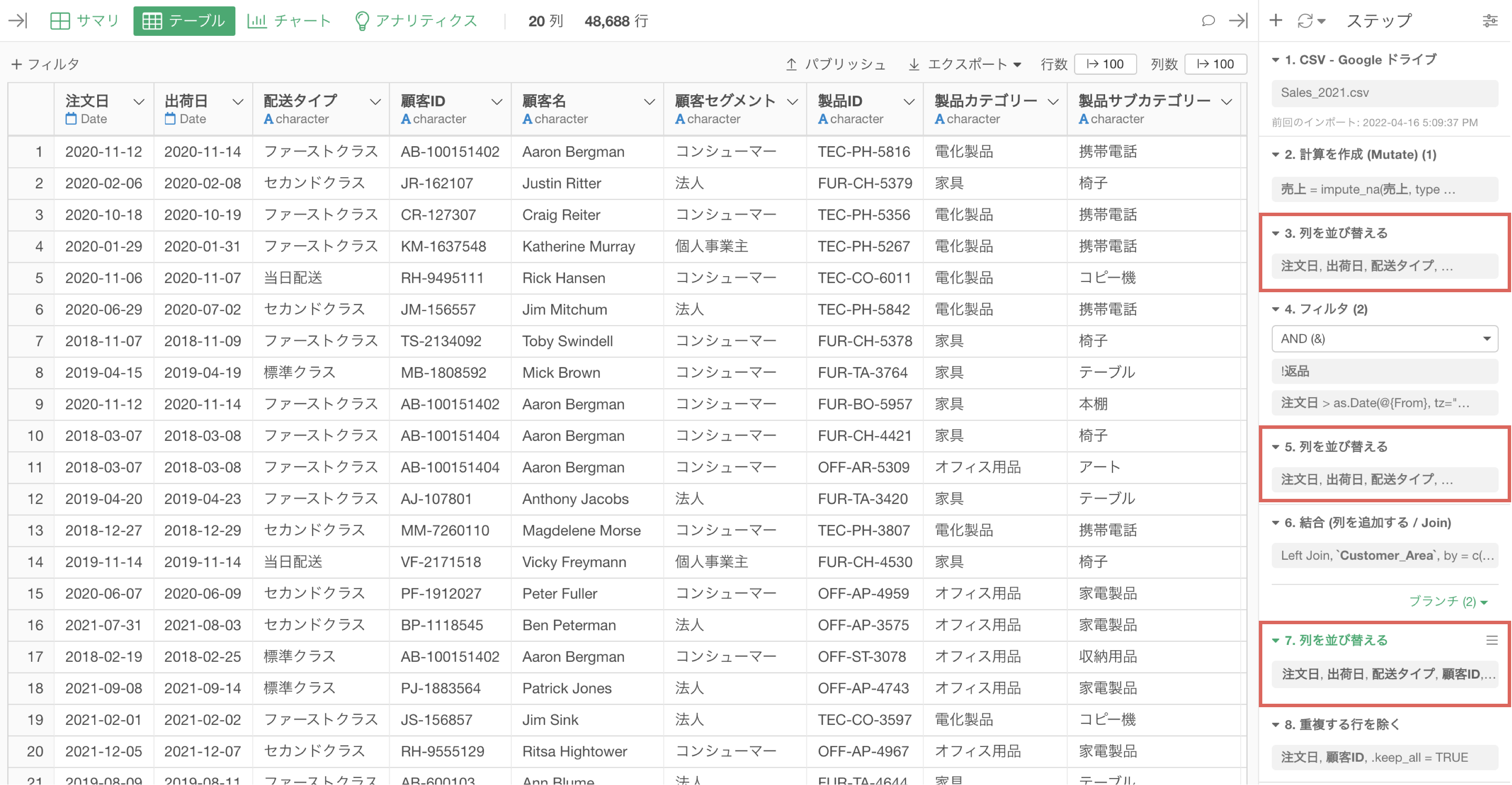
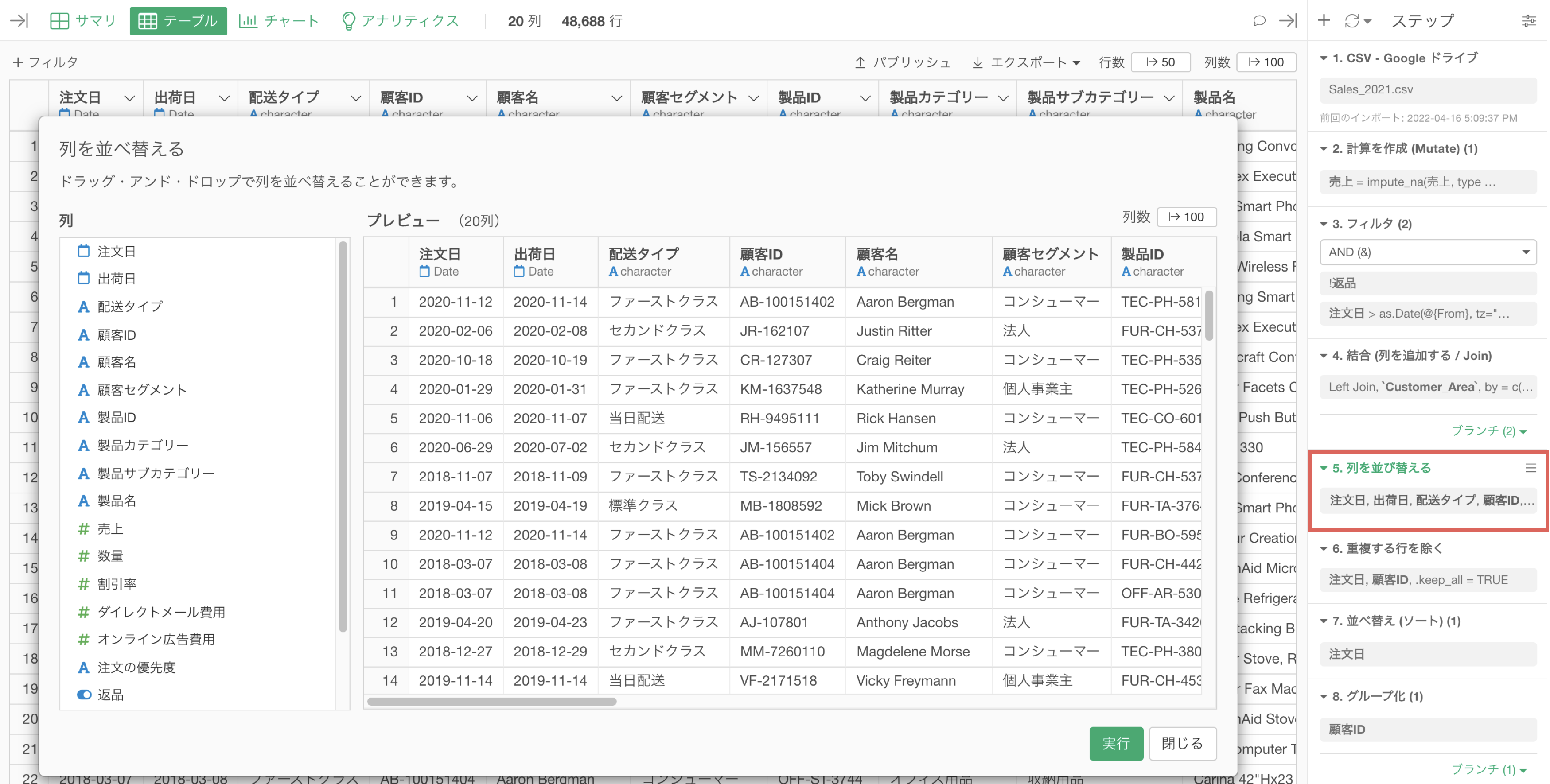
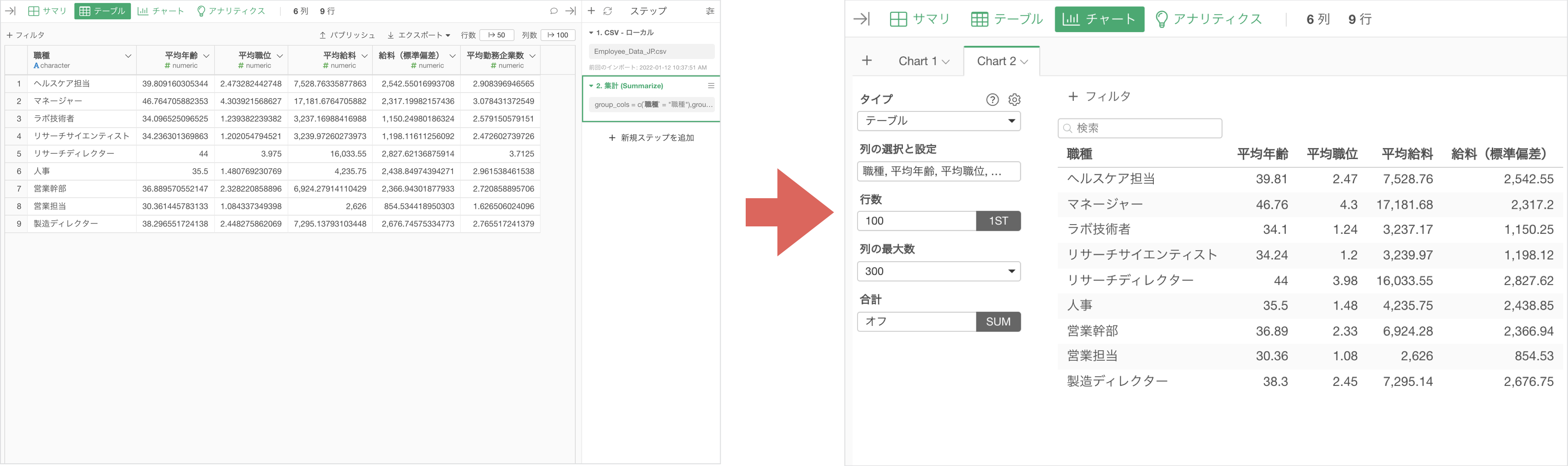
同じような処理は同じステップにまとめる
例えば同じような処理を複数回に渡って実施している場合、不必要にメモリを使用してしまい、パフォーマンスの低下につながります。
例えば、上記の例では、列を並び替える処理を3度に渡って実行していますが、1つのステップに全ての処理まとめられれば、メモリへの負荷を小さくすることが可能です。
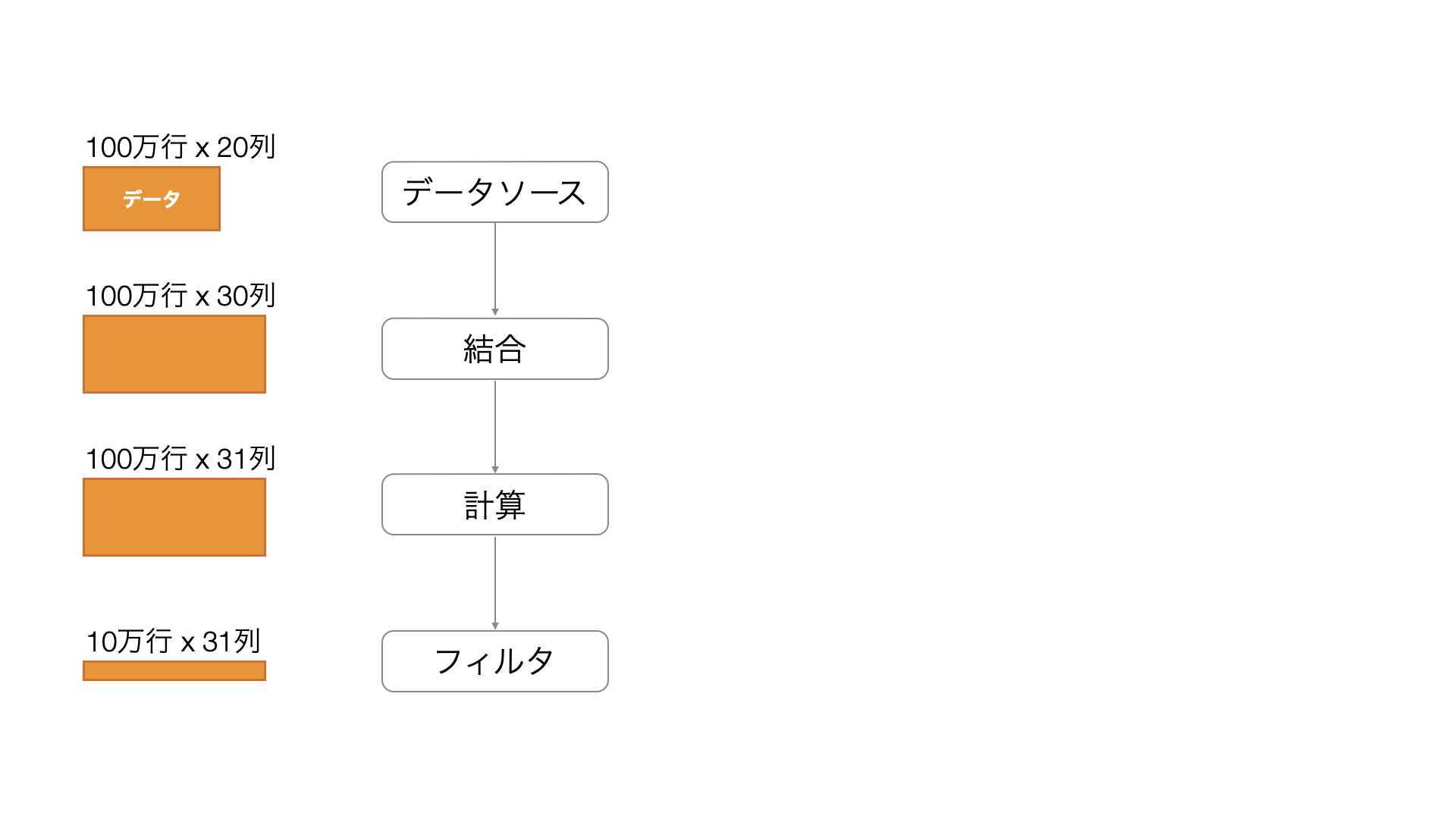
また、同じような処理(処理名が同じステップ)が連続して、複数のステップにまたがっている場合、「ステップごと」に、実行結果がメモリに読み込まれることになり、処理がステップ事に実行される、あるいは、「ステップごと」に、実行結果がメモリに読み込まれることで、パフォーマンスが損なわれる場合があります。
そういったときには、複数のステップを1つのステップにまとめることで、メモリに読み込むデータを最適化できます。
データの再現性が不要なときには、加工済みのデータをエクスポートして利用する
Exploratoryにはステップ機能があるために、以下のようなことを実現できます。
- 後からデータ加工の処理を見直す
- データが更新されたときに、更新されたデータに対して同じ処理を実行する
- 既存のステップを削除、編集したり、新しいステップを追加して、データ加工の処理を部分的に更新する
一方で、データの加工が終わってしていて、前述したような再現性が不要な場合もあります。
例えば、必要なデータが最後のステップのデータでステップの情報がいらない場合、最後のステップの「ステップなし」のファイルやデータフレームとしてデータをエクスポートして、そのデータを利用することが可能です。
ステップを持たない加工済みのデータを利用することで、メモリに使用量を節約することができるわけです。
ただし、このアプローチでは、再現性を失われてしまい、データ加工の履歴が追いづらくなるため注意が必要です。
早めにデータ(行)を小さく(フィルタ)しておく
Exploratoryでデータを加工するときによくやることの1つに「フィルタ」を使ったデータの絞り込みがあります。
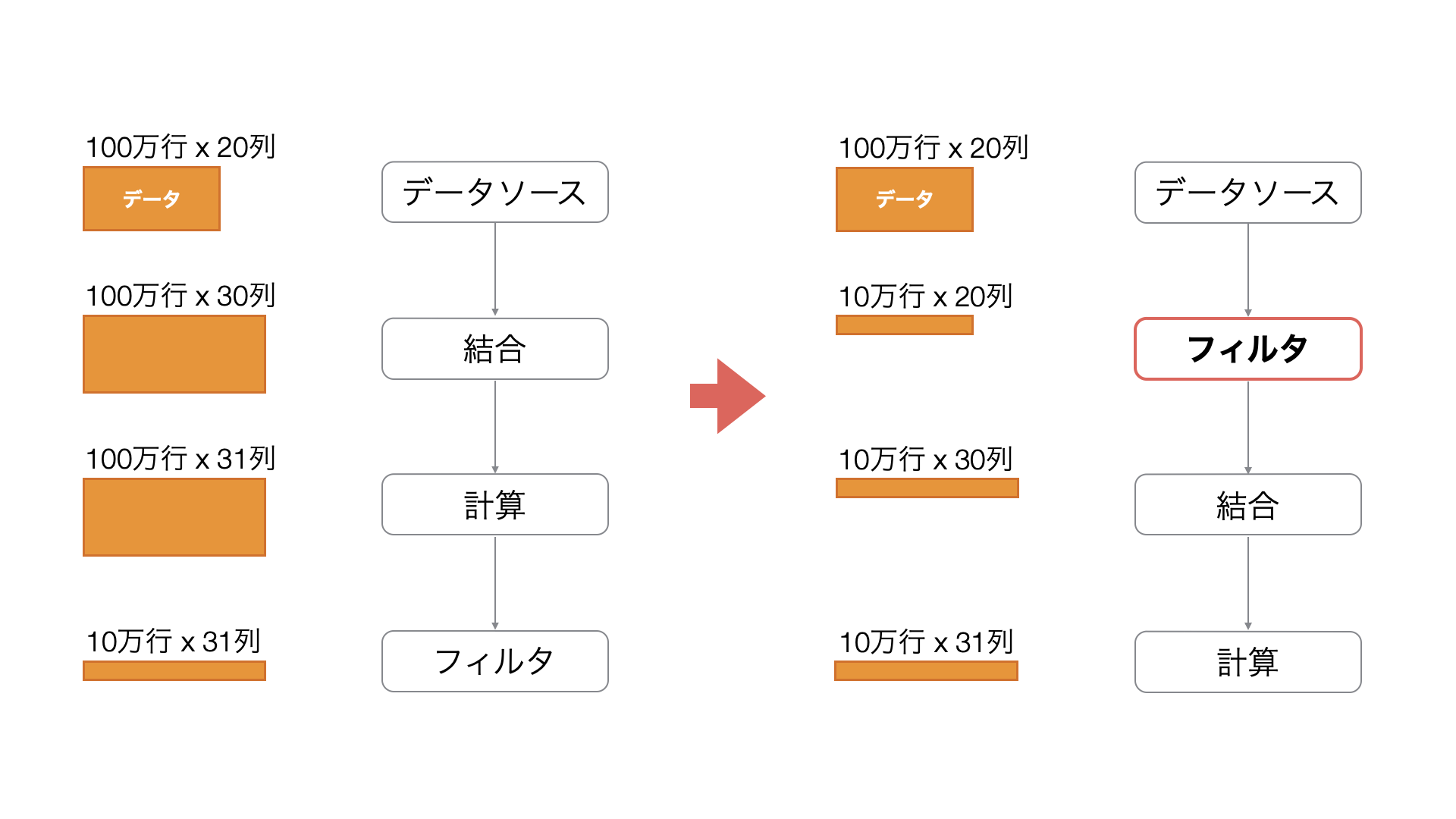
そして、データをフィルタするときに、フィルタのステップを後ろにもってくると、不要な行に対しても、データ加工を実施することになってしまいます。

例えば、上記の例では、最終的にフィルタされることになる行に対して、データを結合したり、計算を実行していることになるため、不要な処理を実行していると考えられます。
フィルタを早い段階で実施しておくと、不要な行に対してデータ加工を実施しないで済むため、メモリへの負荷が小さくなるだけでなく、処理スピードも速くなります。
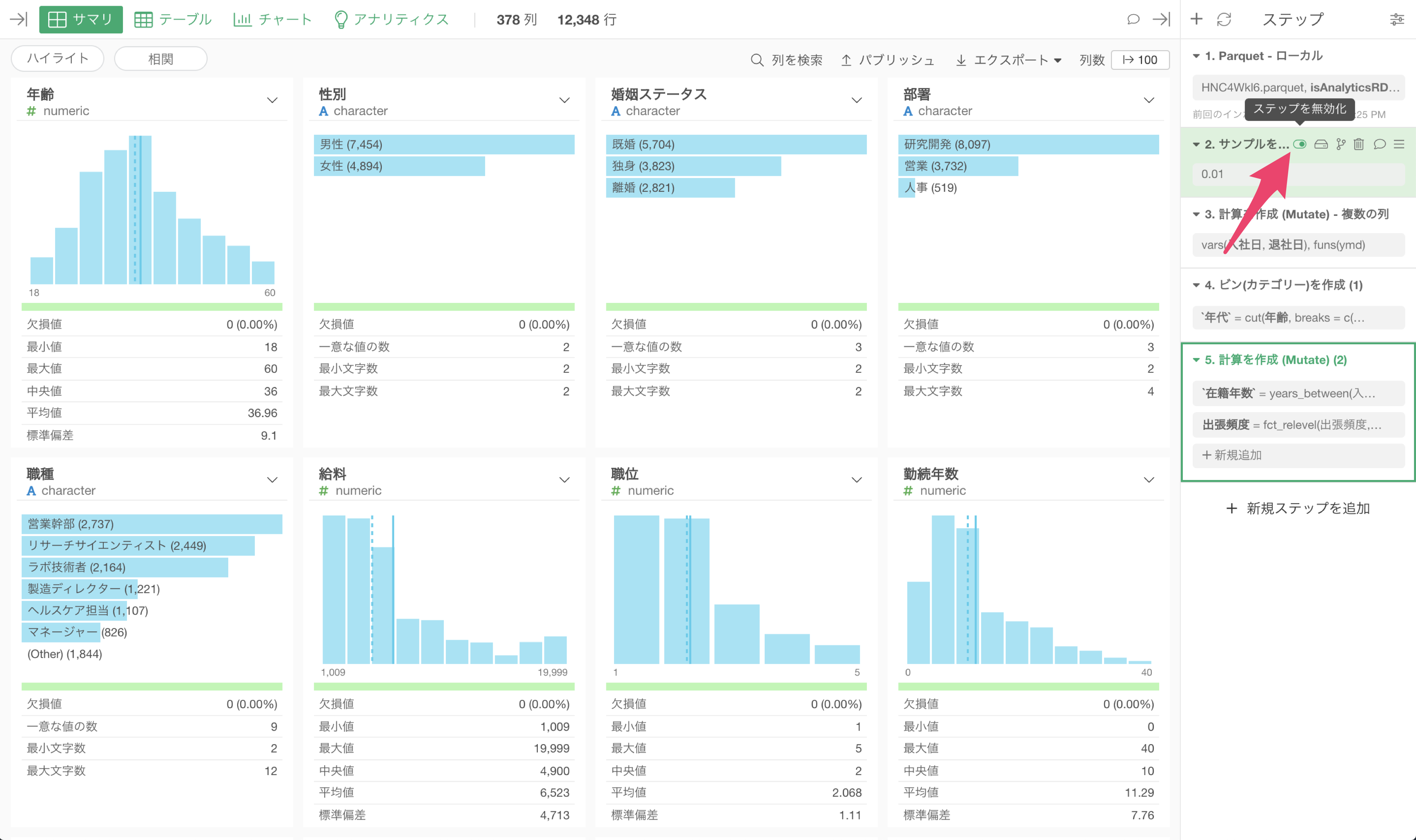
データをサンプリングして、加工が終わったらサンプリングを解除する
探索的にデータを加工したり分析を進めるときや、データ加工のための試行錯誤中には、データのおおまかな分布やサマリ情報だけ理解できていれば良いことも少なくありません。
そのようなときに、ステップを追加/削除する度に生じる処理待ちの時間は、最小減に抑えたいものです。
そのようなときには、ステップの早い段階で「サンプルを抽出」しておくことが有効です。
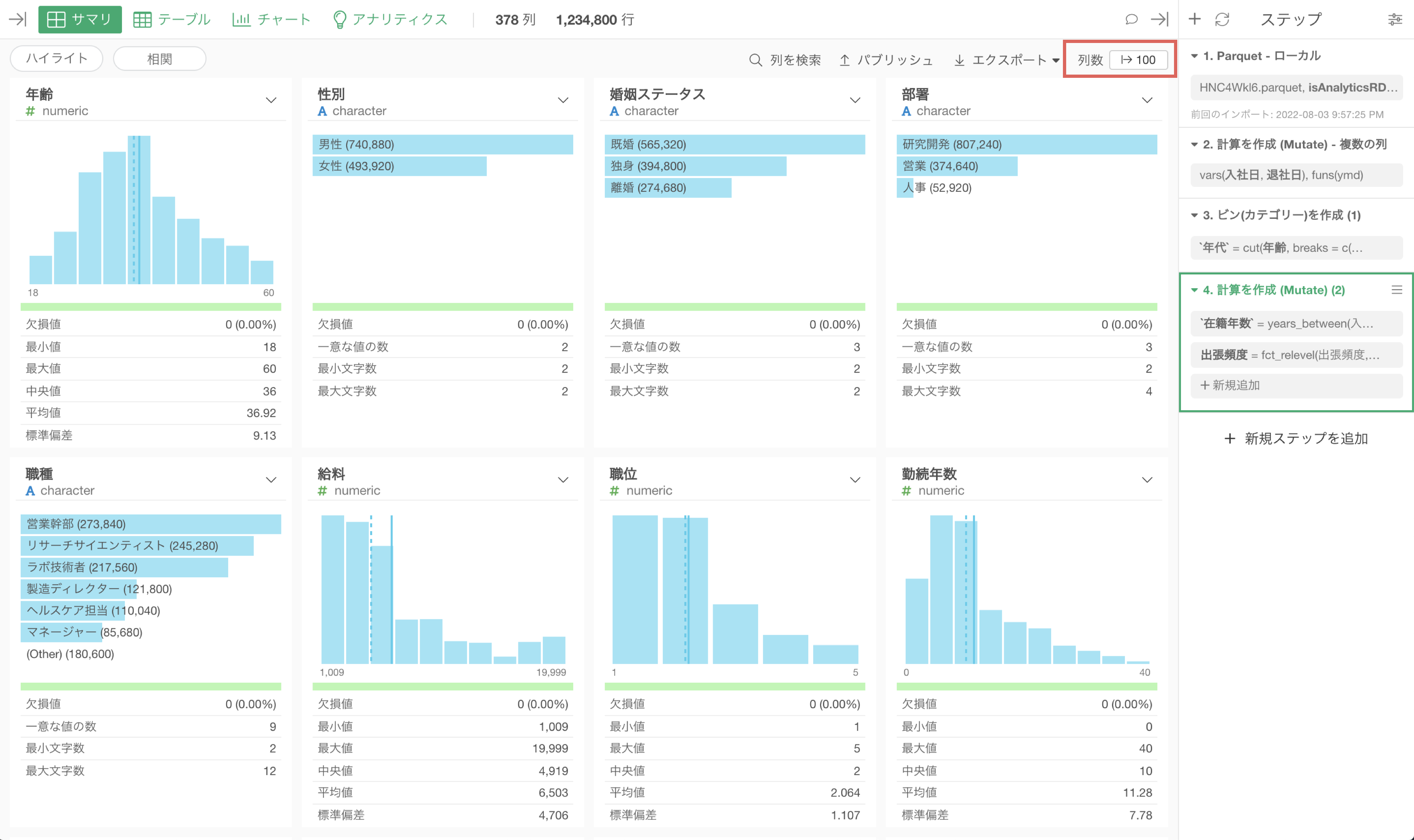
データの加工や探索が一段落したら、「サンプル」のステップを「無効化」あるいは「削除」することで、同じ処理を全データに対して実行することができます。
このようなアプローチをとることで、仮にサイズの大きいデータを扱っていたとしても、サイズの大きいデータに対する処理は一度きりで済ませられます。
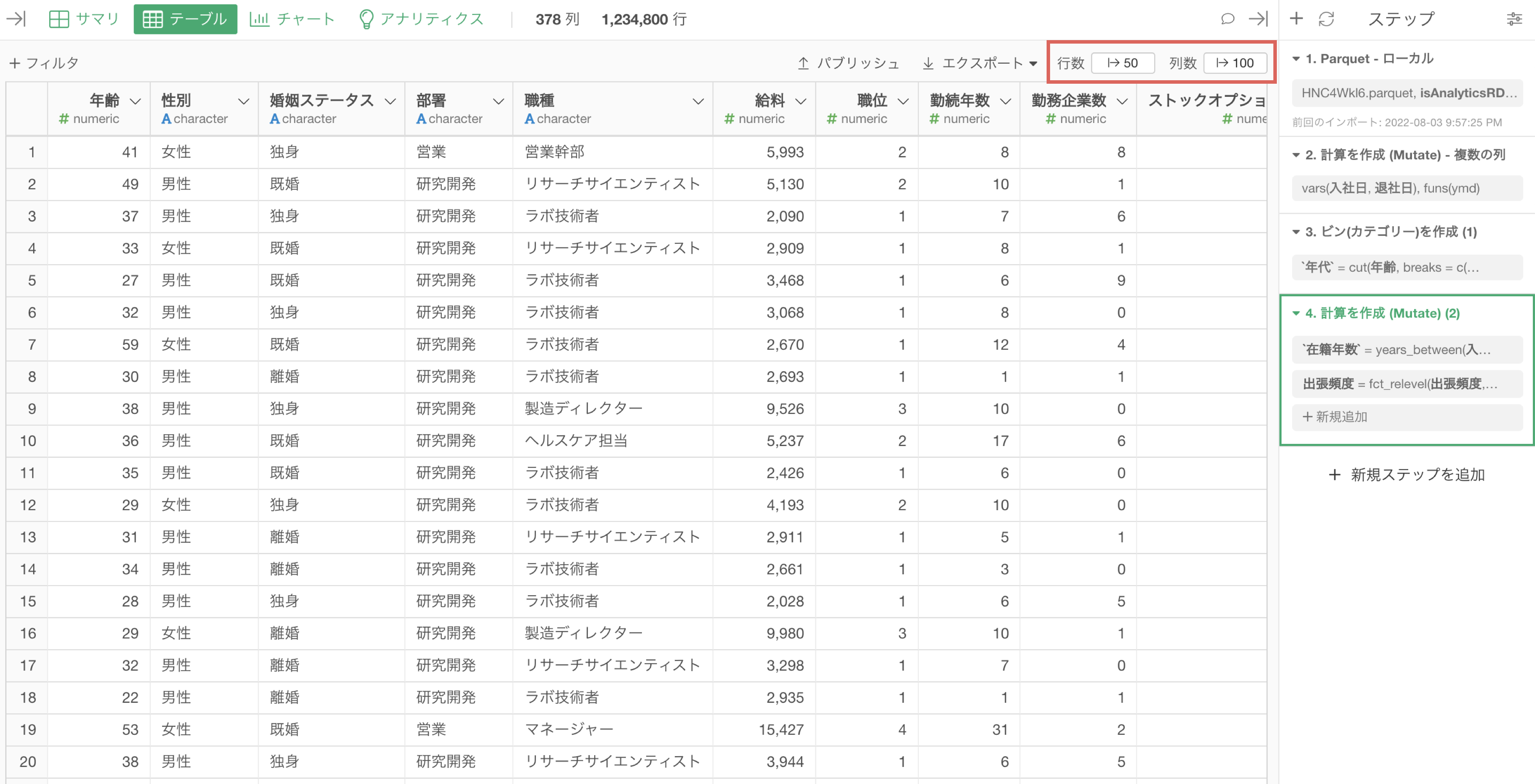
必要な「行数」と「列数」を表示する
Exploratoryは、ステップが追加/変更される度に、全列のサマリ情報を計算したうえで、指定した列数分のサマリ情報を可視化しています。
言い換えれば、ステップを追加/移動する度にサマリの計算と描画が行われるため、表示する列数が、多い場合、描画のための時間が増えることになります。
そこで、表示する列数を少なくしておくことで、描画にかかる時間を短くすることが可能です。
なお、テーブルビューでは、表示する「行数」および「列数」の指定が可能で、いずれも、表示する数が少ないほど描画は速くなります。
キャッシュ機能を利用する
「Exploratoryのデータ処理の仕組み」のセクションで紹介しましたが、Exploratoryではデータをインポートすると、軽量・高速に扱えるparquetファイルが自動で生成されます。
また再度同じプロジェクトを開くときはParquetファイルを読み込み、高速でメモリにデータを読み込むことができるようになっています。
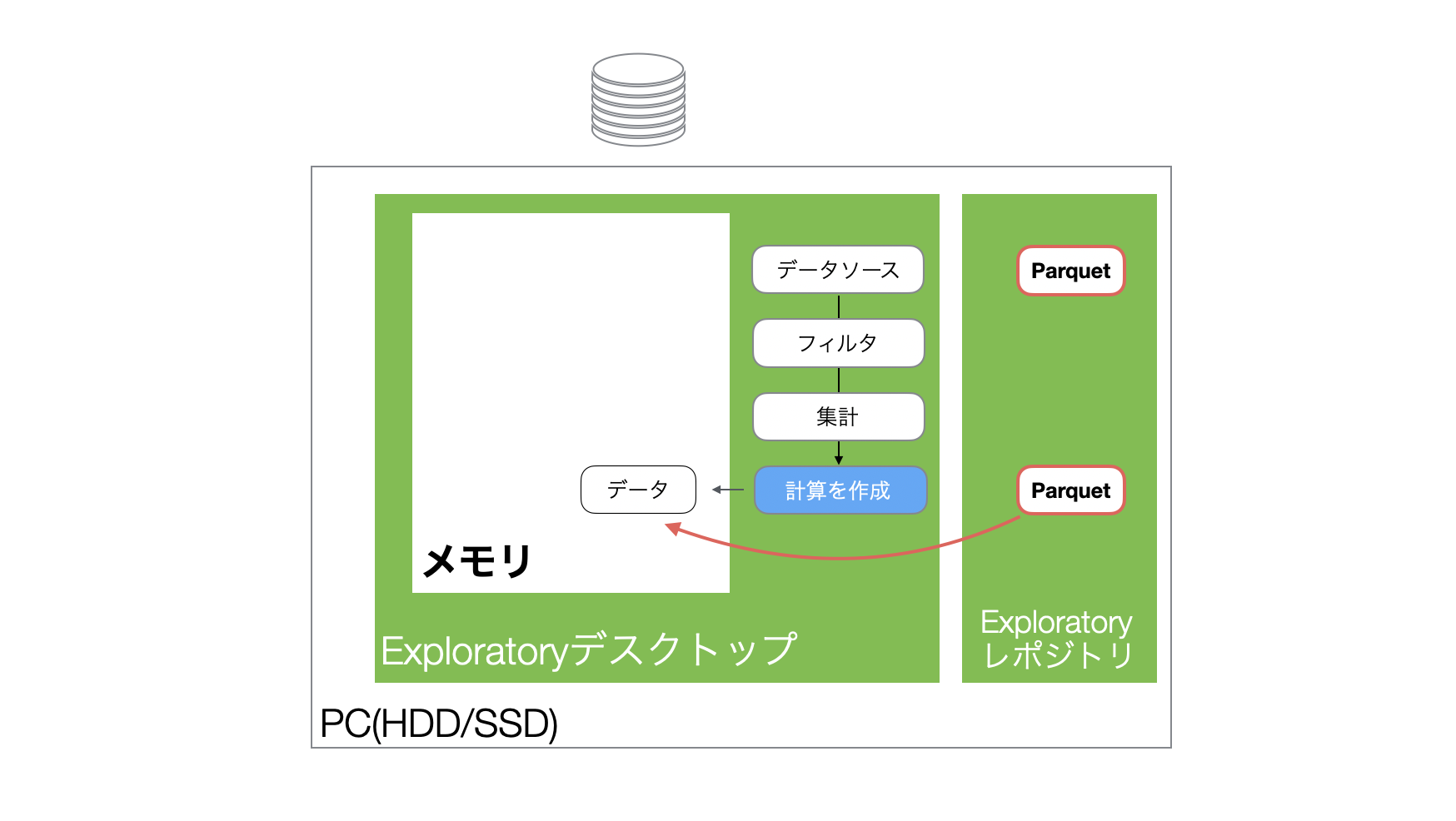
一方で、各ステップのデータが保存されているわけではないため、一度閉じたプロジェクトのデータフレームを開き直すと、Parquetファイルを読み込んだうえで、最後にいたステップまでの処理を再実行することになります。
そのため、サイズの大きいデータを利用していたプロジェクトを開き直すと、ステップの実行の処理待ちが発生してしまい、すぐに作業を開始できないことがあります。
なお、データの加工が終わっていて、特定の(例えば最後の)ステップのみのデータだけが必要な場合、データをエクスポートして利用することが可能ですが、再現性を失いたくないときや、ステップごとにチャートを作りたいときには、そのようなアプローチが有効とは言えません。
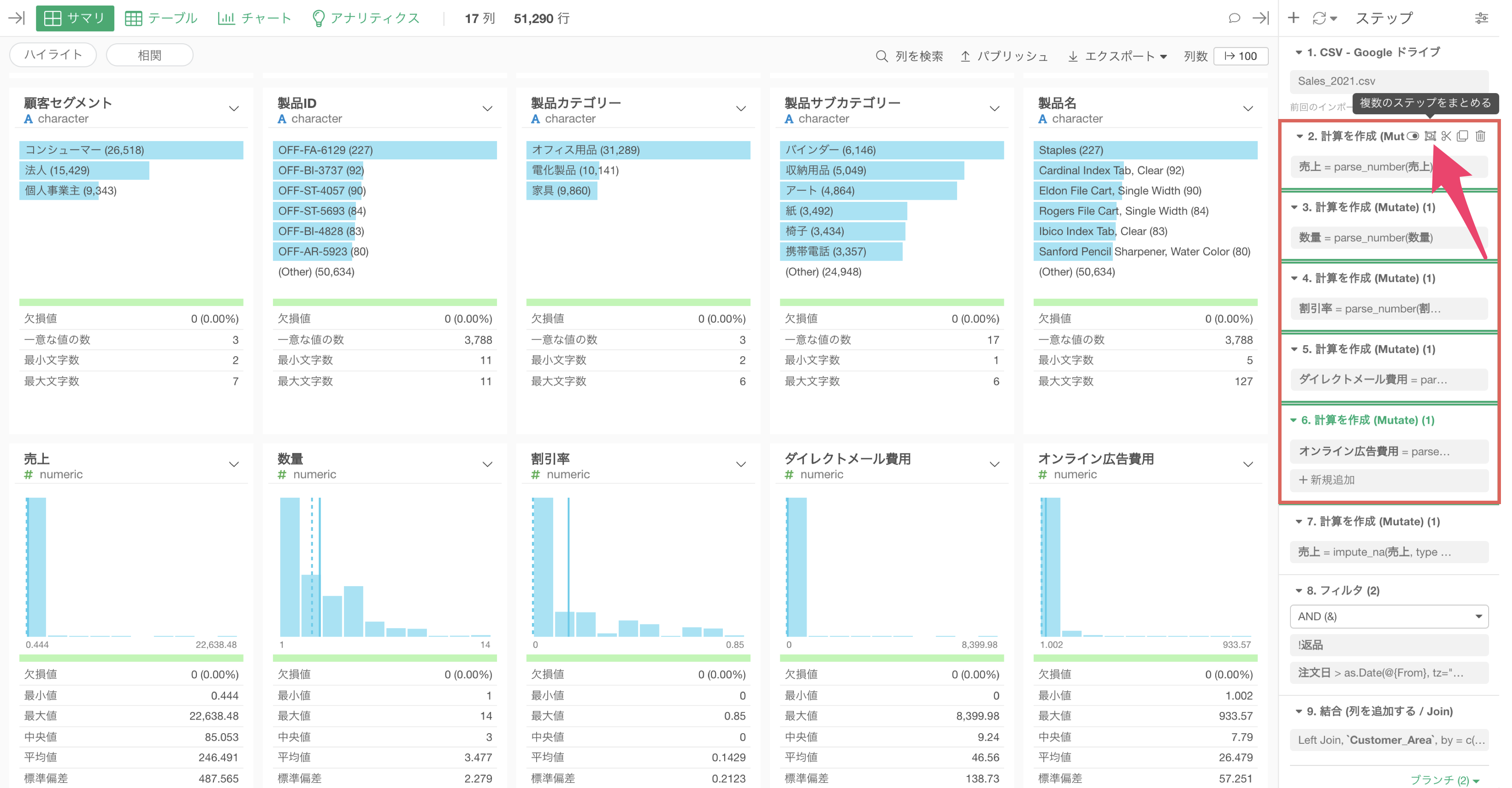
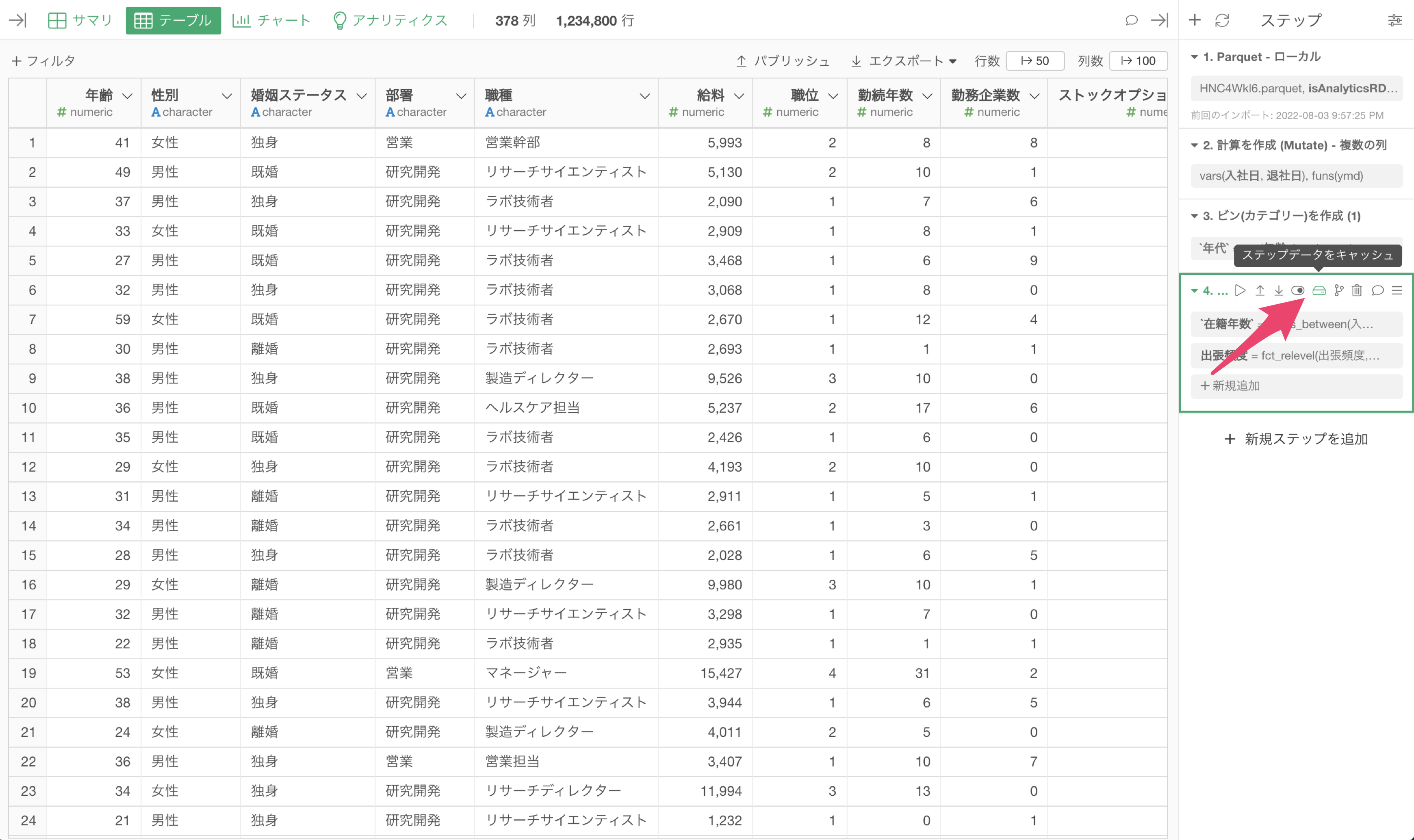
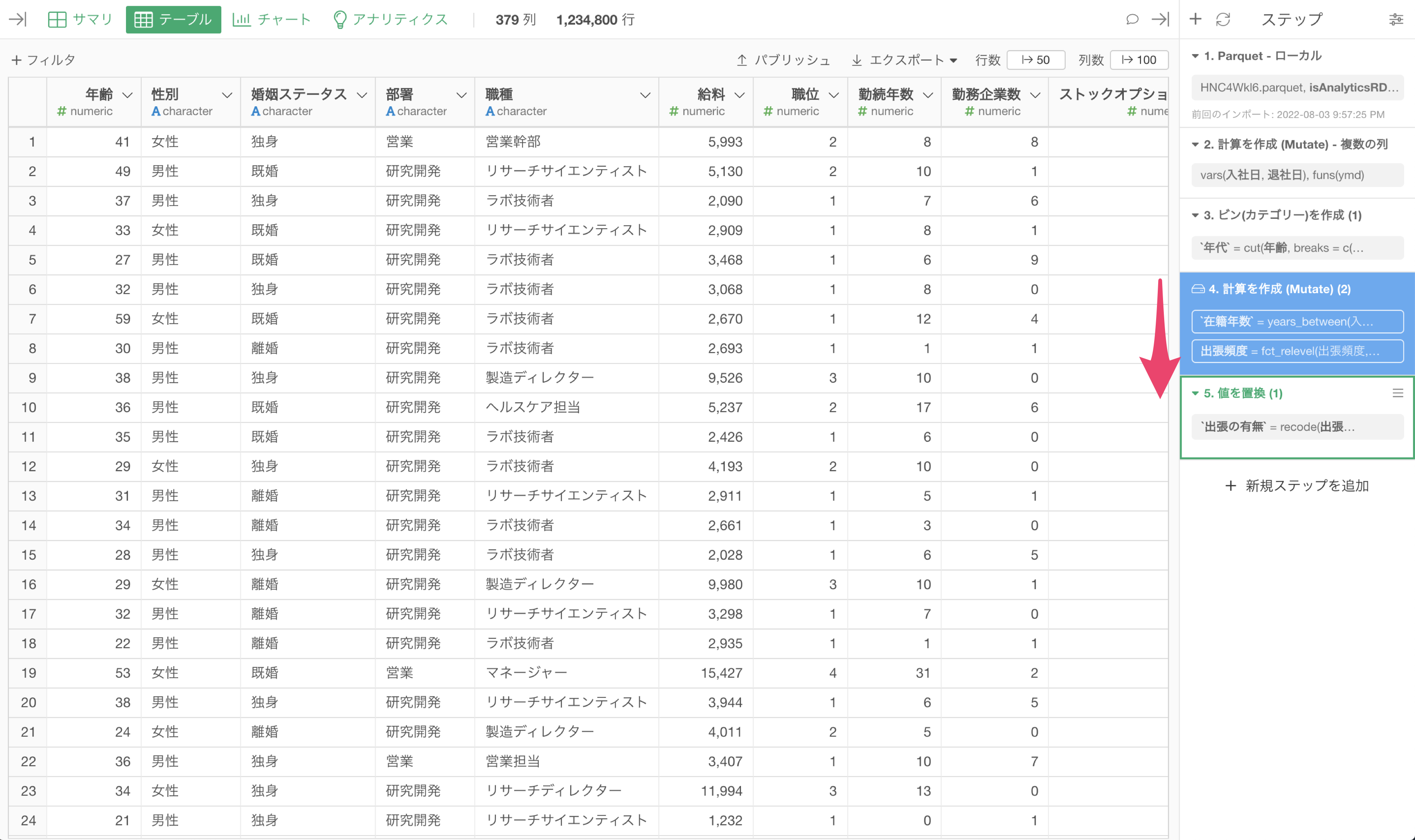
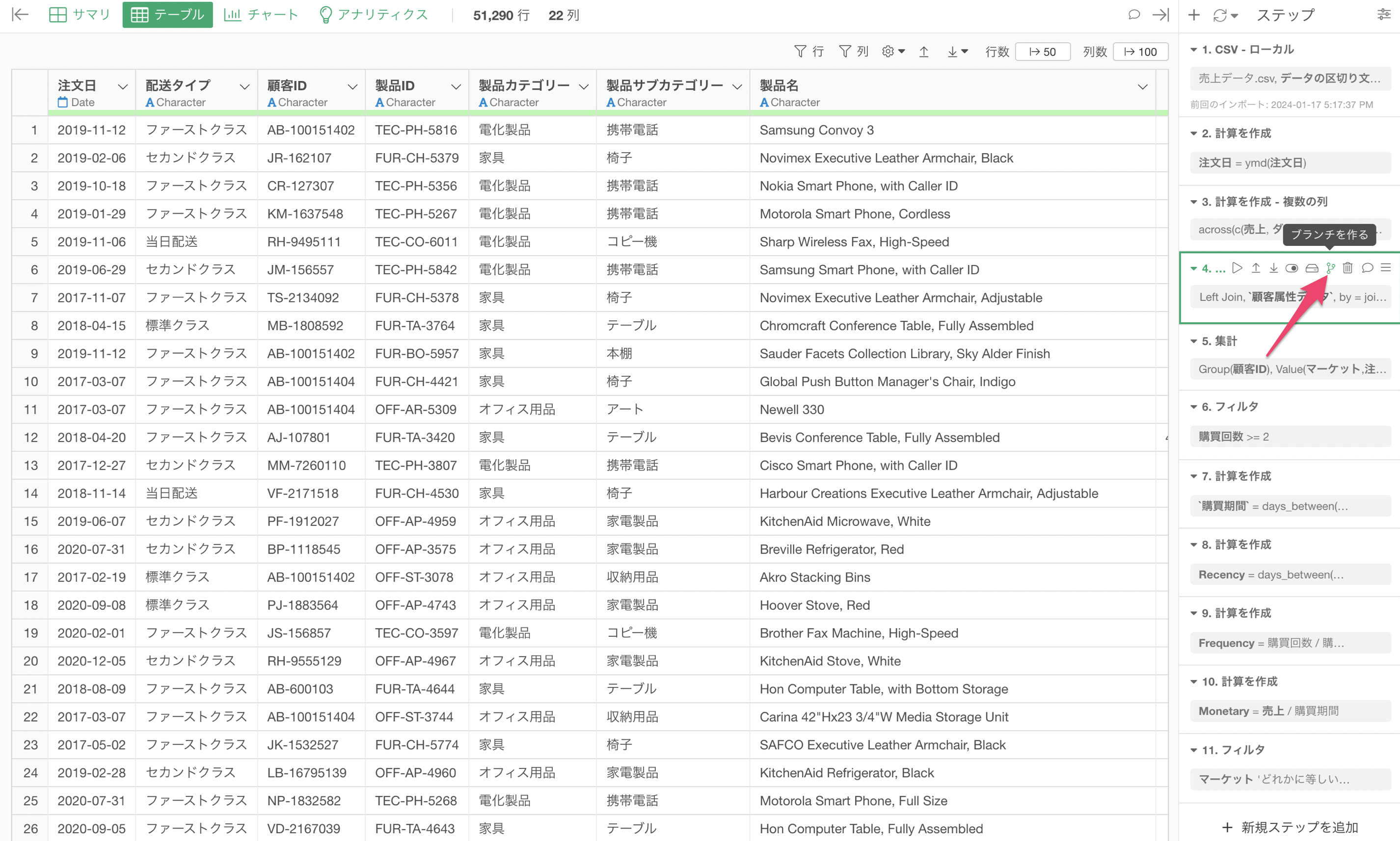
そのようなときには、ステップのデータをキャッシュして、そのステップのデータを保存することが可能です。
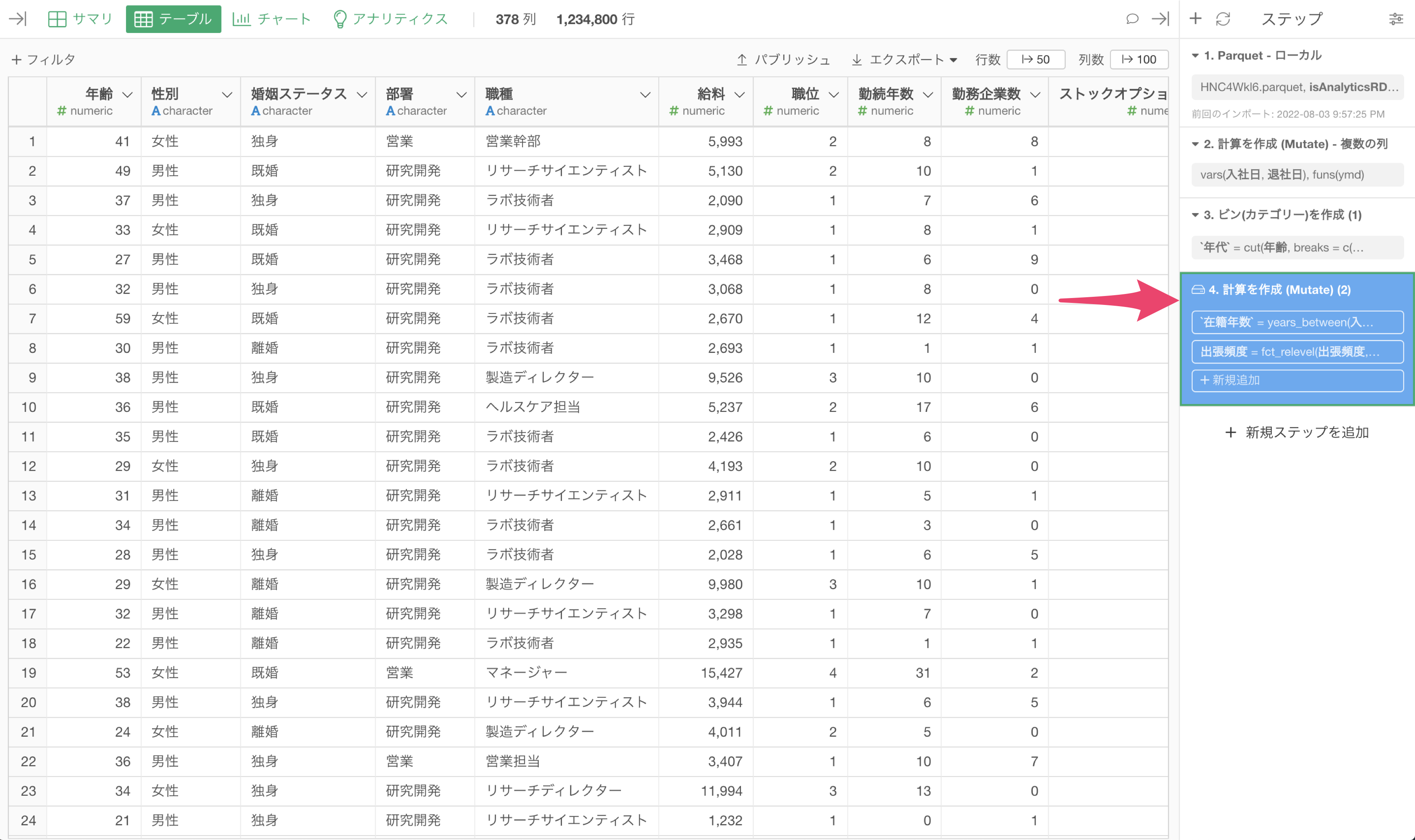
ステップをキャッシュすると、該当のステップが青くなり、それ以前のステップの処理をすることなしに、データを読み込むことができるようになります。
ここからは、このことをもう少し詳しく説明していきます。
ステップを「キャッシュ」すると、Parquetファイルが作られ、PC上のレポジトリに保存されます。
そして、プロジェクトを開き直し、キャッシュされたステップを含む同じデータフレームを開くと、キャッシュされたParquetファイルからデータが読み込まれるます。
なお、キャッシュしたステップの後に、ステップがあった場合は、データフレームを開いた時、キャッシュしたステップ以降の処理が実行されることになります。
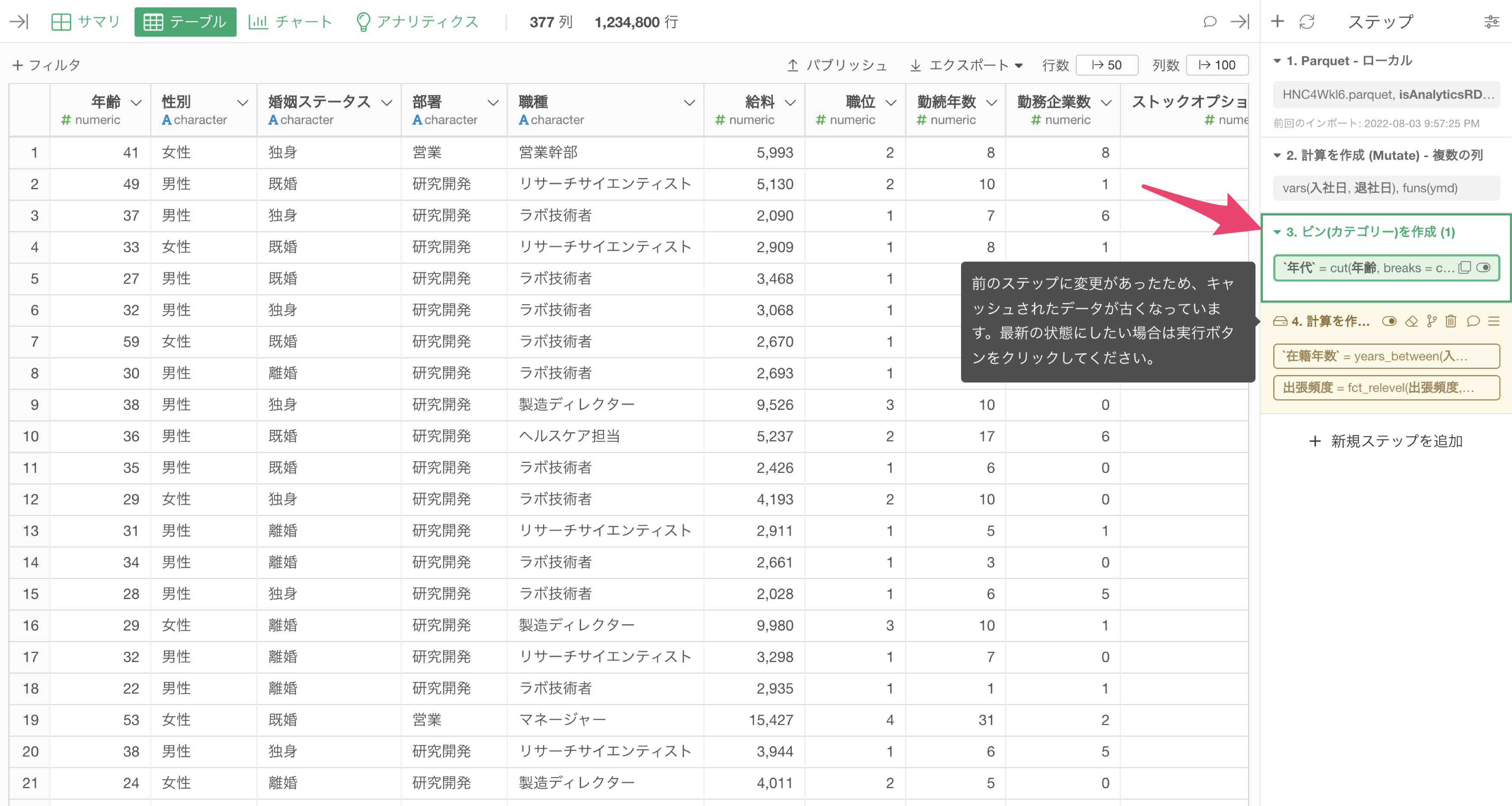
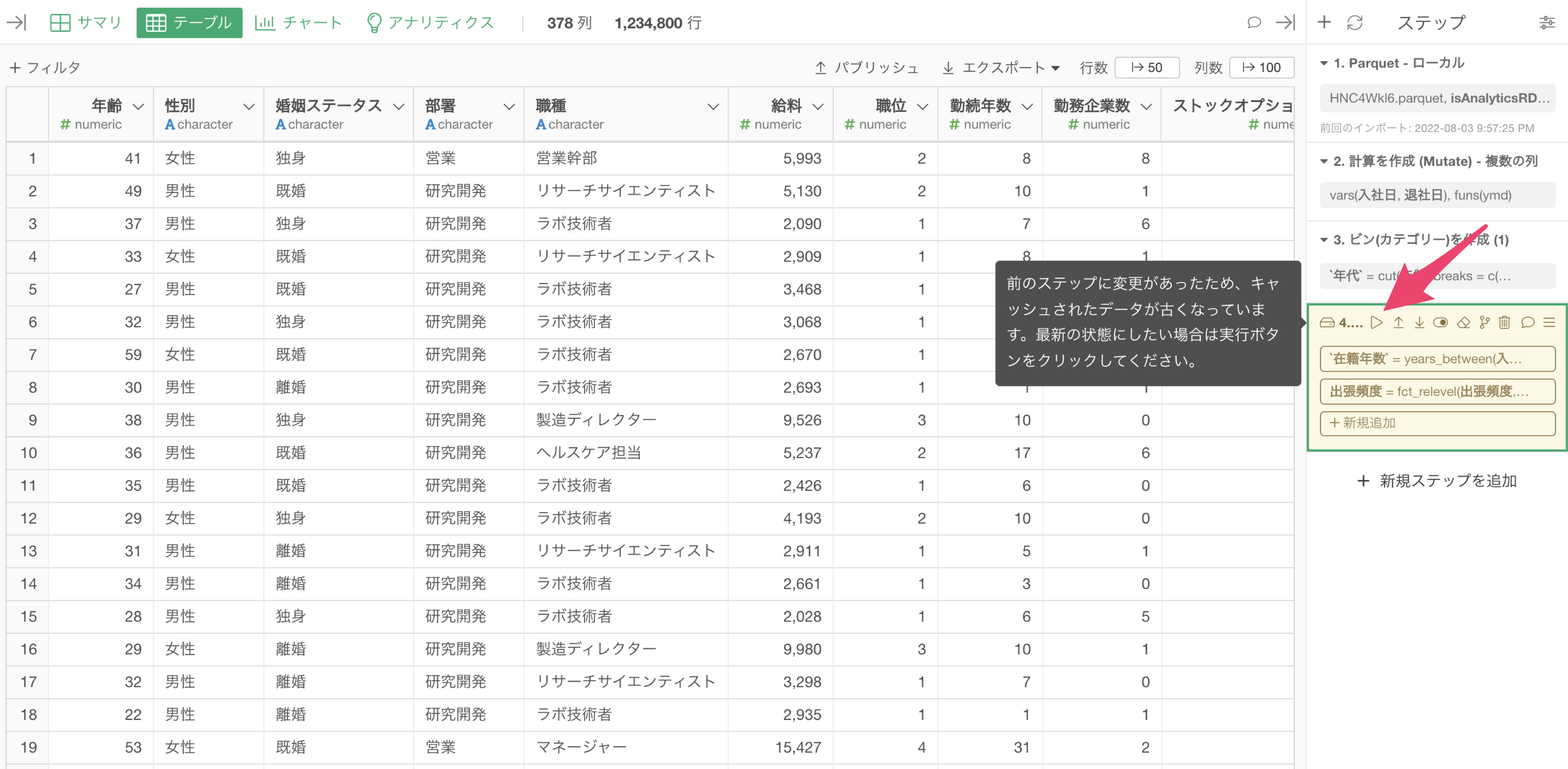
そしてキャッシュされたステップより前のステップに変更があったときは、そのステップの色が黄色に変わり、そのステップのキャッシュされたデータが古くなったことがわかります。
キャッシュされたステップのデータを更新したいときは、キャッシュしたステップで「実行ボタン」をクリックして、キャッシュを更新することが可能です。
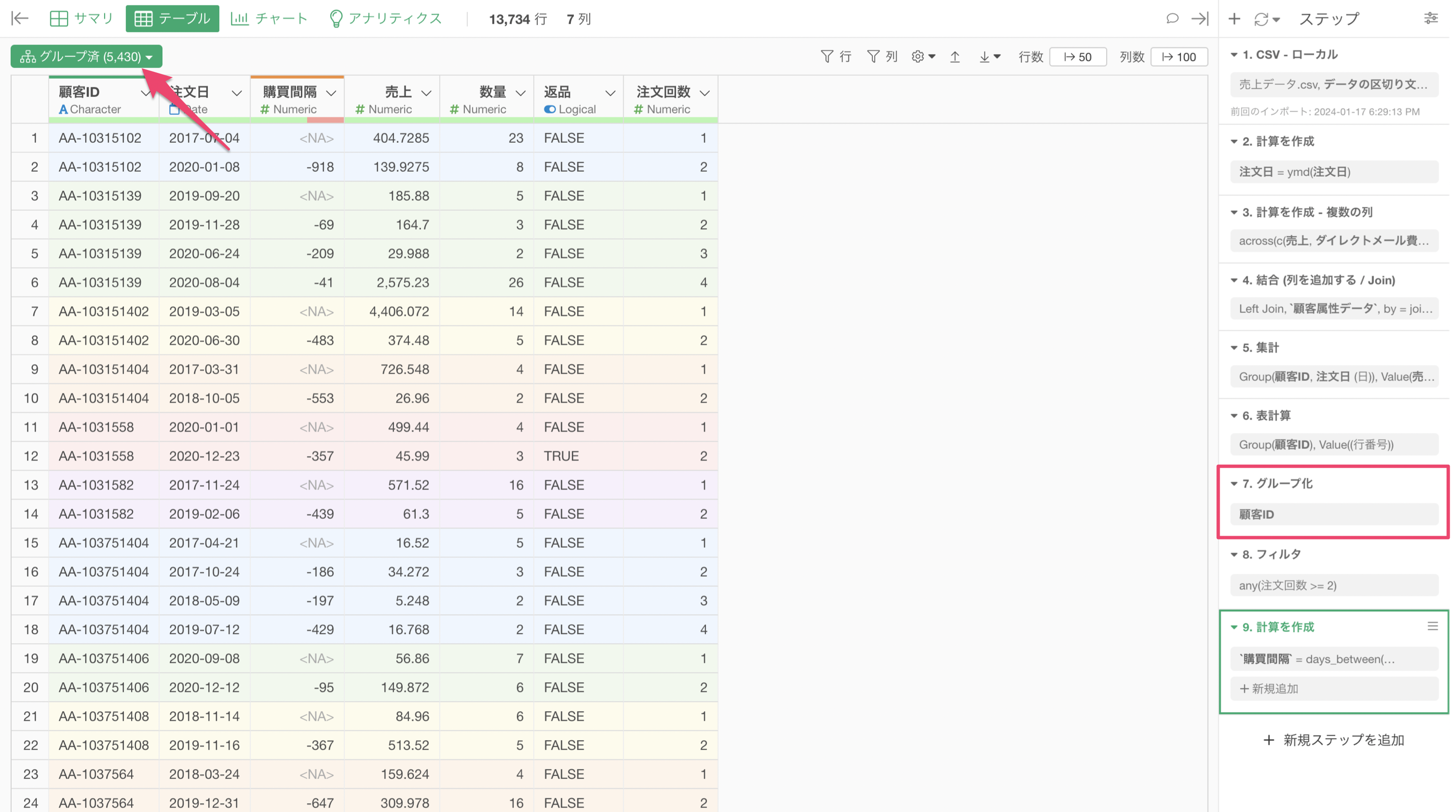
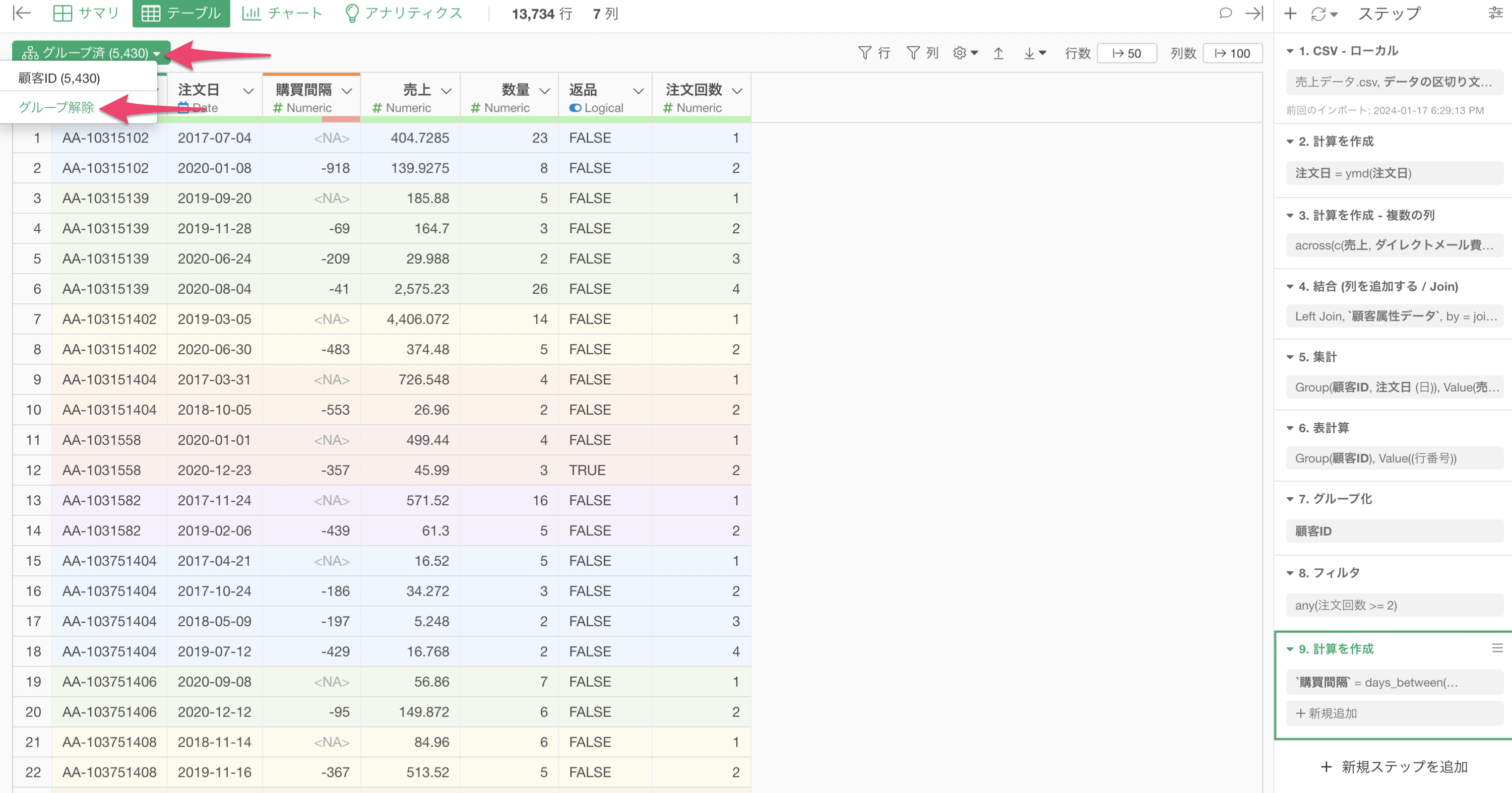
不要なグループ化は解除する
Exploratoryでは、グループごとに計算をしたり、フィルタで絞り込みたい時には「グループ化」の機能を使うことがあります。
グループごとに処理ができるので便利な機能ですが、グループに対する処理が必要ない場合は、グループを解除するべきです。
これは、グループ化がかかったままだと、常にグループ単位での処理がかかってしまい、余計な時間がかかってしまうことがあるためです。
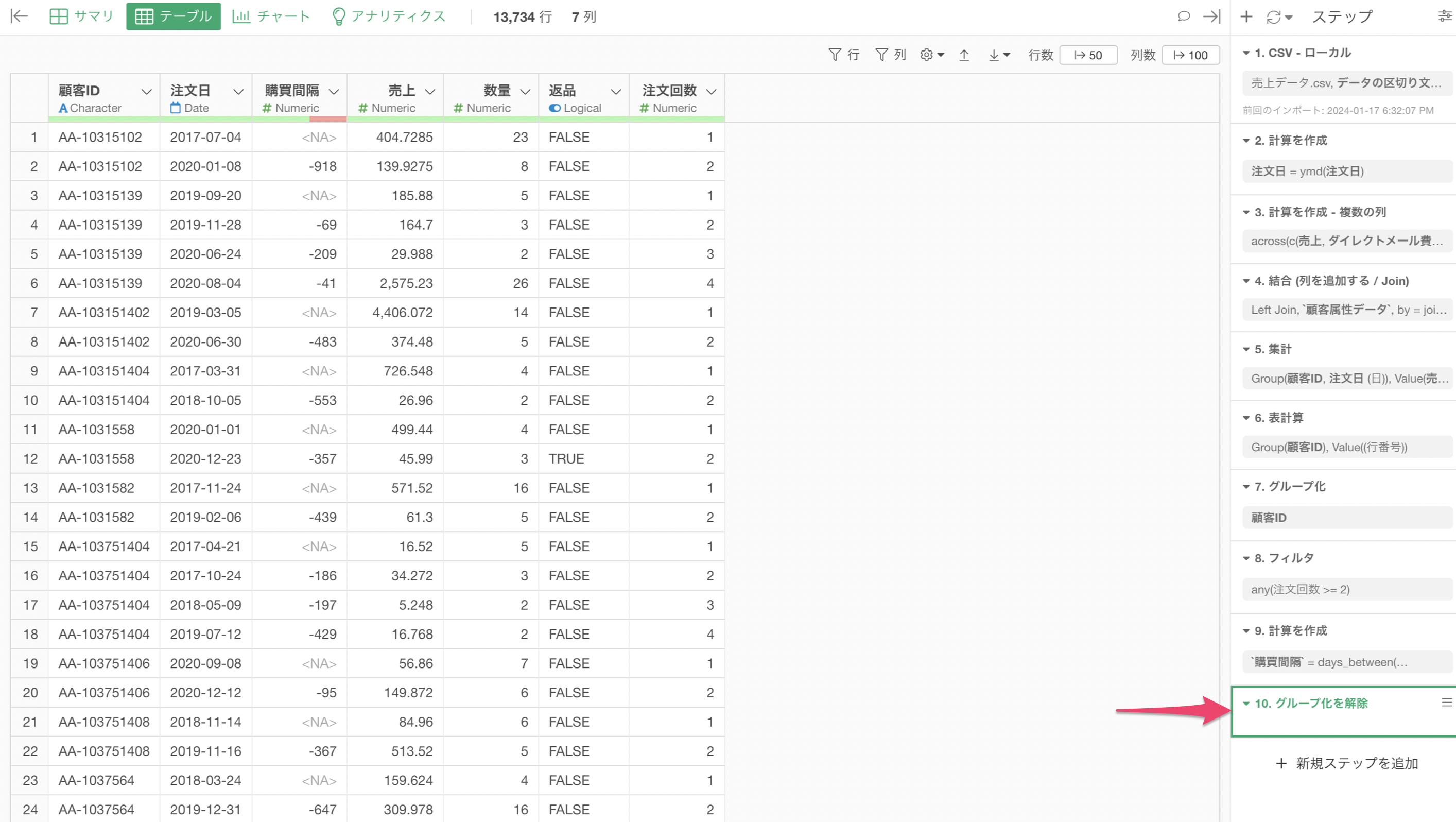
グループ済みの緑のボタンをクリックし、「グループ解除」を行うことで、グループ化を解除することができます。
グループ化の解除は1つのステップとして追加され、それ以降の処理はグループを考慮しない処理となります。
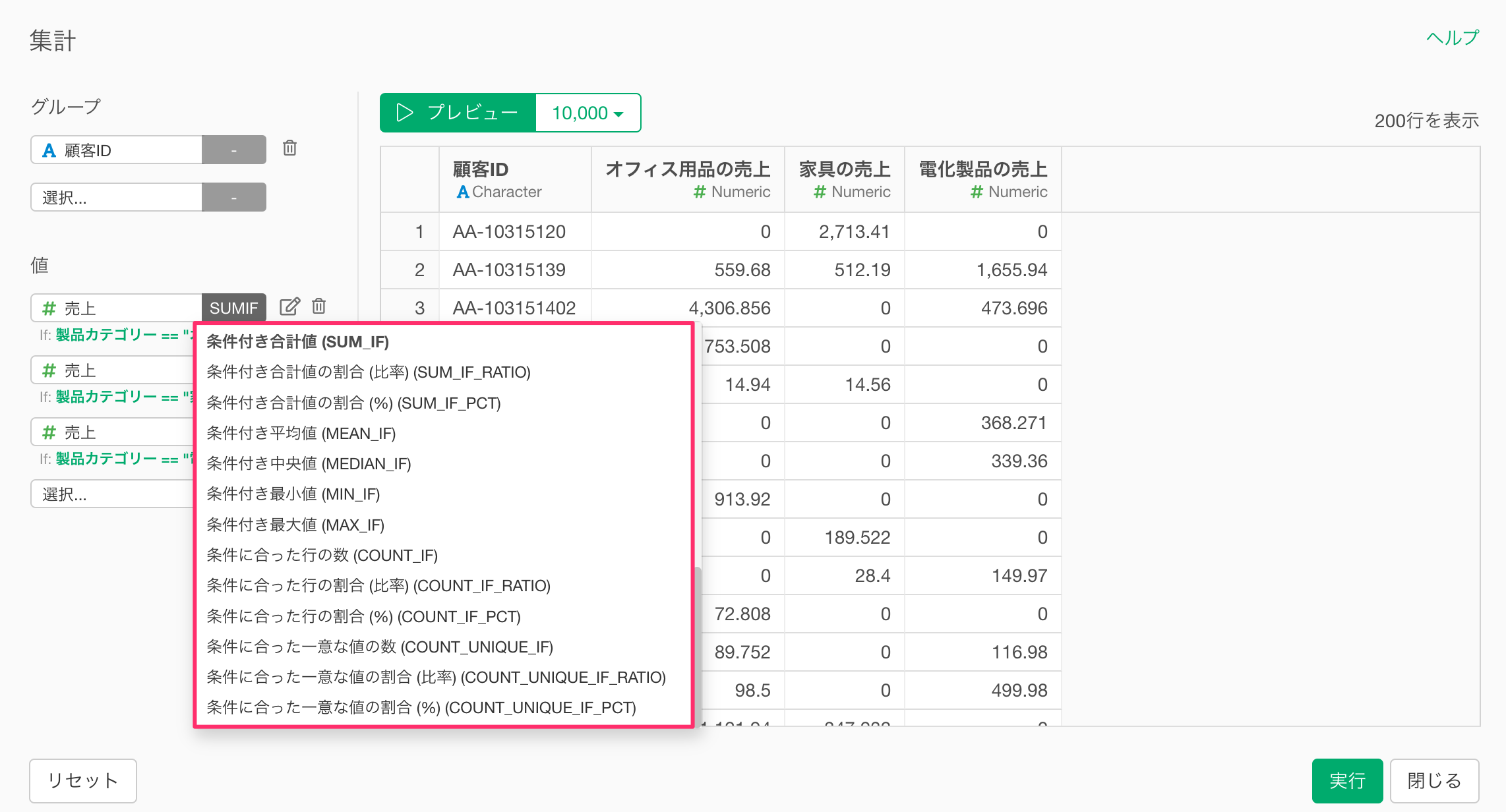
「条件付きの集計関数」は使わずに集計を行う
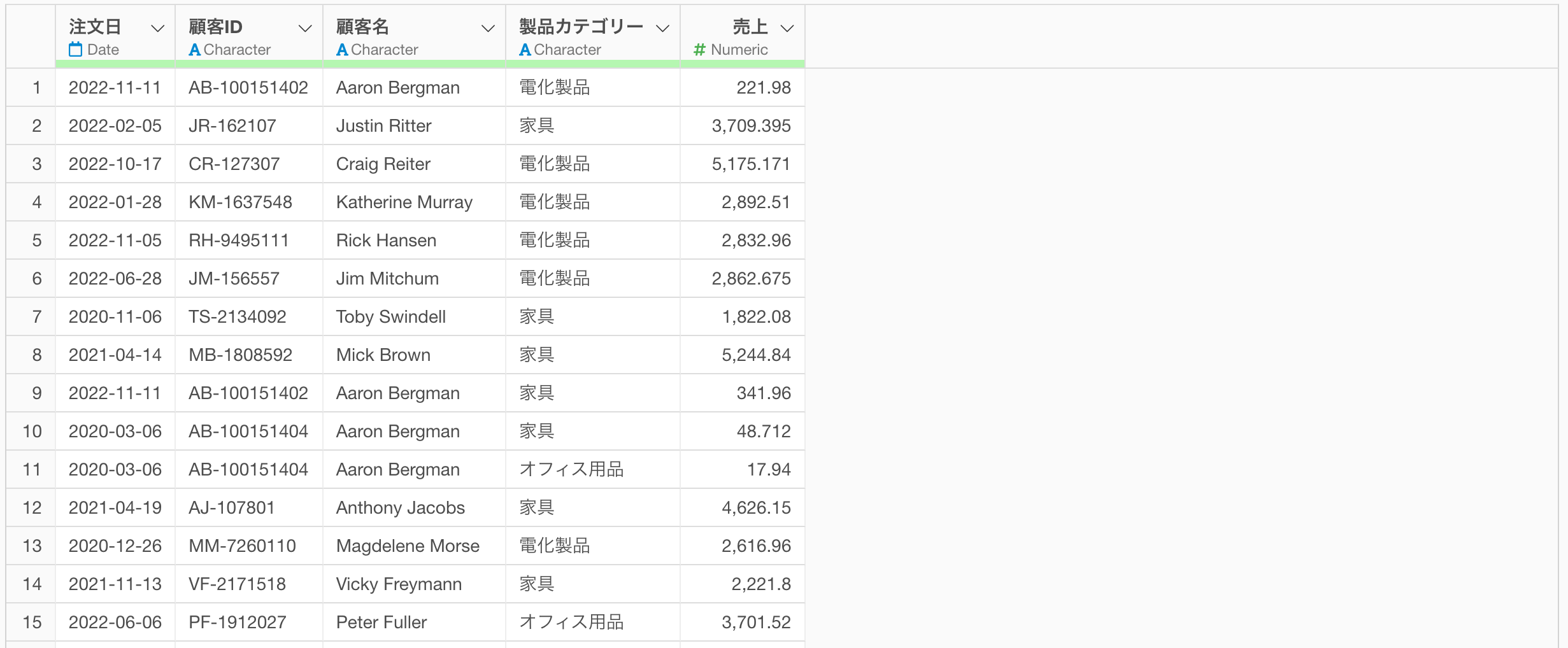
ここでは、以下のような1行が1つの注文を表し、列には「顧客ID」、購入した製品の「製品カテゴリー」や「売上」の情報を持つデータを例に考えてみます。
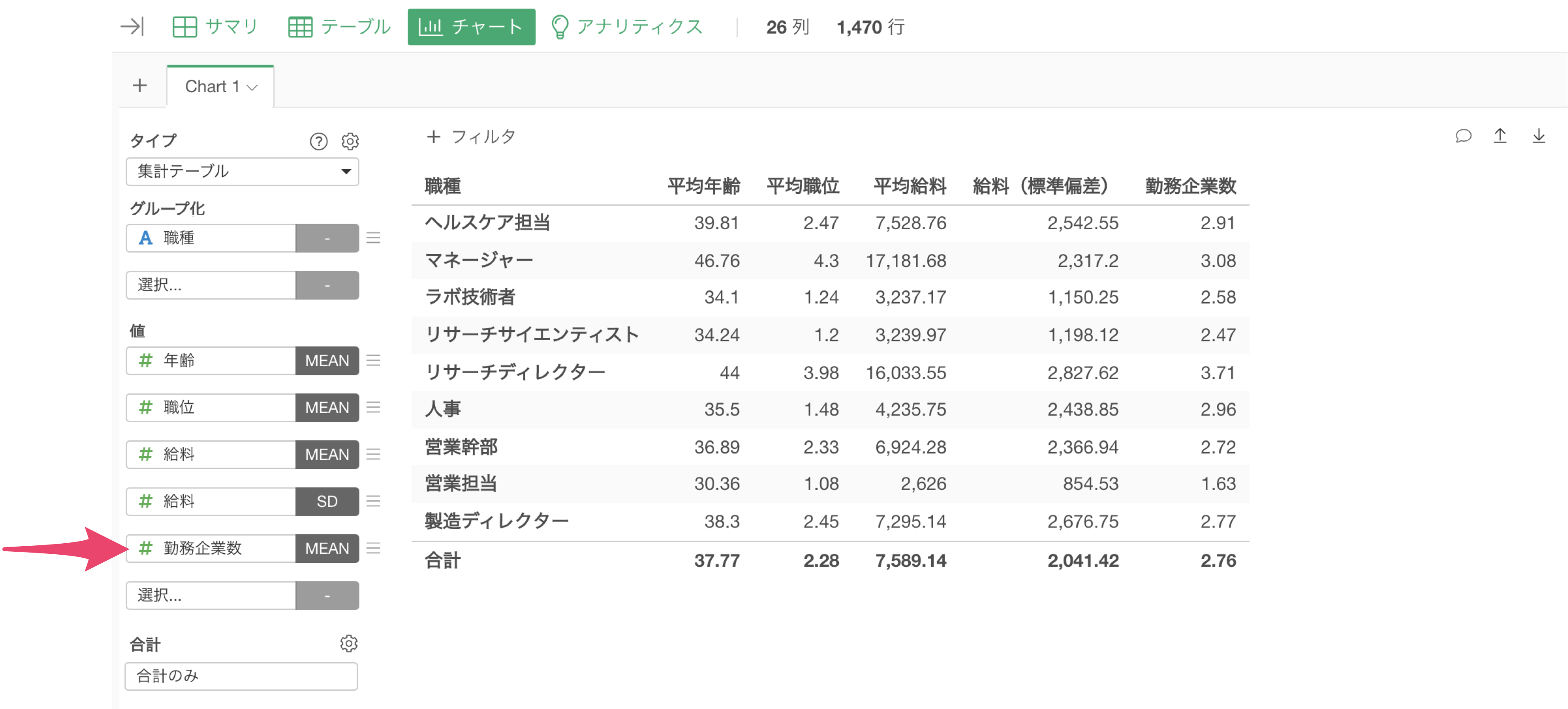
このようなデータを使って、顧客ごとに「電化製品の売上」「家具の売上」を集計したいときには、以下のように、集計ダイアログの中で、条件付きの集計関数を利用して、複雑な条件をもとにした集計を簡単に行うことが可能です。
このような条件付きの集計は、通常の集計よりも複雑な処理になるため、その分だけ処理に時間がかかります。
さらに、「グループ」に選択している列の一意な値の数が多ければ多いほど、処理は重くなります。これは、グループごとに条件にマッチする行を選別し、そのうえで計算処理を行うからです。
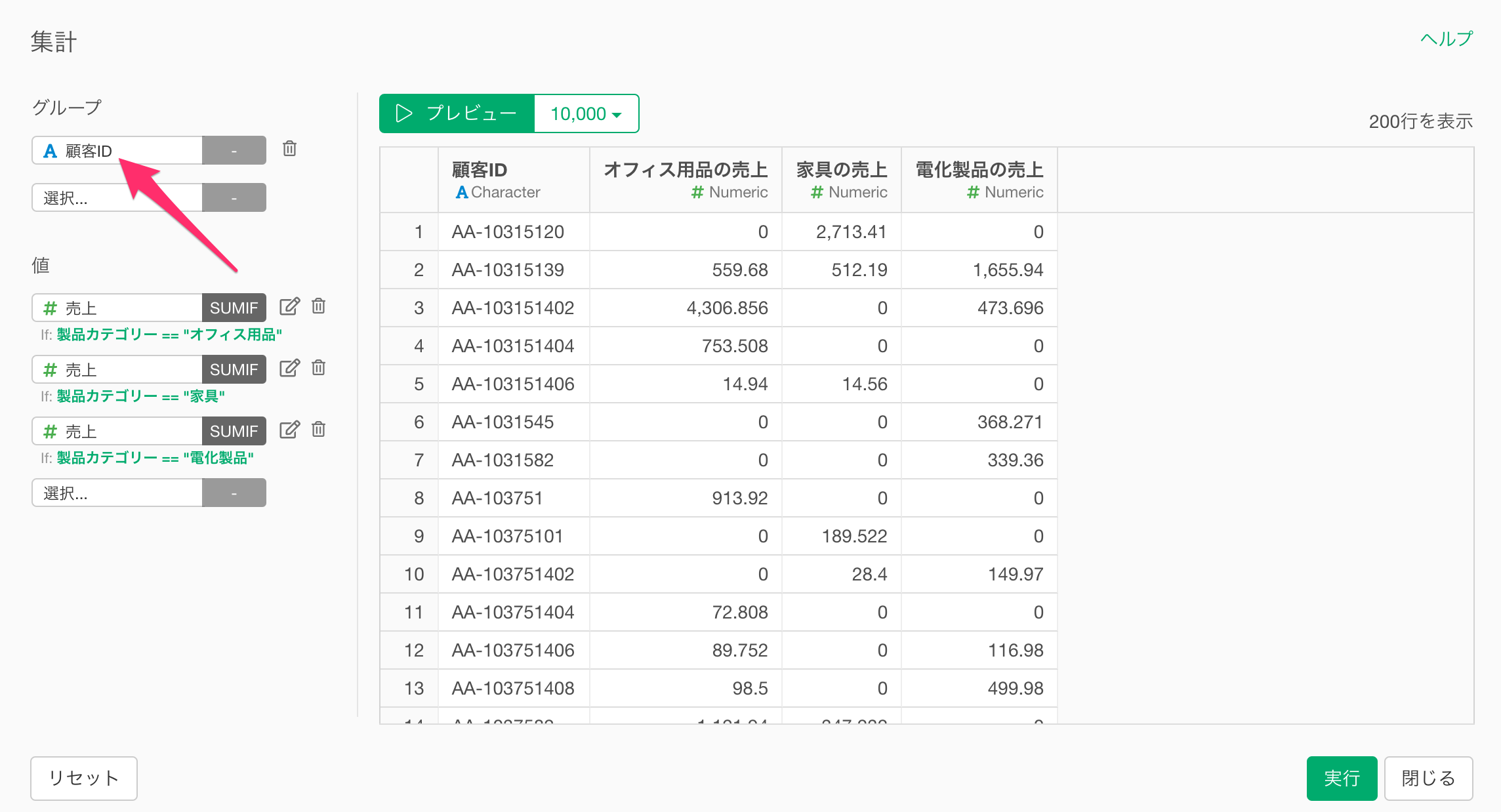
そこで、「グループ」に選択している列の一意な値の数が多いようなデータを使って、条件付きの集計を行いたいときには、集計のダイアログの中で、条件を指定するのではなく、条件に合致する列をあらかじめ追加しておくことで、処理効率を高められます。
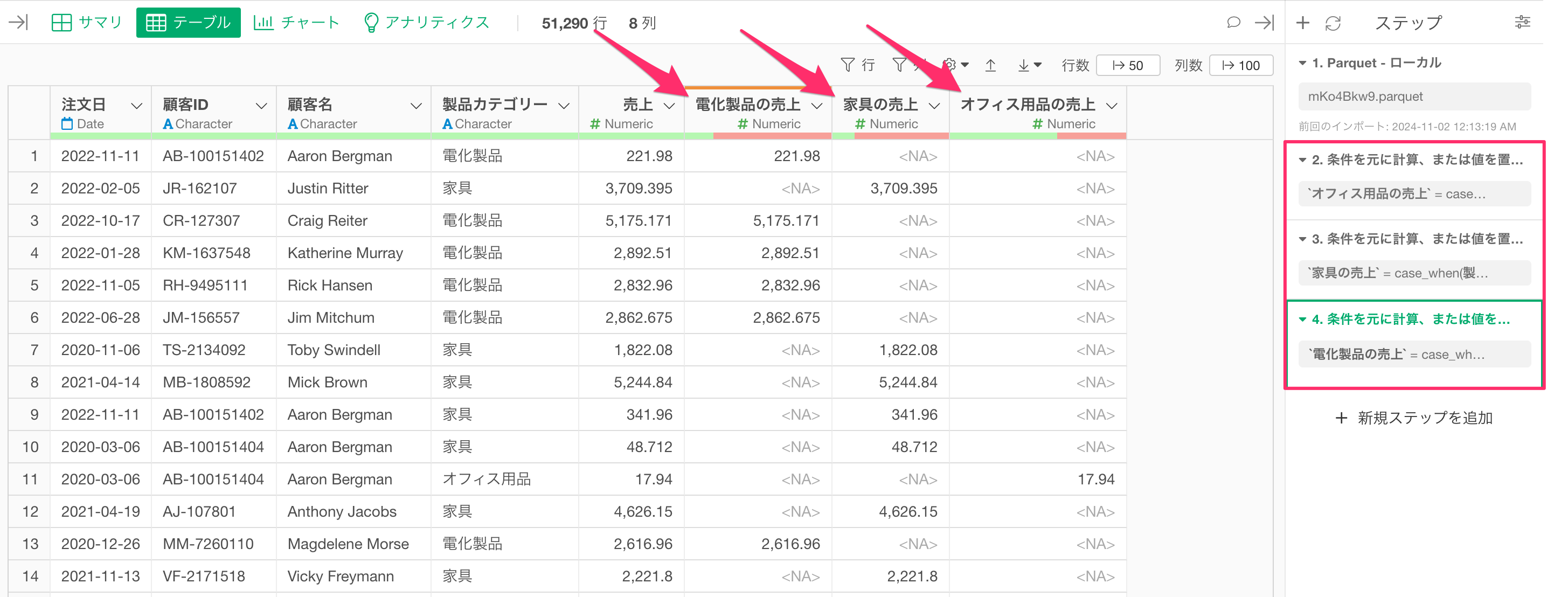
例えば、今回の例の場合、以下のように、製品カテゴリー別の売上の列を「条件をもとに計算」機能を利用して、追加しておきます。
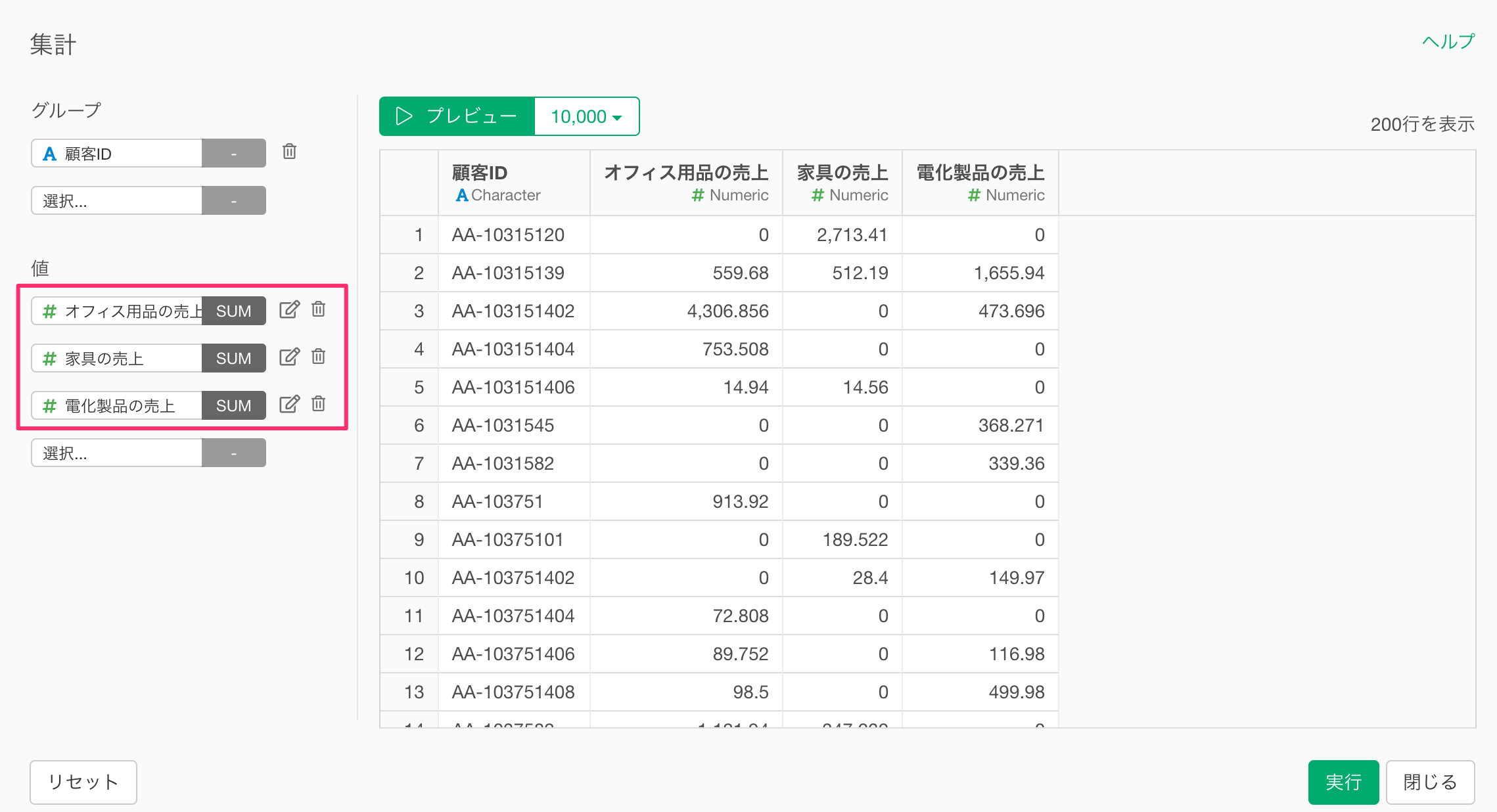
すると、集計のダイアログの中で、条件付きの関数を利用せずに、あらかじめ用意しておいた条件に合致する列を集計するだけで、同じ処理を実現できるため、集計にかかる処理速度を速めることが可能です。
3. チャート/アナリティクス
チャート
集計テーブル・ピボットテーブル
集計テーブル・ピボットテーブルでは、変数を選択する度に、集計処理が走ることになるため、都度処理に時間がかかることになります。
そこで、あらかじめ集計のステップを追加しておき、データを「テーブル」で可視化した方がチャート上で集計処理をする必要がなくなるので、処理が速くなります。
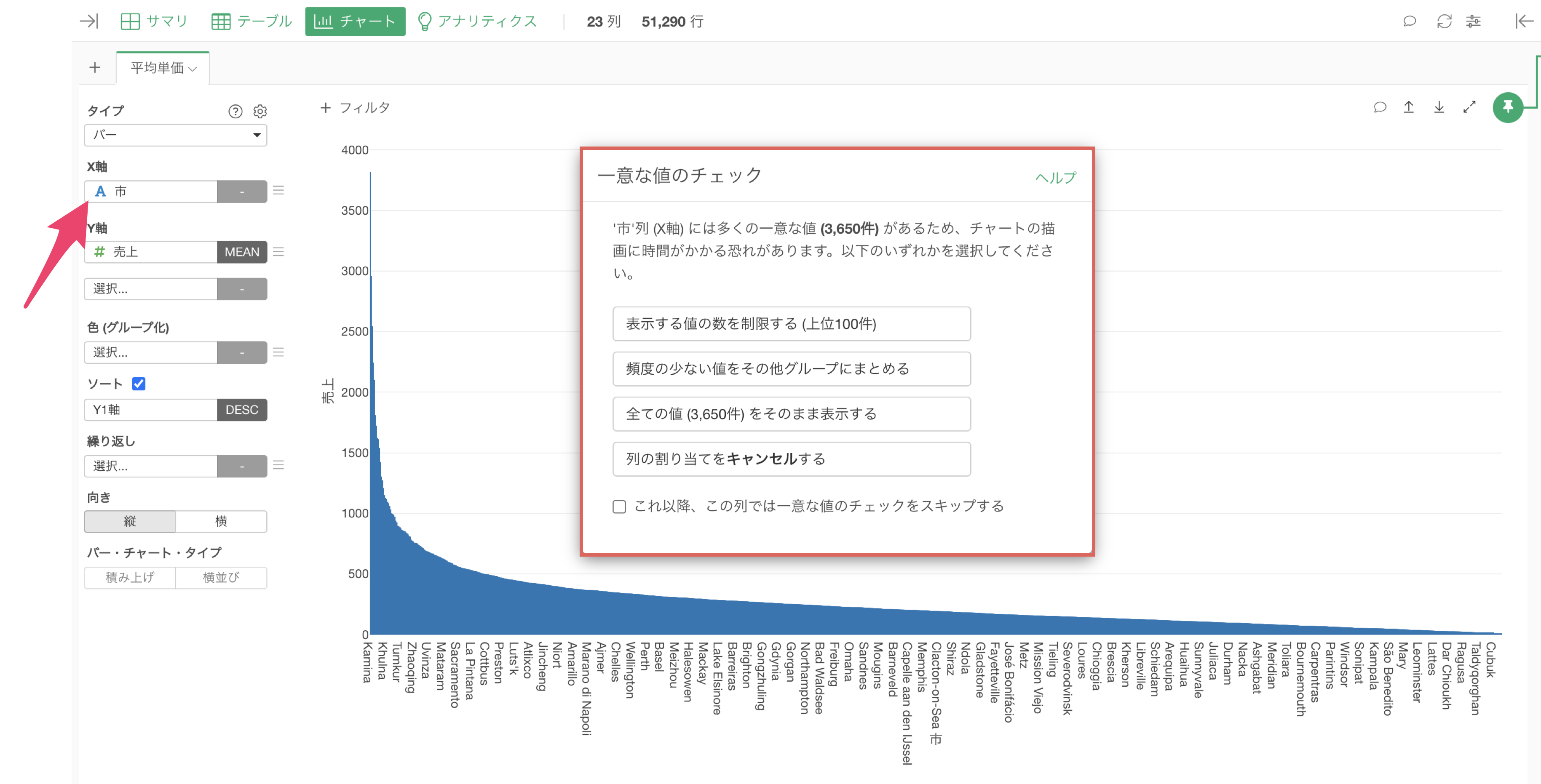
カテゴリー数の多いデータの可視化
データのサイズが大きくなると、カテゴリの数も多くなりがちですが、あまりに多くのカテゴリを可視化しようとすると描画に時間がかかることになります。
そこで、そのような自体を未然に防げるように、あまりにカテゴリが多い列をチャートで選択した場合、「一意な値のチェック」の確認画面が表示され、表示する情報をコントロールできるようになっています。
アナリティクス
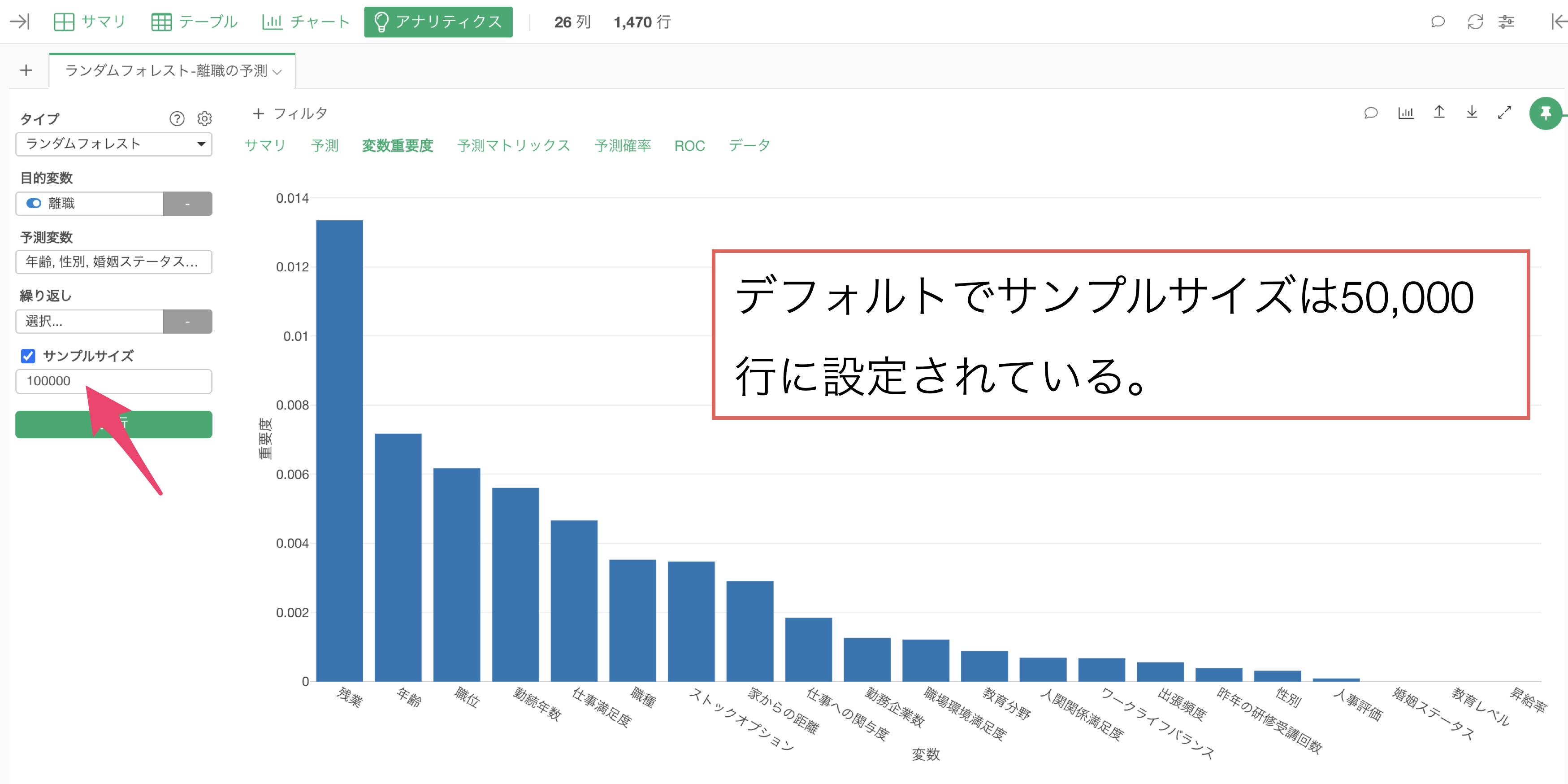
サイズの大きいデータを使ってアナリティクスを実行すると、計算処理に時間がかかることがあります。
大まかな予測精度や相関の傾向を確かめたいときには、アナリティクスを実行する際にサンプルサイズを指定して、モデルの実行スピードを調整することが可能です。
4.ダッシュボード
ダッシュボード実行時の仕組みとパフォーマンスの最適化
Exploratoryでは、チャートをデータフレームから直接開く場合、そのチャートに必要なデータをメモリから高速に読み込んでレンダリングするため、多くの場合、素早く表示されます。
一方で、ダッシュボードを実行する場合は、データソースからのデータの再取得は行わないものの、データソース以外のすべてのステップが再実行されたうえで、チャートがレンダリングされる仕組みとなっています。
そのため、以下のような条件に当てはまる場合は、ダッシュボードの実行に時間がかかることが想定されます。
- サイズの大きいデータを利用している
- データフレームを複数使っている
- ステップの数が多い
- ダッシュボードのページ数やチャート数が多い
- 繰り返しの多いチャートや情報量の多いピボットテーブルを含んでいる
そこで、ダッシュボードの実行パフォーマンスを向上させるうえで有効なアプローチの1つとして、たとえば、複数のデータフレームのマージや複雑な計算といった処理が後方のステップに存在する場合、ダッシュボードを実行するたびにそれらの重い処理が繰り返されることになります。
このような場合には、データカタログなどを活用して加工済みのデータフレームを用意し、そのデータをダッシュボードのチャートに利用することが有効です。
あるいは、そのような立て付けが可能な場合、重い処理を実行する前のステップでチャートをあらかじめ作成しておくことで、ダッシュボード実行のたびに重い処理が走ることを防げます。
ステップをキャッシュしてインタラクティブモードを軽くする
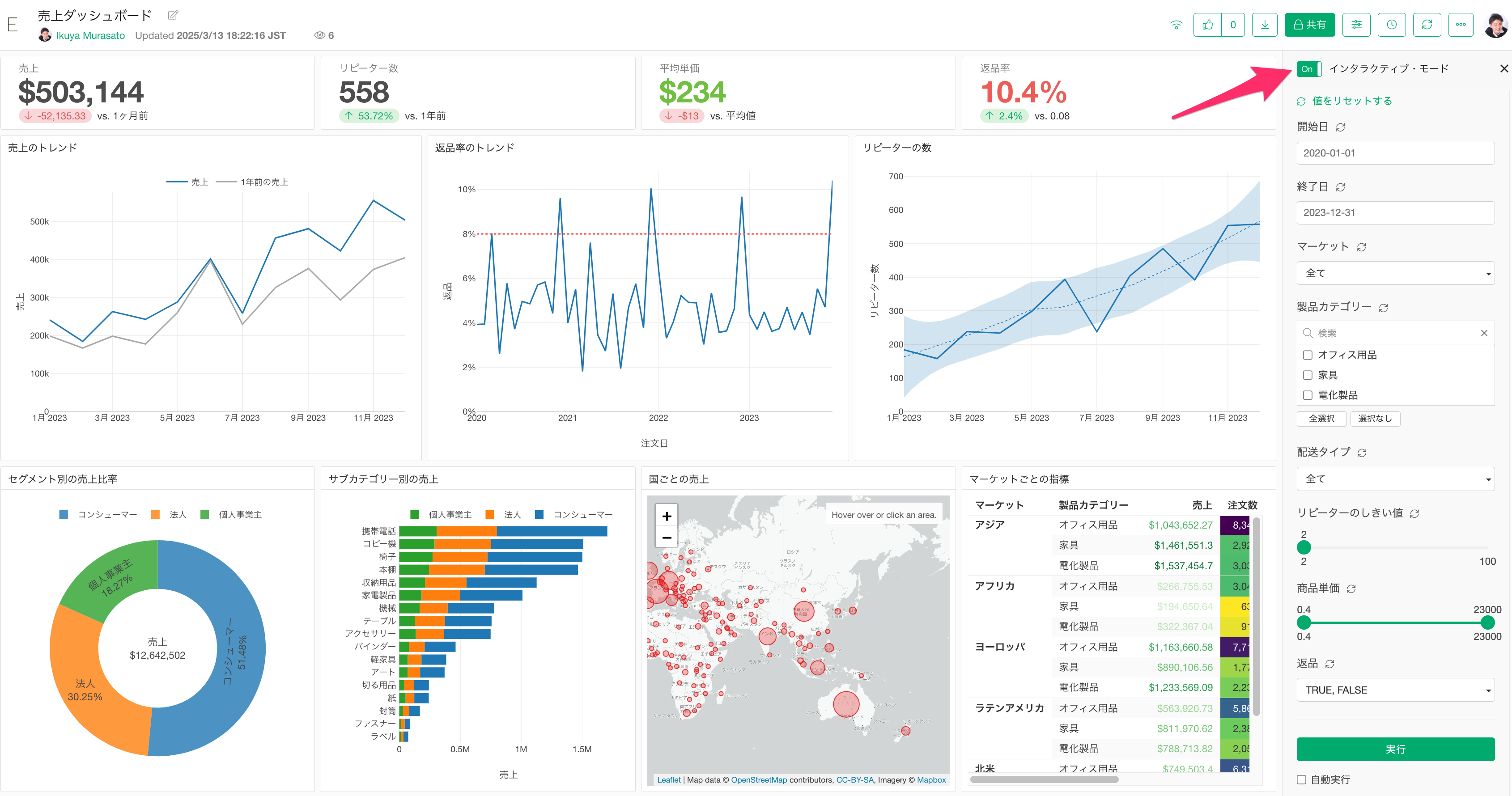
Exploratoryでは、サーバーにパブリッシュしたダッシュボードにて、「インタラクティブモード」といった機能があります。
インタラクティブモードでは、「パラメーターを使ってデータを動的に変える」、「チャートをクリックして他のチャートをフィルタする」といったことが可能です。
ただ、このインタラクティブモードでは、データを絞り込んでいくためにダッシュボードに含まれているチャートで使われているデータを読み込む必要があります。
そのデータで他のデータフレームを結合していたり、時間がかかる処理を行っていた場合、インタラクティブモードの起動や操作に時間がかかってしまいます。
理由としては、ステップが「キャッシュ」されていない場合はデータソースから順にステップの処理を実行していくためです。これにより、元のデータが大きい場合や重たい処理がされていると時間がかかってしまうことにつながってしまいます。
そこで、ステップをキャッシュしておくことで、キャッシュされている時点のデータから読み込まれるために、ステップの処理時間を短縮でき、結果的にインタラクティブモードの起動や操作時間が短縮されることにつながります。
キャッシュ自体の詳細は、こちらのセクションをご覧ください。
以下の例では、10番目のステップでキャッシュされているため、10番目のステップの時点のデータを読み込んだ上で、それ以降のステップのみを処理していくことになります。
つまり、2番目から10番目までのステップ処理はすでに行われた状態になるために、その分の処理時間がかからないことになり、結果としてインタラクティブモードのパフォーマンスが向上します。
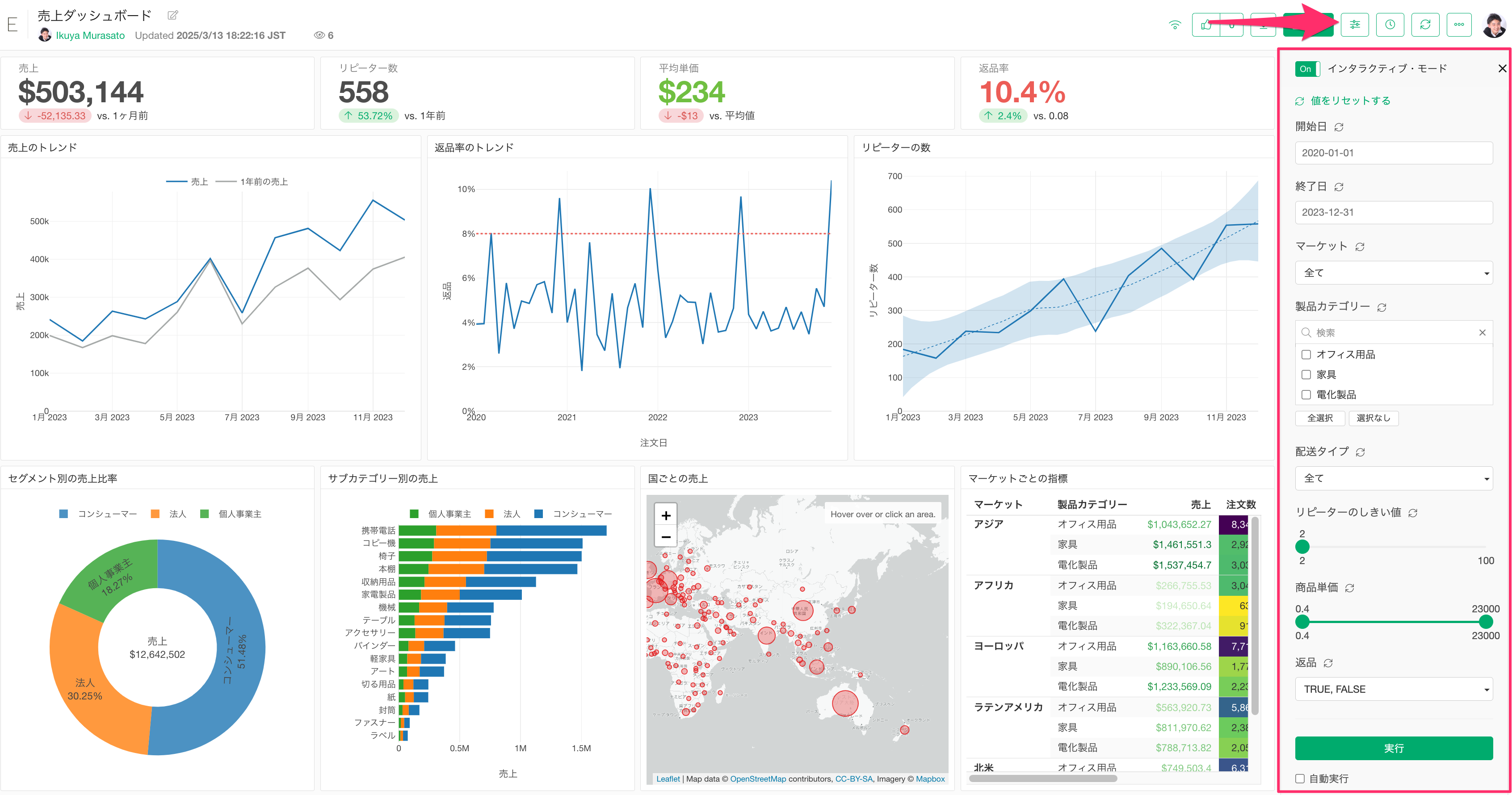
5. パラメーター
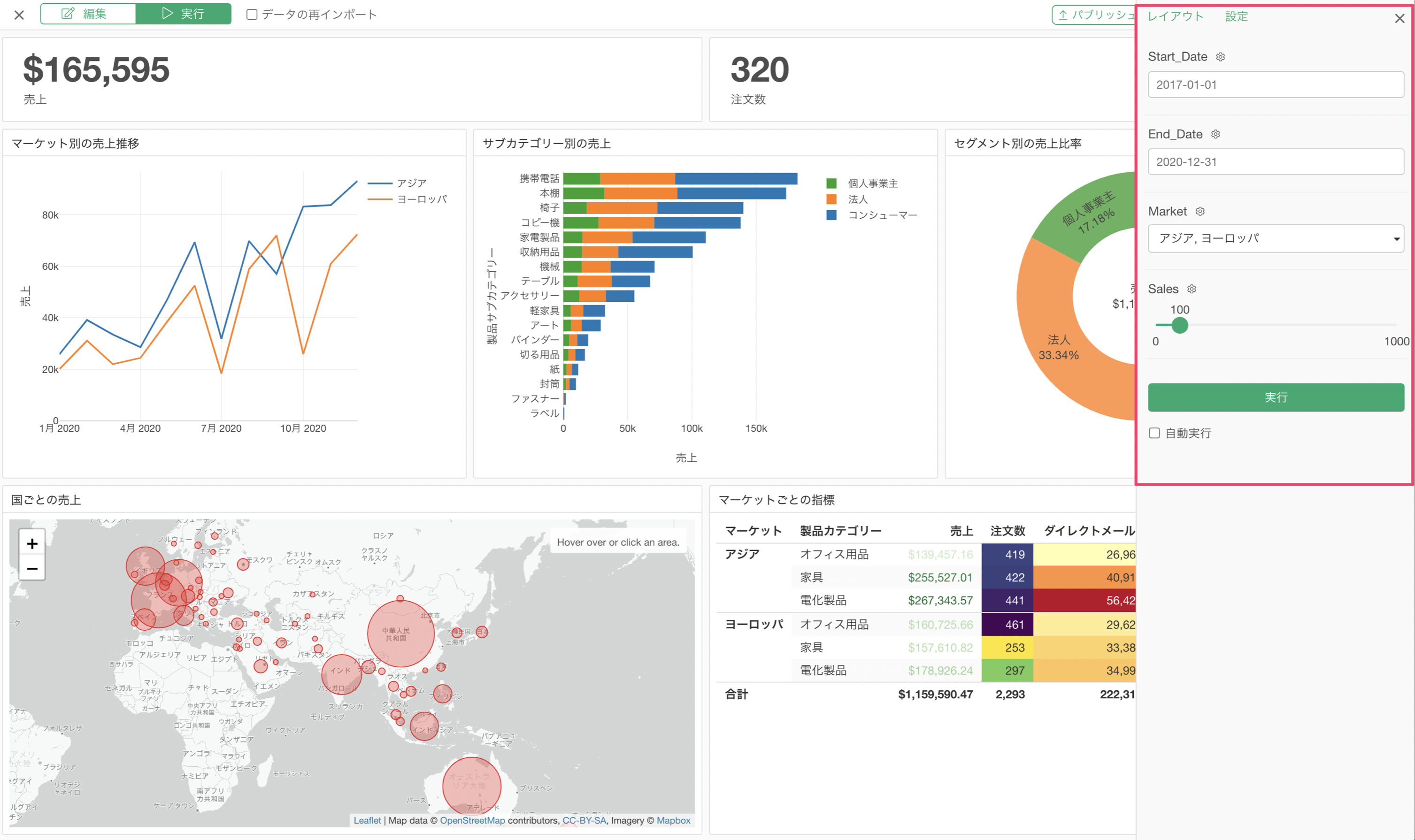
Exploratoryサーバーにパブリッシュしているコンテンツ(ダッシュボードやノートなど)にパラメーターが設定されている場合、そのコンテンツの閲覧権限を持っている方であれば、パラメーターの値を変更して自分が見たい内容にデータをフィルタしたり、計算内容を動的に変更できます。
パラメーターで選択可能な値として表示される情報は、パラメーターの設定画面から直接、定義したり、データフレームから動的に生成することが可能です。
なお、パラメーターを利用するためにインタラクティブ・モードを有効にした際、インタラクティブ・モードの起動に時間がかかる場合があります。
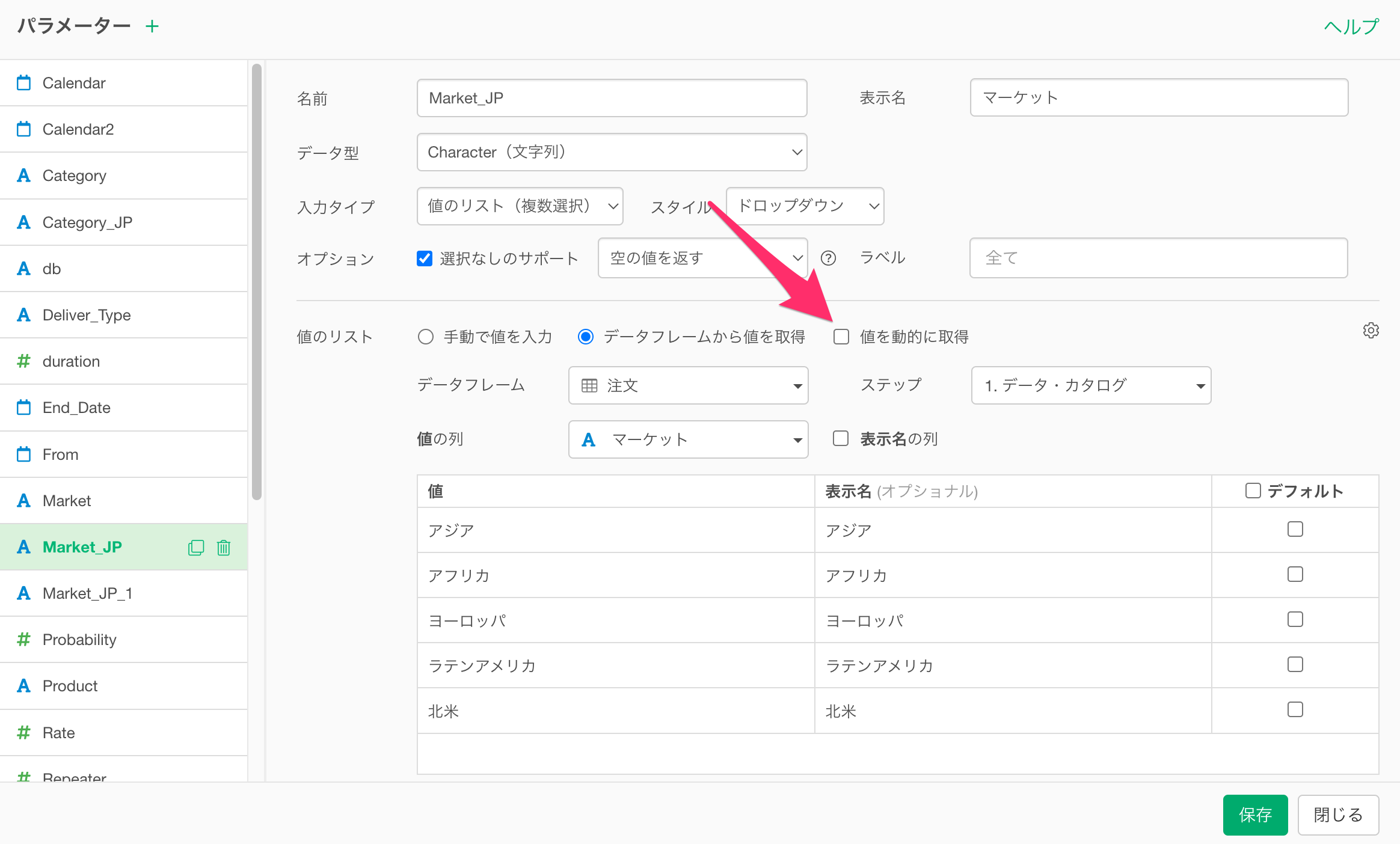
もし値のリストにを動的に生成しているのであれば、それが、インタラクティブ・モードの起動に時間を要している要因の1つである場合があります。
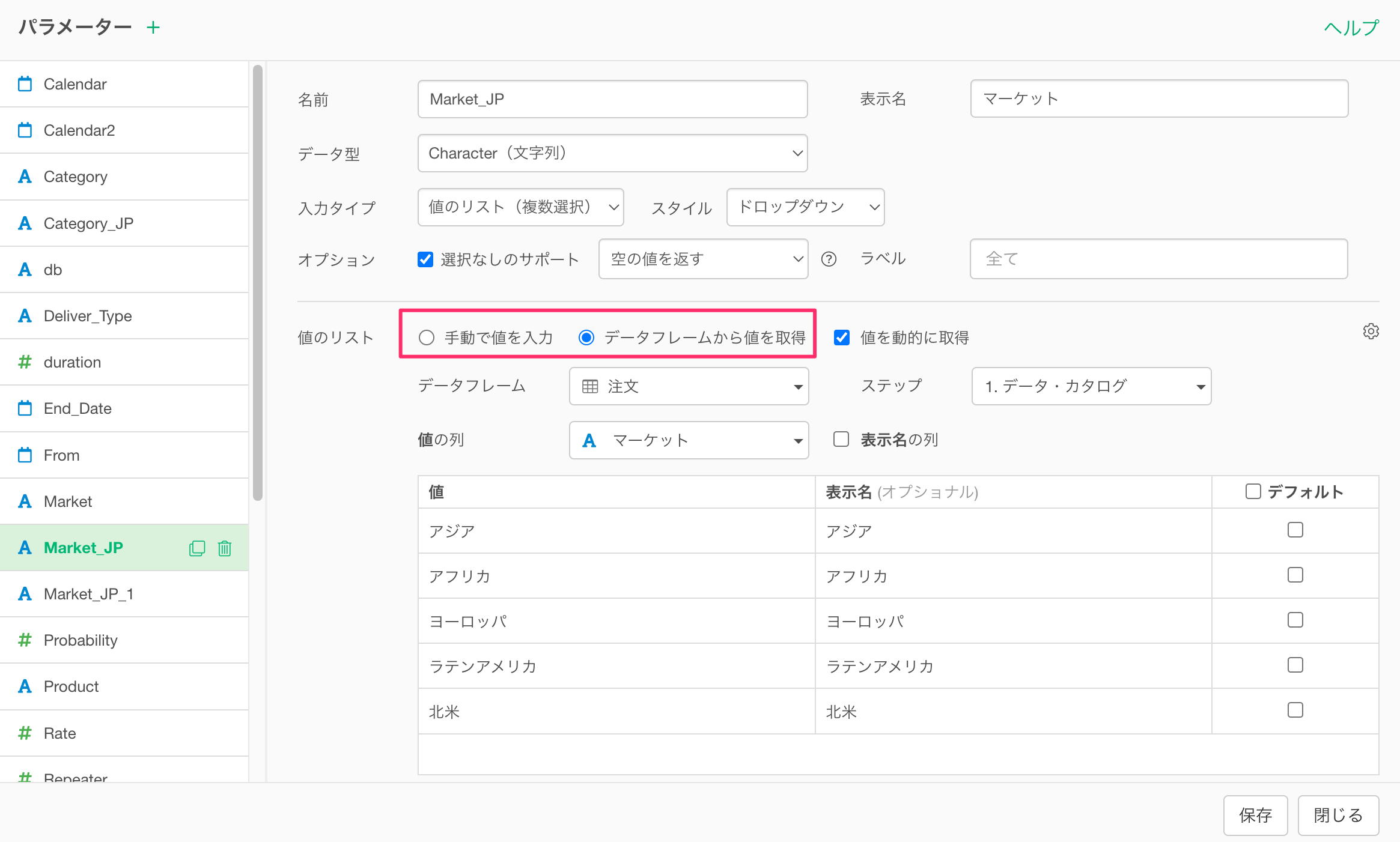
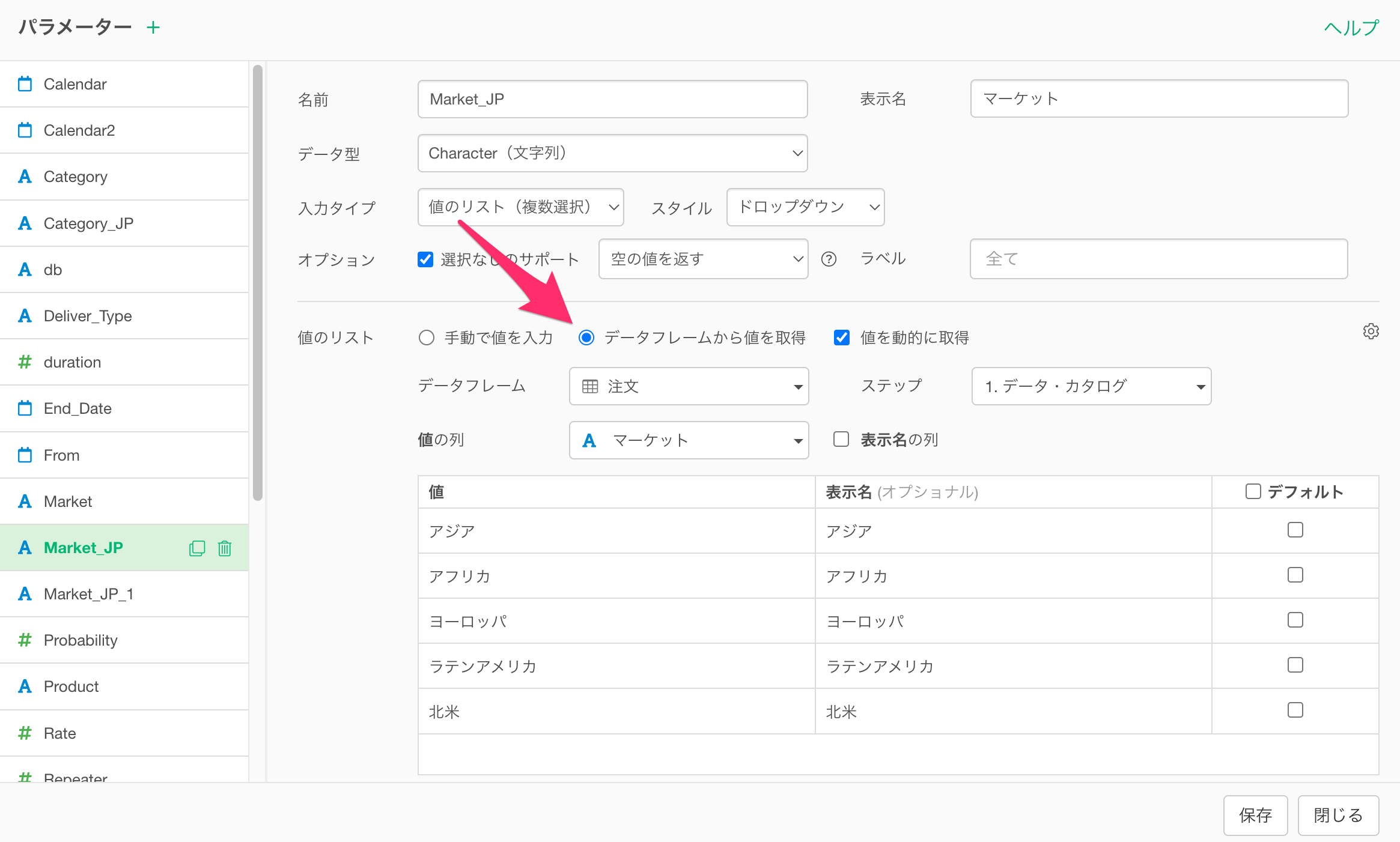
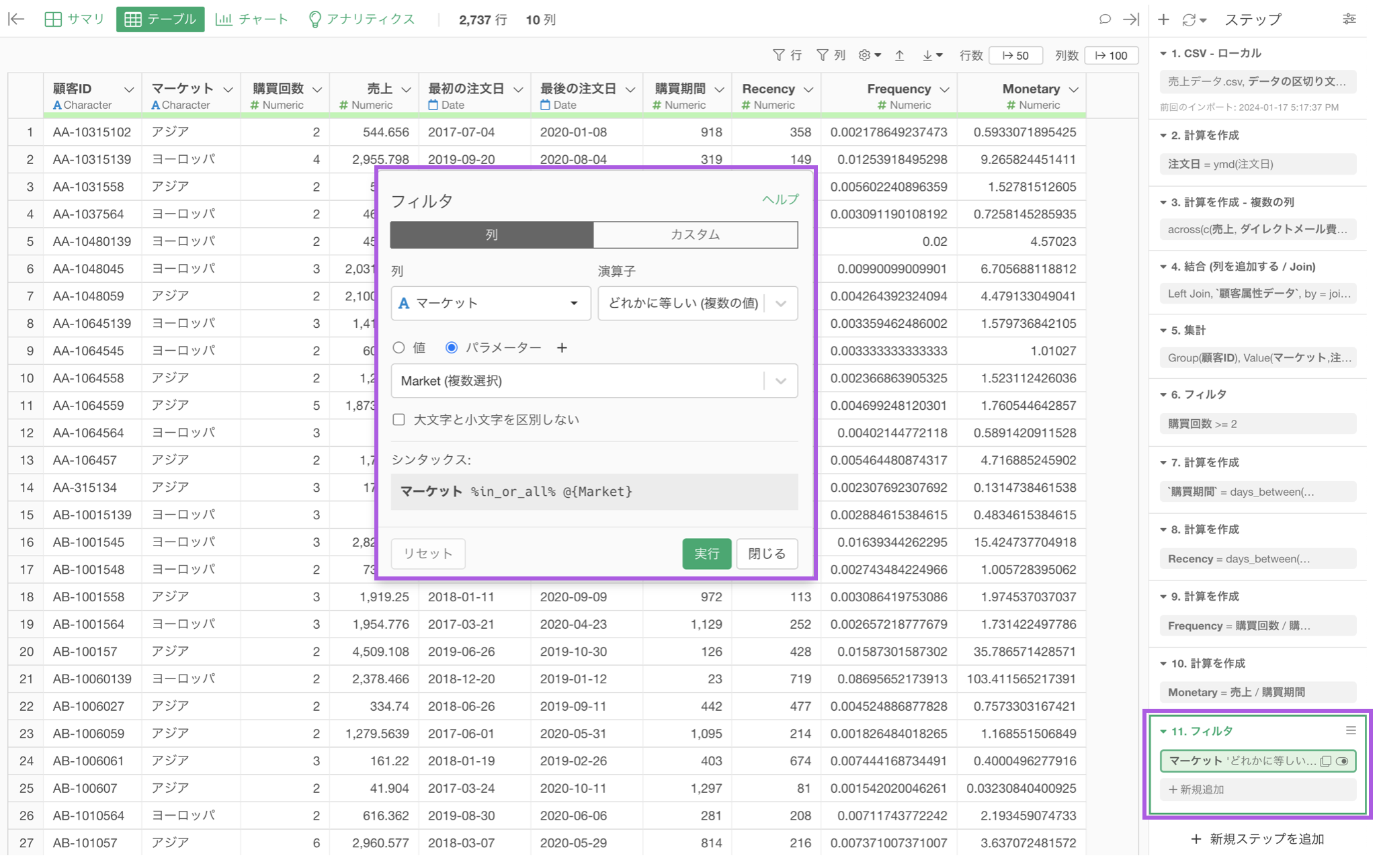
そこで、パラメーターの値のリストを動的に更新する必要がない場合は、パラメーターの設定画面で「値を動的に取得」のチェックを外すことをお勧めします。
この設定により、パラメーターの値のリストがキャッシュされ、毎回動的に生成されることがなくなるため、キャッシュされた値のリストが利用されるようになることで、インタラクティブ・モードが起動するまでの時間が大幅に短縮されます。
なお、「値を動的に取得」にチェックが付いていて、任意のステップのデータを参照して値のリストを生成しているときには、データが更新されると、その内容に応じてパラメーターの値のリストも更新されます。
一方で、「値を動的に取得」のチェックを外した場合、仮にデータが更新されたとしても、キャッシュされている値のリストが利用されますので、パラメーターの値のリストは更新されませんので、ご注意ください。
もし、値を動的に取得のチェックを外している状態で、パラメーターの値のリストを更新したい場合は、Exploratoryデスクトップのパラメーターの設定画面から「値を動的に取得」のチェックを付けて、パラメーターの値のリストを更新してから、再度、「値を動的に取得」にチェックを付けて、パラメーターを保存してください。
データラングリングの処理順序(効率化)
Exploratoryでは、データラングリング(加工・整形)の処理をステップとして管理しており、上から順番にステップの処理が実行されるようになっています。
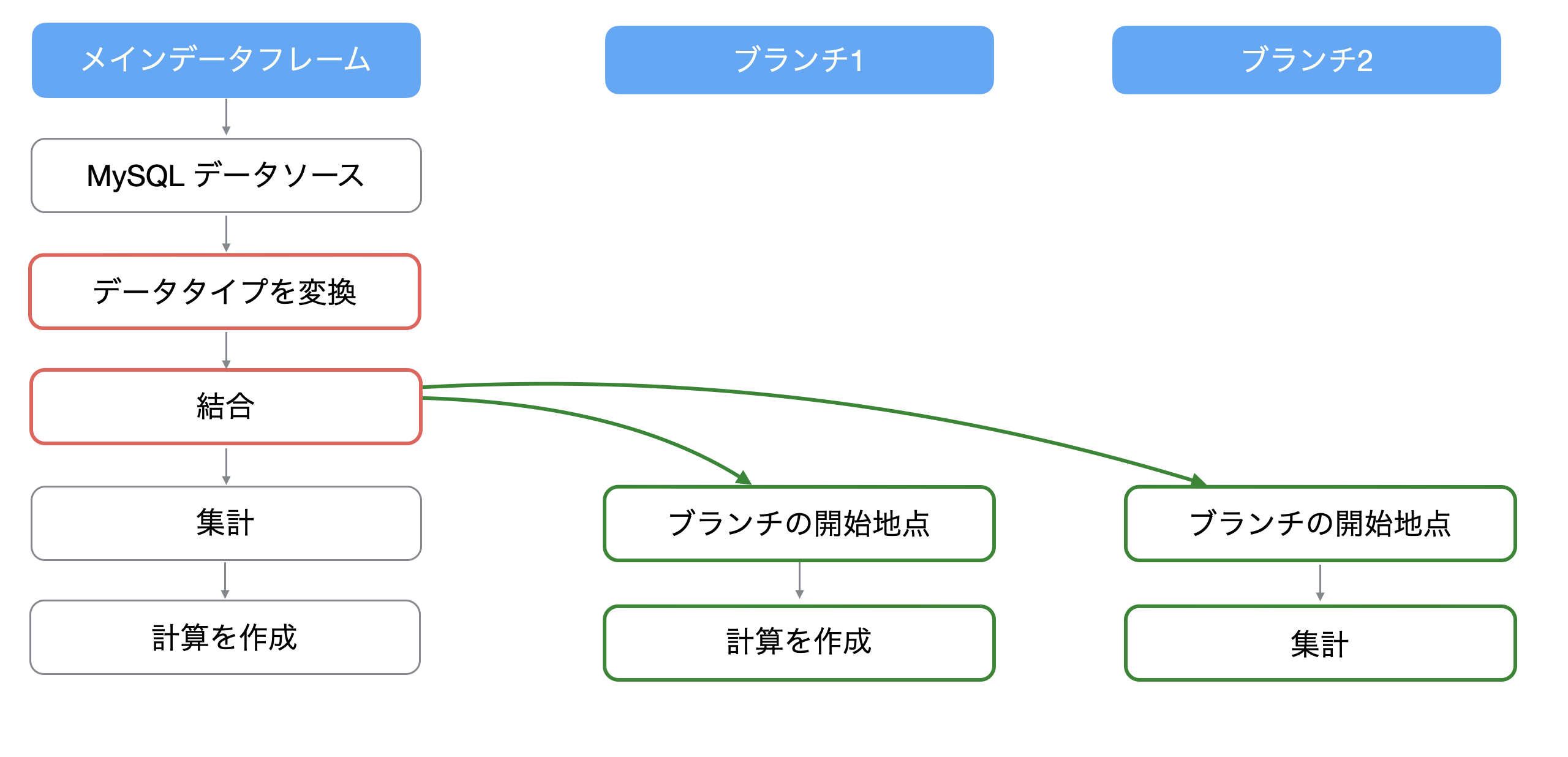
データラングリングは大きく分けると、下記の3つのタイプに分けられ、上から順番に処理をしていくのが望ましいです。
- データをきれいにする処理(前処理)
- チャート、アナリティクス、計算のための処理
- レポートのための処理(パラメーター)
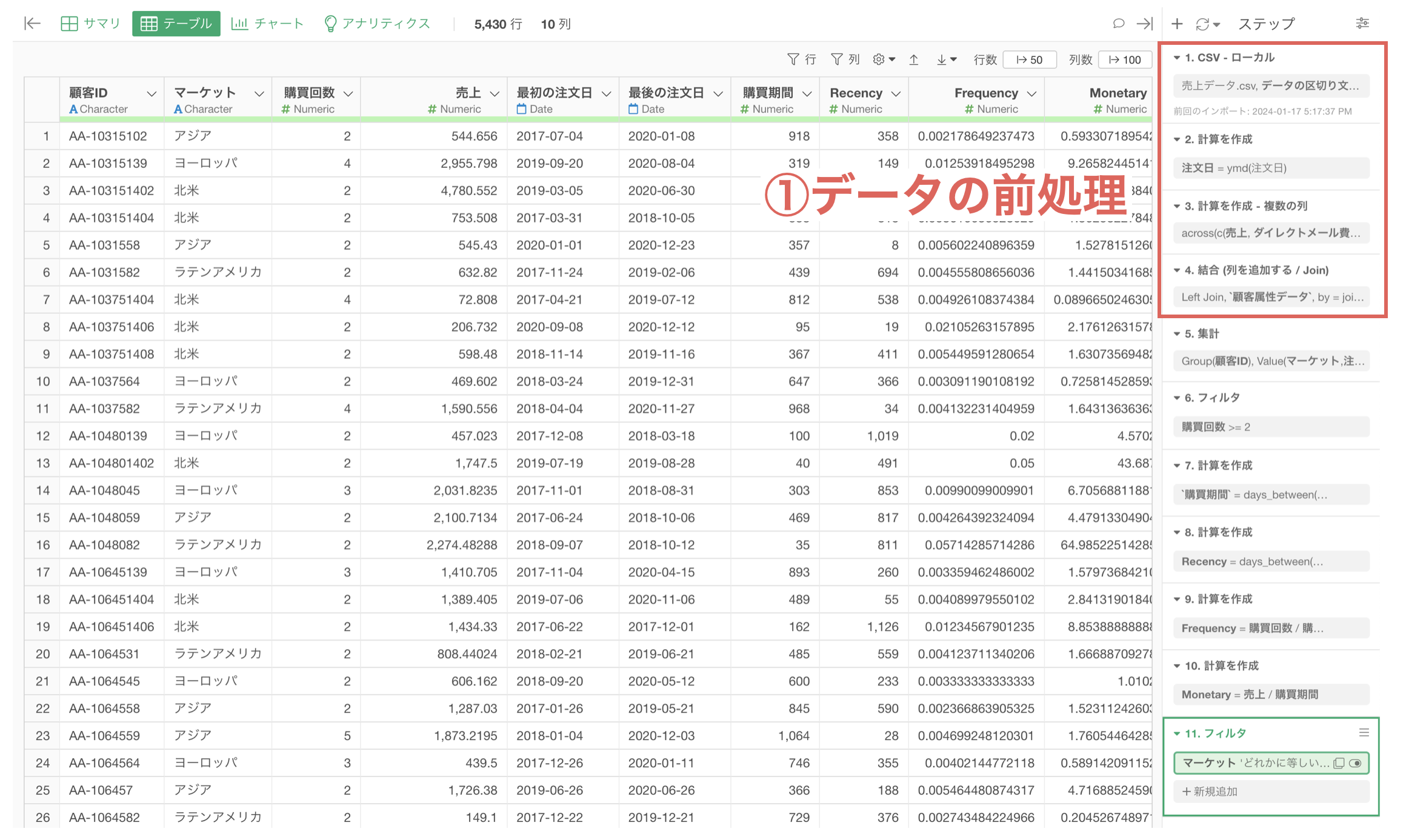
データの前処理を最初に行う必要性
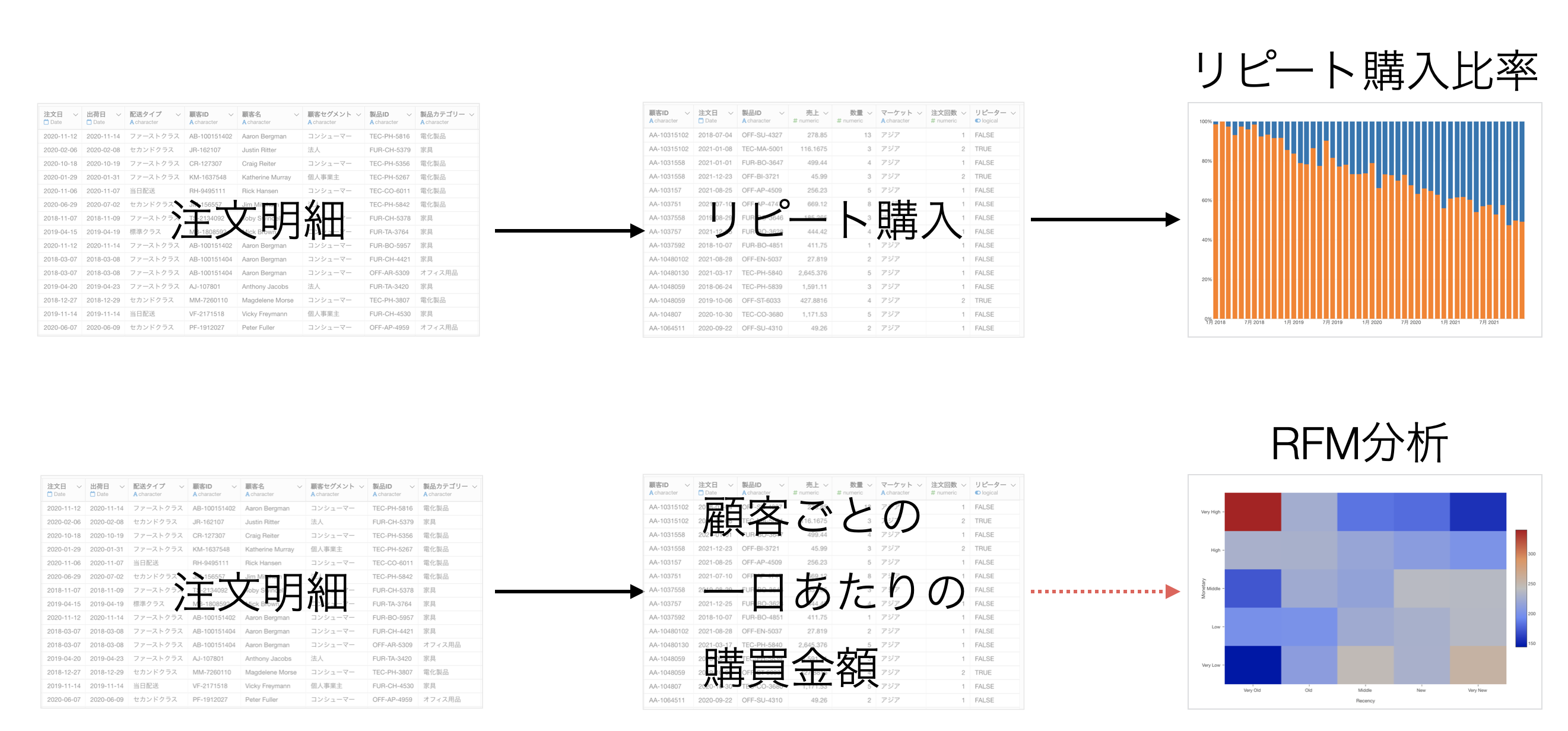
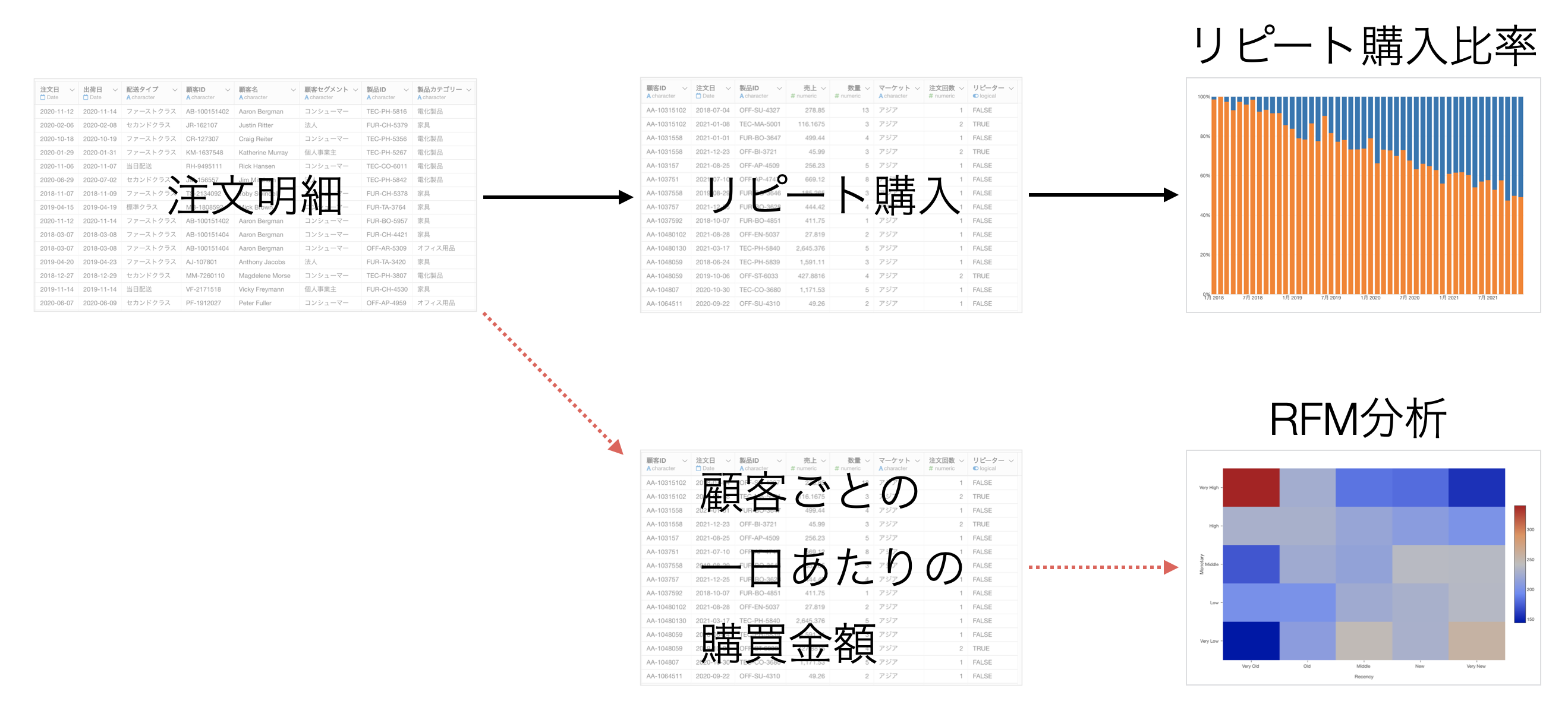
例えば、1行1注文のデータをもとに「リピート購入比率」、「RFM」分析を行いたいとします。
そのために必要なデータの形は異なり、目的に合わせてデータラングリングの処理を行うためには、それぞれでデータフレームを作らなければいけません。
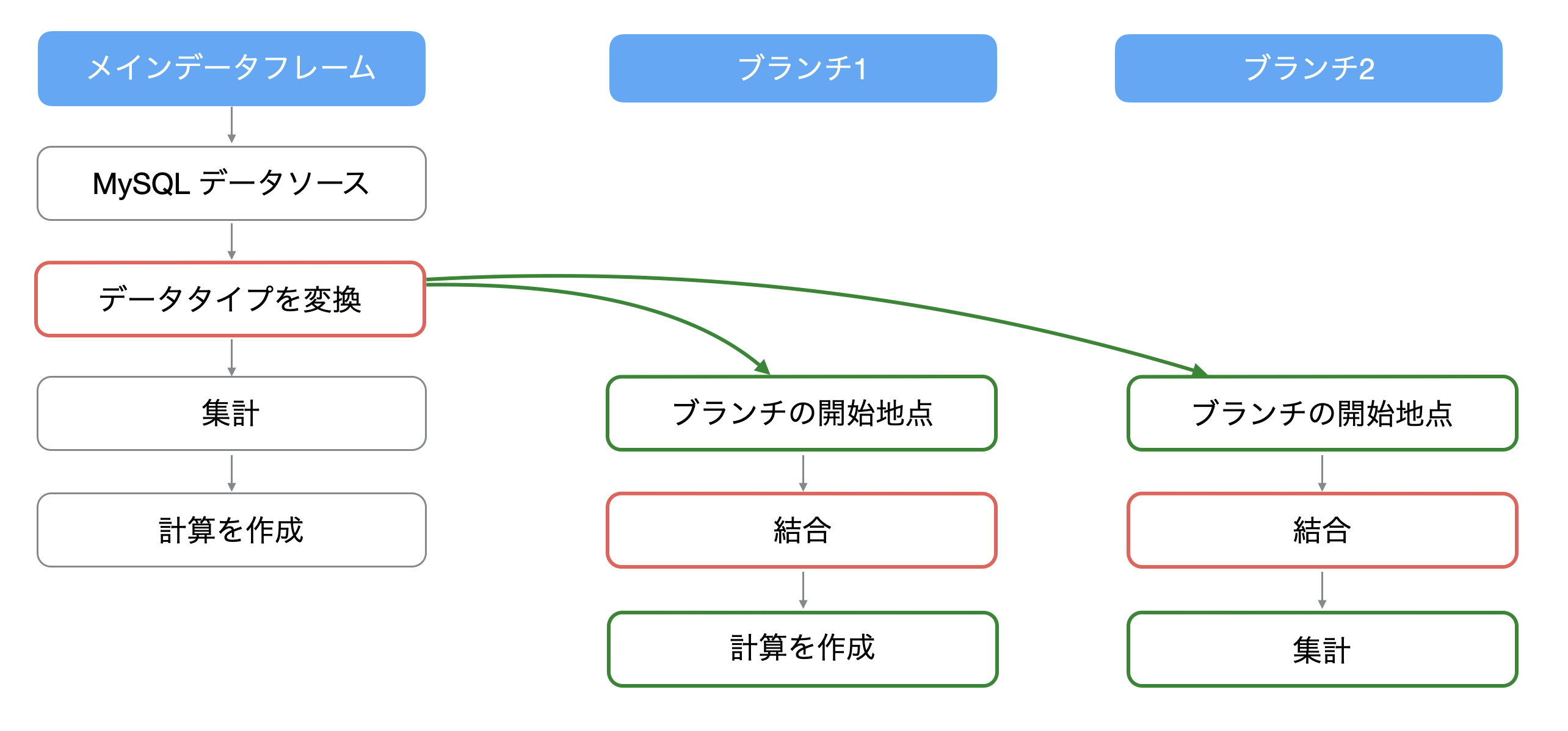
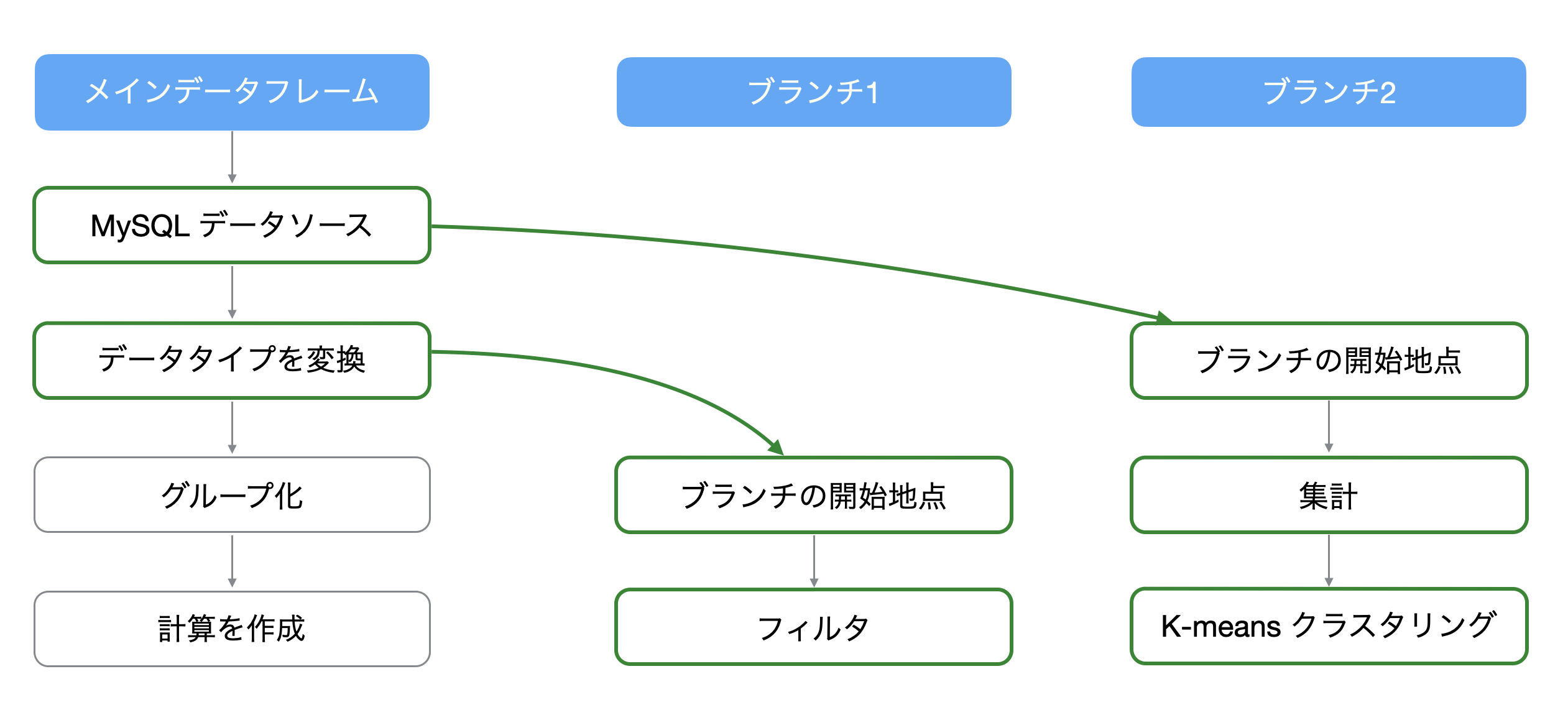
そこで、Exploratoryでは1つのデータフレームから枝分かれさせた「ブランチデータフレーム」を作ることができ、これによってメインとブランチのデータフレームで異なるデータ加工を行うことができます。
ブランチはメインのデータフレームにあるどのステップからでも作ることができ、そのステップを作成した以前の処理を反映させることができます。さらには、ブランチは複数作成することが可能です。
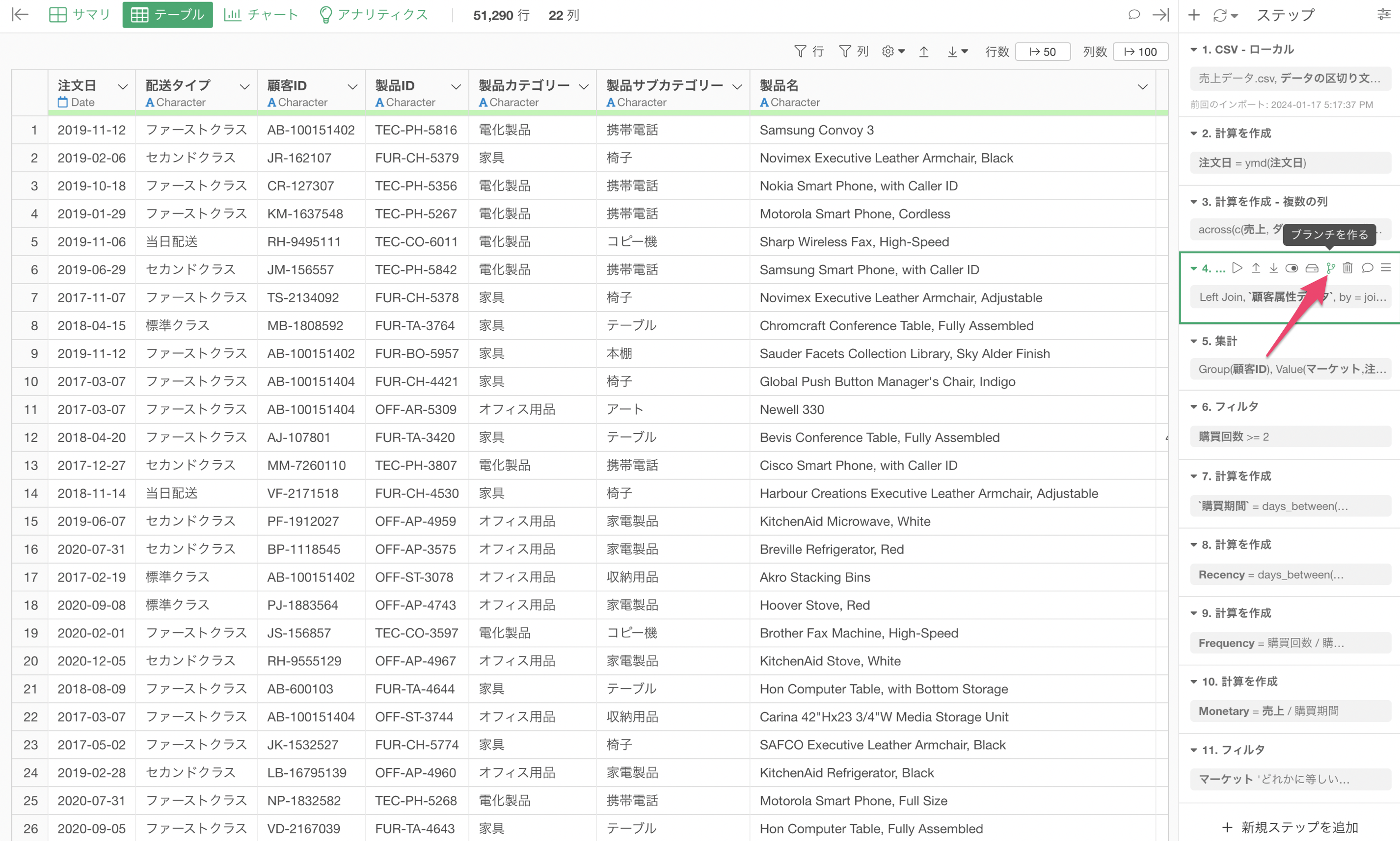
ブランチデータフレームはステップにある「枝」のアイコンから作ることが可能です。
ブランチの詳しい使い方については、こちらをご覧ください。
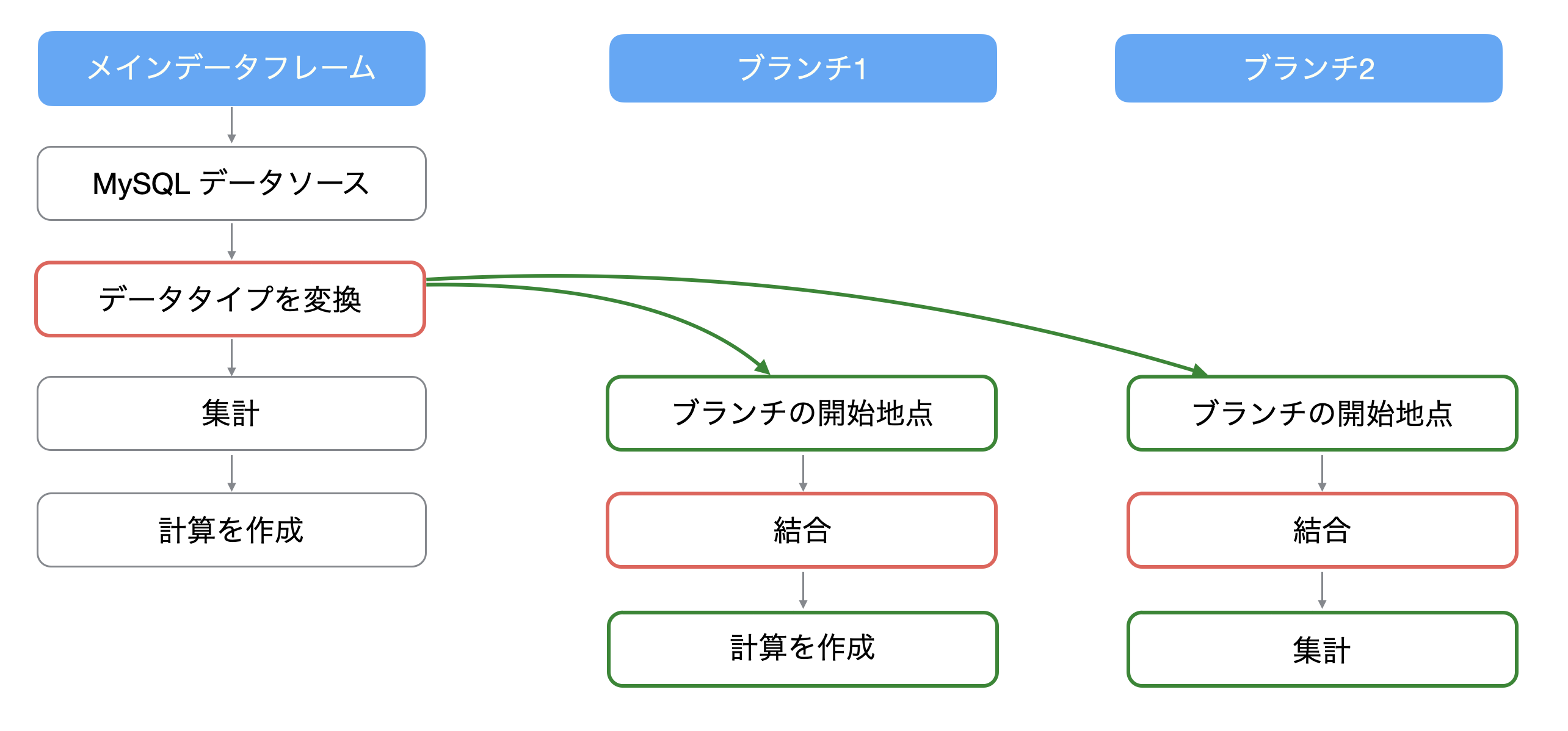
例えば、「結合」を使って属性情報などのデータを列として追加したい時に、ブランチごとに同じ処理をしてしまっては効率が悪いです。
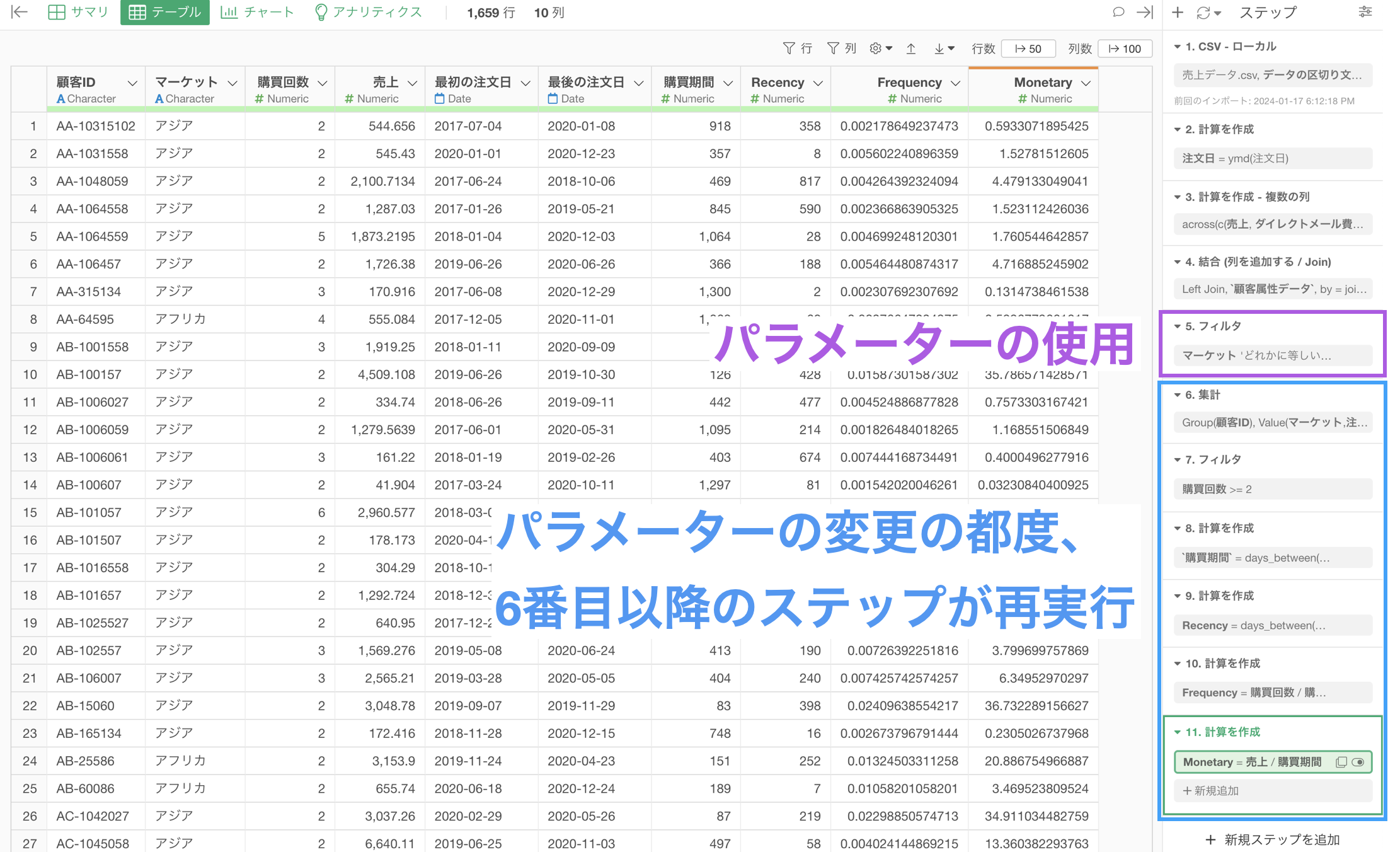
そこで、メインのデータフレームで共通する前処理を行なっておけば、それぞれのブランチでは前処理を行う手間を省くことができます。
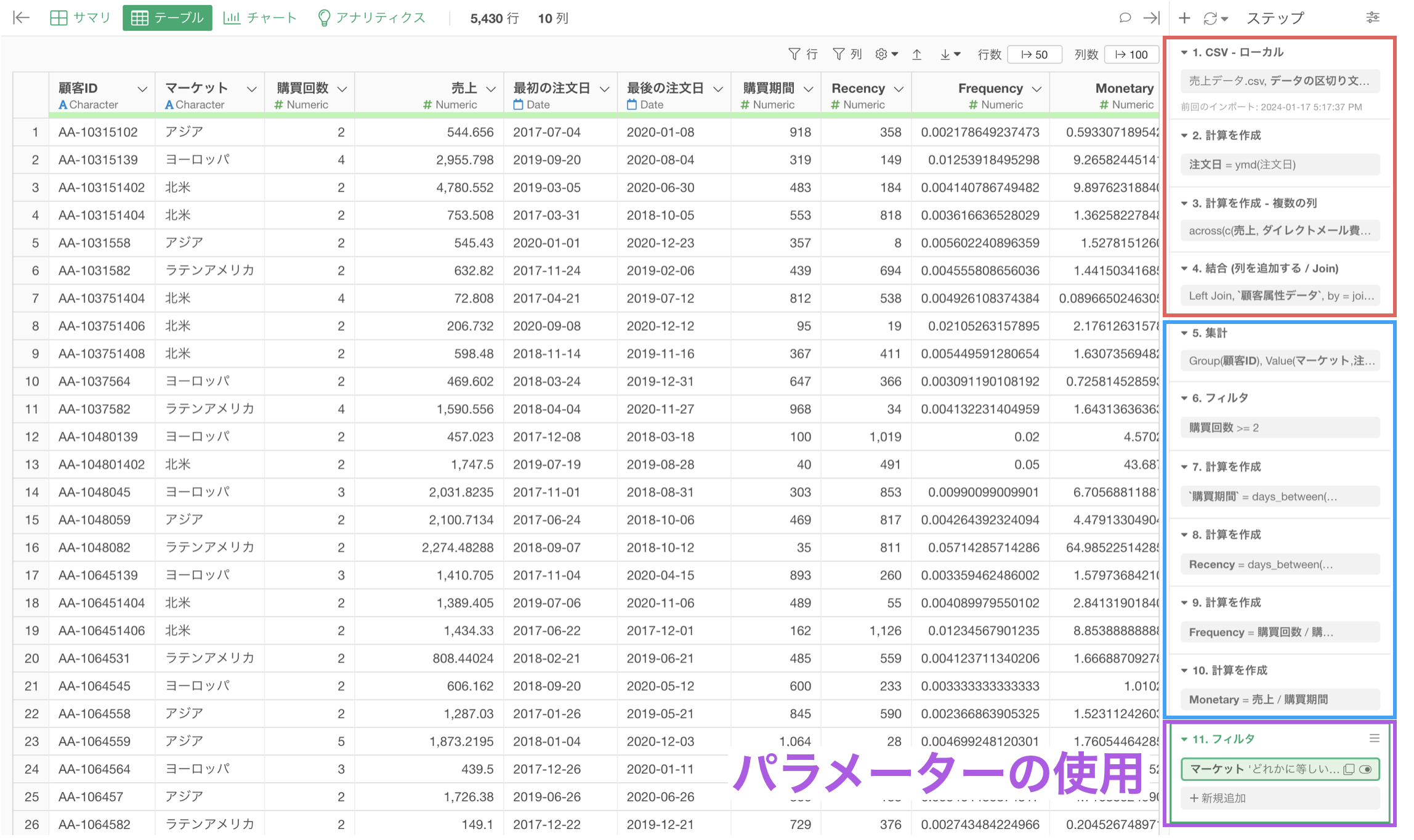
以上のことより、データの前処理は事前に行なっておいた方が、その後にデータラングリングをしていく際に管理がしやすく、さらには同じ処理を複数回行う必要がなくなるため、パフォーマンスを向上させていくことにつながります。
レポートのための処理(パラメーター)
Exploratoryでは、ダッシュボードやノートを通してデータを分析した結果を他の人に効果的にレポートしていくことができます。
その際に、パラメーターの機能を使うことで、ダッシュボード内で表示するチャートのデータを動的に変更していくことができます。
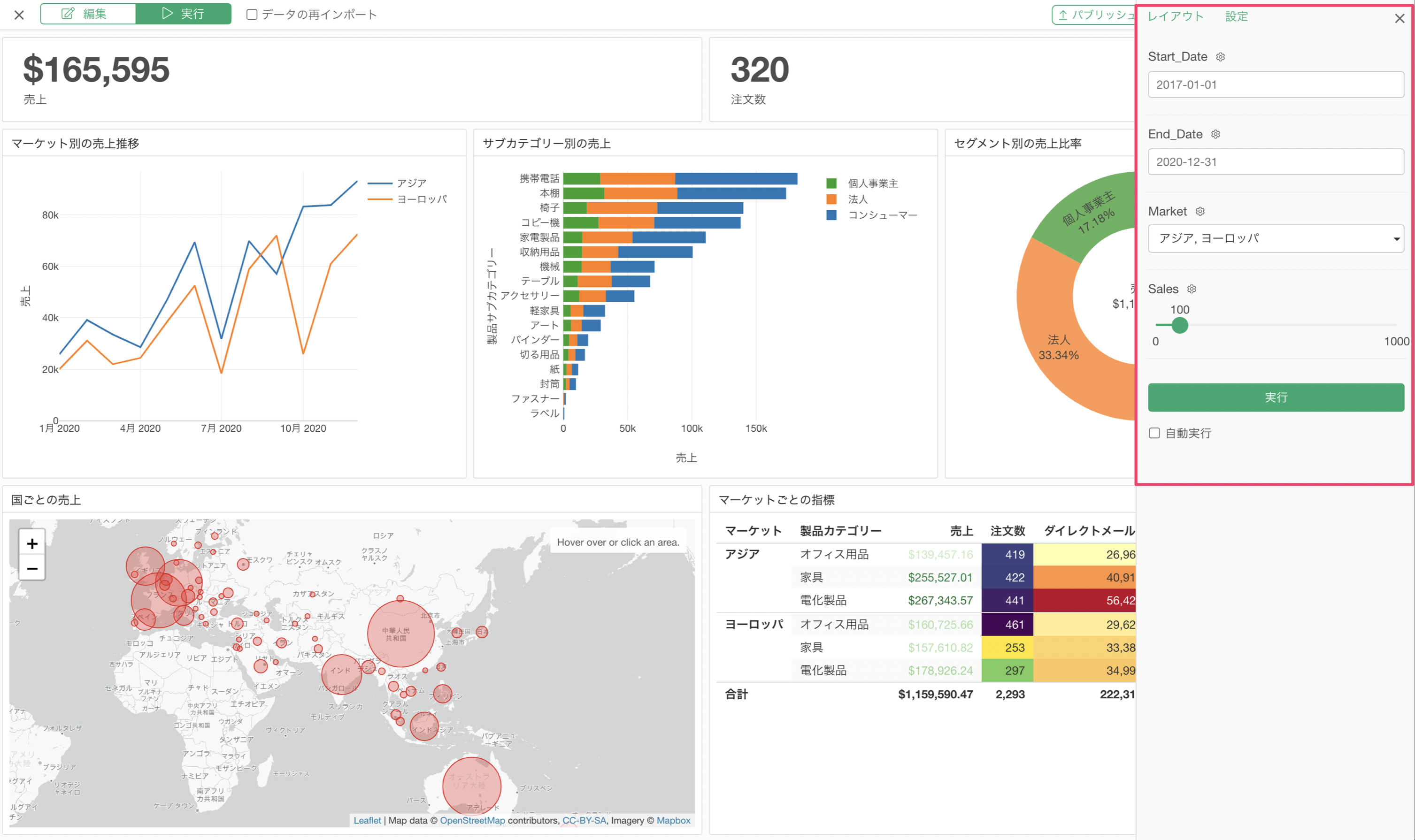
パラメーターの詳しい使い方については、こちらをご覧ください。
また、このパラメーターはデータラングリングのステップとして適用する方法と、チャートやアナリティクス内のフィルターとして適用することができます。
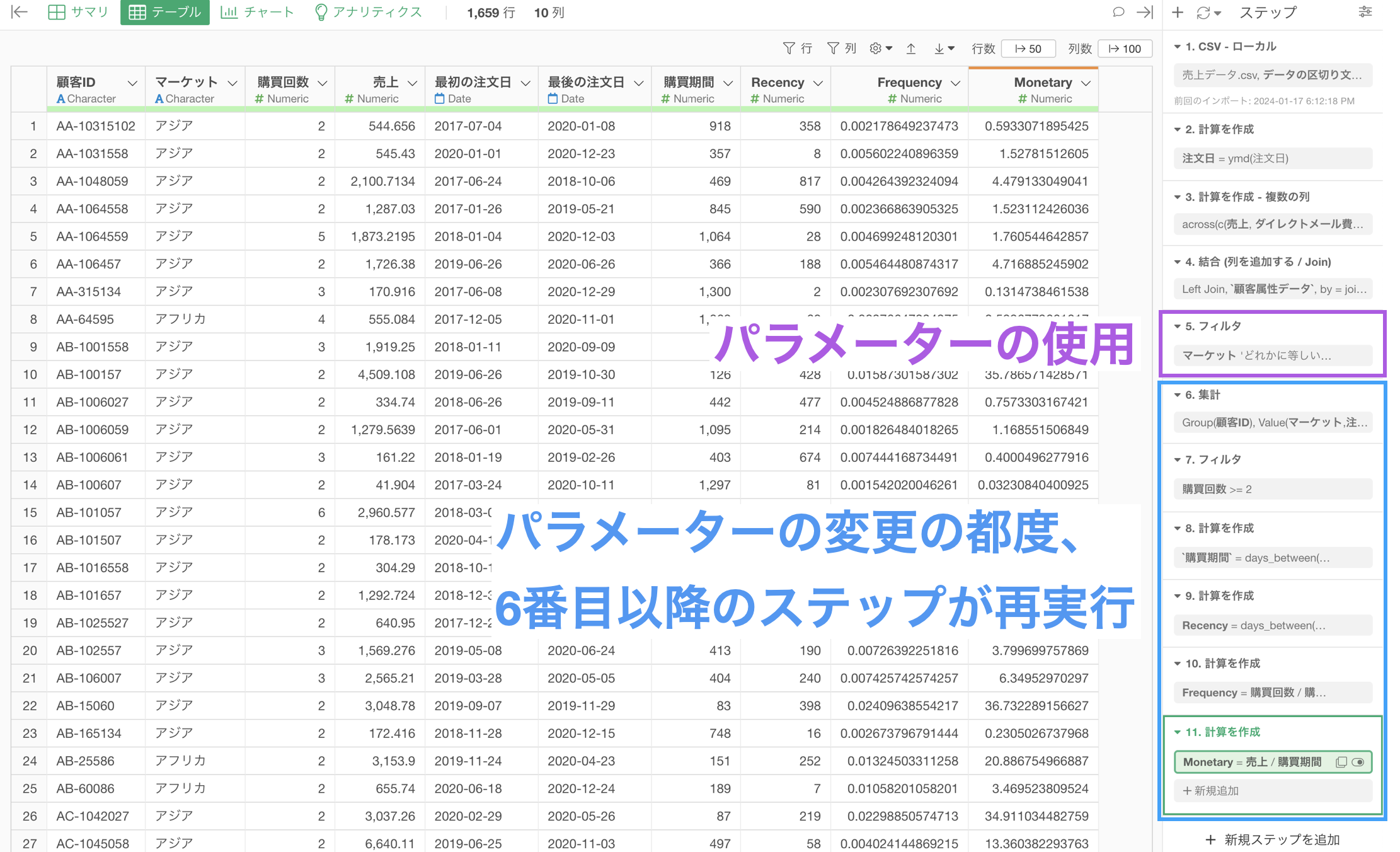
データラングリングのステップ
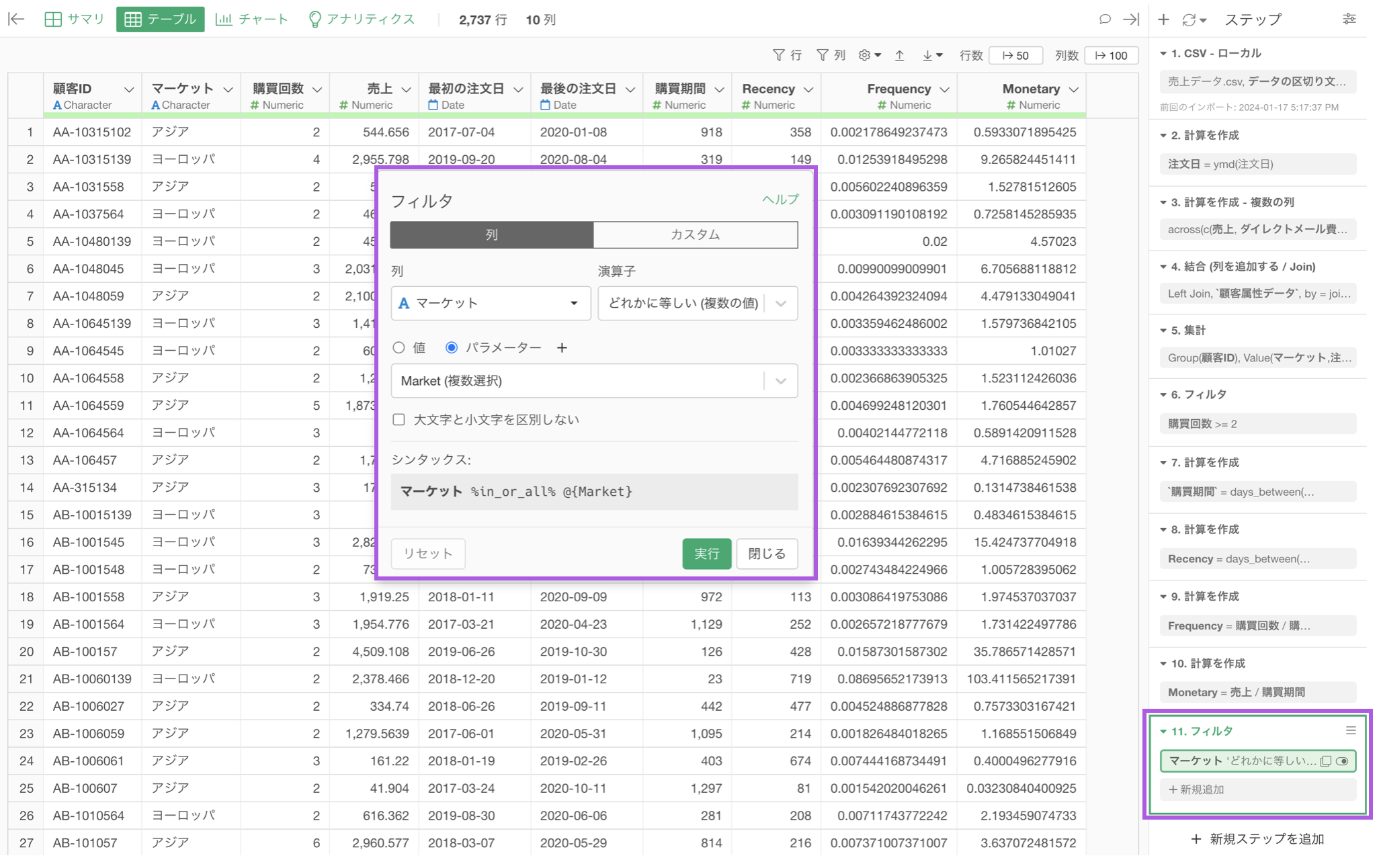
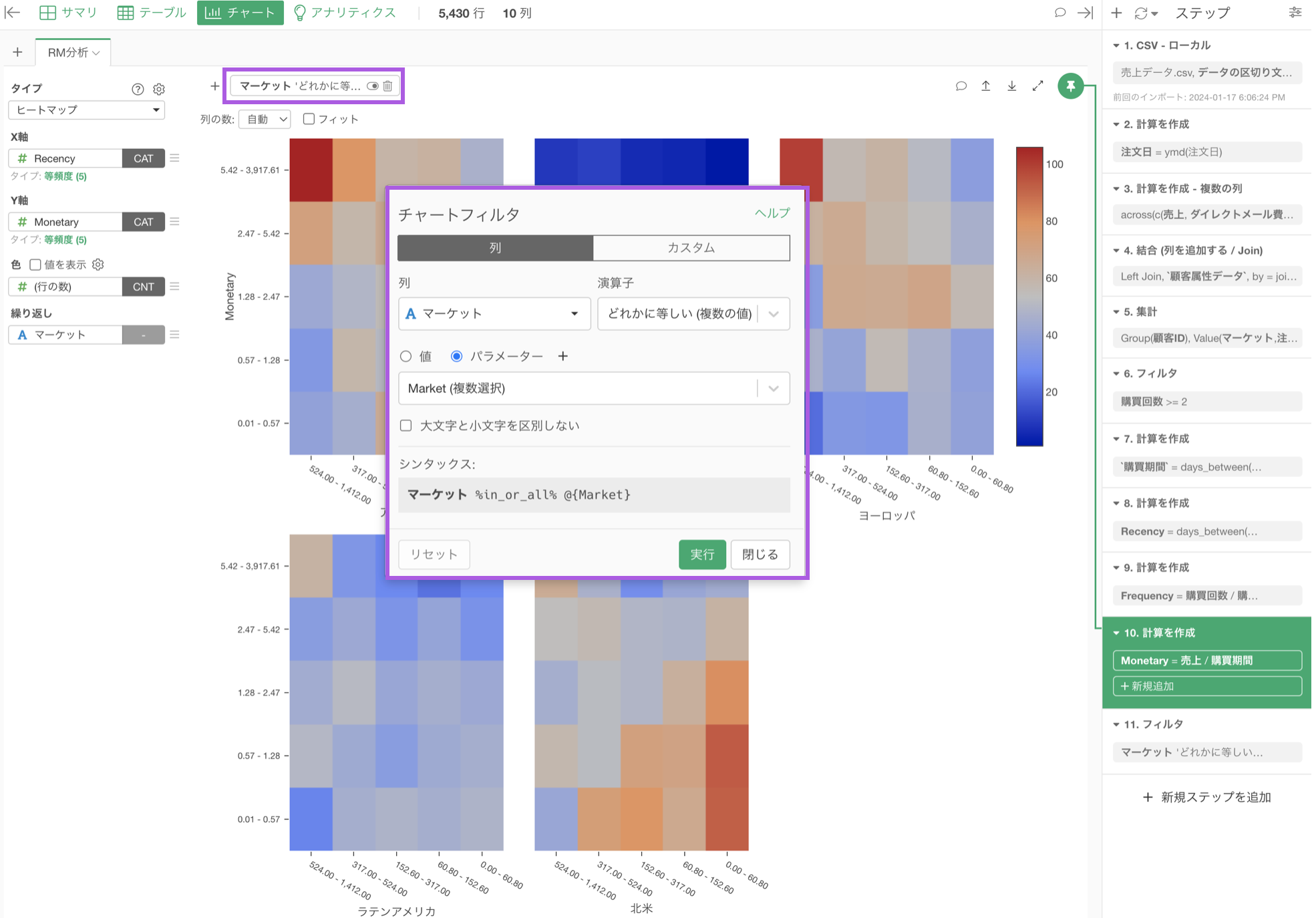
チャートまたはアナリティクス内のフィルタ
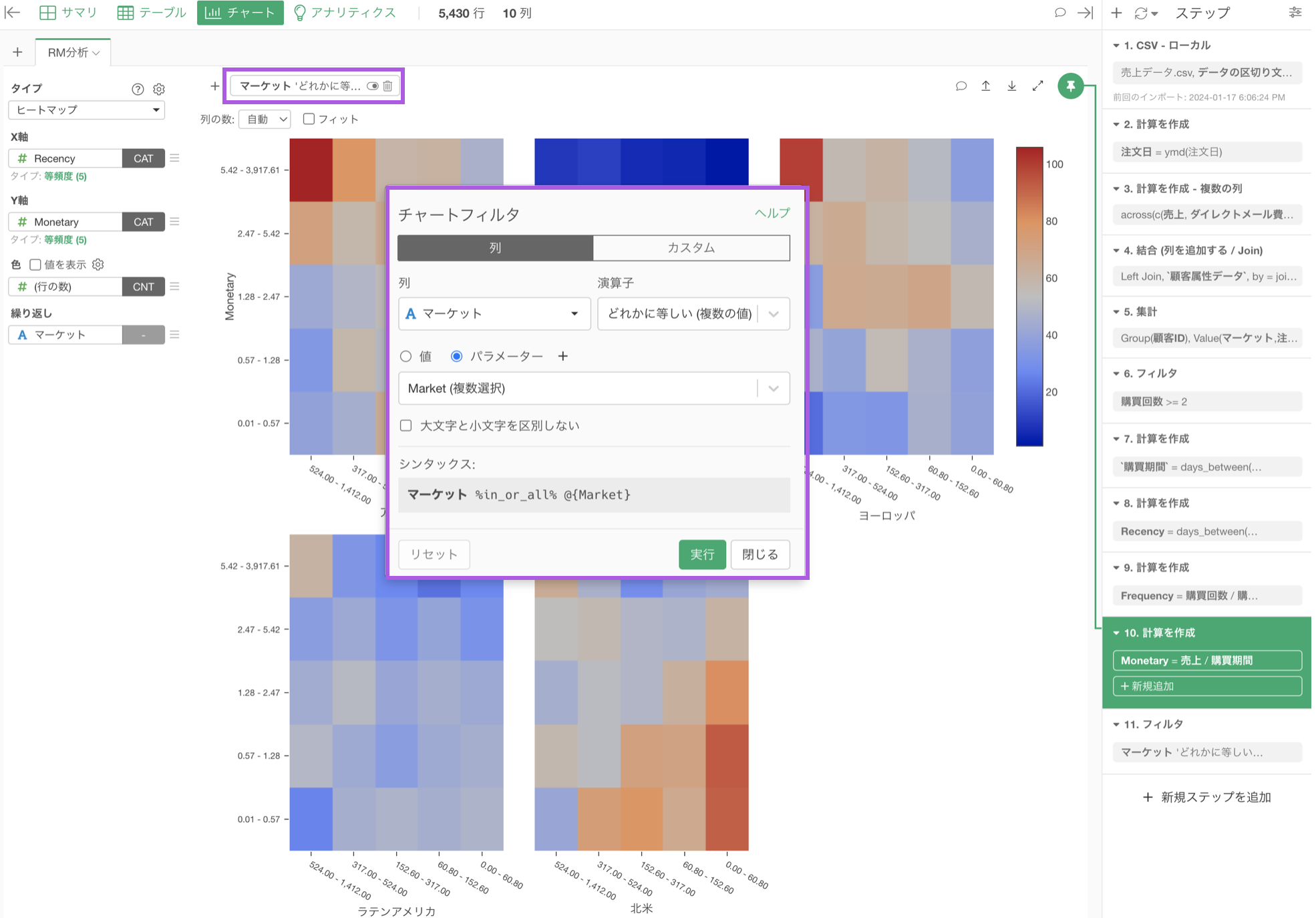
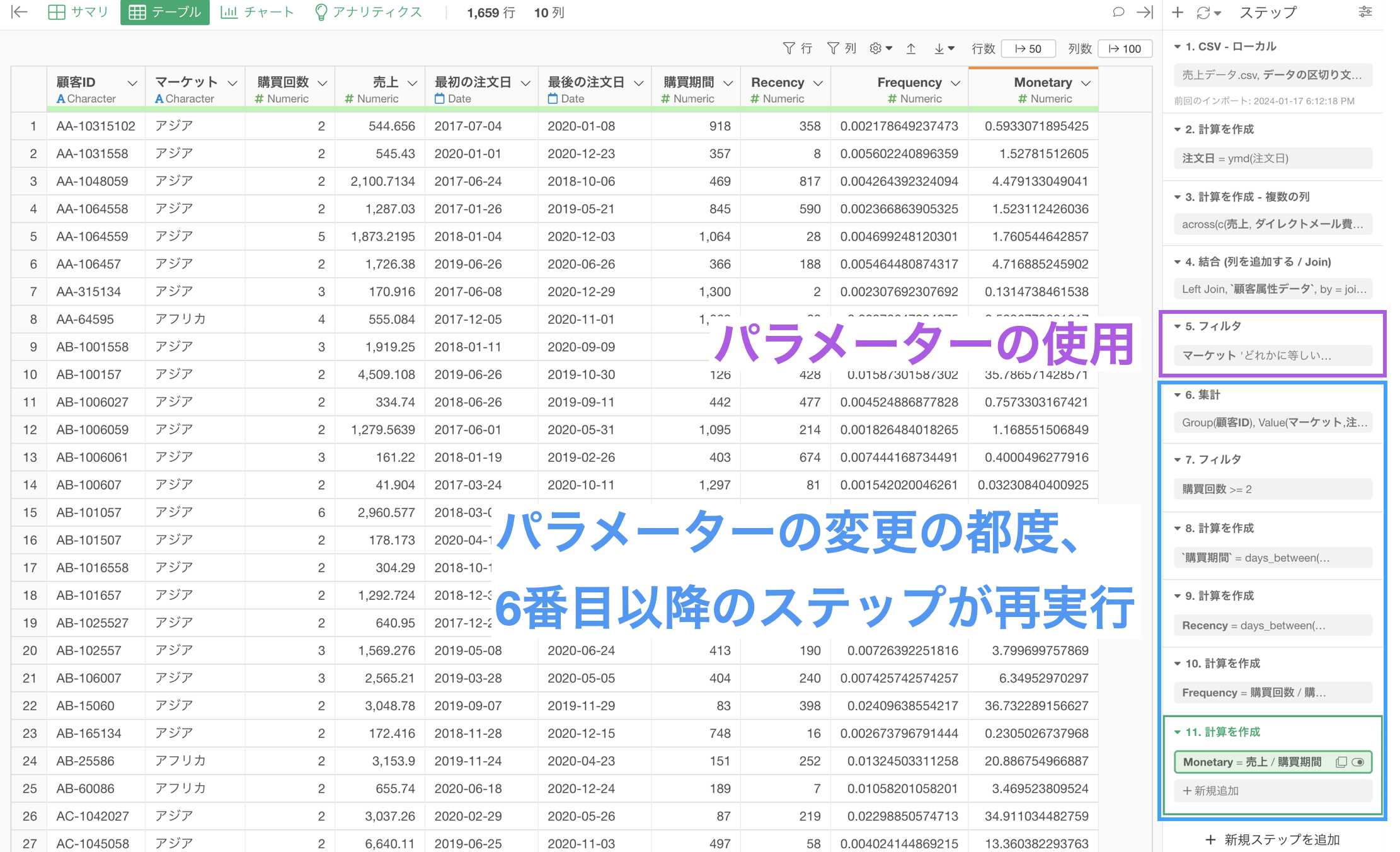
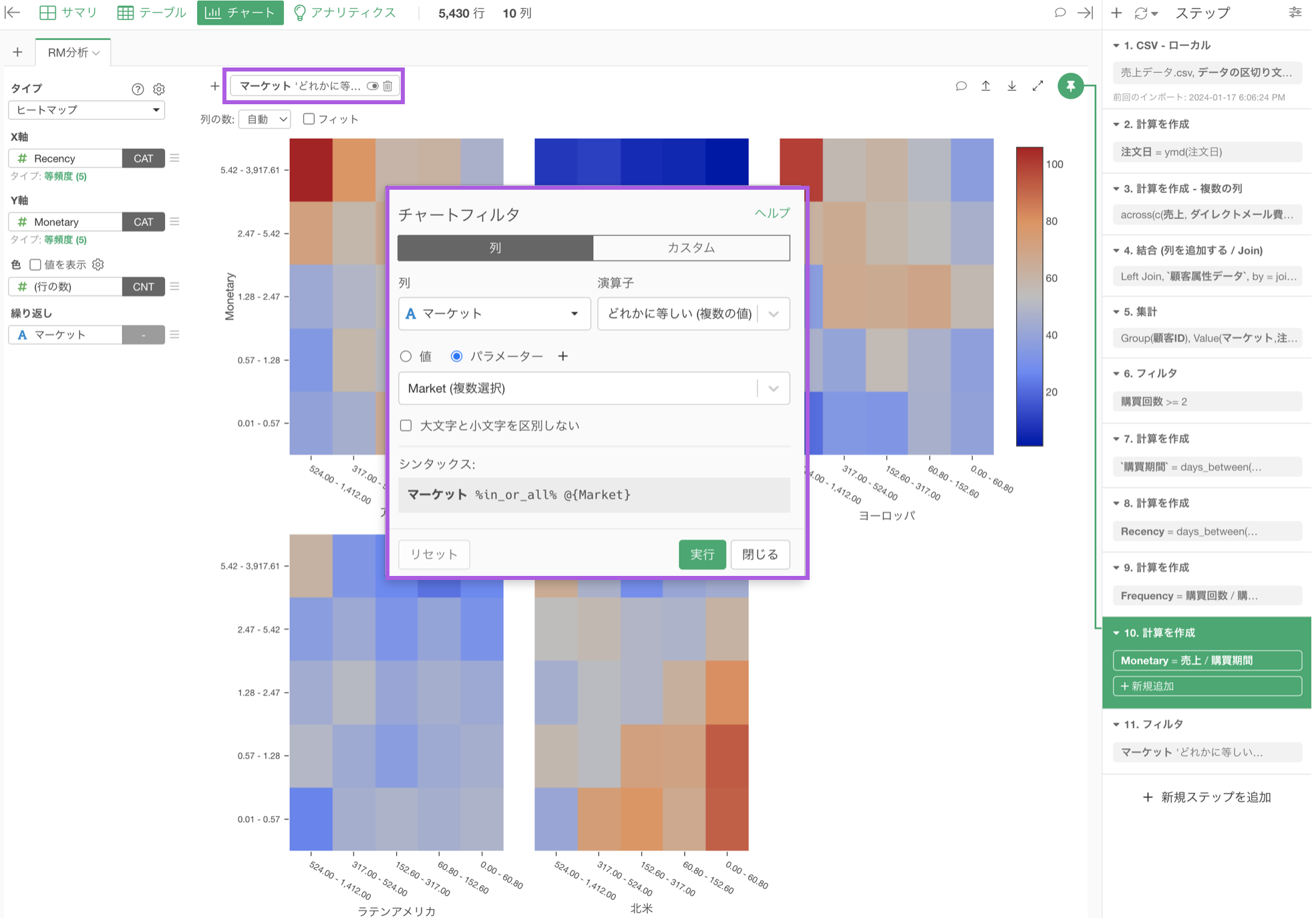
データラングリングのステップとして、パラメーターを設定している場合、ステップの順番によっては処理に時間がかかってしまうことがあります。
例えば、時間がかかる処理の前にパラメーターが埋め込まれている場合、パラメーターで値を変更する度にその後のステップの処理が走り、時間がかかってしまうことがあります。
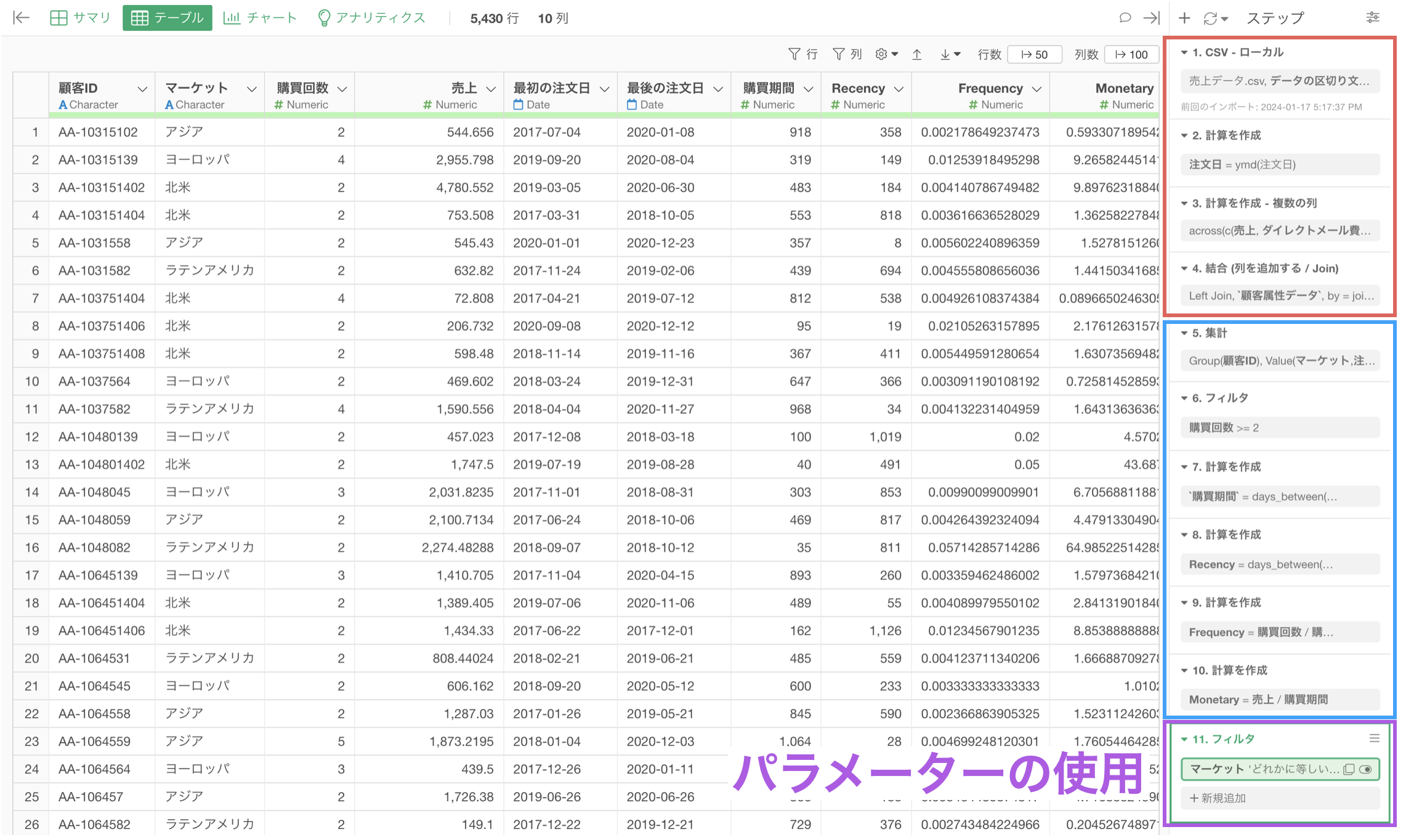
一方で、下記のようにパラメーターを使用するステップを後ろの方に設定している場合、パラメーターで値を変更してもその後に処理が走ることはないため、実行した結果がすぐに返ってきます。
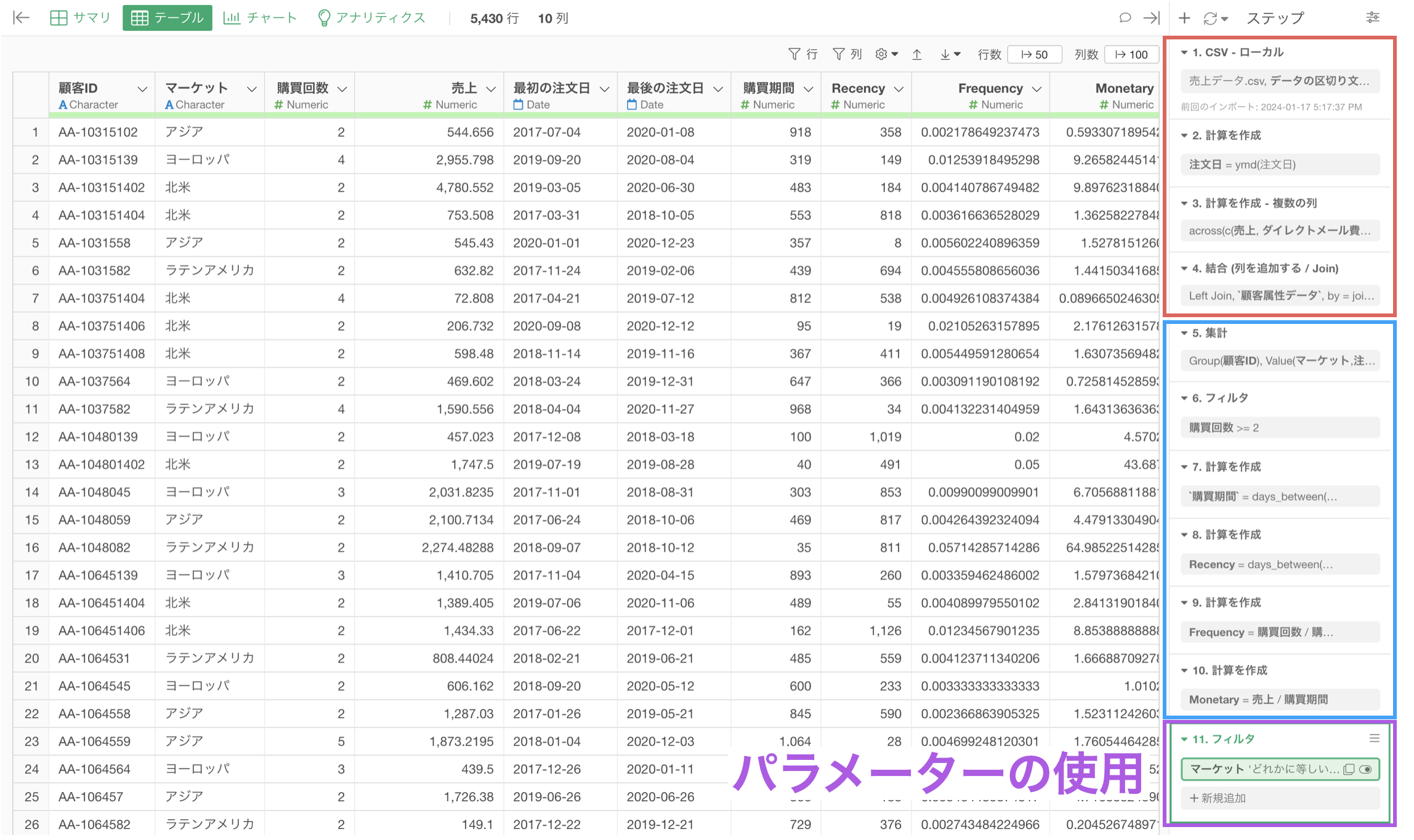
やりたい処理の内容によっては、パラメーターを使用するステップが最初、または途中に挟んだ方が良いこともありますが、一般的にはパラメーターは後ろのステップにあったほうが変更の都度その後の処理の実行がなくなるために、パフォーマンスを向上させることにつながっていきます。